《HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation》論文講解
一、引言
本文提出了 HunyuanCustom,這是一個基于多模態驅動的定制化視頻生成框架。該框架旨在解決現有視頻生成模型在身份一致性(identity consistency)和輸入模態多樣性方面的不足。HunyuanCustom 支持圖像、音頻、視頻和文本等多種條件輸入,能夠生成具有特定主題身份的視頻,廣泛應用于虛擬人廣告、虛擬試穿、唱歌頭像和視頻編輯等領域。
二、相關工作
(一)視頻生成模型
近年來,擴散模型推動了視頻生成技術的發展,從靜態圖像合成進化到動態時空建模。現有方法主要集中在文本引導的視頻生成或基于單一參考圖像的視頻生成,但在生成內容的精細控制和概念驅動編輯方面仍存在不足。
(二)視頻定制化
1. 實例特定視頻定制化
這種方法通過使用與目標身份相同的多張圖像對預訓練的視頻生成模型進行微調,每種身份單獨訓練。例如,Textual Inversion 和 DreamBooth 將圖像身份信息嵌入文本空間,實現與文本的有效交互。然而,這些方法依賴于實例特定優化,難以實現實時或大規模視頻定制化。
2. 端到端視頻定制化
這種方法通過訓練額外的條件網絡將目標圖像的身份信息注入視頻生成模型,使模型在推理階段能夠泛化到任意身份圖像輸入。一些工作專注于保持面部身份,如 ID-Animator 和 ConsisID 等。但現有方法在處理多個主題身份的維護和交互時仍有較大提升空間。
三、方法
(一)概述
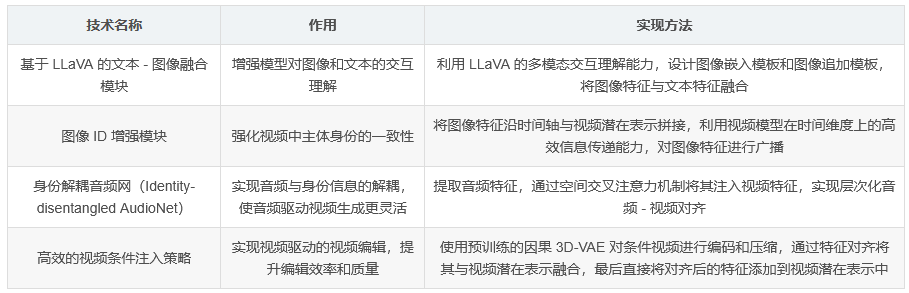
HunyuanCustom 以 Hunyuan Video 生成框架為基礎,通過引入基于 LLaVA 的文本 - 圖像融合模塊和圖像 ID 增強模塊,實現對文本和圖像的交互理解,增強模型對身份信息的把握。此外,為支持音頻和視頻條件注入,分別設計了音頻和視頻的特定注入機制。
(二)多模態任務
HunyuanCustom 支持以下四類任務:
-
文本驅動視頻生成:基于 HunyuanVideo 的文本 - 視頻生成能力,根據文本提示生成對應視頻。
-
圖像驅動視頻定制:以輸入圖像提取身份信息,結合文本描述生成對應視頻,支持人類和非人類身份以及多身份輸入。
-
音頻驅動視頻定制:在圖像驅動定制基礎上融入音頻,在文本描述場景中使主題與音頻同步行動。
-
視頻驅動視頻定制:實現基于身份定制的對象替換或插入,可將目標身份插入背景視頻。
(三)多模態數據構建
數據來源廣泛,涵蓋人類、動物、植物等八大類別。數據處理包括過濾和預處理、主體提取、視頻分辨率標準化、視頻標注和掩碼數據增強等步驟,確保數據質量以提升模型性能。
1. 數據過濾和預處理
利用 PySceneDetect 分割視頻為單鏡頭剪輯,使用 textbpn-plusplus 過濾含過多文本的剪輯,對視頻進行裁剪和對齊,并通過 koala-36M 模型進一步優化。
2. 主體提取
-
單主體提取:使用 Qwen7B 模型標記幀中所有主體并提取 ID,用 Union-Find 算法計算 ID 出現頻率,選擇最高頻 ID 作為目標主體。利用 YOLO11X 和 InsightFace 分別進行人體分割和面部檢測。
-
非人類主體提取:使用 QwenVL 提取視頻主體關鍵詞,并通過 GroundingSAM2 生成掩碼和邊界框。
-
多主體提取:使用 QwenVL 和 Florence2 提取邊界框,再通過 GroundingSAM2 進行主體提取,并進行聚類以去除不包含所有主體的幀。
(四)圖像驅動視頻定制
-
基于 LLaVA 的文本 - 圖像交互:通過設計圖像嵌入模板和圖像追加模板,利用 LLaVA 的多模態交互理解能力,實現文本和圖像的有效融合。
-
身份增強:通過時間軸拼接圖像特征,并利用視頻模型在時間維度上的高效信息傳遞能力,增強視頻身份一致性。
-
多主體定制化:在單主體定制模型基礎上進行微調,為每個條件圖像分配不同的時間索引,以區分不同身份圖像。
(五)多模態主體中心視頻生成
1. 音頻驅動視頻定制
提出身份解耦音頻網(Identity-disentangled AudioNet),提取音頻特征并通過空間交叉注意力機制將其注入視頻特征,實現層次化音頻 - 視頻對齊。
2. 視頻驅動視頻定制
采用高效的視頻條件注入策略,先通過預訓練的因果 3D-VAE 對條件視頻進行編碼和壓縮,再通過特征對齊將其與視頻潛在表示融合,最后直接將對齊后的特征添加到視頻潛在表示中。
四、實驗
(一)實驗設置
使用以下指標評估視頻定制性能:
-
身份一致性:使用 Arcface 檢測并提取參考人臉和生成視頻各幀的嵌入,計算平均余弦相似度。
-
主體相似性:使用 YOLOv11 檢測并分割人類,再計算參考與結果的 DINO-v2 特征相似度。
-
文本 - 視頻對齊:使用 CLIP-B 評估文本提示與生成視頻的對齊程度。
-
時間一致性:使用 CLIPB 模型計算各幀與其相鄰幀及第一幀的相似度。
-
動態程度:根據 VBench 測量物體的運動程度。
(二)單主體視頻定制化比較
1. 基線方法
將 HunyuanCustom 與包括商業產品(Vidu 2.0、Keling 1.6、Pika 和 Hailuo)和開源方法(Skyreels-A2 和 VACE)在內的多種先進視頻定制方法進行比較。
2. 定性比較
HunyuanCustom 在保持身份一致性的同時,具有更好的視頻質量和多樣性。
3. 定量比較
HunyuanCustom 在身份一致性和主體相似性方面表現最佳,與其他指標表現相當。
(三)多主體視頻定制化實驗和應用
1. 定性比較
HunyuanCustom 有效捕捉人類和非人類主體身份,生成符合提示的視頻,且視覺質量高、穩定性好。
2. 虛擬人廣告
HunyuanCustom 能夠生成具有良好互動性的廣告視頻,保持人物身份和產品細節,使視頻符合提示。
(四)音頻驅動視頻定制化實驗
1. 音頻驅動單主體定制化
HunyuanCustom 實現了在文本描述的場景和姿勢中,使角色說出相應音頻,生成多樣化的視頻。
2. 音頻驅動虛擬試穿
結合文本提示和音頻,生成具有指定服裝的人物視頻,同時保持身份一致性。
(五)視頻驅動視頻定制化實驗
在視頻主體替換任務中,與 VACE 和 Keling 相比,HunyuanCustom 有效避免邊界偽影,實現與視頻背景的無縫融合,并保持強烈的身份保護。
(六)消融研究
比較完整模型與三種消融模型(無 LLaVA、無身份增強、通過通道級拼接進行身份增強)的性能,結果表明 LLaVA 不僅傳遞提示信息,還提取關鍵身份特征;身份增強模塊在細化身份細節方面有效;時間拼接有助于通過強大的時間建模先驗有效捕捉目標信息,并最大限度地減少對生成質量的影響。
五、結論
HunyuanCustom 是一種新穎的多模態定制視頻生成模型,能夠實現主體一致的視頻生成,并支持圖像、音頻和視頻與文本驅動條件的結合。通過整合文本 - 圖像融合模塊、圖像 ID 增強模塊和高效的音頻及視頻特征注入過程,確保生成的視頻符合用戶特定要求,達到高保真度和靈活性。大量實驗證明,HunyuanCustom 在各項任務中均優于現有方法,在身份一致性、真實性和視頻 - 文本對齊方面表現出色,是可控視頻定制領域的領先解決方案,為未來可控視頻生成研究鋪平了道路,并拓展了人工智能生成內容(AIGC)在創意產業及其他領域的潛在應用。
六、核心技術匯總表格












(第2版) 學習筆記 07.光照)

)




