首先 zset 與我們常規的 redis 操作有所不同, 這里的時間復雜度基本都是 O(log N) 起步的
目錄
1. zcount?
2. zpopmax
1. zcount?
zcount key min max : 這里求的是 key 中下標在 min 和 max 之間的 元素的數量, 這里是比區間
我們要是想排除端點, 就需要加上 ( , 無論是左端點還是右端點都是要加上 (
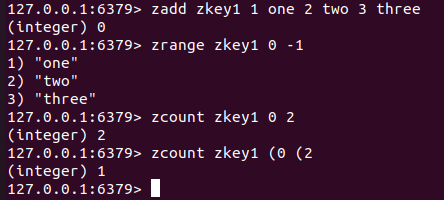
為什么要這樣設計呢??
是因為在開發的時候就已經這樣設定了, 只能去蹲守這樣的規則~~? 后面要是想改過來, 是很難的, 這是因為兼容性的原因, 廣泛使用的軟件, 一旦在新的版本中, 引入和之前不兼容的特性, 成本是非常高的
時間復雜度 : O(log N)
zcount 指定 min 和 max 分數區間的 ~~
先根據 min 找到對應的元素, 在根據 max 找到對應的元素 (log (N))
在上面找到一個的情況下, 如果進行一個遍歷, 是不是就知道這里元素的個數了呢? 如果區間中的元素比較多, 此時要進行遍歷, 復雜度就成了 O(log (N) + M), M市區件中元素的個數, N 使整個有序集合的元素個數 (錯誤的方法)
實際上, zset 內部會記錄每個元素當前的 "排行" / "次序", 查詢到兩個元素, 直接就知道了元素所在的 "次序", 就可以直接把 max 對應的元素次序和 min 對應的元素次序, 減法即可
min 和 max 是可以寫成浮點數(zset分數本身就是浮點數)
在浮點數中,存在兩個特殊的數值:?
? ? ? ? inf : 無窮大
? ? ? ? -inf : 負無窮大 (不是無窮小)
2. zpopmax
zpopmax key count : 對 key 進行尾刪 count 個

如果存在多個元素, 分數相同, 同時為最大值, zpopmax刪的時候, 仍然只刪除其中一個元素 (字典排序)
時間復雜度 : (log (N) * M)?, M : 要刪除的元素個數
既然是尾刪, 為什么我們不把這個最后一個元素的位置特殊記錄下來, 后續山粗不就可以 O(1) 了嗎? 省去了查找的過程.
但是很遺憾, 目前 redis 并沒有這么做, 事實上, redis 的源碼中, 針對有序集合, 確實是記錄了尾部這樣特定的位置~~, 但是在實際刪除的時候, 并沒有用上這個特性, 而是直接調用了一個 "通用的刪除函數" (給定一個 member 的值, 進行查找找到位置之后再刪除~~) (這里應該是可以進行優化的)





)
![[buuctf-misc]喵喵喵](http://pic.xiahunao.cn/[buuctf-misc]喵喵喵)





elasticsearch基礎)





)
DC-DC升壓壓電路原理簡單仿真)