1. 遷移學習
遷移學習(transfer learning)是一種機器學習方法,通過將源數據集(如ImageNet)上訓練得到的模型知識遷移到目標數據集(如特定場景的椅子識別任務)。這種方法的核心在于利用預訓練模型已學習到的通用特征,提升目標任務的性能,尤其是在數據量有限的情況下。
ImageNet等大規模數據集雖然包含多樣化的圖像類別(如動物、植物、人造物體等),但在此類數據集上訓練的模型能夠自動學習低層次和高層次的通用視覺特征。這些特征包括但不限于:
- 邊緣檢測:識別圖像中的輪廓和邊界。
- 紋理分析:捕捉不同材質的表面特性。
- 形狀建模:提取物體的幾何結構。
- 對象組合關系:理解多物體間的空間和語義關聯。
盡管ImageNet可能不直接包含大量椅子圖像,但模型學習到的上述特征仍然能夠有效支持椅子識別任務。例如,椅子的邊緣結構與動物輪廓可能共享相似的檢測模式,而木質或布藝椅子的紋理特征可能與其他物體(如家具或服飾)的紋理分析機制高度相關。
通過遷移學習,目標任務無需從零開始訓練模型,從而顯著減少計算資源和時間成本。此外:
- 在目標數據集較小的情況下,遷移學習能夠避免過擬合問題
- 預訓練模型的高層次特征提取能力可提升目標任務的泛化性能
- 適用于跨領域應用,如醫學影像分析、自動駕駛等場景
2. 微調
遷移學習中的常見技巧:微調(fine-tuning)。
微調包括以下四個步驟。
在源數據集(例如ImageNet數據集)上預訓練神經網絡模型,即源模型。
創建一個新的神經網絡模型,即目標模型。這將復制源模型上的所有模型設計及其參數(輸出層除外)。我們假定這些模型參數包含從源數據集中學到的知識,這些知識也將適用于目標數據集。我們還假設源模型的輸出層與源數據集的標簽密切相關;因此不在目標模型中使用該層。
向目標模型添加輸出層,其輸出數是目標數據集中的類別數。然后隨機初始化該層的模型參數。
在目標數據集(如椅子數據集)上訓練目標模型。輸出層將從頭開始進行訓練,而所有其他層的參數將根據源模型的參數進行微調。
微調中的 權重初始化:
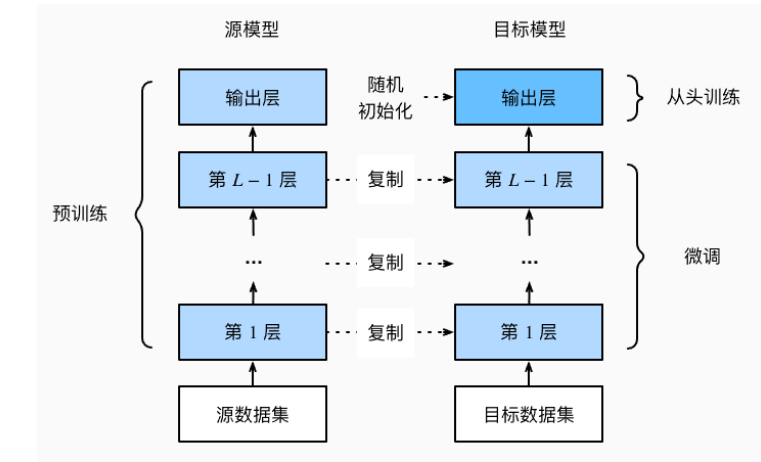

遷移學習將從源數據集中學到的知識遷移到目標數據集,微調是遷移學習的常見技巧。
除輸出層外,目標模型從源模型中復制所有模型設計及其參數,并根據目標數據集對這些參數進行微調。
但是,目標模型的輸出層需要從頭開始訓練。
通常,微調參數使用較小的學習率,而從頭開始訓練輸出層可以使用更大的學習率。
3. 代碼實現
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l#@save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')data_dir = d2l.download_extract('hotdog')train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))下面顯示了前8個正類樣本圖片和最后8張負類樣本圖片。
正如所看到的,圖像的大小和縱橫比各有不同。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);
數據增廣:
對于RGB(紅、綠和藍)顏色通道,我們分別標準化每個通道。 具體而言,該通道的每個值減去該通道的平均值,然后將結果除以該通道的標準差。
# 使用RGB通道的均值和標準差,以標準化每個通道
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize([256, 256]),torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(),normalize])查看源模型:
我們使用在ImageNet數據集上預訓練的ResNet-18作為源模型。
在這里,我們指定pretrained=True以自動下載預訓練的模型參數。 如果首次使用此模型,則需要連接互聯網才能下載。
預訓練的源模型實例包含許多特征層和一個輸出層fc。 此劃分的主要目的是促進對除輸出層以外所有層的模型參數進行微調。
下面給出了源模型的成員變量fc。
pretrained_net = torchvision.models.resnet18(pretrained=True)
pretrained_net.fc輸出:
Linear(in_features=512, out_features=1000, bias=True)定義目標模型finetune_net:【換輸出層】
finetune_net = torchvision.models.resnet18(pretrained=True)載入 在 ImageNet 上預訓練好的 ResNet-18 網絡(權重已固定,特征提取器已具備通用視覺能力)。finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)把 ResNet-18 最后的 1000 類全連接層 替換成 只有 2 個輸出的新層(二分類任務)。in_features保留原模型提取到的特征維度(512)。輸出維度改為 2,對應新任務的類別數。
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight);首先,我們定義了一個訓練函數train_fine_tuning,該函數使用微調,因此可以多次調用。
其中特征提取層學習率低,最后一層輸出層學習率高。
# 如果param_group=True,輸出層中的模型參數將使用十倍的學習率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)devices = d2l.try_all_gpus()loss = nn.CrossEntropyLoss(reduction="none")if param_group:params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]trainer = torch.optim.SGD([{'params': params_1x},{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)else:trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)我們使用較小的學習率,通過微調預訓練獲得的模型參數。
train_fine_tuning(finetune_net, 5e-5)輸出:
loss 0.220, train acc 0.915, test acc 0.939
999.1 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]為了進行比較,我們定義了一個相同的模型,但是將其所有模型參數初始化為隨機值。
由于整個模型需要從頭開始訓練,因此我們需要使用更大的學習率。
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)輸出:
loss 0.374, train acc 0.839, test acc 0.843
1623.8 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)])












)





