文章目錄
- 索引(重點)
- 硬件理解
- 磁盤
- 盤片和扇區
- 定位扇區
- 磁盤的隨機訪問和連續訪問
- 軟件方面的理解
- 建立共識
- 索引的理解

索引(重點)
- 索引可以提高數據庫的性能,它的價值,在于提高一個海量數據的檢索速度。
案例:
建立一個海量表
drop database if exists 'my_index';
create database if not exists 'my_index' default character set utf8;
use 'my_index';--構建一個8000000條記錄的數據
--構建的海量表數據需要有差異性,所以使用存儲過程來創建, 拷貝下面代碼就可以了,暫時不用理解--產生隨機字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin declare chars_str varchar(100) default'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255) default '';declare i int default 0;while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));set i = i + 1;end while;return return_str;end $$
delimiter ;--產生隨機數字
delimiter $$
create function rand_num()
returns int(5)
begin declare i int default 0;set i = floor(10+rand()*500);
return i;
end $$
delimiter ;--創建存儲過程,向雇員表添加海量數據
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0; set autocommit = 0; repeatset i = i + 1;insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());until i = max_numend repeat;commit;
end $$
delimiter ;--執行存儲過程,添加8000000條記錄
call insert_emp(100001, 8000000);
查詢員工編號為998877的員工
select * from emp where empno=998877;

花了6.17秒,就你一個人就花了6秒,如果公司人很多,會死機的
給表加上索引
alter table emp add index(empno);
很明顯加上索引之后,速度明顯變快了

-
硬件->系統->MySQL
-
常見索引分為:
主鍵索引(primary key)
唯一索引(unique)
普通索引(index)
全文索引(fulltext)–解決中子文索引問題。 -
先整一個海量表,在查詢的時候,看看沒有索引時有什么問題?
在海量的數據表中沒有索引查詢起來會變得很慢,如果有索引可以加快查詢的速度 -
給emp表添加索引
alter table emp add index(empno);
硬件理解
磁盤
- MySQL中的每一個表就是一個文件
- MySQL 給用戶提供存儲服務,而存儲的都是數據,數據在磁盤這個外設當中。磁盤是計算機中的一個機械設備,相比于計算機其他電子元件,磁盤效率是比較低的,在加上IO本身的特征,可以知道,如何提交效率,是 MySQL 的一個重要話題。

盤片和扇區
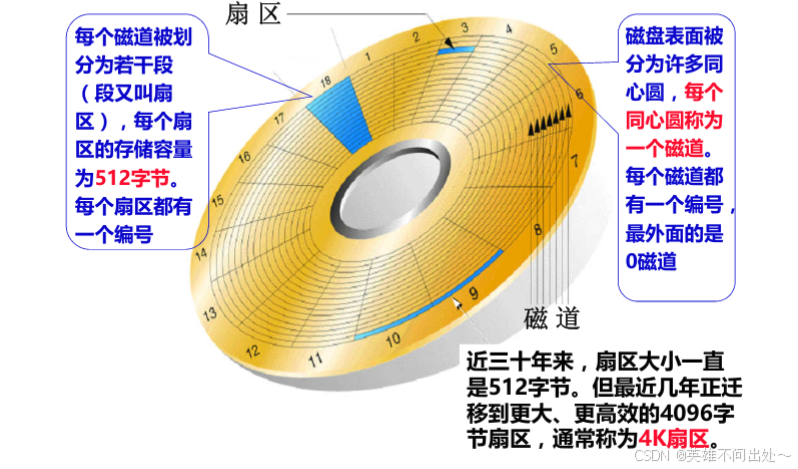
- 扇區:數據庫文件,本質其實就是保存在磁盤的盤片當中。也就是上面的一個個小格子中,就是我們經常所說的扇區。當然,數據庫文件很大,也很多,一定需要占據多個扇區。
- 在半徑方向上,距離圓心越近,扇區越小,距離圓心越遠,扇區越大
- 那么,所有扇區都是默認512字節嗎?目前是的,我們也這樣認為。因為保證一個扇區多大,是由比特位密度決定的。
- 我們在使用Linux,所看到的大部分目錄或者文件,其實就是保存在硬盤當中的。(當然,有一些內存文件系統,如: proc , sys 之類,我們不考慮)
- 數據庫文件,本質其實就是保存在磁盤的盤片當中,就是一個一個的文件,找到一個文件的全部,本質,就是在磁盤找到所有保存文件的扇區。
- 而我們能夠定位任何一個扇區,那么便能找到所有扇區,因為查找方式是一樣的。
定位扇區
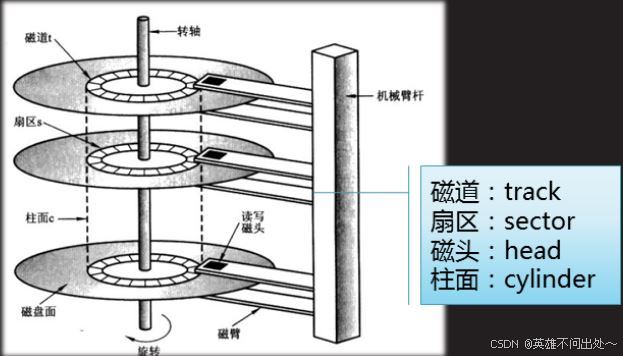
- 先找到柱面,再找磁頭,最后找到扇區(chs)
- 系統讀取磁盤是以塊為單位的,基本單位是4kb,因為不以塊為單位,以扇區為單位的話,一個是效率太慢,磁頭每次都要轉到相應的位置開始讀取,單次是512字節,讀取的量太少,第二個是耦合度太高,不便于硬件或操作系統各自升級
磁盤的隨機訪問和連續訪問
- 隨機訪問:本次IO所給出的扇區地址和上次IO給出扇區地址不連續,這樣的話磁頭在兩次IO操作之間需要作比較大的移動動作才能重新開始讀/寫數據。
- 連續訪問:如果當次IO給出的扇區地址與上次IO結束的扇區地址是連續的,那磁頭就能很快的開始這次IO操作,這樣的多個IO操作稱為連續訪問。
- 因此盡管相鄰的兩次IO操作在同一時刻發出,但如果它們的請求的扇區地址相差很大的話也只能稱為隨機訪問,而非連續訪問。(所以OS的文件系統一般就會將我們的一些IO請求在底層做一些歸類和排序,盡可能地增加連續訪問的可能,另一方面減少了磁頭的擺動次數也能提高磁盤的使用壽命)
- 磁盤是通過機械運動進行尋址的,隨機訪問不需要過多的定位,故效率比較高。
軟件方面的理解
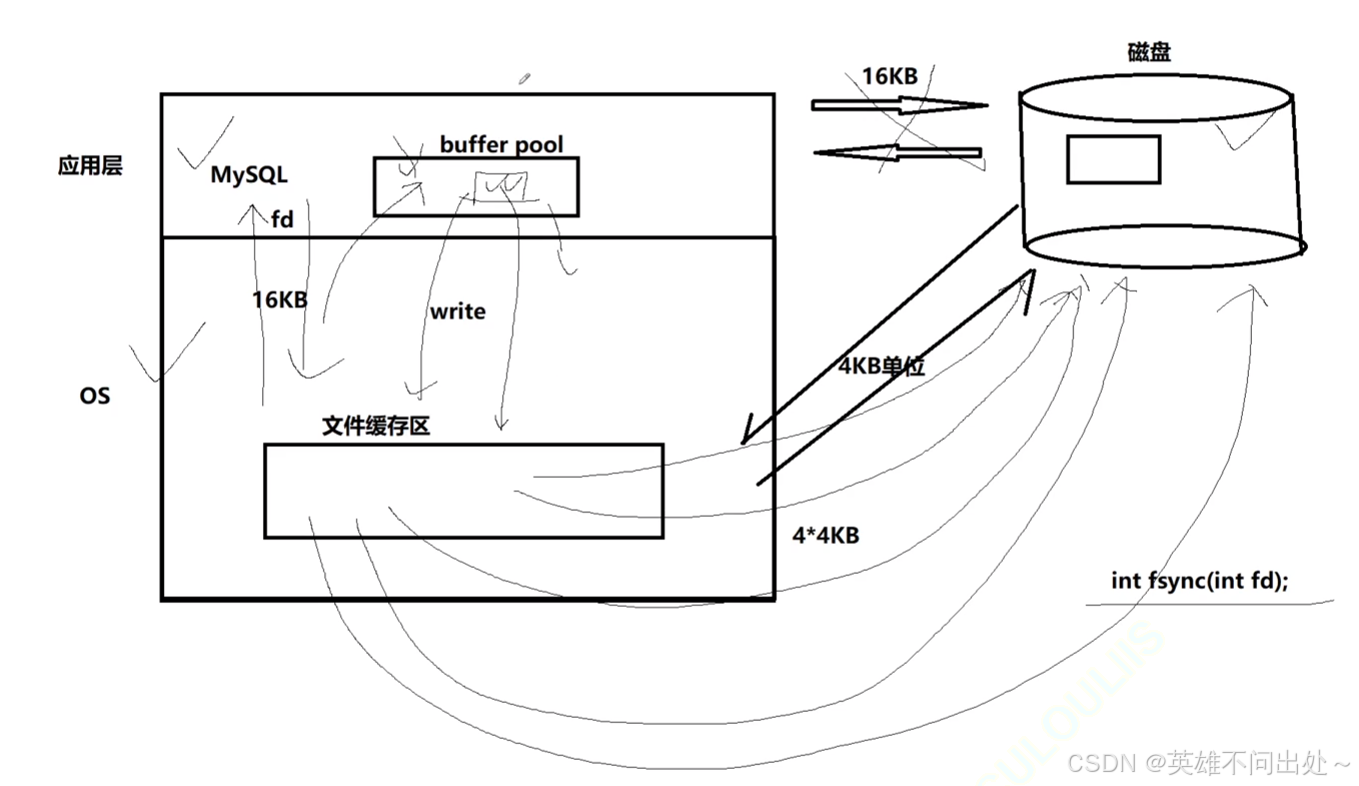
- 為了提高基本的IO效率, MySQL 進行IO的基本單位是 16KB,使用 InnoDB 存儲引擎
- 再數據塊的流動方面都是數據塊給操作系統,操作系統給mysql,mysql給操作系統,操作系統給磁盤
- MySQL 中的數據文件,是以page為單位保存在磁盤當中的。
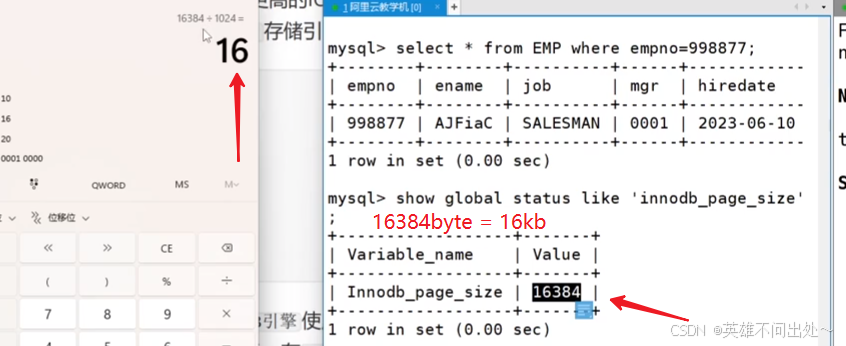
- 證明MySQL是以16kb為單位的
- 也就是說,磁盤這個硬件設備的基本單位是 512 字節,而 MySQL InnoDB引擎使用 16KB 進行IO交互。即, MySQL 和磁盤進行數據交互的基本單位是 16KB 。這個基本數據單元,在 MySQL 這里叫做page(注意和系統的page區分)
建立共識
- MySQL以16kb為單位進行mysql級別的IO
- MySQL要有自己的buff pool(緩沖池),會把數據讀到buff pool里,把buff pool的數據刷新到操作系統的緩沖區里,最后刷新到磁盤
- 一定要盡可能的減少系統和磁盤IO的次數,一次IO的數據量越大,比多次IO數據量小效率更高
- mysql會預先開辟一個128mb的緩沖池
索引的理解
- 建立測試表,存儲引擎默認是InnoDB的
create table if not exists user (id int primary key, --一定要添加主鍵哦,只有這樣才會默認生成主鍵索引age int not null,name varchar(16) not null
);
show create table user \G;
- 插入信息,插入5條無序的數據
--插入多條記錄,注意,我們并沒有按照主鍵的大小順序插入哦
mysql> insert into user (id, age, name) values(3, 18, '楊過');
mysql> insert into user (id, age, name) values(4, 16, '小龍女');
mysql> insert into user (id, age, name) values(2, 26, '黃蓉');
mysql> insert into user (id, age, name) values(5, 36, '郭靖');
mysql> insert into user (id, age, name) values(1, 56, '歐陽鋒');
- 查看表中的內容,發現數據是有序的

4. 理解page

5. 為何io操作要page?
為了減少IO的次數,提高IO的效率,在單個page中,不在單個page中,會進行多次IO操作
你怎么保證,用戶一定下次找的數據,就在這個Page里面?---->我們不能嚴格保證,但是有很大概率再一個Page當中或者是周圍的,因為有局部性原理。
)


)



)



no cameras available,完美解決)
)






