? ? ? ? ?
づ?ど
?🎉?歡迎點贊支持🎉

個人主頁:勵志不掉頭發的內向程序員;
專欄主頁:C++語言;
文章目錄
前言
一、STL簡介
二、string類的優點
三、標準庫中的string類
四、string的成員函數
4.1、構造函數
?4.2、析構函數
4.3、賦值重載
4.4、運算符重載
4.5、迭代器(iterator)
4.6、Capacity相關函數
4.6.1 size/length函數
4.6.2、max_size函數
4.6.3、capacity函數
4.6.4、reserve/resize函數
4.6.5、clear函數
4.6.6、empty函數
4.6.7、shrink_to_fit函數
4.7、插入刪除相關函數
4.7.1、push_back函數
4.7.2、append函數
4.7.3、operator+=函數
4.7.4、insert函數
4.7.5、pop_back函數
4.7.6、erase函數
4.7.7、replace函數
4.8、查找函數
4.8.1、find函數
4.8.2、rfind函數
4.8.3、find_first_of函數
4.8.4、find_last_of函數
4.8.5、find_first_not_of/find_last_not_of函數
4.9、其他函數
4.9.1、c_str函數
4.9.2、copy函數
4.9.3、substr函數
五、非成員函數
5.1、operator+函數
5.2、<>函數
5.3、getline函數
總結
前言
本章節我們就來說說我們C++與C語言又一個巨大的區別,那就是STL庫,在這個庫中收錄了我們很多經常使用的數據結構和算法,我們之后的章節會來具體的講解和學習,接下來我們來一起看看吧。

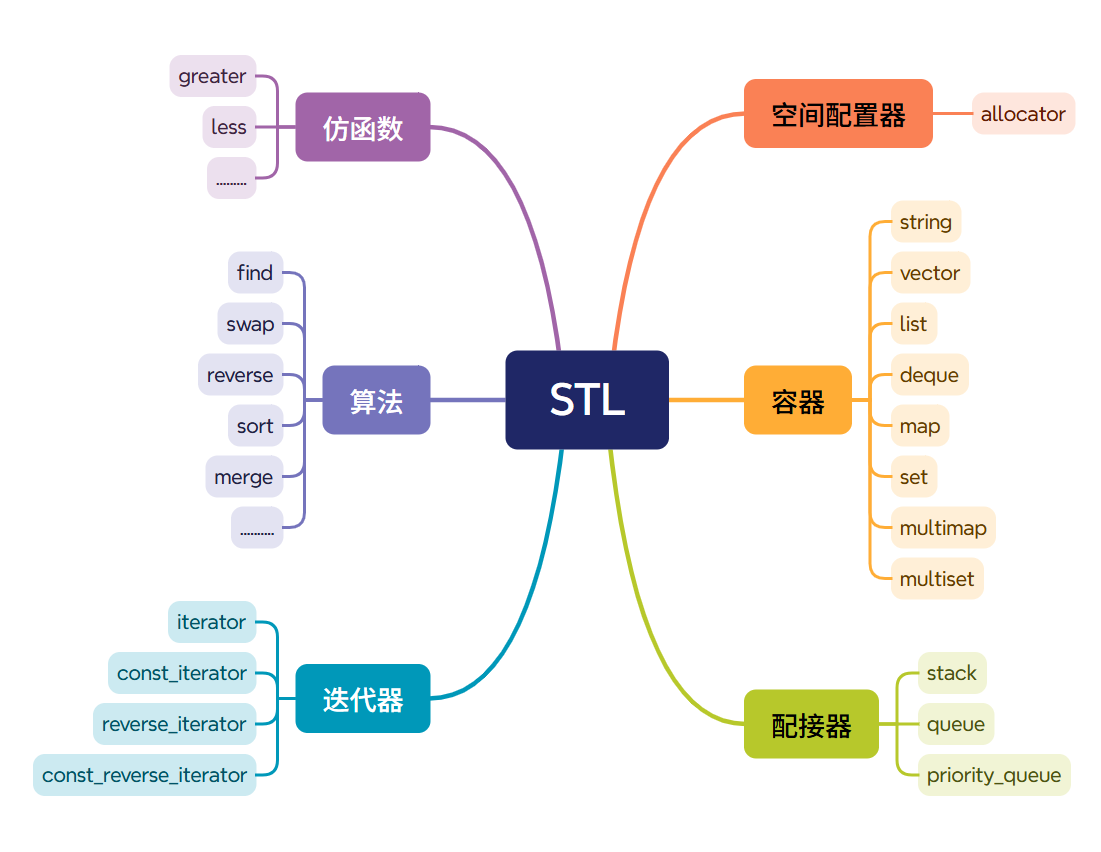
一、STL簡介
STL是C++標準庫的重要組成部分,不僅是一個可復用的組件庫,而且是一個包羅數據結構和算法的軟件框架。
STL的六大組件
二、string類的優點
與C語言相比,我們STL容器中(嚴格來說應該是C++標準庫)引入了我們的string,它的出現幫助我們去管理字符串,這使得我們對字符串的使用更加規范以及更加簡單快捷,出錯率也與自己去實現相比大大的降低了。
三、標準庫中的string類
我們可以看看我們string類中有哪些成員函數,string - C++ Reference
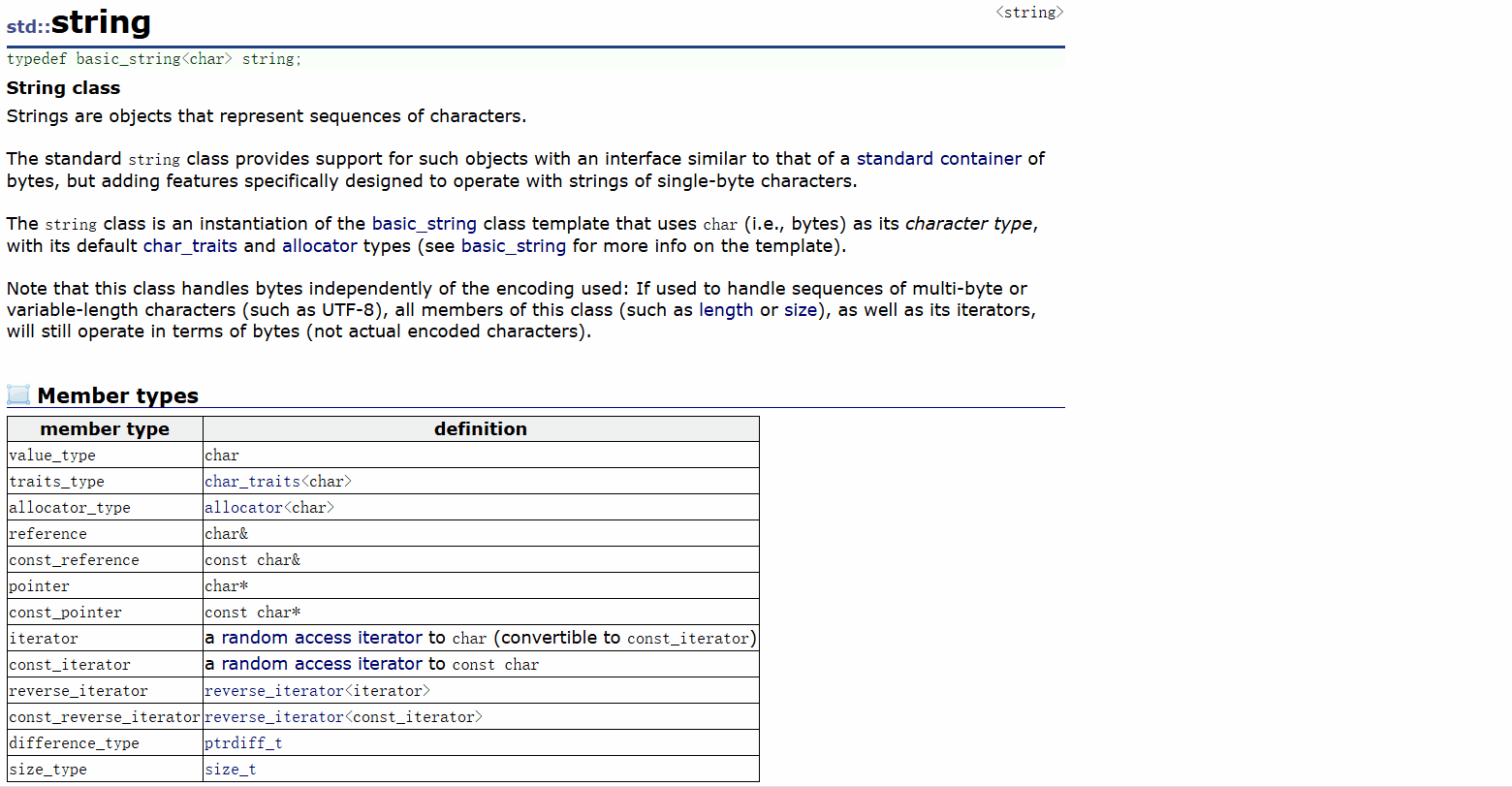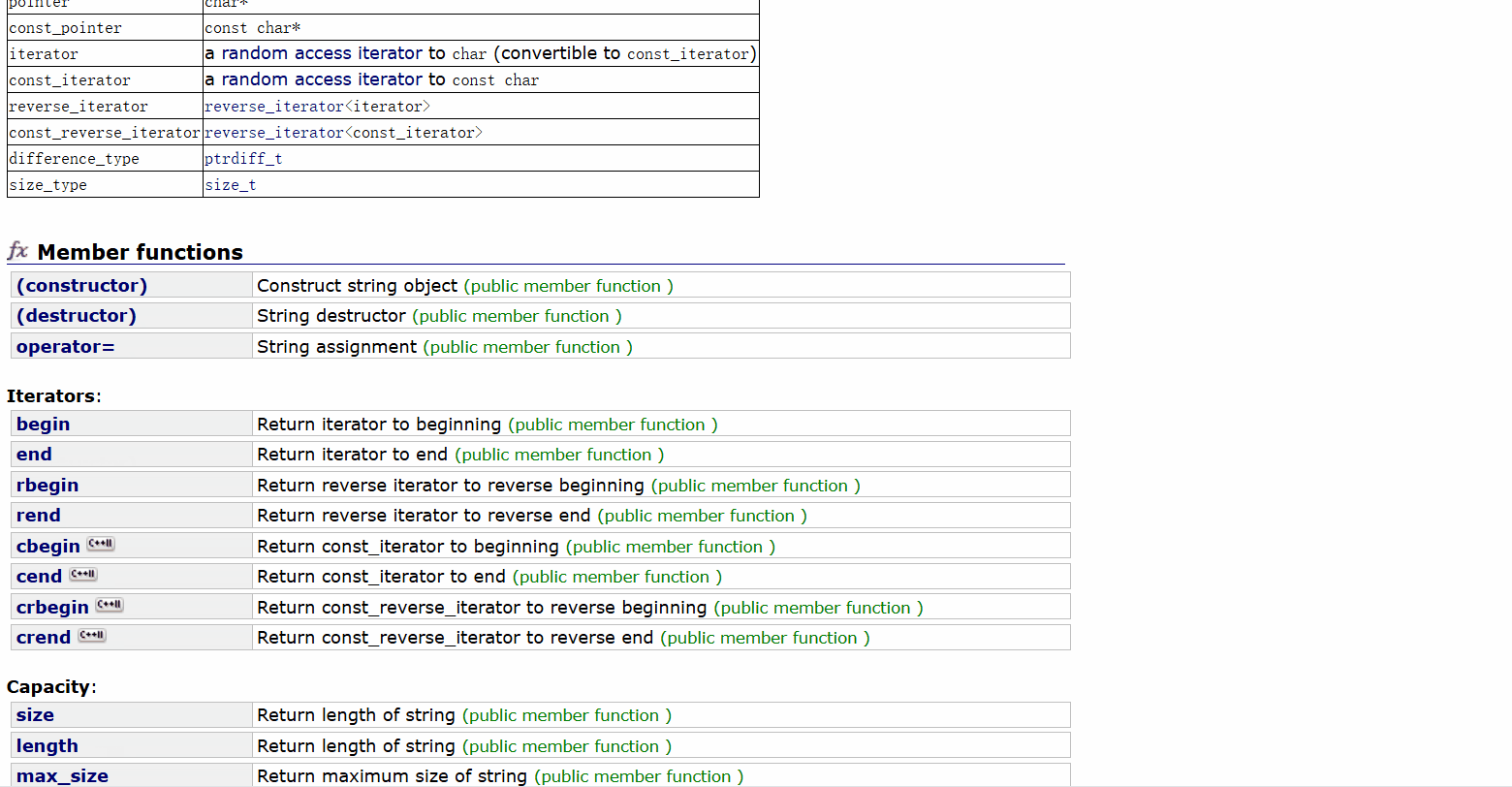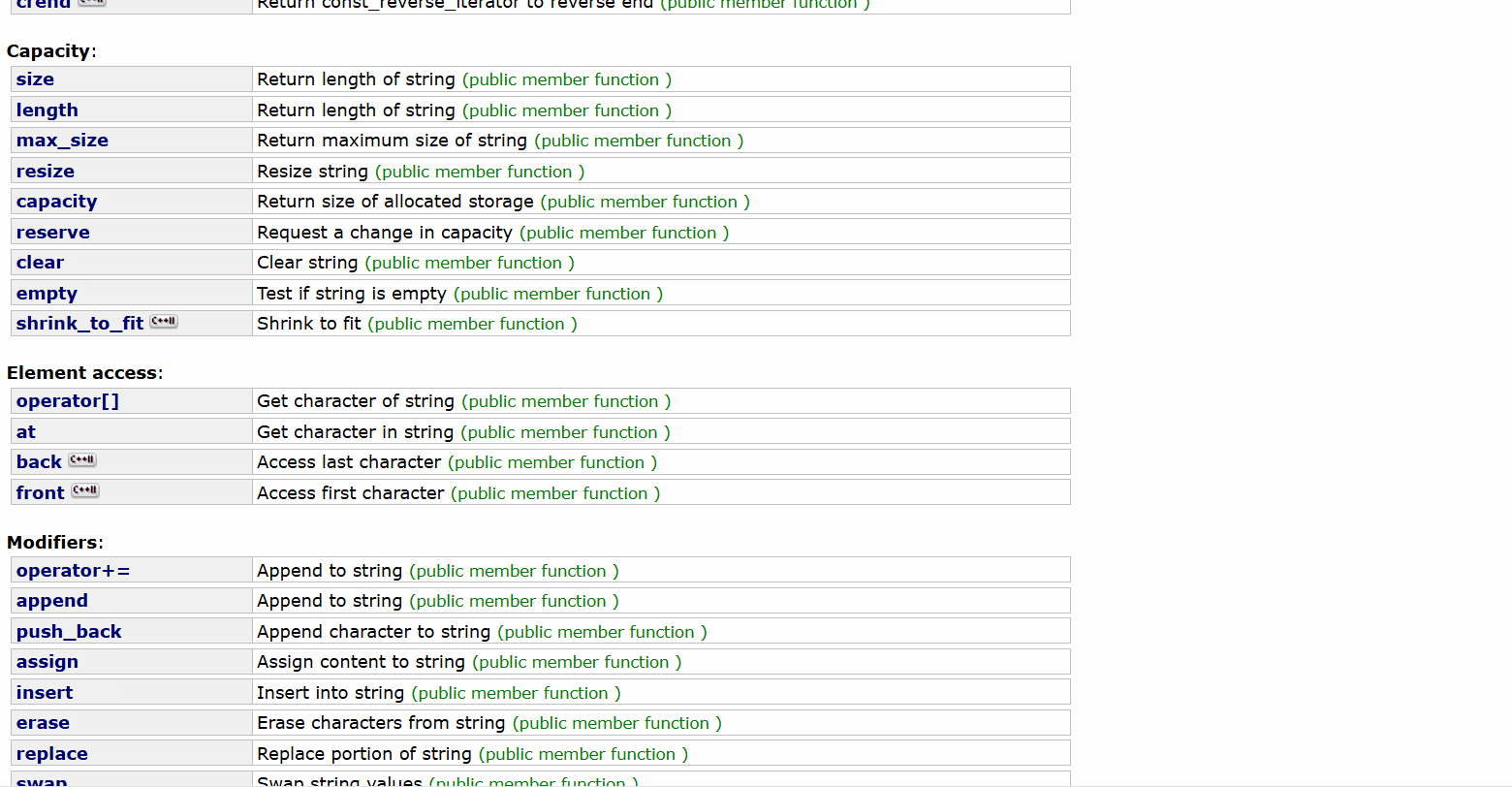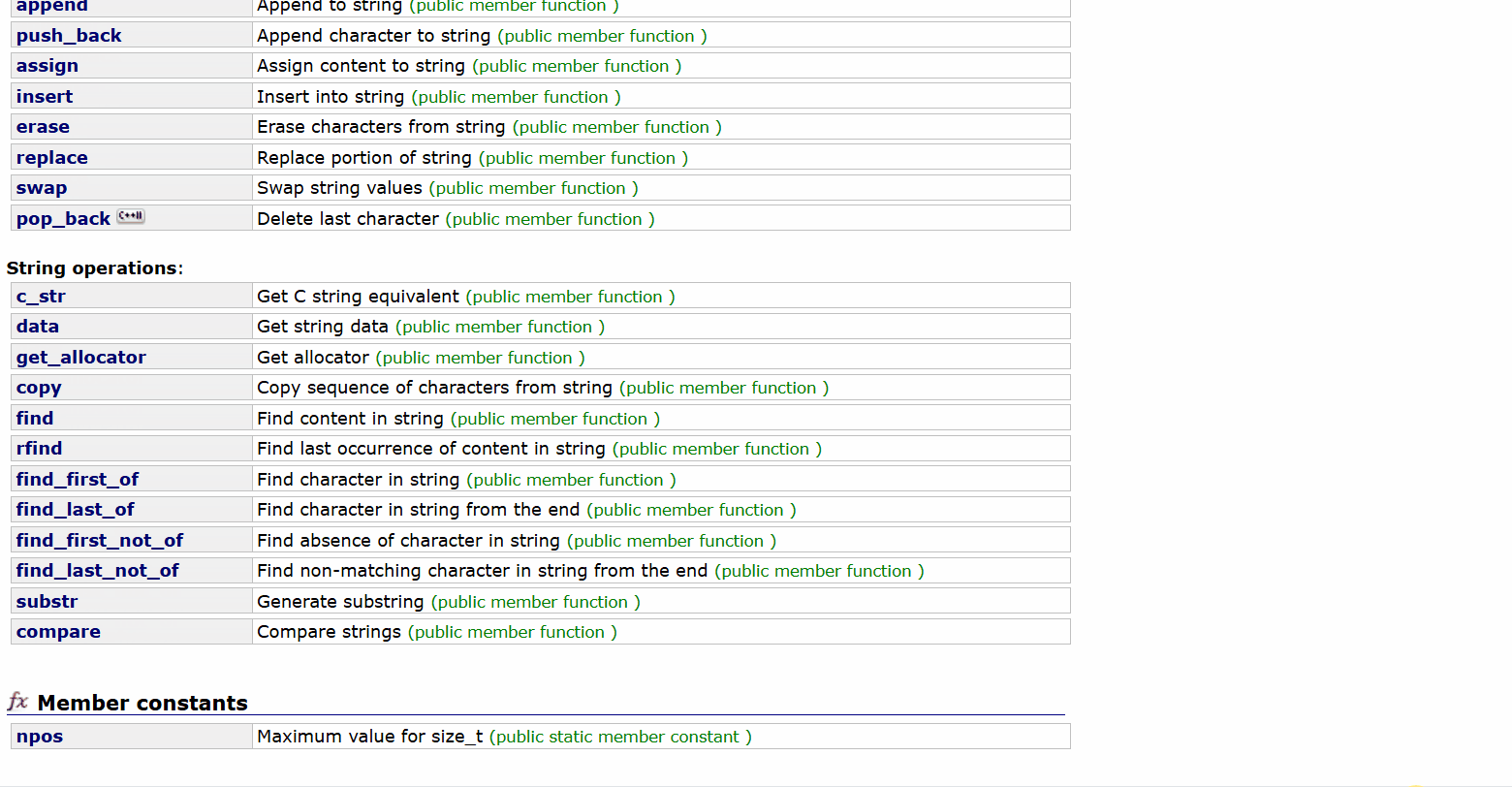
我們可以粗略的看到我們string類的成員變量是很多的,我們為了完全搞懂string類,我們就來一個一個成員函數的學習和模擬實現吧。
四、string的成員函數
我們string類都保存在我們string的頭文件中
#include <string>
4.1、構造函數
我們學習類第一步就應該先去查看它的構造函數
![]()
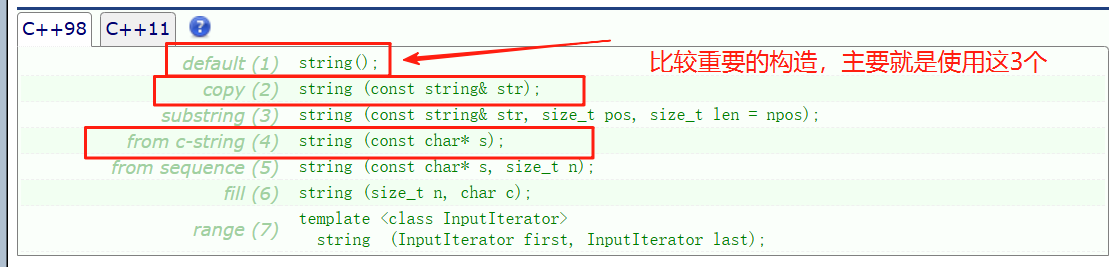
我們string設計時間比STL早,有很多設計沒有參考,所以我們學習時就會覺得它有些設計是十分冗余的,就比如光是string的構造函數就有7種,但是沒有關系,只有string是這樣的,我們只要把經常要用的學會就行,我也只會模擬實現經常要用的成員函數。
#include <string>int main()
{string s1;string s2("11111111");string s3(s2);// 重載了流輸入輸出cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;cin >> s1;cout << s1 << endl;return 0;
}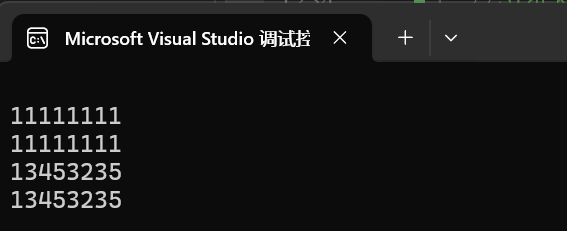
上面3個是我們主要使用的構造函數,接下來講講剩下的幾個。
第3個構造函數是用來構造一個字符串的一部分的。
![]()
第一個參數是用那個字符串構造,第二個則是從哪個位置,第三個參數是拷貝多少字符(如果剩下的不夠就有多少拷貝多少)。
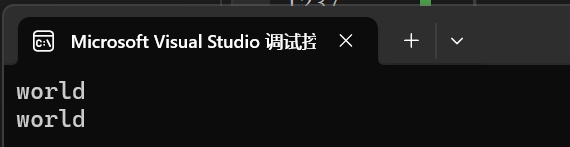
#include <string>int main()
{string s1("hello world");string s2(s1, 6, 5);string s3(s1, 6, 100);cout << s2 << endl;cout << s3 << endl;return 0;
}
當然如果我們不傳最后一個參數,那就是默認拷貝到結尾,它的缺省參數是一個npos
![]()

它是一個靜態成員變量。我們可以試著突破類域去看看它的值是多少。
#include <string>int main()
{cout << string::npos << endl;return 0;
}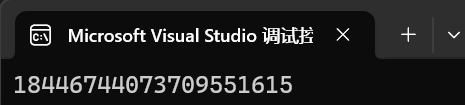
由于我們的字符串不可能有這么長,所以這就可以默認拷貝到最后一個位置了。
第5個構造是用來構造字符串前面一部分的。
![]()
第一個參數是用來輸入字符串的,第二個參數則是確定拷貝前面幾個字符,要是字符數目不夠則是全拷貝。
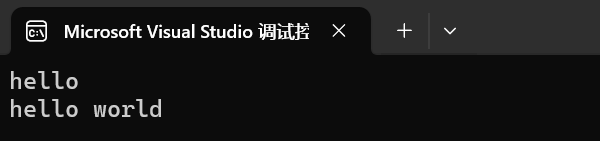
#include <string>int main()
{string s1("hello world", 5);string s2("hello world", 100);cout << s1 << endl;cout << s2 << endl;return 0;
}
第6個構造就是用n個字符c去初始化。
![]()
第一個參數就是要幾個字符,第二個參數就是字符是什么。
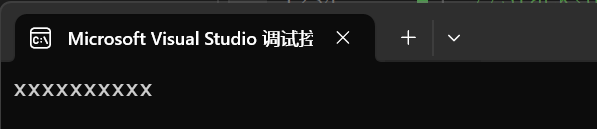
#include <string>int main()
{string s1(10, 'x');cout << s1 << endl;return 0;
}
還有最后一個暫時不講,之后再說明。
?4.2、析構函數
![]()
析構函數沒有什么必要去看,因為它是系統自動調用的,我們無需手動調用。
4.3、賦值重載
![]()

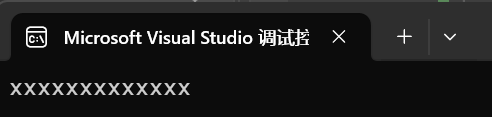
第一種就是把一個string賦值給另外一個string。
int main()
{string s1("xxxxxxxxxxxxx");string s2;s2 = s1;cout << s2 << endl;return 0;
}
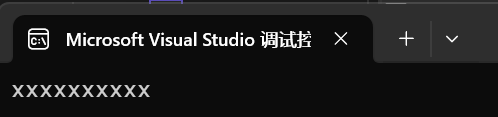
第二種是把我們的字符串賦值給我們的string。
int main()
{string s1;s1 = "xxxxxxxxxx";cout << s1 << endl;return 0;
}
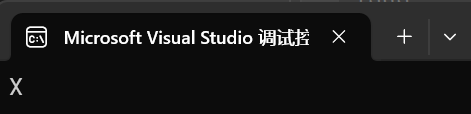
第三種則是把我們字符賦值給我們string。
int main()
{string s1;s1 = 'X';cout << s1 << endl;return 0;
}
我們一般使用第一種和第二種即可,第三種賦值重載沒有必要,因為一個字符也算字符串,也可以用第二種代替。
4.4、運算符重載
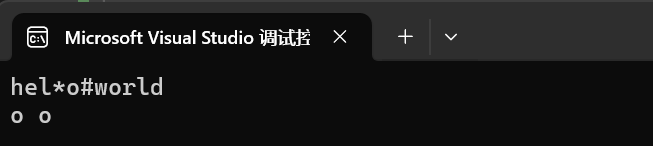
[ ]符重載:
![]()
我們string類將[]符進行了重載,這無疑是一個高明的操作,因為這樣就使得我們的字符串和數組一樣可以非常方便的修改和查詢了。
int main()
{string s1("hello world");//修改指定字符s1[3] = '*';s1[5] = '#';cout << s1 << endl;//查看指定字符cout << s1[4] << " " << s1[7] << endl;return 0;
}
同時我們還可以通過[]符來遍歷我們的字符串。
int main()
{string s1("hello world");//size()是string中返回我們字符串大小的函數for (int i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;return 0;
}
這樣操作主要是通過我們的運算符通過返回我們類型的引用去修改指定位置的字符來實現的,我們下一章節再來細聊。
除了這種遍歷變量的方式,我們還有兩種,下面會講。
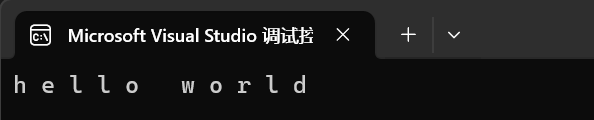
4.5、迭代器(iterator)

我們的迭代器是STL的一大組件,其作用主要就是用來遍歷和訪問我們的容器。我們先來看看它的操作。
int main()
{string s1("hello world");//size()是string中返回我們字符串大小的函數string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;return 0;
}
這樣寫就實現了我們遍歷的效果。我們仔細觀察這些代碼,感覺就很像指針。我們迭代器的實現千變萬化,只要能夠達到我們所需要的效果即可,所以我們也不確定它到底是怎么實現的,可能有的就是用指針實現的。但是我們可以想象成指針。
我們的begin()是返回string空間開始位置的迭代器,而end()是我們返回最后一個有效字符的位置,也就是'\0'的位置的迭代器。
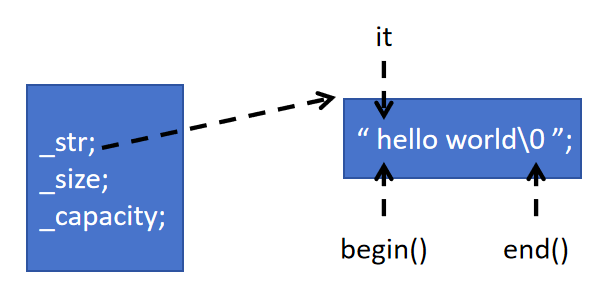
大致就是這個樣子,我們從begin到end,一個一個遍歷過去,如果是指針,那就是一個一個解引用后再++,一直到end后停止,這個很好理解,如果不是指針,那我們就得運算符重載了,把我們'*'、'++'兩個運算符重載成我們和指針那樣的操作了。所以我們的迭代器可能是指針,也可能不是。
iterator給我們STL庫中所有的容器提供了一個通用的遍歷和訪問的方法,讓它們統一起來,這就是迭代器的厲害之處。
當然,我們除了這種正向迭代器,還有反向迭代器
int main()
{string s1("hello world");string::reverse_iterator rit = s1.rbegin();while (rit != s1.rend()){cout << *rit << " ";rit++;}cout << endl;return 0;
}它的寫法和剛才的正向迭代器很像。

它也是使用++,只不過是倒著走的。我們可以這樣子理解
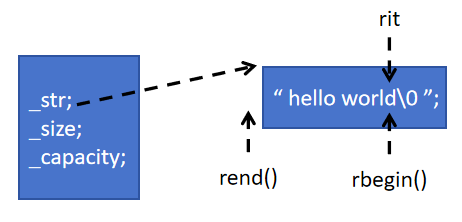
我們封裝了++后使其倒著運行。
當然,有的時候我們會碰到const string,但是我們的普通迭代器可讀可寫,會導致權限放大不能調用怎么辦呢?這個時候就得用const_iterator迭代器了。用法和iterator是一樣的,只是不能修改,只能遍歷。
int main()
{string s1("hello world");string::const_iterator cit = s1.cbegin();while (cit != s1.cend()){cout << *cit << " ";cit++;}cout << endl;return 0;
}
當然,也有const反向迭代器
int main()
{string s1("hello world");string::const_reverse_iterator crit = s1.crbegin();while (crit != s1.crend()){cout << *crit << " ";crit++;}cout << endl;return 0;
}
用法都是類似的,大家記住就好了,等下一章節講解模擬實現是在來細講這些內容。
我們還有一種遍歷變量的方法,就是范圍for
int main()
{string s1("hello world");for (auto ch : s1){cout << ch << " ";}cout << endl;return 0;
}
這個代碼的含義是我們從我們的s1中去取我們的每一個變量,然后傳給我們的ch(自定義的,叫啥無所謂)中去。
我們再來聊聊auto,它代表的是自動推導類型,它會自動去推導我們s1傳過來的是什么類型的變量,auto就是什么類型的,這里是char,所以auto就是char,當然我們自己寫char也可以。
我們auto的主要作用是來簡化我們的代碼而使用的,例如map<string, string>::iterator可以直接用auto代替,是不是簡單多了。但是它的代價是犧牲了可讀性。
當然我們auto必須要初始化,不然它就不知道它因該推導成什么類型。也不能一行定義不同類型的變量。也不能定義數組。
// 不能這樣寫
auto a;
auto a = 1, b = 1.1;
auto array[] = { 1, 2, 3, 4, 5, 6 };我們的auto不能做參數,但是可以做返回值,雖然不建議這么做。
我們接著說范圍for,
for (char ch : s1){cout << ch << " ";}但是我們這里一般都用auto。范圍for可以自動賦值,自動迭代,自動判斷結束,它的底層其實是迭代器,雖然看上去很厲害,但其實就是迭代器套了一層殼。
同時他不會去改變我們s1的內容,它相當于是傳*it給我們的ch而非it。
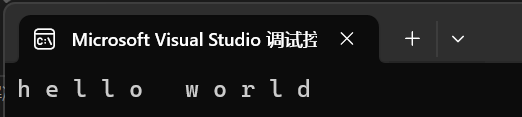
int main()
{string s1("hello world");for (auto ch : s1){ch -= 2;cout << ch << " ";}cout << endl;cout << s1;return 0;
}
我們可以看出它是沒有修改s1的。
如果是想要修改得在auto后加&,相當于從之前傳輸過來的char類型變成了char&類型
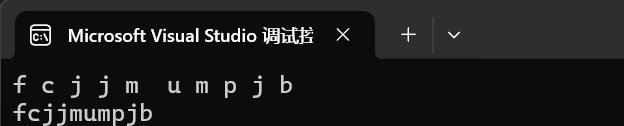
int main()
{string s1("hello world");for (auto& ch : s1){ch -= 2;cout << ch << " ";}cout << endl;cout << s1;return 0;
}
我們所講的3種遍歷方式在性能方面是沒有任何區別的,可以隨便使用。
4.6、Capacity相關函數

4.6.1 size/length函數
這兩個函數都是用來返回我們的字符串中字符的數量的,使用方法也很簡單
int main()
{string s1("hello world");cout << s1.size() << endl;cout << s1.length() << endl;return 0;
}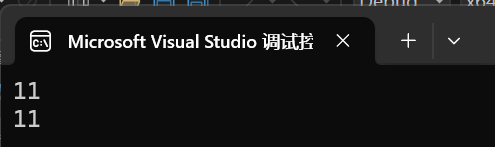
它們就是兩個不同名字但是作用完全一樣的函數。我們length不具有通用性,只屬于string容器,但是我們的size是所有容器都有的。
4.6.2、max_size函數
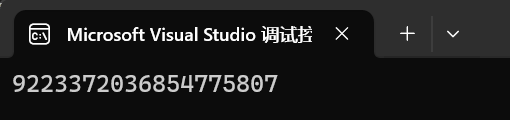
這個函數的作用就是和你說說我們的string最大能開多大,實際就是整型的最大值。沒有什么用處,而且過于理想化,實際上根本開不了這么大。
int main()
{string s1("hello world");cout << s1.max_size() << endl;return 0;
}
4.6.3、capacity函數
返回我們string容量的函數。
int main()
{string s1("hello world");cout << s1.capacity() << endl;return 0;
}
我們可以先來看看我們的string是怎么擴容的
int main()
{string s;// 得到初始內存size_t sz = s.capacity();cout << "capacity changed: " << sz << endl;cout << "make s grow:" << endl;for (int i = 0; i < 100; i++){// 循環插入c去看它擴容s.push_back('c');// 如果擴容了就打印看看新擴容的大小if (sz != s.capacity()){sz = s.capacity();cout << "capacity changed: " << sz << endl;}}
}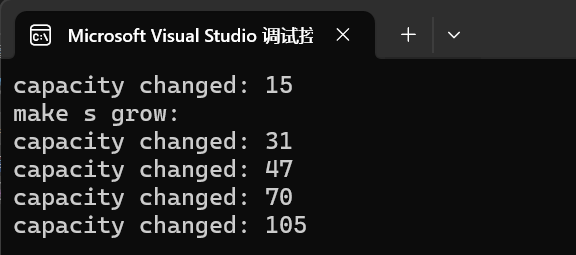
我們可以看到,我們第一次是2倍擴容,其他的時候就是1.5倍擴容。這是因為我們vs的工程師為了防止我們總是使用不滿string,為了效率所以在string上增加了一個buffer[16]的字符串,當我們的字符串沒有滿16個字符時我們的編譯器就不會在堆上開辟空間,而是在棧上的buffer的字符串中。
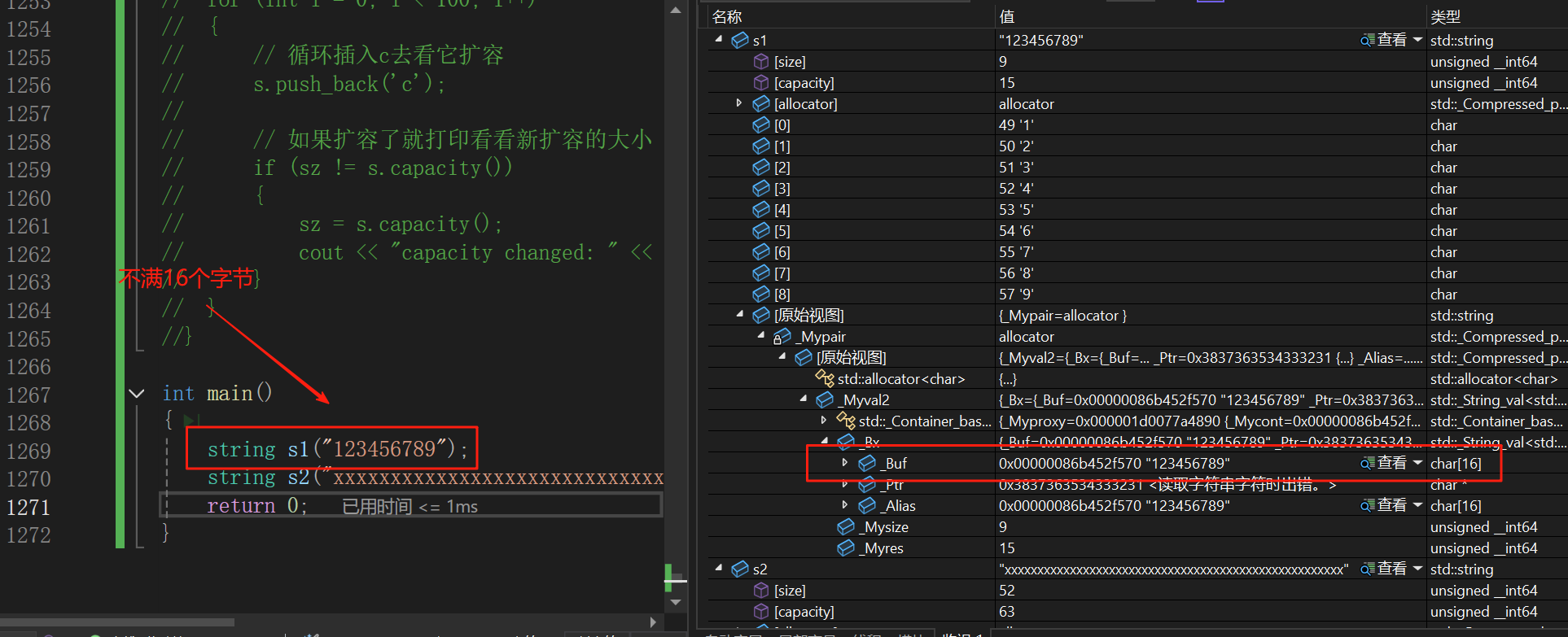
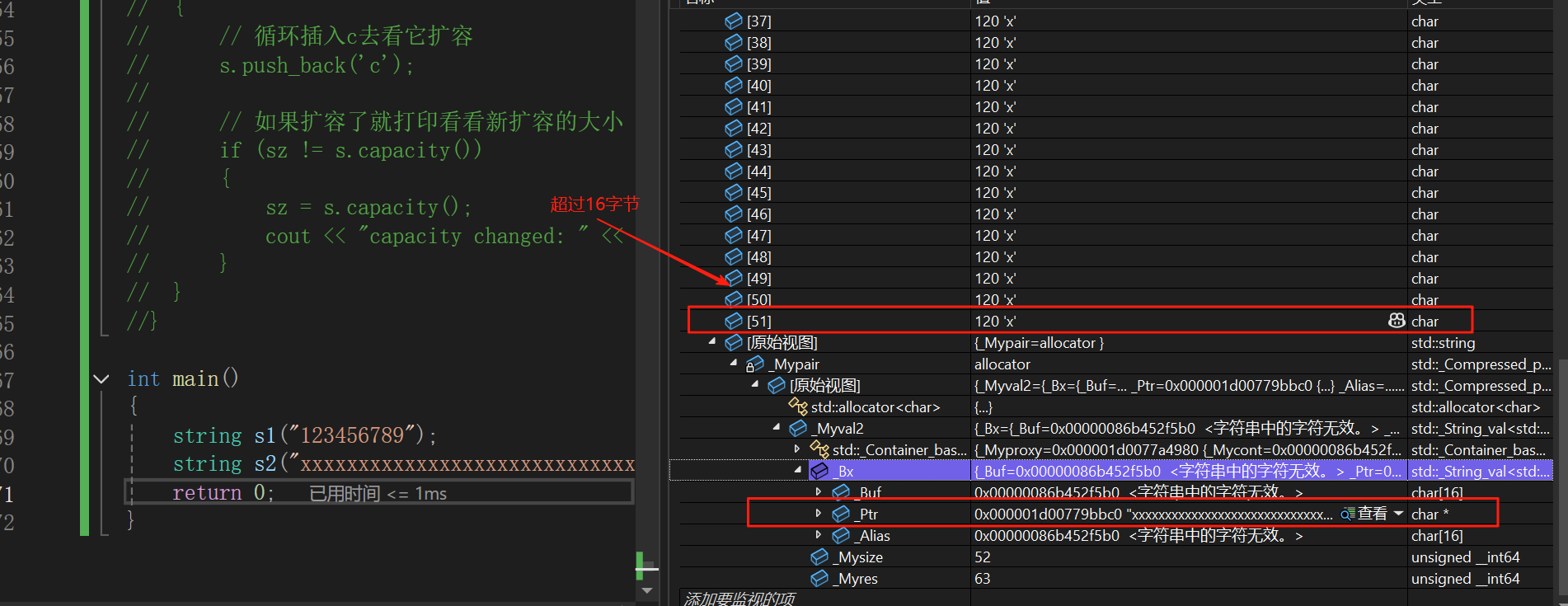
所以我們從第一次擴容是2倍擴容是特殊情況,后面都是1.5倍擴容。當然不同編譯器擴容方式不一樣。
4.6.4、reserve/resize函數
reserve是用來開辟空間的,它能提前開辟好我們指定用到的空間,從而減少擴容次數。
int main()
{string s;s.reserve(100);cout << s.capacity() << endl;return 0;
}
但是其實這個只是讓我們編譯器至少開辟100的空間,具體是多多少得看編譯器操作,因為編譯器會做整數倍對齊。
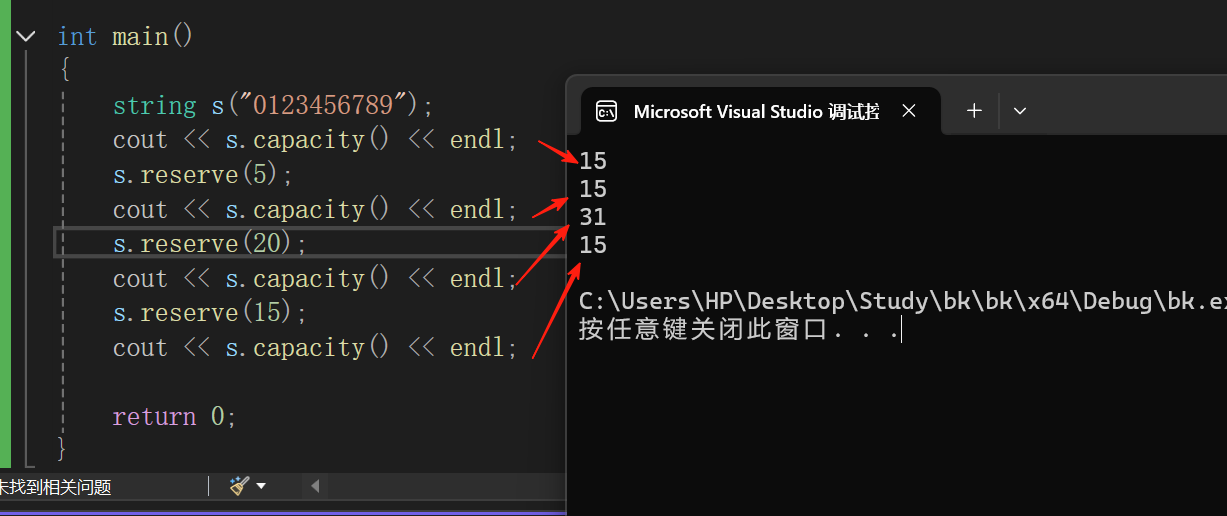
當然,我們的reserve是一般是不會縮容的,但是還是要看具體的服務器。

int main()
{string s("0123456789");cout << s.capacity() << endl;s.reserve(5);cout << s.capacity() << endl;s.reserve(20);s.reserve(15);cout << s.capacity() << endl;return 0;
}
resize則是可以擴容插入,如果它比size小會刪除數據,如果比size大但是capacity小的話會在后面插入數據,如果你沒給會插入默認字符' \0 ',如果比capacity大則會擴容。
4.6.5、clear函數
這個函數是用來清空我們的字符串的數據,但是一般不會清理容量
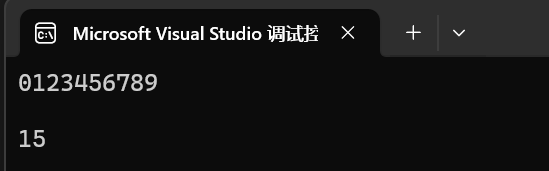
int main()
{string s("0123456789");cout << s << endl;s.clear();cout << s << endl;cout << s.capacity() << endl;return 0;
}
4.6.6、empty函數
判斷我們string是不是空的,有沒有字符。
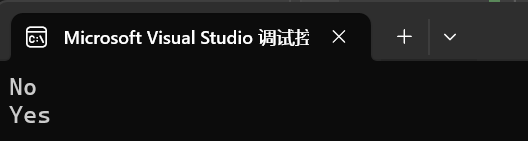
int main()
{string s("0123456789");if (s.empty()) cout << "Yes" << endl;else cout << "No" << endl;s.clear();if (s.empty()) cout << "Yes" << endl;else cout << "No" << endl;return 0;
}
4.6.7、shrink_to_fit函數
這個函數也是用來縮容的,但是和reserve一樣也不一定會成功。
4.7、插入刪除相關函數
4.7.1、push_back函數

這個函數的功能是尾插一個字符,它只能插入一個字符,不能插入字符串,設計的蠻雞肋的。
int main()
{string s("1234");// 如果用雙引號就會報錯,因為不能插入字符串s.push_back('5');cout << s << endl;return 0;
}
4.7.2、append函數
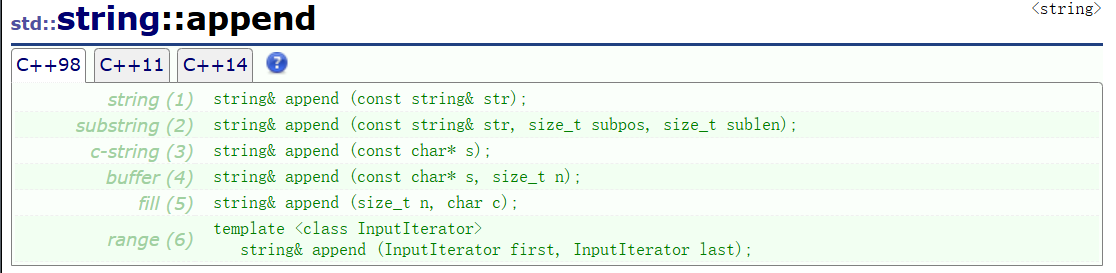
想要插入字符串就可以用append,但是一般我們就使用第三個,別的沒有必要使用,這里簡單介紹一下把
第一個:

單純的在末尾插入一個string字符串。
int main()
{string s1("hello ");string s2("world");s1.append(s2);cout << s1 << endl;return 0;
}
第二個:
![]()
在末尾插入字符串str從subpos位置開始的sublen個字符。
int main()
{string s1("hello ");string s2("world");s1.append(s2, 1, 3);cout << s1 << endl;return 0;
}
如果剩余數不足那就取到末尾。
第三個:
![]()
直接在后面插入一個字符串。
int main()
{string s1("hello ");s1.append("world");cout << s1 << endl;return 0;
}
第四個:
![]()
在末尾插入s前n個字符,如果剩下的不夠,則取到末尾。
int main()
{string s1("hello ");s1.append("world", 3);cout << s1 << endl;return 0;
}
第五個:
![]()
就是在末尾插入n給字符c。
第六個后面再將。
4.7.3、operator+=函數

這個是我們string中最常用的尾插用法,它可以兼容字符和字符串,而且可讀性也很好。
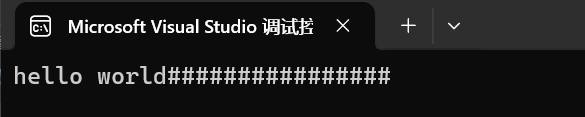
int main()
{string s1("hello");string s2("world");s1 += ' ';s1 += s2;s1 += "################";cout << s1 << endl;return 0;
}
4.7.4、insert函數

我們前面就學了尾插,其他位置的插入就用這個函數,這個函數也十分的冗余,主要用的就2個,如果我們要插入我們的字符串,可以用第1種和第3種。
int main()
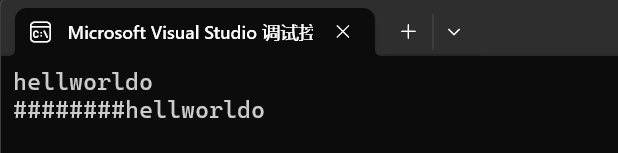
{string s1("hello");string s2("world");// 第一種方法s1.insert(4, s2);cout << s1 << endl;// 第二種方法s1.insert(0, "########");cout << s1 << endl;return 0;
}
插入字符也可以把字符當字符串,但是如果一定得是字符的話那我們就只能用第五種或者第六種辦法了。
int main()
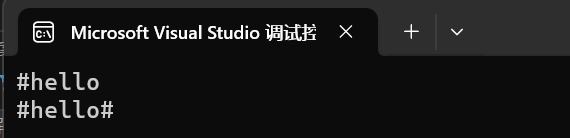
{string s1("hello");char c = '#';// 第五種方法,在第0位置插入1個字符cs1.insert(0, 1, c);cout << s1 << endl;// 第六種方法s1.insert(s1.end(), c);cout << s1 << endl;return 0;
}
其他的不常用,大家可以自己去試試看看怎么用,很簡單。
4.7.5、pop_back函數

這個就不用多說了,就是尾刪。
4.7.6、erase函數

主要就是使用第1個,在pos位置刪除len個字符,如果沒寫len或者剩下的不足那就在pos后面全刪了。
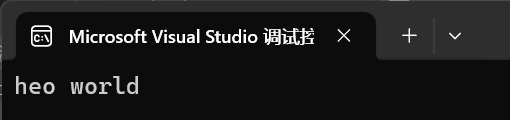
int main()
{string s1("hello world");s1.erase(2, 2);cout << s1 << endl;return 0;
}
第二個則是迭代器刪除,只能刪除一個,
int main()
{string s1("hello world");s1.erase(s1.begin() + 2);cout << s1 << endl;return 0;
}
第3個則是刪除一個區間的。
4.7.7、replace函數

這個函數的主要作用就是替換,設計的也很麻煩,就講幾個經常使用的,大家要是有需要的再查庫就好了。
int main()
{string s1("hello world");// 第5個位置替換成"%%",替換3個字符s1.replace(5, 3, "%%");cout << s1 << endl;return 0;
}
4.8、查找函數
4.8.1、find函數

我們可以查找一個string字符串,或者一個字符,它如果找到了就會返回第一個匹配位置的字符下標,沒找到就會返回npos。這里面的pos表示從哪里開始找起。
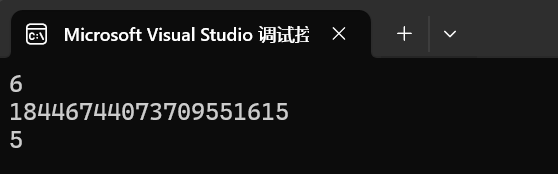
int main()
{string s1("hello world");string s2("wor");size_t pos = s1.find(s2);cout << pos << endl;// 從第7個位置開始找pos = s1.find("s2, 7");cout << pos << endl;pos = s1.find(' ');cout << pos << endl;return 0;
}
4.8.2、rfind函數

rfind和find用法相同,就是rfind是倒著查找的,這里就不多贅述了。返回值就是從后往前第一次出現的下標,如果沒有就返回npos。
4.8.3、find_first_of函數

這個函數的意思不是說找第一個,因為我們find就是第一個,而是說找任意一個,就比如
int main()
{std::string str("Please, replace the vowels in this sentence by asterisks.");std::size_t found = str.find_first_of("abcd");// 一直查找,知道找不到為止while (found != std::string::npos){str[found] = '*';// 從已經找過的位置接著往下找found = str.find_first_of("abcd", found + 1);}std::cout << str << '\n';return 0;
}我們這個函數就是把我們傳進去的字符串"abcd"中的每一個字符和我們的原文進行配對,如果有其中有其中一個字符可以配對上那就返回第一個配對上的下標,所以上面我們str字符串中的a、b、c、d字符全部替換成了我們的*號。

4.8.4、find_last_of函數

和我們的find_first_of一樣,只不過是反向查找。
4.8.5、find_first_not_of/find_last_not_of函數


分別是find_first_of和find_last_of的對立,就是查找除了我們字符串中的字符其他的字符。
int main()
{std::string str("Please, replace the vowels in this sentence by asterisks.");std::size_t found = str.find_first_not_of("abcd");while (found != std::string::npos){str[found] = '*';found = str.find_first_not_of("abcd", found + 1);}std::cout << str << '\n';return 0;
}
4.9、其他函數
4.9.1、c_str函數

此函數的作用就是返回底層字符串的指針。這個函數的意義就是兼容C語言的。
4.9.2、copy函數

這就是一個拷貝,一般用的很少用,而且我們還要手動的去給它增加' \0 ',不然他就無法檢測到什么時候停下,它的返回值就是拷貝了多少個字符。
int main()
{string s1("hello world");char buffer[10];// 從s1中的第3個字符開始拷貝4個字符size_t len = s1.copy(buffer, 4, 3);// 手動增加\0,不然就會出錯cout << buffer << endl;buffer[len] = '\0';cout << buffer << endl;return 0;
}
4.9.3、substr函數

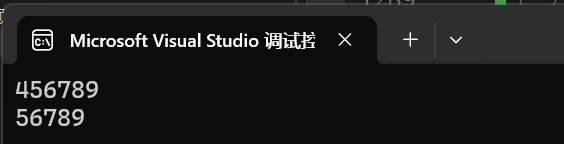
這個是我們獲取字串最常用的方法。是從pos開始的len個字符,如果不給len就拷貝到結尾。
int main()
{string s1("0123456789");string s2, s3;s2 = s1.substr(4, 7);s3 = s1.substr(5);cout << s2 << endl;cout << s3 << endl;return 0;
}
五、非成員函數
5.1、operator+函數

我們operator+沒有重載成成員函數的原因是為了方便更加自由的操作
int main()
{string s1("hello");// 這個重載成成員函數就可以做到string s2 = s1 + "world";cout << s2 << endl;// 這樣如果是重載函數那就做不到了string s3 = "world" + s1;cout << s3 << endl;return 0;
}
這樣就自由了很多。
5.2、<</>>函數
不多贅述,前往都用了很多次了。
5.3、getline函數

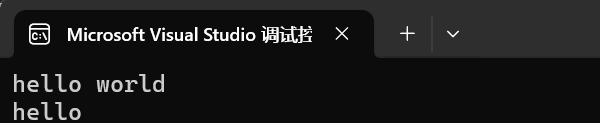
這個函數的作用就是改變我們字符串的分割符,我們的字符串默認是以空格和換行符作為分割,這就使得我們有的時候想要記錄一些句子卻記錄不了,因為有空格。
int main()
{string s1;cin >> s1;cout << s1;return 0;
}
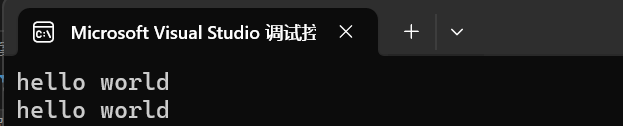
為了避免這種情況,我們就可以用getline來改變分隔符。它的第一個參數是流輸入,一般是cin,第二個參數就是我們要輸入的字符串,第三個參數就是我們想要的分隔符,如果不寫就默認是換行為分隔符。
int main()
{string s1;getline(cin, s1);cout << s1;return 0;
}
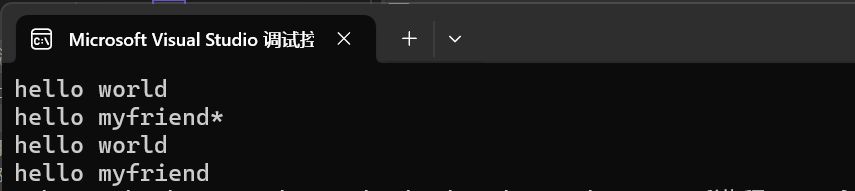
以*為分隔符
int main()
{string s1;getline(cin, s1, '*');cout << s1;return 0;
}
總結
以上便是我們string的各種常用函數的使用方法,雖然很多,但是都不是很難,我們也不用死記硬背,我們之后和日常使用會一次又一次的反復記憶,我們如果忘記了再回來或者查文檔去看看就好了,下一章節我們回來試著模擬實現string,下一章節再見。
🎇堅持到這里已經很厲害啦,辛苦啦🎇
? ? ? ? ?
づ?ど













)






