本文目錄:
- 一、關于數據庫**
- 二、sql語言分類**
- 三、數據庫增刪改查操作**
- 四、庫中表增刪改查操作**
- 五、表中記錄插入**
- 六、表約束**
- 七、單表查詢**
- 八、多表查詢**
- (一)外鍵約束**
- (二)連結查詢**
- 1.交叉連接(笛卡爾積)**
- 2.內連接**
- 3.左外連接**
- 4.右外連接**
- 5.全外連接****
- 6、自連接**
- 九、子查詢**
- 十、開窗函數**(mysql8.0版本以上才有此功能)
- 特別分享1:排名函數**
- 特別分享2:CTE(公用表表達式)**
** MySQL是最好的 RDMS (Relational Database Management System,關系數據庫管理系統) 應用軟件,目前屬于 Oracle 旗下產品,MySQL 是最流行的關系型數據庫管理系統中的一個。**
使用mysql前,需要先下載安裝mysql(通過小皮面板最方便,連接時默認用戶和密碼都是root),然后運行方式可以是通過datagrip,也可以是通過pycharm連接運行(連接時默認用戶是root)。
mysql訪問官網下載頁面:https://dev.mysql.com/downloads/mysql/
*
一、關于數據庫**
數據庫是存儲數據的倉庫,分為關系型數據庫和非關系型數據庫,關系型數據庫遵循sql規范(一整套結構化查詢語言),非關系型數據庫又叫做nosql(not only sql),不需要遵循sql規范。
**
二、sql語言分類**
數據定義語言:簡稱DDL(Data Definition Language)
作用: 用來定義數據庫對象:數據庫,表,列/字段等。
關鍵字: create,drop,alter等
數據操作語言:簡稱DML(Data Manipulation Language)
作用:用來對數據庫中表的記錄進行更新。
關鍵字: insert,delete,update等
數據查詢語言:簡稱DQL(Data Query Language)
作用:用來查詢數據庫中表的記錄。
關鍵字: select,from,where等
數據控制語言:簡稱DCL(Data Control Language)
用來定義數據庫的訪問權限和安全級別,及創建用戶。
**
三、數據庫增刪改查操作**
首先注意:1.每一條sql語句都要用英文分號(;)結尾;2.windows系統里,mysql不區分大小寫。
創建數據庫: create database [if not exists] 數據庫名; 注意: 默認字符集就是utf8
刪除數據庫:** drop database [if exists] 數據庫名**;
使用/切換數據庫: use 數據庫名;
查看所有的數據庫名:** show databases**;
查看當前使用的數據庫: select database();
查看指定庫的建庫語句: show create database 數據庫名;
例:
create database database1;#創建database1(數據庫名)
use database1; #使用database1(使用后才可以建表)
drop database database1; #刪除database1**
四、庫中表增刪改查操作**
創建表: create table [if not exists] 表名(字段1名 字段1類型 [字段1約束] , 字段2名 字段2類型 [字段2約束] …);
刪除表:** drop table [if exists] 表名**;
修改表名: rename table 舊表名 to 新表名;
注意: 修改表中字段本質都是修改表,咱們后面演示此處略
查看所有表: show tables;
查看指定表的建表語句: show create table 表名;
添加表字段: alter table 表名 add [column] 字段名 字段類型 [字段約束];
刪除表字段: alter table 表名 drop [column] 字段名;
修改表字段名和字段類型: ** alter table 表名 change [column] 舊字段名 新字段名 字段類型 [字段約束]**;
modify只修改字段類型: alter table 表名 modify [column] 字段名 字段類型 [字段約束];
查看字段信息: desc 表名;
備注:中括號內容代表可以要也可以不要,后續代碼里中括號均如此功能。
create table student( #創建student(表名)id int,name varchar(100),weight double,height double,
);
show tables; #查看目前所有的表
desc student; # 查看student表結構
#添加gender字段
alter table student add gender varchar(100);
#修改gender字段為sex字段
alter table student change gender sex varchar(100);
#修改sex字段類型為int
alter table student modify sex int;#刪除student
drop table student;
**
五、表中記錄插入**
插入數據記錄: insert into 表名 (字段名1,字段名2…) values (值1.1,值2.1…) , (值1.2,值2.2…);
注意1: 具體值要和前面的字段名以及順序一一對應上
注意2: 如果要插入的是所有字段,那么字段名可以省略(默認代表所有列都要插入數據)
注意3: 如果要插入多條記錄,values后多條數據使用 逗號 分隔
修改數據記錄: update 表名 set 字段名=值 [where 條件];
注意: 如果沒有加條件就是修改對應字段的所有數據
刪除數據記錄:** delete from 表名 [where 條件]**;
注意: 如果沒有加條件就是刪除所有數據
#插入數據到student
insert into student values(1,'john',50.6,1.78),(2,'july',51,1.67),(3,'huahua',53.7,1.89); #改student數據
update student set name='alice' where name='huahua'; 3]
update student set name='alice' where id=3;
清空所有數據:
方式1: delete from 表名; 注意:此方式有警告
方式2: truncate [table] 表名; 注意: 此方式沒有警告
#刪除了student單列數據
delete from student where id=3;
delete from student where name='july';#刪除了student所有數據
delete from student;
#另一種刪除所有數據方法:truncate
truncate student;
備注:delete from與truncate兩者區別在于:1.delete from可以刪除單列數據,但truncate不可以;2.delete from不會重置表主鍵自增,truncate會重置表主鍵自增。
**
六、表約束**
主鍵約束(key primary):每個表只設置一個主鍵,設置后:值非空且唯一。主鍵約束可設置主鍵自增;(auto_increment),設置后不輸入值時、或者輸入0或者輸入null時將直接引起主鍵自增(即主鍵自己按順序增長);
唯一約束(unique):設置后值唯一,不可重復;
非空約束(not null):設置后值非空,必須有;
外鍵約束【construct [約束名] foreign key (字段名) references 主表(主鍵名)】:用于關聯兩個表,關聯表叫子表,被關聯表叫主表;
默認約束(default):設置默認值,不輸入值時默認;
注意:1.約束建議都是在建表時添加,簡單方便;2.主鍵約束每個表只有一個,其它約束可以有多個。
例:
use database1; #使用數據庫
create table student( #創建student(表名)id int primary key auto_increment, #主鍵自增name varchar(100) not null, #非空約束weight double unique, #唯一約束height double default 1.9 #默認約束
);
**
七、單表查詢**
基礎查詢:select */字段名 from 表名
條件查詢:where (比較/邏輯/范圍/模糊/非空判斷)
分組/聚合/統計函數:sum()、avg()、count()、max()、min()
分組查詢:select 分組字段名,聚合函數(字段名)from 表名 group by 分組字段名1,分組字段名2。。。
排序查詢:select 字段名 from 表名 order by 排序字段名1 (asc:升序;desc:降序),排序字段名2(asc:升序;desc:降序)。。。
Limit查詢:select 字段名 from 表名 limit x,y(x為起始索引,y為一次查詢數量)。
備注:被查詢的字段名都可以通過as 起別名(as也可省略,字段名后面可以直接跟別名),但應避免是中文名。
#單表查詢#(1)單表查詢之基礎查詢
select * from student;
select distinct * from student;
select distinct name as n,weight as w from student;#as可省略;#(2)單表查詢之條件查詢
select * from student where name like 'j%';
select * from student where name like '%j%';#查詢name帶有j的
select * from student where name like 'ju__';
select * from student where weight <>51 and weight <>55;#查詢weight不為51也不為55的數據
select * from student where weight not in(51,55);#查詢weight不為51也不為55的數據
select * from student where weight!=51 and weight!=55;#查詢weight不為51也不為55的數據
select * from student where weight not between 51 and 55;#查詢weight不在51和55之間的數據
select * from student where weight is not null;#查詢有weight的數據
select count(*) from student where weight is not null;#個數查詢,推薦
#個數查詢,利用其自動忽略none值,推薦
select count(weight) from student;#(3)聚合函數查詢
select count(weight) c,max(weight) ma,min(weight) mi,
round(avg(weight),2) av,sum(weight) s from student;#(4)分組查詢(分組字段名height必須跟在select后面,可多個分組字段)
select height,count(*) from student group by height ;#(5)排序查詢(可多個字段排序)
select height,name from student order by weight,height ;#(6)limit 查詢
select height,name from student limit 0,2;
查詢注意事項:
1.書寫順序:select-distinct-聚合函數-from-where-group by-having-order by-limit x,y;
特別地,Having也能跟聚合條件,但不建議,會造成效率低下;
2.執行順序:from(從硬盤中掃描真實表文件加載到內存形成偽表)—where—group by(分組,切成運算區)—聚合函數—having—select distinct—order by—limit
**
八、多表查詢**
本質是多個表通過主外鍵關聯關系連接(join)合并成一個大表,再去查詢。
(一)外鍵約束**
建表時添加外鍵約束: … CONSTRAINT [外鍵約束名] FOREIGN KEY (外鍵名) REFERENCES 主表名 (主表主鍵)
建表后添加外鍵約束: alter table 從表名 add CONSTRAINT [外鍵約束名] FOREIGN KEY (外鍵名) REFERENCES 主表名 (主表主鍵)
刪除外鍵約束: alter table 從表名 drop FOREIGN KEY 外鍵約束名;
注意:如果要刪除有外鍵約束的主從表,先刪除從表,再刪除主表。
例:
# 創建分類表(主表)
create table category1
(
cid varchar(32) primary key, # 分類id,設置主鍵
cname varchar(100) # 分類名稱
);# 商品表(從表)
create teble products1
(
pid varchar(32) primary key, #設置主鍵
pname varchar(40),
price double,
category_id varchar(32),
CONSTRAINT FOREIGN KEY (category_id) REFERENCES category1 (cid) #添加外鍵約束
);
注意:只有innodb存儲引擎支持外鍵約束和事務!!!小皮面板里如果要修改數據庫屬性為innodb,需要先關閉掉mysql服務后再修改!!!修改存儲引擎后,只對后面新建的表有效!!!**
外鍵約束作用:
限制從表插入數據: 從表插入數據的時候如果外鍵值是主表主鍵中不存在的,就插入失敗
限制主表刪除數據: 主表刪除數據的時候如果主鍵值已經被從表外鍵的引用,就刪除失敗
外鍵約束好處: 保證數據的準確性和完整性。
**
(二)連結查詢**
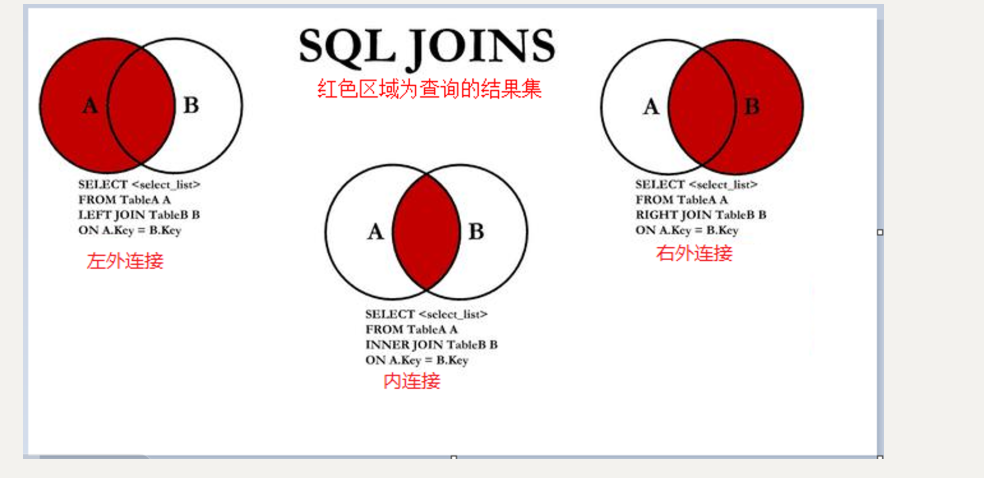
**
1.交叉連接(笛卡爾積)**
顯式交叉連接格式: select * from 左表 cross join 右表;
隱式交叉連接格式: select * from 左表,右表。
**注意:**笛卡爾積本身是一個錯誤,工作中慎用。
例:
# 隱式交叉連接格式: select 字段名 from 左表,右表;
select * from products, category;
# 顯式交叉連接格式: select 字段名 from 左表 cross join右表;
select * from products cross join category;
2.內連接**
顯式內連接格式: select * from 左表 [ inner] join 右表 on 關聯條件;
隱式內連接格式: select * from 左表 , 右表 where 關聯條件;
注意:inner可以省略。
例:
# 隱式內連接格式: select 字段名 from 左表,右表 where 條件;
selectc.id cid,c.name cname,p.id pid,p.name pname
fromproducts p,category c
wherep.category_id = c.id;
# 顯式內連接格式: select 字段名 from 左表 cross join右表;
selectc.id cid,c.name cname,p.id pid,p.name pname
fromproducts pinner join category c on p.category_id = c.id;
3.左外連接**
左連接關鍵字: left [outer] join … on
左外連接格式: select * from 左表 left [outer] join 右表 on 關聯條件;
注意: 1.左表和右表沒有特殊含義,只是在前面是左表,在后面的是右表;2.outer可以省略。
例:
-- 為了方便演示插入一條數據
insert intoproducts(name, price, category_id)
values('百草味紫皮腰果', 9, 5);-- 需求: 分別使用左右連接查詢每個分類下的所有商品,即使沒有商品的分類要展示
-- 分析: 必須以分類表為主
-- 左外連接: left outer join
selectc.id cid,c.name cname,p.id pid,p.name pname
fromcategory cleft outer join products p on p.category_id = c.id;
4.右外連接**
右連接關鍵字: right [outer] join … on
右外連接格式: select * from 左表 right [outer] join 右表 on 關聯條件;
注意: 1.左表和右表沒有特殊含義,只是在前面是左表,在后面的是右表;2.outer可以省略。
-- 右外連接: right outer join
selectc.id cid,c.name cname,p.id pid,p.name pname
fromproducts pright outer join category c on p.category_id = c.id;
5.全外連接****
注意**: mysql中沒有full outer join on這個關鍵字,所以不能用它來完成全外連接!所以只能先查詢左外連接和右外連接的結果,然后用union或者union all來實現!!!
- union : 默認去重
- union all: 不去重
例(全外連接):
# union : 默認去重
select *
fromproducts pleft join category c on p.category_id = c.id
union
select *
fromproducts pright join category c on p.category_id = c.id;# union all: 不去重
select *
fromproducts pleft join category c on p.category_id = c.id
union all
select *
fromproducts pright join category c on p.category_id = c.id;
6、自連接**
解釋: 兩個表進行關聯時,如果左表和右邊是同一張表,這就是自關聯。
注意: 自連接必須起別名!
例:
-- 自連接查詢
-- 查詢'江蘇省'下所有城市
selectshi.id,shi.title,sheng.id,sheng.title
fromareas shengjoin areas shi on shi.pid = sheng.id
wheresheng.title = '江蘇省';-- 查詢'宿遷市'下所有的區縣
selectquxian.id,quxian.title,shi.id,shi.title
fromareas shijoin areas quxian on quxian.pid = shi.id
whereshi.title = '宿遷市';-- 查詢'安徽省'下所有的市,以及市下面的區縣信息
selectquxian.id,quxian.title,shi.id,shi.title,sheng.id,sheng.title
fromareas shengjoin areas shi on shi.pid = sheng.idjoin areas quxian on quxian.pid = shi.id
wheresheng.title = '江蘇省';-- 自連接的妙用
-- 需求1: 求每個月和上月的差額
selectc.month,c.revenue,c.revenue-u.revenue as diff
fromsales cjoin sales u on c.month = u.month + 1;-- 需求2: 求截止到當月累計銷售額
selectc.month,SUM(u.revenue)
fromsales cjoin sales u on c.month >= u.month
group byc.month;
**
九、子查詢**
在一個 SELECT 語句中,嵌入了另外一個 SELECT 語句,那么被嵌入的 SELECT 語句稱之為子查詢語句,外部那個SELECT 語句則稱為主查詢。
作用: 子查詢是輔助主查詢的,它可以充當主查詢的條件、數據源(臨時表)、查詢字段。
例:
-- 查詢'河北省'下所有城市
select * from areas where pid = (select id from areas where title = '河北省');
-- 查詢'邯鄲市'下所有區縣
select * from areas where pid = (select id from areas where title = '邯鄲市');-- **注意:子查詢作為表使用必須加括號,同時起別名!!!**
**
十、開窗函數**(mysql8.0版本以上才有此功能)
開窗函數over():設置每行數據關聯的窗口數據范圍,over()時,每行關聯的數據范圍都是整張表的數據。
over函數一般跟在查詢字段COUNT、SUM、AVG、MAX、MIN、ROW_NUMBER、RANK、DENSE_RANK等后面。
(例)格式:count(字段名) over()
over()里面也可以加入partition by 字段名(分組)、order by 字段名等。
(例)格式1:sum(score) over(partition by gender order by id )
備注:score、gender、id均是字段名。
(例)格式2:rank() over(partition by gender order by id)
備注:gender、id均是字段名。
例:
針對 students 表的數據,計算每個同學的Score分數和整體平均分數的差值
-- 數據準備
create table `students` #建表,反引號用來識別
(
`id` int(11) not null auto_increment,
`name` varchar(24) not null,
`gender` varchar(8) not null,
`score` decimal(5, 2) not null,
primary key (`id`)
);insert into `students` values
(1, 'smart', 'Male', 90.00),
(2, 'linda', 'Female', 81.00),
(3, 'lucy', 'Female', 83.00),
(4, 'david', 'Male', 94.00),
(5, 'Tom', 'Male', 92.00),
(6, 'Jack', 'Male', 88.00);
-- 查詢
select *,avg(score) over() as `avg`,
score - avg(score) over (partiton by gender) as `difference`
from students;分享:
-- partition by 和 group by的區別
-- 使用場景不同
-- partiton by用在窗口函數中,結果是:一進一出
-- group by用在分組聚合中,結果是:多進一出
特別分享1:排名函數**
RANK():產生的排名序號 ,有并列的情況出現時序號不連續,如1224;
DENSE_RANK() :產生的排序序號是連續的,有并列的情況出現時序號會重復,如1223;
ROW_NUMBER() :返回連續唯一的行號,排名序號不會重復,如1234。
**
特別分享2:CTE(公用表表達式)**
CTE(公用表表達式):Common Table Expresssion,類似于子查詢,相當于一張臨時表,可以在 CTE 結果的基礎上,進行進一步的查詢操作。
基礎語法
with tmp1 as (查詢語句), tmp2 as (查詢語句), tmp3 as (查詢語句) select 字段名 from 表名;
例:
-- 需求:獲取每個科目,排名第二的學生信息
-- 查詢結果字段:
-- name、course、score#代碼:
with temp as #基礎式(select *,dense_rank() over (partition by course order by score desc) as dr
from tb_score)
select * from temp where dr = 2;
今天的分享到此為止。


)





![【回溯 剪支 狀態壓縮】# P10419 [藍橋杯 2023 國 A] 01 游戲|普及+](http://pic.xiahunao.cn/【回溯 剪支 狀態壓縮】# P10419 [藍橋杯 2023 國 A] 01 游戲|普及+)








![[創業之路-370]:企業戰略管理案例分析-10-戰略制定-差距分析的案例之小米](http://pic.xiahunao.cn/[創業之路-370]:企業戰略管理案例分析-10-戰略制定-差距分析的案例之小米)

