前面教程中,我們通過優化檢索策略、召回重排略以及基于大模型的查詢重寫策略來提升了RAG系統的檢索精度,但最終回復的結果還需要經過大模型的融合和處理,模型能力的強弱直接影響到最終的結果。這就好比一道好的菜不僅需要有高質量的食材(優化的檢索模塊提供高匹配度文本),還需要有一個好廚師(能力強的LLM融合信息來生成答案)。
本節教程我們將進一步提升RAG系統的精度,深入到RAG系統中的生成模塊,討論大模型在其中的作用,介紹如何通過LazyLLM的微調來顯著提升大模型的生成能力,甚至以小模型超越通用大模型(即:訓練出一個好的廚師),進而提升RAG系統的回復質量。
大模型在RAG系統中的作用
1.RAG流程的回顧
前面教程中,我們已可以快速搭建出RAG系統,讓我們快速回顧一下RAG的運行流程:
-
檢索模塊會根據用戶的Query去查詢知識庫中通過向量相似度來召回Top-K相關的文檔;
-
生成模塊將檢索結果與用戶Query拼接,輸入LLM生成最終響應Response。
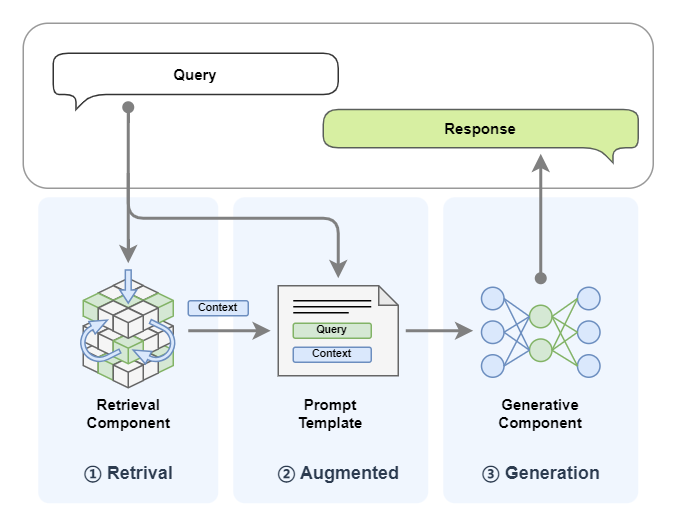
從中我們可以看到LLM大模型在RAG系統中主要承擔內容生成的作用。具體我們可以總結如下:
-
語義理解:解析query的真實意圖;
-
知識融合:協調原始知識(LLM大模型固有的知識)與新增知識(檢索內容)的融合;
-
邏輯推理:基于query的意圖和上下文推理出一個合理的結果。
所以影響RAG系統精度主要有兩個因素
👇
召回的效果?+?模型內容生成的能力
前幾期教程,我們已詳細介紹過如何提升召回效果(快速回看:第7講:檢索升級實踐:親手打造“更聰明”的文檔理解系統!、第8講:不止是cosine!匹配策略決定你召回的質量),本期我們將聚焦在生成模塊的模型能力增強上,來提高模型生成內容的質量。
2.模型能力的影響
在典型RAG架構中,大語言模型(LLM)的基準能力直接影響系統最終輸出的可靠性,其性能瓶頸主要體現在以下三個維度:
1. 領域知識適配性缺陷
通用大模型(如DeepSeek-R1、GPT-4、Claude-3)在開放域知識理解上展現較強能力,但面對垂直領域時表現顯著下降:
-
專業術語解析障礙:
比如IC 在醫學領域可以指 “Intensive Care” (重癥監護),在電子學領域指:“Integrated Circuit” (集成電路)。
-
長尾知識缺失:
??在醫療領域,通用大模型在訓練時可能主要接觸常見疾病的數據,對于罕見疾病的數據接觸較少,導致當模型遇到罕見疾病的病例時,可能無法準確識別或診斷,導致誤診或漏診;
??在自然語言處理中,通用模型通常以普通話或主流語言為主進行訓練,對于地方方言的訓練數據較少;導致模型在處理地方方言時可能出現理解錯誤或無法理解的情況,影響交流效果;
??在文化知識問答或推薦系統中,通用模型對于主流文化知識掌握較好,但對于小眾文化知識了解不足,導致用戶詢問關于小眾文化的問題時,模型可能無法給出準確或相關的回答。
-
領域推理能力局限:
??在法律領域,通用大模型被用于輔助分析案件,在處理復雜法律案件時,可能無法理解深層的法律邏輯和條文之間的關聯,導致模型提供的分析建議可能不夠準確或全面,影響法律決策;
??在教育領域,通用大模型被用于輔助數學問題求解,模型在處理高級數學問題時,可能無法進行深入的推理和計算,模型無法解決復雜數學問題,或給出的解答錯誤;
??在科學研究領域,通用大模型被用于輔助設計實驗,模型可能缺乏對特定科學領域的深入理解,無法考慮到所有實驗變量和潛在影響,導致設計的實驗可能存在缺陷,無法達到預期的研究目標。
2. 結構化輸出控制薄弱
當系統要求固定格式輸出(如JSON數據表、標準化報告)時,模型易受兩個關鍵問題影響:
-
格式漂移現象:
??在金融數據分析中,模型需要輸出標準化的JSON格式數據表。然而,由于模型對格式細節的掌握不夠精確,導致輸出的JSON數據中某些字段的嵌套層級錯誤,如將本應屬于子字段的數據直接放在了父字段下,造成數據解析失敗;
??在電商領域,模型負責生成商品信息的JSON數據。但由于格式漂移,模型輸出的數據中出現了不必要的空格、換行或缺失引號等,導致前端系統在解析時出現錯誤,影響商品展示;
-
幻覺干擾:
??在醫療報告生成場景下,模型需要按照固定格式輸出包含患者基本信息、診斷結果、治療方案等字段的報告。然而,模型在生成報告時自我發揮,虛構了格式之外的非關鍵字段內容,如添加了不存在的檢查項目或治療建議,導致報告內容失真,可能對醫生診斷造成干擾;
??在法律文書生成中,模型需要按照標準模板輸出文書。但由于幻覺干擾,模型在文書中添加了與案件無關的虛構事實或法律條文,導致文書內容不準確,影響法律效力;
3. 性能被部署環境限制
RAG需要的知識庫往往對用戶來說具有隱私性,用戶更希望能在本地部署,這意味著要同時部署本地的大模型,而本地部署大模型又需要算力支持,一般用戶很難有較強的算力,此時在算力資源下往往只能選擇一些較小的LLM模型,比如7B大小的模型,而這些較小的LLM基本能力上無法和600多B的LLM相比,此時模型的能力也就較弱。所以隱私保護需求迫使企業采用本地化部署方案,但由此產生算力約束:
-
模型規模限制:單臺A100服務器(80G顯存)最大支持70B參數模型的部署,而同等成本下云端可調用600B級的DeepSeek-R1;
-
能力代際差異:比如在LLaMA-7B模型的準確率顯著低于LLaMA-65B的準確率。
微調提升大模型能力
上面提及的問題,一定程度上都可以通過具有針對性的微調策略來解決,進而可顯著提升RAG系統中生成模塊的領域適應能力和輸出規范性。
什么是微調?
微調就是基于預訓練大模型,通過特定領域數據二次訓練,使模型適配專業場景的輕量化技術。
1.微調核心方法
-
監督微調(SFT):注入領域QA數據(如法律案例/醫療報告)
-
領域自適應:LoRA低秩適配技術,凍結原參數+訓練適配層
2.核心優勢
-
高效性:7B模型經微調后,特定任務表現可比肩未調優的70B模型
-
低成本:參數高效微調(PEFT)僅需更新0.1%~20%參數量
-
可控性:強化結構化輸出和內容輸出約束(如JSON格式校準)
3.典型應用場景
(1)領域知識適配性增強
a. 垂直領域知識注入:?
基于領域專用數據(如醫學病例、法律文書、科研論文)構建微調數據集,通過指令微調(Instruction Tuning)使模型學習領域內知識表達模式。例如,在醫療場景中,使用<癥狀描述,診斷建議>數據對訓練模型理解醫學術語間的關聯性。
b. 長尾知識補償:?
針對罕見術語或低頻場景(如方言詞匯、小眾文化概念),構造包含此類知識的問答對,通過微調增強模型對長尾特征的捕捉能力。例如,在方言處理任務中,向訓練數據注入方言-標準語對照樣本,強化模型跨語言變體的泛化能力。
(2)結構化輸出控制強化
a. 格式標記顯式學習:
在微調數據中嵌入結構化標記(如{{KEY_START}}診斷結果{{KEY_END}}),強制模型學習格式與內容的分離表達。
b. 抗干擾訓練:
向訓練集注入20%-30%的噪聲樣本(如隨機刪除引號、打亂JSON層級),要求模型在修復格式的同時保持內容準確性。通過這種方式提升模型對格式漂移的魯棒性。
c. 輕量化部署適配環境:
小模型能力增強:通過漸進式知識遷移,將大模型在領域任務中習得的能力蒸餾至小模型。例如,使用大模型生成領域相關數據的偽標簽(也可直接使用相關專業領域內的標注數據),再基于此數據微調小模型,使7B模型在特定任務上逼近65B模型的表現。
這里我們列舉一個具體的場景:
在醫療領域,需要將醫療報告中的文本信息(例如,“患者表現出高血壓癥狀,收縮壓為150mmHg”)轉換為JSON格式,包含癥狀、血壓讀數等關鍵信息。
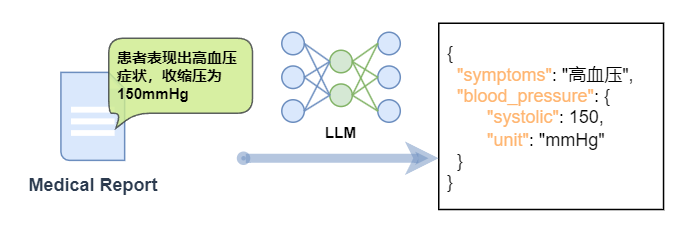
在微調下,針對這類任務可以有以下益處:
1.精確的信息提取:
微調可以幫助模型更準確地從自然語言文本中提取出需要結構化的信息,例如癥狀類型、數值、單位等。
2.上下文理解:?
自然語言中的信息往往依賴于上下文,微調可以讓模型更好地理解這些上下文,從而更準確地轉換信息。
3.特定格式的要求:?
JSON結構化文本通常有嚴格的格式要求,微調可以幫助模型生成符合這些要求的輸出。
4.領域特定術語的處理:
微調可以幫助模型更好地理解和處理專業術語。
自然語言轉換為JSON結構化的文本是一個典型的場景,其中微調可以顯著提高LLM的性能和輸出質量。通過微調,模型可以學習到如何從自然語言中識別和提取關鍵信息,并以一種預定義的結構化格式呈現這些信息。
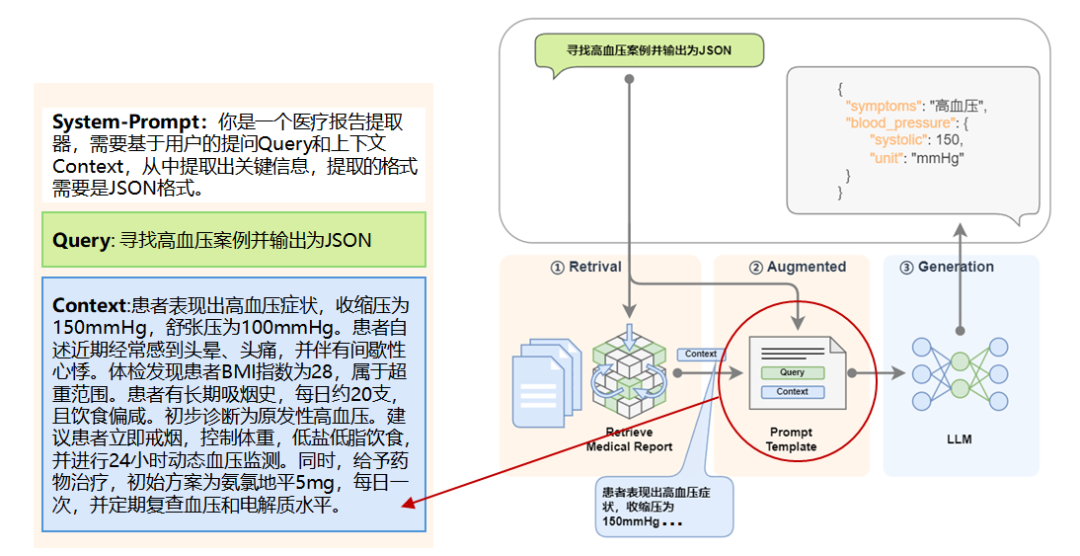
讓我們將微調后的模型放到 RAG 中去,就是這樣子的:
LoRA 微調的原理和方法
上面我們提到微調可以解決各種問題,那么用什么具體的微調方法呢?
針對傳統全參數微調在資源消耗和災難性遺忘方面(過度調整預訓練權重會破壞模型在通用領域的知識表達)的固有挑戰,LoRA(Low-Rank Adaptation)微調提供了有效的優化途徑,成為模型微調領域的常用方法。
1.LoRA微調概述
下面我們以LoRA微調為例,講解一下微調在LazyLLM中的應用。
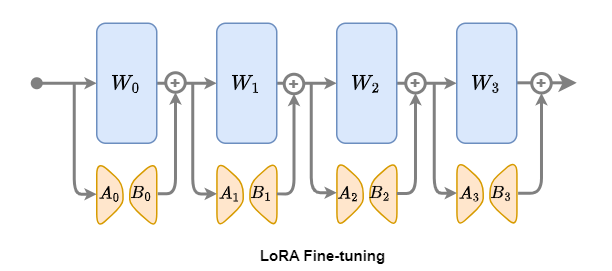

2.LoRA微調步驟
1.加載預訓練模型:首先,選擇一個已經預訓練好的 Transformer 模型作為基礎
2.引入低秩矩陣:在模型的每一層中,添加可訓練的低秩矩陣B ∈ Rd×r和A ∈ Rr×k
3.微調低秩矩陣:將特定任務的數據輸入模型,利用反向傳播算法針對低秩矩陣A和B進行參數更新
4.評估與優化:在驗證集上對微調后的模型進行性能評估,并根據實際需求進一步優化模型
3.LoRA數學解析






參數調優建議
-
任務復雜度與數據量
??簡單任務/小數據:選擇較小 (如 r=4)和中等α?。
??復雜任務/大數據:嘗試較大 (如 r=32 )并調高α。
-
資源限制
??顯存不足時優先降低r,而非減小模型尺寸。
參數總結

基于LazyLLM對大模型進行微調
那么我們應該如何實現微調呢?這里我們基于LazyLLM來具體實現一個LoRA微調。
我們選擇一個小模型,使用CMRC2018數據集中的訓練數據來微調這個小模型,讓它能具有更好的中文閱讀理解信息抽取能力。之前在RAG中使用的模型都會基于我們檢索到的知識庫信息來回答問題,回答得比較發散,自由發揮程度比較高,這里我們希望RAG中的模型有如下特點:
1.根據用戶提問和召回的文段,抽取必要的信息來回答,不要擴展發揮(對應上文提到的:結構化輸出控制薄弱和領域知識適配性差);
2.模型要小,大約7B左右,方便部署,不能用太大的模型(對應上文提到的:輕量化部署需求和模型精度下降的矛盾)。
我們整體的微調步驟如下:
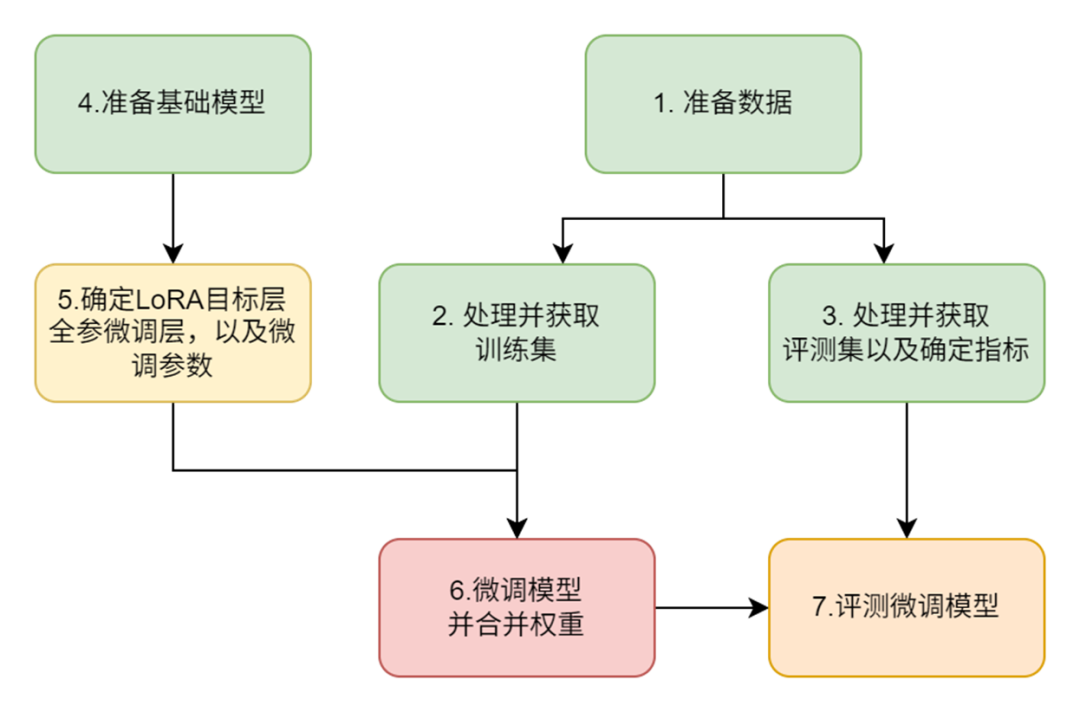
-
問題:原RAG中大模型回答發散,需精簡+準確遵循原文輸出;
-
目標:在7B的小模型上,強化中文閱讀理解信息抽取能力
-
模型選擇:InternLM2-Chat-7B。
-
數據準備:使用CMRC2018訓練數據,聚焦中文問答與信息抽取。
-
微調方法:
??LoRA策略:凍結原始權重,僅訓練低秩矩陣(BA),降低顯存占用。
??控制輸出:強化遵循原文內容且精簡輸出的能力。
1.數據準備
數據集簡介
我們選用CMRC2018數據集,該數據集由近15,000個真實問題組成,這些問題是由人類專家在維基百科段落上標注而成。另外該數據集對應的任務是:“篇章片段抽取型閱讀理解”(Span-Extraction Reading Comprehension),根據給定的一個文檔和一個問題,模型需要從該文檔中抽取出問題的答案,其中答案是該文章某個連續的片段。
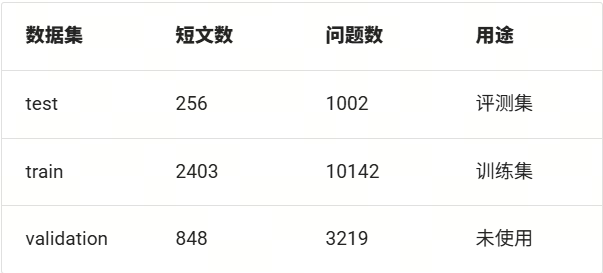
數據集規模
CMRC2018數據集主要由三部分構成:test、validation 和train。這里我們將train部分作為我們的訓練集,test部分作為我們的評測集,validation部分我們不使用。
🚨注意:
-
之前教程中的知識庫是基于 CMRC2018 中的test數據集中的文段來構建的;
-
這里訓練我們使用的 CMRC2018 中的train數據集來進行;
-
評測過程,為避免RAG系統中檢索模塊干擾,我們采用控制變量法,假設召回100%沒問題,即:我們直接使用 CMRC2018 中的test數據集中的文段片段和問題拼接起來作為大模型LLM的輸入,變量是微調前后的兩個7B的模型,以對比查看微調后模型在中文閱讀理解信息抽取能力方面是否有提升。
數據的結構
數據集中的test和train的結構是一致的,我們抽取其中的一條數據來看如下:
[{"id": "TRIAL_154_QUERY_0","context": "尤金袋鼠(\"Macropus eugenii\")是袋鼠科中細小的成員,通常都是就袋鼠及有袋類的研究對象。尤金袋鼠分布在澳洲南部島嶼及西岸地區。由于牠們每季在袋鼠島都大量繁殖,破壞了針鼴島上的生活環境而被認為是害蟲。尤金袋鼠最初是于1628年船難的生還者在西澳發現的,是歐洲人最早有紀錄的袋鼠發現,且可能是最早發現的澳洲哺乳動物。尤金袋鼠共有三個亞種:尤金袋鼠很細小,約只有8公斤重,適合飼養。尤金袋鼠的奶中有一種物質,稱為AGG01,有可能是一種神奇藥及青霉素的改良。AGG01是一種蛋白質,在實驗中證實比青霉素有效100倍,可以殺死99%的細菌及真菌,如沙門氏菌、普通變型桿菌及金黃色葡萄球菌。","question": "尤金袋鼠分布在哪些地區?","answers": {"text": ["尤金袋鼠分布在澳洲南部島嶼及西岸地區"],"answer_start": [52]}},
...上面數據中:
-
context: 是文本段;
-
question:是針對文本段的提問;
-
answers:給出了對應問題的答案,包括:
??text:答案的具體內容,源自文本段;
??answer_start:答案在文本段中的起始位置。
訓練集處理
-
我們從原train數據集中抽取出文章字段context和問題字段question,將它拼接成為用于微調的instruction字段,拼接模板是:"請用下面的文段的原文來回答問題\n\n### 已知文段:{context}\n\n### 問題:{question}\n"。
-
將原數據中的answers及其text字段作為,微調的 output 字段。
-
由于微調還需要一個input字段,而我們這個任務不需要,所以設置為空。
(代碼Github鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter9/run_cmrc.py#L51)
# Template for constructing QA prompts
template = "請用下面的文段的原文來回答問題\n\n### 已知文段:{context}\n\n### 問題:{question}\n"
def build_train_data(data):"""Format training data using predefined template"""extracted_data = []for item in data:extracted_item = {"instruction": template.format(context=item["context"], question=item["question"]),"input": "","output": item["answers"]["text"][0]}extracted_data.append(extracted_item)return extracted_data我們取處理后的一條數據如下:
[{"instruction": "請用下面的文段的原文來回答問題\n\n### 已知文段:黃獨(學名:)為薯蕷科薯蕷屬的植物。多年生纏繞藤本。地下有球形或圓錐形塊莖。葉腋內常生球形或卵圓形珠芽,大小不一,外皮黃褐色。心狀卵形的葉子互生,先端尖銳,具有方格狀小橫脈,全緣,葉脈明顯,7-9條,基出;葉柄基部扭曲而稍寬,與葉片等長或稍短。夏秋開花,單性,雌雄異株,穗狀花序叢生。果期9-10月。分布于大洋洲、朝鮮、非洲、印度、日本、臺灣、緬甸以及中國的江蘇、廣東、廣西、安徽、江西、四川、甘肅、云南、湖南、西藏、河南、福建、浙江、貴州、湖北、陜西等地,生長于海拔300米至2,000米的地區,多生于河谷邊、山谷陰溝或雜木林邊緣,目前尚未由人工引種栽培。在美洲也可發現其蹤跡,對美洲而言是外來種,有機會在農田大量繁殖,攀上高樹爭取日照。英文別名為air potato。黃藥(本草原始),山慈姑(植物名實圖考),零余子薯蕷(俄、拉、漢種子植物名稱),零余薯(廣州植物志、海南植物志),黃藥子(江蘇、安徽、浙江、云南等省藥材名),山慈姑(云南楚雄)\n\n### 問題:黃獨的外皮是什么顏色的?\n","input": "","output": "外皮黃褐色"},
...評測集處理
我們評測集的字段基本都保留了下來,僅對answers字段進行了處理,將其中的內容提取了出來:
(代碼Github鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter9/run_cmrc.py#L39)
def build_eval_data(data):"""Extract necessary fields for evaluation dataset"""extracted_data = []for item in data:extracted_item = {"context": item["context"],"question": item["question"],"answers": item["answers"]["text"][0]}extracted_data.append(extracted_item)return extracted_data我們取處理后的一條數據如下:
[{"context": "芙蓉洞位于重慶武隆縣江口鎮的芙蓉江畔,距武隆縣城20公里。芙蓉洞于1993被發現,1994年對游人開放。2002年被列為中國國家4A級旅游景區,2007年6月作為中國南方喀斯特-武隆喀斯特的組成部分被列入聯合國世界自然遺產,是中國首個被列入世界自然遺產的溶洞。芙蓉洞全長2846米,以豎井眾多、洞穴沉積物類型齊全著稱。芙蓉洞附近的天星鄉境內,有世界上罕見的喀斯特豎井群。在約20平方公里的范圍內,至少散布著50個超過100米的豎井,其中汽坑洞的深度為920米,為亞洲第一。芙蓉洞內有70多種沉積物,幾乎包括了所有經過科學家命名的喀斯特洞穴沉積類型,其中池水沉積堪稱精華。在芙蓉洞的東端有一個“石膏花支洞”,洞內的鹿角狀卷曲石枝長57厘米,為世界第一。目前石膏花支洞被永久封存。在緊鄰芙蓉洞洞口的芙蓉江上已經建起了江口電站大壩,水庫蓄水后對地下水循環及喀斯特景觀的演化造成的影響目前還難以估量。","question": "芙蓉洞位于什么地方?","answers": "重慶武隆縣江口鎮的芙蓉江畔"},...2.微調模型
在數據處理完成后,我們可以開始進行微調了。
值得注意的是:LazyLLM支持微調、部署、推理一條龍!
微調相關配置代碼主要如下所示:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter9/run_cmrc.py#L155)
import lazyllm
from lazyllm import finetune, deploy, launchers
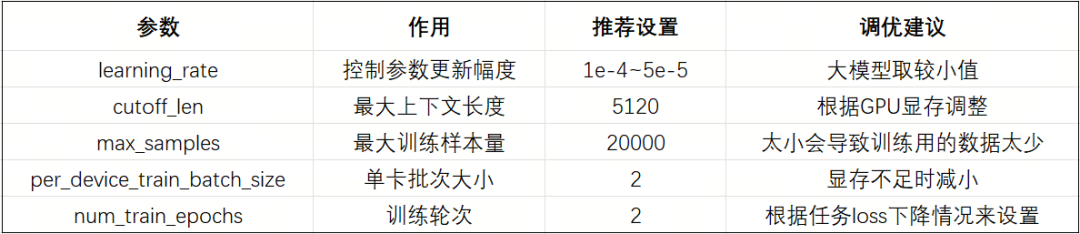
model = lazyllm.TrainableModule(model_path)\.mode('finetune')\.trainset(train_data_path)\.finetune_method((finetune.llamafactory, {'learning_rate': 1e-4,'cutoff_len': 5120,'max_samples': 20000,'val_size': 0.01,'per_device_train_batch_size': 2,'num_train_epochs': 2.0,'launcher': launchers.sco(ngpus=8)}))\.prompt(dict(system='You are a helpful assistant.', drop_builtin_system=True))\.deploy_method(deploy.Vllm)
model.evalset(eval_data)
model.update()上面代碼中,使用LazyLLM的TrainableModule來實現:微調->部署->推理:
-
模型配置:
??model_path指定了我們要微調的模型,這里我們用Internlm2-Chat-7B,直接指定其所在路徑即可;
-
微調配置:
??.mode設置了啟動微調模式finetune;
??.trainset設置了訓練用的數據集路徑,這里用到的就是我們前面處理好的訓練集;
??.finetune_method 設置了用哪個微調框架及其參數,這里傳入了一個元組(只能設置兩個元素):
? ? ? ?🗝?第一個元素指定了使用的微調框架是Llama-Factory:finetune.llamafactory
? ? ? ?🗝?第二個元素是一個字典,包含了對該微調框架的參數配置;
-
推理配置:
??.prompt設置了推理時候用的Prompt,注意,這里為了和微調的Prompt中的system字段保持一致,所以開啟drop_builtin_system以將原system-prompt給替換為`You are a helpful assistant.`
??.deploy_method設置了部署用的推理框架,這里指定了vLLM這個推理框架;
-
評測配置:
??這里通過.evalset來配置了我們之前處理好的評測集;
-
啟動任務:
??.update 觸發任務的開始:模型先進行微調,微調完成后模型會部署起來,部署好后會自動使用評測集全部都過一遍推理以獲得結果;
微調中的一些關鍵參數如下:
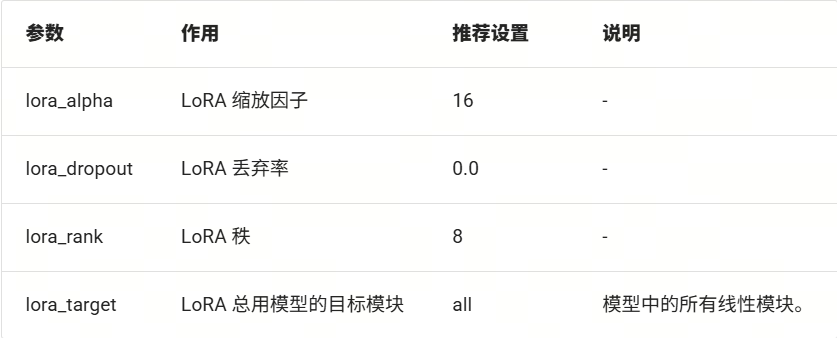
額外,我們還可以配置一些LoRA相關的參數(LazyLLM已經默認設置好了一套經驗的參數,所以上述代碼中沒有體現,這里我們展示如下,您可以嘗試各類參數來煉丹:
3.效果評測
在上一步微調并獲得評測集的推理結果后,我們需要拿著結果和評測集的正確答案做個對比,以確認我們微調的效果是什么樣的。
評測目的
-
驗證微調效果:對比模型輸出與標準答案,量化模型優化成果(是否超越通用大模型)
-
任務適配性檢驗:通用指標(忠誠度、答案相關性)不適用于“篇章片段抽取”任務,需定制化評估
-
優化方向指導:通過指標差異定位模型短板(如完全一致性、語義精準性、原文依賴性)
評測指標設計
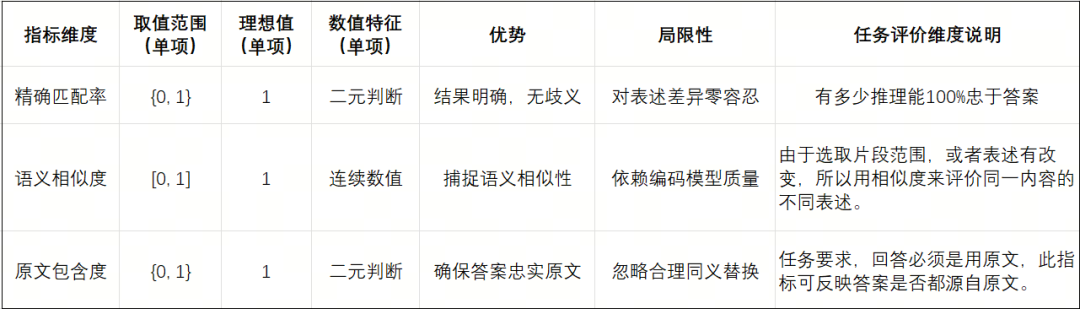
這里,針對我們的任務特點,設計了三個維度的評價指標:
-
精確匹配率(Exact Match)
-
語義相似度(Cosine Score)
-
原文包含度(Origin Score)
我們現在來詳細介紹一下這三個指標的設計細節:
1.精確匹配率
我們將精確匹配度定義如下:
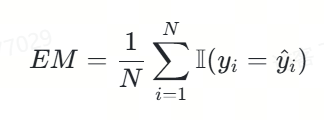

該指標的特性在于:預測結果與標準答案需要完全一致。
在不考慮計算平均值下,只實現其中的一項代碼很簡單,如下所示:
exact_score = 1 if output == true_v else 0代碼功能:
該代碼用于判斷模型對單個樣本的預測結果(output)與該樣本的標準答案(true_v)是否完全一致,并據此給出一個精確匹配得分(exact_score)。
代碼解釋:
-
output:模型對某個樣本的預測結果。
-
true_v:該樣本的標準答案。
-
exact_score:精確匹配得分,取值為1或0。如果預測結果與標準答案完全一致,則得分為1;否則得分為0。
2.語義相似度
我們將語義相似度度定義如下:
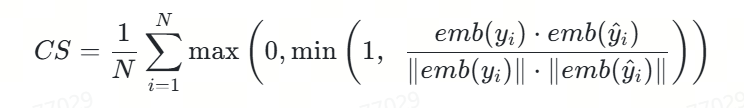

🚨注意:該評價指標將原本[-1,0)的數值進行了截斷,只要是負相關的語義都給0分,得分只能是正相關的。
相應的代碼實現如下,這里不含求平均,只是其中一項,同時假設文本已經被BGE模型向量化了:
import numpy as np
def cosine(x, y):"""Calculate cosine similarity between two vectors"""product = np.dot(x, y)norm = np.linalg.norm(x) * np.linalg.norm(y)raw_cosine = product / norm if norm != 0 else 0.0return max(0.0, min(raw_cosine, 1.0))代碼功能:
該代碼實現了一個計算兩個向量之間余弦相似度的函數,特別適用于評估模型預測結果與標準答案之間的語義相似度。這是上述精確匹配度定義(CS)中的核心計算部分,用于單個樣本的相似度計算。

3.原文包含度
我們將原文包含度定義如下:
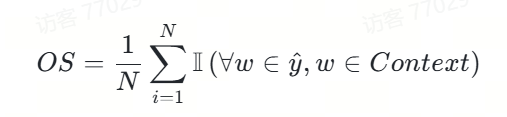

相應的代碼我們實現如下,這里不含求平均,只涉及其中一項:
def check_words_from_content(infer, content):"""Check if all words in inference output exist in original context"""return 1 if all(w in content for w in infer.split()) else 0代碼功能:
該代碼實現了一個函數check_words_from_content,用于檢查模型預測結果中的所有字是否都出現在原文內容中。這是上述原文包含度(OS)定義中的核心計算部分,用于單個樣本的包含度判斷。
代碼解釋:

4. 指標對比分析
我們將上面三個評價指標分別做對比分析:
綜合評測腳本
讓我們將以上評價指標都匯集在一起,實現下面的完整評價:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter9/run_cmrc.py#L84)
def caculate_score(eval_set, infer_set):"""Calculate three evaluation metrics: exact match, cosine similarity, and word containment"""assert len(eval_set) == len(infer_set)# Initialize embedding modelm = lazyllm.TrainableModule('bge-large-zh-v1.5')m.start()accu_exact_score = 0accu_cosin_score = 0accu_origi_score = 0res = []for index, eval_item in enumerate(eval_set):output = infer_set[index].strip()true_v = eval_item['answers']# Exact match scoring:exact_score = 1 if output == true_v else 0accu_exact_score += exact_score# Cosine similarity scoring:outputs = json.loads(m([output, true_v]))cosine_score = cosine(outputs[0], outputs[1])accu_cosin_score += cosine_score# Word containment scoring:origin_score = check_words_from_content(output, eval_item['context'])accu_origi_score += origin_scoreres.append({'context':eval_item['context'],'true': true_v,'infer':output,'exact_score': exact_score,'cosine_score': cosine_score,'origin_score': origin_score})save_res(res, 'eval/infer_true_cp.json')total_score = len(eval_set)return (f'Exact Score : {accu_exact_score}/{total_score}, {round(accu_exact_score/total_score,4)*100}%\n'f'Cosine Score: {accu_cosin_score}/{total_score}, {round(accu_cosin_score/total_score,4)*100}%\n'f'Origin Score: {accu_origi_score}/{total_score}, {round(accu_origi_score/total_score,4)*100}%\n')上面代碼中:
-
首先傳入測試集和推理的結果,并確保兩個集合是一樣大的;
-
然后這里為了實現文本的向量化,我們采用LazyLLM的TrainableModule來加載一個bge-large-zh-v1.5模型,并采用.start給它部署起來;
-
接著我們遍歷所有數據,計算三個指標下的每次得分,并累計起來;
-
最后我們保存所有結果,并計算最終的評價結果并以字符串返回。
評測結果對比
這里我們對比了微調前模型Internlm2-Chat-7B,及其微調后的模型,同時我們還對比了線上模型DeepSeek-V3。
下表結果中,括號內是得分,總分是1002分,百分比是得分占總分的百分比。
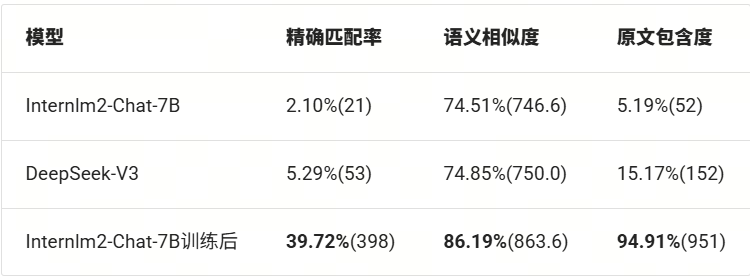
從上面的評測結果我們可以看出,微調后的模型要比微調前,甚至是在線大模型的各項指標都要明顯好。
1.精確匹配率飛躍
-
微調后提升 37.62個百分點(2.10% → 39.72%),超過在線模型近8倍
-
說明模型學會遵循特定答案格式
2.語義相關性優化
-
相似度提升11.68個百分點(74.51% → 86.19%)
-
與在線模型(600多B的大模型)對比:+11.34個百分點優勢
3.原文依賴度質變
-
包含度從5.19%躍升至94.91%,提升幅度達18.3倍
-
表明模型已掌握:
? 關鍵信息定位能力
? 原文提取策略
? 知識邊界控制(避免幻覺)
📌基于實驗數據我們可以得出結論:
RAG系統中,在召回模塊準確和召回無誤的前提下,生成模塊中模型對任務的適應程度大大影響著最終的效果,而微調是一個有效的手段可以提升模型適應下游任務的能力,甚至通過微調后提升的該能力是可以很好超過通用大模型的。
通用評測對比
這里我們基于提升RAG召回![]() https://mp.weixin.qq.com/s?__biz=Mzg2NTIzODc3OQ==&mid=2247485181&idx=1&sn=770e9fe8575f8ae0be336fec28774cf9&scene=21#wechat_redirect中介紹的兩個通用生成模塊的評價指標來評測一下模型,并與我們設計的評價指標做對比。
https://mp.weixin.qq.com/s?__biz=Mzg2NTIzODc3OQ==&mid=2247485181&idx=1&sn=770e9fe8575f8ae0be336fec28774cf9&scene=21#wechat_redirect中介紹的兩個通用生成模塊的評價指標來評測一下模型,并與我們設計的評價指標做對比。
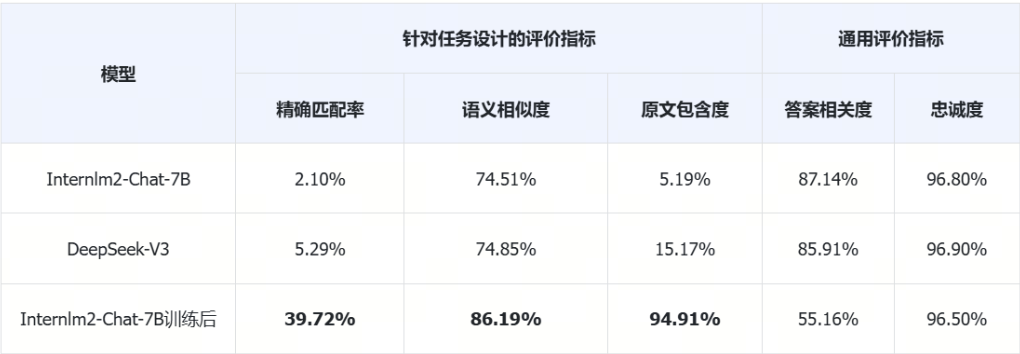
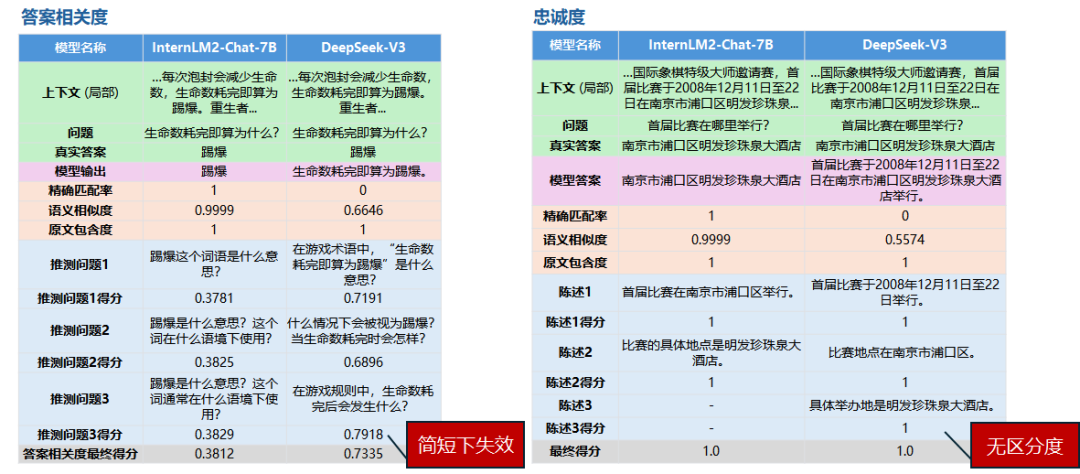
從上面表格的數據我們可以看到通用評價指標顯示,在微調之后模型的答案相關度明顯下降了,在這評價指標下說明微調是失敗的,但真的如此嗎?讓我們抽取評測過程的數據來看看吧:
InternLM2-Chat-7B微調后,答案相關度
{"context": "基于《跑跑卡丁車》與《泡泡堂》上所開發的游戲,由韓國Nexon開發與發行。中國大陸由盛大游戲運營,這是Nexon時隔6年再次授予盛大網絡其游戲運營權。臺灣由游戲橘子運營。玩家以水槍、小槍、錘子或是水炸彈泡封敵人(玩家或NPC),即為一泡封,將水泡擊破為一踢爆。若水泡未在時間內踢爆,則會從水泡中釋放或被隊友救援(即為一救援)。每次泡封會減少生命數,生命數耗完即算為踢爆。重生者在一定時間內為無敵狀態,以踢爆數計分較多者獲勝,規則因模式而有差異。以2V2、4V4隨機配對的方式,玩家可依勝場數爬牌位(依序為原石、銅牌、銀牌、金牌、白金、鉆石、大師) ,可選擇經典、熱血、狙擊等模式進行游戲。若游戲中離,則4分鐘內不得進行配對(每次中離+4分鐘)。開放時間為暑假或寒假期間內不定期開放,8人經典模式隨機配對,采計分方式,活動時間內分數越多,終了時可依該名次獲得獎勵。","exact_score": 1,"cosine_score": 0.9999,"origin_score": 1,"question": "生命數耗完即算為什么?","true_answer": "踢爆","answer": "踢爆","infer_questions": [{"question": "\n踢爆這個詞語是什么意思?","score": 0.3781},{"question": "\n踢爆是什么意思?這個詞在什么語境下使用?","score": 0.3825},{"question": "\n踢爆是什么意思?這個詞通常在什么語境下使用?","score": 0.3829}],"final_score": 0.3812
},DeepSeek-V3,答案相關度
{"context": "基于《跑跑卡丁車》與《泡泡堂》上所開發的游戲,由韓國Nexon開發與發行。中國大陸由盛大游戲運營,這是Nexon時隔6年再次授予盛大網絡其游戲運營權。臺灣由游戲橘子運營。玩家以水槍、小槍、錘子或是水炸彈泡封敵人(玩家或NPC),即為一泡封,將水泡擊破為一踢爆。若水泡未在時間內踢爆,則會從水泡中釋放或被隊友救援(即為一救援)。每次泡封會減少生命數,生命數耗完即算為踢爆。重生者在一定時間內為無敵狀態,以踢爆數計分較多者獲勝,規則因模式而有差異。以2V2、4V4隨機配對的方式,玩家可依勝場數爬牌位(依序為原石、銅牌、銀牌、金牌、白金、鉆石、大師) ,可選擇經典、熱血、狙擊等模式進行游戲。若游戲中離,則4分鐘內不得進行配對(每次中離+4分鐘)。開放時間為暑假或寒假期間內不定期開放,8人經典模式隨機配對,采計分方式,活動時間內分數越多,終了時可依該名次獲得獎勵。","exact_score": 0,"cosine_score": 0.6646,"origin_score": 1,"question": "生命數耗完即算為什么?","true_answer": "踢爆","answer": "生命數耗完即算為踢爆。","infer_questions": [{"question": "\n在游戲術語中,\"生命數耗完即算為踢爆\"是什么意思?","score": 0.7191},{"question": "\n什么情況下會被視為踢爆?當生命數耗完時會怎樣?","score": 0.6896},{"question": "\n在游戲規則中,生命數耗完后會發生什么?","score": 0.7918}],"final_score": 0.7335
},上面對比中,true_answer是標注的答案,answer是模型推理的答案, question是問題,答案相關度需要根據模型推理的答案answer來生成可能的問題(infer_questions中的question),這里是三個,然后讓可能的問題與真實問題在向量化后求余弦相似度。在簡短的answer之下,模型很難推測出和真實問題question相關的問題。
-
微調后的InternLM2-Chat-7B的answer是:"踢爆"
-
DeepSeek-V3的answer是:"生命數耗完即算為踢爆。"
可以看到DeepSeek-V3因為提供的信息更多,所以評價模型推測出來的問題更加準確,所以得分就更高。但實際上這不符合我們的預期,我們希望它簡短準確,正如標準答案"踢爆"一樣!與之對應的我們這里采用的語義相似度cosine_score和exact_score精準匹配度就很好的反映預期。
忠誠度在這里幾乎沒有什么區分度:
InternLM2-Chat-7B微調后,忠誠度:
{"context": "中國(南京)國際象棋超級大賽(Pearl Spring Super Tournament)原名中國(南京)國際象棋特級大師邀請賽,首屆比賽于2008年12月11日至22日在南京市浦口區明發珍珠泉大酒店舉行。本次大賽由南京市人民政府、國家體育總局棋牌運動管理中心主辦,浦口區人民政府、南京市體育局承辦,康緣藥業股份有限公司、揚子晚報、蒙代爾國際企業家大學協辦。被國際棋聯定為21級賽事,也是亞洲迄今為止舉辦的最高水平的國際象棋大賽。雙循環賽制比賽十輪,12月11日至15日進行前5輪,16日休息,17至21日進行后5輪。每方90分鐘,每步棋加30秒。總獎金25萬歐元,其中冠軍8萬歐元,第2至6名依次為5萬5千歐元、4萬歐元、3萬歐元、2萬5千歐元、2萬歐元。結果托帕洛夫奪得冠軍,阿羅尼揚獲得亞軍,卜祥志獲得第三名。2009年2月1日被接納為大滿貫賽事并更名為中國(南京)國際象棋超級大賽。第二屆比賽于2009年9月27日-10月9日舉行。“康緣藥業杯”2010中國(南京)國際象棋超級大賽于2010年10月19-30日舉行","exact_score": 1,"cosine_score": 0.9999,"origin_score": 1,"question": "首屆比賽在哪里舉行?","true_answer": "南京市浦口區明發珍珠泉大酒店","answer": "南京市浦口區明發珍珠泉大酒店","statements": "\n首屆比賽在南京市浦口區舉行。|||比賽的具體地點是明發珍珠泉大酒店。","scores": [{"statement": "首屆比賽在南京市浦口區舉行。","score": 1},{"statement": "比賽的具體地點是明發珍珠泉大酒店。","score": 1}],"final_score": 1.0
},DeepSeek-V3,忠誠度:
{"context": "中國(南京)國際象棋超級大賽(Pearl Spring Super Tournament)原名中國(南京)國際象棋特級大師邀請賽,首屆比賽于2008年12月11日至22日在南京市浦口區明發珍珠泉大酒店舉行。本次大賽由南京市人民政府、國家體育總局棋牌運動管理中心主辦,浦口區人民政府、南京市體育局承辦,康緣藥業股份有限公司、揚子晚報、蒙代爾國際企業家大學協辦。被國際棋聯定為21級賽事,也是亞洲迄今為止舉辦的最高水平的國際象棋大賽。雙循環賽制比賽十輪,12月11日至15日進行前5輪,16日休息,17至21日進行后5輪。每方90分鐘,每步棋加30秒。總獎金25萬歐元,其中冠軍8萬歐元,第2至6名依次為5萬5千歐元、4萬歐元、3萬歐元、2萬5千歐元、2萬歐元。結果托帕洛夫奪得冠軍,阿羅尼揚獲得亞軍,卜祥志獲得第三名。2009年2月1日被接納為大滿貫賽事并更名為中國(南京)國際象棋超級大賽。第二屆比賽于2009年9月27日-10月9日舉行。“康緣藥業杯”2010中國(南京)國際象棋超級大賽于2010年10月19-30日舉行","exact_score": 0,"cosine_score": 0.5574,"origin_score": 1,"question": "首屆比賽在哪里舉行?","true_answer": "南京市浦口區明發珍珠泉大酒店","answer": "首屆比賽于2008年12月11日至22日在南京市浦口區明發珍珠泉大酒店舉行。","statements": "\n首屆比賽于2008年12月11日至22日舉行。|||比賽地點在南京市浦口區。|||具體舉辦地是明發珍珠泉大酒店。","scores": [{"statement": "首屆比賽于2008年12月11日至22日舉行。","score": 1},{"statement": "比賽地點在南京市浦口區。","score": 1},{"statement": "具體舉辦地是明發珍珠泉大酒店。","score": 1}],"final_score": 1.0
},上面的對比中,我們可以看到DeepSeek-V3雖然提供了更多的信息,但它和微調后的模型一樣,基本都按照要求使用原文中的內容來回答,所以雖然它的statement更多(3條),但最終得分和微調后模型一樣。這也就解釋了為什么最終的忠誠度得分沒有區分度。值得注意的是這里用cosine_score語義相似度和exact_score精確匹配度,很好區分了兩者的差異。
從上面的兩個指標的對比結果我們可以看到,如果對RAG系統中的生成模塊有特定的任務要求,常用的評價指標并不能很好衡量,此時就需要針對任務的最終效果需求來進行評價指標的設計!
4.在RAG中使用微調好的大模型
LazyLLM支持微調、部署、推理一條龍,但如果已微調好一個大模型,想直接使用它應該怎么辦呢?很簡單:其中的base_model不變,用target_path指定微調好的模型路徑即可,如下所示:
base_model = 'internlm2-chat-7b'
sft_model = '/path/to/sft/internlm2-chat-7b'
llm = lazyllm.TrainableModule(base_model, sft_model)以基礎的RAG為例就是:
import os
import lazyllm
prompt = ('You will act as an AI question-answering assistant and complete a dialogue task.''In this task, you need to provide your answers based on the given context and questions.')
base_model = 'internlm2-chat-7b'
sft_model = '/path/to/sft/internlm2-chat-7b'
llm = lazyllm.TrainableModule(base_model, sft_model)
documents = lazyllm.Document(dataset_path=os.path.join(os.getcwd(), "KB"), embed=embed = lazyllm.TrainableModule('bge-large-zh-v1.5'), manager=False)
documents.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
with lazyllm.pipeline() as ppl:ppl.retriever = lazyllm.Retriever(doc=documents, group_name="split_sent", similarity="cosine", topk=1, output_format='content', join='')ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | lazyllm.bind(query=ppl.input)ppl.llm = llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
ppl.start()基于LazyLLM對Embedding模型進行微調
在RAG(Retrieval-Augmented Generation)系統中,Embedding模型承擔著關鍵作用:
-
語義編碼:將文本數據轉換為高維向量表示,保留語義信息
-
相似度計算:通過向量余弦相似度實現高效的相關性檢索
-
知識庫索引:預先編碼文檔庫,建立快速檢索的向量索引
-
查詢理解:將用戶query轉換為向量,匹配最相關的知識片段
在本教程中,我們將使用BAAI的bge-large-zh-v1.5作為基礎模型,通過金融領域數據微調(SFT)來提升垂直領域效果。
1.數據準備
在 embedding 學習中,我們的目標是讓:
-
語義相似的樣本(正樣本對,positive pair)在向量空間中更靠近。
-
語義無關或相反的樣本(負樣本對,negative pair)距離更遠。
而負樣本的作用是提供一個對比參照,讓模型知道“哪些是不該靠近的”。例如當我們的query為“ChatGPT是什么?”的時候,我們的正樣本的doc為“ChatGPT 是由 OpenAI 開發的語言模型,基于 Transformer 架構……”,我們的負樣本的doc可以設置為“Midjourney 是一個 AI 圖像生成模型……”。
這里我們使用金融問答數據集:virattt/financial-qa-10K(https://huggingface.co/datasets/virattt/financial-qa-10K)來進行演示:
數據處理流程:
-
加載原始數據集
-
生成負樣本(每個樣本10個負例)
-
創建訓練集/評測集分割(9:1比例)
-
構建知識庫文件
主要代碼實現如下所示:
def build_dataset_corpus(instruction: str, neg_num: int = 10, test_size: float = 0.1, seed: int = 1314) -> tuple:"""Process dataset and create training/evaluation files.Args:instruction (str): Instruction template for promptsneg_num (int): Number of negative samples per instancetest_size (float): Proportion of data for test splitseed (int): Random seed for reproducibilityReturns:tuple: Paths to training data, evaluation data, and knowledge base directory"""# Load and preprocess datasetds = load_dataset("virattt/financial-qa-10K", split="train")ds = ds.select_columns(column_names=["question", "context"])ds = ds.rename_columns({"question": "query", "context": "pos"})# Generate negative samplesnp.random.seed(seed)new_col = []for i in range(len(ds)):ids = np.random.randint(0, len(ds), size=neg_num)while i in ids: # Ensure no self-match in negativesids = np.random.randint(0, len(ds), size=neg_num)neg = [ds[int(i)]["pos"] for i in ids]new_col.append(neg)# Create dataset splitsds = ds.add_column("neg", new_col)def str_to_lst(data):data["pos"] = [data["pos"]]return datads = ds.map(str_to_lst) # Convert pos to list formatds = ds.add_column("prompt", [instruction] * len(ds))split = ds.train_test_split(test_size=test_size, shuffle=True, seed=seed)# Save training datatrain_data_path = build_data_path('dataset', 'train.json')split["train"].to_json(train_data_path)# Process and save evaluation datatest = split["test"].select_columns(["query", "pos"]).rename_column("pos", "corpus")eval_data_path = build_data_path('dataset', 'eval.json')test.to_json(eval_data_path)# Create knowledge basekb_data_path = build_data_path('KB', 'knowledge_base.txt')corpus = "\n".join([''.join(item) for item in test['corpus']])with open(kb_data_path, 'w', encoding='utf-8') as f:f.write(corpus)return train_data_path, eval_data_path, os.path.dirname(kb_data_path)經過處理后,訓練集的一條數據如下(json文件):
{"query":"What was the total stockholder's equity (deficit) for Peloton Interactive, Inc. as of June 30, 2021?","pos":["As of June 30, 2021, Peloton Interactive, Inc.'s consolidated statements reflected a total stockholder's equity (deficit) of $1,754.1 million."],"neg":["In June 2023, the company entered into an ASR agreement to repurchase $500 million of its common stock with a completion date no later than August 2023, and in 2024, the company expects to repurchase $2.0 billion of its common stock.",...,"\u2022Overhead costs as a percentage of net sales increased 40 basis points due to wage inflation and other cost increases, partially offset by the positive scale impacts of the net sales increase and productivity savings."],"prompt":"Represent this sentence for searching relevant passages: "}需要包含如下字段:
-
query: (str)用戶提問
-
pos:(List[str])正確答案段落
-
neg:(List[str])隨機采樣的負樣本
-
prompt: (str)指令模板
評測集的一條數據如下(json文件):
{"query":"How have certain vendors been impacted in the supply chain financing market?","corpus":["Certain vendors have been impacted by volatility in the supply chain financing market."]}需要包含如下字段:
-
query: 用戶提問
-
corpus: 對應提問的正確文本片段
知識庫局部如下(txt文件):
Certain vendors have been impacted by volatility in the supply chain financing market.
Recruitment As the demand for global technical talent continues to be competitive, we have grown our technical workforce and have been successful in attracting top talent to NVIDIA. We have attracted strong talent globally with our differentiated hiring strategies for university, professional, executive and diverse recruits. The COVID-19 pandemic created expanded hiring opportunities in new geographies and provided increased flexibility for employees to work from locations of their choice. Our workforce is about 80% technical and about 50% hold advanced degrees.
In 2023, Moody’s Investors Service upgraded AbbVie’s senior unsecured long-term credit rating to A3 with a stable outlook from Baa1 with a positive outlook.2.微調過程
通過LazyLLM框架進行分布式微調:
embed = lazyllm.TrainableModule(embed_path)\.mode('finetune').trainset(train_data_path)\.finetune_method((lazyllm.finetune.flagembedding,{'launcher': lazyllm.launchers.remote(nnode=1, nproc=1, ngpus=4),'per_device_train_batch_size': 16,'num_train_epochs': 2,}))docs = Document(kb_path, embed=embed, manager=False)
docs.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
retriever = lazyllm.Retriever(doc=docs, group_name="split_sent", similarity="cosine", topk=1)
retriever.update()這里代碼和前面使用LazyLLM的TrainableModule來對LLM進行微調的配置是一致的:
-
embed_path: 用于指定微調的模型;
-
train_data_path:用于訓練的數據集路徑;
-
lazyllm.finetune.flagembedding: 指定微調的框架;
關鍵參數:
-
ngpus=4: 使用4張GPU進行并行訓練
-
per_device_batch_size=16: 每GPU批處理大小
-
num_train_epochs=2: 訓練2個epoch
值得注意的是,這里的代碼我們不僅給了embed的微調配置參數,同時后面還將其放入到了Document中,Document注冊了一個按照換行符來分割知識庫文檔的策略,最后還配置了Retriever作用在文檔及其對應的切分方式上,并以余弦相似度作為度量工具,同時讓只返回最相關的一個文本段(topk=1)。因為LazyLLM是支持一鍵微調、部署和推理的,所以當執行update()后,LazyLLM會先對embed模型進行微調,然后將微調后的模型部署起來,為Document和Retriever提供向量化。
3.效果評測
這里我們使用前面教程介紹過的上下文召回率和上下文相關度來評測我們微調后的模型,作為對照,這里我們采用
bge-large-zh-v1.5來作為基模型,對照其微調前后的兩個指標下的變化。
評價指標的調用如下所示:
from lazyllm.tools.eval import NonLLMContextRecall, ContextRelevance
def evaluate_results(data: list) -> tuple:"""Evaluate retrieval results using multiple metrics.Args:data (list): List of retrieval results to evaluateReturns:tuple: Evaluation scores (context recall, context relevance)"""recall_eval = NonLLMContextRecall(binary=False)relevance_eval = ContextRelevance()return recall_eval(data), relevance_eval(data)微調、部署和推理的邏輯主要如下:
# Prepare dataset
train_data_path, eval_data_path, kb_path = build_dataset_corpus(instruction=args.instruction,neg_num=args.neg_num,test_size=args.test_size,seed=args.seed
)
# Deploy retrieval service
retriever = deploy_serve(kb_path=kb_path,embed_path=args.embed_path,train_data_path=train_data_path,train_flag=args.train_flag,per_device_batch_size=args.per_device_batch_size,num_epochs=args.num_epochs,ngpus=args.ngpus
)
# Run SFT or Evaluation
results = []
query_corpus = load_json(eval_data_path)
for item in tqdm(query_corpus, desc="Processing queries"):query = item['query']inputs = f"{args.instruction}{query}" if args.use_instruction or args.train_flag else queryretrieved = retriever(inputs)results.append({'question': query,'context_retrieved': [text.get_text() for text in retrieved],'context_reference': item['corpus']})
# Save and report results
save_json(results, args.output_path)
recall_score, relevance_score = evaluate_results(results)
print(f"Evaluation Complete!\nContext Recall: {recall_score}\nContext Relevance: {relevance_score}")基于上面的邏輯,我們獲得如下結果:
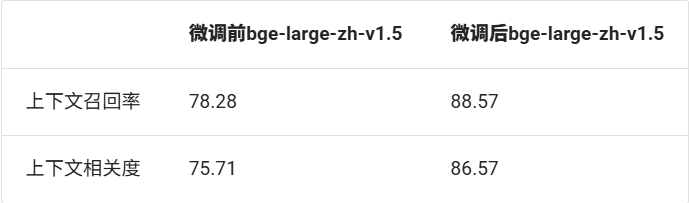
可以看到,在微調后,兩個指標都得到了顯著的提升。說明微調是有效的!整體的評估流程為:加載評測集 → 使用檢索服務(微調后部署起來的服務)→ 執行批量推理 → 計算雙指標。
4.在RAG中使用微調好的Embedding模型
和使用微調好的LLM類似,這里我們也可以使用微調好的Embedding模型,如下所示:
import os
import lazyllm
prompt = ('You will act as an AI question-answering assistant and complete a dialogue task.''In this task, you need to provide your answers based on the given context and questions.')
embed = lazyllm.TrainableModule('bge-large-zh-v1.5', 'path/to/sft/bge')
documents = lazyllm.Document(dataset_path=os.path.join(os.getcwd(), "KB"), embed=embed, manager=False)
documents.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
with lazyllm.pipeline() as ppl:ppl.retriever = lazyllm.Retriever(doc=documents, group_name="split_sent", similarity="cosine", topk=1, output_format='content', join='')ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | lazyllm.bind(query=ppl.input)ppl.llm = lazyllm.OnlineChatModule(source="sensenova")\.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
ppl.start()擴展閱讀
1.更多微調方法
從模型中被更新的參數范圍的角度來看,除了上述介紹的LoRA微調之外,常見的微調有全參數微調、凍結微調等。
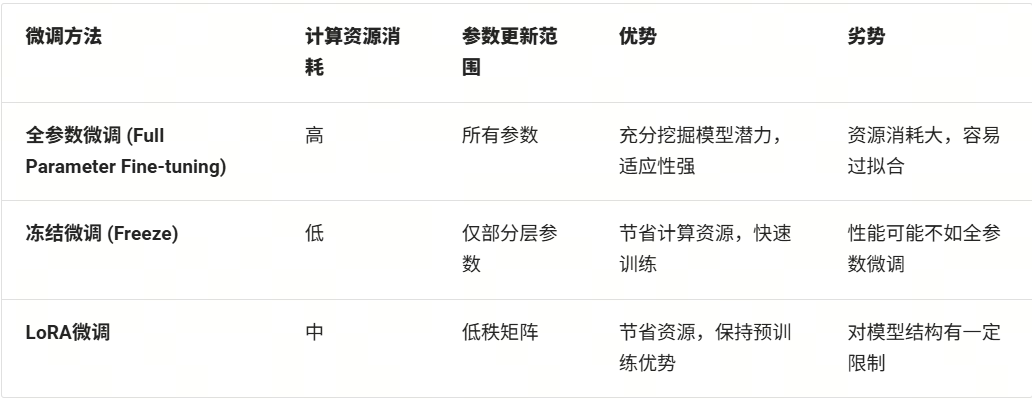
1. 全參數微調
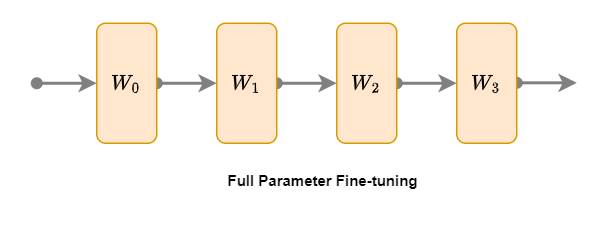
全參數微調(Full Parameter Fine-tuning)是一種最直接的微調方法,其主要思想是在預訓練模型(已微調的模型上也行)的基礎上,針對特定任務對整個模型的所有參數進行微調。如上圖所示,模型四層橙色的參數:W1、W2、W3、W4 都要參與微調。具體步驟如下:
1.加載預訓練模型:使用預訓練好的大語言模型作為基礎模型。
2.準備任務數據:根據特定任務,收集并整理相關數據。
3.微調模型:將任務數據輸入模型,通過反向傳播算法更新模型的所有參數。
4.評估與優化:在驗證集上評估微調后的模型性能,根據需求進行優化。
全參數微調的優勢在于能夠充分挖掘模型在特定任務上的潛力,但缺點是計算資源消耗較大,且容易過擬合。
2. 凍結微調
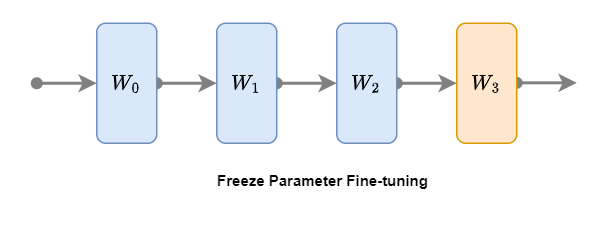
凍結微調(Freeze Parameter Fine-tuning)是一種節省計算資源的微調方法。在凍結微調過程中,預訓練模型(已微調的模型上也行)的底層參數保持不變,僅對部分層參數進行微調(凍結微調可以凍結任意層,常見的是對模型頂層進行微調)。如上圖所示,將模型前三層藍色W0、W1和W2進行凍結,僅微調最后一層(頂層)橙色W3。具體步驟如下:
1.加載預訓練模型:使用預訓練好的大語言模型。
2.凍結底層參數:將模型底層參數固定,不參與訓練。
3.微調頂層參數:將任務數據輸入模型,僅更新頂層參數。
4.評估與優化:在驗證集上評估模型性能,根據需求進行優化。
凍結微調的優勢在于計算資源消耗較小,但相較于全參數微調,模型性能可能會有所下降。
我們將這幾種微調技術總結如下:
2.微調數據格式
前文簡單提及了我們將數據集字段處理成了:Instruction、input和output的格式,這屬于Alpaca指令微調的數據格式。這里我們不僅詳細介紹該指令微調格式,而且還介紹另外一種常用格式:OpenAI 指令微調數據格式。
1. Alpaca 指令微調數據格式
Alpaca 格式是一種用于指令微調的數據格式,它包含了指令、輸入、輸出、系統提示詞和歷史對話等信息。該格式適用于單輪和多輪對話場景,允許模型根據歷史信息生成更準確的回答。
數據基本格式
該數據的基本結構如下:
[{"instruction": "人類的指令(必填)","input": "人類的輸入(選填)","output": "模型的回答(必填)","system": "系統的提示詞(選填)","history": [["第一輪的指令(選填)", "第一輪的回答(選填)"],["第二輪的指令(選填)", "第二的輪回答(選填)"]]}
]1. “instruction”(必填)
-
描述:這個字段包含了用戶給出的指令或問題,是模型需要理解和響應的核心內容。
-
示例:對于單輪對話,可能是“請告訴我今天的天氣情況。”;對于多輪對話,可能是“我想了解關于人工智能的信息。”
2. “input”(選填)
-
描述:這個字段用于提供額外的輸入信息,可能是與指令相關的背景信息、上下文或具體數據。
-
示例:在單輪對話中,如果指令是“翻譯以下句子”,則輸入可能是“Hello, how are you?”;在多輪對話中,可能不填或提供上一輪對話的補充信息。
3. “output”(必填)
-
描述:這個字段包含了模型針對指令和輸入生成的回答或輸出。
-
示例:對于單輪對話,可能是“今天天氣晴朗,溫度為20攝氏度。”;對于多輪對話,可能是“人工智能是模擬人類智能行為的技術。”
4. “system”(選填)
-
描述:這個字段用于提供系統級別的提示詞或指令,可以指導模型的行為或回答風格。
-
示例:可能是“請以正式的語氣回答。”或“在回答時盡量使用簡單詞匯。”
5. “history”(選填)
-
描述:這個字段是一個數組,用于存儲多輪對話的歷史信息,每個元素是一個包含兩個字符串的數組,分別代表一輪對話中的用戶指令和模型回答。
-
示例:在多輪對話中,可能包含如下歷史信息:
[["什么是人工智能?", "人工智能是模擬人類智能行為的技術。"],["人工智能有哪些應用?", "人工智能應用于自動駕駛、語音識別、圖像處理等領域。"]
]單輪對話示例
[{"instruction": "請告訴我今天的天氣情況。","input": "","output": "今天天氣晴朗,溫度為20攝氏度。","system": "","history": []}
]多輪對話示例
[{"instruction": "我想了解關于人工智能的信息。","input": "","output": "人工智能是模擬人類智能行為的技術。","system": "","history": [["什么是人工智能?", "人工智能是模擬人類智能行為的技術。"],["人工智能有哪些應用?", "人工智能應用于自動駕駛、語音識別、圖像處理等領域。"]]}
]2.OpenAI 指令微調數據格式
OpenAI 格式是一種用于指令微調的數據格式,它通過角色(role)和內容(content)來組織對話。角色可以是系統(system)、用戶(user)或助手(assistant),內容則是對應角色的發言。該格式同樣適用于單輪和多輪對話場景。
數據基本格式
該數據的基本結構如下:
{"messages": [{"role": "system","content": "系統提示詞(選填)"},{"role": "user","content": "人類指令"},{"role": "assistant","content": "模型回答"}]
}1. “messages”
-
描述:這個字段是一個數組,包含了整個對話的所有輪次,每個輪次由 “role” 和 “content” 組成。
2. “role”
-
描述:這個字段表示消息的角色,可以是 “system”、“user” 或 “assistant”。
??“system”:系統提示詞,用于提供背景信息或指導模型的行為。
??“user”:用戶角色,表示用戶的指令或問題。
??“assistant”:助手角色,表示模型的回答或輸出。
3. “content”
-
描述:這個字段包含了對應角色的具體內容。
-
示例:對于 “system” 角色,可能是“請以友好的語氣回答。”;對于 “user” 角色,可能是“我想了解關于人工智能的信息。”;對于 “assistant” 角色,可能是“人工智能是模擬人類智能行為的技術。”
單輪對話示例
{"messages": [{"role": "system","content": ""},{"role": "user","content": "請告訴我今天的天氣情況。"},{"role": "assistant","content": "今天天氣晴朗,溫度為20攝氏度。"}]
}多輪對話示例
{"messages": [{"role": "system","content": ""},{"role": "user","content": "我想了解關于人工智能的信息。"},{"role": "assistant","content": "人工智能是模擬人類智能行為的技術。"},{"role": "user","content": "人工智能有哪些應用?"},{"role": "assistant","content": "人工智能應用于自動駕駛、語音識別、圖像處理等領域。"}]
}更多技術內容,歡迎移步“LazyLLM”gzh!





)













