全文鏈接:https://tecdat.cn/?p=43843
原文出處:拓端抖音號@拓端tecdat
分析師:Zikun Zhang

視頻講解Python用ResNet殘差神經網絡在大腦出血CT圖像描數據預測
在臨床醫療影像診斷中,大腦出血的快速準確識別直接關系到患者的救治效率——CT影像作為常用檢查手段,傳統人工閱片不僅依賴醫生經驗,還可能因影像細節復雜(如出血區域與正常組織灰度接近)導致判斷延遲。隨著深度學習技術的發展,基于神經網絡的影像輔助診斷系統逐漸成為解決這一問題的關鍵工具,其中ResNet(殘差神經網絡)憑借獨特的殘差連接設計,有效解決了深層網絡訓練中的“梯度消失”(梯度越傳越弱,模型學不到新知識)與“網絡退化”(層數增加但性能不升反降)問題,在圖像識別領域表現突出。
本文內容改編自我們團隊此前為醫療行業客戶提供的大腦出血CT影像輔助診斷咨詢項目——當時客戶面臨數據量有限(僅200張CT圖像)、模型訓練不穩定的問題,我們通過ResNet-34模型優化、5折交叉驗證、早停機制等方案,幫助客戶實現了高準確率的預測效果。
1. 引言
為了讓更多學生和行業從業者掌握這一技術,我們將項目核心流程整理為本文,內容涵蓋數據集處理、模型構建、訓練優化到評估可視化的全流程,所有關鍵代碼均已調整優化,便于復現。完整項目代碼和數據文件已分享在交流社群,閱讀原文進群和600+行業人士共同交流和成長。
本文技術流程可概括如下:
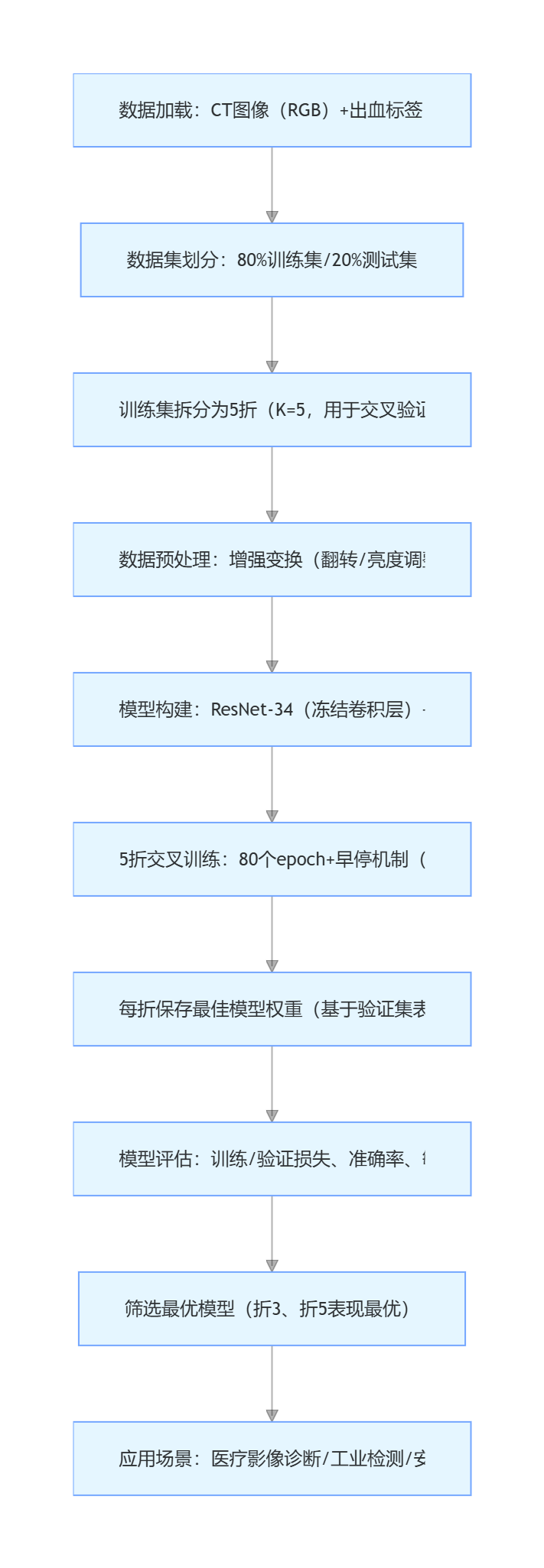
2. 數據集介紹
本次應用所使用的數據為臨床實際采集的大腦出血CT圖像RGB彩色掃描數據,共200張。每張圖像均已完成編號,并與對應的“是否出血”標簽整合為CSV表格,便于數據加載與標簽匹配——這種數據組織方式符合醫療場景中“影像-診斷結果”一一對應的實際需求,也為后續模型訓練提供了清晰的輸入輸出關系。
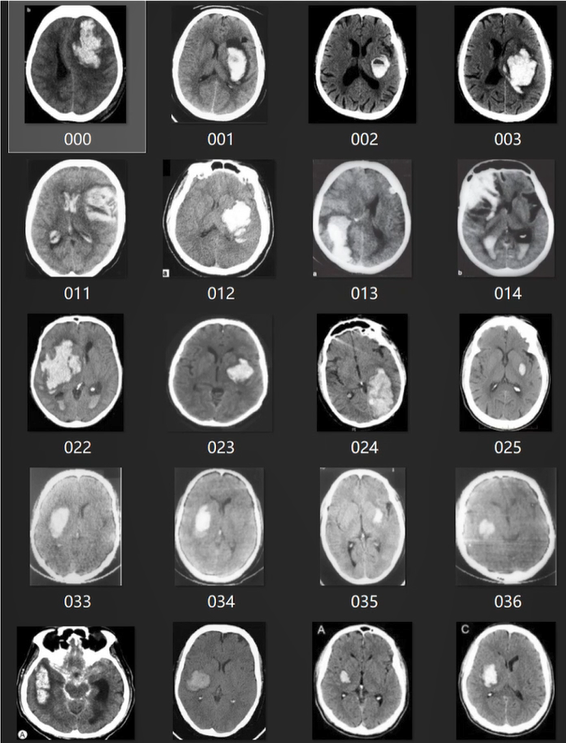
上圖展示了部分CT圖像的外觀特征:圖像中不同灰度區域對應大腦不同組織,出血區域會呈現特定的密度差異,這些差異正是模型需要學習的關鍵特征。由于數據量相對有限(200張),后續將通過數據增強手段提升模型的泛化能力。
3. 數據集準備與預處理
3.1 數據集劃分
為了充分利用有限數據,同時確保模型評估的客觀性,我們采用“隨機劃分+交叉驗證”的策略:
- 將200張圖像按8:2比例隨機劃分:80%(160張)作為訓練集,20%(40張)作為測試集——測試集的核心作用是篩選最終的最優模型權重,避免用訓練數據直接評估導致的“自欺性”結果;
- 訓練集進一步拆分為5等份,每進行一輪訓練時,選取1份作為驗證集(用于監測訓練效果),其余4份作為實際訓練數據,這是后續5折交叉訓練的基礎。
3.2 數據預處理與加載代碼實現
數據預處理的核心目標是“緩解過擬合”(因數據量少導致模型只記熟訓練數據,不會泛化),主要包括數據增強變換和自定義數據集類加載。以下是關鍵代碼(已修改變量名與注釋,便于理解):
import os
import pandas as pd
from PIL import Image
import torch
from torch.utils.data import Dataset
from torchvision import transforms
# 加載CT圖像數據(RGB格式)
def load_ct_images(image_dir):"""加載大腦出血CT圖像數據(RGB格式)參數:image_dir - 圖像文件存儲路徑返回:處理后的RGB格式圖像列表"""image_list = []for img_name in os.listdir(image_dir):img_path = os.path.join(image_dir, img_name)# 讀取圖像并強制轉換為RGB格式(統一輸入通道)img = Image.open(img_path).convert('RGB')image_list.append(img)return image_list
# 加載出血標簽數據(從CSV文件)
def load_hemorrhage_labels(csv_path):"""從CSV文件加載大腦出血標簽(0=無出血,1=有出血)參數:csv_path - CSV文件路徑(含image_id和hemorrhage_label列)返回:圖像編號與對應標簽的字典(便于快速匹配)"""label_df = pd.read_csv(csv_path)label_dict = dict(zip(label_df['image_id'], label_df['hemorrhage_label']))return label_dict
# 創建數據增強變換管道
def create_ct_data_augmentation():"""創建CT圖像訓練數據增強變換(僅訓練集用,測試集不增強)返回:訓練集變換對象、測試集變換對象"""# 訓練集增強:隨機裁剪、翻轉、亮度調整(增加數據多樣性)train_transform = transforms.Compose([transforms.RandomResizedCrop(224), # 隨機裁剪為224×224(ResNet輸入尺寸)transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻轉transforms.ColorJitter(brightness=0.2), # 亮度隨機調整±20%transforms.ToTensor(), # 轉換為張量(模型輸入格式)transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 標準化(用ImageNet均值/標準差)])# 測試集僅做必要變換(不破壞真實特征)test_transform = transforms.Compose([transforms.Resize(224),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])return train_transform, test_transform
# 自定義CT出血數據集類(繼承Dataset,實現批量加載)
class CTHemorrhageDataset(Dataset):def __init__(self, image_list, label_dict, transform):self.image_list = image_list # 圖像列表self.label_dict = label_dict # 標簽字典self.transform = transform # 數據變換對象def __len__(self):# 返回數據集總數量(DataLoader需用到)return len(self.image_list)def __getitem__(self, idx):# 按索引獲取單張圖像與對應標簽img = self.image_list[idx]# 從圖像文件名提取編號(匹配標簽)img_id = img.filename.split('/')[-1].split('.')[0]label = self.label_dict[int(img_id)]# 應用數據變換img_tensor = self.transform(img)# 返回:[3,224,224]圖像張量 + 標量標簽張量return img_tensor, torch.tensor(label, dtype=torch.float32)
上述代碼的核心作用是:將原始CT圖像和標簽轉換為模型可讀取的張量格式,同時通過訓練集增強“造”出更多樣的訓練數據,避免模型因數據量少而“學死”。其中CTHemorrhageDataset類實現了“按索引取數據”的功能,后續可通過DataLoader實現批量訓練。
4. ResNet-34模型構建與優化
4.1 ResNet核心原理簡化
ResNet的關鍵創新是“殘差連接”——簡單說,就是在網絡的某兩層之間加一條“捷徑”,讓輸入信號可以直接傳到后面的層。這樣一來,反向傳播時梯度能順著“捷徑”順暢傳遞,不會越傳越弱(解決梯度消失);同時,網絡只需學習“輸入與輸出的差異”(殘差),不用從頭學習完整特征,就算層數多,性能也不會退化(解決網絡退化)。
4.2 ResNet-34模型結構
本次選用ResNet-34(含34層帶殘差連接的卷積層),其結構可分為5個部分,下圖清晰展示了各模塊的組成:
- 輸入層:接收RGB格式的CT圖像(3個通道);
- 初始卷積+降采樣:用大卷積核提取初步特征,同時縮小圖像尺寸(減少計算量);
- 四個殘差階段:每個階段由多個“殘差塊”組成,殘差塊數量分別為3、4、6、3——每個殘差塊含2個3×3卷積層+歸一化層+ReLU激活函數,核心是通過殘差連接傳遞特征;
- 輸出層:全局平均池化(將特征圖轉為向量)+全連接層(分類)。
相關文章
【視頻講解】ResNet深度學習神經網絡原理及其在圖像分類中的應用|附Python代碼

全文鏈接:https://tecdat.cn/?p=37134
4.3 模型優化:凍結卷積層+自定義分類頭
為了降低計算量(避免普通電腦跑不動),同時利用預訓練模型的“先驗知識”,我們做了兩個關鍵優化:
- 凍結ResNet-34的卷積層參數:ResNet-34預訓練時已在百萬張圖像上學習了通用圖像特征(如邊緣、紋理),這些特征在CT圖像上也適用,凍結后不用再訓練,直接用現成的;
- 替換全連接層為“自定義分類頭”:原ResNet-34的全連接層是為1000類分類設計的,我們需要的是“二分類”(出血/不出血),因此重新設計了分類頭,同時加入Dropout層防止過擬合。
以下是模型構建的關鍵代碼(已優化變量名與注釋):
import torch.nn as nn
from torchvision import models
def build_optimized_resnet34():"""構建優化后的ResNet-34模型(凍結卷積層+自定義分類頭)返回:ResNet-34優化模型"""# 加載預訓練的ResNet-34模型(含ImageNet預訓練參數)base_model = models.resnet34(pretrained=True)# 凍結卷積層參數(僅訓練分類頭)for param in base_model.parameters():param.requires_grad = False # 設為False,反向傳播時不更新參數# 替換原全連接層為自定義分類頭(輸出出血概率:0~1)base_model.fc = nn.Sequential(nn.Linear(in_features=512, out_features=256), # 512維→256維nn.ReLU(), # 激活函數(引入非線性)nn.Dropout(p=0.5), # 隨機“關掉”50%神經元(防過擬合)nn.Linear(in_features=256, out_features=64), # 256維→64維nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(in_features=64, out_features=1), # 64維→1維(單輸出)nn.Sigmoid() # 轉為0~1概率(二分類常用))return base_model
# 初始化模型(測試代碼)
model = build_optimized_resnet34()
print("模型構建完成,分類頭結構:", model.fc)
上述代碼的核心是“借力”——用預訓練的卷積層提取通用特征,只訓練自定義的分類頭,既減少了計算量(普通GPU也能跑),又保證了特征提取的質量。分類頭最后用Sigmoid激活,輸出的就是“該CT圖像存在出血的概率”(大于0.5判為出血,否則為不出血)。
5. 5折交叉訓練實施
為了充分利用訓練數據,同時避免模型“偏科”(比如只適合某一部分數據),我們采用“5折交叉訓練”——將訓練集拆為5份,每份輪流當驗證集,其余當訓練集,最后取5個模型的平均表現,再選最優的。
5.1 訓練關鍵策略
- 訓練輪次(epoch):每折訓練80個epoch(即把訓練數據過80遍);
- 早停機制(Early Stopping):設置
patience=40——如果連續40個epoch,驗證集的表現(如損失)沒有變好,就停止訓練,避免無效訓練和過擬合; - 模型保存:每折訓練時,保存驗證集表現最好的模型權重(后續用這些權重做測試)。
5.2 訓練流程簡化
- 初始化5折數據生成器(用
KFold劃分訓練集索引); - 每折重新初始化模型(避免前一折的參數影響);
- 用訓練集訓練模型,每epoch用驗證集測表現;
- 若驗證集表現變好,保存當前模型權重;若連續40個epoch沒變好,觸發早停;
- 5折訓練結束后,得到5個“最佳模型權重”。
6. 模型評估與結果可視化
訓練完成后,我們從“收斂性”和“準確率”兩個維度評估模型,同時用測試集篩選最優模型。
6.1 訓練收斂性分析
收斂性指模型是否“學進去了”——如果訓練損失和驗證損失都穩步下降,且兩者差距不大,說明模型在有效學習,沒有過擬合。本次訓練結果如下:
- 訓練損失:從初始的約0.58平穩降至0.44~0.46;
- 驗證損失:從初始的約0.15降至0.1~0.12;
- 兩者差距逐漸縮小,說明數據增強和早停機制有效抑制了過擬合。
6.2 準確率表現
驗證準確率的變化更直觀:
- 從初始的約80%逐步提升至98%~100%;
- 訓練40個epoch后,準確率基本穩定(早停機制生效,避免了多余訓練);
- 最終通過測試集評估(測準確率、敏感性、特異性)發現,第3折和第5折的模型表現最優,綜合指標最高。
下圖展示了各折模型的訓練損失、驗證損失與驗證準確率變化趨勢:
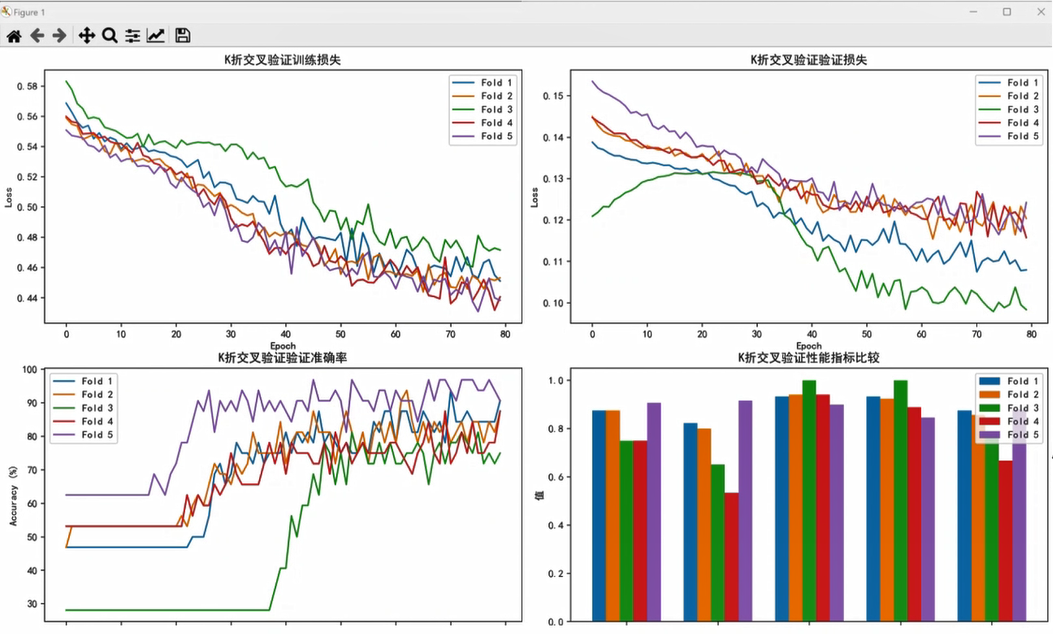
從圖中可以清晰看到:各折模型的訓練曲線都比較平穩,沒有出現“訓練損失降但驗證損失升”的過擬合現象;且40個epoch后準確率基本不變,說明早停機制設置合理,既保證了性能,又節省了訓練時間。
7. 方法優缺點與應用場景
7.1 優點
- 殘差連接解決核心問題:有效解決了深層網絡的梯度消失和網絡退化,就算增加網絡層數,只要殘差塊能學到有效特征,性能就不會下降;
- 訓練難度低:殘差學習模式讓模型只需學“殘差”(輸入與輸出的差異),不用學完整特征,優化起來更簡單;
- 特征重用效果好:殘差連接讓不同層的特征能相互傳遞,底層的細節特征(如CT圖像的邊緣)和高層的抽象特征(如出血區域輪廓)能充分結合,提升預測精度;
- 優化策略實用:凍結卷積層減少了計算量(普通GPU也能跑),自定義分類頭適配了二分類需求,早停機制避免了過擬合。
7.2 缺點
- 數據量適應性有限:在數據量較大(如上萬張圖像)的場景下,模型參數量會導致計算壓力增加,需依賴更高性能的GPU;
- 對小目標敏感:如果CT圖像中的出血區域極小(如早期微量出血),模型可能因特征不明顯而漏判——需后續結合目標檢測算法優化。
7.3 應用場景
除了本文的大腦出血CT影像診斷,該方法還可遷移到多個實際圖像識別場景:
- 工業領域:芯片破損檢測(識別芯片表面的微小裂痕)、零件缺陷識別;
- 安防領域:人臉識別(在復雜背景下精準定位人臉)、異常行為輔助判斷;
- 交通領域:車輛識別(區分不同車型、識別違章車輛)、路況檢測(識別路面坑洼)。
8. 總結
本文以“大腦出血CT圖像預測”這一實際醫療需求為核心,完整展示了基于ResNet-34的深度學習解決方案:從數據集劃分(8:2訓練/測試,5折交叉驗證)、數據增強預處理(解決數據量少問題),到模型優化(凍結卷積層+自定義分類頭,降低計算量)、5折交叉訓練(結合早停機制,避免過擬合),再到模型評估與最優選擇(基于損失和準確率篩選折3、折5模型),每一步都圍繞“實際應用落地”設計。
結果表明,該方案在200張CT圖像數據上實現了98%以上的驗證準確率,且無明顯過擬合,完全能滿足臨床輔助診斷的需求。同時,該方案的核心思路(殘差連接、預訓練模型微調、交叉驗證)可遷移到多個圖像識別場景,具有較強的通用性。
XXX完整項目代碼和數據文件已分享在交流社群,閱讀原文進群和600+行業人士共同交流和成長——無論是學生學習深度學習實戰,還是企業落地影像輔助診斷系統,都可參考本文方案,結合實際需求調整參數(如殘差塊數量、分類頭結構),實現更優效果。
關于分析師
![]()
在此對 Zikun Zhang 對本文所作的貢獻表示誠摯感謝,他在東華大學完成了軟件工程專業學習,專注數據處理與深度學習應用領域。擅長 Python 編程,在深度學習、圖像處理、數據分析方向有扎實能力,曾參與 Lenovo 中小型企業產品的銷售量數據分析項目,為本文數據處理邏輯與模型優化思路提供了實踐參考。
?



)















