? ? ? ? 要在硬盤上存儲文件,必須先將硬盤格式化為特定類型的文件系統。文件系統的主要功能就是組織和管硬盤中的文件。在Linux系統中,最常見的文件系統是Ext2系列,其早期版本為Ext2,后續又發展出Ext3和Ext4。雖然Ext3和Ext4對Ext2進行了功能增強,但其核心設計保持不變。因此,我們仍以較早期的Ext2作為演示示例。
目錄
一、Ext2文件系統的宏觀認識
1、磁盤(Disk)
2、分區(Partition)
3、EXT2文件系統(File System)
4、塊組(Block Group)
5、inode表(Inode Table)
總結
二、Block Group(塊組)
1、Block Group 的組成
2、Block Group 的作用
(1)提高文件訪問效率
(2)提高可靠性
(3)優化存儲分配
3、Block Group 的布局
4、Block Group 的關鍵機制
(1)Super Block(超級塊)
(2)Group Descriptor Table(GDT,組描述符表)
(3)Block Bitmap(塊位圖)
(4)inode Bitmap(inode 位圖)
(5)inode Table(inode 表)
(6)Data Blocks(數據塊)
5、示例:文件存儲過程
6、總結
三、塊組內部構成
1、超級塊(Super Block)
1. 超級塊的作用
2. 超級塊的位置
3. 超級塊的核心字段
2、GDT(Group Descriptor Table,組描述符表)詳解
1. GDT 的作用
2. GDT 的位置
3. GDT 的核心字段(EXT4 為例)
4. GDT 的工作流程
(1)文件系統掛載時
(2)分配新文件時
(3)刪除文件時
3、塊位圖(Block Bitmap)詳解
1. 塊位圖的作用
2. 塊位圖的位置
3. 塊位圖的結構
4. 塊位圖的工作流程
(1)分配新塊
(2)釋放塊
(3)碎片整理
4、inode位圖(Inode Bitmap)詳解
1. inode 位圖的作用
2. inode 位圖的位置
3. inode 位圖的結構
4. inode 位圖的工作流程
(1)分配新 inode
(2)釋放 inode
(3)inode 分配策略優化
5、i節點表(Inode Table)
1. inode 的作用
2. inode 表的位置
3. inode 的結構(EXT4 為例)
4. inode 的數據塊映射
5. inode 表的工作流程
(1)創建文件
(2)讀取文件
(3)刪除文件
6、數據區(Data Block)
1. 數據塊(Data Block)的基本屬性
2. 數據區的組織結構
(1)按 Block Group 劃分
(2)數據塊類型
3. 數據塊分配與尋址
(1)EXT2/EXT3:傳統塊映射
(2)EXT4:Extent 樹(優化大文件)
4. 目錄數據塊的結構
5. 數據區的管理機制
(1)分配流程
(2)釋放流程
(3)碎片整理
四、inode與數據塊映射(弱化版)
1、實現方式:
2、作用:
3、思考:
4、結論:
5、操作演示:
6、創建新文件主要包含以下4個步驟:
五、目錄與文件名
1、關于第一個問題:為什么使用文件名而不是inode號訪問文件?
2、關于第二個問題:目錄是文件嗎?如何理解?
3、代碼解析:目錄遍歷示例(readdir.c)
1. 頭文件引入
2. 主函數參數檢查
3. 打開目錄
4. 遍歷目錄條目
5. 關閉目錄
關鍵數據結構:struct dirent
代碼功能總結
六、文件訪問機制解析
1、路徑解析機制
2、路徑來源
七、路徑緩存機制
Q1:磁盤中是否存在真實的目錄?
Q2:每次都要從根目錄開始解析路徑?
Q3:目錄概念如何產生?
八、通俗易懂解釋:目錄、dentry 和文件系統的關系
概念:目錄 vs. 目錄項(dentry)
1、文件系統就像一個大樓
2、目錄(文件夾)是什么?
3、dentry(目錄項)是什么?
4、為什么需要 dentry?
5、目錄樹是怎么形成的?
6、掛載(Mount)是什么意思?
目錄 vs 分區
為什么分區可以掛載到目錄上?
示例說明
關鍵行為解析
關鍵點總結
注意事項
總結
簡單說:
九、掛載分區
重點:
1.?分區與超級塊(Superblock)的關聯
2.?inode編號的分區內唯一性
3.?目錄項(dentry)與跨分區查找
4.?ext2的塊組(Block Group)與inode分布
5.?掛載機制的關鍵作用
Linux 分區掛載實踐
1. 創建磁盤鏡像文件
2. 格式化磁盤鏡像
3. 創建掛載點
4. 查看當前分區情況
命令解釋:
各列含義:
關鍵信息解讀:
5. 掛載分區
6. 驗證掛載
7. 查看loop設備
8. 卸載分區
關鍵概念理解
進一步實踐建議
技術說明
2、分區與文件系統掛載
十、問題探討:文件系統操作原理解析
1、創建空文件的過程
2、寫入文件的過程
3、文件數據塊管理說明
4、刪除文件的原理
5、拷貝與刪除速度差異
6、目錄的本質
十一、文件系統總結
??1. 進程相關結構體??
??2. 文件訪問相關結構體??
??3. 路徑與目錄結構體??
??4. 文件系統與inode結構體??
??5. 其他輔助結構體??
??總結關系鏈?(超重點!!!)?
一、Ext2文件系統的宏觀認識
????????準備工作已經完成,現在讓我們來了解文件系統。要在硬盤上存儲文件,首先需要將其格式化為特定類型的文件系統。文件系統的主要作用就是組織和管硬盤中的文件數據。在Linux系統中,ext2系列文件系統最為常見,其發展歷程包括最初的ext2,以及后續改進的ext3和ext4版本。雖然ext3/ext4在ext2基礎上有所增強,但核心架構保持不變。因此,我們仍將以ext2作為演示范例。
????????ext2文件系統將整個分區劃分為若干個大小相同的塊組(Block Group),如下圖所示。通過管理一個分區就能實現對所有分區的管理,進而管理整個磁盤上的文件。
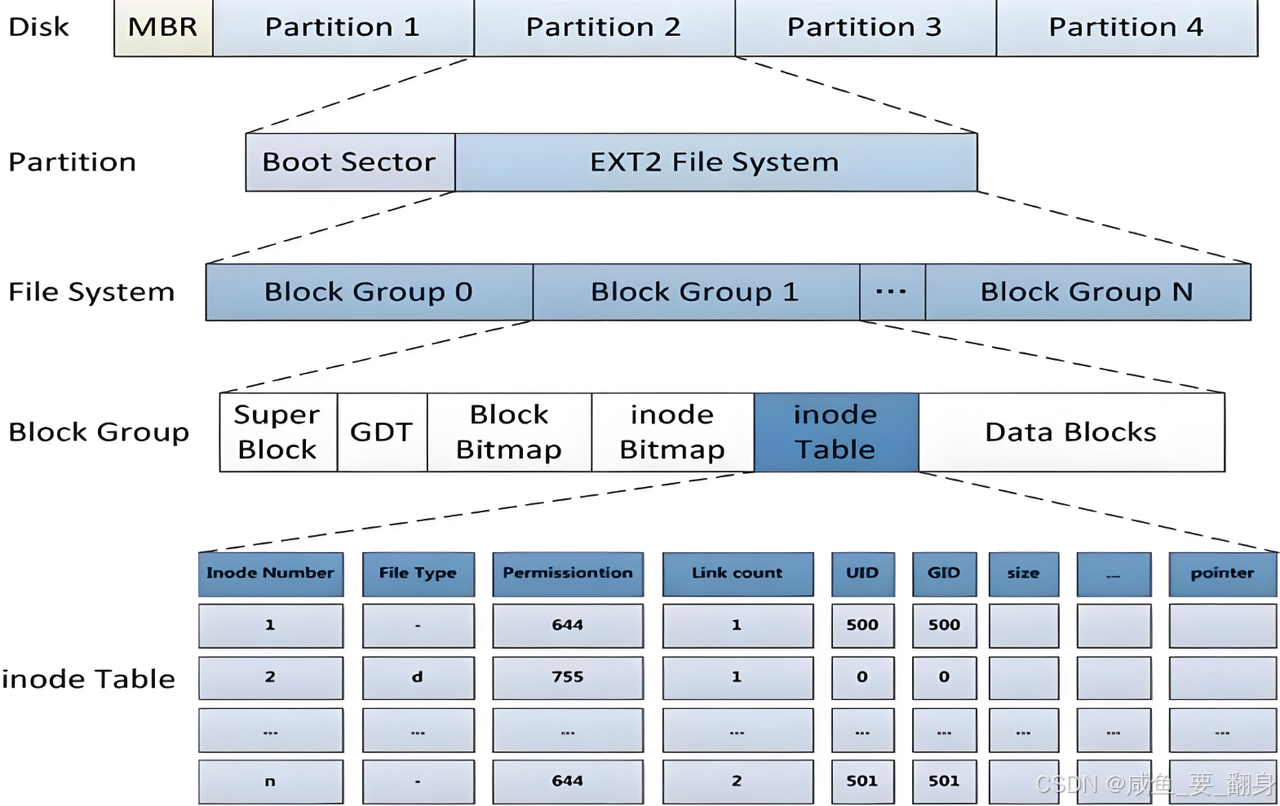
????????上圖中啟動塊(Boot Block/Sector)的大小是確定的,為1KB,由PC標準規定,用來存儲磁盤分區信息和啟動信息,任何文件系統都不能修改啟動塊。啟動塊之后才是ext2文件系統的開始。
????????該圖以層級結構展示了磁盤、分區、文件系統(EXT2)及其核心組件的組成關系。以下是詳細解析:
1、磁盤(Disk)
-
MBR(主引導記錄)
位于磁盤首部,存儲引導程序和分區表信息,負責系統啟動時加載操作系統。 -
分區(Partition 1~4)
磁盤可劃分為最多4個主分區(受MBR限制),每個分區獨立管理數據。
2、分區(Partition)
-
引導扇區(Boot Sector)
分區的起始部分,包含引導代碼(如為啟動分區)和文件系統元數據。 -
EXT2文件系統
一種經典的Linux文件系統,采用固定大小的塊組(Block Group)管理數據。
3、EXT2文件系統(File System)
-
塊組(Block Group 0~N)
文件系統被劃分為多個塊組,每個塊組包含元數據和實際數據塊,提高訪問效率。
4、塊組(Block Group)
-
超級塊(Super Block)
記錄文件系統全局信息(如大小、塊數量、空閑塊等)。 -
組描述符表(GDT)
描述每個塊組的屬性(如塊位圖、inode位圖位置)。 -
塊位圖(Block Bitmap)
標記數據塊的使用情況(1位對應1塊)。 -
inode位圖(inode Bitmap)
標記inode的使用情況。 -
inode表(inode Table)
存儲所有inode條目,每個inode描述一個文件/目錄的元數據。 -
數據塊(Data Blocks)
實際存儲文件內容或目錄結構。
5、inode表(Inode Table)
每個inode條目包含以下字段(示例表格):
| 字段 | 說明 |
|---|---|
| Inode編號 | 唯一標識符(如1, 2, ..., n)。 |
| 文件類型 | -表示普通文件,d表示目錄。 |
| 權限 | 八進制表示(如644:用戶讀寫,組和其他只讀)。 |
| 鏈接數 | 硬鏈接數量(如目錄默認為1,文件增加硬鏈接時計數+1)。 |
| UID/GID | 用戶ID和組ID(如500為普通用戶,0為root)。 |
| 大小 | 文件大小(字節)。 |
| 指針 | 指向數據塊的直接/間接指針(圖中未展開)。 |
示例數據解析:
-
Inode 1:普通文件,權限644,屬主UID 500,無硬鏈接。
-
Inode 2:目錄,權限755,屬主為root(UID 0)。
總結
????????該圖系統性地描述了從物理磁盤到文件內容的層級關系,重點突出了EXT2文件系統的核心結構(塊組、inode、位圖等),適用于理解文件系統如何組織和管理數據。
二、Block Group(塊組)
????????Block Group(塊組)是?EXT2/EXT3/EXT4?文件系統的核心管理單元,它將整個文件系統劃分為多個邏輯塊組,每個塊組獨立管理自己的元數據和數據塊,以提高文件系統的性能和可靠性。下面詳細解析其結構和作用。
1、Block Group 的組成
每個 Block Group 包含以下關鍵部分:
| 組成部分 | 作用 |
|---|---|
| Super Block(超級塊) | 存儲文件系統的全局信息(如總塊數、inode 數、塊大小等)。部分塊組會備份超級塊以提高容錯。 |
| Group Descriptor Table(GDT,組描述符表) | 記錄該塊組的元數據位置(如塊位圖、inode 位圖、inode 表等)。 |
| Block Bitmap(塊位圖) | 用二進制位標記該塊組內哪些數據塊已被占用(1)或空閑(0)。 |
| inode Bitmap(inode 位圖) | 用二進制位標記該塊組內哪些 inode 已被占用(1)或空閑(0)。 |
| inode Table(inode 表) | 存儲該塊組的所有 inode 條目,每個 inode 描述一個文件或目錄的元數據。 |
| Data Blocks(數據塊) | 實際存儲文件內容或目錄結構的數據塊。 |
2、Block Group 的作用
(1)提高文件訪問效率
-
文件系統被劃分為多個 Block Group,每個組管理自己的 inode 和數據塊,減少尋址時間。
-
文件的數據塊盡量存儲在同一 Block Group 內,減少磁盤尋道時間。
(2)提高可靠性
-
超級塊(Super Block)?在多個 Block Group 中備份,防止單點故障導致文件系統損壞。
-
塊位圖(Block Bitmap)和 inode 位圖(inode Bitmap)?單獨管理,避免全局位圖損壞影響整個文件系統。
(3)優化存儲分配
-
新創建的文件優先在當前 Block Group 分配 inode 和數據塊,減少碎片化。
-
如果當前 Block Group 空間不足,文件系統會從其他 Block Group 分配空間。
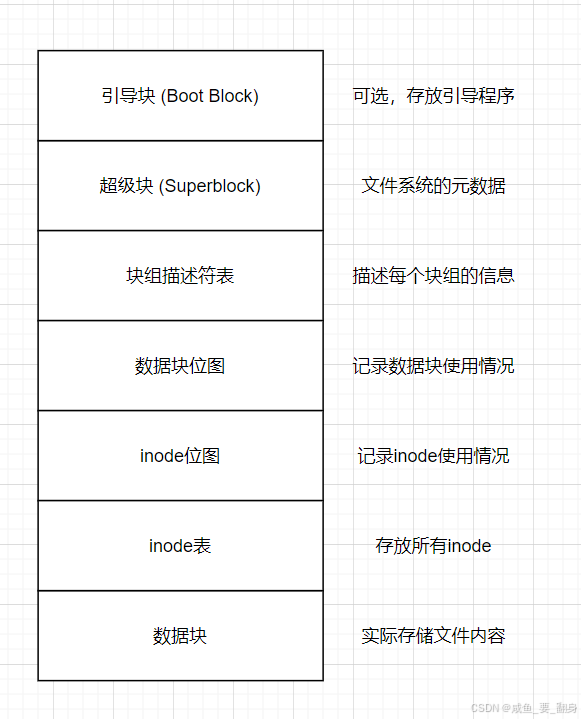
3、Block Group 的布局
EXT2/EXT3/EXT4 文件系統的典型布局如下:

4、Block Group 的關鍵機制
(1)Super Block(超級塊)
-
存儲文件系統的全局信息,如:
-
塊大小(如 1KB、4KB)
-
總塊數、空閑塊數
-
inode 總數、空閑 inode 數
-
文件系統狀態(是否已掛載、是否需要檢查)
-
-
備份機制:部分 Block Group 會存儲超級塊的副本,防止主超級塊損壞。
(2)Group Descriptor Table(GDT,組描述符表)
-
記錄每個 Block Group 的元數據位置,如:
-
塊位圖的起始塊號
-
inode 位圖的起始塊號
-
inode 表的起始塊號
-
空閑塊數和空閑 inode 數
-
-
備份機制:GDT 通常也會在多個 Block Group 中備份。
(3)Block Bitmap(塊位圖)
-
每個 Block Group 有一個塊位圖,每個 bit 代表一個數據塊:
-
1?= 塊已被占用 -
0?= 塊空閑
-
-
文件系統分配新塊時,會掃描塊位圖尋找空閑塊。
(4)inode Bitmap(inode 位圖)
-
每個 Block Group 有一個 inode 位圖,每個 bit 代表一個 inode:
-
1?= inode 已被占用 -
0?= inode 空閑
-
-
創建新文件時,文件系統會查找空閑 inode。
(5)inode Table(inode 表)
-
存儲該 Block Group 的所有 inode 條目,每個 inode 包含:
-
文件類型(普通文件、目錄、符號鏈接等)
-
權限(rwx)
-
所有者(UID/GID)
-
大小、時間戳
-
數據塊指針(直接、間接、雙重間接等)
-
(6)Data Blocks(數據塊)
-
存儲文件內容或目錄結構:
-
普通文件:存儲實際數據。
-
目錄:存儲目錄項(文件名 + inode 號)。
-
5、示例:文件存儲過程
假設我們要存儲一個文件?/home/test.txt,EXT2 文件系統會執行以下步驟:
-
查找空閑 inode:
-
從某個 Block Group 的 inode 位圖中找到空閑 inode。
-
在 inode 表中分配 inode,設置文件元數據。
-
-
分配數據塊:
-
從同一 Block Group 的塊位圖中找到空閑數據塊。
-
將文件內容寫入數據塊,并在 inode 中記錄塊指針。
-
-
更新目錄:在?
/home?目錄的數據塊中添加條目?test.txt -> inode號。
6、總結
-
Block Group 是 EXT2/EXT3/EXT4 的核心管理單元,每個組獨立管理自己的元數據和數據塊。
-
關鍵組件:
-
Super Block(超級塊)→ 全局信息
-
GDT(組描述符表)→ 塊組元數據位置
-
Block Bitmap(塊位圖)→ 數據塊分配狀態
-
inode Bitmap(inode 位圖)→ inode 分配狀態
-
inode Table(inode 表)→ 文件元數據
-
Data Blocks(數據塊)→ 實際文件內容
-
-
優勢:
-
提高文件訪問效率(局部性原理)。
-
增強可靠性(超級塊和 GDT 備份)。
-
優化存儲分配(減少碎片化)。
-
通過 Block Group 的劃分,EXT 系列文件系統能夠高效、可靠地管理大規模存儲設備。
三、塊組內部構成
1、超級塊(Super Block)
????????超級塊(Super Block)?是?EXT2/EXT3/EXT4?文件系統的核心元數據結構,存儲了整個文件系統的全局信息,類似于文件系統的“大腦”。它記錄了文件系統的關鍵參數,確保系統能夠正確識別、掛載和管理存儲設備。
1. 超級塊的作用
????????文件系統通過超級塊(Super Block)來存儲其自身的結構信息,這些信息描述了整個分區的文件系統狀態。主要記錄內容包括:block 和 inode 的總數、剩余可用數量、單個 block 和 inode 的大小、最近掛載時間、最后數據寫入時間、最近磁盤檢查時間等關鍵參數。超級塊一旦損壞,將導致整個文件系統結構失效。
超級塊的主要功能包括:
-
描述文件系統的整體屬性(如大小、塊數量、inode 數量等)。
-
維護文件系統的狀態(如是否已掛載、是否需要檢查)。
-
提供恢復機制(超級塊在多個 Block Group 中備份,防止損壞導致數據丟失)。
-
控制文件系統的行為(如塊大小、保留塊數量等)。
2. 超級塊的位置
????????為確保文件系統在部分磁盤扇區出現物理故障時仍能正常工作,超級塊會在多個塊組(Block Group)中進行備份。每個塊組的起始位置都存有一份超級塊副本(首個塊組必須包含,后續塊組可選)。這些備份的超級塊區域保持數據一致性,以保障文件系統在異常情況下的可訪問性。
-
主超級塊:通常位于?Block Group 0?的開頭(緊隨引導扇區之后)。
-
備份超級塊:EXT 文件系統會在多個 Block Group(如 1、3、5、7…)中存儲超級塊的副本,防止主超級塊損壞導致文件系統無法掛載。
📌 注意:
如果主超級塊損壞,可以使用備份超級塊恢復文件系統(如?
e2fsck -b 32768 /dev/sdX,其中?32768?是備份超級塊的塊號)。備份超級塊的位置取決于文件系統大小和塊大小。
3. 超級塊的核心字段
查看超級塊(Super Block)對應的Linux源碼,如下:
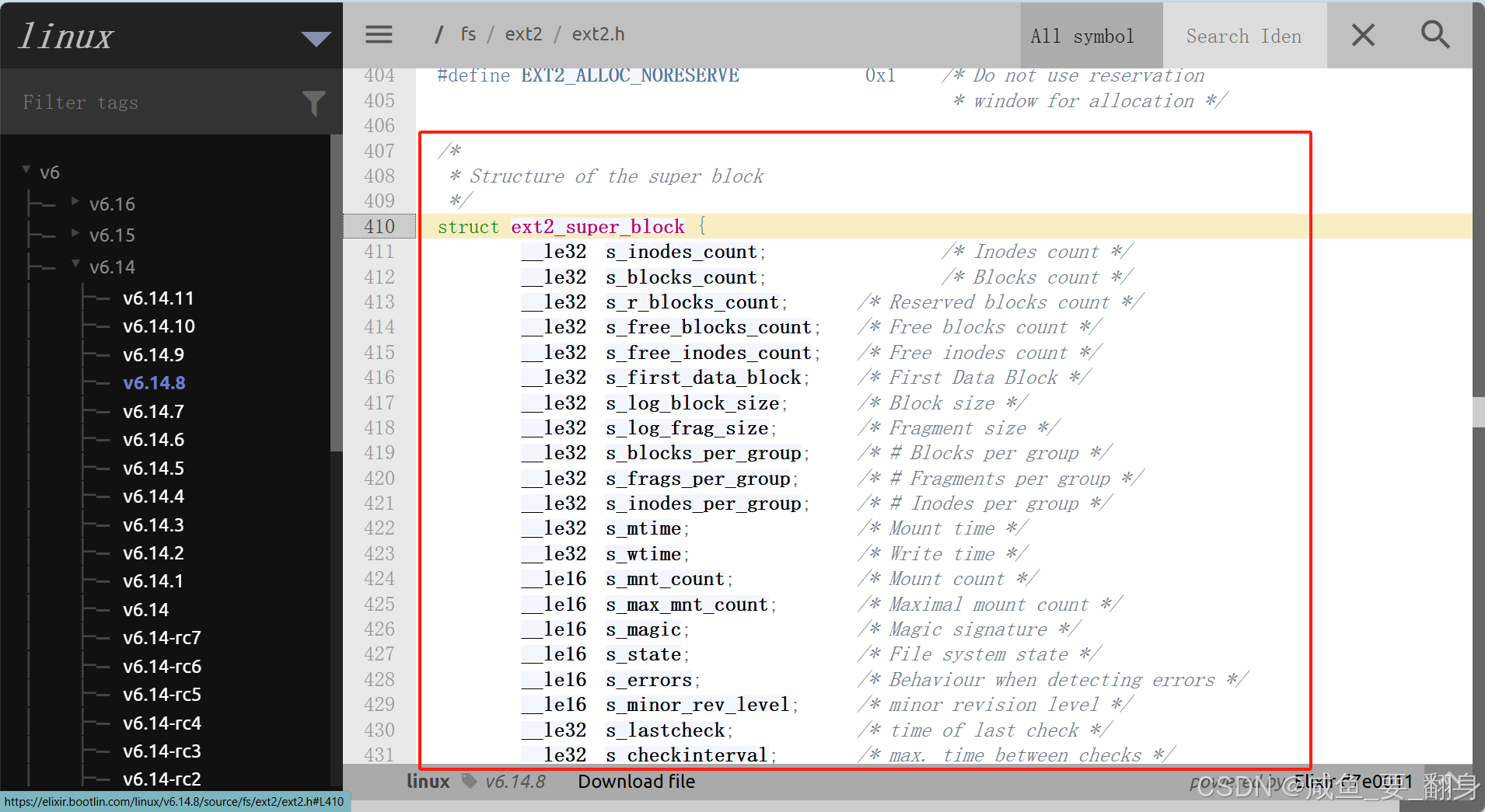
/* Super block structure */
struct ext2_super_block {__le32 s_inodes_count; /* Total inode count */__le32 s_blocks_count; /* Total block count */__le32 s_r_blocks_count; /* Reserved block count */__le32 s_free_blocks_count; /* Free block count */__le32 s_free_inodes_count; /* Free inode count */__le32 s_first_data_block; /* First data block */__le32 s_log_block_size; /* Block size (logarithmic) */__le32 s_log_frag_size; /* Fragment size (logarithmic) */__le32 s_blocks_per_group; /* Blocks per group */__le32 s_frags_per_group; /* Fragments per group */__le32 s_inodes_per_group; /* Inodes per group */__le32 s_mtime; /* Last mount time */__le32 s_wtime; /* Last write time */__le16 s_mnt_count; /* Mount count */__le16 s_max_mnt_count; /* Maximum allowed mounts */__le16 s_magic; /* Magic number */__le16 s_state; /* Filesystem state */__le16 s_errors; /* Error handling behavior */__le16 s_minor_rev_level; /* Minor revision level */__le32 s_lastcheck; /* Last filesystem check time */__le32 s_checkinterval; /* Maximum time between checks */__le32 s_creator_os; /* Creator OS */__le32 s_rev_level; /* Revision level */__le16 s_def_resuid; /* Default UID for reserved blocks */__le16 s_def_resgid; /* Default GID for reserved blocks *//* EXT2_DYNAMIC_REV specific fields */__le32 s_first_ino; /* First non-reserved inode */__le16 s_inode_size; /* Inode structure size */__le16 s_block_group_nr; /* Block group of this superblock */__le32 s_feature_compat; /* Compatible feature set */__le32 s_feature_incompat; /* Incompatible feature set */__le32 s_feature_ro_compat; /* Read-only compatible feature set */__u8 s_uuid[16]; /* Volume UUID */char s_volume_name[16]; /* Volume name */char s_last_mounted[64]; /* Last mount directory */__le32 s_algorithm_usage_bitmap; /* Compression bitmap *//* Performance hints */__u8 s_prealloc_blocks; /* Blocks to preallocate */__u8 s_prealloc_dir_blocks; /* Directory blocks to preallocate */__u16 s_padding1;/* Journaling support */__u8 s_journal_uuid[16]; /* Journal superblock UUID */__u32 s_journal_inum; /* Journal file inode number */__u32 s_journal_dev; /* Journal file device number */__u32 s_last_orphan; /* Orphan inode list start */__u32 s_hash_seed[4]; /* HTREE hash seed */__u8 s_def_hash_version; /* Default hash algorithm */__u8 s_reserved_char_pad;__u16 s_reserved_word_pad;__le32 s_default_mount_opts;__le32 s_first_meta_bg; /* First meta block group */__u32 s_reserved[190]; /* Block padding */
};
可知,超級塊存儲了約?100+ 個字段,以下是關鍵字段及其作用:
| 字段 | 說明 |
|---|---|
s_magic | 文件系統魔數(0xEF53),用于識別 EXT2/EXT3/EXT4。 |
s_inodes_count | 文件系統總的 inode 數量。 |
s_blocks_count | 文件系統總的塊數量。 |
s_free_blocks_count | 當前空閑塊數量。 |
s_free_inodes_count | 當前空閑 inode 數量。 |
s_first_data_block | 第一個數據塊的編號(通常是 1,因為 0 是引導扇區)。 |
s_log_block_size | 塊大小的對數(如?0=1KB,1=2KB,2=4KB)。 |
s_blocks_per_group | 每個 Block Group 包含的塊數量。 |
s_inodes_per_group | 每個 Block Group 包含的 inode 數量。 |
s_mtime | 最后一次掛載時間。 |
s_wtime | 最后一次寫入時間。 |
s_mnt_count | 掛載次數(超過?s_max_mnt_count?時會觸發?fsck?檢查)。 |
s_max_mnt_count | 最大掛載次數(默認 20-30 次,超過后會強制檢查文件系統)。 |
s_state | 文件系統狀態(0=干凈,1=有錯誤)。 |
s_errors | 錯誤處理方式(1=繼續,2=只讀,3=panic)。 |
s_lastcheck | 最后一次文件系統檢查的時間戳。 |
s_feature_compat | 兼容性特性(如?has_journal?表示 EXT3/EXT4 日志支持)。 |
s_feature_incompat | 不兼容特性(如?extent?表示 EXT4 使用 extent 而非塊映射)。 |
s_feature_ro_compat | 只讀兼容特性(如?sparse_super?表示超級塊備份較少)。 |
s_uuid | 文件系統的 UUID(用于唯一標識)。 |
s_volume_name | 卷標名稱(如?rootfs?或?data)。 |
2、GDT(Group Descriptor Table,組描述符表)詳解
????????GDT 是?EXT2/EXT3/EXT4?文件系統的核心元數據結構之一,用于管理?Block Group(塊組)?的元數據信息。它記錄了每個 Block Group 的關鍵屬性(如塊位圖、inode 位圖的位置),使文件系統能夠快速定位和管理數據。
1. GDT 的作用
????????GDT(Group Descriptor Table)是塊組描述符表,用于記錄塊組的屬性信息。整個分區被劃分為多個塊組,每個塊組都對應一個描述符。這些描述符存儲了塊組的關鍵信息,包括:inode Table的起始位置、Data Blocks的起始地址、剩余空閑inode數量以及可用數據塊數量等。值得注意的是,每個塊組的開頭都保存著一份完整的塊組描述符副本。
-
存儲每個 Block Group 的元數據位置
例如:塊位圖(Block Bitmap)、inode 位圖(inode Bitmap)、inode 表(inode Table)的塊號。 -
維護 Block Group 的狀態信息
例如:空閑塊數、空閑 inode 數,幫助文件系統快速分配資源。 -
支持文件系統擴展和恢復
備份 GDT 可防止單點故障導致文件系統損壞。
2. GDT 的位置
-
主 GDT:位于?Block Group 0,緊隨超級塊(Super Block)之后。
-
備份 GDT:在部分 Block Group(如 1、3、5…)中備份,防止主 GDT 損壞。
📌 注意:
GDT 的大小取決于 Block Group 數量,每個組描述符占?32 字節(EXT2)或 64 字節(EXT4)。
如果文件系統很大(Block Group 很多),GDT 可能占用多個塊。
3. GDT 的核心字段(EXT4 為例)
查看GDT(Group Descriptor Table,組描述符表)對應的Ext2的Linux源碼,如下:
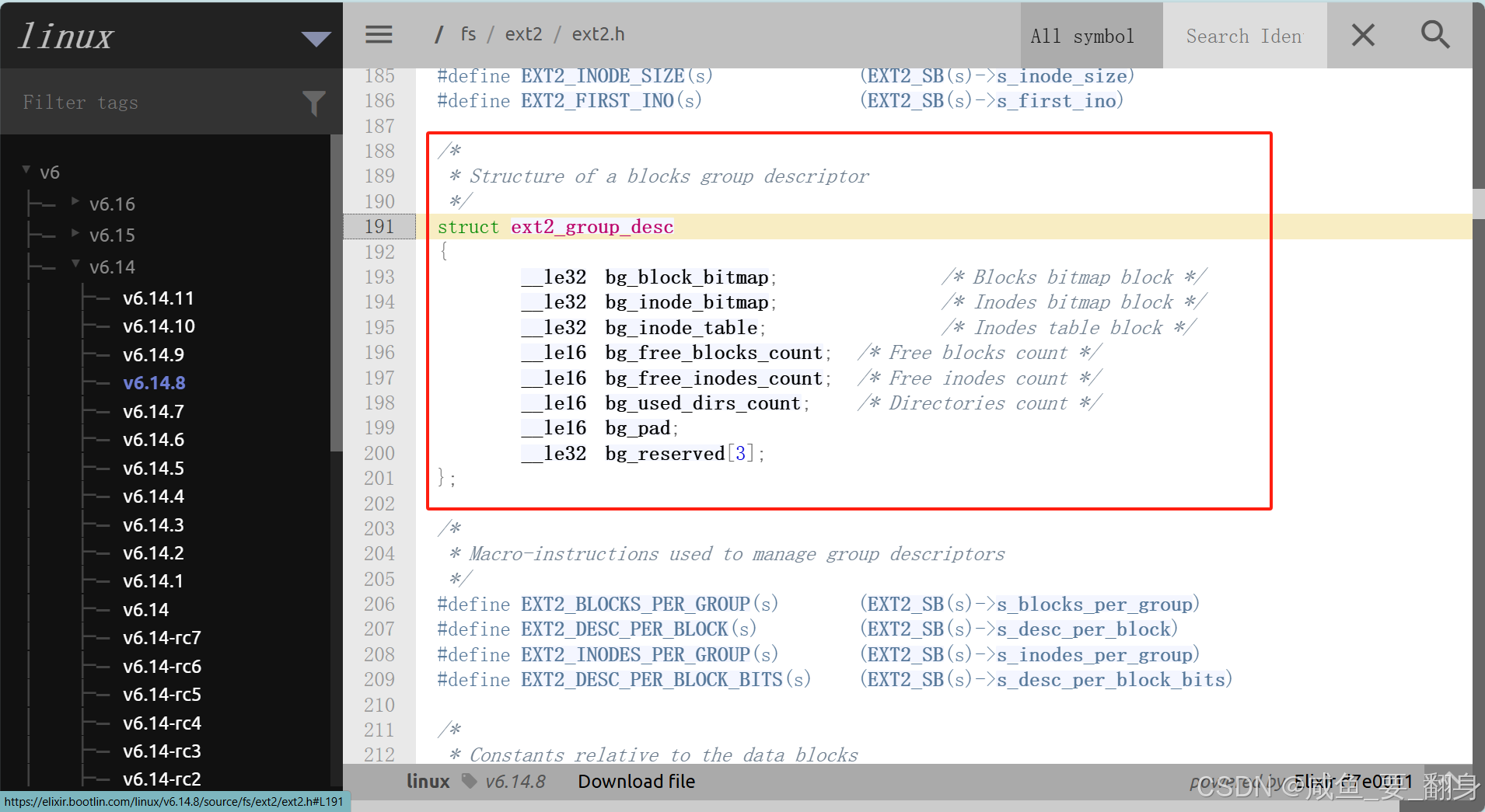
/** Block group descriptor structure*/
struct ext2_group_desc {__le32 bg_block_bitmap; /* Pointer to block bitmap */__le32 bg_inode_bitmap; /* Pointer to inode bitmap */__le32 bg_inode_table; /* Pointer to inode table */__le16 bg_free_blocks_count; /* Number of free blocks */__le16 bg_free_inodes_count; /* Number of free inodes */__le16 bg_used_dirs_count; /* Number of directories */__le16 bg_pad; /* Padding */__le32 bg_reserved[3]; /* Reserved space */
};
每個組描述符包含以下關鍵字段(以?ext4_group_desc?結構體為例):
| 字段 | 說明 |
|---|---|
bg_block_bitmap_lo | 塊位圖的塊號(低 32 位),指向該 Block Group 的塊位圖。 |
bg_inode_bitmap_lo | inode 位圖的塊號(低 32 位),指向該 Block Group 的 inode 位圖。 |
bg_inode_table_lo | inode 表的起始塊號(低 32 位),指向該 Block Group 的 inode 表。 |
bg_free_blocks_count_lo | 空閑塊數量(低 16 位),記錄該 Block Group 剩余可用的數據塊。 |
bg_free_inodes_count_lo | 空閑 inode 數量(低 16 位),記錄該 Block Group 剩余可用的 inode。 |
bg_used_dirs_count_lo | 目錄數量(低 16 位),記錄該 Block Group 中的目錄數(用于優化分配)。 |
bg_flags | 塊組標志(如?inode 表未初始化、塊位圖需檢查)。 |
bg_exclude_bitmap_hi | 排除位圖(高 32 位,EXT4 特有),用于快照和稀疏文件。 |
bg_block_bitmap_hi | 塊位圖塊號(高 32 位),支持大文件系統(>2TB)。 |
bg_inode_bitmap_hi | inode 位圖塊號(高 32 位),支持大文件系統。 |
bg_inode_table_hi | inode 表塊號(高 32 位),支持大文件系統。 |
📌 EXT2 vs EXT4:
EXT2 的組描述符為?32 字節,僅支持 32 位塊號(最大文件系統 16TB)。
EXT4 擴展為?64 字節,支持 48 位塊號(最大文件系統 1EB)。
4. GDT 的工作流程
(1)文件系統掛載時
-
內核讀取?超級塊(Super Block),確定文件系統參數(如塊大小、Block Group 數量)。
-
加載?GDT,建立每個 Block Group 的元數據映射關系。
(2)分配新文件時
-
文件系統根據策略(如?
Orlov 分配算法)選擇一個 Block Group。 -
查詢該 Block Group 的組描述符,獲取:
-
bg_free_blocks_count?→ 是否有空閑塊? -
bg_free_inodes_count?→ 是否有空閑 inode? -
bg_inode_bitmap?→ 定位 inode 位圖,分配空閑 inode。 -
bg_block_bitmap?→ 定位塊位圖,分配空閑數據塊。
-
(3)刪除文件時
-
釋放 inode(更新?
bg_inode_bitmap?和?bg_free_inodes_count)。 -
釋放數據塊(更新?
bg_block_bitmap?和?bg_free_blocks_count)。
3、塊位圖(Block Bitmap)詳解
????????塊位圖(Block Bitmap)是?EXT2/EXT3/EXT4?文件系統中用于管理數據塊分配狀態的核心數據結構,它記錄了當前 Block Group 中哪些數據塊已被占用,哪些仍然空閑。每個 Block Group 都有自己的塊位圖,確保文件系統能高效分配和回收存儲空間。
1. 塊位圖的作用
-
跟蹤數據塊的使用狀態
每個 bit 代表一個數據塊:-
1?= 塊已被占用(已存儲文件數據) -
0?= 塊空閑(可分配)
-
-
優化存儲分配
文件系統通過掃描塊位圖快速找到連續的空閑塊,減少碎片化。 -
支持快速刪除文件
刪除文件時,只需將對應塊在位圖中標記為?0,無需立即擦除數據。
2. 塊位圖的位置
-
每個?Block Group?包含一個塊位圖,其位置由?GDT(組描述符表)?中的?
bg_block_bitmap?字段指定。 -
塊位圖通常占用?1個數據塊(如 4KB 塊大小可管理?
4KB × 8 = 32K?個塊)。
📌 示例:
若 Block Group 包含?
32768?個塊,塊大小為?4KB,則塊位圖正好占用?1個塊(32768 bits = 4096 bytes)。若塊數更多,位圖可能跨多個塊(但 EXT 文件系統會限制 Block Group 大小以避免此情況)。
3. 塊位圖的結構
塊位圖是一個簡單的?二進制位數組,按以下規則映射:
-
位索引:從?
0?開始,對應 Block Group 內的邏輯塊號。-
例如,位?
0?→ 塊?0(通常為超級塊或保留塊,不分配) -
位?
1?→ 塊?1(第一個可分配塊)
-
-
字節序:按小端(Little-Endian)存儲,即位圖的第一個字節的最低有效位(LSB)代表塊?
0。
示例(假設 8 塊對應 1 字節):
| 字節內容(十六進制) | 二進制表示 | 塊狀態(0-7) |
|---|---|---|
0xF0 | 11110000 | 塊 0-3:占用,塊 4-7:空閑 |
4. 塊位圖的工作流程
(1)分配新塊
-
文件系統根據策略(如優先分配同一 Block Group)選擇目標塊組。
-
讀取該 Block Group 的塊位圖,掃描連續的?
0?位。 -
找到空閑塊后:
-
將對應位設為?
1。 -
更新 GDT 中的?
bg_free_blocks_count(空閑塊數減 1)。 -
將塊號寫入文件的 inode 或 extent 樹。
-
(2)釋放塊
-
刪除文件時,文件系統獲取其占用的所有塊號。
-
根據塊號找到對應的 Block Group 和位圖位置。
-
將位圖中的對應位設為?
0,并增加?bg_free_blocks_count。
(3)碎片整理
-
若文件系統碎片化嚴重,可通過?
e4defrag?工具重新分配塊,優化位圖中的連續空閑區域。?
4、inode位圖(Inode Bitmap)詳解
????????inode 位圖是?EXT2/EXT3/EXT4?文件系統中用于管理 inode 分配狀態的關鍵數據結構。它通過二進制位標記每個 inode 是否被占用,確保文件系統能快速分配和回收 inode,從而高效管理文件和目錄的元數據。
1. inode 位圖的作用
-
跟蹤 inode 的使用狀態
每個 bit 代表一個 inode:-
1?= inode 已被占用(對應文件/目錄已存在) -
0?= inode 空閑(可分配給新文件/目錄)
-
-
優化 inode 分配
文件系統通過掃描 inode 位圖快速找到空閑 inode,減少搜索時間。 -
支持快速刪除文件
刪除文件時,只需將對應 inode 在位圖中標記為?0,無需立即清除 inode 表項。
2. inode 位圖的位置
-
每個?Block Group?包含一個 inode 位圖,其位置由?GDT(組描述符表)?中的?
bg_inode_bitmap?字段指定。 -
inode 位圖通常占用?1個數據塊(如 4KB 塊大小可管理?
4KB × 8 = 32K?個 inode)。
📌 示例:
若 Block Group 包含?
8192?個 inode,塊大小為?4KB,則 inode 位圖僅需?1KB(8192 bits = 1024 bytes),但仍占用整個塊(4KB)。文件系統會限制每個 Block Group 的 inode 數量,確保位圖不跨塊。
3. inode 位圖的結構
inode 位圖是一個?二進制位數組,按以下規則映射:
-
位索引:從?
0?開始,對應 Block Group 內的?inode 號。-
例如,位?
0?→ inode?1(inode 號從 1 開始計數) -
位?
1?→ inode?2
-
-
字節序:按小端(Little-Endian)存儲,即位圖的第一個字節的最低有效位(LSB)代表 inode?
1。
示例(假設 8 inode 對應 1 字節):
| 字節內容(十六進制) | 二進制表示 | inode 狀態(1-8) |
|---|---|---|
0x1F | 00011111 | inode 1-5:占用,inode 6-8:空閑 |
📌 注意:
inode 位圖不直接映射到全局 inode 號,而是?Block Group 內的局部 inode 號。
全局 inode 號需通過?
(Block Group ID × inodes_per_group) + 局部 inode 號?計算。
4. inode 位圖的工作流程
(1)分配新 inode
-
文件系統根據策略(如?
Orlov 分配算法)選擇目標 Block Group:-
新目錄優先分配到高目錄數的 Block Group。
-
普通文件優先分配到空閑 inode 較多的 Block Group。
-
-
讀取目標 Block Group 的 inode 位圖,掃描第一個?
0?位。 -
找到空閑 inode 后:
-
將對應位設為?
1。 -
更新 GDT 中的?
bg_free_inodes_count(空閑 inode 數減 1)。 -
初始化 inode 表中的對應條目(設置文件類型、權限等)。
-
(2)釋放 inode
-
刪除文件時,文件系統獲取其 inode 號。
-
根據 inode 號定位 Block Group 和位圖位置:
-
Block Group ID = (inode_num - 1) / inodes_per_group -
局部 inode 號 = (inode_num - 1) % inodes_per_group
-
-
將位圖中的對應位設為?
0,并增加?bg_free_inodes_count。
(3)inode 分配策略優化
-
EXT4 的延遲分配:
文件創建時暫不分配 inode,直到數據寫入時才確定位置,減少碎片。 -
預分配機制:
為連續寫入的文件預留多個 inode,提升性能。
5、i節點表(Inode Table)
????????i節點表(Inode Table)是?EXT2/EXT3/EXT4?文件系統的核心元數據結構,用于存儲文件和目錄的所有元數據信息(如權限、大小、數據塊位置等)。每個文件或目錄對應一個唯一的?inode,而 inode 表則是這些 inode 的集合,是文件系統組織數據的基石。
1. inode 的作用
-
存儲文件/目錄的元數據
包括文件類型、權限、大小、時間戳、所有者(UID/GID)、數據塊指針等。 -
唯一標識文件
每個 inode 有一個唯一的編號(inode number),而非通過文件名直接訪問文件。 -
支持硬鏈接
多個文件名可指向同一個 inode,通過?link count?字段維護引用計數。 - 特性:
- inode編號以分區為單位統一分配
- 不支持跨分區使用
2. inode 表的位置
-
每個?Block Group?有自己的 inode 表,其位置由?GDT(組描述符表)?的?
bg_inode_table?字段指定。 -
inode 表通常占用?多個連續數據塊,具體大小取決于 Block Group 的 inode 數量(由?
s_inodes_per_group?定義)。
📌 示例:
若 Block Group 包含?
8192?個 inode,每個 inode 大小為?256?字節(EXT4 默認),則 inode 表占用?8192 × 256 / 4096 = 512?個塊(假設塊大小為 4KB)。inode 表在格式化文件系統時固定分配,不可動態擴展。
3. inode 的結構(EXT4 為例)
查看i節點表(Inode Table)對應的Ext2的Linux源碼,如下:
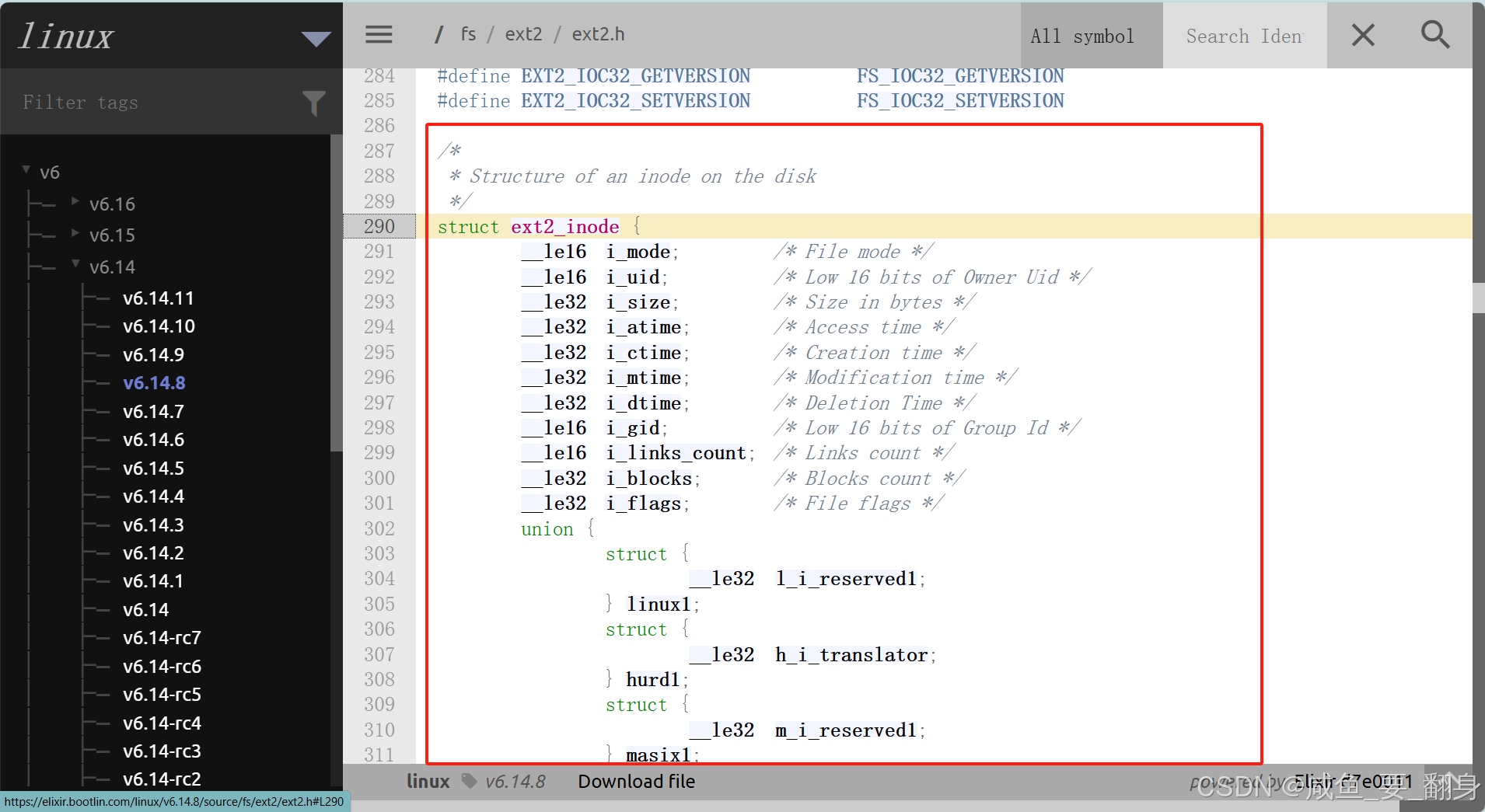
/** Structure of an inode on the disk*/
struct ext2_inode {__le16 i_mode; /* File mode */__le16 i_uid; /* Low 16 bits of Owner Uid */__le32 i_size; /* Size in bytes */__le32 i_atime; /* Access time */__le32 i_ctime; /* Creation time */__le32 i_mtime; /* Modification time */__le32 i_dtime; /* Deletion Time */__le16 i_gid; /* Low 16 bits of Group Id */__le16 i_links_count; /* Links count */__le32 i_blocks; /* Blocks count */__le32 i_flags; /* File flags */union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1; /* OS dependent 1 */__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */__le32 i_generation; /* File version (for NFS) */__le32 i_file_acl; /* File ACL */__le32 i_dir_acl; /* Directory ACL */__le32 i_faddr; /* Fragment address */union {struct {__u8 l_i_frag; /* Fragment number */__u8 l_i_fsize; /* Fragment size */__u16 i_pad1;__le16 l_i_uid_high; /* these 2 fields */__le16 l_i_gid_high; /* were reserved2[0] */__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag; /* Fragment number */__u8 h_i_fsize; /* Fragment size */__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag; /* Fragment number */__u8 m_i_fsize; /* Fragment size */__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2; /* OS dependent 2 */
};每個 inode 條目包含以下字段(以?ext4_inode?結構體為例):
| 字段 | 說明 |
|---|---|
i_mode | 文件類型和權限(如?0x81A4?表示普通文件,權限?644)。 |
i_uid?/?i_gid | 所有者用戶 ID 和組 ID。 |
i_size | 文件大小(字節)。對于目錄,表示目錄條目總大小。 |
i_atime?/?i_mtime?/?i_ctime | 最后訪問時間、最后修改時間、inode 最后變更時間(時間戳)。 |
i_links_count | 硬鏈接計數。歸零時文件被刪除。 |
i_blocks | 文件占用的 512 字節塊數(用于統計,非實際塊數)。 |
i_block[15] | 數據塊指針數組,支持直接、間接、雙重間接、三重間接塊映射(見下文)。 |
i_flags | 擴展屬性(如?immutable、append-only)。 |
i_generation | inode 版本號(用于 NFS 防止重用沖突)。 |
4. inode 的數據塊映射
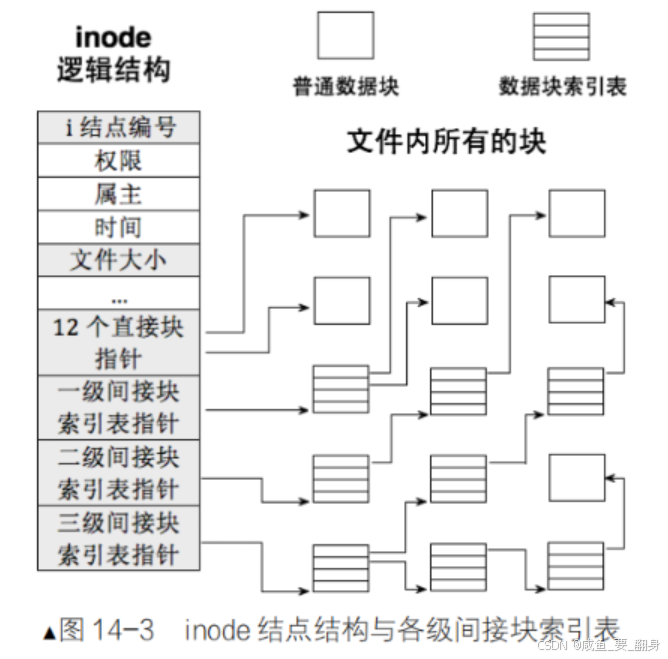
inode 通過?i_block[15]?數組管理文件的數據塊,支持以下映射方式(以 4KB 塊大小為例):
-
直接指針(0-11)
i_block[0]?~?i_block[11]?直接指向?12 個數據塊(最大?12 × 4KB = 48KB?文件)。 -
一級間接指針(12)
i_block[12]?指向一個?間接塊(存儲?1024?個塊號,支持?1024 × 4KB = 4MB)。 -
二級間接指針(13)
i_block[13]?指向一個?雙重間接塊(支持?1024 × 1024 × 4KB = 4GB)。 -
三級間接指針(14)
i_block[14]?指向一個?三重間接塊(支持?10243 × 4KB = 4TB)。
📌 EXT4 的優化:
默認使用?extent 樹(取代塊映射),提升大文件性能。
若文件碎片化嚴重,會回退到傳統塊映射。
5. inode 表的工作流程
(1)創建文件
-
從 inode 位圖中分配一個空閑 inode。
-
在 inode 表中初始化該 inode:
-
設置?
i_mode(文件類型/權限)、i_uid/i_gid(所有者)。 -
將?
i_links_count?設為?1。
-
-
將文件名和 inode 號寫入父目錄的數據塊。
(2)讀取文件
-
通過文件名在目錄中找到 inode 號。
-
從 inode 表讀取 inode,獲取?
i_block[]?或 extent 樹定位數據塊。 -
按需加載數據塊內容。
(3)刪除文件
-
將 inode 位圖中的對應位標記為?
0。 -
減少?
i_links_count,若歸零則:-
釋放數據塊(更新塊位圖)。
-
清除 inode 表條目(部分字段可保留供審計)。
-
6、數據區(Data Block)
- 功能:存儲文件內容的基本單元,由多個數據塊(Block)組成
- 存儲規則:
- 普通文件:文件數據直接存儲在數據塊中
- 目錄:
- 特性:
- 數據塊編號按分區劃分
- 不支持跨分區使用
????????數據區(Data Block)是?EXT2/EXT3/EXT4?文件系統中實際存儲文件內容的區域,由多個固定大小的數據塊(Block)組成。它是文件系統的底層存儲單元,直接承載用戶數據(如文本、圖片、數據庫等),并通過 inode 的指針結構進行管理。
1. 數據塊(Data Block)的基本屬性
| 屬性 | 說明 |
|---|---|
| 塊大小 | 格式化時確定(通常為?1KB、2KB?或?4KB),影響文件系統最大容量和性能。 |
| 塊編號 | 全局唯一編號,從?0?開始(塊?0?通常為引導扇區,不用于數據存儲)。 |
| 分配策略 | 優先從同一 Block Group 分配連續塊,減少碎片。 |
| 用途 | 存儲: - 普通文件內容 - 目錄條目(文件名 + inode 號) - 符號鏈接目標(短鏈接直接存 inode)。 |
📌 塊大小與文件系統限制:
塊大小 最大文件大小 最大文件系統大小 1KB 16GB 2TB 4KB 2TB(EXT4:16TB) 1EB(EXT4)
2. 數據區的組織結構
(1)按 Block Group 劃分
每個 Block Group 包含獨立的數據塊集合,由以下元數據管理:
-
塊位圖(Block Bitmap):標記塊是否空閑。
-
inode 的?
i_block[]?或 extent 樹:指向文件占用的數據塊。
(2)數據塊類型
| 類型 | 說明 |
|---|---|
| 常規數據塊 | 存儲文件的實際內容。 |
| 目錄塊 | 存儲目錄條目(struct ext4_dir_entry),包含文件名和 inode 號。 |
| 間接塊 | 用于擴展大文件的塊映射(存儲其他塊的指針,非直接數據)。 |
| 內聯數據 | (EXT4 特性)小文件內容直接存儲在 inode 中,無需額外數據塊。 |
3. 數據塊分配與尋址
(1)EXT2/EXT3:傳統塊映射
通過 inode 的?i_block[15]?數組實現多級索引:
-
直接塊(0-11):直接指向文件的前 12 個數據塊(最大?
48KB)。 -
間接塊(12):指向一個塊,該塊存儲?
1024?個塊指針(支持?4MB)。 -
雙重間接塊(13):支持?
4GB?文件。 -
三重間接塊(14):支持?
4TB?文件。
示例(4KB 塊大小):
i_block[0] → 數據塊 1000 i_block[12] → 塊 2000(存儲指針:2001→數據塊 3000, 2002→數據塊 3001, ...)
(2)EXT4:Extent 樹(優化大文件)
-
Extent?是一個連續塊范圍的描述(如“塊 1000-1500”),減少指針開銷。
-
inode 的?
i_block[]?存儲一棵?Extent 樹,包含:-
葉子節點:直接指向數據塊范圍。
-
非葉子節點:指向其他 Extent 節點。
-
優勢:
-
減少碎片化,提升大文件讀寫性能。
-
支持更大的文件(理論最大?
16TB)。
4. 目錄數據塊的結構
- 存儲該目錄下所有文件名和目錄名
- 通過ls -i命令顯示的其他信息保存在對應文件的inode中

目錄是一種特殊文件,其數據塊存儲?ext4_dir_entry?結構體:
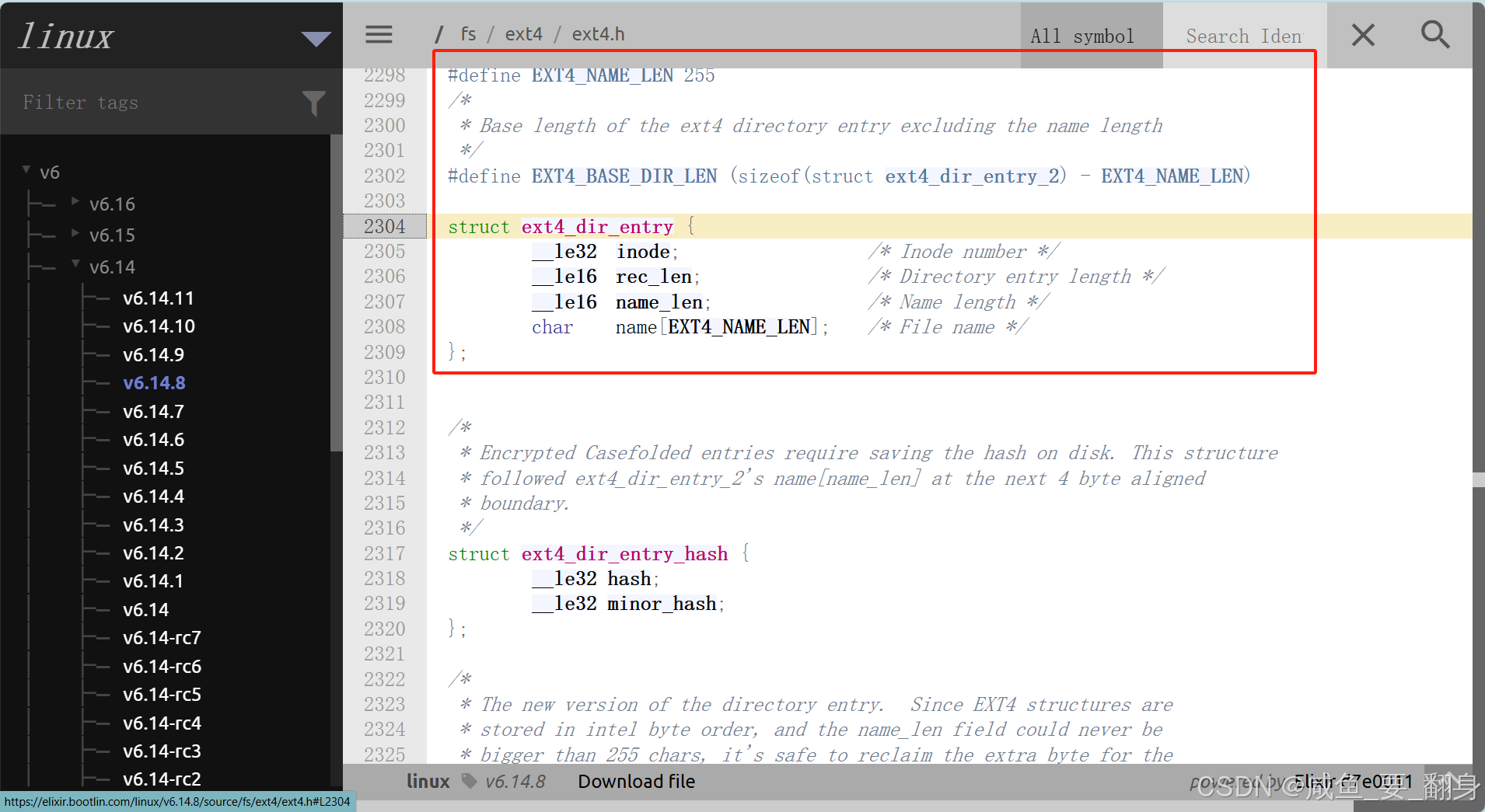
| 字段 | 說明 |
|---|---|
inode | 目錄項的 inode 號。 |
rec_len | 目錄項總長度(用于對齊和刪除填充)。 |
name_len | 文件名長度(最大?255?字節)。 |
file_type | 文件類型(普通、目錄、符號鏈接等)。 |
name | 文件名(變長,不以?\0?結尾)。 |
示例:
| inode: 12345 | rec_len: 12 | name_len: 5 | file_type: regular | name: "test" | | inode: 67890 | rec_len: 16 | name_len: 3 | file_type: dir | name: "bin" |
5. 數據區的管理機制
(1)分配流程
-
文件系統根據策略(如?
Orlov 分配器)選擇目標 Block Group。 -
查詢塊位圖,找到連續的空閑塊。
-
更新 inode 的?
i_block[]?或 Extent 樹,建立映射。
(2)釋放流程
-
從 inode 或 Extent 樹獲取所有數據塊號。
-
在塊位圖中標記這些塊為空閑。
-
更新 GDT 的?
bg_free_blocks_count。
(3)碎片整理
-
使用?
e4defrag?工具合并分散的塊,提升連續性。
四、inode與數據塊映射(弱化版)
1、實現方式:
- inode內部包含
__le32 i_block[EXT2_N_BLOCKS]數組(EXT2_N_BLOCKS=15) - 該數組用于建立inode與數據塊之間的映射關系
2、作用:
- 通過這種機制可以完整定位文件的內容和屬性信息
3、思考:
在已知inode號的情況下,如何在指定分區中對文件進行增刪查改操作?
4、結論:
- 分區格式化操作實質上是將分區劃分為若干組,并在每個組中寫入SB、GDT、Block Bitmap、Inode Bitmap等管理信息,這些信息統稱為文件系統
- 通過inode號可以快速定位到指定分區中的特定分組,進而確定具體inode位置
- 獲取inode后即可訪問文件的全部屬性和內容
5、操作演示:
通過touch命令創建新文件并查看其inode號:
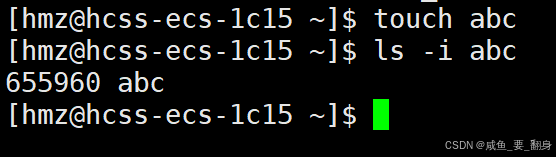
為便于說明,我們將示意圖簡化為:
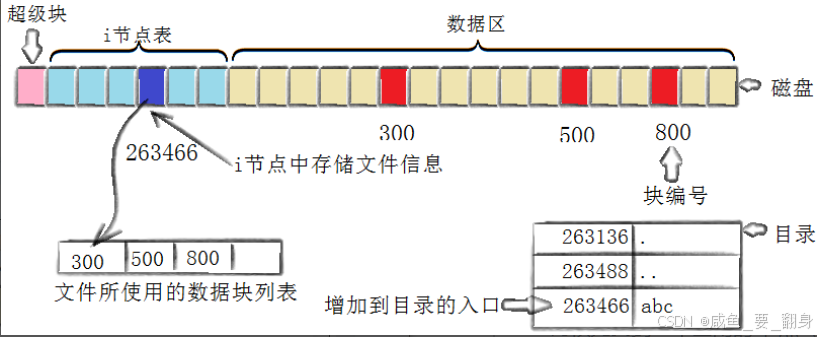
6、創建新文件主要包含以下4個步驟:
-
存儲屬性
內核首先找到一個空閑的i節點(例如263466),并將文件信息記錄在其中。 -
存儲數據
文件數據需要存儲在三個磁盤塊中。內核找到空閑塊300、500和800后,將內核緩沖區的數據依次復制到這些塊中:第一塊到300,第二塊到500,第三塊到800。 -
記錄分配情況
內核在inode的磁盤分布區記錄文件塊的存儲順序:300,500,800。 -
添加文件名到目錄
對于新文件名"abc",內核在當前目錄中添加一個條目(263466,abc)。通過文件名與inode的對應關系,將文件名與文件內容及屬性關聯起來。
五、目錄與文件名
1、關于第一個問題:為什么使用文件名而不是inode號訪問文件?
-
用戶友好性:文件名是人類可讀的、有意義的標識符,而inode號是系統內部使用的數字標識,對用戶不友好。
-
抽象層:文件名提供了對存儲系統的抽象,用戶不需要了解文件系統的底層實現細節。
-
靈活性:多個文件名可以指向同一個inode(硬鏈接),使用文件名可以保持這種靈活性。
-
可移植性:不同文件系統可能有不同的inode實現方式,文件名提供了統一的訪問接口。
2、關于第二個問題:目錄是文件嗎?如何理解?
-
目錄本質上也是文件,但磁盤上并沒有單獨的"目錄"概念,只有文件屬性+文件內容的結構。
-
目錄確實是文件的一種特殊類型:
-
它遵循文件的基本結構(有inode、數據塊等)
-
但它的內容是特殊組織的,存儲文件名到inode號的映射表
-
-
目錄文件的特殊性:
-
內容結構:包含文件名和對應inode號的條目
-
權限位:通常有執行權限(x),表示可進入目錄
-
系統對目錄文件有特殊處理(不能直接寫入,必須通過特定系統調用)
-
-
目錄的組織方式:
-
每個目錄至少包含兩個條目:"."(當前目錄)和".."(父目錄)
-
通過這種層次結構實現文件系統的樹狀組織
-
-
為什么磁盤上沒有單獨的"目錄"概念:
-
文件系統將所有內容統一視為文件(包括目錄、設備等)
-
通過文件類型字段(在inode中)區分普通文件、目錄、符號鏈接等
-
這種統一設計簡化了文件系統的實現
-
這種設計體現了Unix/Linux系統"一切皆文件"的哲學,通過統一的接口處理不同類型的對象。
// readdir.c 目錄遍歷示例代碼
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>int main(int argc, char *argv[]) {if (argc != 2) {fprintf(stderr, "Usage: %s <directory>\n", argv[0]);exit(EXIT_FAILURE);}DIR *dir = opendir(argv[1]);if (!dir) {perror("opendir");exit(EXIT_FAILURE);}struct dirent *entry;while ((entry = readdir(dir)) != NULL) {// 跳過當前目錄和上級目錄if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {continue;}printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);}closedir(dir);return 0;
}
3、代碼解析:目錄遍歷示例(readdir.c)
????????這段代碼演示了如何使用 POSIX 標準庫函數遍歷目錄內容,并輸出文件名及其對應的 inode 編號。以下是逐部分的詳細解析:
1. 頭文件引入
#include <stdio.h> // 標準輸入輸出(如 fprintf, printf)
#include <stdlib.h> // 標準庫函數(如 exit)
#include <string.h> // 字符串處理(如 strcmp)
#include <dirent.h> // 目錄操作(如 DIR, struct dirent, opendir, readdir)
#include <sys/types.h> // 系統類型定義(如 ino_t)
#include <unistd.h> // POSIX API(如 getcwd)-
關鍵頭文件:
dirent.h?提供了目錄操作所需的類型和函數。
2. 主函數參數檢查
if (argc != 2) {fprintf(stderr, "Usage: %s <directory>\n", argv[0]);exit(EXIT_FAILURE);
}-
作用:檢查用戶是否輸入了目錄路徑參數。
-
錯誤處理:若參數不足,打印用法說明并退出(
EXIT_FAILURE?表示非正常退出)。
3. 打開目錄
DIR *dir = opendir(argv[1]);
if (!dir) {perror("opendir");exit(EXIT_FAILURE);
}-
opendir:打開指定目錄(參數?argv[1]),返回?DIR*?指針。 -
錯誤處理:若目錄打開失敗(如路徑不存在),
perror?輸出錯誤原因,程序退出。
4. 遍歷目錄條目
struct dirent *entry;
while ((entry = (readdir(dir)) != NULL)) {// 跳過 "." 和 ".."if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {continue;}printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);
}-
readdir:逐項讀取目錄內容,返回?struct dirent*,包含文件名和 inode 號。-
entry->d_name:當前條目名稱(字符串)。 -
entry->d_ino:當前條目的 inode 編號(ino_t?類型,轉換為?unsigned long?打印)。
-
-
跳過特殊條目:忽略當前目錄(
.)和父目錄(..),避免冗余輸出。
5. 關閉目錄
closedir(dir);
return 0;-
closedir:釋放目錄流資源,防止內存泄漏。 -
返回值:
0?表示程序正常退出。
關鍵數據結構:struct dirent
在 Linux 中,struct dirent?的典型定義如下(實際實現可能因系統略有差異):
struct dirent {ino_t d_ino; // inode 編號off_t d_off; // 目錄偏移量unsigned short d_reclen; // 條目長度unsigned char d_type; // 文件類型(DT_REG=普通文件,DT_DIR=目錄等)char d_name[256]; // 文件名(以 '\0' 結尾)
};代碼功能總結
-
輸入驗證:確保用戶提供目錄路徑。
-
目錄操作:通過?
opendir/readdir/closedir?遍歷目錄。 -
過濾輸出:跳過?
.?和?..,僅顯示有效條目。 -
信息輸出:打印文件名和 inode 號。
執行示例:
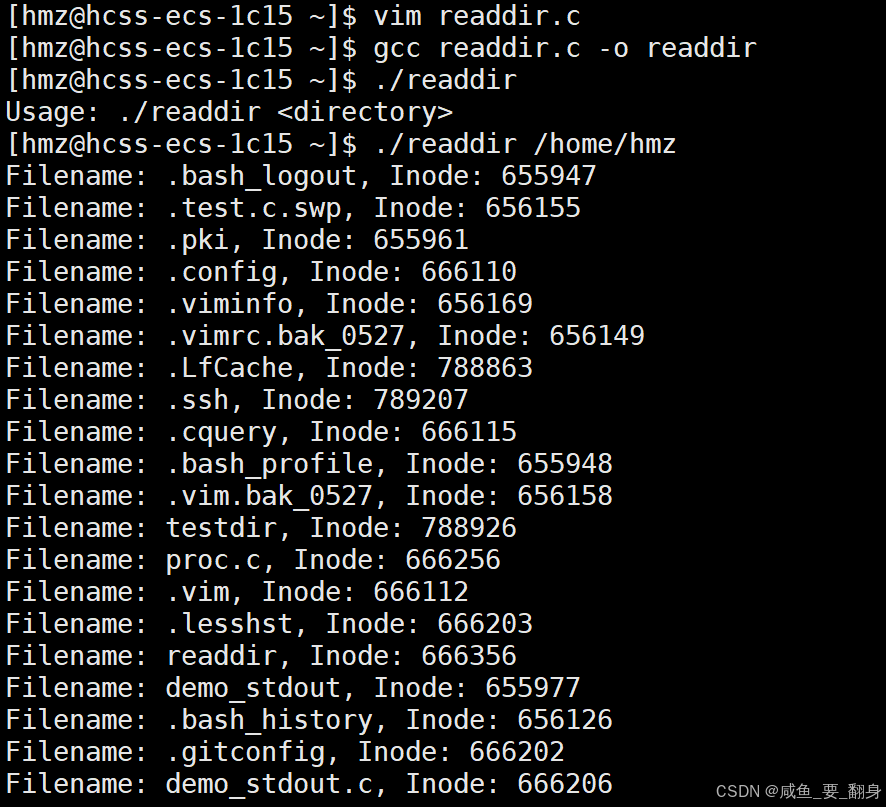
驗證輸出:
ls -ali /home/hmz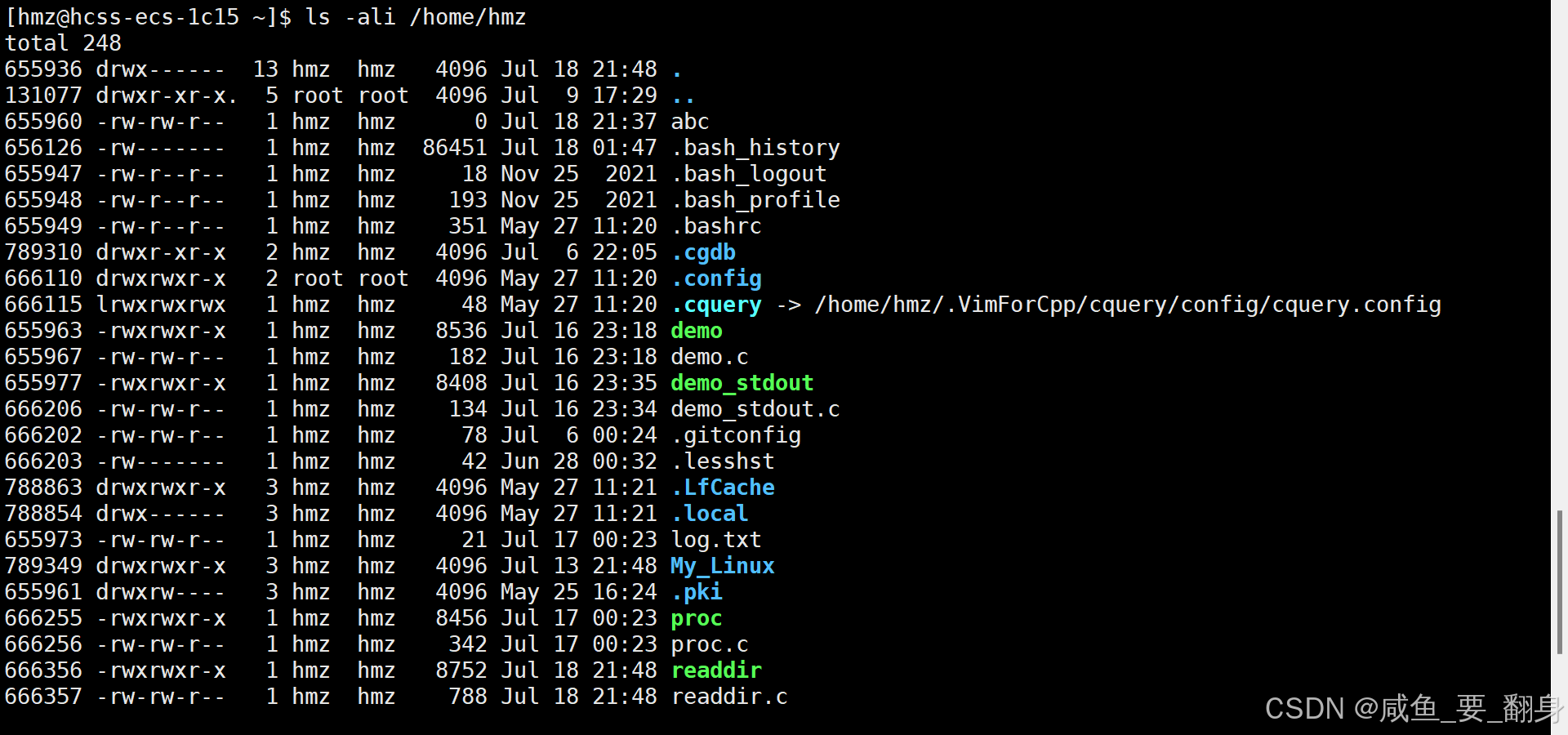
六、文件訪問機制解析
????????要訪問文件,必須首先打開當前工作目錄,根據文件名獲取對應的inode號,然后才能進行文件訪問。這意味著訪問文件必須知曉當前工作目錄,本質上就是能夠打開并查看當前工作目錄文件的內容。
示例:
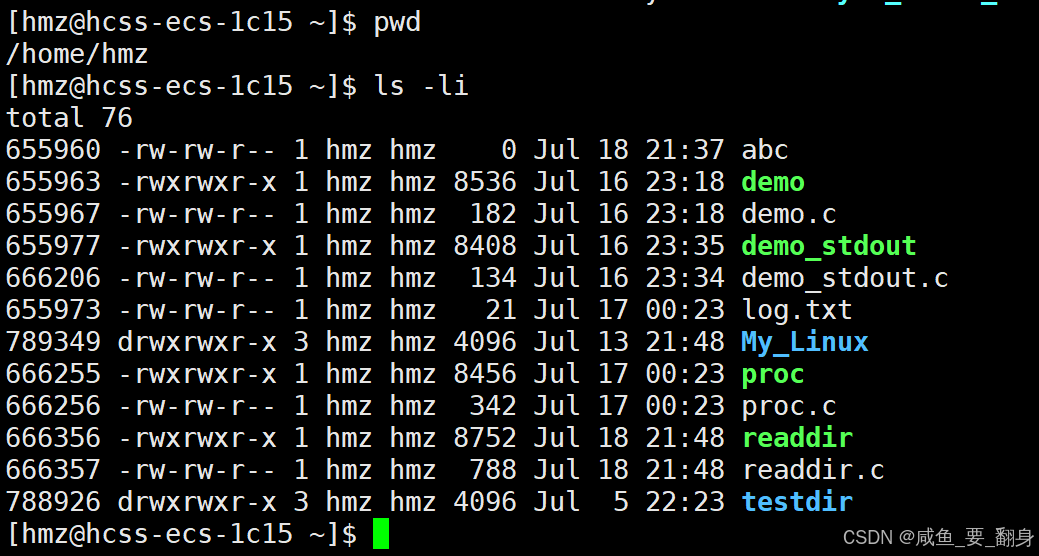
????????比如要訪問demo.c文件,就必須先打開demo所在的目錄(當前工作目錄),才能獲取demo.c對應的inode進而訪問文件。
1、路徑解析機制
核心問題: 訪問當前工作目錄時,我們同樣只知道其文件名。要訪問它,也需要知道其inode號,這似乎陷入循環。
解析過程:
- 需要逐級打開上級目錄
- 這個過程最終會遞歸到根目錄"/"
- 實際訪問路徑(如
/home/whb/code/test/test/test.c)總是從根目錄開始,逐級打開每個子目錄,直到目標文件。這就是Linux的路徑解析過程。
關鍵結論:
- 文件訪問必須通過"目錄+文件名"組成的路徑
- 根目錄具有固定的文件名和inode號,系統啟動時即已知
2、路徑來源
- 文件訪問由進程發起,進程提供當前工作目錄(CWD)
- 用戶通過open等操作提供路徑
- 系統與用戶共同構建完整的Linux路徑結構:
- 系統提供根目錄和默認目錄
- 用戶創建個人目錄和文件
七、路徑緩存機制
Q1:磁盤中是否存在真實的目錄?
不存在,只有文件(包含文件屬性和內容)
Q2:每次都要從根目錄開始解析路徑?
原則上需要,但實際會緩存歷史路徑結構提高效率
Q3:目錄概念如何產生?
????????由操作系統在內存中維護,通過struct dentry內核結構體實現樹狀路徑結構:OS在進行路徑解析的時候,會把我們歷史訪問的所有的目錄(路徑)形成一顆多叉樹,進行保存!!!這便是Linux系統的樹狀目錄結構!!
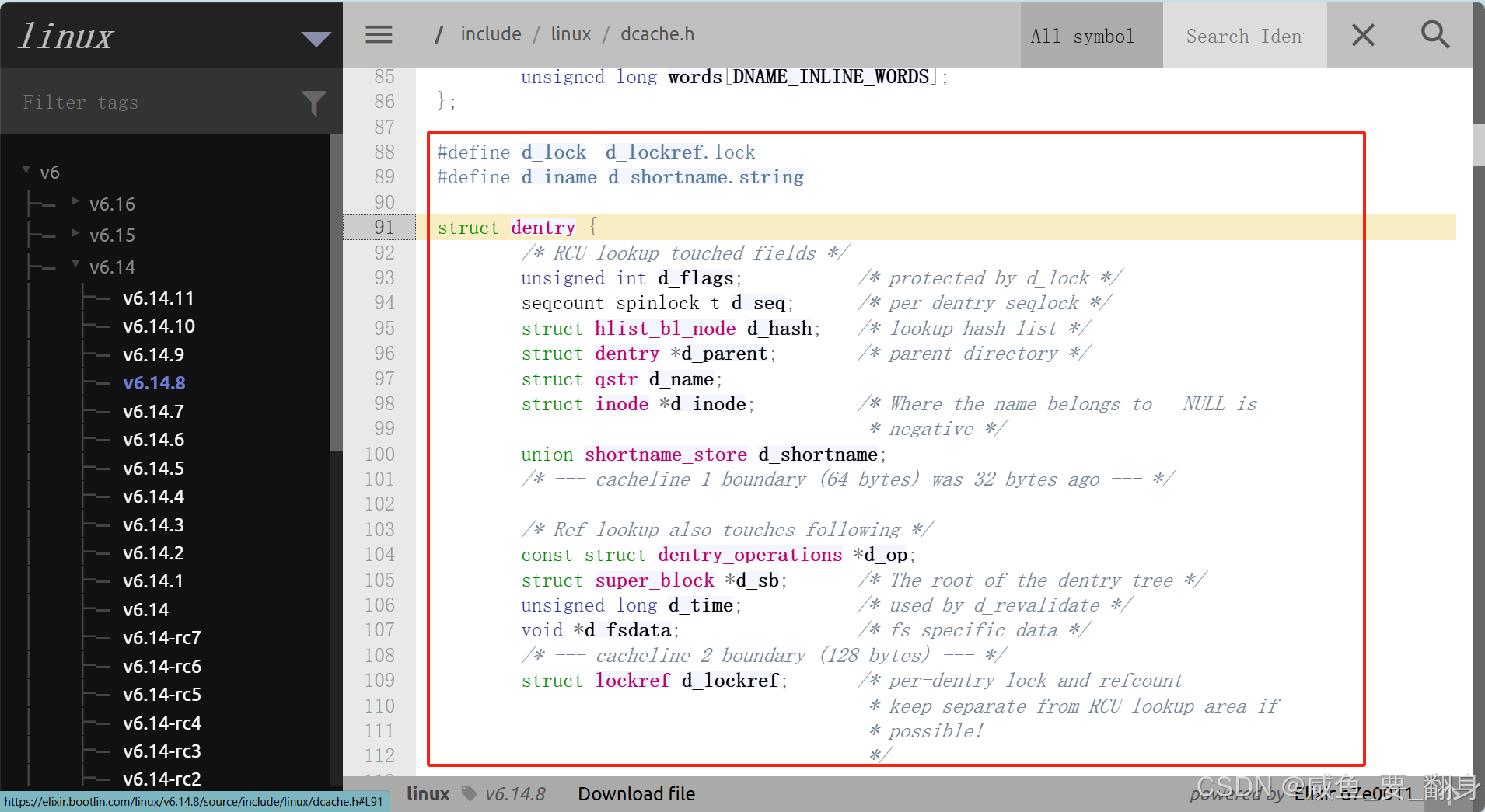
struct dentry {atomic_t d_count;unsigned int d_flags; /* protected by d_lock */spinlock_t d_lock; /* per dentry lock */struct inode *d_inode; /* Where the name belongs to - NULL is negative *//** The next three fields are touched by __d_lookup. Place them here* so they all fit in a cache line.*/struct hlist_node d_hash; /* lookup hash list */struct dentry *d_parent; /* parent directory */struct qstr d_name;struct list_head d_lru; /* LRU list *//** d_child and d_rcu can share memory*/union {struct list_head d_child; /* child of parent list */struct rcu_head d_rcu;} d_u;struct list_head d_subdirs; /* our children */struct list_head d_alias; /* inode alias list */unsigned long d_time; /* used by d_revalidate */struct dentry_operations *d_op;struct super_block *d_sb; /* The root of the dentry tree */void *d_fsdata; /* fs-specific data */#ifdef CONFIG_PROFILINGstruct dcookie_struct *d_cookie; /* cookie, if any */
#endifint d_mounted;unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
注意:
- 每個文件(包括普通文件)都對應一個dentry結構。所有被打開的文件在內存中會形成完整的樹形結構
- 該樹形節點同時隸屬于:
- LRU(最近最少使用)結構,用于節點淘汰
- Hash表,便于快速查找
- 最重要的是,這個樹形結構構成了Linux的路徑緩存機制。訪問文件時:
- 先在緩存樹中根據路徑查找
- 命中則返回inode屬性和內容
- 未命中則從磁盤加載路徑,創建dentry結構并緩存新路徑
八、通俗易懂解釋:目錄、dentry 和文件系統的關系
概念:目錄 vs. 目錄項(dentry)
-
目錄(Directory)
-
在磁盤上(如 ext2),目錄是一個特殊文件,其數據塊存儲的是?
ext2_dir_entry_2?結構體數組,每個條目記錄:struct ext2_dir_entry_2 {__le32 inode; // 關聯的 inode 號__le16 rec_len; // 條目總長度__u8 name_len; // 文件名長度__u8 file_type; // 文件類型char name[]; // 文件名(變長) }; -
一個目錄只有一個 inode,但包含多個目錄項(指向子文件/子目錄的 inode)。
-
-
目錄項(dentry)
-
是內核(VFS 層)在內存中的抽象,通過?
struct dentry?表示,用于加速路徑解析。 -
一個目錄在內存中可能有多個 dentry(因硬鏈接、掛載點、路徑別名等)。
-
1、文件系統就像一個大樓
-
磁盤(硬盤)?= 一棟大樓,里面有很多房間(文件)和樓層(目錄)。
-
分區(Partition)?= 大樓的某一層(比如 1 樓、2 樓),每一層有自己的管理員(超級塊)。
-
inode?= 每個房間的“身份證號”,記錄房間大小、位置、權限等,但不記錄房間名字。
2、目錄(文件夾)是什么?
-
目錄?= 一個“名單本”,記錄這個目錄下有哪些文件和子目錄。
-
比如?
/home?這個目錄,它的“名單本”里可能寫著:user (inode 1001) docs (inode 1002) ...
-
目錄本身也是一個文件,只不過它的內容是“文件名 → inode”的映射表。
-
3、dentry(目錄項)是什么?
-
dentry?=?內存中的“快捷方式”,用來加速查找。
-
比如你經常去?
/home/user,系統會記住這個路徑,下次不用再翻“名單本”(不用讀磁盤)。 -
dentry 是動態生成的,關機就沒了(磁盤上的目錄結構還在)。
-
舉例:
-
你第一次訪問?
/home/user/file.txt,系統要做:-
查?
/?的“名單本”,找到?home?的 inode。 -
查?
home?的“名單本”,找到?user?的 inode。 -
查?
user?的“名單本”,找到?file.txt?的 inode。
-
-
第二次訪問時,系統直接通過 dentry 緩存找到?
file.txt,不用再查“名單本”!
4、為什么需要 dentry?
-
磁盤慢,內存快:每次讀“名單本”(磁盤)很慢,dentry 讓系統“記住”常用路徑。
-
支持掛載:比如?
/home?可能是另一個硬盤(分區),dentry 幫系統無縫切換。 -
硬鏈接:同一個文件可以有多個名字(比如?
backup?和?data?指向同一個 inode),dentry 幫系統管理這些關系。
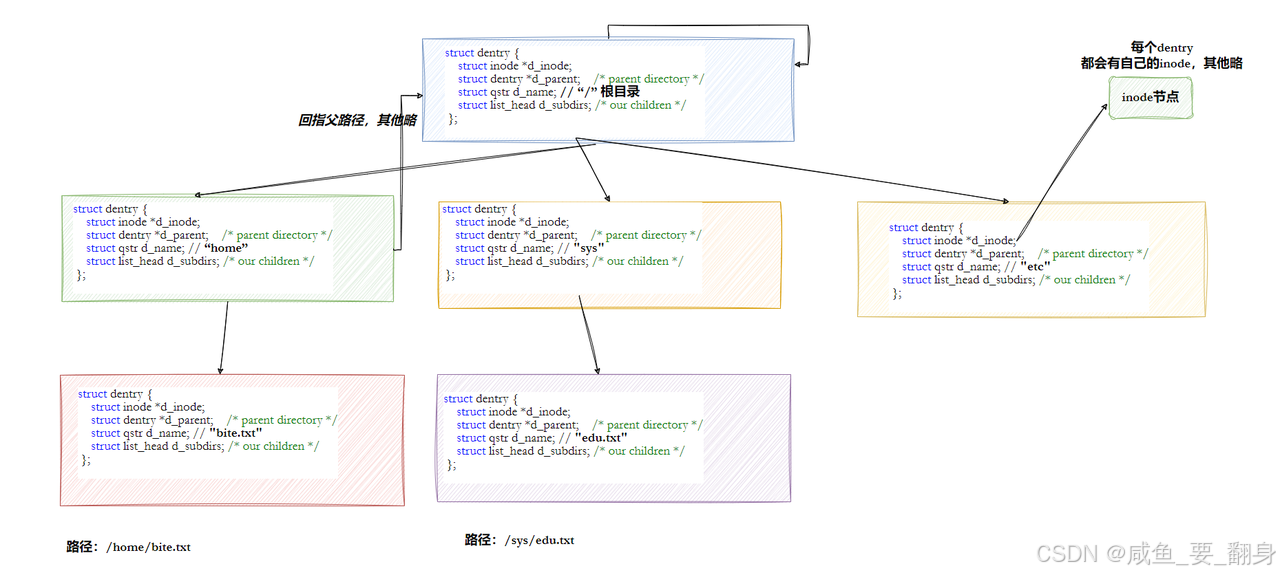
5、目錄樹是怎么形成的?
-
磁盤上:目錄是平鋪的“名單本”,沒有樹結構。
-
比如?
/home/user,實際是:-
/?的名單本里記錄?home?的 inode。 -
home?的名單本里記錄?user?的 inode。
-
-
-
內存中:dentry 通過?
d_parent?和?d_child?把這些“名單本”連成一棵樹:/ (dentry) └── home (dentry)└── user (dentry)└── file.txt (dentry)
這樣路徑解析更快!
6、掛載(Mount)是什么意思?
-
掛載?= 把另一個硬盤(分區)“貼”到當前目錄。
-
比如把 U 盤(
/dev/sdb1)掛載到?/mnt/usb:-
訪問?
/mnt/usb/file?時,系統自動切換到 U 盤的文件系統。 -
dentry 發現?
/mnt/usb?是掛載點,就去找 U 盤的“名單本”。
-
-
????????掛載(Mount)是 Linux/Unix 系統中將存儲設備(如硬盤分區、光盤、網絡存儲等)與文件系統目錄樹關聯的過程。通過掛載,用戶可以通過訪問目錄來讀寫存儲設備中的數據。
目錄 vs 分區
-
目錄
-
是文件系統中的一個邏輯概念,本質是文件路徑的節點。
-
目錄本身不直接占用存儲空間,它只是組織文件的一種方式。
-
-
分區
-
是物理磁盤上劃分的獨立存儲區域(如?
/dev/sda1),具有實際存儲空間。 -
分區需要格式化為文件系統(如 ext4、NTFS)后才能存儲數據。
-
大小關系:
????????分區的容量是固定的(如 100GB),而目錄本身沒有大小限制,其實際可用空間取決于它掛載的分區(或所在文件系統)的剩余空間。
為什么分區可以掛載到目錄上?
-
Linux/Unix 的設計哲學
-
所有文件、設備、資源均以目錄樹形式統一管理(根目錄?
/?為起點)。 -
掛載機制允許將物理存儲動態綁定到目錄樹的任意位置,用戶無需關心底層設備細節。
-
-
掛載的實質
-
掛載點(目錄)是訪問分區內容的“入口”。掛載后,該目錄原有的文件會被臨時隱藏,轉而顯示分區中的內容。
-
例如:將分區?
/dev/sda1?掛載到?/mnt/data?后,訪問?/mnt/data?實際讀寫的是?/dev/sda1?的數據。
-
-
靈活性
-
一個目錄可以掛載不同分區(如臨時掛載U盤到?
/media/usb)。 -
根目錄?
/?本身通常掛載在一個分區上,其他分區(如?/home、/var)可以掛載到子目錄,實現存儲分離。
-
示例說明
-
未掛載時:
/mnt/data?是空目錄,占用根分區(假設為?/dev/sda2)的空間。 -
掛載后:mount /dev/sdb1 /mnt/data # 將新分區掛載到目錄
此時?
/mnt/data?顯示的是?/dev/sdb1?的內容,且其可用空間由?/dev/sdb1?的大小決定。
????????當你執行?mount /dev/sdb1 /mnt/data?后,所有對?/mnt/data?目錄的讀寫操作(包括創建、刪除、修改文件)都會直接作用在?/dev/sdb1?這個分區上,而不是原先掛載點所在的文件系統。
關鍵行為解析
-
文件創建位置
-
在?
/mnt/data?下新建文件(如?touch /mnt/data/test.txt)時,文件實際存儲在?/dev/sdb1?分區中。 -
文件占用的空間會計入?
/dev/sdb1?的可用空間,而非根分區或其他分區。
-
-
原目錄內容的隱藏與恢復
-
掛載前:如果?
/mnt/data?目錄本身已有文件(例如原有文件?old.txt),這些文件會暫時不可見(但未刪除,仍占用原分區的空間)。 -
卸載后:執行?
umount /mnt/data,原目錄內容會重新顯示,而?/dev/sdb1?中的文件不再通過該目錄訪問。
-
-
驗證方法
-
通過?
df -h /mnt/data?命令可以查看該目錄當前掛載的分區及剩余空間。 -
通過?
lsblk?或?mount?命令可確認掛載關系。
-
關鍵點總結
-
目錄是“門”:掛載點目錄是訪問分區數據的通道。
-
分區是“倉庫”:提供實際存儲空間,必須通過掛載才能接入文件系統。
-
層級關系:目錄屬于文件系統層級,分區屬于物理存儲層級,掛載將二者連接。
注意事項
-
權限與所有者:新創建的文件權限和所有者由掛載時分區的文件系統規則決定(如 ext4 的默認權限或?
mount?選項指定的 uid/gid)。 -
持久化掛載:若需重啟后自動掛載,需將掛載信息寫入?
/etc/fstab?文件。 -
嵌套掛載:如果?
/mnt/data?的子目錄被其他設備掛載,操作會轉移到新的掛載點(遵循“就近優先”規則)。 -
同一個分區(如?
/dev/sdb1)可以同時掛載到多個不同的目錄,每個掛載點都會成為訪問該分區內容的獨立入口。
總結
| 概念 | 比喻 | 作用 |
|---|---|---|
| inode | 房間的身份證號 | 記錄文件的實際信息(大小、位置等) |
| 目錄 | 名單本 | 記錄文件名和 inode 的對應關系 |
| dentry | 內存中的快捷方式 | 加速路徑查找,管理目錄樹 |
| 掛載 | 把另一層樓“貼”過來 | 讓多個分區看起來像一個整體 |
簡單說:
-
磁盤:用“名單本”(目錄)記錄文件名和 inode。
-
內存:用 dentry 把“名單本”變成樹,加速訪問。
-
掛載:讓不同硬盤的目錄“無縫拼接”。
這樣設計后,你訪問?/home/user/file.txt?時,系統能快速找到文件,不管它在哪個硬盤!
九、掛載分區
重點:
????????在Linux的ext2文件系統中,inode與分區的關聯以及跨分區/分組的查找機制涉及多個層面的設計。以下從目錄結構、掛載點和分區管理的角度詳細解釋:
1.?分區與超級塊(Superblock)的關聯
每個ext2分區在格式化時都會創建獨立的超級塊,它存儲了整個分區的元數據(如inode總數、塊大小、塊組數量等)。當分區被掛載時:
-
內核通過掛載表(
/proc/mounts或/etc/mtab)記錄掛載點(如/home)與設備(如/dev/sda2)的映射。 -
掛載時,內核讀取分區的超級塊,初始化內存中的文件系統結構(如
struct super_block),后續操作都基于此上下文。
2.?inode編號的分區內唯一性
-
inode號僅在分區內唯一。不同分區的inode號可能重復,但通過
(設備號, inode號)二元組全局唯一標識。 -
設備號(
st_dev)由內核在stat()調用時返回,標識存儲設備(如/dev/sda1的主次設備號為8,1)。
3.?目錄項(dentry)與跨分區查找
目錄的本質是文件名到inode的映射表。當訪問路徑時:
-
示例路徑:
/home/user/file.txt(假設/home是獨立分區/dev/sda2的掛載點)-
內核從根目錄
/(根分區的inode 2)開始解析。 -
找到
home目錄項,發現其inode屬于/dev/sda2分區。 -
掛載點切換:內核根據掛載表跳轉到
/dev/sda2的超級塊,繼續在/dev/sda2的分區內查找user/file.txt。
-
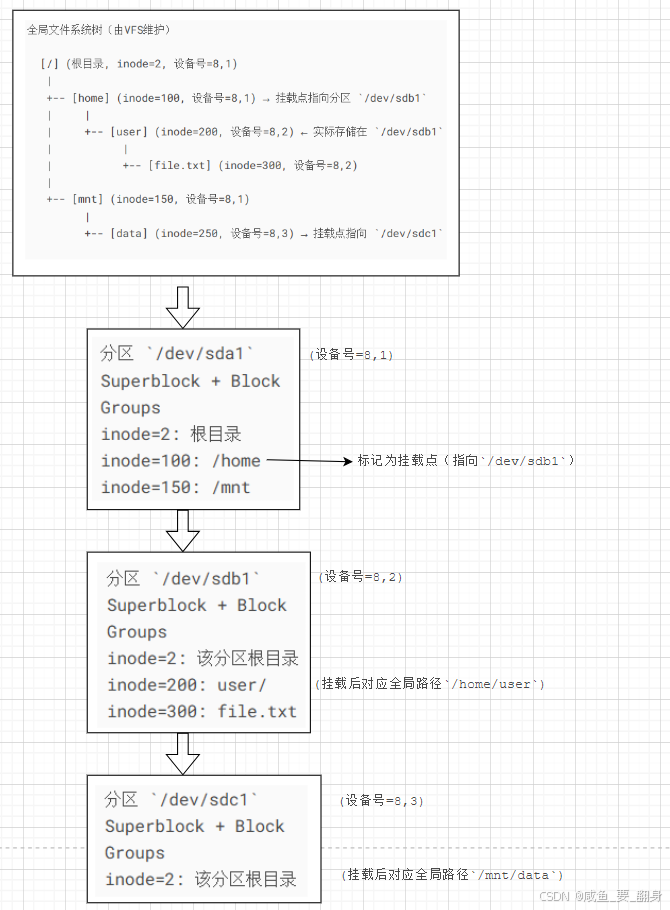
4.?ext2的塊組(Block Group)與inode分布
每個ext2分區被劃分為多個塊組,每個塊組包含:
-
超級塊副本(可選)
-
塊組描述符表(記錄塊組中inode表、數據塊位圖的位置)
-
inode表(存儲該塊組的inode結構體)
-
數據塊
inode定位流程:
-
給定inode號(如1234),通過超級塊中的
inodes_per_group計算所屬塊組:塊組索引 = (inode號 - 1) / inodes_per_group
-
在對應塊組的inode表中找到偏移:
塊組內inode偏移 = (inode號 - 1) % inodes_per_group
5.?掛載機制的關鍵作用
-
掛載隔離性:掛載點將不同分區的文件系統樹拼接成一個統一的視圖。內核通過
vfsmount結構體管理掛載關系。 -
跨分區訪問:當進程
open("/mnt/data/file")時:-
VFS(虛擬文件系統層)根據掛載點決定切換到
/dev/sdb1的文件系統驅動。 -
ext2驅動僅處理分區內的inode和塊組,無需關心其他分區。
-
????????我們已經能夠在指定分區中通過inode號查找文件,也能根據目錄文件內容定位特定inode。在單個分區內,我們幾乎可以自由操作。但問題來了:
- inode不能跨分區使用
- Linux系統可以有多個分區
- 我們如何確定當前操作的是哪個分區?
Linux 分區掛載實踐
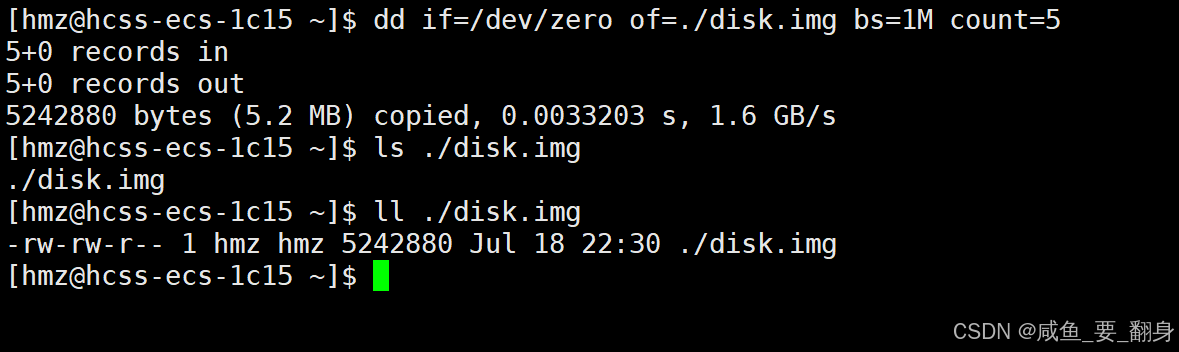
1. 創建磁盤鏡像文件
首先,我們需要創建一個虛擬的磁盤鏡像文件:
dd if=/dev/zero of=./disk.img bs=1M count=5這條命令會創建一個5MB大小的空文件,名為disk.img,內容全為零。
2. 格式化磁盤鏡像
接下來,我們需要在這個"磁盤"上創建文件系統:
mkfs.ext4 disk.img這會在disk.img上創建一個ext4文件系統。你會看到一些輸出信息,顯示文件系統的創建過程。
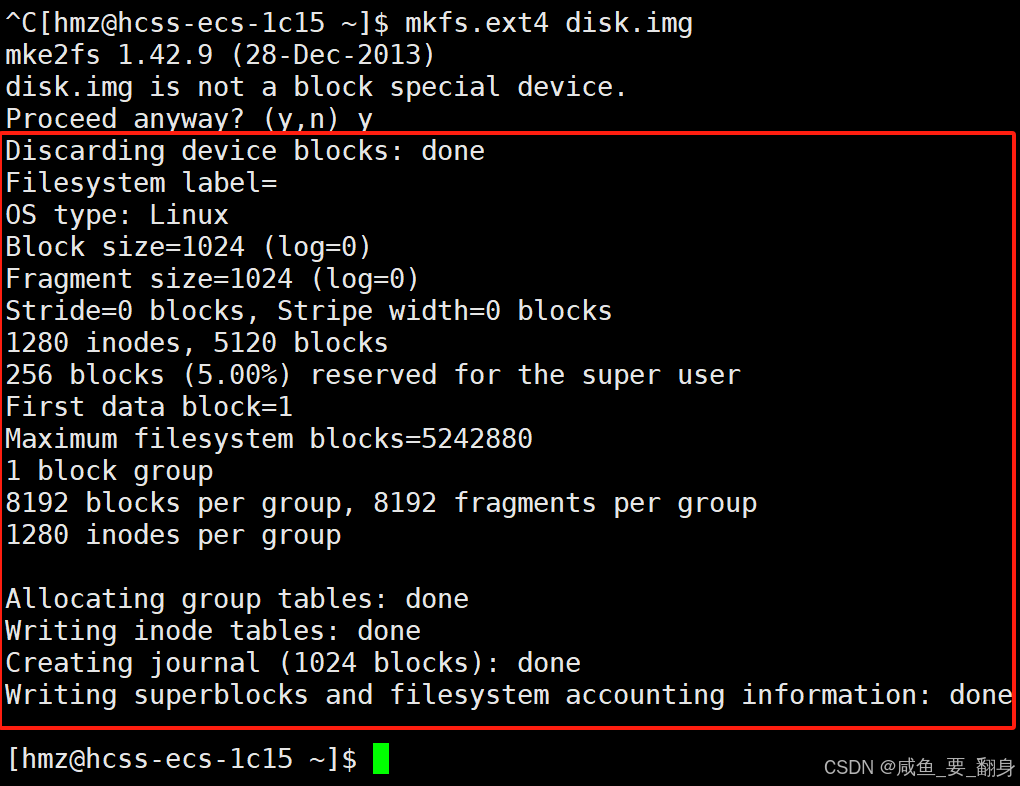
3. 創建掛載點
我們需要一個目錄來掛載這個分區:
sudo mkdir /mnt/mydisk4. 查看當前分區情況
在掛載前,先看看當前系統的分區情況:
df -h這會顯示所有已掛載的文件系統及其使用情況。
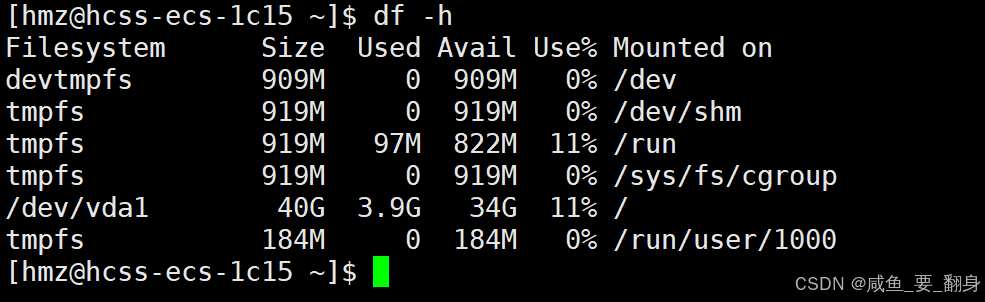
命令解釋:
-
df:disk filesystem 的縮寫,用于報告文件系統的磁盤空間使用情況 -
-h:human-readable,以易讀的格式顯示(自動使用 KB, MB, GB 等單位)
各列含義:
-
Filesystem?- 文件系統/分區名稱
-
Size?- 總容量
-
Used?- 已用空間
-
Avail?- 可用空間
-
Use%?- 使用百分比
-
Mounted on?- 掛載點(訪問該分區的目錄路徑)
關鍵信息解讀:
-
/dev/vda1?通常是主系統分區,掛載在?/(根目錄) -
tmpfs?是臨時文件系統,存在于內存中 -
/dev/loop*?是掛載的鏡像文件或虛擬設備 -
udev?是設備管理文件系統
5. 掛載分區
現在將我們創建的磁盤鏡像掛載到剛創建的目錄:
sudo mount -t ext4 ./disk.img /mnt/mydisk/選項說明:
-
-t ext4:指定文件系統類型為ext4 -
./disk.img:要掛載的磁盤鏡像文件 -
/mnt/mydisk/:掛載點目錄
6. 驗證掛載
再次運行df -h,你應該會看到類似這樣的輸出:
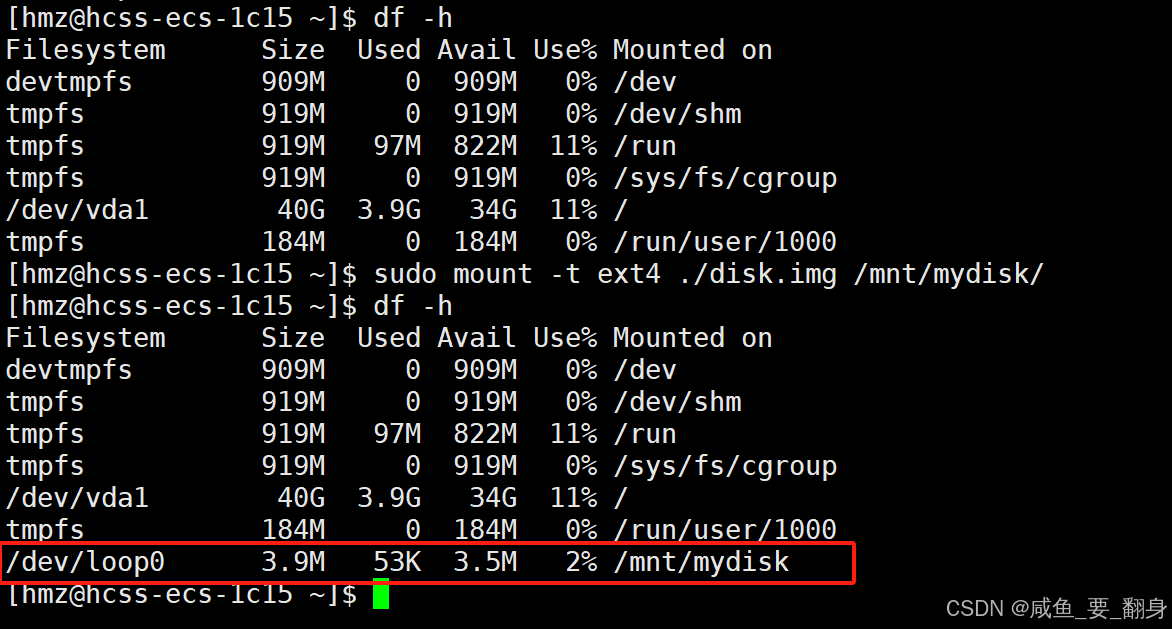
這表示我們的磁盤鏡像已經作為/dev/loop0設備掛載到了/mnt/mydisk。
7. 查看loop設備
查看系統中的loop設備:
ls /dev/loop* -l你會看到類似這樣的輸出:

8. 卸載分區
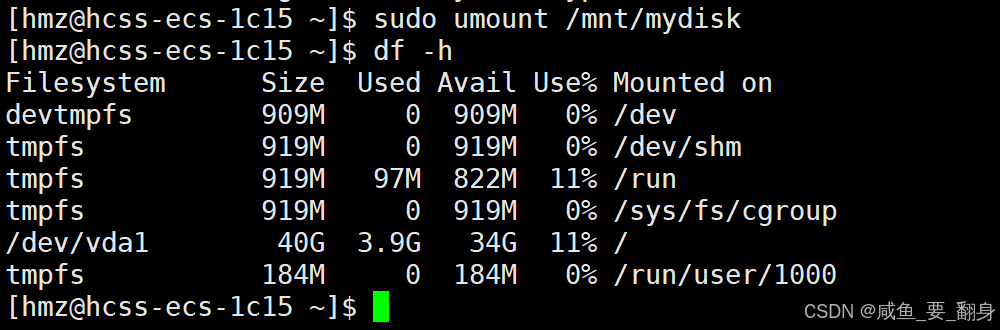
完成實驗后,可以卸載分區:
sudo umount /mnt/mydisk再次運行df -h確認分區已卸載。
關鍵概念理解
-
inode不能跨分區:每個分區有自己獨立的inode編號系統,所以不同分區可以有相同inode號的文件。
-
掛載點的作用:通過將分區掛載到目錄,我們可以通過目錄路徑訪問分區內容。
-
如何知道在哪個分區:通過文件的路徑前綴可以判斷它在哪個分區。例如:
-
/home/user/file?- 可能在根分區或單獨的home分區 -
/mnt/mydisk/file?- 在我們剛掛載的分區
-
-
loop設備:Linux允許將文件當作塊設備使用,這就是loop設備的作用。
進一步實踐建議
-
嘗試在掛載的分區中創建文件,然后卸載后看看文件還在不在
-
使用
mount命令不帶參數查看所有掛載信息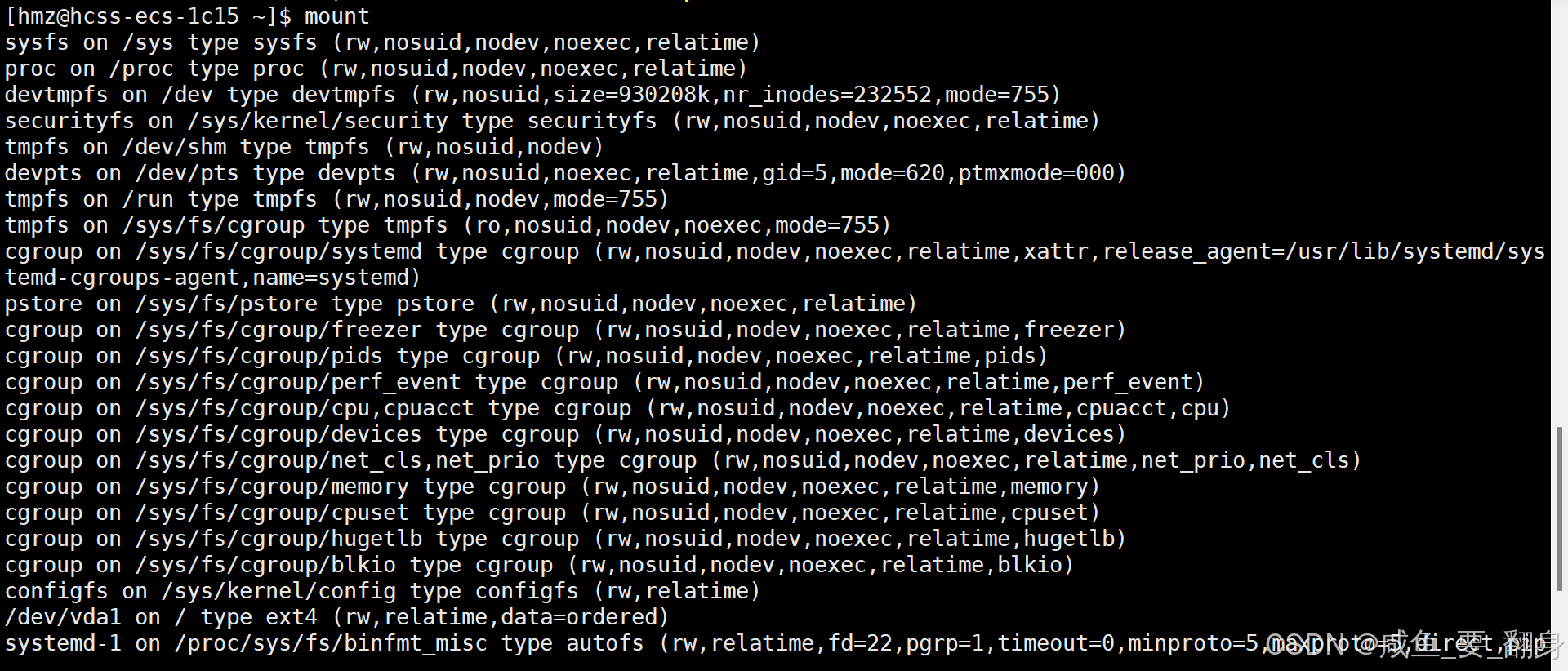
-
嘗試掛載ISO鏡像文件(也是使用loop設備)
技術說明
/dev/loop0是Linux系統中的第一個循環設備(loop device)- 循環設備是一種偽設備,允許將文件當作塊設備使用
- 這種機制可以掛載ISO鏡像等文件,就像物理硬盤分區一樣
2、分區與文件系統掛載
- 分區寫入文件系統后無法直接使用,必須通過掛載到指定目錄才能訪問。
- 因此,可以通過文件路徑的前綴準確識別當前訪問的分區。
十、問題探討:文件系統操作原理解析
1、創建空文件的過程
- 掃描inode位圖尋找空閑的inode
- 在inode表中定位對應inode,并填充文件屬性信息
- 將文件名和inode指針添加到所屬目錄的數據塊中
2、寫入文件的過程
- 通過inode編號定位對應的inode結構
- 根據inode結構找到文件數據塊進行寫入
- 當需要新數據塊時:
- 掃描塊位圖尋找空閑塊
- 在數據區定位該空閑塊
- 寫入數據并建立與inode的關聯
3、文件數據塊管理說明
文件使用一個15元素的數組維護數據塊與inode的映射關系:
- 前12個元素直接映射12個數據塊
- 后3個元素分別是一級、二級和三級索引塊
- 當文件超過12個數據塊時,通過索引塊實現擴展
4、刪除文件的原理
- 在inode位圖中標記對應inode為無效
- 在塊位圖中標記使用過的數據塊為無效
- 恢復可能性說明:
- 刪除操作僅標記資源為可用,未實際擦除數據
- 短時間內可恢復,直到這些資源被新文件重用覆蓋
5、拷貝與刪除速度差異
- 拷貝文件慢:需要完成inode分配、屬性設置、數據塊申請及內容復制全過程
- 刪除文件快:僅需在位圖中標記資源為可用還是不可用,不涉及實際數據清除
類比:建樓需耗時施工,而拆除僅需標記"拆"字即可
6、目錄的本質
- 都說在Linux下一切皆文件,目錄當然也可以被看作為文件。
- 目錄有自己的屬性信息,目錄的inode結構當中存儲的就是目錄的屬性信息,比如目錄的大小、目錄的擁有者等。
- 目錄也有自己的內容,目錄的數據塊當中存儲的就是該目錄下的文件名以及對應文件的inode指針。
注意:
????????每個文件的文件名并沒有存儲在自己的inode結構當中,而是存儲在該文件所處目錄文件的文件內容當中。因為計算機并不關注文件的文件名,計算機只關注文件的inode號,而文件名和文件的inode指針存儲在其目錄文件的文件內容當中后,目錄通過文件名和文件的inode指針即可將文件名和文件內容及其屬性連接起來。
十一、文件系統總結
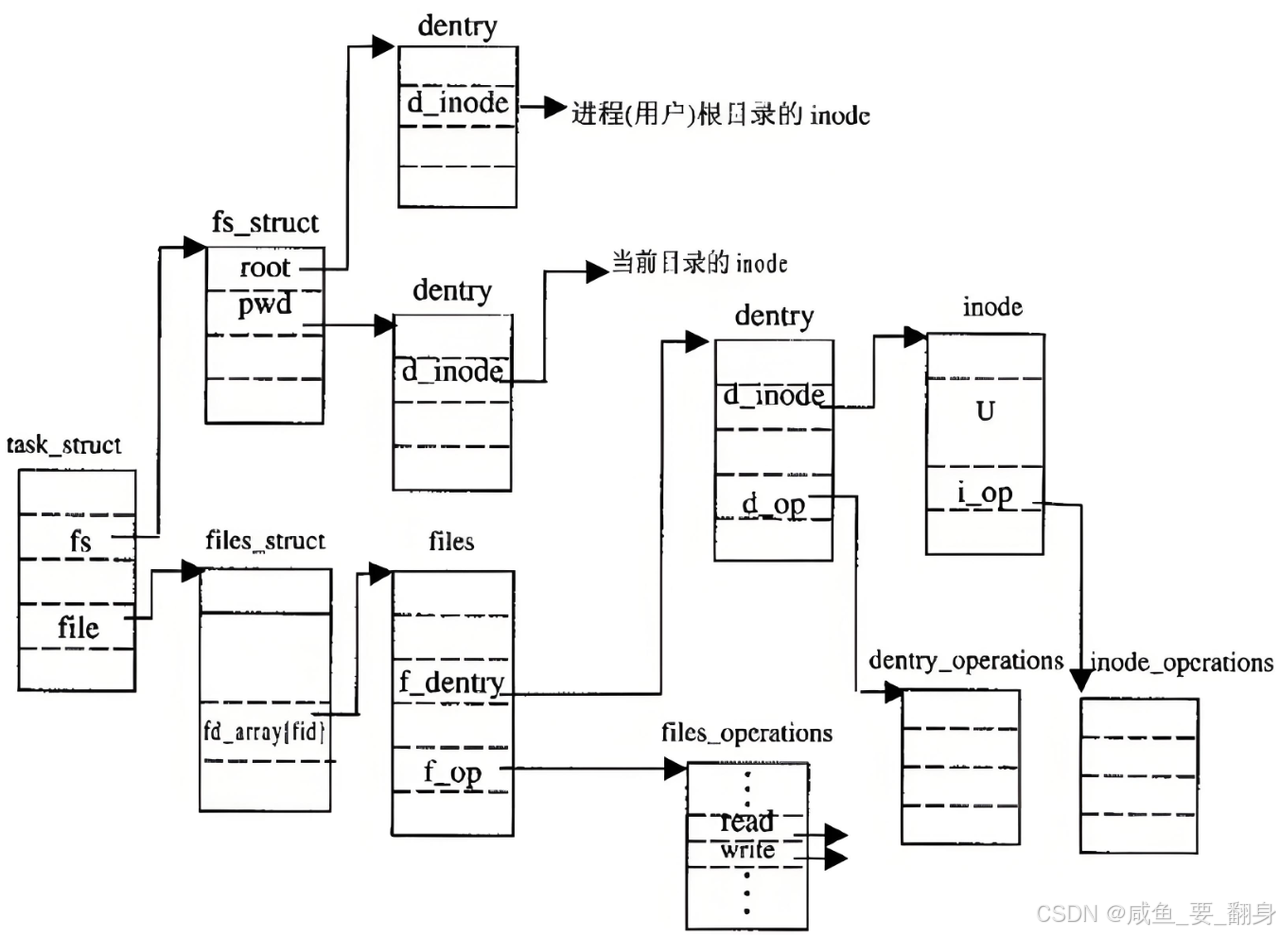
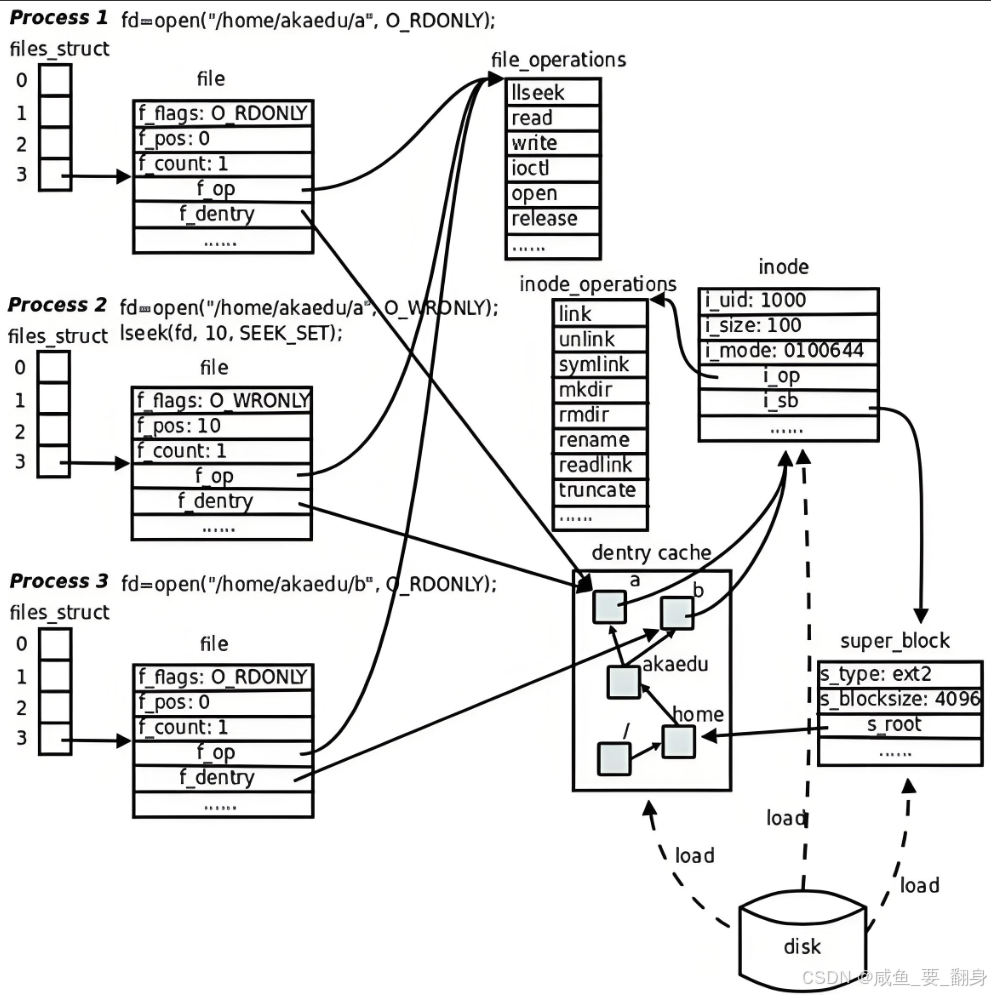
????????以下通過多張示意圖進行總結:其中一張為原創手繪,其余來源于網絡。旨在從不同維度展示文件系統的工作原理。
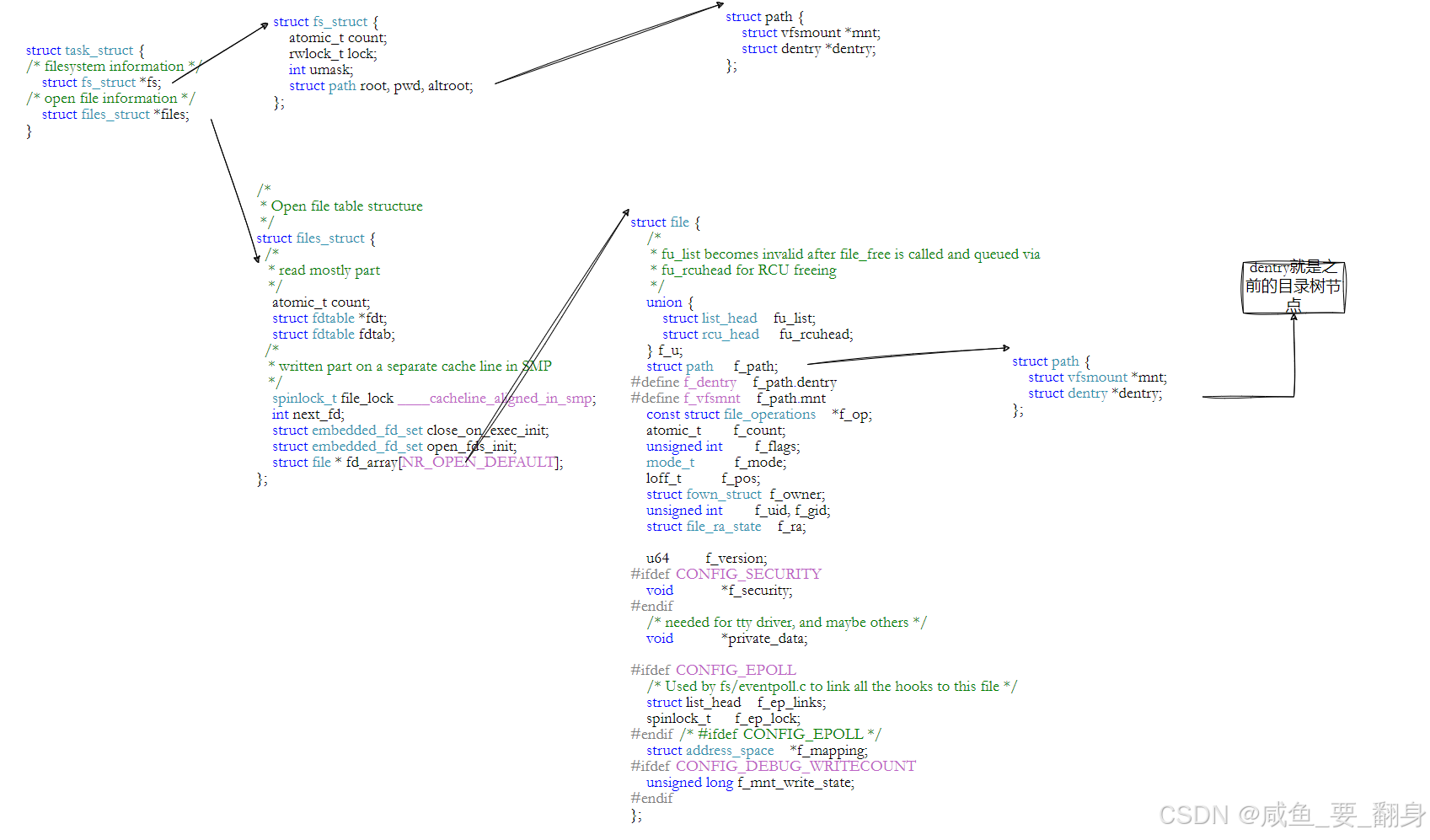
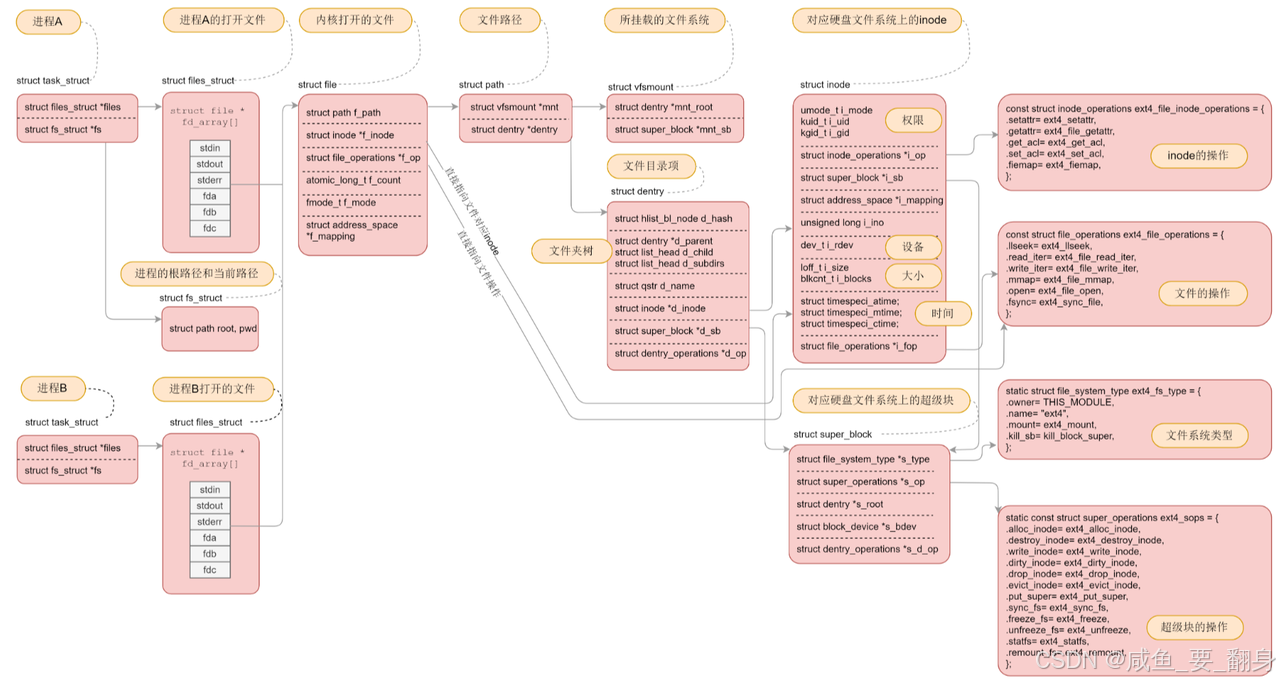
? ? ? ? 上面這張圖片展示了Linux內核中與文件管理和進程相關的核心結構體及其組成關系。以下是圖中出現的結構體名稱及其所屬模塊的簡要分類說明:
??1. 進程相關結構體??
-
??
struct task_struct??表示一個進程/線程的完整描述符,包含進程的所有信息。
-
??
struct files_struct??管理進程打開的文件表(文件描述符表),通過
task_struct->files引用。 -
??
struct fs_struct??管理進程的文件系統上下文(如當前工作目錄、根目錄等),通過
task_struct->fs引用。
??2. 文件訪問相關結構體??
-
??
struct file??表示內核中一個已打開的文件實例,包含文件的讀寫位置、操作函數等(圖中未直接標注名稱,但通過
f_mode、f_count等字段體現)。 -
??
struct file_operations??定義文件操作函數(如
read、write等),圖中以f_op字段出現。
??3. 路徑與目錄結構體??
-
??
struct path??表示一個文件路徑,包含掛載點(
vfsmount)和目錄項(dentry)。 -
??
struct dentry??表示目錄項(目錄條目),緩存文件路徑到inode的映射,包含文件名、父目錄、子目錄等(如
d_parent、d_name)。 -
??
struct vfsmount??表示文件系統的掛載點信息,包含掛載的根目錄(
mnt_root)和超級塊(mnt_sb)。
??4. 文件系統與inode結構體??
-
??
struct super_block??表示一個文件系統的超級塊,管理文件系統的全局信息(如塊大小、inode操作等)。
-
??
struct inode??表示文件在文件系統中的元數據(如權限、時間戳、數據塊位置等),通過
dentry->d_inode關聯。 -
??
struct inode_operations??定義inode操作函數(如
getattr、setattr等),圖中以f_op字段出現。 -
??
struct address_space??管理文件頁緩存與磁盤塊的映射關系,通過
inode->i_mapping關聯。
??5. 其他輔助結構體??
-
??
struct qstr??表示一個文件名字符串(如
dentry->d_name)。 -
??
struct list_head??內核鏈表結構,用于連接多個結構體(如
d_child、d_subdirs)。
??總結關系鏈?(超重點!!!)?
-
??進程??(
task_struct)→ 打開文件表(files_struct)→ 文件對象(file)。 -
??文件對象?? → 路徑(
path)→ 目錄項(dentry)→ inode(inode)。 -
??inode?? → 文件系統(
super_block)→ 實際磁盤數據。
這些結構體通過指針相互引用,形成從進程到磁盤文件的完整訪問路徑。




:軟件信息展示)
![[HDLBits] Cs450/gshare](http://pic.xiahunao.cn/[HDLBits] Cs450/gshare)
![[學習] 雙邊帶調制 (DSB) 與單邊帶調制 (SSB) 深度對比](http://pic.xiahunao.cn/[學習] 雙邊帶調制 (DSB) 與單邊帶調制 (SSB) 深度對比)



:three states)






![[學習] Hilbert變換:從數學原理到物理意義的深度解析與仿真實驗(完整實驗代碼)](http://pic.xiahunao.cn/[學習] Hilbert變換:從數學原理到物理意義的深度解析與仿真實驗(完整實驗代碼))

