我自己的原文哦~? ? ?https://blog.51cto.com/whaosoft/13269720
#FastOcc
推理更快、部署友好Occ算法來啦!
在自動駕駛系統當中,感知任務是整個自駕系統中至關重要的組成部分。感知任務的主要目標是使自動駕駛車輛能夠理解和感知周圍的環境元素,如行駛在路上的車輛、路旁的行人、行駛過程中遇到的障礙物、路上的交通標志等,從而幫助下游模塊做出正確合理的決策和行為。在一輛具備自動駕駛功能的車輛中,通常會配備不同類型的信息采集傳感器,如環視相機傳感器、激光雷達傳感器以及毫米波雷達傳感器等等,從而確保自動駕駛車輛能夠準確感知和理解周圍環境要素,使自動駕駛車輛在自主行駛的過程中能夠做出正確的決斷。
目前,基于純圖像的視覺感知方法相比于基于激光雷達的感知算法需要更低的硬件和部署成本而受到工業界和學術界的廣泛關注,并且已經有許多優秀的視覺感知算法被設計出來用于實現3D目標感知任務以及BEV場景下的語義分割任務。雖然現有的3D目標感知算法已經取得了較為不錯的檢測性能,但依舊有相關問題逐漸在使用過程中暴露了出來:
- 原有的3D目標感知算法無法很好的解決數據集中存在的長尾問題,以及真實世界中存在但是當前訓練數據集中可能沒有標注的物體(如:行駛道路上的大石塊,翻倒的車輛等等)
- 原有的3D目標感知算法通常會直接輸出一個粗糙的3D立體邊界框而無法準確描述任意形狀的目標物體,對物體形狀和幾何結構的表達還不夠細粒度。雖然這種輸出結果框可以滿足大多數的物體場景,但是像有連接的公交車或者具有很長挖鉤的建筑車輛,當前3D感知算法就無法給出準確和清楚的描述了
基于上述提到的相關問題,柵格占用網絡(Occupancy Network)感知算法被提出。本質上而言,Occupancy Network感知算法是基于3D空間場景的語義分割任務。基于純視覺的Occupancy Network感知算法會將當前的3D空間劃分成一個個的3D體素網格,通過自動駕駛車輛配備的環視相機傳感器將采集到的環視圖像送入到網絡模型中,經過算法模型的處理和預測,輸出當前空間中每個3D體素網格的占用狀態以及可能包含的目標語義類別,從而實現對于當前3D空間場景的全面感知。
近年來,基于Occupancy Network的感知算法因其更好的感知優勢而受到了研究者們的廣泛關注,目前已經涌現出了很多優秀的工作用于提升該類算法的檢測性能,這些論文的大概思路方向為:提出更加魯棒的特征提取方法、2D特征向3D特征的坐標變換方式、更加復雜的網絡結構設計以及如何更加準確的生成Occupancy真值標注幫助模型學習等等。然而許多現有的Occupancy Network感知方法在模型預測推理的過程中都存在著嚴重的計算開銷,使得這些算法很難滿足自動駕駛實時感知的要求,很難上車部署。
基于此,我們提出了一種新穎的Occupancy Network預測方法,和目前的SOTA感知算法相比,提出的FastOcc算法具有實時的推理速度以及具有競爭力的檢測性能,提出的算法和其他算法的性能和推理速度如下圖所示。
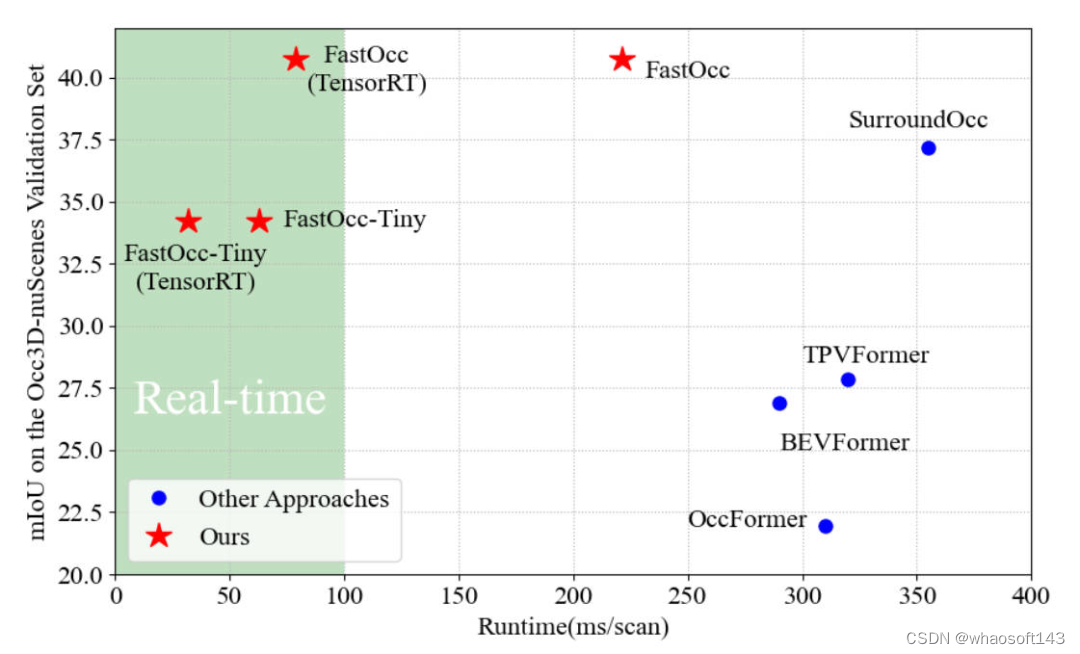
FastOcc算法和其他SOTA算法的精度和推理速度比較
論文鏈接:https://arxiv.org/pdf/2403.02710.pdf
網絡模型的整體架構&細節梳理
為了提高Occupancy Network感知算法的推理速度,我們分別從輸入圖像的分辨率、特征提取主干網絡、視角轉換的方式以及柵格預測頭結構四個部分進行了實驗,通過實驗結果發現,柵格預測頭中的三維卷積或者反卷積具有很大的耗時優化空間。基于此,我們設計了FastOcc算法的網絡結構,如下圖所示。
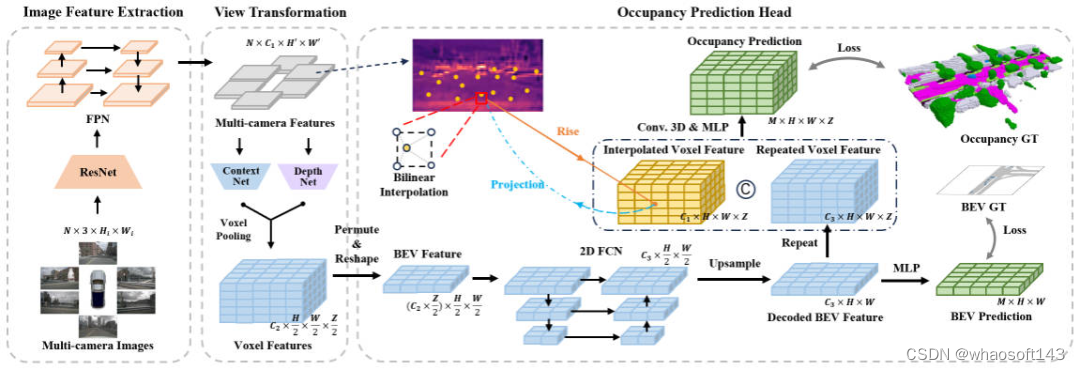
FastOcc算法網絡結構圖
整體而言,提出的FastOcc算法包括三個子模塊,分別是Image Feature Extraction用于多尺度特征提取、View Transformation用于視角轉換、Occupancy Prediction Head用于實現感知輸出,接下來我們會分別介紹這三個部分的細節。
圖像特征提取(Image Feature Extraction)

視角轉換(View Transformation)

- 一類是以BEVFormer為代表的Backward的坐標變換方法。該類方法通常是先在3D空間生成體素Query,然后利用Cross-view Attention的方式將3D空間的體素Query與2D圖像特征進行交互,完成最終的3D體素特征的構建。
- 一類是以LSS為代表的Forward的坐標變換方法。這類方法會利用網絡中的深度估計網絡來同時估計每個特征像素位置的語義特征信息和離散深度概率,通過外積運算構建出語義視錐特征,最終利用VoxelPooling層實現最終的3D體素特征的構建。
考慮到LSS算法具有更好的推理速度和效率,在本文中,我們采用了LSS算法作為我們的視角轉換模塊。同時,考慮到每個像素位置的離散深度都是估計出來的,其不確定性一定程度上會制約模型最終的感知性能。因此,在我們的具體實現中,我們利用點云信息來進行深度方向上的監督,以實現更好的感知結果。
柵格預測頭(Occupancy Prediction Head)
在上圖展示的網絡結構圖中,柵格預測頭還包含三個子部分,分別是BEV特征提取、圖像特征插值采樣、特征集成。接下來,我們將逐一介紹三部分的方法的細節。
BEV特征提取
目前,大多數的Occupancy Network算法都是對視角轉換模塊得到的3D體素特征進行處理。而處理的形式一般是三維的全卷積網絡。具體而言,對于三維全卷積網絡的任意一層,其對輸入的三維體素特征進行卷積所需要的計算量如下:

通過3D和2D處理過程的計算量對比可以看出,通過利用輕量化的2D BEV特征卷積模塊來代替原有的3D體素特征提取可以大大減少模型的計算量。同時,兩類處理過程的可視化流程圖如下圖所示:
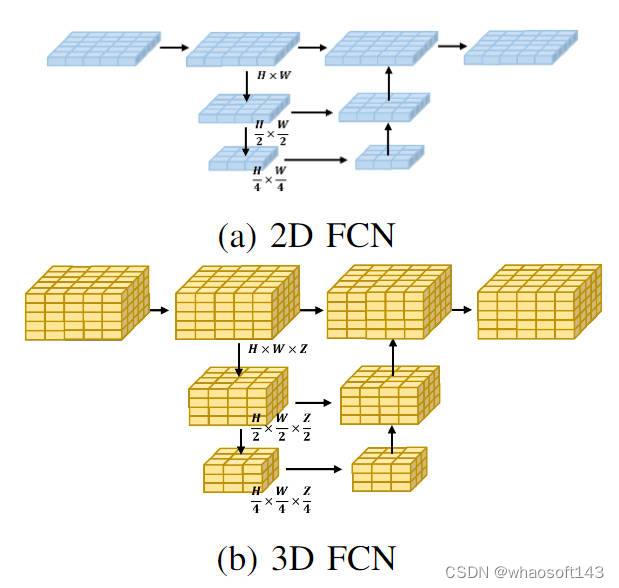
2D FCN和3D FCN網絡結構的可視化情況
圖像特征插值采樣
為了減少柵格預測頭模塊的計算量,我們將視角轉換模塊輸出的3D體素特征的高度進行壓縮,并利用2D的BEV卷積模塊進行特征提取。但為了增加缺失的Z軸高度特征信息并秉持著減少模型計算量的思想出發,我們提出了圖像特征插值采樣方法。

特征集成

上述提到的圖像特征插值采樣和特征集成過程整體可以用下圖進行表示:
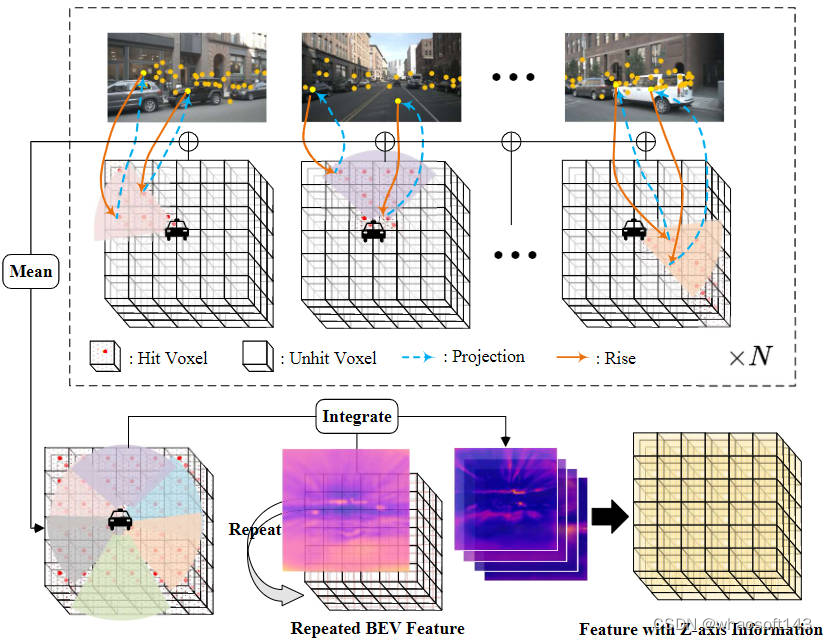
圖像特征插值采樣以及特征集成過程
除此之外,為了進一步確保經過BEV特征提取模塊輸出的BEV特征包含有足夠的特征信息用于完成后續的感知過程,我們采用了一個額外的監督方法,即利用一個語義分割頭來首先語義分割任務,并利用Occupancy的真值來構建語義分割的真值標簽完成整個的監督過程。
實驗結果&評價指標
定量分析部分
首先展示一下我們提出的FastOcc算法在Occ3D-nuScenes數據集上和其他SOTA算法的對比情況,各個算法的具體指標見下表所示
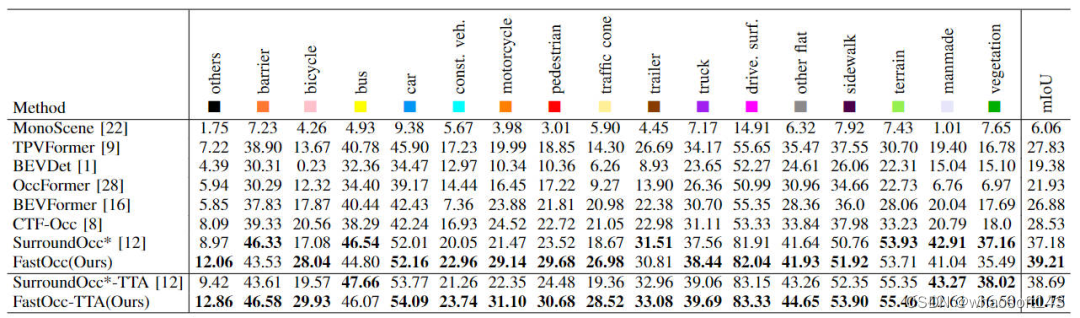
各個算法指標的在Occ3D-nuScenes數據集上的對比
通過表格上的結果可以看出,我們提出的FastOcc算法相比于其他的算法而言,在大多數的類別上都更加的具有優勢,同時總的mIoU指標也實現了SOTA的效果。
除此之外,我們也比較了不同的視角轉換方式以及柵格預測頭當中所使用的解碼特征的模塊對于感知性能以及推理耗時的影響(實驗數據均是基于輸入圖像分辨率為640×1600,主干網絡采用的是ResNet-101網絡),相關的實驗結果對比如下表所示?
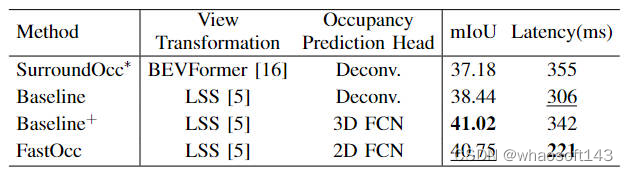
不同視角轉換以及柵格預測頭的精度和推理耗時對比
SurroundOcc算法采用了多尺度的Cross-view Attention視角轉換方式以及3D卷積來實現3D體素特征的提取,具有最高的推理耗時。我們將原有的Cross-view Attention視角轉換方式換成LSS的轉換方式之后,mIoU精度有所提升,同時耗時也得到了降低。在此基礎上,通過將原有的3D卷積換成3D FCN結構,可以進一步的增加精度,但是推理耗時也明顯增加。最后我們選擇采樣LSS的坐標轉換方式以及2D FCN結構實現檢測性能和推理耗時之間的平衡。
此外,我們也驗證了我們提出的基于BEV特征的語義分割監督任務以及圖像特征插值采樣的有效性,具體的消融實驗結果見下表所示:
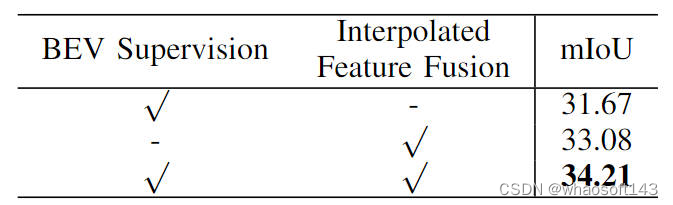
不同模塊的消融實驗對比情況
此外,我們還做了模型上的scale實驗,通過控制主干網絡的大小以及輸入圖像的分辨率,從而構建了一組Occupancy Network感知算法模型(FastOcc、FastOcc-Small、FastOcc-Tiny),具體配置見下表:
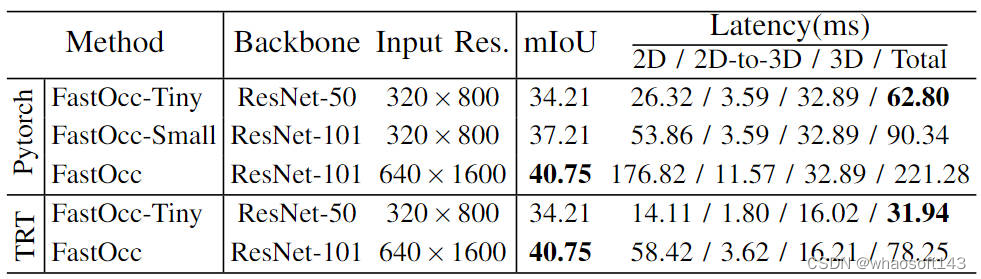
? 不同主干網絡和分辨率配置下的模型能力對比
定性分析部分
下圖展示了我們提出的FastOcc算法模型與SurroundOcc算法模型的可視化結果對比情況,可以明顯的看到,提出的FastOcc算法模型以更加合理的方式填補了周圍的環境元素,并且實現了更加準確的行駛車輛以及樹木的感知。

FastOcc算法與SurroundOcc算法的可視化結果對比情況
結論
在本文中,針對現有的Occupancy Network算法模型檢測耗時長,難以上車部署的問題,我們提出了FastOcc算法模型。通過將原有的處理3D體素的3D卷積模塊用2D卷積進行替代,極大縮短了推理耗時,并且和其他算法相比實現了SOTA的感知結果。
#DriveDreamer-2
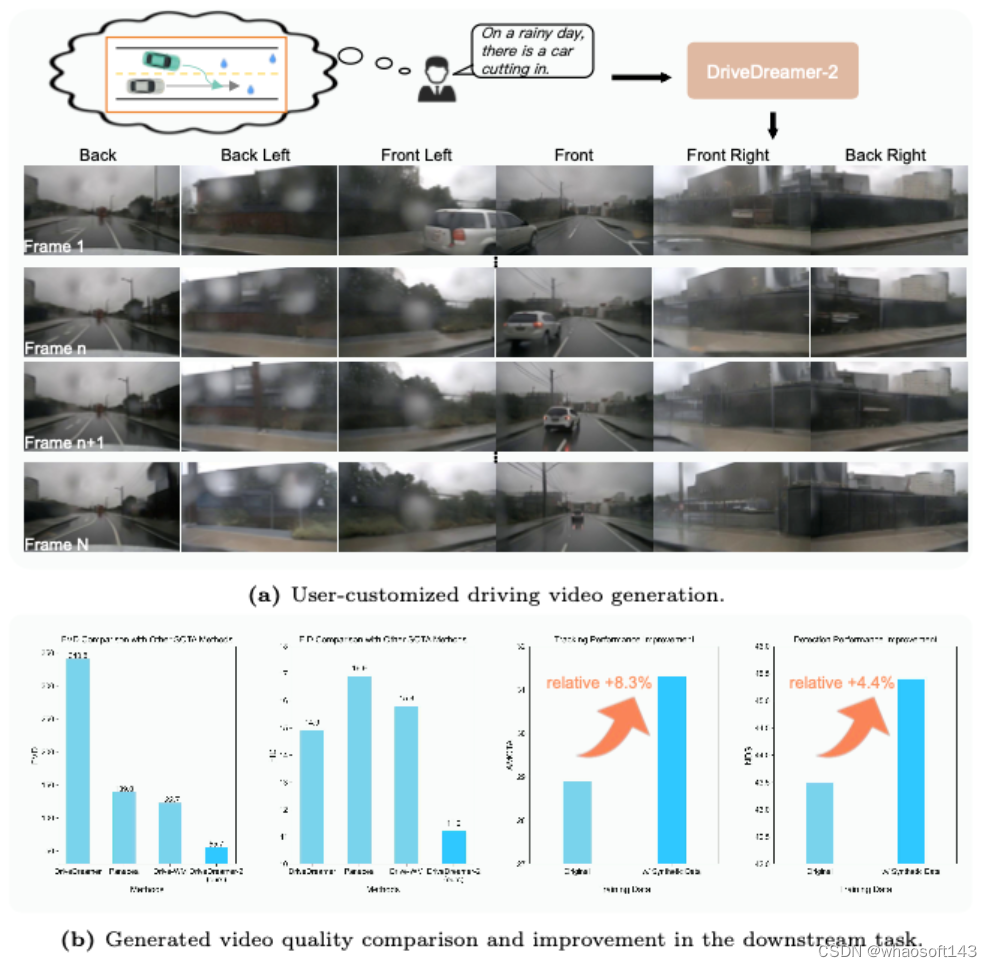
世界車型在自動駕駛方面表現出了優勢,尤其是在多視圖駕駛視頻的生成方面。然而,在生成自定義駕駛視頻方面仍然存在重大挑戰。在本文中,我們提出了DriveDreamer-2,它建立在DriveDreamer的框架上,并結合了一個大語言模型(LLM)來生成用戶定義的駕駛視頻。具體來說,LLM接口最初被合并以將用戶的查詢轉換為代理軌跡。隨后,根據軌跡生成符合交通規則的HDMap。最終,我們提出了統一多視圖模型,以增強生成的駕駛視頻的時間和空間連貫性。DriveDreamer-2是世界上第一款生成自定義駕駛視頻的世界模型,它可以以用戶友好的方式生成不常見的駕駛視頻(例如,車輛突然駛入)。此外,實驗結果表明,生成的視頻增強了駕駛感知方法(如3D檢測和跟蹤)的訓練。此外,DriveDreamer-2的視頻生成質量超過了其他最先進的方法,FID和FVD得分分別為11.2和55.7,相對提高了~30%和~50%。
- 開源鏈接:https://drivedreamer2.github.io/
總結來說,本文的主要貢獻如下:
- 我們推出DriveDreamer-2,這是世界上第一款以用戶友好的方式生成虛擬駕駛視頻的車型。
- 我們提出了一種僅使用文本提示作為輸入的交通仿真管道,可用于生成用于駕駛視頻生成的各種交通條件。
- UniMVM旨在無縫集成視圖內和視圖間的空間一致性,提高生成的駕駛視頻的整體時間和空間一致性。
- 大量實驗表明,DriveDreamer-2可以制作各種定制的駕駛視頻。此外,DriveDreamer-2與以前性能最好的方法相比,可將FID和FVD提高約30%和約50%。此外,DriveDreamer-2生成的駕駛視頻增強了對各種駕駛感知方法的訓練。
相關工作回顧
世界模型
世界方法的主要目標是建立動態環境模型,賦予主體對未來的預測能力。在早期的探索中,變分自動編碼器(VAE)和長短期記憶(LSTM)被用于捕捉過渡動力學和排序功能,在不同的應用中顯示出顯著的成功。構建駕駛世界模型帶來了獨特的挑戰,主要源于現實世界駕駛任務固有的高樣本復雜性。為了應對這些挑戰,ISO Dream引入了將視覺動力學明確分解為可控和不可控狀態的方法。MILE戰略性地將世界建模納入鳥瞰圖(BEV)語義分割空間。最近,DriveDreamer、GAIA-1、ADriver-I和Drive-WM探索了利用強大的擴散模型或自然語言模型在現實世界中訓練駕駛世界模型。然而,這些方法中的大多數在很大程度上依賴于結構化信息(例如,3D框 、HDMaps和光流)作為條件。這種獨立性不僅限制了互動性,也限制了世代的多樣性。
視頻生成
視頻生成和預測是理解視覺世界的關鍵技術。在視頻生成的早期階段,探索了變分自動編碼器(VAE)、基于流的模型和生成對抗網絡(GANs)等方法。語言模型也用于復雜的視覺動力學建模。最近的進展表明,擴散模型對視頻生成的影響越來越大。值得注意的是,視頻擴散模型在生成具有逼真幀和平滑過渡的高質量視頻方面表現出卓越的能力,提供了增強的可控性。這些模型無縫地適應各種輸入條件,包括文本、canny、草圖、語義圖和深度圖。在自動駕駛領域,DriveDreamer-2利用強大的擴散模型學習視覺動力學。
交通仿真
駕駛仿真器是自動駕駛開發的基石,旨在提供一個仿真真實世界條件的受控環境。LCTGen使用LLM將詳細的語言描述編碼為向量,然后使用生成器生成相應的仿真場景。這種方法需要高度詳細的語言描述,包括代理的速度和方向等信息。TrafficGen理解交通場景中的固有關系,從而能夠在同一地圖內生成多樣化和合法的交通流。CTG通過采用符合交通約束的手動設計的損失函數來生成交通仿真。CTG++進一步擴展了CTG,利用GPT-4將用戶語言描述轉換為損失函數,該函數指導場景級條件擴散模型生成相應的場景。在DriveDreamer-2中,我們構建了一個函數庫來微調LLM,以實現用戶友好的文本到流量仿真,消除了復雜的損失設計或復雜的文本提示輸入。
詳解DriveDreamer-2
圖2展示了DriveDreamer-2的總體框架。首先提出了一種定制的交通仿真來生成前臺代理軌跡和后臺HDMaps。具體而言,DriveDreamer-2利用微調后的LLM將用戶提示轉換為代理軌跡,然后引入HDMap生成器,使用生成的軌跡作為條件來仿真道路結構。DriveDreamer-2利用定制的流量仿真管道,能夠為后續視頻生成生成生成各種結構化條件。在DriveDreamer架構的基礎上,提出了UniMVM框架,以統一視圖內和視圖間的空間一致性,從而增強生成的駕駛視頻的整體時間和空間一致性。在接下來的章節中,我們將深入研究定制交通fang'zhen和UniMVM框架的細節。
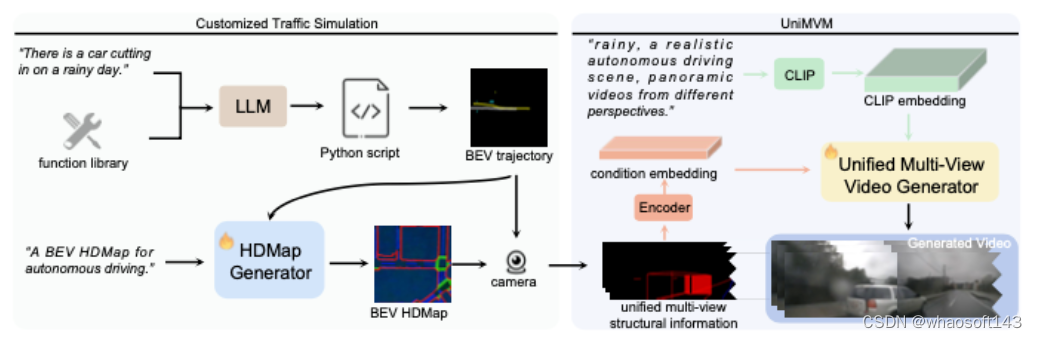
自定義交通仿真
在所提出的定制交通仿真管道中,構建了一個軌跡生成函數庫來微調LLM,這有助于將用戶提示轉移到不同的代理軌跡中,包括切入和掉頭等動作。此外,該管道包含HDMap生成器,用于仿真背景道路結構。在此階段,先前生成的代理軌跡充當條件輸入,確保生成的HDMap符合流量約束。在下文中,我們將詳細介紹LLM的微調過程和HDMap生成器的框架。
用于軌跡生成的微調LLM以前的交通仿真方法需要復雜的參數規范,包括代理的速度、位置、加速度和任務目標等細節。為了簡化這一復雜的過程,我們建議使用構建的軌跡生成函數庫對LLM進行微調,從而將用戶友好的語言輸入有效地轉換為全面的交通仿真場景。如圖3所示,構建的函數庫包括18個函數,包括代理函數(轉向、等速、加速度和制動)、行人函數(行走方向和速度)以及其他實用函數,如保存軌跡。在這些函數的基礎上,文本到Python腳本對是手動策劃的,用于微調LLM(GPT-3.5)。腳本包括一系列基本場景,如變道、超車、跟隨其他車輛和執行掉頭。此外,我們還包括更不常見的情況,如行人突然橫穿馬路,車輛駛入車道。以用戶輸入的車輛切入為例,相應的腳本包括以下步驟:首先生成切入軌跡(agent.cut_in()),然后生成相應的ego-car軌跡(agent.forward());最后利用實用程序的保存功能,以數組形式直接輸出ego-car和其他代理的軌跡。有關更多詳細信息,請參閱補充材料。在推理階段,我們將提示輸入擴展到預定義的模板,微調后的LLM可以直接輸出軌跡陣列。

HDMap生成綜合交通仿真不僅需要前臺代理的軌跡,還需要生成后臺HDMap元素,如車道和人行橫道。因此,提出了HDMap生成器,以確保背景元素與前景軌跡不沖突。在HDMap生成器中,我們將背景元素生成公式化為條件圖像生成問題,其中條件輸入是BEV軌跡圖,目標是BEV HDMap。與以前主要依賴于輪廓條件(邊緣、深度、方框、分割圖)的條件圖像生成方法不同,所提出的HDMap生成器探索前景和背景交通元素之間的相關性。具體地,HDMap生成器是在圖像生成擴散模型上構建的。為了訓練生成器,我們對HDMap數據集進行軌跡規劃。在軌跡圖中,指定不同的顏色來表示不同的代理類別。同時,目標HDMap包括三個通道,分別表示車道邊界、車道分隔線和行人交叉口。在HDMap生成器中,我們使用2D卷積層的堆棧來合并軌跡圖條件。然后,使用將生成的特征圖無縫集成到擴散模型中(有關其他架構詳細信息,請參見補充)。在訓練階段,擴散正向過程逐漸將噪聲ε添加到潛在特征中,從而產生噪聲潛在特征。然后我們訓練εθ來預測我們添加的噪聲,并且HDMap生成器φ通過:
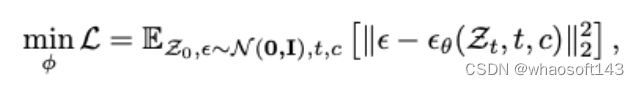
如圖4所示,利用所提出的HDMap生成器,我們可以基于相同的軌跡條件生成不同的HDMap。值得注意的是,生成的HDMaps不僅遵守交通約束(位于車道分隔帶兩側的車道邊界和十字路口的人行橫道),而且與軌跡無縫集成。

UniMVM
利用定制交通仿真生成的結構化信息,可以通過DriveDreamer的框架生成多視圖駕駛視頻。然而,在以前的方法中引入的視圖關注并不能保證多視圖的一致性。為了緩解這個問題,采用圖像或視頻條件來生成多視圖駕駛視頻。雖然這種方法增強了不同觀點之間的一致性,但它是以降低發電效率和多樣性為代價的。在DriveDreamer-2中,我們在DriveDreamer框架中引入了UniMVM。UniMVM旨在統一多視圖駕駛視頻的生成,無論是否具有相鄰視圖條件,這確保了時間和空間的一致性,而不會影響生成速度和多樣性。
多視圖視頻聯合分布可以通過以下方式獲得:
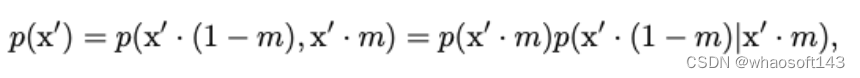
如圖5所示,我們將UniMVM的范式與DriveDreamer[56]和Drive-WM[59]的范式進行了比較。與這些同行相比,UniMVM將多個視圖統一為一個完整的視頻生成補丁,而不引入跨視圖參數。此外,可以通過調整掩碼m來完成各種驅動視頻生成任務。特別地,當m被設置為掩碼未來的T?1幀時,UniMVM基于第一幀的輸入啟用未來視頻預測。將m配置為屏蔽{FL、FR、BR、B、BL}視圖,使UniMVM能夠利用前視圖視頻輸入實現多視圖視頻輸出。此外,當m被設置為屏蔽所有視頻幀時,UniMVM可以生成多視圖視頻,并且定量和定性實驗都驗證了UniMVM能夠以增強的效率和多樣性生成時間和空間相干的視頻。?
.
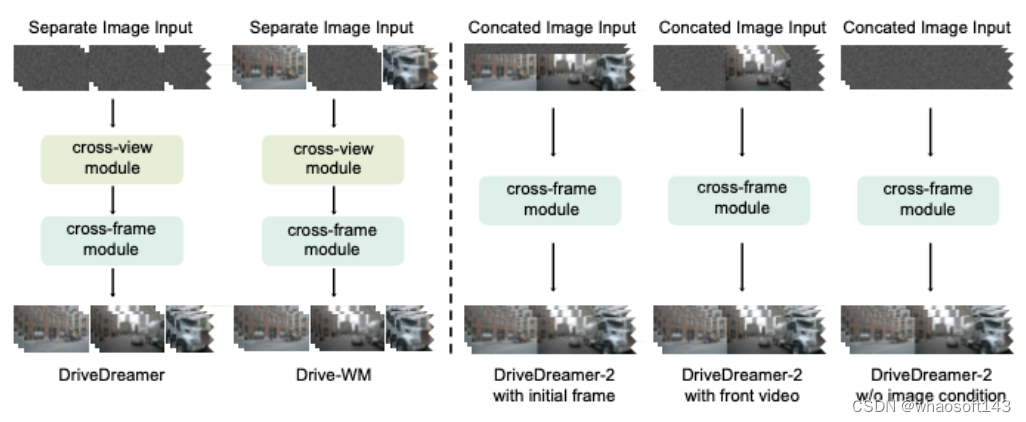
視頻生成基于UniMVM公式,可以在DriveDreamer[56]的框架內生成駕駛視頻。具體來說,我們的方法首先統一了交通結構化條件,這導致了HDMaps和3D盒子的序列。注意,3D框的序列可以從代理軌跡導出,并且3D框的大小是基于相應的代理類別來確定的。與DriveDreamer不同,DriveDreamer-2中的3D盒子條件不再依賴于位置嵌入和類別嵌入。相反,這些框被直接投影到圖像平面上,起到控制條件的作用。這種方法消除了引入額外的控制參數,如[56]中所述。我們采用三個編碼器將HDMaps、3D框和圖像幀嵌入到潛在空間特征yH、yB和yI中。然后,我們將空間對齊的條件yH,yB與Zt連接起來,以獲得特征輸入Zin,其中Zt是通過前向擴散過程從yI生成的噪聲潛在特征。對于視頻生成器的訓練,所有參數都通過去噪分數匹配進行優化[26](詳見補充)。
實驗
用戶自定義駕駛視頻生成
DriveDreamer-2提供了一個用戶友好的界面,用于生成駕駛視頻。如圖1a所示,用戶只需要輸入文本提示(例如,在雨天,有一輛汽車駛入)。然后DriveDreamer-2生成與文本輸入對齊的多視圖駕駛視頻。圖6展示了另外兩個自定義駕駛視頻。上圖描繪了白天ego汽車向左變道的過程。下圖展示了一個意想不到的行人在夜間橫穿馬路,促使ego汽車剎車以避免碰撞。值得注意的是,生成的視頻展示了非凡的真實感,我們甚至可以觀察到遠光燈在行人身上的反射。

生成視頻的質量評估
為了驗證視頻生成質量,我們將DriveDreamer-2與nuScenes驗證集上的各種駕駛視頻生成方法進行了比較。為了進行公平的比較,我們在三種不同的實驗設置下進行了評估——無圖像條件、有視頻條件和第一幀多視圖圖像條件。實驗結果如表1所示,表明DriveDreamer-2在所有三種設置中都能始終如一地獲得高質量的評估結果。具體而言,在沒有圖像條件的情況下,DriveDreamer-2的FID為25.0,FVD為105.1,顯示出比DriveDreamer的顯著改進。此外,盡管僅限于單視圖視頻條件,但與使用三視圖視頻條件的DriveWM相比,DriveDreamer-2在FVD方面表現出39%的相對改善。此外,當提供第一幀多視圖圖像條件時,DriveDreamer-2實現了11.2的FID和55.7的FVD,大大超過了以前的所有方法。
更多可視:


結論和討論
本文介紹了DriveDreamer-2,這是DriveDreamer框架的創新擴展,開創了用戶自定義駕駛視頻的生成。DriveDreamer-2利用大型語言模型,首先將用戶查詢轉移到前臺代理軌跡中。然后,可以使用所提出的HDMap生成器生成背景交通狀況,并將代理軌跡作為條件。生成的結構化條件可以用于視頻生成,我們提出了UniMVM來增強時間和空間的一致性。我們進行了廣泛的實驗來驗證DriveDreamer-2可以生成不常見的駕駛視頻,例如車輛的突然機動。重要的是,實驗結果展示了生成的視頻在增強駕駛感知方法訓練方面的效用。此外,與最先進的方法相比,DriveDreamer-2顯示出卓越的視頻生成質量,FID和FVD得分分別為11.2和55.7。這些分數代表了大約30%和50%的顯著相對改進,肯定了DriveDreamer-2在多視圖駕駛視頻生成方面的功效和進步。
#TrajectoryNAS
一種用于軌跡預測的神經結構搜索
論文鏈接:https://arxiv.org/pdf/2403.11695.pdf
摘要
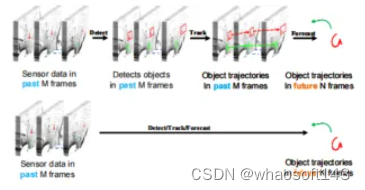
本文介紹了TrajectoryNAS:一種用于軌跡預測的神經結構搜索。自動駕駛系統是一項快速發展的技術,其可以實現無人駕駛汽車的量產。軌跡預測是自動駕駛系統的一個關鍵組成部分,其使汽車能夠預測周圍目標的運動,從而實現安全導航。由于使用激光雷達點云數據的軌跡預測提供了3D信息,因此其比使用2D圖像的軌跡預測表現更好。然而,處理點云數據比2D圖像更復雜、更耗時。因此,使用點云數據的最先進的3D軌跡預測存在速度慢和錯誤預測等問題。本文引入了TrajectoryNAS,這是一種著重于利用點云數據進行軌跡預測的開創性方法。通過利用神經結構搜索(NAS),TrajectoryNAS自動化軌跡預測模型的設計,以凝聚的方式包含目標檢測、跟蹤和預測。這種方法不僅解決了這些任務之間復雜的相互依賴關系,還強調了軌跡建模中準確性和效率的重要性。通過實證研究,TrajectoryNAS展現了其在提高自動駕駛系統性能方面的有效性,標志著該領域取得了重大進展。實驗結果表明,與其它軌跡預測方法相比,TrajectoryNAS在nuScenes數據集上的準確性至少提高了4.8%,延遲至少降低了1.1倍。
主要貢獻
本文的貢獻總結如下:
1)本文提出了TrajectoryNAS,它是自動駕駛軌跡預測領域中的先驅工作。與先前工作不同,本文方法是首次以端到端的方式實現神經架構搜索(NAS),包含目標檢測、跟蹤和預測。這種全面集成解決了子任務(例如點云處理、檢測和跟蹤)之間的相互依賴性所帶來的復雜挑戰;
2)本文利用了高效的小型數據集。為了滿足與神經結構搜索相關的計算要求,本文方法引入了高效的兩步過程。首先,本文采用一個小型數據集來加速最優結構的識別。隨后,將識別的結構應用于完整的數據集,以確保可擴展性和準確性。這種精簡的方法在處理大量數據集時特別有價值;
3)本文設計了開創性的多目標能量函數:本項工作的一個關鍵創新點是引入一種新的多目標能量函數。該能量函數考慮了目標檢測、跟蹤、預測和時間約束。通過將這些不同的要素加入一個統一的框架中,本文方法超越了那些通常忽略這些目標之間復雜關系的現有方法。新的能量函數增強了TrajectoryNAS的預測能力,提高了其在現實世界場景中的性能。
論文圖片和表格
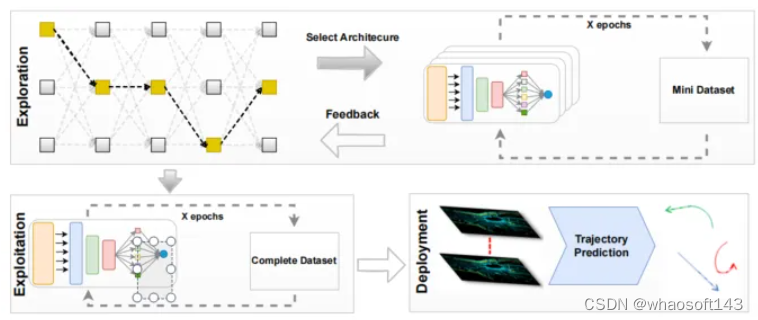
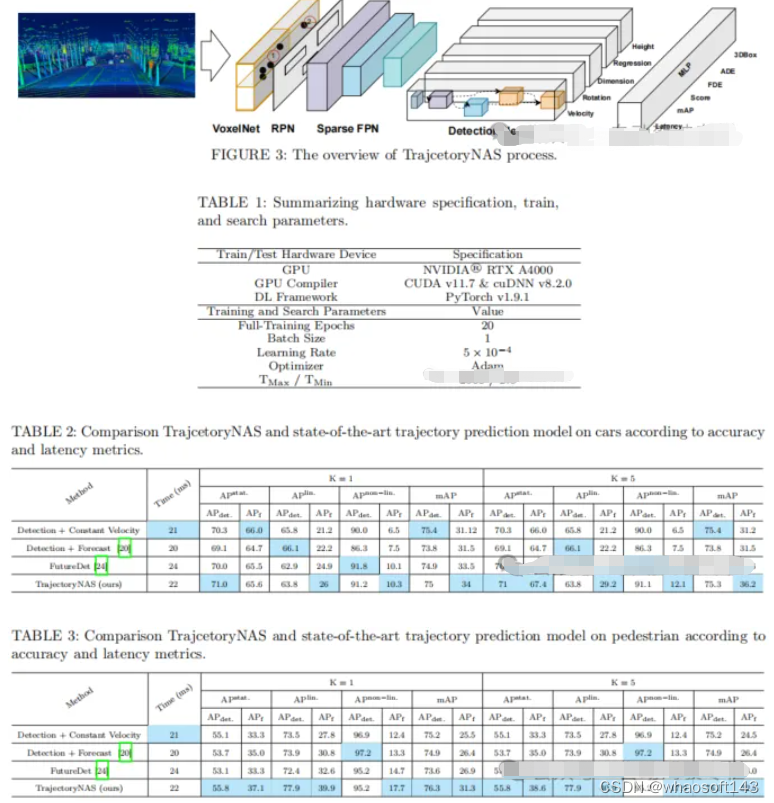
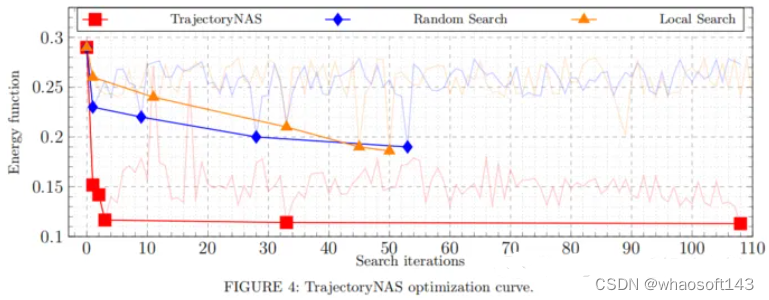
總結
本文提出了TrajectoryNAS,這是一種自動模型設計方法,其顯著增強了自動駕駛的3D軌跡預測。通過在考慮關鍵性能指標的同時對速度和準確性進行優化,TrajectoryNAS在nuScenes數據集上的準確性至少提高了4.8%,延遲至少降低了1.1倍,其優于現有方法。
#DualBEV
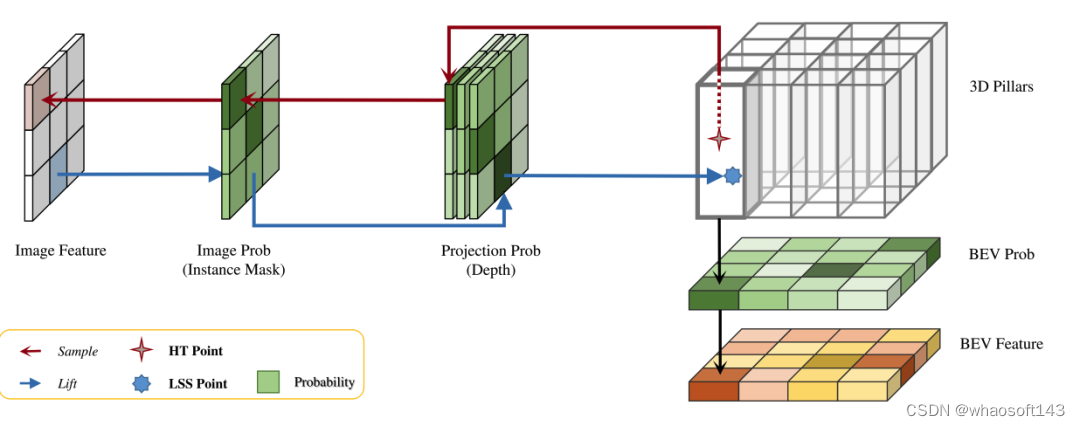
這篇論文探討了在自動駕駛中,從不同視角(如透視圖和鳥瞰圖)準確檢測物體的問題,特別是如何有效地從透視圖(PV)到鳥瞰圖(BEV)空間轉換特征,這一轉換是通過視覺轉換(VT)模塊實施的。現有的方法大致分為兩種策略:2D到3D和3D到2D轉換。2D到3D的方法通過預測深度概率來提升密集的2D特征,但深度預測的固有不確定性,尤其是在遠處區域,可能會引入不準確性。而3D到2D的方法通常使用3D查詢來采樣2D特征,并通過Transformer學習3D和2D特征之間對應關系的注意力權重,這增加了計算和部署的復雜性。?
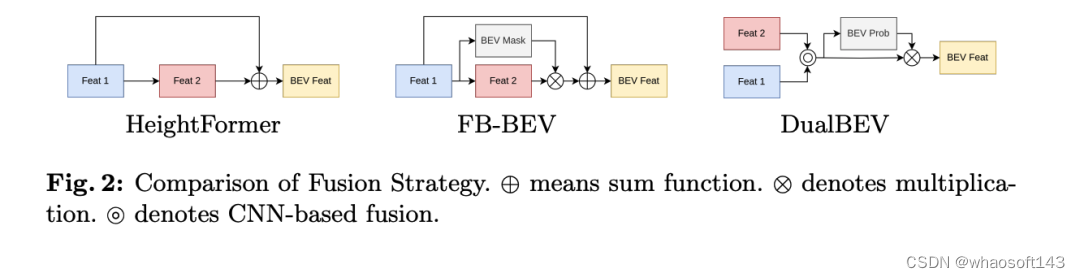
論文指出,現有的方法如HeightFormer和FB-BEV嘗試結合這兩種VT策略,但這些方法通常采用兩階段策略,由于雙VT的特征轉換不同,受到初始特征性能的限制,從而阻礙了雙VT之間的無縫融合。此外,這些方法在實現自動駕駛的實時部署方面仍面臨挑戰。
針對這些問題,論文提出了一種統一的特征轉換方法,適用于2D到3D和3D到2D的視覺轉換,通過三種概率測量來評估3D和2D特征之間的對應關系:BEV概率、投影概率和圖像概率。這一新方法旨在減輕BEV網格中空白區域對特征構建的影響,區分多個對應關系,并在特征轉換過程中排除背景特征。
通過應用這種統一的特征轉換,論文探索了使用卷積神經網絡(CNN)進行3D到2D視覺轉換的新方法,并引入了稱為HeightTrans的方法。除了展示了其卓越的性能外,還展示了通過預計算加速的潛力,使其適用于實時自動駕駛應用。同時,通過整合這種特征轉換,增強了傳統的LSS流程,展示了其對當前檢測器的普適性。
結合HeightTrans和Prob-LSS,論文介紹了DualBEV,這是一種創新的方法,它在一階段內就考慮并融合了來自BEV和透視視圖的對應關系,消除了對初始特征的依賴。此外,提出了一個強大的BEV特征融合模塊,稱為雙特征融合(DFF)模塊,通過利用通道注意力模塊和空間注意力模塊,進一步幫助精細化BEV概率預測。DualBEV遵循“廣泛輸入,嚴格輸出”的原則,通過利用精確的雙視圖概率對應關系來理解和表示場景的概率分布。
論文的主要貢獻如下:
- 揭示了3D到2D和2D到3D視覺轉換之間的內在相似性,并提出了一種統一的特征轉換方法,能夠從BEV和透視視圖兩個方面準確建立對應關系,顯著縮小了雙策略之間的差距。
- 提出了一種新的基于CNN的3D到2D視覺轉換方法HeightTrans,通過概率采樣和查找表的預計算,有效且高效地建立精確的3D-2D對應關系。
- 引入了DFF用于雙視圖特征融合,這種融合策略在一階段內捕獲近遠區域的信息,從而生成全面的BEV特征。
- 他們的高效框架DualBEV在nuScenes測試集上實現了55.2%的mAP和63.4%的NDS,即使沒有使用Transformer,也突顯了捕獲精確雙視圖對應關系對視圖轉換的重要性。
通過這些創新,論文提供了一種克服現有方法限制,實現高效、準確物體檢測的新策略,特別是在自動駕駛等實時應用場景中。
詳解DualBEV
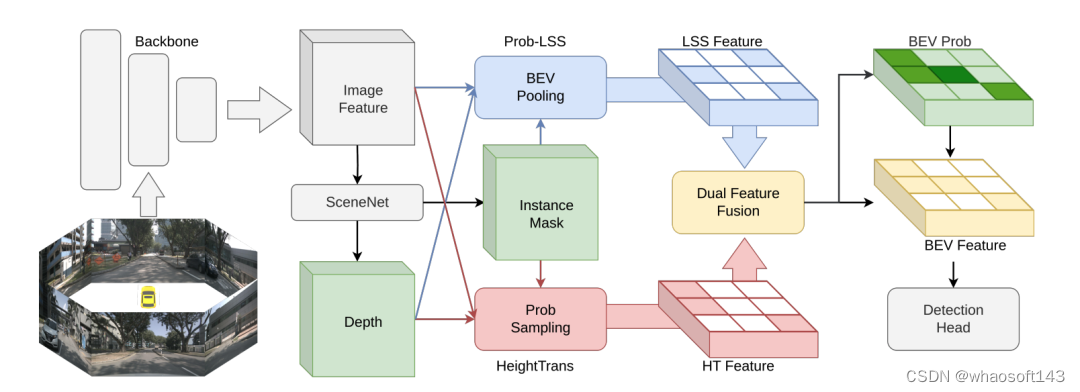
這篇論文提出的方法旨在通過統一的特征轉換框架,DualBEV,解決自動駕駛中的BEV(鳥瞰圖)對象檢測問題。以下是方法部分的主要內容,概括了其不同子部分和關鍵創新。
DualBEV概述

HeightTrans

BEV Height
HeightTrans方法在處理高度時采用了一種多分辨率采樣策略,覆蓋整個高度范圍(從-5米到3米),在興趣區域(ROI,定義為-2米到2米內)的分辨率為0.5米,在此范圍外的分辨率為1.0米。這種策略有助于增加對小物體的關注,這些小物體可能會在更粗糙的分辨率采樣中被遺漏。
Prob-Sampling
HeightTrans在概率采樣方面采用了以下步驟:

加速
通過預計算3D點在BEV空間中的索引,并在推理期間固定圖像特征索引和深度圖索引,HeightTrans能夠加速視覺轉換過程。最終的HeightTrans特征通過對每個BEV網格中預定義
Prob-LSS
Prob-LSS擴展了傳統的LSS(Lift, Splat, Shoot)管道,通過預測每個像素的深度概率來促進其投影到BEV空間。該方法進一步整合了BEV概率,通過以下公式構建LSS特征:
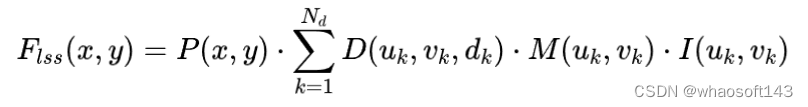
這樣做可以更好地處理深度估計中的不確定性,從而減少BEV空間中的冗余信息。
雙特征融合(Dual Feature Fusion, DFF)
DFF模塊旨在融合來自HeightTrans和Prob-LSS的特征,并有效地預測BEV概率。通過結合通道注意力模塊和空間注意力增強的ProbNet,DFF能夠優化特征選擇和BEV概率預測,以增強對近處和遠處對象的表征。這種融合策略考慮了來自兩個流的特征的互補性,同時也通過計算局部和全局注意力來增強BEV概率的準確性。?
總之,這篇論文提出的DualBEV框架通過結合HeightTrans和Prob-LSS,以及創新的雙特征融合模塊,實現了對3D和2D特征之間對應關系的高效評估和轉換。這不僅橋接了2D到3D和3D到2D轉換策略之間的差距,而且還通過預計算和概率測量加速了特征轉換過程,使其適合實時自動駕駛應用。
該方法的關鍵在于對不同視角下的特征進行精確對應和高效融合,從而在BEV對象檢測中實現了出色的性能。
實驗
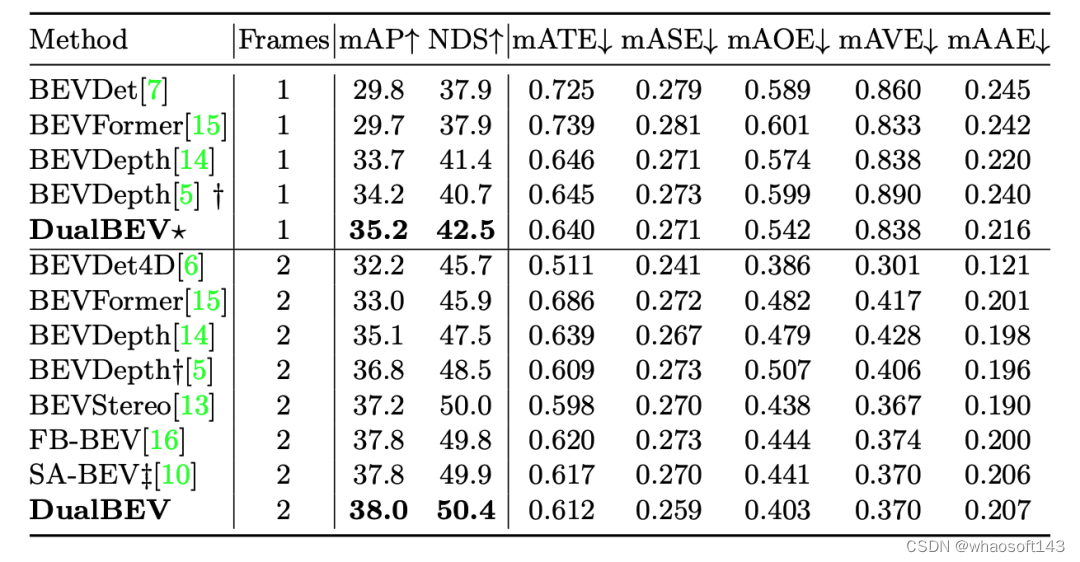
DualBEV方法的變體(帶星號的DualBEV* )在單幀輸入條件下表現最佳,達到了35.2%的mAP和42.5%的NDS,這表明它在準確性和綜合性能上都超過了其他方法。特別是在mAOE上,DualBEV*實現了0.542的分數,這是單幀方法中最好的。然而,它在mATE和mASE上的表現并沒有明顯優于其他方法。
當輸入幀數增加到兩幀時,DualBEV的表現進一步提升,mAP達到38.0%,NDS達到50.4%,這是所有列出方法中最高的NDS,表明DualBEV在處理更復雜的輸入時能夠更全面地理解場景。在多幀方法中,它在mATE、mASE、和mAAE上也展現了較強的性能,特別是在mAOE上有明顯的改善,顯示出其在估計物體方向上的優勢。
從這些結果可以分析得出,DualBEV及其變體在多個重要的性能指標上均有出色表現,尤其是在多幀設置下,表明其對BEV對象檢測任務具有較好的準確性和魯棒性。此外,這些結果還強調了使用多幀數據的重要性,可以提高模型的整體性能和估計準確性。
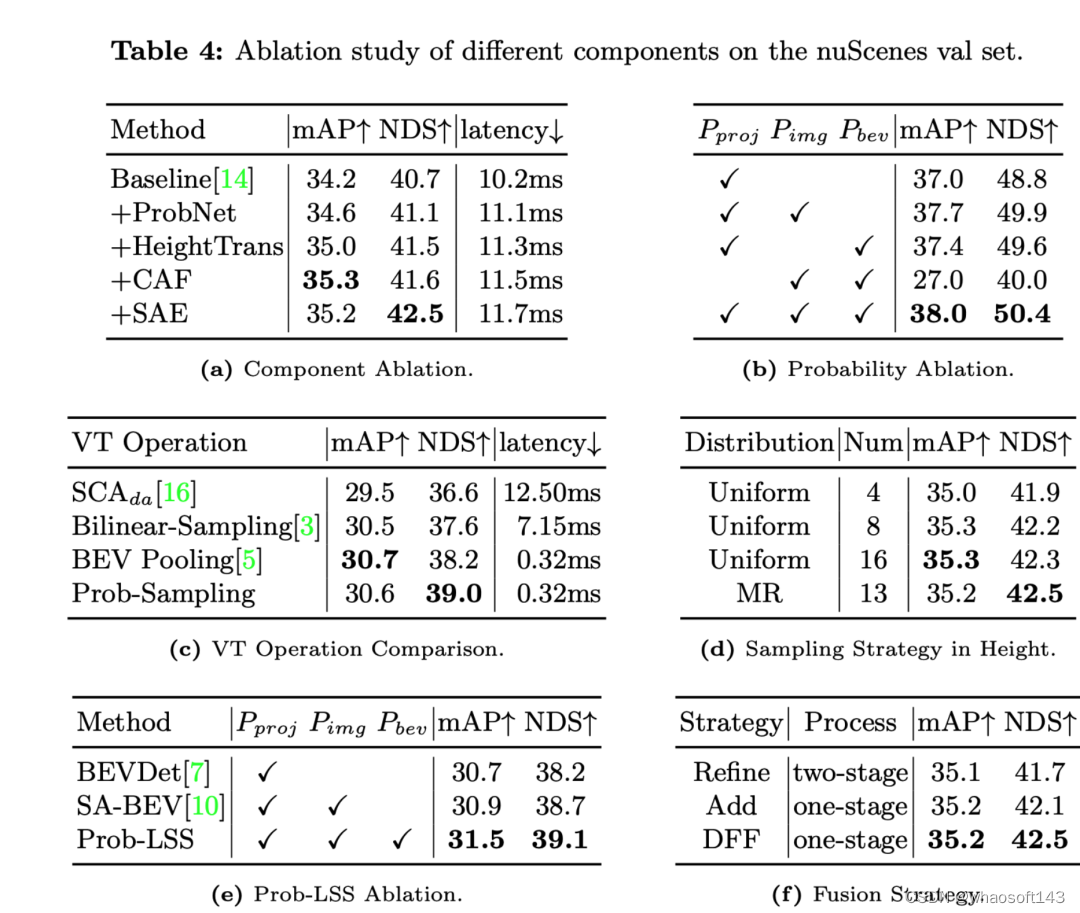
下面是對各個消融實驗結果的分析:
- 添加ProbNet、HeightTrans、CAF(Channel Attention Fusion)、SAE(Spatial Attention Enhanced)等組件逐步提升了Baseline的性能。
- HeightTrans的加入顯著提高了mAP和NDS,這表明在視覺轉換中引入高度信息是有效的。
- CAF進一步提升了mAP,但略微增加了延遲。
- SAE的引入提升了NDS到最高的42.5%,同時對mAP也有提升,說明空間注意力機制有效地增強了模型性能。

- 當全部三種概率同時使用時,模型達到了最高的mAP和NDS,這表明這些概率的結合對于模型性能至關重要。
- Prob-Sampling在相似的延遲下(0.32ms),比其他的VT操作具有更高的NDS(39.0%),這強調了概率采樣在性能上的優越性。
- 多分辨率(MR)采樣策略相對于均勻采樣策略,在使用相同數量的采樣點時能達到相似或更好的性能。
- 通過將投影概率、圖像概率和BEV概率加入到LSS流程,Prob-LSS的表現超過了其他的LSS變體,提高了mAP和NDS,顯示了結合這些概率的有效性。
- 與多階段的精細化(Refine)策略相比,單階段的添加(Add)策略和DFF模塊都能取得更高的NDS,而DFF在mAP上也有輕微的提升,這表明DFF作為一種單階段的融合策略,在效率和性能上都是有益的。
消融實驗表明了HeightTrans、概率措施、Prob-Sampling和DFF等組件及策略對提高模型性能至關重要。此外,多分辨率采樣策略在高度信息上的使用也證明了其有效性。這些發現支持了作者在方法部分提出的每一項技術都對模型性能有正面貢獻的論點。
討論
這篇論文通過一系列消融實驗展示了其方法的性能。從實驗結果可以看出,論文提出的DualBEV框架和它的各個組成部分均對提高鳥瞰圖(BEV)對象檢測的準確性具有積極影響。
論文的方法通過將ProbNet、HeightTrans、CAF(Channel Attention Fusion)、和SAE(Spatial Attention Enhanced)模塊逐步引入到基線模型中,顯示出在mAP和NDS兩個指標上均有顯著提升,這證明了每個組件在整個架構中都發揮了重要作用。尤其是引入SAE后,NDS得分提高到了最高點42.5%,同時延遲只有輕微增加,這表明了該方法在精度和延遲之間取得了良好的平衡。
概率消融實驗結果進一步證實了投影概率、圖像概率和BEV概率在提高檢測性能方面的重要性。當這些概率被逐一引入時,系統的mAP和NDS得分穩步提升,這表明了將這些概率措施集成到BEV對象檢測任務中的重要性。
在視覺轉換(VT)操作的比較中,論文提出的Prob-Sampling方法與其他操作如SCAda和Bilinear-Sampling相比,顯示出較低的延遲和更高的NDS得分,這強調了其在效率和性能上的優勢。此外,對于不同的高度采樣策略,采用多分辨率(MR)策略而不是統一采樣能夠進一步提高NDS得分,這表明了考慮場景中不同高度的信息對于提升檢測性能的重要性。
此外,對于不同的特征融合策略,論文展示了DFF方法在簡化模型的同時,依然能夠維持高NDS得分的能力,這意味著在一階段處理流程中融合雙流特征是有效的。
然而,盡管論文提出的方法在多個方面表現出色,每項改進也都會導致系統復雜度和計算成本的增加。例如,每引入一個新的組件(如ProbNet、HeightTrans等),系統的延遲都會有所增加,盡管延遲的增加是微小的,但在實時或低延遲要求的應用中,這可能成為考慮因素。此外,雖然概率措施有助于性能提升,但也需要額外的計算資源來估計這些概率,可能導致更高的資源消耗。
論文提出的DualBEV方法在提高BEV對象檢測的精度和綜合性能方面取得了顯著的成果,特別是在將深度學習的最新進展與視覺轉換技術相結合的方面。但這些進步是以輕微增加計算延遲和資源消耗為代價的,實際應用時需要根據具體情況權衡這些因素。
結論
該方法在BEV對象檢測任務中表現出色,顯著提高了準確性和綜合性能。通過引入概率采樣、高度轉換、注意力機制和空間關注增強網絡,DualBEV成功地提升了多個關鍵性能指標,特別是在鳥瞰圖(BEV)的精度和場景理解方面。實驗結果表明,論文的方法在處理復雜場景和不同視角數據時尤為有效,這對于自動駕駛和其他實時監控應用至關重要。
#MapUncertaintyPrediction
原標題:Producing and Leveraging Online Map Uncertainty in Trajectory Prediction
論文鏈接:https://arxiv.org/pdf/2403.16439.pdf
代碼鏈接:https://github.com/alfredgu001324/MapUncertaintyPrediction
作者單位:多倫多大學 Vector Institute NVIDIA Research 斯坦福大學
論文思路:
高精(HD)地圖在現代自動駕駛汽車(AV)技術棧的發展中扮演了不可或缺的角色,盡管與此相關的標注和維護成本很高。因此,許多近期的工作提出了從傳感器數據在線估計HD地圖的方法,使自動駕駛汽車能夠在先前繪制的區域(previously-mapped)之外運行。然而,當前的在線地圖估計方法是獨立于其下游任務開發的,這使得它們在自動駕駛技術棧中的整合變得復雜。特別是,它們不生成不確定性或置信度估計。本文擴展了多個最先進的在線地圖估計方法,使其能夠額外估計不確定性,并展示了這如何使在線建圖與軌跡預測更緊密地整合1。在此過程中,本文發現納入不確定性可以使訓練收斂速度提高多達50%,并且在真實世界的nuScenes駕駛數據集上的預測性能提高多達15%。
主要貢獻:
本文提出了一個通用的矢量化地圖不確定性表述,并擴展了多個最先進的在線地圖估計方法,使其額外輸出不確定性估計,而不會降低純建圖性能。
本文通過實證分析潛在的地圖不確定性來源,確認了當前地圖估計方法缺乏置信度的地方,并為未來的研究方向提供了信息。
本文將許多近期的在線地圖估計模型與多個最先進的軌跡預測方法相結合,并展示了如何通過納入在線建圖不確定性顯著提高下游預測模型的性能和訓練特性,加速訓練收斂速度高達50%,并提高在線預測準確性多達15%。
網絡設計:
自動駕駛的一個關鍵組成部分是理解靜態環境,例如,圍繞自動駕駛汽車(AV)的道路布局和連通性。因此,已經開發出高精(HD)地圖來捕捉和提供此類信息,包含了道路邊界、車道分隔線以及厘米級別的道路標記等語義信息。近年來,HD地圖已被證明對于自動駕駛汽車的開發和部署是不可或缺的,今天已被廣泛使用[35]。然而,HD地圖的標注和長期維護成本高昂,并且它們只能在地理圍欄區域(geofenced areas)使用,這限制了自動駕駛汽車的可擴展性(scalability)。
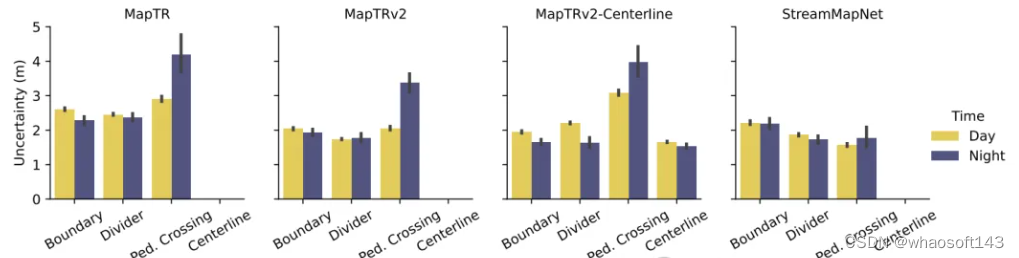
為了解決這些問題,許多近期的研究轉向從傳感器數據在線估計高精(HD)地圖。廣義上,它們的目標是預測地圖元素的位置和類別,通常以多邊形或折線的形式,全部來源于相機圖像和激光雷達(LiDAR)掃描。然而,當前的在線地圖估計方法并未產生任何相關的不確定性或置信度信息。這是有問題的,因為它導致下游使用者(consumers)隱含地假設推斷出的地圖組件是確定的,任何建圖錯誤(例如,地圖元素的移動或放置不正確)可能導致錯誤的下游行為。為此,本文提出揭示在線地圖估計方法中的地圖不確定性,并將其納入下游模塊中。具體來說,本文將地圖不確定性納入軌跡預測,并發現在結合了地圖不確定性的 mapper-predictor 系統中(圖1)與那些沒有結合地圖不確定性的系統相比,性能有顯著提升。
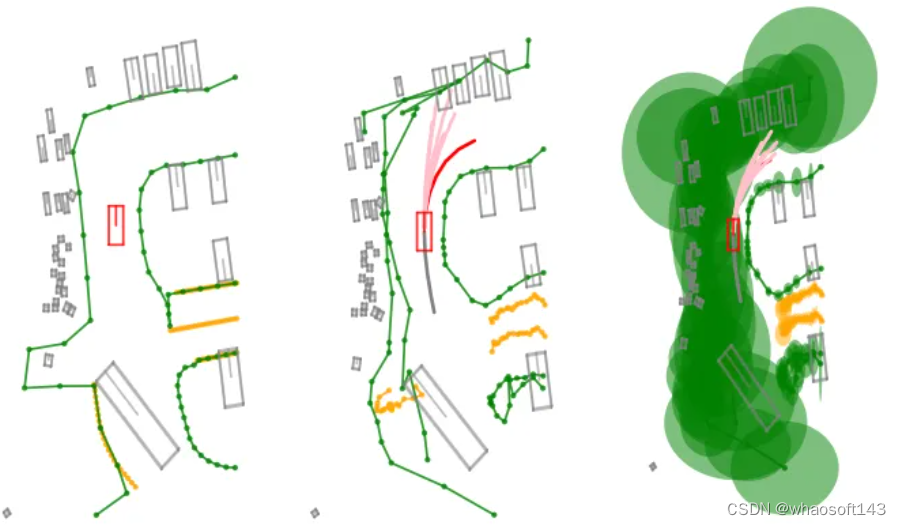
圖1. 從在線高精(HD)地圖估計方法中產生不確定性,并將其納入下游模塊中,帶來了多種好處。左圖:真實的HD地圖和代理位置。中圖:使用MapTR[22]輸出地圖的HiVT[41]預測。右圖:使用MapTR[22]輸出的地圖以及增加了點不確定性(由于左側道路邊界被停放的車輛遮擋,不確定性較大)的HiVT[41]預測。
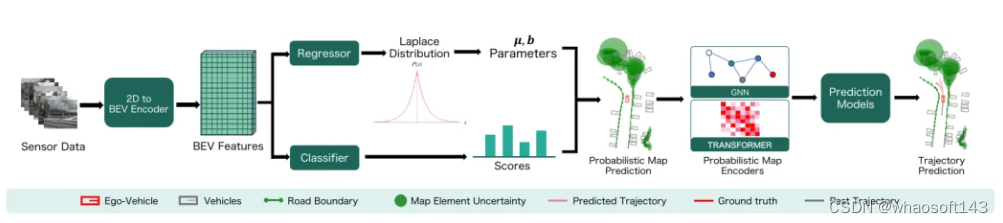
圖2. 許多在線高精矢量地圖估計方法通過編碼多攝像機圖像,將它們轉換到一個共同的鳥瞰圖(BEV)特征空間,并回歸地圖元素的頂點來運作。本文的工作通過增加一個概率回歸頭來增強這種常見的輸出結構,將每個地圖頂點建模為拉普拉斯分布。為了評估由此產生的下游效應,本文進一步擴展了下游預測模型以編碼地圖不確定性,增強了基于圖神經網絡(GNN)和基于 Transformer 的地圖編碼器。?
實驗結果:
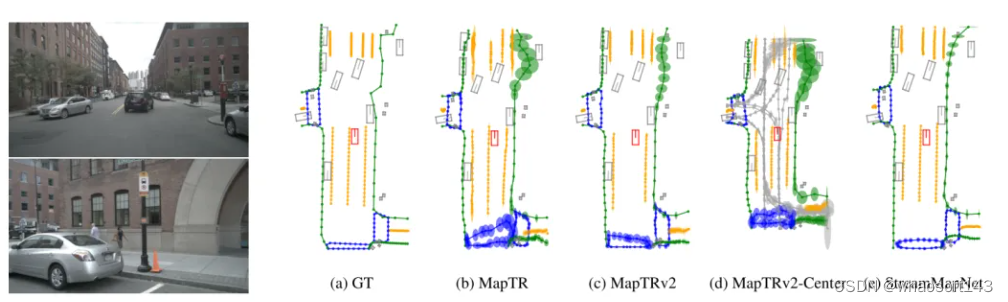
圖3. 本文提出的不確定性表述能夠捕捉由于自動駕駛車輛(AV)的攝像頭與周圍地圖元素之間的遮擋而產生的不確定性。左圖:前方和前右方攝像頭的圖像。右圖:本文增強的在線高精地圖模型生成的HD地圖。橢圓表示分布的標準差。顏色代表道路邊界、車道分隔線、人行橫道和車道中心線。
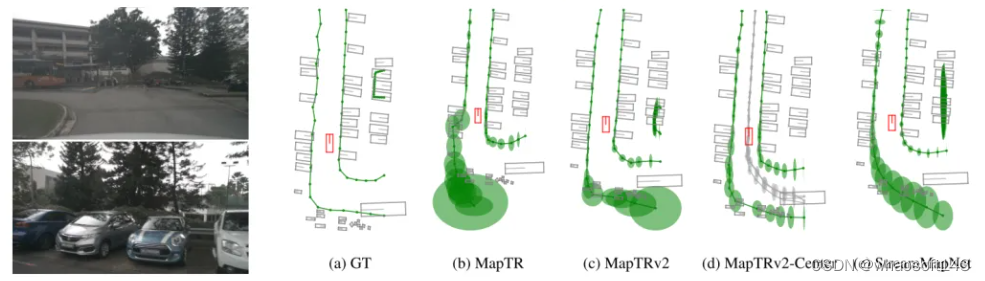
圖4. 在一個密集的停車場中,許多模型未能生成準確的地圖。左圖:后方和后左方攝像頭的圖像。右圖:本文增強的在線高精地圖模型生成的HD地圖。橢圓展示了分布的標準差。顏色代表道路邊界、車道分隔線、人行橫道和車道中心線。
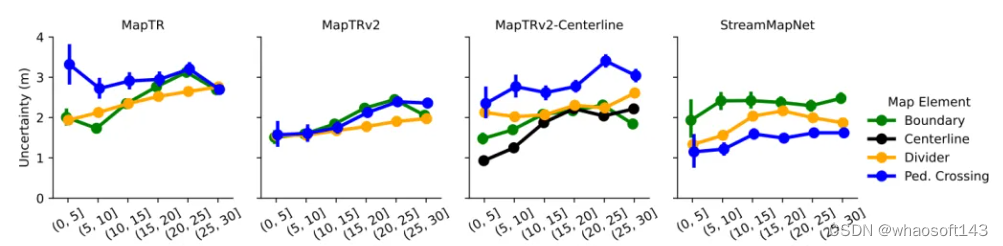
總結:
本文提出了一個通用的矢量化地圖不確定性公式,并擴展了多種最新的在線地圖估計方法,包括MapTR [22]、MapTRv2 [23]和StreamMapNet [38],使它們能夠額外輸出不確定性。本文系統地分析了產生的不確定性,并發現本文的方法捕捉到了許多不確定性來源(遮擋、與攝像頭的距離、一天中的時間和天氣)。最后,本文將這些在線地圖估計模型與最新的軌跡預測方法(DenseTNT [13]和HiVT [41])結合起來,并展示了結合在線地圖不確定性顯著提高了預測模型的性能和訓練特性,分別高達15%和50%。一個激動人心的未來研究方向是利用這些不確定性輸出來衡量地圖模型的校準度(類似于[16])。然而,這一任務因需要進行模糊點集匹配而變得復雜,這本身就是一個具有挑戰性的問題。
#M2DA~
更接近人類駕駛 | 全新LV融合賦予端到端駕駛人類理解能力,上車更進一步!
自動駕駛的端到端實現取得了顯著進展。然而,自動駕駛車輛的廣泛部署尚未實現,主要原因包括:1)多模態環境感知效率低:如何更有效地整合來自多模態傳感器的數據;2)非人類般的場景理解:如何有效地定位和預測交通場景中的關鍵風險因素,就像一名有經驗的駕駛員一樣。為了克服這些挑戰,在本文中,我們提出了M2DA。為了更好地融合多模態數據并實現不同模態之間的更高對齊度,我們提出了一種新穎的激光雷達-視覺融合模塊(LVAFusion)。通過整合駕駛員的注意力,我們賦予了自動駕駛車輛類似于人類的場景理解能力,以精確識別復雜情景中的關鍵區域,并確保安全。
本文貢獻
在多模態自動駕駛模型中,由于點云和圖像信息的無效融合而引起的特征不對齊是應用的一大挑戰。例如,錯誤解釋或忽略特定關鍵數據可能導致障礙物的錯誤判斷或不準確的位置估計。以前關于傳感器融合的研究主要集中在駕駛場景的感知和預測方面。這包括2D和3D物體檢測,以及運動預測。這些方法主要利用卷積神經網絡在3D環境中學習和捕捉幾何和語義信息。然而,這些方法要么假設局部性來在圖像和激光雷達投影空間之間對幾何特征進行對齊,要么簡單地連接多傳感器特征。這些融合技術可能無法有效地捕捉復雜多主體場景中的多模態特征之間的交互作用。
另一方面,交通環境的高度動態、隨機和多樣化特性對自動駕駛提出了嚴峻挑戰。更具體地說,自動駕駛車輛應該處理許多不可預測的情況,例如違反交通信號的車輛或突然從盲點出現的行人。在這種復雜而危險的環境中,熟練的駕駛員能夠迅速識別和預測交通危險。例如,他們可以在未標記的十字路口無意識地搜索來自所有方向的來車,以預防事故。因此,駕駛員注意力(DA)可以作為關鍵的風險指標。同時,自然駕駛和實驗室模擬研究的實驗一直顯示DA在定位潛在沖突對象方面的有效性,最終提升了道路交通安全性。因此,準確預測駕駛員注視點的意義重大,對于端到端自動駕駛系統理解復雜交通場景至關重要。這種預測性洞察對于設計能夠模仿人類般預期技能的系統至關重要,從而提高了自動駕駛車輛的安全性和可靠性。然而,迄今為止,關于將DA集成到端到端自動駕駛中的研究尚未被探索。
為了克服上述挑戰,我們提出了一個新穎的M2DA框架用于自動駕駛,具有兩個核心創新:高效的多模態環境感知和類人場景理解。總的來說,M2DA具有以下貢獻:
- 為了避免多模態情景中關鍵對象的不對齊,我們提出了LVAFusion,一種新穎的多模態融合模塊,利用具有先驗信息的查詢來集成圖像和點云表示。LVAFusion突出顯示兩種傳感器模態共同的關鍵特征,并捕捉特定情景中它們的上下文相互作用。
- 就我們所知,我們是第一個將駕駛員注意力融入到端到端自動駕駛中的工作,這有助于在復雜情景中高效地識別關鍵區域。DA預測的引入不僅為下游決策任務提供了更精細的感知特征以確保安全,而且將場景理解過程更接近人類認知,從而增加了可解釋性。
- 我們在涉及CARLA中對抗性情景的復雜城市環境中對我們的方法進行了實驗驗證。M2DA在Town05 Long基準測試實現了最先進的駕駛性能。
相關工作回顧
2.1端到端自動駕駛
與通常由不同獨立模塊組成的傳統流水線不同,近年來,開發無累積誤差的端到端自動駕駛系統已成為一個活躍的研究課題,在基于CARLA的閉環評估中取得了令人印象深刻的駕駛性能,CARLA是一個3D駕駛模擬平臺。NEAT采用神經注意力場來實現對交通場景邏輯結構的高效推理,特別是在空間和時間維度上。TCP提出了一種綜合方法,將軌跡規劃和端到端自動駕駛中的直接控制方法結合起來,在單目攝像頭輸入的城市駕駛場景中表現出優越性能。Interfuser是一個安全增強的自動駕駛框架,通過集成多模態傳感器信號并生成可解釋特征來解決與全面場景理解和安全性相關的挑戰,以實現更好的約束動作。為了解決資源-任務分配不平衡的問題,ThinkTwice調整了編碼器和解碼器之間的容量分配,并采用兩步預測(即粗粒度預測和細粒度細化)來預測未來位置。Uniad直接將感知、預測和規劃等全棧駕駛任務集成到一個統一的網絡中,有效地避免了傳統模塊化設計方法常見的累積誤差或任務協調不足的問題。盡管近年來的研究取得了令人印象深刻的進展,但我們認為當前端到端自動駕駛仍然可以在兩個方面繼續改進:1)更有效的多模態環境感知,可以更好地集成來自多模態和多視角傳感器的數據;2)更類人的場景理解,可以快速檢測和預測復雜交通場景中的關鍵風險因素,就像一名有經驗的駕駛員一樣。
2.2 自動駕駛的傳感器融合方法
由于不同模態的互補特性,多模態傳感器融合已成為各種研究領域的首選方法。對于端到端自動駕駛來說,傳感器融合意味著將來自不同傳感器類型的異構數據集成到一起,以提高自動駕駛的感知信息準確性,為后續安全可靠的決策提供重要基礎。最近的多模態端到端自動駕駛方法表明,將RGB圖像與深度和語義數據進行集成可以提高駕駛性能。LAV采用PointPainting來融合多模態傳感器,它將從RGB圖像提取的語義類信息與激光雷達點云進行連接。ContFuse利用連續卷積來融合不同分辨率的圖像和激光雷達特征圖。TransFuser是CARLA的一個廣泛使用的基準模型,采用多階段CNN獲取多分辨率特征,并使用自注意力獨立處理圖像和激光雷達表示,但無法學習不同模態之間的復雜相關性。相比之下,交叉注意力在處理多模態特征時表現出更多優勢;因此,它在最近的一些工作(例如Uniad、ReasonNet和Interfuser)中被廣泛使用。然而,這些方法將交叉注意力的可學習查詢初始化為隨機生成的參數,未能利用多模態特征中蘊含的先驗知識。這可能導致同一關鍵對象在多個模態之間的不對齊,最終導致模型學習的收斂速度較慢且不夠優化。為了解決這個問題,我們提出了一種新穎的多模態融合方法,使用交叉注意力來交互圖像和激光雷達表示,預計可以實現不同模態之間更好的對齊。
2.3 駕駛員注意力預測
人類駕駛員的注意力為駕駛提供了重要的視覺線索,因此最近對于利用各種深度神經模型預測駕駛員注意力的興趣日益增加。盡管在駕駛員注意力預測方面取得了如此多的研究進展,但仍然沒有研究嘗試將駕駛員注意力整合到端到端自動駕駛中,以從經驗豐富的人類駕駛員那里獲得出色的場景理解能力,這是本研究要解決的問題。
詳解M2DA
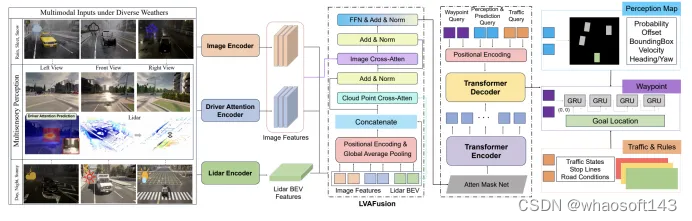
圖1:我們提出了M2DA,一種融合了駕駛員注意力的多模態融合變壓器,用于端到端自動駕駛。M2DA接受多視角圖像和激光雷達點云作為輸入。首先,我們使用一個DA預測模型來模擬駕駛員視覺注視的焦點,將其視為一個蒙版,用于調整原始圖像的權重以增強圖像數據。然后,我們使用基于ResNet的骨干網絡來提取圖像特征和激光雷達的BEV表示。我們利用全局平均池化與位置編碼來對這些提取的表示進行編碼。然后,它們被視為查詢與點云和圖像分別計算交叉注意力,輸出被認為是最終融合的特征,然后被饋送到后續的變壓器編碼器。三種類型的查詢,即路徑點查詢、感知和預測查詢以及交通查詢,被饋送到變壓器解碼器中,以獲取用于下游任務的相應特征。最后,M2DA采用自回歸路徑點預測網絡來預測未來路徑點,并使用MLP來預測周圍對象的感知地圖和交通狀態。
我們采用模仿學習來訓練我們的模型,其目標是學習一個策略πθ,該策略在給定當前場景Π中的車輛狀態時模仿專家行為。這包括多模態傳感器輸入I、車輛在全局坐標系中的位置p、車速v和導航信息n。M2DA需要輸出未來的軌跡W,并使用控制模塊將其轉換為控制信號C,包括橫向控制信號steer ∈ [?1, 1]和縱向控制信號brake ∈ [0, 1]、throttle ∈ [0, 1]。
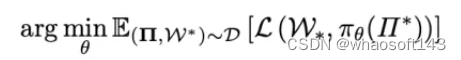
3.1 駕駛員注意力預測
駕駛員注意力的預測可以為自動駕駛代理提供駕駛員的視覺注視,從而增強其理解交通場景的能力,就像一名經驗豐富的人類駕駛員一樣。M2DA中的DA預測模型采用了編碼器-解碼器架構。對于編碼器,我們使用MobileNet-V2作為骨干網絡,以便快速進行預測,因為其內存占用和FLOPs較小。我們使用自注意力機制來處理空間特征。然后,我們采用反向殘差塊來投影這些特征,并將它們饋送到一個帶有128個隱藏通道和3×3內核大小的門控循環神經網絡(GRU)進行序列預測。對于解碼器,我們利用自注意力來處理GRU提取的特征。我們使用三個反向殘差塊來壓縮通道維度,以獲得更好的特征表示。此外,我們使用另一個自注意力來增強通道信息。最后,我們采用最近鄰插值來將特征上采樣到輸入圖像的大小。由于代理駕駛中將面臨各種場景,如果DA模型沒有很強的泛化能力,可能會導致注視點錯誤。為了解決這個問題,我們使用了四個數據集來訓練我們的DA預測模型,同時采用域自適應批歸一化(DABN)我們模型中的DABN可以表示為:
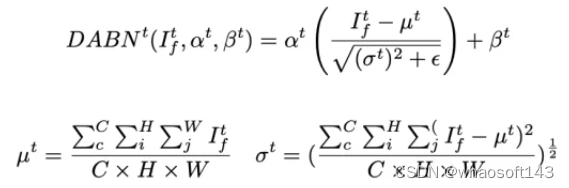
3.2基于注意力的融合模塊LVAFusion
本研究提出了一種新穎的多模態融合模塊LVAFusion,用于整合來自多模態和多視角傳感器的數據。首先,我們使用ResNet作為三個感知編碼器的骨干網絡,即圖像編碼器、注意力編碼器和激光雷達編碼器,以提取多視角圖像特征、駕駛員注意力特征和點云特征。然后,將這些感知特征串聯起來形成一個多模態特征。為了更好地捕獲嵌入在特定模態中的局部語義信息以及在多個模態之間耦合的全局語義信息,我們為每個模態定義了本地傳感器特征和全局傳感器特征。通過使用這些特征作為查詢,LVAFusion可以集中注意力于上下文中最相關的特征,并突出顯示兩種傳感器模態共同的關鍵特征,與采用隨機初始化查詢的方法相比,顯著提高了對它們上下文相互作用的解釋。上述過程可以表示為:

實驗
M2DA 是基于開源的 CARLA 模擬器 0.9.10.1 版本實現的。我們將M2DA與Town05 Long基準測試中的最新方法進行了比較。由于CARLA交通管理器的隨機性和傳感器噪聲的存在,評估結果表明存在一定程度的不確定性。因此,我們重復了每個評估實驗三次,并報告了平均結果。對于Town05 Long基準測試(表1),我們的方法實現了最佳性能,DS為72.6,IS為0.80,這意味著M2DA能夠很好地處理復雜場景并減少違規事件的發生。一些最新方法,例如MILE和DriveAdapter,獲得了更高的RC值;然而,它們表現出更高的碰撞或交通違規事件的發生率。對于使用與M2DA相同傳感器配置的Transfuser和Interfuser,我們的模型在所有指標上優于Transfuser。
表1:M2DA與Town05 Long基準測試中幾種最新方法的比較。↑表示數值越高越好。C代表相機,L代表激光雷達。額外監督指的是除了自車的動作和狀態之外,訓練需要額外的標簽。專家表示從特權代理中提取知識。Box指的是其他代理的邊界框。DriveAdapter的評估只運行一次,用上標1表示。
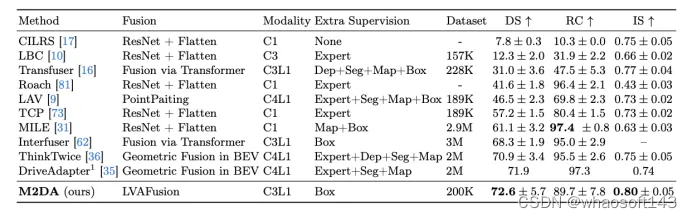
有研究證明收集到的專家數據的規模對駕駛性能有顯著影響。盡管M2DA只是在一個包含200K幀的數據集上進行了訓練,但在Town05基準測試上,其表現優于使用更大訓練數據集的現有最先進模型,例如Interfuser(3M)、MILE(2.9M)和Thinktwice(2M),這意味著M2DA能夠在數據量減少的情況下獲得更優秀的性能。
可視化
我們在M2DA的評估結果中可視化了一些代表性案例(圖2)。第一行顯示了一個沒有明顯風險的正常交通場景,M2DA將其視覺注意力定位在圖像中央的道路消失點上。在第二行中,一個正在奔跑的行人即將橫穿馬路。在這種突然的情況下,就像一名經驗豐富的人類駕駛員一樣,M2DA迅速而準確地捕捉到了當前交通場景中的危險對象,即行人,并做出相應的駕駛決策以避免潛在的碰撞。在第三行描述的更危險的情況中,M2DA也迅速將注意力分配給了十字路口的車輛。與此同時,考慮到車輛的預測未來軌跡,M2DA感知到了碰撞風險很高,并立即啟動緊急制動機動以防止事故發生。

圖2:每一行代表M2DA遇到的一個代表性交通場景。左側的三列分別顯示左側視圖、前方視圖和右側視圖圖像。第四列顯示了駕駛員注意力的預測結果。最后一列表示周圍車輛的感知狀態。黃色框表示自車。白色、淺灰色和灰色框分別表示周圍車輛當前位置、下一個時間間隔的預測位置和下兩個時間間隔的預測位置。綠色點和紅色點分別表示自車的安全未來軌跡和可能發生碰撞的不安全區域。

圖3
上圖在M2DA的評估結果中可視化了行人橫穿的更多細節情況(圖3)。第一行顯示了一個沒有明顯風險的正常交通場景,M2DA將其視覺注意力定位在圖像中央的道路消失點上。在第二行中,一個正在奔跑的行人即將橫穿馬路。在這種突然的情況下,就像一名經驗豐富的人類駕駛員一樣,M2DA迅速而準確地捕捉到了當前交通場景中的危險對象,即行人,并做出相應的駕駛決策以避免潛在的碰撞。在行人橫穿馬路后,M2DA重新聚焦于前方的道路,從而增強了決策過程的可解釋性。
消融研究
我們現在對M2DA的幾個設計選擇進行一系列消融研究,針對Town05 Long基準測試進行分析。
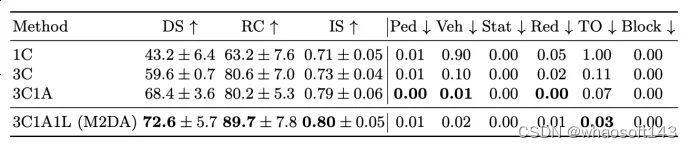
首先,我們通過利用不同的傳感器輸入組合,研究不同傳感器模態的影響。結果如表2所示。1C僅利用前置RGB圖像作為輸入,這使得在自車側面檢測障礙物變得具有挑戰性。因此,它表現出與車輛的碰撞率(Veh)最高以及最長超時時間(TO),最終導致最差的駕駛性能。當左右攝像頭被納入時,3C可以更全面地觀察交通狀況,這不僅降低了車輛碰撞的風險,還減輕了超時情況。然而,僅以攝像頭圖像作為輸入時,3C仍然顯示出較高的闖紅燈率(Red),表明代理程序難以有效捕捉交通燈信息。為了解決這個問題,我們引入了駕駛員注意力作為額外的輸入,并讓模型從經驗豐富的人類駕駛員那里學習,以在接近信號化十字路口時提前將視覺注意力分配到交通燈上。結果,3C1A顯示出較低的闖紅燈率,導致IS和DS的增加。進一步引入激光雷達點云進一步提高了IS,導致DS最高。?
表2:不同傳感器輸入的消融研究。↑表示數值越高越好,而↓表示數值越低越好。1C和3C分別表示使用一個攝像頭(前置)和三個攝像頭(左側、前置、右側)作為輸入。3C1A表示三個攝像頭結合駕駛員注意力特征。3C1A1L進一步引入了一個激光雷達。
M2DA體系結構變化的影響如表3所示。當我們移除融合和DA模塊時,與車輛的碰撞率(Veh)最高。在添加DA模塊后,模型可以更好地捕捉交通燈信息,有效降低了Veh和Red。值得注意的是,添加DA模塊后,方差增加,這可以歸因于人類駕駛員視覺注意力的主觀因素引起的不確定性。引入LVAFusion后,駕駛分數顯著提高,表明所提出的LVAFusion有效處理了多模態信息,并幫助代理程序做出良好的駕駛決策。如預期的那樣,引入LVAFusion和DA模塊后,駕駛性能最佳。
表3:M2DA不同組件的消融研究。↑表示數值越高越好,而↓表示數值越低越好。?表示使用該模塊。

結論
在這項工作中,我們提出了M2DA,一個專注于高效的多模態環境感知和類人場景理解的端到端自動駕駛框架。首先,我們提出了一個新穎的基于激光雷達-視覺-注意力融合(LVAFusion)的模塊,用于更好地融合多模態數據并實現不同模態之間更高的對齊。此外,M2DA通過將來自經驗駕駛員的視覺注意力信息納入到自主車輛中,賦予了自動駕駛車輛類似人類的場景理解能力,以識別關鍵對象。經過驗證,M2DA在兩個競爭性的閉環自動駕駛基準測試中取得了SOTA性能。
#世界模型如何推動自動駕駛
本篇分享最新綜述??The Role of World Models in Shaping Autonomous Driving: A Comprehensive Survey??,世界模型如何推動自動駕駛。
- 論文鏈接:https://arxiv.org/abs/2502.10498
- 最新匯總論文:https://github.com/LMD0311/Awesome-World-Model
背景
駕駛世界模型(Driving World Models, DWM)是預測駕駛場景演化的關鍵技術,能夠幫助自動駕駛系統感知、理解并與動態駕駛環境交互。
近年來,DWM 在提升自動駕駛安全性和可靠性方面的重要性日益凸顯。然而,現有研究仍面臨諸多挑戰,包括多模態數據的高效融合、稀缺數據場景的建模以及模型在復雜場景中的魯棒性。
為此,本文對DWM 的研究現狀進行了全面梳理,系統性總結了方法分類、應用場景、數據集與指標,并深入探討了未來研究方向,為研究者提供了寶貴的參考。
此外,本文還公開了一個名為Awesome World Models for Autonomous Driving的GitHub倉庫,現在已經收獲超700 star,并保持持續更新。
核心內容1. 方法分類與最新進展
本綜述系統性地對 DWM 方法進行了分類,涵蓋了 2D 場景、3D 場景和無場景范式,并詳細介紹了每種方法的核心技術和最新進展:

2D 場景演化
2D 場景方法主要利用生成技術(如自回歸 Transformer 和diffusion模型)生成高保真、物理一致的駕駛場景:
- 時空動態捕獲:GAIA-1 通過diffusion解碼器捕獲駕駛場景中的時空動態和高層結構。
- 多模態控制:DriveDreamer 擴展了條件diffusion框架,支持多模態控制和合成數據生成。
- 一致性提升:Vista 通過stable video diffusion 和新穎的損失函數,提升了場景生成的結構完整性和動態合理性。
3D 場景演化
3D 場景方法利用occupancy和點云數據,捕獲精確的空間幾何關系和動態信息:
- Occupancy生成?OccWorld 使用時空 Transformer 生成未來場景和自車位姿,確保全局一致性。
- 點云生成:Copilot4D 通過離散diffusion實現高效的點云生成和預測。
- 基于視覺的3D生成:ViDAR 從多視圖圖像預測未來點云演變,捕捉語義、3D結構和時間動態的協同學習。
- 多模態融合:BEVWorld 將圖像和點云數據融合為統一的鳥瞰視圖(BEV)表示,生成未來場景并支持自監督學習。
無場景(Scene-free)范式
無場景方法不關注細致的場景預測,而是關注潛在狀態的預測或多智能體行為的建模,提升自動駕駛系統的效率和泛化能力:
- 潛在狀態預測:Think2Drive使用DWM預測未來的潛在狀態,與想象的環境進行并行化的高效交互,從而提升規劃性能。
- 多智能體行為建模:TrafficBots 從預測多智能體的行為,模擬現實駕駛場景中的復雜交互。

2. 應用場景
DWM在自動駕駛中的應用場景廣泛,涵蓋仿真、數據生成、預測與規劃以及4D預訓練等多個方面:

仿真
DWM通過生成多樣化、高保真的駕駛場景,支持自動駕駛模型的訓練與評估。如Vista提供高保真的視頻仿真,支持動作評估;ACT-Bench關注動作保真度,準確遵守condition的控制;TrafficBots模擬多智能體行為,提升動作仿真真實性。
數據生成
DWM通過合成多樣化的數據,彌補真實數據的不足。例如,DrivePhysica生成高質量駕駛視頻,LidarDM生成真實的點云數據,增強下游任務(如3D檢測)的性能。此外,DriveDreame4D還能合成新的駕駛行為視頻,強化下游模型對長尾場景的適應能力。
預見性規劃
DWM通過未來場景預測優化車輛規劃與決策。例如,DriveWM結合獎勵函數選擇最優軌跡,ADriver-I通過多模態預測實現長時間規劃。也可以將場景預測與訓練過程結合,例如AdaWM通過對比預測場景和真實場景的差異來進行微調,LAW通過監督場景預測和未來真實場景一致以強化端到端規劃。
4D預訓練
利用多模態數據進行自監督學習,DWM提升了下游任務性能并降低了對人工標注的依賴。例如,ViDAR通過視覺點云預測學習3D幾何信息,BEVWorld在多傳感器數據上進行統一的BEV表示預訓練。
3. 數據集與評估指標
高質量的數據集和科學的評估指標是推動 DWM 研究的重要基石。本綜述全面梳理了 DWM 領域的主流數據集和常用指標:

- 多模態數據集:如 nuScenes、Waymo Open Dataset,涵蓋圖像、點云和 occupancy 等多種模態。
- 定制化數據集:如 DrivingDojo 專為 DWM 訓練設計,包含復雜的駕駛動態場景。
- 評估指標:DWM的評估指標因任務不同而多樣化,主要包括生成指標和規劃指標:
-

- 生成質量:如FID(Fréchet Inception距離)、FVD(Fréchet視頻距離)等衡量生成數據與真實數據的分布差異。
- 規劃性能:如Collision Rate(碰撞率)、Driving Score(駕駛得分)等評估模型在規劃任務中的表現。
- 一致性與可控性:除了通用的生成與規劃指標外,DWM還需考慮預測場景演變的時空一致性和可控性。為此提出了一些指標,如關鍵點匹配(KPM)和對象操作控制(COM)。
4. 當前挑戰與未來方向
盡管DWM取得了顯著進展,但仍面臨以下挑戰:
- 數據稀缺:高質量、多模態對齊數據的采集成本高昂,如何通過合成數據彌補數據不足是開放問題。
- 運行效率:生成任務的高計算成本限制了實時應用,未來需要探索更高效的表示方法和模型架構。
- 高質量仿真:進一步提高仿真的真實度,解決退化、幻覺等問題,為研究者提供值得信任的依據。
- 統一任務框架:預測與規劃、感知結合以相互促進;與規劃結合以聯合優化,統一的DWM任務框架具有廣闊研究前景。
- 多模態建模:現有方法對多模態數據的融合仍不充分,未來可探索非對齊甚至非配對數據的有效利用。
- 對抗攻擊與防御:針對DWM的對抗攻擊研究較少,開發防御策略以確保駕駛安全性至關重要。
總結與展望
Driving World Models作為自動駕駛領域的核心技術,正在推動感知、預測與規劃的深度融合。
本綜述不僅回顧了DWM的研究進展,還系統性地總結了應用、數據集和指標,并指出了當前的限制與未來的研究機遇。
我們相信,這篇綜述將為DWM領域的初學者提供充實的資料,為研究者和工程師提供有價值的結論和觀點,加速自動駕駛技術的發展。
#HENet
在自動駕駛系統中,感知任務是非常重要的一環,是自動駕駛后續下游軌跡預測以及運動規劃任務的基礎。作為一輛能夠實現自動駕駛功能的汽車而言,其通常會配備環視相機傳感器、激光雷達傳感器以及毫米波雷達傳感器。由于基于純視覺的BEV感知算法需要更低的硬件以及部署成本,同時其輸出的BEV空間感知結果可以很方便被下游任務所使用,受到了來自工業界和學術界的廣泛關注。
隨著目前感知任務需求的增長,比如要實現基于BEV空間的3D檢測任務或者是基于BEV空間的語義分割任務,一個理想的感知算法是可以同時處理像3D檢測或者語義分割等多個任務的。同時,目前的自動駕駛系統更加傾向于采用完全端到端的感知框架,從而簡化整個系統的架構并降低感知算法實現的復雜性。
雖然端到端的多任務感知模型具有諸多的優勢,但是目前依舊存在著諸多挑戰:
- 目前,絕大多數基于相機的3D感知算法,為了提高模型的檢測性能,都會采用更高分辨率的輸入圖像、長時序的輸入信息以及更強大的圖像特征編碼器。但是需要注意的是,在單任務的感知算法模型上同時采用這些技術會導致訓練過程中巨大的訓練成本。
- 由于時序的輸入信息可以更好的提升感知算法模型對于當前環境的理解和感知,目前很多工作都采用了這一策略。這些工作主要將不同幀的信息處理為BEV特征后,直接沿著通道的維度進行求和或者拼接來讓模型能夠獲取到一段時間段內的環境元素信息,但收益卻不是特別的理想。造成這一現象的主要原因是自車周圍環境的運動物體在不同時刻沿著BEV的軌跡是不同的,并且分散在BEV的大片區域中。因此,我們需要引入動態對齊機制的思想來對運動物體的位置進行調整。
- 對于目前已有的多任務學習框架而言,主要都是采用一個共享的圖像編碼網絡來處理不同的感知任務。然而,通過這些論文中列舉的相關實驗結果我們發現,通過多任務聯合學習的方式通常在不同任務上的表現要弱于每個任務單獨訓練的性能。
針對上述提到的端到端多任務感知模型存在的諸多挑戰,在本文中,我們提出了一個用于端到端多任務3D感知的混合特征編碼算法模型HENet,在nuScenes數據集上實現了多個任務的SOTA,如下圖所示。
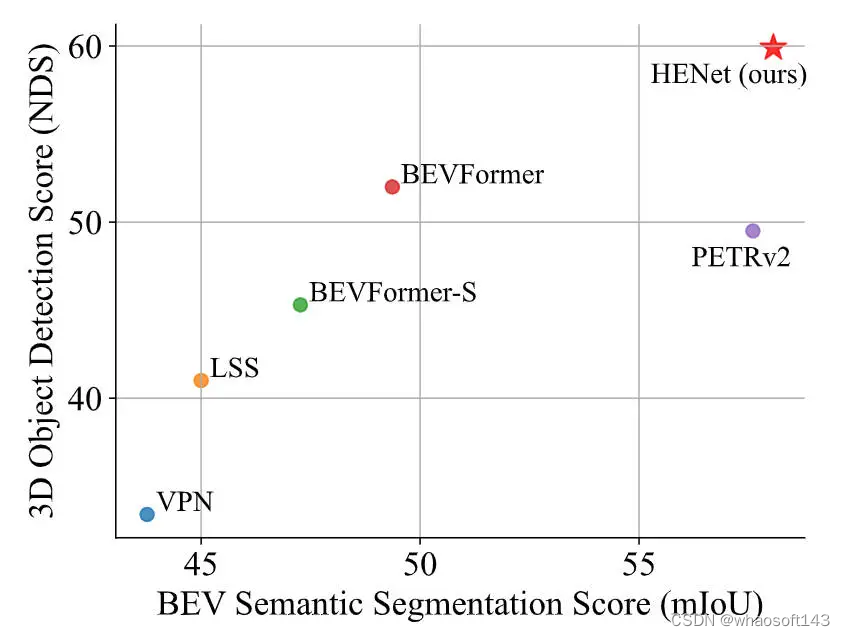
與其他算法模型的語義分割和3D檢測性能指標對比
原標題:HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
論文鏈接:https://arxiv.org/pdf/2404.02517.pdf
代碼鏈接:https://github.com/VDIGPKU/HENet
作者單位:北京大學 長安汽車 加州大學默塞德分校
多相機端到端多任務框架
論文思路:
多視角相機的三維感知是自動駕駛系統中的一個關鍵組成部分,涉及多項任務,如3D目標檢測和鳥瞰圖(BEV)語義分割。為了提高感知精度,最近的3D感知模型采用了大型圖像編碼器、高分辨率圖像和長時序輸入,帶來了顯著的性能提升。然而,由于計算資源的限制,這些技術在訓練和推理場景中常常不兼容。此外,現代自動駕駛系統更傾向于采用端到端框架進行多任務3D感知,這可以簡化整個系統架構并降低實施復雜性。然而,在端到端的3D感知模型中共同優化多個任務時,任務之間經常會出現沖突。為了緩解這些問題,本文提出了一個名為?HENet?的端到端多任務3D感知框架。具體來說,本文提出了一個混合圖像編碼網絡,使用大型圖像編碼器處理短時序幀,使用小型圖像編碼器處理長時序幀。然后,本文引入了一個基于注意力機制的時序特征集成模塊,用于融合兩種混合圖像編碼器提取的不同幀的特征。最后,根據每個感知任務的特點,本文使用不同網格大小的BEV特征、獨立的BEV編碼器和不同任務的任務解碼器。實驗結果表明,HENet在nuScenes基準測試中實現了最先進的端到端多任務3D感知結果,包括3D目標檢測和BEV語義分割。
主要貢獻:
- 本文提出了一個端到端的多任務3D感知框架,采用混合圖像編碼網絡,以較小的訓練成本利用高分辨率圖像、長期輸入和大型圖像編碼器的優勢。
- 本文引入了一個基于注意力機制的時序集成模塊,用于融合多幀BEV特征,并實現移動物體的動態幀間對齊。
- 本文分析了端到端多任務學習中的任務沖突,并提出了特征尺寸選擇和獨立特征編碼來緩解這個問題。
- 本文在nuScenes數據集上的端到端多任務學習中取得了最先進的結果,包括3D目標檢測和BEV語義分割任務。
網絡設計:
多視角相機高效且準確地感知周圍環境對自動駕駛系統至關重要,它是隨后軌跡預測和運動規劃任務的基礎。一個理想的3D感知系統應該能夠同時處理多項任務,包括3D目標檢測和鳥瞰圖(BEV)語義分割。端到端多任務框架越來越受到重視,因為這樣的系統有潛力簡化整體架構并減輕實施復雜性。
然而,端到端的多任務3D感知面臨以下挑戰。首先,在設計基于相機的高性能3D感知模型時,研究人員通常會利用更高分辨率的圖像、更長的時序輸入和更大的圖像編碼器來提高3D感知的準確性。然而,將這些技術同時應用于單一的感知模型將導致訓練成本極高。為了緩解這個問題,一些研究[32, 46]將過去的信息存儲在 memory 中,但這樣做有諸如時序特征不一致和數據增強效率低下等缺點。因此,許多最新的方法[26, 37, 44, 52]并沒有采用這種策略,而是重新計算過去幀的特征,盡管這樣做增加了訓練成本。
其次,為了處理長期的時序輸入,許多研究[11,17,18]直接在沿通道維度的鳥瞰圖(BEV)中將不同幀的特征求和或連接起來,在更長的時間序列中表現出不盡人意的感知性能。原因在于,移動物體的特征在不同幀的鳥瞰圖 (BEV) 中沿其軌跡錯位并分散在較大區域內。因此,有必要引入動態對齊機制[28, 37]來校正移動物體的位置。
第三,對于端到端的多任務學習,現有的研究[8, 19, 28]使用一個共享的編碼網絡和多個解碼器來處理不同的任務。然而,這些研究中的實驗結果表明,端到端地共同學習多個任務往往并不是最優的,即多任務學習中每個任務的性能都低于單獨訓練。為了緩解這個問題,一些研究[28]提出了調整每個任務的損失權重,但沒有全面分析任務之間存在沖突的原因。
本文提出了HENet,這是一個端到端的多任務3D感知框架,專為多視角相機設計。為了整合大型圖像編碼器、高分辨率圖像和長期輸入,本文提出了一種混合圖像編碼網絡,它采用不同的分辨率和圖像編碼器處理不同的幀。具體來說,本文對短期幀使用高分辨率輸入、大型圖像主干網絡和復雜的透視變換網絡,以生成高精度的BEV特征。對于長期幀,選擇低分辨率輸入,并采用小型圖像主干網絡和簡單的透視變換網絡高效生成BEV特征。所提出的混合圖像編碼網絡可以輕松地并入現有的感知模型中。然后,本文引入了一個時序整合模塊,以動態地對齊和融合來自多幀的BEV特征。具體來說,在這個模塊中,本文提出了一個帶有相鄰幀融合模塊(AFFM)的時序前向和后向過程來聚合BEV特征,通過注意力機制解決了對齊移動物體的問題。最后,本文深入分析了多任務學習中3D目標檢測與BEV語義分割之間的沖突,并發現不同任務偏好不同的BEV特征網格大小是關鍵問題。基于這一觀察,本文為不同任務選擇了不同網格大小的BEV特征。所選特征被送入獨立的BEV編碼網絡和任務解碼器,以進一步緩解任務沖突,從而獲得最終的3D感知結果。
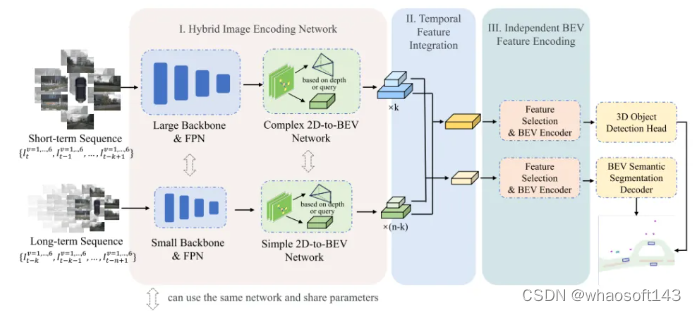
圖2:HENet的整體架構。i) 混合圖像編碼網絡使用不同復雜度的圖像編碼器分別對長序列幀和短期圖像進行編碼。ii) 基于注意力機制的時序特征整合模塊融合了來自多個圖像編碼器的多幀特征。iii) 根據不同任務的特點,本文選擇了合適大小的BEV特征圖,并對每個任務執行獨立的BEV編碼。
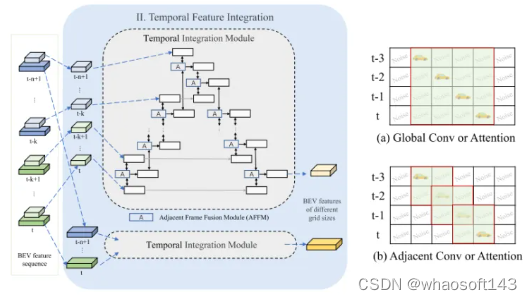
圖3:時序特征整合模塊的架構。本文提出了相鄰幀融合模塊(AFFM),并采用了包含時序前向和后向過程的時序融合策略。
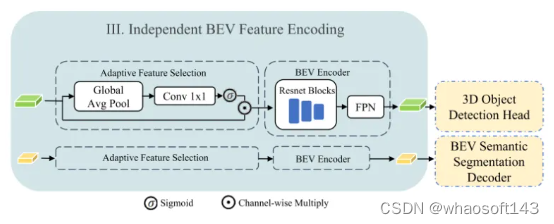
圖4:獨立BEV特征編碼的設計。通過獨立的自適應特征選擇和BEV編碼,為每個任務解碼器提供不同網格大小的BEV特征圖。

實驗結果:
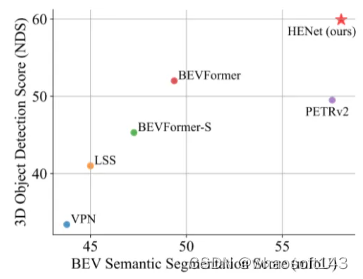
圖1:在nuScenes驗證集上端到端多任務結果的比較。?
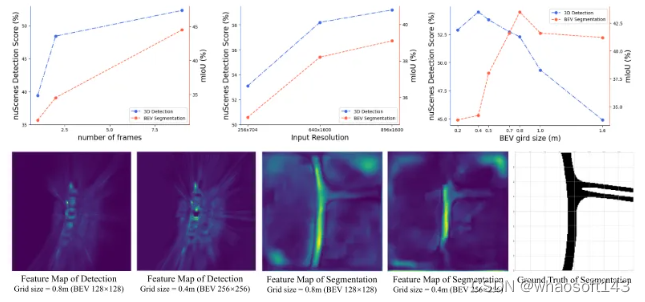
圖5:分析3D目標檢測與BEV語義分割之間的相似性和差異。實驗結果表明,每個任務都有適合的BEV網格大小。BEV語義分割的適宜網格大小 大于 3D目標檢測的適宜網格大小。
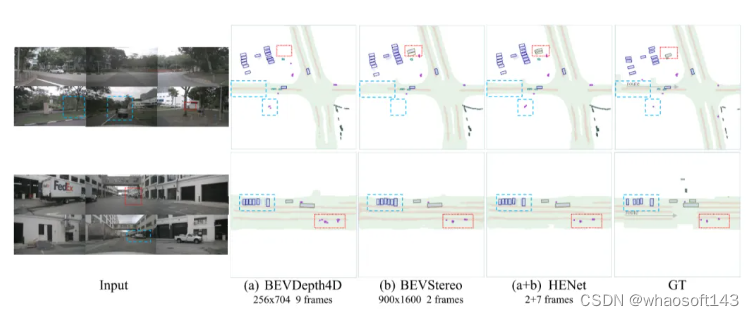
圖6:HENet及基線在端到端多任務處理上的可視化結果。
總結:
本文提出了HENet,這是一個端到端的多任務3D感知框架。本文提出了一種混合圖像編碼網絡和時序特征集成模塊,以高效處理高分辨率和長期時間序列的圖像輸入。此外,本文采用了特定于任務的BEV網格大小、獨立的BEV特征編碼器和解碼器來解決多任務沖突問題。實驗結果表明,HENet在nuScenes上獲得了最先進的多任務結果,包括3D目標檢測和BEV語義分割。
#DriveCoT
近年來,端到端自動駕駛技術取得了顯著進展,表現出系統簡單性和在開環和閉環設置下競爭性駕駛性能的優勢。然而,端到端駕駛系統在駕駛決策方面缺乏可解釋性和可控性,這阻礙了其在真實世界中的部署。本文利用CARLA模擬器收集了一個全面的端到端駕駛數據集,名為DriveCoT。它包含傳感器數據、控制決策和chain-of-thought標簽,用于指示推理過程。利用CARLA排行榜2.0中具有挑戰性的駕駛場景,這些場景涉及高速駕駛和換道,并提出了一個基于規則的專家策略來控制車輛,并為其推理過程和最終決策生成了真值標簽,覆蓋了不同駕駛方面和最終決策的推理過程。該數據集可以作為一個開環端到端駕駛基準,可評估各種推理方面的準確性和最終決策。此外,我們提出了一個名為DriveCoT-Agent的基線模型,它是在我們的數據集上訓練的,用于生成推理鏈預測和最終決策。經過訓練的模型在開環和閉環評估中表現出很強的性能,證明了我們提出的數據集的有效性。
題目:DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
作者單位:香港大學,華為,香港中文大學
開源地址:DriveCoT
DriveCoT,它包括一個新的數據集、基準和端到端自動駕駛的基線模型。傳感器數據,如相機圖像以及指示方向的目標點(左圖像中的黃點),作為模型輸入。如下右圖所示,該模型通過生成不同駕駛方面的預測并進行chain-of-thought推理來獲得最終的速度決策。此外,模型還生成了計劃的未來轉向點(左圖中的藍點)。
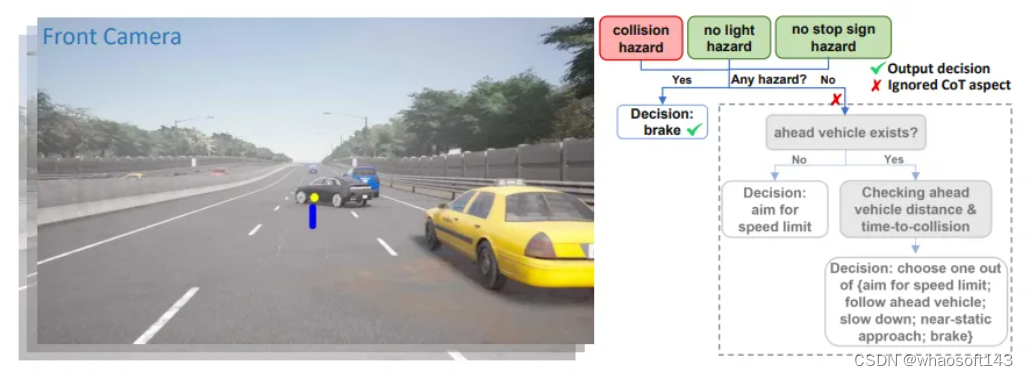
DriveCoT Agent的基線模型將過去一段時間的多視點攝像機視頻和指示方向的目標點作為輸入,以生成關于不同駕駛方面和計劃的未來路線點的CoT預測。沒有使用單幀圖像作為輸入,而是利用多視圖攝像機視頻來捕捉自車和周圍物體的運動,從而能夠早期預測潛在危險并支持高速駕駛。此外,最終的駕駛決策可以通過圖8所示的過程從模型的chain-of-thought預測中得出。除了可解釋性之外,訓練后的模型在DriveCoT驗證數據的開環評估和閉環測試基準方面都顯著優于以前的方法。
DriveCoT Dataset
使用CARLA 0.9.14版本收集數據,并修改了提出的基于規則的專家政策,以適應高速駕駛和更具挑戰性的場景。此外,使用一組跨越城市、住宅、農村和高速公路區域的預定義路線來執行專家政策,并在遇到許多具有挑戰性的場景時駕駛自車。對于每個場景,數據收集在預定義的觸發點啟動,并在超過20秒的模擬時間或達到下一個場景的觸發點時停止。
DriveCoT數據集包括1058個場景和36K個標記樣本,以2Hz頻率收集,每個場景平均17秒。分別以70%、15%和15%的比例將數據集劃分為訓練集、驗證集和測試集,得到25.3K的訓練樣本、5.5K的驗證樣本和5.5K的測試樣本。為了防止數據泄露,將同一場景中的所有數據分配給同一集合。此外,確保CoT方面在所有拆分中的分布是相似的。
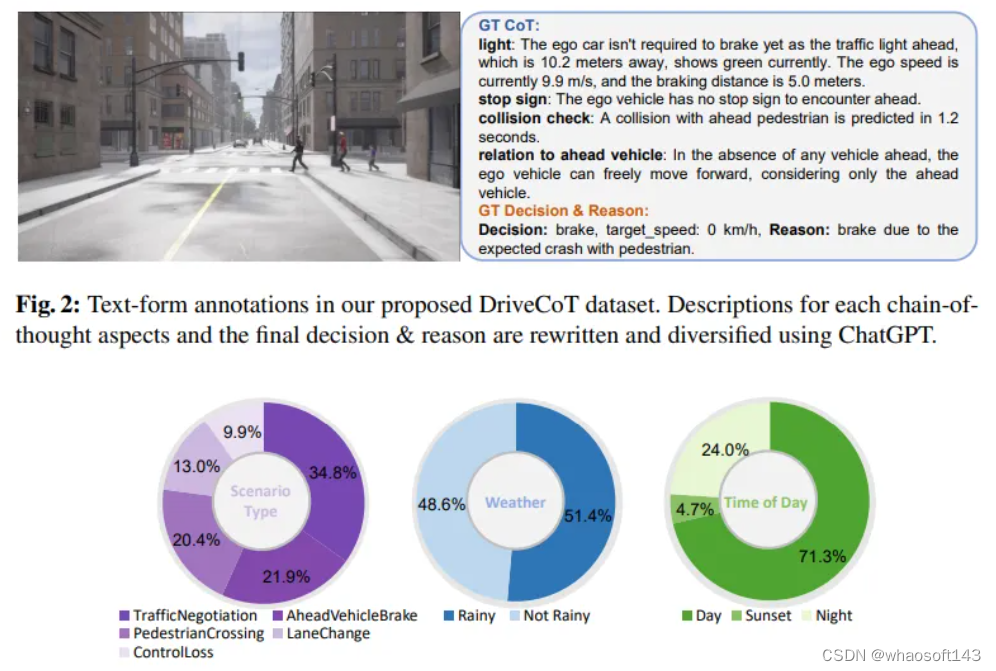
專家策略
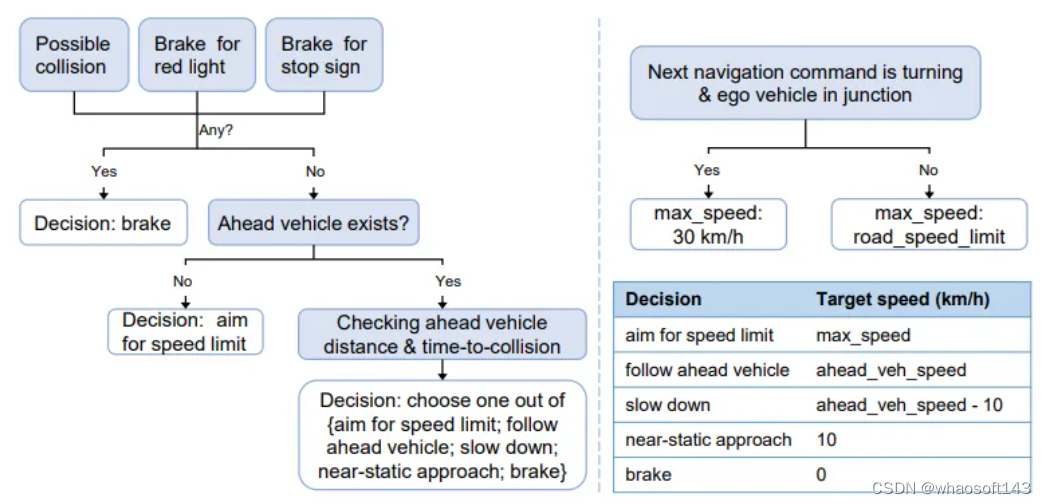
本文提出了一種基于規則的專家政策,該政策可以訪問模擬器,經過有效的修改,使其適用于leaderborad2.0中的高速駕駛。根據自車速度為自車設計動態制動距離,以檢測潛在的危險,包括紅綠燈、停車標志或周圍的車輛和行人。此外,擬議的專家政策還考慮了與同一車道上前方車輛的關系,以產生更微妙的速度決策。對于計劃的未來航路點,收集具有固定距離間隔的專家航路點,類似于Transuser++,而不是固定時間間隔,以將航路點與目標速度區分開來。此外,當自車速度增加以避免振蕩時,計劃的路點被選擇得離自車更遠。
在DriveCoT中,根據場景組織收集的數據。每個場景都有一個元文件,指示場景類型、天氣狀況和一天中的時間。每個幀樣本可以根據文件名與特定場景相關聯,每幀包含來自六個1600×900 RGB相機和一個32線激光雷達傳感器的傳感器數據,以及專家政策的決策過程標簽和文本形式和簡化分類形式的最終決策。如圖8所示,CoT方面包括檢查紅綠燈危險、停車標志危險、與周圍物體的潛在碰撞、與前方車輛的關系等。
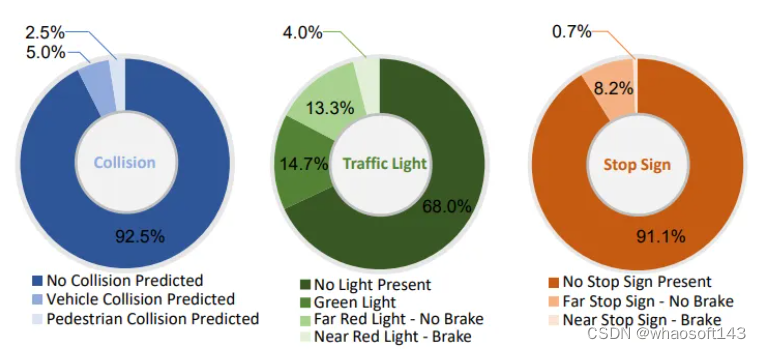
DriveCoT-Agent
所提出的基線模型DriveCoT Agent。它將多視圖相機視頻作為輸入,并通過共享的視頻SwinTransformer為每個視圖提取視頻特征。然后,通過變換器編碼器融合不同視圖的視頻標記。對于不同的chain-of-thought driving aspects,為不同的任務定義了單獨的可學習查詢。這包括碰撞預測、紅綠燈識別、停車標志、路口和前方車輛狀態預測。此外,路徑GRU將相關解碼器輸出與其他導航信息一起用于生成用于引導的計劃路線點。?
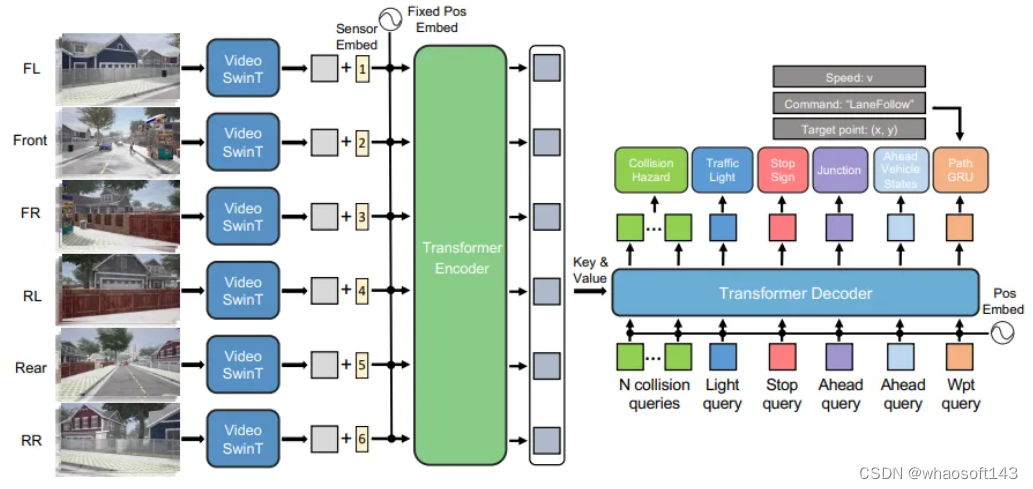
實驗結果
DriveCoT數據集val split的開環評估。以前的方法只能提取二進制速度決策(正常駕駛或制動)。與以前的方法相比,所提出的DriveCoT Agent可以預測更精確、更詳細的速度決策和轉向路線點。
更多消融實驗:

DriveCoT Agent的定性結果。它正確地為(a)車道交通工具、(b)紅色交通燈和行人以及(c)道路中間的過街行人剎車。圖像中的黃點是目標點,表示方向,而藍點和綠點表示地面實況和預測的未來路線點。在(d)中,DriveCoT Agent根據嵌入視頻輸入中的碰撞距離和時間信息,生成與前方車輛有關的適當速度決策!
#BEVCar
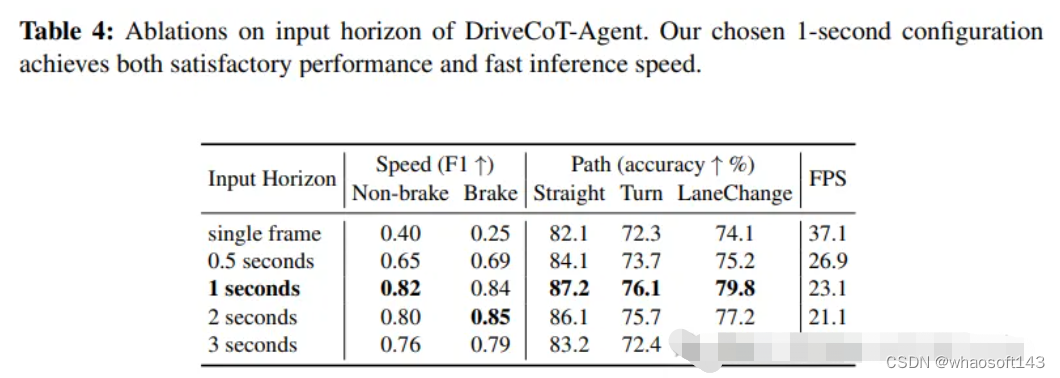
用于BEV地圖和目標分割的RV融合方案
從鳥瞰圖(BEV)的角度進行語義場景分割在促進移動機器人的規劃和決策方面發揮著至關重要的作用。盡管最近的純視覺方法在性能上取得了顯著進步,但它們在下雨或夜間等不利的照明條件下往往會遇到困難。雖然有源傳感器為這一挑戰提供了解決方案,但激光雷達高昂的成本仍然是一個限制因素。
將camera數據與Radar融合是一種更廉價的替代方案,但在之前的研究中受到的關注較少。在這項工作中,我們的目標是通過引入BEVCar來推進這一有前景的途徑,BEVCar是一種用于BEV目標和地圖聯合分割的新方法。核心新穎性在于首先學習原始雷達數據的基于點的編碼,然后利用該編碼來有效地初始化將圖像特征提升到BEV空間中。在nuScenes數據集上進行了大量實驗,證明了BEVCar的性能優于當前的技術水平。此外還表明,結合雷達信息顯著增強了在具有挑戰性的環境條件下的魯棒性,并提高了遠距離物體的分割性能!
鏈接:http://bevcar.cs.uni-freiburg.de
本文主要貢獻:
1) 介紹了一種新的BEVCar框架,用于從相機和雷達數據中分割BEV地圖和目標。
2) 提出了一種新的基于注意力的圖像提升方案,該方案利用稀疏雷達點進行查詢初始化。
3)基于學習的雷達編碼優于原始元數據的使用。
4) 在具有挑戰性的環境條件下將BEVCar與以前的基線進行了廣泛的比較,并展示了利用雷達測量的優勢。
5) 公開了nuScenes上使用的白天/晚上/下雨的分割
網絡結構
下圖為提出的用于BEV地圖和目標分割的相機-雷達融合的BEVCar方法。使用帶有可學習適配器的凍結DINOv2對環視圖圖像進行編碼。受基于激光雷達的感知的啟發,采用了可學習的雷達編碼,而不是處理原始元數據。然后,通過可變形注意力將圖像特征提升到BEV空間,包括新的radar-driven的查詢初始化方案。最后,以基于注意力的方式將提升的圖像表示與學習的雷達特征融合,并對車輛和地圖類別執行多類BEV分割。
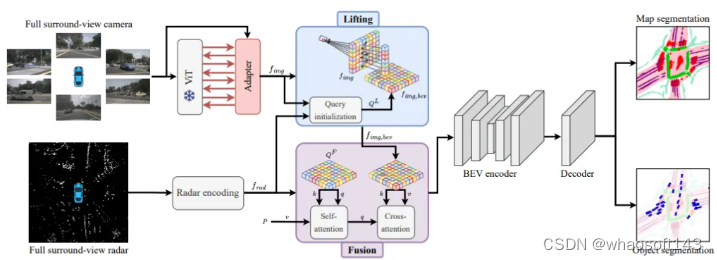
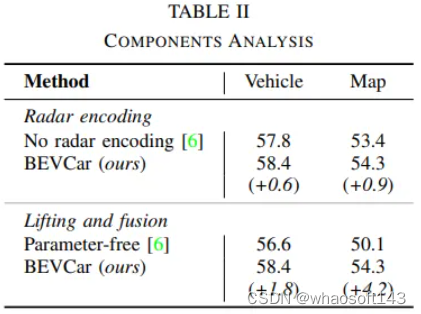
受激光雷達處理的啟發,以逐點方式對具有全連接層(FCN)的雷達數據進行編碼,并使用最大池化來組合體素內的點特征。隨后,采用基于CNN的高度壓縮來獲得BEV空間中的整體雷達特征。
實驗對比
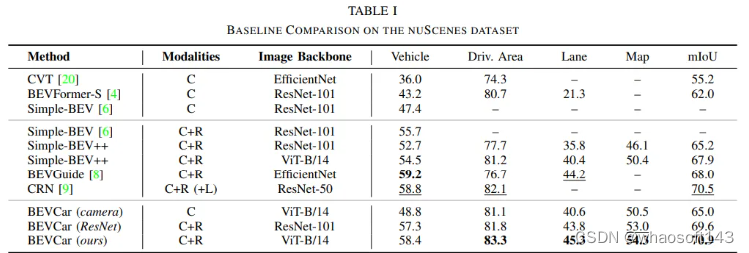
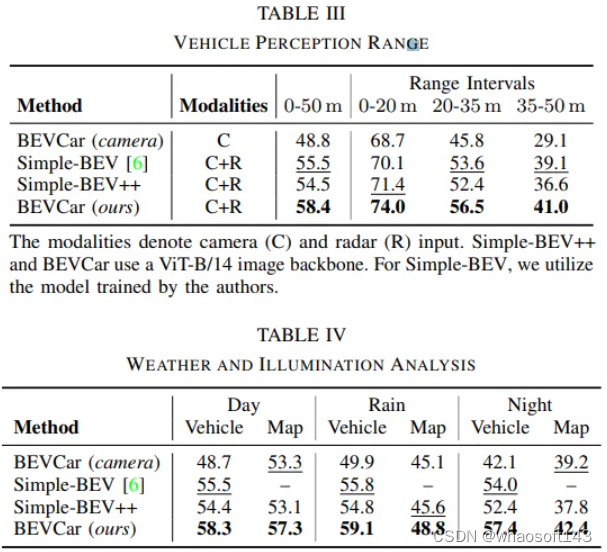
BEVCar是在nuscenes上進行評估,論文進一步將驗證場景分為白天(4449個樣本)、下雨(968個樣本)和夜晚(602個樣本)場景,并將這一劃分包含在代碼中。對于目標分割,組合“車輛”類別的所有子類。對于地圖分割,考慮所有可用的類別,即“可行駛區域”、“停車場區域”、”人行橫道“、”人行道“、”停車線“、”道路分隔帶“和”車道分隔帶“。文中報告了先前工作中已經解決的那些類的IoU度量,并通過“映射”引用了所有映射類的平均IoU。為了將BEVCar與之前預測較少類別的基線進行比較,將“車輛”和“可駕駛面積”的平均值報告為“mIoU”!?
在nuScenes驗證分割上比較了BEVCar與純相機(C)和相機雷達(C+R)BEV分割方法。Simple BEV++是一種定制的Simple BEV,沒有實例感知訓練,但具有與我們的方法相同的雷達元數據和地圖分割頭。為了將BEVCar與這些方法進行比較,將“車輛”和“可駕駛區域”類別的平均值提供為“mIoU。

#BEVTrack
基于鳥瞰圖中的點云跟蹤
0.簡介
本文介紹了BEVTrack:鳥瞰圖中點云跟蹤的簡單基線。由于點云的外觀變化、外部干擾和高度稀疏性,點云的3D單目標跟蹤(SOT)仍然是一個具有挑戰性的問題。值得注意的是,在自動駕駛場景中,目標物體通常在連續幀間保持空間鄰接,多數情況下是水平運動。這種空間連續性為目標定位提供了有價值的先驗知識。然而,現有的跟蹤器通常使用逐點表示,難以有效利用這些知識,這是因為這種表示的格式不規則。因此,它們需要精心設計并且解決多個子任務以建立空間對應關系。本文《BEVTrack: A Simple Baseline for 3D Single Object Tracking in Bird’s-Eye View》(https://arxiv.org/pdf/2309.02185.pdf)中的BEVTrack是一種簡單而強大的三維單目標跟蹤基線框架。在將連續點云轉換為常見的鳥瞰圖表示后,BEVTrack固有地對空間近似進行編碼,并且通過簡單的逐元素操作和卷積層來熟練捕獲運動線索進行跟蹤。此外,為了更好地處理具有不同大小和運動模式的目標,BEVTrack直接學習潛在的運動分布,而不像先前的工作那樣做出固定的拉普拉斯或者高斯假設。BEVTrack在KITTI和NuScenes數據集上實現了最先進的性能,同時維持了122FPS的高推理速度。目前這個項目已經在Github(https://github.com/xmm-prio/BEVTrack)上開源了。
1.主要貢獻
本文的貢獻總結如下:
1)本文提出了BEVTrack,這是一種簡單而強大的三維單目標跟蹤的基線框架。這種開創性的方法通過BEV表示有效地利用了空間信息,從而簡化了跟蹤流程設計;
2)本文提出了一種新型的分布感知回歸策略,其直接學習具有不同大小和各種運動模式的目標的潛在運動分布。該策略為跟蹤提供準確的指導,從而提供了性能,同時避免了額外的計算開銷;
3)BEVTrack在保持高推理速度的同時,在兩個主流的基準上實現了最先進的性能
2.概述

其中F是跟蹤器學習到的映射函數。
根據公式(1),我們提出了BEVTrack,這是一個簡單但強大的3D單目標跟蹤基準框架。BEVTrack的整體架構如圖2所示。它首先利用共享的VoxelNext [29]提取3D特征,然后將其壓縮以獲得BEV表示。隨后,BEVTrack通過串聯和多個卷積層融合BEV特征,并通過MLP回歸目標的平移。為了實現準確的回歸,我們采用了一種新穎的分布感知回歸策略來優化BEVTrack的訓練過程。? ? ?
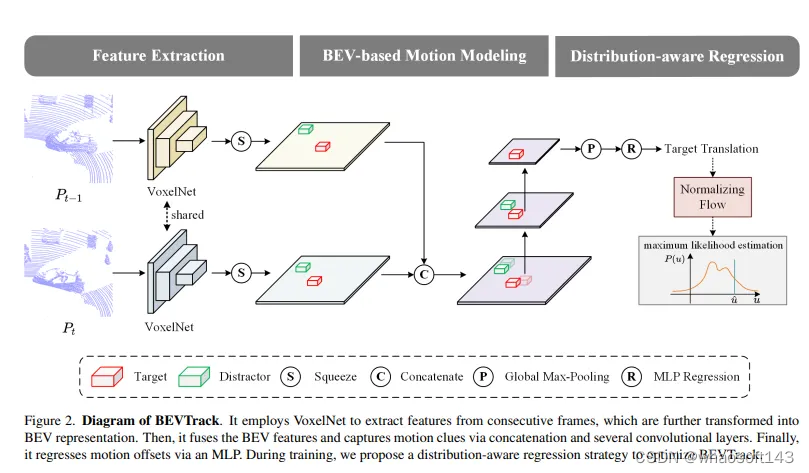
圖2. BEVTrack的示意圖。它使用VoxelNet從連續幀中提取特征,進一步將其轉換為BEV表示。然后,通過串聯和幾個卷積層,它融合BEV特征并捕捉運動線索。最后,通過多層感知機(MLP)回歸運動偏移量。在訓練過程中,我們提出了一種分布感知回歸策略來優化BEVTrack。
3.特征提取

4.基于BEV的運動建模

其中C ∈ \mathbb{R}^6表示目標平移偏移\bar{u} ∈ \mathbb{R}^3的期望值和標準差σ ∈ \mathbb{R}^3,這將在第5節中詳細介紹。通過將平移應用于目標的最后狀態,我們可以在當前幀中定位目標。
5.分布感知回歸
在先前的工作中,通常在訓練過程中使用傳統的L1或L2損失來進行目標位置回歸,這實際上對目標位置的分布做出了固定的拉普拉斯或高斯假設。與之相反,我們提出直接學習底層運動分布,并引入一種新穎的分布感知回歸策略。通過這種方式,可以為跟蹤提供更準確的指導,使BEVTrack能夠更好地處理具有不同大小和移動模式的物體。
在[11]的基礎上,我們使用重新參數化來建模目標平移偏移u~P(u)的分布。具體而言,P(u)可以通過對來自零均值分布z~P_Z(z)進行縮放和平移得到,其中u=\bar{u}+σ·z,其中\bar{u}表示目標平移偏移的期望,σ表示分布的尺度。P_Z(z)可以通過歸一化流模型(例如,real NVP [2])進行建模。給定這個變換函數,可以計算出P(u)的密度函數:

#LightDiff
原標題:Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
論文鏈接:https://arxiv.org/pdf/2404.04804.pdf
作者單位:克利夫蘭州立大學 德克薩斯大學奧斯汀分校 A*STAR 紐約大學 加州大學洛杉磯分校
論文思路:
自動駕駛的視覺中心感知系統由于其成本效益和可擴展性,特別是與激光雷達系統相比,最近受到了相當多的關注。然而,這些系統在低光照條件下常常會遇到困難,可能會影響其性能和安全性。為了解決這個問題,本文介紹了LightDiff ,這是一個為自動駕駛應用中提升低光照圖像質量而設計的定制化框架。具體來說,本文采用了一個多條件控制的擴散模型。LightDiff 無需人工收集的成對數據,而是利用動態數據退化過程(dynamic data degradation process)。它結合了一個新穎的多條件適配器(multi-condition adapter),該適配器能夠自適應地控制來自不同模態的輸入權重,包括深度圖、RGB圖像和文本標題,以有效地照亮黑暗場景的同時保持內容的一致性。此外,為了使增強的圖像與檢測模型的知識相匹配,LightDiff 使用特定于感知的評分作為獎勵,通過強化學習指導擴散訓練過程。在 nuScenes 數據集上進行的廣泛實驗表明,LightDiff 能夠顯著提高多個最新的3D檢測器在夜間條件下的性能,同時實現高視覺質量評分,凸顯了其在保障自動駕駛安全方面的潛力。
主要貢獻:
? 本文提出了 Lighting Diffusion (LightDiff) 模型,以增強自動駕駛中的低光照相機圖像,減少了對大量夜間數據收集的需求,并保持了白天的性能。
? 本文整合了包括深度圖和圖像標題在內的多種輸入模態,并提出了一個多條件適配器,以確保圖像轉換中的語義完整性,同時保持高視覺質量。本文采用了一種實用的過程,從白天數據生成晝夜圖像對,以實現高效的模型訓練。
? 本文為 LightDiff 提出了一種使用強化學習的微調機制,結合了為感知定制的領域知識(可信的激光雷達和統計分布的一致性),以確保擴散過程既有利于人類視覺感知,也有利于感知模型。
? 在 nuScenes 數據集上進行的廣泛實驗表明,LightDiff ?顯著提高了夜間3D車輛檢測的性能,并在多個視覺指標上超越了其他生成模型。
網絡設計:
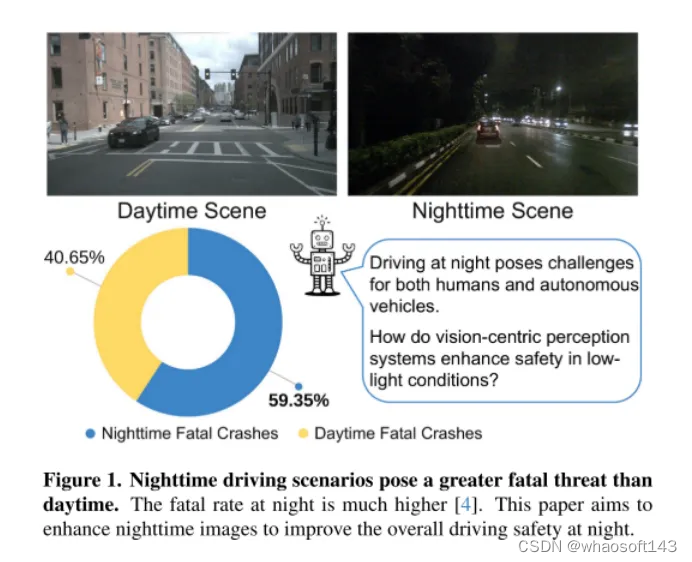
圖1。夜間駕駛場景比白天更具有致命威脅。夜間的致命率要高得多[4]。本文旨在增強夜間圖像,以提高夜間駕駛的整體安全性。
如圖1所示,夜間駕駛對于人類來說是具有挑戰性的,對于自動駕駛汽車來說更是如此。2018年3月18日,一起災難性的事件突顯了這一挑戰,當時 Uber Advanced Technologies Group 的一輛自動駕駛汽車在亞利桑那州撞擊并致死了一名行人[37]。這起事件是由于車輛未能在低光照條件下準確檢測到行人而引起的,它將自動駕駛汽車的安全問題推到了前沿,尤其是在這樣要求苛刻的環境中。隨著以視覺為中心的自動駕駛系統越來越多地依賴于相機傳感器,解決低光照條件下的安全隱患已經變得越來越關鍵,以確保這些車輛的整體安全。
一種直觀的解決方案是收集大量的夜間駕駛數據。然而,這種方法不僅勞動密集、成本高昂,而且由于夜間與白天圖像分布的差異,還有可能損害白天模型的性能。為了應對這些挑戰,本文提出了 Lighting Diffusion (LightDiff )模型,這是一種新穎的方法,它消除了手動數據收集的需求,并保持了白天模型的性能。
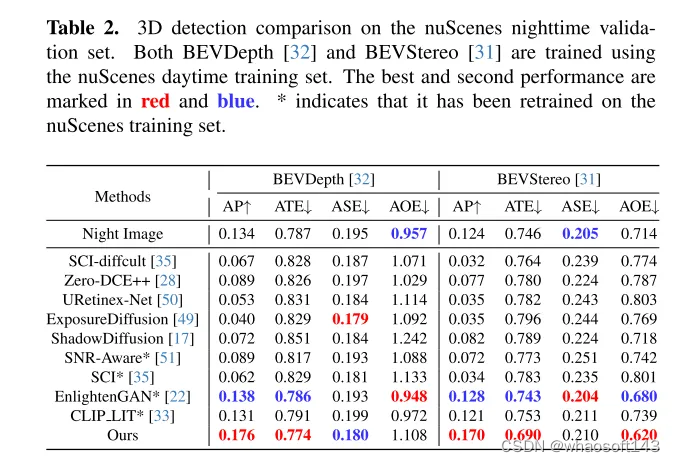
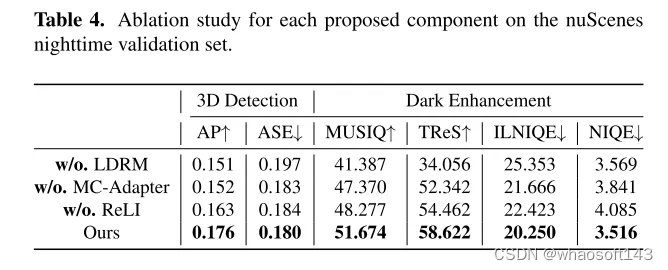
LightDiff 的目標是增強低光照相機圖像,提高感知模型的性能。通過使用動態的低光照衰減過程,LightDiff 從現有的白天數據生成合成的晝夜圖像對進行訓練。接著,本文采用了 Stable Diffusion [44]技術,因為它能夠產生高質量的視覺效果,有效地將夜間場景轉換成白天的等效物。然而,在自動駕駛中保持語義一致性至關重要,這是原始 Stable Diffusion 模型面臨的一個挑戰。為了克服這一點,LightDiff 結合了多種輸入模態,例如估計的深度圖和相機圖像標題,配合一個多條件適配器。這個適配器智能地確定每種輸入模態的權重,確保轉換圖像的語義完整性,同時保持高視覺質量。為了引導擴散過程不僅朝著對人類視覺更亮的方向,而且對感知模型也是如此,本文進一步使用強化學習對本文的 LightDiff 進行微調,循環中加入了為感知量身定制的領域知識。本文在自動駕駛數據集nuScenes [7]上進行了廣泛的實驗,并證明了本文的 LightDiff 可以顯著提高夜間3D車輛檢測的平均精度(AP),分別為兩個最先進模型BEVDepth [32]和BEVStereo [31]提高了4.2%和4.6%。
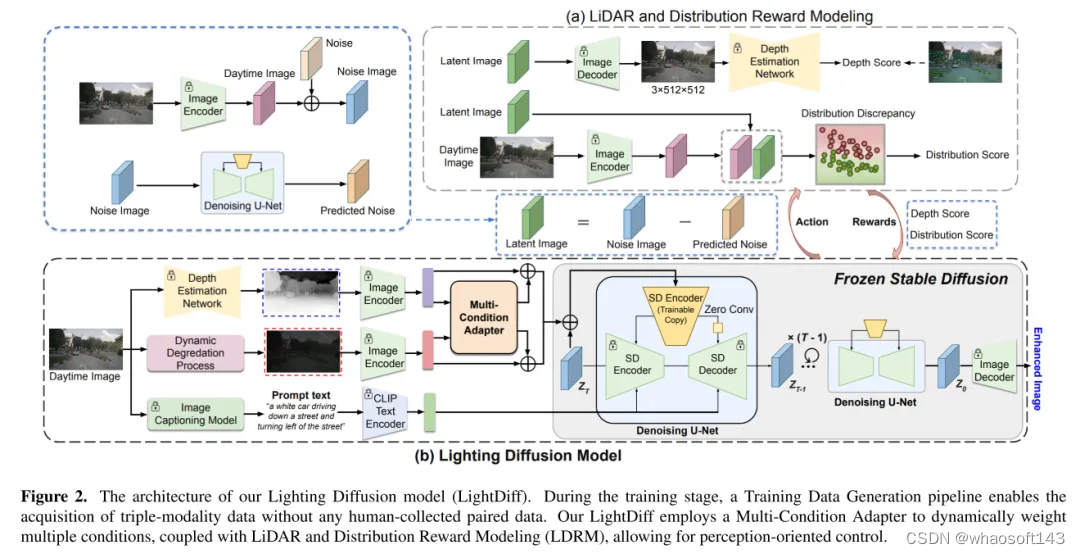
圖2. 本文的 Lighting Diffusion 模型(LightDiff )的架構。在訓練階段,一個訓練數據生成流程使得無需任何人工收集的配對數據就能獲取三模態數據。本文的 LightDiff 使用了一個多條件適配器來動態加權多種條件,結合激光雷達和分布獎勵建模(LDRM),允許以感知為導向的控制。
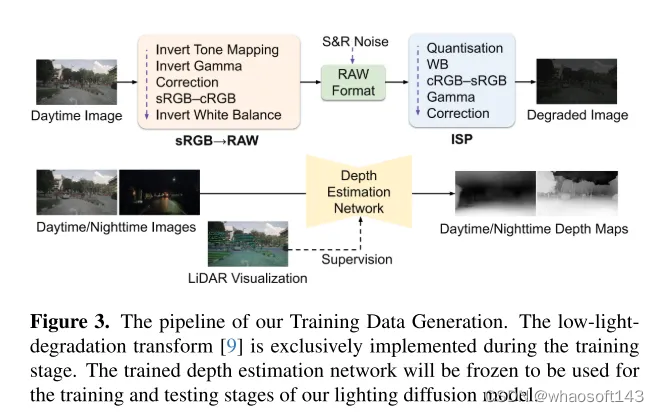
圖3. 本文的訓練數據生成流程。低光照退化轉換[9]僅在訓練階段實施。訓練好的深度估計網絡將被凍結,用于本文 Lighting Diffusion 模型的訓練和測試階段。
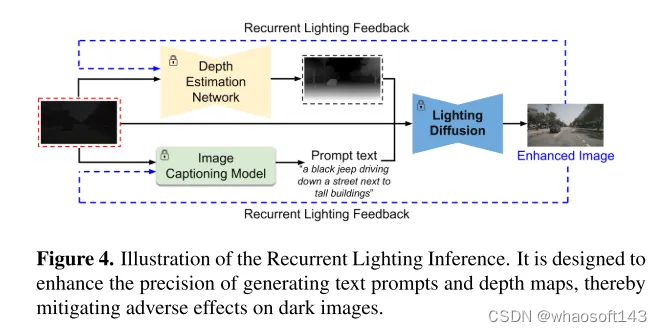
圖4. 循環照明推理(Recurrent Lighting Inference)的示意圖。其設計旨在提高生成文本提示和深度圖的精確度,從而減輕對暗圖像的不利影響。? ? ?
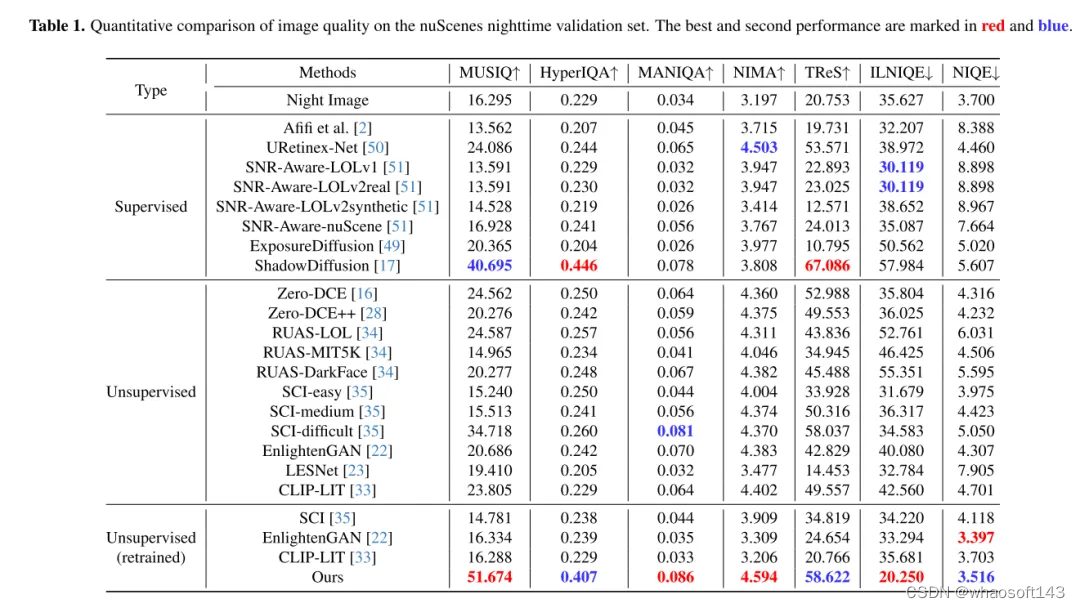
實驗結果:

圖5. 在 nuScenes 驗證集中的夜間圖像示例上的視覺對比。

圖6. 在 nuScenes 驗證集中的夜間圖像示例上的三維檢測結果可視化。本文使用 BEVDepth [32] 作為三維檢測器,并可視化相機的正視圖和鳥瞰圖(Bird’s-Eye-View)。

圖7. 展示本文的 LightDiff ?在有無多條件適配器(MultiCondition Adapter)的情況下的視覺效果。ControlNet [55]的輸入保持一致,包括相同的文本提示和深度圖。多條件適配器在增強過程中實現了更好的顏色對比和更豐富的細節。
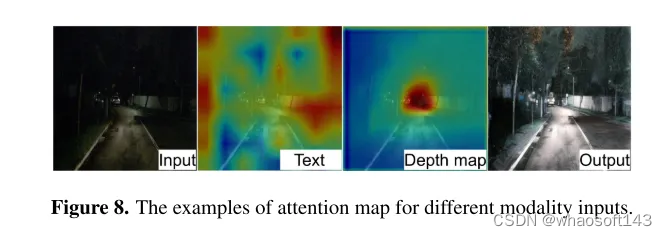
圖8. 不同模態輸入的注意力圖示例。

圖9. 通過循環照明推理(Recurrent Lighting Inference, ReLI)增強多模態生成的示意圖。通過調用一次 ReLI,提高了文本提示和深度圖預測的準確性。
總結:
本文介紹了 LightDiff ,這是一個為自動駕駛應用設計的、針對特定領域的框架,旨在提高低光照環境下圖像的質量,減輕以視覺為中心的感知系統所面臨的挑戰。通過利用動態數據退化過程(dynamic data degradation process)、針對不同輸入模態的多條件適配器,以及使用強化學習的感知特定評分引導獎勵建模,LightDiff ?顯著提升了 nuScenes 數據集夜間的圖像質量和3D車輛檢測性能。這一創新不僅消除了對大量夜間數據的需求,還確保了圖像轉換中的語義完整性,展示了其在提高自動駕駛場景中的安全性和可靠性方面的潛力。在沒有現實的成對晝夜圖像的情況下,合成帶有車燈的暗淡駕駛圖像是相當困難的,這限制了該領域的研究。未來的研究可以集中在更好地收集或生成高質量訓練數據上。
#LeGo-Drive
這篇論文介紹了一種名為LeGo-Drive的基于視覺語言模型的閉環端到端自動駕駛方法。該方法通過預測目標位置和可微分優化器規劃軌跡,實現了從導航指令到目標位置的端到端閉環規劃。通過聯合優化目標位置和軌跡,該方法提高了目標位置預測的準確性,并生成了平滑、無碰撞的軌跡。在多個仿真環境中進行的實驗表明,該方法在自動駕駛指標上取得了顯著改進,目標到達成功率達到81%。該方法具有很好的可解釋性,可用于實際自動駕駛車輛和智能交通系統中。
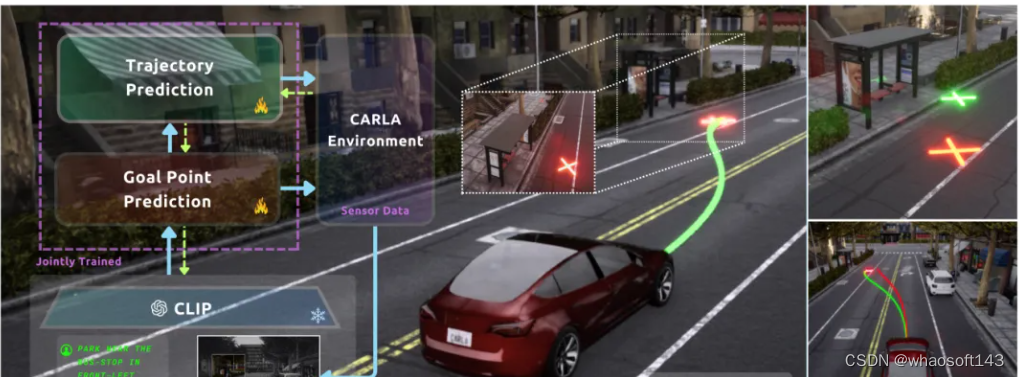
圖1:LeGo-Drive導航到基于語言的目標,該目標與軌跡參數共同優化。“將車停在左前方公交車站附近”等命令的預測目標可能會落在不理想的位置(右上:綠色),這可能會導致容易發生碰撞的軌跡。由于軌跡是唯一直接與環境“交互”的組件,因此我們建議讓感知感知了解軌跡參數,從而將目標位置改善為可導航位置(右下角:紅色)
開源地址:https://reachpranjal.github.io/lego-drive
相關工作回顧
視覺基礎
視覺基礎的目標是將自然語言查詢與視覺場景中最相關的視覺元素或目標關聯起來。早期的研究方法是將視覺基礎任務視為參考表達理解(Referring Expression Comprehension, REC),這涉及到生成區域提案,然后利用語言表達來選擇最佳匹配的區域。相對地,一種稱為Referring Image Segmentation (RIS)的一階段方法,則將語言和視覺特征集成在網絡中,并直接預測目標框。參考文獻使用了RIS方法,基于語言命令來識別可導航區域的任務。然而,這項工作僅限于場景理解,并且不包括導航仿真,因為軌跡規劃依賴于精確的目標點位置,而這一點并未得到解決。
端到端自動駕駛
端到端學習研究在近年來備受關注,其目的是采用數據驅動的統一學習方式,確保安全運動規劃,與傳統基于規則的獨立優化每個任務的設計相比,后者會導致累積誤差。在nuScenes數據集上,UniAD是當前最先進的方法,使用柵格化場景表示來識別P3框架中的關鍵組件。ST-P3是先前的藝術,它探討了基于視覺的端到端ADS的可解釋性。由于計算限制,選擇ST-P3作為我們的運動規劃基準,而不是UniAD。
面向規劃的視覺語言導航
在自動駕駛系統(ADS)領域,大型語言模型(LLMs)因其多模態理解和與人類的自然交互而展現出有前景的結果。現有工作使用LLM來推理駕駛場景并預測控制輸入。然而,這些工作僅限于開環設置。更近的工作關注于適應閉環解決方案。它們要么直接估計控制動作,要么將它們映射到一組離散的動作空間。這些方法較為粗糙,容易受到感知錯誤的影響,因為它們嚴重依賴于VLMs的知識檢索能力,這可能導致在需要復雜控制動作組合的復雜情況下(如泊車、高速公路并線等)產生不流暢的運動。
數據集
詳細闡述了作者為開發結合視覺數據和導航指令的智能駕駛agent而創建的數據集和標注策略。作者利用CARLA仿真器提供的視覺中心數據,并輔以導航指令。他們假設agent擁有執行成功閉環導航所需的特權信息。
數據集概覽:先前的工作,如Talk2Car數據集,主要關注通過為目標引用標注邊界框來進行場景理解。進一步的工作,如Talk2Car-RegSeg,則通過標注可導航區域的分割mask來包含導航。作者在此基礎上擴展了數據集,涵蓋各種駕駛操作,包括車道變更、速度調整、轉彎、繞過其他物體或車輛、通過交叉口以及在行人橫道或交通信號燈處停車,并在其中演示了閉環導航。創建的LeGo-Drive數據集包含4500個訓練點和1000個驗證點。作者使用復雜和簡單的命令標注進行了結果、基準比較和消除實驗。
仿真器設置:LeGo-Drive數據集收集過程包括兩個階段:
- 同步記錄駕駛agent狀態與相機傳感器數據,隨后記錄交通agent,
- 解析和標注收集的數據,以導航指令為標注。
作者以10 FPS的速率錄制數據,為避免連續幀之間的冗余,數據點在10米的距離間隔內進行過濾。對于每個幀,他們收集了自車的狀態(位置和速度)、自車車道(前后各50米范圍)、前RGB相機圖像,以及使用基于規則的專家agent收集的交通agent狀態(位置和速度),所有這些都以自車幀為單位。數據集涵蓋了6個不同的城鎮,具有各種獨特的環境,代表不同的駕駛場景,包括不同的車道配置、交通密度、光照和天氣條件。此外,數據集還包括了戶外場景中常見的各種物體,如公交車站、食品攤位和交通信號燈。
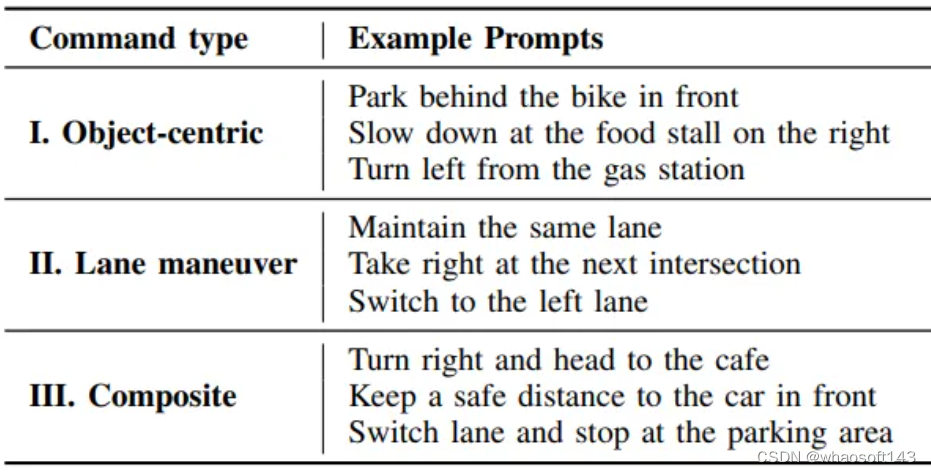
語言命令標注:每個幀都手動標注了適當的導航命令,以目標區域分割mask的形式,以涵蓋各種駕駛場景。作者考慮了3種不同的命令類別:
- 以目標為中心的命令,直接指向當前相機幀中可見的目標,
- 車道操作命令,與車道變更或車道內調整相關的指令,
- 復合命令,連接多個指令以模擬實際駕駛場景。
作者利用ChatGPT API生成具有相似語義含義的不同變體。表I展示了他們數據集中的一些示例指令。值得注意的是,作者并未涵蓋誤導性指令的處理。這種能力對于場景推理模型至關重要,可能被視為未來的擴展范圍;然而,它超出了當前研究的范圍。
表I:LeGo-Drive數據集的導航指令示例
LeGo-Drive架構
本文提出了LeGo-Drive框架,旨在解決從VLA進行控制動作的粗略估計的問題,將這一問題視為一個短期目標實現問題。這是通過學習軌跡優化器的參數和行為輸入,生成并改進與導航指令一致的可實現目標來實現的。


首先,分割mask預測頭與真實分割mask之間的BCE損失進行端到端訓練。在幾個epoch之后,目標點預測頭以平滑L1損失與真實目標點之間的差異進行類似端到端的訓練。
復雜命令和場景理解:為處理最終目標位置在當前幀中不可見的復合指令,通過將復雜命令分解為需要順序執行的原子命令列表來適應他們的方法。例如,“切換到左車道然后跟著黑色汽車”可以分解為“切換到左車道”和“跟著黑色汽車”。為分解這種復雜命令,作者構建了一個原子命令列表L,涵蓋廣泛的簡單操作,如車道變更、轉彎、速度調整和目標引用。在收到復雜命令后,作者利用小樣本學習技術提示LLM將給定復雜命令分解為原子命令列表li,來自L。這些原子命令隨后迭代執行,預測的目標點位置作為中間路點幫助我們達到最終目標點。
神經可微優化器
計劃采用優化問題的形式,其中嵌入有可學習參數,以改進由VLA生成的下游任務的跟蹤目標,并加速其收斂。作者首先介紹了他們軌跡優化器的基本結構,然后介紹了其與網絡的集成。
基本問題公式:作者假設可以獲得車道中心線,并使用它來構建Frenet框架。在Frenet框架中,軌跡規劃具有優勢,即汽車在縱向和橫向運動與Frenet框架的X和Y軸對齊。在給定這種表示的情況下,他們的軌跡優化問題具有以下形式:
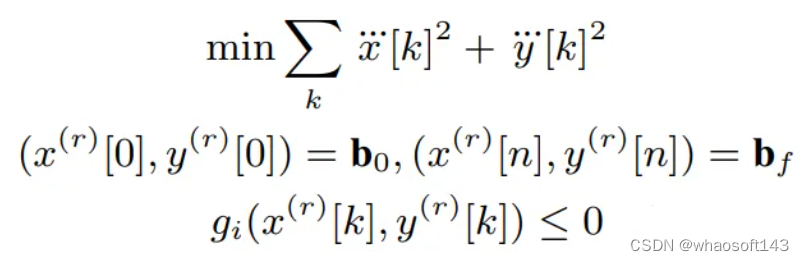

端到端訓練

端到端訓練需要通過優化層建模軌跡規劃過程進行反向傳播,可以通過隱式微分和算法展開兩種方式進行。作者建立了一個自定義的反向傳播程序,遵循算法展開,這種方法可以處理約束,并且反向傳播可以避免矩陣分解。兩種方法的性能在表II中展示,并在后面章節中進行分析。該方法的核心創新在于其模塊化的端到端規劃框架,其中框架優化目標預測模塊,同時優先考慮軌跡優化,確保獲取的行為輸入有效地促進優化器的收斂。不同模塊的迭代改進形成系統設計的基礎,確保系統內部的協同和迭代改進循環。
表II:模型比較:
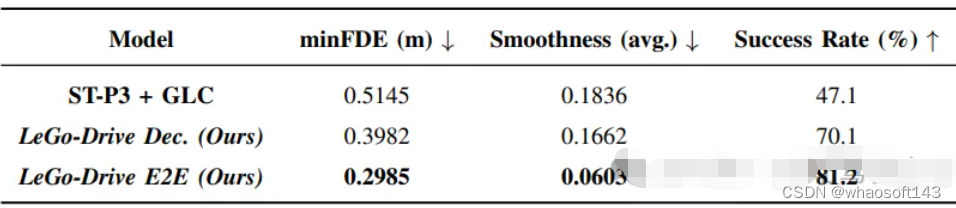
實驗
實現細節
感知模塊輸入:模型輸入包括1600x1200像素的RGB圖像和最大長度為20個詞的語言指令。使用CLIP提取視覺和文本特征,并使用Transformer進行多模態交互,輸出分割mask和目標點預測。

評估指標
目標評估:評估預測目標與mask質心和車道中心的接近程度,以及與最近障礙物的距離。這些指標用于衡量模型在理解語言指令并準確預測目標位置方面的性能。
軌跡評估:使用最小最終位移誤差(minFDE)和成功率(SR)評估軌跡性能。minFDE表示預測軌跡終點與目標位置的歐氏距離,SR表示車輛在3米范圍內成功到達目標的比例。這些指標用于評估模型在生成可行、平滑的軌跡方面的性能。
平滑性:評估軌跡接近目標的平穩程度,采用平滑指數度量。較低的平滑指數表示軌跡更平滑地接近目標,該指標用于衡量模型生成軌跡的平滑性。
實驗結果
目標改進:通過比較解耦訓練和端到端訓練的目標預測指標,結果顯示端到端訓練方法在所有指標上表現更好。特別是在復合指令下,目標改進幅度更大,證明了該方法的有效性。
軌跡改進:與基準方法ST-P3相比,LeGo-Drive模型在目標可達性、軌跡平滑性等方面明顯優于基準方法。特別是復合指令下的最小最終位移誤差降低了60%,進一步證明了端到端訓練的優勢。
模型比較:通過比較端到端方法、解耦訓練和基準方法,結果顯示端到端方法在目標可達性和軌跡平滑性方面明顯優于其他方法。
定性結果:定性結果直觀展示了端到端方法生成的軌跡比基準方法更平滑,進一步驗證了實驗結果。
表Ⅲ: Goal Improvement
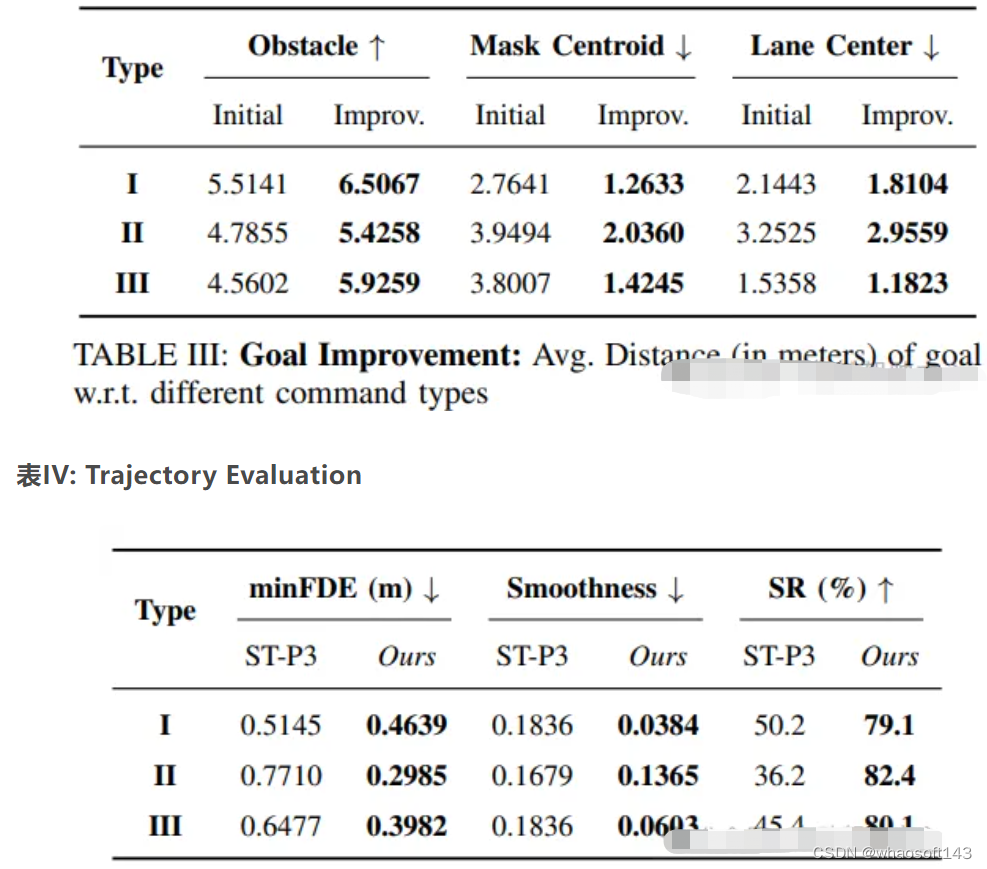
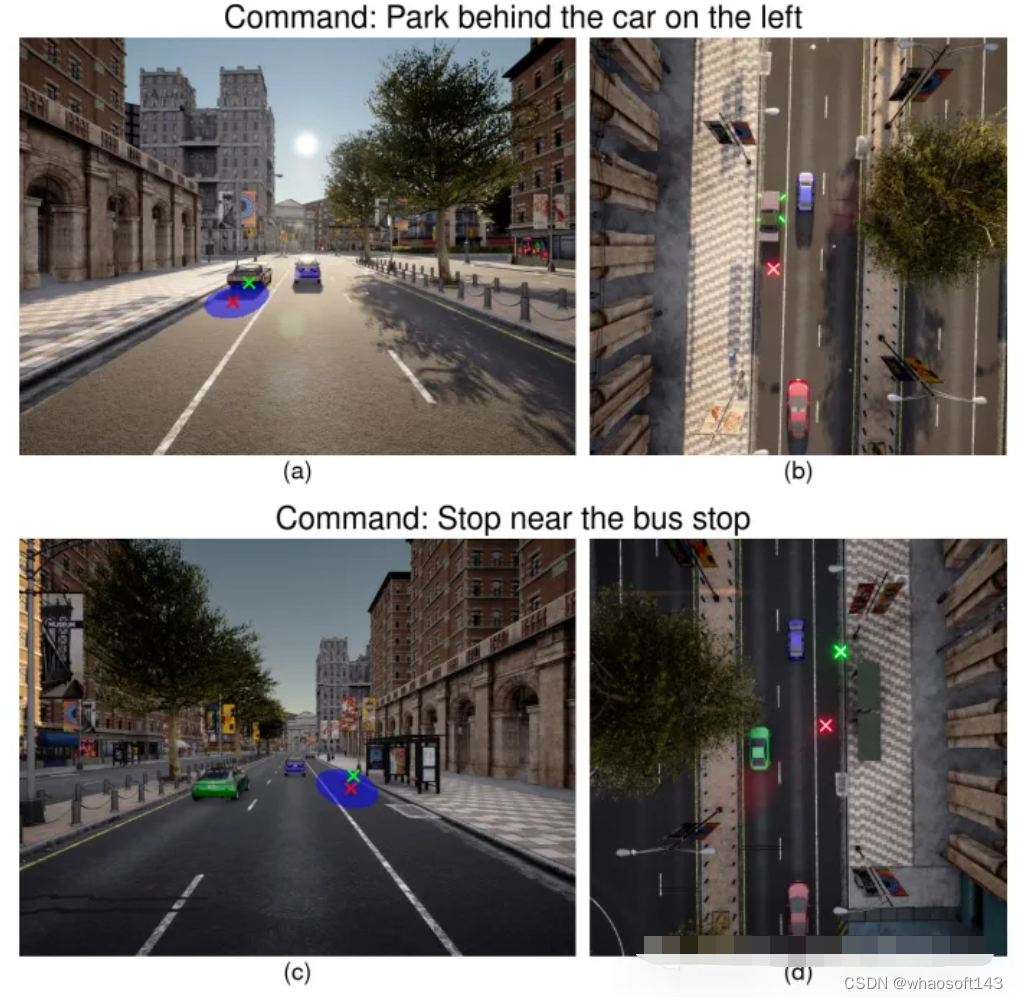
圖4:不同以目標為中心的停車命令的目標改進。(左)查詢命令的前視圖圖像。(右)場景的俯視圖。目標位置從綠色中不理想的位置((a)中的汽車頂部和(b)中的路邊邊緣)改進為紅色中的可到達位置? ? ? ? ? ? ? ?

圖5:車削指令情況下的結果。在這兩幅圖中(上、下),綠色的初始目標與車道中心的偏移量較大。該模型近似于改進版本的紅色顯示到車道中心

圖6:不同導航指令下軌跡改進的定性結果。與我們的(綠色)相比,紅色顯示的基線ST-P3軌跡始終規劃著一個不光滑的軌跡。所有行中的第三張圖顯示了我們在Frenet框架中的規劃,其中紅色矩形表示自我車輛,藍色表示周圍車輛,紅色十字表示目標位置以及用黑色實線表示的車道邊界
實驗結果證明了端到端訓練方法的有效性,能夠提高目標預測的準確性和軌跡的平滑性。
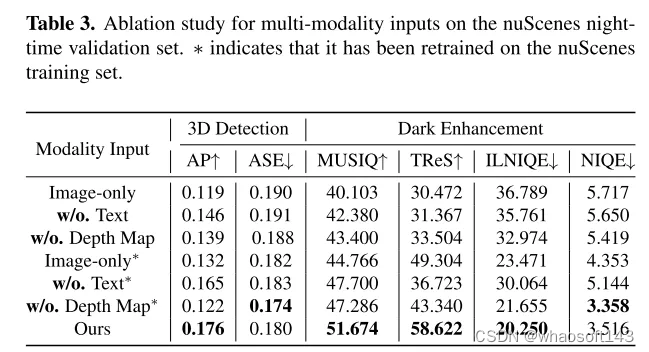
結論
本文通過將所提出的端到端方法作為目標點導航問題來解決,揭示了其與傳統解耦方法相比的明顯優勢。目標預測模塊與基于可微分優化器的軌跡規劃器的聯合訓練突出了方法的有效性,從而提高了準確性和上下文感知目標預測,最終產生更平滑、無碰撞的可導航軌跡。此外,還證明了所提出的模型適用于當前的視覺語言模型,以豐富的場景理解和生成帶有適當推理的詳細導航指令。


)
)



)


)





![【回溯 剪支 狀態壓縮】# P10419 [藍橋杯 2023 國 A] 01 游戲|普及+](http://pic.xiahunao.cn/【回溯 剪支 狀態壓縮】# P10419 [藍橋杯 2023 國 A] 01 游戲|普及+)


