
從單張圖片重建高質量、可動畫化且面部與手部動作豐富的 3D 人體化身,應用前景廣闊。但傳統重建方法依賴多視角或單目視頻,還要針對不同個體訓練,復雜又耗時,且受 SMPLX 限制,難以捕捉面部表情。為解決這些問題,清華大學和 IDEA(粵港澳大灣區數字經濟研究院)研究團隊先引入富有表現力的人體模型(EHM)增強面部表現,開發精確跟蹤方法,進而提出首個快速重建可動畫化上半身 3D 高斯化身的框架 GUAVA。它借助逆紋理映射等技術推斷模型,經優化后,在渲染質量和速度上表現優異,相關代碼已開源。

介紹
創建逼真且富有表現力的上半身人體化身,例如包含細致的面部表情和豐富的手勢,在電影、游戲和虛擬會議等領域具有重要價值 。同時,易于創建和支持實時渲染也是關鍵要求 。然而,僅憑單張圖像實現這些目標仍然是一個的重大挑戰 。
3D Gaussian splatting (3DGS) 的興起催生了許多3D化身重建方法,它們利用 3DGS 實現實時、高質量的化身重建 。然而,這些方法仍然存在一些局限性 :
-
逐ID練:每個個體都需要單獨訓練 。
-
訓練復雜性:該過程耗時,需要標定的多視圖或單目視頻 。
-
表現力有限:頭部重建方法缺乏身體動作表示,而全身方法則忽略了細致的面部表情 。
擴散模型在視頻生成方面取得了顯著成果 。一些工作通過添加額外條件,如關鍵點或 SMPLX渲染圖,來引導擴散模型的生成過程,擴展了模型在生成可控人體動畫視頻上的應用。盡管這些方法實現了良好的視覺效果,但它們仍然面臨一些局限性 :
-
ID一致性:難以保持一致的 ID,尤其是在姿勢發生大變化時 。
-
效率:高計算成本和多步去噪導致推理速度慢,阻礙了實時應用 。
-
視點控制:2D 方法無法輕松調整相機姿勢,從而限制了視點控制 。
我們提出了 GUAVA,第一個從單張圖像創建可驅動上半身 3D高斯化身的框架。與需要多視圖視頻或單人訓練的3D方法不同,GUAVA 可以在秒級時間內完成推理重建,并支持實時動畫和渲染 。與基于擴散模型的2D方法相比,GUAVA使用 3D高斯來確保更好的ID一致性和實時渲染 。并引入一種富有表現力的人體模型EHM,解決了現有模型在捕捉細致面部表情方面的局限性 。還利用逆紋理映射技術以準確地預測高斯紋理,并結合一個神經渲染器來提高渲染質量 。通過充分的實驗也展示了其在渲染質量和效率方面優于現有2D和3D方法 。
相關鏈接
-
論文地址: https://arxiv.org/pdf/2505.03351
-
項目主頁:https://eastbeanzhang.github.io/GUAVA/
-
開源代碼:https://github.com/Pixel-Talk/GUAVA
-
視頻Demo: GUAVA: Generalizable Upper Body 3D Gaussian Avatar_嗶哩嗶哩_bilibili
方法
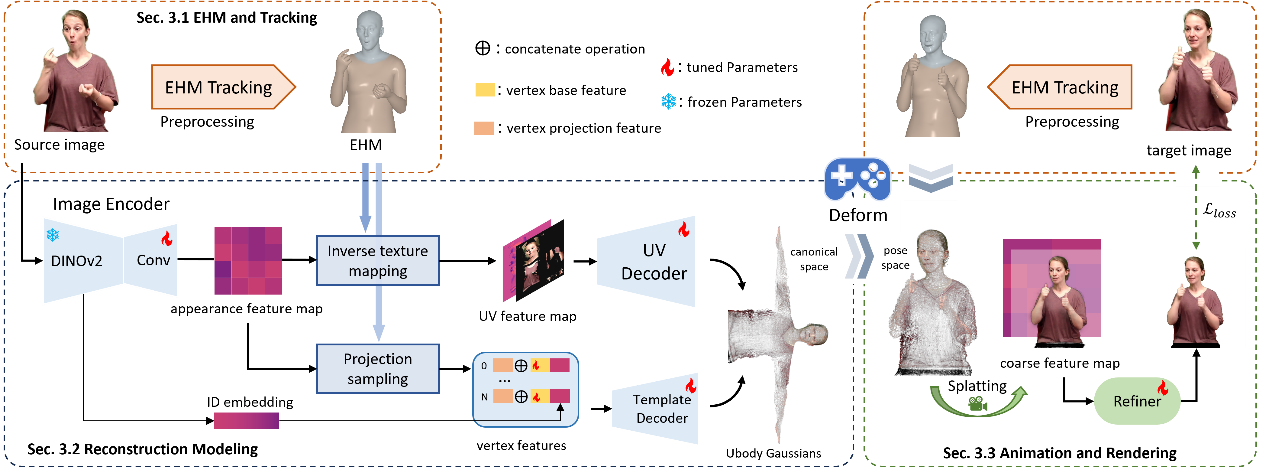
-
EHM 模型與精確跟蹤:為了解決SMPLX 模型在捕捉面部表情上的不足,GUAVA 引入了 EHM(Expressive Human Model)。EHM 結合了 SMPLX 和 FLAME 模型,能夠實現更準確的面部表情表示 。同時我們設計了對應的通過兩階段追蹤方法,實現從單張圖像到姿態的準確估計。首先利用預訓練模型進行粗略估計,然后使用 2D 關鍵點損失進行精細優化,從而為重建提供精確的姿勢和表情參數 。
-
快速重建與雙分支模型: GUAVA基于追蹤后的圖像通過單次前向推理方式完成化身的重建。它包含兩個分支:一個分支根據 EHM 頂點和投影特征預測粗略的“模板高斯”,另一個分支則通過“逆紋理映射”技術,將屏幕特征映射到 UV 空間,生成捕捉精細細節的“UV 高斯”。這兩種高斯組合成完整的 Ubody 高斯,從而在保持幾何結構的同時,捕捉豐富的紋理細節。
-
實時動畫與渲染:重建完成后,Ubody 高斯可以根據新的姿勢參數進行變形和動畫 。最后,通過神經細化器對渲染的圖像進行優化,以增強細節和渲染質量 。
實驗
實驗設置
我們從 YouTube、OSX和 HowToSign收集視頻數據集,主要關注人體上半身視頻。其中訓練集包含超過 62 萬幀,測試集包含 58 個 ID 。為確保評估的全面性,實驗采用了多種指標:自重演(self-reenactment)場景下,通過 PSNR、L1、SSIM 和 LPIPS 評估動畫結果的圖像質量 ;跨重演(cross-reenactment)場景下,使用 ArcFace 計算身份保留分數(IPS)以衡量 ID 一致性 。評估中與 MagicPose、Champ、MimicMotion 等2D方法以及 GART、GaussianAvatar 和 ExAvatar 3D方法進行比較。
定量結果
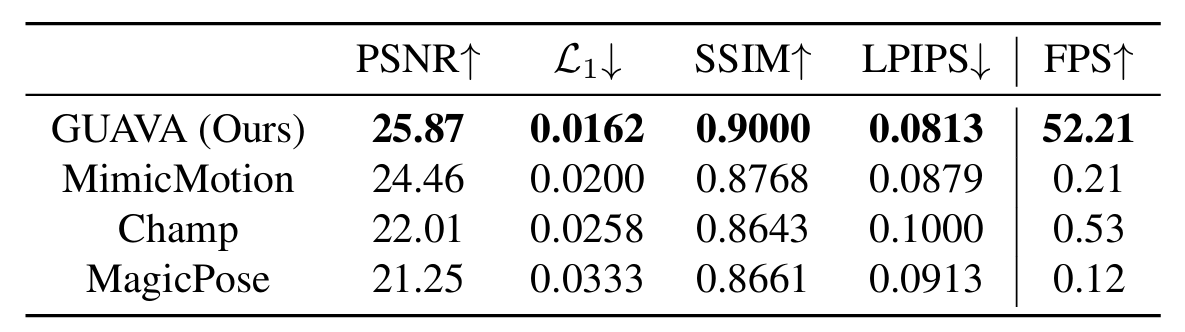
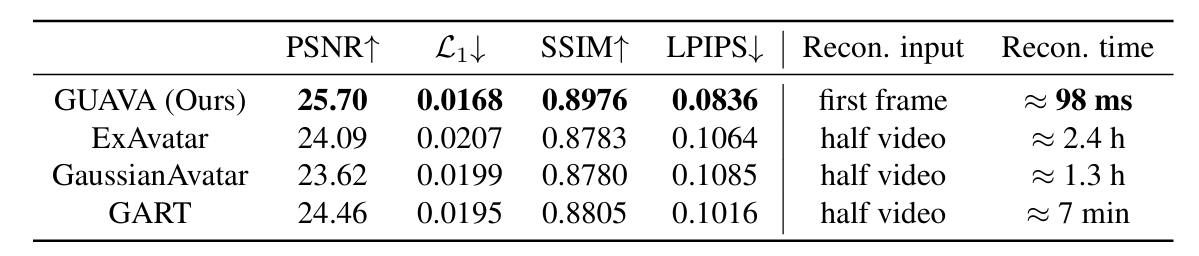
Self-reenactment:與 2D 方法相比,GUAVA 在所有指標(PSNR, L1?, SSIM, LPIPS)上均表現最佳,并在動畫和渲染速度上達到約 50 FPS,而其他方法僅為每秒幾幀 。與 3D 方法相比,GUAVA 的重建時間僅為 0.1 秒左右,而其他方法需要數分鐘到數小時 。
Cross-reenactment:GUAVA 在身份保留分數(IPS)上顯著優于其他所有 2D 方法,證明了其在不同姿勢下保持 ID 一致性的能力 。

定性結果
盡管 2D 方法能生成高質量圖像,但它們在保持 ID 一致性和準確恢復復雜手勢及面部表情方面存在不足 。例如,Champ 的手部模糊 ,MagicPose 存在失真 ,而 MimicMotion 則無法保持 ID 一致性 。3D 方法在處理精細的手指和面部表情方面存在困難,也缺乏泛化能力,在未見區域或極端姿勢下會產生偽影 。GUAVA 則能對未見區域生成合理的結果,在極端姿勢下表現出更好的魯棒性,并提供更準確、更細致的手部和面部表情 。



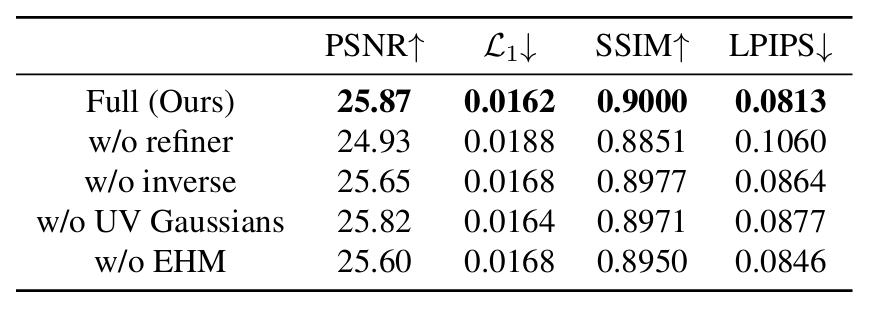
消融實驗
為了驗證方法中各個部分的有效性,在論文中進行了充分的消融實驗。


論文總結
該論文介紹了 GUAVA,一個用于從單張圖像重建可動畫、具有細膩表現力上半身 3D化身的快速框架 。研究通過引入 EHM 模型及其精確跟蹤方法,增強了面部表情、形狀和姿勢的捕捉能力 。論文通過UV 高斯和模板高斯的兩個推理分支共同構建一個上半身高斯 。實驗結果表明,GUAVA 在渲染質量和效率方面均優于現有方法 。它實現了約 0.1 秒的重建時間,并支持實時動畫和渲染 。





)













