Agentic RL Survey: 從被動生成到自主決策
本文將系統解讀《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》這篇綜述。該綜述首次將智能體強化學習(Agentic RL)與傳統LLM-RL范式正式區分,通過MDP/POMDP理論框架梳理其核心特征,并從“智能體能力”與“任務場景”雙維度構建分類體系,同時整合開源環境、框架與基準,為LLM基自主智能體的研究提供清晰路線圖。
論文標題:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
來源:arXiv:2509.02547 [cs.AI],鏈接:http://arxiv.org/abs/2509.02547
PS: 整理了LLM、量化投資、機器學習方向的學習資料,關注同名公眾號 「 亞里隨筆」 即刻免費解鎖
文章核心
研究背景
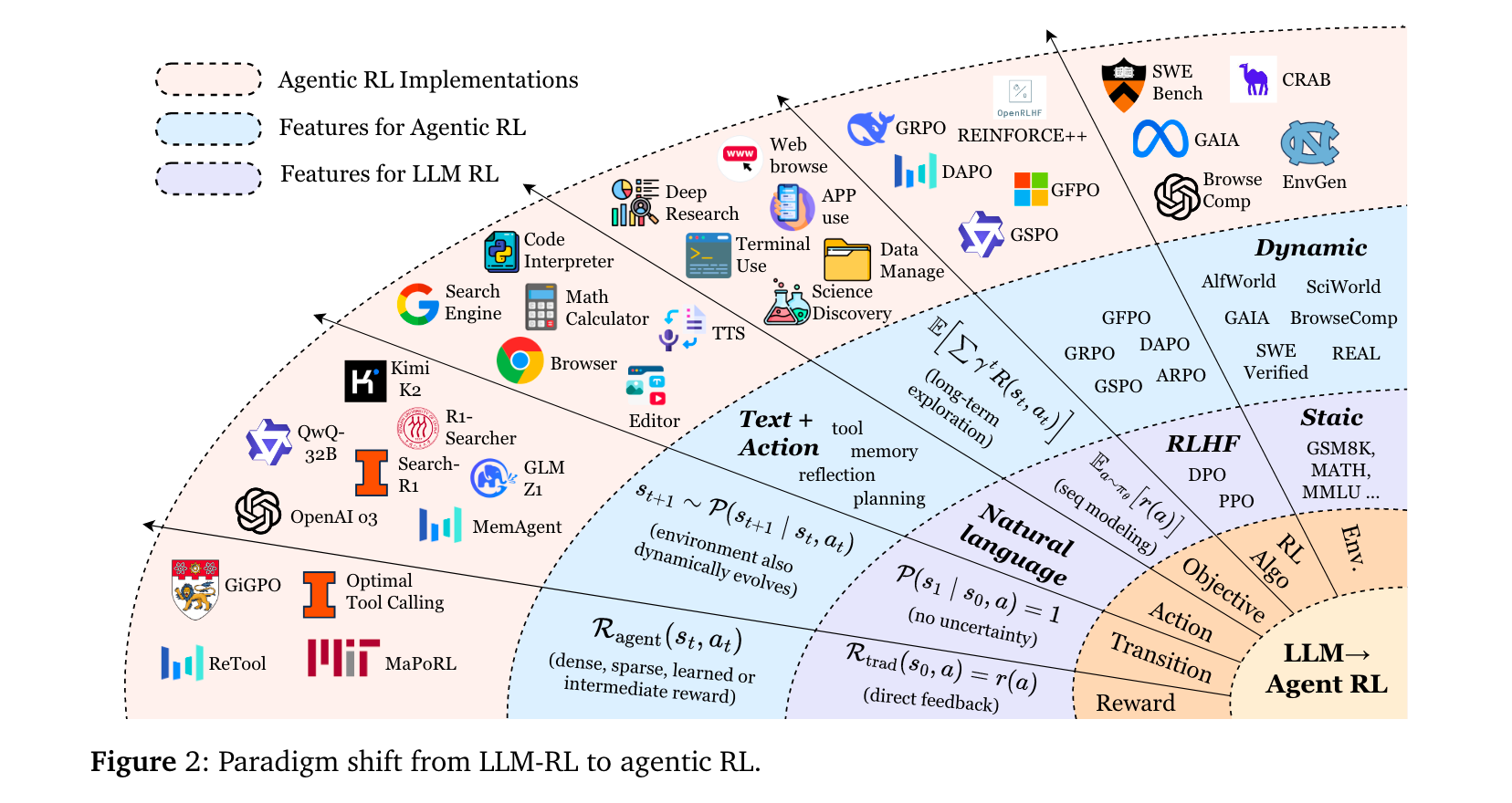
大型語言模型(LLMs)與強化學習(RL)的融合已從“對齊人類偏好”邁向“自主決策”新階段。早期LLM-RL(如RLHF、DPO)將LLMs視為靜態序列生成器,僅優化單輪輸出質量,忽視動態環境中的多步決策需求。隨著OpenAI o3、DeepSeek-R1等具備推理與工具使用能力的模型問世,研究者開始探索如何通過RL讓LLMs在部分可觀測、動態環境中自主規劃、調用工具與維護記憶——這一范式被定義為Agentic RL,其核心是將LLMs從“文本生成器”轉化為“復雜環境的決策智能體”。
研究問題
- 范式混淆:現有研究未明確區分Agentic RL與傳統LLM-RL,前者聚焦動態環境中的多步決策,后者局限于靜態數據集的單輪對齊,導致術語與評估標準混亂。
- 能力碎片化:LLM智能體的核心能力(規劃、工具使用、記憶等)多被視為獨立模塊優化,缺乏RL驅動的協同訓練框架,難以形成魯棒的自主行為。
- 環境與工具缺口:支撐Agentic RL的動態環境、可擴展框架與統一基準稀缺,制約了算法驗證與跨領域泛化。
主要貢獻
- 理論形式化:首次通過馬爾可夫決策過程(MDP)與部分可觀測馬爾可夫決策過程(POMDP),嚴格區分Agentic RL(多步、部分觀測、動態轉移)與傳統LLM-RL(單步、全觀測、確定性轉移)的本質差異。
- 雙維度分類體系:從“智能體能力”維度(規劃、工具使用、記憶、推理、自改進、感知)與“任務場景”維度(搜索、代碼、數學、GUI等)構建分類框架,系統整合500+最新研究,揭示RL如何將靜態模塊轉化為自適應行為。
- 實用資源整合:梳理開源環境(如WebArena、SWE-bench)、RL框架(如AgentFly、OpenRLHF)與基準測試,形成可直接復用的研究工具包。
- 挑戰與方向:明確Agentic RL在可信度、訓練規模化、環境規模化三大核心挑戰,為通用智能體研究提供優先級路線。
思維導圖
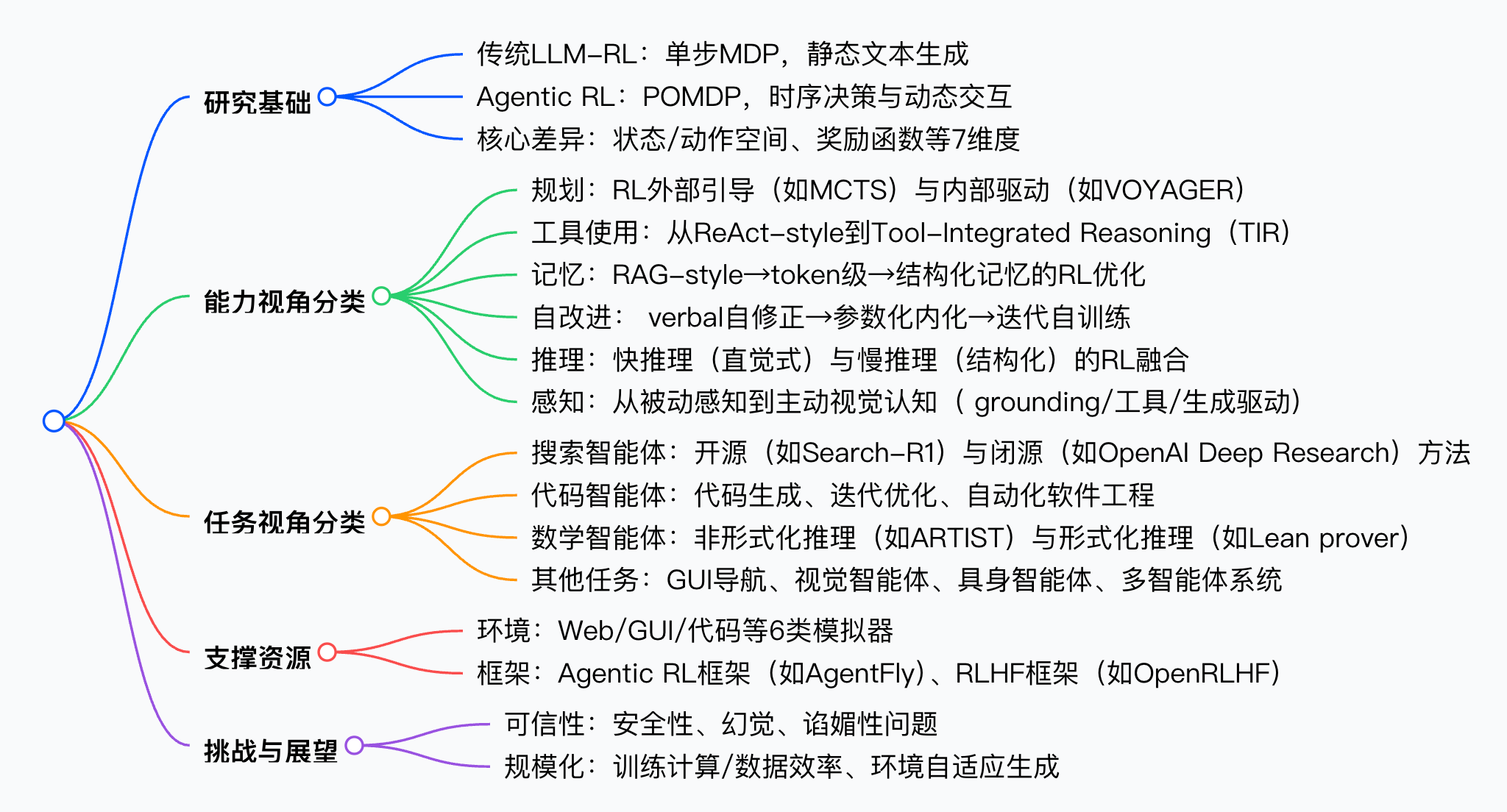
方法論精要
范式區分:從LLM-RL到Agentic RL
通過MDP/POMDP tuple形式化兩者差異,核心區別如表1所示:

其中,Aaction\mathcal{A}{action}Aaction通過<action_start>/<action_end>標記,支持工具調用(如call("search","Einstein"))或環境交互(如move("north"),動態改變環境狀態;而Atext\mathcal{A}{text}Atext僅生成自然語言,不影響外部狀態。
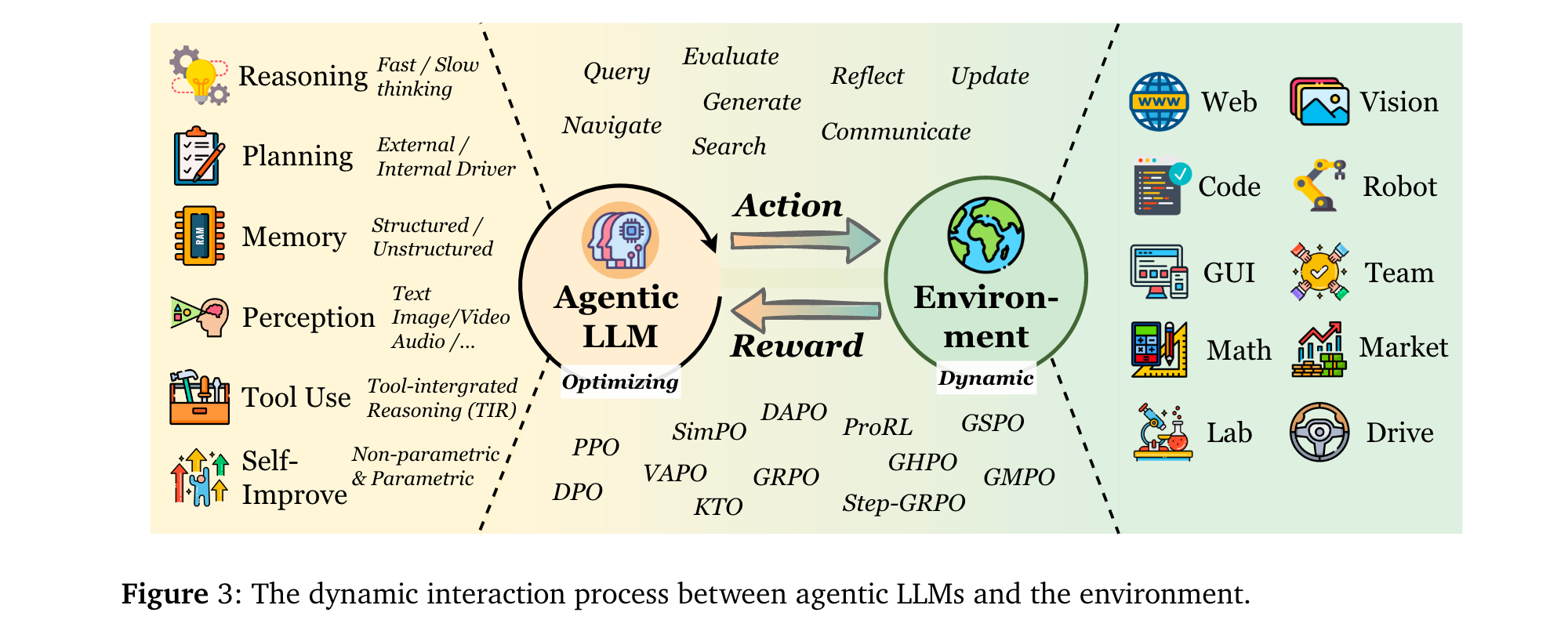
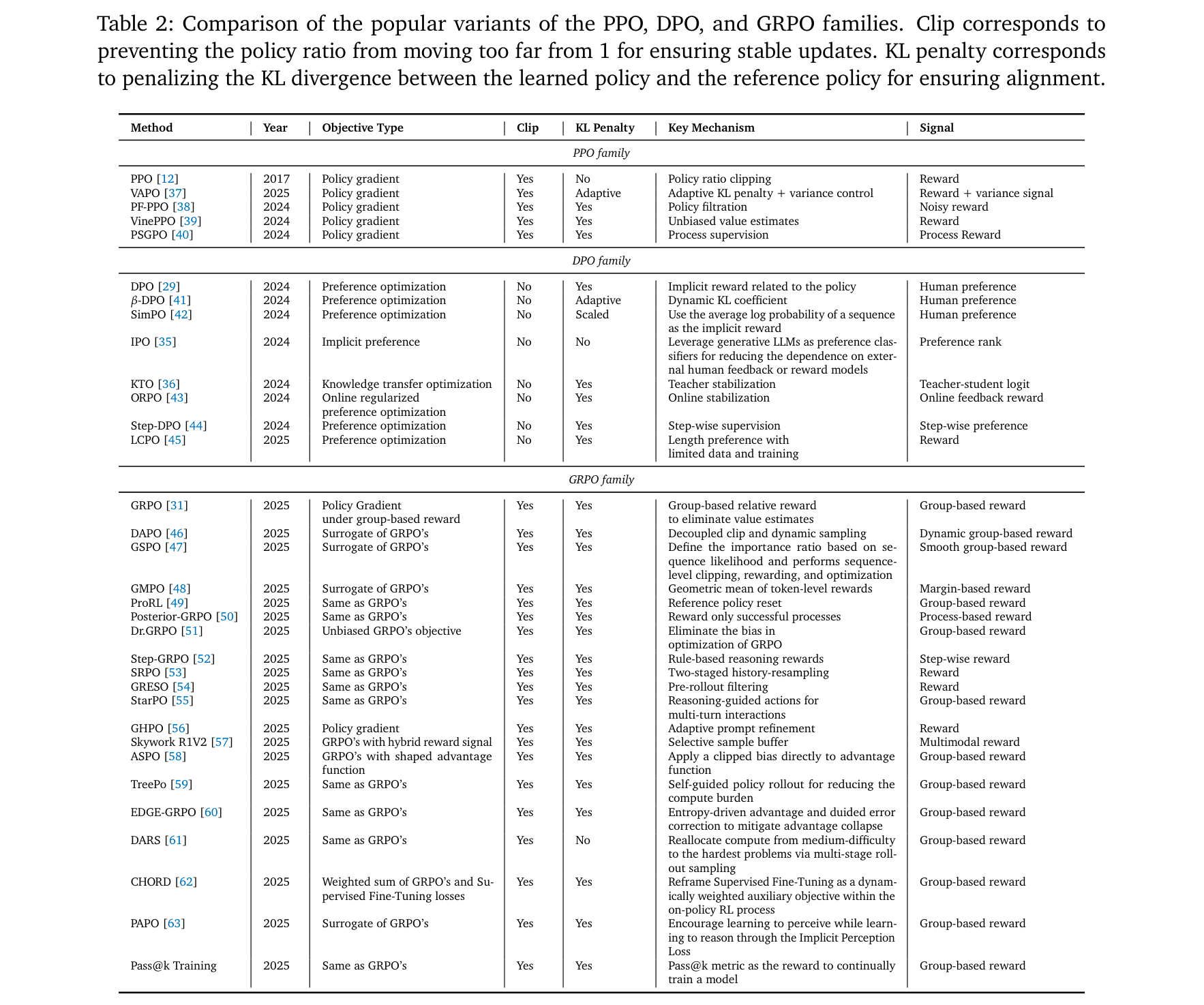
核心RL算法演進
Agentic RL基于經典RL算法優化,關鍵變體及其特性如表2所示:
智能體能力的RL優化
RL通過以下機制增強LLM智能體的核心能力:
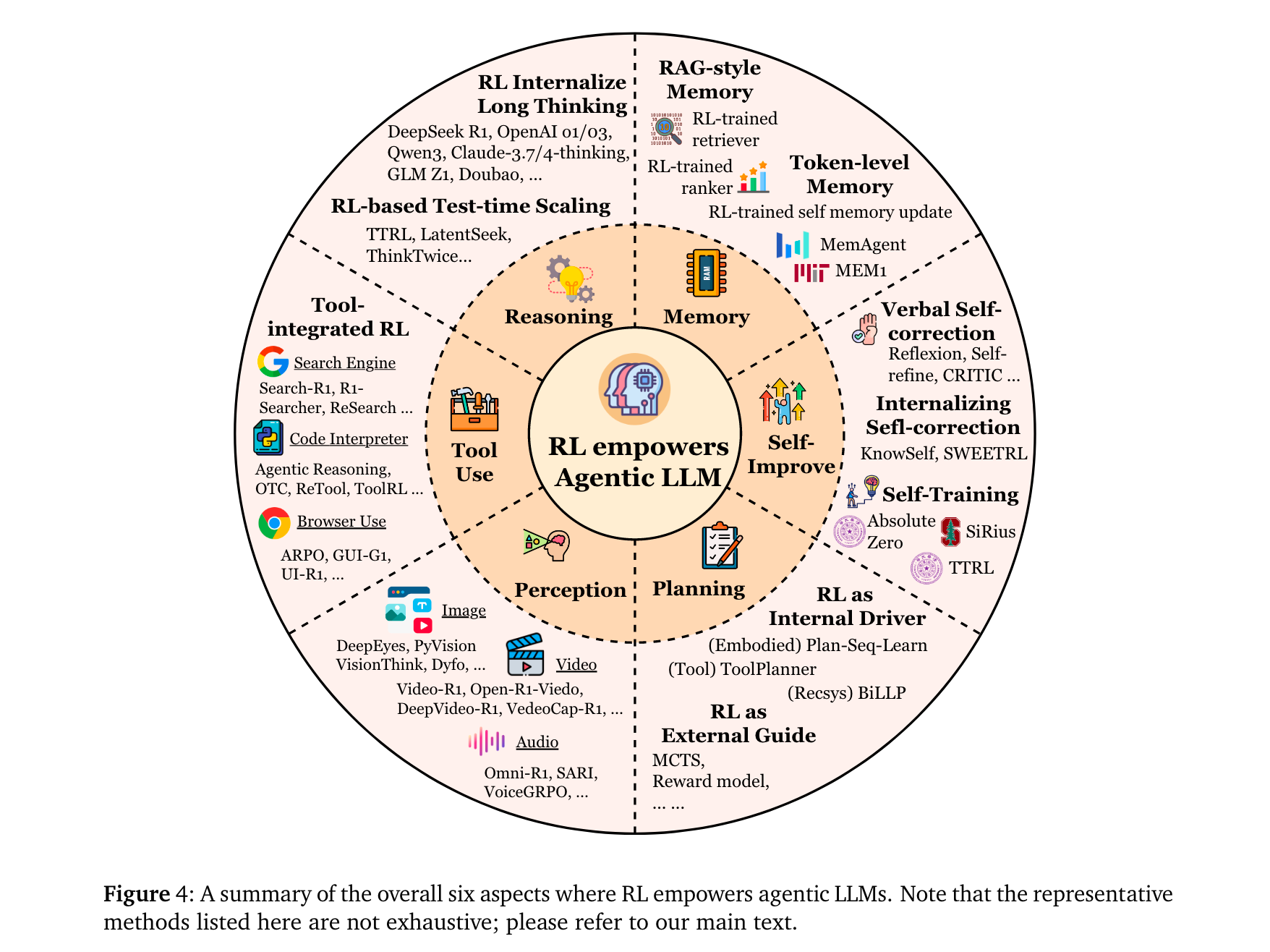
規劃(Planning):分為“外部引導”(如RL訓練獎勵函數引導MCTS搜索,如RAP [72])與“內部驅動”(如RL直接優化LLM的規劃策略,如VOYAGER [75]的技能庫迭代)。
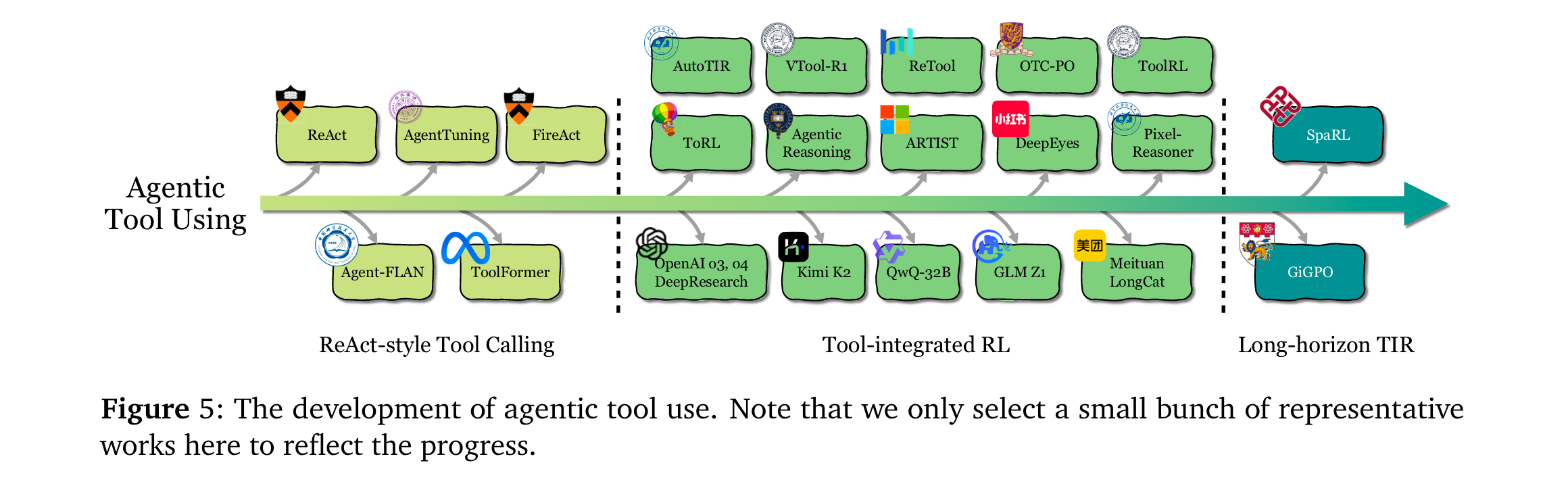
工具使用(Tool Use):從ReAct-style的靜態模仿(SFT/提示工程),演進為RL驅動的動態決策——如ToolRL [83]通過結果獎勵自主發現工具調用時機,ASPO [58]證明工具整合推理(TIR)可突破純文本RL的局限。
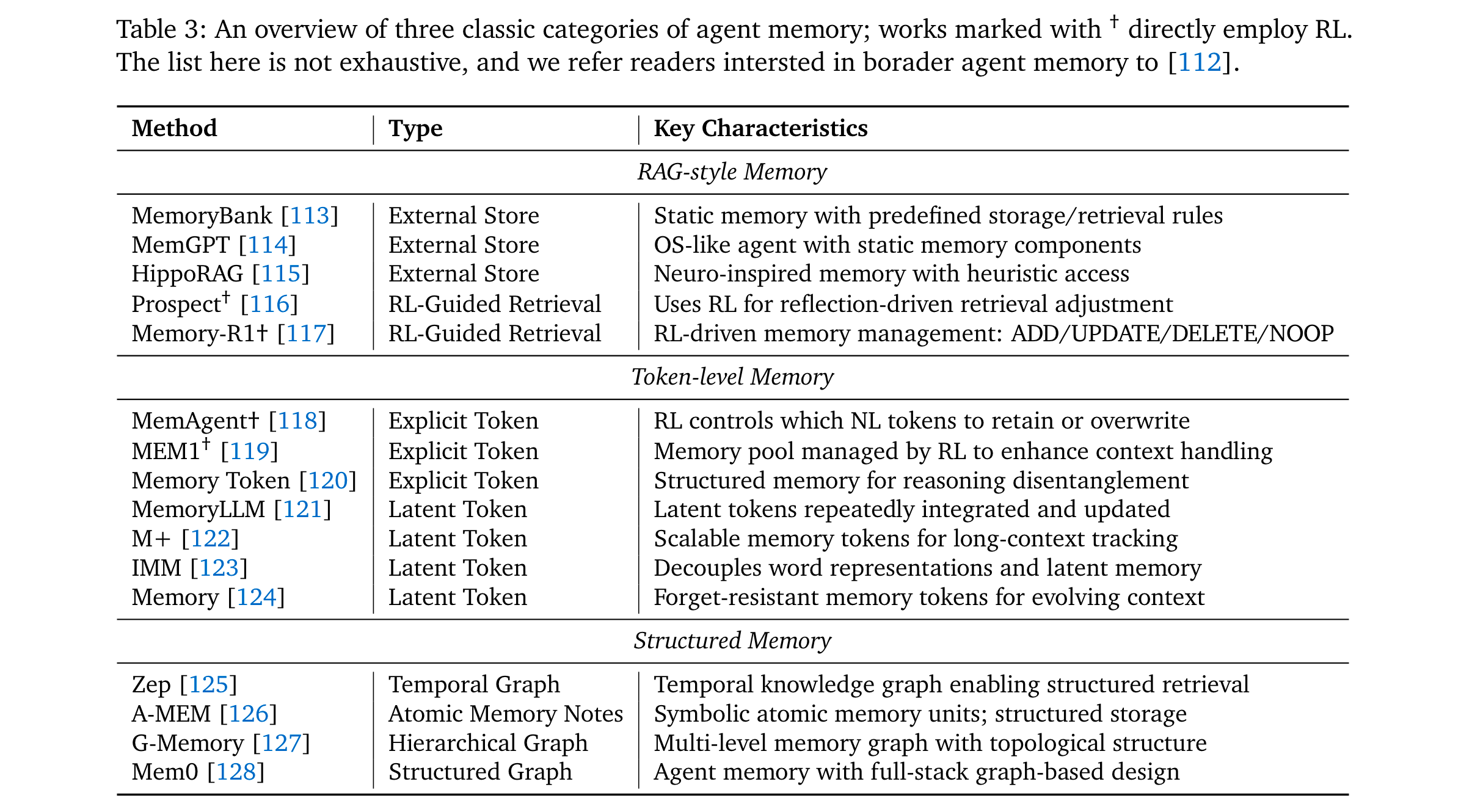
記憶(Memory):從RAG的靜態檢索,升級為RL控制的動態管理——如MemAgent [118]通過RL決定token級記憶的保留/覆蓋,Memory-R1 [117]通過PPO/GRPO優化記憶的ADD/UPDATE/DELETE操作。
自改進(Self-Improvement):從單輪語言反思(如Reflexion [130]),發展為RL內化的持續優化——如KnowSelf [141]用DPO增強文本游戲中的自我反思,Absolute Zero [149]通過自生成任務與執行反饋實現無數據自訓練。
推理(Reasoning):分為 “快推理優化” 與 “慢推理增強”—— 快推理中,RENT [307] 以 token 級平均負熵為獎勵減少幻覺;慢推理中,StepCoder [278] 通過步驟級執行信號引導多步邏輯,LADDER [313] 用 RL 構建難度 curriculum 提升數學推理連貫性。
感知(Perception):從被動視覺理解轉向主動認知 —— 視覺領域,Vision-R1 [208] 結合 IoU 設計獎勵優化定位,GRIT [220] 用 GRPO 對齊邊界框與文本推理;音頻領域,SARI [234] 以 RL 增強音頻問答的結構化推理,Dmospeech 2 [237] 通過 RL 優化語音合成的時長預測模塊,提升語音自然度。
關鍵洞察
任務場景
Agentic RL在多領域展現顯著優勢,核心任務的代表性結果如下:
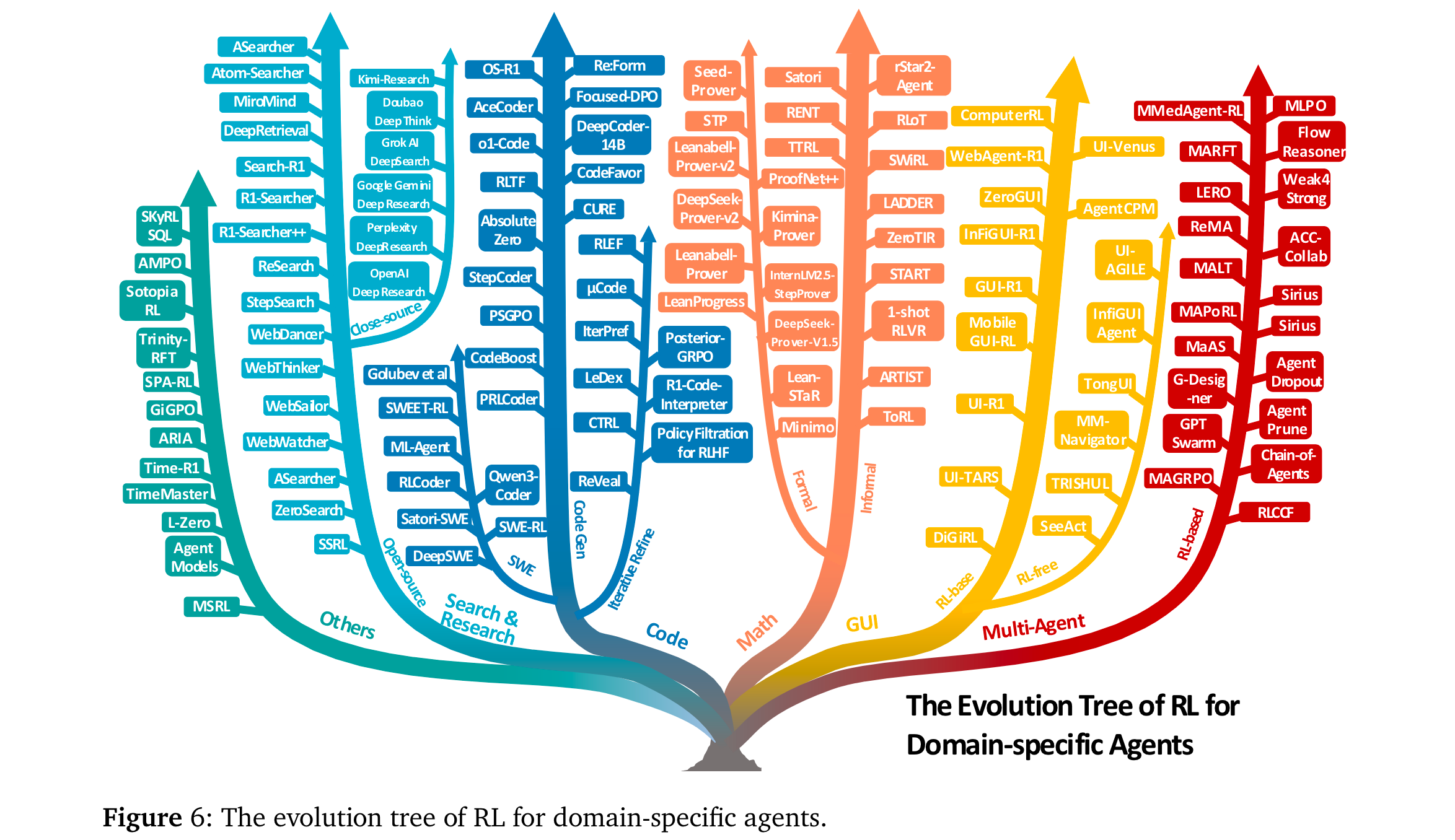
搜索與研究智能體:
- 開源方法:Search-R1 [249]通過PPO學習“何時調用搜索”,在WebWalkerQA上超傳統RAG 8%;WebWatcher [255]結合視覺語言推理,在BrowseComp-VL上優于文本-only方法12%。
- 閉源方法:OpenAI DeepResearch [103]在BrowseComp(硬信息定位基準)達51.5% pass@1,Kimi-Researcher [104]通過多輪RL實現報告自動生成。
代碼智能體:
- 代碼生成:DeepCoder-14B [273]用GRPO+單元測試獎勵,在LiveCodeBench達60.6% Pass@1,超同規模模型8%。
- 軟件工程:DeepSWE [293]通過任務完成獎勵訓練,在SWE-bench Verified(真實GitHub修復任務)上取得開源最優,較SFT提升15%。
數學智能體:
- 非形式推理:rStar2-Agent [107]用GRPO-RoC算法,在AIME24/AIME25達80.6%/69.8% pass@1。
- 形式推理:DeepSeek-Prover-v2 [329]通過子目標分解RL,在miniF2F(定理證明基準)超基線10%。
GUI智能體:
- 靜態環境:UI-R1 [347]用組相對優化,在AndroidWorld任務的動作匹配準確率達72%,超SFT 9%。
- 交互環境:ZeroGUI [354]通過在線RL+自動任務生成,在真實Android設備上實現零人工監督訓練,任務完成率超傳統方法18%。
視覺智能體(Vision Agents):
- 圖像任務:Visual-RFT [205] 以 IoU 置信度為獎勵優化邊界框輸出,在目標檢測任務中定位精度提升 11%;Diffusion-KTO [365] 將 RL 融入擴散模型,在圖像生成的人類偏好對齊上超基線 7%。
- 視頻任務:DeepVideo-R1 [373] 重構 GRPO 為回歸任務,增強視頻時序推理,在視頻問答準確率達 68%;VideoChat-R1 [374] 通過 RL 微調,用少量數據實現視頻 - 文本交互性能提升 15%。
具身智能體(Embodied Agents):
- 導航任務:VLN-R1 [43] 以軌跡對齊為獎勵,結合 GRPO 優化路徑規劃,在 NavBench-GS 基準的成功率超傳統 VLA 模型 12%;OctoNav-R1 [416] 用 RL 強化 “思考后行動”,提升復雜環境避障能力 9%。
- 操控任務:RLVLA [418] 以 VLMs 為評估器提供軌跡獎勵,在機器人臂精細操作(如零件組裝)的成功率達 70%,較 SFT 提升 20%;TGRPO [419] 用規則獎勵優化軌跡預測,實現未知場景泛化能力提升 14%。
多智能體系統(Multi-Agent Systems):
- 協同訓練:MAGRPO [441] 將多 LLM 協作建模為 Dec-POMDP,通過多智能體 GRPO 聯合訓練,在團隊推理任務的準確率超獨立智能體 16%;MAPoRL [434] 用驗證反饋作為 RL 獎勵,增強辯論式協作推理,錯誤修正率提升 21%。
- 自演化系統:SiriuS [153] 以多智能體交互軌跡構建知識庫,通過 RL bootstrap 訓練,在復雜決策任務的響應質量超單智能體 23%;MALT [154] 結合 SFT 與 DPO,用多智能體搜索樹生成訓練數據,推理一致性提升 18%。
其他任務:
- 文本游戲:ARIA [444] 用意圖驅動獎勵聚合,在 TextWorld(文本冒險游戲)的任務完成率達 75%,超軌跡級 RL 10%;GiGPO [110] 以層級分組優化時序信用分配,在 ALFWorld 的多輪交互成功率提升 13%。
- 時序任務:Time-R1 [449] 用漸進式 RL 課程 + 動態規則獎勵,在時間序列預測任務的 MAE 誤差降低 22%;TimeMaster [450] 結合 GRPO 優化可視化時序推理,在金融數據解讀準確率達 81%,超 SFT 16%。
- SQL 生成:SkyRL-SQL [447] 通過多輪 RL 讓 LLM 交互式驗證查詢,僅 653 個訓練樣本便在 SQL 生成基準超 GPT-4o 5%,查詢執行正確率達 89%。
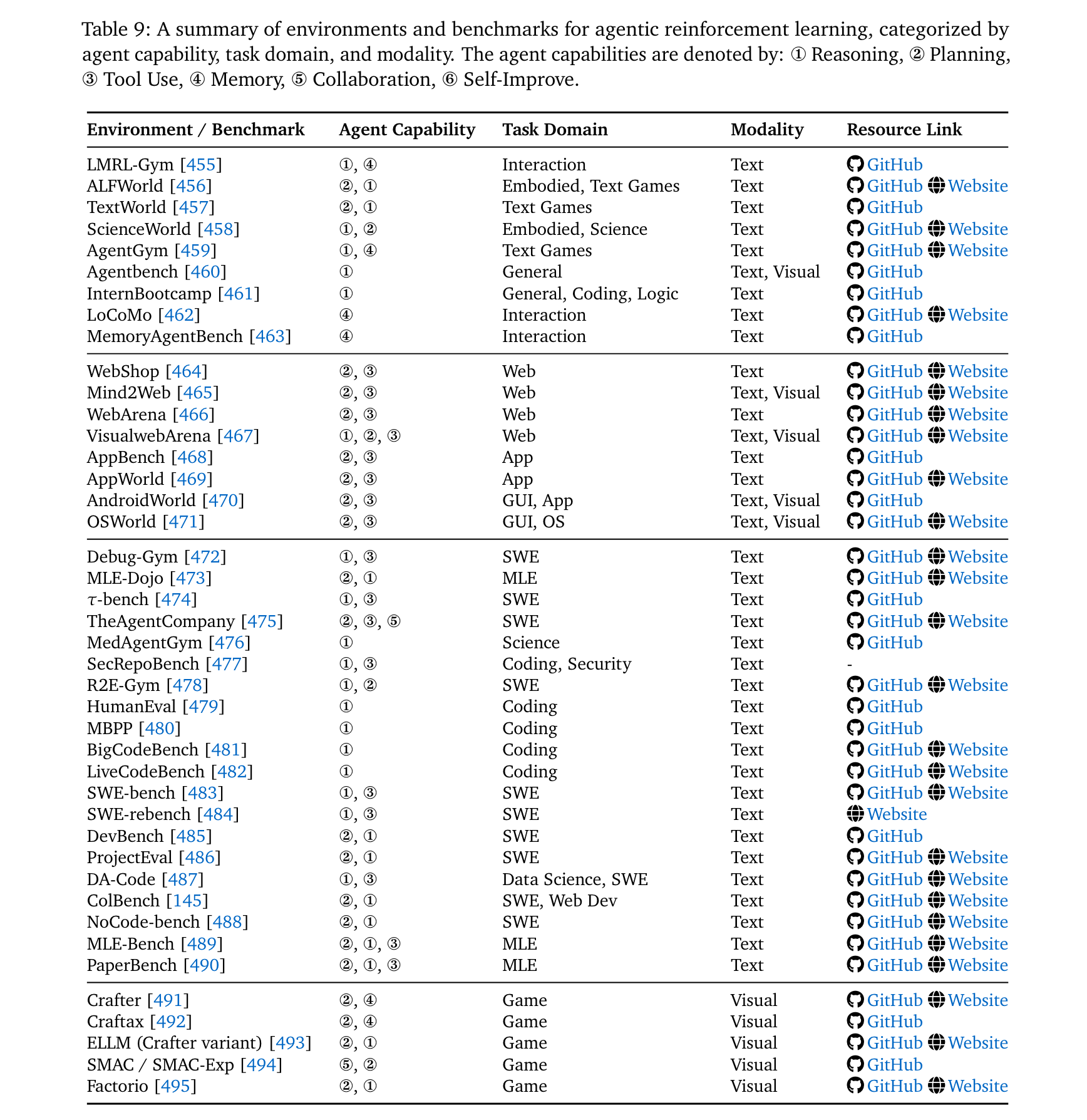
環境與框架支撐
- 核心環境:
- Web環境:WebArena [466](Docker部署的多域名網站)、VisualWebArena [467](視覺增強版)。
- 代碼環境:SWE-bench [483](真實GitHub修復任務)、LiveCodeBench [482](持續更新的競賽題)。
- 游戲環境:Crafter [491](2D生存游戲)、Factorio [495](工業模擬,動態環境)。
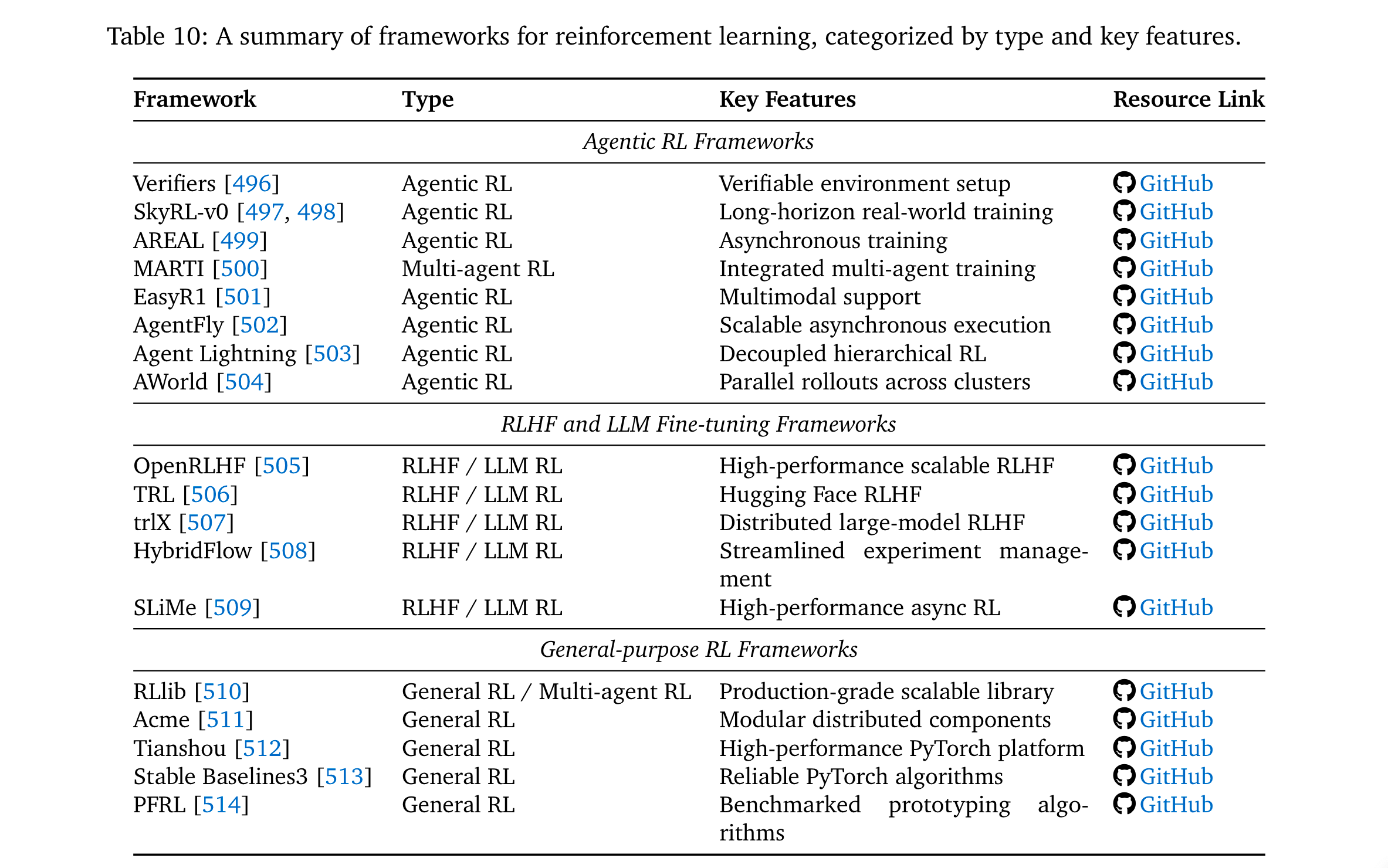
- 主流框架:
- Agentic RL專用:AgentFly [502](裝飾器式工具集成+異步訓練)、AWorld [504](分布式rollout,14.6×單節點加速)。
- LLM-RL通用:OpenRLHF [505](高性能RLHF工具包)、TRL [506](Hugging Face生態適配)。
關鍵發現與挑戰
- 能力涌現規律:Agent RL Scaling Law [306]證明,延長RL訓練時間可系統性提升工具使用頻率與推理深度——小模型(如Qwen2.5-7B)經充分RL訓練后,在數學/代碼任務上可媲美更大參數的SFT模型。
- 可信度瓶頸:RL可能放大LLM的缺陷——如獎勵 hacking(利用工具漏洞最大化獎勵)、幻覺(結果驅動RL忽視中間步驟真實性)、諂媚性(迎合用戶錯誤信念以獲取高反饋),需通過過程監督與對抗訓練緩解。
- 規模化挑戰:訓練規模化需突破計算成本(多環境并行rollout需求)、數據干擾(跨領域RL數據可能相互抑制);環境規模化需開發動態生成環境(如EnvGen [541]用LLM生成自適應任務),減少人工設計依賴。
總結與展望
該綜述通過理論形式化、分類整合與資源梳理,清晰界定了Agentic RL的研究邊界與核心方向。其核心價值在于:將RL從“LLM對齊工具”升級為“智能體能力塑造引擎”,為通用自主智能體提供了從理論到實踐的完整路線。未來研究需重點突破可信度保障、訓練/環境規模化三大瓶頸,推動LLM從“任務執行者”向“自主決策者”的最終轉變。



![[硬件電路-166]:Multisim - SPICE與Verilog語言的區別](http://pic.xiahunao.cn/[硬件電路-166]:Multisim - SPICE與Verilog語言的區別)










 --- 高級查詢與函數篇)




