第5章:純卷積神經網絡(CNN)模型
歡迎回來
在第1章:分類任務配置(二分類 vs. 多分類)中,我們學習了如何提出正確的問題;
在第2章:數據加載與預處理中,我們準備好了數據"食材";
在第3章:經典機器學習模型中,我們探索了傳統工具;
在第4章:深度前饋神經網絡(DNN)模型中,我們首次使用多層神經網絡深入研究了深度學習
DNN非常擅長發現復雜模式,但想象一下,如果安全專家不只是查看單個特征,而是嘗試在事件流中發現特定的序列或形狀
例如,某些網絡標志的快速連續出現可能表明掃描攻擊,而較慢、更謹慎的模式則暗示另一種入侵類型
這正是純卷積神經網絡(CNN)模型的用武之地
雖然CNN以圖像識別(檢測邊緣、形狀和物體)而聞名,但它們也非常擅長在數據序列中發現局部模式,即使這些數據不是圖像。
在我們的網絡入侵檢測(NID)項目中,CNN就像專門的"模式檢測器",在做出決策前系統地掃描網絡流量特征中的重要局部序列或"簽名"。
CNN解決了什么問題?
CNN旨在直接從輸入數據中自動學習層次化特征和模式。
與DNN平等對待每個輸入特征并一次性混合它們不同,CNN使用"過濾器"掃描數據,首先挑選出小的特定模式,然后將這些小模式組合成更大、更復雜的模式。
我們使用CNN的核心用例是從41個網絡特征序列(來自第2章:數據加載與預處理的input_shape=(41, 1))中自動提取這些局部有意義的模式,將網絡連接分類為"正常"或"攻擊"(二分類),或精確定位"攻擊類型"(多分類)。它們特別擅長發現可能出現在特征序列中任何位置的"簽名"。
CNN的關鍵概念
純卷積神經網絡(針對我們的一維網絡數據)主要使用三種類型的層:卷積層、池化層,然后是展平后的密集層。
讓我們分解這些核心部分:
1. 卷積層(Conv1D):模式檢測器
這是CNN的核心。
- 過濾器(核):想象一個小的"放大鏡"或迷你模式檢測器。這個過濾器是一個小窗口,在輸入數據(我們的41個特征)上滑動。當它滑動時,它會與看到的數字進行數學運算(卷積),尋找特定模式。例如,一個過濾器可能被訓練來檢測數據中的"尖峰",另一個可能尋找"低谷"。
- 特征圖:卷積層的輸出。每個過濾器創建自己的"特征圖",顯示它在輸入數據中檢測到其特定模式的位置。如果一個過濾器擅長檢測"尖峰",其特征圖將在發現尖峰的地方有高值。
- 1D卷積:由于我們的網絡數據是41個特征的序列,我們使用
Convolution1D。這意味著我們的"放大鏡"沿單一維度滑動,掃描我們的特征序列。 activation='relu':就像在DNN中一樣,在卷積之后應用relu激活(第4章:深度前饋神經網絡(DNN)模型)以引入非線性,使模型能夠學習復雜關系。
2. 池化層(MaxPooling1D):總結器
在卷積層檢測到模式后,池化層有助于簡化信息并使模型更魯棒。
- 下采樣:
MaxPooling1D層通過在特征圖上滑動窗口并取每個窗口中的最大值來工作。這有效地縮小了特征圖,減少了數據量,同時保留了最重要的信息(最強的模式檢測)。 - 魯棒性:通過取最大值,它使模型對模式的確切位置不那么敏感。如果"尖峰"模式稍微移動,
MaxPooling層仍然可能捕捉到它的存在。 pool_length:這定義了池化層使用的窗口大小。pool_length為2意味著它查看2個值的組并選擇最大的。
3. 展平層:為決策做準備
卷積和池化層以"網格狀"或"序列狀"格式(例如[samples, new_length, new_features])輸出數據。然而,做出分類決策的最終密集(全連接)層需要一個簡單的數字扁平列表。
展平層完全如其名:它將卷積/池化層的3D輸出"展平"為一個長的1D向量(就像展開地毯)。這為數據輸入標準密集分類層做好準備。
4. 密集層:最終分類器
在展平層之后,我們添加一個或多個密集層,就像在DNN中一樣(第4章:深度前饋神經網絡(DNN)模型)。這些層利用卷積和池化層提取的抽象特征做出最終分類決策。
5. Dropout層:防止過擬合
與DNN一樣,添加Dropout層(第4章:深度前饋神經網絡(DNN)模型)以防止模型對訓練數據記憶得太好。這確保它可以泛化到新的、未見過的網絡流量。
如何構建用于入侵檢測的純CNN
我們將使用Keras構建我們的CNN。基本步驟如下:
- 啟動一個
Sequential模型。 - 添加
Convolution1D層:定義過濾器數量、核大小和激活。 - 添加
MaxPooling1D層:對特征圖進行下采樣。 - 添加
展平層:將輸出轉換為密集層。 - 添加
密集層:用于最終分類,使用relu激活。 - 添加
Dropout層:防止過擬合。 - 添加最終的
密集輸出層:根據第1章:分類任務配置(二分類 vs. 多分類)配置為二分類或多分類。 - 編譯模型:定義損失函數、優化器和指標。
記住,我們的輸入數據需要重塑為[samples, time_steps, features],對于我們的KDD數據集是[number_of_connections, 41, 1]。
這在第2章:數據加載與預處理中已經介紹過。
讓我們看一個簡化示例。假設X_train包含我們歸一化和重塑的網絡特征,y_train包含標簽,如第2章和第1章所述。
示例代碼:用于二分類的簡單CNN
以下是構建一個帶有一個卷積塊的基本CNN用于二分類入侵檢測的方法:
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
import numpy as np # 用于數據創建示例# --- 假設 X_train 和 y_train 已準備好并重塑 ---
# 為了演示,我們創建一些虛擬數據(1000個樣本,41個時間步,每個1個特征)
X_train_dummy = np.random.rand(1000, 41, 1)
y_train_dummy = np.random.randint(0, 2, 1000) # 二分類標簽# 1. 開始定義網絡(層的堆疊)
model = Sequential()# 2. 添加第一個卷積層
# - 64個過濾器:64個不同的小模式檢測器
# - kernel_size=3:每個過濾器一次查看3個連續特征
# - activation='relu':如前所述
# - input_shape=(41, 1):告訴Keras我們的輸入形狀(41個時間步,每個時間步1個特征)
model.add(Convolution1D(64, 3, activation="relu", input_shape=(41, 1)))# 3. 添加一個最大池化層
# - pool_size=2:在2的窗口上取最大值
model.add(MaxPooling1D(pool_size=2))# 4. 展平輸出以用于密集層
model.add(Flatten())# 5. 添加一個密集層(全連接)進行更多處理
# - 128個神經元
# - activation='relu'
model.add(Dense(128, activation="relu"))# 6. 添加一個Dropout層以防止過擬合
# - 0.5表示訓練期間隨機關閉50%的神經元
model.add(Dropout(0.5))# 7. 添加輸出層(用于二分類,如第1章所述)
# - 1個神經元用于二分類輸出
# - activation='sigmoid':將輸出壓縮為0到1之間的概率
model.add(Dense(1, activation="sigmoid"))# 8. 編譯模型
# - loss='binary_crossentropy':用于二分類
# - optimizer='adam':流行的優化算法
# - metrics=['accuracy']:跟蹤性能
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=['accuracy'])print("CNN模型創建并編譯完成!")
model.summary() # 打印模型層和參數的摘要
解釋:
Sequential():初始化我們的模型為層的堆疊。Convolution1D(64, 3, activation="relu", input_shape=(41, 1)):這是第一層。它使用64個過濾器,每個查看3個相鄰特征的窗口。input_shape對第一層至關重要。MaxPooling1D(pool_size=2):該層通過保留最重要的信息(最強的模式檢測)來減小特征圖的大小。Flatten():這將卷積/池化層的輸出準備好用于后續的常規密集層。Dense(128, activation="relu"):一個標準的隱藏層,用于進一步處理展平的特征。Dropout(0.5):幫助防止模型過擬合。Dense(1, activation="sigmoid"):用于二分類的最終輸出層,給出0到1之間的概率。model.compile(...):使用適當的損失函數和優化器配置模型進行訓練。
擴展到多個卷積塊和多分類
通過堆疊更多的Convolution1D和MaxPooling1D塊,可以使CNN"更深"。對于多分類,只有輸出層和損失函數會改變,如第1章:分類任務配置(二分類 vs. 多分類)所述。
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
# ...(數據準備和重塑如前所述)...# 多分類示例:假設 num_classes = 5(正常、DoS、Probe、R2L、U2R)
num_classes = 5
# y_train_dummy 應為 one-hot 編碼,例如 to_categorical(y_train_raw, num_classes=5)model_multiclass_deep_cnn = Sequential()
# 第一個卷積塊
model_multiclass_deep_cnn.add(Convolution1D(64, 3, activation="relu", input_shape=(41, 1)))
model_multiclass_deep_cnn.add(MaxPooling1D(pool_size=2))# 第二個卷積塊(更深的網絡)
model_multiclass_deep_cnn.add(Convolution1D(128, 3, activation="relu")) # 更多過濾器用于更復雜的模式
model_multiclass_deep_cnn.add(MaxPooling1D(pool_size=2))model_multiclass_deep_cnn.add(Flatten())
model_multiclass_deep_cnn.add(Dense(128, activation="relu"))
model_multiclass_deep_cnn.add(Dropout(0.5))# 對于多分類(如第1章所述):
model_multiclass_deep_cnn.add(Dense(num_classes, activation="softmax"))model_multiclass_deep_cnn.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])print("\n用于多分類的深度CNN模型創建并編譯完成!")
model_multiclass_deep_cnn.summary()
多分類的關鍵區別:
Dense(num_classes, activation="softmax"):輸出層現在有num_classes(例如5)個神經元,softmax激活確保輸出是每個類的概率,總和為1。loss="categorical_crossentropy":當標簽是one-hot編碼時(多分類問題中應該如此),這是合適的損失函數。
幕后:CNN如何處理數據
將CNN想象為一個專業的安全團隊。
首先,有許多初級官員(Convolution1D過濾器),每個都訓練來發現特定的細節(例如"數據包的突然爆發")。然后,主管(MaxPooling1D)總結初級官員的發現,只記錄最顯著的檢測。這個過程重復進行,更高級別的官員(Convolution1D層)尋找這些總結細節的更復雜組合。最后,所有總結的發現交給首席分析師(展平和密集層)做出最終決定。
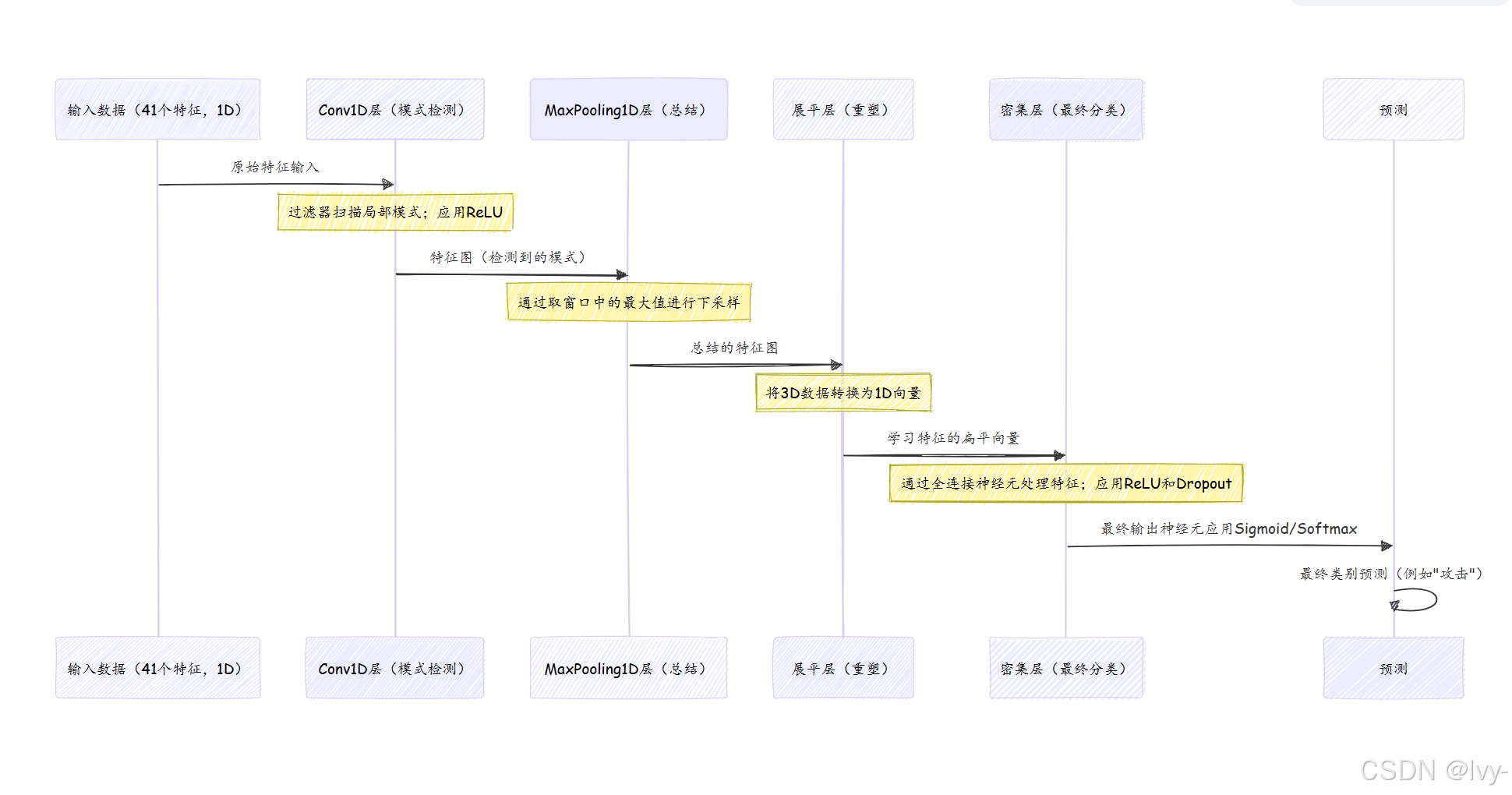
在訓練期間,這個流程會反復進行。每次傳遞后,模型將其預測與真實標簽進行比較,計算loss,然后微妙地調整內部參數(過濾器的權重、密集層)以嘗試在下一次減少loss。
深入項目代碼參考
讓我們看看實際項目代碼文件,了解純CNN是如何實現的。你可以在KDDCup 99/CNN/文件夾(以及NSL-KDD、UNSW-NB15等其他數據集的類似文件夾)中找到這些內容。
1. 簡單CNN(1個卷積+池化塊)- 二分類
查看KDDCup 99/CNN/binary/cnn1.py或NSL-KDD/CNN/binary/cnn1.py。在數據加載、歸一化和重塑步驟(如第2章:數據加載與預處理所述)之后:
# 來自 KDDCup 99/CNN/binary/cnn1.py(簡化版)
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
import numpy as np # 用于np.reshape(如果尚未導入)# ...(X_train, y_train, X_test, y_test 已準備好并重塑)...cnn = Sequential()
# 卷積層:64個過濾器,核大小3,relu激活,輸入形狀(41,1)
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu", input_shape=(41, 1)))
# 池化層:池長度2
cnn.add(MaxPooling1D(pool_length=(2)))
# 展平層
cnn.add(Flatten())
# 密集層:128個神經元,relu激活
cnn.add(Dense(128, activation="relu"))
# Dropout層:0.5(50%)的丟棄率
cnn.add(Dropout(0.5))
# 輸出層:1個神經元,用于二分類的sigmoid激活
cnn.add(Dense(1, activation="sigmoid"))print(cnn.summary()) # 查看模型的架構
# cnn.compile(...) # 編譯代碼在原代碼片段中被注釋掉
觀察:
input_shape=(41, 1)正確指定了第一個Convolution1D層的輸入維度。Convolution1D中的border_mode="same"意味著輸出特征圖將與輸入長度相同,必要時填充邊緣。Convolution1D、MaxPooling1D、Flatten、Dense、Dropout和最終Dense層的堆疊構成了完整的CNN。- 輸出層(
Dense(1, activation="sigmoid"))和相關的binary_crossentropy損失(在注釋掉的編譯部分中)與我們在第1章中的二分類設置一致。
2. 更深CNN(多個卷積+池化塊)- 二分類
現在,我們來看KDDCup 99/CNN/binary/cnn3.py。這個文件通過堆疊更多的卷積和池化層展示了"更深"的CNN:
# 來自 KDDCup 99/CNN/binary/cnn3.py(簡化版)
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout# ...(X_train, y_train, X_test, y_test 已準備好并重塑)...cnn = Sequential()
# 第一個卷積塊
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu", input_shape=(41, 1)))
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu")) # 另一個Conv1D
cnn.add(MaxPooling1D(pool_length=(2)))
# 第二個卷積塊
cnn.add(Convolution1D(128, 3, border_mode="same", activation="relu")) # 更多過濾器用于更復雜的模式
cnn.add(Convolution1D(128, 3, border_mode="same", activation="relu"))
cnn.add(MaxPooling1D(pool_length=(2)))
# 展平和密集層用于分類
cnn.add(Flatten())
cnn.add(Dense(128, activation="relu"))
cnn.add(Dropout(0.5))
cnn.add(Dense(1, activation="sigmoid"))# cnn.compile(...) # 編譯代碼
# cnn.fit(...) # 訓練代碼
觀察:
- 這個模型使用了兩個
Convolution1D層后跟一個MaxPooling1D層,然后用更多過濾器(128而不是64)重復這個模式。這使得網絡能夠學習逐漸更復雜和抽象的模式。 - 過濾器的數量通常在更深的層中增加,因為它們學習將更簡單的特征組合成更復雜的特征。
- 輸出層和損失函數與
cnn1.py相同,因為它仍然是二分類任務。
3. 簡單CNN(1個卷積+池化塊)- 多分類
最后,我們來看KDDCup 99/CNN/multiclass/cnn1.py。它使用類似的CNN結構,但適應了多分類:
# 來自 KDDCup 99/CNN/multiclass/cnn1.py(簡化版)
from keras.models import Sequential
from keras.layers import Convolution1D, MaxPooling1D, Flatten, Dense, Dropout
from keras.utils.np_utils import to_categorical # 用于標簽準備
import numpy as np# ...(X_train, y_train1, X_test, y_test1 已準備好)...
# 數據準備:對多分類標簽進行one-hot編碼
y_train = to_categorical(y_train1)
y_test = to_categorical(y_test1)cnn = Sequential()
# 卷積和池化層保持不變用于特征提取
cnn.add(Convolution1D(64, 3, border_mode="same", activation="relu", input_shape=(41, 1)))
cnn.add(MaxPooling1D(pool_length=(2)))
cnn.add(Flatten())
cnn.add(Dense(128, activation="relu"))
cnn.add(Dropout(0.5))
# 輸出層:5個神經元(用于5個類別),softmax激活
cnn.add(Dense(5, activation="softmax"))# cnn.compile(...) # 編譯代碼
# cnn.fit(...) # 訓練代碼
觀察:
- 關鍵的是,
y_train和y_test標簽在輸入模型前使用to_categorical(one-hot編碼)轉換,如第1章所述。 - 特征提取部分(
Convolution1D和MaxPooling1D層)與二分類版本相同。 - 輸出層使用
Dense(5)(假設多分類數據集中有5個類別)和activation="softmax"。 - 損失函數現在是
categorical_crossentropy,適用于one-hot編碼標簽。
這些示例清楚地展示了使用Convolution1D和MaxPooling1D層提取模式是CNN的核心,而輸出層和損失函數則根據具體分類任務進行調整。
結論
現在,已經了解了純卷積神經網絡(CNN)模型在網絡入侵檢測中的基礎知識
理解了Convolution1D層如何作為模式檢測器,MaxPooling1D層如何總結這些檢測,以及展平層如何將這些見解準備好用于傳統的密集分類層。你還看到了如何使用Keras構建這些模型,并為二分類和多分類入侵檢測任務配置它們,這些建立在前面章節的基礎知識之上。
CNN在自動學習網絡流量特征中的"簽名"方面非常有效,這對于發現復雜和不斷演變的威脅至關重要。
接下來,我們將探索另一種強大的深度學習模型:循環神經網絡(RNN)。雖然CNN擅長發現局部模式,但RNN設計用于記住較長序列中的信息,這對于理解網絡流量的時間性質特別有用。
第6章:循環神經網絡(RNN)模型(LSTM/GRU/SimpleRNN)


:用戶界面及系統管理界面布局)








![[硬件電路-166]:Multisim - SPICE與Verilog語言的區別](http://pic.xiahunao.cn/[硬件電路-166]:Multisim - SPICE與Verilog語言的區別)







