目錄
卷積層介紹
Conv2d
卷積動畫演示
卷積代碼演示?
綜合代碼案例
卷積層介紹
卷積層是卷積神經網絡(CNN)的核心組件,它通過卷積運算提取輸入數據的特征。
基本原理
卷積層通過卷積核(過濾器)在輸入數據(如圖像)上滑動,進行逐元素乘法并求和,從而提取局部特征。每個卷積核學習不同的特征(如邊緣、紋理),最終生成多個特征圖。
-
局部連接:卷積核只關注輸入的局部區域,減少參數數量。
-
權值共享:同一個卷積核在整個輸入上滑動,降低過擬合風險。
-
特征提取:不同卷積核可以檢測不同特征,如水平邊緣、垂直邊緣等。
核心參數
-
卷積核大小:通常為 3x3、5x5 等,決定感受野。
-
步長(Stride):卷積核滑動的步距,影響輸出尺寸。
-
填充(Padding):在輸入周圍添加零值,控制輸出尺寸與輸入一致。
-
卷積核數量:決定輸出特征圖的通道數。
?
?
Conv2d
Conv2d:二維卷積操作
相關參數如下:?

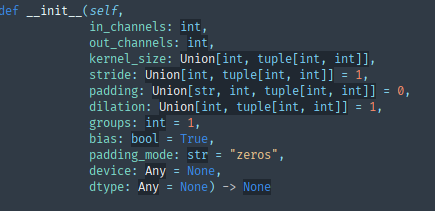
參數:
in_channels?(int) – 輸入圖像中的通道數
out_channels?(int) – 卷積產生的通道數
kernel_size?(int?或?tuple) – 卷積核的大小
stride?(int?或?tuple,?可選的) – 卷積的步長。默認值:1
padding?(int,?tuple?或?str,?可選的) – 輸入四邊添加的填充。默認值:0
dilation?(int?或?tuple,?可選的) – 內核元素之間的間距。默認值:1
groups?(int,?可選的) – 從輸入通道到輸出通道的組連接數。默認值:1
bias?(bool,?可選的) – 如果為?
True,則向輸出添加一個可學習的偏置項。默認值:Truepadding_mode?(str,?可選的) –?
'zeros',?'reflect',?'replicate'?或?'circular'。默認值:'zeros'
?
?
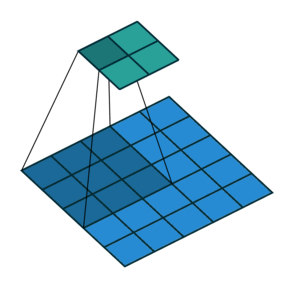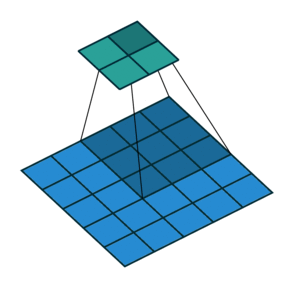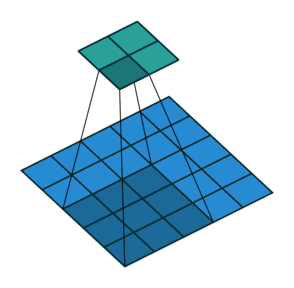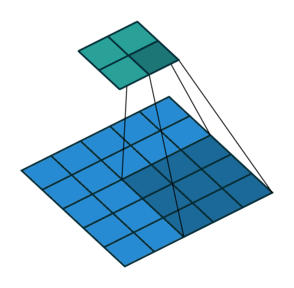
卷積動畫演示
注意:藍色映射是輸入,青色映射是輸出。
? ? ? ?No padding, no strides? ? ? ? ? ? ? ? ? ? ?? Arbitrary padding, no strides
? ? ??沒有填充,沒有步幅? ? ? ? ? ? ? ? ? ? ? ? ? ?任意填充,無步幅
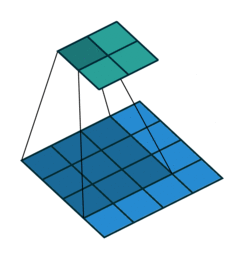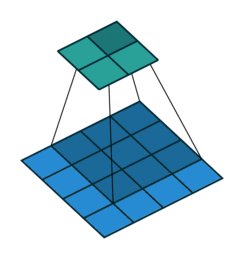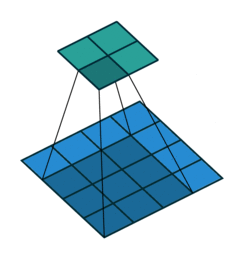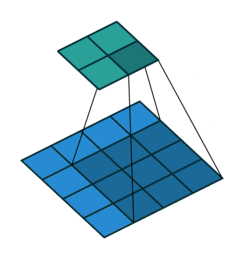
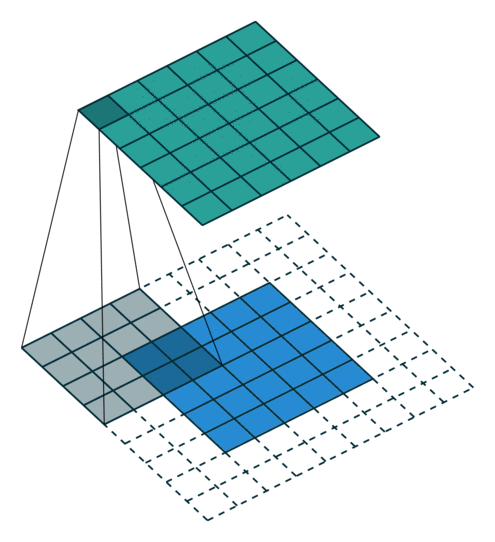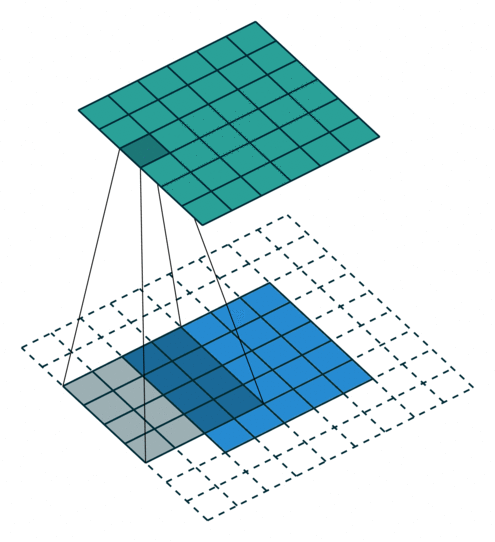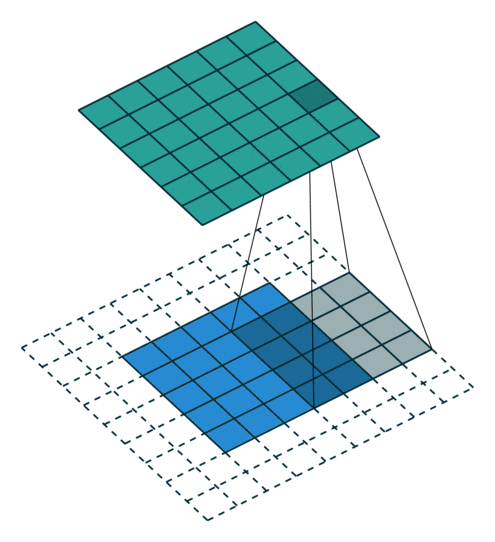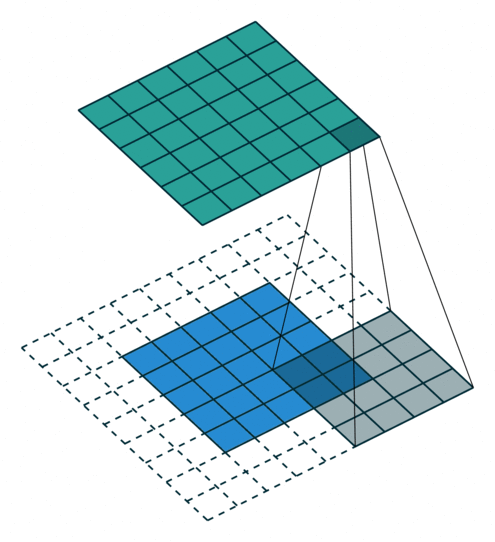
? ? ? ? ? Half padding, no strides? ? ? ? ? ? ? ? Full padding, no strides
? ? ? ? ?半填充,無步幅? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??全填充,無步幅
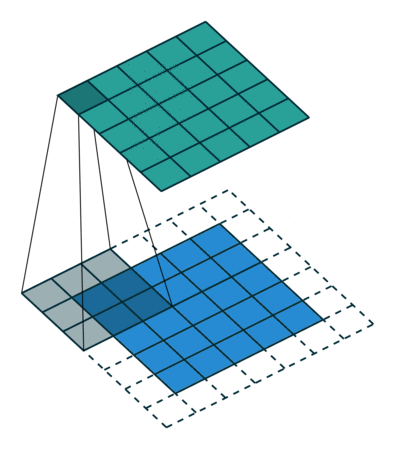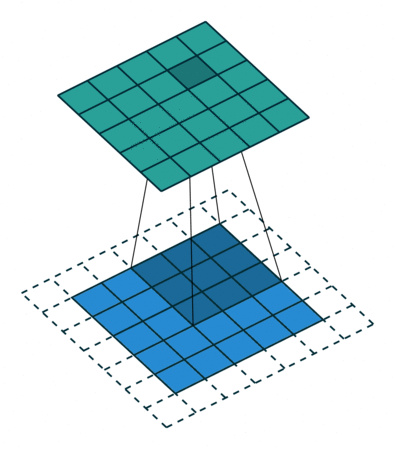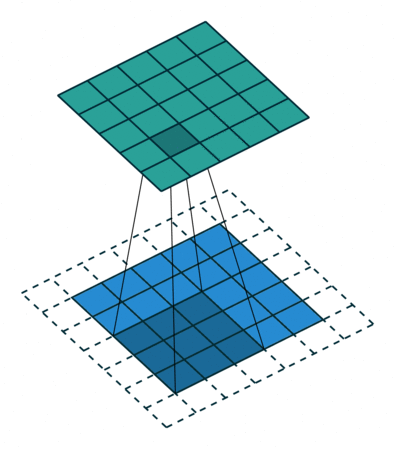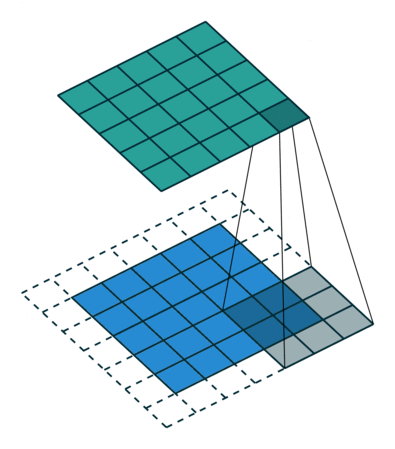
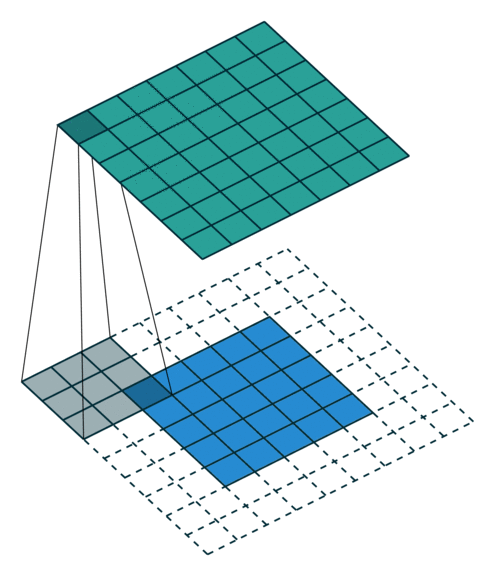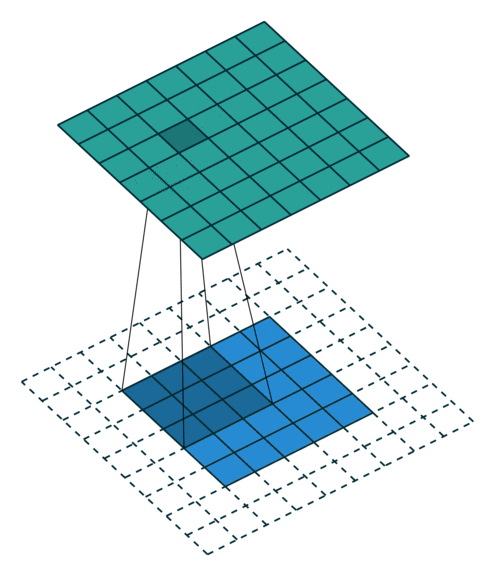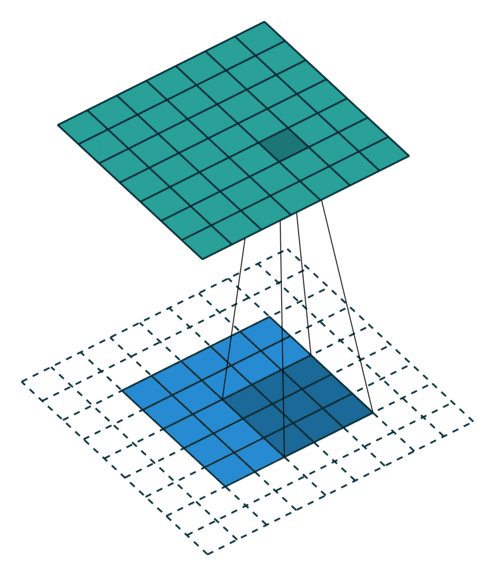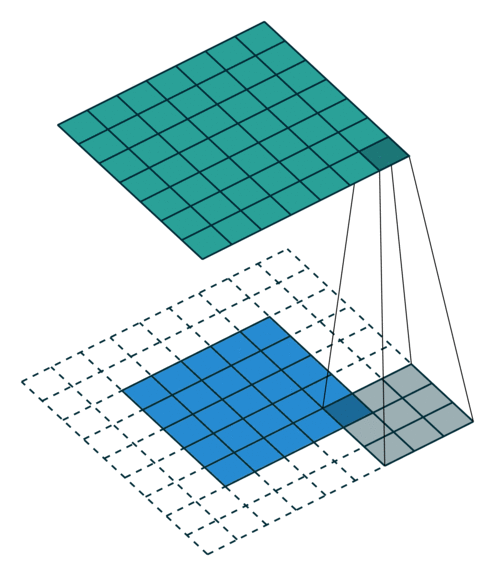
? ? ? ? No padding, strides? ? ? ? ? ? ? ? ? ? ? ? ? ? ?Padding, strides
? ? ? ? ?沒有填充,沒有步幅? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?填充、步幅
?
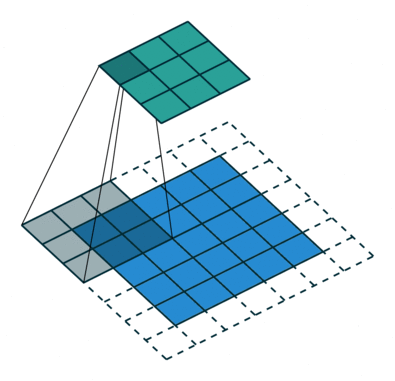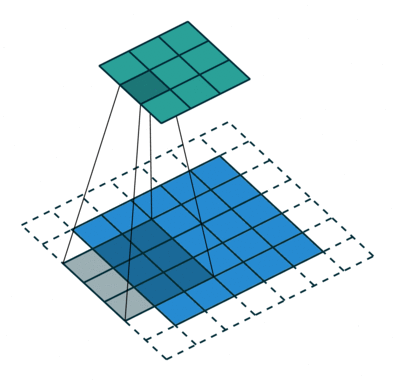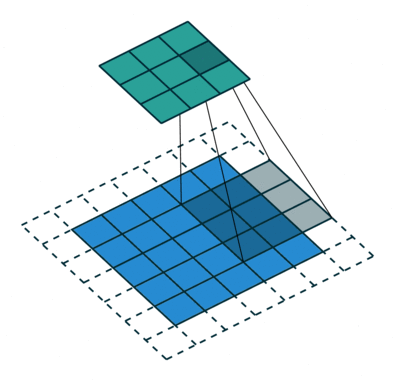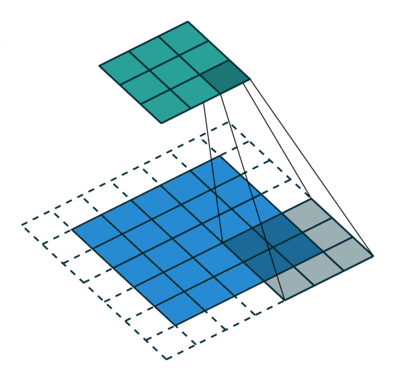
? ? ?Padding, strides (odd)
? ? ?填充、步幅(奇數)
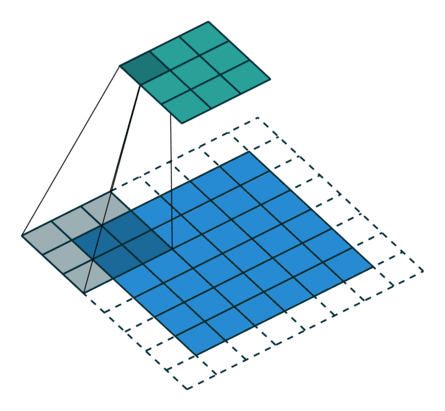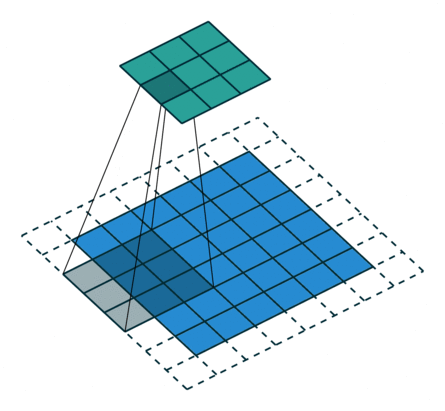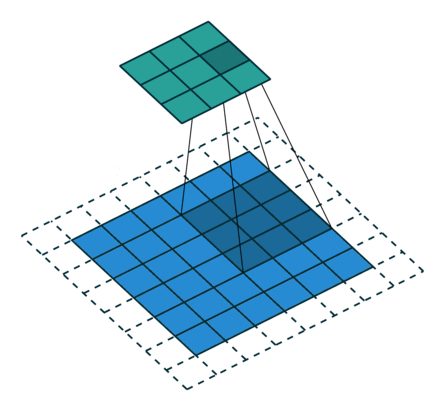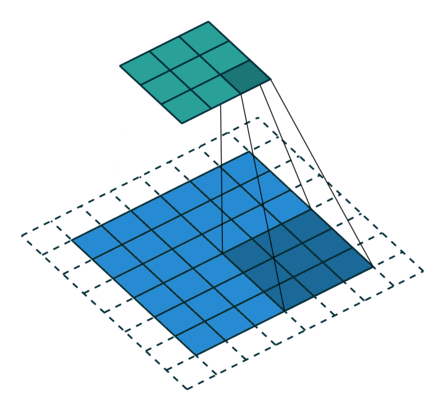
?
卷積代碼演示?
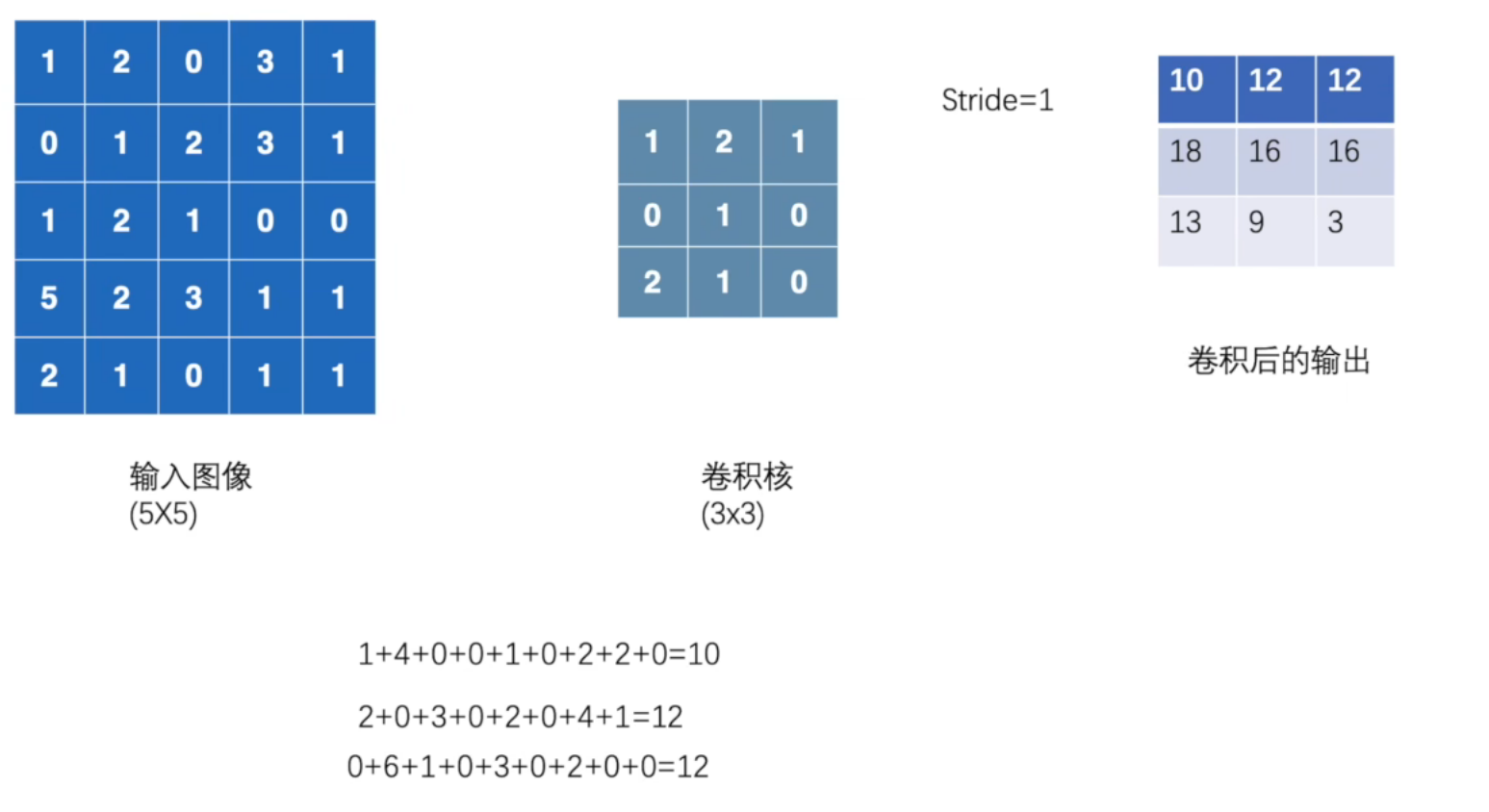
import torch
import torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]
])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]
])print(input.shape)
print(kernel.shape)
"""
打印結果:
torch.Size([5, 5])
torch.Size([3, 3])
不符合卷積層的輸入要求
在最簡單的情況下,輸入尺寸為 (N,C,H,W)
N:批量數
C:通道數
H:高度
W:寬度
"""# 尺寸變換
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
"""
打印結果:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
"""output = F.conv2d(input, kernel, stride=1)
print(output)
"""
打印結果:
tensor([[[[10, 12, 12],[18, 16, 16],[13, 9, 3]]]])
"""
# stride為2時
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
"""
打印結果:
tensor([[[[10, 12],[13, 3]]]])
"""
卷積操作分析:?
當設置了padding時候?,輸入的量得到了填充 默認填充為0
進行卷積操作的時候,還是從左上角開始?

# 設置padding
output3=F.conv2d(input,kernel,stride=1,padding=1)
print(output3)
"""
打印結果:
tensor([[[[ 1, 3, 4, 10, 8],[ 5, 10, 12, 12, 6],[ 7, 18, 16, 16, 8],[11, 13, 9, 3, 4],[14, 13, 9, 7, 4]]]])
"""?
綜合代碼案例
?
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
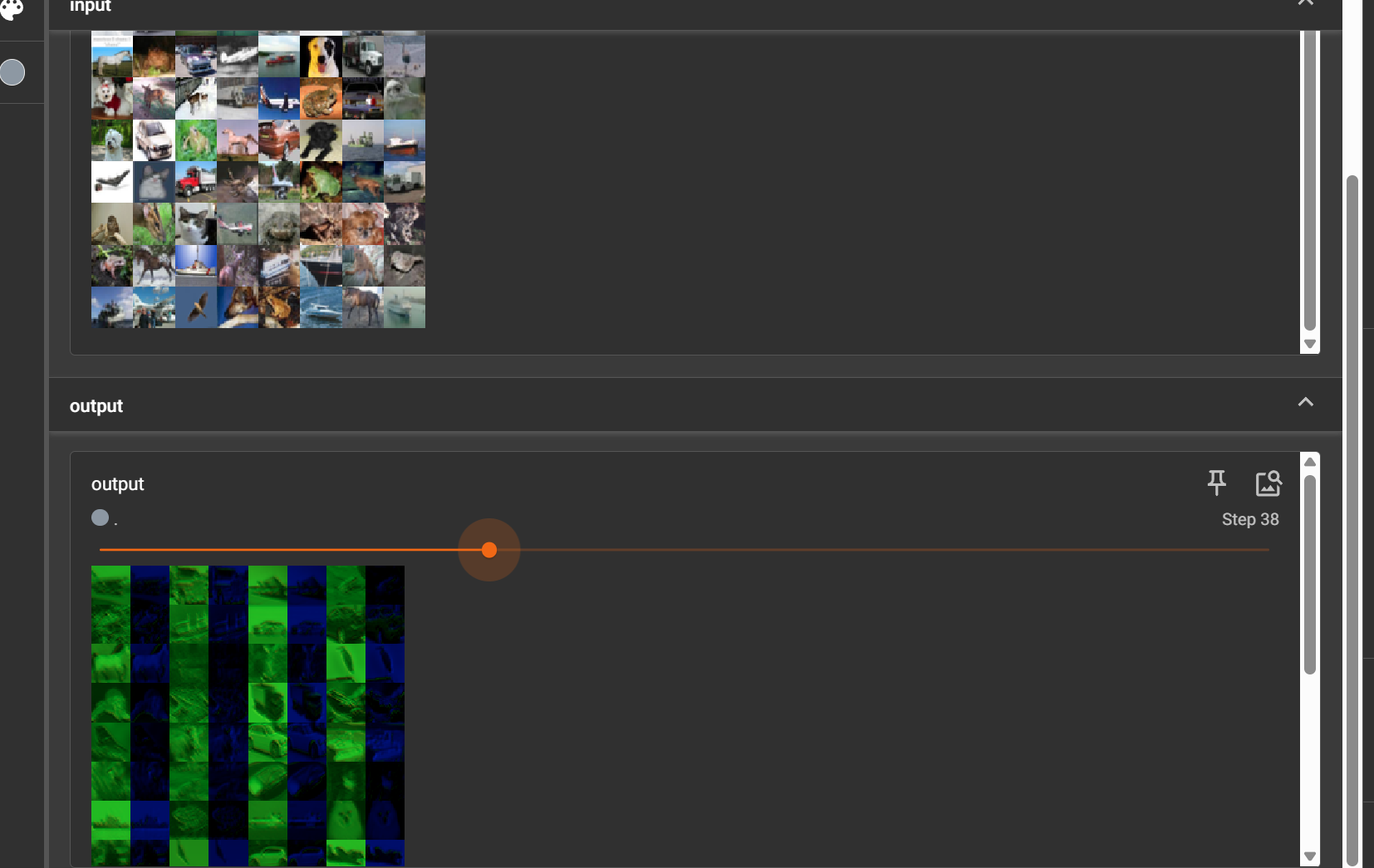
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("../torchvision_dataset", train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)class MyModel(nn.Module):def __init__(self):super().__init__()self.conv1 = Conv2d(3, 6, 3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return xmodule1 = MyModel()
step = 0
writer = SummaryWriter("logs_test3")
for data in dataloader:imgs, target = dataoutput = module1(imgs)print("卷積前", imgs.shape)print("卷積后", output.shape)# 卷積前 torch.Size([64, 3, 32, 32])writer.add_images("input", imgs, step)# 卷積后 torch.Size([64, 6, 30, 30])# 直接用會報錯 因為6通道不好顯示# 一個不嚴謹的方法:reshape為3通道# [64, 6, 30, 30]->[***, 3, 30, 30]output = torch.reshape(output, (-1, 3, 30, 30)) # 參數為-1時,會根據后面的自己計算writer.add_images("output", output, step)step += 1
 ?
?
?在卷積操作中,輸出通道數由卷積核的數量決定。
每個輸出通道由一個卷積核掃描 3 個輸入通道后求和
輸入: 32×32×3(3通道)┌───────────┐ ┌───────────┐ ┌───────────┐│ 紅通道 │ │ 綠通道 │ │ 藍通道 ││ 32×32×1 │ │ 32×32×1 │ │ 32×32×1 │└───────────┘ └───────────┘ └───────────┘│ │ │└────────┬────────┴────────┬────────┘│ │6個3×3×3卷積核 ││ │┌────────┴─────────────────┘▼
輸出: 30×30×6(6通道)┌───────────┐ ┌───────────┐ ┌───────────┐│ 特征圖1 │ │ 特征圖2 │ │ 特征圖3 ││ 30×30×1 │ │ 30×30×1 │ │ 30×30×1 │└───────────┘ └───────────┘ └───────────┘│ │ │┌───────────┐ ┌───────────┐ ┌───────────┐│ 特征圖4 │ │ 特征圖5 │ │ 特征圖6 ││ 30×30×1 │ │ 30×30×1 │ │ 30×30×1 │└───────────┘ └───────────┘ └───────────┘?3*3*3卷積核的理解:
不是3個一樣的3*3的子核(每一個子核也不一樣),也不是3個卷積核
一個完整的卷積核是包含所有輸入通道對應子核的集合,而不是單個通道的子核。
輸出第 1 個通道的特征圖,就是由 “第 1 個完整卷積核”(包含 3 個子核)分別對 RGB 三個通道計算后相加得到的。
“卷積核” 指的是對應 1 個輸出通道的整體結構(3×3×3),而子核只是其內部組成部分。就像 “1 輛汽車由 4 個輪子組成,但我們說‘1 輛車’而不是‘4 個輪子’”—— 這里的邏輯是一致的。
調用前后圖片尺寸發生變化
?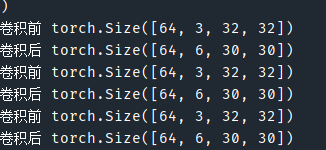
圖像尺寸從 32×32 變為 30×30 是由卷積操作的數學特性決定的。因為使用了3×3 的卷積核且沒有添加填充(padding=0),導致邊緣像素無法被卷積核完全覆蓋。?
計算輸出尺寸的公式:?
輸出尺寸 = 向下取整[(輸入尺寸 - 卷積核大小 + 2×填充) ÷ 步長] + 1
官方公式:
 ?
?
?
?
為什么需要多個輸出通道?
卷積神經網絡的核心思想是用多個卷積核提取不同的特征。每個輸出通道對應一個獨特的卷積核,它會學習檢測特定的模式(如邊緣、紋理、顏色等)。
例如:
-
第 1 個卷積核可能學會檢測水平邊緣。
-
第 2 個卷積核可能學會檢測垂直邊緣。
-
第 3-6 個卷積核可能學會檢測更復雜的紋理或顏色模式。
?
?




 文件對話框 QFileDialog 篇二:源碼帶注釋)

)












