這里所說的“學習”是指從訓練數據中自動獲取最優權重參數的過程。為了使神經網絡能進行學習,將導入損失函數這一指標。而學習的目的就是以該損失函數為基準,找出能使它的值達到最小的權重參數。為了找出盡可能小的損失函數的值,我們將介紹利用了函數斜率的梯度法。
1. 從數據中學習
神經網絡的特征就是可以從數據中學習。所謂“從數據中學習”,是指可以由數據自動決定權重參數的值。這是非常了不起的事情!因為如果所有的參數都需要人工決定的話,工作量就太大了。在第 2 章介紹的感知機的例子中,我們對照著真值表,人工設定了參數的值,但是那時的參數只有 3 個。而在實際的神經網絡中,參數的數量成千上萬,在層數更深的深度學習中,參數的數量甚至可以上億,想要人工決定這些參數的值是不可能的。神經網絡的學習,即利用數據決定參數值的方法,并用 Python 實現對 MNIST 手寫數字數據集的學習。
1.1 數據驅動
數據是機器學習的命根子。從數據中尋找答案、從數據中發現模式、根據數據講故事……這些機器學習所做的事情,如果沒有數據的話,就無從談起。因此,數據是機器學習的核心。這種數據驅動的方法,也可以說脫離了過往以人為中心的方法。
通常要解決某個問題,特別是需要發現某種模式時,人們一般會綜合考慮各種因素后再給出回答。“這個問題好像有這樣的規律性?”“不對,可能原因在別的地方。”——類似這樣,人們以自己的經驗和直覺為線索,通過反復試驗推進工作。而機器學習的方法則極力避免人為介入,嘗試從收集到的數據中發現答案(模式)。神經網絡或深度學習則比以往的機器學習方法更能避免人為介入。
現在我們來思考一個具體的問題,比如如何實現數字“5”的識別。數字 5 是圖 4-1 所示的手寫圖像,我們的目標是實現能區別是否是 5 的程序。這個問題看起來很簡單,大家能想到什么樣的算法呢?

圖 4-1 手寫數字 5 的例子:寫法因人而異,五花八門
如果讓我們自己來設計一個能將 5 正確分類的程序,就會意外地發現這是一個很難的問題。人可以簡單地識別出 5,但卻很難明確說出是基于何種規律而識別出了 5。此外,從圖 4-1 中也可以看到,每個人都有不同的寫字習慣,要發現其中的規律是一件非常難的工作。
因此,與其絞盡腦汁,從零開始想出一個可以識別 5 的算法,不如考慮通過有效利用數據來解決這個問題。一種方案是,先從圖像中提取 特征量 ,再用機器學習技術學習這些特征量的模式。這里所說的“特征量”是指可以從輸入數據(輸入圖像)中準確地提取本質數據(重要的數據)的轉換器。圖像的特征量通常表示為向量的形式。在計算機視覺領域,常用的特征量包括 SIFT、SURF 和 HOG 等。使用這些特征量將圖像數據轉換為向量,然后對轉換后的向量使用機器學習中的 SVM、KNN 等分類器進行學習。
機器學習的方法中,由機器從收集到的數據中找出規律性。與從零開始想出算法相比,這種方法可以更高效地解決問題,也能減輕人的負擔。但是需要注意的是,將圖像轉換為向量時使用的特征量仍是由人設計的。對于不同的問題,必須使用合適的特征量(必須設計專門的特征量),才能得到好的結果。比如,為了區分狗的臉部,人們需要考慮與用于識別 5 的特征量不同的其他特征量。也就是說,即使使用特征量和機器學習的方法,也需要針對不同的問題人工考慮合適的特征量。
到這里,我們介紹了兩種針對機器學習任務的方法。將這兩種方法用圖來表示,如圖 4-2 所示。圖中還展示了神經網絡(深度學習)的方法,可以看出該方法不存在人為介入。
如圖 4-2 所示,神經網絡直接學習圖像本身。在第 2 個方法,即利用特征量和機器學習的方法中,特征量仍是由人工設計的,而在神經網絡中,連圖像中包含的重要特征量也都是由機器來學習的。
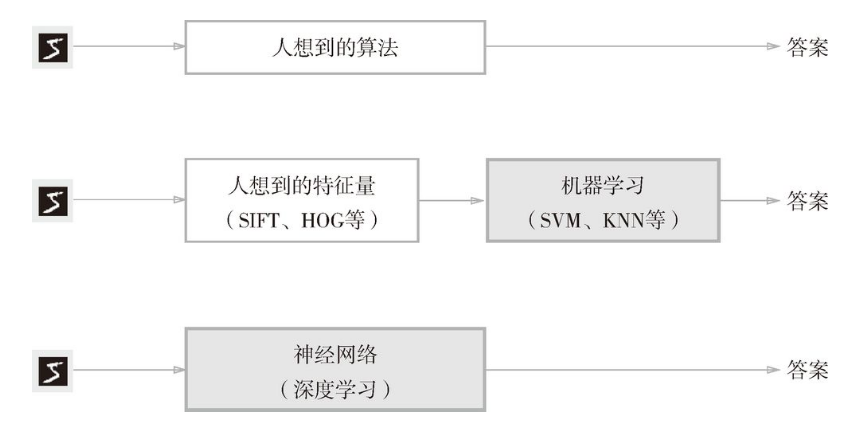
圖 4-2 從人工設計規則轉變為由機器從數據中學習:沒有人為介入的方塊用灰色表示
深度學習有時也稱為端到端機器學習(end-to-end machine learning)。這里所說的 端到端 是指從一端到另一端的意思,也就是從原始數據(輸入)中獲得目標結果(輸出)的意思。
神經網絡的優點是對所有的問題都可以用同樣的流程來解決。比如,不管要求解的問題是識別 5,還是識別狗,抑或是識別人臉,神經網絡都是通過不斷地學習所提供的數據,嘗試發現待求解的問題的模式。也就是說,與待處理的問題無關,神經網絡可以將數據直接作為原始數據,進行“端對端”的學習。
1.2 訓練數據和測試數據
機器學習中,一般將數據分為 訓練數據 和 測試數據 兩部分來進行學習和實驗等。首先,使用訓練數據進行學習,尋找最優的參數;然后,使用測試數據評價訓練得到的模型的實際能力。為什么需要將數據分為訓練數據和測試數據呢?因為我們追求的是模型的泛化能力。為了正確評價模型的泛化能力 ,就必須劃分訓練數據和測試數據。另外,訓練數據也可以稱為監督數據 。
泛化能力是指處理未被觀察過的數據(不包含在訓練數據中的數據)的能力。獲得泛化能力是機器學習的最終目標。比如,在識別手寫數字的問題中,泛化能力可能會被用在自動讀取明信片的郵政編碼的系統上。此時,手寫數字識別就必須具備較高的識別“某個人”寫的字的能力。注意這里不是“特定的某個人寫的特定的文字”,而是“任意一個人寫的任意文字”。如果系統只能正確識別已有的訓練數據,那有可能是只學習到了訓練數據中的個人的習慣寫法。
因此,僅僅用一個數據集去學習和評價參數,是無法進行正確評價的。這樣會導致可以順利地處理某個數據集,但無法處理其他數據集的情況。順便說一下,只對某個數據集過度擬合的狀態稱為 過擬合 (over fitting)。避免過擬合也是機器學習的一個重要課題。
2. 損失函數
如果有人問你現在有多幸福,你會如何回答呢?一般的人可能會給出諸如“還可以吧”或者“不是那么幸福”等籠統的回答。如果有人回答“我現在的幸福指數是 10.23”的話,可能會把人嚇一跳吧。因為他用一個數值指標來評判自己的幸福程度。
這里的幸福指數只是打個比方,實際上神經網絡的學習也在做同樣的事情。神經網絡的學習通過某個指標表示現在的狀態。然后,以這個指標為基準,尋找最優權重參數。和剛剛那位以幸福指數為指引尋找“最優人生”的人一樣,神經網絡以某個指標為線索尋找最優權重參數。神經網絡的學習中所用的指標稱為損失函數 (loss function)。這個損失函數可以使用任意函數,但一般用均方誤差和交叉熵誤差等。
損失函數是表示神經網絡性能的“惡劣程度”的指標,即當前的神經網絡對監督數據在多大程度上不擬合,在多大程度上不一致。以“性能的惡劣程度”為指標可能會使人感到不太自然,但是如果給損失函數乘上一個負值,就可以解釋為“在多大程度上不壞”,即“性能有多好”。并且,“使性能的惡劣程度達到最小”和“使性能的優良程度達到最大”是等價的,不管是用“惡劣程度”還是“優良程度”,做的事情本質上都是一樣的。
2.1 均方誤差
可以用作損失函數的函數有很多,其中最有名的是均方誤差 (mean squared error)。均方誤差如下式所示。
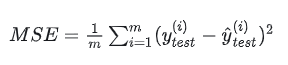
這里, y_test是表示神經網絡的輸出,y^_test 表示監督數據。比如,在 手寫數字識別的例子中, y_test, y^_test 是由如下 10 個元素構成的數據。
>>> y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]>>> t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
數組元素的索引從第一個開始依次對應數字“0”“1”“2”……這里,神經網絡的輸出 y 是 softmax 函數的輸出。由于 softmax 函數的輸出可以理解為概率,因此上例表示“0”的概率是 0.1,“1”的概率是 0.05,“2”的概率是 0.6 等。t 是監督數據,將正確解標簽設為 1,其他均設為 0。這里,標簽“2”為 1,表示正確解是“2”。將正確解標簽表示為 1,其他標簽表示為 0 的表示方法稱為 one-hot 表示 。
如式(4.1)所示,均方誤差會計算神經網絡的輸出和正確解監督數據的各個元素之差的平方,再求總和。現在,我們用 Python 來實現這個均方誤差,實現方式如下所示。
import numpy as npdef mean_squared_error(y, t):# return (np.sum((y - t) ** 2))/y.sizereturn np.mean(np.square(y - t))# 標記第三個元素為正解
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
# 第三個元素的概率最高, 與正解對應
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
print(mean_squared_error(y, t))
# 第八個元素概率最高,與正解不符
y = np.array([0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0])
print(mean_squared_error(y, t))輸出:
0.019500000000000007
0.11950000000000001
如實驗結果所示,我們發現第一個例子的損失函數的值更小,和監督數據之間的誤差較小。也就是說,均方誤差顯示第一個例子的輸出結果與監督數據更加吻合。
2.2 交叉熵誤差
除了均方誤差之外,交叉熵誤差 (cross entropy error)也經常被用作損失函數。交叉熵誤差如下式所示。
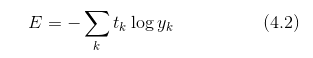
這里,log 表示以e為底數的自然對數(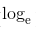 )。y_k 是神經網絡的輸出,t_k 是正確解標簽。并且,t_k 中只有正確解標簽的索引為 1,其他均為 0(one-hot 表示)。因此,式(4.2)實際上只計算對應正確解標簽的輸出的自然對數。比如,假設正確解標簽的索引是“2”,與之對應的神經網絡的輸出是 0.6,則交叉熵誤差是 -log 0.6 = 0.51;若“2”對應的輸出是 0.1,則交叉熵誤差為 -log 0.1 = 2.30。也就是說,交叉熵誤差的值是由正確解標簽所對應的輸出結果決定的。
)。y_k 是神經網絡的輸出,t_k 是正確解標簽。并且,t_k 中只有正確解標簽的索引為 1,其他均為 0(one-hot 表示)。因此,式(4.2)實際上只計算對應正確解標簽的輸出的自然對數。比如,假設正確解標簽的索引是“2”,與之對應的神經網絡的輸出是 0.6,則交叉熵誤差是 -log 0.6 = 0.51;若“2”對應的輸出是 0.1,則交叉熵誤差為 -log 0.1 = 2.30。也就是說,交叉熵誤差的值是由正確解標簽所對應的輸出結果決定的。
自然對數的圖像如圖 4-3 所示。
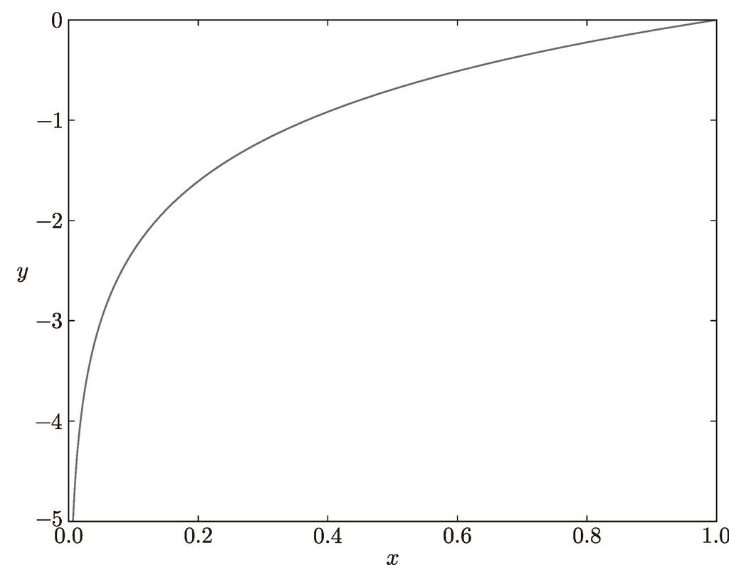
圖 4-3 自然對數 y = log x 的圖像
如圖 4-3 所示,x 等于 1 時,y 為 0;隨著 x 向 0 靠近,y 逐漸變小。因此,正確解標簽對應的輸出越大,式(4.2)的值越接近 0;當輸出為 1 時,交叉熵誤差為 0。此外,如果正確解標簽對應的輸出較小,則式(4.2)的值較大。
import numpy as npdef cross_entropy_error(y,t):delta = 1e-7return -np.sum(t*np.log(y+delta))# 標記第三個元素為正解
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
# 第三個元素的概率最高, 與正解對應
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
print(cross_entropy_error(y, t))
# 第八個元素概率最高,與正解不符
y = np.array([0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0])
print(cross_entropy_error(y, t))輸出:
0.510825457099338
2.302584092994546
這里,參數 y 和 t 是 NumPy 數組。函數內部在計算 np.log 時,加上了一個微小值 delta 。這是因為,當出現 np.log(0) 時,np.log(0) 會變為負無限大的 -inf ,這樣一來就會導致后續計算無法進行。作為保護性對策,添加一個微小值可以防止負無限大的發生。
第一個例子中,正確解標簽對應的輸出為 0.6,此時的交叉熵誤差大約為 0.51。第二個例子中,正確解標簽對應的輸出為 0.1 的低值,此時的交叉熵誤差大約為 2.3。由此可以看出,這些結果與我們前面討論的內容是一致的。
2.3 mini-batch 學習
機器學習使用訓練數據進行學習。
使用訓練數據進行學習,嚴格來說,就是針對訓練數據計算損失函數的值,找出使該值盡可能小的參數。因此,計算損失函數時必須將所有的訓練數據作為對象。也就是說,如果訓練數據有 100 個的話,我們就要把這 100 個損失函數的總和作為學習的指標。
前面介紹的損失函數的例子中考慮的都是針對單個數據的損失函數。如果要求所有訓練數據的損失函數的總和,以交叉熵誤差為例,可以寫成下面的式(4.3)。
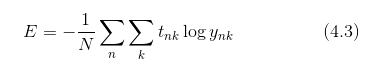
這里,假設數據有 N 個, t_nk表示第 n 個數據的第 k 個元素的值( y_nk是神經網絡的輸出, t-nk是監督數據)。式子雖然看起來有一些復雜,其實只是把求單個數據的損失函數的式(4.2)擴大到了 N 份數據,不過最后還要除以 N 進行正規化。通過除以 N ,可以求單個數據的“平均損失函數”。通過這樣的平均化,可以獲得和訓練數據的數量無關的統一指標。比如,即便訓練數據有 1000 個或 10000 個,也可以求得單個數據的平均損失函數。
另外,MNIST 數據集的訓練數據有 60000 個,如果以全部數據為對象求損失函數的和,則計算過程需要花費較長的時間。再者,如果遇到大數據,數據量會有幾百萬、幾千萬之多,這種情況下以全部數據為對象計算損失函數是不現實的。因此,我們從全部數據中選出一部分,作為全部數據的“近似”。神經網絡的學習也是從訓練數據中選出一批數據(稱為 mini-batch, 小批量),然后對每個 mini-batch 進行學習。比如,從 60000 個訓練數據中隨機選擇 100 筆,再用這 100 筆數據進行學習。這種學習方式稱為 mini-batch 學習 。
from mnist import load_mnist(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
print(x_train.shape)
print(t_train.shape)
輸出:
(60000, 784)
(60000, 10)
load_mnist 函數是用于讀入 MNIST 數據集的函數。讀入數據時,通過設定參數 one_hot_label=True ,可以得到 one-hot 表示(即僅正確解標簽為 1,其余為 0 的數據結構)。
讀入上面的 MNIST 數據后,訓練數據有 60000 個,輸入數據是 784 維(28 × 28)的圖像數據,監督數據是 10 維的數據。因此,上面的 x_train 、t_train 的形狀分別是 (60000, 784) 和 (60000, 10) 。
那么,如何從這個訓練數據中隨機抽取 10 筆數據呢?我們可以使用 NumPy 的 np.random.choice() ,np.random.choice() 可以從指定的數字中隨機選擇想要的數字。比如,np.random.choice(60000, 10) 會從 0 到 59999 之間隨機選擇 10 個數字, 之后,我們只需指定這些隨機選出的索引,取出 mini-batch,然后使用這個 mini-batch 計算損失函數即可。
a = np.random.choice(6000, 10)
print(a)
輸出:
[ 770 2035 5672 3293 5212 506 1026 2167 393 4240]
2.4 mini-batch 版交叉熵誤差的實現
只要改良一下之前實現的對應單個數據的交叉熵誤差就可以了。這里,我們來實現一個可以同時處理單個數據和批量數據(數據作為 batch 集中輸入)兩種情況的函數。
def cross_entropy_error(y, t):if y.ndim == 1:y = y.reshape(1, y.size)t = t.reshape(1, t.size)batch_size = t.shape[0]return -np.sum(t * np.log(y + 1e-7)) / batch_size
這里,y 是神經網絡的輸出,t 是監督數據。y 的維度為 1 時,即求單個數據的交叉熵誤差時,需要改變數據的形狀。并且,當輸入為 mini-batch 時,要用 batch 的個數進行正規化,計算單個數據的平均交叉熵誤差。
此外,當監督數據是標簽形式(非 one-hot 表示,而是像“2”“7”這樣的標簽)時,交叉熵誤差可通過如下代碼實現。
def cross_entropy_error(y, t):if y.ndim == 1:t = t.reshape(1, t.size)y = y.reshape(1, y.size)batch_size = y.shape[0]return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
實現的要點是,由于 one-hot 表示中 t 為 0 的元素的交叉熵誤差也為 0,因此針對這些元素的計算可以忽略。換言之,如果可以獲得神經網絡在正確解標簽處的輸出,就可以計算交叉熵誤差。因此,t 為 one-hot 表示時通過 t * np.log(y) 計算的地方,在 t 為標簽形式時,可用 np.log( y[np.arange (batch_size), t] ) 實現相同的處理(為了便于觀察,這里省略了微小值 1e-7 )。
np.arange (batch_size) 會生成一個從 0 到 batch_size-1 的數組。比如當 batch_size 為 5 時,np.arange(batch_size) 會生成一個 NumPy 數組 [0, 1, 2, 3, 4] 。因為 t 中標簽是以 [2, 7, 0, 9, 4] 的形式存儲的,所以 y[np.arange(batch_size), t] 能抽出各個數據的正確解標簽對應的神經網絡的輸出(在這個例子中,y[np.arange(batch_size), t] 會生成 NumPy 數組 [y[0,2], y[1,7], y[2,0], y[3,9], y[4,4]] )。
2.5 為何要設定損失函數
既然我們的目標是獲得使識別精度盡可能高的神經網絡,那不是應該把識別精度作為指標嗎?為何要設定損失函數呢
對于這一疑問,我們可以根據“導數”在神經網絡學習中的作用來回答。下一節中會詳細說到,在神經網絡的學習中,尋找最優參數(權重和偏置)時,要尋找使損失函數的值盡可能小的參數。為了找到使損失函數的值盡可能小的地方,需要計算參數的導數(確切地講是梯度),然后以這個導數為指引,逐步更新參數的值。
假設有一個神經網絡,現在我們來關注這個神經網絡中的某一個權重參數。此時,對該權重參數的損失函數求導,表示的是“如果稍微改變這個權重參數的值,損失函數的值會如何變化”。如果導數的值為負,通過使該權重參數向正方向改變,可以減小損失函數的值;反過來,如果導數的值為正,則通過使該權重參數向負方向改變,可以減小損失函數的值。不過,當導數的值為 0 時,無論權重參數向哪個方向變化,損失函數的值都不會改變,此時該權重參數的更新會停在此處。
之所以不能用識別精度作為指標,是因為這樣一來絕大多數地方的導數都會變為 0,導致參數無法更新。話說得有點多了,我們來總結一下上面的內容。
在進行神經網絡的學習時,不能將識別精度作為指標。因為如果以識別精度為指標,則參數的導數在絕大多數地方都會變為 0。
為什么用識別精度作為指標時,參數的導數在絕大多數地方都會變成 0 呢?為了回答這個問題,我們來思考另一個具體例子。假設某個神經網絡正確識別出了 100 筆訓練數據中的 32 筆,此時識別精度為 32 %。如果以識別精度為指標,即使稍微改變權重參數的值,識別精度也仍將保持在 32 %,不會出現變化。也就是說,僅僅微調參數,是無法改善識別精度的。即便識別精度有所改善,它的值也不會像 32.0123 … % 這樣連續變化,而是變為 33 %、34 % 這樣的不連續的、離散的值。而如果把損失函數作為指標,則當前損失函數的值可以表示為 0.92543 … 這樣的值。并且,如果稍微改變一下參數的值,對應的損失函數也會像 0.93432 … 這樣發生連續性的變化。
識別精度對微小的參數變化基本上沒有什么反應,即便有反應,它的值也是不連續地、突然地變化。作為激活函數的階躍函數也有同樣的情況。出于相同的原因,如果使用階躍函數作為激活函數,神經網絡的學習將無法進行。如圖 4-4 所示,階躍函數的導數在絕大多數地方(除了 0 以外的地方)均為 0。也就是說,如果使用了階躍函數,那么即便將損失函數作為指標,參數的微小變化也會被階躍函數抹殺,導致損失函數的值不會產生任何變化。
階躍函數,只在某個瞬間產生變化。而 sigmoid 函數,如圖 4-4 所示,不僅函數的輸出(豎軸的值)是連續變化的,曲線的斜率(導數)也是連續變化的。也就是說,sigmoid 函數的導數在任何地方都不為 0。這對神經網絡的學習非常重要。得益于這個斜率不會為 0 的性質,神經網絡的學習得以正確進行。
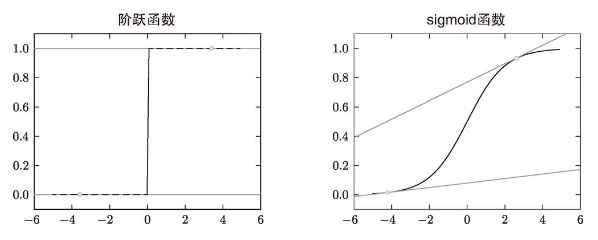
圖 4-4 階躍函數和 sigmoid 函數:階躍函數的斜率在絕大多數地方都為 0,而 sigmoid 函數的斜率(切線)不會為 0
















)

)
