1、Android地址
https://github.com/google-research/android_world/tree/main?tab=readme-ov-file#installation
這里有排行榜,提交方式為手工提交到共享表格
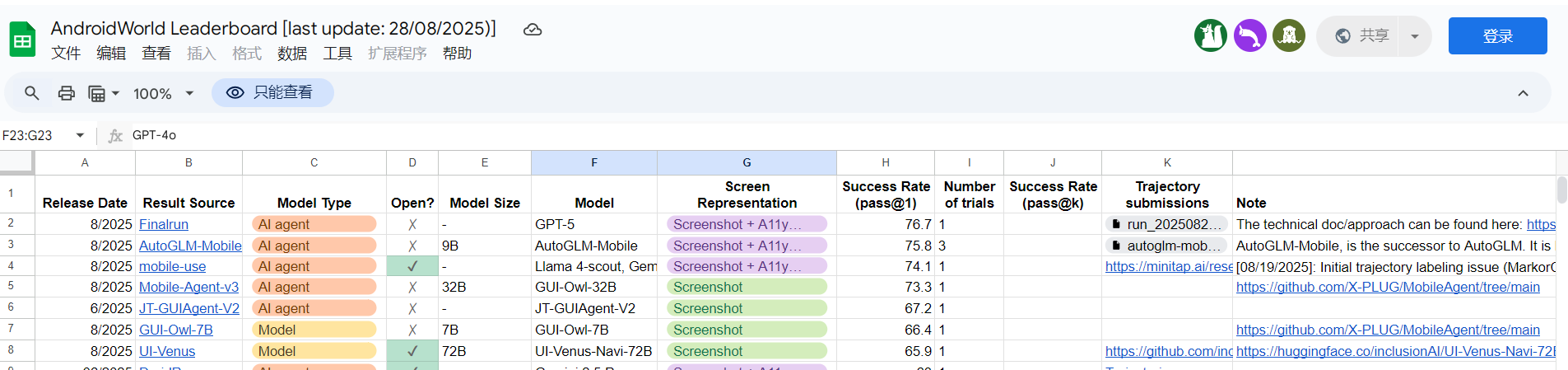
https://docs.google.com/spreadsheets/d/1cchzP9dlTZ3WXQTfYNhh3avxoLipqHN75v1Tb86uhHo/edit?gid=0#gid=0
1.1 評測方式
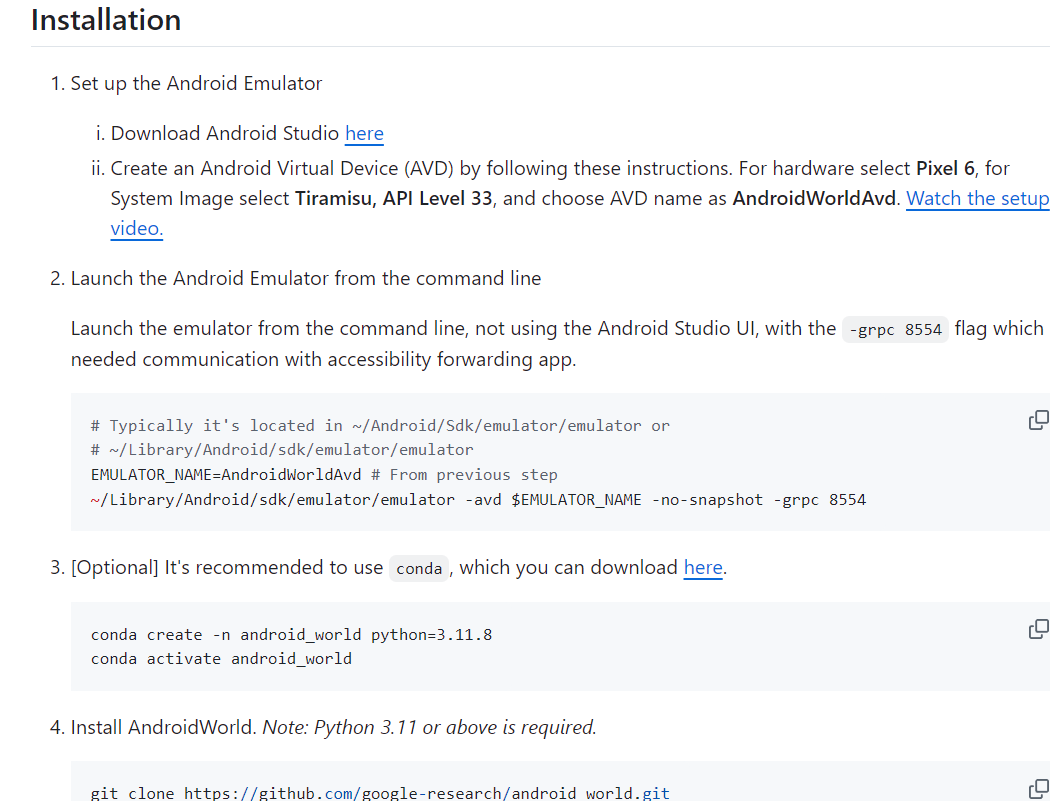
需要在windows安裝android studio,通過在模擬器和模型訪問地址進行交互。部署還是比較麻煩。后來?Droidrun?進行精簡,也可以參考這個項目,有點類似。
https://github.com/droidrun/droidrun-android-world?tab=readme-ov-file
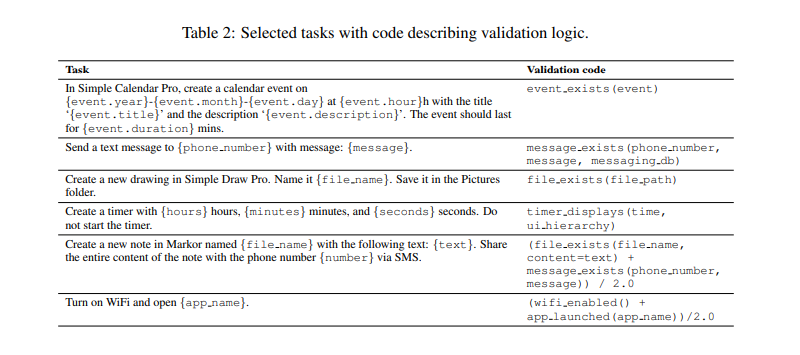
具體評估方案可以見:https://arxiv.org/pdf/2405.14573
與現有的測試環境(MiniWoB++ (Shi et al.,?2017) 是一個值得注意的例外)不同,ANDROIDWORLD 中的每個任務都是使用隨機生成的參數動態實例化的,從而以數百萬個獨特的任務目標和條件來挑戰代理。雖然 MiniWob++ 由簡單的合成網站組成,但 ANDROIDWORLD 利用了實際的 Android 應用程序。ANDROIDWORLD 必須解決的一個主要挑戰是如何在使用真實世界的應用程序和動態變化的任務參數時,確保獎勵信號的持久性
除了116個Android任務之外,我們通過將MiniWoB++ (Shi et al.,?2017; Liu et al.,?2018a) 基準集成到ANDROIDWORLD中,從而擴展了其Web任務。
AndroidEnv (Toyama et al.,?2021) 提供了一種管理與 Android 模擬器通信的機制,類似于 Playwright 和 Selenium 在 Web 環境中的應用
ANDROIDWORLD 實施了一種非侵入式的獎勵機制,使其能夠為源代碼不可用的應用程序創建一個基準測試套件,并在不同的應用程序中重復使用驗證組件。這種方法使 ANDROIDWORLD 能夠涵蓋更廣泛的真實移動任務。
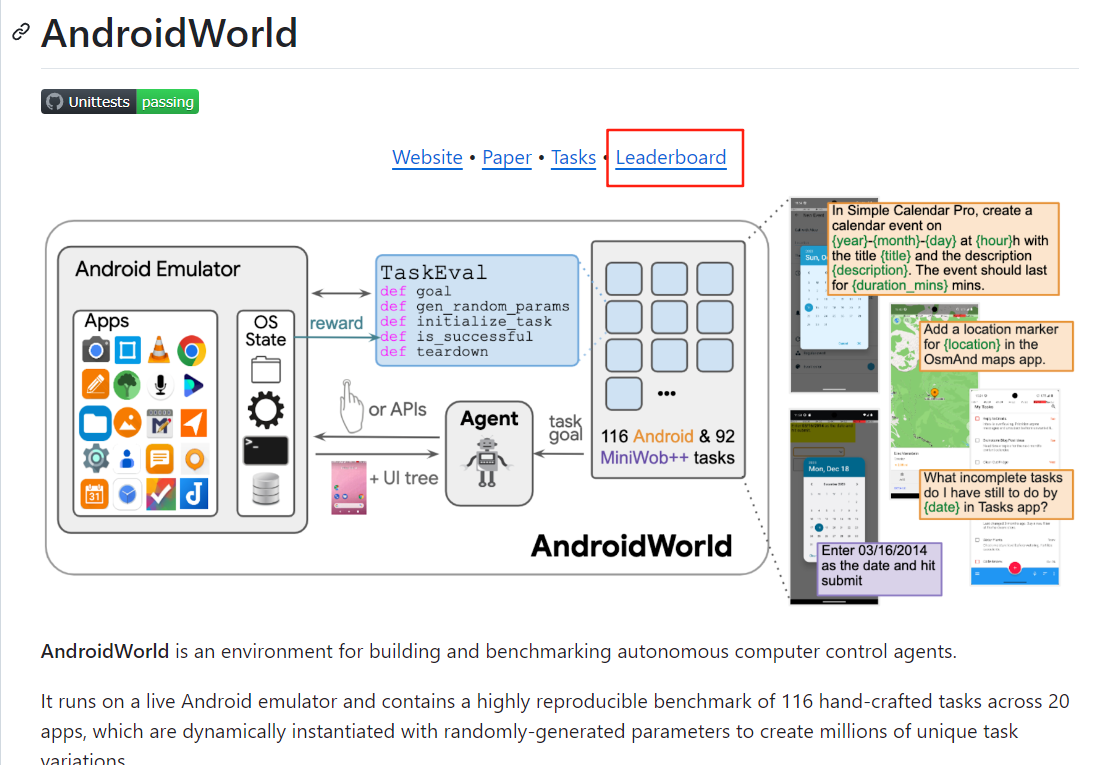
ANDROIDWORLD包含一套116個任務,分布在20個不同的應用程序中(更多細節請參見附錄D)。這些任務模擬了實際的日常活動,包括記筆記、安排約會、通過消息傳遞進行交流以及與系統實用程序進行交互。該套件由開源應用程序和內置的Android系統應用程序組成,例如“設置”和“聯系人”。正如人類所評估的那樣,這些任務在難度、持續時間和類別上各不相同(圖2)。
為了在真實場景中實現高度的可重復性,ANDROIDWORLD 通過多種方式精確控制操作系統和應用程序的狀態。Android 操作系統是固定的,由運行 Android 13 的 Pixel 6 模擬器組成。在每個任務開始時,ANDROIDWORLD 將設備時間戳重置為 2023 年 10 月 15 日 15:34 UTC,確保所有執行過程中時間相關的行為保持一致。ANDROIDWORLD 中的所有應用程序都是功能齊全的,包括開源應用程序和 Android 操作系統自帶的操作系統級別應用程序。對于開源應用程序,ANDROIDWORLD 通過安裝從 F-Droid 獲取的每個應用程序的固定版本來維持一個恒定的環境。5?操作系統級別應用程序的版本由 Android 操作系統決定,而 Android 操作系統也是固定的。為了維持一個可重復的環境,ANDROIDWORLD 使用不需要登錄/身份驗證并且可以在設備上存儲其應用程序數據的應用程序。
除了管理應用程序和操作系統的狀態之外,ANDROIDWORLD 精確地定義和控制任務執行期間的狀態。每個任務都有其自己獨特的設置、獎勵確定邏輯和清理程序(更多細節請參見附錄 D.2 和 D.3),從而確保了一套完全可重現的任務。
自動任務參數化是ANDROIDWORLD獨有的關鍵機制,用于在比當前基準測試所支持的更大、更真實的suite任務上評估代理。實現這一點需要比隨機生成新任務參數付出更多的努力,因為它涉及到開發在不同任務實例化中保持有效的評估邏輯。正是通過其仔細的狀態管理,除了可重復性之外,AndroidWorld還確保獎勵機制正常運行。任務參數在每個任務開始時基于受控的隨機種子隨機初始化,決定初始狀態并影響獎勵結果。與MiniWoB++ (Shi et al.,?2017; Liu et al.,?2018a) 類似,ANDROIDWORLD由幾乎無限的、不同的初始條件和成功標準組成。
這種方法能夠對智能體的適應性進行更細粒度的分析,這對于現實世界的部署至關重要。除了魯棒性測試之外,動態任務構建還支持在線學習,特別是強化學習(Shi et al.,?2017;Liu et al.,?2018a;Humphreys et al.,?2022;Gur et al.,?2022a),同時也簡化了監督學習的訓練/測試數據集生成(Humphreys et al.,?2022;Shaw et al.,?2023;Furuta et al.,?2023)。
ANDROIDWORLD通過檢查屏幕上的UI元素來驗證任務完成情況

1.2、訓練數據集
沒有訓練數據集,不過MOBILERL: ADVANCING MOBILE USE AGENTS WITH ADAPTIVE ONLINE REINFORCEMENT LEARNING 這篇論文中,參考測試數據構造了測試集。
對于強化學習,我們通過改變初始狀態、任務需求和任務組成,從兩個基準測試中構建擴展的訓練集,同時確保排除與評估集的任何重疊。由此產生的訓練語料庫包括AndroidWorld的完整訓練集和大約1k個從AndroidLab中提取的任務,并以4:1的固定比例應用混合抽樣(AndroidWorld: AndroidLab)。對于AndroidWorld,我們直接采用其基于規則的軌跡獎勵,而對于不提供訓練獎勵的AndroidLab,我們采用表2:專有模型和開源模型在AndroidWorld和AndroidLab移動GUI交互任務基準測試上的成功率(SR,%)。AUTOGLM-Mobile-9B在這兩個基準測試上都取得了最高的性能。文章核心點如下:
2、MobileRL
構建的環境的作用是什么? 為什么不用已有的數據集的答案做獎勵
您提出了兩個非常好的問題,一個關于構建的環境的作用,另一個關于為什么不用已有數據集的答案做獎勵。這兩個問題都觸及了論文核心方法論的設計動機。
1. 構建的環境的作用:解決在線強化學習的挑戰
論文中構建了一個分布式采樣框架 (distributed sampling framework),用于在線強化學習(Online Reinforcement Learning)。這個環境的主要作用是為了解決在訓練移動 GUI 代理時面臨的幾個實際挑戰,尤其是在大規模、高并發的在線交互中實現高效、可復現的采樣。
核心作用與解決的問題:
-
大規模高并發采樣 (Large-scale, High-concurrency Sampling):
- 挑戰:?訓練移動 GUI 代理需要大量的交互數據,而部署和管理數百個并發移動實例是資源密集型的,難以在不同設置中復現,并且通常采樣吞吐量較低 (P2, "Large-scale mobile environment sampling bottlenecks")。
- 構建環境的作用:?論文采用了一個 gRPC 控制器來協調數百個 Dockerized 的 Android 虛擬設備 (AVDs) 跨多臺機器進行采樣。這種設置能夠并發地與超過 1000 個環境進行交互?(P2, "This setup enables concurrent interaction with over 1000 environments")。
- 優勢:?這種大規模并發能力顯著提高了數據收集效率,是進行在線強化學習的基石。
-
降低早期探索成本 (Lowering Early Exploration Cost):
- 挑戰:?未經調整的基礎模型在復雜 GUI 指令下難以穩定生成動作命令,且移動模擬的成本和延遲很高,導致成功的 Rollout 很少,早期探索數據效率低下 (P2, "Complex instruction following under sparse positive signals")。
- 構建環境的作用:?通過大規模并發采樣,可以更快地收集到更多的交互數據,即使早期成功率不高,也能加速數據積累,從而間接降低了探索成本。
-
提高指令遵循度 (Improving Instruction Adherence):
- 挑戰:?復雜的移動 GUI 任務需要代理遵循詳細的指令,而基礎模型可能難以做到。
- 構建環境的作用:?在線強化學習允許代理通過與環境的持續交互來學習如何更好地遵循指令,而這個大規模環境提供了充足的交互機會來優化這一能力。
-
可復現性 (Reproducibility):
- 挑戰:?不同的環境設置可能導致行為不可復現。
- 構建環境的作用:?論文指出,由于現有的大多數開源基準和模擬器都基于 Android 操作系統,他們設計的環境確保了無縫兼容性和對環境行為的忠實復現?(P2, "this design ensures seamless compatibility and faithful reproduction of environment behaviors")。
總結來說,構建的環境是為了提供一個高效、穩定、可擴展且可復現的平臺,以支持 MOBILERL 框架中大規模在線強化學習的需求,克服了移動 GUI 代理訓練中數據稀疏、探索成本高和環境采樣效率低下的問題。
2. 為什么不用已有數據集的答案做獎勵:稀疏獎勵與效率問題
論文中并沒有完全“不用”已有數據集的答案做獎勵,而是對獎勵機制進行了重新設計和調整,以適應移動 GUI 任務的特點,尤其是稀疏獎勵 (sparse reward)?和多步交互 (multi-turn interaction)?的挑戰。
挑戰與現有數據集獎勵的局限性:
-
稀疏獎勵問題 (Sparse Reward Problem):
- 在移動 GUI 任務中:?獎勵通常是二元的終端獎勵 (binary terminal reward),即只有在任務完全成功時才獲得 +1 獎勵,否則為 0 (P4, "R(st, at) is a sparse reward that yields 1 iff the task is completed at step T and 0 otherwise")。
- 局限性:?這種稀疏獎勵信號在多步任務中難以提供足夠的信息,導致模型難以學習有效的中間步驟。如果只用最終答案作為獎勵,模型在早期探索時幾乎總是獲得 0 獎勵,導致學習效率低下。
-
多步交互與中間推理缺失 (Multi-turn Interaction & Missing Intermediate Reasoning):
- 在現有專家演示數據中:?移動使用專家演示數據通常只包含最終的動作序列,而省略了中間的推理步驟?(P2, "mobile-use expert demonstrations typically contain only the final action sequences, while omitting intermediate reasoning steps")。
- 局限性:?如果直接將這些“黑盒”軌跡作為獎勵信號,模型學會的策略會變得不透明,并且許多未標記的任務無法被利用。代理需要學會長期的規劃和多步推理能力,而單一的最終答案獎勵無法有效地指導這一過程。
-
低效的探索 (Inefficient Exploration):
- 挑戰:?簡單地將終端獎勵廣播到每個時間步 (P6, "Previous approaches typically broadcast this reward to every timestep") 會導致訓練偏向于更長的軌跡,因為它們貢獻了更多的梯度項。這與用戶偏好(通常是更短、更高效的解決方案)相悖。
MOBILERL 如何改進獎勵機制:
為了克服上述局限性,MOBILERL 引入了?Difficulty-Adaptive GRPO (DGRPO),其中包含了三個關鍵的獎勵調整機制:
-
最短路徑獎勵調整 (Shortest-Path Reward Adjustment, SPA):
- 作用:?重新調整每個成功軌跡的獎勵,使其偏好更短、更高效的解決方案。
- 機制:?對于成功完成的任務,SPA 不僅給 +1 獎勵,還會根據軌跡長度相對于最短成功軌跡長度的比例進行懲罰。軌跡越短,獎勵越高。
- 解決問題:?Counteracts the bias toward verbose solutions and aligns rewards with user preferences for efficiency (P6)。
-
難度自適應正向回放 (Difficulty-Adaptive Positive Replay, DAPR):
- 作用:?維護一個高質量、有挑戰性的成功軌跡的精選緩沖區,并與新的在線采樣樣本進行平衡。
- 機制:?在稀疏獎勵環境中,困難的成功案例雖然罕見但信息量很大。DAPR 通過回放這些軌跡來放大它們的學習信號并穩定策略更新?(P2, P7)。
- 解決問題:?提升了稀疏獎勵下學習的效率,特別是對于難以解決的任務。
-
失敗課程過濾 (Failure Curriculum Filtering, FCF):
- 作用:?篩選掉那些持續無法解決的任務,將計算預算重新分配給有挑戰性但可行的任務。
- 機制:?對于連續多個 epoch 都產生零獎勵的任務,FCF 會降低其采樣概率,甚至永久從采樣池中移除 (P7)。
- 解決問題:?避免了在“死胡同”任務上浪費計算資源和探索預算,提高了樣本效率。
總結來說,論文并非完全放棄利用已有數據集的“答案”作為獎勵,而是:
- 將其作為基礎的二元成功信號 (binary success signal)。
- 在此基礎上,通過 SPA、DAPR 和 FCF 等機制對獎勵信號進行“整形”和“優化”,使其更具信息量,更適應多步交互和稀疏獎勵的挑戰,并引導代理學習更高效、更魯棒的策略。
這種設計使得代理不僅知道“任務是否完成”,更能理解“如何高效且正確地完成任務”,從而克服了傳統稀疏獎勵和單一最終答案獎勵的局限性。


—— Nginx反向代理與負載均衡實戰指南)
:人工智能、機器學習與深度學習)
![[網絡入侵AI檢測] 純卷積神經網絡(CNN)模型 | CNN處理數據](http://pic.xiahunao.cn/[網絡入侵AI檢測] 純卷積神經網絡(CNN)模型 | CNN處理數據)


:用戶界面及系統管理界面布局)








![[硬件電路-166]:Multisim - SPICE與Verilog語言的區別](http://pic.xiahunao.cn/[硬件電路-166]:Multisim - SPICE與Verilog語言的區別)


