1.數倉開發語言概述
理論上來說,任何一款編程語言只要具備讀寫數據、處理數據的能力,都可以用于數倉的開發。比如大家耳熟能詳的C、java、Python等;
關鍵在于編程語言是否易學、好用、功能是否強大。遺憾的是上面所列出的C、Python等編程語言都需要一定的時間進行語法的學習,并且學習語法之后還需要結合分析的業務場景進行編碼,跑通業務邏輯。
不管從學習成本還是開發效率來說,上述所說的編程語言都不是十分友好的。
在數據分析領域,不得不提的就是SQL編程語言,應該稱之為分析領域主流開發語言。
2. SQL語言介紹
結構化查詢語言(Structured Query Language)簡稱SQL,是一種數據庫查詢和程序設計語言,用于存取數據以及查詢、更新和管理數據。
SQL語言使我們有能力訪問數據庫,并且SQL是一種ANSI(美國國家標準化組織)的標準計算機語言,
各大數據庫廠商在生產數據庫軟件的時候,幾乎都會去支持SQL的語法,以使得
用戶在使用軟件時更加容易上手,以及在不同廠商軟件之間進行切換時更加適應,因為大家的SQL語法都差不多。select列名from 表名where 條件
3.數倉與SQL
大數據數倉領域,很多軟件都會去支持SQL語法
1.學習sql成本低
2.sql語言對于數據分析非常友好
4結構化數據
5.二維表結構

6.SQL語法的分類
數據定義語言 DDL數據操縱語言 DMLDDL賦予我們創建或刪除表 以及數據庫、索引等各種對象 ,不涉及表中的具體操作。create database --創建數據庫create table --創建數據表
DML語法針對于數據表的相關操作
select-- 從數據庫表中獲取數據
update --更新數據庫表中的數據
delete --刪除數據庫表中數據
insert --向數據庫表中插入數據
7.Apache Hive 概述
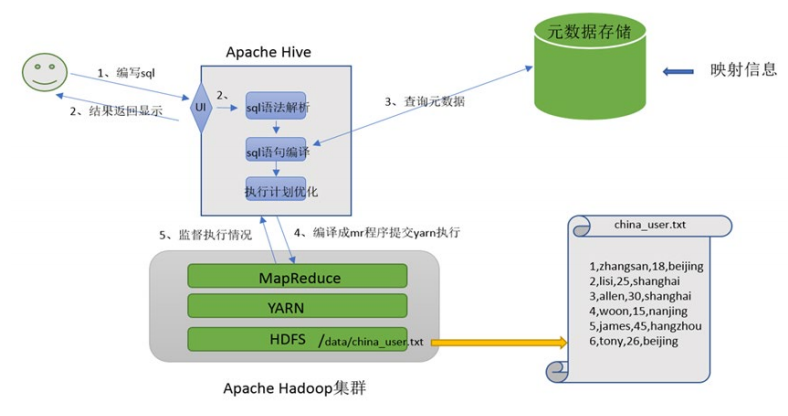
Apache Hive 是一款建立在Hadoop之上的開源數據倉庫 系統,可以將存儲在Hadoop文件中的結構化 半結構化數據文件映射成一張數據庫表,基于表提供一種類似于SQL的查詢模型,稱為Hive查詢語言(HQL )
用戶訪問和分析存儲在Hadoop文件中的大型數據集.
核心是將HQL轉換為MapReduce程序,提交到Hadoop集群中執行。
Hive是由Facebook 實現并開源

8. 為什么用Hive
使用hadoop mapreduce直接處理數據面臨的問題
人員學習成本高 需要掌握java語言
mapreduce 實現復雜的查詢開發難度大
使用hive的好處
操作使用類似于SQL的語法 簡單 容易上手
減少開發人員學習成本
支持自定義函數
背靠Hadoop ,擅長存儲分析海量數據集
9.Hive和Hadoop關系
從功能上講: 數據倉庫,具備兩個能力
存儲數據
分析數據
Hive具備上述兩個能力
Hive借助Hadoop實現了上述兩個能力
Hive利用HDFS存儲數據
利用MapReduce查詢分析數據
Hive最大的魅力值讓用戶專注于編寫HQL,Hive能幫助我們轉化成為MapReduce程序完成對數據的分析

10.模擬Apache Hive 的功能
Hive的理解:
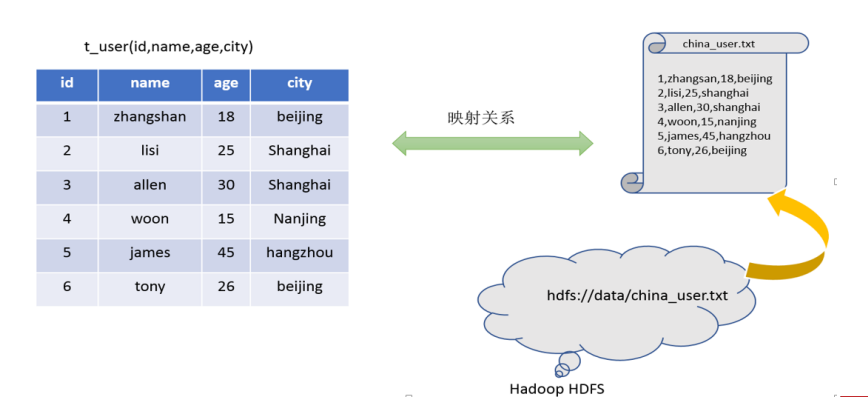
hive能將數據文件映射成一張表嗎?這個映射指的是什么?
能
文件和表之間的對應關系
Hive本身到底承擔什么職責?
SQL語法解析編譯成為MapReduce程序
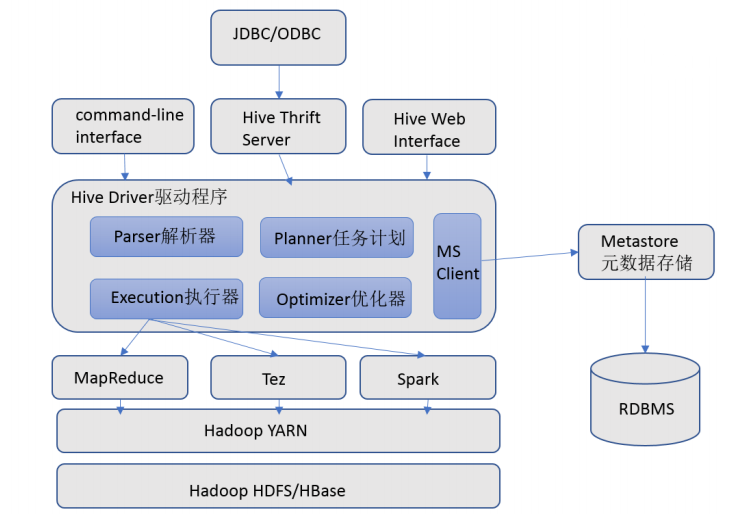
11.官方架構圖
下一步:
分別啟動 node1 node2 node3
測試保證我們的hadoop集群是健康可用的!!!
jps 查看 4 3 2
訪問兩個web頁面讓其正常顯示!!!












)






![[硬件電路-120]:模擬電路 - 信號處理電路 - 在信息系統眾多不同的場景,“高速”的含義是不盡相同的。](http://pic.xiahunao.cn/[硬件電路-120]:模擬電路 - 信號處理電路 - 在信息系統眾多不同的場景,“高速”的含義是不盡相同的。)