萬事開頭難,苦盡便是甜
????????????????????????????????????????? —— 25.4.8
一、什么是強化學習
強化學習和有監督學習是機器學習中的兩種不同的學習范式
強化學習:目標是讓智能體通過與環境的交互,學習到一個最優策略以最大化長期累積獎勵。
????????不告訴具體路線,首先去做,做了之后,由環境給你提供獎勵,根據獎勵的多少讓模型進行學習,最終找到正確路線?
????????例如:在機器人導航任務中,智能體需要學習如何在復雜環境中移動,以最快速度到達目標位置,同時避免碰撞障礙物,這個過程中智能體要不斷嘗試不同的行動序列來找到最優路徑。
監督學習:旨在學習一個從輸入特征到輸出標簽的映射函數,通常用于預測、分類和回歸等任務。
????????給出標準答案,讓模型朝著正確答案方向去進行學習?
????????例如:根據歷史數據預測股票價格走勢,或者根據圖像特征對圖像中的物體進行分類,模型通過學習已知的輸入輸出對來對新的未知數據進行預測
二、強化學習的重要概念
1.智能體和環境
智能體是個很寬泛的概念,可以是一個深度學習模型,也可以是一個實體機器人
環境可能隨智能體的動作發生變化,為智能體提供獎勵
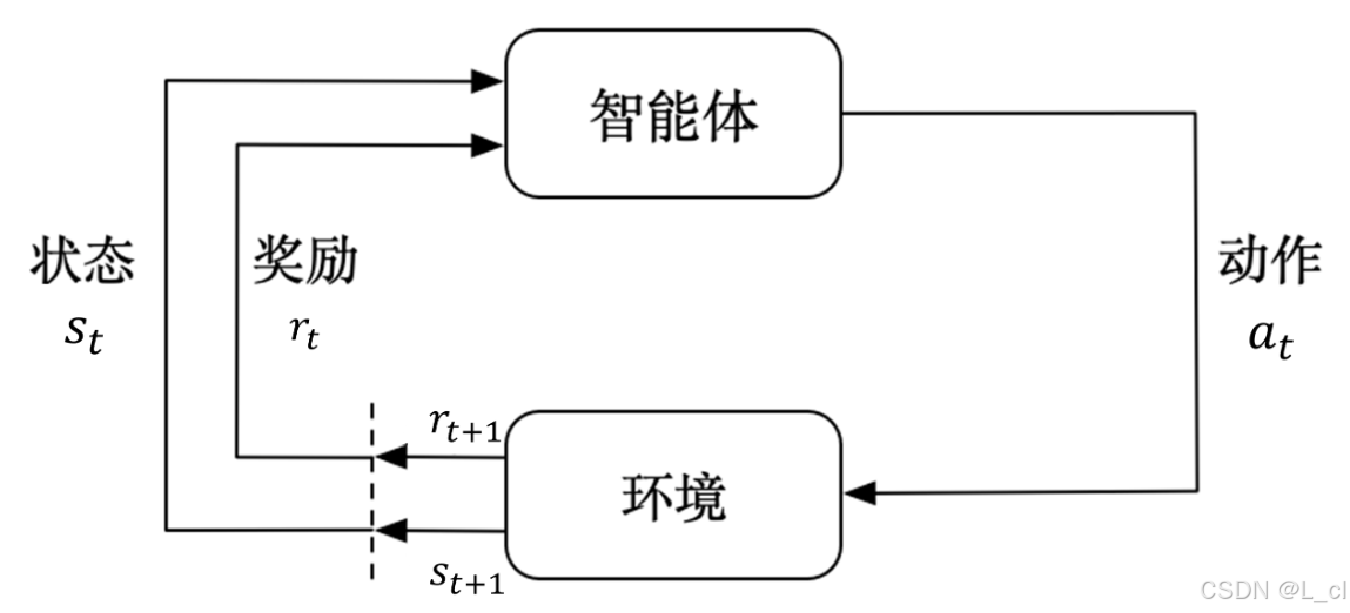
例:
以一個圍棋智能體為例,圍棋規則即是環境
狀態(State):當前的盤面即是一種狀態
行動(Action):接下來在棋盤中的下法是一種行動
獎勵(Reward):輸贏是一種由環境給出的獎勵,獎勵隨每個動作逐個傳遞
獎勵黑客(reward hacking):在強化學習(RL)中,智能體通過利用獎勵函數中的漏洞或模糊性來獲得高獎勵,而沒有真正完成預期任務的行為。
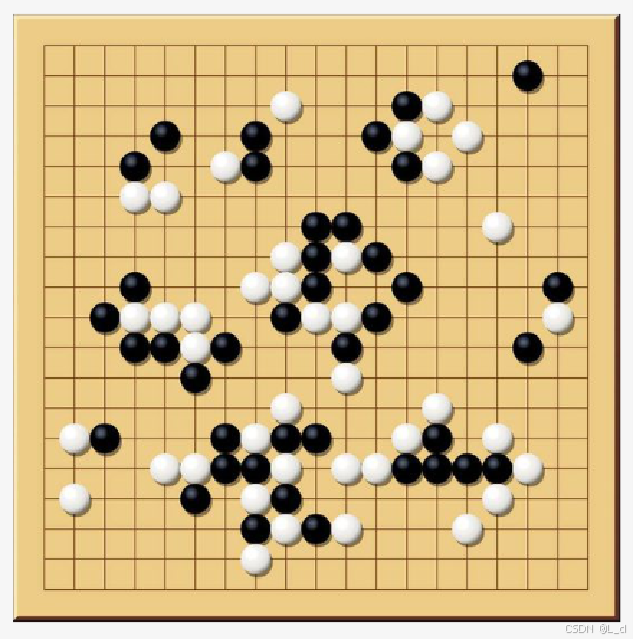
2.強化學習基礎流程
智能體在狀態 s_t 下,選擇動作 a_t
環境根據動作 a_t 轉移到新狀態 s_t+1,并給出獎勵 r_t
智能體根據獎勵 r_t 和新狀態 s_t+1 更新策略或價值函數
重復上述過程,直到達到終止條件
① 智能體與環境交互:智能體(Agent)在環境中執行動作(Action),環境根據智能體的動作給出反饋,即獎勵(Reward),并轉移到新的狀態(State)?
② 狀態感知與動作選擇:智能體根據當前的狀態,依據某種策略(Policy)選擇下一個動作。策略可以是確定性的,也可以是隨機的?
③ 獎勵反饋:環境根據智能體的動作給予獎勵,獎勵可以是即時的,也可以是延遲的。智能體的目標是最大化累積獎勵?
④ 策略更新:智能體根據獲得的獎勵和新的狀態,更新其策略或價值函數(Value Function),以優化未來的決策?
⑤ 循環迭代:上述過程不斷重復,智能體通過不斷的試錯和學習,逐步優化其策略,以達到最大化累積獎勵的目標
強化學習的核心在于智能體通過與環境的交互,不斷優化其策略,以實現長期獎勵的最大化
2.策略(Policy)
智能體要學習的內容 ——?策略(Policy):用于根據當前狀態,選擇下一步的行動
以圍棋來說,可以理解為在當前盤面下,下一步走每一格的概率
策略 π 是一個:輸入狀態(state)?和?輸出動作(action)?的函數
![]()
或者是一個:輸入為狀態+動作,輸出為概率的函數
有了策略之后,就可以不斷在每個狀態下,決定執行什么動作,進而進入下一個狀態,依次類推完成整個任務
s1 -> a1 -> s2 -> a2 -> s3....基于前一個狀態,產生下一個動作,這就是所謂的“馬爾可夫決策過程” 【MDP】
強化學習有多種策略?
3.價值函數(Value Function)【獎勵】
智能體要學習的內容 ——?價值函數(Value Function):基于策略 π 得到的函數,具體分為兩種:
① 狀態價值函數 ? V(s)
最終未來的收益
表示從狀態 s?開始,遵循策略 π 所能獲得的長期累積獎勵(r_t)的期望
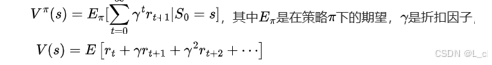
折扣因子 γ ∈ [0,1],反映對于未來獎勵的重視程度,γ 越接近于1,表示模型越看重未來的獎勵,γ 越接近于0,代表模型越看重當前的獎勵
② 動作價值函數 ? Q(s, a)
下在某點時,未來的收益
表示在狀態 s 下采取動作 a,遵循策略 π 所能獲得的長期累積獎勵的期望
![]()
狀態價值函數評估的是當前環境局面怎么樣
動作價值函數評估的是當前環境下采取某一個動作收益會怎么樣
二者關系:![]()
????????在每一個狀態下,執行每個動作得到的獎勵乘以執行每個動作的概率,再求和,就等于當前狀態下的狀態價值函數,也就是所謂的全概率公式
4.優勢估計函數
優化目標 —— 優勢估計函數:類似于損失函數Loss,但區別在于我們需要最大化這個值,表示在當前狀態下我應該選取的最好的動作
????????A(s, a) = Q(s, a) - V(s)
動作價值函數Q 和 狀態價值函數V 都是基于策略 π 的函數,所以整個函數也是一個基于策略?π 的函數
策略 π 可以是一個神經網絡,要優化這個網絡的參數
訓練過程中,通過最大化優勢估計函數 A(s,a),來更新策略網絡的參數
也就是說優勢估計函數的作用類似于loss函數,是一個優化目標,可以通過梯度反傳(梯度上升)來優化
這是強化學習中的一種方法,一般稱為策略梯度算法
策略梯度算法 是強化學習中與NLP任務最有關的方法?
三、強化學習 與 NLP
將文本生成過程看作一個序列決策過程
狀態(state) = 已經生成的部分文本
動作(action) = 選擇下一個要生成的token
強化學習適用于NLP 中的 推理任務 和 泛模型
做某種任務最終結果進行推理 ,不在乎中間結果,對泛化性要求較高,適合使用強化學習
先輸入一個提示詞(當前的狀態),然后輸出接下來的詞,重點在于設計獎勵

四、PPO算法
1.定義
????????PPO(Proximal Policy Optimization,近端策略優化)是OpenAI于2017年提出的一種策略梯度算法,旨在改進傳統策略梯度方法的訓練穩定性。其核心思想是通過限制策略更新幅度,避免因步長過大導致的性能崩潰,同時平衡探索與利用
?2.核心機制
?①?剪切(Clipping)?:通過截斷新舊策略概率比(如設置閾值ε=0.2),限制策略突變。
?②?重要性采樣:利用歷史數據調整梯度權重,提升樣本效率。
?③?Actor-Critic框架:策略網絡(Actor)生成動作,價值網絡(Critic)評估長期收益
3.訓練目標
?多階段流程??:獎勵模型訓練 → Critic網絡預訓練 → 策略迭代優化
??動態優勢估計??:通過Critic網絡預測狀態價值,計算TD誤差??
穩定性控制??:KL散度懲罰防止策略突變,熵獎勵鼓勵探索
4.核心公式
![]()
????????r_t(θ) = π_θ(a_t | s_t)/ π_old(a_t | s_t):策略更新比率
????????A_t:GAE(廣義優勢估計)
????????ξ:Clipping閾值(通常為0.1 ~ 0.2)
5.算法流程
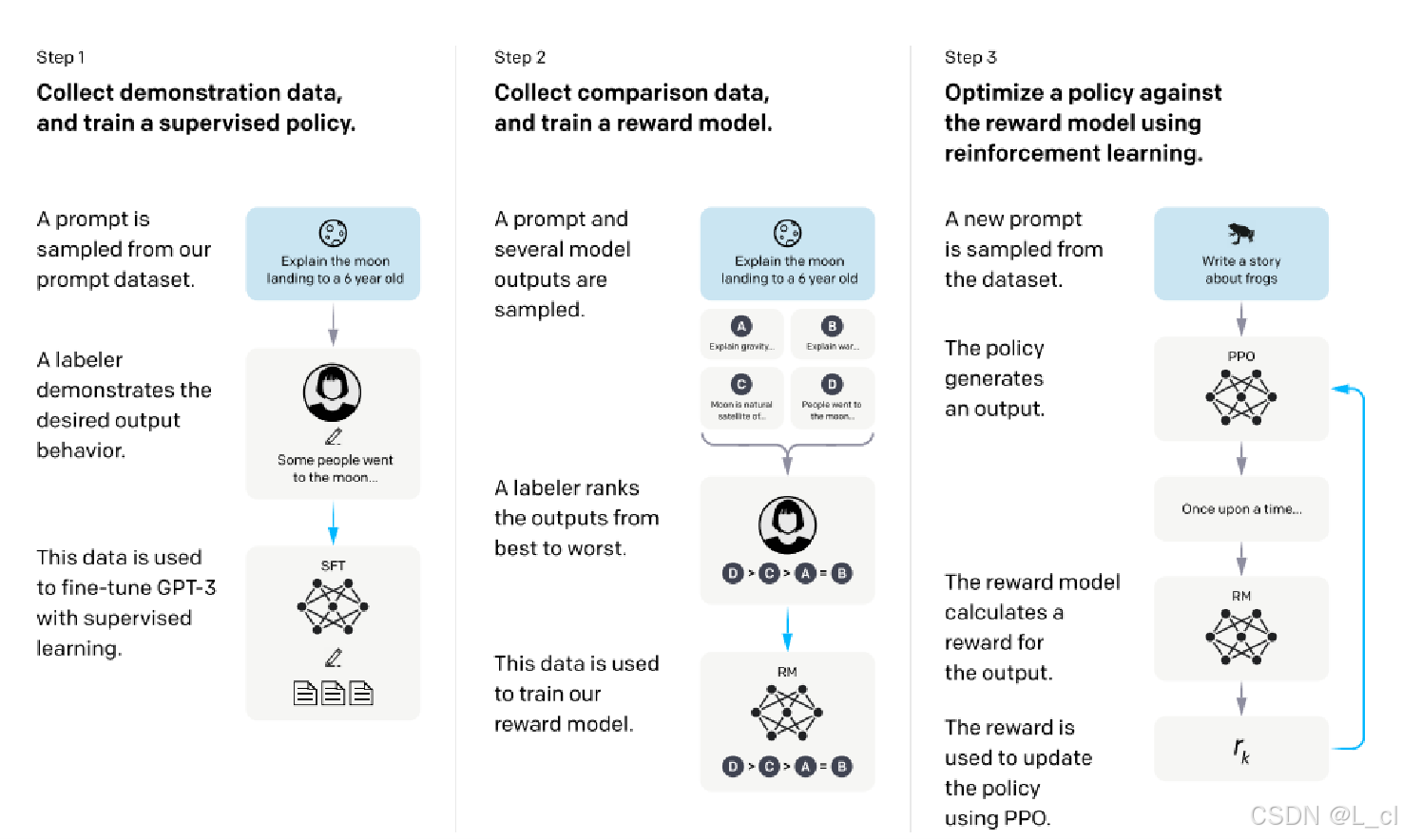
第一個階段:SFT,把模型從續寫轉換為問答,標準的有監督學習過程(收集數據,給一些提示詞,由人來標注對應的希望的答案,讓模型進行學習)
第二個階段:訓練一個所謂的獎勵模型(給一個提示詞到若干個模型,若干個模型會輸出若干個結果,然后有一個標注人員將這些結果按照優劣進行排序,然后用一個專門的模型按排序的順序學習結果的優劣,來進行排序比較誰比誰好)
第三個階段:利用第二步訓練的獎勵模型函數policy,優化我們的語言模型,使用強化學習的方法(用一個新的提示詞生成新的答案,計算其獎勵數值,利用獎勵模型計算獎勵分數,然后用PPO算法優化選擇的策略模型)
6.RW訓練(獎勵模型訓練)
訓練目標:訓練一個獎勵模型(Reward Model),將人類偏好或環境反饋映射為標量獎勵。
?輸入:標注的偏好數據(如“答案A比答案B好”)或環境交互數據。
作用:為RL訓練提供獎勵信號,指導策略優化。
對于一個輸入問題,獲取若干可能的答案,由人工進行排序打分,兩兩一組進行Reward Model訓練
Ⅰ、獎勵公式
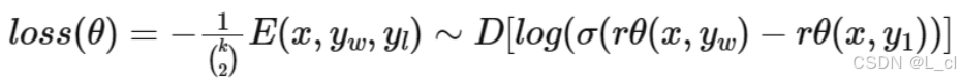
x:問題(prompt)
y_w:相對好的答案
y_l:相對差的答案
rθ:一個交互式文本匹配模型,輸入為一個問答對(x,y),輸出為標量(0 ~?1),輸出的 rθ分數?越接近于0,答案越不好;輸出的 rθ分數? 越接近于1,答案越好;rθ?也就是強化學習中的獎勵模型
Ⅱ、如何判斷是否是一個好的答案:
????????最大化?rθ(x, y_w) -?rθ(x, y_l)?作為訓練目標,最小化?-rθ(x, y_w) -?rθ(x, y_l)?作為loss損失
????????訓練好的?rθ分數 越接近于0,答案越不好;輸出的 rθ分數 越接近于1,答案越好
示例: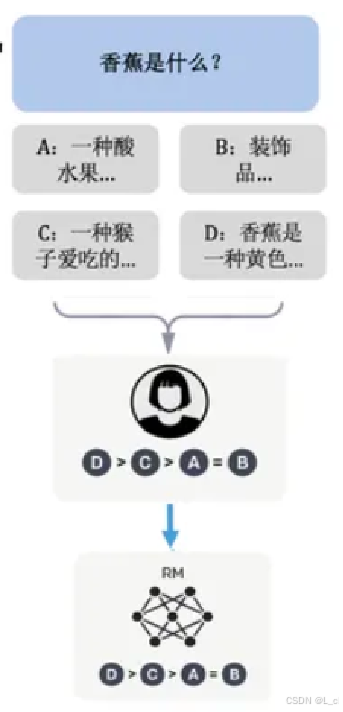
5.RL訓練(強化學習訓練)
目標:通過PPO算法優化策略模型(Actor),最大化累積獎勵。
流程:
?????????數據采樣:當前策略生成交互數據(狀態-動作-獎勵)。?
????????優勢估計:使用GAE(廣義優勢估計)計算動作長期收益。?
????????策略更新:通過剪切目標函數調整策略參數,限制KL散度。

RLHF訓練目標
新舊兩版模型,多關注二者的差異,少關注二者的共性

6.PPO加入約束


五、DPO算法
1.定義
????????DPO(Direct Preference Optimization,直接偏好優化)是一種替代PPO的輕量化RLHF(基于人類反饋的強化學習)方法,由斯坦福團隊提出。其核心思想是跳過顯式獎勵模型訓練reward model,直接利用偏好數據優化策略。
? ? ? ? 實際上DPO并不是嚴格意義上的強化學習,更適合叫對比學習
2.核心公式

????????β:溫度系數,控制優化強度
????????σ:Sigmoid函數,將概率差映射為偏好得分
????????π_ref:參考策略(如SFT模型)
3.訓練目標
單階段優化??:直接利用偏好對數據(y_w?,y_l?)訓練,無需獨立獎勵模型
??策略對齊??:通過KL散度約束,確保新策略π_θ?與參考策略π_ref?不過度偏離
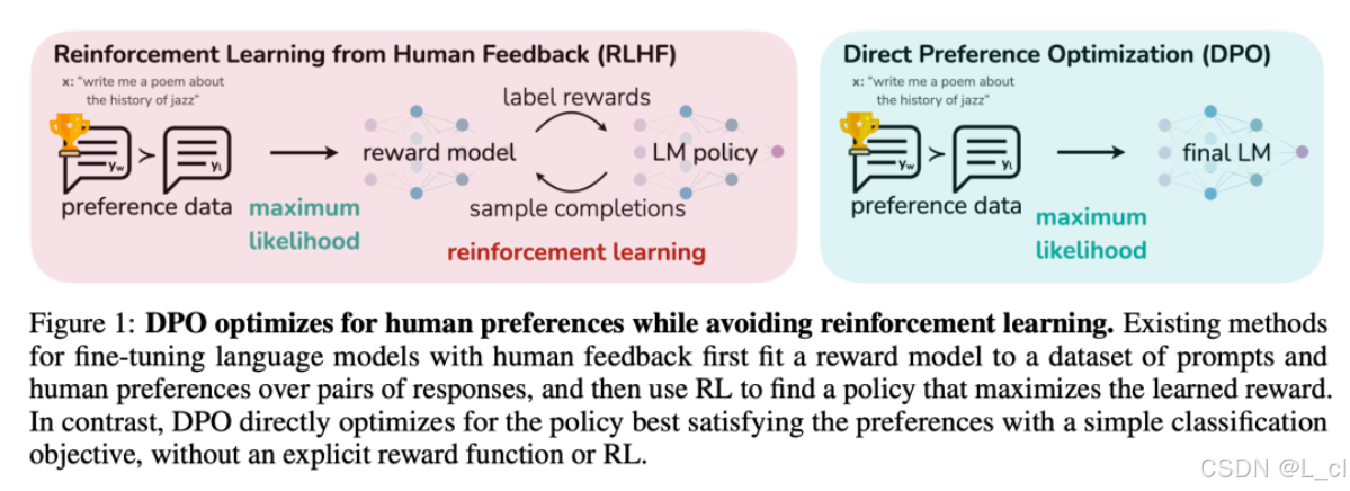
4.DPO 與 PPO的核心區別
| ?維度 | ?PPO | ?DPO |
|---|---|---|
| ?訓練流程 | 需獎勵模型(RM)+策略模型(Actor / Policy) | 僅策略模型Policy(直接優化偏好數據) |
| ?數據依賴 | 環境交互數據 + 獎勵模型標注 | 人類偏好對(無需獎勵模型) |
| ?計算復雜度 | 高(需多模型協同訓練) | 低(單模型優化) |
| ?適用場景 | 復雜任務(如游戲AI、機器人控制) | 對齊任務(如對話生成、文案優化) |
| ?穩定性 | 依賴剪切機制和獎勵模型設計 | 更穩定(避免獎勵模型誤差傳遞) |
| ?多樣性 | 支持多目標優化(如探索與利用) | 可能受限于偏好數據分布 |
六、GRPO算法
1.定義
GRPO由DeepSeek提出,通過??組內歸一化優勢估計??替代Critic網絡,核心優勢在于:
?多候選生成??:同一提示生成多個響應(如G=8),計算組內相對獎勵??
動態基線計算??:用組內均值和標準差歸一化優勢值,公式為:?A_i = (r_i - μ_group) / σ_group?
資源優化??:省去Critic網絡,顯存占用降低50%
2.核心公式
![]()
3.PPO、GRPO算法目標對比
PPO算法:追求??絕對獎勵最大化??,通過剪切機制和KL約束平衡探索與利用,適合復雜動態環境;
GRPO算法:聚焦??組內相對優勢優化??,通過統計歸一化和自對比降低計算成本,更適合資源受限的靜態推理任務。
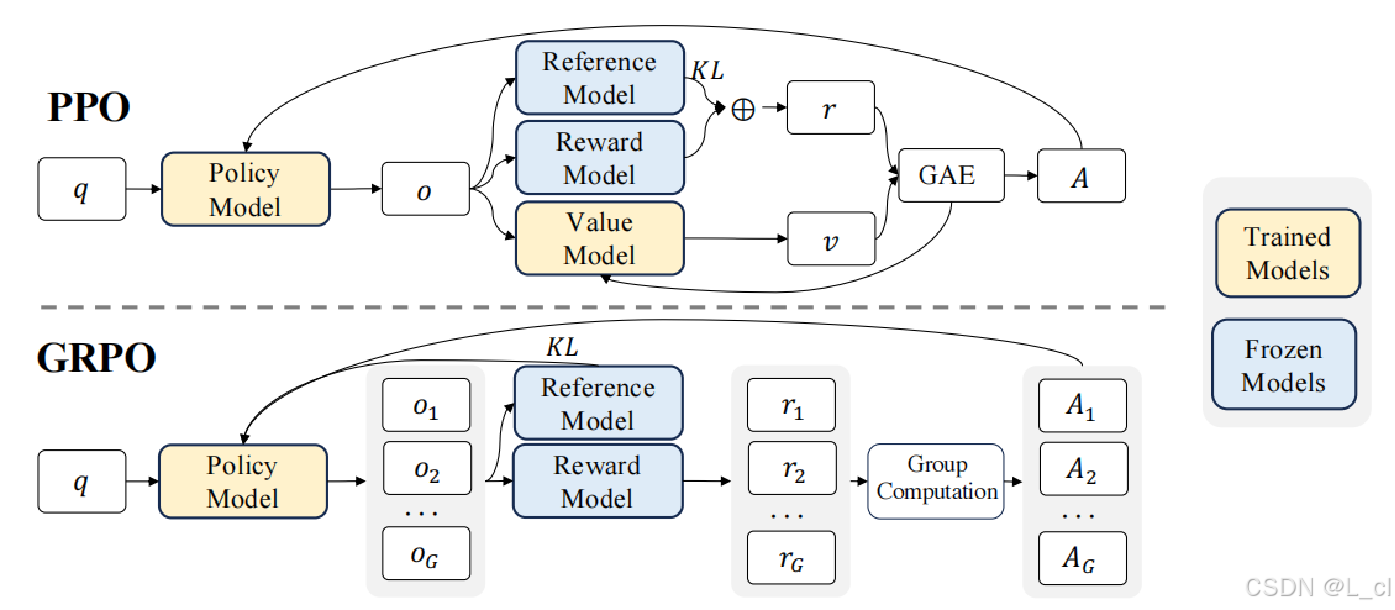
獎勵(Reward model)可以是硬規則,如:
????????① 問題是否回答正確,正確為1,錯誤為0
????????② 生成代碼是否可運行,可運行為1,不可運行為0
????????③ 回復格式是否符合要求,符合要求為1,不符合為0
????????④ 回復文本是否包含不同語種,不包含為1,包含為0
七、DeepSeek-R1

模型輸出格式:
<think>
……
</think>
<answer>
……
</answer>
這種先輸出一段think思考過程,再輸出一段answer答案的模型現在我們稱為Reasoning Model
如何得到R1模型
第一步:預訓練 + SFT 得到DeepSeek - v3 - Base模型
第二步:通過一些帶有長思維鏈的數據再做SFT
第三步:做強化學習得到R1模型
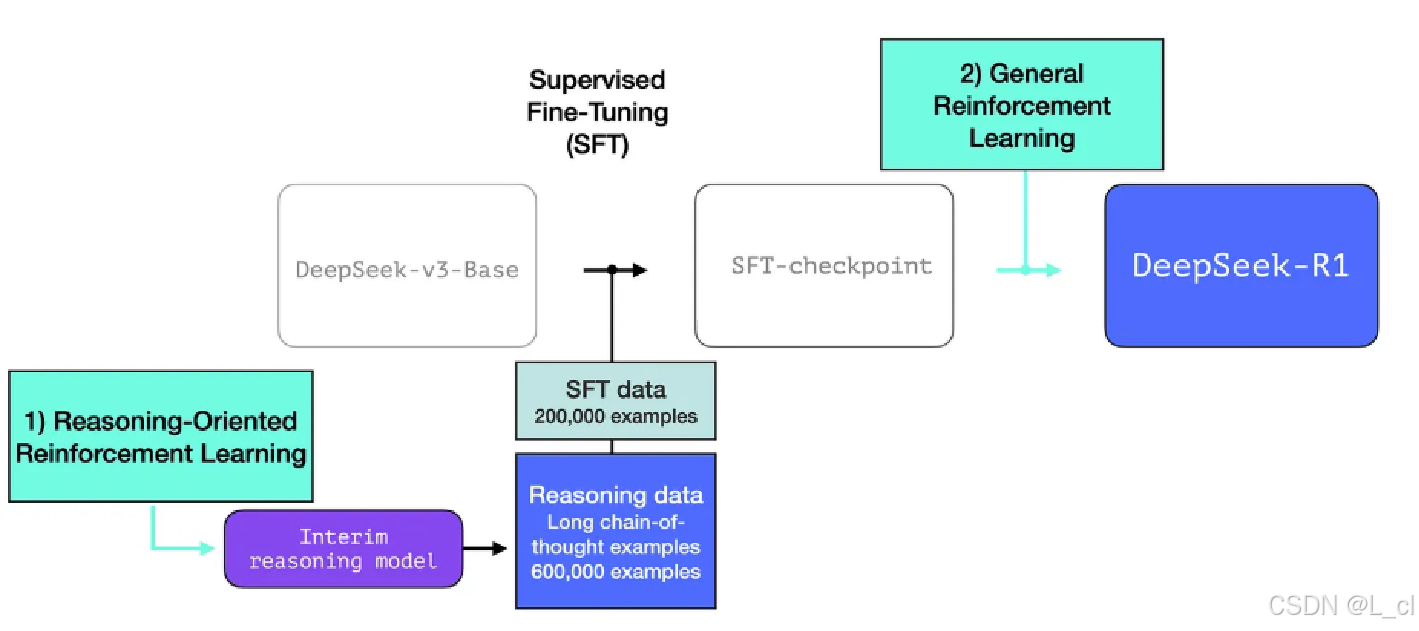
R1-zero
帶有長思維鏈的數據從R1-zero模型訓練得到
R1-zero:使用一個預訓練模型,不做SFT,直接使用GRPO,用規則替換獎勵,再進行強化學習,在訓練過程中模型就可以自發直接得到R1-zero,這個模型可以自然得到長的推理鏈
????????使用GRPO + 規則獎勵,直接從基礎模型(無sft)進行強化學習得到 模型在回復中會產生思維鏈,包含反思,驗證等邏輯 雖然直接回答問題效果有缺陷,但是可以用于生成帶思維鏈的訓練數據




)

![C++Cherno 學習筆記day17 [66]-[70] 類型雙關、聯合體、虛析構函數、類型轉換、條件與操作斷點](http://pic.xiahunao.cn/C++Cherno 學習筆記day17 [66]-[70] 類型雙關、聯合體、虛析構函數、類型轉換、條件與操作斷點)

:使用dashboard用戶界面(需要訪問外網獲取yaml))
和線性回歸(Linear Regression)對比實驗)



)

JavaScript庫(防抖、節流、函數柯里化)JS庫)
)


