
1. 引言
傳統企業通常將常見問題(FAQ)發布在網站上,方便客戶自助查找信息。然而,隨著生成式 AI 技術的迅速發展與商業滲透,這些企業正積極探索構建智能問答系統的新途徑。這類系統不僅能顯著提升客戶體驗,還能有效降低人工支持成本,實現客戶服務的智能化轉型。
本文將詳細分享如何利用 Amazon Q Developer CLI(以下簡稱 Q CLI) 和 Amazon Bedrock Knowledge Bases(以下簡稱 Bedrock KB) 快速構建端到端的智能問答系統。我們將從網頁爬取 FAQ 開始,到構建高效知識庫,實現全流程自動化,幫助企業輕松邁入 AI 客戶服務新時代。
📢限時插播:Amazon Q Developer 來幫你做應用啦!
🌟10分鐘幫你構建智能番茄鐘應用,1小時搞定新功能拓展、測試優化、文檔注程和部署
?快快點擊進入《Agentic Al 幫你做應用 -- 從0到1打造自己的智能番茄鐘》實驗
免費體驗企業級 AI 開發工具的真實效果吧
構建無限,探索啟程!
2. 智能問答系統構建
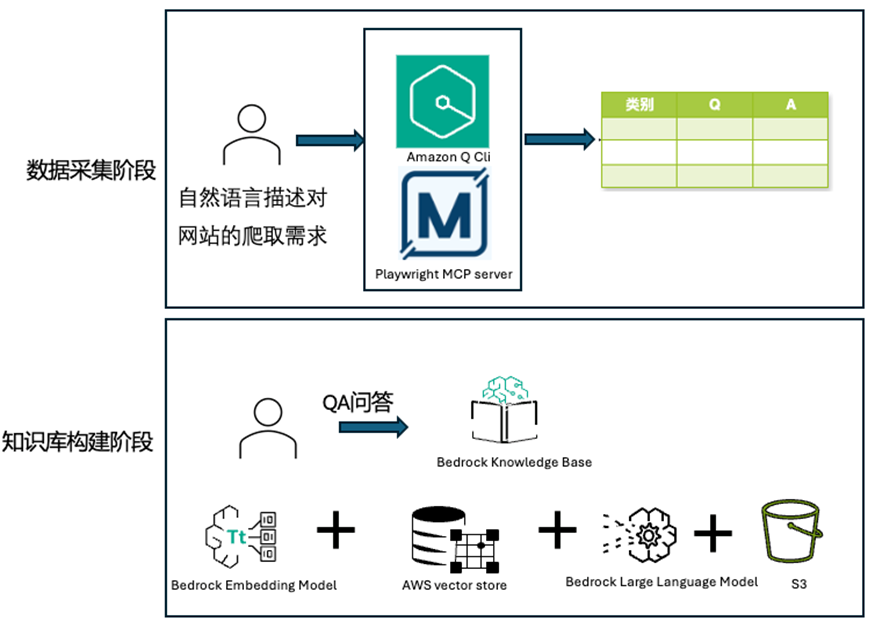
我們的解決方案分為兩個核心階段:
1、數據采集階段 – 利用 Q CLI 和 Playwright MCP Server 自動從網頁爬取 Q&A 問答對,整理到 Excel 表中。
該階段主要解決的問題是從網頁中快速、自動提取結構化信息,特別是對于常見問題解答(FAQ)頁面,能夠自動化提取問答對并將其轉化為結構化數據,可以為知識庫建設、客戶支持系統和智能問答機器人提供信息資源。本文將分享如何利用 Q CLI 和 Playwright MCP Server 快速構建一個自動化工作流,實現網頁爬取、內容識別和問答對提取。
2、知識庫構建階段 – 將結構化數據導入 Bedrock KB,構建 Q&A 系統。
該階段主要解決的核心問題是:如何將結構化的 Q&A 對 Excel 文件轉化為智能可查詢的知識庫,并確保系統能準確理解和匹配用戶問題。這一挑戰尤為關鍵,因為網站 FAQ 中的問題通常按類別組織,在原始上下文中意義清晰,但一旦脫離分類結構,同樣的問題可能變得模糊不清。例如,”如何修改訂單?”這個問題在不同業務場景下可能有完全不同的答案。我們需要確保智能問答系統不僅存儲問答對,還能根據上下文進行問題分類,以實現精準的語義匹配和回答檢索。
架構圖如下:
3. 基于 Q CLI + Playwright MCP Server 的自動化數據采集
Amazon Q CLI 是亞馬遜推出的一種命令行工具,作為 Amazon Q Developer 的一部分,它允許開發者直接在命令行界面與 Amazon Q 的人工智能能力進行交互。為了延伸 Q CLI 調用外部工具的能力,Q CLI 從 1.9.0 版本開始支持模型上下文協議(Model Context Protocol MCP),借助外部 MCP Server,可以極大地擴充 Q CLI 的能力。
Playwright 是一款開源瀏覽器自動化框架,提供了跨瀏覽器的自動化測試和網頁交互能力。而 Playwright MCP Server 則是基于 MCP 協議為大語言模型(LLM)提供了使用 Playwright 進行瀏覽器自動化的能力。具有以下核心功能:
-
網頁導航與交互:允許 AI 模型打開網頁、點擊按鈕、填寫表單,等等。
-
屏幕截圖和網站文字獲取:捕獲當前網頁的截圖,幫助 AI 分析頁面內容。
-
JavaScript 執行:在瀏覽器環境中運行 JavaScript 代碼,實現復雜交互,等等。
當 Q CLI 集成 Playwright MCP Server 后,我們在 Q CLI 中通過自然語言交互就能夠實現網頁的打開、點擊,網頁文字內容的讀取存儲和解析,無需手工操作處理。
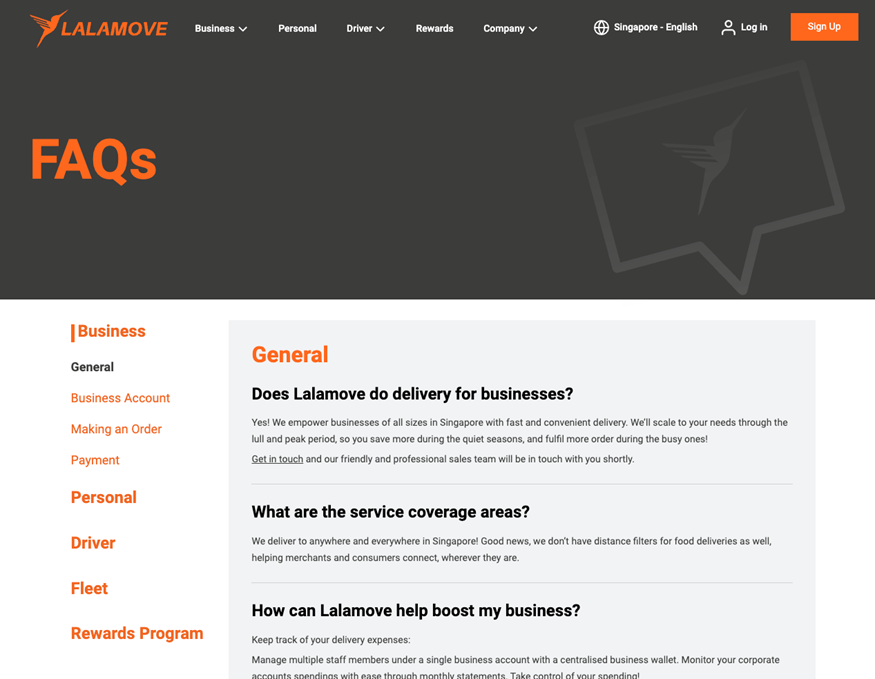
比如如下的網頁,Q&A 已經使用問答形式將客戶關心的問題和答案做了分類整理,但如果我們想導入知識庫,就需要把網站的內容導出到 Excel 文件,便于后續處理。
下面我們就向大家一步步展示 Q CLI 集成 Playwright MCP Server 后的強大能力。
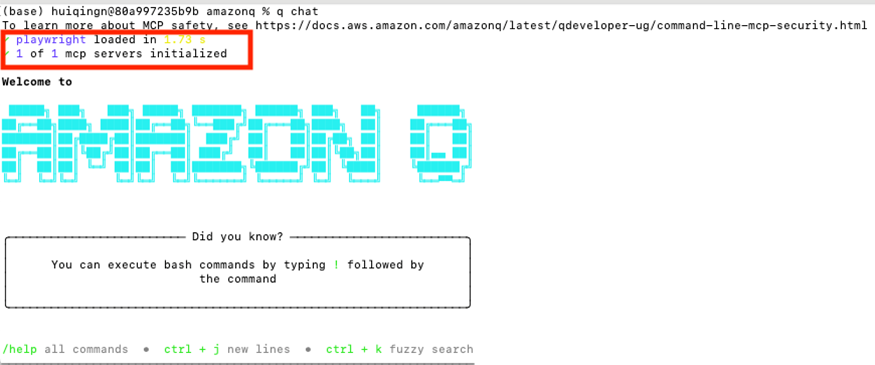
3.1 配置 Q CLI 集成 Playwright MCP Server
在 Q CLI 中集成 MCP Server 非常簡單,在 Q Developer 的安裝目錄,通常是~/.aws/amazonq/mcp.json 文件中配置 playwright MCP Server,如下:
參考:https://github.com/executeautomation/mcp-playwright
{"mcpServers": {"playwright": {"command": "npx","args": ["-y", "@executeautomation/playwright-mcp-server"]}}
}啟動 Q Chat 可以看到配置的 Playwright MCP server 已經正常啟動了。
3.2 通過自然語言交互實現爬網
在 Q Chat 中輸入:
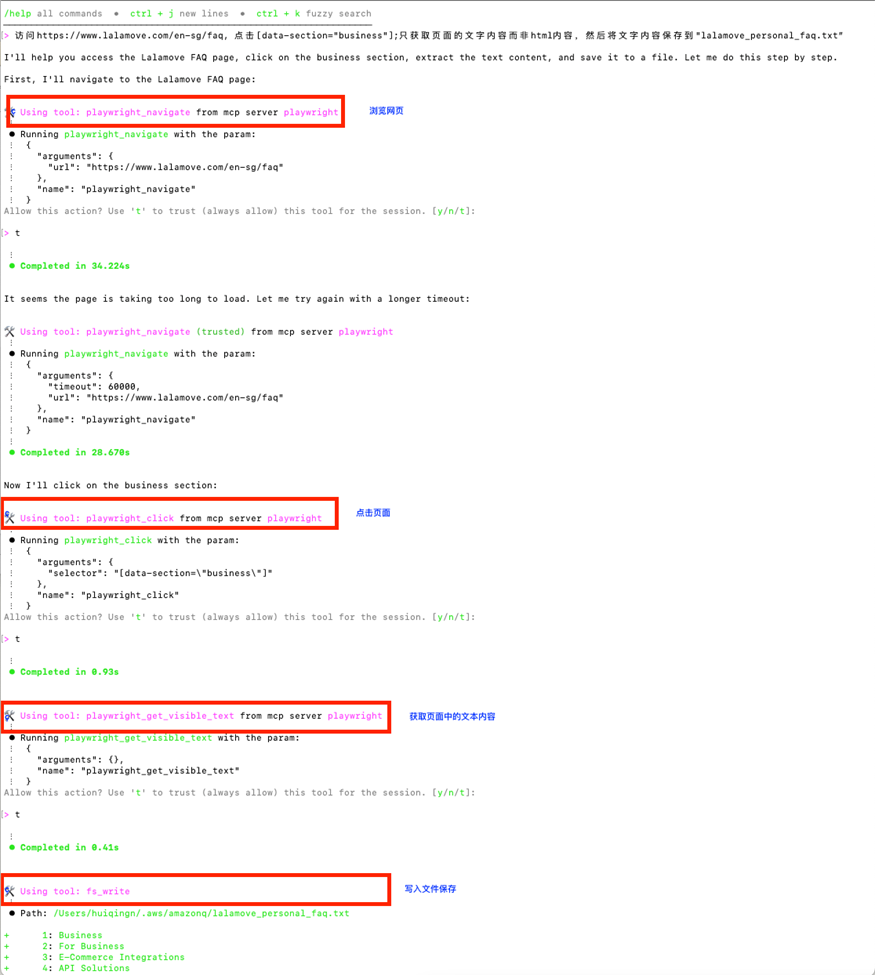
訪問 Courier & Delivery Services FAQs | Lalamove Singapore,點擊[data-section=”business”];只獲取頁面的文字內容而非 html 內容,然后將文字內容保存到”lalamove_personal_faq.txt”
就可以看到 Amazon Q 已經開始理解我們的需求,并調用 Playwright MCP Server 提供的合適的工具開始爬網了。它分別使用:
-
playwright_navigate 工具打開指定的網站
-
playwright_click 點擊上面網頁的“Business”鏈接
-
playwright_get_visible_text 工具獲得網站上的文字內容
-
fs_write 將文字內容保存在本地文件
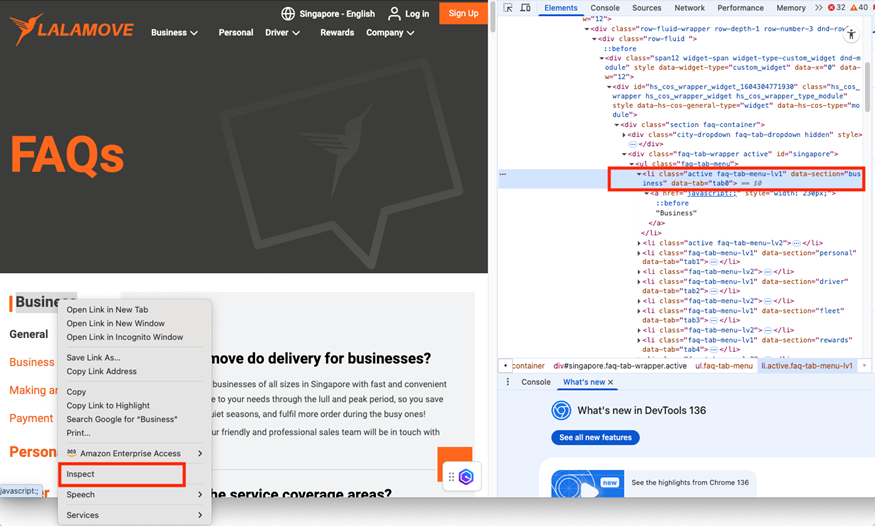
這里有個有趣的點值得一提:你會發現我們的提示詞里面特別添加了點擊[data-section=”business”]
訪問 Courier & Delivery Services FAQs | Lalamove Singapore,點擊[data-section=”business”];只獲取頁面的文字內容而非 html 內容,然后將文字內容保存到”lalamove_personal_faq.txt”
這樣做的原因是,網站中有多個“business”的字樣,如果不做特別說明,LLM 通常會根據開發習慣猜測點擊時使用的 selector,將該參數傳遞給 Playwright 工具,當與實際情況不符時,Playwright 往往難以點擊到正確的鏈接。我們通過如下的方法獲得準確的 selector 放入指令中,LLM 就可以生成準確的參數,實現精準的點擊。
3.3 通過自然語言交互實現文本到 Excel 的轉換
我們繼續與 Q CLI 進行交互:
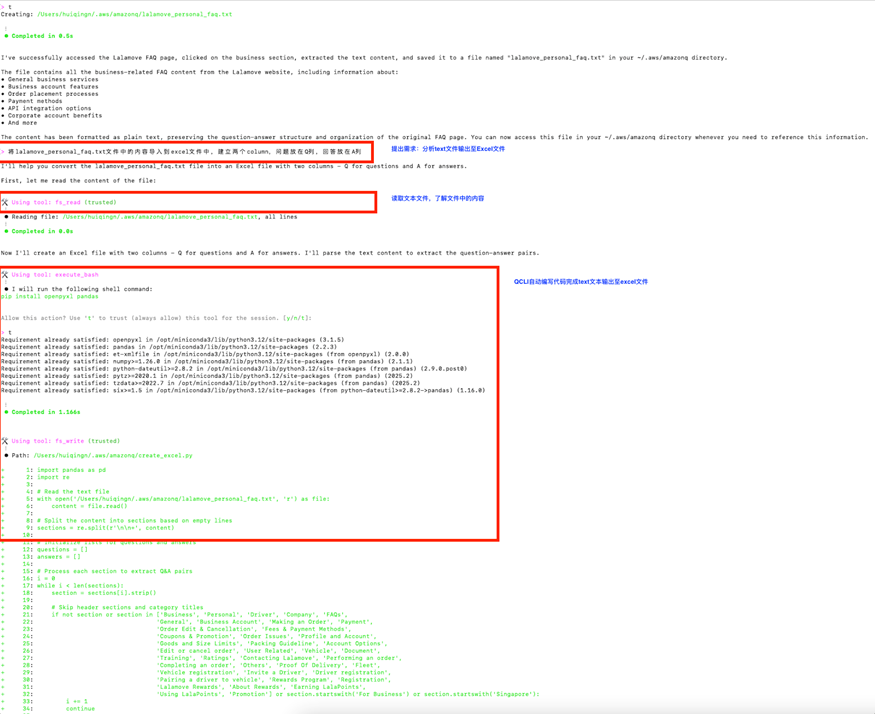
Q CLI 經過上面的一系列的自動操作幾分鐘之內就將網頁的 Q&A 對整理到 Excel 文件中:

4. 基于 Amazon Bedrock Knowledge Bases 的知識庫構建
該項目中我們主要遇到兩個挑戰:
-
網站中的 FAQ 是按類別組織的,同樣的問題在不同上下文回答可能完全不同。
為了解決這個問題,我們利用 Bedrock KB 的元數據過濾功能(Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy | AWS Machine Learning Blog),允許您根據文檔的特定屬性細化搜索結果,提高檢索準確性和響應的相關性。
-
客戶是通過多輪會話進行提問的,每輪會話的意圖(或是對應的分類)都有可能變化。
為了解決這個問題,我們采用結合歷史會話和當前問題進行問題分類,結合 Bedrock KB 的元數據過濾能力進行知識庫的問題搜索。
4.1 基于元數據的 Q&A 問題導入
為了實現基于元數據的 Q&A 問題導入,我們對前面整理出來的 Excel 文件進行拆解,每個 Q&A 問題對都對應一個 Excel 文件和一個元數據 metadata.json 文件,如下:
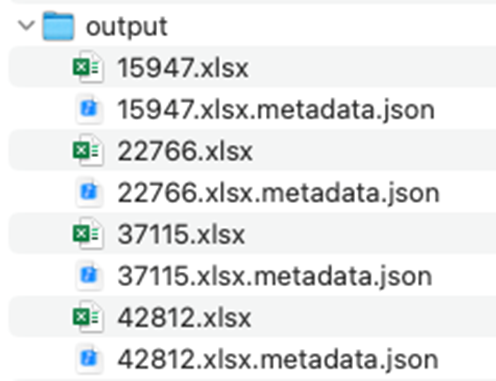
每個 Excel 文件內容:

對應的 metadata.json 文件內容:
{"metadataAttributes": {"Category": "Business","Sub-Category": "General"}
}將這些文件作為數據統一放在 S3 中作為數據源導入到 Bedrock KB 中。
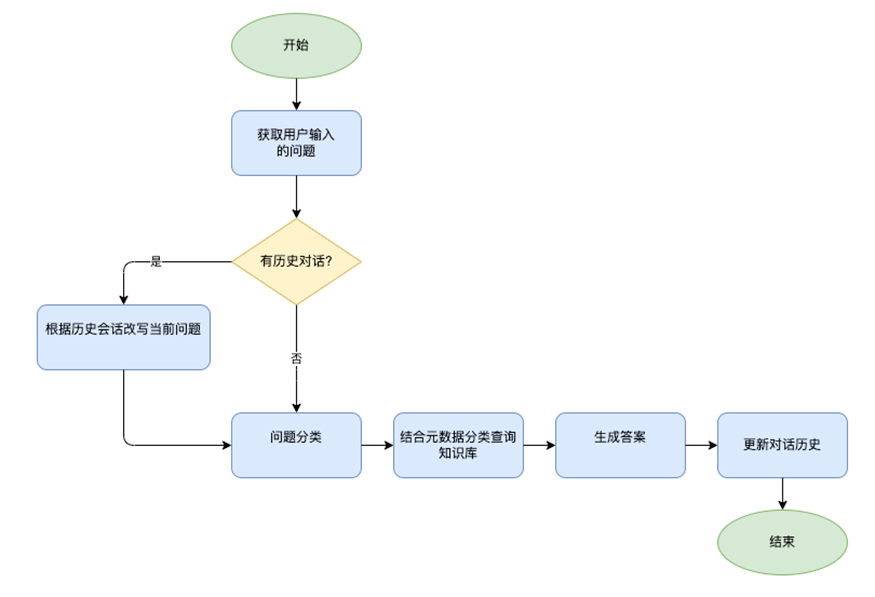
4.2 基于多輪會話的意圖識別和 Bedrock KB 查詢
結合歷史會話做意圖分類的邏輯如下:
基于 Bedrock KB 做信息檢索的代碼片段:
try:# 設置Bedrock KB配置最多返回3條信息retrieval_config = {'vectorSearchConfiguration': {'numberOfResults': 3}}# 根據問題做的分類來添加過查詢bedrock KB的過濾條件if category != "others":# 添加分類過濾條件retrieval_config['vectorSearchConfiguration']['filter'] = {'equals': {'key': 'Category','value': category}}logger.info(f"使用分類過濾: {category}")else:logger.info("未使用分類過濾,將搜索所有分類")# 調用知識庫檢索APIresponse = bedrock_agent_runtime.retrieve(retrievalQuery={'text': query},knowledgeBaseId=KNOWLEDGE_BASE_ID,retrievalConfiguration=retrieval_config)# 打印檢索結果logger.info(json.dumps(response['retrievalResults'], ensure_ascii=False, indent=2))return response['retrievalResults']except Exception as e:logger.error(f"查詢知識庫時出錯: {str(e)}")return []基于 Bedrock KB 的回取內容做答案生成的代碼片段:
try:# 結合客戶需求,當知識庫中沒有相關信息時直接返回,不需要LLM做總結。if not reference_items: return "抱歉,知識庫中沒有找到相關信息。"# 構建提示詞system_prompt, user_message = build_prompts(query, reference_items)# 設置對話消息system_prompts = [{"text": system_prompt}]messages = [{"role": "user","content": [{"text": user_message}]}]# 設置推理參數inference_config = {"temperature": 0}additional_model_fields = {"top_k": 50}# 調用模型APIresponse = bedrock_runtime.converse(modelId=MODEL,messages=messages,system=system_prompts,inferenceConfig=inference_config,additionalModelRequestFields=additional_model_fields)# 獲取模型響應output_message = response['output']['message']response_text = output_message['content'][0]['text']return response_textexcept Exception as e:logger.error(f"生成答案時出錯: {str(e)}")return f"處理您的問題時出錯: {str(e)}"5. 總結
Amazon Q CLI 可以與 MCP Server 實現方便的集成。本項目通過 Q CLI 與 Playwright MCP 集成,為網頁內容提取和問答對識別提供了一種高效、智能的解決方案。通過簡單的自然語言指令,我們就可以快速實現從網頁爬取到結構化數據生成的全流程自動化。這不僅大大提高了開發效率,也為構建智能知識庫和問答系統提供了堅實基礎。
同時,結合 Amazon Bedrock Knowledge Bases 的元數據過濾功能,我們可以首先基于歷史會話對問題進行分類,在準確的類別中再完成知識庫的搜索和答案生成,進一步提升 Q&A 回復的準確率。
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
本篇作者
本期最新實驗為《Agentic AI 幫你做應用 —— 從0到1打造自己的智能番茄鐘》
? 自然語言玩轉命令行,10分鐘幫你構建應用,1小時搞定新功能拓展、測試優化、文檔注釋和部署
💪 免費體驗企業級 AI 開發工具,質量+安全全掌控
??[點擊進入實驗] 即刻開啟 AI 開發之旅構建無限, 探索啟程!





——進程(控制篇——下))



)


)


算法深度解析)



