阿爾茲海默病(Alzheimer's?Disease,?AD)是一種以認知能力下降和記憶喪失為特征的漸進性神經退行性疾病,及早發現對于其干預和治療至關重要。近期,清華大學語音與音頻技術實驗室(SATLab)提出了一種將停頓信息進行編碼,并與語言模型中的文本嵌入融合的方法,可以有效提升基于自發語音的AD檢測效果。該論文已發表于ICASSP 2025。

論文鏈接:https://arxiv.org/abs/2501.06727
背景介紹
阿爾茲海默病(Alzheimer's?Disease,?AD)是一種神經退行性疾病。患上阿爾茲海默病后,患者的大腦會發生病理變化,導致認知能力下降、表達能力退化等現象。臨床研究表明,早期治療可以有效延緩阿爾茲海默病的惡化。因此,AD檢測方法的開發對于該疾病的及早診治至關重要。
阿爾茲海默病對患者自發語音內容的影響促使人們探索自然語言處理技術,以實現可靠的AD檢測。而AD檢測中另一個關鍵指標是語音中的停頓,而通過語音停頓檢測阿爾茲海默病在最近的文獻中得到了廣泛關注。
雖然目前已有一些將停頓信息與語言特征相結合的嘗試,但還沒有一種方法能將停頓信息深度融合到語言模型中。在本文中,我們提出了一種方法,在語言模型的編碼階段將停頓與文本內容相結合,以捕捉語音中的語義和副語言特征,從而提高 AD 檢測的性能。
工作原理
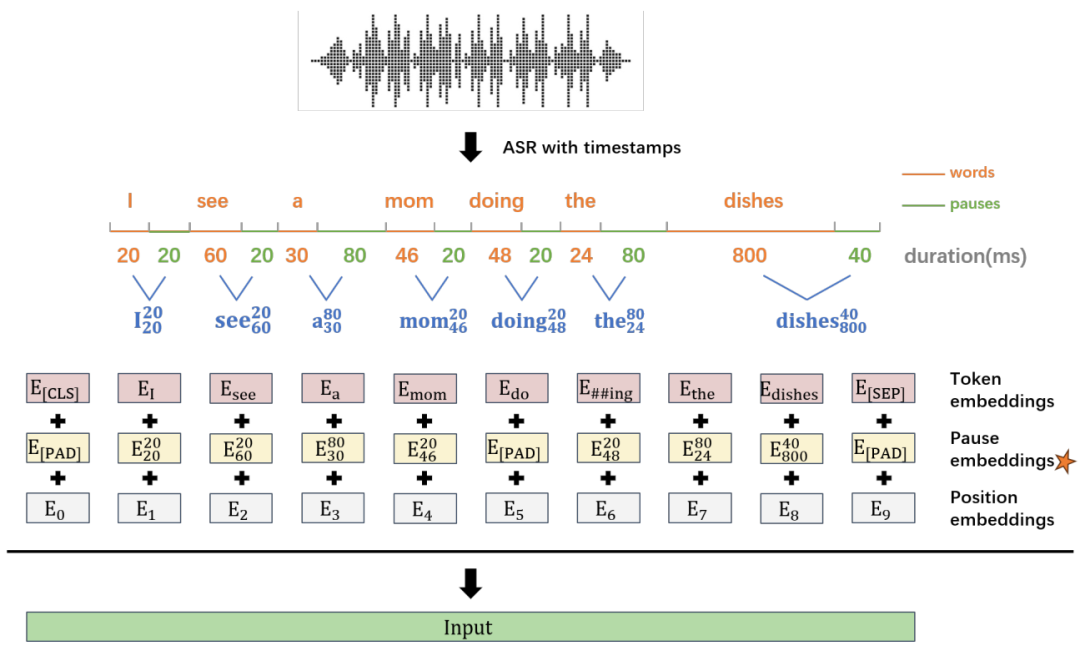
在我們的方法中,我們利用預訓練的?BERT?模型作為基礎模型來捕捉語義信息。而停頓信息在被編碼后與現有的詞嵌入一起集成到?BERT?模型架構中。我們采用可學習的嵌入映射方法, 將每一個單詞的持續時間和停頓時間分別編碼為嵌入。然后,將這兩個嵌入在特征維度上拼接起來,并將其添加到詞嵌入中,從而在?BERT?模型的編碼階段將停頓信息與文本信息融合在一起。
在停頓信息的編碼過程中,我們引入了一種將時間特征編碼到嵌入中的新方法。使用WhisperX語音識別模型轉錄自發語音后,我們提取轉錄文本中每個單詞的持續時間和停頓時間,將它們結合為一個停頓標記,并在一定區間內進行均勻量化,得到一個停頓標記的碼本,之后對其進行可學習的嵌入映射。
實驗結果
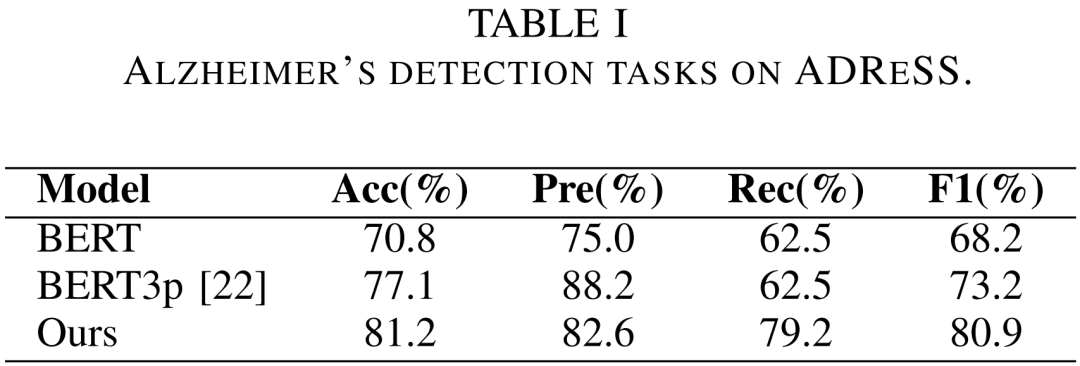
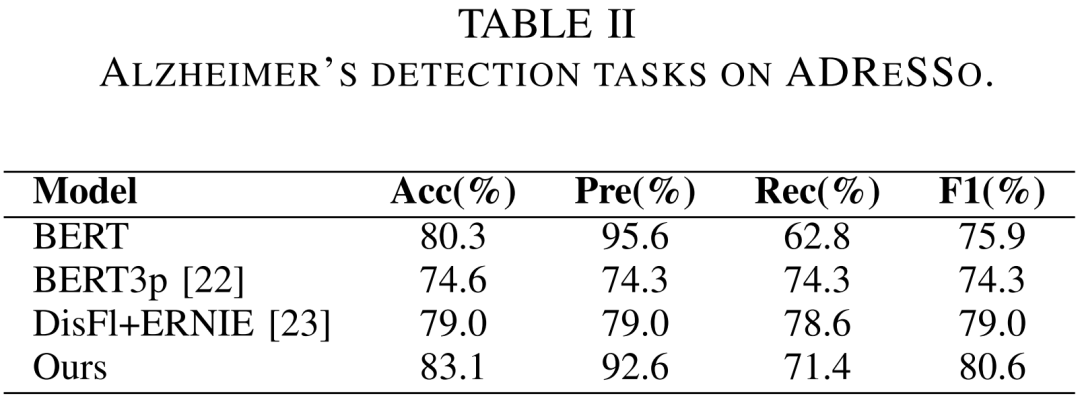
在ADReSS數據集上,所提出的模型取得了81.2%的準確率,優于之前結合停頓與文本特征的模型BERT3p;在ADReSSo數據集上,所提出的模型展現了更好的泛化性,83.1%的準確率優于BERT3p及其他使用停頓特征的模型。該結果證明了所提出方法的有效性。
結 論
本文研究表明,將停頓信息融入語言模型能夠有效提升阿爾茲海默病的檢測性能。通過捕捉自發語音中的時間特征,模型在區分AD患者與健康個體方面表現出更強的判別能力,驗證了停頓作為潛在生物標志物在AD早期檢測中的應用價值。本研究為構建更精準、非侵入性、低成本的AD檢測手段提供了新思路,對推動神經退行性疾病的早期診斷和治療具有重要意義。
學生作者信息

蒲鈺,清華大學電子系二年級碩士生,研究方向為阿爾茲海默病檢測和端到端語音交互。
點擊下面【閱讀原文】跳轉arXiv獲取全文:














)

)


)