YOLOv1:開啟實時目標檢測的新篇章
在深度學習目標檢測領域,YOLO(You Only Look Once)系列算法無疑占據著重要地位。其中,YOLOv1作為開山之作,以其獨特的設計理念和高效的檢測速度,為后續的目標檢測發展奠定了堅實基礎。今天,就讓我們深入探索YOLOv1的奧秘。
一、YOLOv1誕生的背景
在YOLOv1出現之前,傳統目標檢測算法如R-CNN系列,采用多階段處理方式,先生成候選框,再對候選框進行分類和回歸。這種方式雖然在準確率上有一定保障,但檢測速度較慢,難以滿足實時檢測的需求。隨著深度學習的快速發展,研究者們開始探索更高效的目標檢測方法,YOLOv1應運而生。它由Joseph Redmon等人于2016年提出,創新性地將目標檢測問題轉化為一個回歸問題,通過一個神經網絡直接預測目標的類別和位置,極大地提高了檢測速度。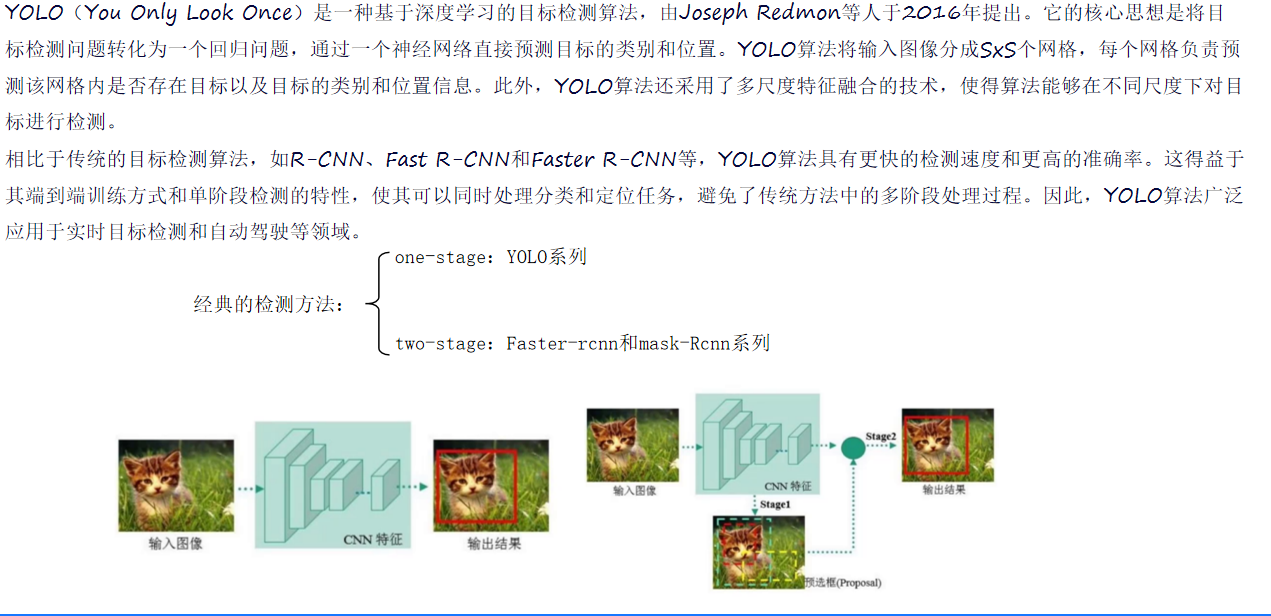

二、YOLOv1的核心原理
(一)將檢測問題轉化為回歸問題
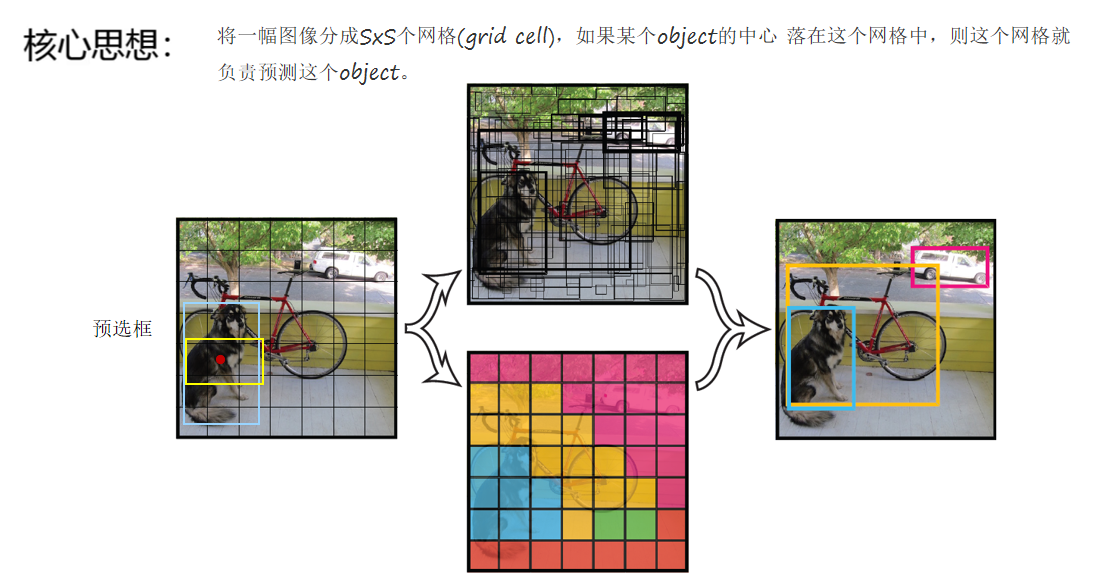
YOLOv1把輸入圖像分成SxS個網格(grid cell),如果某個物體的中心落在這個網格中,那么這個網格就負責預測這個物體。每個網格會預測B個邊界框(bounding box)以及這些邊界框中物體的類別概率。最終,網絡輸出的是SxSx(B*5 + C)的張量,其中B表示每個網格預測的邊界框數量,5代表每個邊界框包含的信息(中心坐標x、y,寬w,高h以及置信度c),C則是數據集中的類別數。
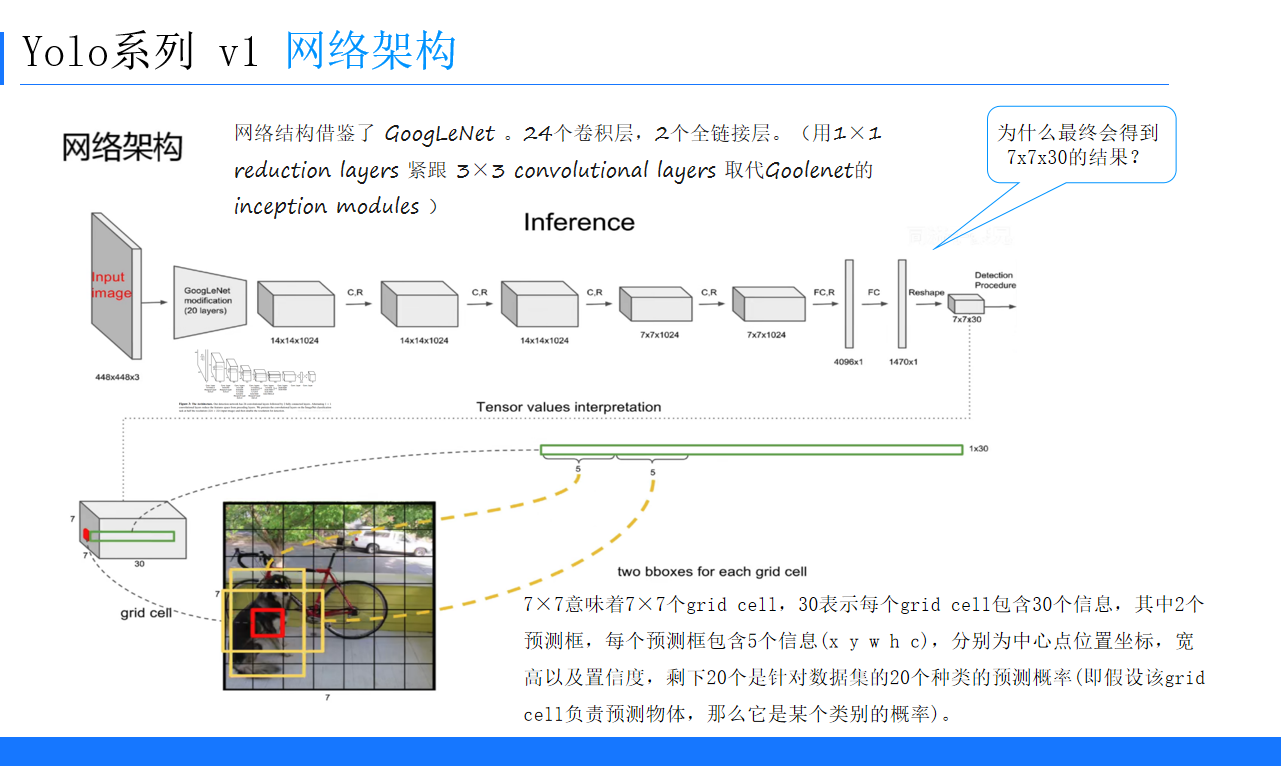
(二)網絡架構
YOLOv1的網絡結構借鑒了GoogLeNet,包含24個卷積層和2個全連接層。它使用1×1 reduction layers緊跟3×3 convolutional layers取代了GoogLeNet的inception modules。最終輸出7x7x30的結果,7x7表示網格數量,30維中包含2個預測框(每個預測框5個信息)以及20個類別概率。
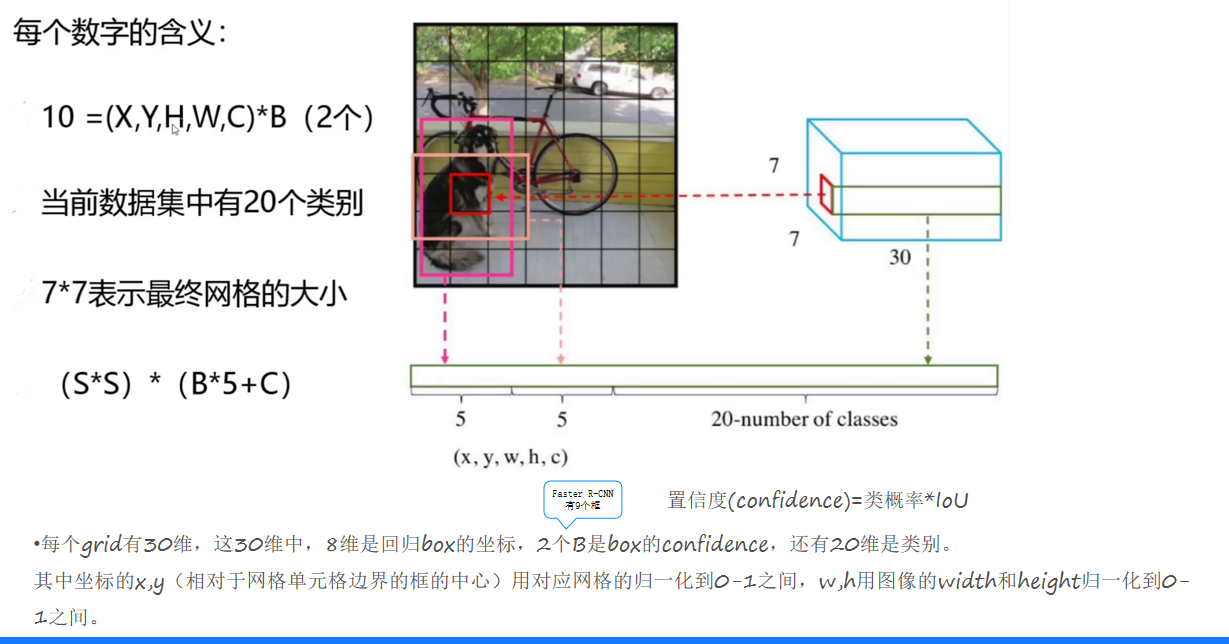
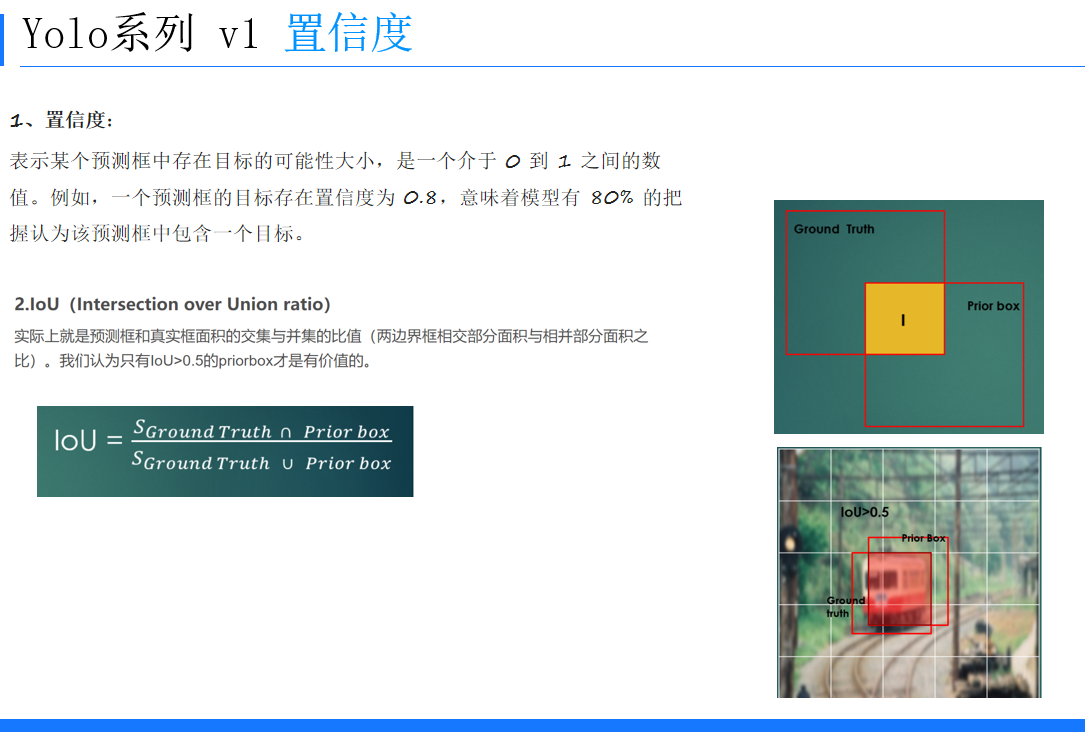
(三)置信度與預測框
置信度表示某個預測框中存在目標的可能性大小,取值介于0到1之間。預測框的坐標(x, y, w, h)通過相對于網格單元格邊界和圖像的寬高進行歸一化處理,使其在0 - 1之間。例如,坐標x、y是相對于網格單元格邊界的框的中心位置,w、h是相對于圖像width和height的比例。
(四)損失函數
YOLOv1的損失函數包含三部分:位置誤差、confidence誤差和分類誤差。通過對這三部分誤差的加權求和,實現對網絡的訓練優化,使坐標、置信度和分類三個方面達到平衡。比如,對于負責檢測物體的邊界框,會計算其中心點定位誤差和寬高定位誤差,并且在計算寬高定位誤差時,開根號操作能讓小框對誤差更敏感。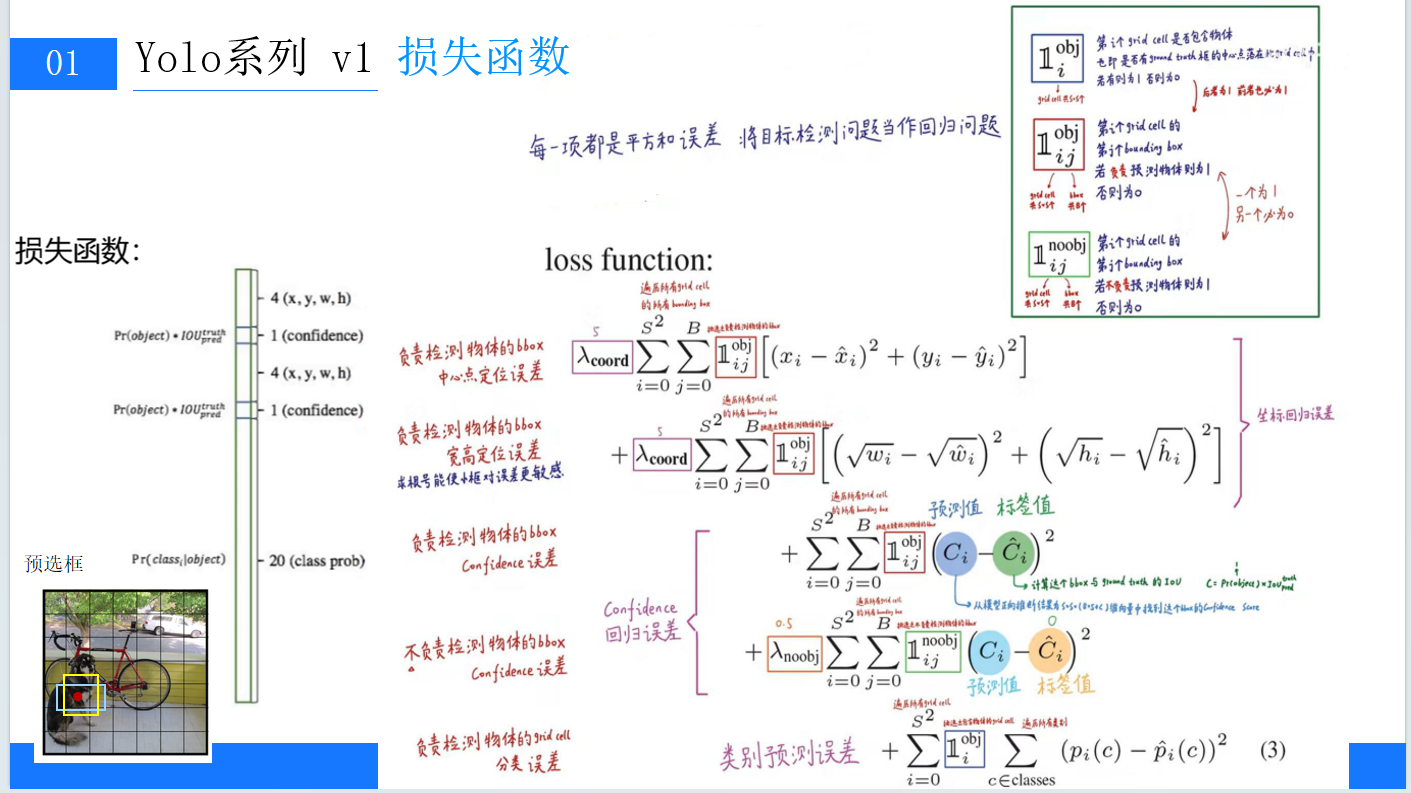
三、YOLOv1的優勢與不足
(一)優勢
- 檢測速度快:將目標檢測視為回歸問題,避免了傳統方法的多階段處理,實現了端到端的訓練和檢測,能夠對視頻進行實時檢測,在一些場景下檢測速度可達45FPS。
- 簡單高效:整體算法結構相對簡單,易于理解和實現,為后續目標檢測算法的發展提供了新思路。
(二)不足
- 類別預測局限性:每個網格只能預測1個類別,如果多個物體的中心落在同一個網格內且屬于不同類別,無法很好地解決重疊物體的檢測問題。
- 小物體檢測效果不佳:對于小物體,由于其在圖像中所占像素較少,YOLOv1的檢測效果一般,且其先驗框的長寬比可選但單一,不能很好地適應不同形狀的小物體。
四、YOLOv1的應用領域
盡管YOLOv1存在一些不足,但憑借其快速的檢測速度,在眾多領域得到了廣泛應用。在智能安防領域,可用于實時監控視頻中的目標檢測,如識別人員、車輛等;在自動駕駛領域,能夠快速檢測道路上的行人、車輛、交通標志等,為自動駕駛系統提供重要的決策依據;在工業檢測中,也能對生產線上的產品進行實時檢測,識別缺陷和異常。YOLOv1作為目標檢測領域的經典算法,雖然有其局限性,但它開啟了實時目標檢測的新時代。它的創新思想和設計理念為后續YOLO系列算法以及其他目標檢測算法的發展提供了寶貴經驗。隨著技術的不斷進步,目標檢測算法也在持續優化和改進,未來我們有望看到更高效、更精準的檢測算法出現。



)






![[論文閱讀]ControlNET: A Firewall for RAG-based LLM System](http://pic.xiahunao.cn/[論文閱讀]ControlNET: A Firewall for RAG-based LLM System)








