嘿,各位AI技術愛好者們,你是不是經常遇到這樣的情況:辛辛苦苦訓練的AI助手,面對專業問題時卻"一問三不知"或者"胡言亂語"?明明你已經喂了它一堆PDF和Word文檔,為啥它就是不會用?
就像你去米其林餐廳,廚師拿著一堆未處理的食材直接上桌一樣荒謬!沒錯,RAG系統也需要一個"廚房",而文檔處理與知識庫構建,就是這個廚房里最重要的"烹飪工藝"!
RAG為什么需要文檔處理?
想象一下,你有一位朋友叫小明,他是一個"人肉搜索引擎":
"小明啊,我想知道去年公司年會的預算是多少?"
小明翻開一堆文件,快速找到了答案:"是38.5萬元,在第三季度財報的第17頁。"
而大語言模型(LLM)可沒這么聰明。如果你直接把原始文檔扔給它,那就像是把一堆雜志、書籍、報紙和便利貼一股腦兒塞給一個五歲小孩,然后期待他能準確回答你的問題。
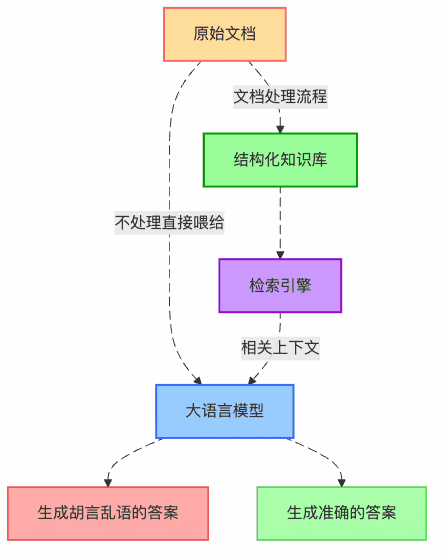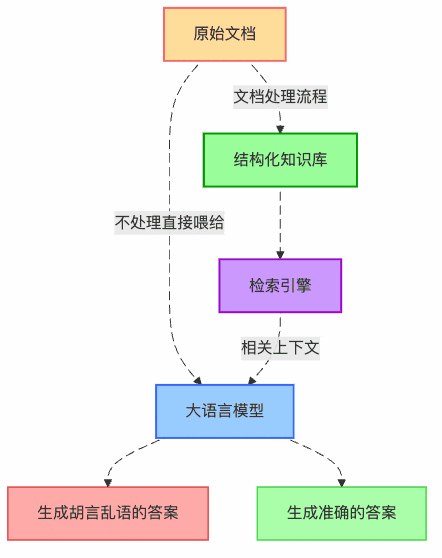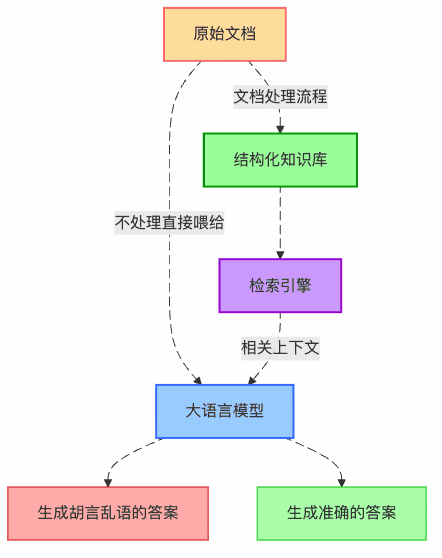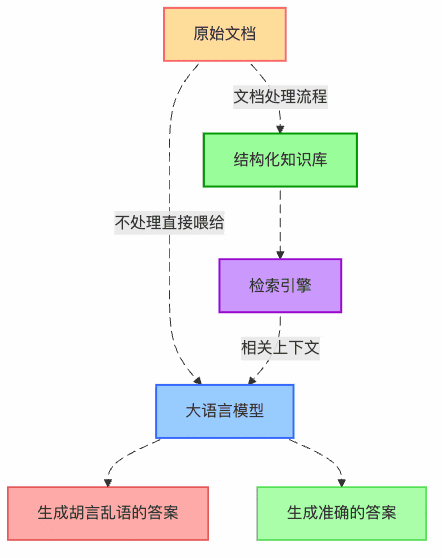
圖1:RAG系統中文檔處理的核心價值
所以,今天我們就來聊聊這個AI廚房里的美食制作流程!
第一道菜:文檔預處理——把"生肉"變成"食材"
多格式文檔解析:百變食材的統一處理
我們的文檔就像是各種不同的食材:PDF是牛排、Word是雞肉、HTML是魚、Markdown是蔬菜。每種食材都需要不同的處理方式,但最終目標是一樣的——提取出可口的"文本營養"。
你有沒有試過直接打開PDF復制內容,結果表格變成了一團亂碼,頁眉頁腳混入正文,分欄文本順序全錯?這就像你想吃牛排,但還沒去除筋膜和多余的脂肪一樣。
「文檔解析食譜」
📋 準備工作
食材識別器(文件擴展名檢測)
多位專業廚師(各種解析器)
🔪 烹飪步驟
查看食材標簽(檢查文件擴展名)
- 根據食材類型,安排專業廚師:
如遇到牛排(PDF文檔),請牛排師傅處理
如遇到雞肉(Word文檔),請雞肉師傅處理
如遇到魚類(HTML文檔),請魚類師傅處理
其他食材,請基礎廚師處理
? 小貼士:每種文檔都有自己的"紋理",用合適的工具才能提取出最佳口感!
文本清洗和標準化:洗菜、切菜的藝術
拿到了各種"生食材"后,下一步就是洗菜切菜。在數據世界里,這一步叫做"文本清洗"。
想象一下你的文檔里混入了廣告、亂碼、重復內容,這就像菜里混入了沙子、泥土和農藥殘留。沒人想吃這些東西,對吧?

圖2:文本清洗流水線,就像洗菜臺上的操作
有個笑話說,一個數據科學家花了80%的時間清洗數據,剩下的20%時間用來抱怨數據清洗。RAG系統也一樣,你的文本清洗做得越好,后面的"菜"就越好吃!
「文本清洗食譜」
📋 原料
一份粗糙文本(可能帶有雜質)
正則表達式清洗工具
🔪 清洗步驟
先去除多余水分:擠干所有多余空格、換行和制表符
統一切割形狀:將各種引號統一為標準形式
修剪邊緣:去除首尾多余空白
完成裝盤:返回干凈整齊的文本
? 小貼士:就像廚師反復清洗蔬菜直到水變清澈,文本清洗也常需要多輪處理!
文檔結構化提取:食材精細化處理
一篇文檔不僅僅是一堆文字,還有標題、段落、列表、表格等結構。就像煎牛排不僅要考慮肉質,還要考慮火候、調味和擺盤。
你可能會問:"為什么要保留文檔結構?直接提取文本不就行了嗎?"
哈!那就像問為什么要把牛排切成小塊再吃,而不是整塊塞進嘴里一樣天真。文檔結構是理解上下文的關鍵,沒有它,AI就像在黑暗中吃飯,不知道嘴里的是牛排還是鞋底。
第二道菜:文檔分塊策略——把"食材"變成"配料"
固定長度分塊:簡單粗暴的切菜法
最簡單的分塊方法就是按固定長度切割,比如每1000個字符一塊。這就像新手廚師用刻度尺量著切菜:每塊黃瓜必須是5厘米長。

圖3:固定長度分塊示意圖
簡單?是的。效率高?當然。問題是什么?哦,你可能會在句子中間切斷,就像把一只雞腿切成兩半,一半在這個盤子,一半在那個盤子,吃起來就很尷尬了。
語義分塊技術:有藝術感的刀工
優秀的廚師會順著食材的紋理和結構切割,讓每一塊都保持完整的口感和風味。語義分塊也是這樣,它尊重文本的自然邊界:段落、句子、主題。
「語義分塊烹飪指南」
📋 原料準備
一份完整文檔文本
段落分離工具
一個衡量籃(最大塊大小限制)
🔪 烹飪步驟
首先將文本按自然段落分開(就像識別食材的節點)
準備一個空盤子(空的結果列表)
- 開始逐段處理:
看看當前盤子里的食材加上新食材是否會太多
如果放得下,就放在一起(保持味道融合)
如果放不下,就完成當前盤子,開始新盤子
別忘了處理最后一盤(可能還有剩余食材)
呈上所有盤子(返回所有文本塊)
? 秘訣:好的分塊就像好的分菜——每一份都應該是一個完整的味覺體驗,而不是半塊肉或半截蔬菜!
重疊窗口設計:食材的藝術重疊
知道為什么米其林大廚做的千層面這么好吃嗎?因為每層之間有恰到好處的重疊,讓味道融合得天衣無縫!
文檔分塊也是如此。當我們在塊與塊之間設置重疊,就像是讓相鄰的兩盤菜共享一些共同的配料,確保在從一道菜過渡到另一道菜時不會有突兀的味道轉變。
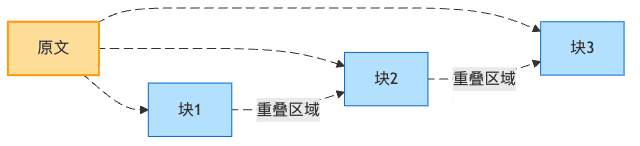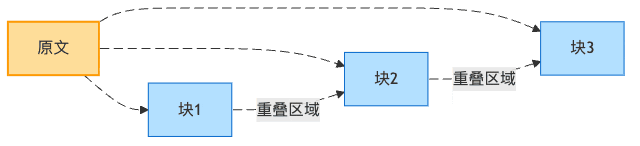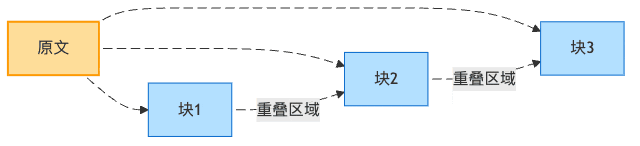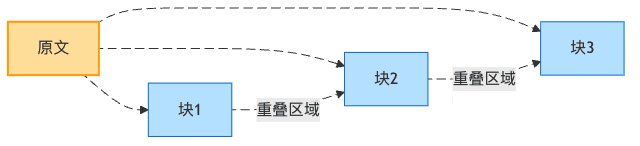
圖4:文檔分塊的重疊窗口設計
想象一下,如果沒有這種重疊,一個重要概念的解釋被切分在兩個塊中,AI可能只檢索到其中一個塊,導致理解不完整。這就像你嘗到了菜的前半部分味道,卻錯過了后半部分的精華。
第三道菜:知識庫設計——把"配料"變成"美食"
知識庫架構設計:廚房布局的藝術
一個好的廚房需要合理的布局:食材區、備菜區、烹飪區、裝盤區...每個區域各司其職又緊密協作。知識庫的架構設計也是如此。
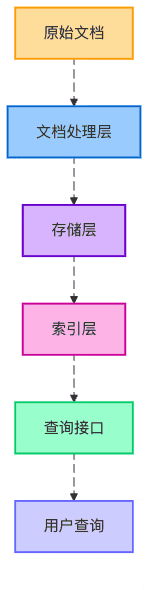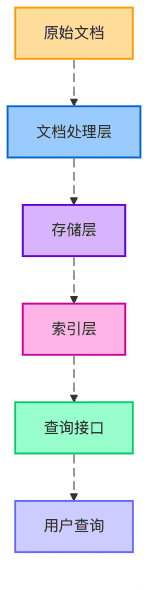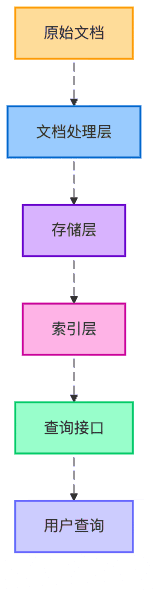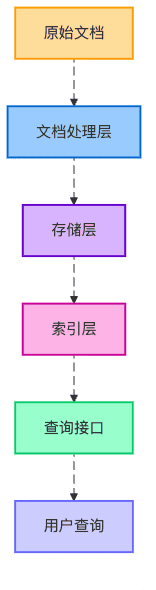
圖5:知識庫的分層架構
有次我做了一個知識庫,把所有文本都塞進一個大文件里,結果查詢時系統差點崩潰。這就像把所有食材都放在一個大鍋里煮,最后得到的不是美食,而是災難。
元數據管理策略:為美食添加標簽
元數據就像菜品的標簽和說明:這道菜的主要成分是什么?辣度如何?適合什么人群?過敏原是什么?
在RAG系統中,元數據讓我們能夠更精確地檢索和過濾信息:
「菜品標簽示例」
📝 菜名:2023年財務報告 👨?🍳 主廚:財務部 張三 🗓? 制作日期:2023-12-31 🏢 所屬餐區:財務 🔒 食用限制:內部 🏷? 關鍵配料:財報、預算、收入、支出
想象一下,當用戶問"我們公司去年的IT預算是多少?",有了元數據,系統就能優先檢索財務部門的文檔,而不是去翻技術部門寫的代碼文檔。
數據質量保證:食品安全與品控
米其林餐廳有嚴格的食材篩選標準,知識庫也應如此。數據質量差,輸出的答案再好看也是"有毒"的。
我曾見過一個RAG系統,它的知識庫里混入了一些虛假數據。結果可想而知,就像廚師用了變質的食材,無論烹飪技巧多么精湛,食客也會"食物中毒"。
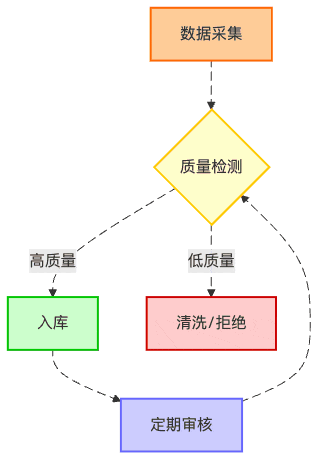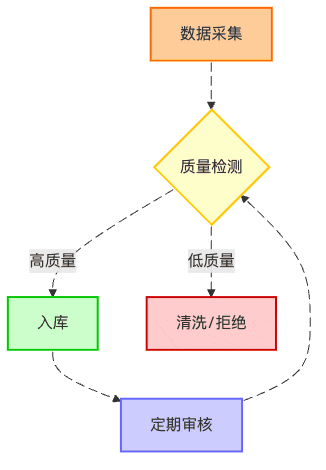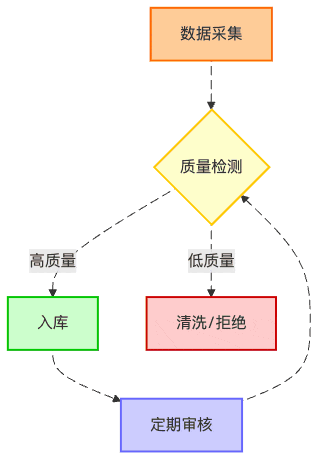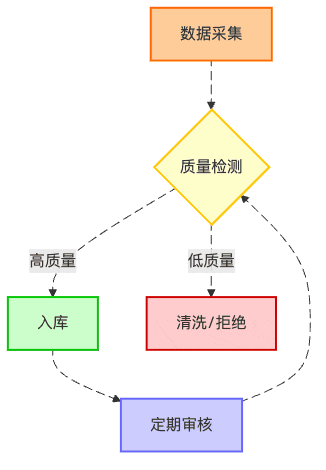
圖6:知識庫的質量保證循環
實戰案例:打造一個企業文檔RAG系統
讓我們把這些"烹飪技巧"應用到一個實際場景:一家公司想用自己的內部文檔(產品手冊、技術文檔、會議記錄等)構建一個RAG系統,讓員工能快速獲取準確信息。
第一步:文檔收集與預處理
首先,我們需要梳理所有文檔源:
公司網盤上的Word和PDF文檔
內部Wiki系統
郵件中的重要討論
產品需求文檔和技術規格說明
就像大廚去市場采購最新鮮的食材一樣,我們需要找到最權威、最新的信息源。
第二步:清洗與結構化
接下來,我們對這些文檔進行"去骨去刺"處理:
去除頁眉頁腳和版權聲明
提取表格數據并轉換為結構化文本
識別文檔的層次結構(章節、標題等)
統一格式和編碼
第三步:智能分塊
根據公司文檔的特點,我們設計了混合分塊策略:
會議記錄:按議題分塊
產品手冊:按功能模塊分塊
技術文檔:按章節分塊,確保代碼片段完整
每個塊都設置20%的重疊,確保上下文連貫。
第四步:知識庫構建
最后,我們設計了一個三層架構的知識庫:
基礎存儲層:所有文檔塊的原始存儲
向量索引層:使用embedding模型生成的向量索引
元數據索引層:基于文檔屬性的結構化索引
就像一家餐廳有前廚、后廚和傳菜區,每個區域各司其職,共同保障出品質量。
總結:成為RAG的數據魔術師
回到我們開始的問題:為什么你的AI助手回答專業問題時總是"掉鏈子"?現在你知道了,可能不是模型不行,而是你沒給它一個好的"廚房"和優質的"食材"。
文檔處理與知識庫構建就像是AI的烹飪藝術:
文檔預處理是備料和洗菜
文檔分塊是刀工和切配
知識庫設計是烹飪和裝盤
掌握了這些技巧,你的RAG系統就能從"路邊攤"升級為"米其林餐廳",用戶提問時再也不用擔心得到"夾生飯"或"隔夜菜"了!
記住,在RAG的世界里,數據處理不是枯燥的技術活,而是充滿創意的藝術。就像廚師對待食材一樣,對待你的文檔,它們會回報你意想不到的"美味"!
下次當有人問你:"RAG系統最重要的是什么?"
你可以自信地回答:"大模型很強大,但沒有經過精心處理的知識庫,它就像一個天才廚師站在空蕩蕩的廚房里——巧婦難為無米之炊啊!"




—— Nginx反向代理與負載均衡實戰指南)
:人工智能、機器學習與深度學習)
![[網絡入侵AI檢測] 純卷積神經網絡(CNN)模型 | CNN處理數據](http://pic.xiahunao.cn/[網絡入侵AI檢測] 純卷積神經網絡(CNN)模型 | CNN處理數據)


:用戶界面及系統管理界面布局)








![[硬件電路-166]:Multisim - SPICE與Verilog語言的區別](http://pic.xiahunao.cn/[硬件電路-166]:Multisim - SPICE與Verilog語言的區別)
