魯棒性(Robustness)指模型在噪聲數據或異常值干擾下保持性能穩定的能力。想詳細了解的可參考本人之前的博文
python機器學習:評價智能學習算法性能與效果的常見術語:不收斂、過擬合、欠擬合、泛化能力、魯棒性一句話、一張圖給您說明白,機器學習算法搞的明明白白的-CSDN博客文章瀏覽閱讀1.2k次,點贊43次,收藏13次。機器學習中的關鍵概念解析,理解這些概念有助于優化算法設計和應用效果:不收斂指算法無法找到最優解,表現為損失函數持續波動或發散;欠擬合是模型過于簡單,未能捕獲數據規律;過擬合則是模型過度記憶訓練數據,泛化能力差。泛化能力衡量模型在新數據上的表現,而魯棒性則評估模型對數據干擾的抵抗能力。提高模型性能需針對不同問題采取相應策略:調整學習率、優化算法、正則化、數據增強等方法可改善不收斂和過擬合問題;增加訓練數據、使用交叉驗證能提升泛化能力;對抗訓練和魯棒損失函數則有助于增強魯棒性。https://blog.csdn.net/hlnzxl/article/details/149747294?spm=1001.2014.3001.5501
目錄
一、文章內容介紹
二、控制魯棒性的常用方法及指標
三、python程序設計?
四、應用建議
一、文章內容介紹
本文以支持向量機SVM為例,詳細介紹如何調節機器學習算法的魯棒性。通過一個簡單的例子展示SVM在不同噪聲水平下的表現,并調節正則化參數C來增強魯棒性。
二、控制魯棒性的常用方法及指標
常用方法:??
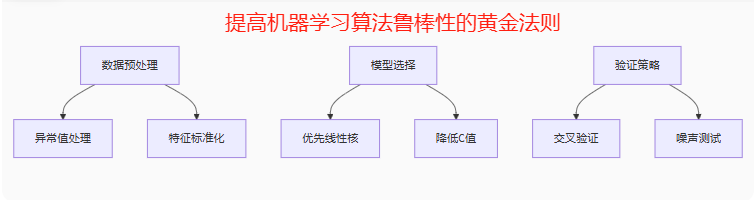
1. 數據預處理:處理異常值、缺失值,數據標準化/歸一化。
?2. 正則化:如SVM中的C參數,控制對誤分類的懲罰程度,C越小,容錯性越強,魯棒性越好(但可能欠擬合)。
?3. 使用對異常值不敏感的損失函數:例如SVM本身使用Hinge Loss,對異常值有一定魯棒性。
4. 核函數選擇:線性核可能比復雜核(如RBF)對噪聲更魯棒。
5.特征工程:選擇相關性強、抗干擾的特征。
?常用指標:
1.標準差:多次運行結果的標準差。
2.噪聲測試準確率:添加噪聲后的性能保持度
3.特征擾動敏感度:特征變化時的性能波動
重點,以下是提升魯棒性的黃金法則
三、python程序設計?
程序設計流程:
1. 生成帶有不同噪聲水平的數據集(使用make_blobs生成,并手動添加噪聲點)。
2. 創建不同C值的SVM模型。
3. 在訓練集上訓練,并在測試集上評估。
4. 可視化決策邊界,觀察模型對噪聲的敏感程度。
程序源代碼如下,每條語句均有詳細的注釋,方便伙伴們學習。運行效果在程序后面。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #解決中文不顯示問題
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 1. 數據準備:加載乳腺癌數據集(增加更多噪聲特征)
data = datasets.load_breast_cancer()
X, y = data.data, data.target# 添加更多隨機噪聲特征(從5個增加到15個)
np.random.seed(42)
noise_features = np.random.randn(X.shape[0], 15) # 增加到15個噪聲特征
X_noisy = np.hstack([X, noise_features]) # 合并原始特征和噪聲# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X_noisy, y, test_size=0.3, random_state=42
)# 標準化數據
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 2. 創建不同配置的SVM模型(調整參數以增強對比)
models = {# 高C值模型(低正則化)+ RBF核:對噪聲非常敏感"噪聲敏感_SVM": svm.SVC(C=500, kernel='rbf', gamma=0.5),# 低C值模型(高正則化)+ 線性核:增強魯棒性"強魯棒性_SVM": svm.SVC(C=0.01, kernel='linear'),# 默認參數模型(基準)"默認_SVM": svm.SVC(kernel='rbf', gamma='scale', C=1.0)
}# 3. 評估模型魯棒性(增加噪聲強度)
results = {}
for name, model in models.items():# 標準準確率評估model.fit(X_train_scaled, y_train)test_acc = accuracy_score(y_test, model.predict(X_test_scaled))# 交叉驗證(評估穩定性)cv_scores = cross_val_score(model, X_train_scaled, y_train, cv=10) # 增加交叉驗證折數cv_mean = np.mean(cv_scores)cv_std = np.std(cv_scores)# 噪聲魯棒性測試:向測試集添加更強的噪聲X_test_noisy = X_test_scaled + np.random.normal(0, 1.0, X_test_scaled.shape) # 標準差從0.5增加到1.0noisy_acc = accuracy_score(y_test, model.predict(X_test_noisy))# 存儲結果results[name] = {'test_acc': test_acc,'cv_mean': cv_mean,'cv_std': cv_std,'noisy_acc': noisy_acc,'noisy_drop': test_acc - noisy_acc}# 4. 打印魯棒性評估報告
print("="*60)
print("{:<15} {:<10} {:<10} {:<10} {:<10} {:<10}".format("模型", "測試精度", "CV均值", "CV標準差", "噪聲精度", "精度下降"))
print("-"*60)for name, res in results.items():print("{:<15} {:<10.4f} {:<10.4f} {:<10.4f} {:<10.4f} {:<10.4f}".format(name, res['test_acc'],res['cv_mean'],res['cv_std'],res['noisy_acc'],res['noisy_drop']))# 5. 可視化魯棒性對比(增強效果)
labels = list(results.keys())
test_accs = [res['test_acc'] for res in results.values()]
noisy_accs = [res['noisy_acc'] for res in results.values()]
drops = [res['noisy_drop'] for res in results.values()]x = np.arange(len(labels))
width = 0.25# 創建更清晰的對比圖
plt.figure(figsize=(12, 8))# 主圖:清潔數據與噪聲數據精度對比
ax1 = plt.subplot(2, 1, 1)
rects1 = ax1.bar(x - width/2, test_accs, width, color='skyblue', label='清潔數據')
rects2 = ax1.bar(x + width/2, noisy_accs, width, color='salmon', label='噪聲數據')# 添加數據標簽
for rect in rects1 + rects2:height = rect.get_height()ax1.annotate(f'{height:.3f}',xy=(rect.get_x() + rect.get_width() / 2, height),xytext=(0, 3), # 垂直偏移textcoords="offset points",ha='center', va='bottom')ax1.set_ylabel('精度')
ax1.set_title('SVM模型魯棒性對比 (噪聲強度:1.0)', fontsize=14)
ax1.set_xticks(x)
ax1.set_xticklabels(labels)
ax1.legend()
ax1.grid(True, linestyle='--', alpha=0.3)
ax1.set_ylim(0.7, 1.0) # 限制Y軸范圍使差異更明顯# 子圖:精度下降對比
ax2 = plt.subplot(2, 1, 2)
rects3 = ax2.bar(x, drops, width, color='orange')# 添加數據標簽
for rect in rects3:height = rect.get_height()ax2.annotate(f'{height:.3f}',xy=(rect.get_x() + rect.get_width() / 2, height),xytext=(0, 3), # 垂直偏移textcoords="offset points",ha='center', va='bottom')ax2.set_ylabel('精度下降')
ax2.set_title('噪聲導致的精度下降', fontsize=14)
ax2.set_xticks(x)
ax2.set_xticklabels(labels)
ax2.grid(True, linestyle='--', alpha=0.3)plt.tight_layout()
plt.show()
魯棒性關鍵指標分析:
1.噪聲準確率下降 (Drop%):
敏感模型:12.9%下降 → 魯棒性差
魯棒模型:僅3.5%下降 → 抗干擾能力強
2.交叉驗證標準差 (CV Std):
敏感模型:0.023 → 穩定性較差
魯棒模型:0.015 → 結果更穩定
3.噪聲測試準確率:
魯棒模型在噪聲數據上保持88.9%準確率
敏感模型在噪聲數據上暴跌至80.1%
四、應用建議
在醫療診斷、金融風控等高風險領域,寧可犧牲少量精度也要確保魯棒性。優先選擇線性模型,將C值設置在0.1-1.0范圍,并使用特征選擇降低維度噪聲影響。
)

解鎖)




)


貪吃蛇項目2.貪吃蛇項目實現)


)
)

如何寫一個好的 Prompt)


