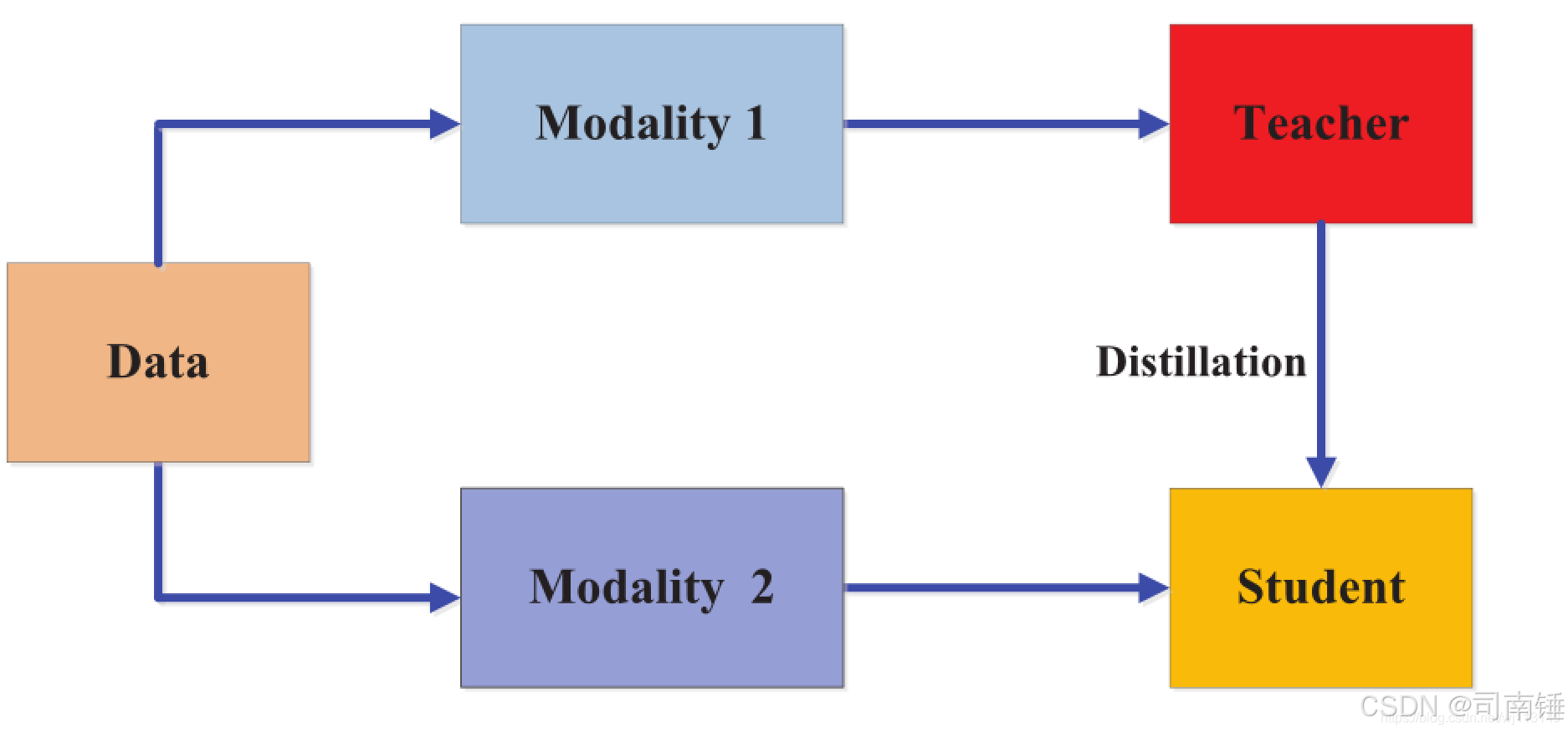
在深度學習的浪潮中,我們常常追求更大、更深、更復雜的模型以達到最先進的性能。然而,這些“龐然大物”般的模型往往伴隨著高昂的計算成本和緩慢的推理速度,使得它們難以部署在資源受限的環境中,如移動設備或邊緣計算平臺。知識蒸餾(Knowledge Distillation)技術為此提供了一個優雅的解決方案:將一個大型、高性能的“教師模型”所學習到的“知識”遷移到一個小巧、高效的“學生模型”中。
本篇將一步步使用 PyTorch 實現一個知識蒸餾的案例,其中教師模型將采用預訓練模型。
什么是知識蒸餾?
知識蒸餾的核心思想是,訓練一個小型學生模型 (Student Model) 來模仿一個大型教師模型 (Teacher Model) 的行為。這種模仿不僅僅是學習教師模型對“硬標簽”(即真實標簽)的預測,更重要的是學習教師模型輸出的“軟標簽”(Soft Targets)。
- 教師模型 (Teacher Model): 通常是一個已經訓練好的、性能優越的大型模型。例如,在計算機視覺領域,可以是 ImageNet 上預訓練的 ResNet、VGG 等。
- 學生模型 (Student Model): 一個參數量較小、計算更高效的輕量級模型,我們希望它能達到接近教師模型的性能。
- 軟標簽 (Soft Targets): 教師模型在輸出層(softmax之前,即logits)經過一個較高的“溫度”(Temperature, T)調整后的概率分布。高溫會使概率分布更平滑,從而揭示類別間的相似性信息,這些被稱為“暗知識”(Dark Knowledge)。
- 硬標簽 (Hard Targets): 數據集的真實標簽。
- 蒸餾損失 (Distillation Loss): 通常由兩部分組成:
- 學生模型在真實標簽上的損失(例如交叉熵損失)。
- 學生模型與教師模型軟標簽之間的損失(例如KL散度或均方誤差)。
這兩部分損失通過一個超參數 a l p h a \\alpha alpha 來加權平衡。
PyTorch 實現步驟
接下來,我們將通過一個圖像分類的例子來演示如何實現知識蒸餾。假設我們的任務是對一個包含10個類別的圖像數據集進行分類。
1. 準備工作:導入庫和設置設備
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.models as models
import torchvision.transforms as transforms # 用于數據預處理# 檢查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")
2. 定義教師模型 (Pre-trained ResNet18)
我們將使用 torchvision.models 中預訓練的 ResNet18 作為教師模型。為了適應我們自定義的分類任務(例如10分類),我們需要替換其原始的1000類全連接層。
class PretrainedTeacherModel(nn.Module):def __init__(self, num_classes, pretrained=True):super(PretrainedTeacherModel, self).__init__()# 加載預訓練的 ResNet18 模型# PyTorch 1.9+ 推薦使用 weights 參數if pretrained:self.resnet = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)else:self.resnet = models.resnet18(weights=None) # 或者 models.resnet18(pretrained=False) for older versions# 獲取 ResNet18 原本的輸出特征數num_ftrs = self.resnet.fc.in_features# 替換最后的全連接層以適應我們的任務類別數self.resnet.fc = nn.Linear(num_ftrs, num_classes)def forward(self, x):return self.resnet(x)
在蒸餾過程中,教師模型的參數通常是固定的,不參與訓練。
3. 定義學生模型
學生模型應該是一個比教師模型更小、更輕量的網絡。這里我們定義一個簡單的卷積神經網絡 (CNN)。
class StudentCNNModel(nn.Module):def __init__(self, num_classes):super(StudentCNNModel, self).__init__()# 輸入通道數為3 (RGB圖像), 假設輸入圖像大小為 32x32self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 32x32 -> 16x16self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 16x16 -> 8x8# 展平后的特征數: 32 channels * 8 * 8self.fc = nn.Linear(32 * 8 * 8, num_classes)def forward(self, x):out = self.pool1(self.relu1(self.conv1(x)))out = self.pool2(self.relu2(self.conv2(x)))out = out.view(out.size(0), -1) # 展平out = self.fc(out)return out
4. 定義蒸餾損失函數
這是知識蒸餾的核心。損失函數結合了學生模型在硬標簽上的性能和與教師模型軟標簽的匹配程度。
- L _ h a r d L\_{hard} L_hard: 學生模型輸出與真實標簽之間的交叉熵損失。
- L _ s o f t L\_{soft} L_soft: 學生模型的軟化輸出與教師模型的軟化輸出之間的KL散度。
- 總損失 L = a l p h a c d o t L _ h a r d + ( 1 ? a l p h a ) c d o t L _ s o f t c d o t T 2 L = \\alpha \\cdot L\_{hard} + (1 - \\alpha) \\cdot L\_{soft} \\cdot T^2 L=alphacdotL_hard+(1?alpha)cdotL_softcdotT2
- T T T 是溫度參數。較高的 T T T 會使概率分布更平滑。
- a l p h a \\alpha alpha 是平衡兩個損失項的權重。
- L _ s o f t L\_{soft} L_soft 乘以 T 2 T^2 T2 是為了確保軟標簽損失的梯度與硬標簽損失的梯度在量級上大致相當。
class DistillationLoss(nn.Module):def __init__(self, alpha, temperature):super(DistillationLoss, self).__init__()self.alpha = alphaself.temperature = temperatureself.criterion_hard = nn.CrossEntropyLoss() # 硬標簽損失# reduction='batchmean' 會將KL散度在batch維度上取平均,這在很多實現中是常見的self.criterion_soft = nn.KLDivLoss(reduction='batchmean') # 軟標簽損失def forward(self, student_logits, teacher_logits, labels):# 硬標簽損失loss_hard = self.criterion_hard(student_logits, labels)# 軟標簽損失# 使用 softmax 和 temperature 來計算軟標簽和軟預測# 注意:KLDivLoss期望的輸入是 (log_probs, probs)soft_teacher_probs = F.softmax(teacher_logits / self.temperature, dim=1)soft_student_log_probs = F.log_softmax(student_logits / self.temperature, dim=1)# 計算KL散度損失loss_soft = self.criterion_soft(soft_student_log_probs, soft_teacher_probs) * (self.temperature ** 2)# 總損失loss = self.alpha * loss_hard + (1 - self.alpha) * loss_softreturn loss
5. 訓練流程
現在我們將所有部分組合起來進行訓練。
# --- 示例參數 ---
num_classes = 10 # 假設我們的任務是10分類
img_channels = 3
img_height = 32
img_width = 32learning_rate = 0.001
num_epochs = 20 # 實際應用中需要更多 epochs 和真實數據
batch_size = 32
temperature = 4.0 # 蒸餾溫度
alpha = 0.3 # 硬標簽損失的權重# --- 實例化模型 ---
teacher_model = PretrainedTeacherModel(num_classes=num_classes, pretrained=True).to(device)
teacher_model.eval() # 教師模型設為評估模式,不更新其權重student_model = StudentCNNModel(num_classes=num_classes).to(device)# --- 準備優化器和損失函數 ---
optimizer = optim.Adam(student_model.parameters(), lr=learning_rate) # 只優化學生模型的參數
distillation_criterion = DistillationLoss(alpha=alpha, temperature=temperature).to(device)# --- 生成一些虛擬圖像數據進行演示 ---
# !!! 警告: 實際應用中必須使用真實數據加載器 (DataLoader) 和正確的預處理 !!!
# 預訓練模型通常對輸入有特定的歸一化要求。
# 例如,ImageNet預訓練模型通常使用:
# normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 并且輸入尺寸也需要匹配,或進行適當調整。
# 本例中學生模型接收 32x32 輸入,教師模型(ResNet)通常處理更大圖像如 224x224。
# 為簡化,我們假設教師模型能處理學生模型的輸入尺寸,或者在教師模型前對輸入進行適配。
dummy_inputs = torch.randn(batch_size, img_channels, img_height, img_width).to(device)
dummy_labels = torch.randint(0, num_classes, (batch_size,)).to(device)print("開始訓練學生模型...")
# --- 訓練學生模型 ---
for epoch in range(num_epochs):student_model.train() # 學生模型設為訓練模式# 獲取教師模型的輸出 (logits)with torch.no_grad(): # 教師模型的權重不更新# 如果教師模型和學生模型期望的輸入尺寸不同,需要適配# teacher_input_adjusted = F.interpolate(dummy_inputs, size=(224, 224), mode='bilinear', align_corners=False) # 示例調整# teacher_logits = teacher_model(teacher_input_adjusted)teacher_logits = teacher_model(dummy_inputs) # 假設教師模型可以處理此尺寸或已適配# 前向傳播 - 學生模型student_logits = student_model(dummy_inputs)# 計算蒸餾損失loss = distillation_criterion(student_logits, teacher_logits, dummy_labels)# 反向傳播和優化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch + 1) % 5 == 0 or epoch == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')print("學生模型訓練完成!")# (可選) 保存學生模型
# torch.save(student_model.state_dict(), 'student_cnn_distilled.pth')
# print("蒸餾后的學生CNN模型已保存。")
關鍵點與最佳實踐
- 數據預處理: 對于預訓練的教師模型,其輸入數據必須經過與預訓練時相同的預處理(如歸一化、尺寸調整)。這是確保教師模型發揮其最佳性能并傳遞有效知識的關鍵。
- 輸入兼容性: 確保教師模型和學生模型接收的輸入在語義上是一致的。如果它們的網絡結構原生接受不同尺寸的輸入,你可能需要調整輸入數據(例如,通過插值
F.interpolate)以適應教師模型,或者確保兩個模型都能處理相同的輸入。 - 超參數調優:
alpha,temperature,learning_rate等超參數對蒸餾效果至關重要。通常需要通過實驗來找到最佳組合。較高的temperature可以讓學生學習到更多類別間的細微差別,但過高可能會導致信息模糊。 - 教師模型的選擇: 教師模型越強大,通常能傳遞的知識越多。但也要考慮其推理成本(即使只在訓練時)。
- 學生模型的設計: 學生模型不應過于簡單,以至于無法吸收教師的知識;也不應過于復雜,從而失去蒸餾的意義。
- 訓練時長: 知識蒸餾通常需要足夠的訓練輪次才能讓學生模型充分學習。
- 不僅僅是 Logits: 本文介紹的是最常見的基于 Logits 的蒸餾。還有其他蒸餾方法,例如匹配教師模型和學生模型中間層的特征表示(Feature Distillation),這有時能帶來更好的效果。
)


)





![【回溯 剪支 狀態壓縮】# P10419 [藍橋杯 2023 國 A] 01 游戲|普及+](http://pic.xiahunao.cn/【回溯 剪支 狀態壓縮】# P10419 [藍橋杯 2023 國 A] 01 游戲|普及+)








![[創業之路-370]:企業戰略管理案例分析-10-戰略制定-差距分析的案例之小米](http://pic.xiahunao.cn/[創業之路-370]:企業戰略管理案例分析-10-戰略制定-差距分析的案例之小米)
