文章目錄
1、前置說明
1、定義二叉樹結點結構
2、創建新節點
3、手動創建二叉樹
2、二叉樹的遍歷
1、前序,中序和后序遍歷
1.1、二叉樹前序遍歷
1.2、二叉樹中序遍歷
1.3、二叉樹后序遍歷
2、二叉樹層序遍歷
?3、二叉樹的基礎操作
1、二叉樹節點總數
2、葉子節點個數
3、二叉樹高度
4、二叉樹第k層節點數
5、查找目標節點
6、通過前序遍歷的數組"ABD##E#H##CF##G##"構建二叉樹
7、銷毀
4、經典算法OJ
1、單值二叉樹
2、檢查兩顆樹是否相同
3、另一棵樹的子樹
1、前置說明
前面的文章我們根據完全二叉樹的結構特點,用順序存儲的方式實現了堆相關的接口以及堆排序。下面我們用鏈式結構來實現普通二叉樹的基本操作,但在實現之前,我們需要先創建一棵二叉樹,然后才能學習相關的操作,由于我們對二叉樹的結構掌握還不夠深入,我們就先手動地創建一棵二叉樹,等我們對二叉樹的結構有了進一步的理解,再反過來實現二叉樹真正的創建。
二叉樹是: 1、空樹
2、非空:根結點,根結點的左子樹、根結點的右子樹組成的。
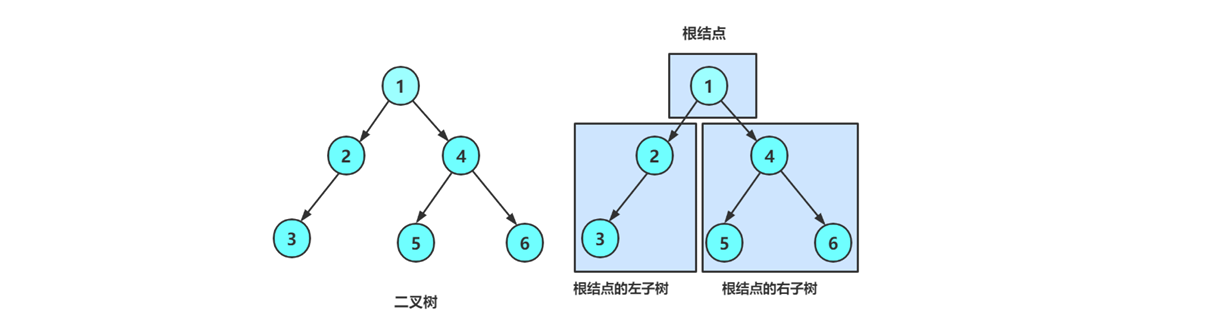
從概念中可以看出,二叉樹定義是遞歸式的,因此后序基本操作中基本都是按照該概念實現的。?
1、定義二叉樹結點結構
用鏈式結構實現二叉樹,節點結構就類似于鏈表的節點。同時,我們還需要兩個結構體類型的指針來連接孩子節點。
//定義二叉樹存儲的數據類型
typedef int BTDateType;
//定義節點結構
typedef struct BinaryTree
{BTDateType val;struct BinaryTree* left;struct BinaryTree* right;
}BTNode;2、創建新節點
BTNode* BuyBTNode(BTDateType x)
{BTNode* pst = (BTNode*)malloc(sizeof(BTNode));if (pst == NULL){perror("malloc");exit(1);}pst->val = x;pst->left = NULL;pst->right = NULL;
}3、手動創建二叉樹
BTNode* BinaryTreeCreat()
{//創建二叉樹的節點BTNode* s1 = BuyBTNode(1);BTNode* s2 = BuyBTNode(2);BTNode* s3 = BuyBTNode(3);BTNode* s4 = BuyBTNode(4);BTNode* s5 = BuyBTNode(5);BTNode* s6 = BuyBTNode(6);//連接節點成為二叉樹s1->left = s2;s2->left = s3;s2->right = s7;s1->right = s4;s4->left = s5;s4->right = s6;return s1;
}2、二叉樹的遍歷
1、前序,中序和后序遍歷
所謂二叉樹遍歷(Traversal)是按照某種特定的規則,依次對二叉樹中的結點進行相應的操作,并且每個結點只操作一次。訪問結點所做的操作依賴于具體的應用問題。 遍歷 是二叉樹上最重要的運算之一,也是二叉樹上進行其它運算的基礎。
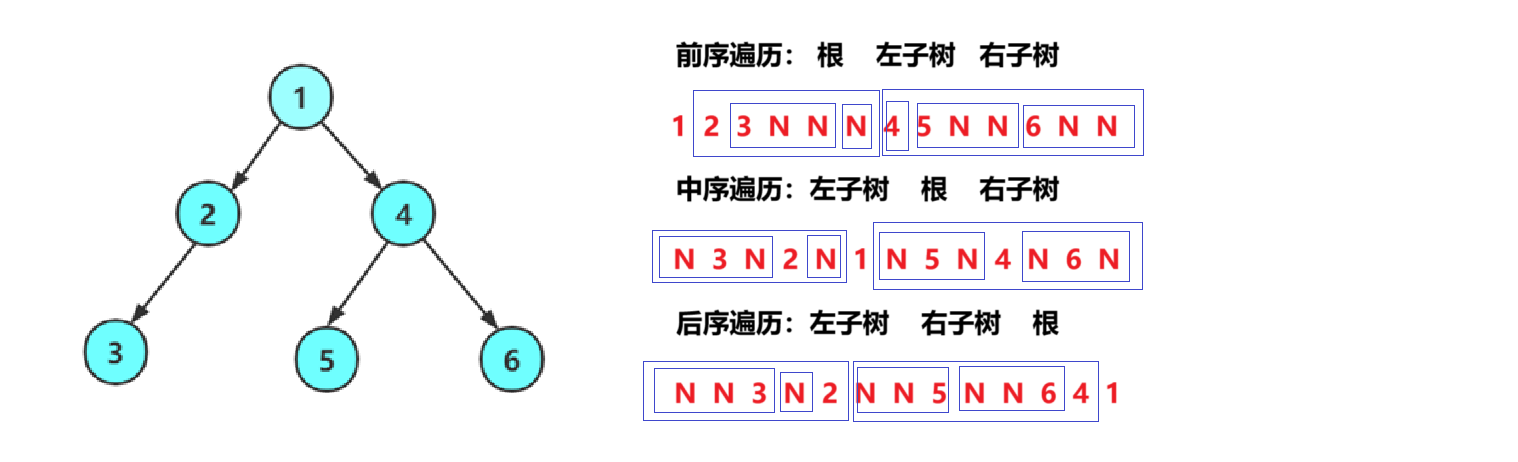
按照規則,二叉樹的遍歷有:前序/中序/后序的遞歸結構遍歷:
1. 前序遍歷(先序遍歷)——訪問根結點的操作發生在遍歷其左右子樹之前,根->左子樹->右子樹。
2. 中序遍歷——訪問根結點的操作發生在遍歷其左右子樹之中(間),左子樹->根->右子樹。
3. 后序遍歷——訪問根結點的操作發生在遍歷其左右子樹之后,左子樹->右子樹->根。
由于被訪問的結點必是某子樹的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解釋為 根、根的左子樹和根的右子樹。NLR、LNR和LRN分別又稱為先根遍歷、中根遍歷和后根遍歷。?
// 二叉樹前序遍歷
void prevOrder(BTNode* root);
// 二叉樹中序遍歷
void midOrder(BTNode* root);
// 二叉樹后序遍歷
void afterOrder(BTNode* root);1.1、二叉樹前序遍歷
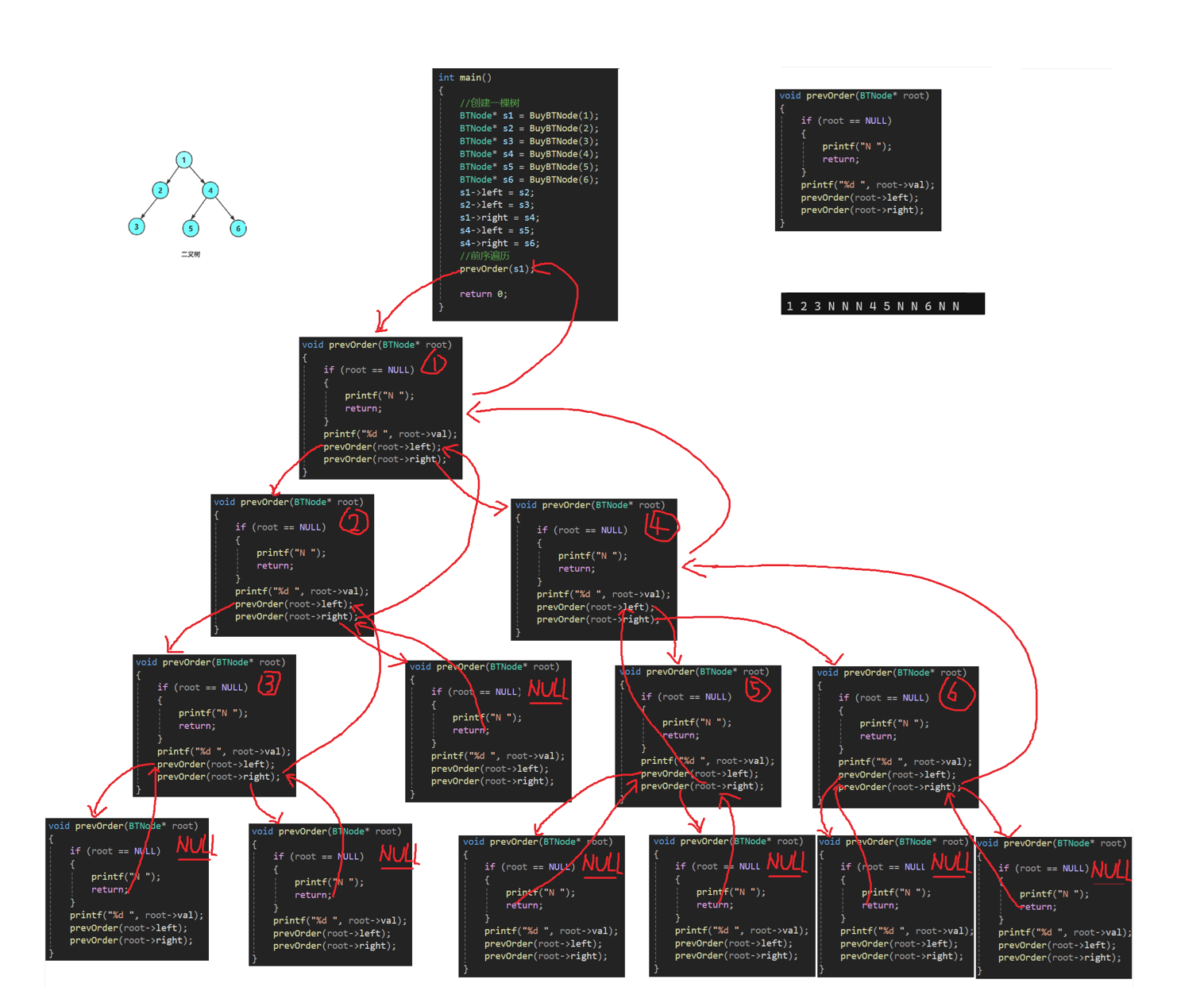
前序遍歷遞歸圖解:
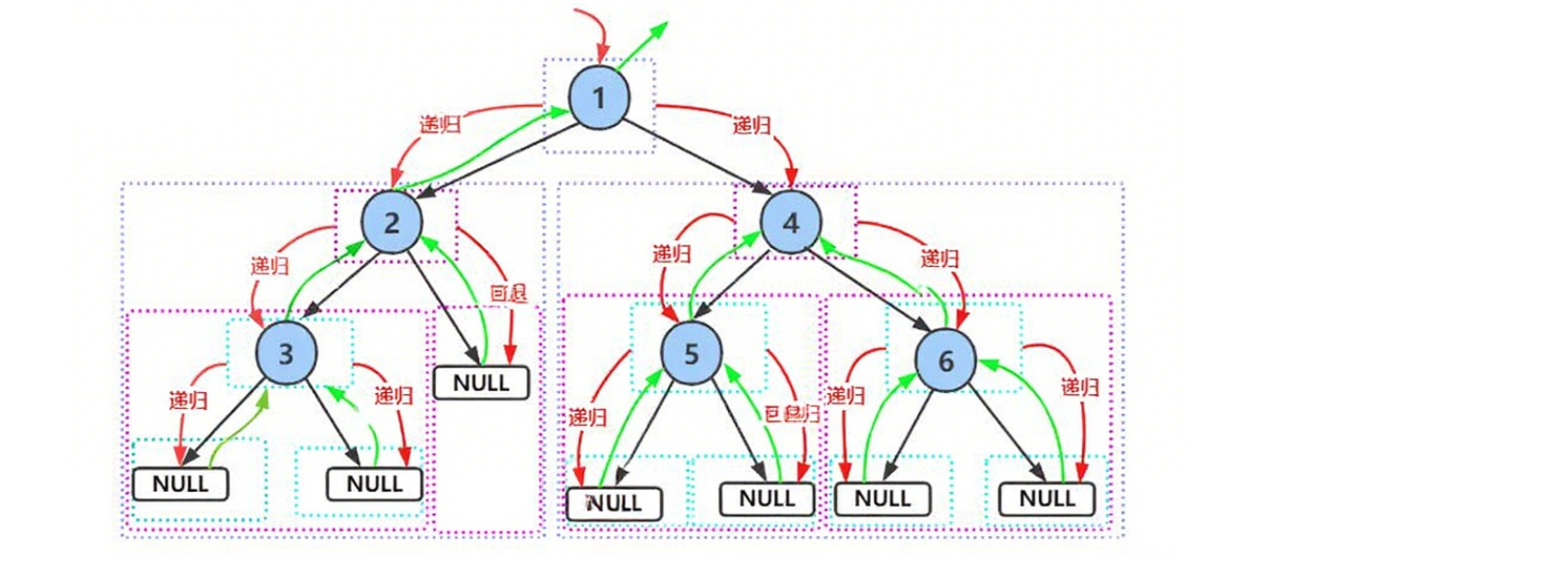
//前序遍歷:根 左子樹 右子樹
void prevOrder(BTNode* root)
{//打印空節點if (root == NULL){printf("N ");return;}//打印根節點的值printf("%d ", root->val);//遞歸遍歷左子樹prevOrder(root->left);//遞歸遍歷右子樹prevOrder(root->right);
}輸出結果:
1 2 3 N N N 4 5 N N 6 N N為了能夠更加直觀的理解遞歸調用的過程,我們畫圖來感受一下,后面用遞歸實現接口的過程中,我們也可以用類似的方法來畫圖,幫助我們理解!!!
1.2、二叉樹中序遍歷
//中序遍歷:左子樹 根 右子樹
void midOreder(BTNode* root)
{ //打印空節點if (root == NULL){printf("N ");return;}//遞歸遍歷左子樹midOreder(root->left);//打印根節點的值printf("%d ", root->val);//遞歸遍歷右子樹midOreder(root->right);
}輸出結果
N 3 N 2 N 1 N 5 N 4 N 6 N1.3、二叉樹后序遍歷
//后序遍歷:左子樹 右子樹 根
void afterOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}//遞歸遍歷左子樹afterOrder(root->left);//遞歸遍歷右子樹afterOrder(root->right);//打印根節點的值printf("%d ", root->val);
}輸出結果
N N 3 N 2 N N 5 N N 6 4 12、二叉樹層序遍歷
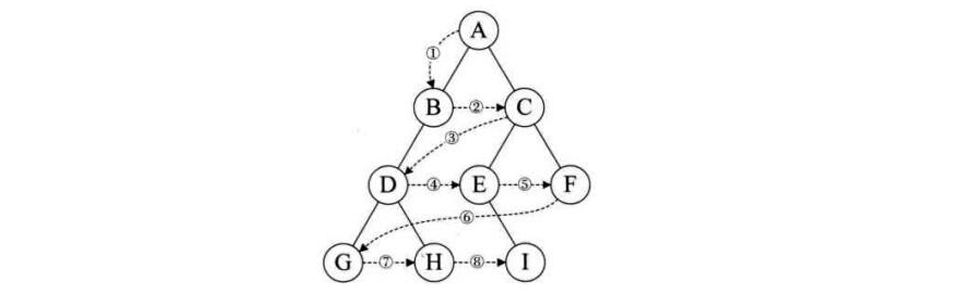
層序遍歷:除了先序遍歷、中序遍歷、后序遍歷外,還可以對二叉樹進行層序遍歷。設二叉樹的根結點所在 層數為1,層序遍歷就是從所在二叉樹的根結點出發,首先訪問第一層的樹根結點,然后從左到右訪問第2層 上的結點,接著是第三層的結點,以此類推,自上而下,自左至右逐層訪問樹的結點的過程就是層序遍歷。
?3、二叉樹的基礎操作
1、二叉樹節點總數
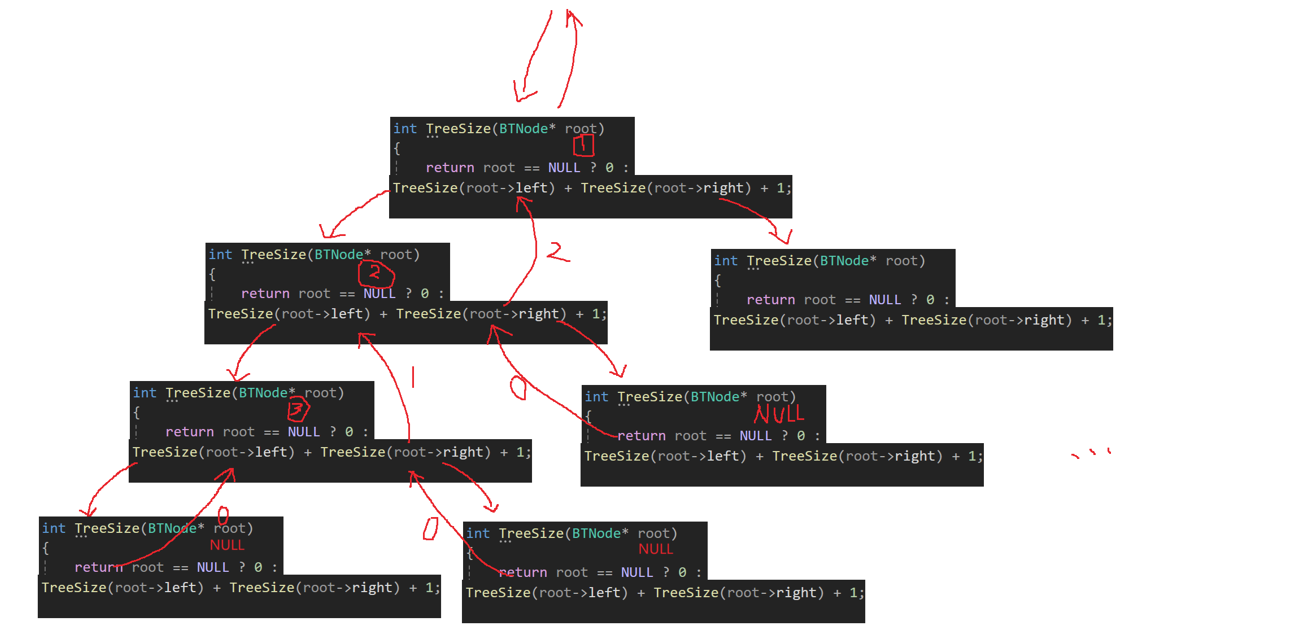
思路1:遍歷二叉樹,創建一個變量來記錄節點個數,但是,每次函數調用都是在棧區開辟空間,數據在函數調用結束后就會銷毀,所以要創建全局變量,或者用static修飾的全局變量(但是在調用之前需要初始化為0)。當遇到某個節點的左孩子或者右孩子為空時,遞歸結束,開始返回。
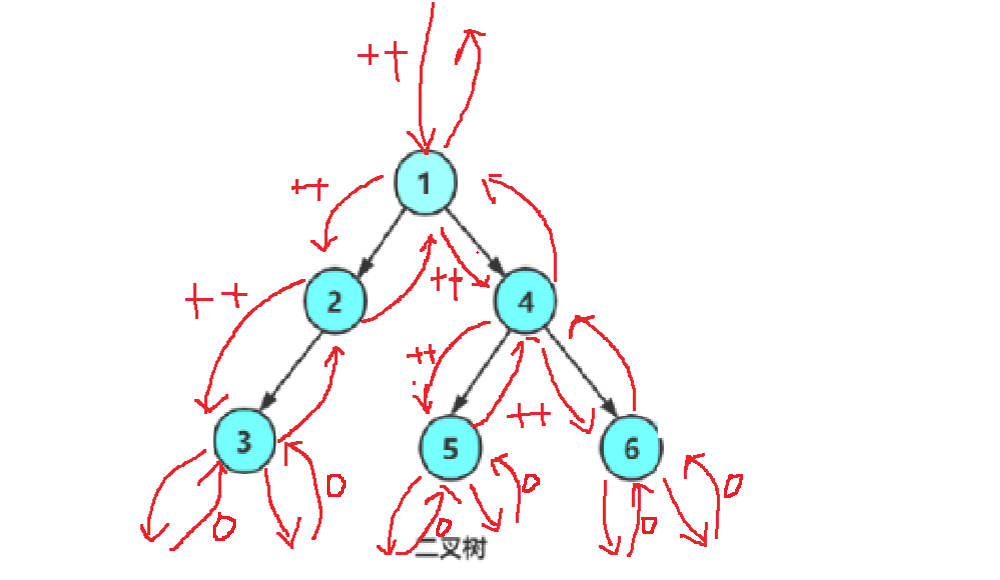
int size = 0;//全局變量
//static int size = 0;int TreeSize(BTNode* root)
{//遞歸結束,遇到空樹,返回if (root == NULL)return 0;else++size;//遍歷二叉樹TreeSize(root->left);TreeSize(root->right);return size;
}還有一種簡單的寫法,用三目操作符來判斷,但是不容易理解
int TreeSize(BTNode* root)
{return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}
遞歸調用圖解:?
?思路2:將size作為實參,但是為了讓形參改變的同時改變實參的值,我們需要傳實參的地址。
//將size作為參數
void TreeSize(BTNode* root, int* psize)
{if (root == NULL)return 0;else++(*psize);TreeSize(root->left, psize);TreeSize(root->right, psize);
}2、葉子節點個數
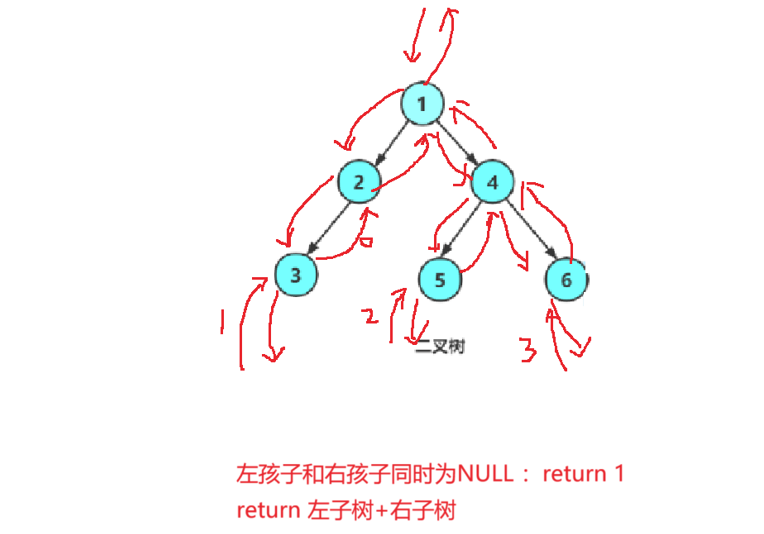
思路:遍歷二叉樹,將二叉樹不斷分為左子樹與右子樹,找左孩子與右孩子都不存在的節點,即葉子節點,然后將所有左子樹與右子樹的葉子節點加起來。
//計算葉子節點個數
int TreeLeafCount(BTNode* root)
{//遇到空節點,遞歸結束條件if (root == NULL){return 0;}//當左子樹與右子樹同時為空時為葉子節點if ((root->left == NULL) && (root->right == NULL)){return 1;}//葉子節點數等于左子樹+右子樹return TreeLeafCount(root->left) + TreeLeafCount(root->right);
}3、二叉樹高度
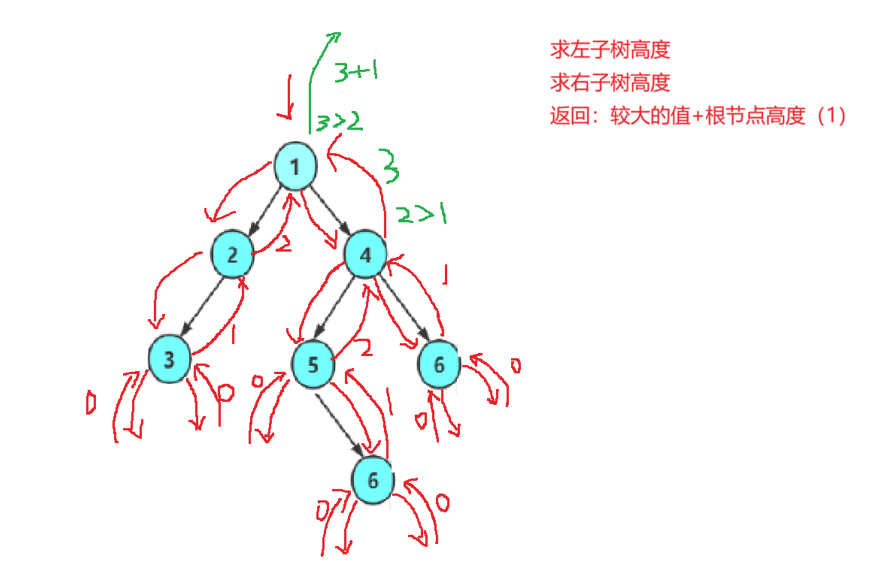
思路:遞歸遍歷二叉樹的左子樹與右子樹的同時,記下左子樹與右子樹的高度,然后比較左子樹與右子樹,二叉樹的高度就是較高的一個加上根節點的高度。
//計算二叉樹高度
int TreeHeight(BTNode* root)
{//遞歸結束條件if (root == NULL){return 0;}//記下返回值,防止造成時間效率低下//左子樹高度int leftheight = TreeHeight(root->left);//右子樹高度int rightheight = TreeHeight(root->right);//高度為較大的高度+根節點的高度if (leftheight > rightheight)return leftheight + 1;elsereturn rightheight + 1;//三目操作符//return leftheight > rightheight ? leftheight + 1 : rightheight + 1;
}
4、二叉樹第k層節點數
思路:計算二叉樹第k層節點數,遞歸遍歷二叉樹的左子樹與右子樹,計算第k-1層的節點的不為空的左孩子和右孩子的個數,返回左子樹與右子樹k-1層的節點的不為空的左孩子和右孩子的個數的和。
//計算第k層有多少個節點
int TreeNodecount_k(BTNode* root, int k)
{//遞歸結束條件if (root == NULL)return 0;//處理特殊情況if (k == 1)return 1;//注意不能使用k--或者--k,這樣遞歸一次,后一次調用相當于k-1-1return TreeNodecount_k(root->left, k - 1) + TreeNodecount_k(root->right, k - 1);
}5、查找目標節點
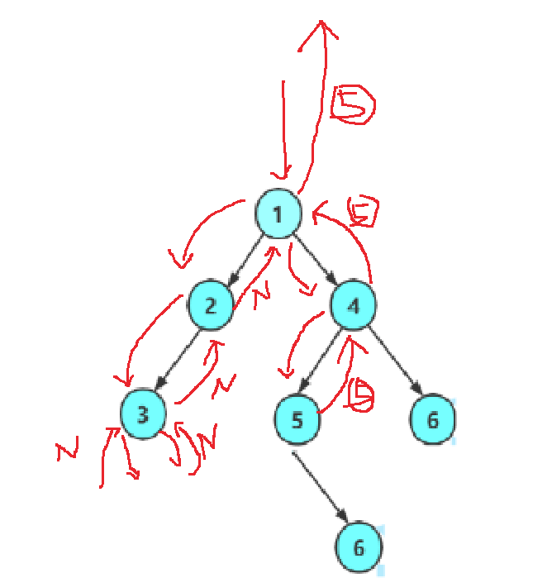
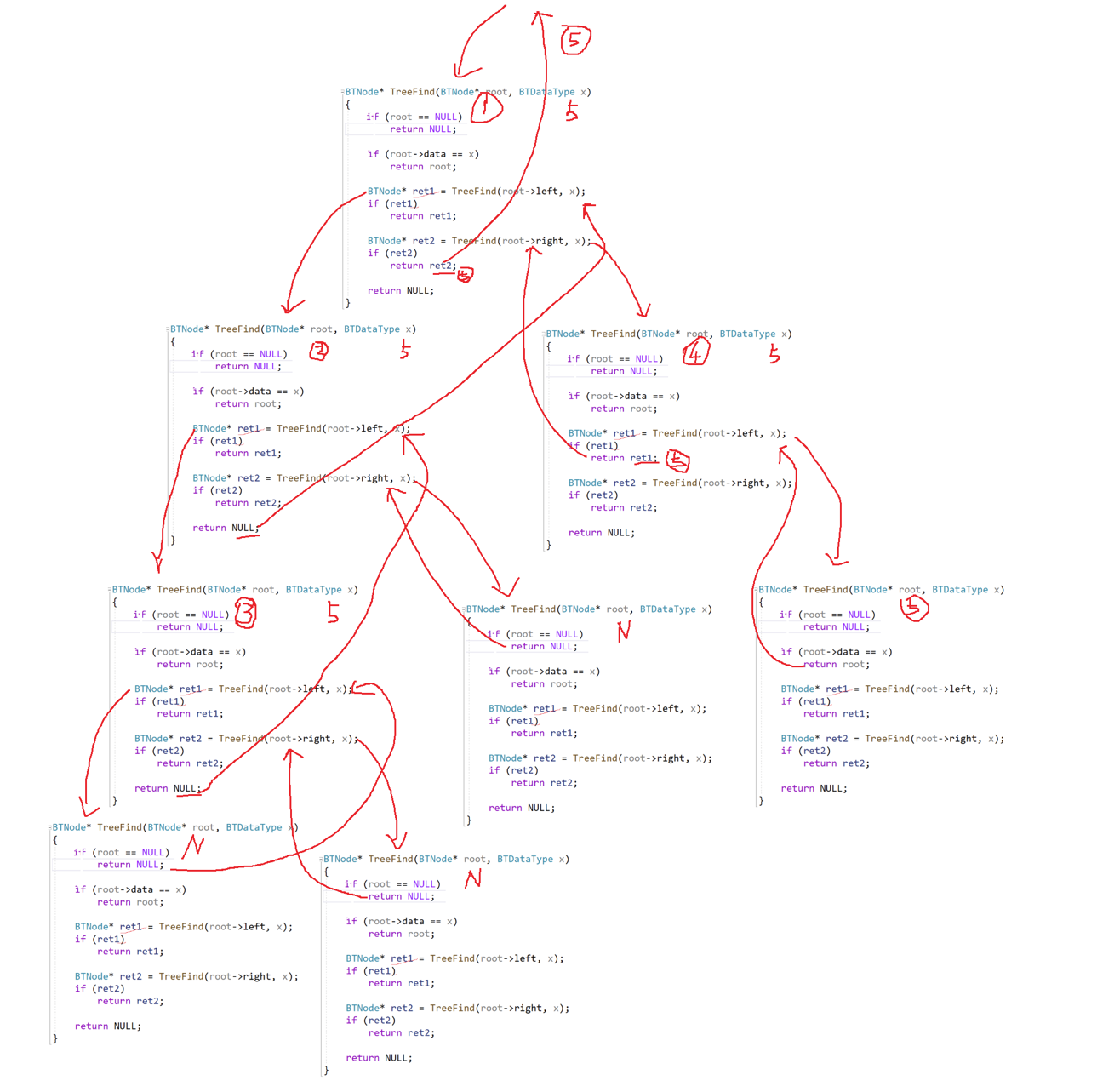
遞歸遍歷左子樹與右子樹
//查找目標節點
BTNode* TreeFind(BTNode* root, BTDateType x)
{if (root == NULL)return NULL;if (root->val == x){return root;}//記下返回值BTNode* ret1 = TreeFind(root->left, x);//找到了,就返回if (ret1)return ret1;BTNode* ret2 = TreeFind(root->right, x);if (ret2)return ret2;return NULL;
}
6、通過前序遍歷的數組"ABD##E#H##CF##G##"構建二叉樹
//定義二叉樹存儲的數據類型
typedef char BTDateType;?ABC##DE#G##F### 其中“#”表示的是空格,空格字符代表空樹。
//創建一顆二叉樹
BTNode* CreatTree(char* a, int* pi)
{//遞歸結束條件,同時處理空樹if (a[*pi] == '#'){(*pi)++;return NULL;}//不是'#'就為節點開辟空間BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));newnode->val = a[(*pi)++];//遞歸遍歷數組newnode->left = CreatTree(a, pi);newnode->right = CreatTree(a, pi);return newnode;
}int main()
{char arr[] = { "ABD##E#H##CF##G##" };int i = 0;BTNode* root = CreatTree(arr, &i);return 0;
}7、銷毀
思路:遞歸遍歷二叉樹,用后序遍歷,防止將根釋放而找不到左子樹與右子樹。
//銷毀二叉樹
//后序遍歷:左子樹->右子樹->根,防止將根釋放而找不到左子樹與右子樹
void TreeDestry(BTNode* root)
{if (root == NULL){return;}//遞歸遍歷左子樹TreeDestry(root->left);//遞歸遍歷右子樹TreeDestry(root->right);free(root);
}4、完整源碼?
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<math.h>
#include"Queue.h"//定義二叉樹的節點
typedef int BTDateType;
typedef struct BinaryTree
{BTDateType val;struct BinaryTree* left;struct BinaryTree* right;
}BTNode;BTNode* BuyBTNode(BTDateType x)
{BTNode* pst = (BTNode*)malloc(sizeof(BTNode));if (pst == NULL){perror("malloc");exit(1);}pst->val = x;pst->left = NULL;pst->right = NULL;
}
BTNode* BinaryTreeCreat()
{//創建一棵樹BTNode* s1 = BuyBTNode(1);BTNode* s2 = BuyBTNode(2);BTNode* s3 = BuyBTNode(3);BTNode* s4 = BuyBTNode(4);BTNode* s5 = BuyBTNode(5);BTNode* s6 = BuyBTNode(6);BTNode* s7 = BuyBTNode(7);s1->left = s2;s2->left = s3;s2->right = s7;s1->right = s4;s4->left = s5;s4->right = s6;//s5->right = s7;return s1;
}
//前序遍歷:根 左子樹 右子樹
void prevOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}printf("%d ", root->val);prevOrder(root->left);prevOrder(root->right);
}//中序遍歷:左子樹 根 右子樹
void midOreder(BTNode* root)
{if (root == NULL){printf("N ");return;}midOreder(root->left);printf("%d ", root->val);midOreder(root->right);
}
//后序遍歷:左子樹 右子樹 根
void afterOrder(BTNode* root)
{if (root == NULL){printf("N ");return;}afterOrder(root->left);afterOrder(root->right);printf("%d ", root->val);
}//計算節點總數
//每次函數調用都是在棧區開辟空間,數據在函數調用結束后就會銷毀,所以要創建全局變量,或者用static修飾的全局變量(但是在調用之前需要初始化為0)//錯誤示范:static修飾的變量在函數作用域內,又static修飾的變量不會銷毀,所以在main函數中反復調用會導致結果不斷增加
//int TreeNodeCount(BTNode* root)
//{
// static int size = 0;
// if (root == NULL)
// {
// return 0;
// }
// size++;
// TreeNodeCount(root->left);
// TreeNodeCount(root->right);
// return size;
//}int size = 0;//全局變量
//static int size = 0;int TreeSize(BTNode* root)
{if (root == NULL)return 0;else++size;TreeSize(root->left);TreeSize(root->right);return size;
}////將size作為參數
//void TreeSize(BTNode* root, int* psize)
//{
// if (root == NULL)
// return 0;
// else
// ++(*psize);
//
// TreeSize(root->left, psize);
// TreeSize(root->right, psize);
//}//int TreeSize(BTNode* root)
//{
// return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
//}//計算葉子節點個數
int TreeLeafCount(BTNode* root)
{if (root == NULL){return 0;}if ((root->left == NULL) && (root->right == NULL)){return 1;}return TreeLeafCount(root->left) + TreeLeafCount(root->right);
}//計算二叉樹高度
int TreeHeight(BTNode* root)
{if (root == NULL){return 0;}//記下返回值,防止造成時間效率低下int leftheight = TreeHeight(root->left);int rightheight = TreeHeight(root->right);//高度為較大的高度+根節點的高度if (leftheight > rightheight)return leftheight + 1;elsereturn rightheight + 1;//三目操作符//return leftheight > rightheight ? leftheight + 1 : rightheight + 1;
}////使用fmax()函數求較大的值
//int TreeHeight(BTNode* root)
//{
// if (root == NULL)
// return 0;
//
// return fmax(TreeHeight(root->left), TreeHeight(root->right)) + 1;
//}//計算第k層有多少個節點
int TreeNodecount_k(BTNode* root, int k)
{if (root == NULL)return 0;if (k == 1)return 1;//注意不能使用k--或者--k,這樣遞歸一次,后一次調用相當于k-1-1return TreeNodecount_k(root->left, k - 1) + TreeNodecount_k(root->right, k - 1);
}//查找目標節點
BTNode* TreeFind(BTNode* root, BTDateType x)
{if (root == NULL)return NULL;if (root->val == x){return root;}//記下返回值BTNode* ret1 = TreeFind(root->left, x);//找到了,就返回if (ret1)return ret1;BTNode* ret2 = TreeFind(root->right, x);if (ret2)return ret2;return NULL;
}//銷毀二叉樹
//后序遍歷:左子樹->右子樹->根,防止將根釋放而找不到左子樹與右子樹
void TreeDestry(BTNode* root)
{if (root == NULL){return;}TreeDestry(root->left);TreeDestry(root->right);free(root);
}//測試
int main()
{BTNode* root = BinaryTreeCreat();//前序遍歷prevOrder(root);printf("\n");//中序遍歷midOreder(root);printf("\n");//后序遍歷afterOrder(root);printf("\n");//計算二叉樹節點總個數//size = 0;//printf("TreeSize:%d\n", TreeSize(root));//size = 0;//printf("TreeSize:%d\n", TreeSize(root));//size = 0;//printf("TreeSize:%d\n", TreeSize(root));//int size = 0;//TreeSize(root, &size);//printf("TreeSize:%d\n", size);//size = 0;//TreeSize(root, &size);//printf("TreeSize:%d\n", size);//printf("%d ", TreeSize(root));//printf("%d ", TreeSize(root));//求葉子節點的個數//printf("%d\n", TreeLeafCount(root));////求二叉樹的高度//printf("%d\n", TreeHeight(root));////求二叉樹第k層有多少個節點//printf("%d\n",TreeNodecount_k(root, 3));////查找目標節點//BTNode* ret = TreeFind(root, 5);//printf("%d\n", ret->val);return 0;
}5、經典算法OJ
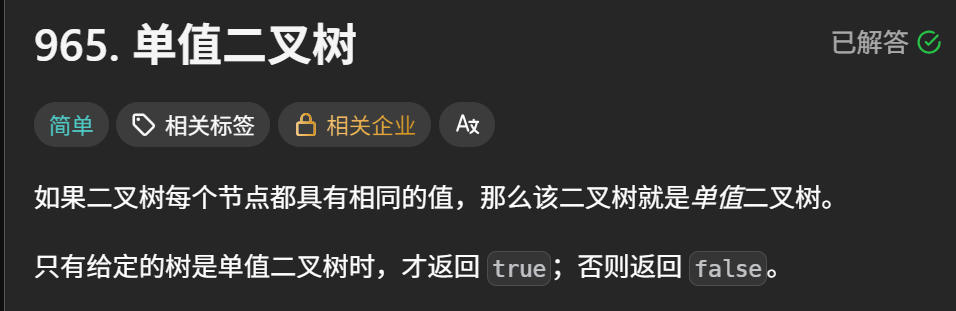
1、單值二叉樹
965. 單值二叉樹 - 力扣(LeetCode)
題目描述:
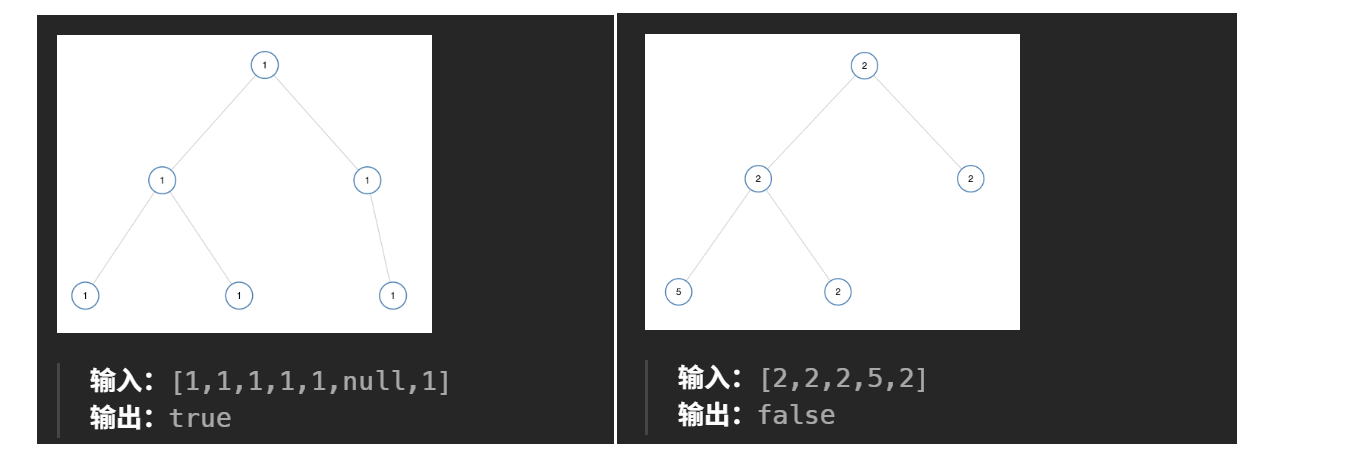
示例:?
bool _isUnivalTree(struct TreeNode* root,int x)
{ //處理空樹情況,同時為遞歸結束條件if(root==NULL){return true;}//排除空樹,且只要不等于根結點的值,就返回falseif(root->left&&root->left->val!=x){return false;}if(root->right&&root->right->val!=x){return false;}//遞歸遍歷左子樹與右子樹return _isUnivalTree(root->left, x)&&_isUnivalTree(root->right,x);
}bool isUnivalTree(struct TreeNode* root)
{return _isUnivalTree(root,root->val);
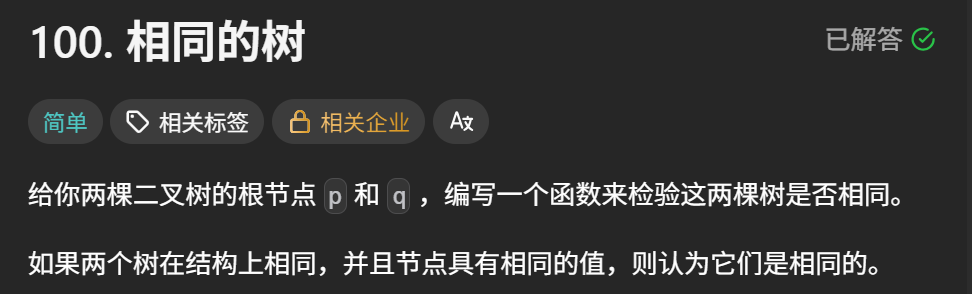
}2、檢查兩顆樹是否相同
100. 相同的樹 - 力扣(LeetCode)
題目描述:
示例:?
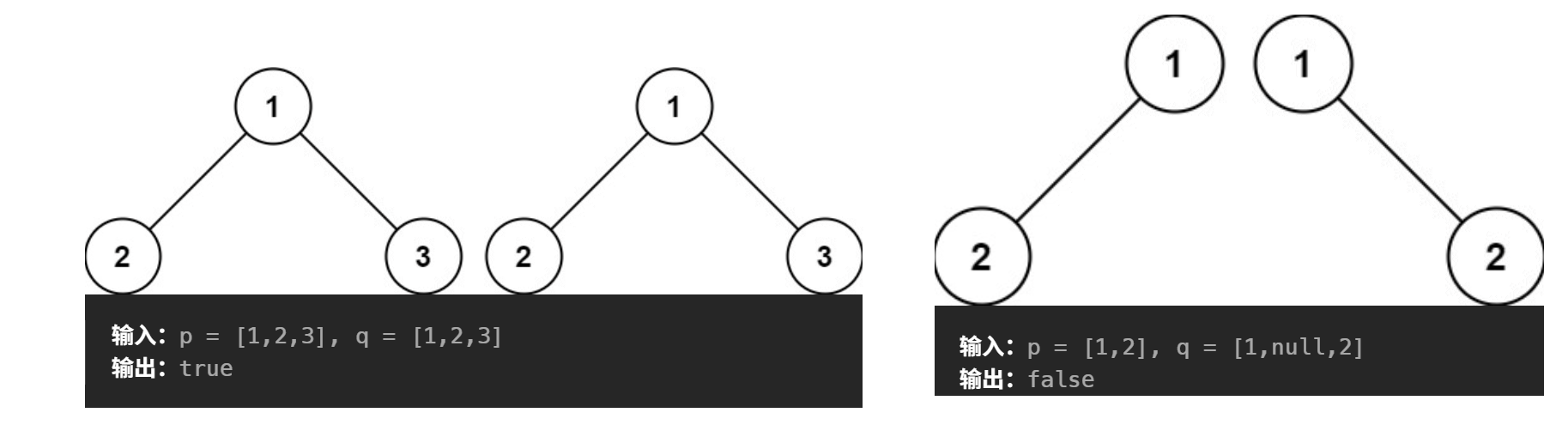
?首先判斷如果都是空樹時返回真;一個為空一個不為空時返回false;值不相等,返回false。然后遞歸遍歷左子樹和右子樹,左子樹與左子樹比較,右子樹與右子樹比較,當遞歸到都是空時返回true(與剛開始的判空對應),遞歸到一個為空一個不為空時返回false(與剛開始的判斷一個為空一個不為空對應),最后左子樹與左子樹相等且右子樹與右子樹相等則返回true;反之,返回false。
bool isSameTree(struct TreeNode* p, struct TreeNode* q)
{//都是空樹或遞歸到都是空時返回真if(p==NULL&&q==NULL){return true;}//一個為空一個不為空或遞歸到一個為空一個不為空時返回falseif(p==NULL||q==NULL){return false;}//值不相等,返回falseif(p->val!=q->val){return false;}//遞歸遍歷左子樹和右子樹,左子樹與左子樹比較,右子樹與右子樹比較return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);
}3、另一棵樹的子樹
572. 另一棵樹的子樹 - 力扣(LeetCode)
題目描述:
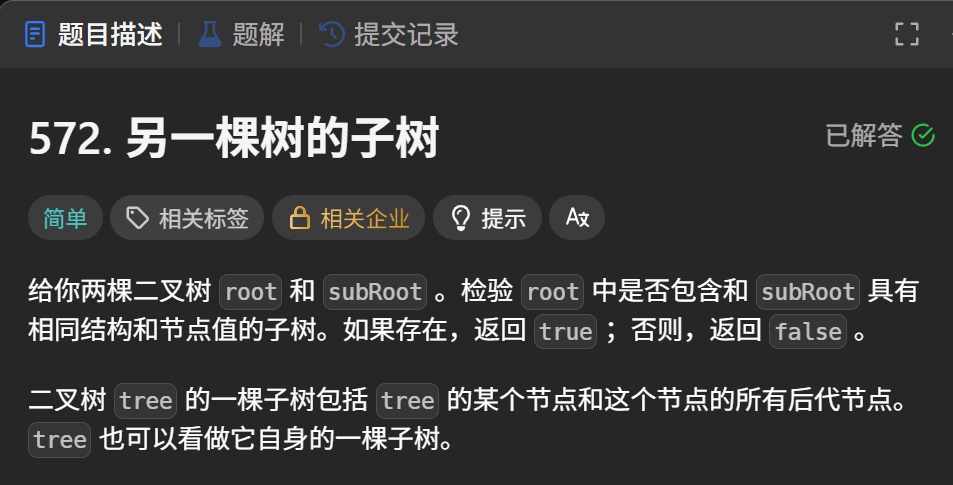
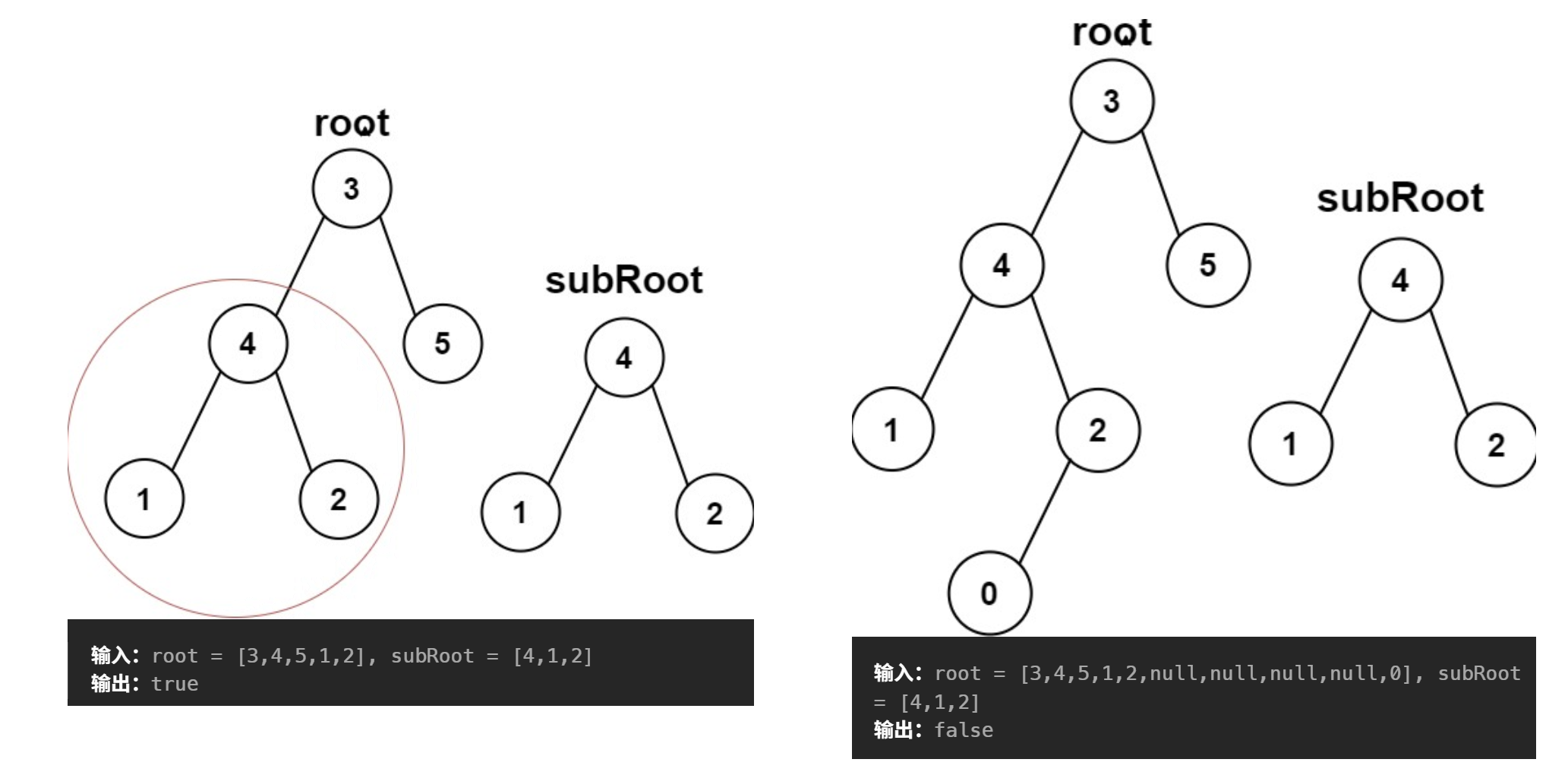 ?不斷遞歸遍歷一棵樹的左子樹和右子樹,然后判斷這棵樹的左子樹與右子樹與另一棵樹是否相等。可以借助前面實現的判斷兩棵樹是否相等的函數。?
?不斷遞歸遍歷一棵樹的左子樹和右子樹,然后判斷這棵樹的左子樹與右子樹與另一棵樹是否相等。可以借助前面實現的判斷兩棵樹是否相等的函數。?
bool isSameTree(struct TreeNode*p,struct TreeNode*q)
{//都為空if(p==NULL&&q==NULL){return true;}//一個為空,一個不為空if(p==NULL||q==NULL){return false;}if(p->val!=q->val){return false;}return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);
}bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot)
{if(root==NULL){return false;}if((root->val==subRoot->val) && (isSameTree(root,subRoot))){ return true;}//將root拆分為左子樹和右子樹與subRoot比較return isSubtree(root->left,subRoot)||isSubtree(root->right,subRoot);
}

貪吃蛇項目2.貪吃蛇項目實現)


)
)

如何寫一個好的 Prompt)








技術架構與工程實踐:從原理到部署)
)
數據庫安裝教程)