測試中的自動化分為兩類:
- 1.ui自動化(web、移動端)
- 2.接口自動化
前面的博客中,我們已經講解了web端的ui自動化,感興趣的同學可以去看看:軟件測試——自動化測試常見函數_自動化測試代碼編寫-CSDN博客
今天我們來學習一下接口自動化測試。
想要掌握好接口自動化需要以下技能:

除了Python,其他都會在接下來的章節中講到
1. 接口測試
我們先了解一下什么是接口測試
1.1 接口的概念
我們可以打開一個網頁的開發者工具,然后就可以查看到該網頁對應的接口了。
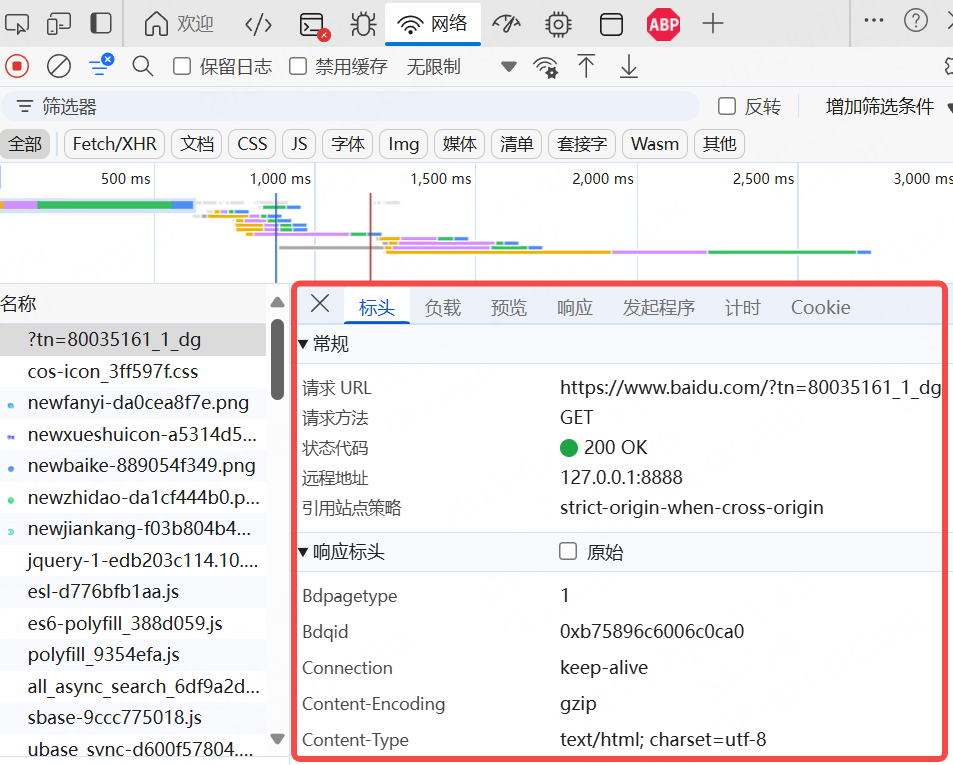
接口一般來說有兩種,一種是程序內部的接口,一種是系統對外的接口。
- 程序內部的接口:方法與方法之間,模塊與模塊之間的交互,程序內部拋出的接口,比如貼吧系統, 有登錄模塊、發帖模塊等等,那你要發帖就必須先登錄,要發帖就得登錄,那么這兩個模塊就得有交互,它就會拋出?個接口,供內部系統進行調用。
- 系統對外的接口:比如你要從別的網站或服務器上獲取資源或信息,別人肯定不會把數據庫共享給你,他只能給你提供?個他們寫好的方法來獲取數據,你引用他提供的接口就能使用他寫好的方法, 從而達到數據共享的目的,比如說咱們用的app、網址這些它在進行數據處理的時候都是通過接口來進行調用的。
接口類型有很多,如HTTP API接口、RPC等等,接下來我們基于HTTP API接口繼續講解。
1.2 接口測試
1.2.1 概念
接口測試是測試系統組件間接口的一種測試。接口測試主要用于檢測外部系統與系統之間以及內部各個子系統之間的交互點。測試的重點是要檢查數據的交換,傳遞和控制管理過程,以及系統間的相互邏輯依賴關系等。 簡而言之,所謂接口測試就是通過測試不同情況下的入參與之相應的出參信息來判斷接口是否符合或 滿足相應的功能性、安全性要求。
其實接口測試很簡單,比一般的功能測試還簡單,因為功能測試是從頁面輸入值,然后通過點擊按鈕或鏈接等傳值給后端,而且功能測試還要測UI、前端交互等功能,但接口測試沒有頁面,它是通過接口規范文檔上的調用地址、請求參數,拼接報文,然后發送請求,檢查返回結果,所以它只需測入參和出參就行了,相對來說簡單了不少。
1.2.2 接口組成
接口文檔應該包含以下內容:
- 接口說明
- 調用url
- 請求方法(get \ post)
- 請求參數、參數類型、請求參數說明
- 返回參數說明
我們可以查看微信官方給出的接口調用憑證文檔:接口調用憑證 / 獲取穩定版接口調用憑據

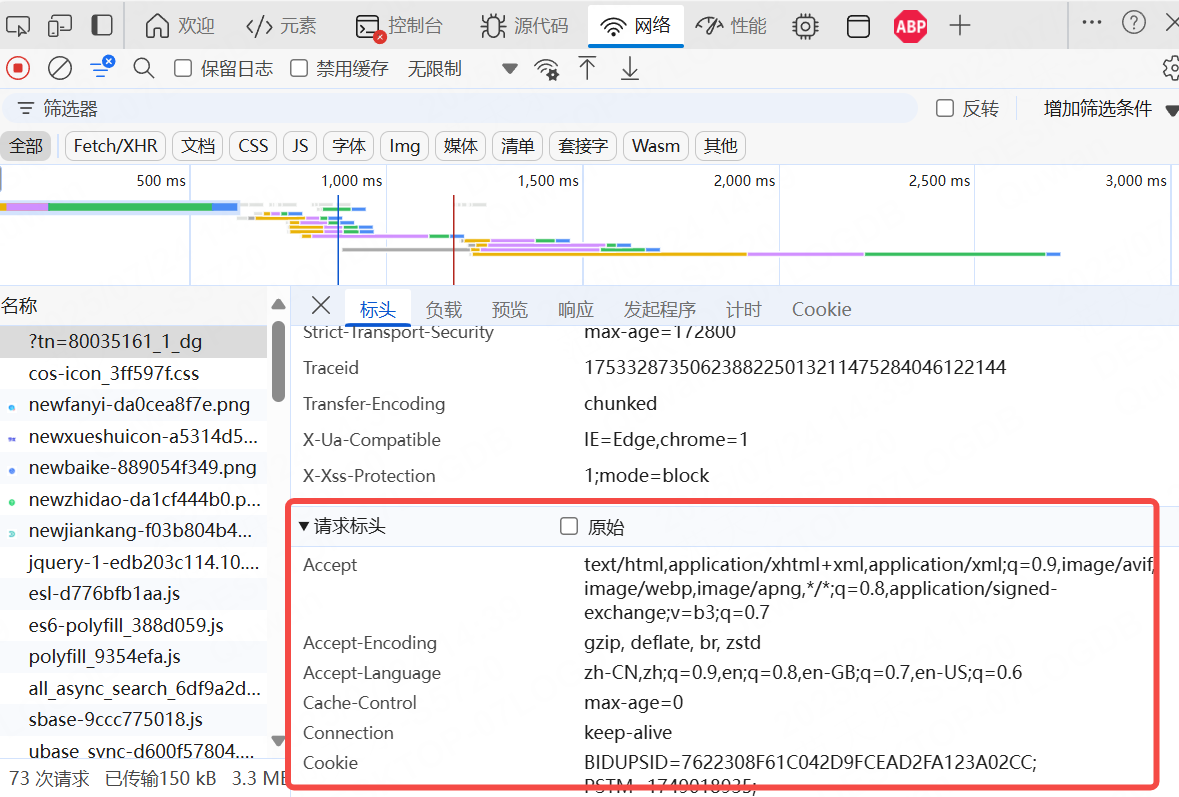
由接口文檔可知,接口至少應有請求地址、請求方法、請求參數(入參和出參)組成,部分接口有請求頭 header
標頭(header):是服務器以HTTP協議傳HTML資料到瀏覽器前所送出的字符串,在標頭與HTML文件之間尚需空一行分隔,一般存放 cookie 、 token 等信息
header 和入參有什么關系?它們不都是發送到服務器的參數嗎?
它們確實都是發送到服務器里的參數,但它們是有區別的,header里存放的參數一般存放的是?些校驗信息,比如cookie,它是為了校驗這個請求是否有權限請求服務器,如果有,它才能請求服務器,然后把請求地址連同入參?起發送到服務器,然后服務器會根據地址和?參來返回出參。也就是說, 服務器是先接受header信息進行判斷該請求是否有權限請求,判斷有權限后,才會接受請求地址和入參的。
請求頭也是可以從開發者工具中查看到的
1.3 接口測試重要性
接口其實就是前端頁面或APP等調用與后端做交互用的,有人會問,功能測試都測好了,為什么還要測接口呢?
先舉個栗子:比如測試用戶注冊功能,規定用戶名為6~18個字符,包含字母(區分大小寫)、數字、下劃線。
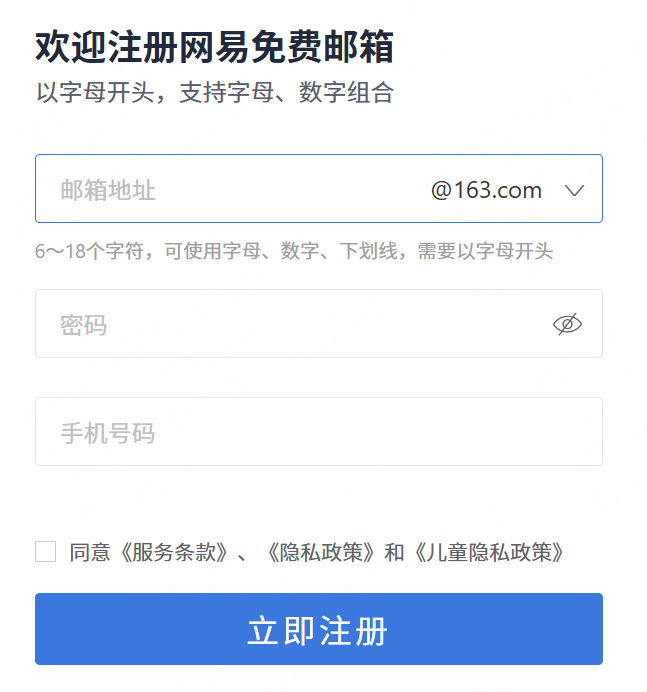
首先功能測試時肯定會對用戶名規則進行測試時,比如輸入20個字符、輸入特殊字符等,但這些可能只是在前端做了校驗,后端可能沒做校驗,如果有人通過抓包繞過前端校驗直接發送到后端怎么辦呢?試想?下,如果用戶名和密碼未在后端做校驗,而人又繞過前端校驗的話,那用戶名和密碼不就可以隨便輸了嗎?如果是登錄可能會通過SQL注入等手段來隨意登錄,甚至可以獲取管理員權限, 那這樣不是很恐怖?
所以,接口測試的必要性就體現出來了:
- 可以發現很多在頁面上操作發現不了的bug
- 檢查系統的異常處理能力
- 檢查系統的安全性、穩定性
- 前端隨便變,接口測好了,后端不用變
1.4 如何執行接口測試
在進行接口測試前,還需要了解:
- 1. get和post請求:get和post是常見的請求方法。如果是get請求的話,直接在瀏覽器里輸入就行了,只要在瀏覽器里面直接能請求到的,都是get請求,如果是post的請求的話,就不行了,就得借助工具來發送。
- 2. http狀態碼:每發出一個http請求之后,都會有?個響應,http本身會有一個狀態碼,來標示這個請求是否成功,常見的狀態碼有以下幾種:
- 200 2開頭的都表示這個請求發送成功,最常見的就是200,就代表這個請求是ok的,服務器也返回了。
- 300 3開頭的代表重定向,最常見的是302,把這個請求重定向到別的地方了。
- 400 400代表客戶端發送的請求有語法錯誤,401代表訪問的頁面沒有授權,403表示沒有權限訪問這個頁面,404代表沒有這個頁面。
- 500 5開頭的代表服務器有異常,500代表服務器內部異常,504代表服務器端超時,沒返回結果
接口測試分兩步走:通過接口設計用例+結合業務邏輯來設計用例
1.4.1 接口用例的編寫
1. 通過性驗證:首先肯定要保證這個接口功能是好使的,也就是正常的通過性測試,按照接口文檔上的參數,正常傳入,是否可以返回正確的結果。
2. 參數組合:現在有?個操作商品的接口,有個字段type,傳1的時候代表修改商品,商品id、商品名稱、價格有?個是必傳的,type傳2的時候是刪除商品,商品id是必傳的,這樣的,就要測參數組合了,type傳1的時候,只傳商品名稱能不能修改成功,id、名稱、價格都傳的時候能不能修改成功。
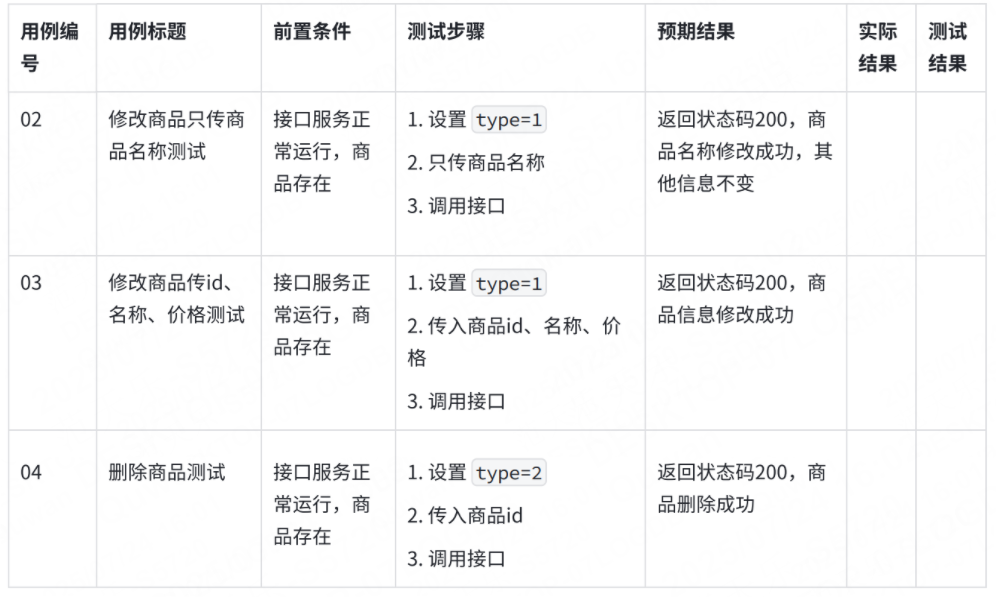
3. 接口安全:
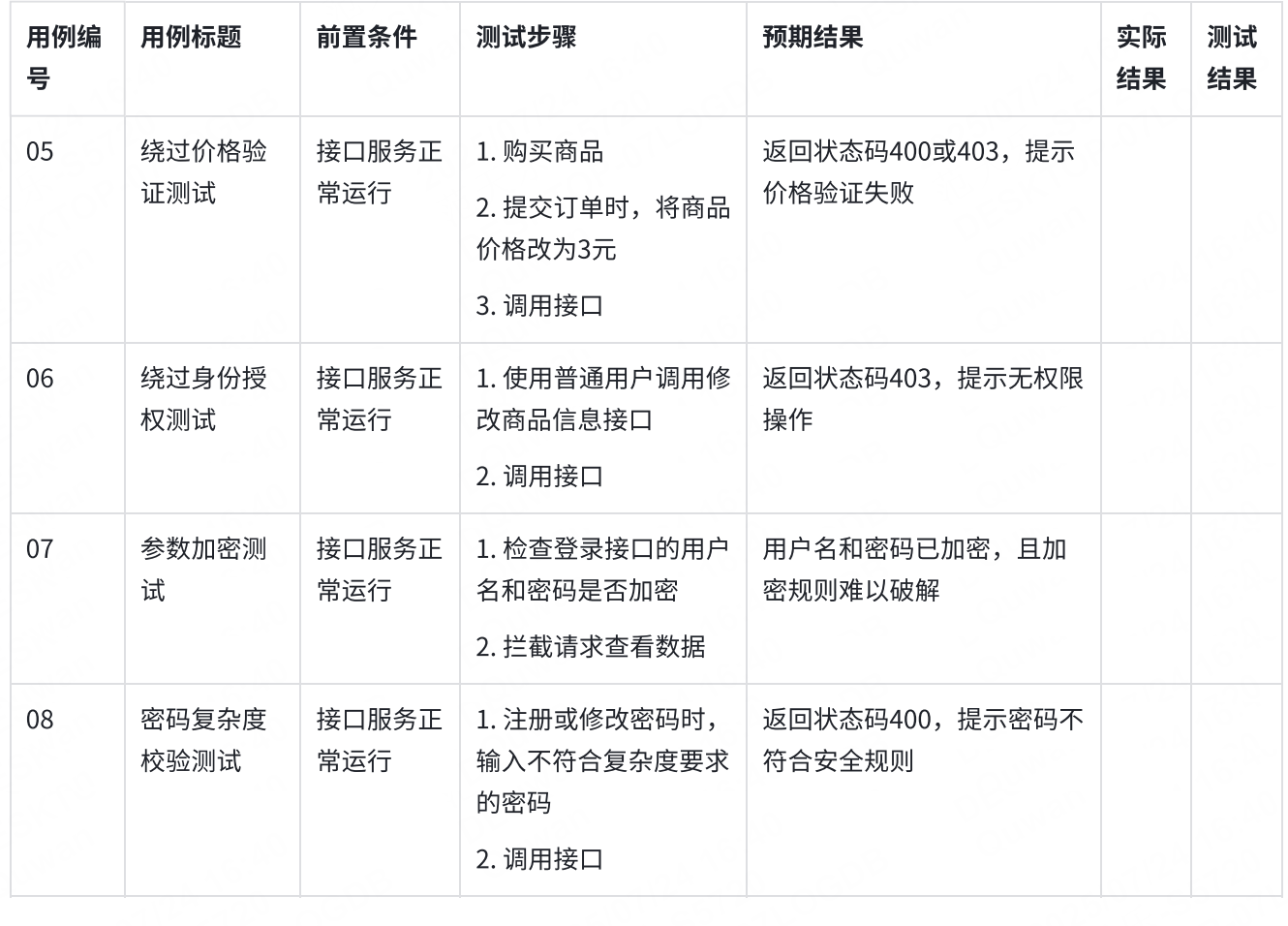
- 繞過驗證,比如說購買了一個商品,它的價格是300元,那我在提交訂單時候,我把這個商品的價格改成3元,后端有沒有做驗證,更狠點,我把錢改成-3,是不是我的余額還要增加?
- 繞過身份授權,比如說修改商品信息接口,那必須得是賣家才能修改,那我傳一個普通用戶,能不能修改成功,我傳一個其他的賣家能不能修改成功
- 參數是否加密,比如說我登陸的接口,用戶名和密碼是不是加密,如果不加密的話,別人攔截到你的請求,就能獲取到你的信息了,加密規則是否容易破解。
- 密碼安全規則,密碼的復雜程度校驗
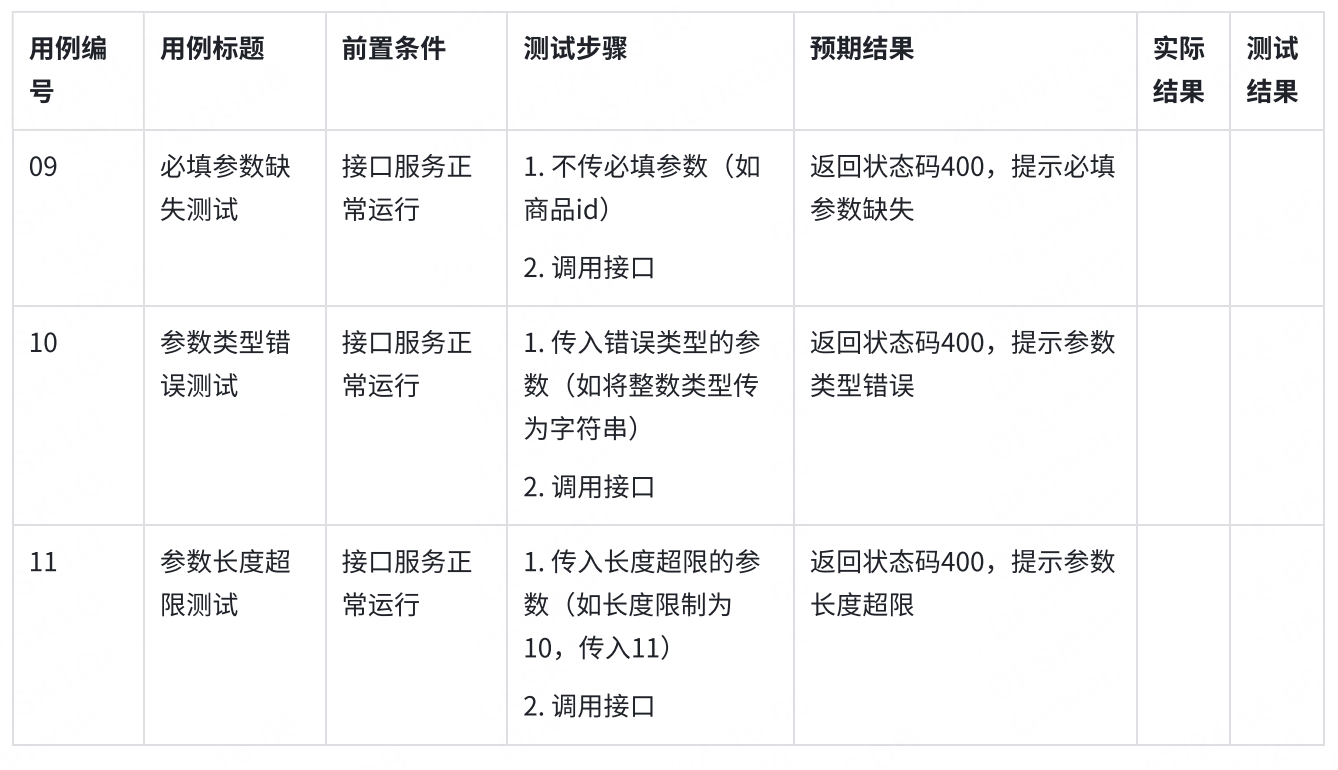
4. 異常驗證:
所謂異常驗證,也就是我不按照你接口文檔上的要求輸入參數,來驗證接口對異常情況的校驗。比如說必填的參數不填,輸入整數類型的,傳入字符串類型,長度是10的,傳11,總之就是你說怎么來,我就不怎么來,其實也就這三種,必傳非必傳、參數類型、入參長度。
1.4.2 結合業務邏輯來設計用例
根據業務邏輯來設計的話,就是根據自己系統的業務來設計用例,這個每個公司的業務不?樣,就得具體的看自己公司的業務了,其實這也和功能測試設計用例是?樣的。
舉個例子,拿貼吧來說,貼吧的需求是這樣的:
- 1. 登錄失敗5次,就需要等待15分鐘之后再登錄
- 2. 新注冊的用戶需要過了實習期才能發帖
- 3. 刪除帖子扣除積分
- 4. ......
像這樣需要把這些測試點列出來,然后再去造數據測試對應的測試點。
2. 接口自動化測試
2.1 概念
接口自動化是通過對接口進行測試和模擬,以確保軟件系統內部的各個組件能夠正確地相互通信和交換數據。接口自動化測試可以顯著提高測試效率和準確性。因為接口測試專注于測試系統內部的邏輯和數據傳輸,而不是像UI測試那樣關注用戶的操作和交互。同時,由于接口測試直接針對系統內部的結構和功能,可以更容易地發現和定位問題,減少測試成本和時間。
2.2 接口自動化流程
1. 需求分析
- 分析請求:明確接口的URL、請求方法(如get、post、PUT、DELETE等)、請求頭、請求參數和請求體等信息。
- 分析響應:確定接口返回的數據格式、狀態碼以及可能的錯誤信息。
2. 挑選自動化接口
- 根據項目的時間、人員安排和接口的復雜度,挑選適合動化測試的接口。
- 優先選擇核心業務接口、頻繁使用的接口以及容易出錯的接口進行自動化測試。
- 功能復雜度:優先選擇功能復雜、邏輯分支多的接口進行自動化測試。例如,涉及多種支付方式、多種訂單狀態轉換的訂單管理接口,手動測試難以全面覆蓋所有場景,自動化測試可以更高效地進行測試.
- 高風險功能:選擇對業務影響大、風險高的接口進行自動化測試,確保其穩定性和可靠性。例如,涉及資金操作的支付接口,一旦出現問題可能導致嚴重的經濟損失,因此需要進行充分的自動化測試.
- 重復性高:對于需要頻繁執行的測試任務,如回歸測試中的接口測試,自動化測試可以避免重復手動測試的繁瑣和低效,提高測試效率.
假設我們正在開發?個在線教育平臺,該平臺包含以下接口:
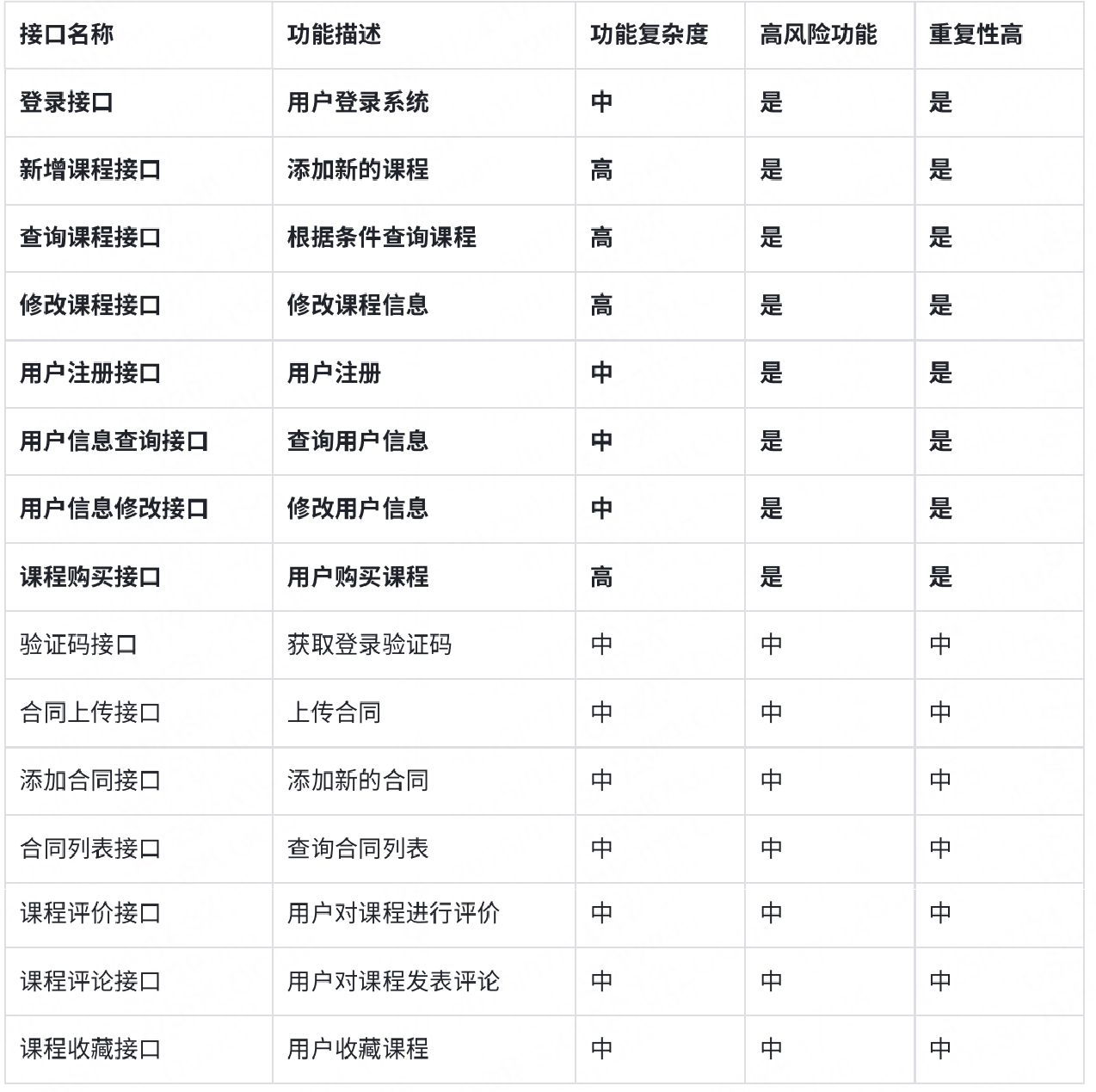
功能復雜度:
- 新增課程接口:涉及多個參數(課程名稱、課程描述、課程價格等),需要與其他模塊(如課程分類模塊)交互。
- 查詢課程接口:支持多種查詢條件(課程名稱、課程類型、課程狀態等),邏輯復雜。
- 課程購買接口:涉及支付流程、訂單生成等復雜邏輯。
高風險功能:
- 登錄接口:用戶登錄是系統的核心功能,任何問題都會影響用戶體驗。
- 新增課程接口:課程信息的正確性直接影響平臺的運營。
- 用戶注冊接口:用戶注冊是系統的基礎功能,任何問題都會影響用戶獲取服務。
重復性高:
- 登錄接口:用戶每次使用系統都需要登錄。
- 查詢課程接口:用戶頻繁查詢課程信息。
- 用戶信息查詢接口:用戶經常查看自己的信息。
3. 設計自動化測試用例
- 如果在功能測試階段已經設計了測試用例,可以直接拿來使用。
- 根據接口需求和功能,設計正向測試用例(正常場景)和反向測試用例(異常場景),包括邊界值測試、參數組合測試等。
4. 搭建自動化測試環境
- 選擇合適的編程語言(如Python、Java等)和開發環境(如PyCharm、IntelliJ IDEA等)來實現自動化測試。
- 以Python為例,安裝必要的依賴庫,如requests用于發送HTTP請求,pytest用于測試框架。
5. 設計自動化執行框架
- 設計?個框架來執行測試用例,包括報告生成、參數化處理和用例執行邏輯。
6. 編寫代碼
- 根據設計好的測試用例和框架,編寫自動化測試腳本。
7. 執行用例
- 使用測試框架(如unittest、pytest)來執行編寫的測試用例。
8. 生成測試報告
- 測試完成后,生成測試報告。可以使用?具如HtmlTestRunner或Allure來生成易于閱讀的報告。
tips:接口自動化流程是面試考點
2.3 第一個簡單的接口自動化
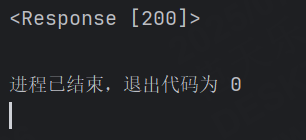
示例:對百度接口發起請求
import requestsr = requests.get("https://www.baidu.com")
print(r)運行結果:
2.4 requests模塊
2.4.1 安裝
有些同學可能會遇到如下問題:
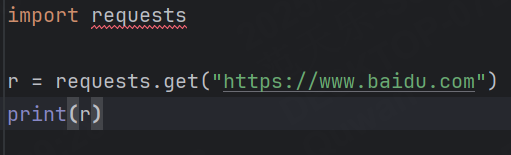

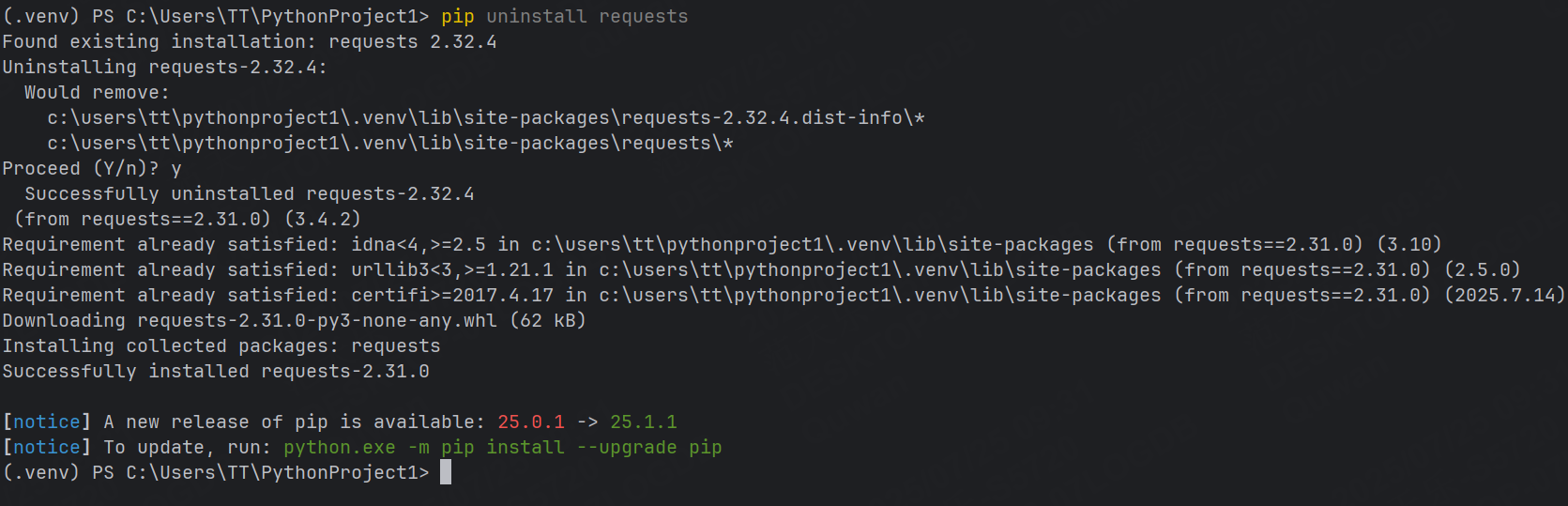
這是因為requests包沒有下載,我們可以使用命令行通過pip工具進行安裝,命令:
pip install requests==2.31.0我這里使用的是2.32.0的版本,同學可以根據自己的需要來變更版本,安裝成功后會出現如下界面
我們還可以檢查當前項目下包是否更新:
pip list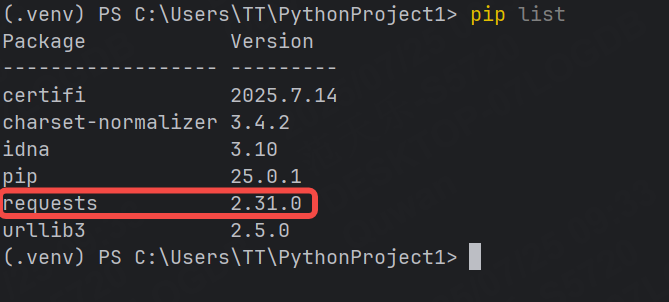
2.4.2 介紹
requests 庫是一個非常流行的HTTP客戶端庫,用于發送HTTP請求。
- requests.get 方法用于發送?個HTTP get 請求到指定的URL
- requests.get 方法返回?個 Response 對象,這個對象包含了服務器返回的所有信息。
如:
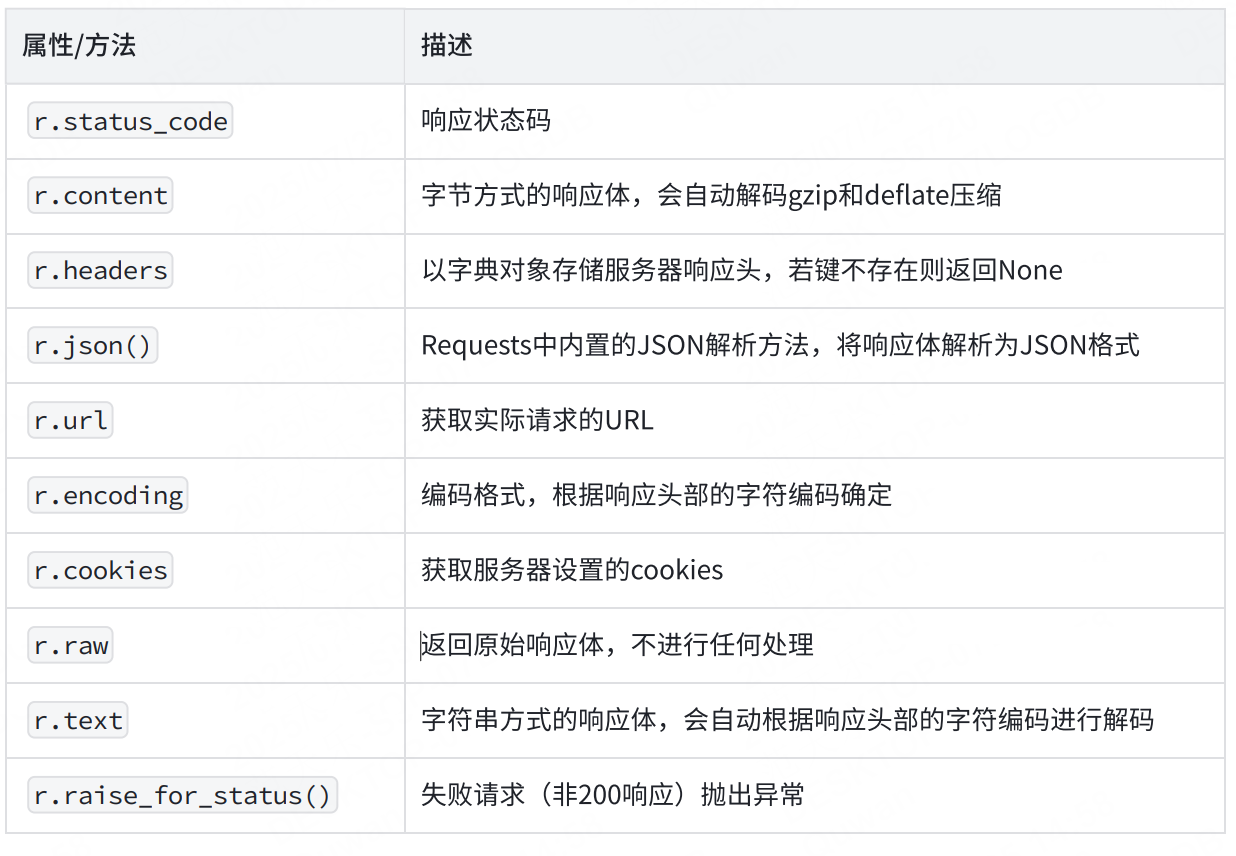
Response 對象提供的屬性 / 方法介紹:
注意:
- 如果響應格式為JSON格式,則必須以JSON格式打印(不能以text方式打印)
- 如果響應格式為html格式,則必須以text格式打印(不能以JSON方式打印)
演示:
返回的響應為html,所以我們先使用text進行打印
import requestsr = requests.get("https://www.baidu.com")
print(r.status_code) #狀態碼
print(r.text) #響應體

運行結果沒什么問題,現在我們再嘗試使用JSON打印一下試試
import requestsr = requests.get("https://www.baidu.com")
print(r.status_code) #狀態碼
print(r.text) #響應體
print(r.json()) #響應體運行結果:
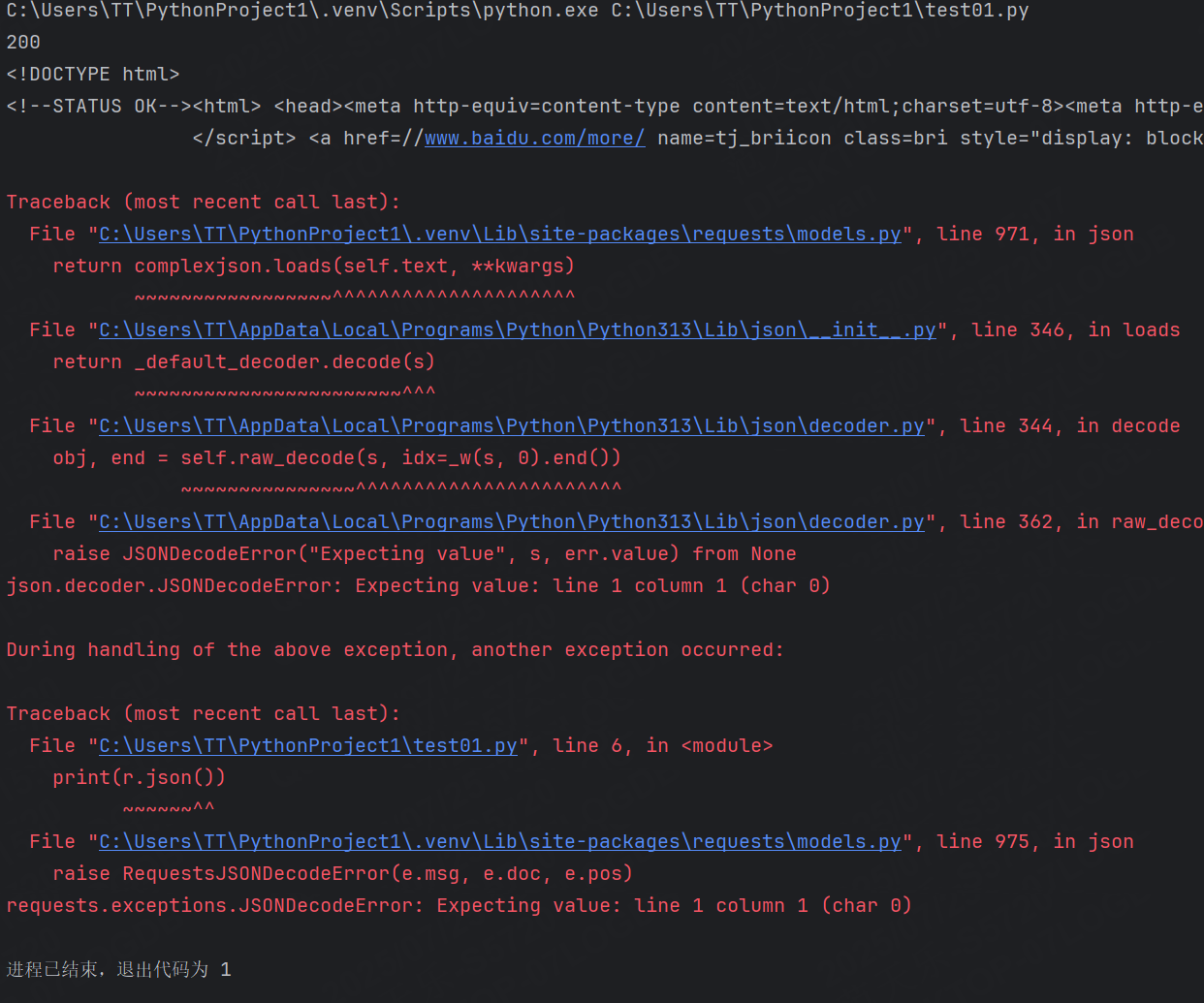
原因就是我們使用了錯誤的打印方式。
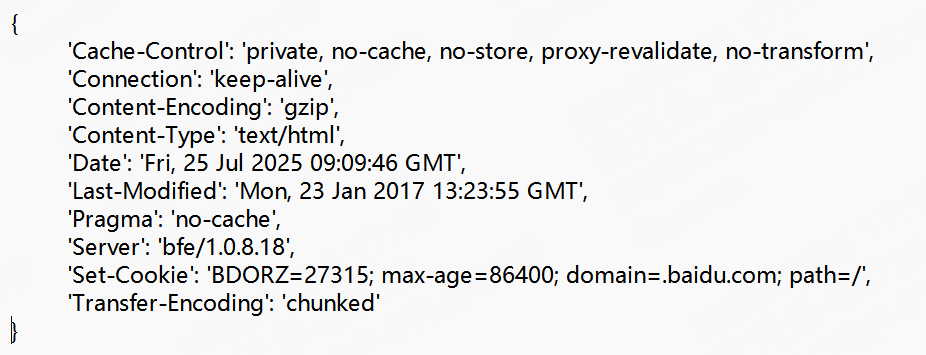
查看請求頭
我們再來查看一下請求頭
import requestsr = requests.get("https://www.baidu.com")
print(r.status_code) #狀態碼
print(r.text) #響應體
print(r.headers) #響應頭
運行結果:

為了方便展示,我將打印的格式修改一下:
我們再來查看從網頁的開發者工具中返回的響應頭:
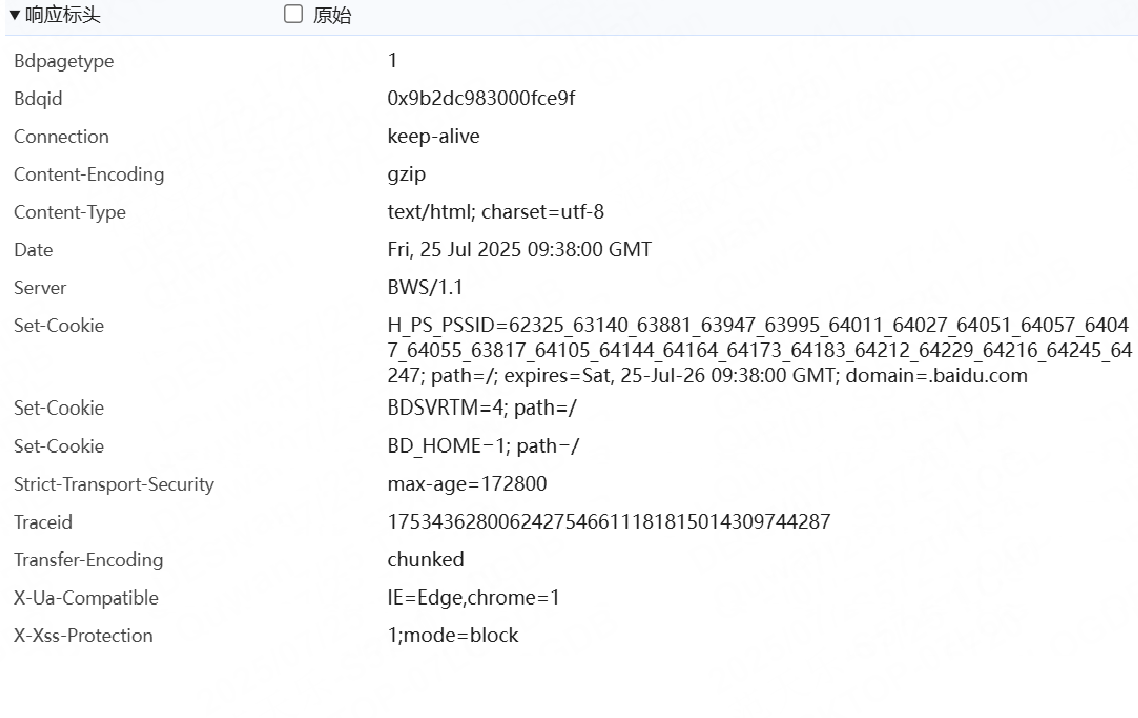
可以看到大多數的數據都是一樣的,網頁查看和代碼的方式會有一些差異所以并不是完全一樣的。
2.4.3 常見請求方法
requests庫中包含了https常用的請求方法:
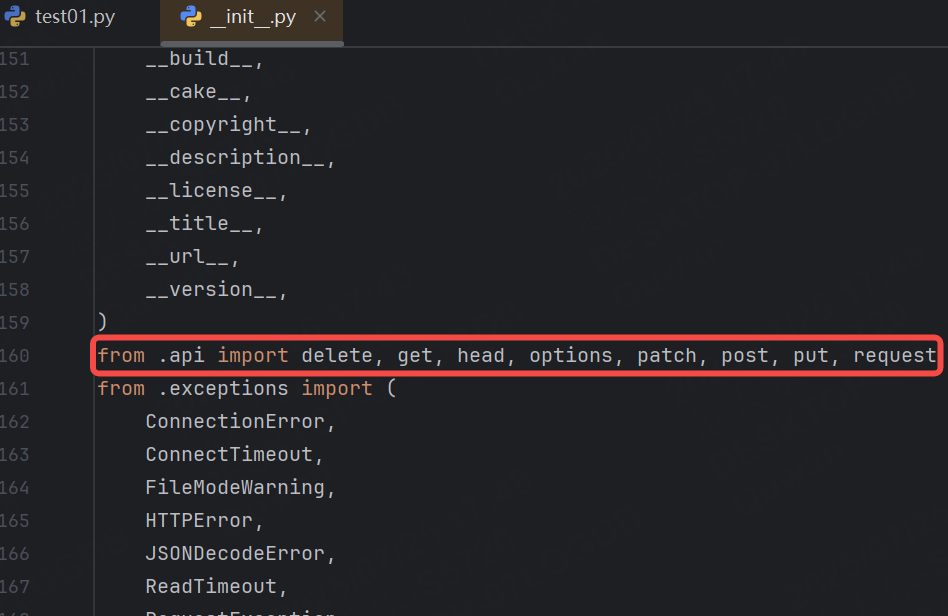
常用函數:
#發起get請求
def get(url, params=None, **kwargs)#發起post請求
def post(url, data=None, json=None, **kwargs)#?持不同請求?式,method:指定請求?法,
#?持``get``, ``OPTIONS``, ``HEAD``, ``post``, ``PUT``, ``PATCH``, or ``DELETE``
def request(method, url, **kwargs)- url:需要請求的資源
- params:一個字典、列表或者字符串,將作為查詢字符串附加到URL上(一般是get請求,參數可以拼接在url上)
- kwargs:其他要攜帶的參數
- data:一個字典、列表或者字符串,包含要發送的請求體數據(post請求,參數是表單格式)
- json:一個字典,將被轉換為JSON格式并發送(post請求,參數是JSON格式)
- method:請求方法(想使用什么請求方法,method就填寫什么)
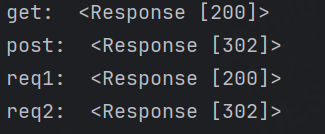
使用示例:
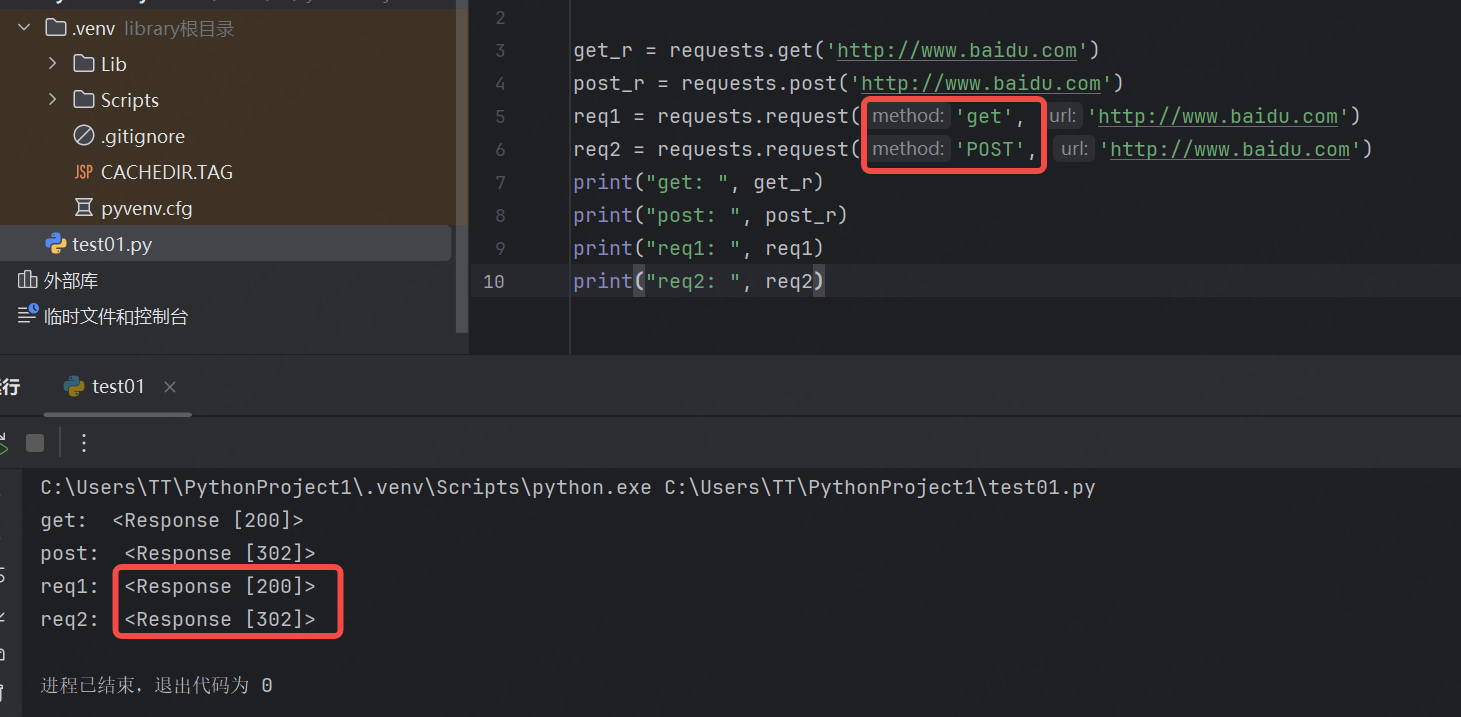
import requestsget_r = requests.get('http://www.baidu.com')
post_r = requests.post('http://www.baidu.com')
req1 = requests.request('GET', 'http://www.baidu.com')
req2 = requests.request('POST', 'http://www.baidu.com')
print("get: ", get_r)
print("post: ", post_r)
print("req1: ", req1)
print("req2: ", req2)結果:
如果我們再使用轉包工具來查看響應結果呢?
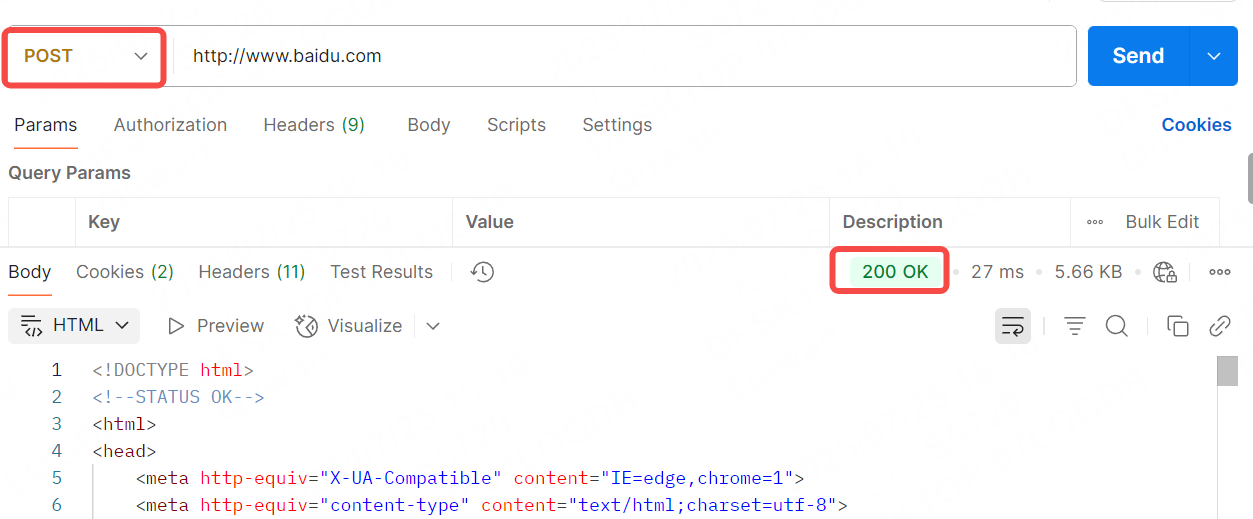
可以看到使用POST方法得到的響應碼是200,和前面使用代碼得到的結果不太一樣,這個不用太關心,網頁和代碼方式會存在一些差異。
注意:
requests中的method參數中傳大寫和小寫都是可以的。
2.4.4 添加請求信息
get() 、 post() 底層都是調用?request() 方法,因此這三個方法在發送請求時,傳參無太大區別,我們可以查看一下他們的源代碼:
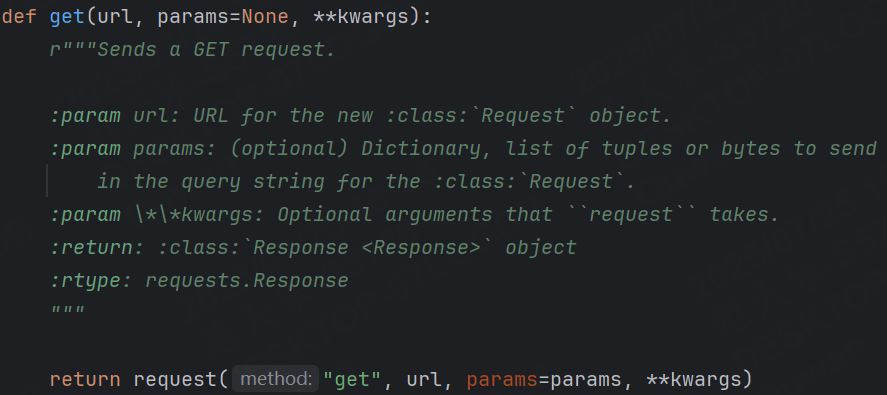
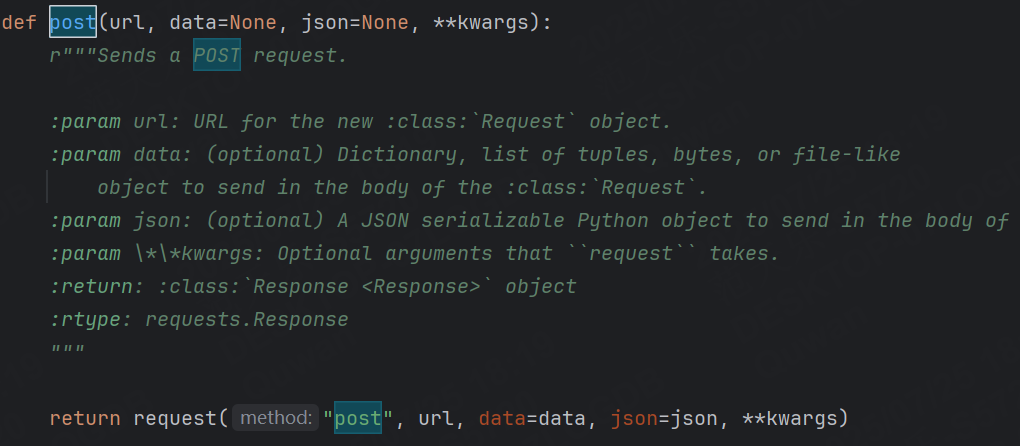
可傳遞的參數展示如下:

演示添加參數場景
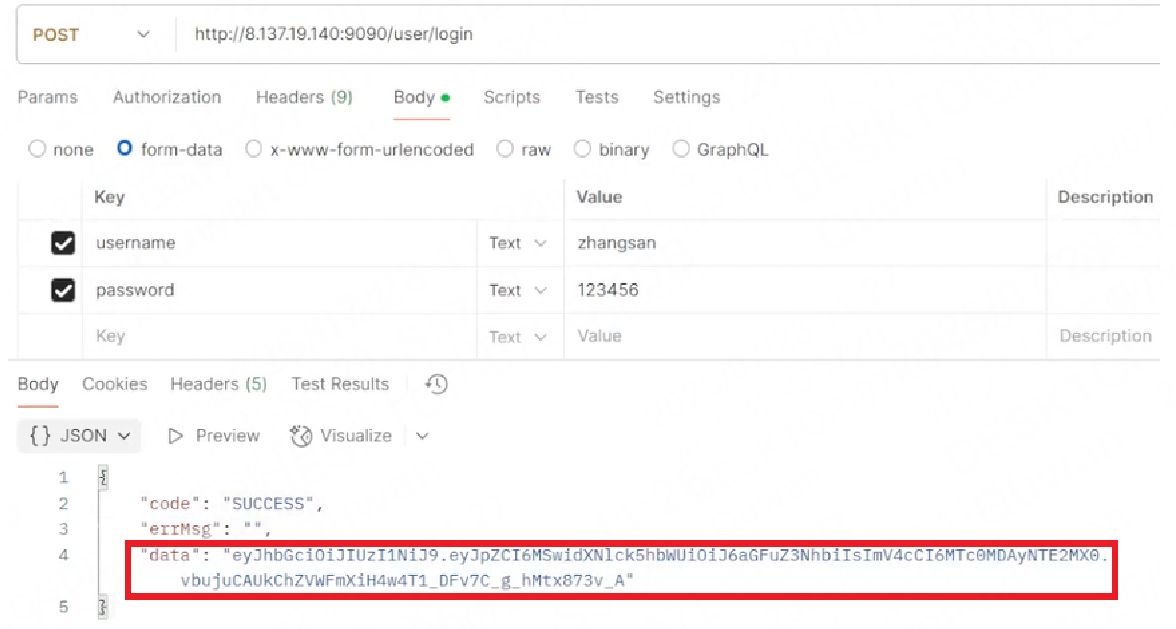
例如現在有一個博客系統,在登錄成功后會返回一個user_token字段,在往后的請求服務中都需要攜帶該字段來標明用戶身份,如果沒有user_token字段則說明該用戶是無效身份,不能提供服務,會返回401狀態碼。
1.登錄成功后返回user_token(就是下圖中的data)
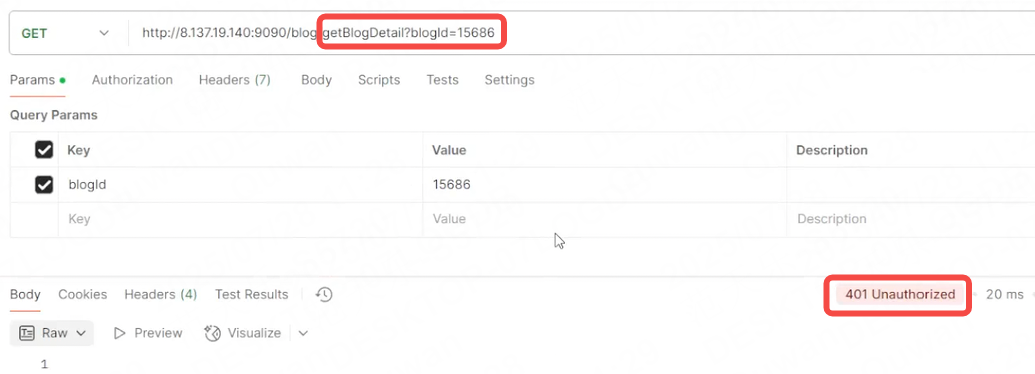
2.在沒有攜帶user_token字段時請求獲取博客列表時,返回401狀態碼
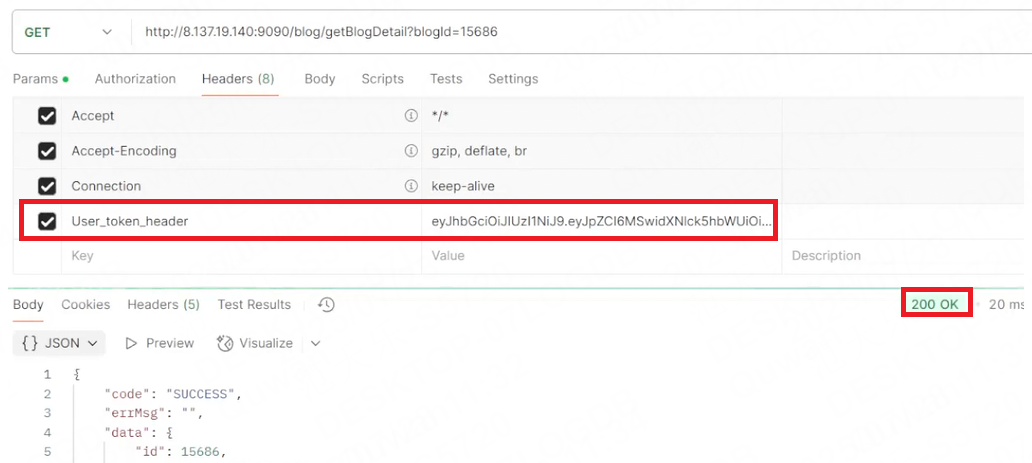
3.攜帶了user_token字段時請求獲取博客列表時,返回200狀態碼,成功
總結:上面的場景中必須要攜帶user_token參數,否則請求失敗。
在對這個接口有一定了解后,我們就可以使用代碼來編寫自動化腳本了。
示例一:博客詳情頁接口
url = "http://8.137.19.140:9090/blog/getBlogDetail"# 定義查詢參數
params = {"blogId":9773
} # 定義請求頭信息
header = {"user_token_header":"eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwidXNlck5hbWUiOiJ6aGFuZ3Nhb
iIsImV4cCI6MTczNTU1ODk2Mn0.72oh-gQ-5E6_aIcLsjotWL4ZHmgy0jF1794JDE-uUkg",
"x-requested-with":"XMLHttpRequest"
}
r = requests.post(url=url, params=params, headers=header)
print(r.json())url中沒有攜帶參數,所以我們需要額外定義一個params參數,然后將blogId字段填進去(注意:也可以將參數直接添加到url中,就不需要params參數了)
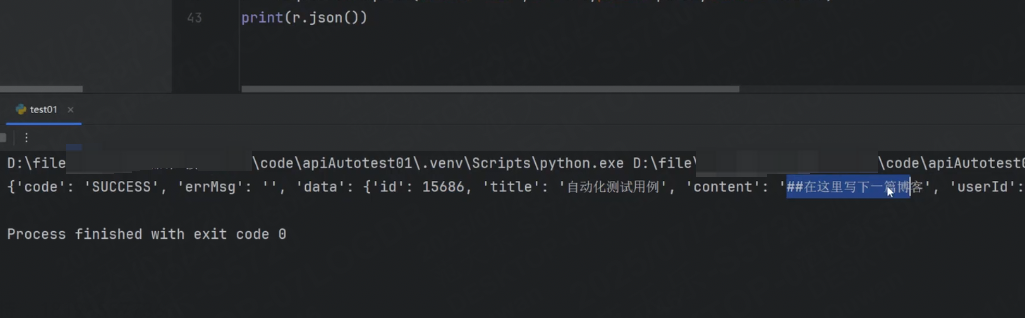
返回的結果是SUCCESS,也就是正確的,說明user_token字段被成功傳遞進去了。
示例2:博客登錄接口
上面演示了使用user_token的場景,我們再來嘗試一下獲取user_token,即在登錄界面發送請求。
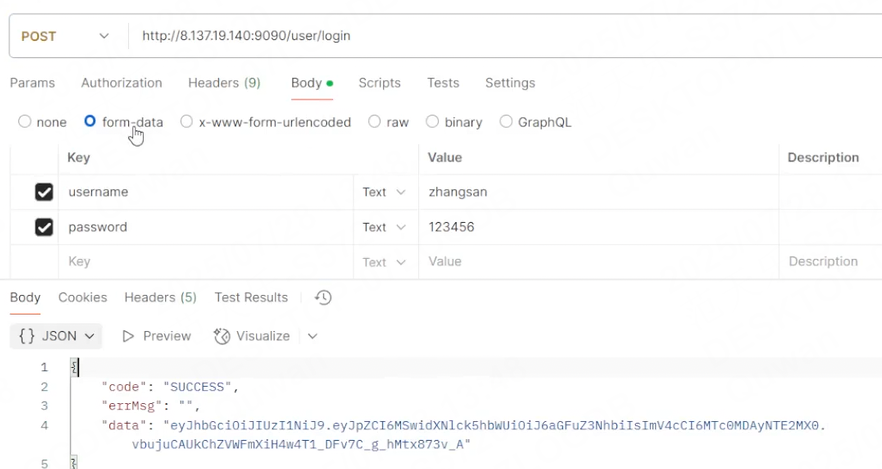
使用抓包工具可以返回正確的data,再來嘗試一下代碼的方式。
url = "http://8.137.19.140:9090/user/login"# 定義要發送的數據
data = {"username":"zhangsan","password": "123456"
}
r = requests.post(url=url, data=data)
print(r.json())運行結果:
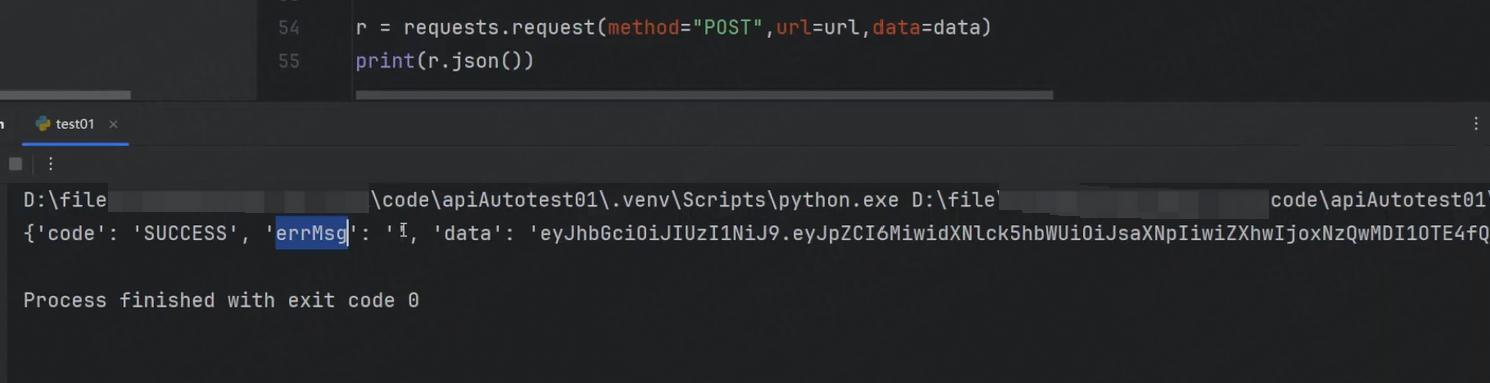
可以看到成功返回了user_token字段(data)
示例3:添加 cookie 信息
以博客園接口為例:https://account.cnblogs.com/user/userinfo
未登錄狀態下的接口返回值:
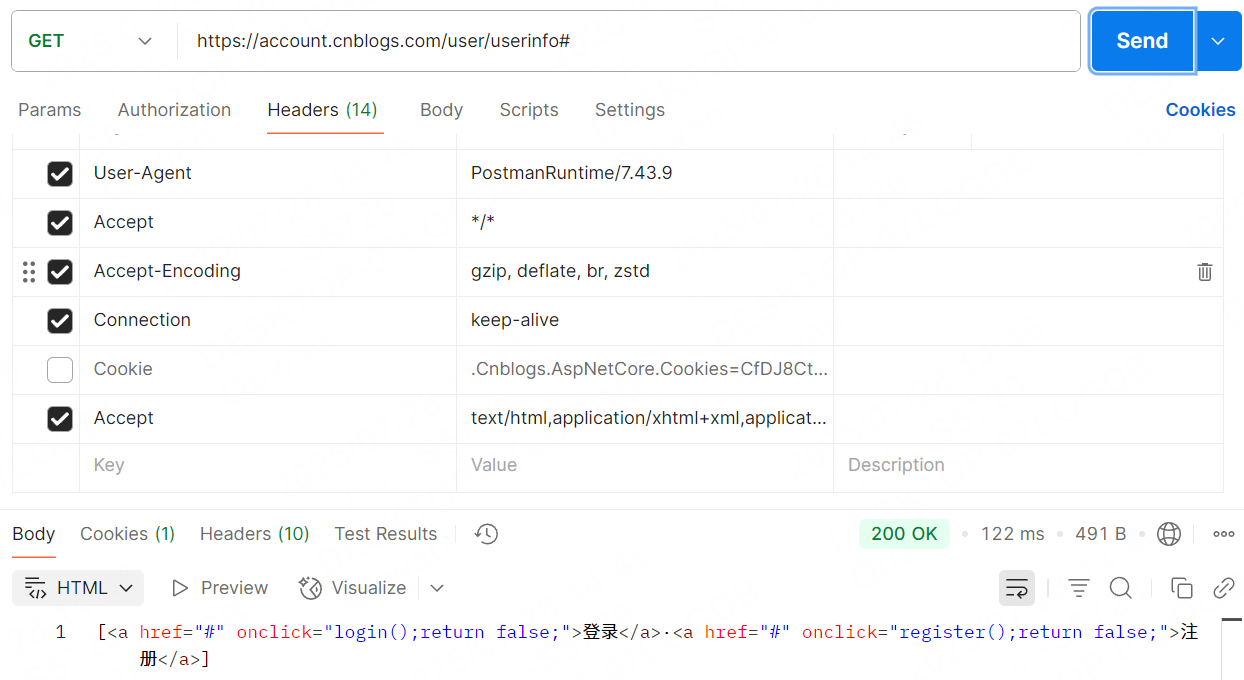
登錄狀態下的接口返回值:
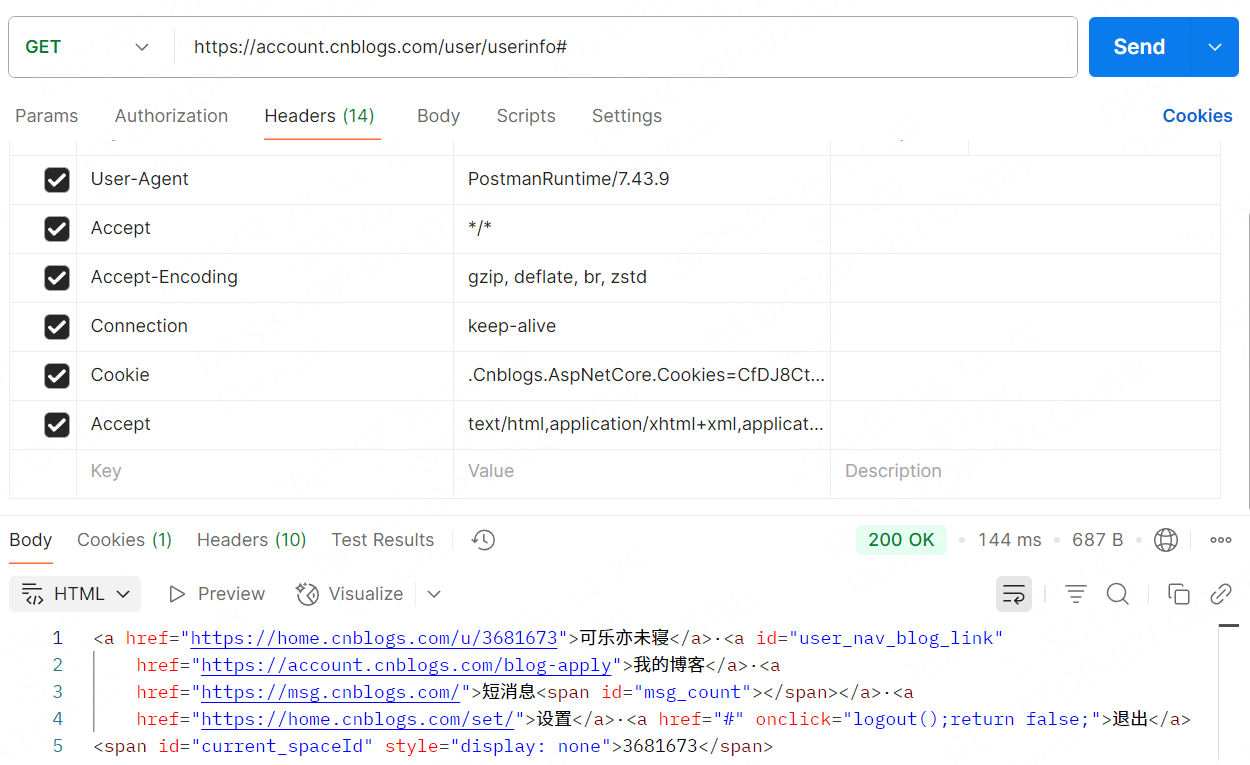
兩者最主要的區別就是是否攜帶Cookie信息。
import requestsurl = "https://account.cnblogs.com/user/userinfo"# 定義請求頭信息
header = {"Accept":"application/json, text/javascript, */*; q=0.01"
}# 定義cookie信息
cookie = {".Cnblogs.AspNetCore.Cookies":"CfDJ8Ct_7-Gh-gZNte6RB_khjDrB1LrbhEsj64A""S3hXoD4Yk6yuxVsSRkWLpG0DxDq89PB2bDWehXw4EnfAQ6fkCdR-zgZ3XAn7ErFBJo9gzyy""9PJbhpFo7K5HMO5heP9fq5MZtRIkodlCQ8gDzFsjfUdSaM27-QLTvSA5DUneqqM21WQV0QwWT""ZsvP1ZSd2D9m4BwucG4U7lDhCFMqCqDH4LsET_qkqrlMW2Cx4pbtr4VXAmQLmAf0WtJhKRGvGE""5vOv71RdeAzEBqso4n0-Cnyv-U7_PEOsUHAGjNagwSxKYcF0Bg3zugkrxrCp0iNffPlTNcGU6e""ukI1gz6AF40H8cwNp49vEo7X6QnZscGfPojG4MCApz0MWTFSqHWL0OoqxpbQBBfG2XrsUXltm3D""RVM17-suyFTxMr1BkWooKc8JHljXvfofWN6wxlf5p9YRPEfwFa-lVniwlySkvUncrZkjTBcCyw5a""Qa0oU_WXhsDKp5BJxk-Efw6SBLtuANJDREqZV7IwcaraeuU9z74C-BVQLSaYDF8JuooUlwhVWPDrJn5bo0YN5mDB32rhYtDGIQUw; "
}
r = requests.post(url=url, headers=header, cookies=cookie)
print(r.json())運行結果:
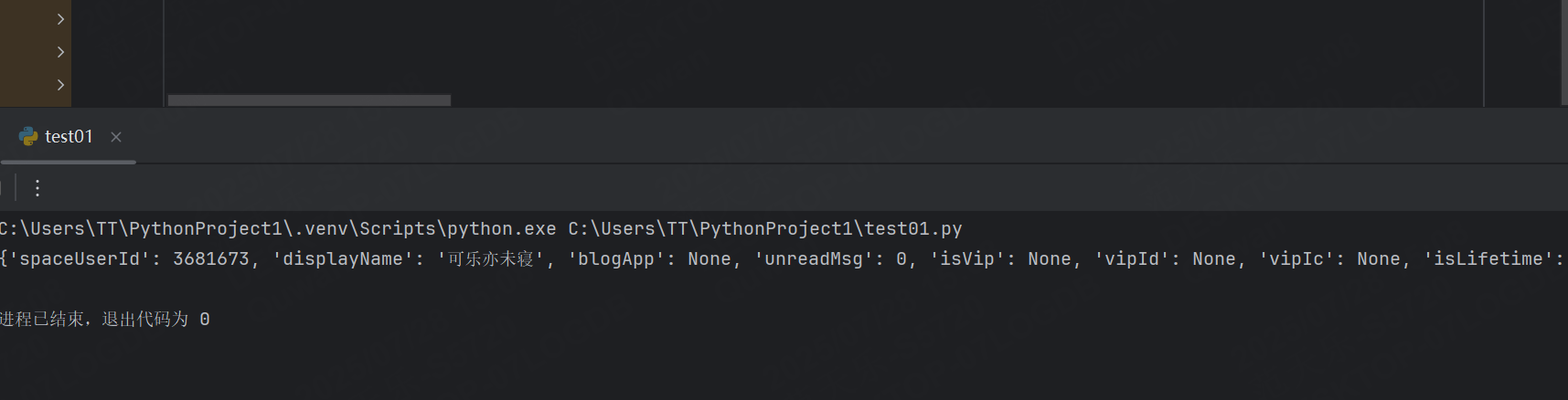 成功顯示出了登錄信息。
成功顯示出了登錄信息。
問題:上傳參數選擇 params 、 json 還是 data ?
- params 用于在URL中傳遞查詢參數(Query Parameters),通常用于GET 請求,但也可以用于其他類型的請求。
- json 用于在請求體(Body)中傳遞 JSON 格式的數據,通常用于POST 或 PUT 請求。
- data 用于在請求體(Body)中傳遞表單數據,通常用于POST 或 PUT 請求。
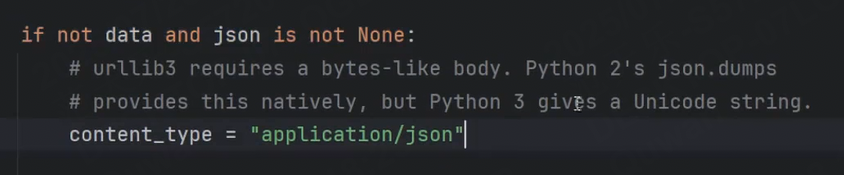
注意:若參數上傳格式選擇為 json 格式, Content-Type 會自動被設置為application/json
我們來看一下源碼,只要沒有設置data,并且json非空,就將content_type設置為json。
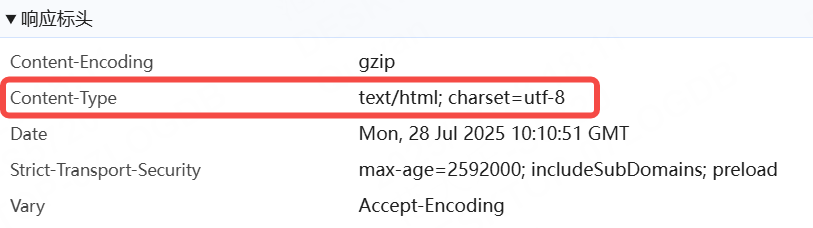
Content-Type既可以在請求頭中也可以在響應頭中,請求頭標識請求參數的格式,響應頭表示響應
數據的格式
有了 requests 庫,可以實現對接口發起 http 請求,然而自動化測試中,我們需要編寫大量的測試用例,這些用例的組織、執行和管理也需要使用其他更強大的框架 ? pytest 框架。
requests 庫專注于HTTP請求的發送,而?pytest 框架則提供了測試的組織、執行和管理功能。
?
2.5 自動化框架pytest
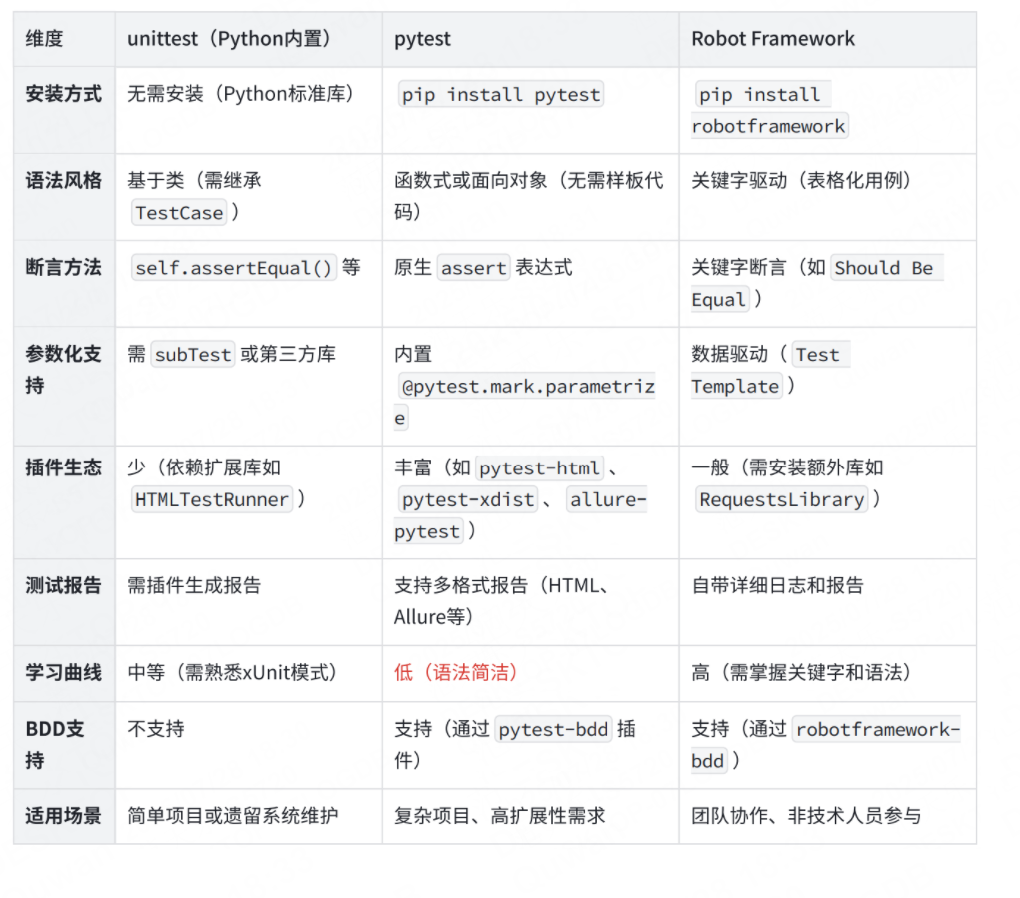
支持Python語言的接口自動化框架有很多,以下是支持Python的接口自動化主流框架對比分析: 主流框架對比表:
2.5.1 pytest介紹
pytest官方文檔:Get Started - pytest documentation
pytest 是一個非常流行且高效的Python測試框架,它提供了豐富的功能和靈活的用法,使得編寫和運行測試用例變得簡單而高效。
為什么選擇pytest:
- 簡單易用: pytest 的語法簡潔清晰,對于編寫測試用例非常友好,幾乎可以在幾分鐘內上手。
- 強大的斷言庫: pytest 內置了豐富的斷言庫,可以輕松地進行測試結果的判斷。
- 支持參數化測試: pytest 支持參數化測試,允許使用不同的參數多次運行同?個測試函數,這大大提高了測試效率。
- 豐富的插件?態系統: pytest 有著豐富的插件生態系統,可以通過插件擴展各種功能,比如覆蓋率測試、測試報告生成(如 pytest-html 插件可以生成完美的HTML測試報告)、失敗用例重復執行(如 pytest-rerunfailures 插件)等。此外, pytest 還支持與selenium、requests、appinum等結合,實現Web自動化、接口自動化、App自動化測試。
- 靈活的測試控制: pytest 允許跳過指定用例,或對某些預期失敗的case標記成失敗,并支持重復執行失敗的case。
2.5.2 安裝
安裝 pytest8.3.2 要求 python 版本在3.8及以上。
pip install pytest==8.3.2若python版本低于3.8,可參考表格不同的pytest 版本支持的python版本:
安裝成功示例:
使用pip list也可以看到pytest被安裝成功了。
安裝好 pytest 后,確認pycharm中python解釋器已經更新,來看?下有 pytest 框架和沒有pytest 框架編寫代碼的區別:
未安裝:
運行結果:
已安裝:
運行結果:
兩張對比圖可以明顯看出來,未安裝pytest框架的情況下需要編寫 main 函數,在 main 函數中手動調用測試用例test01;安裝了 pytest 框架后方法名前有直接運行標志。
然而并不是所有的方法都可以直接運行,需要遵循 pytest 中的用例命名規則。
2.5.3 用例運行規則
- 文件名必須以 test_ 開頭或者 _test 結尾
- 測試類必須以 Test 開頭,并且不能有 __init__ 方法。
- 測試方法必須以 test 開頭
當滿足以上要求后,可通過命令行參數 pytest 直接運行符合條件的用例:
我們再創建兩個文件,分別寫上下面內容:
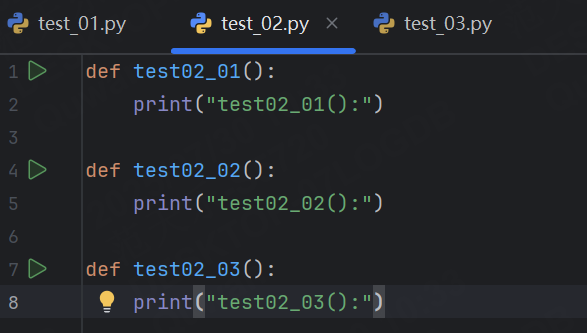
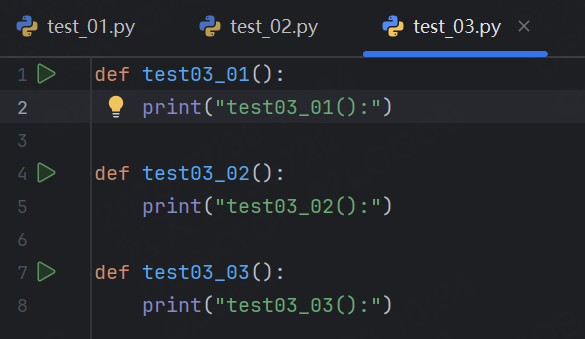
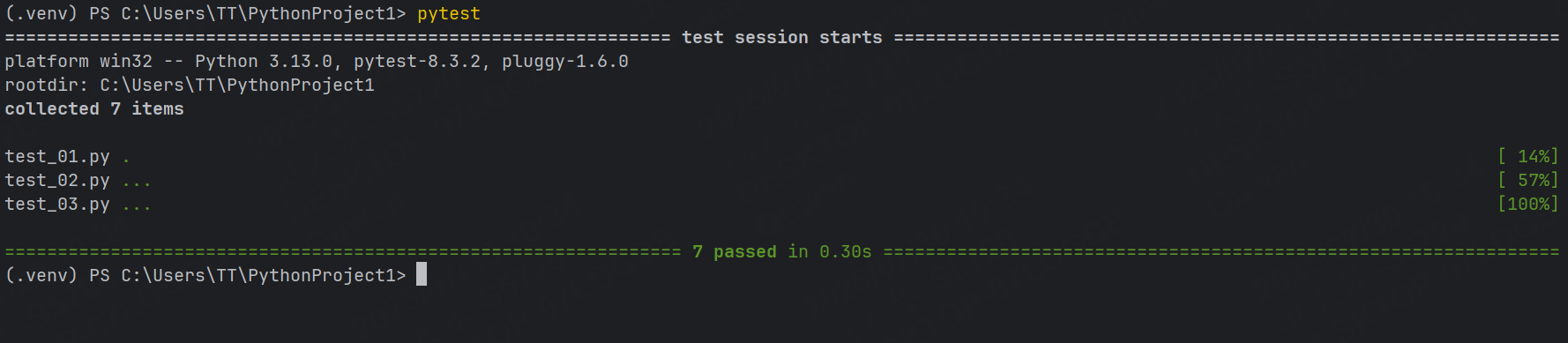
我們通過命令行輸入pytest,就會幫我們運行所有符合命名規則文件中符合規則的函數,所以最終顯示運行了7個用例。
注意:Python類中不可以添加init方法
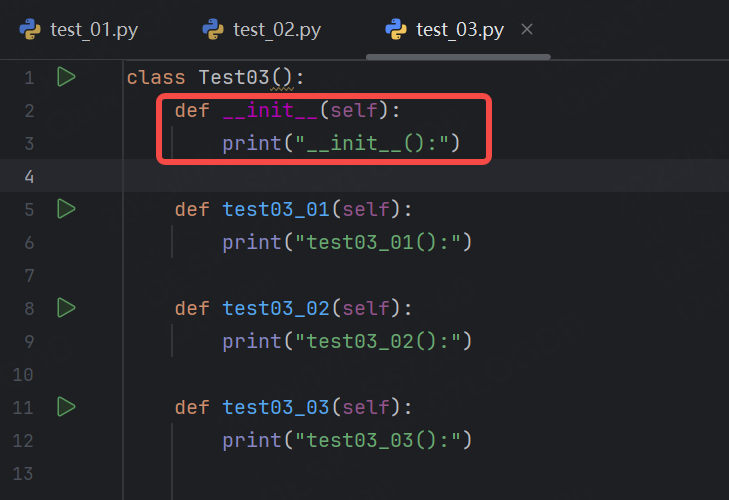
運行結果:
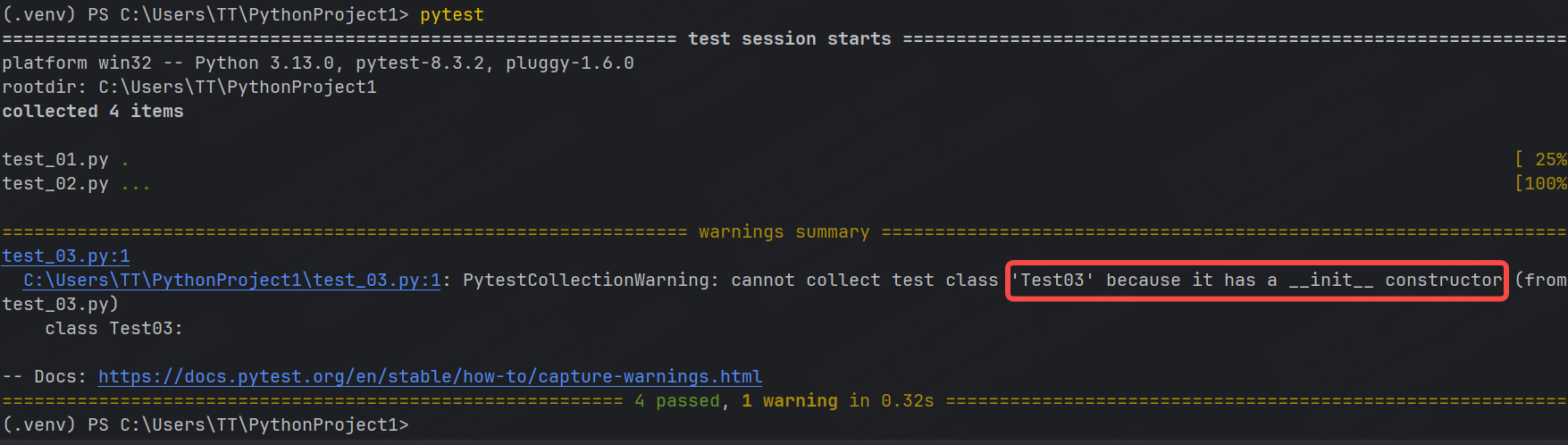
由于 pytest 的測試收集機制,測試類中不可以定義 __init__ 方法。 pytest 采用自動發現機制來收集測試用例。它會自動實例化測試類并調用其所有以 test 結尾的方法作為測試用例。如果測試類中定義了 __init__ 方法,那么當 pytest 實例化該類時, __init__ 方法會被調用,這可能會掩蓋測試類的實際測試邏輯,并引入額外的副作用,影響測試結果的準確性。
若測試類中存在初始化操作該采取什么方案?
為了避免使用?__init__ 方法,建議在 pytest 中使用其他替代方案,如使用?setUp() 和tearDown() 方法、使用類屬性、使用?fixture 函數(具體使用后續會講解)
2.5.4 pytest命令參數
pytest 提供了豐富的命令行選項來控制測試的執行。以下是?些常用的 pytest 命令行參數及其使用說明。
示例1:運行符合運行規則的用例
pytest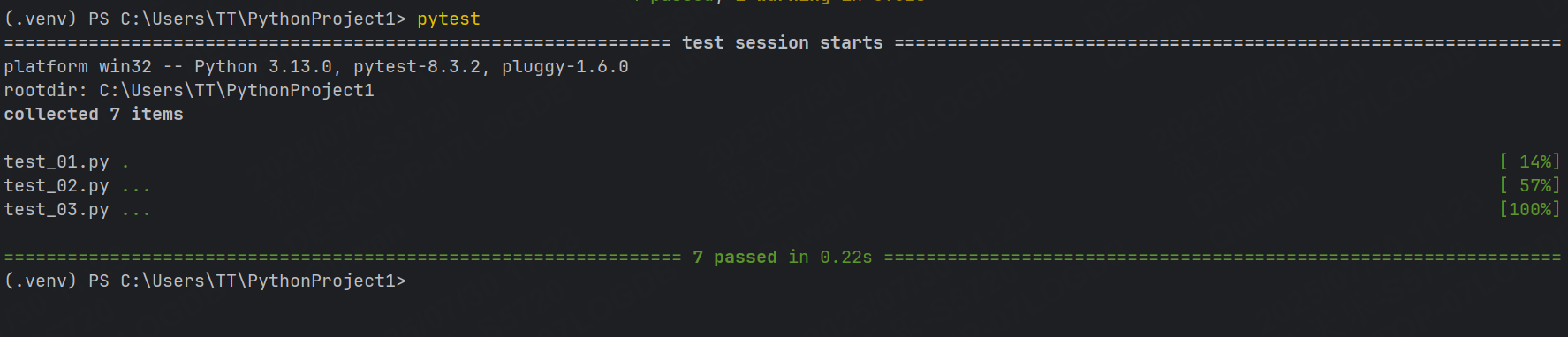
注意,這里不會輸出測試用例中printf內容
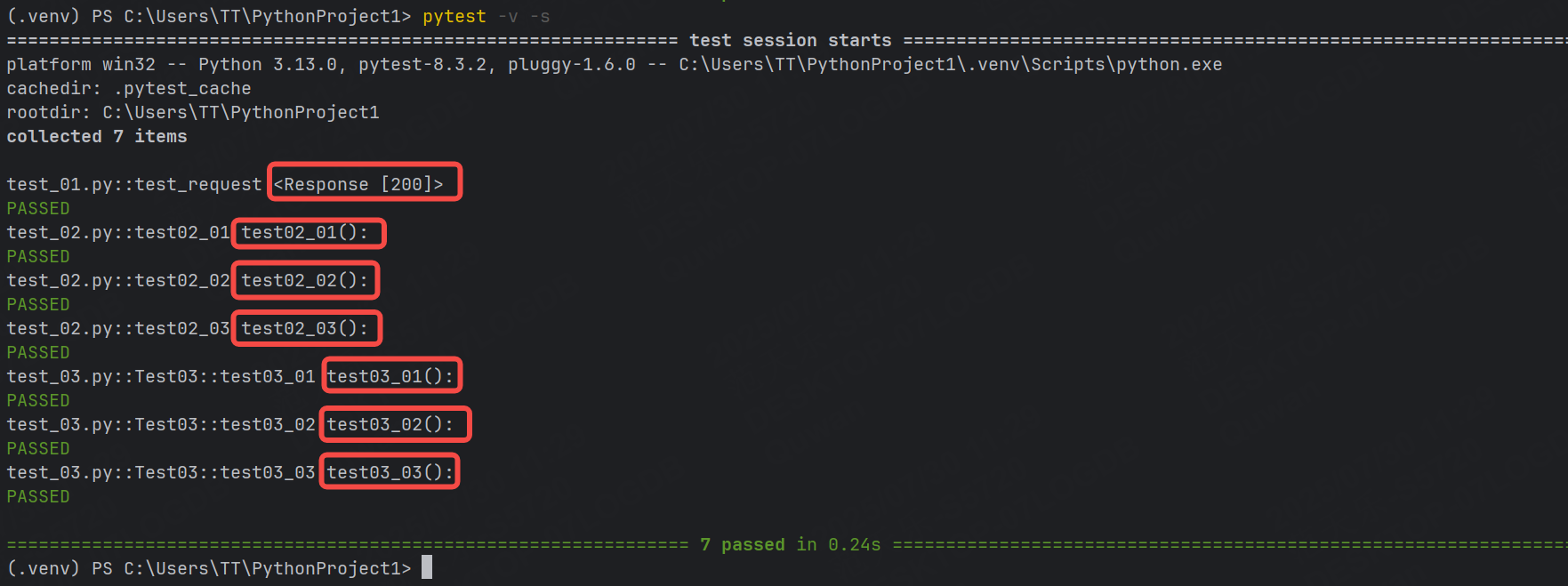
示例2:詳細打印,并輸入print內容
pytest -s -v 或者 pytest -sv (可以連寫)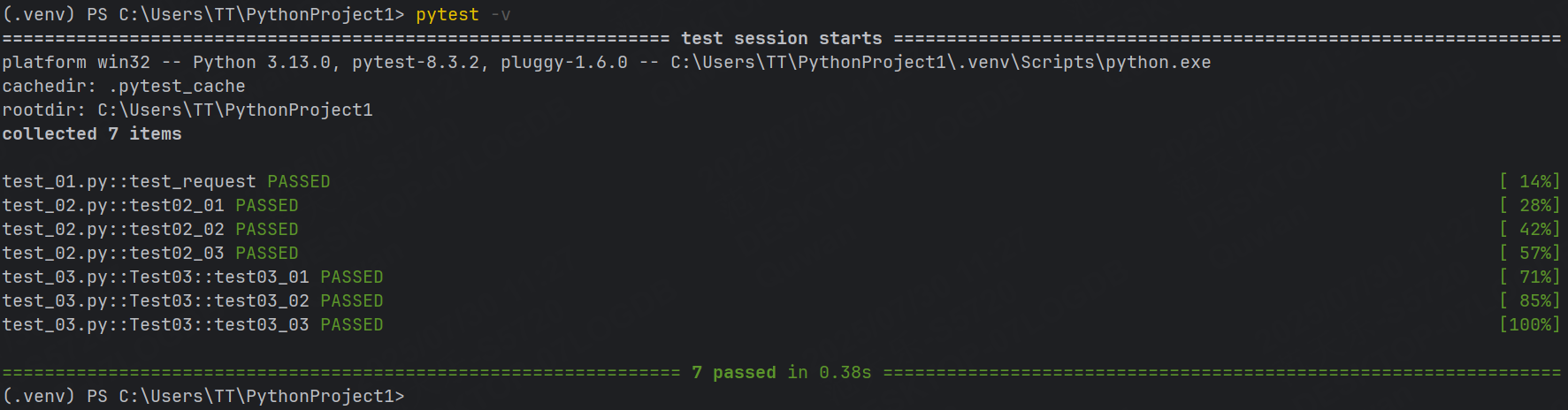
示例3:指定文件 / 測試用例
#指定?件:pytest 包名/?件名
pytest cases/test_01.py#指定測試?例: pytest 包名/?件名::類名::?法名
pytest cases/test_01.py::Test::test_a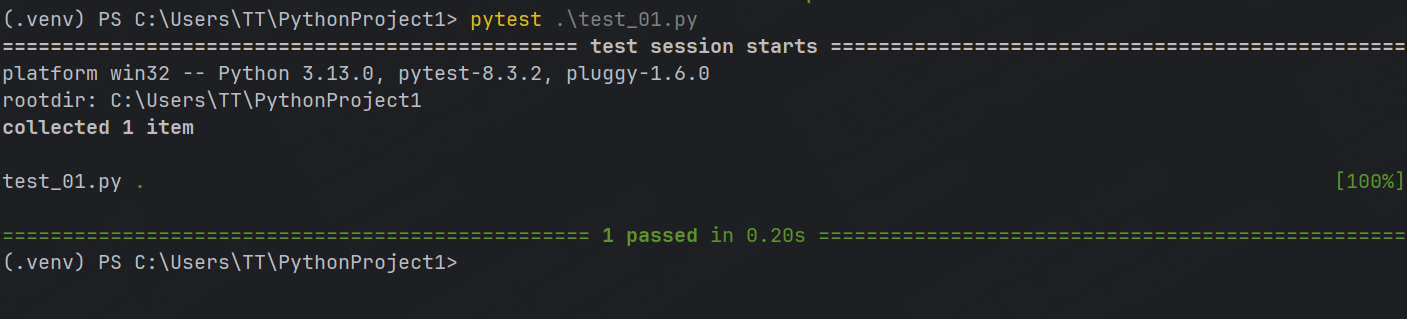

問題:當我們既要詳細輸出,又要指定文件時,命令會又臭又長,而且每次運行都需要手動輸入命令,如何解決?
將需要的相關配置參數統一放到 pytest 配置文件中
2.5.5 pytest配置文件
在當前項目下創建 pytest.ini 文件,該文件為 pytest 的配置文件
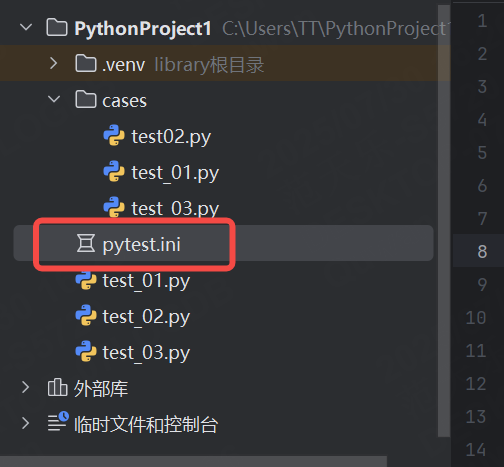
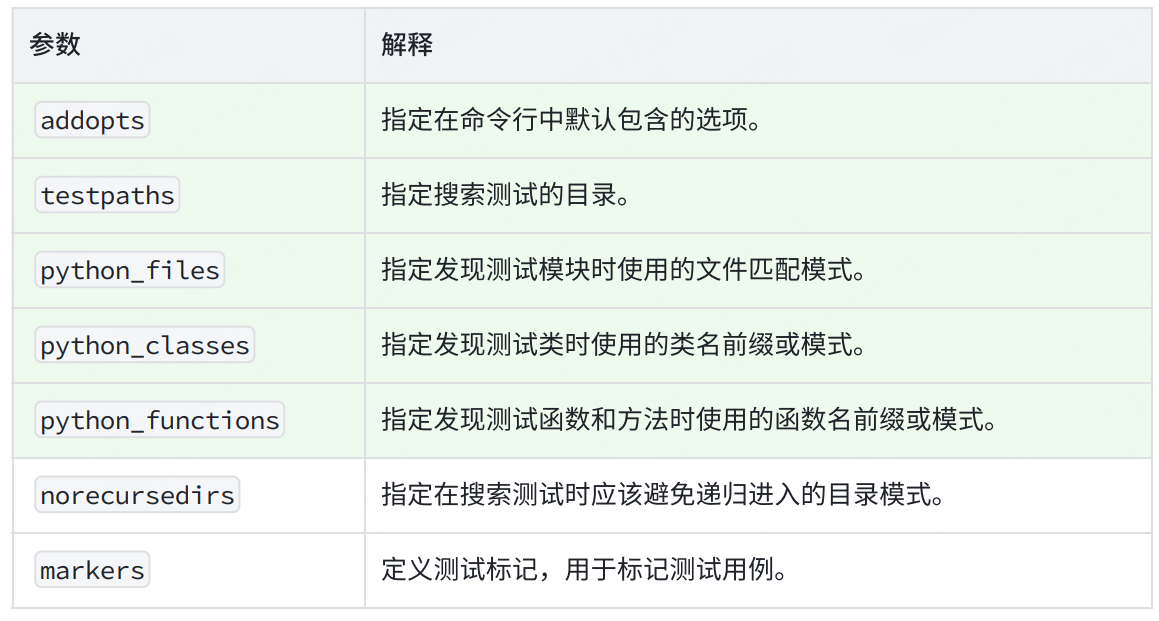
以下為常見的配置選項:
示例:詳細輸出 cases 包下文件名以 test_ 開頭且類名以 A?開頭的所有用例
[pytest]
addopts = -vs
testpaths = ./cases
python_files = test_*.py
python_classes = A*目錄結構如下:
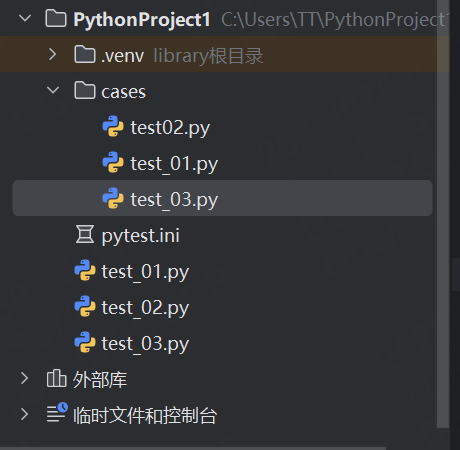
若cases目錄下3個test文件內容如下:
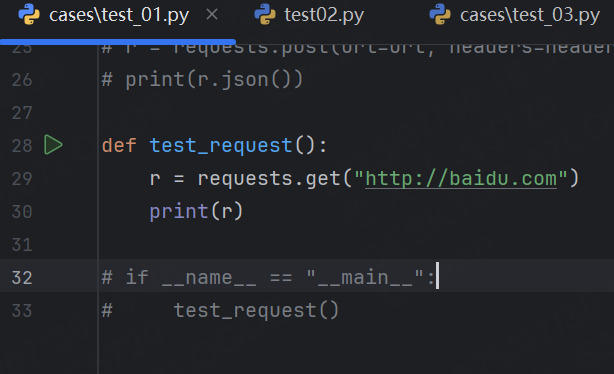
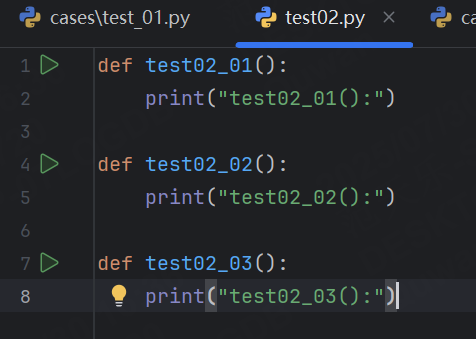
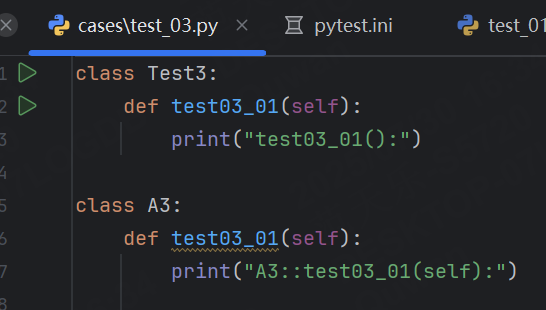
預期結果:
- 因為test02文件不符合 python_files 的命名規則,所以該文件下的用例不會被執行
- test_03文件下的Test3不符合?python_classes 的命名規則,所以也不會被執行
- 最終執行的是test_01文件下的 test_requests 和 test_03 文件下A3目錄的test03_01函數
配置好 pytest.ini 文件后,命令行執行?pytest 命令即可,無需再額外指定其他參數:
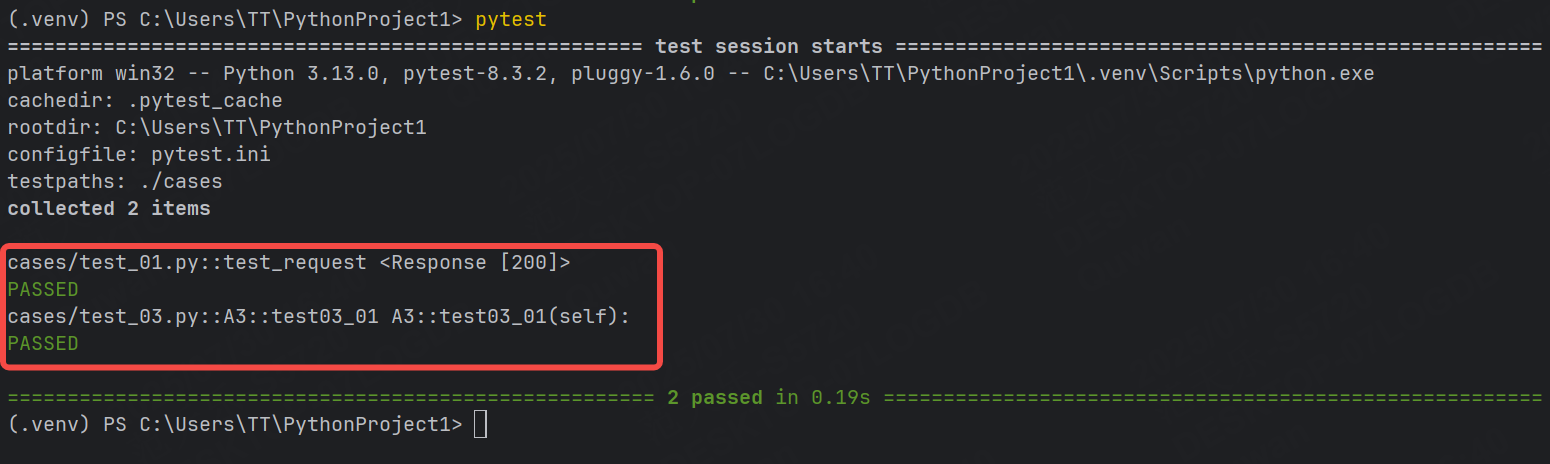
符合我們的預期。
pytest.ini 文件通常位于項目的根目錄下。通過在 pytest.ini 中定義配置項,可以覆蓋pytest 的默認行為,以滿足項目的需求。
2.5.6 前后置
遺留問題:使用 pytest 框架,測試類中不可以添加init()方法,如何進行數據的初始化?
在測試框架中,前后置是指在執行測試用例前和測試用例后執行一些額外的操作,這些操作可以用于設置測試環境、準備測試數據等,以確保測試的可靠性
pytest 框架提供三種方法做前后置的操作:
- setup_method 和 teardown_method :這兩個方法用于類中的每個測試方法的前置和后置操作。
- setup_class 和 teardown_class :這兩個方法用于整個測試類的前置和后置操作。
- fixture :這是 pytest 推薦的方式來實現測試用例的前置和后置操作。 fixture 提供了更靈活的控制和更強大的功能。(該內容后續在 fixture 章節中詳細講解)
示例1: setup_method 和 teardown_method
class Test4:def setup_method(self):print("setup_method()")def teardown_method(self):print("teardown_method()")def test_04_01(self):print("test_04_01():")def test_04_02(self):print("test_04_02():")運行結果:
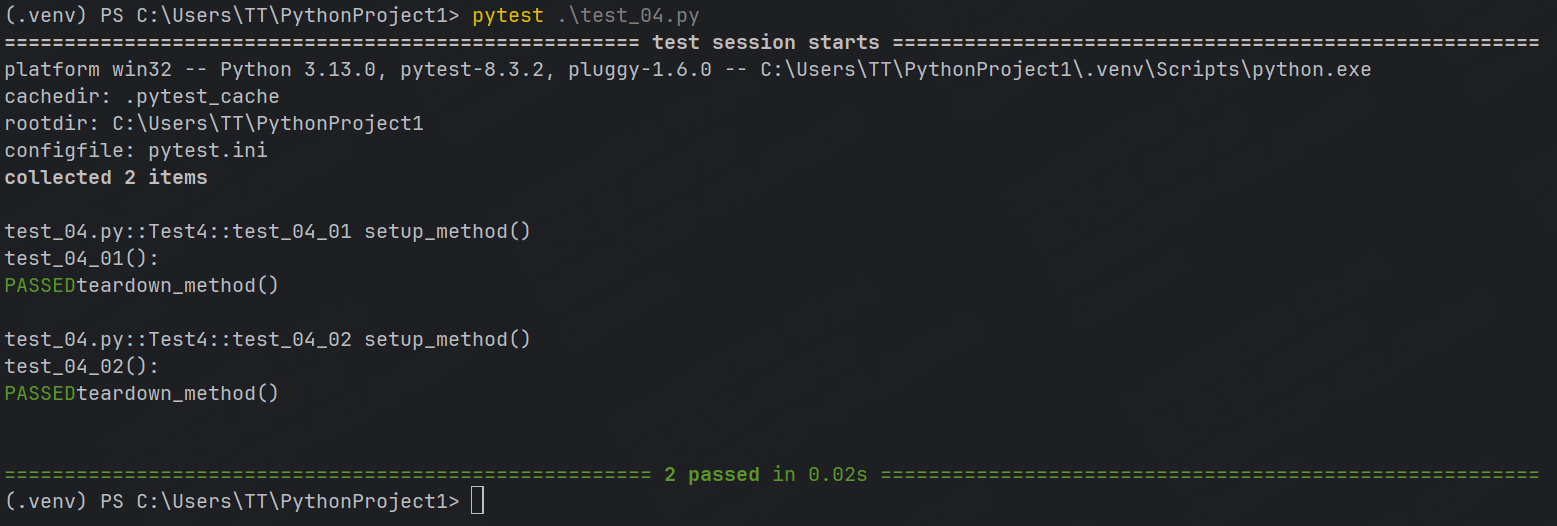
每個用例執行之前都會調用setup_method(),每個用例執行之后都會調用teardown_method()。
示例2: setup_class 和 teardown_class
class Test04:def setup_class(self):print("setup_class():")def teardown_class(self):print("teardown_class():")def test_04_01(self):print("test_04_01():")def test_04_02(self):print("test_04_02():")運行結果:
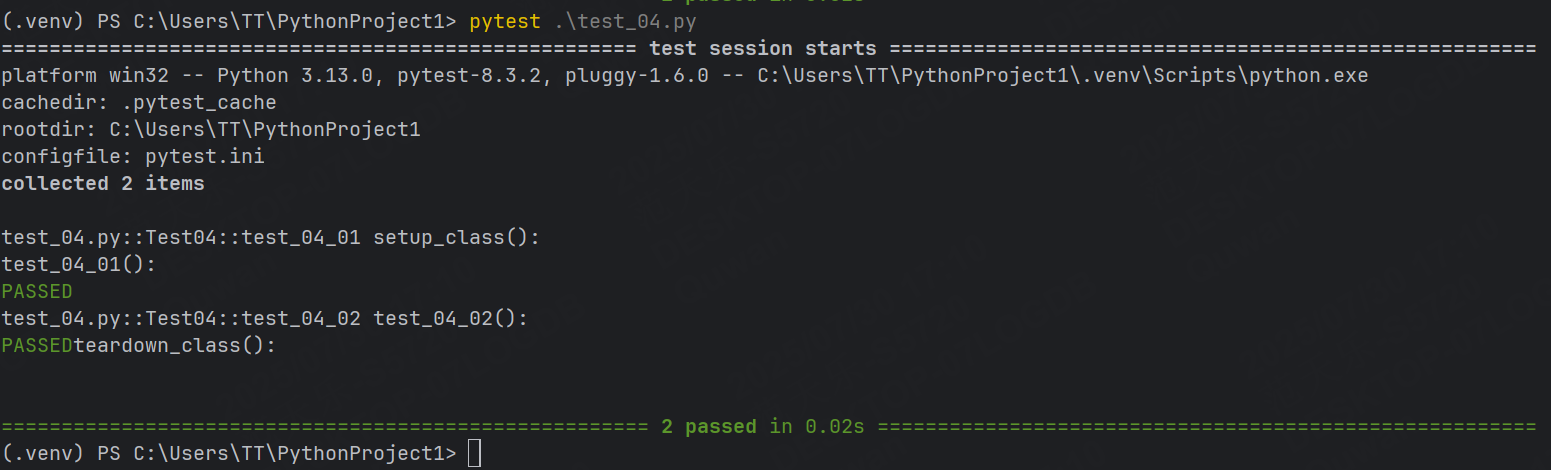
所有用例執行之前會調用setup_class(),所有用例執行之后會調用teardown_class()。
2.5.7 斷言
斷言( assert )是?種調試輔助工具,用于檢查程序的狀態是否符合預期。如果斷言失敗(即條件為假),Python解釋器將拋出一個 AssertionError 異常。斷言通常用于檢測程序中的邏輯錯誤。
pytest 允許你在 Python 測試中使用標準的 Python assert 語句來驗證預期和值。
基本語法:
assert 條件, 錯誤信息- 條件 :必須是?個布爾表達式。
- 錯誤信息 :當條件為假時顯?的錯誤信息,可選。
免費學習API資源:JSONPlaceholder - Free Fake REST API
示例1:基本數據類型的斷言
def test_05_01():a = 1b = 1assert a == bstr1 = "hello"str2 = "world"assert str1 == str2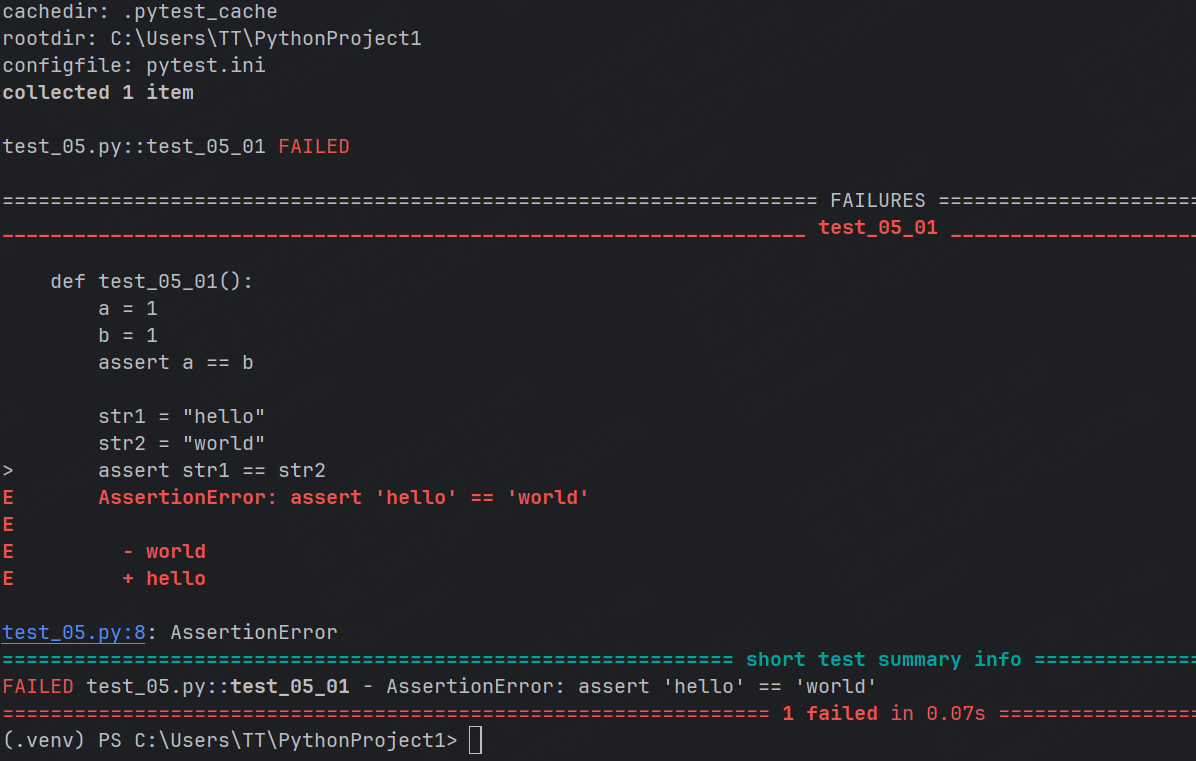
斷言失敗后會給我們提示信息告訴我們哪里出錯了
示例2:數據結構斷言
def test_05_02():#斷言列表expect_list1 = [1, "hello", 3.14]expect_list2 = [1, "hello", 3.14]assert expect_list1 == expect_list2#斷言元組expect_tuple1 = (1, "apple", 3.14)expect_tuple2 = (1, "apple", 3.14)assert expect_tuple1 == expect_tuple2#斷言字典expect_dict1 = {"apple": 3.14}expect_dict2 = {"applef": 3.14}assert expect_dict1 == expect_dict2#斷言集合expect_set1 = {1, 2, 3, "apple"}expect_set2 = {1, 2, 3, "apple"}assert expect_set1 == expect_set2運行結果:
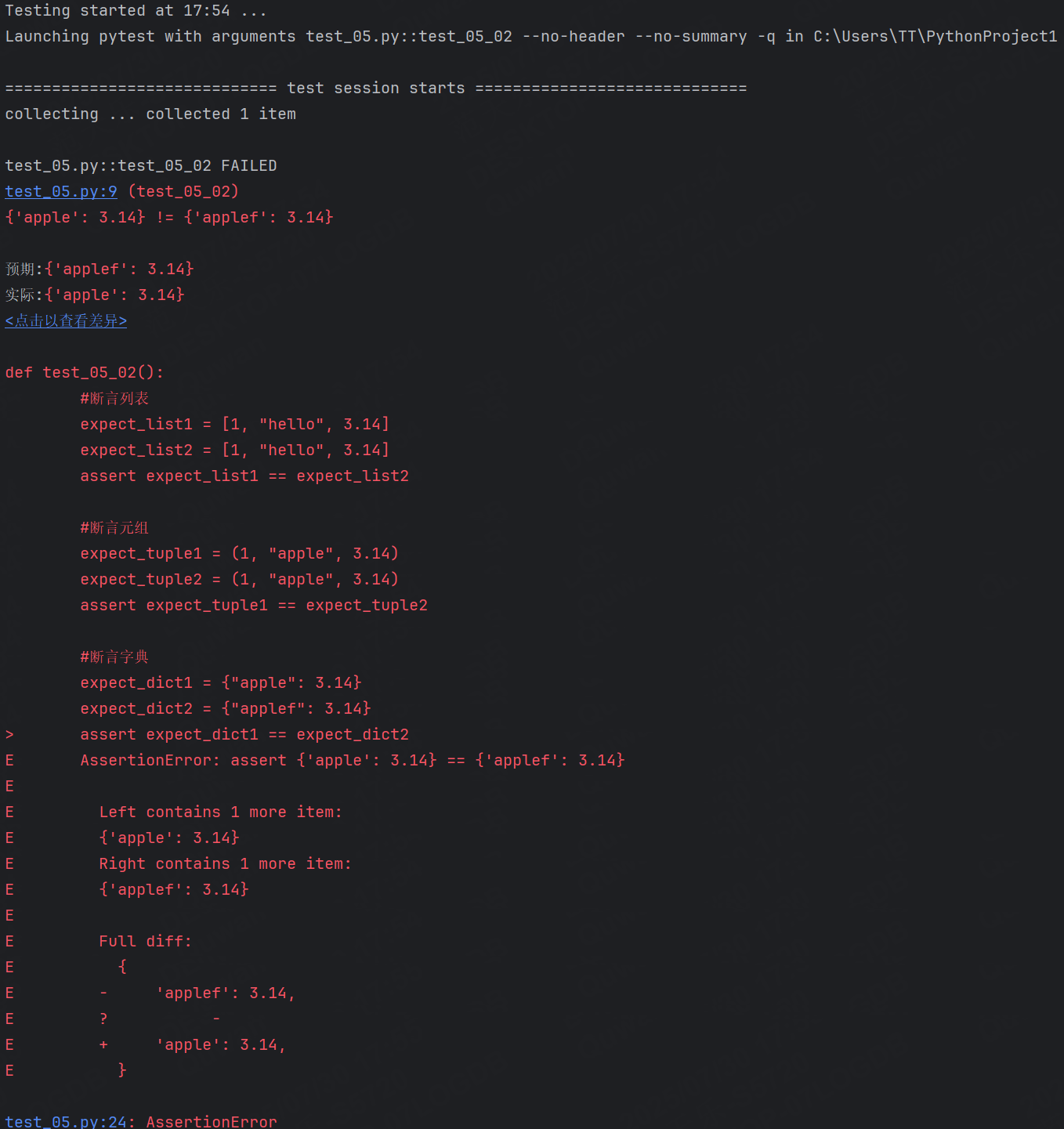
提示斷言失敗的信息還是比較直觀明顯的
示例3:函數斷言
def divide(a, b):assert b != 0, "除數不能為0"return a / bdef test_05_03():# 正常情況print(divide(10, 2)) # 輸出 5.0# 觸發斷?print(divide(10, 0)) # 拋出 AssertionError: 除數不能為0運行結果:
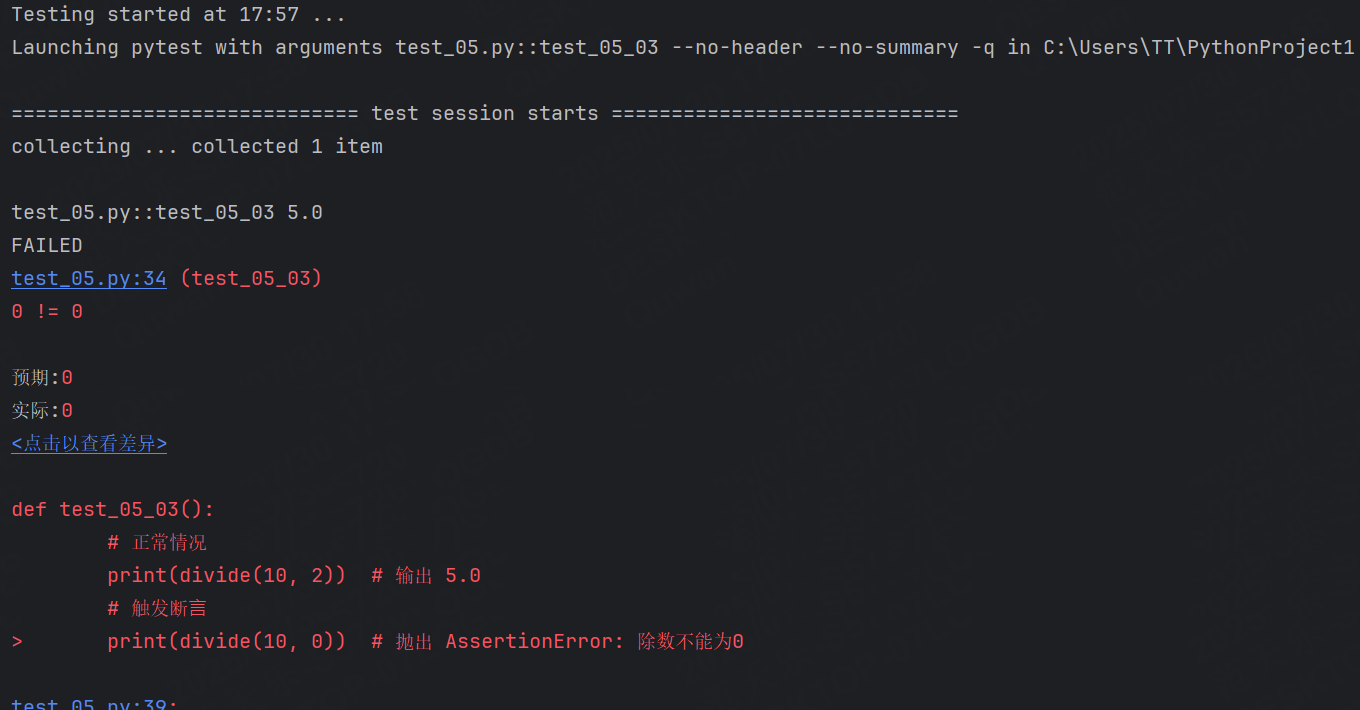
示例4:接口返回值斷言
我們使用前面給的學習API的網站JSONPlaceholder - Free Fake REST API? ?往下翻可以看到給了很多的請求方法
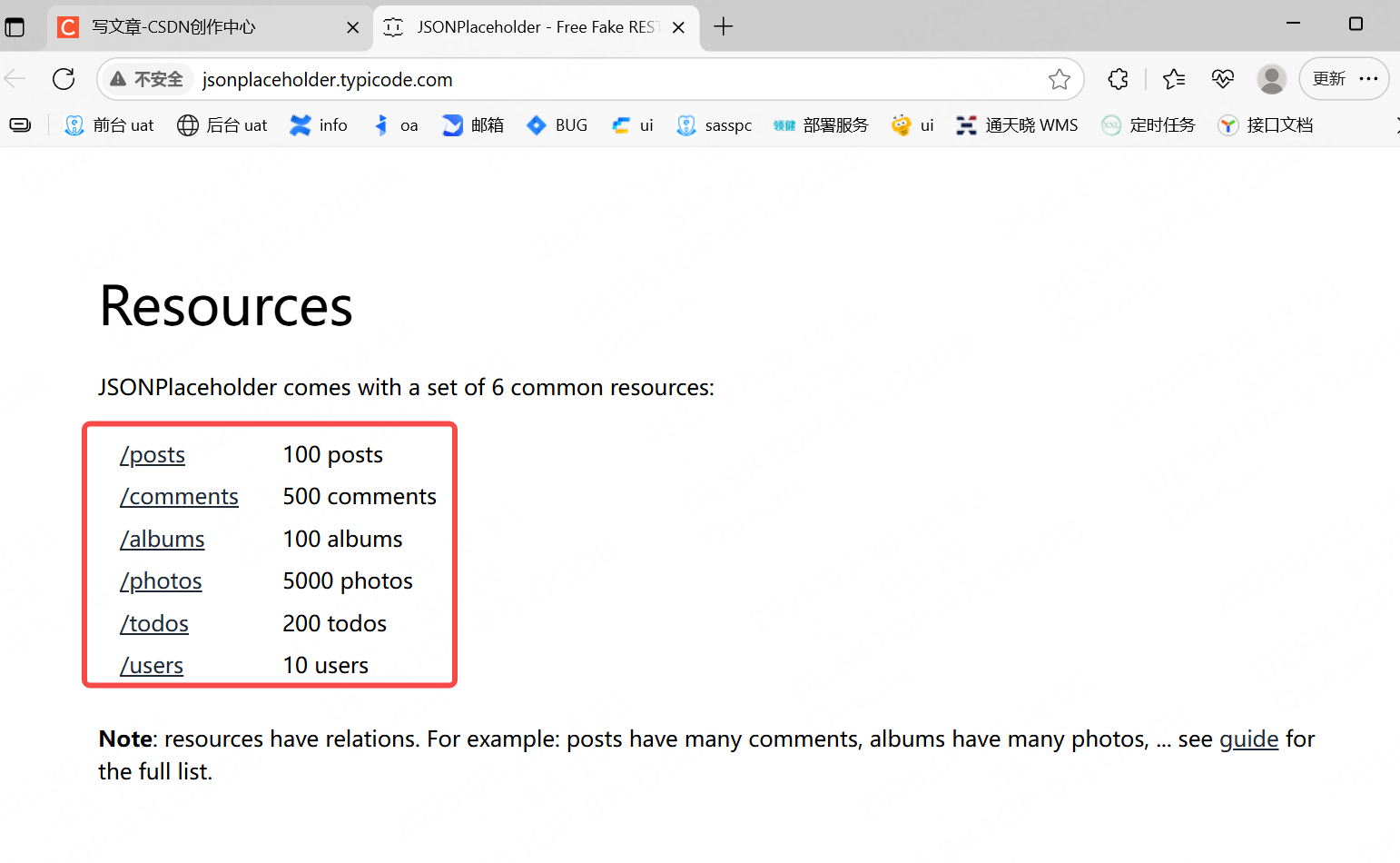
我們選擇/posts
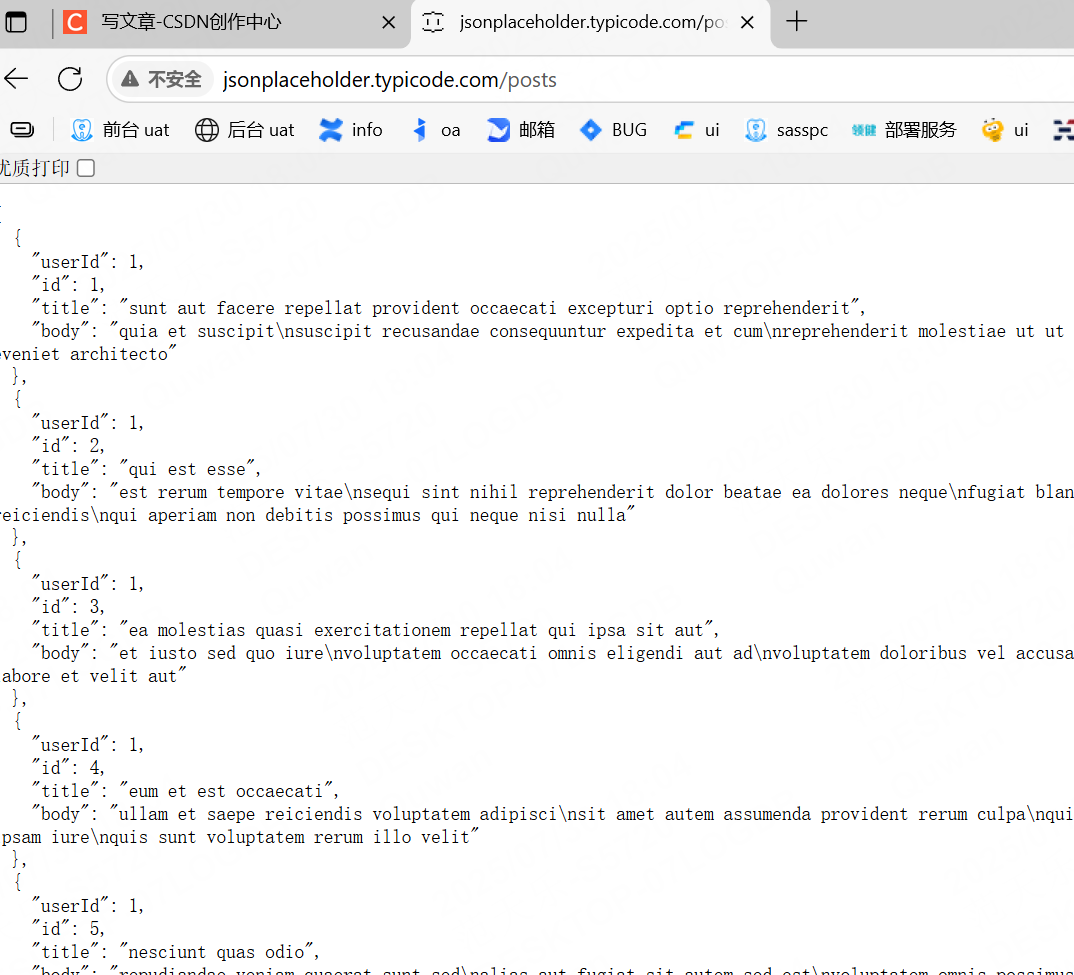
可以看到返回了很多數據
我們選擇posts/1即可
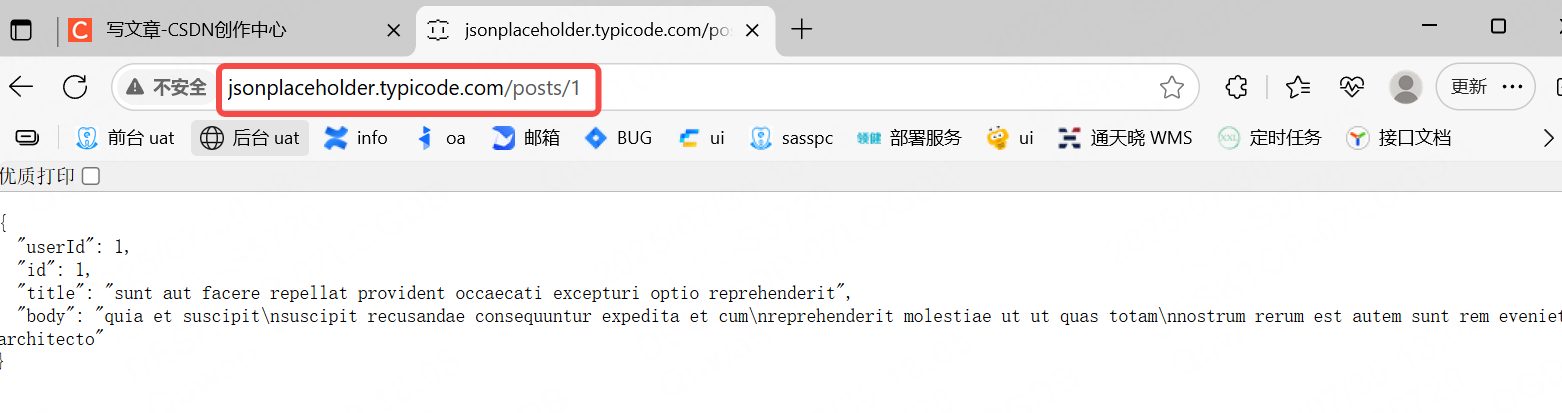
接下來我們可以嘗試訪問這個接口,得到的返回值是不是上面給出的響應數據。
def test_05_04():url = "http://jsonplaceholder.typicode.com/posts/1"r = requests.get(url=url)expect_data = {"userId": 1,"id": 1,"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit","body": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto"}actual_data = r.json()assert actual_data == expect_data運行結果:
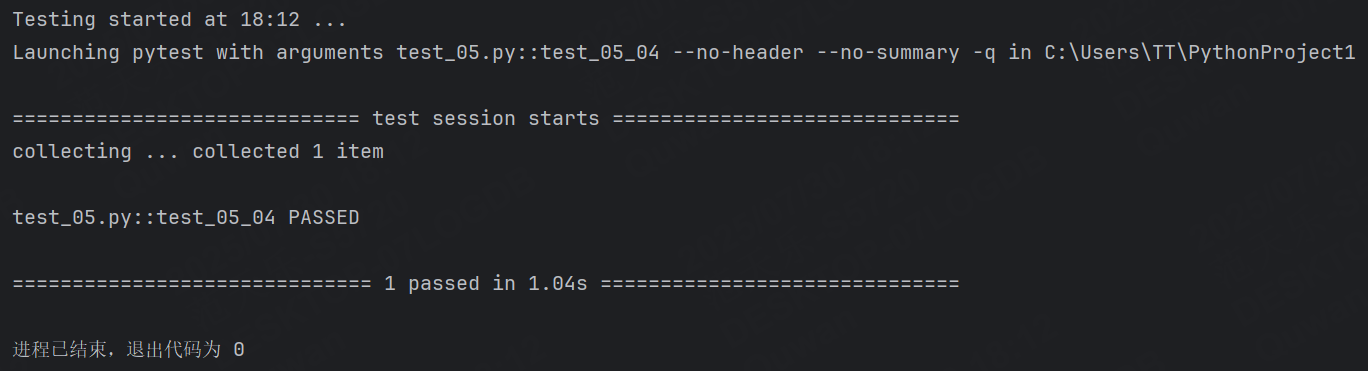
我們再修改一個數據,讓實際結果和預期結果不一樣再來觀察一下,這里將id由原來的1改成2
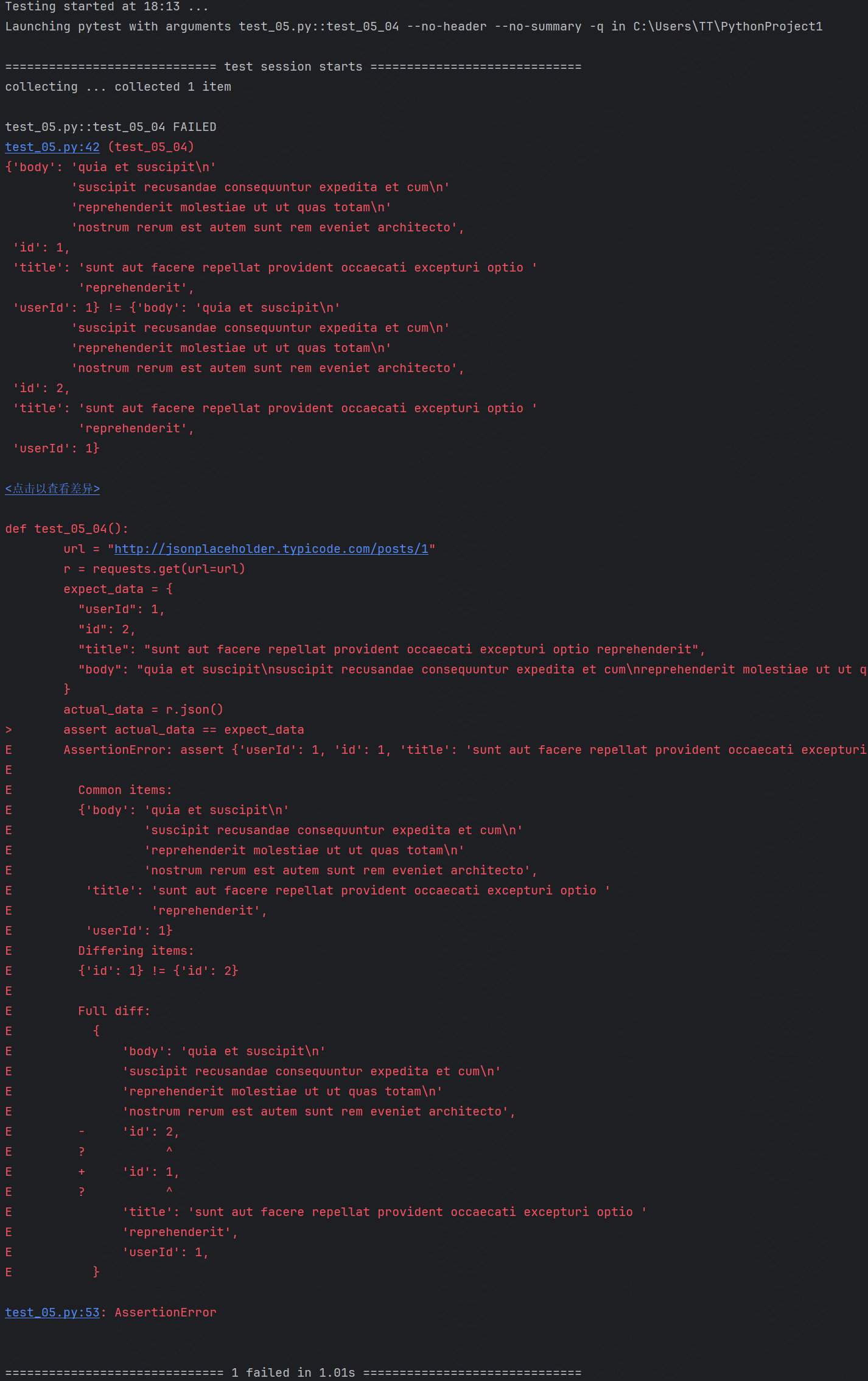
可以看到立馬就指出了不一樣的地方。
如果響應結果比較復雜,如何進行斷言?
例如下圖這種場景,json里面還會嵌套json,并且響應數據非常多,我們不可能把所有的都拷貝過去進行比較。
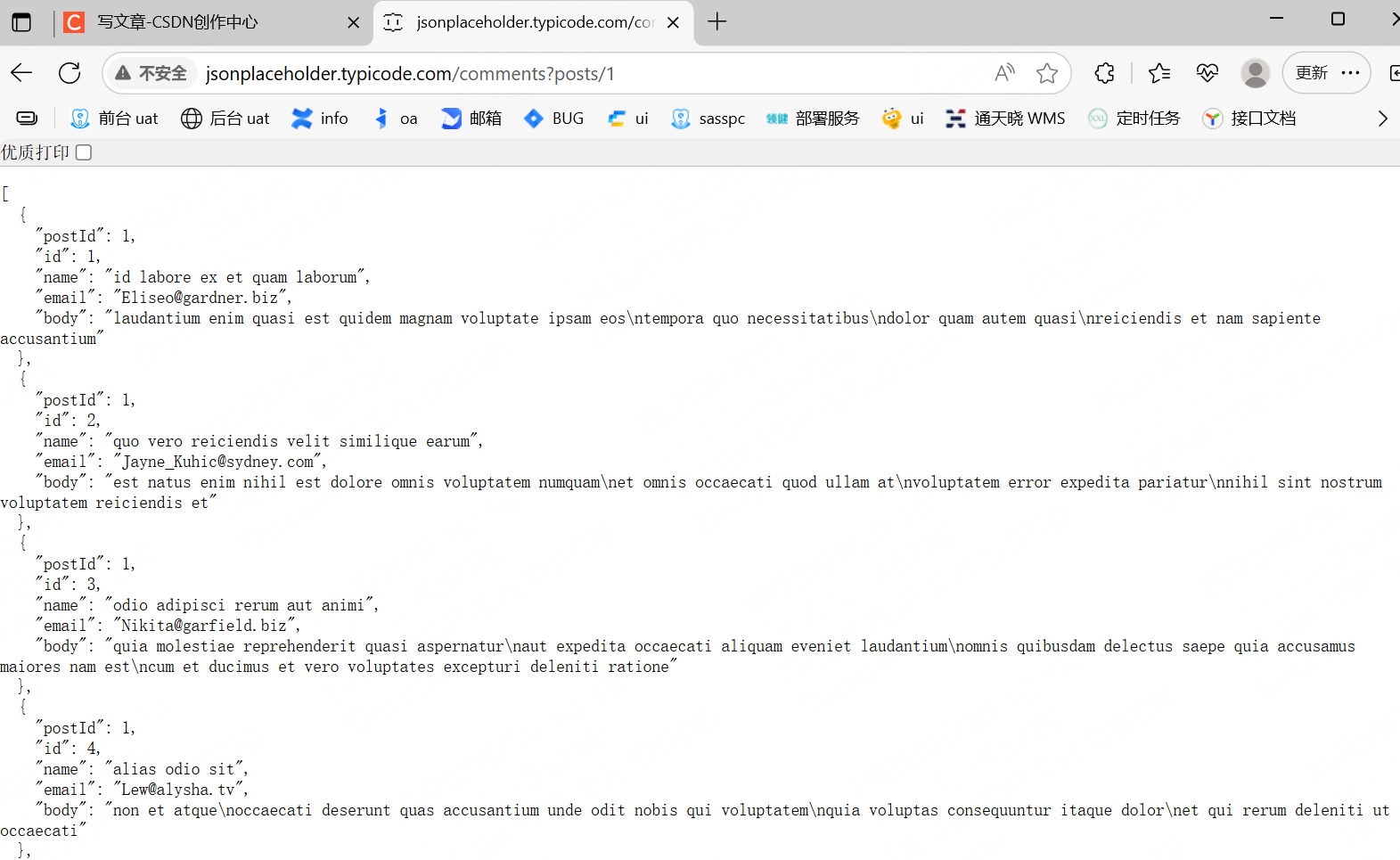
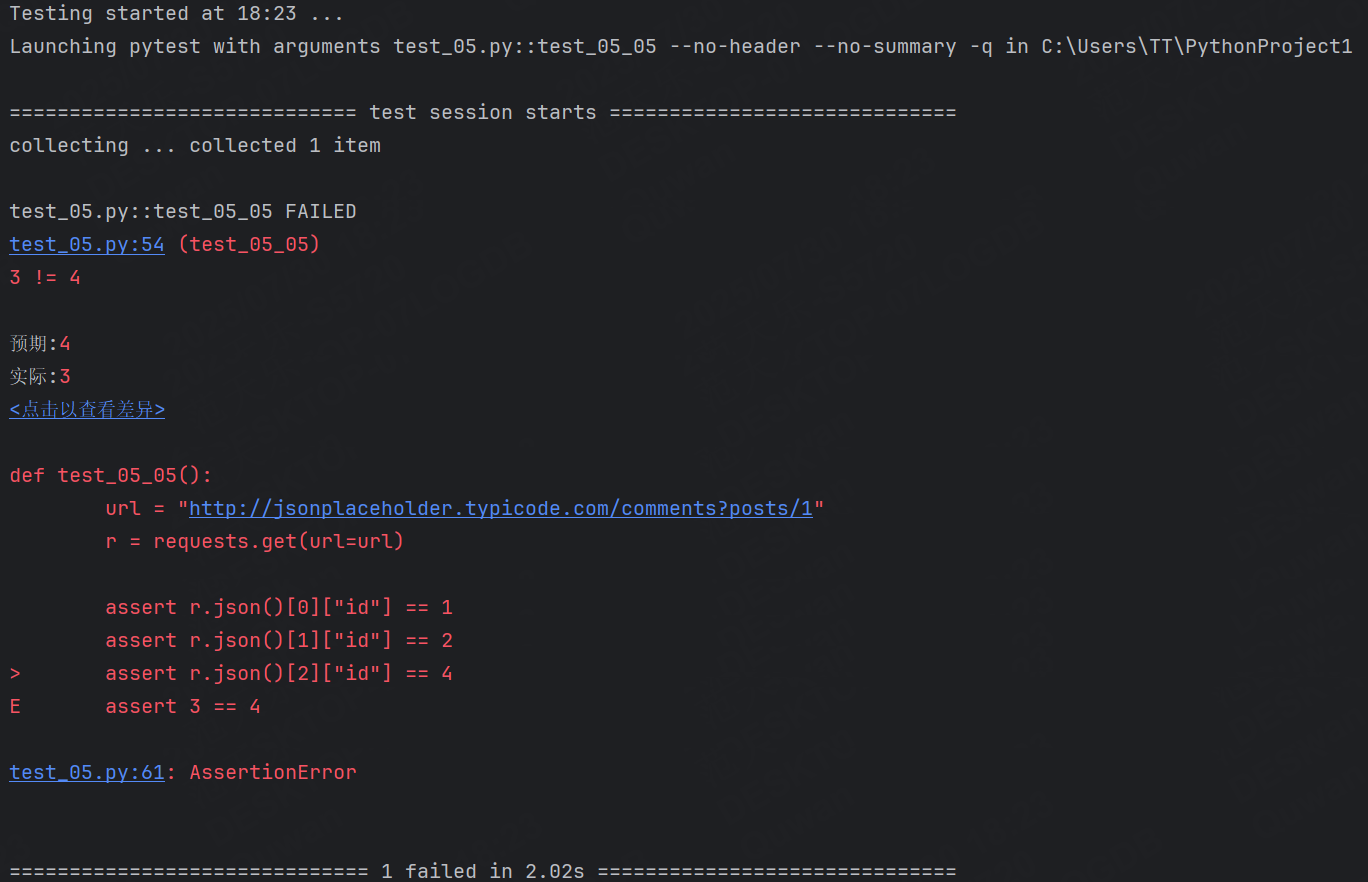
這種情況下我們可以對關鍵字段進行校驗,例如上面的每組的name,email,body可能一樣,但是id一定不一樣,所以我們就對id進行校驗
def test_05_05():url = "http://jsonplaceholder.typicode.com/comments?posts/1"r = requests.get(url=url)assert r.json()[0]["id"] == 1assert r.json()[1]["id"] == 2assert r.json()[2]["id"] == 4運行結果:
響應結果是text格式,可以打印嗎?
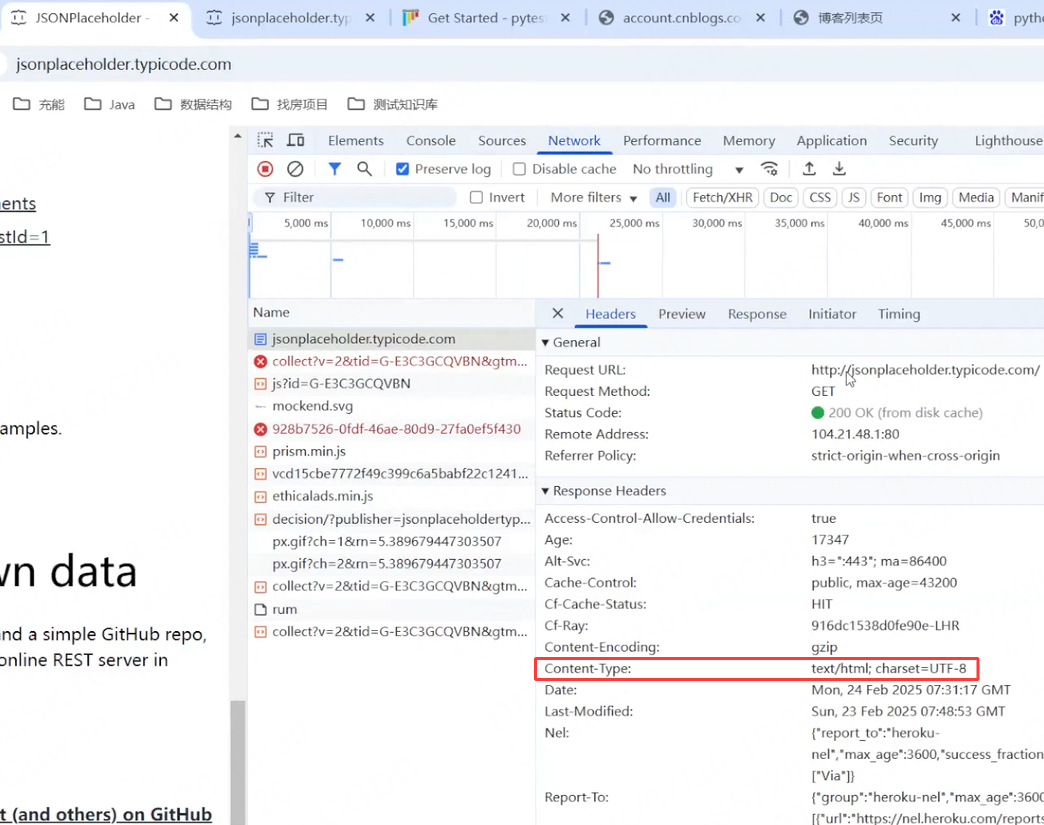
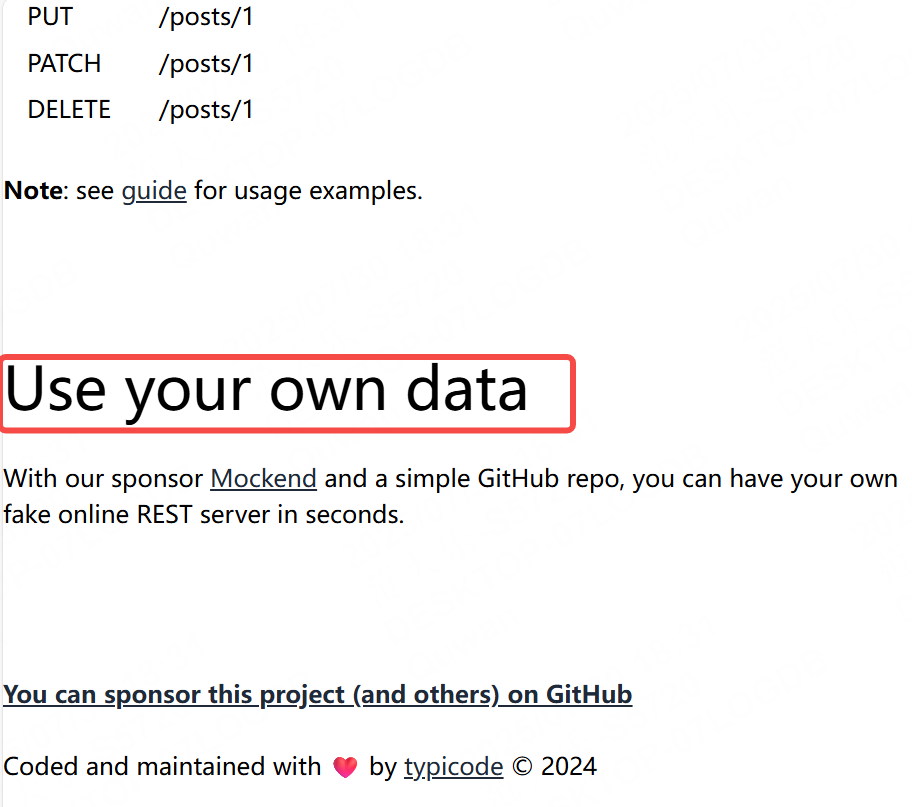
我們查看到改網站的主頁面的響應結果是text,我們接下來就查看該網站能否找到Use your won data這個文本
編寫代碼:
def test_05_06():url = "http://jsonplaceholder.typicode.com/"r = requests.get(url=url)text = "Use your own data"assert text in r.text
再來看一下斷言失敗的結果:
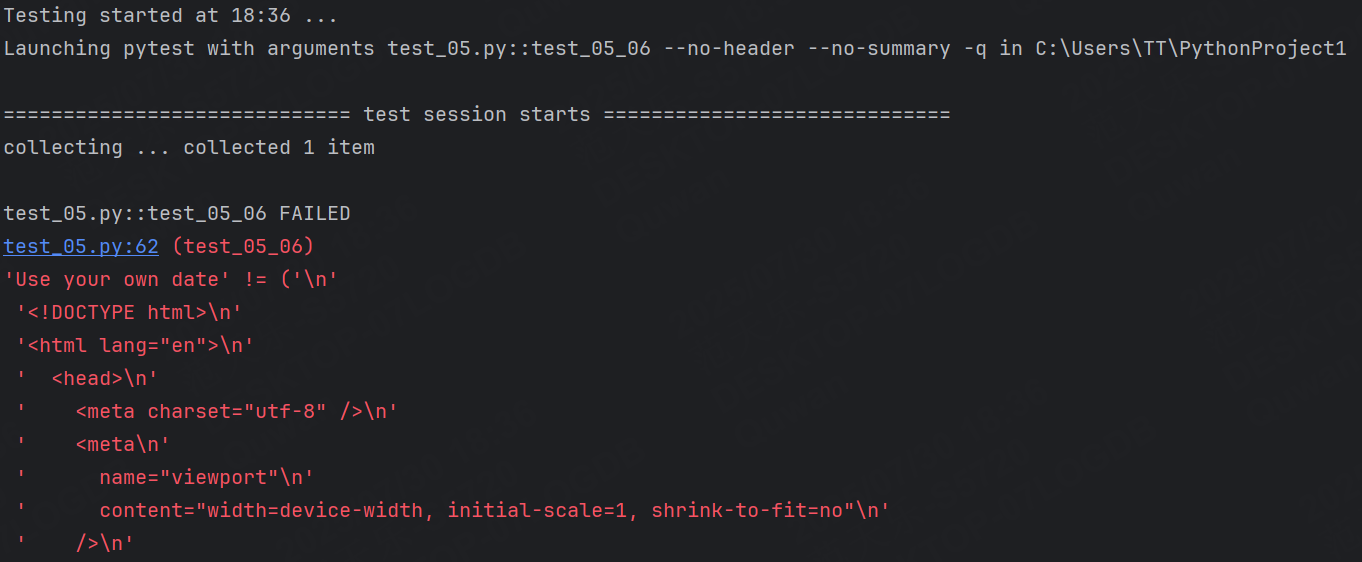
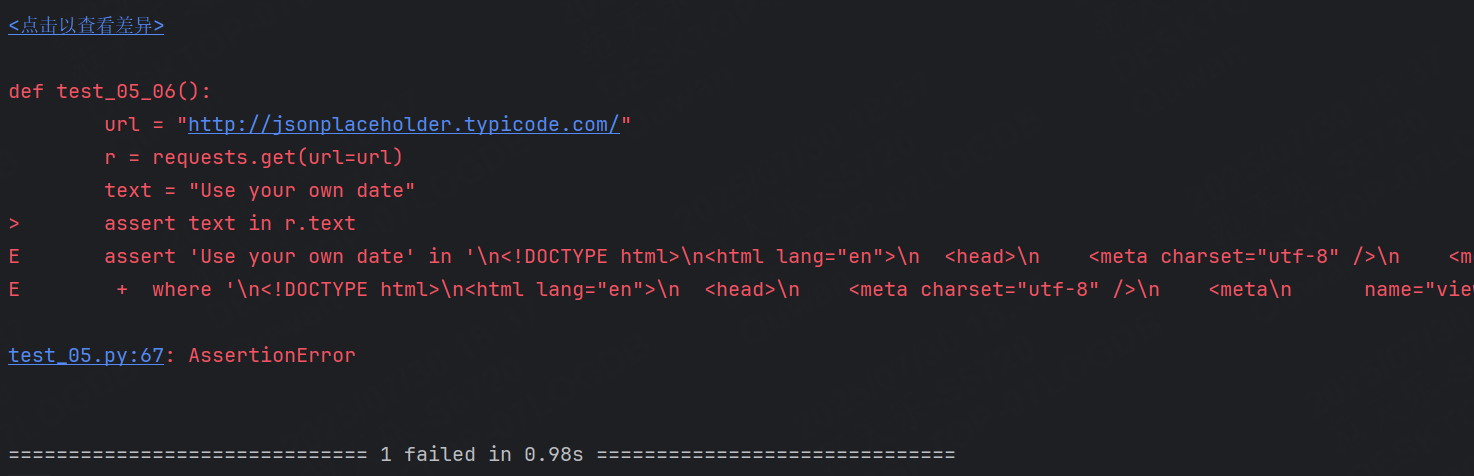
最終也是成功表示該字符串沒有找到。
2.5.8 參數化
參數化設計是自動化設計中的一個重要組成部分,它通過定義設計參數和規則,使得設計過程更加靈活和可控。
假如現在有一個郵箱登錄頁面,內部由兩個文本輸入框,如果針對這兩個輸入框來設計測試用例其實是可以設計很多的,比如可以設計正常登錄情況,異常登錄情況等。
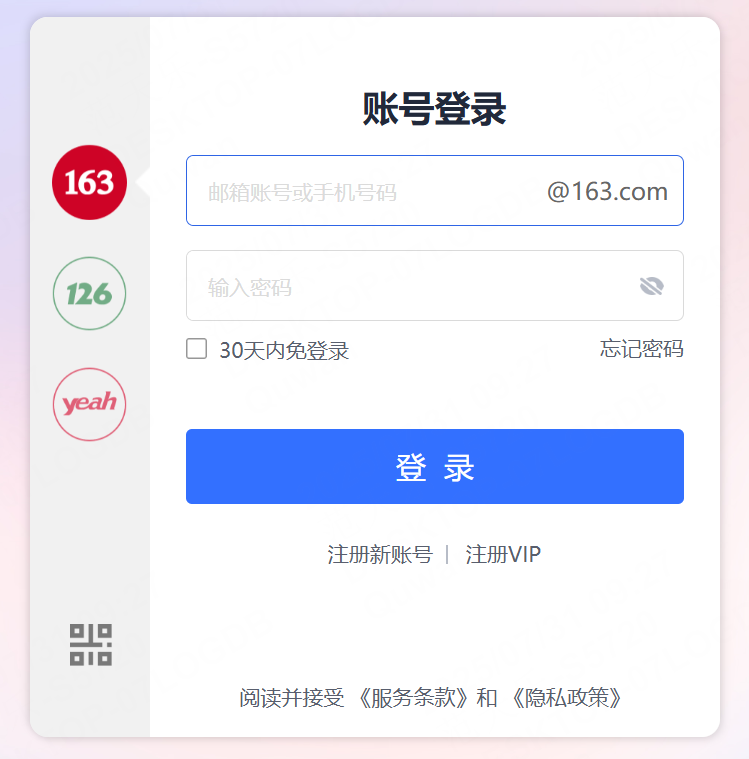
我們針對每一個測試用例都需要寫一個test函數進行測試,但其實每個test函數內部邏輯都是一樣的,只是email和password兩個參數不同。
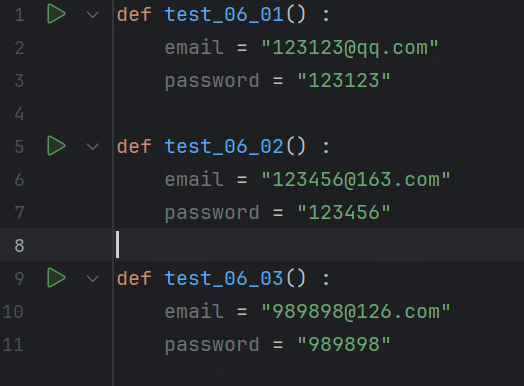
針對上面這個問題,我們可以使用參數化的方式來解決,即將email和password作為函數參數。
pytest中內置的 pytest.mark.parametrize 裝飾器允許對測試函數的參數進行參數化。
示例1:單個參數使用參數化
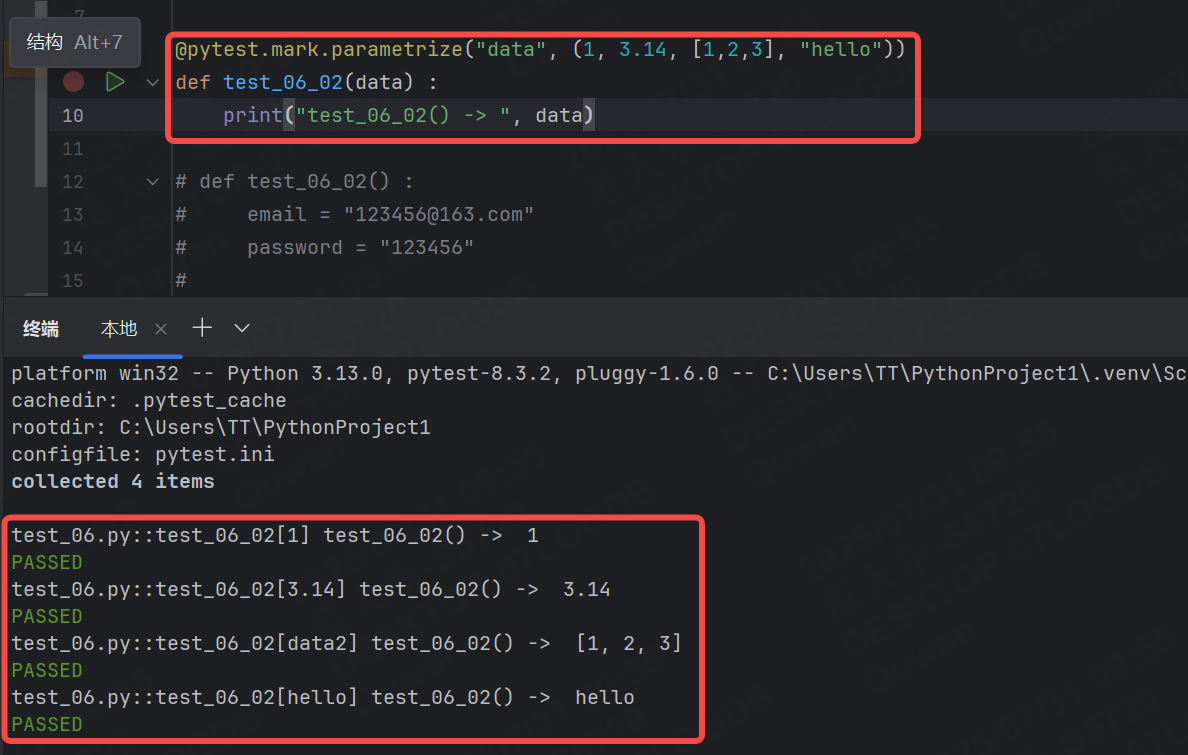
@pytest.mark.parametrize("data", (1, 2, 3, 4))
def test_06_02(data) :print("test_06_02() -> ", data)這里, @parametrize 裝飾器的第一個參數表示要參數化的變量名,第二個元組表示該變量的所有取值。
運行結果:
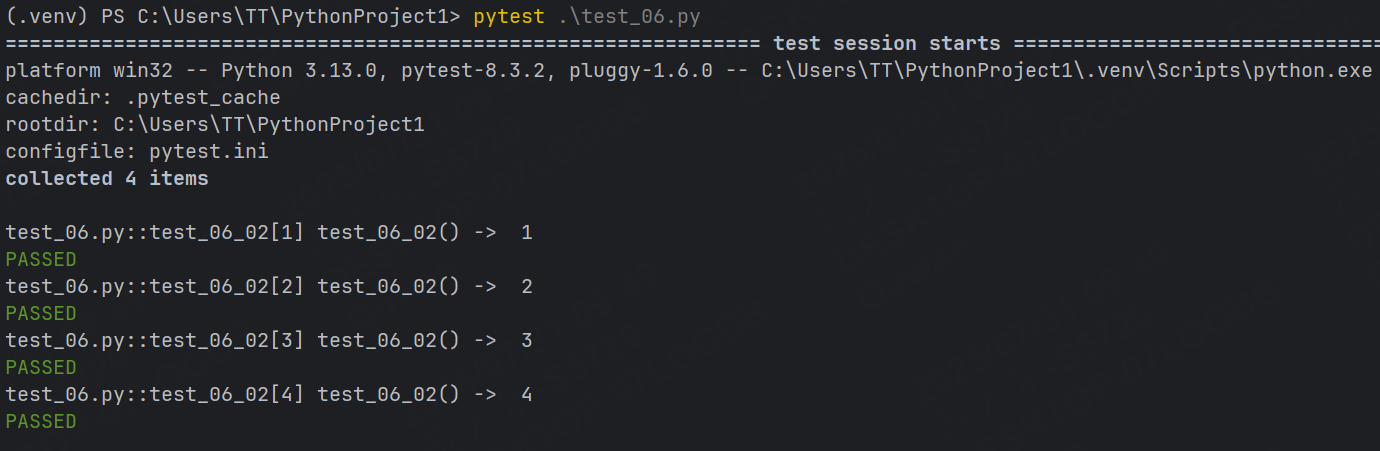
可以看到參數化將parametrize中元組參數中的所有取值用例都執行了一遍。
注意,python中的元組可以是不同的數據類型。
示例2:多個參數使用參數化
import pytest
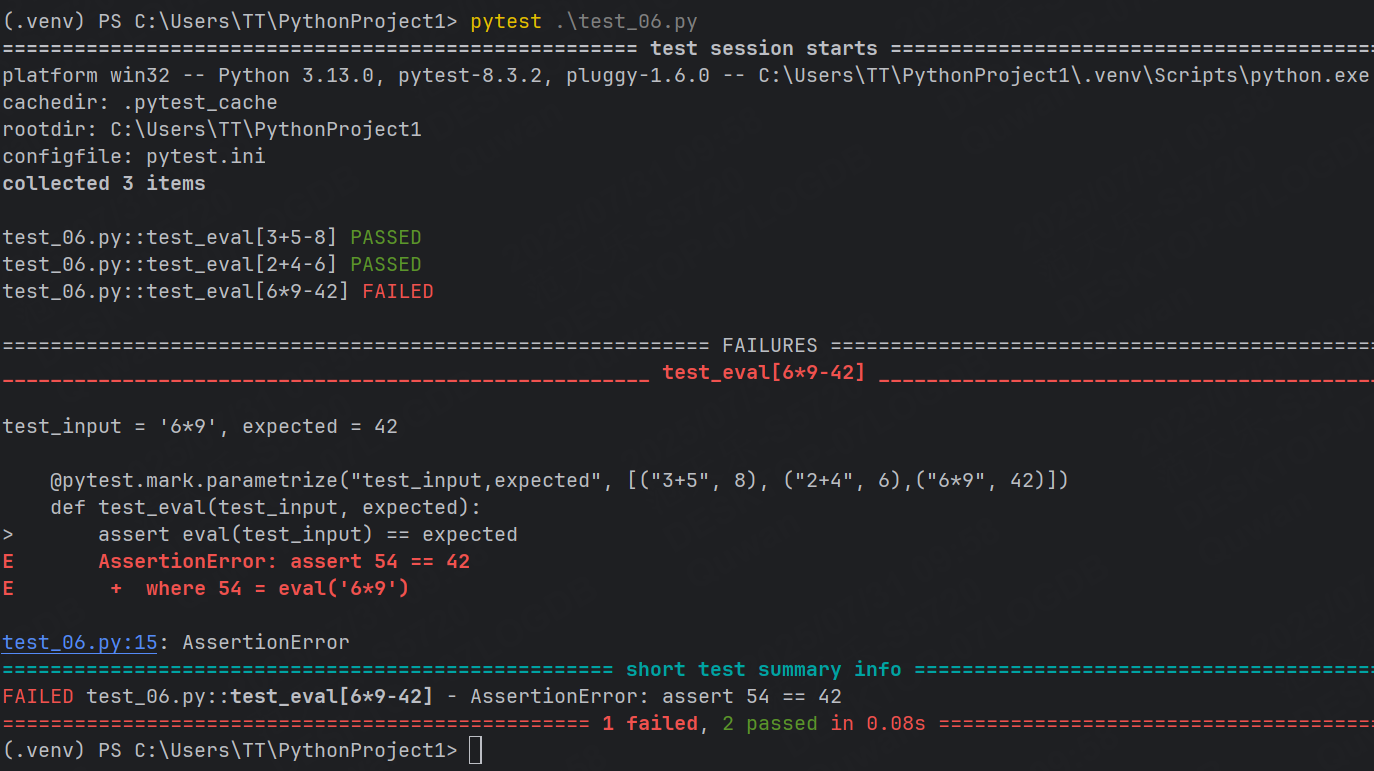
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+4", 6),("6*9", 42)])
def test_eval(test_input, expected):assert eval(test_input) == expected這里, @parametrize 裝飾器定義了三個不同的 (test_input,expected) 元組,以便test_eval 函數將依次使用它們運行三次。
也可以在類或模塊上使用?parametrize 標記,這將使用參數集調用多個函數
示例3:在類上使用參數化
import pytest
@pytest.mark.parametrize("n,expected", [(1, 2), (3, 4)])
class TestClass:def test_simple_case(self, n, expected):assert n + 1 == expecteddef test_weird_simple_case(self, n, expected):assert (n * 1) + 1 == expected運行結果:
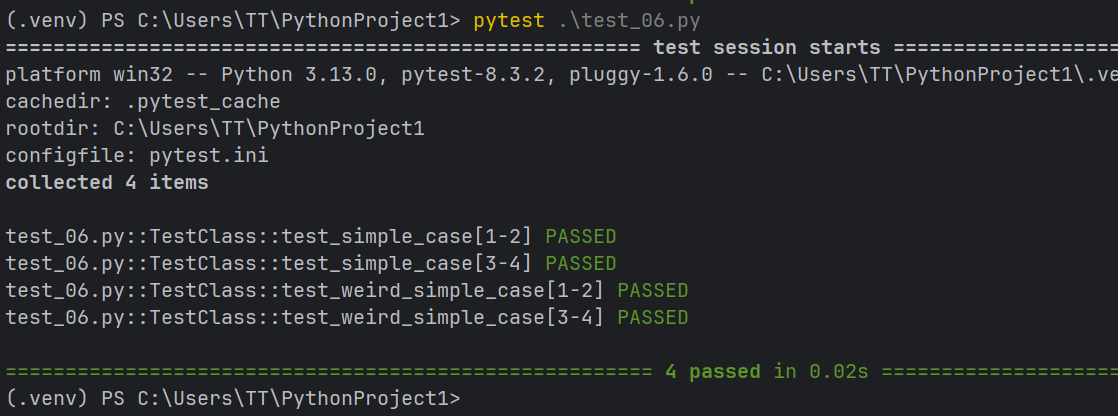
類中每個符合規則的方法都會執行列表參數,所以一共執行了4次。
要對模塊中的所有測試進行參數化,你可以將 pytestmark 全局變量賦值:
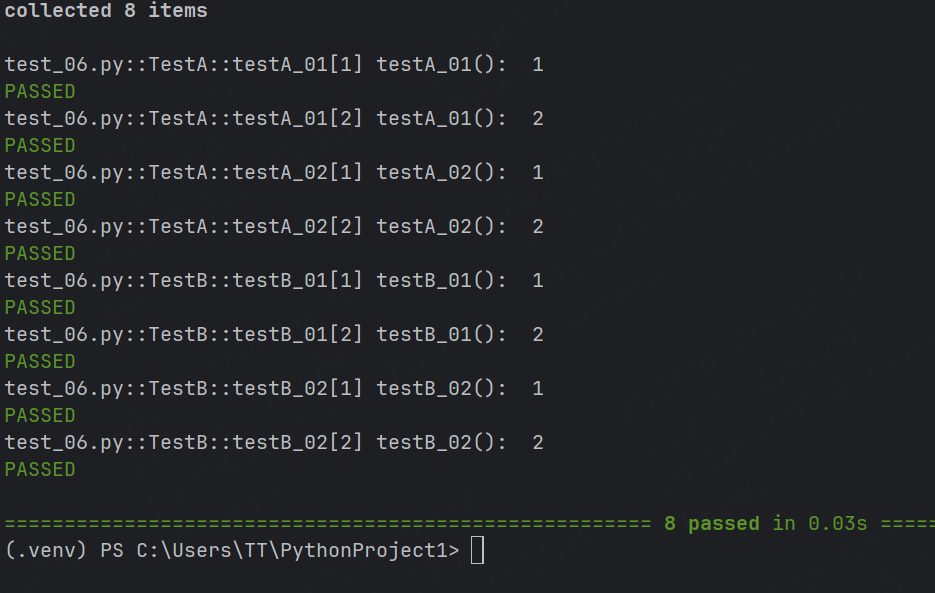
@pytest.mark.parametrize("data", (1, 2))
class TestA:def testA_01(self, data) :print("testA_01(): ", data)def testA_02(self, data) :print("testA_02(): ", data)class TestB:def testB_01(self, data):print("testB_01(): ", data)def testB_02(self, data):print("testB_02(): ", data)針對上面這個代碼,其實會運行錯誤,因為TestB中的data沒有參數。
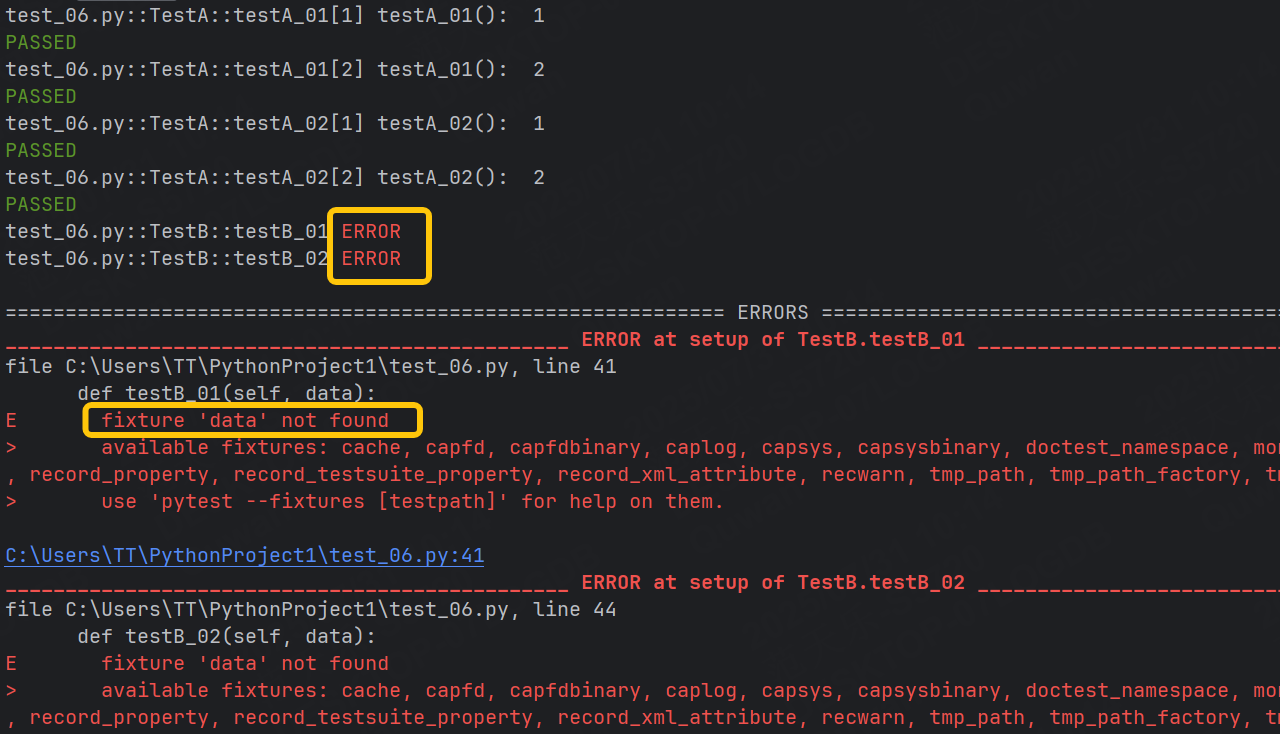
解決方法也很簡單,直接將TestA上的參數化拿過來即可,然后這又會涉及到重復的問題,為了解決這個問題,我們將 pytestmark 全局變量賦值。
pytestmark = pytest.mark.parametrize("data", (1, 2))
class TestA:def testA_01(self, data) :print("testA_01(): ", data)def testA_02(self, data) :print("testA_02(): ", data)class TestB:def testB_01(self, data):print("testB_01(): ", data)def testB_02(self, data):print("testB_02(): ", data)運行結果:
除了使用?@parametrize 添加參數化外, pytest.fixture() 允許對 fixture 函數進行參數化
示例4:自定義參數化數據源
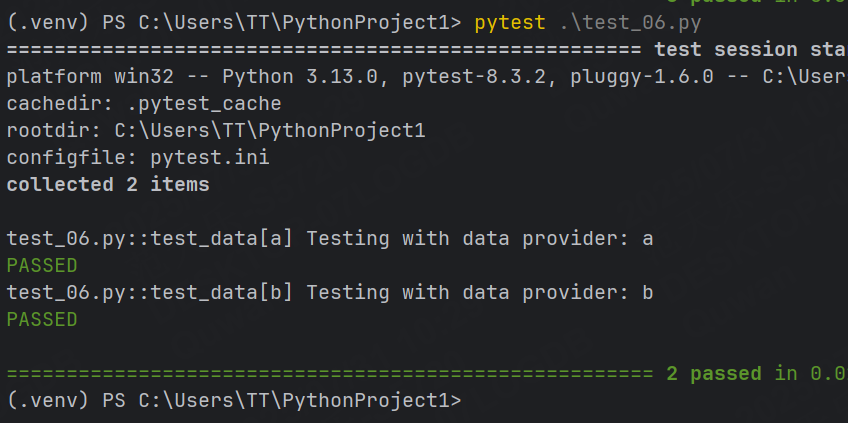
大多數場景中我們的參數并不是寫死的,而是其他函數的返回值。
def data_provider():return ["a", "b"]
# 定義?個測試函數,它依賴于上?函數的返回值
@pytest.mark.parametrize("data", data_provider())
def test_data(data):assert data != Noneprint(f"Testing with data provider: {data}")運行結果:
2.5.9 fixture
pytest 中的 fixture 是一種強大的機制,用于提供測試函數所需的資源或上下文。它可以用于設置測試環境、準備數據等。以下是 fixture 的一些核心概念和使用場景。
2.5.9.1 基本使用
示例1:使用與不使用fixture標
未使用fixture:
#未標記fixture方法的調用——函數名來調用
def fixture_01():print("第一個fixture方法")def test_01():fixture_01()print("第一個測試用例")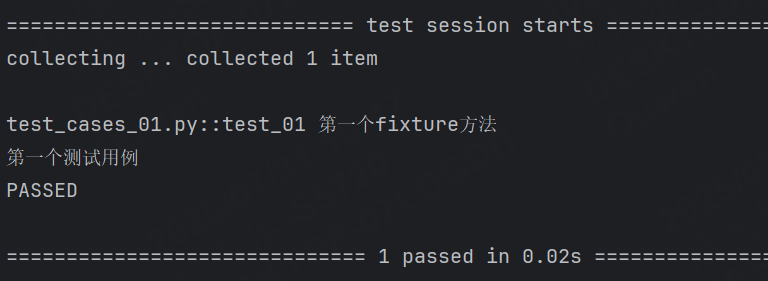
使用fixture:
@pytest.fixture
def fixture_01():print("第一個fixture方法")def test_02(fixture_01):print("第二個測試用例")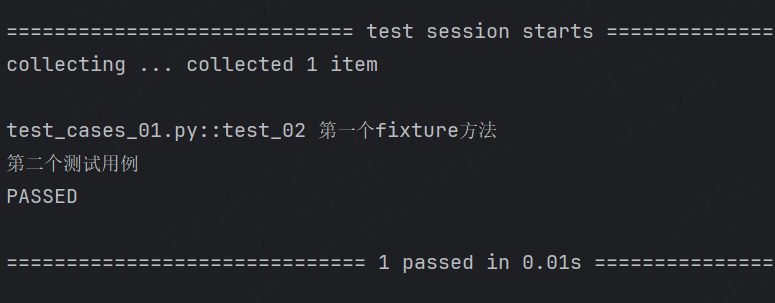
未標記 fixture 方法的調用與 fixture 標記的方法調用完全不?樣,前者需要在方法體中調用,而后者可以將函數名作為參數進行調用。
測試腳本中存在的很多重復的代碼、公共的數據對象時,使用?fixture 最為合適
示例2:訪問列表頁和詳情頁之前都需要執行登錄操作
import pytest
@pytest.fixture
def login():print("---執?登陸操作-----")
def test_list(login):print("---訪問列表?")
def test_detail(login):print("---訪問詳情?")運行結果:
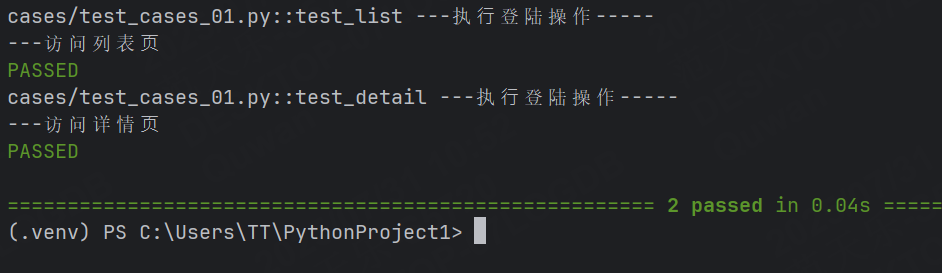
通過使用?@pytest.fixture 裝飾器來告訴 pytest ?個特定函數是?個 fixture,通過運行結果可見,在執行列表頁和詳情頁之前都會先執行?login 方法。
2.5.9.2 fixture嵌套
@pytest.fixture
def first():print("First")@pytest.fixture
def second(first):print("Second")def test(second):print("Test")運行結果:
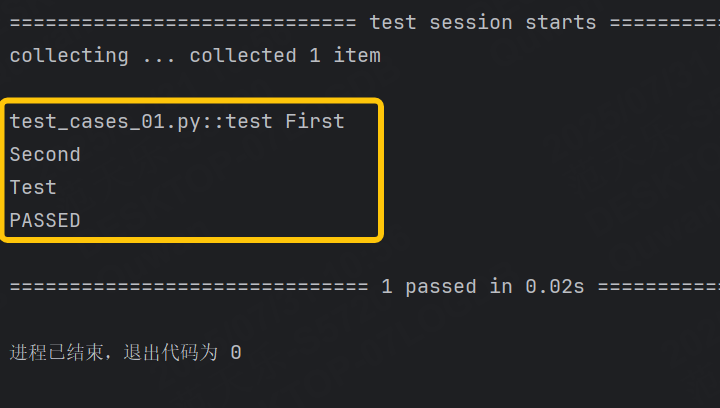
比較兩個列表是否相等
@pytest.fixture
def first_entry():return "a"@pytest.fixture
def order(first_entry):return [first_entry]def test_string(order):order.append("b")assert order == ["a", "b"]運行結果:
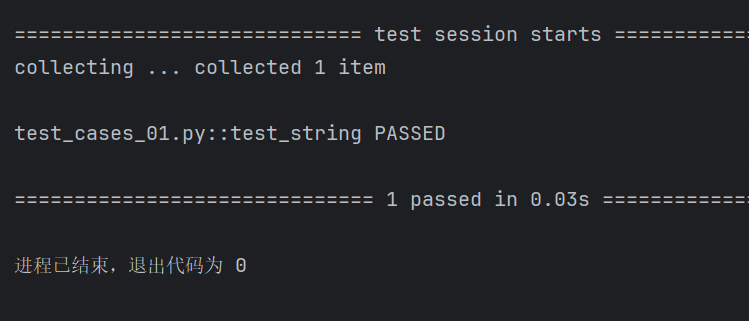
測試不必局限于單個 fixture ,它們可以依賴于您想要的任意數量的 fixture ,并且 fixture 也可以使用其他 fixture 。 pytest 最偉大的優勢之一是其極其靈活的 fixture 系統,它允許我們將測試的復雜需求簡化為更簡單和有組織的函數,我們只需要每個函數描述它們所依賴的事物。
2.5.9.3 請求多個fixture
class Fruit:def __init__(self, name):self.name = namedef __eq__(self, other):return self.name == other.name@pytest.fixture
def my_fruit():return Fruit("Apple")@pytest.fixture
def your_fruit(my_fruit):return [my_fruit, Fruit("Banana")]def test_fruit(my_fruit, your_fruit):assert my_fruit in your_fruit注意:pytest的需要測試的類(以Test開頭)不可以設置__init__函數,其他不需要收集的類是可以設置__init__函數的。
上面代碼的意思是Fruit有一個水果類,my_fruit函數表示我有一個Apple,your_fruit函數會調用my_firit,并且自己有一個Banana,所以your_fruit中有Apple和Banana。最后再調用test_fruit來測試my_fruit是否屬于your_fruit。
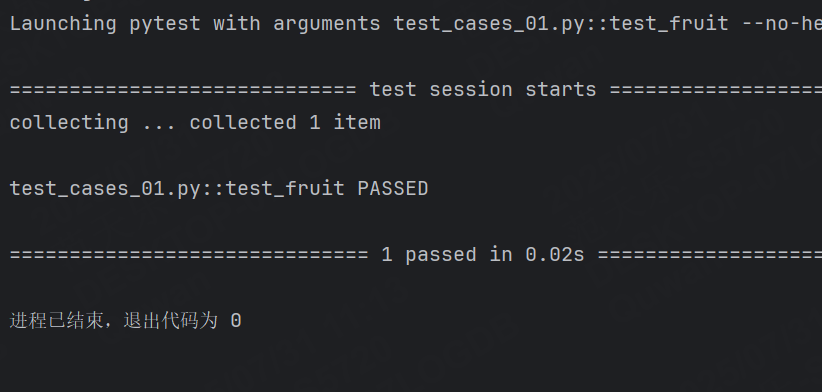
測試和 fixture 不僅限于?次請求單個 fixture ,它們可以請求任意多個。
2.5.9.4 yield fixture
當我們運行測試時,我們希望確保它們能夠自我清理,以便它們不會干擾其他測試(同時也避免留下大量測試數據來膨脹系統)。pytest中的 fixture 提供了?個非常有用拆卸系統,它允許我們為每個 fixture 定義具體的清理步驟。
“Yield” fixture 使用?yield 而不是 return 。有了這些 fixture ,我們可以運行一些代碼,并將對象返回給請求的 fixture/test ,就像其他 fixture ?樣。唯?的不同是:
- return 被替換為 yield 。
- 該 fixture 的任何拆卸代碼放置在 yield 之后。
一旦 pytest 確定了 fixture 的線性順序,它將運行每個 fixture 直到它返回或 yield ,然后繼續執行列表中的下?個 fixture 做同樣的事情。
測試完成后, pytest 將逆向遍歷 fixture 列表,對于每個 yield 的 fixture ,運行?yield語句之后的代碼。
示例1
@pytest.fixture
def operator():print("前置操作:數據初始化")yieldprint("后置操作:數據清洗")def test_operator(operator):print("測試用例")運行結果:
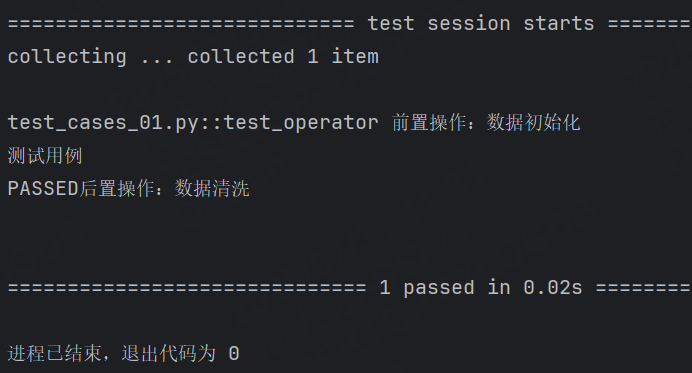
執行順序:
- 先執行operator函數,打印了第一句話。
- 然后遇到yield直接返回,到第二個函數test_operator,打印第二句話。
- 所有用例都執行完之后,開始遍歷fixture列表,執行yield語句之后的代碼。
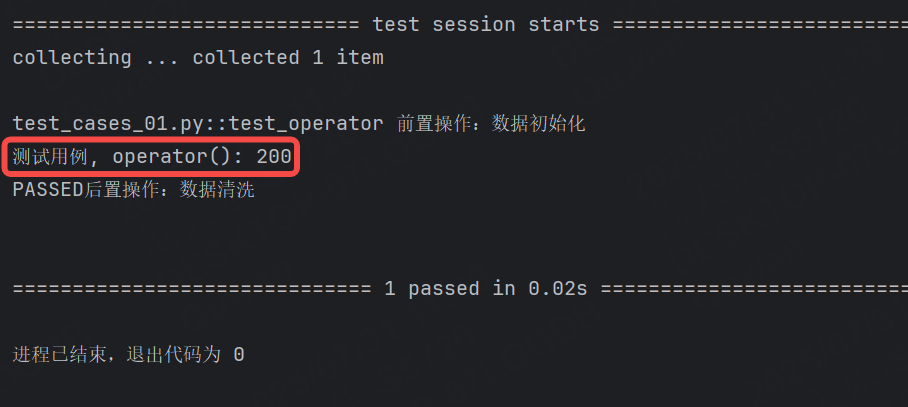
示例2:yiele返回值
@pytest.fixture
def operator():print("前置操作:數據初始化")yield 100print("后置操作:數據清洗")def test_operator(operator):print("測試用例, operator():", operator + 100)運行結果:
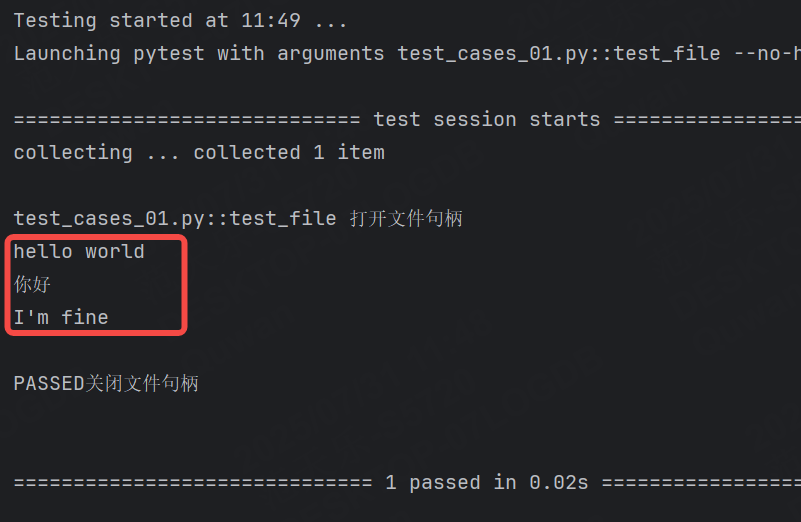
示例2:創建文件句柄與關閉文件
@pytest.fixture
def file_read():print("打開文件句柄")file = open("file.txt", "r", encoding="utf-8")yield fileprint("關閉文件句柄")file.close()def test_file(file_read):r = file_readstr = r.read()print(str)file.txt文件內容如下:
運行結果:
沒有什么問題,接下來我們再加入寫文件
@pytest.fixture
def file_read():print("打開文件句柄")file = open("file.txt", "r", encoding="utf-8")yield fileprint("關閉文件句柄")file.close()@pytest.fixture
def file_write():print("打開文件句柄")file = open("file.txt", "w", encoding="utf-8")yield fileprint("關閉文件句柄")file.close()def test_file(file_read, file_write):#向文件中寫入數據w = file_writew.write("Hello CSDN")#讀取到剛剛寫入的數據r = file_readstr = r.read()print(str)運行結果:
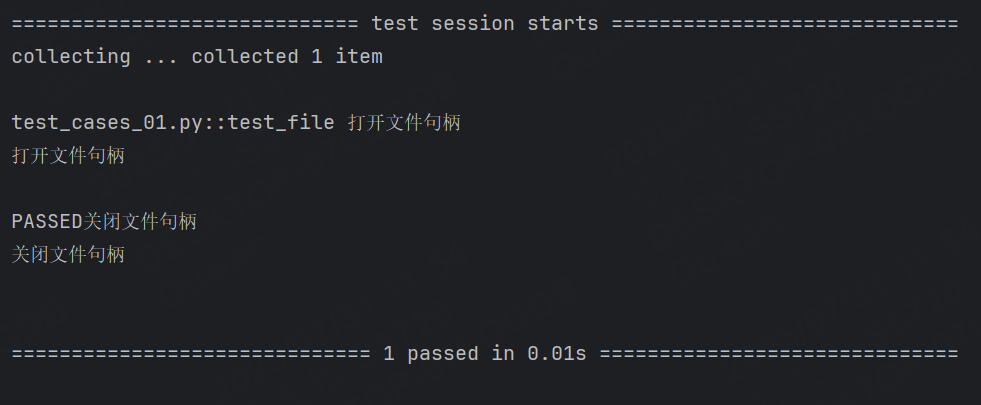
結果看上去沒什么問題,但是這段代碼存在一個小小的bug,首先我們先打開文件句柄,并向文件中寫入數據,寫完后該文件句柄仍然是打開狀態,并沒有被關閉。(雖然我們的file_write中在yield后添加了關閉文件句柄的代碼,但是yield后面的代碼是在整個用例執行之后才會被調用)
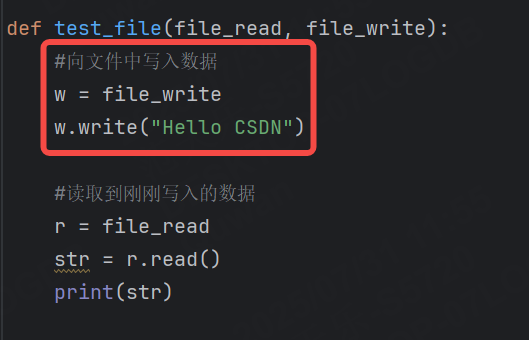
我們向在寫完數據之后將文件句柄關閉,下次使用時再重新打開,如果直接在讀取完數據之后添加一個close代碼,這種方式也不可行,因為在用例結束后又會重新調用一次file_write中的close導致重復關閉問題。
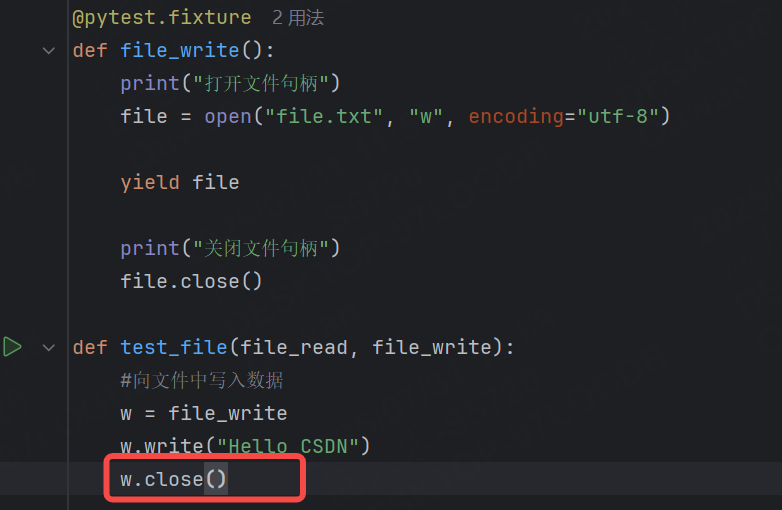
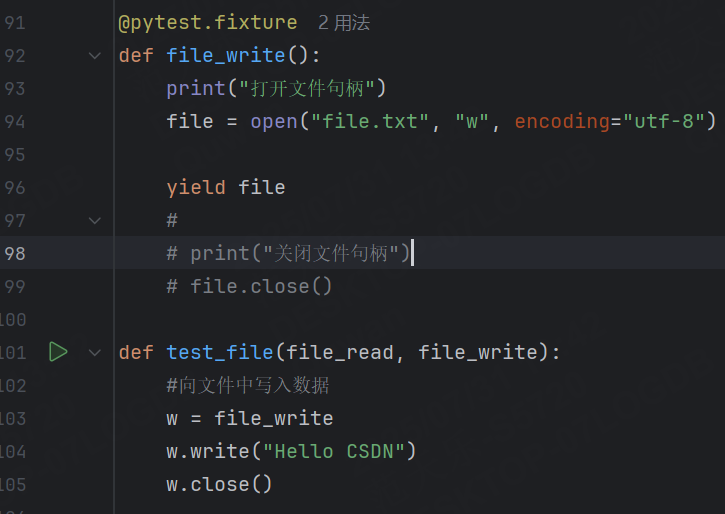
為了解決這個問題,我們只需要將file_weite中的關閉文件句柄的代碼刪去,后續使用時手動調用close。
2.5.9.5 帶參數的fixture
pytest.fixture(scope='', params='', autouse='', ids='', name='')參數詳解:
- scope 參數用于控制fixture的作用范圍,決定了fixture的生命周期。可選值有:
- function (默認):每個測試函數都會調用一次fixture。
- class :在同一個測試類中共享這個fixture。
- module :在同一個測試模塊中共享這個fixture。(一個文件里)
- session :整個測試會話中共享這個fixture。
- autouse 參數默認為 False 。如果設置為 True ,則每個測試函數都會自動調用該fixture,無需顯式傳入
- params 參數用于參數化fixture,支持列表傳入。每個參數值都會使fixture執行?次,類似于for循環
- ids 參數與 params 配合使用,為每個參數化實例指定可讀的標識符(給參數取名字)
- name 參數用于為fixture顯式設置一個名稱。如果使用了 name ,則在測試函數中需要使用這個名稱來引用?fixture (給fixture取名字)
2.5.9.5.1 scope
示例1: scope 的使用
scope="function":
@pytest.fixture(scope="function")
def test_fixture01():print("test_fixture01(): 初始化")yieldprint("test_fixture01(): 數據清洗")class Test1:def test_01(self, test_fixture01):print("test_01(): ")def test_02(self, test_fixture01):print("test_02(): ")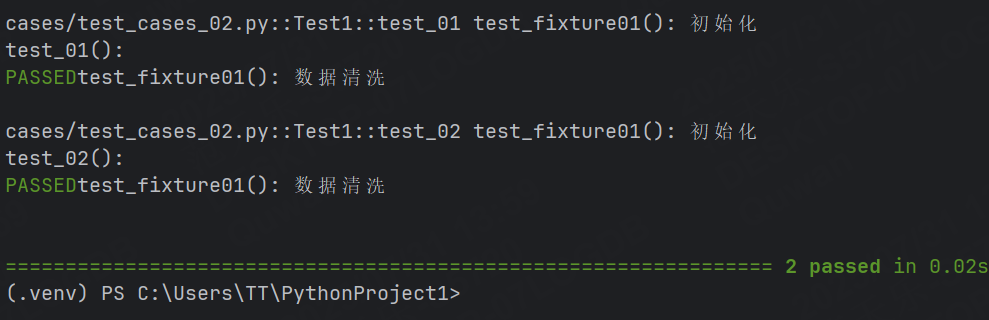
function針對的是函數,每個函數調用之前都會去調用test_fixture01()函數yield之前的語句,每個函數調用完之后都會去調用test_fixture01()函數yield之后的語句
scope="class":
@pytest.fixture(scope="class")
def test_fixture01():print("test_fixture01(): 初始化")yieldprint("test_fixture01(): 數據清洗")class Test1:def test_01(self, test_fixture01):print("test_01(): ")def test_02(self, test_fixture01):print("test_02(): ")class Test2:def test_03(self, test_fixture01):print("test_03(): ")def test_04(self, test_fixture01):print("test_04(): ")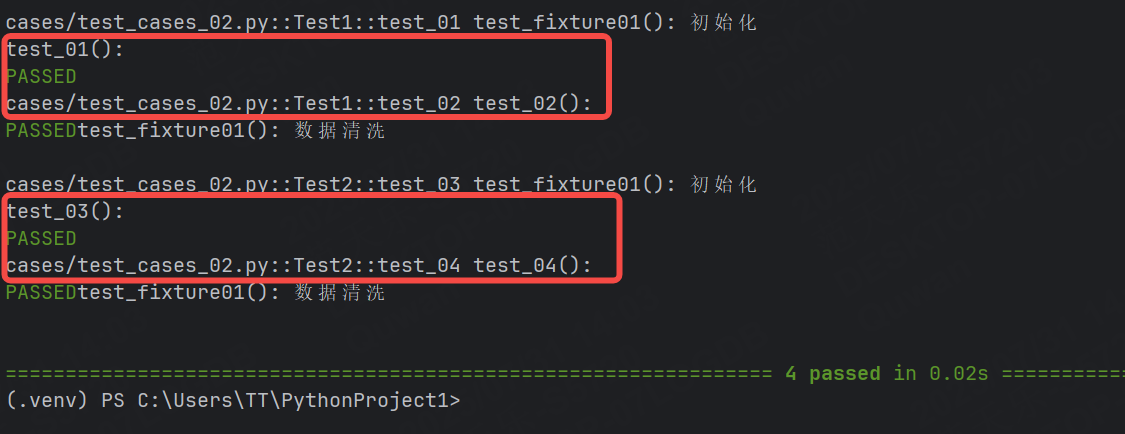
function針對的是類,每個類調用之前都會去調用test_fixture01()函數yield之前的語句,每個類調用完之后都會去調用test_fixture01()函數yield之后的語句
結論:
- scope 默認為 function ,這里的 function 可以省略不寫,當 scope="function" 時,每個測試函數都會調用一次 fixture 。 scope="class" 時,在同?個測試類中, fixture只會在類中的第?個測試函數開始前執行一次,并在類中的最后一個測試函數結束后執行清理。
- 當 scope="moudle" 、 scope="session" 時可用于實現全局的前后置應用,這里需要多個文件的配合。
示例2: scope="moudle" 、 scope="session" 實現全局的前后置應用
scope="module":
import pytest@pytest.fixture(scope="module")
def test_fixture01():print("test_fixture01(): 初始化")yieldprint("test_fixture01(): 數據清洗")class Test1:def test_01(self, test_fixture01):print("test_01(): ")def test_02(self, test_fixture01):print("test_02(): ")class Test2:def test_03(self, test_fixture01):print("test_03(): ")def test_04(self, test_fixture01):print("test_04(): ")運行結果:
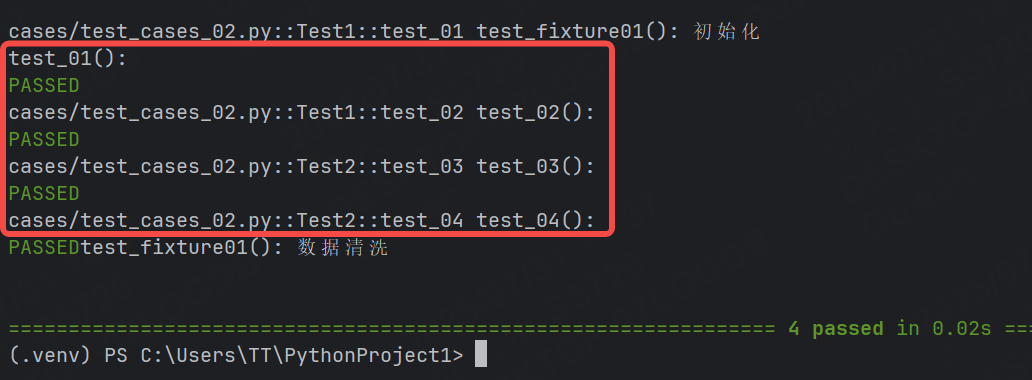
function針對的是文件,每個文件開始執行第一個用例之前都會去調用test_fixture01()函數yield之前的語句,每個類執行完所有用例之后之后都會去調用test_fixture01()函數yield之后的語句
上面是只有一個文件的場景,那如果是多個文件呢?
conftest.py 和 @pytest.fixture 結合使用實現全局的前后置應用
@pytest.fixture 與 conftest.py 文件結合使用,可以實現在多個測試模塊( .py )文件中共享前后置操作,這種結合的方式使得可以在整個測試項目中定義和維護通用的前后置邏輯,使測試代碼更加模塊化和可維護。
規則:
- conftest.py 是?個單獨存放的夾具配置文件,名稱是固定的不能修改
- 你可以在項目中的不同目錄下創建多個 conftest.py 文件,每個 conftest.py 文件都會對其所在目錄及其子目錄下的測試模塊生效。
- 在不同模塊的測試中需要用到 conftest.py 的前后置功能時,不需要做任何的import導入操作
- 作用:可以在不同的 .py 文件中使用同一個 fixture 函數
此時我們不能只修改test_cases_02.py文件當中的scope為module,當測試用例存在不同的文件時,需要將fixture放到配置conftest.py文件中。
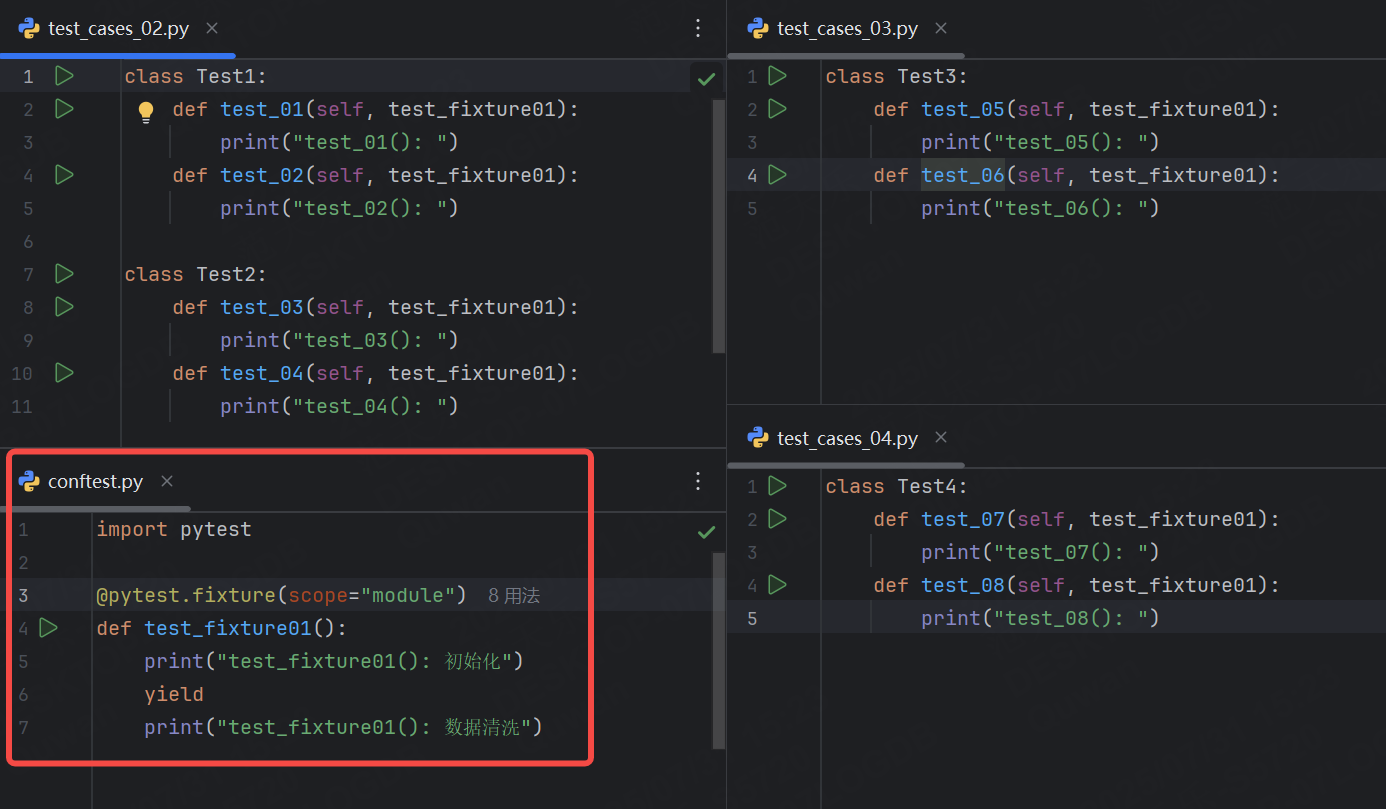
運行結果:
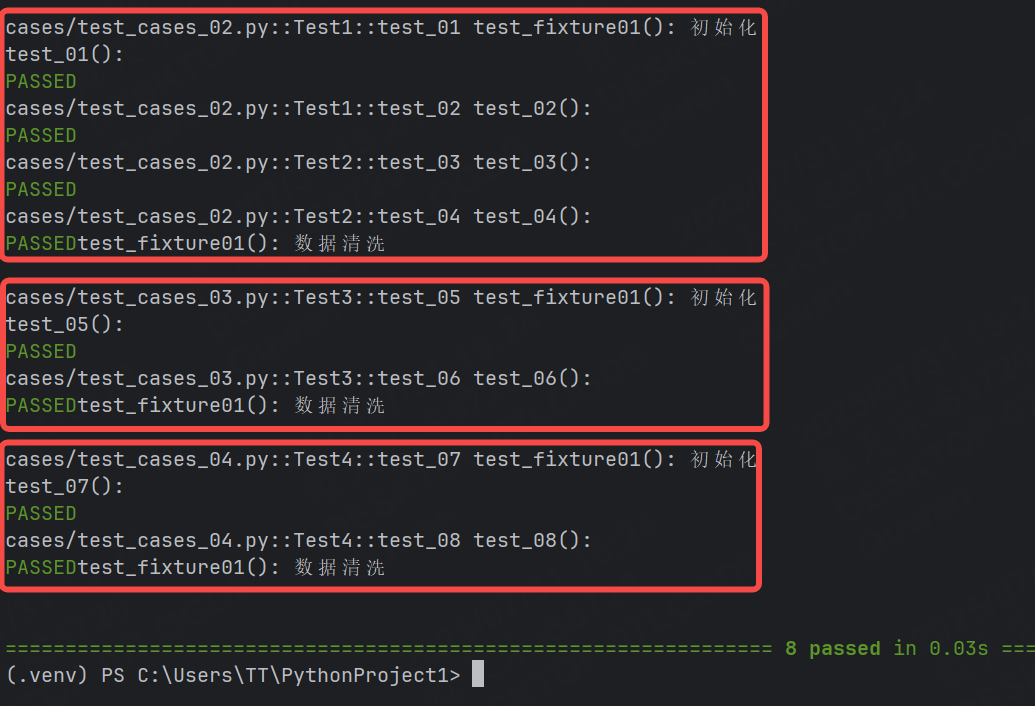
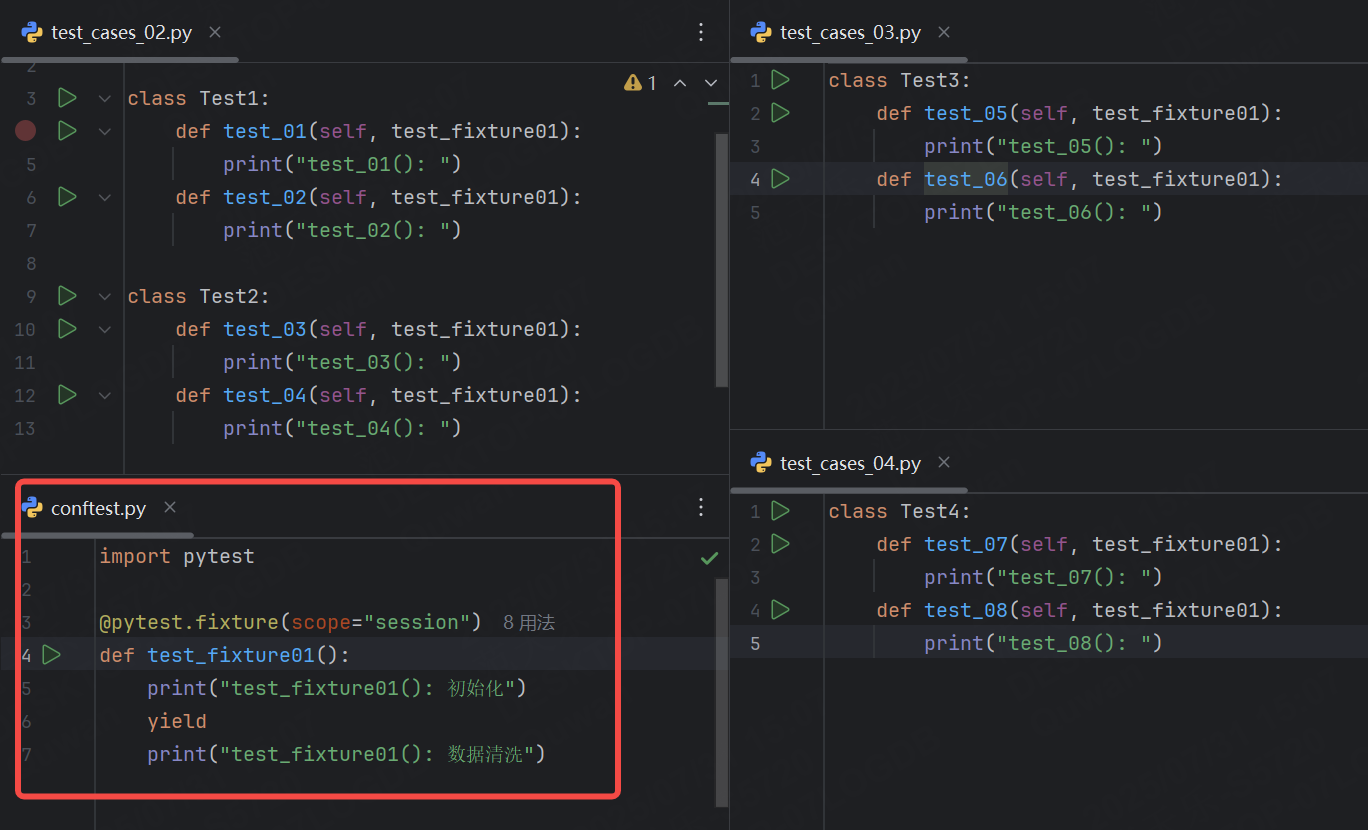
scope="session":
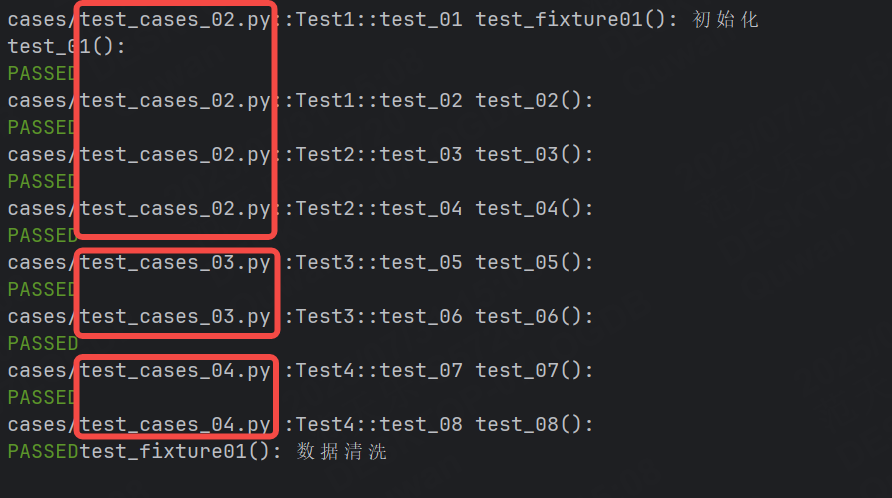
只要修改conftest.py文件中的scope屬性為session即可。
運行結果:
2.5.9.5.2?autouse
autouse 參數默認為 False 。如果設置為 True ,則每個測試函數都會自動調用該fixture,無需顯式傳入
import pytest@pytest.fixture(autouse=True)
def test_fixture01():print("test_fixture01(): 初始化")yieldprint("test_fixture01(): 數據清洗")class Test5:def test_09(self):print("test_09(): ")def test_10(self):print("test_010(): ")運行結果:
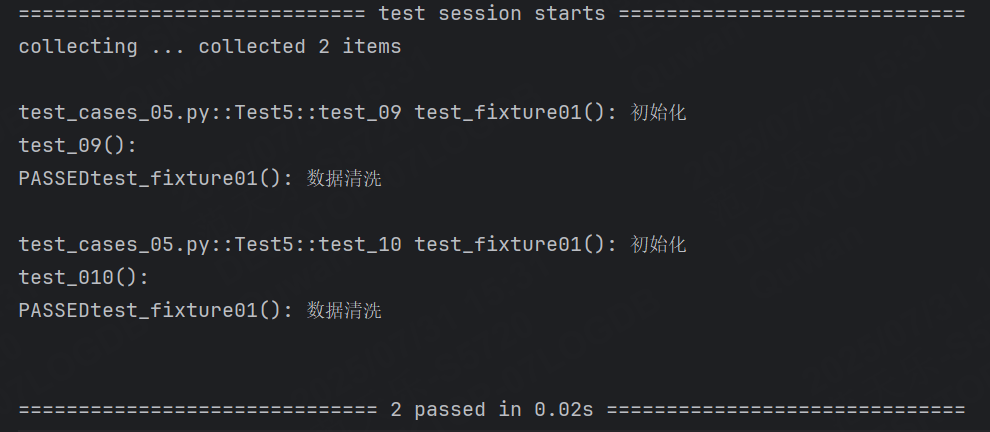
- autouse 默認為 False ,即當前的 fixture 需要手動顯示調用,在該案例之前我們默認使用的都是 autouse=False
- 當 autouse=True 時, fixture 會在所有測試函數執行之前自動調用,無論這些測試函數是否顯式地引用了該 fixture
2.5.9.5.3?params
params 參數用于參數化fixture,支持列表傳入。每個參數值都會使fixture執行一次,類似于for循環。
@pytest.fixture(params=[1, 2, 3])
def fixture(request):return request.paramdef test_fixture(fixture):print(fixture)運行結果:
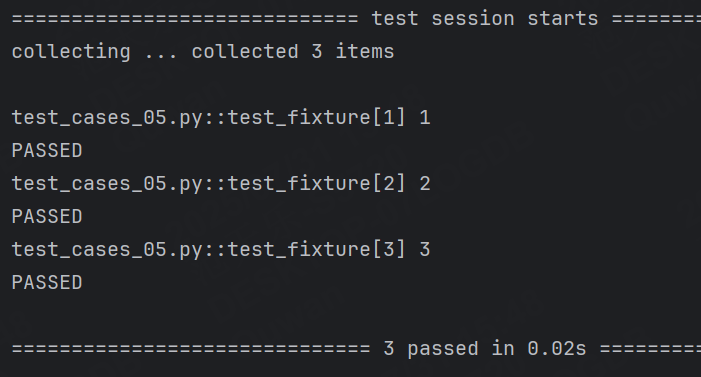
前面我們已經學過pytest中通過 @pytest.mark.parametrize 實現參數化,通過 fixture 也可以實現參數化,那么到底哪?種更好呢?
如果測試場景主要涉及簡單的參數傳遞,且不需要復雜的資源管理,建議使用?parametrize,因為它更簡單直接;如果測試需要動態加載外部數據,或者需要管理復雜的測試資源(如數據庫連接、文件操作等),建議使用?fixture,在某些情況下,也可以結合使用?parametrize 和 fixture,以充分利用兩者的優點。總結來說,parametrize 更適合簡單場景,而?fixture 更適合需要動態數據和資源管理的復雜場景。
2.6 YAML
官方文檔:pyyaml.org/wiki/PyYAMLDocumentation
YAML是?種數據序列化語言,用于以人類可讀的形式存儲信息。它最初代表“Yet Another Markup Language”,但后來更改為“ YAML Ain’t Markup Language”(YAML不是一種標記語言),以區別于真正的標記語言。
它類似于XML和JSON文件,但使用更簡潔的語法。
特點:
- YAML 是一種非常簡單的基于文本的人類可讀的語言,用于在人和計算機之間交換數據。
- YAML 不是一種編程語言。它主要用于存儲配置信息。
- YAML 的縮進就像 Python 的縮進一樣優雅。
- YAML 還減少了 JSON 和 XML 文件中的大部分“噪音”格式,例如引號、方括號和大括號。
注意:
- YAML 是區分大小寫。
- YAML 不允許使用制表符 Tab 鍵,(你之所按下 Tab YAML 仍能使用,是因為編輯器被配置為按下Tab 鍵會導致插入適當數量的空格)。
- YAML 是遵循嚴格縮進的。
2.6.1 YAML介紹
YAML 文件的后綴名是 .yaml 或 .yml ,本著能少寫不多寫的原則,我們常用的是 .yml 。yaml 中支持不同數據類型,但在寫法上稍有區別,詳見下表:

以上語法若短時間內無法掌握,我們也有很多工具可供使用,如json轉yaml:JSON 轉 YAML 工具 | 簡化數據格式轉換 - 嘉澍工具
2.6.2 使用
yaml 文件通常作為配置文件來使用,可以使用?yaml 庫來讀取和寫入?YAML 文件
1.安裝yaml庫:
pip install PyYAML==6.0.12.創建yaml文件:
3.讀取和寫入yaml文件:
寫入yaml文件所使用的函數:
def safe_dump(data, stream=None, **kwds):return dump_all([data], stream, Dumper=SafeDumper, **kwds)- data表示要寫入的數據
- stream是文件流(從哪個文件,以什么方式寫入)
import yamldef write_yaml(data):with open("../test.yaml", encoding="utf-8", mode='a+') as f:yaml.safe_dump(data, f)def test_write_yaml():data = {"name":"zhangsan","age":28}write_yaml(data)運行結果:
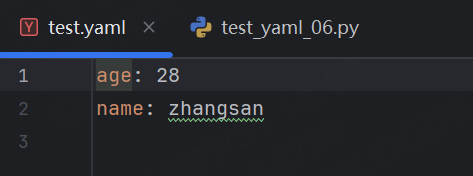
可以看到yaml與json相比,去除掉了多余的括號和引號
讀取yaml文件所使用的函數:
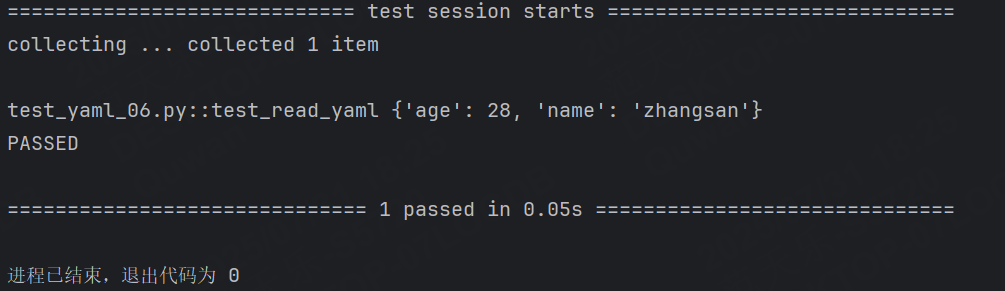
def safe_load(stream):return load(stream, SafeLoader)- stream是文件流(從哪個文件,以什么方式讀取)
def read_yaml():with open("../test.yaml", encoding="utf-8", mode='r') as f:return yaml.safe_load(f)def test_read_yaml():data = read_yaml()print(data)運行結果:
清空yaml文件:
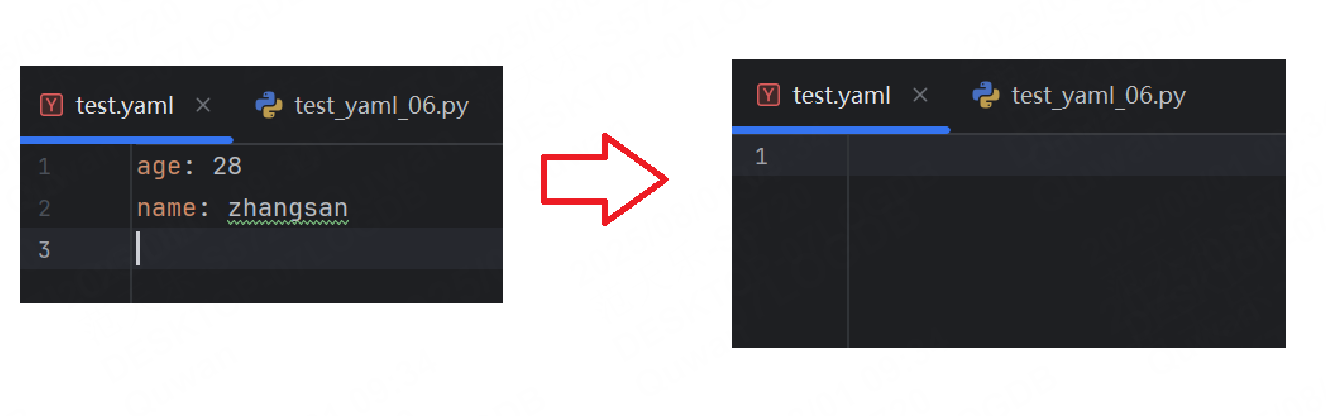
注意該方法并非yaml文件提供的,因為yaml文件也是一個文件,所以我們使用python自帶的清空函數truncate
def clear_yaml():with open("../test.yaml", encoding="utf-8", mode='w') as f:f.truncate()def test_clear_yaml():clear_yaml()運行結果:
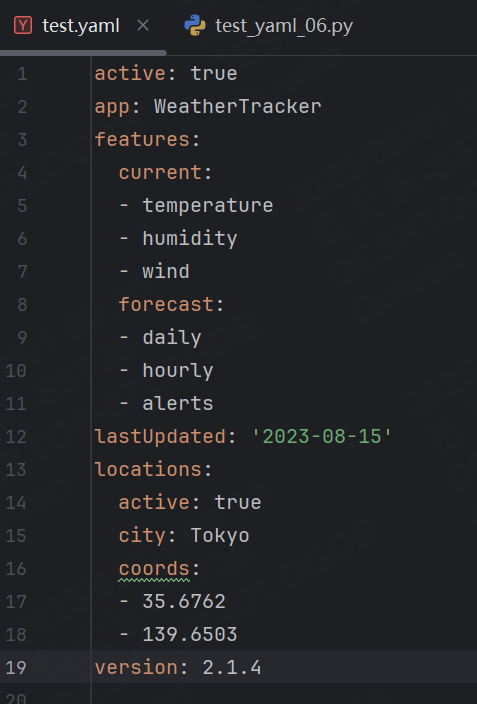
前面的json格式較為簡單,我們再來看一個復雜的json轉成yaml是什么樣子的。
data = {"app": "WeatherTracker","version": "2.1.4","active": True,"features": {"current": ["temperature", "humidity", "wind"],"forecast": ["daily", "hourly", "alerts"]},"locations": {"city": "Tokyo","coords": [35.6762, 139.6503],"active": True},"lastUpdated": "2023-08-15"
}結果為:
我們可以和JSON來對比一下
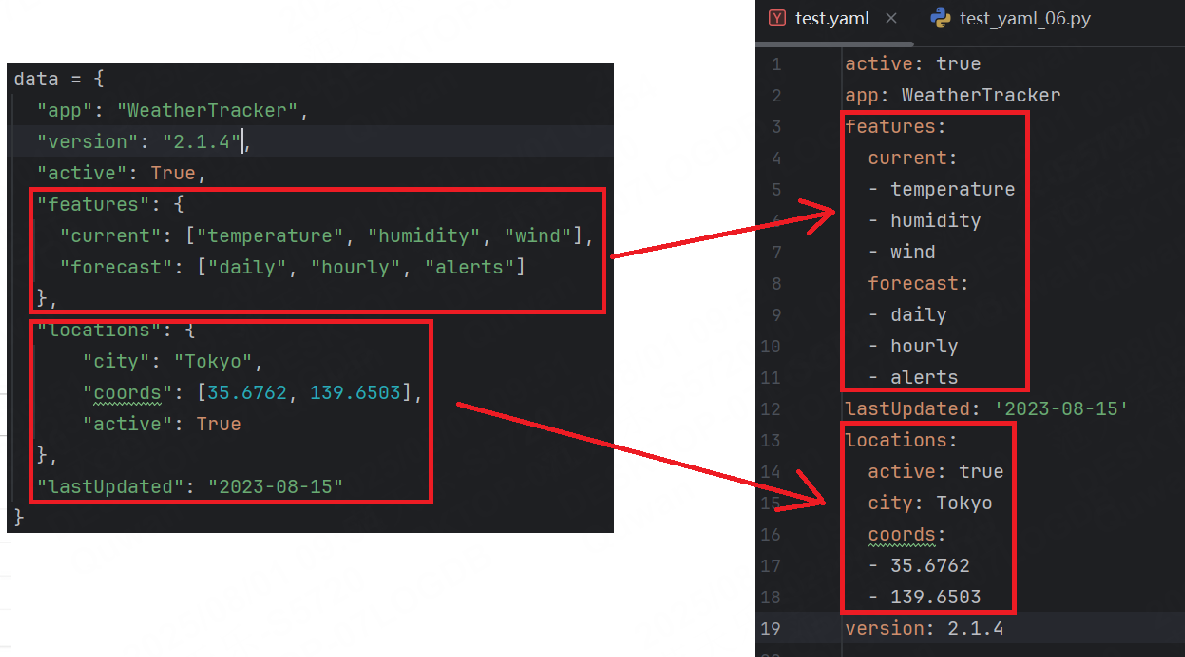
可以明顯觀察到大部分多余的引號,方括號,大括號被去掉了,更加的簡潔
2.7 JSON Schema
JSON Schema一個用來定義和校驗JSON的web規范,簡而言之,JSON Schema是用來校驗json是否符合預期。
根據 json 創建 JSON Schema 后,你可以使用你選擇的語言中的驗證器將示例數據與你的模式進行驗證。
2.7.1 安裝
pip install jsonschema==4.23.0
2.7.2 介紹

通過上面的對比可見, JSON Schema 從多個方面對 JSON 數據進行校驗。
如“ type ”、“ required ”、“ properties ”等以確保其正確性和一致性。接下來我們來了解 JSON Schema 中的關鍵詞以及作用。
json轉JSON Schema太麻煩?使用現有工具自動轉換:在線JSON轉Schema工具 - ToolTT在線工具箱
注意:工具不是萬能的,結果可能存在錯誤,要對自動生成的結果進行二次檢查
上面轉換的JSON Schema是正確的嗎?我們可以來驗證一下。jsonschema庫中有一個validate包,可以用于驗證JSON轉換的JSON Schema是否正確。
def validate(instance, schema, cls=None, *args, **kwargs):- instance:要驗證的原生數據
- schema:instance對應的JSON Schema
validate主要驗證的是:
- 返回的字段是否都存在
- 返回的字段名都是一致的
- 保證數據的類型是一致的
代碼:
from jsonschema import validatedef test_jsonSchema():data = {"code": "SUCCESS","errMsg": "","data": False}json_schema = {"type": "object","required": [],"properties": {"code": {"type": "string"},"errMsg": {"type": "string"},"data": {"type": "string"}}}validate(data, json_schema)運行結果:
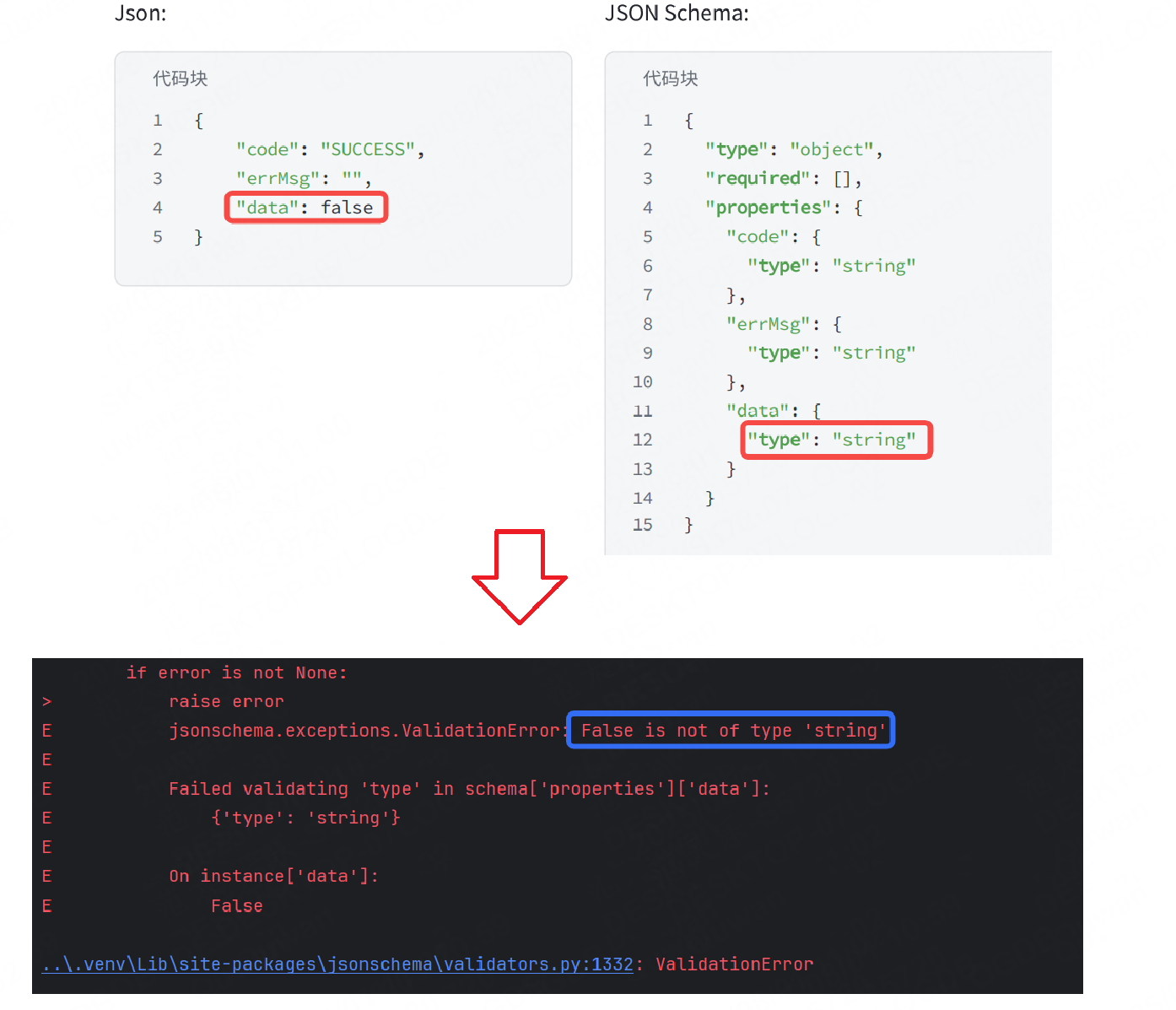
可以看到有不一樣的地方可以成功校驗出來。
示例:校驗百度搜索“測試”返回的json數據
先通過代碼獲取返回的JSON:
def test_jsonSchema2():url = "https://www.baidu.com/sugrec?pre=1&p=3&ie=utf-8&json=1&prod=pc&wd=測試"response = requests.get(url)print(response.json())運行結果:
{"q": "測試","p": false,"g": [{"type": "sug","sa": "s_1","q": "測試抑郁程度的問卷"},{"type": "sug","sa": "s_2","q": "測試infp人格"},{"type": "sug","sa": "s_3","q": "測試網速"},{"type": "sug","sa": "s_4","q": "測試抑郁癥心理測試題免費"},{"type": "sug","sa": "s_5","q": "測試MBTI人格免費"},{"type": "sug","sa": "s_6","q": "測試培訓"},{"type": "sug","sa": "s_7","q": "測試智商的測試題免費"},{"type": "sug","sa": "s_8","q": "測試的英文"},{"type": "sug","sa": "s_9","q": "測試工程師"},{"type": "sug","sa": "s_10","q": "測試反應速度"}],"slid": "50153000091310","queryid": "0x2252d9d27c13eae"
}然后我們再將上面得到的JSON轉換成Schema。
{"type": "object","required": [],"properties": {"q": {"type": "string"},"p": {"type": "string"},"g": {"type": "array","items": {"type": "object","required": [],"properties": {"type": {"type": "string"},"sa": {"type": "string"},"q": {"type": "string"}}}},"slid": {"type": "string"},"queryid": {"type": "string"}}
}接下來我們就可以測試了,通過validate校驗。
def test_jsonSchema2():url = "https://www.baidu.com/sugrec?pre=1&p=3&ie=utf-8&json=1&prod=pc&wd=測試"response = requests.get(url)schema_data = {"type": "object","required": [],"properties": {"q": {"type": "string"},"p": {"type": "string"},"g": {"type": "array","items": {"type": "object","required": [],"properties": {"type": {"type": "string"},"sa": {"type": "string"},"q": {"type": "string"}}}},"slid": {"type": "string"},"queryid": {"type": "string"}}}validate(response.json(), schema_data)運行結果:
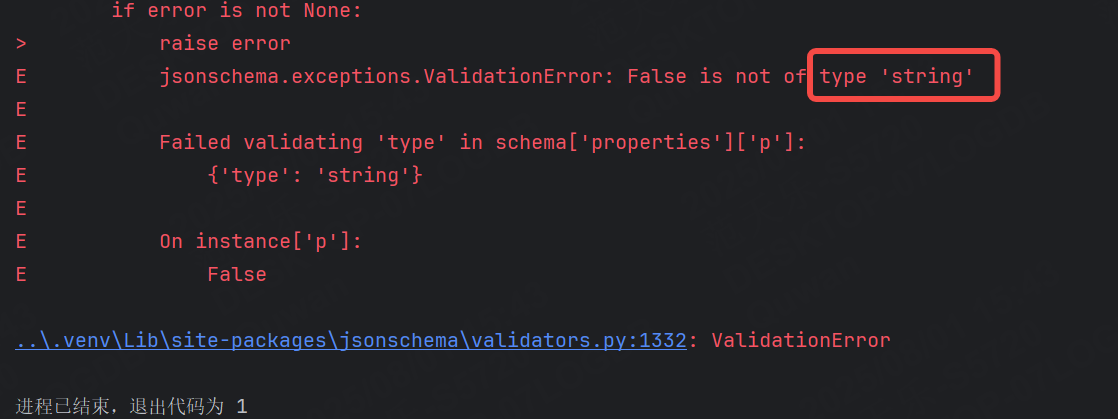
原因和前面的例子一樣,type是bool類型,結果被轉換成了字符串。
所以說我們不能過度依賴工具,工具生成完之后需要手工檢查一遍。
"p": {"type": "boolean"
},將p的類型轉化成boolean之后就可以成功運行了。
2.7.2.1 數據類型
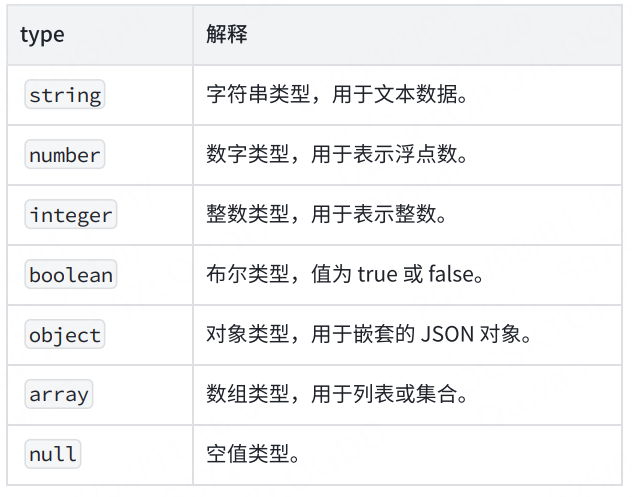
type 關鍵字指定了數據類型。
可以驗證 JSON 數據中每個屬性的數據類型是否符合預期。常用的數據類型包括:
示例:

- type表示當前的JSON對象
- properties 是一個驗證關鍵字。當你定義 properties 時,你創建了一個對象,其中每個屬性代表正在驗證的 JSON 數據中的一個鍵。
2.7.2.2 最大最小值
- minimum 和 maximum :指定數值的最小值和最大值。
- exclusiveMinimum 和 exclusiveMaximum :指定數值必須嚴格大于或小于某個值(不包含等于)。
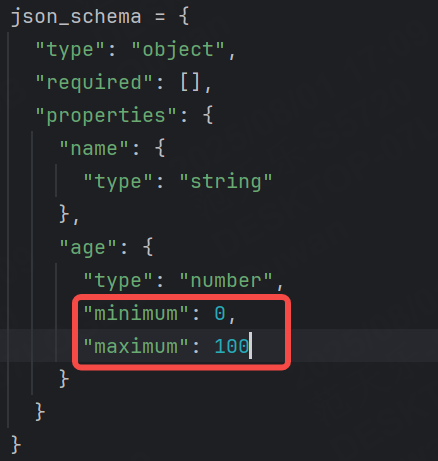
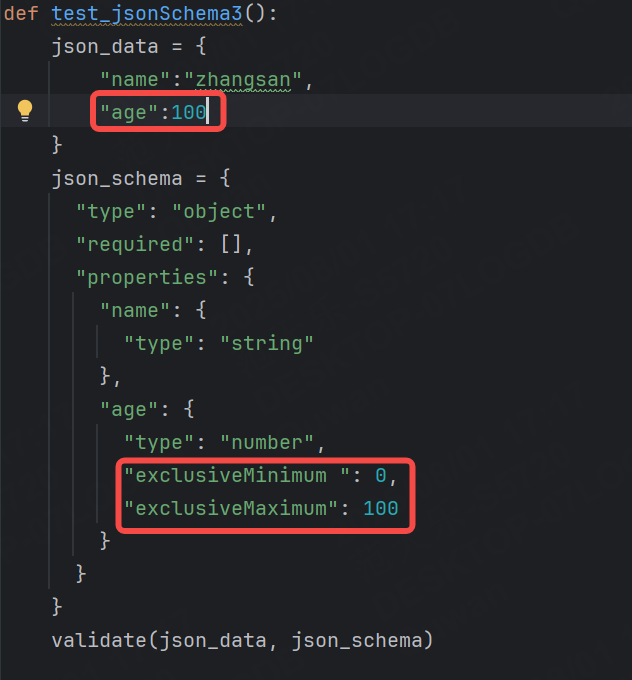
我們手動為age字段設置minimum和maximum。
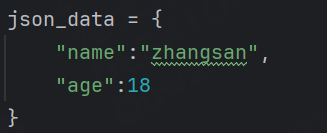
現在的age是18,符合區間范圍(0~100),所以調用validate函數應該是可以通過的。
如果將age修改成130呢?
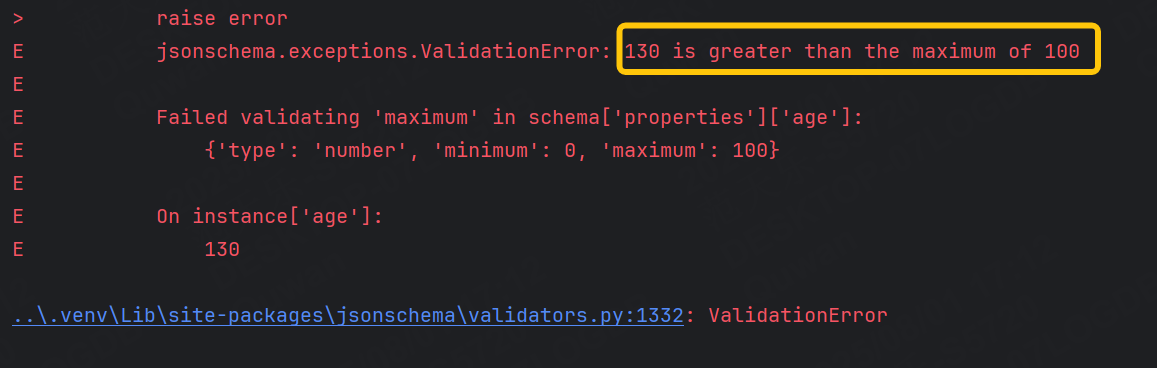
可以看到成功提示:130超過了最大值。
minimum 和 maximum表示的是大于等于(>=)和小于等于(<=)。
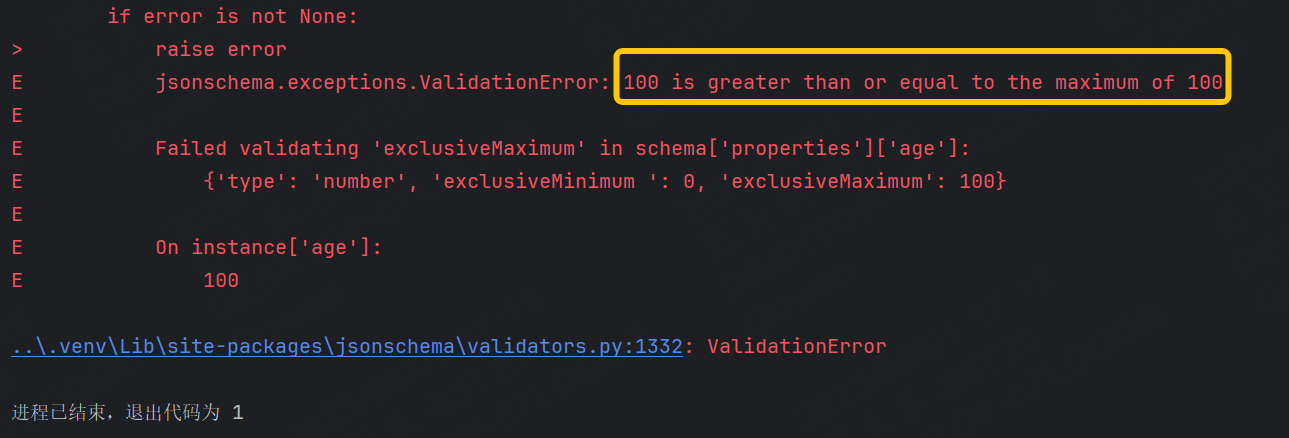
如果不想要等于的話就需要使用到exclusiveMinimum 和 exclusiveMaximum。
運行結果:
2.7.2.3 字符串特殊校驗
? pattern :使用正則表達式來驗證字符串是否符合特定的模式。
json_schema = {"type": "object","required": [],"properties": {"name": {"type": "string","pattern": "\S{2,20}"},"age": {"type": "number",}}
}如上面的name的pattern我們設置為正則表達式。\S表示匹配一個非空字符,{2,20}表示長度要在2到20之間。所以這個正則表達式匹配的就是長度在2~20之間的字符串。(注意:這里并不是說超過20的字符串就匹配不到,20表示的是最多匹配,即匹配前20個字符也算成功匹配)
zhangsan這個字符串長度在2~20之間,所以可以通過測試用例
我們再把匹配規則的長度調整到{10,20}
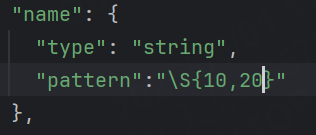
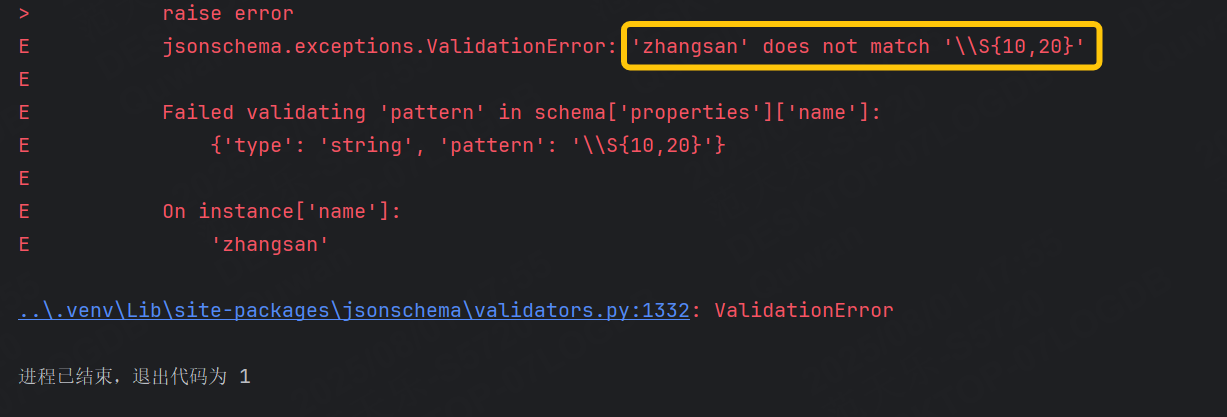
2.7.2.4 數組約束
- minItems 和 maxItems :指定數組的最小和最大長度。
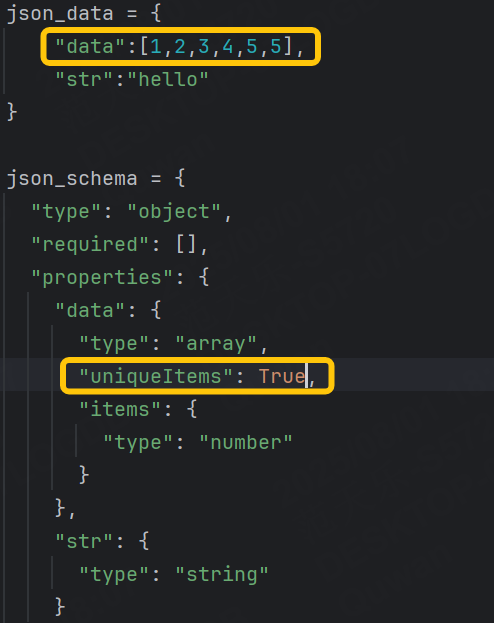
- uniqueItems :確保數組中的元素是唯?的。
- items :定義數組中每個元素的類型和約束。
JSON和Schema如下:
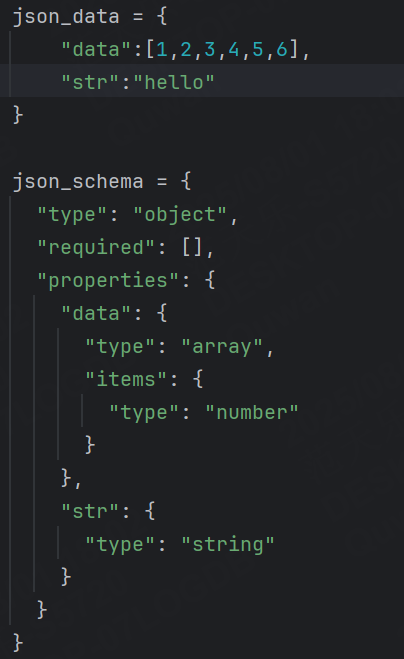
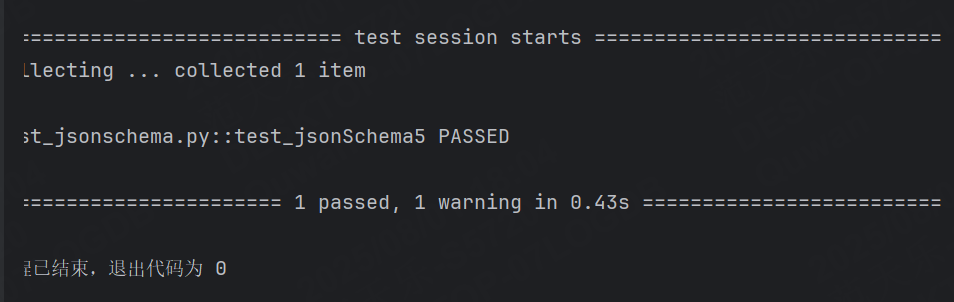
minItems 和 maxItems :指定數組的最小和最大長度。
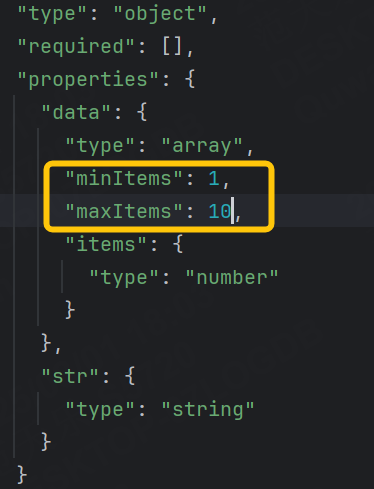
設置最小1個,最大10個。
運行成功:
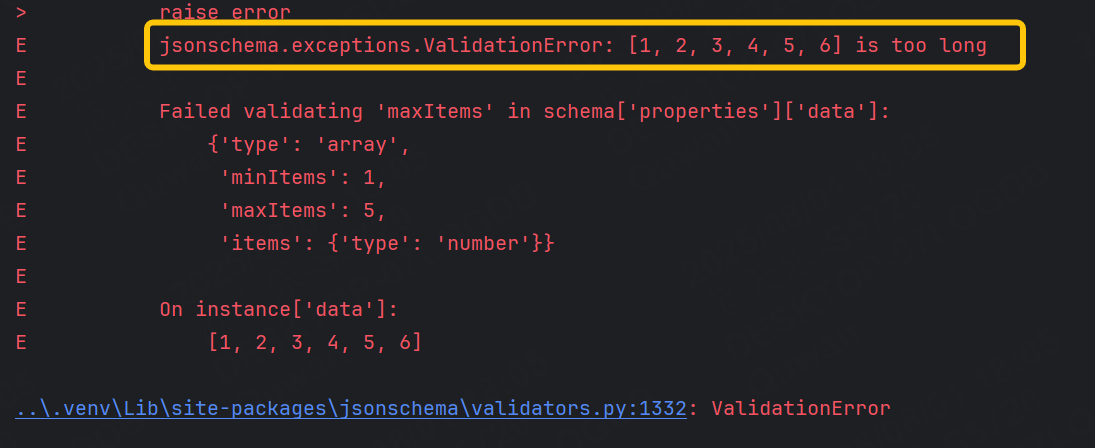
再把最大調整為5,觀察一下運行失敗的情況:
uniqueItems :確保數組中的元素是唯?的。
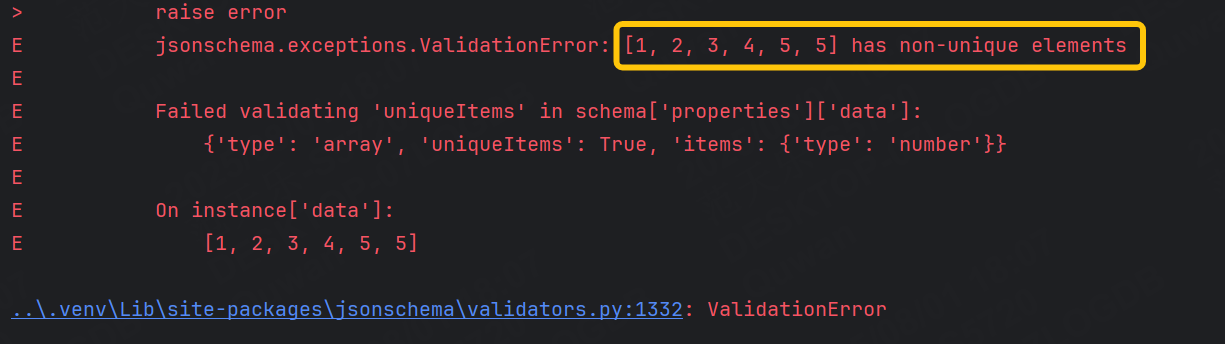
運行結果:
items :定義數組中每個元素的類型和約束。
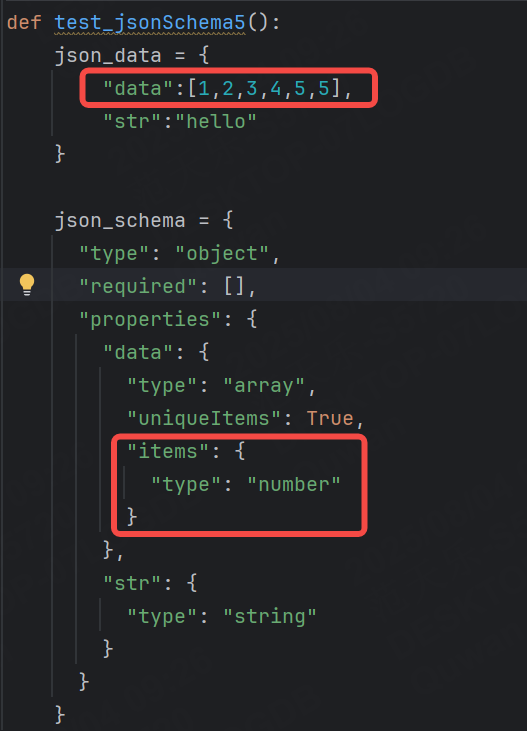
表示數組中的元素都是number類型,如果是其他類型就會報錯。
2.7.2.5 對象約束
- minProperties 和 maxProperties :指定對象的最小和最大屬性數量。
- additionalProperties :控制是否允許對象中存在未在 properties 中定義的額外屬性,默認為True。
示例:校驗百度搜索“測試”返回的json數據
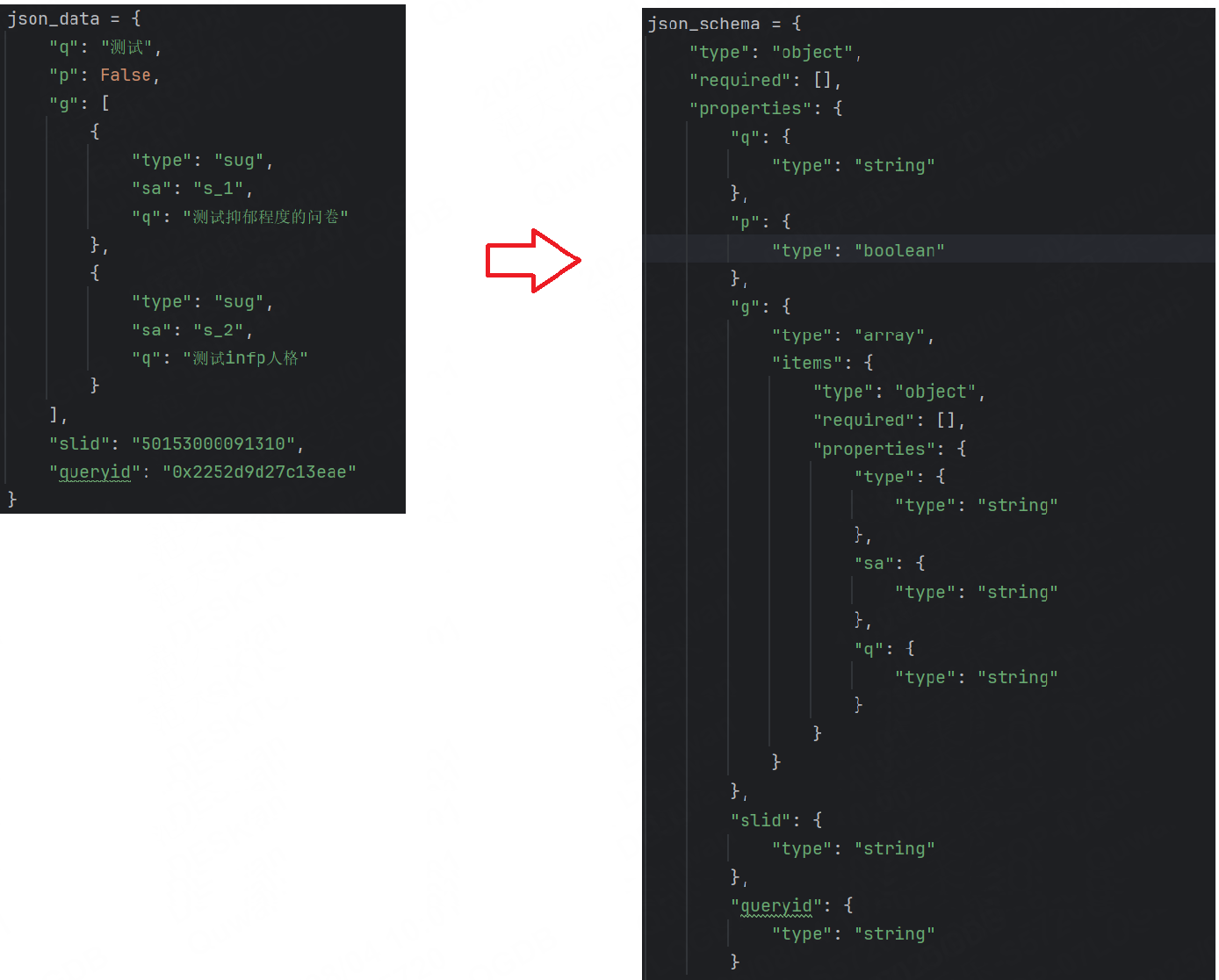
additionalProperties :控制是否允許對象中存在未在 properties 中定義的額外屬性,默認為True。
比如,此時我手動在json_data中添加一個x字段,該字段就是json_schema中未出現的,因為additionalProperties默認為True,所以添加該字段后可以運行通過。
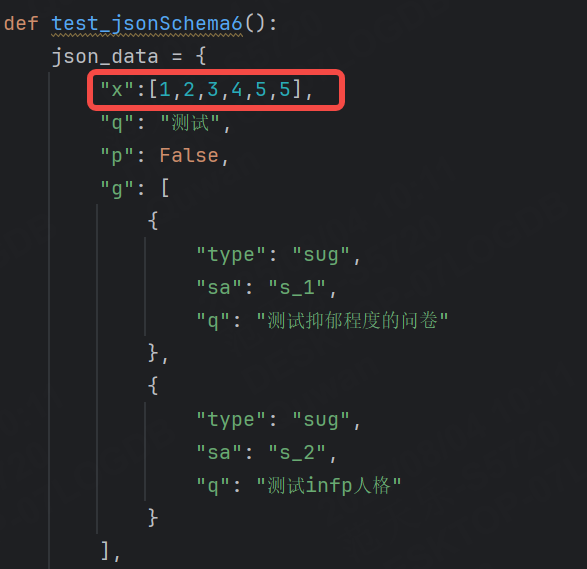
運行結果:
如果說現在我們不允許添加額外的字段,就可以在json_schema中把additionalproperties設置為False。
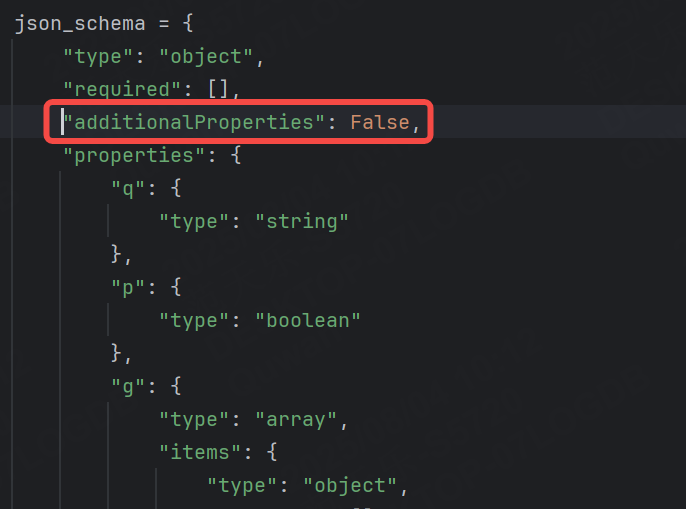
運行結果:
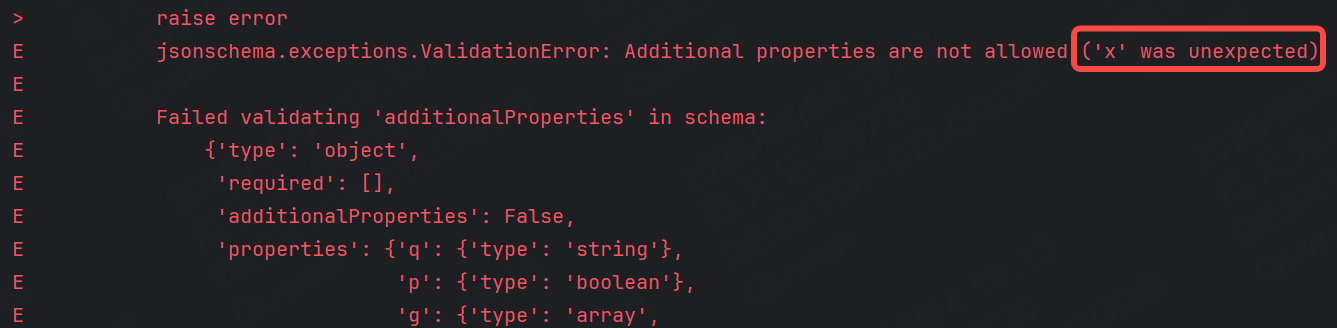
注意:additionalProperties放的位置很重要,你把他放在哪,他的作用域就在哪
此時的json_data其實是有兩層的,一層是json對象的參數,第二層的"g"字段的參數,如果我們此時在第二層額外添加一個參數,然后將additionalProperties設置在第一層,此時還能起作用嗎?
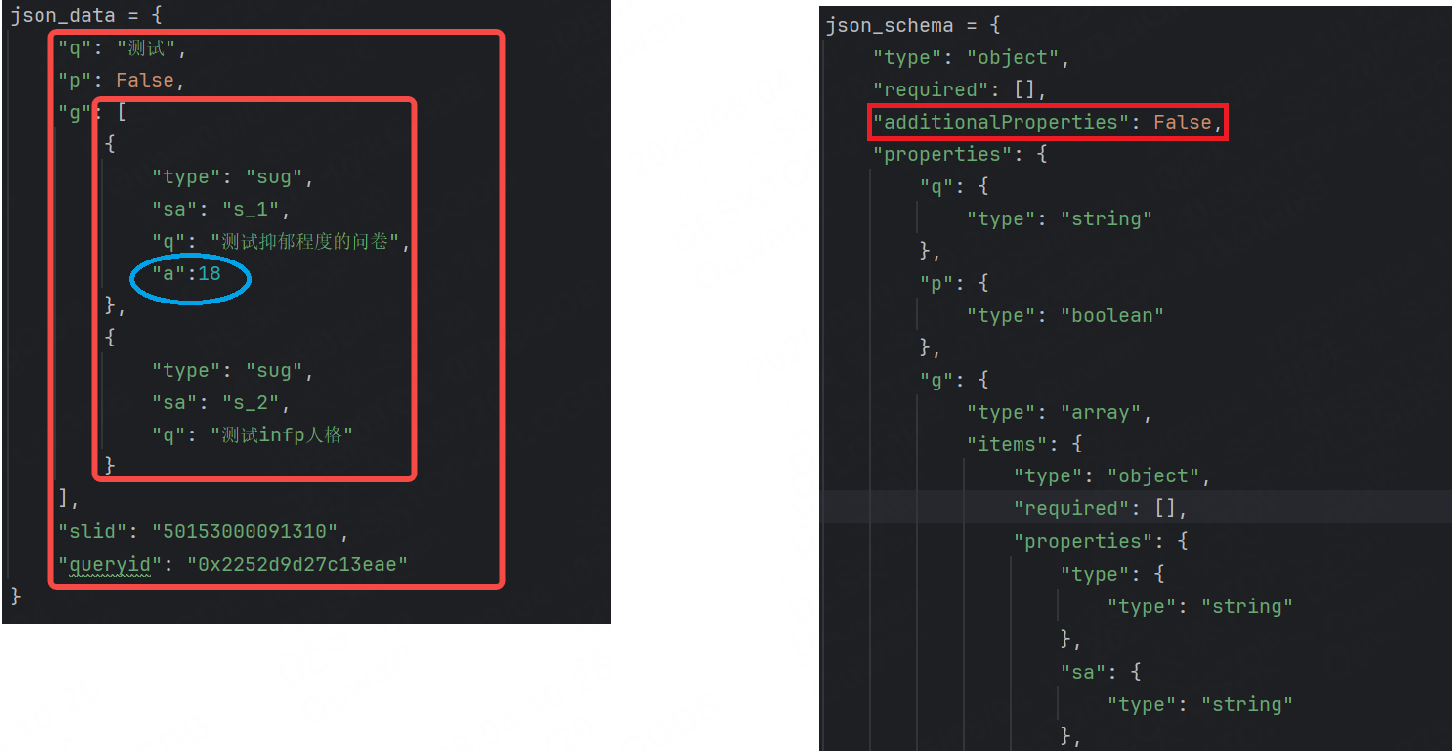
此時運行是通過的,因為additionalProperties只作用在第一層,第二層的additionalProperties還是默認的True。
我們再給第二層也添加上additionalProperties。
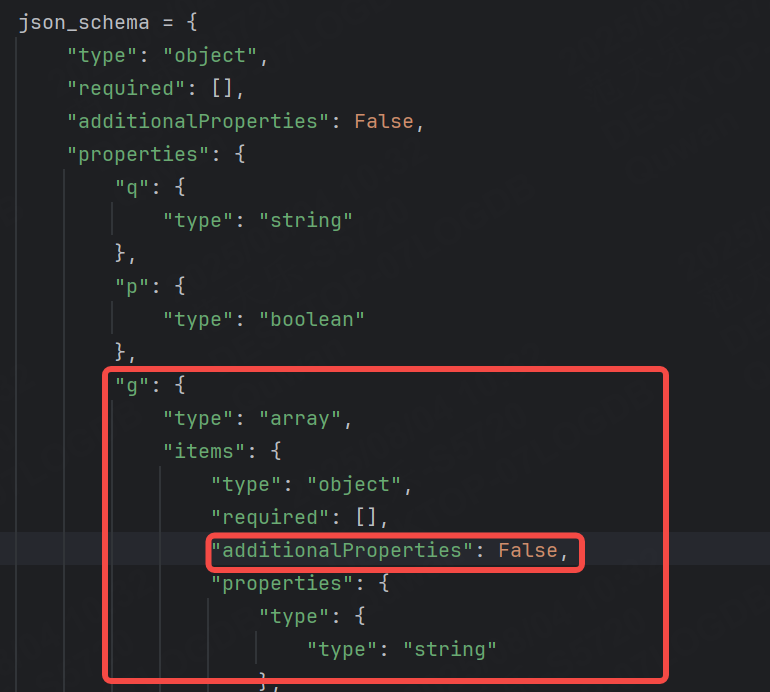
運行結果:
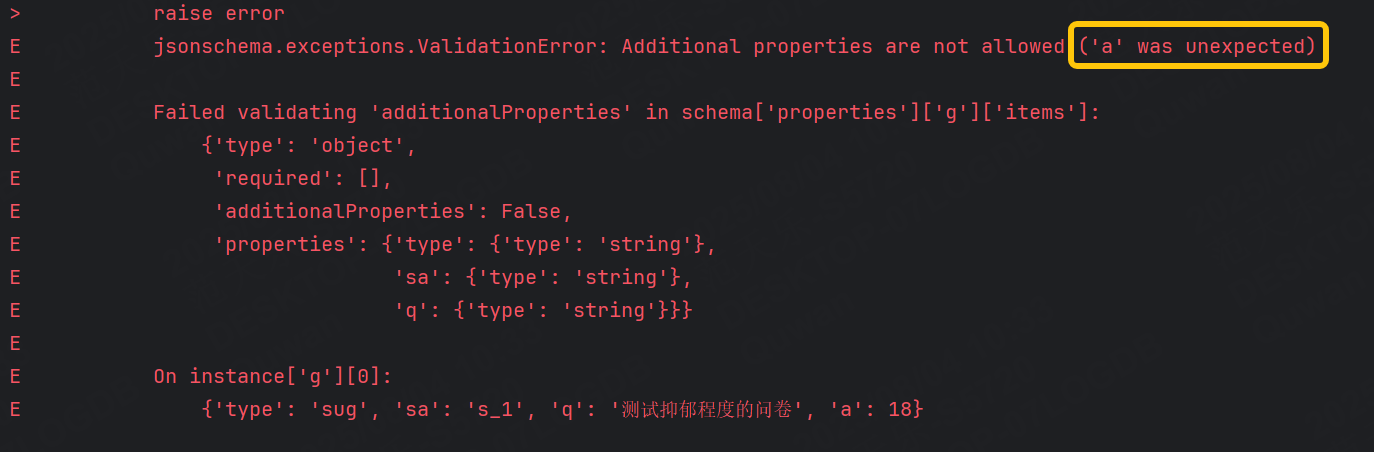
minProperties 和 maxProperties :指定對象的最小和最大屬性數量。
例如:此時的json對象中只有5個字段:"q"、"p"、"g"、"slid"、"queryid"。
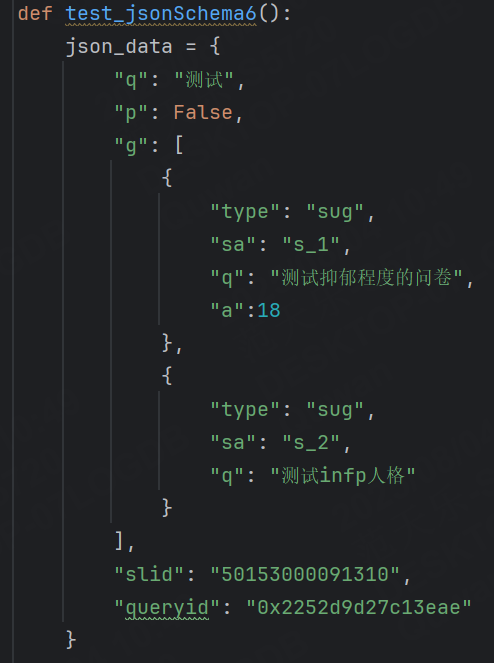
我們可以設置最小有5個字段,最多不超過7個。
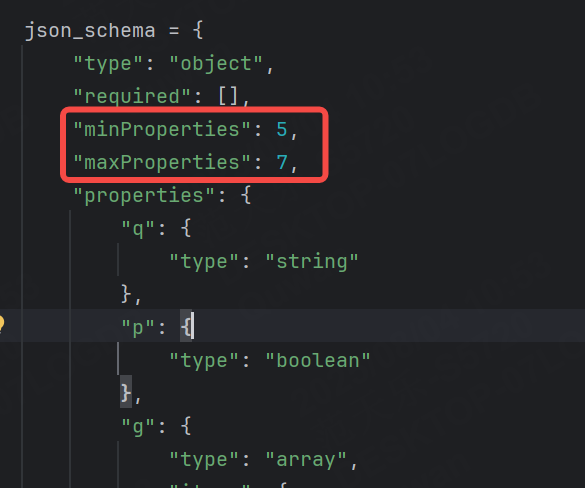
此時可以運行成功,那如果再額外添加幾個字段,讓字段數超過范圍呢?
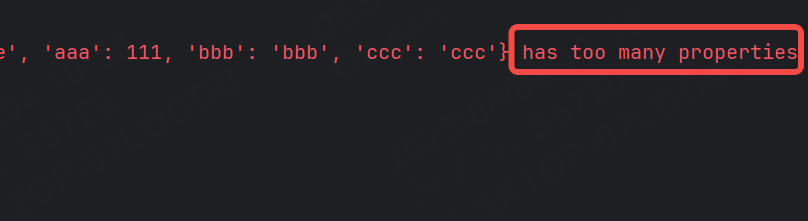
2.7.2.6 必需屬性
通過 required 關鍵字,JSON Schema 可以指定哪些屬性是必需的。如果 JSON 實例中缺少這些必需屬性,驗證將失敗。
可能會出現下面的場景:JSON Schema中約束了字段,但是JSON返回值中沒有出現該字段,但是用例跑通過的錯誤情況。
例如此時的json中的"g"字段沒有接受到,但是運行結果是正確的。
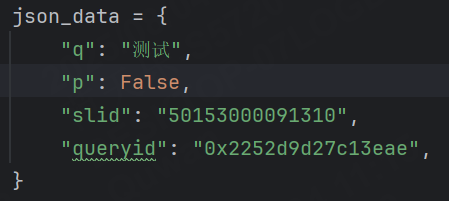
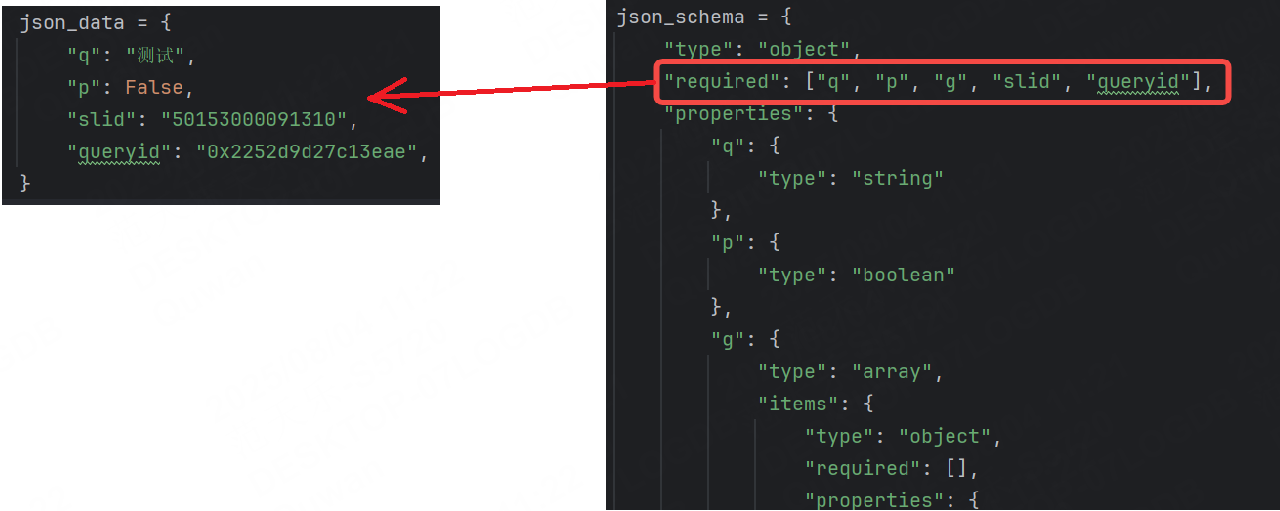
此時我們就需要設置?required 關鍵字,表示該字段是必需的。
我們使用JSON轉Schema工具時,會自動幫我們生成 required 關鍵字

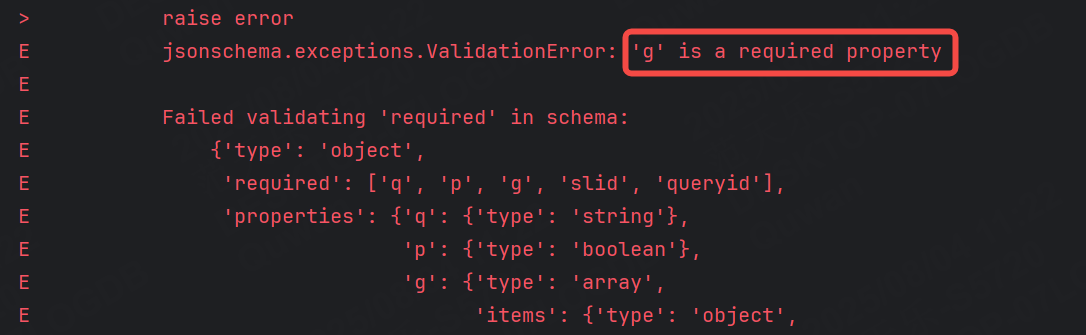
演示:
運行結果:
2.7.2.7 依賴關系
dependentRequired 可以定義屬性之間的依賴關系。例如,如果某個屬性存在,則必須存在另一個屬性。
示例:json有如下字段,如果我們設置height依賴于age,如果age存在,那么height也一定存在。
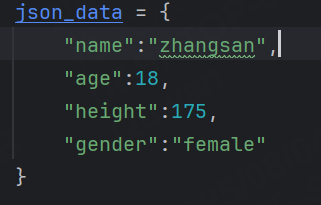
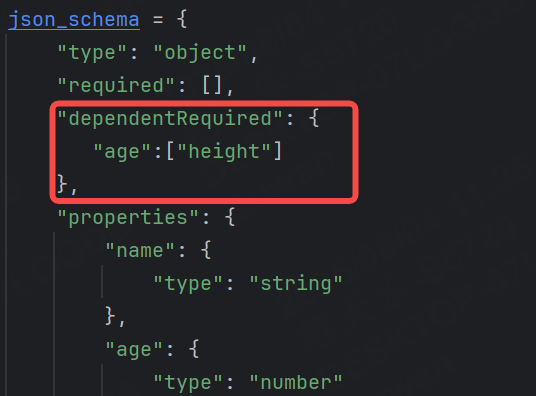
接下來我們分別演示以下幾種情況:
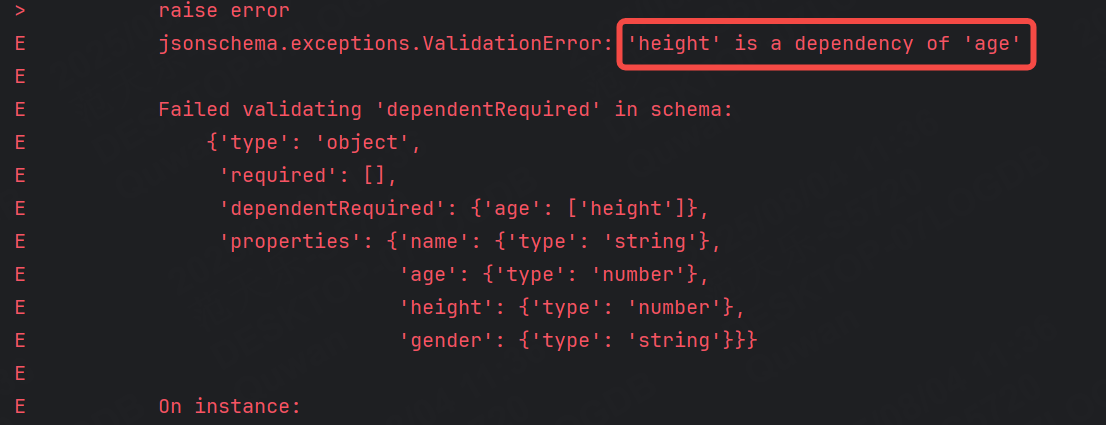
1.刪除json中的height:
2.刪除json中的age
3.刪除json中的age和height
結論:age存在時,height必須存在,如果age不存在,則height存不存在都可以。
2.8 logging日志模塊
2.8.1 介紹
logging 是 Python 標準庫中的一個模塊,它提供了靈活的日志記錄功能。通過 logging ,開發者可以方便地將日志信息輸出到控制臺、文件、網絡等多種目標,同時支持不同級別的日志記錄,以滿足不同場景下的需求。
2.8.2 使用
示例1:全局logging
import logginglogging.debug('This is a debug message')
logging.info('This is a info message')
logging.warning('This is a warning message')
logging.error('This is a error message')
logging.critical('This is a critical message')運行結果:
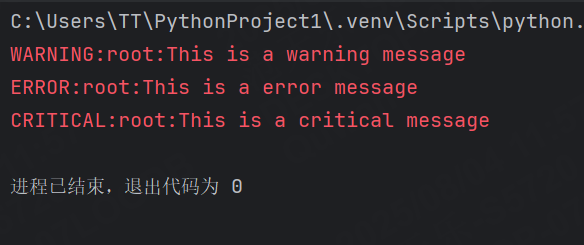
默認情況下,logging只會打印warning及以上級別的日志。
要想修改默認打印日志級別,例如將級別修改成Info
logging.basicConfig(level=logging.INFO)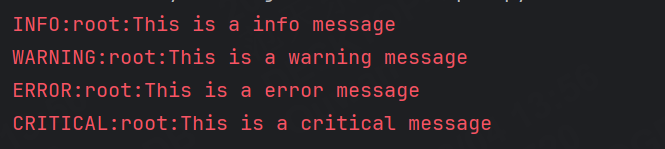
示例2:自定義logger并輸出到控制臺
logging.basicConfig(level=logging.INFO)logger = logging.getLogger("my_logger")
#設置logger的日志級別
logger.setLevel(logging.DEBUG)logger.debug('This is a debug message')
logger.info('This is a info message')
logger.warning('This is a warning message')
logger.error('This is a error message')
logger.critical('This is a critical message')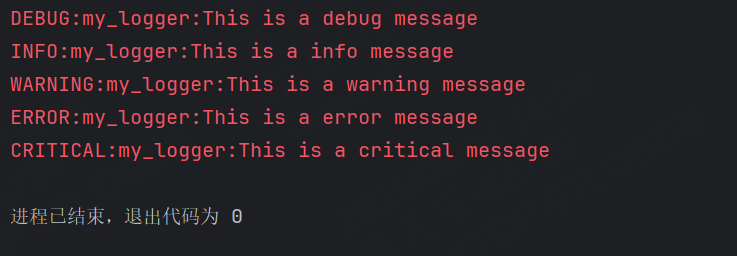
雖然全局的logging設置的級別是INFO,但是我們可以自定義一個logger,并且設置對應的級別。在打印時會按照自定義的logger來打印。
示例3:自定義logger并輸出到日志文件
logger = logging.getLogger("my_logger")
#設置logger的日志級別
logger.setLevel(logging.DEBUG)#創建文件處理器,將日志輸出到文件中(可以自動創建)
handler = logging.FileHandler("my_logger.log")
#將處理器添加到日志記錄器中
logger.addHandler(handler)logger.debug('This is a debug message')
logger.info('This is a info message')
logger.warning('This is a warning message')
logger.error('This is a error message')
logger.critical('This is a critical message')- 獲取日志記錄器: logging.getLogger(__name__) 獲取一個日志記錄器對象, name 是當前模塊的名稱。使用模塊名稱作為日志記錄器的名稱有助于在大型項目中區分不同模塊的目志。
- 設置日志級別: logger.setLevel(logging.DEBUG) 將日志記錄器的級別設置為DEBUG ,這意味著所有 DEBUG 及以上級別的日志都會被記錄。
- 日志級別金字塔:DEBUG < INFO < WARNING < ERROR < CRITICAL
- 高于設定級別的日志才會被處理
- 創建文件處理器: logging.FileHandler(filename="my_logger.log") 創建一個文件處理器,將日志信息寫入到名為 my_logger.log 的文件中。
- 添加處理器: logger.addHandler(handler) 將文件處理器添加到?志記錄器中,這樣日志記錄器就會使用這個處理器來處理日志信息。
示例4:設置日志格式
import logginglogger = logging.getLogger("my_logger")#設置logger的日志級別
logger.setLevel(logging.DEBUG)#創建文件處理器,將日志輸出到文件中(可以自動創建)
handler = logging.FileHandler("my_logger.log")# 創建?個?志格式器對象
formatter = logging.Formatter("%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s:%(lineno)d)] - %(message)s"
)
#將格式器設置到處理器上)
handler.setFormatter(formatter)#將處理器添加到日志記錄器中
logger.addHandler(handler)logger.debug('This is a debug message')
logger.info('This is a info message')
logger.warning('This is a warning message')
logger.error('This is a error message')
logger.critical('This is a critical message')運行結果:
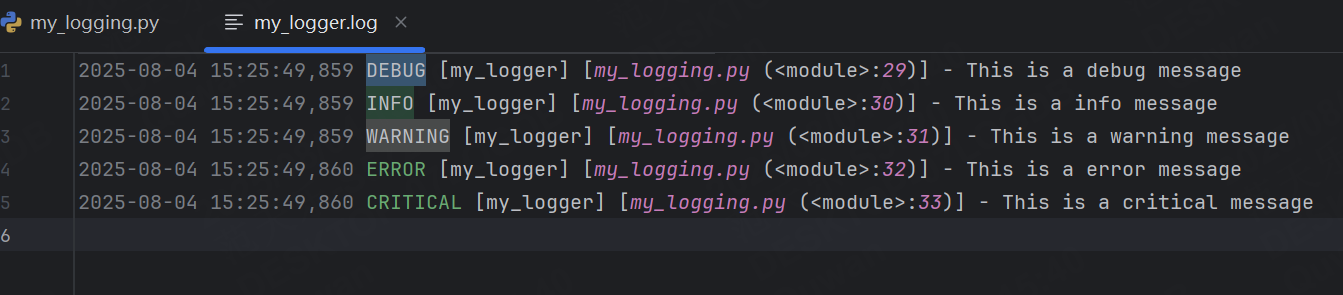
logging.Formatter 是用于定義日志輸出格式的類。在構造函數中,傳遞了?個格式字符串,用于指定日志信息的格式。格式字符串中使用了一些特殊的占位符(以 % 開頭),這些占位符會被替換為相應的日志信息內容
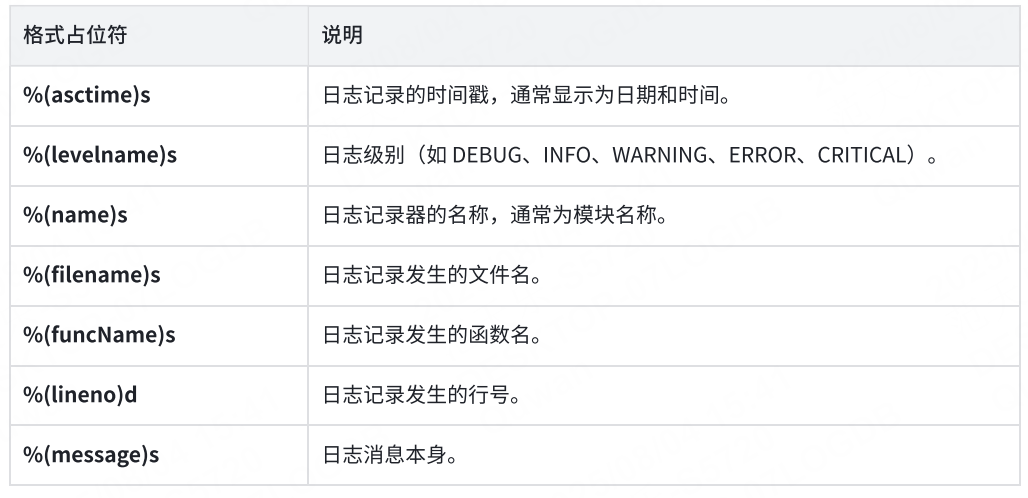
handler.setFormatter(formatter) 將創建的格式器對象設置到處理器上。這意味著處理器在處理日志信息時,會使用這個格式器來格式化日志信息。
通過這種方式,你可以控制日志信息的輸出格式,使其包含你感興趣的信息,如時間戳、日志級別、文件名、函數名、行號等。
2.9 測試報告allure
官方文檔:Allure Report Docs – Pytest configuration
2.9.1 介紹與安裝
介紹:
Allure Report 由一個框架適配器和 allure 命令行工具組成,是一個流行的開源工具,用于可視化測試運行的結果。它可以以很少甚至零配置的方式添加到您的測試工作流中。它生成的報告可以在任何地方打開,并且任何人都可以閱讀,無需深厚的技術知識
安裝:
1)下載allure-pytest包
pip install allure-pytest==2.13.52)下載Windows版Allure報告
- 下載壓縮包:allure下載鏈接
 https://github.com/allure-framework/allure2/releases/download/2.30.0/allure- 2.30.0.zip
https://github.com/allure-framework/allure2/releases/download/2.30.0/allure- 2.30.0.zip - 解壓
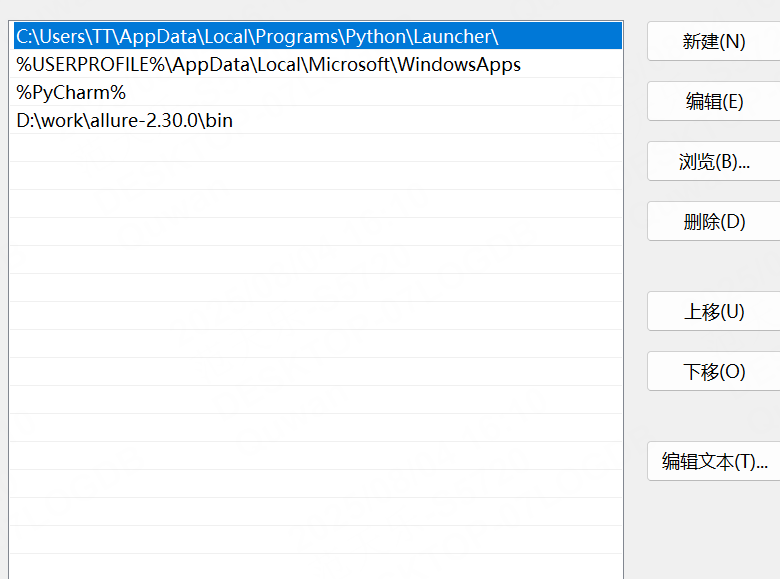
- 添加系統環境變量
將allure-2.29.0對應bin目錄添加到系統環境變量中
- 確認結果
打開cmd,查看allure版本

出現 allure 版本則安裝成功。
若出現cmd中執行?allure --version 可以打印版本,但是pycharm控制臺執行命令提示命題找不到,則需要修改pycharm中命令行環境,如下:
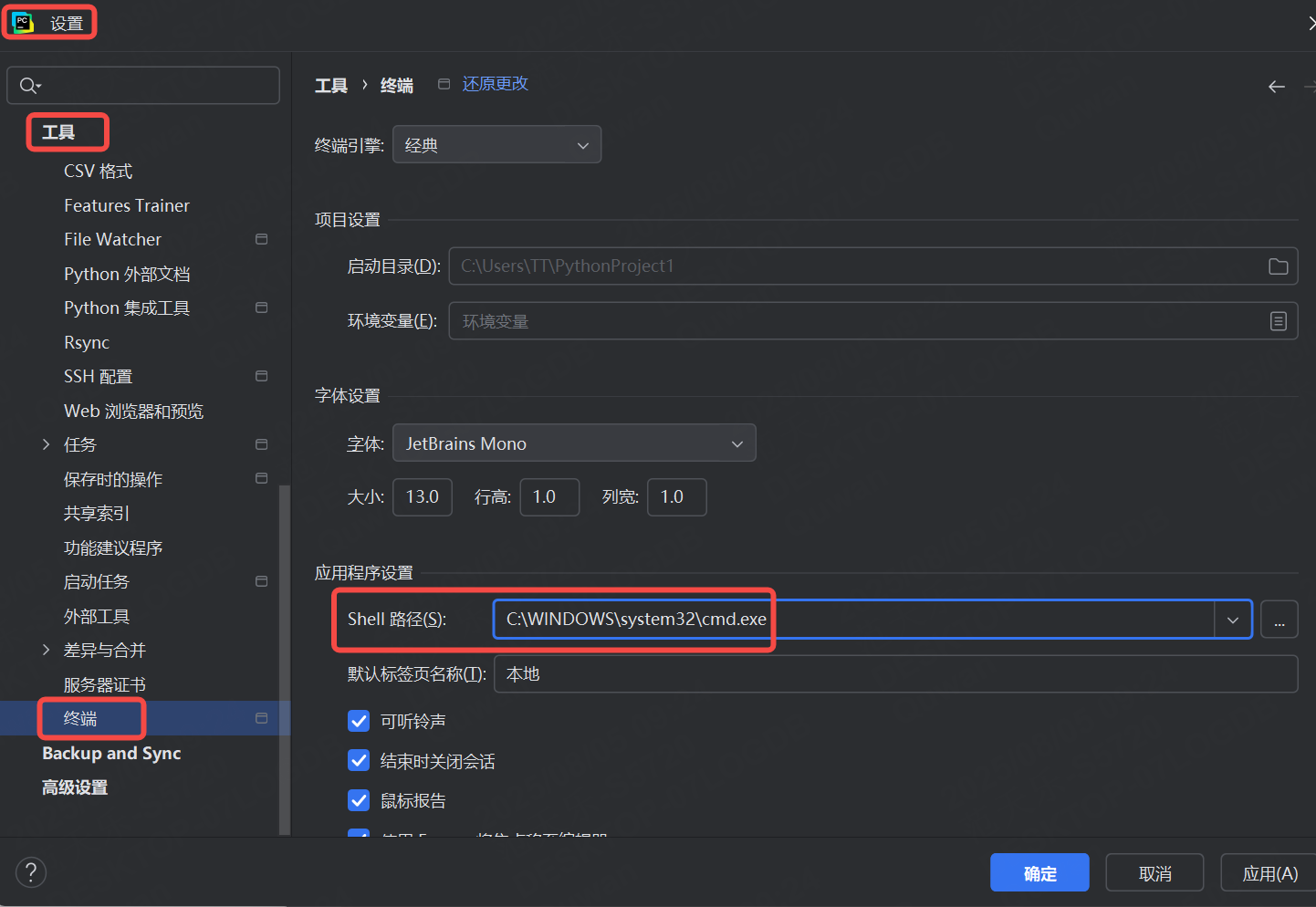
保存后需要重啟pycharm!!!!!!
檢查pycharm中命令行是否可以使用allure命令

2.9.2?使用
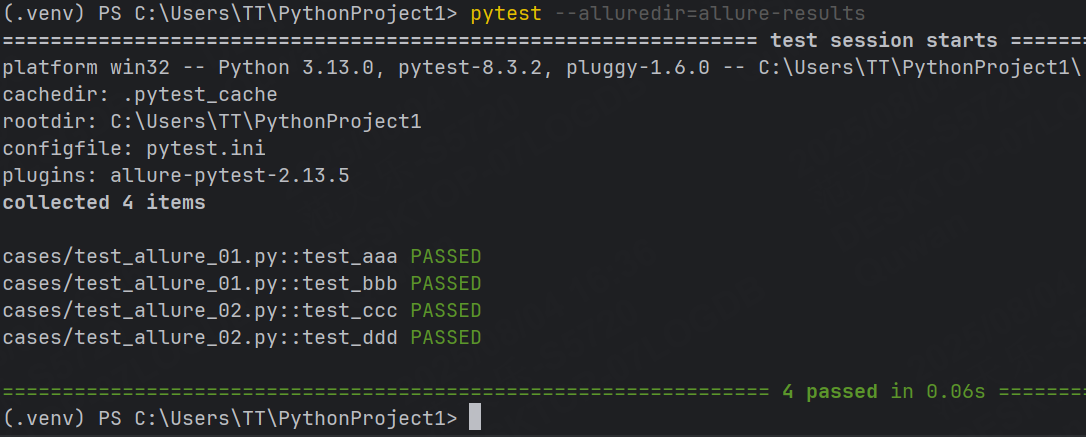
step1:運行自動化,并指定測試報告放置路徑
pytest --alluredir=results_dir(保存測試報告的路徑)?例:pytest --alluredir=allure-results將測試報告保存至allure-resultes文件夾中(不存在則創建)
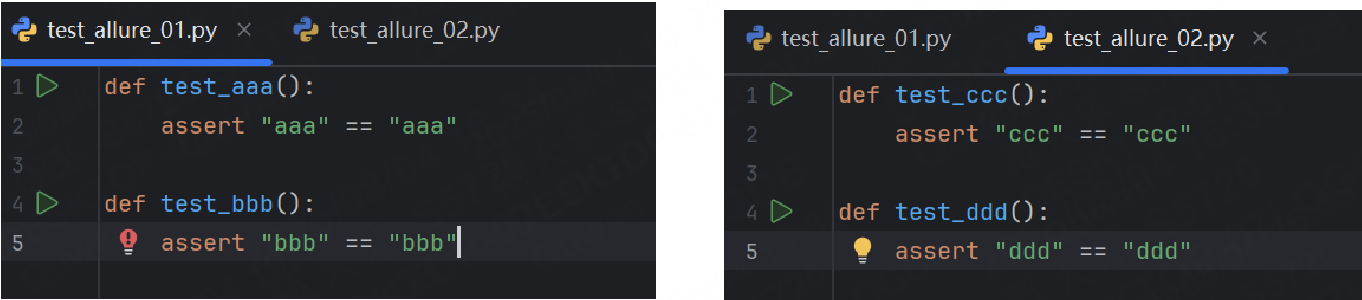
我們先創建如下兩個文件的測試用例
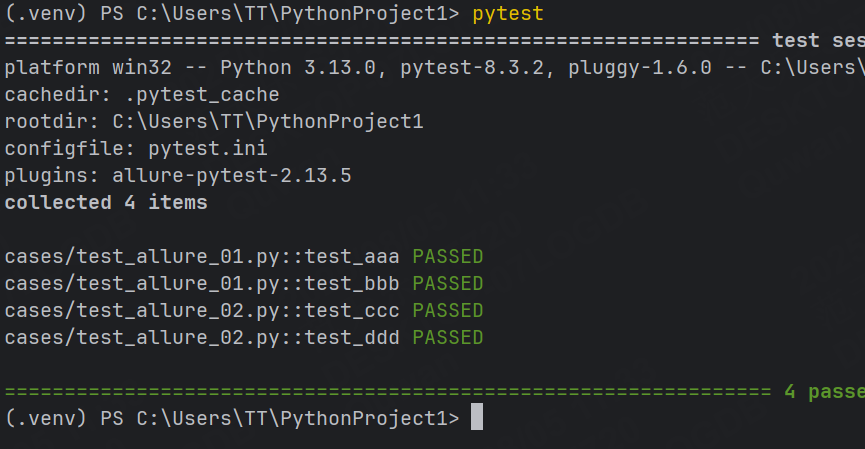
運行命令:
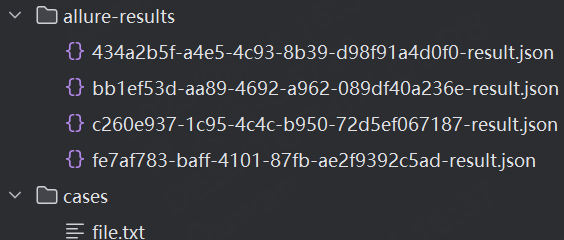
當前項目下自動生成 allre-results 文件夾,存放報告相關文件
?清除上一次生成的測試報告:--clean-alluredir
#清除上?次?成的測試報告
pytest --alluredir=./allure-results --clean-alluredir例如:現在的allure-results中包含了8個測試報告。
如果我們想讓兩次生成的測試報告相互之間不影響,那我們就可以使用上面的命令
修改配置文件中的測試報告存放路徑:
如果嫌每次敲命令都需要攜帶測試報告路徑比較麻煩,我們可以在配置文件中進行修改。
生成測試報告可以在控制臺通過命令將結果保存在 allre-results 文件夾中,也可以在pytest.ini文件中配置測試報告放置路徑
addopts = -vs --alluredir allure-results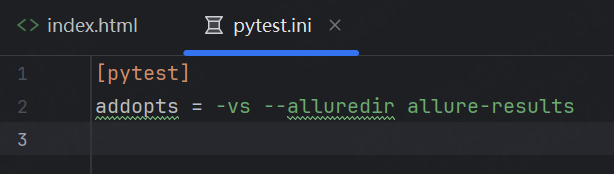
此時我們只需要輸入pytest命令即可。
step2:查看測試報告
1)方法一:啟動一個本地服務器來在瀏覽器中展示測試報告
終端執行命令: allure serve [options] <allure-results> ,自動在瀏覽器打開測試報告
- --host :指定服務器監聽的主機地址,默認為 localhost。
- --port :指定服務器監聽的端口號,默認為 0(自動選擇空閑端口)
- --clean-alluredir :清除上一次生成的測試報告
一.不指定端口號和主機地址:
#不指定端?號和主機地址
allure serve .\allure-results\
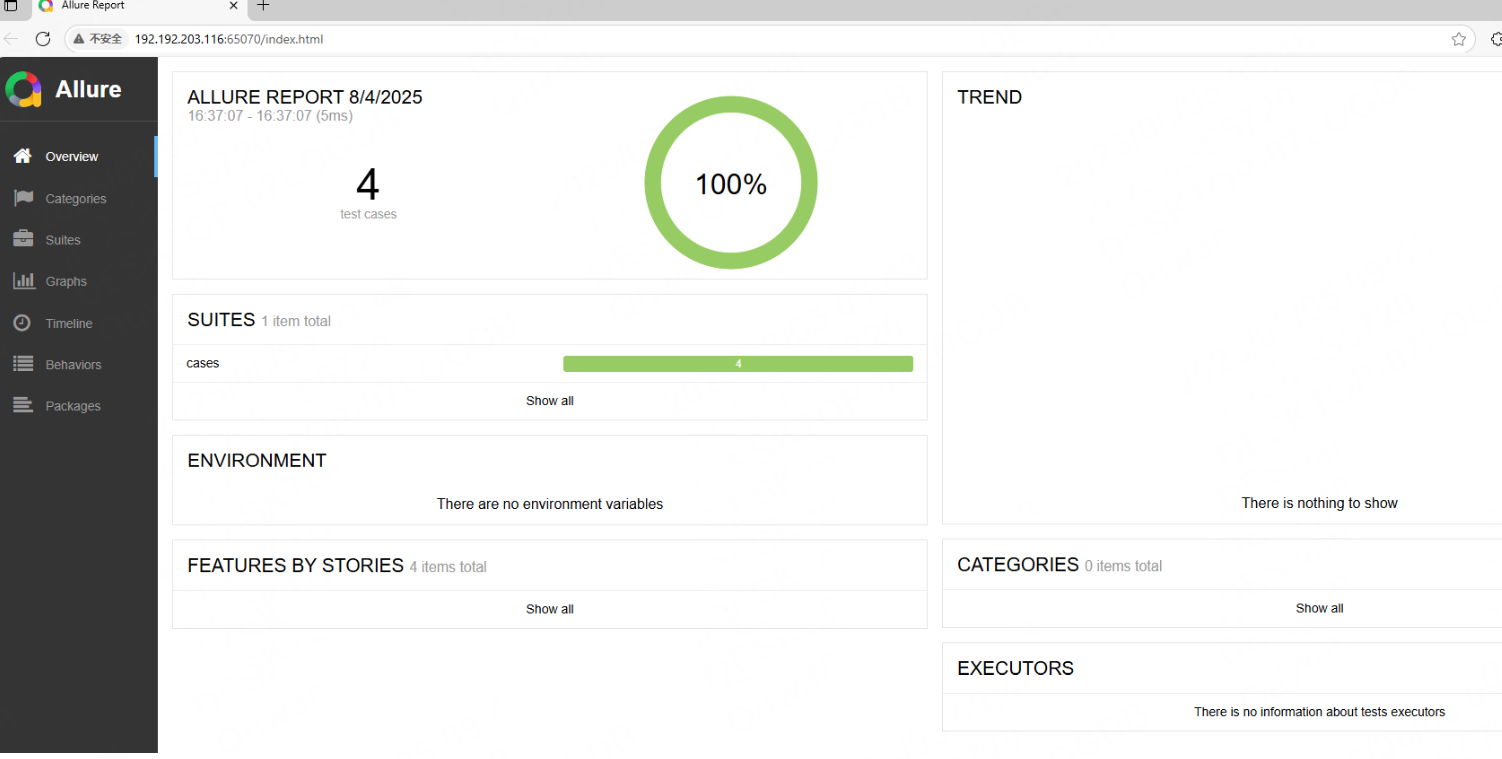
通過終端命令最終打開了一個網頁版測試報告
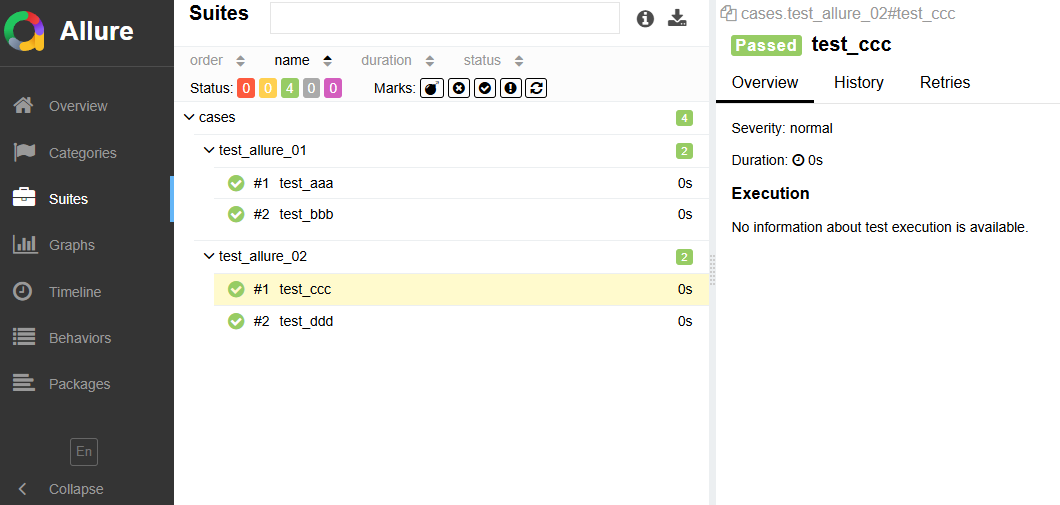
Suites會展示所有的測試用例,右側的界面展示每個界面的執行結果以及運行時間。
二.指定端口號:
#指定端?號
allure serve --port 8787 .\allure-results\
指定的端口號必須是空閑的,不能被占用。
2)方法二:從測試結果生成測試報告
終端執行命令: allure generate [options] <allure-results> -o <reports>
- allure-results:測試結果文件夾
- reports:測試報告文件夾
示例:

自動幫我們生成allure-report文件夾
選擇其中的index.html,可以選擇使用不同的瀏覽器去訪問。
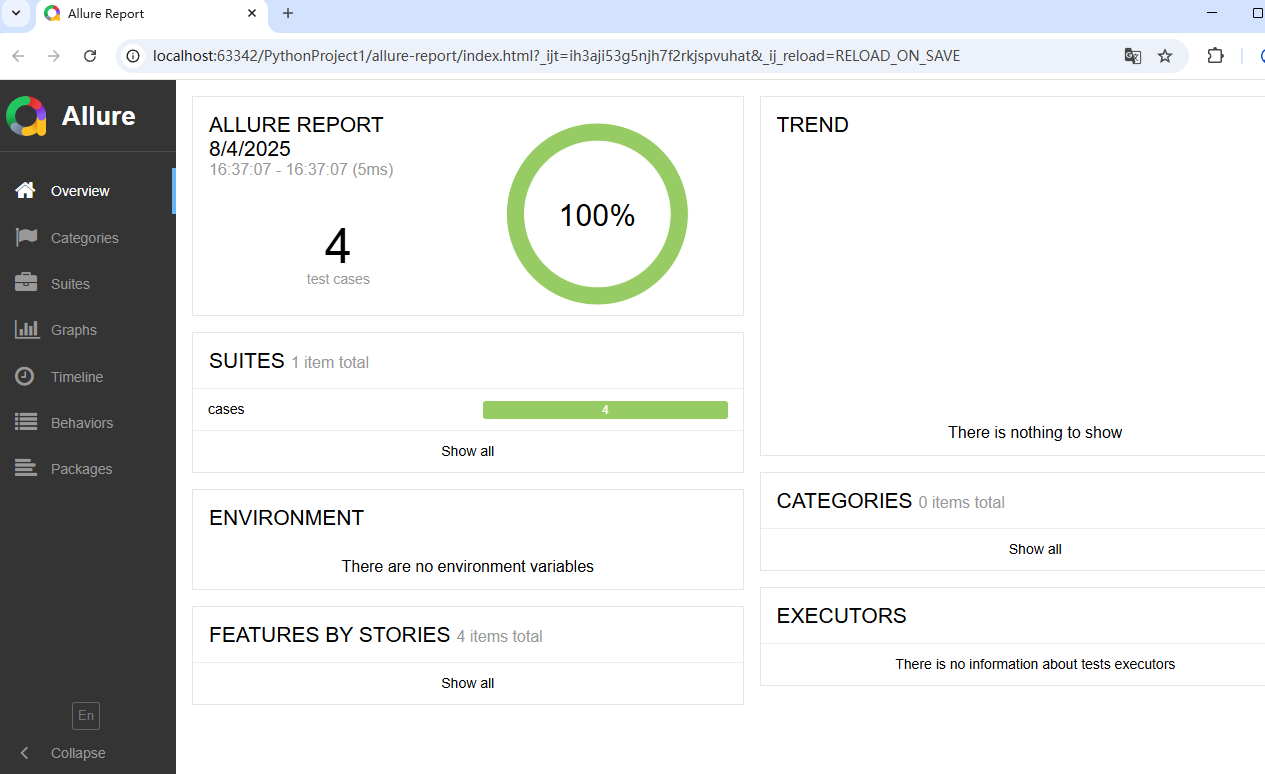
并且打開后,和之前直接在瀏覽器打開是一樣的。
注意:如果歷史生成的測試結果json文件不清空,生成的測試報告會整合歷史的運行情況,并集成到一個測試報告中。
例如:我們再生成一下測試結果,現在就有8條了,有4條是上一次的,有4條是這一次的。
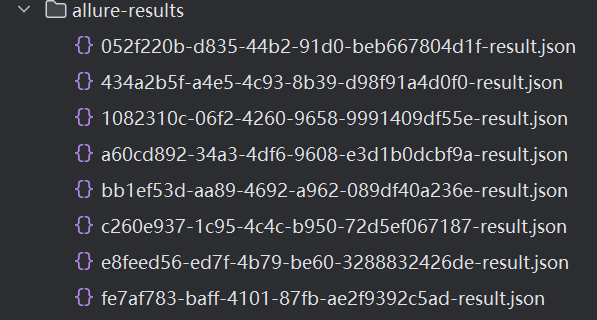
生成的測試報告如下:在Suites中查看每一條測試用力的Retries,可以看到多了一些內容,這些就是歷史的執行結果。
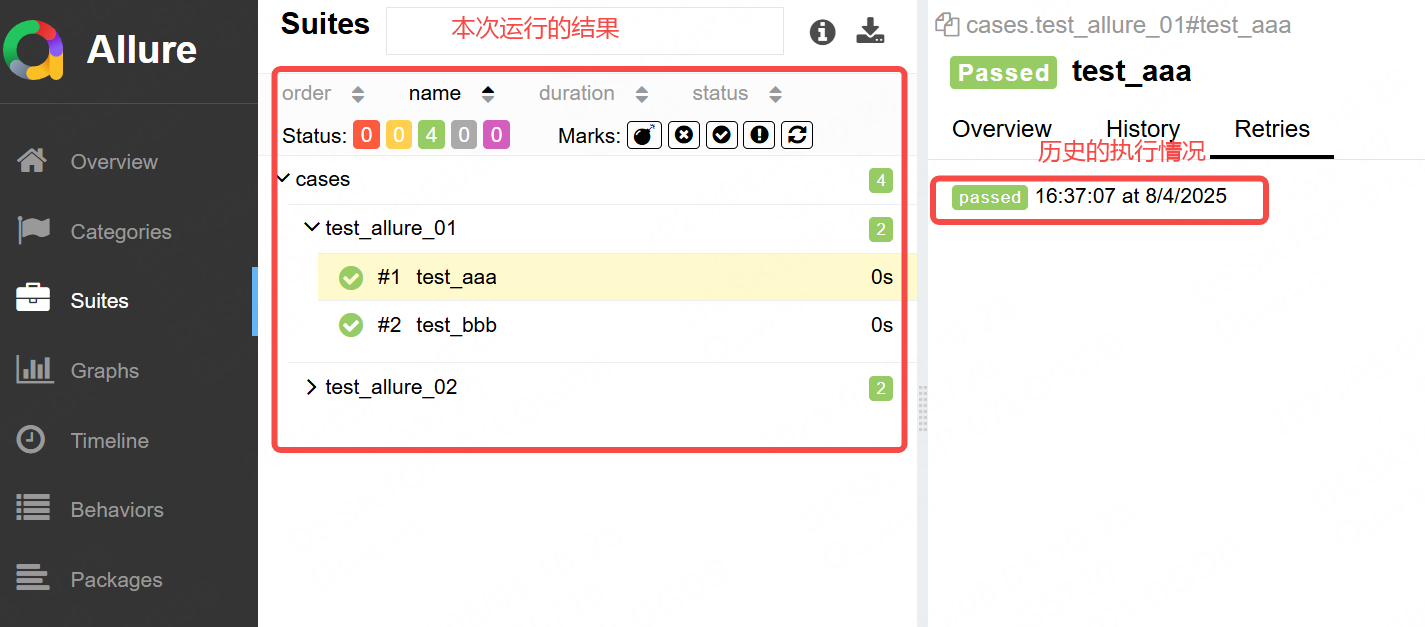
注意:測試報告只能同事存在一份,如果已經在一個文件夾中生成了一份測試報告,再在該文件夾下繼續生成就會出錯,如下所示:

報錯信息中也提示了我們需要使用--clean命令。
allure generate .\allure-results\ -o .\allure-report --clean
此時舊的就被覆蓋掉了。











)






![[硬件電路-120]:模擬電路 - 信號處理電路 - 在信息系統眾多不同的場景,“高速”的含義是不盡相同的。](http://pic.xiahunao.cn/[硬件電路-120]:模擬電路 - 信號處理電路 - 在信息系統眾多不同的場景,“高速”的含義是不盡相同的。)
