一、作品詳細簡介
1.1附件文件夾程序代碼截圖
全部完整源代碼,請在個人首頁置頂文章查看:
學行庫小秘_CSDN博客?編輯https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.5343
1.2各文件夾說明
1.2.1 main.m主函數文件
這段 MATLAB 代碼實現了基于支持向量機(SVM)的回歸預測任務,主要步驟分解如下:
1. 數據導入與預處理
- 從 Excel 文件?數據集.xlsx?中讀取數據,存儲到矩陣?res?中。
- 假設數據包含 103 個樣本,每個樣本有 7 個特征(1-7列)和 1 個目標變量(第8列)。
2. 劃分訓練集與測試集
- randperm(103): 生成 1~103 的隨機排列,實現數據隨機打亂。
- 訓練集: 取前 80 個樣本的特征(P_train)和目標值(T_train)。
- 測試集: 取剩余 23 個樣本的特征(P_test)和目標值(T_test)。
- 轉置操作?'?使每列代表一個樣本(符合后續 SVM 輸入要求)。
3. 數據歸一化
- mapminmax: 將數據歸一化到?[0, 1]?區間。
- 訓練集歸一化: 計算歸一化參數?ps_input(特征)和?ps_output(目標值)。
- 測試集歸一化: 直接應用訓練集的歸一化參數(避免數據泄露)。
4. 調整數據維度
- 轉置操作將數據還原為?行樣本格式(每行一個樣本),以滿足后續?svmtrain?的輸入要求。
5. 創建 SVM 回歸模型
- 參數說明:
- -t 2: 使用徑向基核函數(RBF Kernel)。
- -c 4.0: 懲罰因子,控制過擬合。
- -g 0.8: RBF 核函數的 gamma 參數。
- -s 3: 回歸任務類型(ε-SVR)。
- -p 0.01: ε-不敏感損失函數的參數。
- svmtrain: 訓練 SVM 模型,輸出?model。
6. 模型預測
- svmpredict: 對訓練集和測試集進行預測,返回預測值 (t_sim1,?t_sim2) 和誤差指標。
7. 反歸一化
- 將歸一化的預測結果還原到原始數據量綱。
8. 評估指標計算
均方根誤差 (RMSE)
- RMSE 衡量預測值與真實值的偏差(越小越好)。
決定系數 (R2)
- R2 接近 1 表示模型擬合效果好。
平均絕對誤差 (MAE)
- MAE 反映預測誤差的絕對平均值。
平均偏差誤差 (MBE)
- MBE 表示預測值的系統性偏差(正負值指示偏差方向)。
9. 結果可視化
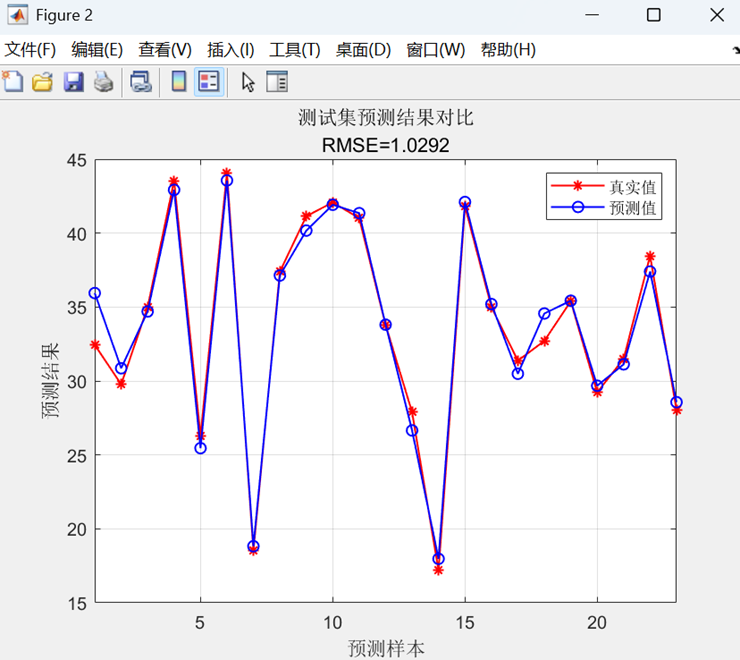
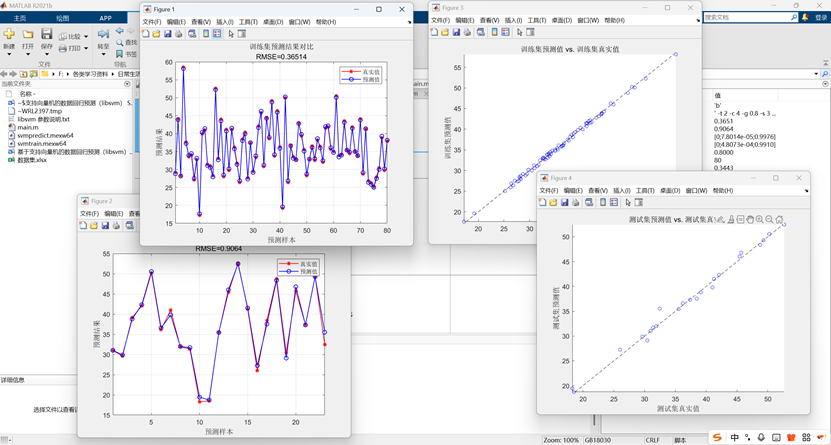
預測值與真實值對比曲線
- 繪制訓練集/測試集的真實值與預測值對比曲線,標注 RMSE。
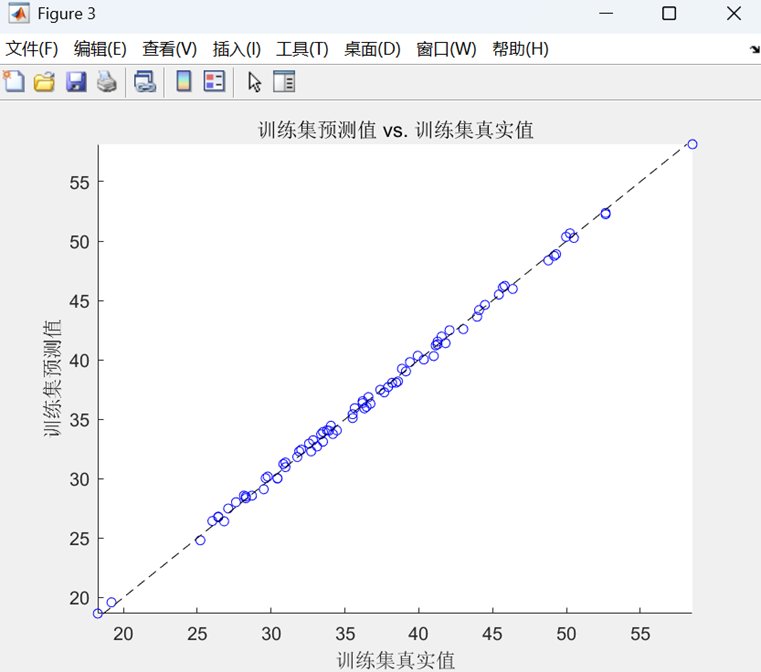
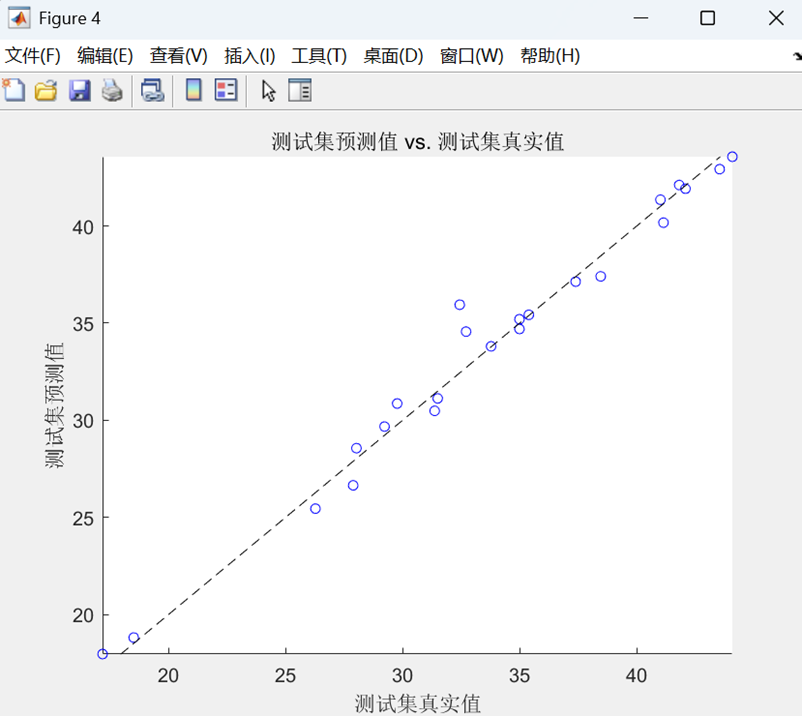
預測值與真實值散點圖
- 散點圖與參考線?y=x?結合,直觀展示預測準確性(點越靠近直線越好)。
關鍵注意事項
- 數據隨機性:?randperm?確保每次運行訓練/測試集劃分不同(可固定隨機種子復現結果)。
- 歸一化重要性: 避免特征量綱差異影響 SVM 性能。
- SVM 參數調優: 代碼中?c=4.0,?g=0.8?為預設值,實際需通過交叉驗證優化。
- 維度轉換: 多次轉置操作旨在適配不同函數對輸入格式的要求。
- 反歸一化: 確保誤差計算和可視化在原始量綱下進行。
此代碼完整實現了從數據預處理、模型訓練、預測到結果評估與可視化的全流程,適用于回歸預測任務。
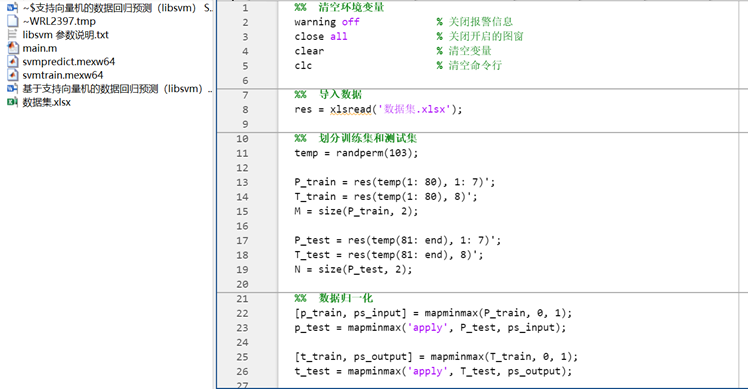
圖2? main.m主函數文件部分代碼
1.2.2 數據集文件
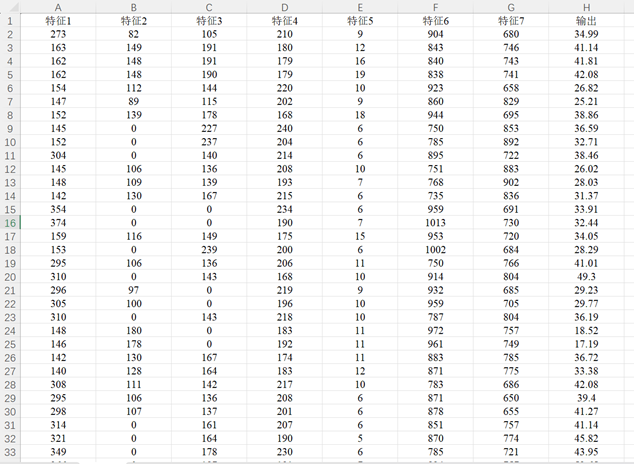
數據集為Excel數據csv格式文件,可以方便地直接替換為自己的數據運行程序。原始數據文件包含7列特征列數據和1列輸出標簽列數據,一共包含103條樣本數據,具體如圖所示。
二、代碼運行結果展示
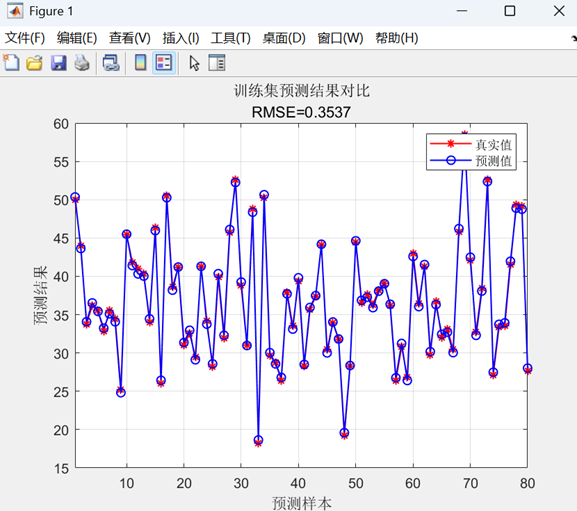
? ? ? ?該代碼實現了一個基于支持向量機(SVM)的回歸預測模型,用于建立特征與目標變量之間的映射關系。
? ? ? ?首先,代碼導入數據并隨機劃分80%樣本作為訓練集、23%樣本作為測試集,同時對特征和目標值進行歸一化處理;
? ? ? ?其次,使用徑向基核函數(RBF)配置SVM回歸模型參數(懲罰因子c=4.0,核參數g=0.8),訓練模型并分別在訓練集和測試集上進行預測;
? ? ? ?最后,通過反歸一化處理將預測結果還原到原始量綱,計算RMSE、R2、MAE和MBE等評估指標,并繪制預測值對比曲線和真實值-預測值散點圖來可視化模型性能。

三、注意事項:
1.程序運行軟件推薦Matlab 2018B版本及以上;
2.所有程序都經過驗證,保證程序可以運行。此外程序包含簡要注釋,便于理解。
3.如果不會運行,可以幫忙遠程運行原始程序以及講解和其它售后,該服務需另行付費。
4. 代碼包含詳細的文件說明,以及對每個程序文件的功能注釋,說明詳細清楚。
5.Excel數據,可直接修改數據,替換數據后直接運行即可。


 的用法及區別,分別適合什么場景使用?)






![[矩陣置零]](http://pic.xiahunao.cn/[矩陣置零])
)




)

)

