這是一個技術爆炸的時代。一起來看看 GPT 誕生后,與BERT 的角逐。
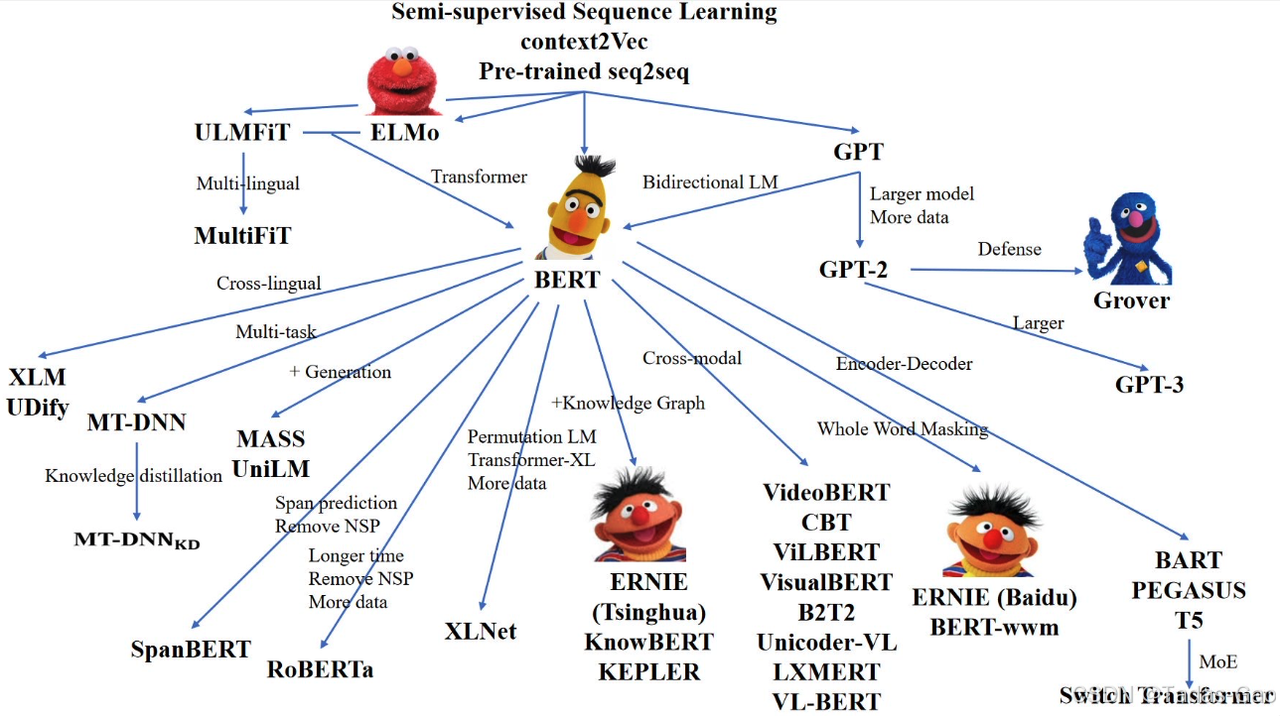
BERT 和 GPT 是基于 Transformer 模型架構的兩種不同類型的預訓練語言模型。它們之間的角逐可以從 Transformer 的編碼解碼結構角度來分析。
BERT(Bidirectional Encoder Representations from Transformers):
- Bert 主要基于編碼器結構,采用了雙向 Transformer 編碼器的架構。它在預訓練階段使用了大量的無標簽文本數據,通過 Masked Language Model(MLM)任務來學習雙向上下文表示。Bert 只使用編碼器,不包含解碼器部分,因此在生成文本方面有一定局限性。
- Bert 的優勢在于能夠更好地理解句子中的上下文信息,適用于各種自然語言處理任務,如文本分類、語義理解和命名實體識別等。
GPT(Generative Pre-trained Transformer):
- GPT 則是基于 Transformer 的解碼器結構,采用了自回歸的方式來進行預訓練。它通過語言模型任務來學習生成文本的能力,可以根據輸入文本生成連續的文本序列。GPT 在預測下一個詞的過程中,考慮了所有前面的詞,從而能夠逐步生成連貫的文本。
- GPT 在生成文本方面表現出色,能夠生成流暢的語言并保持一致性。但由于沒有編碼器部分,GPT 不擅長處理雙向上下文信息。
BERT 和 GPT 在編碼解碼結構方面有著明顯的差異。BERT 更適用于需要雙向上下文信息的任務,而 GPT 則擅長生成連貫的文本。在實際應用中,可以根據任務需求選擇合適的模型進行使用。
GPT(Generative Pre-trained Transformer)誕生于2018年,采用解碼器架構,以無監督學習方式預訓練。它通過大規模文本數據的學習,能夠生成自然流暢的文本,并在多項自然語言處理任務中取得了較好的成績。然而,雖然GPT在生成型任務上表現卓越,但在理解和聯系信息方面相對較弱。
相比之下,BERT(Bidirectional Encoder Representations from Transformers)于2018年底問世,采用編碼器架構,通過雙向訓練方式將上下文信息有效地融入到語言表示中。BERT的出現引領了預訓練技術的新浪潮,迅速成為自然語言處理領域的一匹黑馬。其優勢在于對上下文信息的充分利用,使得在理解和推斷任務上有著出色的表現。
不可否認,BERT家族的發展壯大,吸引了眾多研究者和工程師的關注,取得了許多重要的突破。然而,GPT作為一種全新的生成式模型,也順利地在自然語言處理領域站穩了腳跟。它在生成任務上展現出的出色表現,逐漸贏得了更多人的喜愛和認可。
在兩個頂尖模型之間的角逐中,GPT雖然起步較晚,但其獨特的架構和顛覆性的設計,使得它在自然語言處理的發展中扮演著不可或缺的角色。BERT的強大并不意味著GPT的失敗,兩者各有所長,相互之間的競爭與合作將推動自然語言處理技術的不斷進步和創新。在未來的發展中,無論是GPT還是BERT,都將在人工智能領域繼續書寫屬于自己的輝煌篇章。
從 GPT 的發展來看技術的演進過程。
GPT-1:學會微調(Finetune)
GPT-1的訓練數據是從哪里獲取的呢?GPT-1是基于海量的無標簽數據,通過對比學習來進行訓練的。這個思路來源于從 Word2Vec 到 ELMo 的發展過程中積累的經驗。它們都通過在大規模文本數據上進行無監督預訓練,學習到了豐富的語言知識。
GPT-1的微調方法是,使用預訓練好的模型來初始化權重,同時在 GPT-1 的預訓練模型后面增加一個線性層,最后只要根據下游具體 NLP 任務的訓練數據來微調更新模型的參數就可以了。
下圖展示了四個經典 NLP 場景的改造方法,分別是文本分類、蘊含關系檢測、相似性檢測和多項選擇題的改造方式。通過這樣的微調策略,GPT-1能夠迅速適應各種NLP任務,而無需重新訓練整個模型。
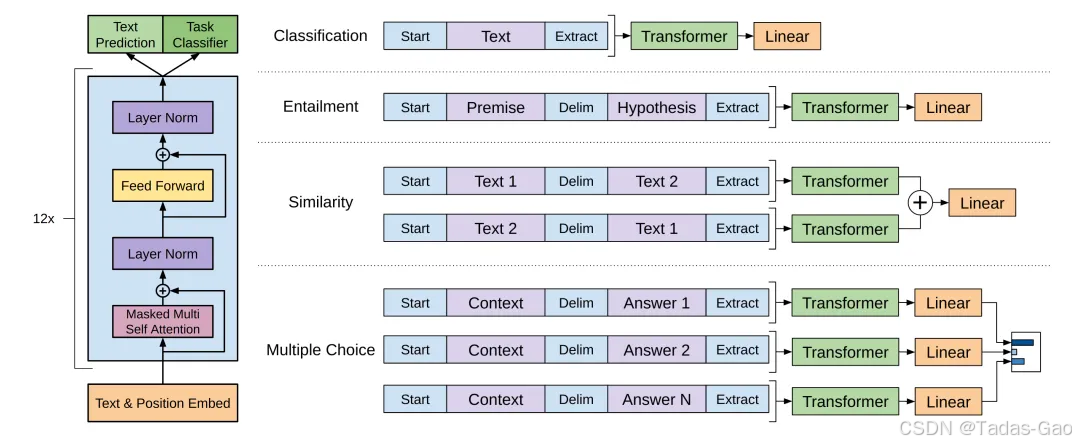
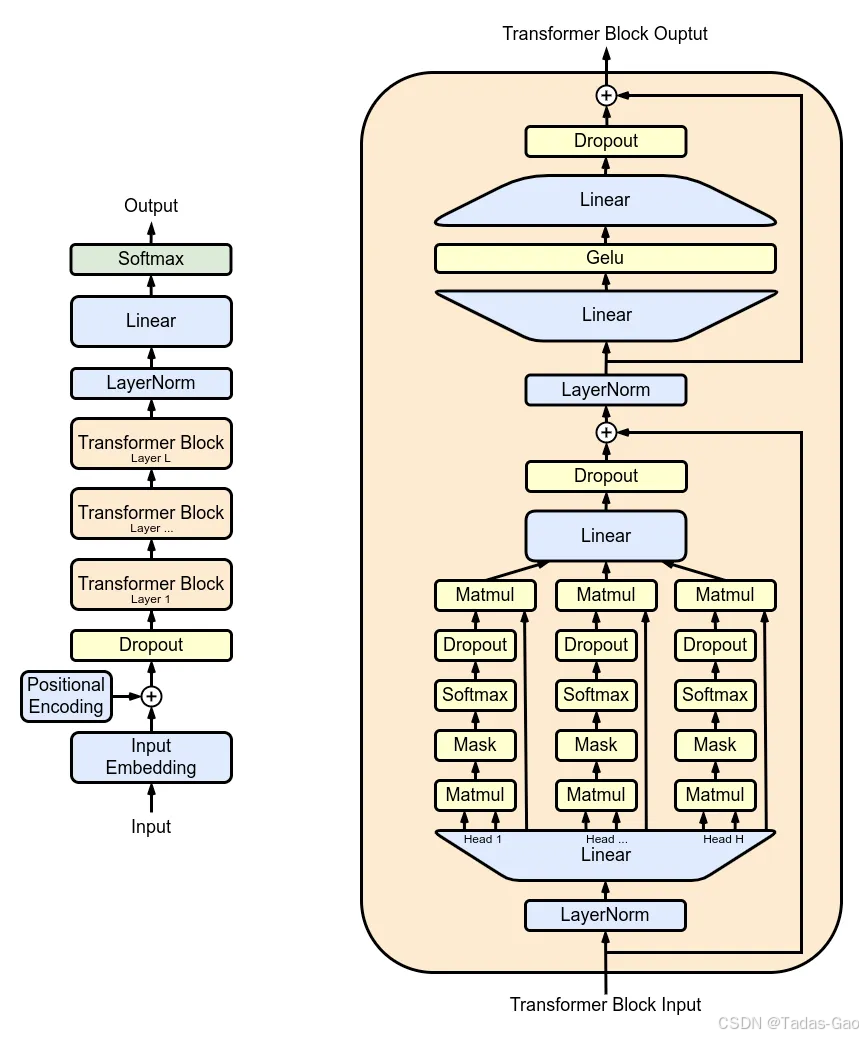
GPT-1的模型結構其實就是 Transformer 的架構。與 Transformer 不同的是,GPT-1 使用了一個只包含解碼器部分的架構。它是一個單向的語言模型,通過自回歸地生成文本,來模擬序列生成的過程。自回歸指的是使用前面的觀測值,來預測未來的值,GPT模型一個詞一個詞往外“蹦”,就是源于它的特性。
| Transformer層 | 類比的語言層級 | 具體功能示例 |
| 第1層 | 單詞/局部語法 | - 識別詞性(動詞/名詞) - 捕捉鄰近詞關系(如“吃”→“蘋果”) |
| 第2~3層 | 句子結構 | - 分析主謂賓關系 - 處理短距離指代(如“他”→“醫生”) |
| 深層(4~6+層) | 篇章/語義 | - 理解長程依賴(如跨句指代) - 把握情感傾向或邏輯連貫性 |
具體層數分配因模型規模和任務而異,例如BERT-base有12層,GPT-3多達96層。
在自回歸生成的過程中,GPT-1 會為序列開始后的每個時刻生成一個詞,并把它當作下一個時刻生成的上下文。
GPT-1 在訓練過程中則會根據海量數據,統籌考量不同上下文語境下生成的文本在語法和語義上的合理性,來動態調整不同詞的生成概率,這個能力主要由它所使用的 12 個 Transformer 共同提供。
這便是 GPT-1 所提供的一整套完備的預訓練加微調的 NLP PTM 方法論,它也是第一個提出這種方法的。從這個角度說,GPT-1 的創新度是在 BERT 之上的。
GPT-2:放下微調(Zero-shot)
BERT 是在 GPT-1 誕生后不久發布的,BERT 使用了與 GPT-1 類似的思想和更大數據集,達到了比它更好的效果,所以 OpenAI 團隊一直在憋著想要打贏這場翻身仗,他們的反擊,就是 GPT-2。
GPT-2 第一次推出了 WebText 這個百萬級別的數據集。BERT 你的數據多是吧?我比你還多。而且,GPT-2 還使用了比 BERT 更大的 15 億參數的 Transformer,BERT 你模型大吧?我比你還大。有了更大的數據集和參數,GPT-2 就能更好地捕捉復雜的語言特征和更長距離的上下文語義關系。
事實證明,GPT-2在各種標準任務中表現出色。然而,OpenAI團隊并沒有滿足于在標準任務上取得的進步,而是想到既然已經投入了大量資源來構建這個“小怪物”,為什么還需要下游任務進行微調呢?
零樣本學習就此誕生。
那什么是零樣本學習呢,就是創造一個通用的、不需要任何額外樣本,就能解決所有下游任務的預訓練大模型。
于是,這次 OpenAI 索性就把所有可能用到的下游任務數據匯集成了一個多任務學習(MTL)的數據集,并將這些數據都加入到了 GPT-2 模型的訓練數據當中,想要看看到底能合成出一個什么樣的“新物種”。
這個想法很有吸引力,但是如果不進行下游任務的微調,模型要怎么知道自己該做什么任務呢。這時,OpenAI 提出了一種影響了后續所有語言模型工作的方法,那就是通過提示詞(prompt)的方式,來告知模型它需要解決什么問題。
OpenAI 在預訓練過程中,將各類 NLP 任務的數據都放到 GPT-2 的訓練數據中,幫助大模型更好地理解和生成文本。在經過這些步驟以后,GPT-2 的預訓練模型在未經過任何微調的情況下,就能戰勝許多下游任務的最佳結果。
它不僅在很多 NLP 任務上超越了 BERT,還成功地提出并完成了 “零樣本學習” 這個更為困難的任務。
GPT-3:超越微調(in-Context Learning)
“零樣本學習”的方式仍然存在一定的局限性,因為下游的使用者,很難把新的下游數據注入到模型中,因為 GPT-3 預訓練模型的規模已經變得非常龐大了,它是當時規模最大的模型之一,具有驚人的 1750 億個參數,很少有機構有能力承擔微調所需的巨大算力成本。
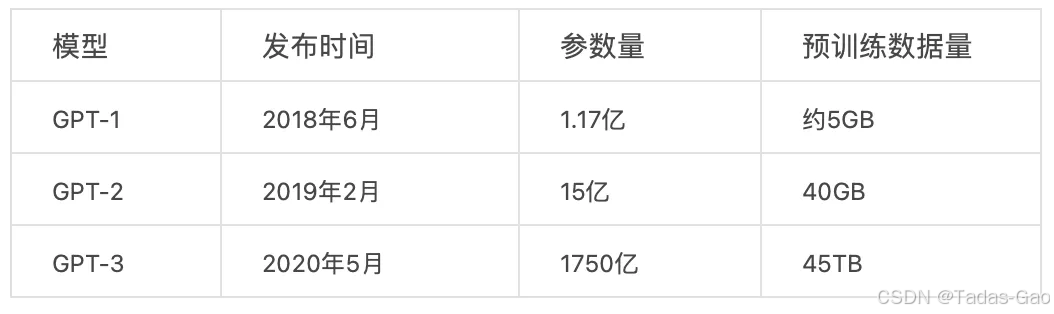
于是,OpenAI 提出了一個更新的理念,也就是全新的“少樣本學習”(Few-Shot Learning)的概念。這和傳統意義上模型微調的“少樣本學習”是不一樣的。GPT-3 所提出的方式是,允許下游使用者通過提示詞(prompt)直接把下游任務樣本輸入到模型中,讓模型在提示語中學習新樣本的模式和規律,這種方法的學名叫做in-context learning。
def translate(text, model):instruction = "Translate the following English text to French:\n"example = "sea otter => loutre de mer\n"task = text + " => "# Construct the promptprompt = f"{instruction}{example}{task}"translation = model.generate_text(prompt)return translation這種方法也存在缺點,其中最明顯的問題是,注入樣本的數量完全受限于模型能接收的最大提示詞長度。這就導致 GPT 向著參數規模越來越大、訓練數據越來越多,還有提示詞輸入長度越來越長這樣的趨勢發展。你在 GPT-4 的各項參數中,一定也發現了這個規律。
正是 GPT-3 這種基于提示詞的開放輸入方式,讓用戶可以直接與大語言模型(LLM)進行互動,逐漸開始感受到了大模型的"涌現"和"思維鏈"等能力的魅力和價值。
GPT-3 的問世也引發了中小企業的擔憂,這么高昂的訓練成本可能會導致大公司在技術方面形成壟斷,這讓全球各公司逐漸認識到當中蘊含的價值,紛紛開始加入這場技術軍備競賽,這直接導致了 NVIDIA 的公司股價持續攀升。
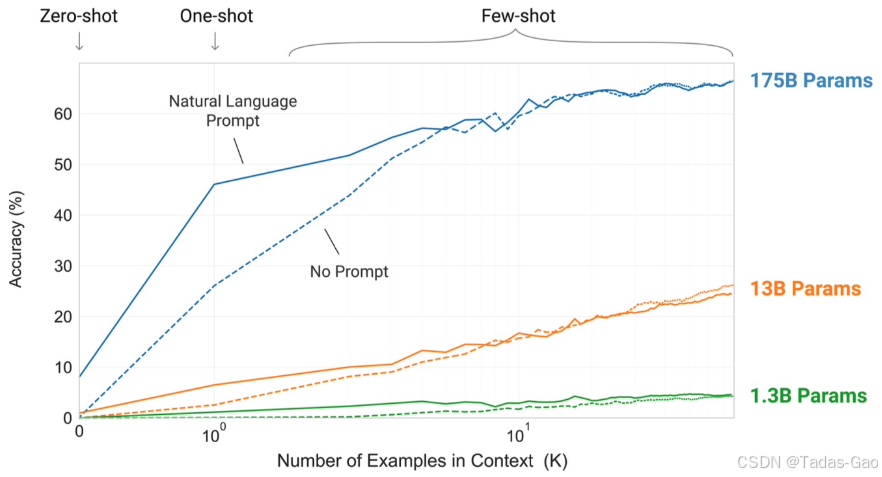
從上圖可看出:不管多少參數量下,少樣本學習的效果都明顯優于零樣本學習和One-shot。
OpenAI 的模型迭代:預訓練與微調的共舞
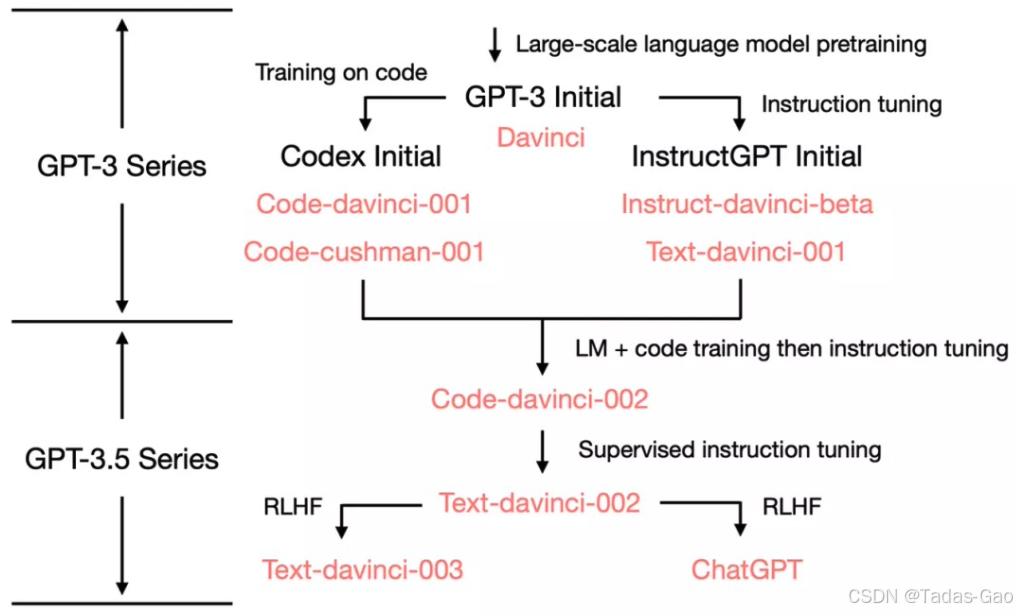
1. GPT-3 Initial(起點)
-
這是最初的 GPT-3 基礎模型,發布于 2020 年。
-
從這一起點分出兩條主要路徑:
-
Codex 分支(面向代碼生成)
-
InstructGPT 分支(面向指令微調)
-
2. 第一條分支:Codex Initial
-
目標:專注于代碼生成和補全任務。
-
衍生模型:
-
Code-davinci-001:早期代碼生成模型,能力較強。
-
Code-cushman-001:輕量級代碼模型,響應速度更快。
-
3. 第二條分支:InstructGPT Initial
-
目標:優化對指令的理解和響應,更適合交互式任務。
-
衍生模型:
-
Instruct-davinci-beta:早期指令調優的實驗性模型。
-
Text-davinci-001:初步融合代碼和指令能力的模型。
-
4. 分支合并:Code-davinci-002?進入 GPT-3.5 系列
-
關鍵節點:Code-davinci-002?的能力被整合到 GPT-3.5 系列中。
-
產出模型:
-
Text-davinci-002:作為 GPT-3.5 系列的起點,兼具代碼和文本能力。
-
5. GPT-3.5 系列的進一步分化
從?Text-davinci-002?開始,分出兩條新的路徑:
-
Text-davinci-003
-
迭代優化的通用文本模型,改進了指令微調和生成質量。
-
主要用于 API 和文本生成任務。
-
-
ChatGPT
-
專注于對話交互的模型,基于人類反饋強化學習(RLHF)優化。
-
發布于 2022 年 11 月,成為面向大眾的對話式 AI。
-
關鍵點
-
Codex 和 InstructGPT 是平行發展的兩條技術路線,分別側重代碼和指令理解。
-
GPT-3.5 系列是技術整合的產物,尤其是 Code-davinci-001 的代碼能力被融入。
-
ChatGPT 是 GPT-3.5 的對話專用分支,通過 RLHF 大幅優化交互體驗。
這一路徑反映了 OpenAI 從通用模型(GPT-3)到垂直優化(代碼、指令),再通過技術整合推出更強的通用模型(GPT-3.5)的戰略。
遇見都是天意,記得點贊收藏哦!
,用于解決無人機三維路徑規劃問題,Matlab代碼實現)

![MCP:讓AI工具協作變得像聊天一樣簡單 [特殊字符]](http://pic.xiahunao.cn/MCP:讓AI工具協作變得像聊天一樣簡單 [特殊字符])








![洛谷P12610 ——[CCC 2025 Junior] Donut Shop](http://pic.xiahunao.cn/洛谷P12610 ——[CCC 2025 Junior] Donut Shop)

Java/python/JavaScript/C++/C語言/GO六種最佳實現)



)

