🌟 引言:注意力為何改變CNN的命運?
就像人類視覺會優先聚焦于重要信息,深度學習模型也需要"學會看重點"。從2018年SENet首提通道注意力,到2024年SSCA探索空間-通道協同效應,注意力機制正成為CNN性能提升的核武器,這些注意力機制思想不僅不斷改造提升著CNN,也影響到了Transformer架構中的注意力設計。本文帶大家穿越6年技術迭代,揭秘那些改變視覺模型的注意力模塊!
第一站:SENet(2018 CVPR)- 通道注意力的開山之作

核心思想:
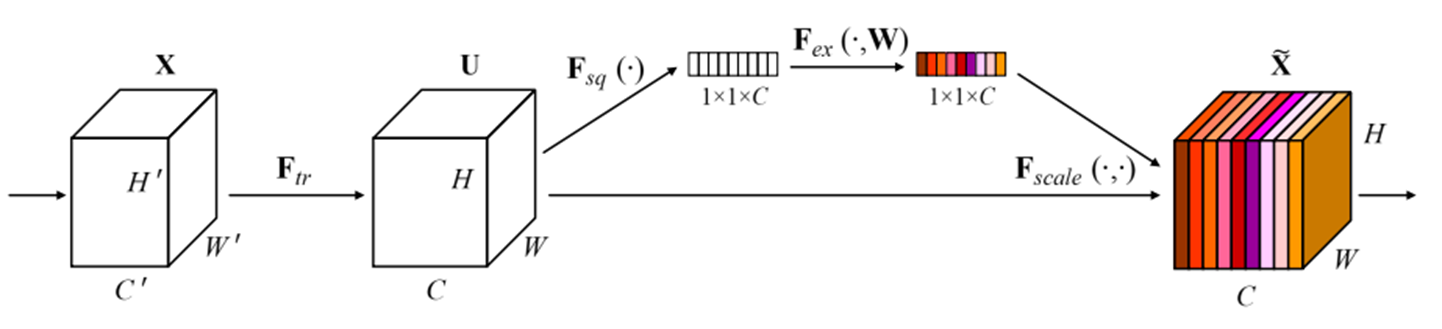
- Squeeze操作:用全局平均池化將H×W×C特征圖壓縮成1×1×C的通道描述符
- Excitation機制:通過全連接層+Sigmoid生成通道權重,實現特征的"有選擇放大"
性能提升:在ResNet基礎上Top-1準確率提升2.3%,參數僅增加0.5M
代碼實現:
import torch
import torch.nn as nnclass SE(nn.Module):def __init__(self, channel, reduction= 16):super(SE, self).__init__()# part 1:(H, W, C) -> (1, 1, C)self.avg_pool = nn.AdaptiveAvgPool2d(1)# part 2, compute weight of each channelself.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid(), # nn.Softmax is OK here)def forward(self, x) :b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * yif __name__ == '__main__':# 創建隨機輸入張量,假設輸入形狀為(batch_size, channels, height, width)input_tensor = torch.randn(1, 64, 32, 32) # batch_size=1, channels=64, height=32, width=32# 創建SE塊實例se_block = SE(channel=64)# 測試SE塊output_se = se_block(input_tensor)print("Output shape of SE block:", output_se.shape)
第二站:CBAM(2018 ECCV)- 空間×通道的雙重視角

創新點:
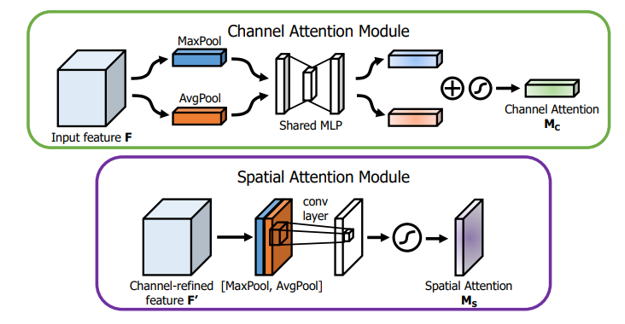
- 通道注意力:融合最大池化+平均池化,通過MLP學習通道間相關性。
- 空間注意力:在空間維度上進行注意力分配。它通過對輸入特征圖進行通道間的全局平均池化和全局最大池化,然后將這兩個結果進行拼接,并通過一個7x7的卷積層來學習空間位置之間的相關性,最后使用sigmoid函數生成空間注意力權重。
亮點:在ResNet50上僅增加1.4%計算量,準確率提升3.1%
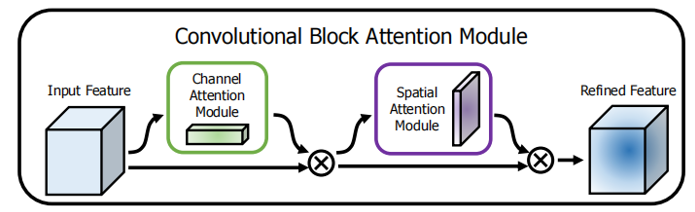
結構示意:輸入 → 通道注意力 → 空間注意力 → 輸出
代碼實現:
import torch.nn as nn
import torchclass CBAM(nn.Module):def __init__(self,in_chans,reduction= 16,kernel_size= 7,min_channels= 8,):super(CBAM, self).__init__()# channel-wise attentionhidden_chans = max(in_chans // reduction, min_channels)self.mlp_chans = nn.Sequential(nn.Conv2d(in_chans, hidden_chans, kernel_size=1, bias=False),nn.ReLU(),nn.Conv2d(hidden_chans, in_chans, kernel_size=1, bias=False),)# space-wise attentionself.mlp_spaces = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=3, bias=False)self.gate = nn.Sigmoid()def forward(self, x: torch.Tensor) -> torch.Tensor:# (B, C, 1, 1)avg_x_s = x.mean((2, 3), keepdim=True)# (B, C, 1, 1)max_x_s = x.max(dim=2, keepdim=True)[0].max(dim=3, keepdim=True)[0]# (B, C, 1, 1)x = x * self.gate(self.mlp_chans(avg_x_s) + self.mlp_chans(max_x_s))# (B, 1, H, W)avg_x_c = x.mean(dim=1, keepdim=True)max_x_c = x.max(dim=1, keepdim=True)[0]x = x * self.gate(self.mlp_spaces(torch.cat((avg_x_c, max_x_c), dim=1)))return xif __name__ == '__main__':input_tensor = torch.randn(1, 64, 32, 32)ca_module = CBAM(in_chans=64)output_tensor = ca_module(input_tensor)print(output_tensor.shape)
第三站:DA(2019 CVPR)- 空間與通道的雙重依賴

核心思想:
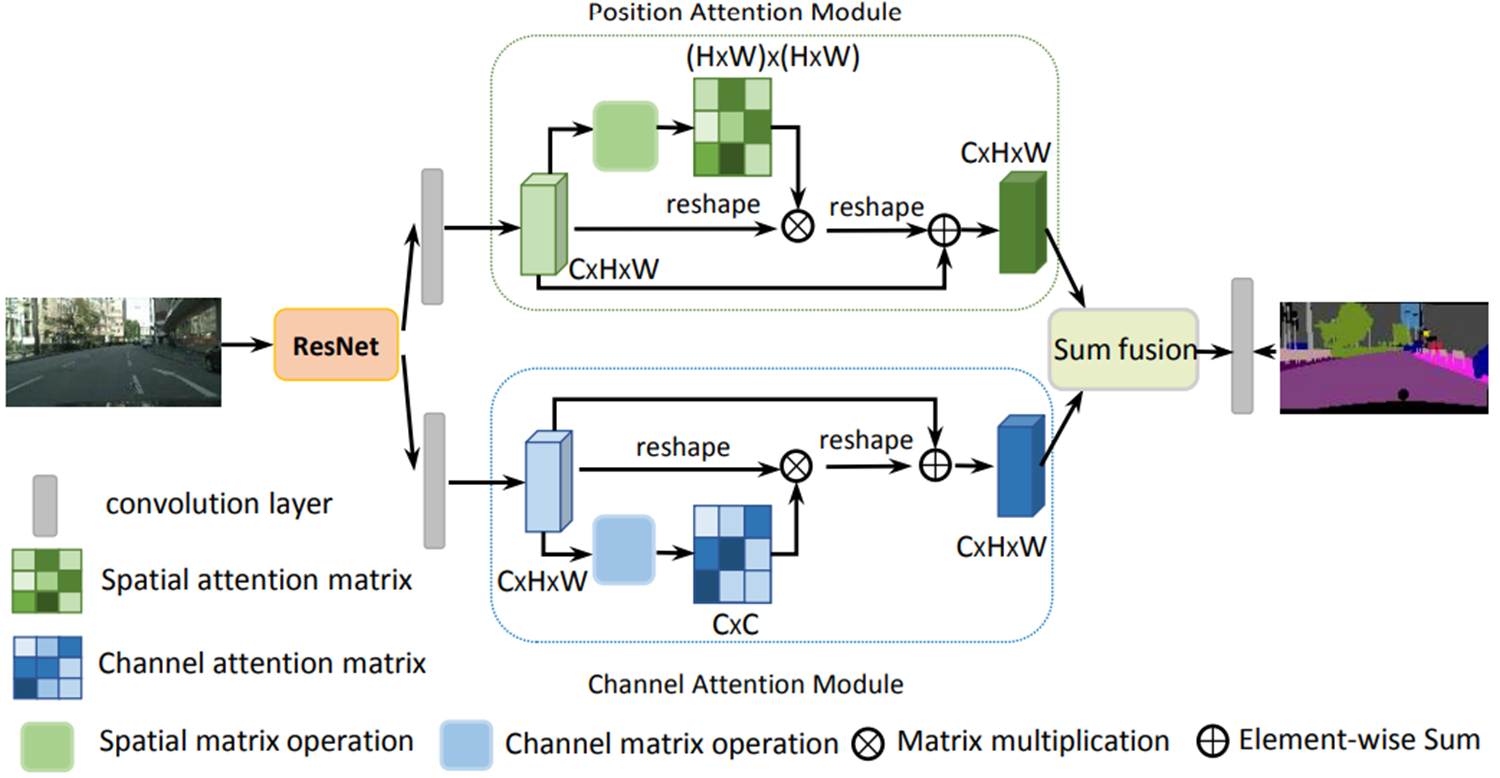
- 位置注意力模塊:通過自注意力機制捕捉特征圖中任意兩個位置之間的空間依賴性
- 通道注意力模塊:通過自注意力機制捕捉任意兩個通道圖之間的通道依賴性
- 融合策略:將兩種注意力模塊的輸出進行融合,增強特征表示
結構示意:
-
在傳統的擴張FCN之上附加了兩種類型的注意力模塊,分別模擬空間和通道維度中的語義相互依賴性
-
位置注意力模塊通過自注意力機制捕捉特征圖中任意兩個位置之間的空間依賴
-
通道注意力模塊使用類似的自注意力機制捕捉任意兩個通道圖之間的通道依賴性
-
最后,將這兩個注意力模塊的輸出進行融合,以進一步增強特征表示
代碼實現:
import torch
import torch.nn as nnclass PAM(nn.Module):"""position attention module with self-attention mechanism位置注意力模塊,使用自注意力機制"""def __init__(self, in_chans: int):super(PAM, self).__init__()self.in_chans = in_chans# 定義三個卷積層:q、k、v,分別用于計算查詢(Query)、鍵(Key)、值(Value)特征。self.q = nn.Conv2d(in_chans, in_chans // 8, kernel_size=1) # 查詢卷積self.k = nn.Conv2d(in_chans, in_chans // 8, kernel_size=1) # 鍵卷積self.v = nn.Conv2d(in_chans, in_chans, kernel_size=1) # 值卷積# 定義一個可學習的縮放因子gammaself.gamma = nn.Parameter(torch.zeros(1))# Softmax操作用于計算注意力權重self.softmax = nn.Softmax(dim=-1)def forward(self, x: torch.Tensor):b, c, h, w = x.size() # 獲取輸入張量的尺寸,b為batch大小,c為通道數,h為高度,w為寬度# (B, HW, C) 計算查詢q的形狀,B是batch size,HW是特征圖的空間展平后長度,C是通道數q = self.q(x).view(b, -1, h * w).permute(0, 2, 1) # 計算查詢q,并將其展平成(B, HW, C)的形狀,并做轉置# (B, C, HW) 計算鍵k的形狀,展平特征圖為(B, C, HW)k = self.k(x).view(b, -1, h * w)# (B, C, HW) 計算值v的形狀,展平特征圖為(B, C, HW)v = self.v(x).view(b, -1, h * w)# (B, HW, HW) 計算注意力矩陣,q與k的乘積,再做softmax處理,得到注意力權重attn = self.softmax(torch.bmm(q, k)) # q和k的乘積,計算注意力分數并應用softmax# (B, C, HW) 計算輸出結果,注意力矩陣與值v相乘,得到最終加權后的特征out = torch.bmm(v, attn.permute(0, 2, 1)) # 計算加權后的輸出,注意力矩陣需要轉置# 將輸出的形狀還原為原來的尺寸(B, C, H, W)out = out.view(b, c, h, w)# 使用gamma進行縮放,并將原始輸入x與輸出相加,形成殘差連接out = self.gamma * out + xreturn outclass CAM(nn.Module):"""channel attention module with self-attention mechanism通道注意力模塊,使用自注意力機制"""def __init__(self, in_chans: int):super(CAM, self).__init__()self.in_chans = in_chans# 定義一個可學習的縮放因子gammaself.gamma = nn.Parameter(torch.zeros(1))# Softmax操作用于計算注意力權重self.softmax = nn.Softmax(dim=-1)def forward(self, x: torch.Tensor) -> torch.Tensor:b, c, w, h = x.size() # 獲取輸入張量的尺寸,b為batch大小,c為通道數,w為寬度,h為高度# (B, C, HW) 將輸入張量展平為(B, C, HW),HW表示寬度和高度的展平q = x.view(b, c, -1)# (B, HW, C) 轉置得到(B, HW, C)形狀,以便后續計算注意力k = x.view(b, c, -1).permute(0, 2, 1)# (B, C, HW) 直接用輸入張量展平得到(B, C, HW)v = x.view(b, c, -1)# (B, C, C) 計算q和k的矩陣乘積,得到能量矩陣energy = torch.bmm(q, k)# 通過max操作處理能量矩陣,找到每個通道的最大能量,進行縮放energy_new = torch.max(energy, dim=-1, keepdim=True)[0].expand_as(energy) - energy# 計算注意力權重,使用softmax對縮放后的能量進行歸一化attn = self.softmax(energy_new)# (B, C, HW) 使用注意力權重對v加權,得到加權后的輸出out = torch.bmm(attn, v)# 將輸出的形狀還原為原來的尺寸(B, C, H, W)out = out.view(b, c, h, w)# 使用gamma進行縮放,并將原始輸入x與輸出相加,形成殘差連接out = self.gamma * out + xreturn outclass DualAttention(nn.Module):def __init__(self, in_chans: int):super(DualAttention, self).__init__()self.in_chans = in_chansself.pam = PAM(in_chans)self.cam = CAM(in_chans)def forward(self, x: torch.Tensor) -> torch.Tensor:pam = self.pam(x)cam = self.cam(x)return pam + camif __name__ == '__main__':model = DualAttention(in_chans=64)x = torch.rand((3, 64, 40, 40))print(model(x).size())
第四站:SK(2019 CVPR)- 選擇性核注意力

核心思想:
- 多核選擇:通過不同大小的卷積核(如3×3、5×5)提取多尺度特征
- 自適應融合:根據輸入特征動態選擇最優卷積核大小,平衡計算復雜度和特征表達能力
結構示意:
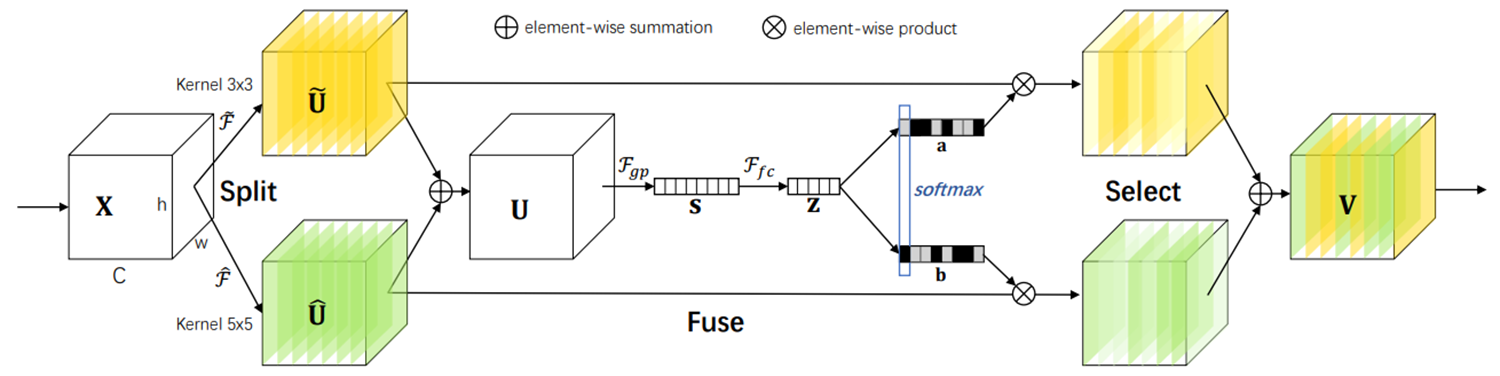
-
輕量級和高效性:ECA模塊只涉及少量參數,同時帶來明顯的性能提升。它避免了傳統注意力機制中的復雜降維和升維過程,通過局部跨通道交互策略,以一維卷積的方式高效實現。
-
局部跨通道交互:ECA模塊通過一維卷積捕捉通道間的依賴關系,這種策略不需要降維,從而顯著降低了模型復雜性。
-
自適應卷積核大小:ECA模塊開發了一種方法來自適應選擇一維卷積的核大小,以確定局部跨通道交互的覆蓋范圍。
性能表現:在ResNet50基礎上Top-1準確率提升1.5%,計算量僅增加2.3%
代碼實現:
import torch
import torch.nn as nn
import torch.nn.functional as Fdef auto_pad(k, d=1):"""自動計算卷積操作所需的填充量,確保輸出尺寸符合要求。:param k: 卷積核的大小 (kernel size),通常為單一整數或者元組。:param d: 膨脹系數 (dilation),通常默認為1。膨脹系數影響卷積核的有效大小。:return: 填充量 (padding)"""# 如果卷積核大小是整數,轉換為元組if isinstance(k, int):k = (k, k)# 如果膨脹系數大于1,卷積核的有效大小會增大effective_kernel_size = (k[0] - 1) * d + 1 # 計算膨脹后的卷積核大小# 假設我們希望使用“same”填充來保持輸出尺寸和輸入尺寸相同padding = (effective_kernel_size - 1) // 2 # 保證輸出尺寸與輸入尺寸一致return paddingclass ConvModule(nn.Module):def __init__(self,in_chans, hidden_chans, kernel_size,stride,groups=1,padding=0, dilation=0,norm_cfg='BN', act_cfg='ReLU'):super().__init__()self.conv = nn.Conv2d(in_chans,hidden_chans,kernel_size=kernel_size,stride=stride,groups=groups,padding=padding,dilation=dilation)if norm_cfg == 'BN':self.norm = nn.BatchNorm2d(hidden_chans)elif norm_cfg == 'GN':self.norm = nn.GroupNorm(32, hidden_chans)if act_cfg == 'ReLU':self.act = nn.ReLU(inplace=True)elif act_cfg == 'LeakyReLU':self.act = nn.LeakyReLU(inplace=True)elif act_cfg == 'HSwish':self.act = nn.Hardswish(inplace=True)def forward(self, x):x = self.conv(x)x = self.norm(x)x = self.act(x)return xclass SK(nn.Module):def __init__(self,in_chans,out_chans,num= 2,kernel_size= 3,stride= 1,groups= 1,reduction= 16,norm_cfg='BN',act_cfg='ReLU'):super(SK, self).__init__()self.num = numself.out_chans = out_chansself.kernel_size = kernel_sizeself.conv = nn.ModuleList()for i in range(num):self.conv.append(ConvModule(in_chans, out_chans, kernel_size, stride=stride, groups=groups, dilation=1 + i,padding=auto_pad(k=kernel_size, d=1 + i), norm_cfg=norm_cfg, act_cfg=act_cfg))# fc can be implemented by 1x1 convself.fc = nn.Sequential(# use relu act to improve nonlinear expression abilityConvModule(in_chans, out_chans // reduction, kernel_size=1,stride=stride, norm_cfg=norm_cfg, act_cfg=act_cfg),nn.Conv2d(out_chans // reduction, out_chans * self.num, kernel_size=1, bias=False))# compute channels weightself.softmax = nn.Softmax(dim=1)def forward(self, x: torch.Tensor) -> torch.Tensor:# use different convolutional kernel to convtemp_feature = [conv(x) for conv in self.conv]x = torch.stack(temp_feature, dim=1)# fuse different output and squeezeattn = x.sum(1).mean((2, 3), keepdim=True)# excitationattn = self.fc(attn)batch, c, h, w = attn.size()attn = attn.view(batch, self.num, self.out_chans, h, w)attn = self.softmax(attn)# selectx = x * attnx = torch.sum(x, dim=1)return xif __name__ == "__main__":model = SK(in_chans=64,out_chans=64)x = torch.rand((3, 64, 40, 40))print(model(x).size())
第五站:ECA-Net(2020 CVPR)- 用1D卷積顛覆傳統注意力

革命性設計:
- 用1D卷積替代全連接層,降低98%參數量
- 自適應核大小選擇算法,動態調整感受野
性能對比:
| 模塊 | 參數量 | Top-1提升 |
|---|---|---|
| SENet | 1.5M | +2.3% |
| ECA-Net | 2.8k | +2.7% |
核心結構:
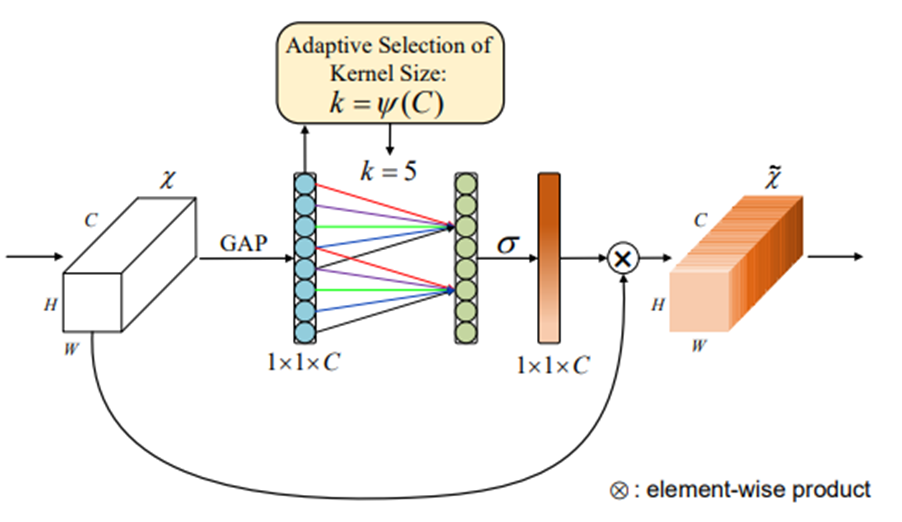
-
輕量級和高效性:ECA模塊只涉及少量參數,同時帶來明顯的性能提升。它避免了傳統注意力機制中的復雜降維和升維過程,通過局部跨通道交互策略,以一維卷積的方式高效實現。
-
局部跨通道交互:ECA模塊通過一維卷積捕捉通道間的依賴關系,這種策略不需要降維,從而顯著降低了模型復雜性。
-
自適應卷積核大小:ECA模塊開發了一種方法來自適應選擇一維卷積的核大小,以確定局部跨通道交互的覆蓋范圍。
第六站:CA(2021 CVPR)- 坐標注意力的巧妙設計

核心思想:
- 方向感知特征圖:通過沿垂直和水平方向的全局平均池化,將特征圖分解為兩個獨立的方向感知特征圖
- 長距離依賴:在保留位置信息的同時,捕獲特征圖中不同位置的長距離依賴關系
- 高效融合:將兩個方向感知特征圖編碼為注意力張量,實現空間和通道信息的高效融合
結構示意:
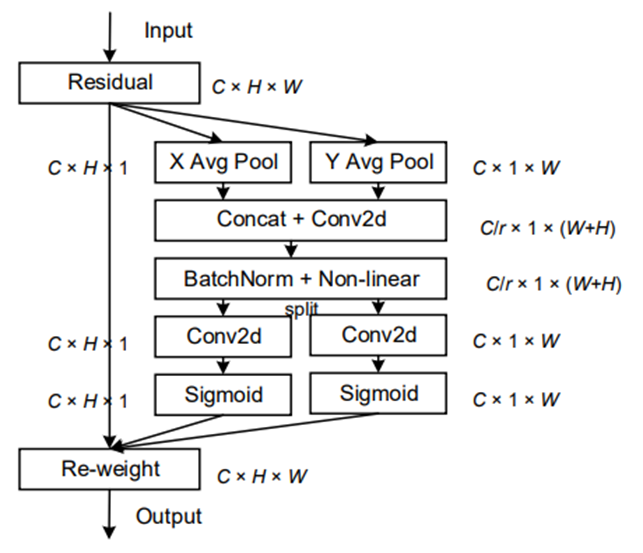
-
考慮了空間維度注意力和通道維度注意力,這有助于模型定位、識別和增強更有趣的對象。
-
CA利用兩個2-D全局平均池化(GAP)操作分別沿著垂直和水平方向聚合輸入特征到兩個獨立的方向感知特征圖中。然后,分別將這兩個特征圖編碼成一個注意力張量。
-
在這兩個特征圖(Cx1xW和CxHx1)中,一個使用GAP來模擬特征圖在空間維度上的長距離依賴,同時在另一個空間維度保留位置信息。在這種情況下,兩個特征圖、空間信息和長距離依賴相互補充。
性能表現:在MobileNetV2上Top-1準確率提升5.1%,計算量僅增加1.2%
代碼實現:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ConvModule(nn.Module):def __init__(self,in_chans, hidden_chans, kernel_size=1, norm_cfg='BN', act_cfg='HSwish'):super().__init__()self.conv = nn.Conv2d(in_chans, hidden_chans, kernel_size=kernel_size)if norm_cfg == 'BN':self.norm = nn.BatchNorm2d(hidden_chans)elif norm_cfg == 'GN':self.norm = nn.GroupNorm(32, hidden_chans)if act_cfg == 'ReLU':self.act = nn.ReLU(inplace=True)elif act_cfg == 'LeakyReLU':self.act = nn.LeakyReLU(inplace=True)elif act_cfg == 'HSwish':self.act = nn.Hardswish(inplace=True)def forward(self, x):x = self.conv(x)x = self.norm(x)x = self.act(x)return xclass CoordinateAttention(nn.Module):"""坐標注意力模塊,用于將位置信息嵌入到通道注意力中。"""def __init__(self,in_chans,reduction=32,norm_cfg='BN',act_cfg='HSwish'):super(CoordinateAttention, self).__init__()self.in_chans = in_chanshidden_chans = max(8, in_chans // reduction)self.conv = ConvModule(in_chans, hidden_chans, kernel_size=1, norm_cfg=norm_cfg, act_cfg=act_cfg)self.attn_h = nn.Conv2d(hidden_chans, in_chans, 1)self.attn_w = nn.Conv2d(hidden_chans, in_chans, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):b, c, h, w = x.size()# (b, c, h, 1)x_h = x.mean(3, keepdim=True)# (b, c, 1, w) -> (b, c, w, 1)x_w = x.mean(2, keepdim=True).permute(0, 1, 3, 2)# (b, c, h + w, 1)y = torch.cat((x_h, x_w), dim=2)y = self.conv(y)# split# x_h: (b, c, h, 1), x_w: (b, c, w, 1)x_h, x_w = torch.split(y, [h, w], dim=2)# (b, c, 1, w)x_w = x_w.permute(0, 1, 3, 2)# compute attentiona_h = self.sigmoid(self.attn_h(x_h))a_w = self.sigmoid(self.attn_w(x_w))return x * a_w * a_h# 示例用法
if __name__ == "__main__":# 創建一個輸入特征圖,假設批次大小為1,通道數為64,高度和寬度為32input_tensor = torch.randn(1, 64, 32, 32)# 創建CA模塊實例,假設輸入通道數為64,中間通道數為16ca_module = CoordinateAttention(in_chans=64, reduction=32)# 前向傳播,獲取帶有坐標注意力的特征圖output_tensor = ca_module(input_tensor)print(output_tensor.shape) # 輸出形狀應與輸入特征圖相同
第七站:SA(2021 ICASSP)- 洗牌注意力的創新

核心思想:
- 通道重排:通過通道重排操作打亂通道順序,增強模型對通道特征的表達能力
- 分組處理:將輸入特征圖的通道維度分成多個小組,分別計算通道注意力和空間注意力
- 信息交流:通過通道重排操作將不同子特征之間的信息進行交流
結構示意:
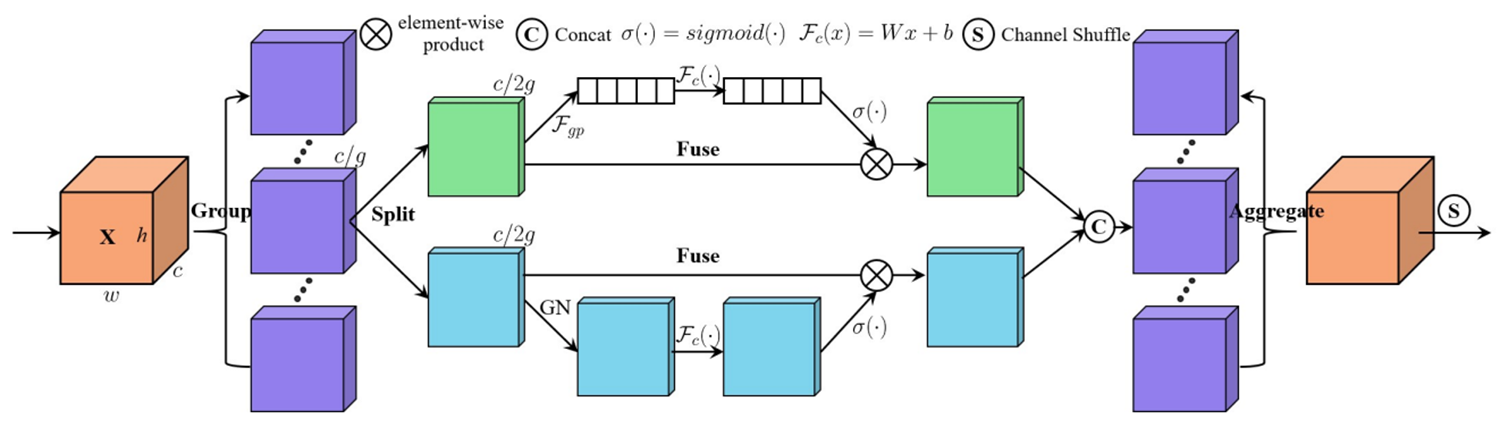
-
結合空間和通道注意力
-
通道重排技術:引入了通道重排,通過通道重排操作將通道順序打亂,以增強模型對通道特征的表達能力。
-
SA先將輸入特征圖的通道維度分成多個小組,并進行分組處理。然后,對于每個子特征,使用全局平均池化和組歸一化分別計算通道注意力和空間注意力。最后,使用通道重排操作將不同子特征之間的信息進行交流
性能表現:在輕量級模型中Top-1準確率提升3.8%,計算量僅增加1.5%
代碼實現:
import torch
import torch.nn as nnclass SA(nn.Module):"""Shuffle Attention"""def __init__(self, in_chans: int, group_num: int = 64):super(SA, self).__init__() # 調用父類 (nn.Module) 的構造函數self.in_chans = in_chans # 輸入的通道數self.group_num = group_num # 分組數,默認為64# channel weight and bias:定義通道的權重和偏置self.c_w = nn.Parameter(torch.zeros((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 通道的權重self.c_b = nn.Parameter(torch.ones((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 通道的偏置# spatial weight and bias:定義空間的權重和偏置self.s_w = nn.Parameter(torch.zeros((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 空間的權重self.s_b = nn.Parameter(torch.ones((1, in_chans // (2 * group_num), 1, 1)), requires_grad=True) # 空間的偏置self.gn = nn.GroupNorm(in_chans // (2 * group_num), in_chans // (2 * group_num)) # 定義 GroupNorm 層,用于歸一化self.gate = nn.Sigmoid() # 定義 Sigmoid 激活函數,用于生成門控權重@staticmethoddef channel_shuffle(x: torch.Tensor, groups: int):b, c, h, w = x.shape # 獲取輸入張量的尺寸,b = batch size,c = 通道數,h = 高度,w = 寬度x = x.reshape(b, groups, -1, h, w) # 將輸入張量按照 groups 分組,重塑形狀x = x.permute(0, 2, 1, 3, 4) # 交換維度,使得通道分組在第二維# flatten:將分組后的張量展平x = x.reshape(b, -1, h, w) # 將分組后的張量恢復為原始的通道數維度return x # 返回重新排列后的張量def forward(self, x: torch.Tensor) -> torch.Tensor:b, c, h, w = x.size() # 獲取輸入 x 的尺寸,b = batch size,c = 通道數,h = 高度,w = 寬度# (B, C, H, W) -> (B * G, C // G, H, W):將輸入張量按照分組數進行重塑x = x.reshape(b * self.group_num, -1, h, w) # 將輸入按分組數分組并重新形狀x_0, x_1 = x.chunk(2, dim=1) # 將張量 x 沿著通道維度 (dim=1) 切分成兩個部分,分別命名為 x_0 和 x_1# (B * G, C // 2G, H, W) -> (B * G, C // 2G, 1, 1):計算通道權重xc = x_0.mean(dim=(2, 3), keepdim=True) # 對 x_0 在高寬維度 (dim=(2, 3)) 上取均值,得到每個通道的平均值xc = self.c_w * xc + self.c_b # 乘以通道權重并加上通道偏置xc = x_0 * self.gate(xc) # 使用 Sigmoid 激活函數進行門控操作,對 x_0 應用門控權重# (B * G, C // 2G, H, W) -> (B * G, C // 2G, 1, 1):計算空間權重xs = self.gn(x_1) # 對 x_1 進行 GroupNorm 歸一化xs = self.s_w * xs + self.s_b # 乘以空間權重并加上空間偏置xs = x_1 * self.gate(xs) # 使用 Sigmoid 激活函數進行門控操作,對 x_1 應用門控權重out = torch.cat((xc, xs), dim=1) # 在通道維度上拼接 xc 和 xs,得到最終的輸出out = out.reshape(b, -1, h, w) # 恢復為原始的形狀 (B, C, H, W)out = self.channel_shuffle(out, 2) # 對輸出張量進行通道洗牌,增加模型的表現力return out # 返回最終的輸出張量if __name__ == '__main__':model = SA(in_chans=64,group_num=8)x = torch.rand((3, 64, 40, 40))print(model(x).size())
第八站 2023雙子星之CPCA(Computers in Biology and Medicine 2023)

核心貢獻:
- 醫學圖像專用的通道先驗機制
- 在腦腫瘤分割任務Dice系數提升6.8%
結構示意:
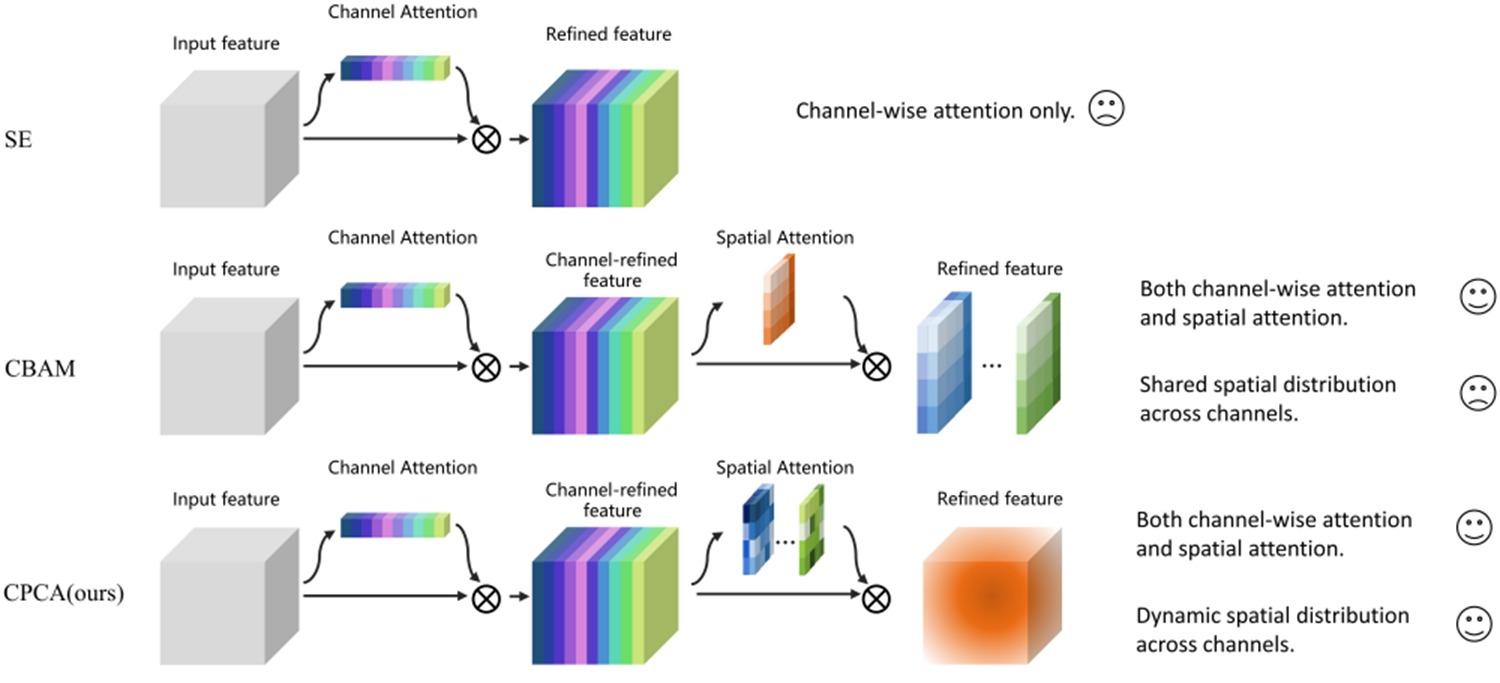
-
動態分配注意力權重:在通道和空間兩個維度上動態分配注意力權重,CBAM只是在通道動態。
-
深度可分離卷積模塊:采用不同尺度的條形卷積核來提取像素間的空間映射關系,降低計算復雜度的同時,確保了有效信息的提取。
-
通道先驗:通過輸入特征和通道注意力圖的元素相乘來獲得通道先驗,然后將通道先驗輸入到深度卷積模塊中以生成空間注意力圖
代碼實現:
import torch
import torch.nn as nnclass ChannelAttention(nn.Module):"""Channel attention module based on CPCAuse hidden_chans to reduce parameters instead of conventional convolution"""def __init__(self, in_chans: int, hidden_chans: int):super().__init__()self.fc1 = nn.Conv2d(in_chans, hidden_chans, kernel_size=1, stride=1, bias=True)self.fc2 = nn.Conv2d(hidden_chans, in_chans, kernel_size=1, stride=1, bias=True)self.act = nn.ReLU(inplace=True)self.in_chans = in_chansdef forward(self, x: torch.Tensor) -> torch.Tensor:"""x dim is (B, C, H, W)"""# (B, C, 1, 1)# 均值池化# 得到通道的全局描述,保留了通道的整體信息,但沒有考慮局部的最強特征x1 = x.mean(dim=(2, 3), keepdim=True)x1 = self.fc2(self.act(self.fc1(x1)))x1 = torch.sigmoid(x1)# (B, C, 1, 1)# 最大池化# 保留了通道中的局部最強特征,能夠突出圖像中最顯著的部分,而抑制較弱的特征x2 = x.max(dim=2, keepdim=True)[0].max(dim=3, keepdim=True)[0]x2 = self.fc2(self.act(self.fc1(x2)))x2 = torch.sigmoid(x2)x = x1 + x2x = x.view(-1, self.in_chans, 1, 1)return xclass CPCA(nn.Module):"""Channel Attention and Spatial Attention based on CPCA"""def __init__(self, in_chans, reduction= 16):super(CPCA, self).__init__()self.in_chans = in_chanshidden_chans = in_chans // reduction# 通道注意力(Channel Attention)self.ca = ChannelAttention(in_chans, hidden_chans)# 空間注意力(Spatial Attention)# 使用不同大小的卷積核來捕捉不同感受野的空間信息# 5x5深度可分離卷積self.dwc5_5 = nn.Conv2d(in_chans, in_chans, kernel_size=5, padding=2, groups=in_chans)# 1x7深度可分離卷積self.dwc1_7 = nn.Conv2d(in_chans, in_chans, kernel_size=(1, 7), padding=(0, 3), groups=in_chans)# 7x1深度可分離卷積self.dwc7_1 = nn.Conv2d(in_chans, in_chans, kernel_size=(7, 1), padding=(3, 0), groups=in_chans)# 1x11深度可分離卷積self.dwc1_11 = nn.Conv2d(in_chans, in_chans, kernel_size=(1, 11), padding=(0, 5), groups=in_chans)# 11x1深度可分離卷積self.dwc11_1 = nn.Conv2d(in_chans, in_chans, kernel_size=(11, 1), padding=(5, 0), groups=in_chans)# 1x21深度可分離卷積self.dwc1_21 = nn.Conv2d(in_chans, in_chans, kernel_size=(1, 21), padding=(0, 10), groups=in_chans)# 21x1深度可分離卷積self.dwc21_1 = nn.Conv2d(in_chans, in_chans, kernel_size=(21, 1), padding=(10, 0), groups=in_chans)# 用于建模不同感受野之間的特征連接self.conv = nn.Conv2d(in_chans, in_chans, kernel_size=1, padding=0)self.act = nn.GELU()def forward(self, x):x = self.conv(x) # 先用1x1卷積壓縮通道x = self.act(x)channel_attn = self.ca(x) # 計算通道注意力x = channel_attn * x # 通道注意力加權輸入特征# 計算空間注意力部分x_init = self.dwc5_5(x) # 先通過5x5卷積x1 = self.dwc1_7(x_init) # 1x7卷積x1 = self.dwc7_1(x1) # 7x1卷積x2 = self.dwc1_11(x_init) # 1x11卷積x2 = self.dwc11_1(x2) # 11x1卷積x3 = self.dwc1_21(x_init) # 1x21卷積x3 = self.dwc21_1(x3) # 21x1卷積# 合并不同卷積結果,形成空間注意力spatial_atn = x1 + x2 + x3 + x_init # 將不同感受野的特征求和spatial_atn = self.conv(spatial_atn) # 再通過1x1卷積進行處理y = x * spatial_atn # 將通道加權后的特征與空間注意力加權的特征相乘y = self.conv(y)return yif __name__ == '__main__':input_tensor = torch.randn(1, 64, 32, 32)attention_module = CPCA(in_chans=64)output_tensor = attention_module(input_tensor)print(output_tensor.shape)
第九站 :2023雙子星之EMA**(ICASSP 2023)**

核心思想:
- 多尺度并行子網絡捕獲跨維度交互
- 在目標檢測任務中mAP提升4.2%
結構示意:
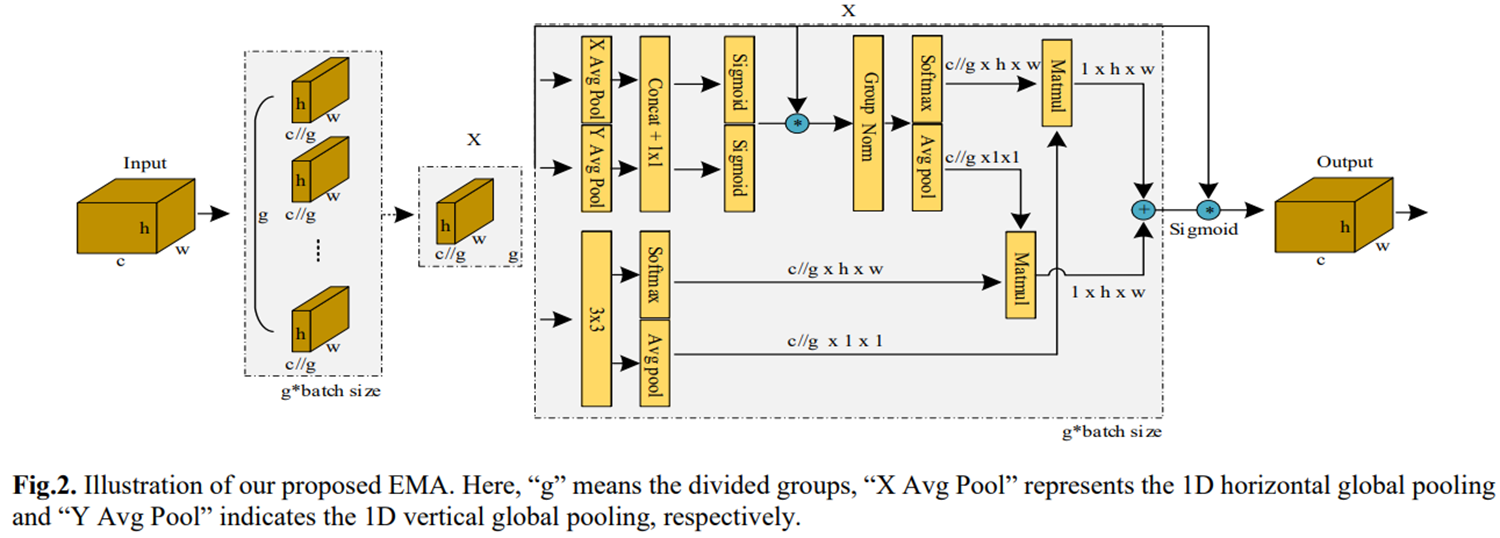
-
通道和空間注意力的結合
-
多尺度并行子網絡:包括一個處理1x1卷積核和一個處理3x3卷積核的并行子網絡。這種結構有助于有效捕獲跨維度交互作用。
-
坐標注意力(CA)的再審視:EMA模塊在坐標注意力(CA)的基礎上進行了改進和優化。CA模塊通過將位置信息嵌入通道注意力圖中,實現了跨通道和空間信息的融合。EMA模塊在此基礎上進一步發展,通過并行子網絡塊有效捕獲跨維度交互作用,建立不同維度之間的依賴關系
代碼實現:
import torch
import torch.nn as nnclass EMA(nn.Module):"""EMA: Exponential Moving Average (指數移動平均)"""def __init__(self, channels, factor=32):super(EMA, self).__init__() # 調用父類 (nn.Module) 的構造函數self.groups = factor # 將 factor 賦值給 groups,決定分組數量assert channels // self.groups > 0 # 確保通道數可以被分組數整除,避免出錯self.softmax = nn.Softmax(-1) # 定義 Softmax 激活函數,在最后一維進行歸一化self.agp = nn.AdaptiveAvgPool2d((1, 1)) # 定義自適應平均池化層,將輸入大小壓縮為 1x1self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # 定義自適應池化層,按高度進行池化self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # 定義自適應池化層,按寬度進行池化self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 定義 GroupNorm 層self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1,padding=0) # 定義 1x1 卷積層self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1,padding=1) # 定義 3x3 卷積層def forward(self, x):b, c, h, w = x.size() # 獲取輸入 x 的尺寸,分別為 batch size (b), 通道數 (c), 高度 (h), 寬度 (w)group_x = x.reshape(b * self.groups, -1, h, w) # 將輸入 x 重塑為 (b * groups, c//groups, h, w),用于分組處理x_h = self.pool_h(group_x) # 對每組的輸入進行高度方向上的池化x_w = self.pool_w(group_x).permute(0, 1, 3, 2) # 對每組的輸入進行寬度方向上的池化,并調整維度順序hw = self.conv1x1(torch.cat([x_h, x_w], dim=2)) # 將池化后的結果在維度2 (高度和寬度) 上拼接,然后通過 1x1 卷積層x_h, x_w = torch.split(hw, [h, w], dim=2) # 將卷積后的結果分割為高度和寬度兩個部分x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid()) # 對分組后的輸入做加權操作并通過 GroupNormx2 = self.conv3x3(group_x) # 對分組后的輸入做 3x3 卷積操作x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 對 x1 進行池化,Softmax 歸一化x12 = x2.reshape(b * self.groups, c // self.groups, -1) # 將 x2 重塑為形狀 (b*g, c//g, hw)x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 對 x2 進行池化,Softmax 歸一化x22 = x1.reshape(b * self.groups, c // self.groups, -1) # 將 x1 重塑為形狀 (b*g, c//g, hw)# 計算加權矩陣weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)# 將加權后的結果與輸入相乘,并恢復為原始輸入形狀return (group_x * weights.sigmoid()).reshape(b, c, h, w)if __name__ == '__main__':model = EMA(channels=64)x = torch.rand((3, 64, 40, 40))print(model(x).size())
終章:SSCA(2024 arXiv)- 空間×通道的協同革命

技術亮點:
-
空間注意力(SMSA):
-
4路特征拆分+多核1D卷積(3/5/7/9)
-
Concat+GN+Sigmoid生成空間權重
-
-
通道注意力(PCSA):
-
漸進式特征池化+自注意力矩陣計算
-
在MobileNetV2上Top-1準確率提升5.1%
-
結構示意:
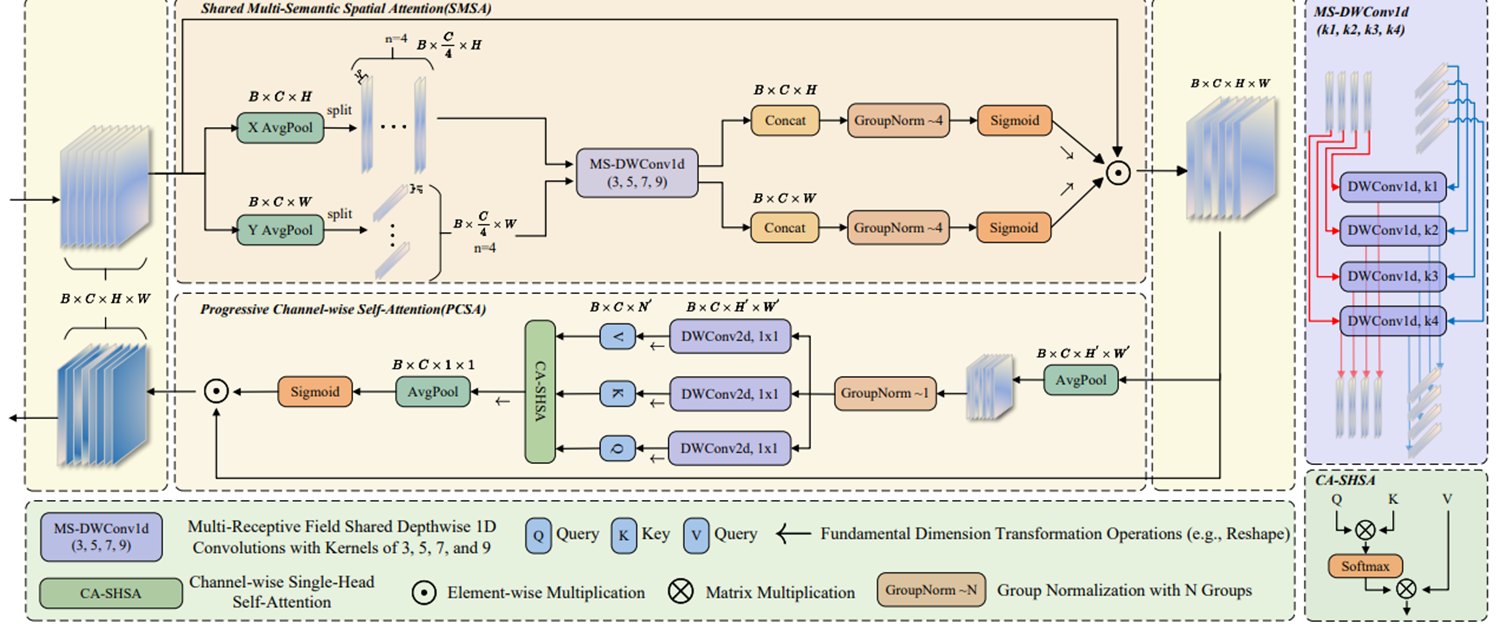
SMSA空間注意力實現原理
-
**平均池化:**分別沿高度和寬度方向
-
**特征拆分:**4等分
-
**特征提取:**四個深度共享1D卷積(卷積核大小分別為3,5,7,9)對各部分特征進行處理
-
空間注意力計算:Concat+GN+Sigmoid
PCSA 通道自注意力實現原理(漸進式)
-
下采樣:可選平均池化、最大池化或重組合
-
特征歸一化與變換:GN+1×1深度卷積生成查詢(q)、鍵(k)和值(v)
-
注意力矩陣計算:
代碼實現:
import typing as t
import torch
import torch.nn as nn
from einops import rearrangeclass SCSA(nn.Module):def __init__(self,dim: int,head_num: int,window_size: int = 7,group_kernel_sizes: t.List[int] = [3, 5, 7, 9],qkv_bias: bool = False,fuse_bn: bool = False,down_sample_mode: str = 'avg_pool',attn_drop_ratio: float = 0.,gate_layer: str = 'sigmoid',):super(SCSA, self).__init__() # 調用 nn.Module 的構造函數self.dim = dim # 特征維度self.head_num = head_num # 注意力頭數self.head_dim = dim // head_num # 每個頭的維度self.scaler = self.head_dim ** -0.5 # 縮放因子self.group_kernel_sizes = group_kernel_sizes # 分組卷積核大小self.window_size = window_size # 窗口大小self.qkv_bias = qkv_bias # 是否使用偏置self.fuse_bn = fuse_bn # 是否融合批歸一化self.down_sample_mode = down_sample_mode # 下采樣模式assert self.dim % 4 == 0, 'The dimension of input feature should be divisible by 4.' # 確保維度可被4整除self.group_chans = group_chans = self.dim // 4 # 分組通道數# 定義局部和全局深度卷積層self.local_dwc = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[0],padding=group_kernel_sizes[0] // 2, groups=group_chans)self.global_dwc_s = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[1],padding=group_kernel_sizes[1] // 2, groups=group_chans)self.global_dwc_m = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[2],padding=group_kernel_sizes[2] // 2, groups=group_chans)self.global_dwc_l = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[3],padding=group_kernel_sizes[3] // 2, groups=group_chans)# 注意力門控層self.sa_gate = nn.Softmax(dim=2) if gate_layer == 'softmax' else nn.Sigmoid()self.norm_h = nn.GroupNorm(4, dim) # 水平方向的歸一化self.norm_w = nn.GroupNorm(4, dim) # 垂直方向的歸一化self.conv_d = nn.Identity() # 直接連接self.norm = nn.GroupNorm(1, dim) # 通道歸一化# 定義查詢、鍵和值的卷積層self.q = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)self.k = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)self.v = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)self.attn_drop = nn.Dropout(attn_drop_ratio) # 注意力丟棄層self.ca_gate = nn.Softmax(dim=1) if gate_layer == 'softmax' else nn.Sigmoid() # 通道注意力門控# 根據窗口大小和下采樣模式選擇下采樣函數if window_size == -1:self.down_func = nn.AdaptiveAvgPool2d((1, 1)) # 自適應平均池化else:if down_sample_mode == 'recombination':self.down_func = self.space_to_chans # 重組合下采樣# 維度降低self.conv_d = nn.Conv2d(in_channels=dim * window_size ** 2, out_channels=dim, kernel_size=1, bias=False)elif down_sample_mode == 'avg_pool':self.down_func = nn.AvgPool2d(kernel_size=(window_size, window_size), stride=window_size) # 平均池化elif down_sample_mode == 'max_pool':self.down_func = nn.MaxPool2d(kernel_size=(window_size, window_size), stride=window_size) # 最大池化def forward(self, x: torch.Tensor) -> torch.Tensor:"""輸入張量 x 的維度為 (B, C, H, W)"""# 計算空間注意力優先級b, c, h_, w_ = x.size() # 獲取輸入的形狀# (B, C, H)x_h = x.mean(dim=3) # 沿著寬度維度求平均l_x_h, g_x_h_s, g_x_h_m, g_x_h_l = torch.split(x_h, self.group_chans, dim=1) # 拆分通道# (B, C, W)x_w = x.mean(dim=2) # 沿著高度維度求平均l_x_w, g_x_w_s, g_x_w_m, g_x_w_l = torch.split(x_w, self.group_chans, dim=1) # 拆分通道# 計算水平注意力x_h_attn = self.sa_gate(self.norm_h(torch.cat(( self.local_dwc(l_x_h),self.global_dwc_s(g_x_h_s),self.global_dwc_m(g_x_h_m),self.global_dwc_l(g_x_h_l),), dim=1)))x_h_attn = x_h_attn.view(b, c, h_, 1) # 調整形狀# 計算垂直注意力x_w_attn = self.sa_gate(self.norm_w(torch.cat(( self.local_dwc(l_x_w),self.global_dwc_s(g_x_w_s),self.global_dwc_m(g_x_w_m),self.global_dwc_l(g_x_w_l)), dim=1)))x_w_attn = x_w_attn.view(b, c, 1, w_) # 調整形狀# 計算最終的注意力加權x = x * x_h_attn * x_w_attn# 基于自注意力的通道注意力# 減少計算量y = self.down_func(x) # 下采樣y = self.conv_d(y) # 維度轉換_, _, h_, w_ = y.size() # 獲取形狀# 先歸一化,然后重塑 -> (B, H, W, C) -> (B, C, H * W),并生成 q, k 和 vy = self.norm(y) # 歸一化q = self.q(y) # 計算查詢k = self.k(y) # 計算鍵v = self.v(y) # 計算值# (B, C, H, W) -> (B, head_num, head_dim, N)q = rearrange(q, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),head_dim=int(self.head_dim))k = rearrange(k, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),head_dim=int(self.head_dim))v = rearrange(v, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),head_dim=int(self.head_dim))# 計算注意力attn = q @ k.transpose(-2, -1) * self.scaler # 點積注意力計算attn = self.attn_drop(attn.softmax(dim=-1)) # 應用注意力丟棄# (B, head_num, head_dim, N)attn = attn @ v # 加權值# (B, C, H_, W_)attn = rearrange(attn, 'b head_num head_dim (h w) -> b (head_num head_dim) h w', h=int(h_), w=int(w_))# (B, C, 1, 1)attn = attn.mean((2, 3), keepdim=True) # 求平均attn = self.ca_gate(attn) # 應用通道注意力門控return attn * x # 返回加權后的輸入if __name__ == "__main__":#參數: dim特征維度; head_num注意力頭數; window_size = 7 窗口大小scsa = SCSA(dim=32, head_num=8, window_size=7)# 隨機生成輸入張量 (B, C, H, W)input_tensor = torch.rand(1, 32, 256, 256)# 打印輸入張量的形狀print(f"輸入張量的形狀: {input_tensor.shape}")# 前向傳播output_tensor = scsa(input_tensor)# 打印輸出張量的形狀print(f"輸出張量的形狀: {output_tensor.shape}")
后續發展:注意力機制的三個趨勢
- 高效性:向輕量化、無參數方向發展(如ECA、ELA)
- 多模態融合:探索視覺+語言的跨模態注意力
- 自適應機制:動態調整計算資源分配
結語
從SE到SSCA,注意力機制正從"單一增強"走向"協同進化"。下一個突破點會是動態可重構的注意力嗎?讓我們共同見證深度學習的新篇章!

)

JavaScript庫(防抖、節流、函數柯里化)JS庫)
)










![STM32單片機入門學習——第27節: [9-3] USART串口發送串口發送+接收](http://pic.xiahunao.cn/STM32單片機入門學習——第27節: [9-3] USART串口發送串口發送+接收)



)