Apache Doris
- 一、簡介
- 1.1、Apache Doris簡介
- 1.2、Apache Doris 與傳統大數據架構相比
- 1.3、doris是java團隊掌控大數據能力最優選擇
- 1.4、 OLTP(在線事務處理) 與 OLAP(在線分析處理)
- 1.5、發展歷程
- 1.6、應用現狀
- 1.7、整體架構
- 1.7.1、存算一體架構
- 1.7.2、存算分離架構
- 1.8、Apache Doris 的核心特性
- 1.9、技術特點
- 1.9.1、使用接口
- 1.9.2、存儲引擎
- 1.9.3、查詢引擎
- 二、部署前準備
- 2.1、軟硬件環境檢查
- 2.1.1、硬件環境檢查
- 2.1.2、服務器建議配置
- 2.1.3、硬盤空間計算
- 2.1.4、Java 環境檢查
- 2.2、集群規劃
- 2.2.1、架構規劃
- 2.2.2、端口規劃
- 2.2.3、節點數量規劃
- 2.3、操作系統檢查
- 2.3.1、關閉 swap 分區
- 2.3.2、關閉系統透明大頁
- 2.3.3、增加虛擬內存區域
- 2.3.4、禁用 CPU 省電模式
- 2.3.5、網絡連接溢出時自動重置新連接
- 2.3.6、相關端口暢通
- 2.3.7、增加系統的最大文件句柄數
- 2.3.8、安裝并配置 NTP 服務
- 三、部署doris
- 3.1、手動部署存算一體集群
- 3.1.1、部署 FE Master 節點
- 3.1.2、部署 FE 集群(可選)
- 3.1.3、部署 BE 節點
- 3.1.4、驗證集群正確性
- 3.2、手動部署存算分離集群
- 3.2.1、準備 FoundationDB
- 3.2.2、安裝 S3 或 HDFS 服務(可選)
- 3.2.3、Meta Service 部署
- 3.2.4、數據回收功能獨立部署(可選)
- 3.2.5、啟動 FE Master 節點
- 3.2.6、注冊 FE Follower/Observer 節點
- 3.2.7、添加 BE 節點
- 3.2.8、添加 Storage Vault
- 3.2.9、注意事項
- 3.3、Doris 內置的 Web UI
- 四、數據表設計
- 4.1、數據模型
- 4.1.1、明細模型
- 4.1.2、主鍵模型
- 4.1.3、聚合模型
- 4.2、數據劃分
- 4.2.1、數據分布概念
- 4.2.2、手動分區
- 4.2.2.1、Range 分區
- 4.2.2.2、List 分區
- 4.2.2.3、NULL 分區
- 4.2.3、動態分區
- 4.2.3.1、使用限制
- 4.2.3.2、創建動態分區
- 4.2.3.3、動態分區參數說明
- 4.2.3.4、管理動態分區
- 4.2.3.5、動態分區最佳實踐
- 4.2.4、自動分區
- 4.2.4.1、使用場景
- 4.2.4.2、語法
- 4.2.4.3、場景示例
- 4.2.4.4、與動態分區聯用
- 4.2.4.5、分區管理
- 4.2.4.6、注意事項
- 4.2.5、數據分桶
- 4.2.5.1、分桶方式
- 4.2.5.1.1、Hash 分桶
- 4.2.5.1.2、Random 分桶
- 4.2.5.2、選擇分桶鍵
- 4.2.5.3、選擇分桶數量
- 4.2.5.3.1、手動設置分桶數
- 4.2.5.3.2、自動設置分桶數
- 4.2.5.3.3、維護數據分桶
- 4.3、數據類型
- 4.4、表索引
- 4.4.1、前綴索引與排序鍵
- 4.4.1.1、索引原理
- 4.4.1.2、使用場景
- 4.4.1.3、管理索引
- 4.4.1.4、使用索引
- 4.4.1.5、使用示例
- 4.4.2、倒排索引
- 4.4.2.1、索引原理
- 4.4.2.2、使用場景
- 4.4.2.3、管理索引
- 4.4.2.4、使用索引
- 4.4.2.5、使用示例
- 4.4.3、BloomFilter 索引
- 4.4.3.1、索引原理
- 4.4.3.2、使用場景
- 4.4.3.3、管理索引
- 4.4.3.4、使用索引
- 4.4.3.5、使用示例
- 4.4.4、N-Gram 索引
- 4.4.4.1、索引原理
- 4.4.4.2、使用場景
- 4.4.4.3、管理索引
- 4.4.4.4、使用索引
- 4.4.4.5、使用示例
- 4.5、自增列
- 4.5.1、功能
- 4.5.2、語法
- 4.5.3、使用方式
- 4.6、冷熱數據分層
- 4.6.1、冷熱數據分層概述
- 4.6.2、SSD 和 HDD 層級存儲
- 4.6.2.1、動態分區與層級存儲
- 4.6.2.2、參數說明
- 4.6.2.3、示例
- 4.6.3、遠程存儲
- 4.6.3.1、使用方法
- 4.6.3.2、限制
- 4.6.3.3、冷數據空間
- 4.6.3.4、查詢與性能優化
一、簡介
1.1、Apache Doris簡介
Apache Doris 是一款基于 MPP 架構的高性能、實時分析型數據庫。它以高效、簡單和統一的特性著稱,能夠在亞秒級的時間內返回海量數據的查詢結果。Doris 既能支持高并發的點查詢場景,也能支持高吞吐的復雜分析場景。
- MPP(Massively Parallel Processing,大規模并行處理)架構通過將任務分解為多個子任務,分配到獨立的計算節點并行執行,顯著提升數據處理效率。其核心特點是節點間無共享資源(Shared-Nothing),每個節點擁有獨立的CPU、內存和存儲,通過網絡互聯協同工作。
基于這些優勢,Apache Doris 非常適合用于報表分析、即席查詢、統一數倉構建、數據湖聯邦查詢加速等場景。用戶可以基于 Doris 構建大屏看板、用戶行為分析、AB 實驗平臺、日志檢索分析、用戶畫像分析、訂單分析等應用。
1.2、Apache Doris 與傳統大數據架構相比
Apache Doris 與傳統大數據架構(如 Hadoop + Hive + Spark/Impala)相比,在實時分析、運維復雜度、成本效率上有顯著優勢,但也存在特定場景的局限性。
核心優勢對比(Doris vs. 傳統架構)
| 能力維度 | Apache Doris | 傳統架構(Hadoop生態) | 優勢說明 |
|---|---|---|---|
| 實時性 | ?? 秒級響應 | ?? 分鐘~小時級延遲 | Doris支持流式數據實時寫入即可查,替代傳統T+1數倉 |
| 架構復雜度 | ?? 一體化架構(FE/BE) | ?? 多組件堆砌(HDFS+Hive+Spark+ZK…) | Doris免去組件協調成本,運維負擔降低70%+ |
| 查詢性能 | ?? 亞秒~秒級(MPP+列存+向量化) | ?? 依賴計算引擎(如Impala秒~分鐘級) | 高并發場景下Doris吞吐量提升5-10倍 |
| 數據新鮮度 | ?? 支持秒級數據接入(Kafka/CDC) | ?? 批量導入為主(小時級) | Doris實現實時分析(如監控大屏、風控) |
| 運維成本 | ?? 自動化分片/副本/均衡 | ?? 需手動調優HDFS/YARN/計算引擎 | Doris無需專職Hadoop團隊維護 |
| 存儲成本 | ? 列存壓縮(ZSTD/LZ4) | ? HDFS三副本+列存(ORC/Parquet) | 兩者相當 |
| 數據更新 | ?? 支持Upsert(主鍵模型) | ?? Hive不支持,需重寫分區 | Doris滿足實時更新需求(如用戶畫像) |
| 聯邦查詢 | ?? 統一查詢Hive/Iceberg/MySQL等 | ?? 需Presto/Trino額外組件 | Doris減少數據搬遷,直查數據湖 |
典型案例提升:某電商公司用Doris替換Hive+Spark,訂單分析延遲從15分鐘降至3秒,服務器資源減少60%。
適用場景對比
| 場景 | Apache Doris 推薦度 | 傳統架構推薦度 | 原因 |
|---|---|---|---|
| 實時交互式 BI 報表 | ?????????? | ???? | Doris 高并發查詢優勢明顯 |
| 實時數倉(分鐘級延遲) | ?????????? | ?? | Doris 流批一體,簡化鏈路 |
| 大規模離線 ETL(T+1) | ?? | ?????????? | Spark 更擅長復雜批處理 |
| 日志分析(PB 級) | ???????? | ?????? | Doris 壓縮比高,但 ES 更擅長文本檢索 |
| 高并發點查(在線服務) | ???????? | ?? | Doris 主鍵模型支持毫秒級 KV 查詢 |
| 機器學習/數據科學 | ?? | ?????????? | Spark MLlib 生態更成熟 |
什么情況下選擇doris
| 指標 | 推薦選擇 Doris | 推薦傳統架構 |
|---|---|---|
| 延遲要求 | 秒級~分鐘級響應 | 小時級~天級延遲可接受 |
| 數據規模 | 單集群 ≤10PB | ≥10PB 超大規模離線數據 |
| 團隊規模 | 中小團隊(需降低運維復雜度) | 有專職 Hadoop 團隊 |
| 業務場景 | 實時大屏/Ad-hoc 查詢/高并發報表 | 復雜 ETL/機器學習/非結構化數據分析 |
| 更新需求 | 需要實時 Upsert 或刪除數據 | 僅追加寫入(Append-only) |
1.3、doris是java團隊掌控大數據能力最優選擇
如果你的團隊是Java語言團隊,在無大數據專家的情況下處理海量數據存儲與分析,Apache Doris 是更簡單、高效且成本可控的解決方案。它能讓您用最小技術代價獲得實時分析能力,避免陷入 Hadoop 生態的復雜運維泥潭。
核心價值點
-
零大數據棧依賴
→ 開箱即用,免部署 Hadoop/Hive/Spark,節省 80% 運維成本。 -
Java 技術棧無縫銜接
→ FE 用 Java 開發,兼容 MySQL 協議/JDBC,團隊可立即上手開發。 -
實時分析與簡化架構
→ 支持 秒級數據接入+亞秒級查詢,替代傳統 T+1 數倉,性能提升 10 倍+。 -
彈性擴展
→ 從 3 節點起步,隨業務增長一鍵擴容,硬件成本降低 50%。
java團隊使用doris與傳統架構對比優勢
| 痛點 | 傳統方案(Hive/Spark) | Doris 方案 |
|---|---|---|
| 學習成本 | 需掌握 Hive/Scala/Spark 等多技術棧 | 僅需 Java + SQL 基礎 |
| 實時性 | 分鐘~小時級延遲 | 秒級響應 |
| 運維復雜度 | 需專職大數據團隊維護 | 開發兼職運維 |
| 開發效率 | 需編寫 Spark 作業并調優,周期長 | JDBC 直連 + 標準 SQL,快速開發 |
Apache Doris 與 Elasticsearch 的核心對比及選型建議
| 能力維度 | Apache Doris | Elasticsearch (ES) | 適用場景建議 |
|---|---|---|---|
| 數據模型 | 結構化數據(強類型、表結構) | 半結構化/JSON 文檔(Schema-less) | 固定分析用 Doris,多變日志用 ES |
| 查詢類型 | 高性能聚合分析(GROUP BY/JOIN/窗口函數) | 全文檢索/模糊匹配/KNN 向量搜索 | 數值分析選 Doris,文本搜索選 ES |
| 實時寫入 | 支持 Upsert,數據寫入即可查(毫秒級) | 近實時(1s 刷新間隔) | 兩者均滿足實時需求 |
| 并發能力 | ?? 支持 10K+ QPS(高并發點查+聚合) | ?? 高聚合負載下并發受限(通常 ≤1K QPS) | 高并發報表用 Doris |
| 運維復雜度 | 自動化分片/均衡,擴縮容一條 SQL | 需手動調優分片、副本、路由規則 | Java 團隊首選 Doris(省心 50%) |
| 存儲成本 | 列存壓縮(ZSTD),節省空間 | 倒排索引占空間(原始數據 1.5-2 倍) | 成本敏感選 Doris |
| SQL 支持 | 完整 ANSI SQL,兼容 MySQL 協議 | SQL 為插件(功能受限),主用 DSL | Java 開發者更熟悉 Doris |
| 生態整合 | 聯邦查詢 Hive/MySQL,BI 工具無縫對接 | Kibana 生態強,但 BI 對接復雜 | 多源分析用 Doris,日志看板用 ES |
給 Java 團隊的建議:
-
純分析場景 → 100% 選擇 Doris:
-
用 JDBC 直連,開發效率高,無需學習 ES 的 DSL。
-
省去 ES 集群的運維負擔(分片均衡、JVM 調優)。
-
-
日志為主場景 → ES 為核心,Doris 輔助分析:
- 原始日志存 ES,每日聚合結果同步到 Doris 做深度分析。
-
新項目啟動 → 從 Doris 開始:
- 未來擴展檢索能力時再引入 ES,避免初期架構過重。
結構化數據分析用 Doris,文本檢索用 ES,兩者混合能應對 99% 的海量數據處理需求。作為 Java 團隊,Doris 的 MySQL 協議和簡潔架構會讓您事半功倍。
文本檢索大家都清楚,上面一直說的分析是什么?
分析: 指從原始數據中提取有價值信息的過程,通過系統性的計算、統計和邏輯推理,揭示數據背后的規律、趨勢和洞見。
分析的核心目標
-
描述現狀
回答 “發生了什么?”
例:統計昨日訂單量、用戶活躍地域分布。
-
診斷原因
回答 “為什么發生?”
例:分析某商品銷量驟降是否因價格上調導致。
-
預測趨勢
回答 “未來會怎樣?”
例:基于歷史數據預測下季度營收。
-
指導決策
回答 “該怎么做?”
例:通過用戶行為漏斗分析優化產品轉化路徑。
簡單分析示例:
| 操作類型 | 示例場景 | SQL 實現(Doris/ES) |
|---|---|---|
| 聚合計算 | 統計每日總銷售額 | SELECT SUM(sales) FROM orders GROUP BY dt |
| 過濾查詢 | 查詢某用戶最近3次訂單 | SELECT * FROM orders WHERE user_id=123 ORDER BY dt DESC LIMIT 3 |
| 多維度分組 | 分地區/品類計算銷量TOP10 | SELECT region, category, SUM(sales) FROM orders GROUP BY region, category ORDER BY SUM(sales) DESC LIMIT 10 |
| 去重統計 | 計算每日活躍用戶數(UV) | SELECT dt, COUNT(DISTINCT user_id) FROM logs GROUP BY dt |
1.4、 OLTP(在線事務處理) 與 OLAP(在線分析處理)
OLTP(Online Transaction Processing在線事務處理)與OLAP(Online Analytical Processing在線分析處理)核心區別:
- OLTP 是“寫操作”為主的實時業務系統(如訂單支付),OLAP 是“讀操作”為主的分析系統(如銷售報表)。
- 兩者如同汽車的 發動機(OLTP) 和 儀表盤(OLAP) —— 一個負責運行,一個負責洞察。
OLTP與OLAP對比表格
| 對比維度 | OLTP(如MySQL) | OLAP(如Doris) | 典型應用場景建議 |
|---|---|---|---|
| 核心目標 | 處理日常高并發事務 | 執行復雜數據分析 | 事務處理用MySQL,分析用Doris |
| 讀寫比例 | 讀寫均衡(70%寫+30%讀) | 讀為主(5%寫+95%讀) | 報表類業務適合OLAP |
| 數據規模 | 處理當前數據(GB~TB級) | 分析歷史海量數據(TB~PB級) | 海量日志/行為數據存儲到Doris |
| 操作類型 | CRUD操作(增刪改查) | 復雜查詢(GROUP BY/JOIN/窗口函數) | 分析語句遷移后性能提升顯著 |
| 響應速度 | 毫秒級(保障業務流暢性) | 秒級(容忍更高延遲) | 報表查詢從分鐘級優化到秒級 |
| 數據結構 | 高度規范化(3NF減少冗余) | 星型/雪花模型(優化分析效率) | Doris寬表設計簡化分析邏輯 |
| 典型系統 | 訂單系統、用戶數據庫 | 數據倉庫、BI平臺 | 用Doris構建實時數倉 |
MySQL 適合事務處理(OLTP),Doris 專為海量數據分析(OLAP)設計。
1.5、發展歷程
Apache Doris 最初是百度廣告報表業務的 Palo 項目。2017 年正式對外開源,2018 年 7 月由百度捐贈給 Apache 基金會進行孵化。在 Apache 導師的指導下,由孵化器項目管理委員會成員進行孵化和運營。2022 年 6 月,Apache Doris 成功從 Apache 孵化器畢業,正式成為 Apache 頂級項目(Top-Level Project,TLP)。
1.6、應用現狀
Apache Doris 在中國乃至全球范圍內擁有廣泛的用戶群體。截至目前,Apache Doris 已經在全球超過 5000 家中大型企業的生產環境中得到應用。在中國市值或估值排行前 50 的互聯網公司中,有超過 80% 長期使用 Apache Doris,包括百度、美團、小米、京東、字節跳動、阿里巴巴、騰訊、網易、快手、微博等。同時,在金融、消費、電信、工業制造、能源、醫療、政務等傳統行業也有著豐富的應用。
在中國,幾乎所有的云廠商,如阿里云、華為云、天翼云、騰訊云、百度云、火山引擎等,都在提供托管的 Apache Doris 云服務。
1.7、整體架構
Apache Doris 采用 MySQL 協議,高度兼容 MySQL 語法,支持標準 SQL。用戶可以通過各類客戶端工具訪問 Apache Doris,并支持與 BI 工具無縫集成。
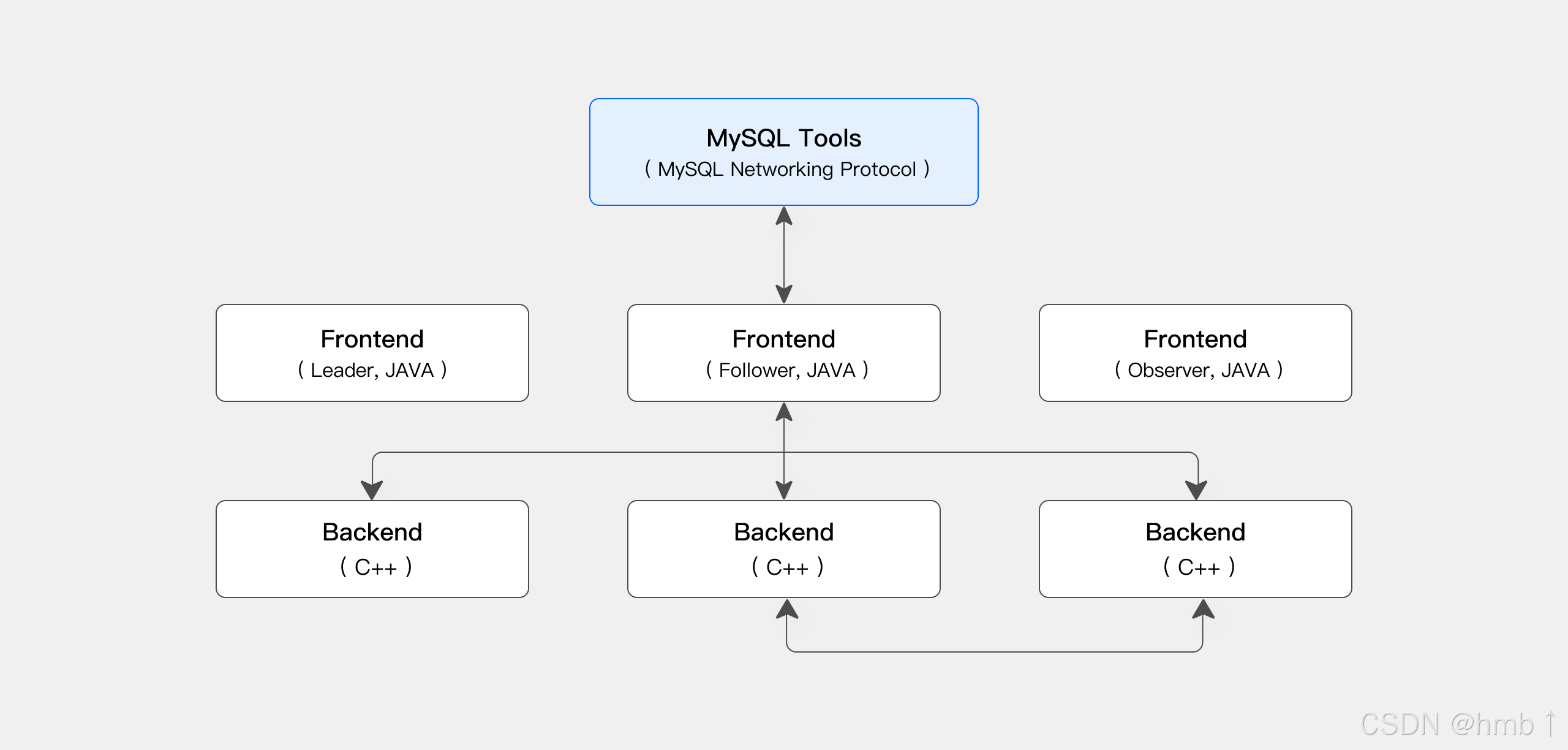
1.7.1、存算一體架構
Apache Doris 存算一體架構精簡且易于維護。它包含以下兩種類型的進程:
-
Frontend (FE): 主要負責接收用戶請求、查詢解析和規劃、元數據管理以及節點管理。
-
Backend (BE): 主要負責數據存儲和查詢計劃的執行。數據會被切分成數據分片(Shard),在 BE 中以多副本方式存儲。
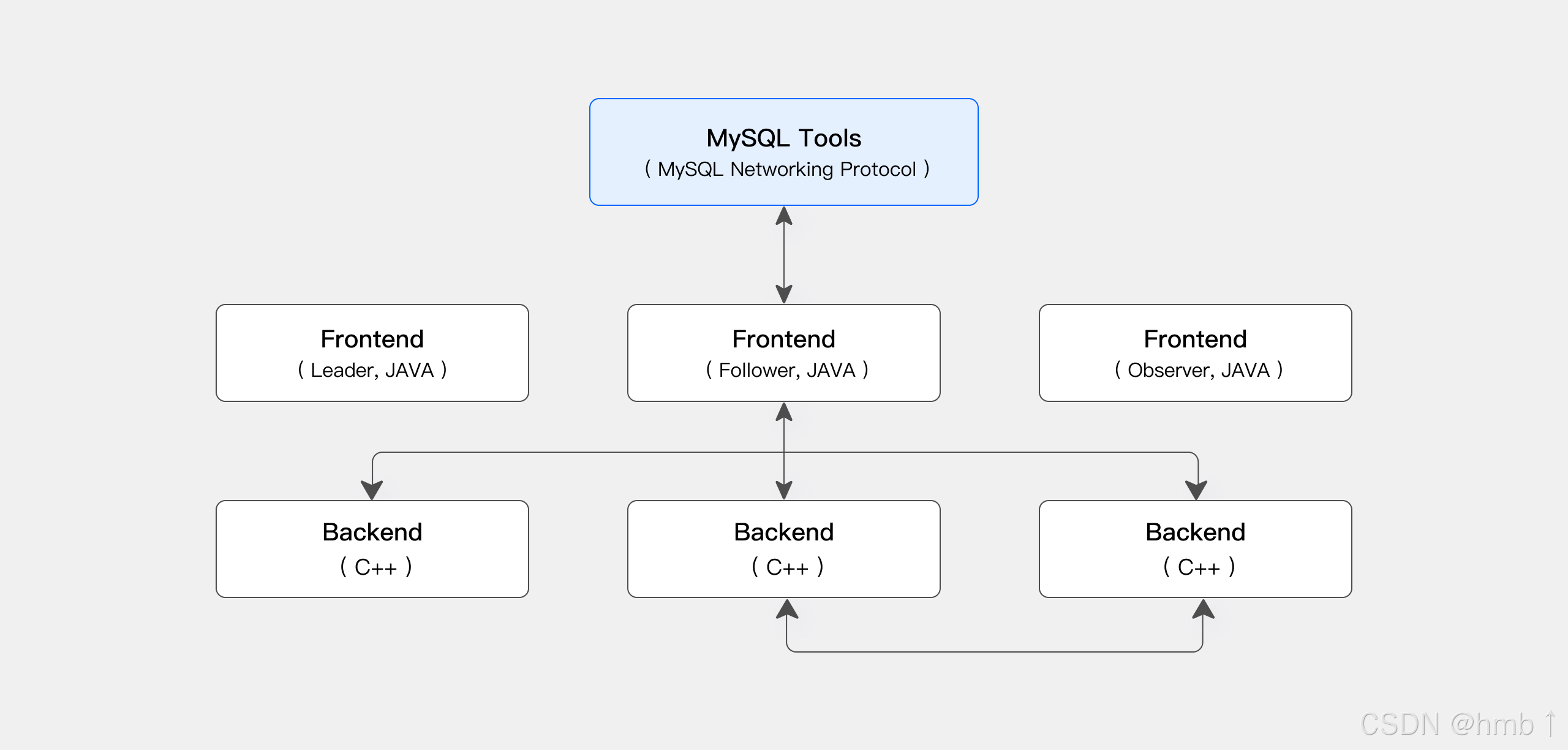
在生產環境中,可以部署多個 FE 節點以實現容災備份。每個 FE 節點都會維護完整的元數據副本。FE 節點分為以下三種角色:
| 角色 | 功能 |
|---|---|
| Master | FE Master 節點負責元數據的讀寫。當 Master 節點的元數據發生變更后,會通過 BDB JE 協議同步給 Follower 或 Observer 節點。 |
| Follower | Follower 節點負責讀取元數據。當 Master 節點發生故障時,可以選取一個 Follower 節點作為新的 Master 節點。 |
| Observer | Observer 節點負責讀取元數據,主要目的是增加集群的查詢并發能力。Observer 節點不參與集群的選主過程。 |
FE 和 BE 進程都可以橫向擴展。單個集群可以支持數百臺機器和數十 PB 的存儲容量。FE 和 BE 進程通過一致性協議來保證服務的高可用性和數據的高可靠性。存算一體架構高度集成,大幅降低了分布式系統的運維成本。
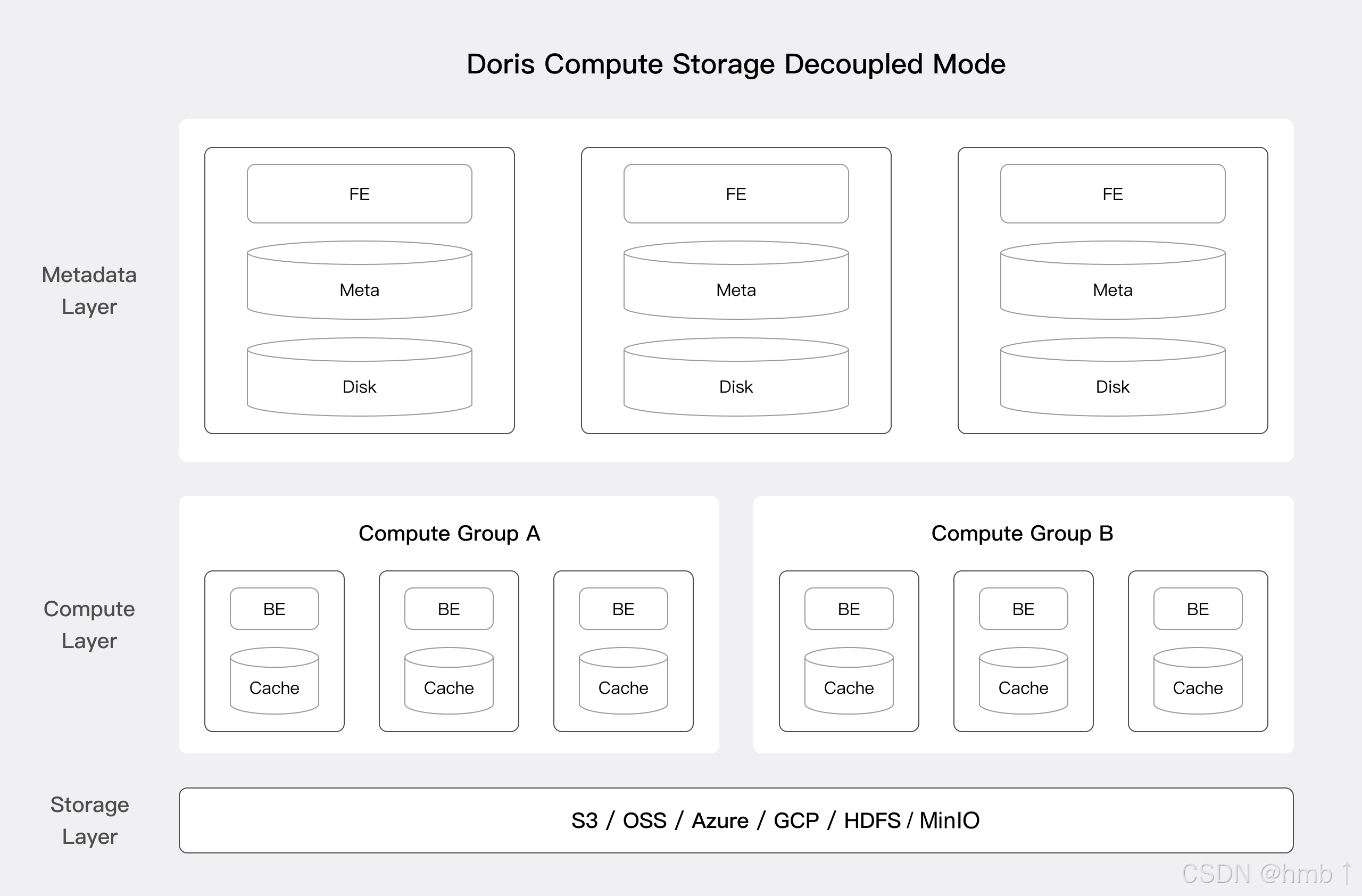
1.7.2、存算分離架構
從 3.0 版本開始,可以選擇存算分離部署架構。Apache Doris 存算分離版使用統一的共享存儲層作為數據存儲空間。存儲和計算分離后,用戶可以獨立擴展存儲容量和計算資源,從而實現最佳性能和成本效益。存算分離架構分為以下三層:
-
元數據層: 負責請求規劃、查詢解析以及元數據的存儲和管理。
-
計算層: 由多個計算組組成。每個計算組可以作為一個獨立的租戶承擔業務計算。每個計算組包含多個無狀態的 BE 節點,可以隨時彈性伸縮 BE 節點。
-
存儲層: 可以使用 S3、HDFS、OSS、COS、OBS、Minio、Ceph 等共享存儲來存放 Doris 的數據文件,包括 Segment 文件和反向索引文件等。
1.8、Apache Doris 的核心特性
-
高可用: Apache Doris 的元數據和數據均采用多副本存儲,并通過 Quorum 協議同步數據日志。當大多數副本完成寫入后,即認為數據寫入成功,從而確保即使少數節點發生故障,集群仍能保持可用性。Apache Doris 支持同城和異地容災,能夠實現雙集群主備模式。當部分節點發生異常時,集群可以自動隔離故障節點,避免影響整體集群的可用性。
-
高兼容: Apache Doris 高度兼容 MySQL 協議,支持標準 SQL 語法,涵蓋絕大部分 MySQL 和 Hive 函數。通過這種高兼容性,用戶可以無縫遷移和集成現有的應用和工具。Apache Doris 支持 MySQL 生態,用戶可以通過 MySQL 客戶端工具連接 Doris,使得操作和維護更加便捷。同時,可以使用 MySQL 協議對 BI 報表工具與數據傳輸工具進行兼容適配,確保數據分析和數據傳輸過程中的高效性和穩定性。
-
實時數倉: 基于 Apache Doris 可以構建實時數據倉庫服務。Apache Doris 提供了秒級數據入庫能力,上游在線聯機事務庫中的增量變更可以秒級捕獲到 Doris 中。依靠向量化引擎、MPP 架構及 Pipeline 執行引擎等加速手段,可以提供亞秒級數據查詢能力,從而構建高性能、低延遲的實時數倉平臺。
-
湖倉一體: Apache Doris 可以基于外部數據源(如數據湖或關系型數據庫)構建湖倉一體架構,從而解決數據在數據湖和數據倉庫之間無縫集成和自由流動的問題,幫助用戶直接利用數據倉庫的能力來解決數據湖中的數據分析問題,同時充分利用數據湖的數據管理能力來提升數據的價值。
-
靈活建模: Apache Doris 提供多種建模方式,如寬表模型、預聚合模型、星型/雪花模型等。數據導入時,可以通過 Flink、Spark 等計算引擎將數據打平成寬表寫入到 Doris 中,也可以將數據直接導入到 Doris 中,通過視圖、物化視圖或實時多表關聯等方式進行數據的建模操作。
1.9、技術特點
1.9.1、使用接口
Apache Doris 采用 MySQL 協議,高度兼容 MySQL 語法,支持標準 SQL。用戶可以通過各類客戶端工具訪問 Apache Doris,并支持與 BI 工具無縫集成。Apache Doris 當前支持多種主流的 BI 產品,包括 Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Superset 等。只要支持 MySQL 協議的 BI 工具,Apache Doris 就可以作為數據源提供查詢支持。
1.9.2、存儲引擎
在存儲引擎方面,Apache Doris 采用列式存儲,按列進行數據的編碼、壓縮和讀取,能夠實現極高的壓縮比,同時減少大量非相關數據的掃描,從而更有效地利用 IO 和 CPU 資源。
Apache Doris 也支持多種索引結構,以減少數據的掃描:
-
Sorted Compound Key Index: 最多可以指定三個列組成復合排序鍵。通過該索引,能夠有效進行數據裁剪,從而更好地支持高并發的報表場景。
-
Min/Max Index: 有效過濾數值類型的等值和范圍查詢。
-
BloomFilter Index: 對高基數列的等值過濾裁剪非常有效。
-
Inverted Index: 能夠對任意字段實現快速檢索。
在存儲模型方面,Apache Doris 支持多種存儲模型,針對不同的場景做了針對性的優化:
-
明細模型(Duplicate Key Model): 適用于事實表的明細數據存儲。
-
主鍵模型(Unique Key Model): 保證 Key 的唯一性,相同 Key 的數據會被覆蓋,從而實現行級別數據更新。
-
聚合模型(Aggregate Key Model): 相同 Key 的 Value 列會被合并,通過提前聚合大幅提升性能。
Apache Doris 也支持強一致的單表物化視圖和異步刷新的多表物化視圖。單表物化視圖在系統中自動刷新和維護,無需用戶手動選擇。多表物化視圖可以借助集群內的調度或集群外的調度工具定時刷新,從而降低數據建模的復雜性。
1.9.3、查詢引擎
Apache Doris 采用大規模并行處理(MPP)架構,支持節點間和節點內并行執行,以及多個大型表的分布式 Shuffle Join,從而更好地應對復雜查詢。
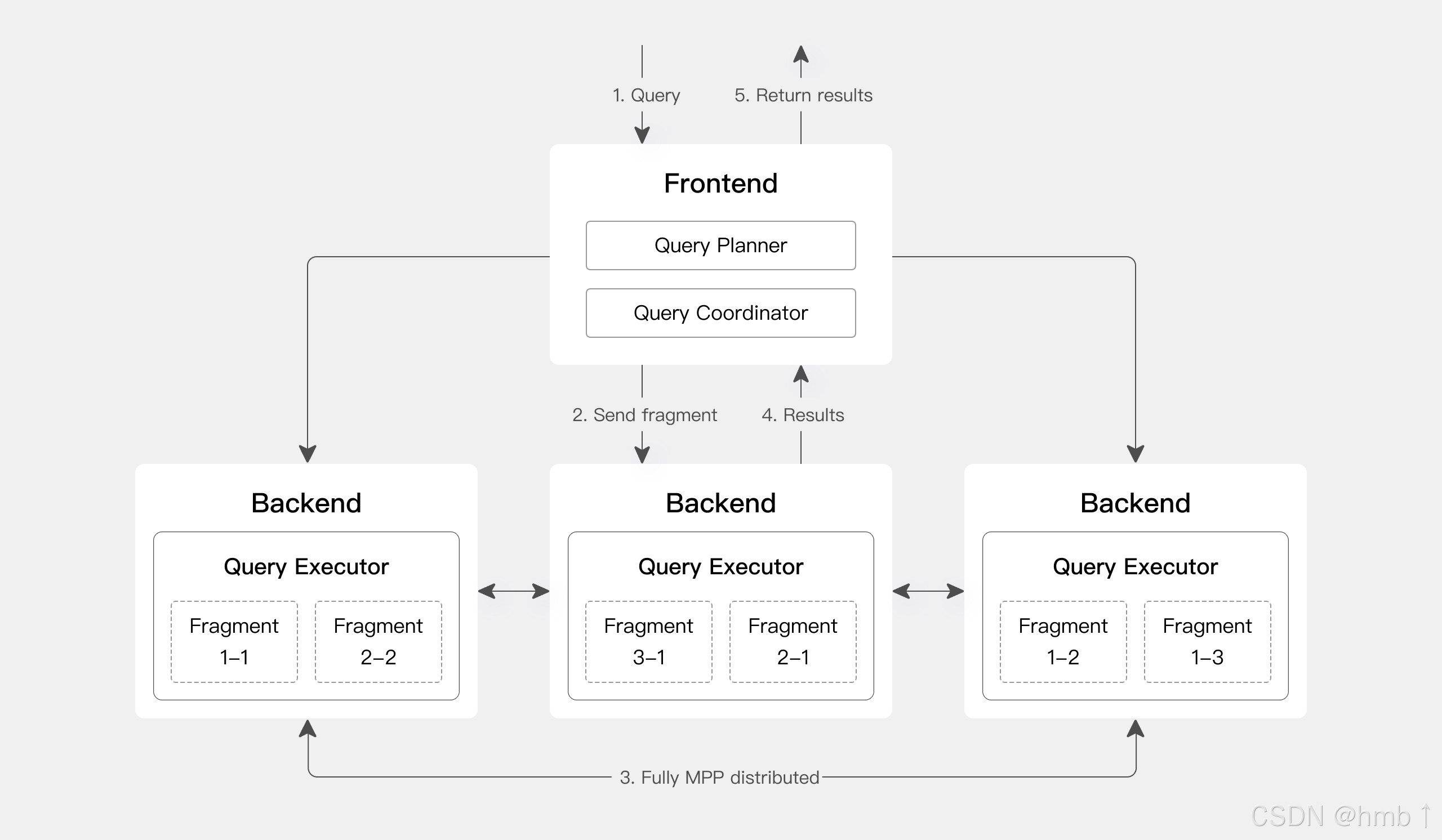
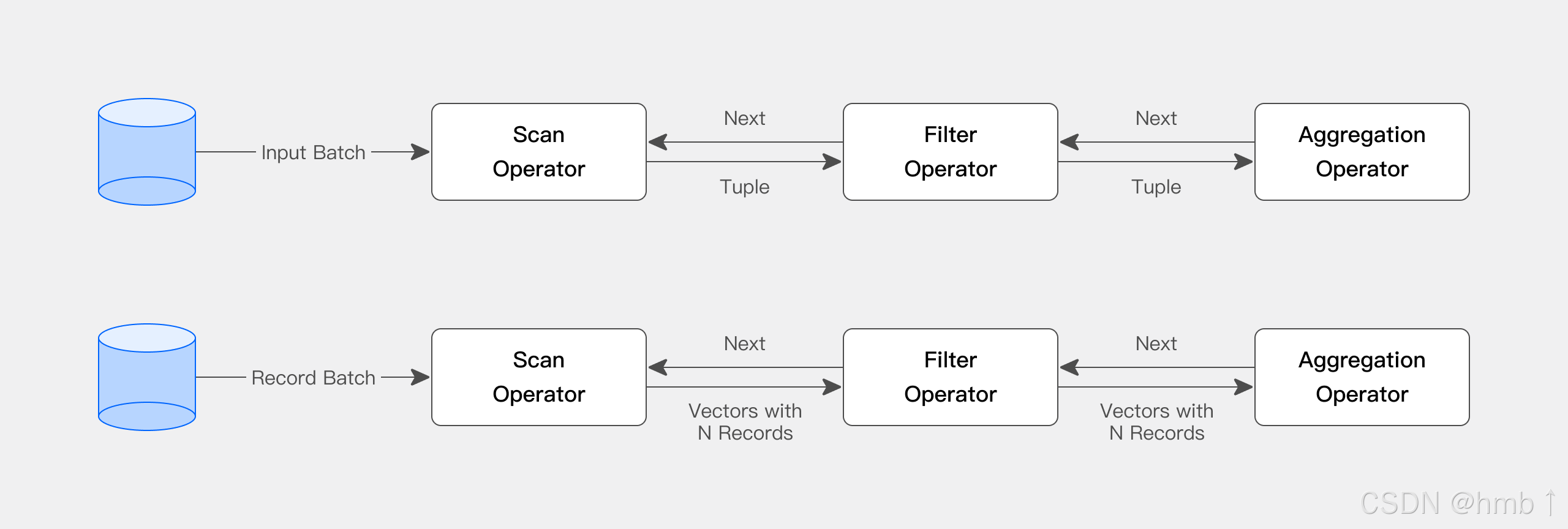
Doris 查詢引擎是向量化引擎,所有內存結構均按列式布局,可顯著減少虛函數調用,提高緩存命中率,并有效利用 SIMD 指令。在寬表聚合場景下,性能是非向量化引擎的 5-10 倍。
Doris 采用自適應查詢執行(Adaptive Query Execution)技術,根據運行時統計信息動態調整執行計劃。例如,通過運行時過濾(Runtime Filter)技術,可以在運行時生成過濾器并將其推送到 Probe 端,并自動將過濾器穿透到 Probe 端最底層的 Scan 節點,從而大幅減少 Probe 端的數據量,加速 Join 性能。Doris 的運行時過濾器支持 In/Min/Max/Bloom Filter。
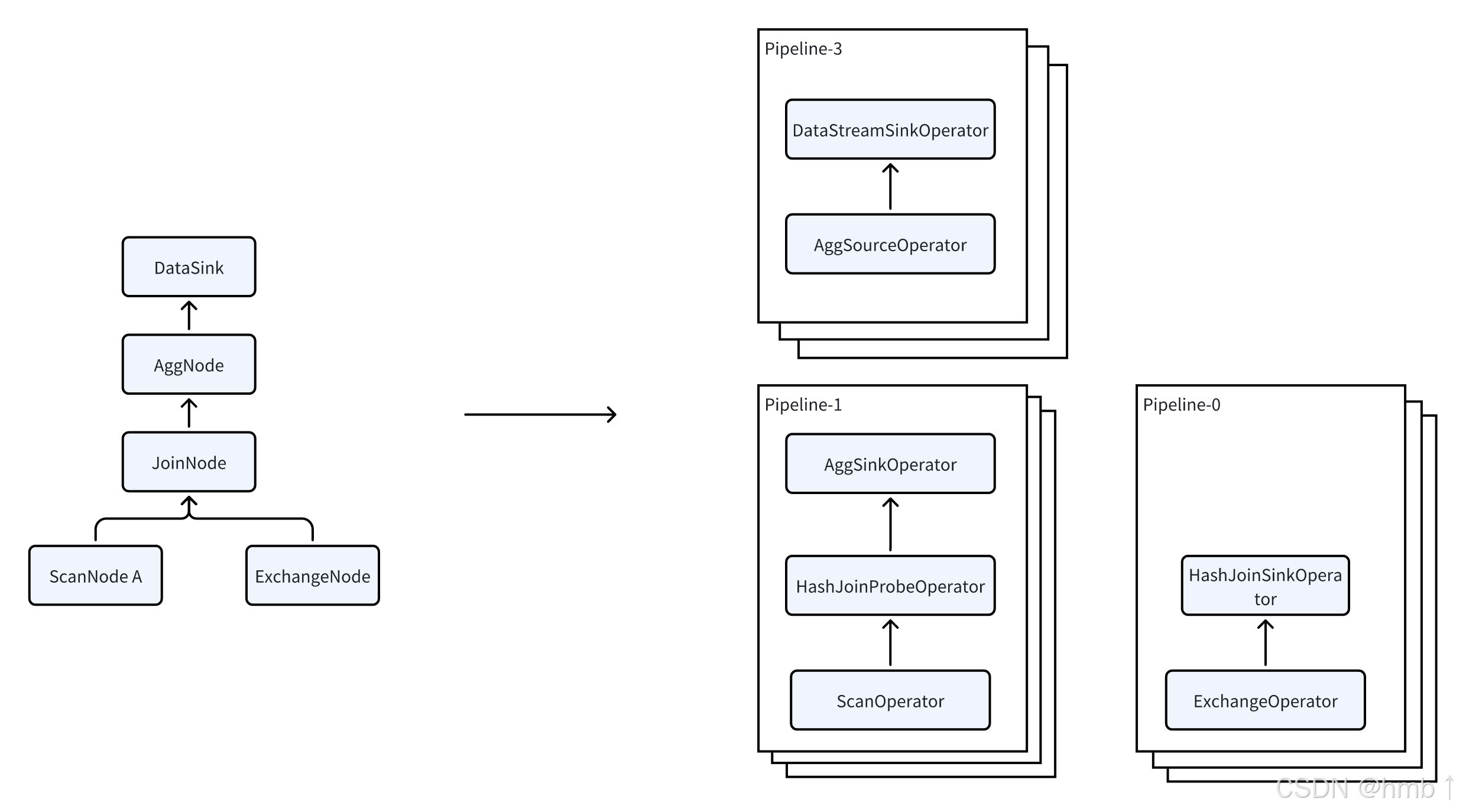
Doris 使用 Pipeline 執行引擎,將查詢分解為多個子任務并行執行,充分利用多核 CPU 的能力,同時通過限制查詢線程數來解決線程膨脹問題。Pipeline 執行引擎減少數據拷貝和共享,優化排序和聚合操作,從而顯著提高查詢效率和吞吐量。
在優化器方面,Doris 采用 CBO、RBO 和 HBO 相結合的優化策略。RBO 支持常量折疊、子查詢重寫和謂詞下推等優化,CBO 支持 Join Reorder 等優化,HBO 能夠基于歷史查詢信息推薦最優執行計劃。多種優化措施確保 Doris 能夠在各類查詢中枚舉出性能優異的查詢計劃。
二、部署前準備
2.1、軟硬件環境檢查
2.1.1、硬件環境檢查
在硬件環境檢查中,要對以下硬件條件進行檢查
| 檢查項 | 建議配置 |
|---|---|
| CPU | 支持 AVX2 指令集 |
| 內存 | 建議至少 CPU 4 倍 |
| 存儲 | 推薦 SSD 硬盤 |
| 文件系統 | ext4 或 xfs 文件系統 |
| 網卡 | 10GbE 網卡 |
- CPU 檢查
當安裝 Doris 時,建議選擇支持 AVX2 指令集的機器,以利用 AVX2 的向量化能力實現查詢向量化加速。
運行以下命令,有輸出結果,及表示機器支持 AVX2 指令集。
cat /proc/cpuinfo | grep avx2
如果機器不支持 AVX2 指令集,可以使用 no AVX2 的 Doris 安裝包進行部署。
- 內存檢查
Doris 沒有強制的內存限制。一般在生產環境中,可以根據以下建議選擇內存大小:
| 組件 | 推薦內存配置 |
|---|---|
| FE | 建議至少 16GB 以上 |
| BE | 建議內存至少是 CPU 核數的 4 倍(例如,16 核機器至少配置 64G 內存)。在內存是 CPU 核數的 8 倍時,會得到更好的性能。 |
- 存儲檢查
Doris 支持將數據存儲在 SSD(固態硬盤,Solid State Drive)、HDD(機械硬盤,Hard Disk Drive) 或對象存儲(Object Storage)中。
在以下幾種場景中建議使用 SSD 作為數據存儲:
-
大規模數據量下的高并發點查場景
-
大規模數據量下的高頻數據更新場景
存儲技術對比
| 維度 | HDD | SSD | 對象存儲 |
|---|---|---|---|
| 存儲介質 | 磁性盤片 + 機械結構 | 閃存芯片(NAND Flash) | 分布式服務器集群 |
| 讀寫速度 | 慢(MB 級 / 秒) | 快(GB 級 / 秒) | 中等(依賴網絡和集群) |
| 成本(單位容量) | 低 | 高 | 中低 |
| 適用數據類型 | 結構化 / 小文件 | 高頻訪問數據 | 非結構化 / 海量數據 |
| 典型場景 | 冷備份、大容量存儲 | 系統盤、高性能計算 | 云存儲、媒體歸檔 |
- 文件系統檢查
Doris 推薦使用 EXT4 或 XFS 文件系統:
-
EXT4 文件系統:具有良好的穩定性、性能和較低的碎片化問題。
-
XFS 文件系統:在處理大規模數據和高并發寫操作時表現優越,適合高吞吐量應用。
- 網卡檢查
Doris 的計算過程涉及數據分片和并行處理,可能產生網絡資源開銷。為了最大程度優化 Doris 性能并降低網絡資源開銷,強烈建議在部署時選用萬兆網卡(10 Gigabit Ethernet,即 10GbE)或者更快網絡。如果有多塊網卡,建議使用鏈路聚合方式將多塊網卡綁定成一塊網卡,提高網絡帶寬、冗余性和復雜均衡的能力。
2.1.2、服務器建議配置
Doris 支持運行和部署在 x86-64 架構的服務器平臺或 ARM64 架構的服務器上。
-
開發及測試環境
開發與測試環境中可以混合部署 FE 與 BE 實例,遵循以下規則:-
驗證測試環境中可以在一臺服務器上混合部署一個 FE 與 BE,但不建議部署多個 FE 與 BE 實例;
-
如果需要 3 副本數據,至少需要 3 臺服各部署一個 BE 實例。
-
服務器規格建議如下:
| 模塊 | CPU | 內存 | 磁盤(存儲類型+容量) | 網絡配置 | 實例數量(最低要求) |
|---|---|---|---|---|---|
| Frontend | 8 核 + | 8 GB+ | SSD/SATA,10 GB+ | 1GbE/10GbE 網卡 | 1 |
| Backend | 8 核 + | 16 GB+ | SSD/SATA,50 GB+ | 1GbE/10GbE 網卡 | 1 |
-
生產環境
生產環境中建議 FE 與 BE 實例獨立部署,遵循以下規則:-
如果環境資源緊張,將 FE 與 BE 混部在一臺服務器上,建議 FE 與 BE 數據放在不同的硬盤;
-
BE 節點可以配置多塊硬盤存儲,在一個 BE 實例上綁定多塊 HDD 或 SSD 盤。
-
服務器規格建議如下:
| 模塊 | CPU | 內存 | 磁盤 | 網絡 | 實例數量(最低要求) |
|---|---|---|---|---|---|
| Frontend | 16 核 + | 64 GB+ | SSD,100GB+ | 10GbE 網卡 | 1 |
| Backend | 16 核 + | 64 GB+ | SSD 或 SATA,100GB+ | 10GbE 網卡 | 3 |
2.1.3、硬盤空間計算
在 Doris 集群中,FE 主要用于元數據存儲,包括元數據 edit log 和 image。BE 的磁盤空間主要用于存放數據,需要根據業務需求計算。
| 組件 | 磁盤空間說明 |
|---|---|
| FE | 建議預留 100GB 以上的存儲空間,使用 SSD 硬盤 |
| BE | Doris 默認 LZ4 壓縮方式存儲(壓縮比 0.3-0.5),按總數據量 * 3(3副本)計算空間,并額外預留40%用于后臺 compaction 及臨時數據存儲 |
2.1.4、Java 環境檢查
Doris 的所有進程都依賴 Java。
-
在 2.1(含)版本之前,請使用
Java 8,推薦版本:jdk-8u352 之后版本。 -
從 3.0(含)版本之后,請使用
Java 17,推薦版本:jdk-17.0.10 之后版本。
2.2、集群規劃
2.2.1、架構規劃
在部署 Doris 時,可以根據業務選擇存算一體或存算分離架構:
-
存算一體:存算一體架構部署簡單,性能優異,不依賴與外部的共享存儲設備,適合不需要極致彈性擴縮容的業務場景;
-
存算分離:存算分離架構依賴于共享存儲,實現了計算資源的彈性伸縮,適合需要動態調整計算資源的業務場景。
2.2.2、端口規劃
Doris 的各個實例通過網絡進行通信,其正常運行需要網絡環境提供以下端口。管理員可以根據實際環境自行調整 Doris 的端口配置:
以下是整理后的表格格式:
| 實例名稱 | 端口名稱 | 默認端口 | 通信方向 | 說明 |
|---|---|---|---|---|
| BE | be_port | 9060 | FE -> BE | BE 上 Thrift Server 的端口,用于接收來自 FE 的請求 |
| BE | webserver_port | 8040 | BE <-> BE | BE 上的 HTTP Server 端口 |
| BE | heartbeat_service_port | 9050 | FE -> BE | BE 上的心跳服務端口(Thrift),用于接收來自 FE 的心跳 |
| BE | brpc_port | 8060 | FE <-> BE,BE <-> BE | BE 上的 BRPC 端口,用于 BE 之間的通信 |
| FE | http_port | 8030 | FE <-> FE,Client <-> FE | FE 上的 HTTP Server 端口 |
| FE | rpc_port | 9020 | BE -> FE,FE <-> FE | FE 上的 Thrift Server 端口,每個 FE 的配置需保持一致 |
| FE | query_port | 9030 | Client <-> FE | FE 上的 MySQL Server 端口 |
| FE | edit_log_port | 9010 | FE <-> FE | FE 上的 bdbje 通信端口 |
2.2.3、節點數量規劃
- FE 節點數量
FE 節點主要負責用戶請求的接入、查詢解析規劃、元數據管理及節點管理等工作。
對于生產集群,一般建議部署至少 3 個節點的 FE 以實現高可用環境。FE 節點分為以下兩種角色:
-
Follower 節點:參與選舉操作,當 Master 節點宕機時,會選擇一個可用的 Follower 節點成為新的 Master。
-
Observer 節點:僅從 Leader 節點同步元數據,不參與選舉,可用于橫向擴展以提升元數據的讀服務能力。
通常情況下,建議部署至少 3 個 Follower 節點。在高并發的場景中,可以通過增加 Observer 節點的數量來提高集群的連接數。
- BE 節點數量
BE 節點負責數據的存儲與計算。在生產環境中,為了數據的可靠性和容錯性,通常會使用 3 副本存儲數據,因此建議部署至少 3 個 BE 節點。
BE 節點支持橫向擴容,通過增加 BE 節點的數量,可以有效提升查詢的性能和并發處理能力。
2.3、操作系統檢查
在部署 Doris 時,需要對以下操作系統項進行檢查:
-
確保關閉 swap 分區
-
確保系統關閉透明大頁
-
確保系統有足夠大的虛擬內存區域
-
確保 CPU 不使用省電模式
-
確保網絡連接溢出時自動重置新連接
-
確保 Doris 相關端口暢通或關閉系統防火墻
-
確保系統有足夠大的打開文件句柄數
-
確定部署集群機器安裝 NTP 服務
2.3.1、關閉 swap 分區
在部署 Doris 時,建議關閉 swap 分區。swap 分區是內核發現內存緊張時,會按照自己的策略將部分內存數據移動到配置的 swap 分區,由于內核策略不能充分了解應用的行為,會對 Doris 性能造成較大影響。所以建議關閉。
通過以下命令可以臨時或者永久關閉。
臨時關閉,下次機器啟動時,swap 還會被打開。
swapoff -a
永久關閉,使用 Linux root 賬戶,注釋掉 /etc/fstab 中的 swap 分區,重啟即可徹底關閉 swap 分區。
# /etc/fstab
# <file system> <dir> <type> <options> <dump> <pass>
tmpfs /tmp tmpfs nodev,nosuid 0 0
/dev/sda1 / ext4 defaults,noatime 0 1
# /dev/sda2 none swap defaults 0 0
/dev/sda3 /home ext4 defaults,noatime 0 2
2.3.2、關閉系統透明大頁
在高負載低延遲的場景中,建議關閉操作系統透明大頁(Transparent Huge Pages, THP),避免其帶來的性能波動和內存碎片問題,確保 Doris 能夠穩定高效地使用內存。
使用以下命令臨時關閉透明大頁:
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
echo madvise > /sys/kernel/mm/transparent_hugepage/defrag
如果需要永久關閉透明大頁,可以使用以下命令,在下一次宿主機重啟后生效:
cat >> /etc/rc.d/rc.local << EOFecho madvise > /sys/kernel/mm/transparent_hugepage/enabledecho madvise > /sys/kernel/mm/transparent_hugepage/defrag
EOF
chmod +x /etc/rc.d/rc.local
2.3.3、增加虛擬內存區域
為了保證 Doris 有足夠的內存映射區域來處理大量數據,需要修改 VMA(虛擬內存區域)。如果沒有足夠的內存映射區域,Doris 在啟動或運行時可能會遇到 Too many open files 或類似的錯誤。
通過以下命令可以永久修改虛擬內存區域至少為 2000000,并立即生效:
cat >> /etc/sysctl.conf << EOF
vm.max_map_count = 2000000
EOF# Take effect immediately
sysctl -p
2.3.4、禁用 CPU 省電模式
在部署 Doris 時檢修關閉 CPU 的省電模式,以確保 Doris 在高負載時提供穩定的高性能,避免由于 CPU 頻率降低導致的性能波動、響應延遲和系統瓶頸,提高 Doris 的可靠性和吞吐量。如果您的 CPU 不支持 Scaling Governor,可以跳過此項配置。
通過以下命令可以關閉 CPU 省電模式:
echo 'performance' | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
2.3.5、網絡連接溢出時自動重置新連接
在部署 Doris 時,需要確保在 TCP 連接的發送緩沖區溢出時,連接會被立即中斷,以防止 Doris 在高負載或高并發情況下出現緩沖區阻塞,避免連接被長時間掛起,從而提高系統的響應性和穩定性。
通過以下命令可以永久設置系統自動重置新鏈接,并立即生效:
cat >> /etc/sysctl.conf << EOF
net.ipv4.tcp_abort_on_overflow=1
EOF# Take effect immediately
sysctl -p
2.3.6、相關端口暢通
如果發現端口不通,可以試著關閉防火墻,確認是否是本機防火墻造成。如果是防火墻造成,可以根據配置的 Doris 各組件端口打開相應的端口通信。
sudo systemctl stop firewalld.service
sudo systemctl disable firewalld.service
2.3.7、增加系統的最大文件句柄數
Doris 由于依賴大量文件來管理表數據,所以需要將系統對程序打開文件數的限制調高。
通過以下命令可以調整最大文件句柄數。在調整后,需要重啟會話以生效配置:
vi /etc/security/limits.conf
* soft nofile 1000000
* hard nofile 1000000
2.3.8、安裝并配置 NTP 服務
Doris 的元數據要求時間精度要小于 5000ms,所以所有集群所有機器要進行時鐘同步,避免因為時鐘問題引發的元數據不一致導致服務出現異常。
通常情況下,可以通過配置 NTP 服務保證各節點時鐘同步。
sudo systemctl start_ntpd.service
sudo systemctl enable_ntpd.service
三、部署doris
3.1、手動部署存算一體集群
在完成前置檢查及規劃后,如環境檢查、操作系統檢查、集群規劃,可以開始部署集存算一體集群。
存算一體集群架構如下,部署存算一體集群分為四步:
-
部署 FE Master 節點:部署第一個 FE 節點作為 Master 節點;
-
部署 FE 集群:部署 FE 集群,添加 Follower 或 Observer FE 節點;
-
部署 BE 節點:向 FE 集群中注冊 BE 節點;
-
驗證集群正確性:部署完成后連接并驗證集群正確性。
3.1.1、部署 FE Master 節點
- 創建元數據路徑
在部署 FE 時,建議與 BE 節點數據存儲在不同的硬盤上。
在解壓安裝包時,會默認附帶 doris-meta 目錄,建議為元數據創建獨立目錄,并將其軟連接到默認的 doris-meta 目錄。生產環境應使用單獨的 SSD 硬盤,不建議將其放在 Doris 安裝目錄下;開發和測試環境可以使用默認配置。
## Use a separate disk for FE metadata
mkdir -p <doris_meta_created>## Create FE metadata directory symlink
ln -s <doris_meta_created> <doris_meta_original>
就是創建一個獨立目錄,然后軟連接doris的doris-meta的目錄
- 修改 FE 配置文件
FE 的配置文件在 FE 部署路徑下的 conf 目錄中,啟動 FE 節點前需要修改conf/fe.conf。
在部署 FE 節點之前,建議調整以下配置:
## modify Java Heap
JAVA_OPTS="-Xmx16384m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$DORIS_HOME/log/fe.gc.log.$DATE"## modify case sensitivity
lower_case_table_names = 1## modify network CIDR
priority_networks = 10.1.3.0/24## modify Java Home
JAVA_HOME = <your-java-home-path>
| 參數 | 修改建議 |
|---|---|
| JAVA_OPTS | 指定參數 -Xmx 調整 Java Heap,生產環境建議 16G 以上。 |
| lower_case_table_names | 設置大小寫敏感,建議調整為 1,即大小寫不敏感。 |
| priority_networks | 網絡 CIDR,根據網絡 IP 地址指定。在 FQDN 環境中可以忽略。 |
| JAVA_HOME | 建議 Doris 使用獨立于操作系統的 JDK 環境。 |
更多詳細配置項請參考 FE 配置項: https://doris.apache.org/zh-CN/docs/3.0/admin-manual/config/fe-config
- 啟動 FE 進程
通過以下命令可以啟動 FE 進程
bin/start_fe.sh --daemon
FE 進程將在后臺啟動,日志默認保存在 log/ 目錄。如果啟動失敗,可通過查看 log/fe.log 或 log/fe.out 文件獲取錯誤信息。
- 檢查 FE 啟動狀態
通過 MySQL 客戶端連接 Doris 集群,初始化用戶為 root,默認密碼為空。
mysql -uroot -P<fe_query_port> -h<fe_ip_address>
鏈接到 Doris 集群后,可以通過 show frontends 命令查看 FE 的狀態,通常要確認以下幾項
-
Alive 為 true 表示節點存活;
-
Join 為 true 表示節點加入到集群中,但不代表當前還在集群內(可能已失聯);
-
IsMaster 為 true 表示當前節點為 Master 節點。
3.1.2、部署 FE 集群(可選)
生產環境建議至少部署 3 個節點。在部署過 FE Master 節點后,需要再部署兩個 FE Follower 節點。
- 創建元數據目錄
參考部署 FE Master 節點,創建 doris-meta 目錄
- 修改 FE Follower 節點配置文件
參考部署 FE Master 節點,修改 FE Follower 節點配置文件。通常情況下,可以直接復制 FE Master 節點的配置文件。
- 在 Doris 集群中注冊新的 FE Follower 節點
在啟動新的 FE 節點前,需要先在 FE 集群中注冊新的 FE 節點。
## connect a alive FE node
mysql -uroot -P<fe_query_port> -h<fe_ip_address>## registe a new FE follower node
ALTER SYSTEM ADD FOLLOWER "<fe_ip_address>:<fe_edit_log_port>"
如果要添加 observer 節點,可以使用 ADD OBSERVER 命令
## register a new FE observer node
ALTER SYSTEM ADD OBSERVER "<fe_ip_address>:<fe_edit_log_port>"
注意
- FE Follower(包括 Master)節點的數量建議為奇數,建議部署 3 個組成高可用模式。
- 當 FE 處于高可用部署時(1 個 Master,2 個 Follower),我們建議通過增加 Observer FE 來擴展 FE 的讀服務能力
- 啟動 FE Follower 節點
通過以下命令,可以啟動 FE Follower 節點,并自動同步元數據。
bin/start_fe.sh --helper <helper_fe_ip>:<fe_edit_log_port> --daemon
其中,helper_fe_ip 是 FE 集群中任何存活節點的 IP 地址。–helper 參數僅在第一次啟動 FE 時需要,之后重啟無需指定。
- 判斷 Follower 節點狀態
與 FE Master 節點狀態判斷相同,添加 Follower 節點后,可通過 show frontends 命令查看節點狀態,IsMaster 應為 false。
3.1.3、部署 BE 節點
- 創建數據目錄
BE 進程應用于數據的計算與存儲。數據目錄默認放在 be/storage 下。生產環境通常將 BE 數據與 BE 部署文件分別存儲在不同的硬盤上。BE 支持數據分布在多盤上以更好的利用多塊硬盤的 I/O 能力。
## Create a BE data storage directory on each data disk
mkdir -p <be_storage_root_path>
- 修改 BE 配置文件
BE 的配置文件在 BE 部署路徑下的 conf 目錄中,啟動 BE 節點前需要修改 conf/be.conf
## modify storage path for BE node,上一步新建的storage目錄,可以建多個放不同盤storage_root_path=/home/disk1/doris,medium:HDD;/home/disk2/doris,medium:SSD## modify network CIDR priority_networks = 10.1.3.0/24## modify Java Home in be/conf/be.confJAVA_HOME = <your-java-home-path>
| 參數 | 修改建議 |
|---|---|
| priority_networks | 網絡 CIDR,根據網絡 IP 地址指定。在 FQDN (Fully Qualified Domain Name,完全限定域名)環境中可以忽略。 |
| JAVA_OPTS | 指定參數 -Xmx 調整 Java Heap,生產環境建議 2G 以上。 |
| JAVA_HOME | 建議 Doris 使用獨立于操作系統的 JDK 環境。 |
- 在 Doris 中注冊 BE 節點
在啟動 BE 節點前,需要先在 FE 集群中注冊該節點:
## connect a alive FE node
mysql -uroot -P<fe_query_port> -h<fe_ip_address>## registe BE node
ALTER SYSTEM ADD BACKEND "<be_ip_address>:<be_heartbeat_service_port>"
- 啟動 BE 進程
通過以下命令可以啟動 BE 進程:
bin/start_be.sh --daemon
BE 進程在后臺啟動,日志默認保存在 log/ 目錄。如果啟動失敗,請檢查 log/be.log 或 log/be.out 文件以獲取錯誤信息。
- 查看 BE 啟動狀態
連接 Doris 集群后,可通過show backends 命令查看 BE 節點的狀態。
## connect a alive FE node
mysql -uroot -P<fe_query_port> -h<fe_ip_address>## check BE node status
show backends;
通常情況下需要注意以下幾項狀態:
-
Alive 為 true 表示節點存活
-
TabletNum 表示該節點上的分片數量,新加入的節點會進行數據均衡,TabletNum 逐漸趨于平均。
3.1.4、驗證集群正確性
- 登錄數據庫
使用 MySQL 客戶端登錄 Doris 集群。
## connect a alive fe node
mysql -uroot -P<fe_query_port> -h<fe_ip_address>
- 檢查 Doris 安裝信息
通過 show frontends 與 show backends 可以查看數據庫各實例的信息。
-- check fe status
show frontends \G-- check be status
show backends \G
- 修改 Doris 集群密碼
在創建 Doris 集群時,系統會自動創建一個名為 root 的用戶,并默認設置其密碼為空。為了提高安全性,建議在集群創建后立即為 root 用戶設置一個新密碼。
-- check the current user
select user();
+------------------------+
| user() |
+------------------------+
| 'root'@'192.168.88.30' |
+------------------------+ -- modify the password for current user
SET PASSWORD = PASSWORD('doris_new_passwd');
- 創建測試表并插入數據
為了驗證集群的正確性,可以在新創建的集群中創建一個測試表,并插入測試數據。
create database testdb;-- create a test table
CREATE TABLE testdb.table_hash
(k1 TINYINT,k2 DECIMAL(10, 2) DEFAULT "10.5",k3 VARCHAR(10) COMMENT "string column",k4 INT NOT NULL DEFAULT "1" COMMENT "int column"
)
COMMENT "my first table"
DISTRIBUTED BY HASH(k1) BUCKETS 32;
Doris 兼容 MySQL 協議,可以使用 INSERT 語句插入數據。
-- insert data
INSERT INTO testdb.table_hash VALUES
(1, 10.1, 'AAA', 10),
(2, 10.2, 'BBB', 20),
(3, 10.3, 'CCC', 30),
(4, 10.4, 'DDD', 40),
(5, 10.5, 'EEE', 50);-- check the data
SELECT * from testdb.table_hash;
+------+-------+------+------+
| k1 | k2 | k3 | k4 |
+------+-------+------+------+
| 3 | 10.30 | CCC | 30 |
| 4 | 10.40 | DDD | 40 |
| 5 | 10.50 | EEE | 50 |
| 1 | 10.10 | AAA | 10 |
| 2 | 10.20 | BBB | 20 |
+------+-------+------+------+
3.2、手動部署存算分離集群
在完成前置檢查及規劃后,如環境檢查、集群規劃、操作系統檢查后,可以開始部署集群。部署集群分為八步:
-
準備 FoundationDB 集群:可以使用已有的 FoundationDB 集群,或新建 FoundationDB 集群;
-
部署 S3 或 HDFS 服務:可以使用已有的共享存儲,或新建共享存儲;
-
部署 Meta Service:為 Doris 集群部署 Meta Service 服務;
-
部署數據回收進程:為 Doris 集群獨立部署數據回收進程,可選操作;
-
啟動 FE Master 節點:啟動第一個 FE 節點作為 Master FE 節點;
-
創建 FE Master 集群:添加 FE Follower/Observer 節點組成 FE 集群;
-
添加 BE 節點:向集群中添加并注冊 BE 節點;
-
添加 Storage Vault:使用共享存儲創建一個或多個 Storage Vault。
3.2.1、準備 FoundationDB
本節提供了腳本 fdb_vars.sh 和 fdb_ctl.sh 配置、部署和啟動 FDB(FoundationDB)服務的分步指南。您可以下載 doris tools 并從 fdb 目錄獲取 fdb_vars.sh 和 fdb_ctl.sh。
- 機器要求
通常,至少需要三臺配備 SSD 的機器來組成具有雙副本、單機故障容忍的 FoundationDB 集群。如果是測試/開發環境,單臺機器也能搭建 FoundationDB。
- 配置
fdb_vars.sh腳本
在配置 fdb_vars.sh 腳本時,必須指定以下配置:
| 參數名 | 描述 | 類型 | 示例 | 注意事項 |
|---|---|---|---|---|
| DATA_DIRS | 指定 FoundationDB 存儲的數據目錄 | 以逗號分隔的絕對路徑列表 | /mnt/foundationdb/data1,/mnt/foundationdb/data2,/mnt/foundationdb/data3 | 運行腳本前確保目錄已創建,生產環境建議使用 SSD 和獨立目錄 |
| FDB_CLUSTER_IPS | 定義集群 IP | 字符串(以逗號分隔的 IP 地址) | 172.200.0.2,172.200.0.3,172.200.0.4 | 生產集群至少應有 3 個 IP 地址,第一個 IP 地址將用作協調器,為高可用性,將機器放置在不同機架上 |
| FDB_HOME | 定義 FoundationDB 主目錄 | 絕對路徑 | /fdbhome | 默認路徑為 /fdbhome,確保此路徑是絕對路徑 |
| FDB_CLUSTER_ID | 定義集群 ID | 字符串 | SAQESzbh | 每個集群的 ID 必須唯一,可使用 mktemp -u XXXXXXXX 生成 |
| FDB_CLUSTER_DESC | 定義 FDB 集群的描述 | 字符串 | dorisfdb | 建議更改為對部署有意義的內容 |
可以選擇指定以下自定義配置:
| 參數 | 描述 | 類型 | 示例 | 注意事項 |
|---|---|---|---|---|
| MEMORY_LIMIT_GB | 定義 FDB 進程的內存限制,單位為 GB | 整數 | MEMORY_LIMIT_GB=16 | 根據可用內存資源和 FDB 進程的要求調整此值 |
| CPU_CORES_LIMIT | 定義 FDB 進程的 CPU 核心限制 | 整數 | CPU_CORES_LIMIT=8 | 根據可用的 CPU 核心數量和 FDB 進程的要求設置此值 |
- 部署 FDB 集群
使用 fdb_vars.sh 配置環境后,您可以在每個節點上使用 fdb_ctl.sh 腳本部署 FDB 集群。
./fdb_ctl.sh deploy
- 啟動 FDB 服務
FDB 集群部署完成后,您可以使用 fdb_ctl.sh 腳本啟動 FDB 服務。
./fdb_ctl.sh start
以上命令啟動 FDB 服務,使集群工作并獲取 FDB 集群連接字符串,后續可以用于配置 MetaService。
注意:fdb_ctl.sh 腳本中的 clean 命令會清除所有 fdb 元數據信息,可能導致數據丟失,嚴禁在生產環境中使用!
3.2.2、安裝 S3 或 HDFS 服務(可選)
Doris 的存算分離模式依賴于 S3 或 HDFS 服務來存儲數據,如果您已經有相關服務,直接使用即可。 如果沒有,本文檔提供 MinIO 的簡單部署教程:
-
在 MinIO 的下載頁面選擇合適的版本以及操作系統,下載對應的 Server 以及 Client 的二進制包或安裝包。
-
啟動 MinIO Server
export MINIO_REGION_NAME=us-east-1
export MINIO_ROOT_USER=minio # 在較老版本中,該配置為 MINIO_ACCESS_KEY=minio
export MINIO_ROOT_PASSWORD=minioadmin # 在較老版本中,該配置為 MINIO_SECRET_KEY=minioadmin
nohup ./minio server /mnt/data 2>&1 &
- 配置 MinIO Client
# 如果你使用的是安裝包安裝的客戶端,那么客戶端名為 mcli,直接下載客戶端二進制包,則其名為 mc
./mc config host add myminio http://127.0.0.1:9000 minio minioadmin
- 創建一個桶
./mc mb myminio/doris
- 驗證是否正常工作
# 上傳一個文件
./mc mv test_file myminio/doris
# 查看這個文件
./mc ls myminio/doris
3.2.3、Meta Service 部署
- 配置
在./conf/doris_cloud.conf文件中,主要需要修改以下兩個參數:
brpc_listen_port:Meta Service 的監聽端口,默認為 5000。fdb_cluster:FoundationDB 集群的連接信息,部署 FoundationDB 時可以獲取。(如果使用 Doris 提供的 fdb_ctl.sh 部署的話,可在 $FDB_HOME/conf/fdb.cluster 文件里獲取該值)。
示例配置:
brpc_listen_port = 5000
fdb_cluster = xxx:yyy@127.0.0.1:4500
注意:fdb_cluster 的值應與 FoundationDB 部署機器上的 /etc/foundationdb/fdb.cluster文件內容一致(如果使用 Doris 提供的 fdb_ctl.sh 部署的話,可在 $FDB_HOME/conf/fdb.cluster 文件里獲取該值)。
示例,文件的最后一行就是要填到 doris_cloud.conf 里 fdb_cluster 字段的值:
cat /etc/foundationdb/fdb.clusterDO NOT EDIT!
This file is auto-generated, it is not to be edited by hand.
cloud_ssb:A83c8Y1S3ZbqHLL4P4HHNTTw0A83CuHj@127.0.0.1:4500
- 啟動與停止
在啟動前,需要確保已正確設置 JAVA_HOME 環境變量,指向 OpenJDK 17,進入 ms 目錄。
啟動命令如下:
export JAVA_HOME=${path_to_jdk_17}
bin/start.sh --daemon
啟動腳本返回值為 0 表示啟動成功,否則啟動失敗。啟動成功同時標準輸出的最后一行文本信息為 “doris_cloud start successfully”。
停止命令如下:
bin/stop.sh
生產環境中請確保至少有 3 個 Meta Service 節點。
3.2.4、數據回收功能獨立部署(可選)
Meta Service 本身具備了元數據管理和回收功能,這兩個功能可以獨立部署,如果需要獨立部署數據回收功能,可參考以下步驟。
- 創建新的工作目錄(如 recycler),并復制 ms 目錄內容到新目錄:
cp -r ms recycler
- 在新目錄的配置文件中修改 BRPC 監聽端口 brpc_listen_port 和 fdb_cluster 的值。
啟動數據回收功能
export JAVA_HOME=${path_to_jdk_17}
bin/start.sh --recycler --daemon
啟動僅元數據操作功能
export JAVA_HOME=${path_to_jdk_17}
bin/start.sh --meta-service --daemon
3.2.5、啟動 FE Master 節點
- 配置 fe.conf 文件
在 fe.conf 文件中,需要配置以下關鍵參數:
deploy_mode- 描述:指定 doris 啟動模式
- 格式:cloud 表示存算分離模式,其它存算一體模式
- 示例:
cloud
cluster_id- 描述:存算分離架構下集群的唯一標識符,不同的集群必須設置不同的 cluster_id。
- 格式:int 類型
- 示例:可以使用如下 shell 腳本
echo $(($((RANDOM << 15)) | $RANDOM))生成一個隨機 id 使用。 - 注意:不同的集群必須設置不同的 cluster_id
meta_service_endpoint- 描述:Meta Service 的地址和端口
- 格式:
IP地址:端口號 - 示例:
127.0.0.1:5000,可以用逗號分割配置多個 meta service。
- 啟動 FE Master 節點
啟動命令:
bin/start_fe.sh --daemon
第一個 FE 進程初始化集群并以 FOLLOWER 角色工作。使用 mysql 客戶端連接 FE 使用 show frontends 確認剛才啟動的 FE 是 master。
3.2.6、注冊 FE Follower/Observer 節點
其他節點同樣根據上述步驟修改配置文件并啟動,使用 mysql 客戶端連接 Master 角色的 FE,并用以下 SQL 命令添加額外的 FE 節點:
ALTER SYSTEM ADD FOLLOWER "host:port";
將 host:port 替換為 FE 節點的實際地址和編輯日志端口。更多信息請參見 ADD FOLLOWER和 ADD OBSERVER。
生產環境中,請確保在 FOLLOWER 角色中的前端(FE)節點總數,包括第一個 FE,保持為奇數。一般來說,三個 FOLLOWER 就足夠了。觀察者角色的前端節點可以是任意數量。
3.2.7、添加 BE 節點
要向集群添加 Backend 節點,請對每個 Backend 執行以下步驟:
- 配置 be.conf
- 在
be.conf文件中,需要配置以下關鍵參數:deploy_mode- 描述:指定 doris 啟動模式
- 格式:cloud 表示存算分離模式,其它存算一體模式
- 示例:
cloud
file_cache_path- 描述:用于文件緩存的磁盤路徑和其他參數,以數組形式表示,每個磁盤一項。path 指定磁盤路徑,total_size 限制緩存的大小;-1 或 0 將使用整個磁盤空間。
- 格式: [{“path”:“/path/to/file_cache”,“total_size”:21474836480},{“path”:“/path/to/file_cache2”,“total_size”:21474836480}]
- 示例: [{“path”:“/path/to/file_cache”,“total_size”:21474836480},{“path”:“/path/to/file_cache2”,“total_size”:21474836480}]
- 默認: [{“path”:“${DORIS_HOME}/file_cache”}]
- 啟動 BE 進程
使用以下命令啟動 Backend:
bin/start_be.sh --daemon
- 將 BE 添加到集群
使用 MySQL 客戶端連接到任意 FE 節點:
ALTER SYSTEM ADD BACKEND "<ip>:<heartbeat_service_port>" [PROTERTIES propertires];
將 替換為新 Backend 的 IP 地址,將 <heartbeat_service_port> 替換為其配置的心跳服務端口(默認為 9050)。
可以通過 PROPERTIES 設置 BE 所在的 計算組。
更詳細的用法請參考 ADD BACKEND 和 REMOVE BACKEND。
- 驗證 BE 狀態
檢查 Backend 日志文件(be.log)以確保它已成功啟動并加入集群。
您還可以使用以下 SQL 命令檢查 Backend 狀態:
SHOW BACKENDS;
這將顯示集群中所有 Backend 及其當前狀態。
3.2.8、添加 Storage Vault
Storage Vault 是 Doris 存算分離架構中的重要組件。它們代表了存儲數據的共享存儲層。您可以使用 HDFS 或兼容 S3 的對象存儲創建一個或多個 Storage Vault。可以將一個 Storage Vault 設置為默認 Storage Vault,系統表和未指定 Storage Vault 的表都將存儲在這個默認 Storage Vault 中。默認 Storage Vault 不能被刪除。以下是為您的 Doris 集群創建 Storage Vault 的方法:
- 創建 HDFS Storage Vault
要使用 SQL 創建 Storage Vault,請使用 MySQL 客戶端連接到您的 Doris 集群
CREATE STORAGE VAULT IF_NOT_EXISTS hdfs_vaultPROPERTIES ("type"="hdfs","fs.defaultFS"="hdfs://127.0.0.1:8020"
);
- 創建 S3 Storage Vault
要使用兼容 S3 的對象存儲創建 Storage Vault,請按照以下步驟操作:
- 使用 MySQL 客戶端連接到您的 Doris 集群。
- 執行以下 SQL 命令來創建 S3 Storage Vault:
CREATE STORAGE VAULT IF_NOT_EXISTS s3_vaultPROPERTIES ("type"="S3","s3.endpoint"="s3.us-east-1.amazonaws.com","s3.access_key" = "ak","s3.secret_key" = "sk","s3.region" = "us-east-1","s3.root.path" = "ssb_sf1_p2_s3","s3.bucket" = "doris-build-1308700295","provider" = "S3"
);
要在其他對象存儲上創建 Storage Vault,請參考 創建 Storage Vault
- 設置默認 Storage Vault
使用如下 SQL 語句設置一個默認 Storage Vault。
SET <storage_vault_name> AS DEFAULT STORAGE VAULT
3.2.9、注意事項
- 僅元數據操作功能的 Meta Service 進程應作為 FE 和 BE 的
meta_service_endpoint配置目標。 - 數據回收功能進程不應作為
meta_service_endpoint配置目標。
3.3、Doris 內置的 Web UI
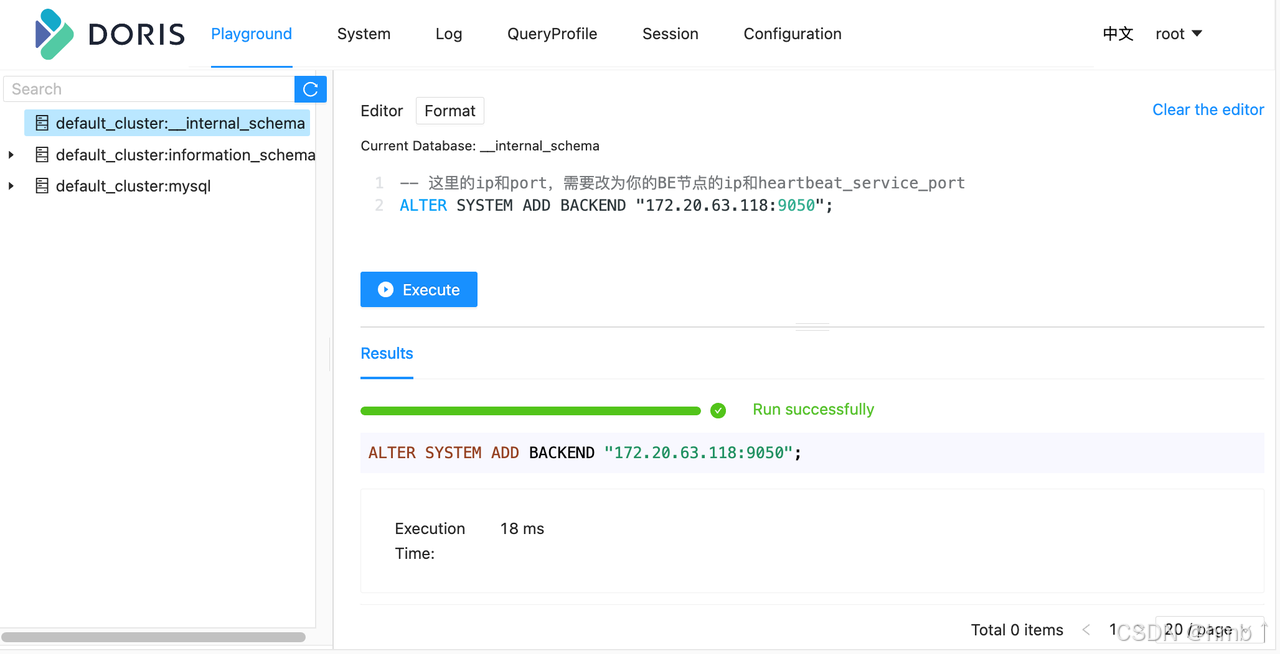
Doris FE 內置 Web UI。用戶無須安裝 MySQL 客戶端,即可通過內置的 Web UI 進行 SQL 查詢和其它相關信息的查看。
在瀏覽器中輸入 http://fe_ip:fe_port, 比如 http://172.20.63.118:8030,打開 Doris 內置的 Web 控制臺。
內置 Web 控制臺,主要供集群 root 賬戶使用,默認安裝后 root 賬戶密碼為空。

比如,在 Playground 中,執行如下語句,可以完成對 BE 節點的添加。
ALTER SYSTEM ADD BACKEND "be_host_ip:heartbeat_service_port";
警告
-
Playground 中執行這種和具體數據庫/表沒有關系的語句,務必在左側庫欄里隨意選擇一個數據庫,才能執行成功,這個限制,稍后會去掉。
-
當前內置的 Web 控制臺,還不能執行 SET 類型的 SQL 語句,所以,在 Web 控制臺,當前還不能通過執行 SET PASSWORD FOR ‘user’ = PASSWORD(‘user_password’) `類似語句。
四、數據表設計
- 創建表
使用 CREATE TABLE 語句在 Doris 中創建一個表,也可以使用 CREATE TABKE LIKE 或 CREATE TABLE AS 子句從另一個表派生表定義。
-
表屬性
Doris 的建表語句中可以指定建表屬性,包括:-
分桶數 (buckets):決定數據在表中的分布;
-
存儲介質 (storage_medium):控制數據的存儲方式,如使用 HDD、SSD 或遠程共享存儲;
-
副本數 (replication_num):控制數據副本的數量,以保證數據的冗余和可靠性;
-
冷熱分離存儲策略 (storage_policy) :控制數據的冷熱分離存儲的遷移策略;
-
這些屬性作用于分區,即分區創建之后,分區就會有自己的屬性,修改表屬性只對未來創建的分區生效,對已經創建好的分區不生效,關于屬性更多的信息請參考修改表屬性。
-
注意事項
-
選擇合適的數據模型:數據模型不可更改,建表時需要選擇一個合適的數據模型;
-
選擇合適的分桶數:已經創建的分區不能修改分桶數,可以通過替換分區來修改分桶數,可以修改動態分區未創建的分區分桶數;
-
添加列操作:加減 VALUE 列是輕量級實現,秒級別可以完成,加減 KEY 列或者修改數據類型是重量級操作,完成時間取決于數據量,大規模數據下盡量避免加減 KEY 列或者修改數據類型;
-
優化存儲策略:可以使用層級存儲將冷數據保存到 HDD 或者 S3 / HDFS。
-
創建示例:
-- ======================================================================
-- 數據庫創建
-- ======================================================================
CREATE DATABASE IF NOT EXISTS ecommerce_analysis
COMMENT "電商用戶行為分析數據庫";USE ecommerce_analysis;-- ======================================================================
-- 存儲資源創建(需提前配置)
-- ======================================================================
-- 創建SSD資源(熱數據)
CREATE RESOURCE IF NOT EXISTS SSD_RESOURCE PROPERTIES ("type" = "local", -- 本地存儲"medium" = "ssd", -- SSD介質"path" = "/path/to/ssd/" -- SSD存儲路徑
) COMMENT "熱數據存儲資源";-- HDD資源(冷數據)
CREATE RESOURCE IF NOT EXISTS HDD_RESOURCE PROPERTIES ("type" = "local","medium" = "hdd","path" = "/data/doris/hdd/" -- 替換為實際HDD路徑
);-- ======================================================================
-- 用戶行為明細表(完整Doris 3.0建表語句)
-- ======================================================================
CREATE TABLE IF NOT EXISTS user_events (-- ================== 維度列(用于過濾、分組)==================event_time DATETIME NOT NULL COMMENT "事件精確時間(毫秒級)", event_date DATE NOT NULL COMMENT "事件日期(分區鍵)", user_id BIGINT NOT NULL COMMENT "用戶ID(分桶鍵)",device_type VARCHAR(20) COMMENT "設備類型(手機/PC/平板)",province VARCHAR(50) COMMENT "用戶所在省份",city VARCHAR(50) COMMENT "用戶所在城市",-- ================== 指標列(用于聚合計算)==================page_view BIGINT SUM DEFAULT "0" COMMENT "頁面瀏覽次數",cart_add BIGINT SUM DEFAULT "0" COMMENT "加購操作次數",order_count BIGINT SUM DEFAULT "0" COMMENT "下單次數",order_amount DOUBLE SUM DEFAULT "0" COMMENT "訂單總金額(元)",bounce_rate DOUBLE SUM DEFAULT "0" COMMENT "跳出率",-- ================== 主鍵/唯一標識列 ==================event_id VARCHAR(36) COMMENT "事件唯一ID(UUID格式)",-- ================== 其他輔助列 ==================session_id VARCHAR(64) COMMENT "會話ID",referrer VARCHAR(256) COMMENT "來源頁面URL",user_agent VARCHAR(256) COMMENT "用戶代理信息"
)
-- ================== 存儲引擎配置 ==================
ENGINE = OLAP -- OLAP引擎(必須)-- ================== 數據模型(三選一)==================
-- 選項1:聚合模型(適合預聚合報表)
AGGREGATE KEY(event_date, event_time, user_id, device_type, province, city, event_id)-- 選項2:主鍵模型(支持實時更新,適合需要行級更新的場景)
-- UNIQUE KEY(event_id, event_time) -- 主鍵(唯一標識行)
-- COMMENT "主鍵模型:支持行級更新,適用于需要精確更新的場景"-- 選項3:明細模型(存儲原始日志,無聚合)
-- DUPLICATE KEY(event_time, user_id, event_date) -- 排序鍵
-- COMMENT "明細模型:存儲原始事件日志,適用于全量數據分析"-- ================== 分區配置 ==================
PARTITION BY RANGE(event_date) (-- 初始分區(動態分區會自動創建后續分區)PARTITION p_20240101 VALUES [('2024-01-01'), ('2024-01-02')),PARTITION p_20240102 VALUES [('2024-01-02'), ('2024-01-03'))
)
COMMENT "按天分區,自動管理生命周期"-- ================== 分桶配置 ==================
DISTRIBUTED BY HASH(user_id) BUCKETS 32
COMMENT "按用戶ID哈希分桶,32個分桶"-- ================== 冷熱分層存儲策略 ==================
PROPERTIES (-- ***** 冷熱分層核心配置 ****"storage_policy" = "hot_cold_policy", -- 存儲策略名稱"storage_policy.hot.storage_resource" = "SSD_RESOURCE", -- 熱數據存儲資源"storage_policy.cold.storage_resource" = "HDD_RESOURCE", -- 冷數據存儲資源-- 下面的動態分區配置優先級比較高"storage_policy.hot.cooldown_ttl" = "7 days", -- 熱數據保留7天"storage_policy.cold.cooldown_ttl" = "365 days",-- 冷數據保留1年-- ***** 動態分區配置(自動管理分區)*****"dynamic_partition.enable" = "true", -- 啟用動態分區"dynamic_partition.time_unit" = "DAY", -- 按天分區"dynamic_partition.start" = "-30", -- 保留最近30天分區"dynamic_partition.end" = "7", -- 預創建未來7天分區"dynamic_partition.prefix" = "p_", -- 分區名前綴"dynamic_partition.buckets" = "32", -- 每個分區分桶數"dynamic_partition.hot_partition_num" = "7", -- 關鍵參數:最近7天為熱分區(存儲在SSD)-- ***** 數據副本與高可用 *****"replication_num" = "3", -- 每個分桶3副本(生產環境必須≥3)"replication_allocation" = "tag.location.default: 3", -- 副本分配策略-- ***** 存儲優化參數 *****"compression" = "ZSTD", -- 列存壓縮算法(推薦ZSTD)"light_schema_change" = "true",-- 3.0新增:快速schema變更"enable_unique_key_merge_on_write" = "true", -- 主鍵模型寫時合并-- ***** 性能優化參數 *****"disable_auto_compaction" = "false", -- 啟用自動compaction"storage_format" = "V2", -- 存儲格式版本(V2性能更好)"bloom_filter_columns" = "user_id,event_id", -- 布隆過濾器加速查詢-- ***** 其他配置 *****"in_memory" = "false", -- 全表不在內存(熱數據自動緩存)"tablet_type" = "COLUMN", -- 列式存儲(默認)"dynamic_schema" = "false" -- 禁用動態schema
)
COMMENT "電商用戶行為明細表(Doris 3.0冷熱分層存儲)";
4.1、數據模型
在 Doris 中支持三種表模型:
-
明細模型(Duplicate Key Model):允許指定的 Key 列重復,Doirs 存儲層保留所有寫入的數據,適用于必須保留所有原始數據記錄的情況;
-
主鍵模型(Unique Key Model):每一行的 Key 值唯一,可確保給定的 Key 列不會存在重復行,Doris 存儲層對每個 key 只保留最新寫入的數據,適用于數據更新的情況;
-
聚合模型(Aggregate Key Model):可根據 Key 列聚合數據,Doris 存儲層保留聚合后的數據,從而可以減少存儲空間和提升查詢性能;通常用于需要匯總或聚合信息(如總數或平均值)的情況。
在建表后,表模型的屬性已經確認,無法修改。針對業務選擇合適的模型至關重要:
-
Duplicate Key:適合任意維度的 Ad-hoc 查詢。雖然同樣無法利用預聚合的特性,但是不受聚合模型的約束,可以發揮列存模型的優勢(只讀取相關列,而不需要讀取所有 Key 列)。
-
Unique Key:針對需要唯一主鍵約束的場景,可以保證主鍵唯一性約束。但是無法利用 ROLLUP 等預聚合帶來的查詢優勢。
-
Aggregate Key:可以通過預聚合,極大地降低聚合查詢時所需掃描的數據量和查詢的計算量,非常適合有固定模式的報表類查詢場景。但是該模型對 count(*) 查詢很不友好。同時因為固定了 Value 列上的聚合方式,在進行其他類型的聚合查詢時,需要考慮語意正確性。
表模型能力對比
| 能力對比項 | 明細模型 | 主鍵模型 | 聚合模型 |
|---|---|---|---|
| Key 列唯一約束 | 不支持(Key 列可重復) | 支持 | 支持 |
| 同步物化視圖 | 支持 | 支持 | 支持 |
| 異步物化視圖 | 支持 | 支持 | 支持 |
| UPDATE 語句 | 不支持 | 支持 | 不支持 |
| DELETE 語句 | 部分支持 | 支持 | 不支持 |
| 導入時整行更新 | 不支持 | 支持 | 不支持 |
| 導入時部分列更新 | 不支持 | 支持 | 部分支持 |
4.1.1、明細模型
明細模型是 Doris 中的默認建表模型,用于保存每條原始數據記錄。在建表時,通過 DUPLICATE KEY 指定數據存儲的排序列,以優化常用查詢。一般建議選擇三列或更少的列作為排序鍵
-
保留原始數據:明細模型保留了全量的原始數據,適合于存儲與查詢原始數據。對于需要進行詳細數據分析的應用場景,建議使用明細模型,以避免數據丟失的風險;
-
不去重也不聚合:與聚合模型與主鍵模型不同,明細模型不會對數據進行去重與聚合操作。即使兩條相同的數據,每次插入時也會被完整保留;
-
靈活的數據查詢:明細模型保留了全量的原始數據,可以從完整數據中提取細節,基于全量數據做任意維度的聚合操作,從而進行元數數據的審計及細粒度的分析。
使用場景
一般明細模型中的數據只進行追加,舊數據不會更新。明細模型適用于需要存儲全量原始數據的場景:
-
日志存儲:用于存儲各類的程序操作日志,如訪問日志、錯誤日志等。每一條數據都需要被詳細記錄,方便后續的審計與分析;
-
用戶行為數據:在分析用戶行為時,如點擊數據、用戶訪問軌跡等,需要保留用戶的詳細行為,方便后續構建用戶畫像及對行為路徑進行詳細分析;
-
交易數據:在某些存儲交易行為或訂單數據時,交易結束時一般不會發生數據變更。明細模型適合保留這一類交易信息,不遺漏任意一筆記錄,方便對交易進行精確的對賬。
建表說明
在建表時,可以通過 DUPLICATE KEY 關鍵字指定明細模型。明細表必須指定數據的 Key 列,用于在存儲時對數據進行排序。下例的明細表中存儲了日志信息,并針對于 log_time、log_type 及 error_code 三列進行了排序:
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(log_time DATETIME NOT NULL,log_type INT NOT NULL,error_code INT,error_msg VARCHAR(1024),op_id BIGINT,op_time DATETIME
)
DUPLICATE KEY(log_time, log_type, error_code)
DISTRIBUTED BY HASH(log_type) BUCKETS 10;
數據插入與存儲
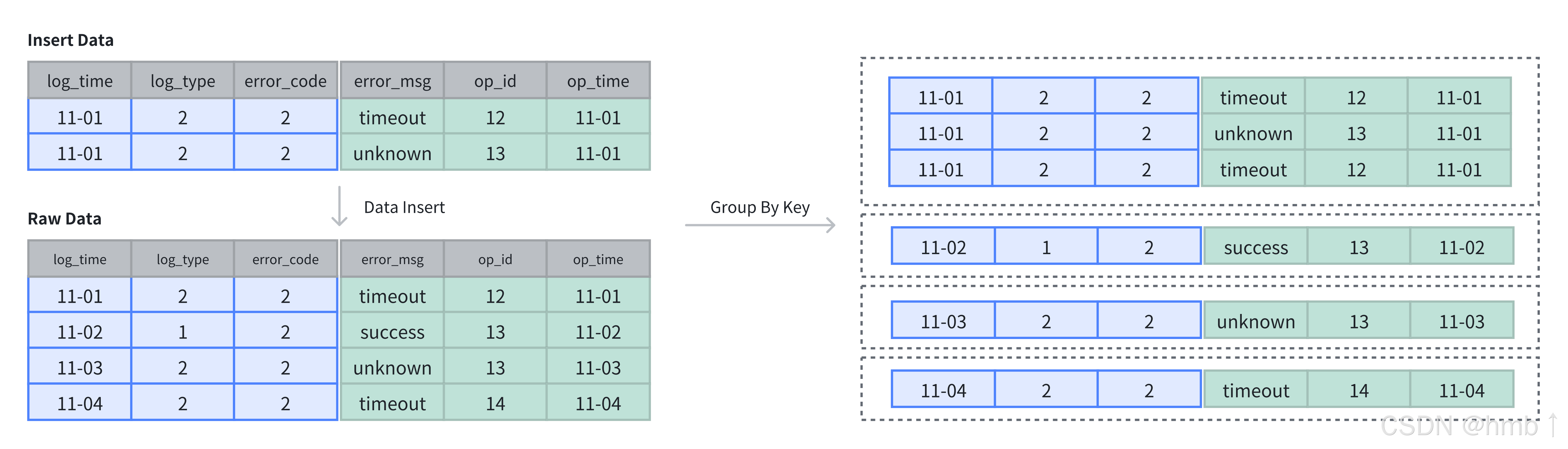
4.1.2、主鍵模型
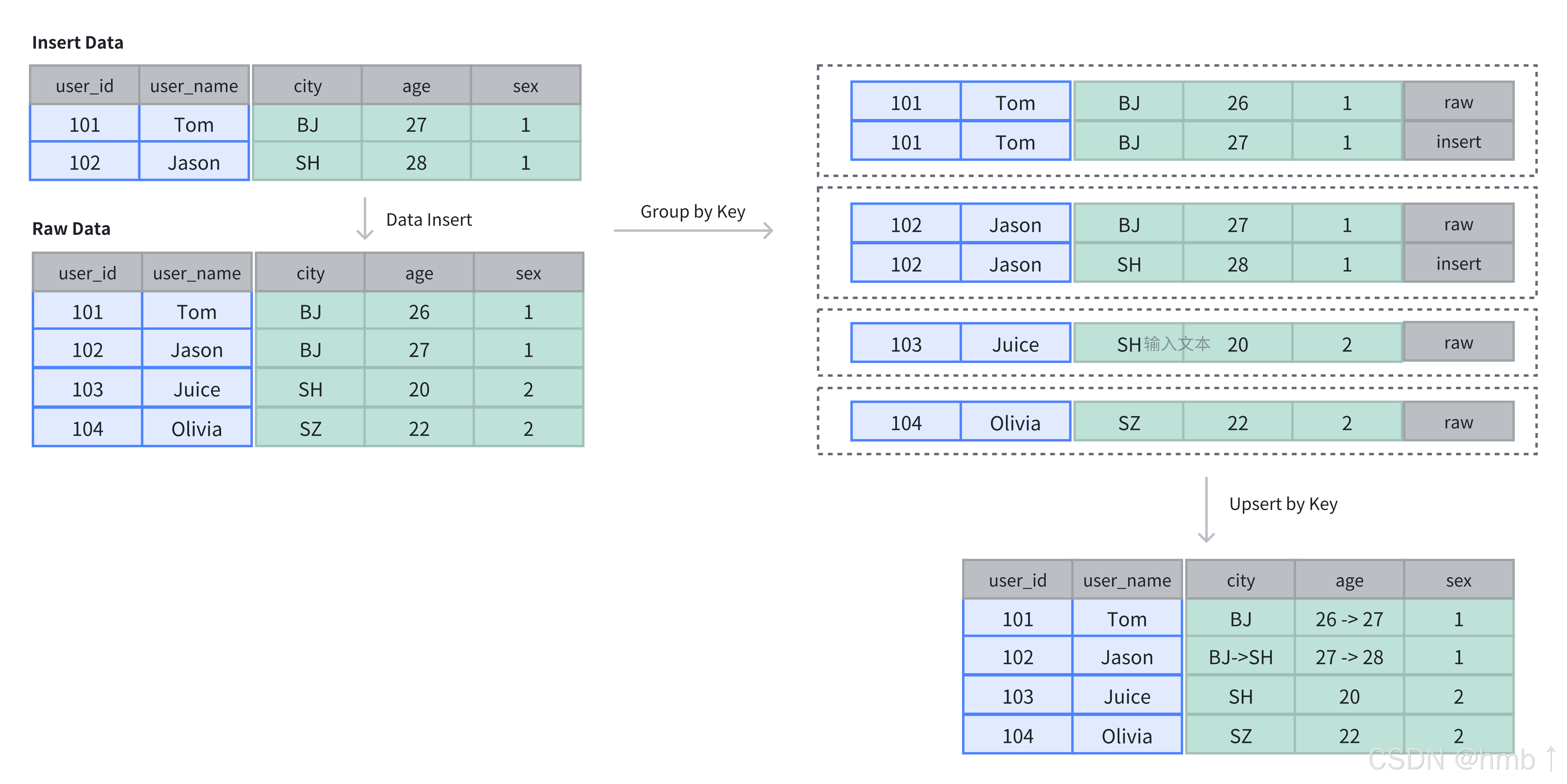
當需要更新數據時,可以選擇主鍵模型(Unique Key Model)。該模型保證 Key 列的唯一性,插入或更新數據時,新數據會覆蓋具有相同 Key 的舊數據,確保數據記錄為最新。與其他數據模型相比,主鍵模型適用于數據的更新場景,在插入過程中進行主鍵級別的更新覆蓋。
主鍵模型有以下特點:
-
基于主鍵進行 UPSERT:在插入數據時,主鍵重復的數據會更新,主鍵不存在的記錄會插入;
-
基于主鍵進行去重:主鍵模型中的 Key 列具有唯一性,會對根據主鍵列對數據進行去重操作;
-
高頻數據更新:支持高頻數據更新場景,同時平衡數據更新性能與查詢性能。
使用場景
-
高頻數據更新:適用于上游 OLTP 數據庫中的維度表,實時同步更新記錄,并高效執行 UPSERT 操作;
-
數據高效去重:如廣告投放和客戶關系管理系統中,使用主鍵模型可以基于用戶 ID 高效去重;
-
需要部分列更新:如畫像標簽場景需要變更頻繁改動的動態標簽,消費訂單場景需要改變交易的狀態。通過主鍵模型部分列更新能力可以完成某幾列的變更操作。
實現方式
在 Doris 中主鍵模型有兩種實現方式:
- 寫時合并(merge-on-write):自 1.2 版本起,Doris 默認使用寫時合并模式,數據在寫入時立即合并相同 Key 的記錄,確保存儲的始終是最新數據。寫時合并兼顧查詢和寫入性能,避免多個版本的數據合并,并支持謂詞下推到存儲層。大多數場景推薦使用此模式;
在建表時,使用 UNIQUE KEY 關鍵字可以指定主鍵表。通過顯示開啟 enable_unique_key_merge_on_write 屬性可以指定寫時合并模式。自 Doris 2.1 版本以后,默認開啟寫時合并:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(user_id LARGEINT NOT NULL,user_name VARCHAR(50) NOT NULL,city VARCHAR(20),age SMALLINT,sex TINYINT
)
UNIQUE KEY(user_id, user_name)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("enable_unique_key_merge_on_write" = "true"
);
- 讀時合并(merge-on-read):在 1.2 版本前,Doris 中的主鍵模型默認使用讀時合并模式,數據在寫入時并不進行合并,以增量的方式被追加存儲,在 Doris 內保留多個版本。查詢或 Compaction 時,會對數據進行相同 Key 的版本合并。讀時合并適合寫多讀少的場景,在查詢是需要進行多個版本合并,謂詞無法下推,可能會影響到查詢速度。
在建表時,使用 UNIQUE KEY 關鍵字可以指定主鍵表。通過顯示關閉 enable_unique_key_merge_on_write 屬性可以指定讀時合并模式。在 Doris 2.1 版本之前,默認開啟讀時合并:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(user_id LARGEINT NOT NULL,username VARCHAR(50) NOT NULL,city VARCHAR(20),age SMALLINT,sex TINYINT
)
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("enable_unique_key_merge_on_write" = "false"
);
在 Doris 中基于主鍵模型更新有兩種語義:
-
整行更新:Unique Key 模型默認的更新語義為整行UPSERT,即
UPDATE OR INSERT,該行數據的 Key 如果存在,則進行更新,如果不存在,則進行新數據插入。在整行 UPSERT 語義下,即使用戶使用 Insert Into 指定部分列進行寫入,Doris 也會在 Planner 中將未提供的列使用 NULL 值或者默認值進行填充。 -
部分列更新:如果用戶希望
更新部分字段,需要使用寫時合并實現,并通過特定的參數來開啟部分列更新的支持。
數據插入與存儲
在主鍵表中,Key 列不僅用于排序,還用于去重,插入數據時,相同 Key 的記錄會被覆蓋。
4.1.3、聚合模型
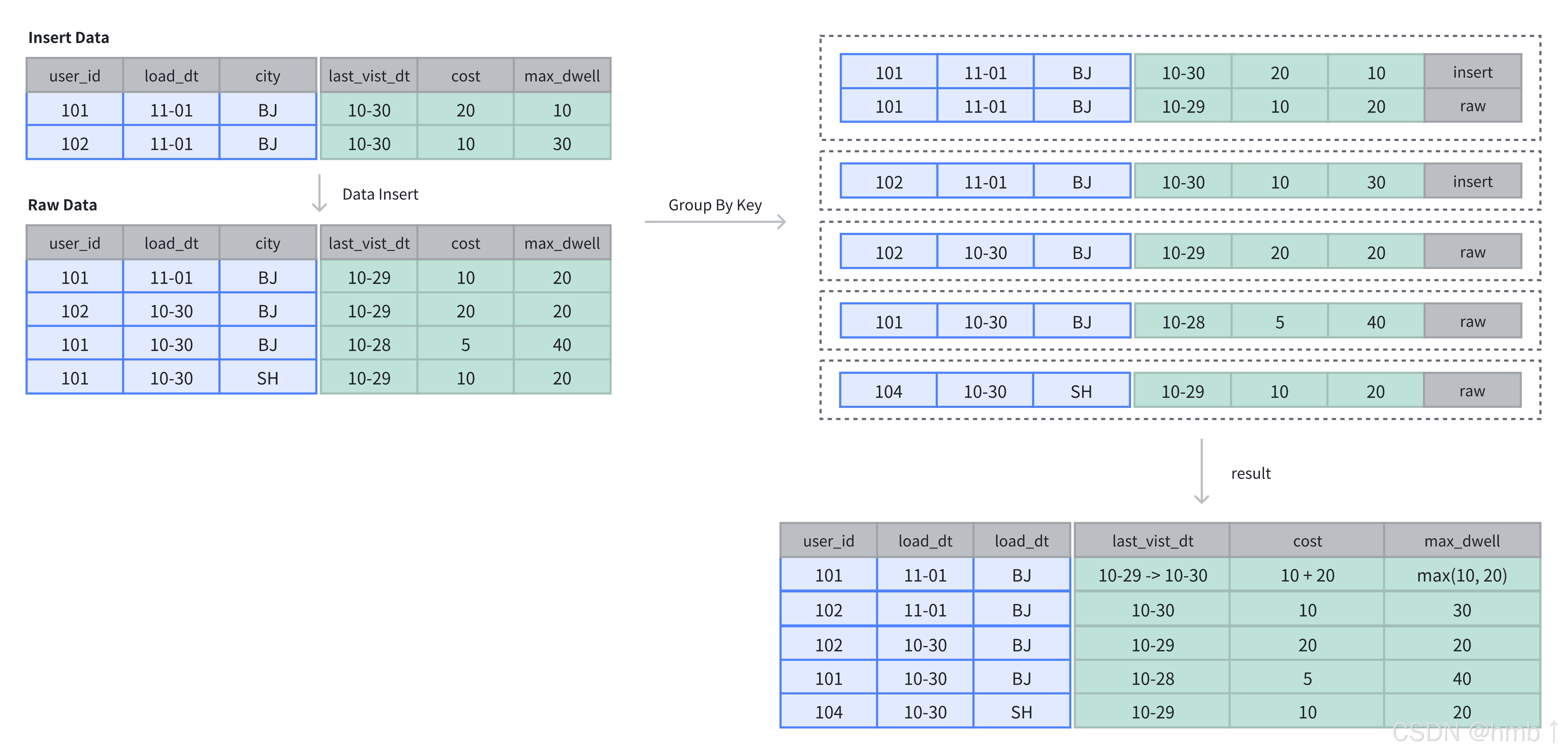
Doris 的聚合模型專為高效處理大規模數據查詢中的聚合操作設計。它通過預聚合數據,減少重復計算,提升查詢性能。聚合模型只存儲聚合后的數據,節省存儲空間并加速查詢。
使用場景
-
明細數據進行匯總:用于電商平臺的月銷售業績、金融風控的客戶交易總額、廣告投放的點擊量等業務場景中,進行多維度匯總;
-
不需要查詢原始明細數據:如駕駛艙報表、用戶交易行為分析等,原始數據存儲在數據湖中,僅需存儲匯總后的數據。
原理
每一次數據導入會在聚合模型內形成一個版本,在 Compaction 階段進行版本合并,在查詢時會按照主鍵進行數據聚合:
-
數據導入階段:數據按批次導入,每批次生成一個版本,并對相同聚合鍵的數據進行初步聚合(如求和、計數);
-
后臺文件合并階段(Compaction):多個版本文件會定期合并,減少冗余并優化存儲;
-
查詢階段:查詢時,系統會聚合同一聚合鍵的數據,確保查詢結果準確。
建表說明
使用 AGGREGATE KEY 關鍵字在建表時指定聚合模型,并指定 Key 列用于聚合 Value 列。注意下發sql有寫了聚合方式,如REPLACE DEFAULT、SUM、MAX
CREATE TABLE IF NOT EXISTS example_tbl_agg
(user_id LARGEINT NOT NULL,load_dt DATE NOT NULL,city VARCHAR(20),last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",cost BIGINT SUM DEFAULT "0",max_dwell INT MAX DEFAULT "0",
)
AGGREGATE KEY(user_id, load_dt, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
上例中定義了用戶信息和訪問的行為事實表,將 user_id、load_dt、city作為 Key 列進行聚合操作。數據導入時,Key 列會聚合成一行,Value 列會按照指定的聚合類型進行維度聚合。
在聚合表中支持以下類型的維度聚合:
| 聚合方式 | 描述 |
|---|---|
| SUM | 求和,多行的 Value 進行累加。 |
| REPLACE | 替代,下一批數據中的 Value 會替換之前導入過的行中的 Value。 |
| MAX | 保留最大值。 |
| MIN | 保留最小值。 |
| REPLACE_IF_NOT_NULL | 非空值替換。與 REPLACE 的區別在于對 null 值,不做替換。 |
| HLL_UNION | HLL 類型的列的聚合方式,通過 HyperLogLog 算法聚合。 |
| BITMAP_UNION | BITMAP 類型的列的聚合方式,進行位圖的并集聚合。 |
數據插入與存儲
在聚合表中,數據基于主鍵進行聚合操作。數據插入后及完成聚合操作。
4.2、數據劃分
4.2.1、數據分布概念
在 Doris 中,數據分布通過合理的分區和分桶策略,將數據高效地映射到各個數據分片(Tablet)上,從而充分利用多節點的存儲和計算能力,支持大規模數據的高效存儲和查詢。
1、數據分布概覽
- 數據寫入
數據寫入時,Doris 首先根據表的分區策略將數據行分配到對應的分區。接著,根據分桶策略將數據行進一步映射到分區內的具體分片,從而確定了數據行的存儲位置。
- 查詢執行
查詢運行時,Doris 的優化器會根據分區和分桶策略裁剪數據,最大化減少掃描范圍。在涉及 JOIN 或聚合查詢時,可能會發生跨節點的數據傳輸(Shuffle)。合理的分區和分桶設計可以減少 Shuffle 并充分利用 Colocate Join 優化查詢性能。
2、數據分片(Tablet)
BE 節點的存儲數據分片的數據,每個分片是 Doris 中數據管理的最小單元,也是數據移動和復制的基本單位。
BE存儲目錄結構
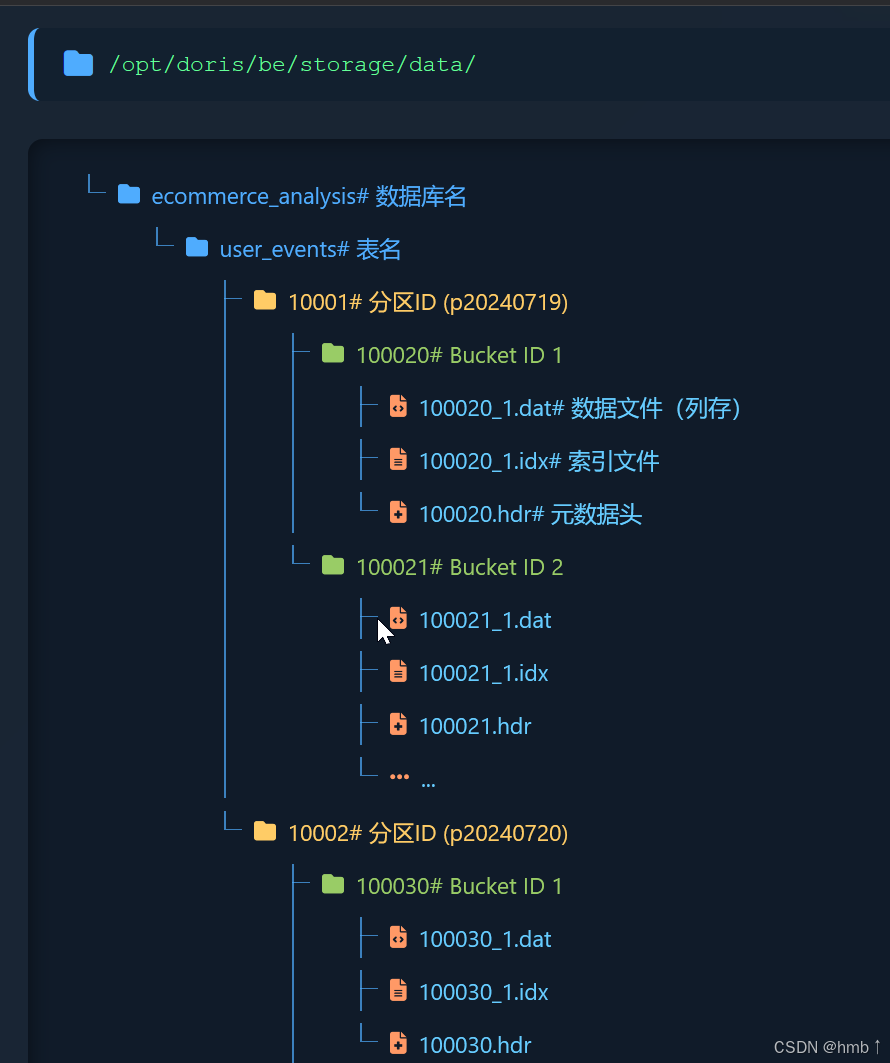
3、分區策略
分區是數據組織的第一層邏輯劃分,用于將表中的數據劃分為更小的子集。Doris 提供以下兩種分區類型和三種分區模式:
-
分區類型
- Range 分區:根據分區列的值范圍將數據行分配到對應分區。
- List 分區:根據分區列的具體值將數據行分配到對應分區。
-
分區模式
- 手動分區:用戶手動創建分區(如建表時指定或通過 ALTER 語句增加)。
- 動態分區:系統根據時間調度規則自動創建分區,但寫入數據時不會按需創建分區。
- 自動分區:數據寫入時,系統根據需要自動創建相應的分區,使用時注意臟數據生成過多的分區。
4、分桶策略
分桶是數據組織的第二層邏輯劃分,用于在分區內將數據行進一步劃分到更小的單元。Doris 支持以下兩種分桶方式:
- Hash 分桶:通過計算分桶列值的
crc32哈希值,并對分桶數取模,將數據行均勻分布到分片中。 - Random 分桶:隨機分配數據行到分片中。使用
Random分桶時,可以使用 load_to_single_tablet 優化小規模數據的快速寫入。
5、數據分布目標
-
均勻數據分布 確保數據均勻分布在各 BE 節點上,避免數據傾斜導致部分節點過載,從而提高系統整體性能。
-
優化查詢性能 合理的分區裁剪可以大幅減少掃描的數據量,合理的分桶數可以提升計算并行度,合理利用 Colocate 可以降低 Shuffle 成本,提升 JOIN 和聚合查詢效率。
-
靈活數據管理
- 按時間分區保存冷數據(HDD)與熱數據(SSD)。
- 定期刪除歷史分區釋放存儲空間。
-
控制元數據規模 每個分片的元數據存儲在 FE 和 BE 中,因此需要合理控制分片數量。經驗值建議:
- 每 1000 萬分片,FE 至少需 100G 內存。
- 單個 BE 承載的分片數應小于 2 萬。
-
優化寫入吞吐
- 分桶數應合理控制(建議 < 128),以避免寫入性能下降。
- 每次寫入的分區數量應適量(建議每次寫入少量分區)。
通過精心設計和管理分區與分桶策略,Doris 能夠高效地支持大規模數據的存儲與查詢處理,滿足各種復雜業務需求。
4.2.2、手動分區
分區列
- 分區列可以指定一列或多列,分區列必須為 KEY 列。
- 不論分區列是什么類型,在寫分區值時,都需要加雙引號。
- 分區數量理論上沒有上限。但默認限制每張表 4096 個分區,如果想突破這個限制,可以修改 FE 配置
max_multi_partition_num和max_dynamic_partition_num。 - 當不使用分區建表時,系統會自動生成一個和表名同名的,全值范圍的分區。該分區對用戶不可見,并且不可刪改。
- 創建分區時不可添加范圍重疊的分區。
4.2.2.1、Range 分區
分區列通常為時間列,以方便的管理新舊數據。Range 分區支持的列類型 DATE, DATETIME, TINYINT, SMALLINT, INT, BIGINT, LARGEINT。
分區信息,支持四種寫法:
- FIXED RANGE:定義分區的左閉右開區間。
PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES [("2017-01-01"), ("2017-02-01")),PARTITION `p201702` VALUES [("2017-02-01"), ("2017-03-01")),PARTITION `p201703` VALUES [("2017-03-01"), ("2017-04-01"))
)
- LESS THAN:僅定義分區上界。下界由上一個分區的上界決定。
PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01"),PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01")),PARTITION `other` VALUES LESS THAN (MAXVALUE)
)
- BATCH RANGE:批量創建數字類型和時間類型的 RANGE 分區,定義分區的左閉右開區間,設定步長。
PARTITION BY RANGE(age)
(FROM (1) TO (100) INTERVAL 10
)
-- 從2000年開始到2021年結束,每 2年 創建一個分區
PARTITION BY RANGE(`date`)
(FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 2 YEAR
)
- MULTI RANGE:批量創建 RANGE 分區,定義分區的左閉右開區間。
PARTITION BY RANGE(col)
( FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR, FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH, FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK, FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
)
4.2.2.2、List 分區
分區列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 數據類型,分區值為枚舉值。只有當數據為目標分區枚舉值其中之一時,才可以命中分區。
Partition 支持通過 VALUES IN (...) 來指定每個分區包含的枚舉值。
PARTITION BY LIST(city)
(PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),PARTITION `p_jp` VALUES IN ("Tokyo")
)
List 分區也支持多列分區,示例如下:
PARTITION BY LIST(id, city)
(PARTITION p1_city VALUES IN (("1", "Beijing"), ("1", "Shanghai")),PARTITION p2_city VALUES IN (("2", "Beijing"), ("2", "Shanghai")),PARTITION p3_city VALUES IN (("3", "Beijing"), ("3", "Shanghai"))
)
4.2.2.3、NULL 分區
PARTITION 列默認必須為 NOT NULL 列,如果需要使用 NULL 列,應設置 session variable allow_partition_column_nullable = true。對于 LIST PARTITION,我們支持真正的 NULL 分區。對于 RANGE PARTITION,NULL 值會被劃歸最小的 LESS THAN 分區, 沒有 LESS THAN 分區時,無法插入。
4.2.3、動態分區
動態分區會按照設定的規則,滾動添加、刪除分區,從而實現對表分區的生命周期管理(TTL),減少數據存儲壓力。在日志管理,時序數據管理等場景,通常可以使用動態分區能力滾動刪除過期的數據。
下圖中展示了使用動態分區進行生命周期管理,其中指定了以下規則:
-
動態分區調度單位
dynamic_partition.time_unit為 DAY,按天組織分區; -
動態分區起始偏移量
dynamic_partition.start設置為 -1,保留一天前分區; -
動態分區結束偏移量
dynamic_partition.end設置為 2,保留未來兩天分區
依據以上規則,隨著時間推移,總會保留 4 個分區,即過去一天分區,當天分區與未來兩天分區:
4.2.3.1、使用限制
在使用動態分區時,需要遵守以下規則:
- 動態分區與跨集群復制(CCR)同時使用時會失效;
- 動態分區只支持在
DATE/DATETIME列上進行Range類型的分區; - 動態分區只支持單一分區鍵。
4.2.3.2、創建動態分區
在建表時,通過指定dynamic_partition屬性,可以創建動態分區表。
CREATE TABLE test_dynamic_partition(order_id BIGINT,create_dt DATE,username VARCHAR(20)
)
DUPLICATE KEY(order_id)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(order_id) BUCKETS 10
PROPERTIES("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-1","dynamic_partition.end" = "2","dynamic_partition.prefix" = "p","dynamic_partition.create_history_partition" = "true"
);
4.2.3.3、動態分區參數說明
動態分區的規則參數以 dynamic_partition 為前綴,可以設置以下規則參數:
| 參數 | 必選 | 說明 |
|---|---|---|
dynamic_partition.enable | 否 | 是否開啟動態分區特性。可指定為 TRUE 或 FALSE。如果指定了動態分區其他必填參數,默認為 TRUE。 |
dynamic_partition.time_unit | 是 | 動態分區調度的單位。可選值:HOUR、DAY、WEEK、MONTH、YEAR。分別表示按小時、按天、按星期、按月、按年進行分區創建或刪除。 |
dynamic_partition.start | 否 | 動態分區的起始偏移,為負數。默認值為 -2147483648,即不刪除歷史分區。根據 time_unit 的不同,以當天(星期/月)為基準,分區范圍在此偏移之前的分區將被刪除。 |
dynamic_partition.end | 是 | 動態分區的結束偏移,為正數。根據 time_unit 的不同,以當天(星期/月)為基準,提前創建對應范圍的分區。 |
dynamic_partition.prefix | 是 | 動態創建的分區名前綴。 |
dynamic_partition.buckets | 否 | 動態創建的分區所對應的分桶數。設置后會覆蓋 DISTRIBUTED 中指定的分桶數。 |
dynamic_partition.replication_num | 否 | 動態創建的分區所對應的副本數量。如果不填寫,默認為該表創建時指定的副本數量。 |
dynamic_partition.create_history_partition | 否 | 默認為 false。當置為 true 時,系統會自動創建所有分區。max_dynamic_partition_num 參數會限制總分區數量。 |
dynamic_partition.history_partition_num | 否 | 當 create_history_partition 為 true 時,指定創建歷史分區數量。默認值為 -1(未設置)。與 start 作用相同,建議只設置一個。 |
dynamic_partition.start_day_of_week | 否 | 當 time_unit 為 WEEK 時,指定每周的起始點。取值范圍 1 到 7(1 表示周一,7 表示周日)。默認 1。 |
dynamic_partition.start_day_of_month | 否 | 當 time_unit 為 MONTH 時,指定每月的起始日期。取值范圍 1 到 28(1 表示每月 1 號)。默認 1。不支持 29、30、31 日。 |
dynamic_partition.reserved_history_periods | 否 | 需要保留的歷史分區時間范圍。格式: - DAY/WEEK/MONTH/YEAR:[yyyy-MM-dd,yyyy-MM-dd],[...,...]- HOUR:[yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...]默認 NULL。 |
dynamic_partition.time_zone | 否 | 動態分區時區,默認為服務器系統時區(如 Asia/Shanghai)。更多時區可參考時區管理。 |
FE 配置參數
可以在 FE 配置文件或通過 ADMIN SET FRONTEND CONFIG 命令修改 FE 中的動態分區參數配置:
| 參數 | 默認值 | 說明 |
|---|---|---|
| dynamic_partition_enable | false | 是否開啟 Doris 的動態分區功能。該參數只影響動態分區表的分區操作,不影響普通表。 |
| dynamic_partition_check_interval_seconds | 600 | 動態分區線程的執行頻率,單位為秒。 |
| max_dynamic_partition_num | 500 | 用于限制創建動態分區表時可以創建的最大分區數,避免一次創建過多分區。 |
4.2.3.4、管理動態分區
- 修改動態分區屬性
提示:在使用 ALTER TABLE 語句修改動態分區時,不會立即生效。會以 dynamic_partition_check_interval_seconds 參數指定的時間間隔輪訓檢查 dynamic partition 分區,完成需要的分區創建與刪除操作。
下例中通過 ALTER TABLE 語句,將非動態分區表修改為動態分區:
CREATE TABLE test_dynamic_partition(order_id BIGINT,create_dt DATE,username VARCHAR(20)
)
DUPLICATE KEY(order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 10;ALTER TABLE test_partition SET ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-1","dynamic_partition.end" = "2","dynamic_partition.prefix" = "p","dynamic_partition.create_history_partition" = "true"
);
- 查看動態分區調度情況
通過 SHOW DYNAMIC PARTITION TABLES [ FROM <db_name> ] 可以查看當前數據庫下,所有動態分區表的調度情況:
可選參數:<db_name>指定展示動態分區表狀態的 DB 名稱,如果不指定,則默認展示當前 DB 下的所有動態分區表狀態。
SHOW DYNAMIC PARTITION TABLES;
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| TableName | Enable | TimeUnit | Start | End | Prefix | Buckets | StartOf | LastUpdateTime | LastSchedulerTime | State | LastCreatePartitionMsg | LastDropPartitionMsg | ReservedHistoryPeriods |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
| d3 | true | WEEK | -3 | 3 | p | 1 | MONDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | [2021-12-01,2021-12-31] |
| d5 | true | DAY | -7 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d4 | true | WEEK | -3 | 3 | p | 1 | WEDNESDAY | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d6 | true | MONTH | -2147483648 | 2 | p | 8 | 3rd | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d2 | true | DAY | -3 | 3 | p | 32 | N/A | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
| d7 | true | MONTH | -2147483648 | 5 | p | 8 | 24th | N/A | 2020-05-25 14:29:24 | NORMAL | N/A | N/A | NULL |
+-----------+--------+----------+-------------+------+--------+---------+-----------+----------------+---------------------+--------+------------------------+----------------------+-------------------------+
7 rows in set (0.02 sec)
返回值:
| 列名 | 類型 | 說明 |
|---|---|---|
| TableName | varchar | 當前 DB 或指定 DB 的表名稱 |
| Enable | varchar | 是否開啟了表的動態分區屬性 |
| TimeUnit | varchar | 動態分區表的分區粒度,有 HOUR,DAY,WEEK,MONTH,YEAR |
| Start | varchar | 動態分區的起始偏移,為負數。默認值為 -2147483648,即不刪除歷史分區。根據 time_unit 屬性的不同,以當天(星期/月)為基準,分區范圍在此偏移之前的分區將會被刪除。 |
| End | varchar | 動態分區的結束偏移,為正數。根據 time_unit 屬性的不同,以當天(星期/月)為基準,提前創建對應范圍的分區。 |
| Prefix | varchar | 動態創建的分區名前綴。 |
| Buckets | varchar | 動態創建的分區所對應的分桶數量。 |
| ReplicationNum | varchar | 動態創建的分區所對應的副本數量,如果不填寫,則默認為該表創建時指定的副本數量。 |
| ReplicaAllocation | varchar | 動態創建的分區所對應的副本分布策略,如果不填寫,則默認為該表創建時指定的副本分布策略。 |
| StartOf | varchar | 動態分區每個分區粒度的起始點。當 time_unit 為 WEEK 時,該字段表示每周的起始點,取值為 MONDAY 到 SUNDAY;當 time_unit 為 MONTH 時,表示每月的起始日期,取值為 1rd 至 28rd;當 time_unit 為 MONTH 時,該值默認為 NULL。 |
| LastUpdateTime | varchar | 動態分區的上一次更新時間,默認為 NULL。 |
| LastSchedulerTime | datetime | 動態分區的上一次調度時間。 |
| State | varchar | 動態分區的創建狀態。 |
| LastCreatePartitionMsg | varchar | 最后一次執行動態添加分區調度的錯誤信息。 |
| LastDropPartitionMsg | varchar | 最后一次執行動態刪除分區調度的錯誤信息。 |
| ReservedHistoryPeriods | varchar | 動態分區保留的歷史分區的分區區間,它表示在動態分區表中,哪些歷史分區應該被保留,而不是被自動刪除。 |
- 歷史分區管理
在使用 start 與 end 屬性指定動態分區數量時,為了避免一次性創建所有的分區造成等待時間過長,不會創建歷史分區,只會創建當前時間以后得分區。如果需要一次性創建所有分區,需要開啟 create_history_partition 參數。
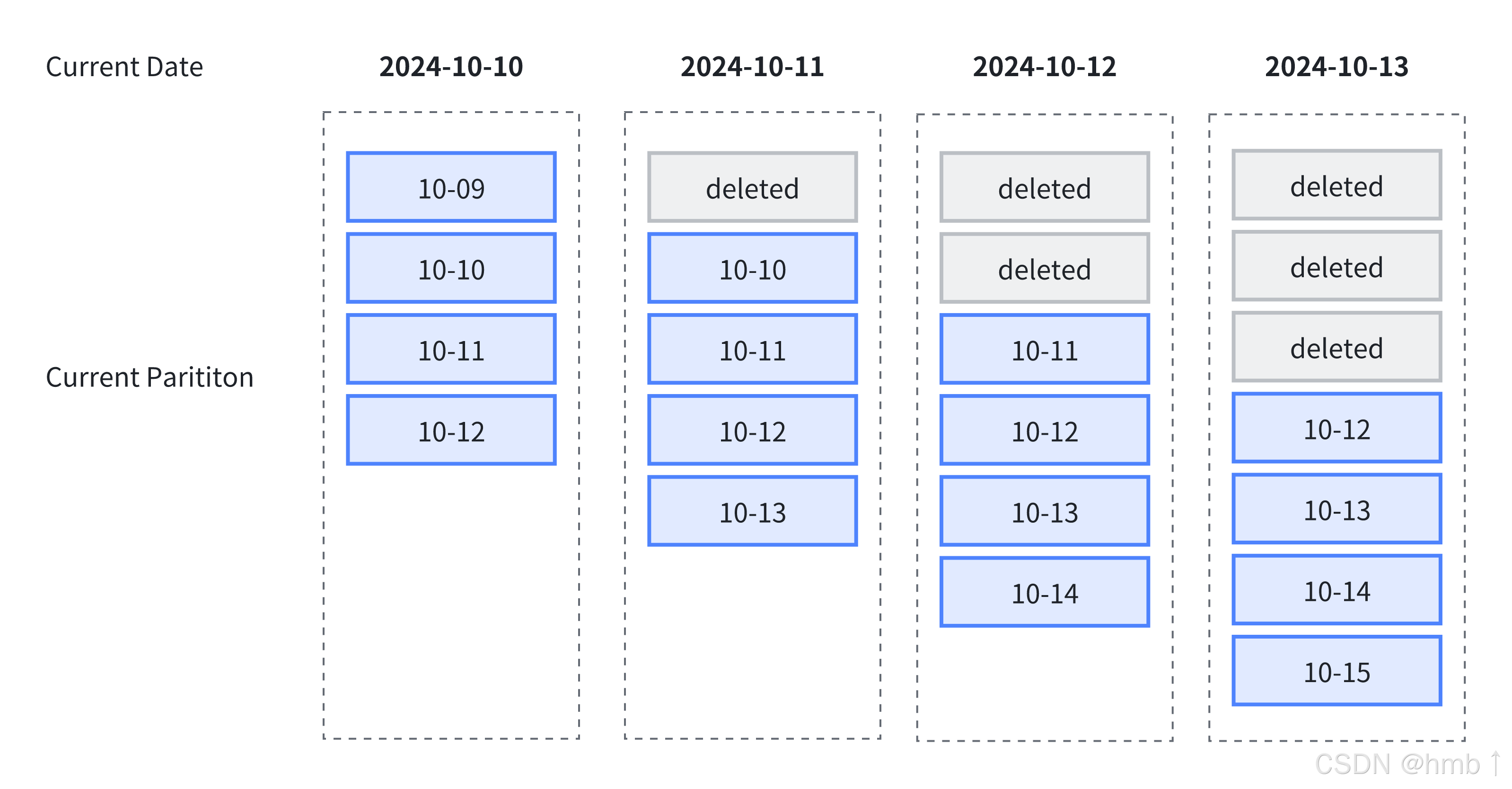
例如當前日期為 2024-10-11,指定 start = -2,end = 2:
-
如果指定了
create_history_partition = true,立即創建所有分區,即 [10-09, 10-13] 五個分區; -
如果指定了
create_history_partition = false,只創建包含 10-11 以后的分區,即 [10-11, 10-13] 三個分區。
4.2.3.5、動態分區最佳實踐
- 按天分區,只保留過去 7 天的及當天分區,并且預先創建未來 3 天的分區。
CREATE TABLE tbl1 (order_id BIGINT,create_dt DATE,username VARCHAR(20)
)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(create_dt)
PROPERTIES ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-7","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "32"
);
- 按月分區,不刪除歷史分區,并且預先創建未來 2 個月的分區。同時設定以每月 3 號為起始日。
CREATE TABLE tbl1 (order_id BIGINT,create_dt DATE,username VARCHAR(20)
)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(create_dt)
PROPERTIES ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "MONTH","dynamic_partition.end" = "2","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "8","dynamic_partition.start_day_of_month" = "3"
);
- 按天分區,保留過去 10 天及未來 10 天分區,并且保留 [2020-06-01,2020-06-20] 及 [2020-10-31,2020-11-15] 期間的歷史數據。
CREATE TABLE tbl1 (order_id BIGINT,create_dt DATE,username VARCHAR(20)
)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(create_dt)
PROPERTIES ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-10","dynamic_partition.end" = "10","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "8","dynamic_partition.reserved_history_periods"="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"
);
4.2.4、自動分區
4.2.4.1、使用場景
自動分區功能主要解決了用戶預期基于某列對表進行分區操作,但該列的數據分布比較零散或者難以預測,在建表或調整表結構時難以準確創建所需分區,或者分區數量過多以至于手動創建過于繁瑣的問題。
以時間類型分區列為例,在動態分區功能中,我們支持了按特定時間周期自動創建新分區以容納實時數據。對于實時的用戶行為日志等場景該功能基本能夠滿足需求。但在一些更復雜的場景下,例如處理非實時數據時,分區列與當前系統時間無關,且包含大量離散值。此時為提高效率我們希望依據此列對數據進行分區,但數據實際可能涉及的分區無法預先掌握,或者預期所需分區數量過大。這種情況下動態分區或者手動創建分區無法滿足我們的需求,自動分區功能很好地覆蓋了此類需求。
假設我們的表 DDL 如下:
CREATE TABLE `DAILY_TRADE_VALUE`
(`TRADE_DATE` datev2 NOT NULL COMMENT '交易日期',`TRADE_ID` varchar(40) NOT NULL COMMENT '交易編號',......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
PARTITION BY RANGE(`TRADE_DATE`)
(PARTITION p_2000 VALUES [('2000-01-01'), ('2001-01-01')),PARTITION p_2001 VALUES [('2001-01-01'), ('2002-01-01')),PARTITION p_2002 VALUES [('2002-01-01'), ('2003-01-01')),PARTITION p_2003 VALUES [('2003-01-01'), ('2004-01-01')),PARTITION p_2004 VALUES [('2004-01-01'), ('2005-01-01')),PARTITION p_2005 VALUES [('2005-01-01'), ('2006-01-01')),PARTITION p_2006 VALUES [('2006-01-01'), ('2007-01-01')),PARTITION p_2007 VALUES [('2007-01-01'), ('2008-01-01')),PARTITION p_2008 VALUES [('2008-01-01'), ('2009-01-01')),PARTITION p_2009 VALUES [('2009-01-01'), ('2010-01-01')),PARTITION p_2010 VALUES [('2010-01-01'), ('2011-01-01')),PARTITION p_2011 VALUES [('2011-01-01'), ('2012-01-01')),PARTITION p_2012 VALUES [('2012-01-01'), ('2013-01-01')),PARTITION p_2013 VALUES [('2013-01-01'), ('2014-01-01')),PARTITION p_2014 VALUES [('2014-01-01'), ('2015-01-01')),PARTITION p_2015 VALUES [('2015-01-01'), ('2016-01-01')),PARTITION p_2016 VALUES [('2016-01-01'), ('2017-01-01')),PARTITION p_2017 VALUES [('2017-01-01'), ('2018-01-01')),PARTITION p_2018 VALUES [('2018-01-01'), ('2019-01-01')),PARTITION p_2019 VALUES [('2019-01-01'), ('2020-01-01')),PARTITION p_2020 VALUES [('2020-01-01'), ('2021-01-01')),PARTITION p_2021 VALUES [('2021-01-01'), ('2022-01-01'))
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);
該表內存儲了大量業務歷史數據,依據交易發生的日期進行分區。可以看到在建表時,我們需要預先手動創建分區。如果分區列的數據范圍發生變化,例如上表中增加了 2022 年的數據,則我們需要通過ALTER-TABLE-PARTITION對表的分區進行更改。如果這種分區需要變更,或者進行更細粒度的細分,修改起來非常繁瑣。此時我們就可以使用 AUTO PARTITION 改寫該表 DDL。
4.2.4.2、語法
建表時,使用以下語法填充CREATE-TABLE時的 partition_info 部分:
- AUTO RANGE PARTITION:
AUTO PARTITION BY RANGE (FUNC_CALL_EXPR)()
其中
FUNC_CALL_EXPR ::= date_trunc ( <partition_column>, '<interval>' )
示例:
CREATE TABLE `date_table` (`TIME_STAMP` datev2 NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`TIME_STAMP`)
AUTO PARTITION BY RANGE (date_trunc(`TIME_STAMP`, 'month'))
(
)
DISTRIBUTED BY HASH(`TIME_STAMP`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
- AUTO LIST PARTITION:
AUTO PARTITION BY LIST(`partition_col1`[, `partition_col2`, ...])()
示例:
CREATE TABLE `str_table` (`str` varchar not null
) ENGINE=OLAP
DUPLICATE KEY(`str`)
AUTO PARTITION BY LIST (`str`)
(
)
DISTRIBUTED BY HASH(`str`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
- NULL 值分區
當開啟 session variable allow_partition_column_nullable 后:
- 對于 AUTO LIST PARTITION,可以使用 NULLABLE 列作為分區列,會正常創建對應的 NULL 值分區:
- 對于 AUTO RANGE PARTITION,不支持 NULLABLE 列作為分區列。
約束:
- 在 AUTO LIST PARTITION 中,
分區名長度不得超過 50. 該長度來自于對應數據行上各分區列內容的拼接與轉義,因此實際容許長度可能更短。 - 在 AUTO RANGE PARTITION 中,分區函數僅支持
date_trunc,分區列僅支持DATE或者DATETIME類型; - 在 AUTO LIST PARTITION 中,不支持函數調用,分區列支持
BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR數據類型,分區值為枚舉值。 - 在 AUTO LIST PARTITION 中,分區列的每個當前不存在對應分區的取值,都會創建一個獨立的新 PARTITION。
4.2.4.3、場景示例
在使用場景一節中的示例,在使用 AUTO PARTITION 后,該表 DDL 可以改寫為:
CREATE TABLE `DAILY_TRADE_VALUE`
(`TRADE_DATE` datev2 NOT NULL,`TRADE_ID` varchar(40) NOT NULL,......
)
UNIQUE KEY(`TRADE_DATE`, `TRADE_ID`)
AUTO PARTITION BY RANGE (date_trunc(`TRADE_DATE`, 'year'))
(
)
DISTRIBUTED BY HASH(`TRADE_DATE`) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);
以此表只有兩列為例,此時新表沒有默認分區:
show partitions from `DAILY_TRADE_VALUE`;
Empty set (0.12 sec)
經過插入數據后再查看,發現該表已經創建了對應的分區:
insert into `DAILY_TRADE_VALUE` values ('2012-12-13', 1), ('2008-02-03', 2), ('2014-11-11', 3);show partitions from `DAILY_TRADE_VALUE`;
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+
| 180060 | p20080101000000 | 2 | 2023-09-18 21:49:29 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2008-01-01]; ..types: [DATEV2]; keys: [2009-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true |
| 180039 | p20120101000000 | 2 | 2023-09-18 21:49:29 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2012-01-01]; ..types: [DATEV2]; keys: [2013-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true |
| 180018 | p20140101000000 | 2 | 2023-09-18 21:49:29 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2014-01-01]; ..types: [DATEV2]; keys: [2015-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | NULL | 0.000 | false | tag.location.default: 1 | true |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+----------+------------+-------------------------+-----------+
經過自動分區功能所創建的 PARTITION,與手動創建的 PARTITION 具有完全一致的功能性質。
4.2.4.4、與動態分區聯用
Doris 支持自動分區和動態分區同時使用。此時,二者的功能都生效:
- 自動分區將會
自動在數據導入過程中按需創建分區; - 動態分區將會
自動創建、回收、轉儲分區。
二者語法功能不存在沖突,同時設置對應的子句/屬性即可。
最佳實踐
需要對分區生命周期設限的場景,可以將 Dynamic Partition 的創建功能關閉,創建分區完全交由 Auto Partition 完成,通過 Dynamic Partition 動態回收分區的功能完成分區生命周期的管理:
create table auto_dynamic(k0 datetime(6) NOT NULL
)
auto partition by range (date_trunc(k0, 'year'))
(
)
DISTRIBUTED BY HASH(`k0`) BUCKETS 2
properties("dynamic_partition.enable" = "true","dynamic_partition.prefix" = "p","dynamic_partition.start" = "-50","dynamic_partition.end" = "0", --- Dynamic Partition 不創建分區"dynamic_partition.time_unit" = "year","replication_num" = "1"
);
這樣我們同時具有了 Auto Partition 的靈活性,且分區名上保持了一致性。
4.2.4.5、分區管理
當啟用自動分區后,分區名可以通過 auto_partition_name 函數映射到分區。partitions 表函數可以通過分區名產生詳細的分區信息。仍然以 DAILY_TRADE_VALUE 表為例,在我們插入數據后,查看其當前分區:
select * from partitions("catalog"="internal","database"="optest","table"="DAILY_TRADE_VALUE") where PartitionName = auto_partition_name('range', 'year', '2008-02-03');
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+-----------+------------+-------------------------+-----------+--------------------+--------------+
| PartitionId | PartitionName | VisibleVersion | VisibleVersionTime | State | PartitionKey | Range | DistributionKey | Buckets | ReplicationNum | StorageMedium | CooldownTime | RemoteStoragePolicy | LastConsistencyCheckTime | DataSize | IsInMemory | ReplicaAllocation | IsMutable | SyncWithBaseTables | UnsyncTables |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+-----------+------------+-------------------------+-----------+--------------------+--------------+
| 127095 | p20080101000000 | 2 | 2024-11-14 17:29:02 | NORMAL | TRADE_DATE | [types: [DATEV2]; keys: [2008-01-01]; ..types: [DATEV2]; keys: [2009-01-01]; ) | TRADE_DATE | 10 | 1 | HDD | 9999-12-31 23:59:59 | | \N | 985.000 B | 0 | tag.location.default: 1 | 1 | 1 | \N |
+-------------+-----------------+----------------+---------------------+--------+--------------+--------------------------------------------------------------------------------+-----------------+---------+----------------+---------------+---------------------+---------------------+--------------------------+-----------+------------+-------------------------+-----------+--------------------+--------------+
這樣每個分區的 ID 和取值就可以精準地被篩選出,用于后續針對分區的具體操作(例如 insert overwrite partition)。
4.2.4.6、注意事項
- 如同普通分區表一樣,AUTO LIST PARTITION 支持多列分區,語法并無區別。
- 在數據的插入或導入過程中如果創建了分區,而整個導入過程沒有完成(失敗或被取消),被創建的分區不會被自動刪除。
- 使用 AUTO PARTITION 的表,只是分區創建方式上由手動轉為了自動。表及其所創建分區的原本使用方法都與非 AUTO PARTITION 的表或分區相同。
- 為防止意外創建過多分區,我們通過FE 配置項中的
max_auto_partition_num控制了一個 AUTO PARTITION 表最大容納分區數。如有需要可以調整該值 - 向開啟了 AUTO PARTITION 的表導入數據時,Coordinator 發送數據的輪詢間隔與普通表有所不同。具體請見BE 配置項中的
olap_table_sink_send_interval_auto_partition_factor。開啟前移(enable_memtable_on_sink_node = true)后該變量不產生影響。 - 在使用insert-overwrite插入數據時 AUTO PARTITION 表的行為詳見 INSERT OVERWRITE 文檔。
- 如果導入創建分區時,該表涉及其他元數據操作(如 Schema Change、Rebalance),則導入可能失敗。
4.2.5、數據分桶
一個分區可以根據業務需求進一步劃分為多個數據分桶(bucket)。每個分桶都作為一個物理數據分片(tablet)存儲。合理的分桶策略可以有效降低查詢時的數據掃描量,提升查詢性能并增加并發處理能力。
4.2.5.1、分桶方式
Doris 支持兩種分桶方式:Hash 分桶與 Random 分桶。
4.2.5.1.1、Hash 分桶
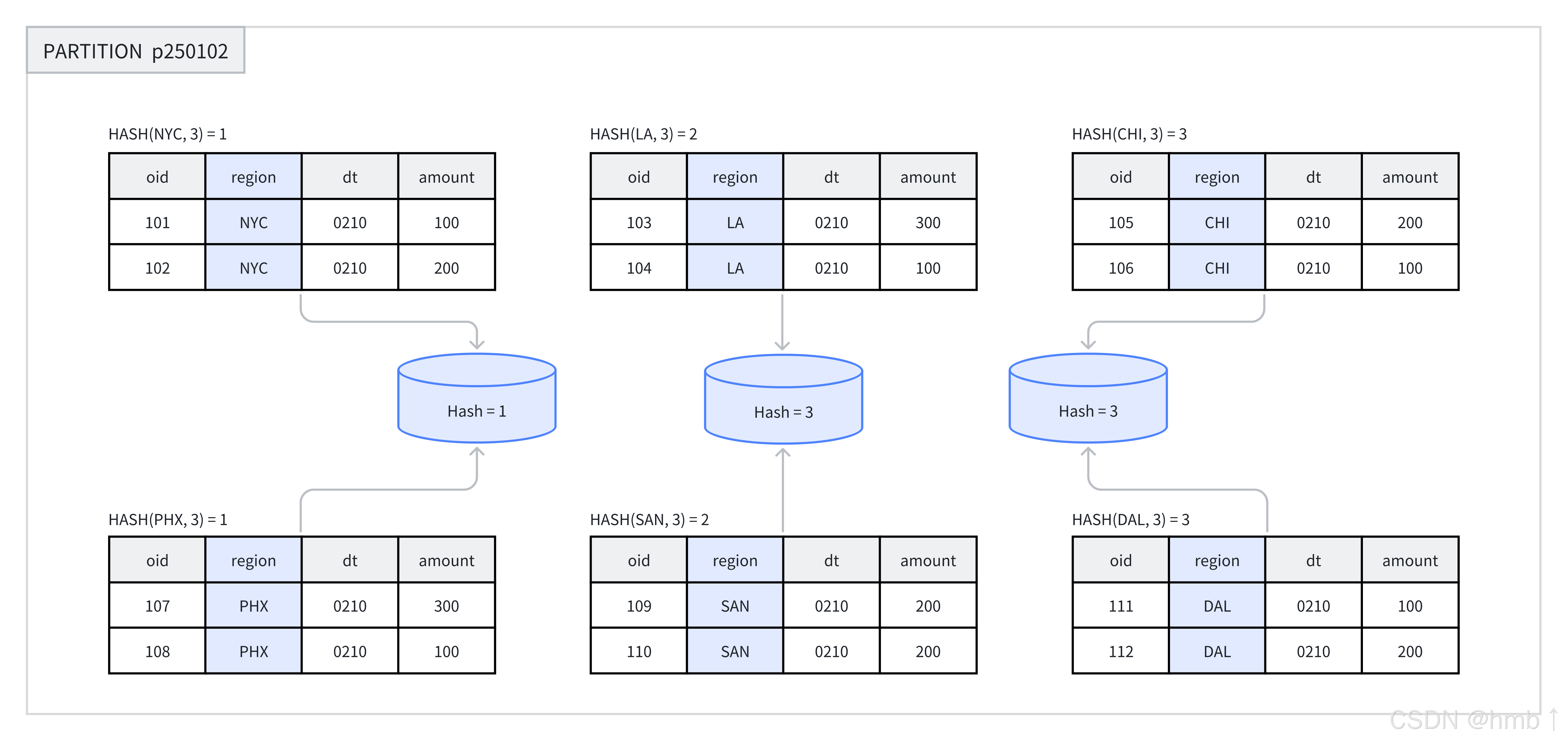
在創建表或新增分區時,用戶需選擇一列或多列作為分桶列,并明確指定分桶的數量。在同一分區內,系統會根據分桶鍵和分桶數量進行哈希計算。哈希值相同的數據會被分配到同一個分桶中。例如,在下圖中,p250102 分區根據 region 列被劃分為 3 個分桶,哈希值相同的行被歸入同一個分桶。
推薦在以下場景中使用 Hash 分桶:
-
業務需求頻繁基于某個字段進行過濾時,可將該字段作為分桶鍵,利用 Hash 分桶提高查詢效率。
-
當表中的數據分布較為均勻時,Hash 分桶同樣是一種有效的選擇。
以下示例展示了如何創建帶有 Hash 分桶的表。
CREATE TABLE demo.hash_bucket_tbl(oid BIGINT,dt DATE,region VARCHAR(10),amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (PARTITION p250101 VALUES LESS THAN("2025-01-01"),PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
示例中,通過 DISTRIBUTED BY HASH(region) 指定了創建 Hash 分桶,并選擇 region 列作為分桶鍵。同時,通過 BUCKETS 8 指定了創建 8 個分桶。
4.2.5.1.2、Random 分桶
在每個分區中,使用 Random 分桶會隨機地將數據分散到各個分桶中,不依賴于某個字段的 Hash 值進行數據劃分。Random 分桶能夠確保數據均勻分散,從而避免由于分桶鍵選擇不當而引發的數據傾斜問題。
在導入數據時,單次導入作業的每個批次會被隨機寫入到一個 tablet 中,以此保證數據的均勻分布。例如,在一次操作中,8 個批次的數據被隨機分配到 p250102 分區下的 3 個分桶中。
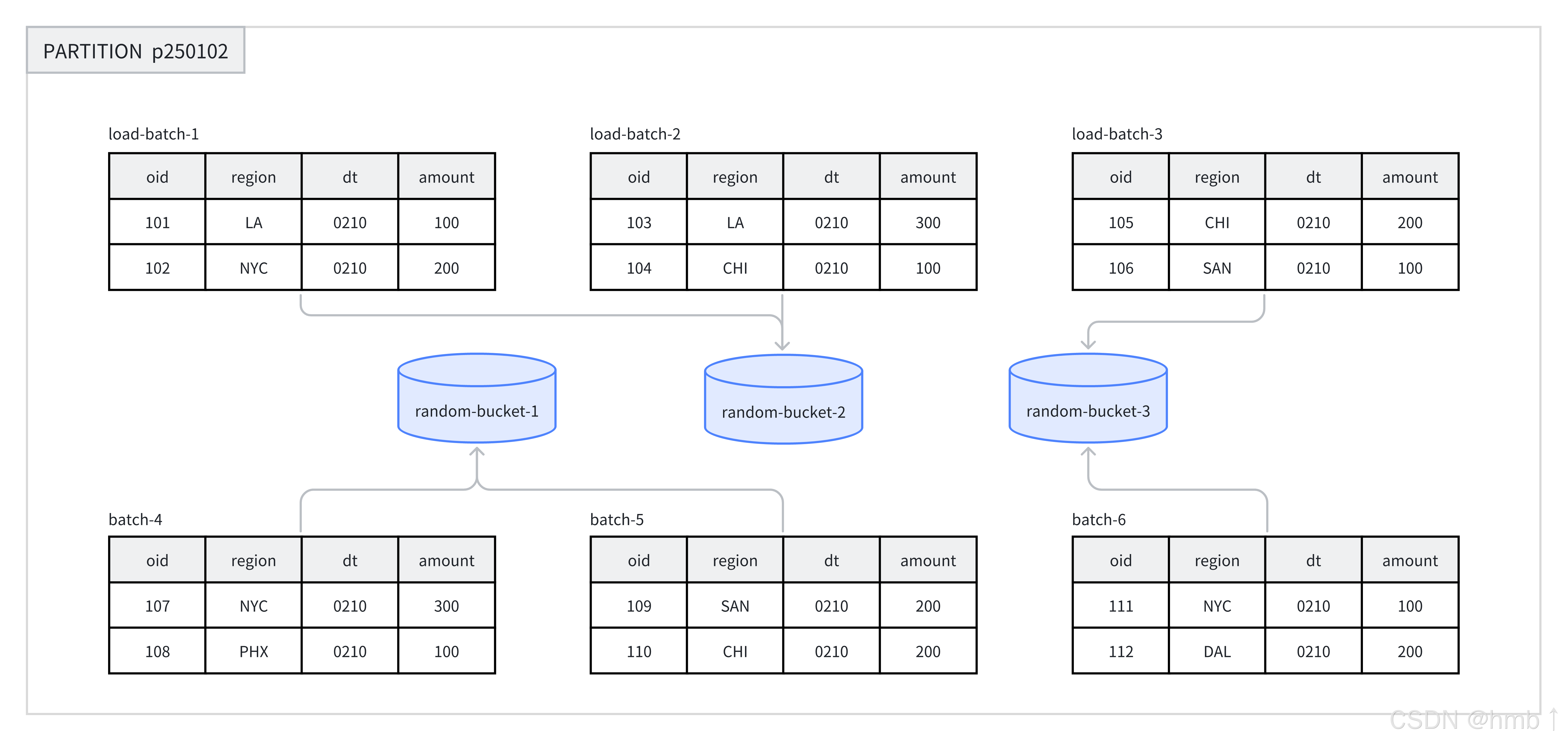
在使用 Random 分桶時,可以啟用單分片導入模式(通過設置 load_to_single_tablet 為 true)。這樣,在大規模數據導入過程中,單個批次的數據僅寫入一個數據分片,能夠提高數據導入的并發度和吞吐量,減少因數據導入和壓縮(Compaction)操作造成的寫放大問題,從而確保集群穩定性。
在以下場景中,建議使用 Random 分桶:
-
在任意維度分析的場景中,業務沒有特別針對某一列頻繁進行過濾或關聯查詢時,可以選擇 Random 分桶;
-
當經常查詢的列或組合列數據分布極其不均勻時,使用 Random 分桶可以避免數據傾斜。
-
Random 分桶無法根據分桶鍵進行剪裁,會掃描命中分區的所有數據,不建議在點查場景下使用;
-
只有 DUPLICATE 表可以使用 Random 分區,UNIQUE 與 AGGREGATE 表無法使用 Random 分桶;
以下示例展示了如何創建帶有 Random 分桶的表。
CREATE TABLE demo.random_bucket_tbl(oid BIGINT,dt DATE,region VARCHAR(10),amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (PARTITION p250101 VALUES LESS THAN("2025-01-01"),PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY RANDOM BUCKETS 8;
示例中,通過 DISTRIBUTED BY RANDOM 語句指定了使用 Random 分桶,創建 Random 分桶無需選擇分桶鍵,通過 BUCKETS 8 語句指定創建 8 個分桶。
4.2.5.2、選擇分桶鍵
分桶鍵可以是一列或者多列。如果是 DUPLICATE 表,任何 Key 列與 Value 列都可以作為分桶鍵。如果是 AGGREGATE 或 UNIQUE 表,為了保證逐漸的聚合性,分桶列必須是 Key 列。
通常情況下,可以根據以下規則選擇分桶鍵:
-
利用查詢過濾條件:使用查詢中的過濾條件進行 Hash 分桶,有助于數據的剪裁,減少數據掃描量;
-
利用高基數列:選擇高基數(唯一值較多)的列進行 Hash 分桶,有助于數據均勻的分散在每一個分桶中;
-
高并發點查場景:建議選擇單列或較少列進行分桶。點查可能僅觸發一個分桶掃描,不同查詢之間觸發不同分桶掃描的概率較大,從而減小查詢間的 IO 影響。
-
大吞吐查詢場景:建議選擇多列進行分桶,使數據更均勻分布。若查詢條件不能包含所有分桶鍵的等值條件,將增加查詢吞吐,降低單個查詢延遲。
4.2.5.3、選擇分桶數量
在 Doris 中,一個 bucket 會被存儲為一個物理文件(tablet)。一個表的 Tablet 數量等于 partition_num(分區數)乘以 bucket_num(分桶數)。一旦指定 Partition 的數量,便不可更改。
在確定 bucket 數量時,需預先考慮機器擴容情況。自 2.0 版本起,Doris 支持根據機器資源和集群信息自動設置分區中的分桶數。
4.2.5.3.1、手動設置分桶數
通過 DISTRIBUTED 語句可以指定分桶數量:
-- Set hash bucket num to 8
DISTRIBUTED BY HASH(region) BUCKETS 8-- Set random bucket num to 8
DISTRIBUTED BY RANDOM BUCKETS 8
在決定分桶數量時,通常遵循數量與大小兩個原則,當發生沖突時,優先考慮大小原則:
-
大小原則:建議一個 tablet 的大小在
1-10G范圍內。過小的 tablet 可能導致聚合效果不佳,增加元數據管理壓力;過大的 tablet 則不利于副本遷移、補齊,且會增加 Schema Change 操作的失敗重試代價; -
數量原則:在不考慮擴容的情況下,一個表的 tablet 數量建議略多于整個集群的磁盤數量。
例如,假設有 10 臺 BE 機器,每個 BE 一塊磁盤,可以按照以下建議進行數據分桶:
| 單表大小 | 建議分桶數量 |
|---|---|
| 500MB | 4-8 個分桶 |
| 5GB | 6-16 個分桶 |
| 50GB | 32 個分桶 |
| 500GB | 建議分區,每個分區 50GB,每個分區 16-32 個分桶 |
| 5TB | 建議分區,每個分區 50GB,每個分桶 16-32 個分桶 |
提示:表的數據量可以通過 SHOW DATA 命令查看。結果需要除以副本數,及表的數據量。
4.2.5.3.2、自動設置分桶數
自動推算分桶數功能會根據過去一段時間的分區大小,自動預測未來的分區大小,并據此確定分桶數量。
-- Set hash bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")-- Set random bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
在創建分桶時,可以通過 estimate_partition_size 屬性來調整前期估算的分區大小。此參數為可選設置,若未給出,Doris 將默認取值為 10GB。請注意,該參數與后期系統通過歷史分區數據推算出的未來分區大小無關。
4.2.5.3.3、維護數據分桶
目前,Doris 僅支持修改新增分區的分桶數量,對于以下操作暫不支持:
- 不支持修改分桶類型
- 不支持修改分桶鍵
- 不支持修改已創建的分桶的分桶數量
4.3、數據類型
Apache Doris 已支持的數據類型列表如下:
數值類型
| 類型名 | 存儲空間(字節) | 描述 |
|---|---|---|
| BOOLEAN | 1 | 布爾值,0 代表 false,1 代表 true。 |
| TINYINT | 1 | 有符號整數,范圍 [-128, 127]。 |
| SMALLINT | 2 | 有符號整數,范圍 [-32768, 32767]。 |
| INT | 4 | 有符號整數,范圍 [-2147483648, 2147483647]。 |
| BIGINT | 8 | 有符號整數,范圍 [-9223372036854775808, 9223372036854775807]。 |
| LARGEINT | 16 | 有符號整數,范圍 [-2^127 + 1 ~ 2^127 - 1]。 |
| FLOAT | 4 | 浮點數,范圍 [-3.4E+38 ~ 3.4E+38]。 |
| DOUBLE | 8 | 浮點數,范圍 [-1.79E+308 ~ 1.79E+308]。 |
| DECIMAL | 4/8/16/32 | 高精度定點數,格式:DECIMAL(P[,S])。P 為有效數字,S 為小數位數。 |
日期類型
| 類型名 | 存儲空間(字節) | 描述 |
|---|---|---|
| DATE | 4 | 日期類型,范圍 [‘0000-01-01’, ‘9999-12-31’]。 |
| DATETIME | 8 | 日期時間類型,支持微秒精度(0-6位小數)。 |
字符串類型
| 類型名 | 存儲空間(字節) | 描述 |
|---|---|---|
| CHAR | M | 定長字符串,M 為字節長度(1-255)。 |
| VARCHAR | 不定長 | 變長字符串,M 為字節長度(1-65533)。 |
| STRING | 不定長 | 變長字符串,默認支持 1MB,可調至 2GB。僅用于 Value 列。 |
半結構類型
| 類型名 | 存儲空間(字節) | 描述 |
|---|---|---|
| ARRAY | 不定長 | 由 T 類型元素組成的數組。 |
| MAP | 不定長 | 由 K, V 類型元素組成的 map。 |
| STRUCT | 不定長 | 由多個 Field 組成的結構體。 |
| JSON | 不定長 | 二進制 JSON 類型,通過 JSON 函數訪問。 |
| VARIANT | 不定長 | 動態可變數據類型,專為半結構化數據設計。 |
聚合類型
| 類型名 | 存儲空間(字節) | 描述 |
|---|---|---|
| HLL | 不定長 | 模糊去重,誤差約 1%-2%。 |
| BITMAP | 不定長 | 用于高效去重計算。 |
| QUANTILE_STATE | 不定長 | 計算分位數近似值。 |
| AGG_STATE | 不定長 | 聚合函數,需配合函數組合器使用。 |
IP 類型
| 類型名 | 存儲空間(字節) | 描述 |
|---|---|---|
| IPv4 | 4 | 存儲 IPv4 地址,配合 ipv4_* 函數使用。 |
| IPv6 | 16 | 存儲 IPv6 地址,配合 ipv6_* 函數使用。 |
可通過 SHOW DATA TYPES; 語句查看 Apache Doris 支持的所有數據類型。
4.4、表索引
數據庫索引是用于查詢加速的,為了加速不同的查詢場景,Apache Doris 支持了多種豐富的索引。
索引分類和原理
從加速的查詢和原理來看,Apache Doris 的索引分為點查索引和跳數索引兩大類。
- 點查索引:常用于加速點查,原理是通過索引定位到滿足 WHERE 條件的有哪些行,直接讀取那些行。點查索引在滿足條件的行比較少時效果很好。Apache Doris 的點查索引包括前綴索引和倒排索引。
- 前綴索引:Apache Doris 按照排序鍵以有序的方式存儲數據,并每隔 1024 行數據創建一個稀疏前綴索引。索引中的 Key 是當前 1024 行中第一行中排序列的值。如果查詢涉及已排序列,系統將找到相關 1024 行組的第一行并從那里開始掃描。
- 倒排索引:對創建了倒排索引的列,建立每個值到對應行號集合的倒排表。對于等值查詢,先從倒排表中查到行號集合,然后直接讀取對應行的數據,而不用逐行掃描匹配數據,從而減少 I/O 加速查詢。倒排索引還能加速范圍過濾、文本關鍵詞匹配,算法更加復雜但是基本原理類似。(備注:之前的 BITMAP 索引已經被更強的倒排索引取代)
- 跳數索引:常用于加速分析,原理是通過索引確定不滿足 WHERE 條件的數據塊,跳過這些不滿足條件的數據塊,只讀取可能滿足條件的數據塊并再進行一次逐行過濾,最終得到滿足條件的行。跳數索引在滿足條件的行比較多時效果較好Apache Doris 的跳數索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
- ZoneMap 索引:自動維護每一列的統計信息,為每一個數據文件(Segment)和數據塊(Page)記錄最大值、最小值、是否有 NULL。對于等值查詢、范圍查詢、IS NULL,可以通過最大值、最小值、是否有 NULL 來判斷數據文件和數據塊是否可以包含滿足條件的數據,如果沒有則跳過不讀對應的文件或數據塊減少 I/O 加速查詢。
- BloomFilter 索引:將索引對應列的可能取值存入 BloomFilter 數據結構中,它可以快速判斷一個值是否在 BloomFilter 里面,并且 BloomFilter 存儲空間占用很低。對于等值查詢,如果判斷這個值不在 BloomFilter 里面,就可以跳過對應的數據文件或者數據塊減少 I/O 加速查詢。
- NGram BloomFilter 索引:用于加速文本 LIKE 查詢,基本原理與 BloomFilter 索引類似,只是存入 BloomFilter 的不是原始文本的值,而是對文本進行 NGram 分詞,每個詞作為值存入 BloomFilter。對于 LIKE 查詢,將 LIKE 的 pattern 也進行 NGram 分詞,判斷每個詞是否在 BloomFilter 中,如果某個詞不在則對應的數據文件或者數據塊就不滿足 LIKE 條件,可以跳過這部分數據減少 I/O 加速查詢。
上述索引中,前綴索引和 ZoneMap 索引是 Apache Doris 自動維護的內建智能索引,無需用戶管理,而倒排索引、BloomFilter 索引、NGram BloomFilter 索引則需要用戶自己根據場景選擇,手動創建、刪除。
各種類型索引特點對比
| 類型 | 索引 | 優點 | 局限 |
|---|---|---|---|
| 點查索引 | 前綴索引 | 內置索引,性能最好 | 一個表只有一組前綴索引 |
| 點查索引 | 倒排索引 | 支持分詞和關鍵詞匹配,任意列可建索引,多條件組合,持續增加函數加速 | 索引存儲空間較大,與原始數據相當 |
| 跳數索引 | ZoneMap 索引 | 內置索引,索引存儲空間小 | 支持的查詢類型少,只支持等于、范圍 |
| 跳數索引 | BloomFilter 索引 | 比 ZoneMap 更精細,索引空間中等 | 支持的查詢類型少,只支持等于 |
| 跳數索引 | NGram BloomFilter 索引 | 支持 LIKE 加速,索引空間中等 | 支持的查詢類型少,只支持 LIKE 加速 |
索引加速的運算符和函數列表
| 運算符 / 函數 | 前綴索引 | 倒排索引 | ZoneMap 索引 | BloomFilter 索引 | NGram BloomFilter 索引 |
|---|---|---|---|---|---|
| = | YES | YES | YES | YES | NO |
| != | YES | YES | NO | NO | NO |
| IN | YES | YES | YES | YES | NO |
| NOT IN | YES | YES | NO | NO | NO |
| >, >=, <, <=, BETWEEN | YES | YES | YES | NO | NO |
| IS NULL | YES | YES | YES | NO | NO |
| IS NOT NULL | YES | YES | NO | NO | NO |
| LIKE | NO | NO | NO | NO | YES |
| MATCH, MATCH_* | NO | YES | NO | NO | NO |
| array_contains | NO | YES | NO | NO | NO |
| array_overlaps | NO | YES | NO | NO | NO |
| is_ip_address_in_range | NO | YES | NO | NO | NO |
索引設計指南
數據庫表的索引設計和優化跟數據特點和查詢很相關,需要根據實際場景測試和優化。雖然沒有 “銀彈”,Apache Doris 仍然不斷努力降低用戶使用索引的難度,用戶可以根據下面的簡單建議原則進行索引選擇和測試。
-
最頻繁使用的過濾條件指定為 Key 自動建前綴索引,因為它的過濾效果最好,但是一個表只能有一個前綴索引,因此要用在最頻繁的過濾條件上
-
對非 Key 字段如有過濾加速需求,首選建倒排索引,因為它的適用面廣,可以多條件組合,次選下面兩種索引:
- 有字符串 LIKE 匹配需求,再加一個 NGram BloomFilter 索引
- 對索引存儲空間很敏感,將倒排索引換成 BloomFilter 索引 -
如果性能不及預期,通過 QueryProfile 分析索引過濾掉的數據量和消耗的時間,具體參考各個索引的詳細文檔
4.4.1、前綴索引與排序鍵
4.4.1.1、索引原理
Doris 的數據存儲在類似 SSTable(Sorted String Table)的數據結構中。該結構是一種有序的數據結構,可以按照指定的一個或多個列進行排序存儲。在這種數據結構上,以排序列的全部或者前面幾個作為條件進行查找,會非常的高效。
在 Aggregate、Unique 和 Duplicate 三種數據模型中。底層的數據存儲,是按照各自建表語句中,Aggregate Key、Unique Key 和 Duplicate Key 中指定的列進行排序存儲的。這些 Key,稱為排序鍵(Sort Key)。借助排序鍵,在查詢時,通過給排序列指定條件,Doris 不需要掃描全表即可快速找到需要處理的數據,降低搜索的復雜度,從而加速查詢。
在排序鍵的基礎上,又引入了前綴索引(Prefix Index)。前綴索引是一種稀疏索引。表中按照相應的行數的數據構成一個邏輯數據塊 (Data Block)。每個邏輯數據塊在前綴索引表中存儲一個索引項,索引項的長度不超過 36 字節,其內容為數據塊中第一行數據的排序列組成的前綴,在查找前綴索引表時可以幫助確定該行數據所在邏輯數據塊的起始行號。由于前綴索引比較小,所以,可以全量在內存緩存,快速定位數據塊,大大提升了查詢效率。
提示:數據塊一行數據的前 36 個字節作為這行數據的前綴索引。當遇到 VARCHAR 類型時,前綴索引會直接截斷。如果第一列即為 VARCHAR,那么即使沒有達到 36 字節,也會直接截斷,后面的列不再加入前綴索引。
4.4.1.2、使用場景
前綴索引可以加速等值查詢和范圍查詢。
4.4.1.3、管理索引
前綴索引沒有專門的語法去定義,建表時自動取表的 Key 的前 36 字節作為前綴索引。
前綴索引選擇建議
因為一個表的 Key 定義是唯一的,所以一個表只有一組前綴索引,因此設計表結構時選擇合適的前綴索引很重要,可以參考下面的建議:
- 選擇查詢中最常用于 WHERE 過濾條件的字段作為 Key。
- 越常用的字段越放在前面,因為前綴索引只對 WHERE 條件中字段在 Key 的前綴中才有效。
使用其他不能命中前綴索引的列作為條件進行的查詢來說,效率上可能無法滿足需求,有兩種解決方案:
- 對需要加速查詢的條件列創建倒排索引,由于一個表的倒排索引可以有很多個。
- 對于 Duplicate 表可以通過創建相應的調整了列順序的單表強一致物化視圖來間接實現多種前綴索引
4.4.1.4、使用索引
前綴索引用于加速 WHERE 條件中的等值和范圍查詢,能加速時自動生效,沒有特殊語法。
可以通過 Query Profile 中的下面幾個指標分析前綴索引的加速效果。
- RowsKeyRangeFiltered 前綴索引過濾掉的行數,可以與其他幾個 Rows 值對比分析索引過濾效果
4.4.1.5、使用示例
- 假如表的排序列為如下 5 列,那么前綴索引為:user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
| ColumnName | Type |
|---|---|
| user_id | BIGINT |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
- 假如表的排序列為如下 5 列,則前綴索引為 user_name(20 Bytes)。即使沒有達到 36 個字節,因為遇到 VARCHAR,所以直接截斷,不再往后繼續。
| ColumnName | Type |
|---|---|
| user_name | VARCHAR(20) |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
- 當我們的查詢條件,是前綴索引的前綴時,可以極大地加快查詢速度。比如在第一個例子中,執行如下查詢:
SELECT * FROM table WHERE user_id=1829239 and age=20;
該查詢的效率會遠高于如下查詢:
SELECT * FROM table WHERE age=20;
所以在建表時,正確選擇列順序,能夠極大地提高查詢效率。
4.4.2、倒排索引
4.4.2.1、索引原理
倒排索引,是信息檢索領域常用的索引技術,將文本分成一個個詞,構建 詞 -> 文檔編號 的索引,可以快速查找一個詞在哪些文檔出現。
從 2.0.0 版本開始,Doris 支持倒排索引,可以用來進行文本類型的全文檢索、普通數值日期類型的等值范圍查詢,快速從海量數據中過濾出滿足條件的行。
在 Doris 的倒排索引實現中,Table 的一行對應一個文檔、一列對應文檔中的一個字段,因此利用倒排索引可以根據關鍵詞快速定位包含它的行,達到 WHERE 子句加速的目的。
與 Doris 中其他索引不同的是,在存儲層倒排索引使用獨立的文件,跟數據文件一一對應、但物理存儲上文件相互獨立。這樣的好處是可以做到創建、刪除索引不用重寫數據文件,大幅降低處理開銷。
4.4.2.2、使用場景
倒排索引的使用范圍很廣泛,可以加速等值、范圍、全文檢索(關鍵詞匹配、短語系列匹配等)。一個表可以有多個倒排索引,查詢時多個倒排索引的條件可以任意組合。
倒排索引的功能簡要介紹如下:
- 加速字符串類型的全文檢索
-
支持關鍵詞檢索,包括同時匹配多個關鍵字
MATCH_ALL、匹配任意一個關鍵字MATCH_ANY -
支持短語查詢
MATCH_PHRASE- 支持指定詞距
slop - 支持短語 + 前綴
MATCH_PHRASE_PREFIX
- 支持指定詞距
-
支持分詞正則查詢
MATCH_REGEXP -
支持英文、中文以及 Unicode 多種分詞
- 加速普通等值、范圍查詢,覆蓋原來 BITMAP 索引的功能,代替 BITMAP 索引
-
支持字符串、數值、日期時間類型的 =, !=, >, >=, <, <= 快速過濾
-
支持字符串、數字、日期時間數組類型的 =, !=, >, >=, <, <=
- 支持完善的邏輯組合
-
不僅支持 AND 條件加速,還支持 OR NOT 條件加速
-
支持多個條件的任意 AND OR NOT 邏輯組合
- 靈活高效的索引管理
-
支持在創建表上定義倒排索引
-
支持在已有的表上增加倒排索引,而且支持增量構建倒排索引,無需重寫表中的已有數據
-
支持刪除已有表上的倒排索引,無需重寫表中的已有數據
- 倒排索引的使用有下面一些限制
-
存在精度問題的浮點數類型 FLOAT 和 DOUBLE 不支持倒排索引,原因是浮點數精度不準確。解決方案是使用精度準確的定點數類型 DECIMAL,DECIMAL 支持倒排索引。
-
部分復雜數據類型還不支持倒排索引,包括:MAP、STRUCT、JSON、HLL、BITMAP、QUANTILE_STATE、AGG_STATE。其中 MAP、STRUCT 會逐步支持,JSON 類型可以換成 VARIANT 類型獲得支持。其他幾個類型因為其特殊用途暫不需要支持倒排索引。
-
DUPLICATE 和 開啟 Merge-on-Write 的 UNIQUE 表模型支持任意列建倒排索引。但是 AGGREGATE 和 未開啟 Merge-on-Write 的 UNIQUE 模型僅支持 Key 列建倒排索引,非 Key 列不能建倒排索引,這是因為這兩個模型需要讀取所有數據后做合并,因此不能利用索引做提前過濾。
4.4.2.3、管理索引
- 建表時定義倒排索引
在建表語句中 COLUMN 的定義之后是索引定義:
CREATE TABLE table_name
(column_name1 TYPE1,column_name2 TYPE2,column_name3 TYPE3,INDEX idx_name1(column_name1) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment'],INDEX idx_name2(column_name2) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment']
)
table_properties;
語法說明如下:
-
idx_column_name(column_name)是必須的,column_name是建索引的列名,必須是前面列定義中出現過的,idx_column_name是索引名字,必須表級別唯一,建議命名規范:列名前面加前綴idx_ -
USING INVERTED 是必須的,用于指定索引類型是倒排索引 -
COMMENT 是可選的,用于指定索引注釋 -
PROPERTIES是可選的,用于指定倒排索引的額外屬性,目前支持的屬性如下:
parser 指定分詞器- 默認不指定代表不分詞
- `english` 是英文分詞,適合被索引列是英文的情況,用空格和標點符號分詞,性能高
- `chinese` 是中文分詞,適合被索引列主要是中文的情況,性能比 English 分詞低
- `unicode` 是多語言混合類型分詞,適用于中英文混合、多語言混合的情況。它能夠對郵箱前綴和后綴、IP 地址以及字符數字混合進行分詞,并且可以對中文按字符分詞分詞的效果可以通過 `TOKENIZE SQL` 函數進行驗證,具體參考后續章節。
parser_mode用于指定分詞的模式,目前 parser = chinese 時支持如下幾種模式:- fine_grained:細粒度模式,傾向于分出比較短、較多的詞,比如 '武漢市長江大橋' 會分成 '武漢', '武漢市', '市長', '長江', '長江大橋', '大橋' 6 個詞
- coarse_grained:粗粒度模式,傾向于分出比較長、較少的詞,,比如 '武漢市長江大橋' 會分成 '武漢市' '長江大橋' 2 個詞
- 默認 coarse_grained
support_phrase用于指定索引是否支持 MATCH_PHRASE 短語查詢加速- true 為支持,但是索引需要更多的存儲空間- false 為不支持,更省存儲空間,可以用 MATCH_ALL 查詢多個關鍵字- 從 2.0.14, 2.1.5 和 3.0.1 版本開始,如果指定了 parser 則默認為 true,否則默認為 false例如下面的例子指定中文分詞,粗粒度模式,支持短語查詢加速。INDEX idx_name(column_name) USING INVERTED PROPERTIES("parser" = "chinese", "parser_mode" = "coarse_grained", "support_phrase" = "true")
char_filter用于指定在分詞前對文本進行預處理,通常用于影響分詞行為char_filter_type:指定使用不同功能的 char_filter(目前僅支持 char_replace)char_replace 將 pattern 中每個 char 替換為一個 replacement 中的 char- char_filter_pattern:需要被替換掉的字符數- char_filter_replacement:替換后的字符數組,可以不用配置,默認為一個空格字符例如下面的例子將點和下劃線替換成空格,達到將點和下劃線作為單詞分隔符的目的,影響分詞行為。INDEX idx_name(column_name) USING INVERTED PROPERTIES("parser" = "unicode", "char_filter_type" = "char_replace", "char_filter_pattern" = "._", "char_filter_replacement" = " ")
ignore_above用于指定不分詞字符串索引(沒有指定 parser)的長度限制- 長度超過 ignore_above 設置的字符串不會被索引。對于字符串數組,ignore_above 將分別應用于每個數組元素,長度超過 ignore_above 的字符串元素將不被索引。- 默認為 256,單位是字節
lower_case是否將分詞進行小寫轉換,從而在匹配的時候實現忽略大小寫- true: 轉換小寫
- false:不轉換小寫
- 從 2.0.7 和 2.1.2 版本開始默認為 true,自動轉小寫,之前的版本默認為 false
stopwords指明使用的停用詞表,會影響分詞器的行為默認的內置停用詞表包含一些無意義的詞:'is'、'the'、'a' 等。在寫入或者查詢時,分詞器會忽略停用詞表中的詞。- none: 使用空的停用詞表
- 已有表增加倒排索引
ADD INDEX
支持CREATE INDEX 和 ALTER TABLE ADD INDEX 兩種語法,參數跟建表時索引定義相同
-- 語法 1
CREATE INDEX idx_name ON table_name(column_name) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment'];
-- 語法 2
ALTER TABLE table_name ADD INDEX idx_name(column_name) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment'];
BUILD INDEX
CREATE / ADD INDEX 操作只是新增了索引定義,這個操作之后的新寫入數據會生成倒排索引,而存量數據需要使用 BUILD INDEX 觸發:
-- 語法 1,默認給全表的所有分區 BUILD INDEX
BUILD INDEX index_name ON table_name;
-- 語法 2,可指定 Partition,可指定一個或多個
BUILD INDEX index_name ON table_name PARTITIONS(partition_name1, partition_name2);
通過 SHOW BUILD INDEX 查看 BUILD INDEX 進度:
SHOW BUILD INDEX [FROM db_name];
-- 示例 1,查看所有的 BUILD INDEX 任務進展
SHOW BUILD INDEX;
-- 示例 2,查看指定 table 的 BUILD INDEX 任務進展
SHOW BUILD INDEX where TableName = "table1";
通過 CANCEL BUILD INDEX 取消 BUILD INDEX:
CANCEL BUILD INDEX ON table_name;
CANCEL BUILD INDEX ON table_name (job_id1,jobid_2,...);
提示
-
BUILD INDEX會生成一個異步任務執行,在每個 BE 上有多個線程執行索引構建任務,通過 BE 參數alter_index_worker_count可以設置,默認值是 3。 -
2.0.12 和 2.1.4 之前的版本
BUILD INDEX會一直重試直到成功,從這兩個版本開始通過失敗和超時機制避免一直重試。3.0 存算分離模式暫不支持此命令。- 一個 tablet 的多數副本
BUILD INDEX失敗后,整個BUILD INDEX失敗結束 - 時間超過
alter_table_timeout_second (),BUILD INDEX超時結束 - 用戶可以多次觸發
BUILD INDEX,已經 BUILD 成功的索引不會重復 BUILD
- 一個 tablet 的多數副本
-
已有表刪除倒排索引
-- 語法 1
DROP INDEX idx_name ON table_name;
-- 語法 2
ALTER TABLE table_name DROP INDEX idx_name;
DROP INDEX 會刪除索引定義,新寫入數據不會再寫索引,同時會生成一個異步任務執行索引刪除操作,在每個 BE 上有多個線程執行索引刪除任務,通過 BE 參數 alter_index_worker_count 可以設置,默認值是 3。
- 查看倒排索引
-- 語法 1,表的 schema 中 INDEX 部分 USING INVERTED 是倒排索引
SHOW CREATE TABLE table_name;-- 語法 2,IndexType 為 INVERTED 的是倒排索引
SHOW INDEX FROM idx_name;
4.4.2.4、使用索引
- 利用倒排索引加速查詢
-- 1. 全文檢索關鍵詞匹配,通過 MATCH_ANY MATCH_ALL 完成
SELECT * FROM table_name WHERE column_name MATCH_ANY | MATCH_ALL 'keyword1 ...';-- 1.1 content 列中包含 keyword1 的行
SELECT * FROM table_name WHERE content MATCH_ANY 'keyword1';-- 1.2 content 列中包含 keyword1 或者 keyword2 的行,后面還可以添加多個 keyword
SELECT * FROM table_name WHERE content MATCH_ANY 'keyword1 keyword2';-- 1.3 content 列中同時包含 keyword1 和 keyword2 的行,后面還可以添加多個 keyword
SELECT * FROM table_name WHERE content MATCH_ALL 'keyword1 keyword2';-- 2. 全文檢索短語匹配,通過 MATCH_PHRASE 完成
-- 2.1 content 列中同時包含 keyword1 和 keyword2 的行,而且 keyword2 必須緊跟在 keyword1 后面
-- 'keyword1 keyword2','wordx keyword1 keyword2','wordx keyword1 keyword2 wordy' 能匹配,因為他們都包含 keyword1 keyword2,而且 keyword2 緊跟在 keyword1 后面
-- 'keyword1 wordx keyword2' 不能匹配,因為 keyword1 keyword2 之間隔了一個詞 wordx
-- 'keyword2 keyword1',因為 keyword1 keyword2 的順序反了
-- 使用 MATCH_PHRASE 需要再 PROPERTIES 中開啟 "support_phrase" = "true"
SELECT * FROM table_name WHERE content MATCH_PHRASE 'keyword1 keyword2';-- 2.2 content 列中同時包含 keyword1 和 keyword2 的行,而且 keyword1 keyword2 的 `詞距`(slop)不超過 3
-- 'keyword1 keyword2', 'keyword1 a keyword2', 'keyword1 a b c keyword2' 都能匹配,因為 keyword1 keyword2 中間隔的詞分別是 0 1 3 都不超過 3
-- 'keyword1 a b c d keyword2' 不能能匹配,因為 keyword1 keyword2 中間隔的詞有 4 個,超過 3
-- 'keyword2 keyword1', 'keyword2 a keyword1', 'keyword2 a b c keyword1' 也能匹配,因為指定 slop > 0 時不再要求 keyword1 keyword2 的順序。這個行為參考了 ES,與直覺的預期不一樣,因此 Doris 提供了在 slop 后面指定正數符號(+)表示需要保持 keyword1 keyword2 的先后順序
SELECT * FROM table_name WHERE content MATCH_PHRASE 'keyword1 keyword2 ~3';
-- slop 指定正號,'keyword1 a b c keyword2' 能匹配,而 'keyword2 a b c keyword1' 不能匹配
SELECT * FROM table_name WHERE content MATCH_PHRASE 'keyword1 keyword2 ~3+';-- 2.3 在保持詞順序的前提下,對最后一個詞 keyword2 做前綴匹配,默認找 50 個前綴詞(session 變量 inverted_index_max_expansions 控制)
-- 需要保證 keyword1, keyword2 在原文分詞后也是相鄰的,不能中間有其他詞
-- 'keyword1 keyword2abc' 能匹配,因為 keyword1 完全一樣,最后一個 keyword2abc 是 keyword2 的前綴
-- 'keyword1 keyword2' 也能匹配,因為 keyword2 也是 keyword2 的前綴
-- 'keyword1 keyword3' 不能匹配,因為 keyword3 不是 keyword2 的前綴
-- 'keyword1 keyword3abc' 也不能匹配,因為 keyword3abc 也不是 keyword2 的前綴
SELECT * FROM table_name WHERE content MATCH_PHRASE_PREFIX 'keyword1 keyword2';-- 2.4 如果只填一個詞會退化為前綴查詢,默認找 50 個前綴詞(session 變量 inverted_index_max_expansions 控制)
SELECT * FROM table_name WHERE content MATCH_PHRASE_PREFIX 'keyword1';-- 2.5 對分詞后的詞進行正則匹配,默認匹配 50 個(session 變量 inverted_index_max_expansions 控制)
-- 類似 MATCH_PHRASE_PREFIX 的匹配規則,只是前綴變成了正則
SELECT * FROM table_name WHERE content MATCH_REGEXP 'key.*';-- 3. 普通等值、范圍、IN、NOT IN,正常的 SQL 語句即可,例如
SELECT * FROM table_name WHERE id = 123;
SELECT * FROM table_name WHERE ts > '2023-01-01 00:00:00';
SELECT * FROM table_name WHERE op_type IN ('add', 'delete');-- 4. 多列全文檢索匹配,通過 multi_match 函數完成
-- 參數說明:
-- 前N個參數是要匹配的列名
-- 倒數第二個參數指定匹配模式:'any'/'all'/'phrase'/'phrase_prefix'
-- 最后一個參數是要搜索的關鍵詞或短語-- 4.1 在col1,col2,col3任意一列中包含'keyword1'的行(OR邏輯)
SELECT * FROM table_name WHERE multi_match(col1, col2, col3, 'any', 'keyword1');-- 4.2 在col1,col2,col3所有列中都包含'keyword1'的行(AND邏輯)
SELECT * FROM table_name WHERE multi_match(col1, col2, col3, 'all', 'keyword1');-- 4.3 在col1,col2,col3任意一列中包含完整短語'keyword1'的行(精確短語匹配)
SELECT * FROM table_name WHERE multi_match(col1, col2, col3, 'phrase', 'keyword1');-- 4.4 在col1,col2,col3任意一列中包含以'keyword1'開頭的短語的行(短語前綴匹配)
-- 例如會匹配"keyword123"這樣的內容
SELECT * FROM table_name WHERE multi_match(col1, col2, col3, 'phrase_prefix', 'keyword1');
- 通過 profile 分析索引加速效果
倒排查詢加速可以通過 session 變量 enable_inverted_index_query 開關,默認是 true 打開,有時為了驗證索引加速效果可以設置為 false 關閉。
可以通過 Query Profile 中的下面幾個指標分析倒排索引的加速效果。
-
RowsInvertedIndexFiltered 倒排過濾掉的行數,可以與其他幾個 Rows 值對比分析索引過濾效果
-
InvertedIndexFilterTime 倒排索引消耗的時間
- InvertedIndexSearcherOpenTime 倒排索引打開索引的時間
- InvertedIndexSearcherSearchTime 倒排索引內部查詢的時間
-
用分詞函數驗證分詞效果
如果想檢查分詞實際效果或者對一段文本進行分詞行為,可以使用 TOKENIZE 函數進行驗證。
TOKENIZE 函數的第一個參數是待分詞的文本,第二個參數是創建索引指定的分詞參數。
SELECT TOKENIZE('武漢長江大橋','"parser"="chinese","parser_mode"="fine_grained"');
+-----------------------------------------------------------------------------------+
| tokenize('武漢長江大橋', '"parser"="chinese","parser_mode"="fine_grained"') |
+-----------------------------------------------------------------------------------+
| ["武漢", "武漢長江大橋", "長江", "長江大橋", "大橋"] |
+-----------------------------------------------------------------------------------+SELECT TOKENIZE('武漢市長江大橋','"parser"="chinese","parser_mode"="fine_grained"');
+--------------------------------------------------------------------------------------+
| tokenize('武漢市長江大橋', '"parser"="chinese","parser_mode"="fine_grained"') |
+--------------------------------------------------------------------------------------+
| ["武漢", "武漢市", "市長", "長江", "長江大橋", "大橋"] |
+--------------------------------------------------------------------------------------+SELECT TOKENIZE('武漢市長江大橋','"parser"="chinese","parser_mode"="coarse_grained"');
+----------------------------------------------------------------------------------------+
| tokenize('武漢市長江大橋', '"parser"="chinese","parser_mode"="coarse_grained"') |
+----------------------------------------------------------------------------------------+
| ["武漢市", "長江大橋"] |
+----------------------------------------------------------------------------------------+SELECT TOKENIZE('I love Doris','"parser"="english"');
+------------------------------------------------+
| tokenize('I love Doris', '"parser"="english"') |
+------------------------------------------------+
| ["i", "love", "doris"] |
+------------------------------------------------+SELECT TOKENIZE('I love CHINA 我愛我的祖國','"parser"="unicode"');
+-------------------------------------------------------------------+
| tokenize('I love CHINA 我愛我的祖國', '"parser"="unicode"') |
+-------------------------------------------------------------------+
| ["i", "love", "china", "我", "愛", "我", "的", "祖", "國"] |
+-------------------------------------------------------------------+
4.4.2.5、使用示例
用 HackerNews 100 萬條數據展示倒排索引的創建、全文檢索、普通查詢,包括跟無索引的查詢性能進行簡單對比。
- 建表
CREATE DATABASE test_inverted_index;USE test_inverted_index;-- 創建表的同時創建了 comment 的倒排索引 idx_comment
-- USING INVERTED 指定索引類型是倒排索引
-- PROPERTIES("parser" = "english") 指定采用 "english" 分詞,還支持 "chinese" 中文分詞和 "unicode" 中英文多語言混合分詞,如果不指定 "parser" 參數表示不分詞CREATE TABLE hackernews_1m
(`id` BIGINT,`deleted` TINYINT,`type` String,`author` String,`timestamp` DateTimeV2,`comment` String,`dead` TINYINT,`parent` BIGINT,`poll` BIGINT,`children` Array<BIGINT>,`url` String,`score` INT,`title` String,`parts` Array<INT>,`descendants` INT,INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");
- 導入數據
通過 Stream Load 導入數據
wget https://qa-build.oss-cn-beijing.aliyuncs.com/regression/index/hacknernews_1m.csv.gzcurl --location-trusted -u root: -H "compress_type:gz" -T hacknernews_1m.csv.gz http://127.0.0.1:8030/api/test_inverted_index/hackernews_1m/_stream_load
{"TxnId": 2,"Label": "a8a3e802-2329-49e8-912b-04c800a461a6","TwoPhaseCommit": "false","Status": "Success","Message": "OK","NumberTotalRows": 1000000,"NumberLoadedRows": 1000000,"NumberFilteredRows": 0,"NumberUnselectedRows": 0,"LoadBytes": 130618406,"LoadTimeMs": 8988,"BeginTxnTimeMs": 23,"StreamLoadPutTimeMs": 113,"ReadDataTimeMs": 4788,"WriteDataTimeMs": 8811,"CommitAndPublishTimeMs": 38
}
SQL 運行 count() 確認導入數據成功
SELECT count() FROM hackernews_1m;
+---------+
| count() |
+---------+
| 1000000 |
+---------+
- 查詢
- 01 全文檢索
- 用 LIKE 匹配計算 comment 中含有 ‘OLAP’ 的行數,耗時 0.18s
SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%';
+---------+
| count() |
+---------+
| 34 |
+---------+
- 用基于倒排索引的全文檢索
MATCH_ANY計算 comment 中含有’OLAP’的行數,耗時 0.02s,加速 9 倍,在更大的數據集上效果會更加明顯
這里結果條數的差異,是因為倒排索引對 comment 分詞后,還會對詞進行進行統一成小寫等歸一化處理,因此 MATCH_ANY 比 LIKE 的結果多一些
SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLAP';
+---------+
| count() |
+---------+
| 35 |
+---------+
- 同樣的對比統計 ‘OLTP’ 出現次數的性能,0.07s vs 0.01s,由于緩存的原因
LIKE和MATCH_ANY都有提升,倒排索引仍然有 7 倍加速
SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 48 |
+---------+SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLTP';
+---------+
| count() |
+---------+
| 51 |
+---------+
- 同時出現 ‘OLAP’ 和 ‘OLTP’ 兩個詞,0.13s vs 0.01s,13 倍加速。
要求多個詞同時出現時(AND 關系)使用 MATCH_ALL ‘keyword1 keyword2 …’
SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 14 |
+---------+SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
- 任意出現 ‘OLAP’ 和 ‘OLTP’ 其中一個詞,0.12s vs 0.01s,12 倍加速
只要求多個詞任意一個或多個出現時(OR 關系)使用 MATCH_ANY ‘keyword1 keyword2 …’
SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' OR comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 68 |
+---------+SELECT count() FROM hackernews_1m WHERE comment MATCH_ANY 'OLAP OLTP';
+---------+
| count() |
+---------+
| 71 |
+---------+
- 02 普通等值、范圍查詢
- DataTime 類型的列范圍查詢
SELECT count() FROM hackernews_1m WHERE timestamp > '2007-08-23 04:17:00';
+---------+
| count() |
+---------+
| 999081 |
+---------+
- 為 timestamp 列增加一個倒排索引
-- 對于日期時間類型 USING INVERTED,不用指定分詞
-- CREATE INDEX 是第一種建索引的語法,另外一種在后面展示
CREATE INDEX idx_timestamp ON hackernews_1m(timestamp) USING INVERTED;
BUILD INDEX idx_timestamp ON hackernews_1m;
- 查看索引創建進度,通過 FinishTime 和 CreateTime 的差值,可以看到 100 萬條數據對 timestamp 列建倒排索引只用了 1s
SHOW ALTER TABLE COLUMN;
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | IndexName | IndexId | OriginIndexId | SchemaVersion | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| 10030 | hackernews_1m | 2023-02-10 19:44:12.929 | 2023-02-10 19:44:13.938 | hackernews_1m | 10031 | 10008 | 1:1994690496 | 3 | FINISHED | | NULL | 2592000 |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
-- 若 table 沒有分區,PartitionName 默認就是 TableName
SHOW BUILD INDEX;
+-------+---------------+---------------+----------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+---------------+---------------+----------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 10191 | hackernews_1m | hackernews_1m | [ADD INDEX idx_timestamp (`timestamp`) USING INVERTED], | 2023-06-26 15:32:33.894 | 2023-06-26 15:32:34.847 | 3 | FINISHED | | NULL |
+-------+---------------+---------------+----------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
- 索引創建后,范圍查詢用同樣的查詢方式,Doris 會自動識別索引進行優化,但是這里由于數據量小性能差別不大
SELECT count() FROM hackernews_1m WHERE timestamp > '2007-08-23 04:17:00';
+---------+
| count() |
+---------+
| 999081 |
+---------+
- 在數值類型的列 Parent 進行類似 timestamp 的操作,這里查詢使用等值匹配
SELECT count() FROM hackernews_1m WHERE parent = 11189;
+---------+
| count() |
+---------+
| 2 |
+---------+-- 對于數值類型 USING INVERTED,不用指定分詞
-- ALTER TABLE t ADD INDEX 是第二種建索引的語法
ALTER TABLE hackernews_1m ADD INDEX idx_parent(parent) USING INVERTED;-- 執行 BUILD INDEX 給存量數據構建倒排索引
BUILD INDEX idx_parent ON hackernews_1m;SHOW ALTER TABLE COLUMN;
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | IndexName | IndexId | OriginIndexId | SchemaVersion | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| 10030 | hackernews_1m | 2023-02-10 19:44:12.929 | 2023-02-10 19:44:13.938 | hackernews_1m | 10031 | 10008 | 1:1994690496 | 3 | FINISHED | | NULL | 2592000 |
| 10053 | hackernews_1m | 2023-02-10 19:49:32.893 | 2023-02-10 19:49:33.982 | hackernews_1m | 10054 | 10008 | 1:378856428 | 4 | FINISHED | | NULL | 2592000 |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+SHOW BUILD INDEX;
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 11005 | hackernews_1m | hackernews_1m | [ADD INDEX idx_parent (`parent`) USING INVERTED], | 2023-06-26 16:25:10.167 | 2023-06-26 16:25:10.838 | 1002 | FINISHED | | NULL |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+SELECT count() FROM hackernews_1m WHERE parent = 11189;
+---------+
| count() |
+---------+
| 2 |
+---------+
- 對字符串類型的
author建立不分詞的倒排索引,等值查詢也可以利用索引加速
SELECT count() FROM hackernews_1m WHERE author = 'faster';
+---------+
| count() |
+---------+
| 20 |
+---------+-- 這里只用了 USING INVERTED,不對 author 分詞,整個當做一個詞處理
ALTER TABLE hackernews_1m ADD INDEX idx_author(author) USING INVERTED;-- 執行 BUILD INDEX 給存量數據加上倒排索引:
BUILD INDEX idx_author ON hackernews_1m;-- 100 萬條 author 數據增量建索引僅消耗 1.5s
SHOW ALTER TABLE COLUMN;
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishTime | IndexName | IndexId | OriginIndexId | SchemaVersion | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+
| 10030 | hackernews_1m | 2023-02-10 19:44:12.929 | 2023-02-10 19:44:13.938 | hackernews_1m | 10031 | 10008 | 1:1994690496 | 3 | FINISHED | | NULL | 2592000 |
| 10053 | hackernews_1m | 2023-02-10 19:49:32.893 | 2023-02-10 19:49:33.982 | hackernews_1m | 10054 | 10008 | 1:378856428 | 4 | FINISHED | | NULL | 2592000 |
| 10076 | hackernews_1m | 2023-02-10 19:54:20.046 | 2023-02-10 19:54:21.521 | hackernews_1m | 10077 | 10008 | 1:1335127701 | 5 | FINISHED | | NULL | 2592000 |
+-------+---------------+-------------------------+-------------------------+---------------+---------+---------------+---------------+---------------+----------+------+----------+---------+SHOW BUILD INDEX order by CreateTime desc limit 1;
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 13006 | hackernews_1m | hackernews_1m | [ADD INDEX idx_author (`author`) USING INVERTED], | 2023-06-26 17:23:02.610 | 2023-06-26 17:23:03.755 | 3004 | FINISHED | | NULL |
+-------+---------------+---------------+----------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+-- 創建索引后,字符串等值匹配也有明顯加速
SELECT count() FROM hackernews_1m WHERE author = 'faster';
+---------+
| count() |
+---------+
| 20 |
+---------+
4.4.3、BloomFilter 索引
4.4.3.1、索引原理
BloomFilter 索引是基于 BloomFilter 的一種跳數索引。它的原理是利用 BloomFilter 跳過等值查詢指定條件不滿足的數據塊,達到減少 I/O 查詢加速的目的。
BloomFilter 是由 Bloom 在 1970 年提出的一種多哈希函數映射的快速查找算法。通常應用在一些需要快速判斷某個元素是否屬于集合,但是并不嚴格要求 100% 正確的場合,BloomFilter 有以下特點:
-
空間效率高的概率型數據結構,用來檢查一個元素是否在一個集合中。
-
對于一個元素檢測是否存在的調用,BloomFilter 會告訴調用者兩個結果之一:可能存在或者一定不存在。
BloomFilter 是由一個超長的二進制位數組和一系列的哈希函數組成。二進制位數組初始全部為 0,當給定一個待查詢的元素時,這個元素會被一系列哈希函數計算映射出一系列的值,所有的值在位數組的偏移量處置為 1。
下圖所示出一個 m=18, k=3(m 是該 Bit 數組的大小,k 是 Hash 函數的個數)的 BloomFilter 示例。集合中的 x、y、z 三個元素通過 3 個不同的哈希函數散列到位數組中。當查詢元素 w 時,通過 Hash 函數計算之后只要有一個位為 0,因此 w 不在該集合中。但是反過來全部都是 1 只能說明可能在集合中、不能肯定一定在集合中,因為 Hash 函數可能出現 Hash 碰撞。
反過來如果某個元素經過哈希函數計算后得到所有的偏移位置,若這些位置全都為 1,只能說明可能在集合中、不能肯定一定在集合中,因為 Hash 函數可能出現 Hash 碰撞。這就是 BloomFilter“假陽性”,因此基于 BloomFilter 的索引只能跳過不滿足條件的數據,不能精確定位滿足條件的數據。
Doris BloomFilter 索引以數據塊(page)為單位構建,每個數據塊存儲一個 BloomFilter。寫入時,對于數據塊中的每個值,經過 Hash 存入數據塊對應的 BloomFilter。查詢時,根據等值條件的值,判斷每個數據塊對應的 BloomFilter 是否包含這個值,不包含則跳過對應的數據塊不讀取,達到減少 I/O 查詢加速的目的。
4.4.3.2、使用場景
BloomFilter 索引能夠對等值查詢(包括 = 和 IN)加速,對高基數字段效果較好,比如 userid 等唯一 ID 字段。
BloomFilter 的使用有下面一些限制:
-
對 IN 和 = 之外的查詢沒有效果,比如 !=, NOT INT, >, < 等
-
不支持對 Tinyint、Float、Double 類型的列建 BloomFilter 索引。
-
對低基數字段的加速效果很有限,比如“性別”字段僅有兩種值,幾乎每個數據塊都會包含所有取值,導致 BloomFilter 索引失去意義。
如果要查看某個查詢 BloomFilter 索引效果,可以通過 Query Profile 中的相關指標進行分析。
-
BlockConditionsFilteredBloomFilterTime 是 BloomFilter 索引消耗的時間
-
RowsBloomFilterFiltered 是 BloomFilter 過濾掉的行數,可以與其他幾個 Rows 值對比分析 BloomFilter 索引過濾效果
4.4.3.3、管理索引
- 建表時創建 BloomFilter 索引
由于歷史原因,BloomFilter 索引定義的語法與倒排索引等通用 INDEX 語法不一樣。BloomFilter 索引通過表的 PROPERTIES “bloom_filter_columns” 指定哪些字段建 BloomFilter 索引,可以指定一個或者多個字段。
PROPERTIES (
"bloom_filter_columns" = "column_name1,column_name2"
);
- 查看 BloomFilter 索引
SHOW CREATE TABLE table_name;
- 已有表增加、刪除 BloomFilter 索引
通過 ALTER TABLE 修改表的 bloom_filter_columns 屬性來完成。
為 column_name3 增加 BloomFilter 索引
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name1,column_name2,column_name3");
刪除 column_name1 的 BloomFilter 索引
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name2,column_name3");
4.4.3.4、使用索引
BloomFilter 索引用于加速 WHERE 條件中的等值查詢,能加速時自動生效,沒有特殊語法。
可以通過 Query Profile 中的下面幾個指標分析 BloomFilter 索引的加速效果。
- RowsBloomFilterFiltered BloomFilter 索引過濾掉的行數,可以與其他幾個 Rows 值對比分析索引過濾效果
- BlockConditionsFilteredBloomFilterTime BloomFilter 索引消耗的時間
4.4.3.5、使用示例
下面通過實例來看看 Doris 怎么創建 BloomFilter 索引。
Doris BloomFilter 索引的創建是通過在建表語句的 PROPERTIES 里加上 “bloom_filter_columns”=“k1,k2,k3”, 這個屬性,k1,k2,k3 是要創建的 BloomFilter 索引的 Key 列名稱,例如下面對表里的 saler_id,category_id 創建了 BloomFilter 索引。
CREATE TABLE IF NOT EXISTS sale_detail_bloom (sale_date date NOT NULL COMMENT "銷售時間",customer_id int NOT NULL COMMENT "客戶編號",saler_id int NOT NULL COMMENT "銷售員",sku_id int NOT NULL COMMENT "商品編號",category_id int NOT NULL COMMENT "商品分類",sale_count int NOT NULL COMMENT "銷售數量",sale_price DECIMAL(12,2) NOT NULL COMMENT "單價",sale_amt DECIMAL(20,2) COMMENT "銷售總金額"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1",
"bloom_filter_columns"="saler_id,category_id"
);
4.4.4、N-Gram 索引
4.4.4.1、索引原理
n-gram 分詞是將一句話或一段文字拆分成多個相鄰的詞組的分詞方法。NGram BloomFilter 索引和 BloomFilter 索引類似,也是基于 BloomFilter 的跳數索引。
與 BloomFilter 索引不同的是,NGram BloomFilter 索引用于加速文本 LIKE 查詢,它存入 BloomFilter 的不是原始文本的值,而是對文本進行 NGram 分詞,每個詞作為值存入 BloomFilter。對于 LIKE 查詢,將 LIKE ‘%pattern%’ 的 pattern 也進行 NGram 分詞,判斷每個詞是否在 BloomFilter 中,如果某個詞不在則對應的數據塊就不滿足 LIKE 條件,可以跳過這部分數據減少 IO 加速查詢。
4.4.4.2、使用場景
NGram BloomFilter 索引只能加速字符串 LIKE 查詢,而且 LIKE pattern 中的連續字符個數要大于等于索引定義的 NGram 中的 N。
-
NGram BloomFilter 只支持字符串列,只能加速 LIKE 查詢。
-
NGram BloomFilter 索引和 BloomFilter 索引為互斥關系,即同一個列只能設置兩者中的一個。
-
NGram BloomFilter 索引的效果分析,跟 BloomFilter 索引類似。
4.4.4.3、管理索引
- 創建 NGram BloomFilter 索引
在建表語句中 COLUMN 的定義之后是索引定義:
INDEX `idx_column_name` (`column_name`) USING NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="1024") COMMENT 'username ngram_bf index'
語法說明如下:
-
idx_column_name(column_name)是必須的,column_name是建索引的列名,必須是前面列定義中出現過的,idx_column_name 是索引名字,必須表級別唯一,建議命名規范:列名前面加前綴 idx_ -
USING NGRAM_BF 是必須的,用于指定索引類型是 NGram BloomFilter 索引 -
PROPERTIES 是可選的,用于指定 NGram BloomFilter 索引的額外屬性,目前支持的屬性如下:-
gram_size:NGram 中的 N,指定 N 個連續字符分詞一個詞,比如 ‘This is a simple ngram example’ 在 N = 3 的時候分成 ‘This is a’, ‘is a simple’, ‘a simple ngram’, ‘simple ngram example’ 4 個詞。
-
bf_size:BloomFilter 的大小,單位是 Bit。bf_size 決定每個數據塊對應的索引大小,這個值越大占用存儲空間越大,同時 Hash 碰撞的概率也越低。
-
gram_size 建議取 LIKE 查詢的字符串最小長度,但是不建議低于 2。一般建議設置 “gram_size”=“3”, “bf_size”=“1024”,然后根據 Query Profile 調優。
-
-
COMMENT是可選的,用于指定索引注釋
- 查看 NGram BloomFilter 索引
-- 語法 1,表的 schema 中 INDEX 部分 USING NGRAM_BF 是倒排索引
SHOW CREATE TABLE table_name;-- 語法 2,IndexType 為 NGRAM_BF 的是倒排索引
SHOW INDEX FROM idx_name;
- 刪除 NGram BloomFilter 索引
ALTER TABLE table_ngrambf DROP INDEX idx_ngrambf;
- 修改 NGram BloomFilter 索引
CREATE INDEX idx_column_name2(column_name2) ON table_ngrambf USING NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="1024") COMMENT 'username ngram_bf index';ALTER TABLE table_ngrambf ADD INDEX idx_column_name2(column_name2) USING NGRAM_BF PROPERTIES("gram_size"="3", "bf_size"="1024") COMMENT 'username ngram_bf index';
4.4.4.4、使用索引
使用 NGram BloomFilter 索引需設置如下參數(enable_function_pushdown 默認為 false):
SET enable_function_pushdown = true;
NGram BloomFilter 索引用于加速 LIKE 查詢,比如:
SELECT count() FROM table1 WHERE message LIKE '%error%';
可以通過 Query Profile 中的下面幾個指標分析 BloomFilter 索引(包括 NGram)的加速效果。
- RowsBloomFilterFiltered BloomFilter 索引過濾掉的行數,可以與其他幾個 Rows 值對比分析索引過濾效果
- BlockConditionsFilteredBloomFilterTime BloomFilter 索引消耗的時間
4.4.4.5、使用示例
以亞馬遜產品的用戶評論信息的數據集 amazon_reviews 為例展示 NGram BloomFilter 索引的使用和效果。
- 建表
CREATE TABLE `amazon_reviews` ( `review_date` int(11) NULL, `marketplace` varchar(20) NULL, `customer_id` bigint(20) NULL, `review_id` varchar(40) NULL,`product_id` varchar(10) NULL,`product_parent` bigint(20) NULL,`product_title` varchar(500) NULL,`product_category` varchar(50) NULL,`star_rating` smallint(6) NULL,`helpful_votes` int(11) NULL,`total_votes` int(11) NULL,`vine` boolean NULL,`verified_purchase` boolean NULL,`review_headline` varchar(500) NULL,`review_body` string NULL
) ENGINE=OLAP
DUPLICATE KEY(`review_date`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`review_date`) BUCKETS 16
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"compression" = "ZSTD"
);
- 導入數據
用 wget 或者其他工具從下面的地址下載數據集
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2010.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2011.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2012.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2013.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2014.snappy.parquet
https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2015.snappy.parquet
用 stream load 導入數據
curl --location-trusted -u root: -T amazon_reviews_2010.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2011.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2012.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2013.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2014.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2015.snappy.parquet -H "format:parquet" http://127.0.0.1:8030/api/${DB}/amazon_reviews/_stream_load
SQL 運行 count() 確認導入數據成功
mysql> SELECT COUNT() FROM amazon_reviews;
+-----------+
| count(*) |
+-----------+
| 135589433 |
+-----------+
- 查詢
首先在沒有索引的時候運行查詢,WHERE 條件中有 LIKE,耗時 7.60s
SELECTproduct_id,any(product_title),AVG(star_rating) AS rating,COUNT() AS count
FROMamazon_reviews
WHEREreview_body LIKE '%is super awesome%'
GROUP BYproduct_id
ORDER BYcount DESC,rating DESC,product_id
LIMIT 5;+------------+------------------------------------------+--------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+--------------------+-------+
| B00992CF6W | Minecraft | 4.8235294117647056 | 17 |
| B009UX2YAC | Subway Surfers | 4.7777777777777777 | 9 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 4.875 | 8 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+--------------------+-------+
5 rows in set (7.60 sec)
然后添加 NGram BloomFilter 索引,再次運行相同的查詢耗時 0.93s,性能提升了 8 倍
ALTER TABLE amazon_reviews ADD INDEX review_body_ngram_idx(review_body) USING NGRAM_BF PROPERTIES("gram_size"="10", "bf_size"="10240");
+------------+------------------------------------------+--------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+--------------------+-------+
| B00992CF6W | Minecraft | 4.8235294117647056 | 17 |
| B009UX2YAC | Subway Surfers | 4.7777777777777777 | 9 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 4.875 | 8 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+--------------------+-------+
5 rows in set (0.93 sec)
4.5、自增列
在 Doris 中,自增列(Auto Increment Column)是一種自動生成唯一數字值的功能,常用于為每一行數據生成唯一的標識符,如主鍵。每當插入新記錄時,自增列會自動分配一個遞增的值,避免了手動指定數字的繁瑣操作。使用 Doris 自增列,可以確保數據的唯一性和一致性,簡化數據插入過程,減少人為錯誤,并提高數據管理的效率。這使得自增列成為處理需要唯一標識的場景(如用戶 ID 等)時的理想選擇。
4.5.1、功能
對于具有自增列的表,Doris 處理數據寫入的方式如下:
-
自動填充(列排除): 如果寫入的數據不包括自增列,Doris 會生成并填充該列的唯一值。
-
部分指定(列包含):
- 空值:Doris 會用系統生成的唯一值替換寫入數據中的空值。
- 非空值:用戶提供的值保持不變。用戶提供的非空值可能會破壞自增列的唯一性。
唯一性
Doris 保證自增列中生成的值具有表級唯一性。但是:
- 保證唯一性:這僅適用于系統生成的值。
- 用戶提供的值:Doris 不會驗證或強制執行用戶在自增列中指定的值的唯一性。這可能導致重復條目。
聚集性
Doris 生成的自增值通常是密集的,但有一些考慮:
-
潛在的間隙:由于性能優化,可能會出現間隙。每個后端節點(BE)會預分配一塊唯一值以提高效率,這些塊在節點之間不重疊。
-
非時間順序值:Doris 不保證后續寫入生成的值大于早期寫入的值。自增值不能用于推斷寫入的時間順序。
4.5.2、語法
要使用自增列,需要在建表CREATE-TABLE時為對應的列添加AUTO_INCREMENT屬性。若要手動指定自增列起始值,可以通過建表時AUTO_INCREMENT(start_value)語句指定,如果未指定,則默認起始值為 1。
示例
- 創建一個 Dupliciate 模型表,其中一個 key 列是自增列
CREATE TABLE `demo`.`tbl` (`id` BIGINT NOT NULL AUTO_INCREMENT,`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
- 創建一個 Dupliciate 模型表,其中一個 key 列是自增列,并設置起始值為 100
CREATE TABLE `demo`.`tbl` (`id` BIGINT NOT NULL AUTO_INCREMENT(100),`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
- 創建一個 Dupliciate 模型表,其中一個 value 列是自增列
CREATE TABLE `demo`.`tbl` (`uid` BIGINT NOT NULL,`name` BIGINT NOT NULL,`id` BIGINT NOT NULL AUTO_INCREMENT,`value` BIGINT NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY HASH(`uid`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
- 創建一個 Unique 模型表,其中一個 key 列是自增列
CREATE TABLE `demo`.`tbl` (`id` BIGINT NOT NULL AUTO_INCREMENT,`name` varchar(65533) NOT NULL,`value` int(11) NOT NULL
) ENGINE=OLAP
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
- 創建一個 Unique 模型表,其中一個 value 列是自增列
CREATE TABLE `demo`.`tbl` (`text` varchar(65533) NOT NULL,`id` BIGINT NOT NULL AUTO_INCREMENT,
) ENGINE=OLAP
UNIQUE KEY(`text`)
DISTRIBUTED BY HASH(`text`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
約束和限制
- 僅 Duplicate 模型表和 Unique 模型表可以包含自增列。
- 一張表最多只能包含一個自增列。
- 自增列的類型必須是 BIGINT 類型,且必須為 NOT NULL。
- 自增列手動指定的起始值必須大于等于 0。
4.5.3、使用方式
以下表為例:
CREATE TABLE `demo`.`tbl` (`id` BIGINT NOT NULL AUTO_INCREMENT,`name` varchar(65533) NOT NULL,`value` int(11) NOT NULL
) ENGINE=OLAP
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 3"
);
使用 insert into 語句導入并且不指定自增列id時,id列會被自動填充生成的值。
insert into tbl(name, value) values("Bob", 10), ("Alice", 20), ("Jack", 30);select * from tbl order by id;
+------+-------+-------+
| id | name | value |
+------+-------+-------+
| 1 | Bob | 10 |
| 2 | Alice | 20 |
| 3 | Jack | 30 |
+------+-------+-------+
4.6、冷熱數據分層
4.6.1、冷熱數據分層概述
為了幫助用戶節省存儲成本,Doris 針對冷數據提供了靈活的選擇。
| 冷數據選擇 | 適用條件 | 特性 |
|---|---|---|
| 存算分離 | 用戶具備部署存算分離的條件 | - 數據以單副本完全存儲在對象存儲中 - 通過本地緩存加速熱數據訪問 - 存儲與計算資源獨立擴展,顯著降低存儲成本 |
| 本地分層 | 存算一體模式下,用戶希望進一步優化本地存儲資源 | - 支持將冷數據從 SSD(固態硬盤) 冷卻到 HDD(機械硬盤) - 充分利用本地存儲層級特性,節省高性能存儲成本 |
| 遠程分層 | 存算一體模式下,使用廉價的對象存儲或者 HDFS 進一步降低成本 | - 冷數據以單副本形式保存到對象存儲或者 HDFS 中 - 熱數據繼續使用本地存儲 - 不能對一個表和本地分層混合使用 |
通過上述模式,Doris 能夠靈活適配用戶的部署條件,實現查詢效率與存儲成本的平衡。
4.6.2、SSD 和 HDD 層級存儲
Doris 支持在不同磁盤類型(SSD 和 HDD)之間進行分層存儲,結合動態分區功能,根據冷熱數據的特性將數據從 SSD 動態遷移到 HDD。這種方式既降低了存儲成本,又在熱數據的讀寫上保持了高性能。
4.6.2.1、動態分區與層級存儲
通過配置動態分區參數,用戶可以設置哪些分區存儲在 SSD 上,以及冷卻后自動遷移到 HDD 上。
- 熱分區:最近活躍的分區,優先存儲在 SSD 上,保證高性能。
- 冷分區:較少訪問的分區,會逐步遷移到 HDD,以降低存儲開銷。
4.6.2.2、參數說明
dynamic_partition.hot_partition_num
-
功能:
- 指定最近的多少個分區為熱分區,這些分區存儲在 SSD 上,其余分區存儲在 HDD 上。
-
注意:
- 必須同時設置
dynamic_partition.storage_medium = HDD,否則此參數不會生效。 - 如果存儲路徑下沒有 SSD 設備,則該配置會導致分區創建失敗。
- 必須同時設置
示例說明:
假設當前日期為 2021-05-20,按天分區,動態分區配置如下:
dynamic_partition.hot_partition_num = 2
dynamic_partition.start = -3
dynamic_partition.end = 3
系統會自動創建以下分區,并配置其存儲介質和冷卻時間:
p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
dynamic_partition.storage_medium
-
功能:
- 指定動態分區的最終存儲介質。默認是 HDD,可選擇 SSD。
-
注意:
- 當設置為 SSD 時,hot_partition_num 屬性將不再生效,所有分區將默認為 SSD 存儲介質并且冷卻時間為 9999-12-31 23:59:59。
4.6.2.3、示例
- 創建一個分層存儲表
CREATE TABLE tiered_table (k DATE)PARTITION BY RANGE(k)()DISTRIBUTED BY HASH (k) BUCKETS 5PROPERTIES("dynamic_partition.storage_medium" = "hdd","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.hot_partition_num" = "2","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "5","dynamic_partition.create_history_partition"= "true","dynamic_partition.start" = "-3");
- 檢查分區存儲介質
SHOW PARTITIONS FROM tiered_table;
可以看見 7 個分區,5 個使用 SSD, 其它的 2 個使用 HDD。
p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00
參數詳解:
dynamic_partition.time_unit
指定動態分區的時間粒度。這里設置為 DAY,表示按天來創建和管理分區。可選值包括 DAY、WEEK、MONTH。
dynamic_partition.end
預先創建的未來分區的時間范圍(相對于當前時間)。這里的 3 表示創建從當前時間(不含)開始,到未來第3天(含)的分區。
計算示例:
如果今天是 2025-07-31,動態分區功能會確保以下未來分區存在:
- p20250801(明天,未來第1天)
- p20250802(后天,未來第2天)
- p20250803(大后天,未來第3天)
dynamic_partition.start
動態分區管理的歷史分區的時間范圍(相對于當前時間)。這里的 -3 表示管理從當前時間(含)開始,回溯到3天前(含)的分區。結合 end 定義了動態分區管理的總時間窗口。
計算示例:
如果今天是 2025-07-31,動態分區管理的時間窗口是:
- p20250728(3天前)
- p20250729(2天前)
- p20250730(1天前)
- p20250731(今天)
- p20250801(明天)
- p20250802(后天)
- p20250803(大后天)
總共 7 個分區(3過去 + 1今天 + 3未來)。
注意:start 為負數表示過去,end 為正數表示未來,時間窗口包含 start 和 end 定義的天數。
dynamic_partition.prefix
動態生成的分區名稱的前綴。分區名稱由 prefix + 分區對應日期的字符串組成。
示例:對于日期 2025-07-31,分區名將是 p20250731。
dynamic_partition.buckets
動態創建的分區所使用的分桶數量。此值會覆蓋表級 DISTRIBUTED BY … BUCKETS … 語句中指定的分桶數(在動態分區場景下)。 確保每個新創建的動態分區都使用 5 個 Bucket 進行數據分布。
與建表語句關聯:建表語句中的 DISTRIBUTED BY HASH (k) BUCKETS 5 設置了表級默認分桶數和分桶列。動態分區的 buckets 參數 5 確保每個動態分區繼承此分桶數。如果設置為 10,動態分區會用 10 個 Bucket,而建表語句的 BUCKETS 5 只對非動態分區或初始分區有效。
dynamic_partition.create_history_partition
啟用動態分區功能時,是否自動創建歷史分區。
- true:啟用動態分區時,Doris 會立即根據 start 和 end 的值,創建當前時間窗口 [start, end] 內所有還不存在的分區(包括歷史分區和未來分區)。
- false:只創建未來的分區([當前日期+1, end]),歷史分區需手動創建或通過數據導入觸發創建。
本例設置為 true,結合 start=-3 和 end=3,在啟用動態分區的瞬間,Doris 會自動創建 p20250728、p20250729、p20250730、p20250731、p20250801、p20250802、p20250803 這 7 個分區(如果它們之前不存在)。
dynamic_partition.hot_partition_num
定義熱分區的數量。熱分區是指距離當前時間最近的幾個分區。
計算:熱分區范圍是 [當前日期 - (hot_partition_num - 1), 當前日期]。
本例 hot_partition_num=2,如果今天是 2025-07-31,則熱分區是:
- p20250730(昨天)
- p20250731(今天)
作用:Doris 內部可能對熱分區進行優化,例如存儲策略、查詢優化器等。
限制:hot_partition_num 的值必須小于等于 -dynamic_partition.start(即 start 負數的絕對值)。本例中 -start=3,hot_partition_num=2(2 ≤ 3)合法;若設置為 4(4 > 3)則為非法配置。
dynamic_partition.storage_medium
動態創建的分區使用的初始存儲介質。可選值為 SSD(固態硬盤)或 HDD(機械硬盤)。
作用:結合 hot_partition_num 和 Doris 的存儲策略功能,可后續通過額外配置自動遷移數據(如熱分區到 SSD、冷分區回 HDD)。此參數僅設置分區初始存儲位置。
注意:需 BE 節點的存儲路徑配置同時指定 SSD 和 HDD 才有效。若所有存儲路徑均為 HDD,設置為 SSD 也不會生效。
4.6.3、遠程存儲
遠程存儲支持將冷數據放到外部存儲(例如對象存儲,HDFS)上。
遠程存儲的數據只有一個副本,數據可靠性依賴遠程存儲的數據可靠性,您需要保證遠程存儲有 ec(擦除碼)或者多副本技術確保數據可靠性。
4.6.3.1、使用方法
- 冷數據保存到 S3 兼容存儲
第一步: 創建 S3 Resource。
CREATE RESOURCE "remote_s3"
PROPERTIES
("type" = "s3","s3.endpoint" = "bj.s3.com","s3.region" = "bj","s3.bucket" = "test-bucket","s3.root.path" = "path/to/root","s3.access_key" = "bbb","s3.secret_key" = "aaaa","s3.connection.maximum" = "50","s3.connection.request.timeout" = "3000","s3.connection.timeout" = "1000"
);
創建 S3 RESOURCE 的時候,會進行 S3 遠端的鏈接校驗,以保證 RESOURCE 創建的正確。
第二步: 創建 STORAGE POLICY。
之后創建 STORAGE POLICY,關聯上文創建的 RESOURCE:
CREATE STORAGE POLICY test_policy
PROPERTIES("storage_resource" = "remote_s3","cooldown_ttl" = "1d"
);
第三步: 建表時使用 STORAGE POLICY。
CREATE TABLE IF NOT EXISTS create_table_use_created_policy
(k1 BIGINT,k2 LARGEINT,v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES("enable_unique_key_merge_on_write" = "false","storage_policy" = "test_policy"
);
注意:UNIQUE 表如果設置了 "enable_unique_key_merge_on_write" = "true" 的話,無法使用此功能。
- 冷數據保存到 HDFS(分布式文件系統)
第一步: 創建 HDFS RESOURCE:
CREATE RESOURCE "remote_hdfs" PROPERTIES ("type"="hdfs","fs.defaultFS"="fs_host:default_fs_port","hadoop.username"="hive","hadoop.password"="hive","root_path"="/my/root/path","dfs.nameservices" = "my_ha","dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2","dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port","dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port","dfs.client.failover.proxy.provider.my_ha" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
第二步: 創建 STORAGE POLICY。
CREATE STORAGE POLICY test_policy PROPERTIES ("storage_resource" = "remote_hdfs","cooldown_ttl" = "300"
)
第三步: 使用 STORAGE POLICY 創建表。
CREATE TABLE IF NOT EXISTS create_table_use_created_policy (k1 BIGINT,k2 LARGEINT,v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES(
"enable_unique_key_merge_on_write" = "false",
"storage_policy" = "test_policy"
);
注意:UNIQUE 表如果設置了 "enable_unique_key_merge_on_write" = "true" 的話,無法使用此功能。
- 存量表冷卻到遠程存儲
除了新建表支持設置遠程存儲外,Doris 還支持對一個已存在的表或者 PARTITION,設置遠程存儲。
對一個已存在的表,設置遠程存儲,將創建好的 STORAGE POLICY 與表關聯:
ALTER TABLE create_table_not_have_policy set ("storage_policy" = "test_policy");
對一個已存在的 PARTITION,設置遠程存儲,將創建好的 STORAGE POLICY 與 PARTITON 關聯:
ALTER TABLE create_table_partition MODIFY PARTITION (*) SET("storage_policy"="test_policy");
注意,如果用戶在建表時給整張 Table 和部分 Partition 指定了不同的 Storage Policy,Partition 設置的 Storage policy 會被無視,整張表的所有 Partition 都會使用 table 的 Policy. 如果您需要讓某個 Partition 的 Policy 和別的不同,則可以使用上文中對一個已存在的 Partition,關聯 Storage policy 的方式修改。
-
配置 compaction
-
BE 參數cold_data_compaction_thread_num可以設置執行遠程存儲的 Compaction 的并發,默認是 2。
-
BE 參數cold_data_compaction_interval_sec可以設置執行遠程存儲的 Compaction 的時間間隔,默認是 1800,單位:秒,即半個小時。
-
4.6.3.2、限制
-
使用了遠程存儲的表不支持備份。
-
不支持修改遠程存儲的位置信息,比如 endpoint、bucket、path。
-
Unique 模型表在開啟 Merge-on-Write 特性時,不支持設置遠程存儲。
-
Storage policy 支持創建、修改和刪除,刪除前需要先保證沒有表引用此 Storage policy。
4.6.3.3、冷數據空間
查看
方式一:通過 show proc '/backends’可以查看到每個 BE 上傳到對象的大小,RemoteUsedCapacity 項,此方式略有延遲。
方式二:通過 show tablets from tableName 可以查看到表的每個 tablet 占用的對象大小,RemoteDataSize 項。
垃圾回收
遠程存儲上可能會有如下情況產生垃圾數據:
- 上傳 rowset 失敗但是有部分 segment 上傳成功。
- 上傳的 rowset 沒有在多副本達成一致。
- Compaction 完成后,參與 compaction 的 rowset。
垃圾數據并不會立即清理掉。BE 參數remove_unused_remote_files_interval_sec可以設置遠程存儲的垃圾回收的時間間隔,默認是 21600,單位:秒,即 6 個小時。
4.6.3.4、查詢與性能優化
為了優化查詢的性能和對象存儲資源節省,引入了本地 Cache。在第一次查詢遠程存儲的數據時,Doris 會將遠程存儲的數據加載到 BE 的本地磁盤做緩存,Cache 有以下特性:
-
Cache 實際存儲于 BE 本地磁盤,不占用內存空間。
-
Cache 是通過 LRU 管理的,不支持 TTL。




)





: 帶有循環的Looping Graph(練習解答))







