??本文將以我個人的理解去閱讀該篇流量加密論文,并在下一篇盡力對其中的實驗部分進行復現。話不多說,先從論文開始著手。

內容介紹
??傳統的DNS(Domain Name System)協議是以明文傳輸的。DNS作為互聯網的基礎設施,最初設計時主要考慮的是功能和效率,而沒有充分重視安全性問題。傳統DNS查詢和響應通過UDP或TCP協議傳輸,數據未經加密,可以被路徑上的任何節點查看和記錄。
??這種明文傳輸特性帶來了幾個顯著問題:
- 隱私泄露風險?:第三方可以監控用戶訪問的網站
- 篡改風險?:中間人可修改DNS響應內容
- 審查風險?:政府或ISP可基于DNS查詢進行過濾
??加上DNS協議是映射域名和IP的重要協議,諸如防火墻之類的安全設施通常不會阻止DNS數據包,這意味著攻擊者經常將DNS用作秘密通道,也稱為DNS隧道。
以下舉個簡單的DNS隧道攻擊例子:
攻擊場景描述:假設某公司內網有一臺被入侵的服務器,攻擊者試圖將敏感文件"secret.txt"(內容為"ABC123")外傳到外部控制的服務器。
攻擊實施步驟:
- 域名控制準備:
? 攻擊者注冊域名"evil.com"
? 設置該域名的NS記錄指向攻擊者控制的服務器(如ns1.evil.com) - 數據編碼傳輸:
? 被入侵主機將文件內容進行Base64編碼:“ABC123” → “QUJDMTIz”
? 構造特殊子域名查詢:“QUJDMTIz.evil.com”
? 本地DNS服務器將查詢轉發至攻擊者的NS服務器 - 數據接收解碼:
? 攻擊者的NS服務器記錄下所有查詢的子域名
? 從"QUJDMTIz.evil.com"中提取"QUJDMTIz"并解碼還原為"ABC123"

??所以檢測DNS隧道吸引了過去十年來吸引研究人員的廣泛關注。然而過去的檢測通常基于域名的結構,語言和統計特征。這種方法通常基于一個前提,即DNS未被加密。,DNS消息以純文本傳輸,允許任何第三方監視DNS流量并獲取域信息。
??因此,之后衍生出了經過加密的DNS協議,例如DoH(將DNS查詢封裝在HTTPS中傳輸)、DoT(在TCP協議上建立TLS加密連接,從而傳輸DNS協議),本文的重心放在DoH協議上。DOH的目的是通過加密的HTTPS請求來執行DNS查詢和響應,從而阻止了明文DNS查詢和響應被第三方竊聽或篡改。雖然如此,這也意味著基于DNS的惡意活動可以通過DoH進行加密隱藏(也就是創建DoH隧道輸送惡意流量),這是我們不想看到的,本文的重點便是如何去檢測惡意的DoH流量。
??對此,研究者希望建立一個有效的分類器,以區分DOH隧道流量和良性DOH流量。為了實現這一功能,需要從加密的DoH流量中提取特征。由于DoH將DNS流量包裝在HTTPS中,因此觀察到的DoH流可以分為兩個階段:
- 第一階段由HTTPS客戶端-服務器握手過程生成。
- 在第二階段,客戶端和服務器互相發送加密的數據包,其中包含DNS查詢/響應。
是故可以從這兩個階段提取可以檢測DoH隧道流量的特征。
??客戶端和服務器在握手過程中發送的前幾個數據包包含明文信息,該信息可用于識別連接來自哪個應用程序(TLS指紋識別技術)。是故可以根據這些識別得到的應用程序構建白名單,從而初步檢測基于TLS指紋的DoH隧道。對于加密流量,統計特征被認為在執行分析方面非常強大。研究者分析了DoH隧道的特點,從包含DNS查詢/響應的加密流量中提取基于流的特征,并構建分類器來檢測DoH隧道,后續進行詳細介紹。

背景介紹
域名解析系統(Domain Name System,DNS)
??DNS將易于閱讀的域名解析為數字IP地址(例如www.baidu.com對應的ip為 223.109.82.16,但是一般不能直接ip訪問,具體原因可查閱此篇博客)。通常,為了解析域名,客戶端向遞歸解析器發送DNS查詢。如果遞歸解析器沒有緩存查詢的域名,它將從根名稱服務器遞歸地與權威名稱服務器通信,直到解析器對用戶的查詢有權威答案。客戶端可以使用解析的IP地址連接到目標主機。遞歸解析器通常由互聯網服務提供商或組織提供,以服務于多個用戶。
通過DNS的數據泄露
??如果主機連接到萬維網,那么防火墻通常被配置為允許將UDP端口53(由DNS使用)上的數據包發送到內部DNS服務器,甚至允許直接將所有數據包發送到UDP端口53上,因為DNS對于幾乎所有應用程序來說都是至關重要的服務。因此,DNS是攻擊者理想的隱蔽渠道。
??DNS隱蔽通道或DNS隧道本質上是對DNS查詢中的數據進行編碼和封裝。具體來說,數據被編碼到目標域名的子域名中。為了接收數據,攻擊者需要接管目標域名的名稱服務器(NS),以便目標域名的所有子域名解析請求最終將到達受控NS。目標域名的子域名(即,編碼的信息)在一段時間內(在生存時間內)不會重復,因此循環解析器無法在高速緩存中找到域名。這樣,域名查詢始終轉發到受控NS。受控NS上的工具對查詢中封裝的信息進行解碼,以獲得過濾數據。最終,響應被發送回請求主機。具體攻擊方式如圖上述提到過的簡單的DNS隧道攻擊例子。

通過DNS的數據泄露
??近年來,隨著安全性和隱私受到越來越多的關注,安全DNS的多個協議也逐漸得到實施。早期的工作包括DNSSEC和DNSCrypt。DNSSEC在DNS中添加了簽名機制來保護DNS的完整性,可以有效防止中間人對DNS的篡改。然而,DNSSEC不提供機密性,即DNS查詢仍然是明文的。DNSCrypt由開源社區實施,同時提供完整性和機密性。然而,它沒有提交用于標準化的FEC,支持DNSCrypt的應用程序非常有限。
??之后出現了DNS over TLS(DoT)。DoT通過傳輸層安全(TLS)協議加密和包裝DNS查詢和響應。具體來說,客戶端在端口853上與遞歸解析器建立TLS會話,并通過加密連接傳輸DNS查詢和響應。
??隨之又出現了DNS over HTTPS(DoH)。DoH將DNS查詢和響應封裝到HTTP請求的主體中。客戶端與遞歸解析器建立TLS會話,HTTP請求通過HTTP over TLS(HTTPS)協議傳輸。

??與DoT相比,DoH允許將DNS集成到HTTP生態系統中,并且DoH的編程接口更加簡單。DoH利用HTTP/2的功能,例如服務器推送機制,使服務器能夠搶先推送客戶端稍后需要的DNS響應,從而減少延遲。因此研究者相信DoH是加密DNS的主流選擇,故在這項工作中重點關注DoH。
HTTPS攔截
- 傳統HTTPS安全檢查方法(透明代理的運作原理)
-
核心機制:
中間設備(如企業防火墻)作為透明代理攔截HTTPS流量:
- 終止客戶端的TLS連接
- 用中間件的CA證書解密流量
- 分析明文HTTP內容
- 重新加密并轉發到目標服務器
-
實現條件:
需在客戶端設備預裝中間件的CA證書,否則會觸發證書警告。
-
存在的問題:
- 部署成本高:
需大規模部署和管理CA證書(尤其對移動設備/IoT設備困難)。 - 隱私風險:
中間人可完全查看/修改所有HTTPS流量,違反端到端加密原則。 - 安全降級:
研究表明,多數HTTPS攔截工具會:- 使用弱加密算法(如降低TLS版本)
- 錯誤驗證證書鏈(引入中間人攻擊漏洞)
- 緩存敏感數據(增加泄露風險)
- 部署成本高:
- 研究者的替代方案(僅分析DoH的未加密特征)
- 放棄解密:
不破解TLS加密內容,避免上述隱私與安全問題。 - 聚焦未加密特征:
通過以下外部可觀測指標檢測異常:- TLS握手特征:客戶端指紋(如JA3/JA3S)、協議版本
- 流量模式:數據包時序、大小分布、查詢頻率
- DNS協議元數據:查詢類型(TXT記錄濫用)、響應延遲
- 優勢:
- 無需部署CA證書
- 不降低連接安全性
- 符合加密DNS的隱私設計初衷
DNS通過HTTPS的數據泄露
??由于第三方無法看到DoH流量,因此將隧道隱藏在DoH中將大大增加攻擊者逃避檢測的可能性。甚至已經出現了將DoH作為武器的黑客組織。
威脅模型和擬議方法概述
威脅模型
??研究者考慮如下圖的情形,即攻擊者設法危害客戶端并使用DoH隧道進行數據泄露。
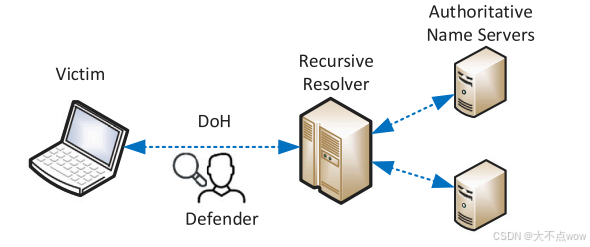
??因此,重點是如何通過受害主機與遞歸解析器之間的DoH流量來檢測DoH隧道。對此,不考慮去解密DoH流量,而是假設DoH流量和非加密DNS流量可以區分,再假設DoH流量和非DoH的HTTPS(標準的HTTPS)流量可以區分(這一點并不難,可以通過簡單地觀察數據包的IP地址和SSL握手字段中的服務器名稱指示(SNI)字段來確定它是否是DoH流量)。上述兩種假設并不是本文討論的重點,而且已經有相關辦法可以實現兩種區分。最后,假設攻擊者可以在DNS協議允許的范圍內自由改變DNS查詢的包長度,攻擊者還可以自由設置DNS查詢的包發送率。攻擊者不會危害受害者主機上的其他應用程序,例如危害瀏覽器。
檢測方法概述
??DoH流的結構和所提出的檢測方法如下圖所示。
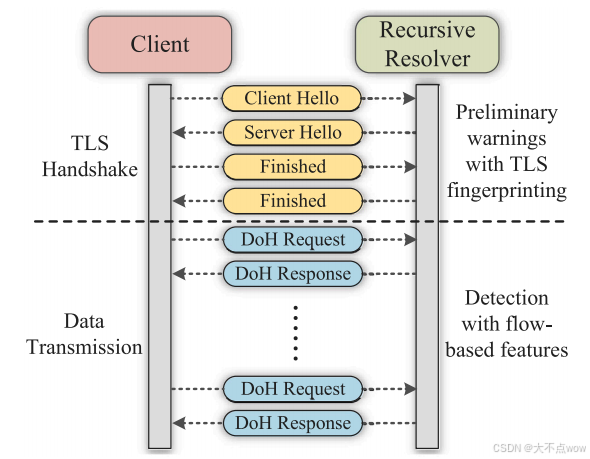
一般而言,DoH流可分為兩個階段。在第一階段,客戶端和遞歸解析器交換密鑰以建立連接,這個過程稱為TLS握手。在第二階段,客戶端和遞歸解析器開始向彼此發送DNS查詢/響應。所提出的檢測方法受到這樣的DoH流結構的啟發,該結構包括與DoH流的兩個階段相對應的兩個檢測步驟。
- 第一步是基于TLS握手的指紋,客戶端一啟動連接就可以執行檢測該指紋,從而提供潛在DoH隧道的初步警告。
- 第二步是提取數據傳輸階段的基于流的特征,并將這些特征輸入到經過訓練的分類器中以檢測DoH隧道。
??具體來說,對于第一個檢測步驟,可以使用TLS握手期間的明文信息進行TLS指紋識別。通過測量當前支持DoH的客戶端的TLS指紋,發現它們的TLS指紋都是唯一的。這意味著如果攻擊者在沒有模仿常見的TLS執行器(例如瀏覽器)的情況下發起隧道連接,那么防御者可以觀察到其不同的唯一的TLS指紋。盡管這不是準確的檢測,但它可以提供初步警告,特別是可以在握手階段(數據傳輸之前)執行的TLS指紋識別。
??在TLS握手并建立HTTPS連接后,客戶端和遞歸解析器開始相互發送DNS查詢/響應。可以在數據傳輸階段提取DoH流的特征并構建分類器。由于流量是加密的,所以只能觀察數據包大小和時間戳等特征。經過分析和選擇與DoH隧道相關的特征,并通過實驗證明,使用這些基于流的特征訓練的分類器可以有效地執行檢測。
基于TLS指紋的檢測
??建立TLS連接時,客戶端和服務器首先協商建立連接的參數,包括支持的密碼套件、證書等,然后生成會話密鑰來加密通信數據。此過程稱為“TLS握手”。握手的第一步是客戶端向服務器發送ClientHello消息,該消息以明文形式發送。
??ClientHello消息為服務器提供客戶端支持的密碼套件和擴展列表。密碼套件列表根據客戶端的偏好排序,并且每個密碼套件定義了一組密碼算法,例如,AES-GCM-256。擴展向服務器提供促進擴展功能的附加信息,例如,服務器名稱指示是一種擴展,客戶端通過它指示其試圖連接到哪個主機名。密碼套件和擴展的多樣性使得TLS具有很大的參數空間,不同的程序通常支持不同的密碼套件和擴展。這允許基于ClientHello消息進行TLS指紋識別,該消息已在學術文獻中進行了研究,并被開源社區使用。
??通過收集TLS指紋來構建數據庫,然后將觀察到的指紋與數據庫中的指紋進行比較。盡管這種僅基于TLS指紋識別惡意軟件的方法不夠有效,但TLS指紋識別提供了有價值的信息,可以與其他指標結合進行進一步檢測。受這一結論的啟發,研究者相信DoH連接的TLS指紋識別可能有助于DoH隧道檢測。
??為了彌補針對DoH客戶端的TLS指紋空白,研究者針對三種客戶端程序進行了測量:一、瀏覽器;二、DoH代理程序;三、DoH隧道的概念驗證(其實就是能夠實現DoH隧道加密的程序)。對于瀏覽器,選擇Chrome和Firefox,這兩個是支持DoH的最具代表性的應用程序。由于瀏覽器以外的應用程序通常還不支持DoH,因此開發了各種DoH代理軟件。DoH代理監聽和攔截本地非加密DNS查詢,并將非加密DNS查詢封裝到DoH。DoH隧道的概念驗證實現了DoH上的數據外流,可以使用特定提供的TLS指紋識別方法進行測量。使用每個DoH客戶端通過三個公共遞歸解析器(Cloudflare、Google、Quad9)啟動10個會話并記錄指紋。這些應用的詳細信息和指紋識別結果見表如下:
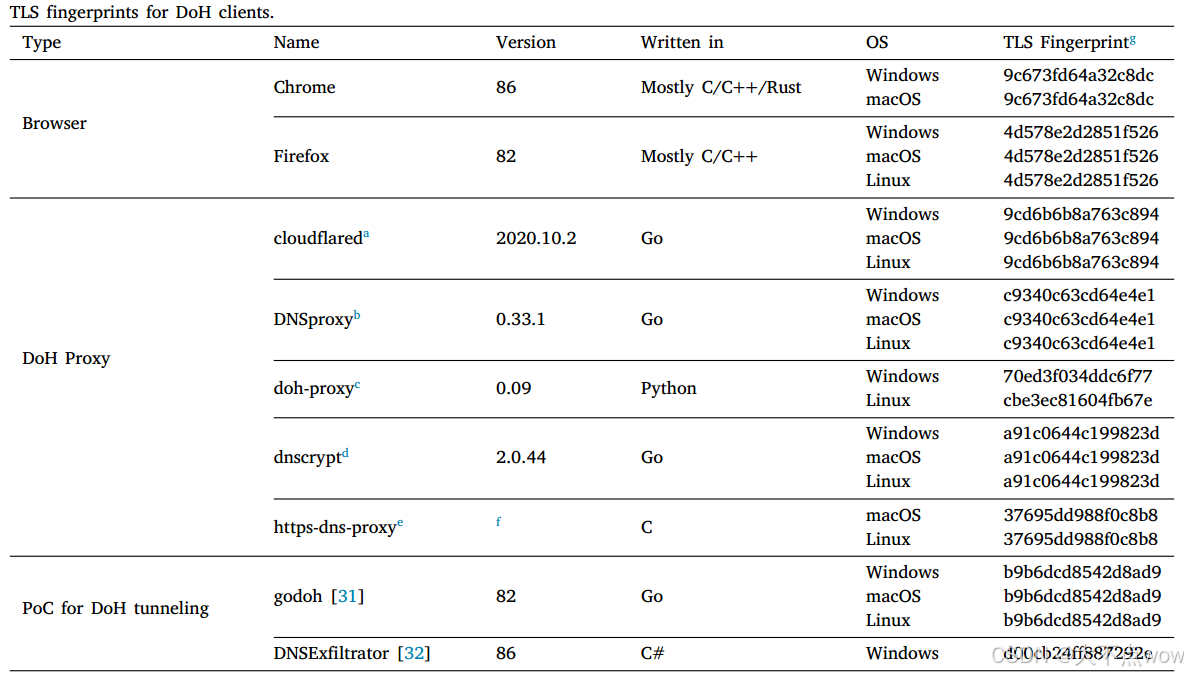
結果表明,測量的DoH客戶端都具有不同的TLS指紋。之前的研究指出,客戶端對密碼套件和擴展的支持與操作系統和編程語言相關(因為通常在開發過程中調用與TLS相關的庫)。DoH客戶的指紋識別結果符合這一趨勢。由不同編程語言實現的客戶端具有不同的指紋。同一客戶端在不同的操作系統上運行時可能具有不同的指紋。由于實現方法的多樣性,使用相同編程語言編寫的不同DoH客戶端也可能具有不同的指紋。
??DoH客戶端指紋的唯一性為DoH隧道檢測提供了一種簡單但有效的初步方法,建立基于TLS指紋的白名單機制。這是因為,與常見的HTTPS不同,DoH連接是由極少數應用程序生成的(因為目前大多數應用程序并不原生支持DoH)。絕大多數DoH連接可能由瀏覽器生成,少數由DoH代理生成。將瀏覽器和DoH代理的指紋添加到白名單后,如果其指紋與白名單不匹配,則更有可能是惡意的。
??指紋不能直接表明DoH隧道的存在,但為防御者提供了進一步調查的方向。特別是,指紋識別基于DoH的第一個數據包,這意味著在數據傳輸之前可以進行預警。在實踐中,需要收集和更新指紋數據庫。由于支持DoH的應用程序數量比支持TLS的應用程序少得多,因此維護DoH指紋數據庫的成本相對較低,并且現有的TLS指紋相關工具鏈可以重復使用。為了逃避基于TLS指紋的檢測,攻擊者需要模仿流行的TLS實現,例如瀏覽器。但是由于不同的庫支持不同的TLS功能,因此TLS實現可能很難正確模仿。此外,由于良性應用程序(例如瀏覽器)的指紋會隨著版本更新而變化,攻擊者知道哪些指紋是模仿的好候選者也是一個負擔。總而言之,雖然僅基于TLS指紋的檢測可能不夠有效,但它可以為管理員提供有效的初步警告,并大大增加成功攻擊的難度。

基于流量進行識別
??檢測的基本思想很簡單:從DoH跟蹤中提取特征并訓練分類器,然后使用訓練好的分類器進行檢測。遵循這一策略,收集大量的DoH流量(包括良性和隧道流量)來訓練和測試模型。
數據收集
??為了收集良性和隧道DoH流量,可以采用各種設置來模擬受害者和攻擊者之間可能的環境差異。這是因為實際上受害者和攻擊者之間的環境是不同的,這可能會影響檢測。例如,如果攻擊者的服務器在地理上距離受害者較遠,那么與良性DNS相比,隧道的DNS查詢和響應可能具有較高的延遲,因為良性DNS查詢通常由于緩存而直接由遞歸服務器響應,而隧道的DNS查詢必須發送到攻擊者的服務器。因此,這種延遲可以用作區分DoH流量是否惡意的特征。下表是不同的環境設置對比:

對于良性和隧道流量,使用2個不同的位置和3個不同的解析器。對于良性流量,可以通過DoH查詢1500個網站的DNS記錄。對于隧道流量,使用7個不同的時間間隔和227個數據包長度來模擬攻擊者可能用來泄露數據的不同設置。
??研究者設置了三個虛擬機,運行Ubuntu 20.04作為操作系統。兩臺虛擬機位于西雅圖,另一臺位于新加坡。新加坡的一臺虛擬機和西雅圖的一臺虛擬機模擬受害者,位于西雅圖的另外一臺虛擬機模擬受攻擊者控制。所有虛擬機都配置了公共IP地址,并且可以相互通信。對于遞歸解析器,選擇Cloudflare、Google和Quad9,這些都是知名的公共解析器。研究者使用tcpdump捕獲虛擬機和遞歸解析器之間的網絡流量,并通過IP地址和端口過濾流量以獲得最終的DoH流量跟蹤。最終只關注具有應用程序數據的TLS數據包,并過濾沒有有效負載的無關緊要的數據包,例如TCPACK數據包。
??對于良性DoH流量,通過兩個模擬受害者的虛擬機自動訪問Alexa Top Sites中排名前1500的網站,并通過三個不同的遞歸解析器發送DNS請求,從而獲得良心DoH流量。
??要配置DoH隧道,需要向Godaddy注冊一個域,使用西雅圖的虛擬機作為該域的名稱服務器(NS),并在此虛擬機上運行DNSExfiltrator的服務器端程序(即,此虛擬機被模擬為由攻擊者控制)。另外兩個虛擬機被模擬為受害者,運行DNSExfiltrator的客戶端程序,并使用三個不同的遞歸解析器通過DoH隧道將本地文件(使用文本文件)發送到攻擊者控制的服務器。每次通過DoH隧道執行數據泄露時,設置不同的DNS查詢時間間隔或不同的完整域名長度。研究者將每一組執行三次并收集交通痕跡。具體來說,兩個查詢之間的時間間隔是隨機的。DoH流的總體平均時間間隔約為1、5、10、20、100、500、1000 ms(總共7個時間間隔設置)。完整域名的長度范圍從27到253(總共227個數據包長度設置)。每個DoH隧道流至少包含5組DNS查詢和響應。
特征
??DoH流量跟蹤可以被認為是數據包的時間序列。由于DoH流量加密,只有大小、時間戳和方向對檢測有用(目的端口(通常為443)是一個常數,目的IP地址屬于遞歸解析器)。對于當前考慮的場景,DoH流可以被定義為客戶端和遞歸服務器之間通過特定端口通過HTTPS傳輸的流量流。具體來說,可以將客戶端表示為源,將遞歸服務器表示為目的地。從源發送到目的地的數據包是DNS查詢,反之亦然。研究者將DoH流量跟蹤重新組裝到流中,并根據每個流的包大小、時間戳和方向提取流級統計特征。特別是,計算每個流量水平特征的最小、最大、平均值、標準差。特征值是小數,可以直接由機器學習模型消耗。受到之前關于DNS隧道和加密流量的工作的啟發,可以結合DoH的特征來選擇功能。下表列出了使用的所有功能,下面給出了每個功能的詳細信息和理論分析,后面還會證明本文中選擇的特征足以用于DoH隧道檢測。
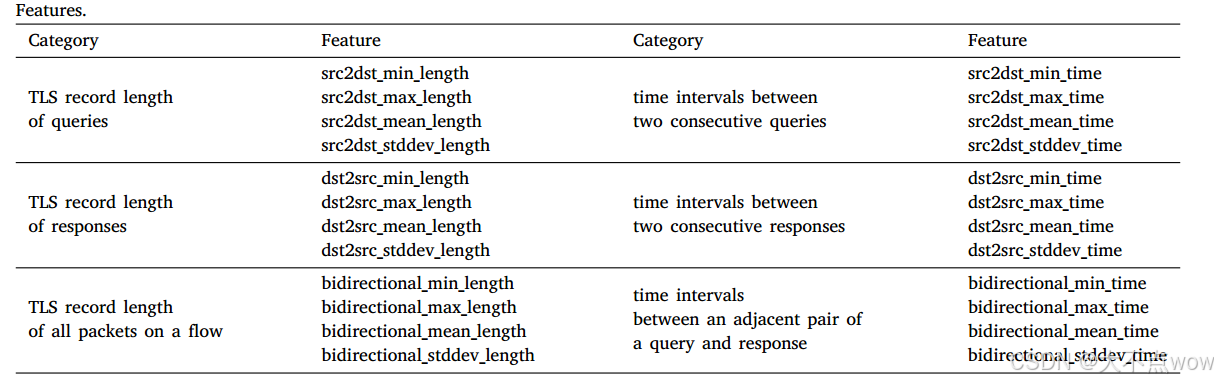
TLS記錄長度
??查詢域名的長度在以前的工作中被用作檢測DNS隧道的重要特征,這是因為通過DNS進行的數據泄漏本質上是將數據編碼為子域字符串,并使用該字符串和高級域名構造查詢的域名。隧道應用程序發出解析該域名的請求,然后由攻擊者控制的NS將接收該請求并通過解碼子域字符串來獲取信息。因此,較長的域名有助于傳輸更多的數據
??然而在加密DNS場景下,無法直接觀測查詢域名的長度,因此可以轉而關注DoH數據包的TLS記錄長度,該指標可在一定程度上間接反映域名長度特征。由于DNS查詢/響應存在長度限制(域名總長度不超過255字節),即使被封裝在HTTP請求中,大多數情況下仍能完整容納于單個TLS記錄內。
??TLS中的加密套件可分為流加密(如ChaCha20)和分組加密(如AES)兩類。對于流加密算法,其按字節加密的特性使得密文長度與明文長度相等;而分組加密算法需要對固定長度的數據塊進行加密,末端數據可能需要填充以滿足分組整數倍要求。雖然密文與明文長度可能不完全一致,但二者仍保持正相關關系。總體而言,當DNS查詢未進行填充處理時,我們仍可通過TLS記錄長度間接推斷域名長度特征。具體而言,考慮以下三類TLS記錄長度特征:
- 查詢方向的TLS記錄長度(src2dst)
- 響應方向的TLS記錄長度(dst2src)
- 流中所有數據包的TLS記錄長度(bidirectional)
時間間隔
??數據包之間的時間間隔是檢測DNS隧道的常見特征。遞歸解析器通常會緩存有關之前DNS查找的信息以減少延遲。當DNS響應包括生存時間(TLR)值時,接收的遞歸解析器將在TLR指定的時間內緩存該記錄。然后,如果遞歸解析器在到期時間之前收到查詢,它只需回復已經緩存的記錄,而不是再次從權威DNS服務器檢索。相反,遞歸解析器無法在緩存中找到DNS隧道生成的域名,因此接收到的每個查詢都被轉發到由攻擊者控制的NS。相應的響應將從NS返回,而不是直接從遞歸解析器的緩存返回。是故,隧道流量的查詢和響應的相鄰對之間的時間間隔通常比正常DNS流量的時間間隔長。此外,正常的DNS流量通常是隨機的,而通過DNS傳輸數據時,DNS請求通常以相對穩定的速率發送。幸運的是,與時間相關的特征的提取不受加密的影響。一般來說,考慮相鄰的查詢和響應對之間的時間間隔(雙向),以及兩個連續查詢(SRC 2dst)和兩個連續響應(dst 2SRC)之間的時間間隔。
被舍棄的特征分析
??不同查詢生成的DoH流量(如訪問不同網站產生的DoH查詢)可能在累計字節數或持續時間上存在差異。從直覺上看,基于流量的累計字節數或持續時間進行區分似乎是可行的。先前關于加密DNS流量的研究曾使用過此類特征。例如,有文獻利用流持續時間作為區分DoH流量與非加密DNS流量的特征之一;還有文獻將流中查詢/響應的總數和累計字節數作為網站指紋特征。
??對于用于數據外泄的DoH隧道而言,理論上其產生的字節數會多于正常流量。這是否意味著累計字節數和流持續時間可以作為檢測DoH隧道的有效特征?答案是否定的。因為先前研究使用這些特征時隱含了一個重要前提:即假設每個DoH流僅包含用戶單次操作(如一次網站訪問)產生的查詢/響應,因此不同DoH流會呈現不同的累計特征。然而實際情況是,瀏覽器可能同時訪問多個網站,此時產生的查詢/響應可能集中在單個DoH流中,這意味著正常DoH流同樣可能具有較大的累計字節數或持續時間。基于此,本研究最終未采用此類特征。
簡單來說:
??研究人員原本考慮用"總流量大小"和"持續時間"來檢測惡意流量,但后來發現這些指標不太靠譜,就像用"快遞包裹的總重量"來判斷是不是違禁品一樣——正常快遞也可能很重。
詳細解釋:
- ?最初的想法?:
- 假設:惡意軟件用DoH隧道傳數據時,會產生比正常瀏覽更多的流量(就像小偷用貨車運贓物,比普通人網購的包裹多)
- 前人研究確實用過"流量總字節數"和"連接持續時間"這類特征(好比快遞站記錄每個客戶的月包裹總重量)
- ?發現問題?:
- 這個假設有個漏洞:正常用戶也可能同時開很多網頁(比如你一邊看視頻一邊刷微博),這時產生的DoH流量也會很大
- 就像快遞站發現:有些正常客戶(比如開網店的)每月包裹量可能比小偷還多
- ?關鍵矛盾?:
- 惡意軟件傳數據往往持續發送小包裹(比如每分鐘發10個小DNS查詢)
- 正常用戶可能突然產生大流量(比如打開視頻網站)
- 兩者在"總量"上可能重疊,就像小偷的貨車和網店老板的貨車可能裝得一樣滿
- ??最終決定?:
- 放棄這些容易混淆的特征(就像快遞站不再單純靠包裹重量抓小偷)
- 改用更精準的特征組合(比如同時檢查"發送頻率+包裹大小規律性"等)

模型的選擇
??與其他領域中提取高維特征的一些工作不同,由于加密,可以從DoH流量中提取的特征的數量是有限的。因此,不需要構建復雜的分類器甚至神經網絡。相反,如果簡單的分類器有效,它可以帶來可接受的工程成本。
此外,神經網絡的可解釋性可能不夠。在網絡安全領域,可解釋性可以幫助防御者分析安全事件并采取更適當的策略。是故,選擇了三種可解釋的監督模型:增強決策樹(DT)、隨機森林(RF)和邏輯回歸(LR)。研究者在實驗中基于模型的可解釋性進行了大量分析。特別是,實驗包括對抗性考慮,并證明模型的可解釋性可以幫助在攻擊者逃避檢測時確定DoH流的優先級(越像隧道流量的優先級越高),從而為防御者提供攻擊調查的有用信息。
??研究者沒有選擇特定的模型,而是在所有實驗中采用了這三個模型。從初步結果來看,發現RF和DT在大多數情況下表現更好。然而,LR作為線性模型,發現在根據LR的分數對DoH流進行優先級排序方面具有獨特的優勢。
??此外,與僅使用良性流量進行訓練的異常檢測模型相比,同時使用良性和惡意流量訓練模型的監督學習方法通常具有更高的準確性,因為該模型可以直接匹配兩種類型數據的決策邊界。但顯然,所需的標記惡意流量數據增加了模型訓練的難度和工作量。研究者收集的惡意流量很簡單,由具有基本配置的開源工具生成(如之前所述)。在下一部分中,將評估訓練模型對于試圖逃避檢測的更高級攻擊者的有效性,從而用實驗證明,在良性流量和簡單惡意流量上訓練的模型在大多數情況下仍然可以有效對抗高級攻擊者(最多需要對模型進行一些細微的調整)。這意味著只需使用簡單、易于收集的惡意流量來訓練模型,而不是收集高級攻擊者可能使用的惡意流量。因此,數據收集的難度大大降低,提高了該種方法的實用性。
基于流量的檢測評估
評估設置
??對于基于流量的檢測評估,可以將數據集按照4:1的比例劃分為訓練集和測試集。研究者采用5重交叉驗證來訓練模型,并選擇在驗證集上F1分數最高的模型(閾值為0.5)進行測試。使用的測試指標包括準確率(accuracy)、精確率(precision)、召回率(recall)和F1分數(F1-score)。
5重交叉驗證的工作原理:
-
數據分割?:將原始數據集隨機分成5個大小相等(或近似相等)的子集,稱為"重"(folds)
-
迭代訓練與驗證?:
- 每次使用其中4個折(80%數據)作為訓練集
- 剩下的1個折(20%數據)作為驗證集
- 這個過程重復5次,確保每個子集都被用作驗證集一次
- ?性能評估?:最后將5次驗證的結果進行平均,得到模型的整體性能評估
閾值0.5的工作原理:
??在二分類問題中,分類器通常會輸出一個0到1之間的概率值,表示樣本屬于正類(本文中指良性DoH流量)的概率。閾值0.5的含義是:
- ?決策邊界?:
- 當模型輸出的概率 ≥ 0.5時,樣本被分類為正類(良性)
- 當模型輸出的概率 < 0.5時,樣本被分類為負類(惡意/隧道流量)
- 在本文中的應用?:
- 研究人員選擇在驗證集上F1分數最高的模型時使用0.5作為默認閾值
- 這個閾值是二分類問題中最常用的默認值
- 它表示對正負類采取對稱的重視程度
- 可調整性?:
- 在實際應用中,可以根據具體需求調整這個閾值
- 例如,如果更重視檢測率(召回率),可以降低閾值
- 如果更重視準確率,可以提高閾值
??具體而言,當一個流量被標記為良性時,我們稱之為陽性(positive)。真陽性(true-positive, TP)是指被正確標記為良性的DoH流量,假陽性(false-positive, FP)是指被錯誤標記為良性的DoH隧道流量。相反,真陰性(true-negative, TN)是指被正確標記為惡性的DoH隧道流量,假陰性(false-negative, FN)是指被錯誤標記為惡性的良性DoH流量。基于這些定義,我們可以計算以下指標:
準確率=TP+TNTP+FN+FP+TN準確率 = \frac{TP + TN}{TP + FN + FP + TN}準確率=TP+FN+FP+TNTP+TN?
精確率=TPTP+FP精確率 = \frac{TP}{TP + FP}精確率=TP+FPTP?
召回率=TPTP+FN召回率 = \frac{TP}{TP + FN}召回率=TP+FNTP?
F1分數=2×精確率×召回率精確率+召回率F1分數 = 2 ×\frac{精確率 × 召回率}{精確率 + 召回率}F1分數=2×精確率+召回率精確率×召回率?
??研究者評估考慮了不同場景下的多種因素變化,包括地理位置、DoH遞歸解析器選擇、填充方式等,以評估這些因素對模型性能的影響。為此,設計了一系列異構實驗。在每個實驗中,只改變一個因素(如位置或遞歸解析器)來評估分類器的性能,并討論攻擊者可能的規避檢測方法。
??具體來說,首先使用所有訓練數據和特征來訓練和測試模型,這是一個理想場景,展示了模型性能的上限。然后測試位置、DoH遞歸解析器、填充和時間間隔對模型性能的影響。此外,還模擬了攻擊者可能規避檢測的場景。研究者發現攻擊者要實現這種規避非常困難(甚至僅在理論上可行),此時隧道的傳輸速率極低。更重要的是,在這種情況下,該方法仍然可以幫助管理員更快地調查安全狀態。
總體數據集的評估
??首先進行一個簡單的實驗來初步測試分類器的性能,將所有收集的數據組合到一個總體數據集中,分類器使用所有特征(總共24個特征,請參閱前面的表格)進行訓練和測試。這種實驗性設置意味著不考慮不同位置和遞歸服務器的可能影響,并假設攻擊者沒有采取措施來逃避檢測。

實驗結果總結于上表中。LR存在一些假陽性,因此其F1評分相對較低,為0.978。盡管該實驗設置是在上述理想化場景中進行的,但實驗結果可以證明DoH隧道流量與正常DoH流量不同,并且提取的特征可以表達這種差異以構建高效的分類器。
??在上述分類器中,尤其是RF和DT,在這個實驗中表現出色。這是否意味著DoH隧道可以被有效檢測到?答案當然不是。事實上,攻擊者可以輕松改變流的一些特征值,例如數據包發送率。理論上,攻擊者可能會逃避檢測。面對實際對手時,需要考慮檢測方法的穩健性。
??因此,除了模型本身的有效性之外,應該更關心攻擊者如何逃避檢測。換句話說,我們希望找到所提出方法檢測能力的下限,而不僅僅是模型在理想化數據集上的性能。如果攻擊者需要支付極高的成本(甚至僅在理論上可行)來規避所提出的方法,則所提出的方法對于DoH隧道檢測是有效的。在隨后的實驗中,研究者從攻擊者和防御者的角度分析了所提出的方法。通過改變一個因素(例如,位置或遞歸解析器),以評估分類器的性能,并討論攻擊者逃避檢測的可能方法。
位置的影響
??DoH痕跡可能因地點而異。對于良性DNS查詢,因為網站可能會將其內容調整到特定的地理區域,并且解析器緩存的資源可能會因不同的區域而異。對于DoH隧道,通過隧道的查詢將不可避免地到達攻擊者控制的NS。因此,直觀地說,通過隧道將數據從不同位置傳輸到同一NS所需的時間是不同的。
在這個實驗中,通過在不同位置收集的數據集進行交叉驗證。受害者分別位于新加坡和西雅圖,攻擊者控制的NS位于西雅圖。在新加坡收集的良性DoH跟蹤和DoH隧道跟蹤形成一個數據集,而另一個在西雅圖。這兩個數據集分別作為訓練集和測試集進行驗證。
下表顯示了交叉這些數據集進行訓練和測試時的分類器性能。
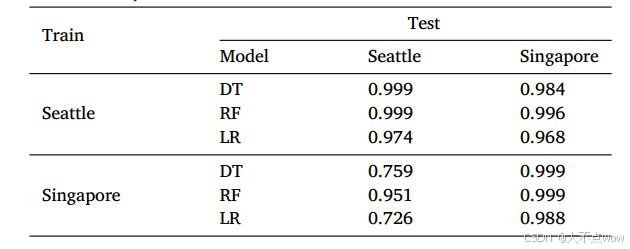
??當在同一位置進行訓練和測試時,分類器的結果與整個數據集中的結果相似,一些F1分數甚至增加了約0.1%。當在不同地點進行訓練和測試時,F1分數會下降4%至26%。下降主要發生在對新加坡收集的數據集的訓練和對西雅圖收集的數據集的測試中。RF的性能優于DT和LR。具體來說,研究者發現F1評分低的主要原因是大量假陽性,但假陰性并不多。例如,當LR的F1得分為0.726時,精度為0.585,召回率為0.958。當DT的F1評分為0.759時,精確度為0.611,召回率為0.999。
??出現上述這一結果的原因是時間相關特征在分類器中具有更高的重要性,而不同地理位置生成的DoH流量軌跡的時間相關特征存在差異。在實驗設置中,從新加坡的受害者向西雅圖的NS服務器傳輸數據包需要較長時間,而在西雅圖本地只需很短時間。因此,基于新加坡收集數據訓練的分類器,其針對時間相關特征的決策邊界不完全適用于西雅圖收集的數據。反之,基于西雅圖收集數據訓練的分類器具有更嚴格的決策邊界,因此在新加坡收集的數據上仍表現良好。
較好解釋:
在西雅圖訓練的模型當中,一部分是使用DoH隧道訪問西雅圖的NS服務器,另一部分是用DoH去訪問正常的網站,而訪問正常的網站通常會被引導到最近的服務節點,所以上述二者的傳輸時間沒有非常大的差別。因此,模型在構建的時候,重點會考慮除了時間以外的特征(不是說不考慮時間特征,只是權重小一點)。而對于在新加坡訓練的模型來說,由于攻擊者的NS服務器是在西雅圖,所以傳輸時間往往較長,這和自己本地DoH訪問正常網站產生的流量在時間上有著很大的差別,導致模型誤以為時間過長的就是惡意流量,所以最后在西雅圖的數據集上表現非常差。
??對于良性DoH流量,解析器通常會緩存熱門資源,且解析器和CDN會使用地理位置方法來實現請求的負載均衡(例如訪問同一個網站,會被引導訪問最近的一個服務節點)。因此良性DoH軌跡在不同位置變化不大,交叉驗證的召回率沒有顯著下降。至于模型的性能表現,研究者認為RF能保持相對較好效果的原因是其多數表決機制降低了時間相關特征的影響,且TLS記錄長度相關特征對檢測有所幫助。
??根據本實驗結果,對防御者而言,需要使用本地訓練的分類器來確保有效性。對攻擊者而言,需要使受控的NS服務器盡可能在地理位置上接近受害者,從而減少從受害者到NS服務器的DoH隧道延遲。然而,僅靠地理位置的接近并不足以逃避檢測(在同一位置訓練和測試模型時仍可獲得較高的F1分數)。
DoH遞歸分解器的影響
??研究者基于三個公共遞歸解析器(Cloudflare、Google、Quad9)收集數據,這些數據分別作為訓練集和測試集進行驗證。由于篇幅限制,下表僅展示了西雅圖主機使用隨機森林(RF)模型獲得的部分F1分數結果。基于決策樹(DT)和邏輯回歸(LR)模型的結果與下表相似(差異在5%以內)。新加坡主機的測試結果也與下表相似(差異在3%以內)。
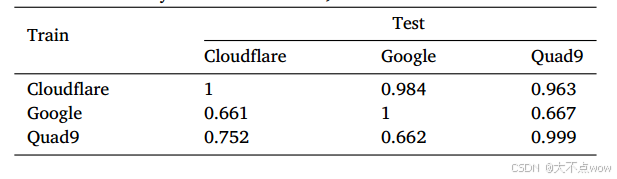
總體而言,使用相同解析器數據進行訓練和測試時獲得最佳結果,這符合預期。在其他情況下,模型性能會出現下降。具體表現為:基于Cloudflare數據集訓練的模型在Google和Quad9數據集上仍能保持相對良好的效果(F1分數下降1.6%-3.7%)。而基于Google或Quad9數據集訓練的模型在其他數據集上的F1分數會顯著下降25%-44%。
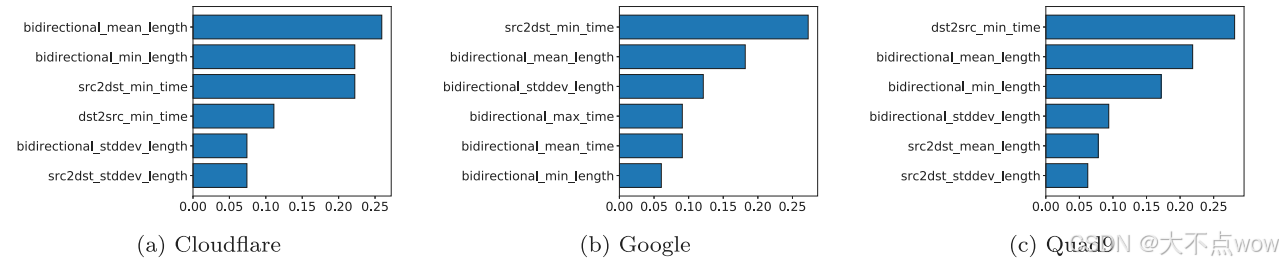
??為探究這種不對稱的性能下降現象,研究者根據特征重要性對分類器進行了排序分析。下圖展示了西雅圖主機使用不同解析器數據集訓練隨機森林模型時的歸一化特征重要性(由于篇幅限制,僅展示前6個重要特征)。發現,Cloudflare數據集中的重要特征在Google和Quad9數據集中同樣重要(如bidirectional_mean_length)。而Google或Quad9數據集中的某些重要特征(如dst2src_min_time是Quad9數據集中最重要的特征)在其他數據集中并不突出(在Google數據集的前6重要特征中未出現)。這種特征重要性分布的差異可能是由于不同解析器的實現方式和部署策略不同所導致,例如在解析域名時采用不同的緩存策略會導致響應時間特征的差異。特征重要性的差異可能導致決策樹在早期分裂時產生錯誤劃分,從而引起性能下降。
??根據這些實驗結果,防御者應當收集來自不同遞歸解析器的數據進行訓練。對于攻擊者而言,則需要了解不同解析器的特性差異,并嘗試利用這些差異來規避檢測。
EDNS(0)填充的影響
??之前的實驗模擬了攻擊者試圖通過改變受控NS的地理位置和遞歸解析器來逃避檢測的情況,結果表明這些變化不足以逃避檢測。從攻擊者的角度來看,有必要從分類器的特征中找到可能的逃避方法。一般來說,分類器的特征由兩種類型組成:與TLS記錄長度相關的特征和與時間相關的特征。在本實驗中,研究者評估了TLS記錄長度對檢測的影響。
??顯然,逃避檢測的基本思想是使TLS記錄長度與良性DoH數據包的記錄長度相似。如果攻擊者僅調整域名的長度和編碼信息的長度,則不容易確定最佳長度值來逃避檢測。如前所述,我們希望找到所提出方法的檢測能力的下限。因此,我們假設對攻擊者最有利的場景,即良性DoH流量和DoH隧道流量都使用EDNS(0)填充選項進行了完美填充。
??DNS擴展機制(EDNS)是一種增加DNS功能的規范[39]。EDNS(0)填充用于將DNS查詢和響應填充到所需的大小,這使得基于數據包長度的流量分析更加困難。預計填充將與DoH一起使用以更好地保護隱私。在嚴格的填充策略下,所有DoH數據包都具有固定長度。因此,在本假設場景中,所有與TLS記錄長度相關的特征都無效。在本實驗中,評估了僅基于時間相關特征的分類器的性能。分類器分別使用整體數據集、西雅圖和新加坡數據集進行訓練和測試。實驗結果總結在下表中。與之前的實驗相比,所有分類器的性能都有所下降。LR模型的F1分數下降了13%。相比之下,RF和DT的性能下降較小,F1分數下降了約1%。
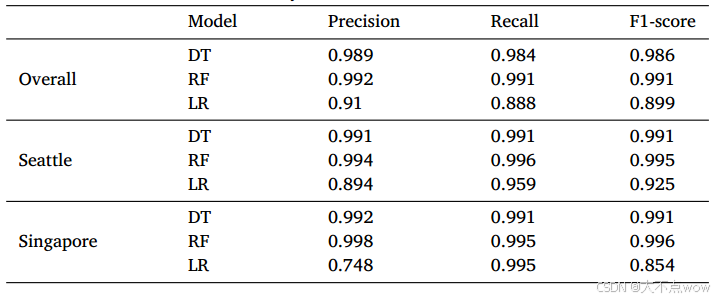 ??這一實驗結果表明,雖然與TLS記錄長度相關的特征確實會影響檢測結果,但分類器仍能保持可接受的性能。此外,最近的工作指出,目前支持填充的客戶端并不多,而且填充的實現還不夠標準化。這意味著在當前的現實世界中,攻擊者不太可能具備假設的理想條件。總之,防御者應該**僅基于時間相關特征訓練分類器**,以檢測潛在的基于填充的逃避,而攻擊者僅通過修改TLS記錄長度很難逃避檢測。
??這一實驗結果表明,雖然與TLS記錄長度相關的特征確實會影響檢測結果,但分類器仍能保持可接受的性能。此外,最近的工作指出,目前支持填充的客戶端并不多,而且填充的實現還不夠標準化。這意味著在當前的現實世界中,攻擊者不太可能具備假設的理想條件。總之,防御者應該**僅基于時間相關特征訓練分類器**,以檢測潛在的基于填充的逃避,而攻擊者僅通過修改TLS記錄長度很難逃避檢測。

時間間隔的影響
??根據上述實驗結果,攻擊者只能基于時間相關特征尋找可能的規避檢測方法。在本實驗中,研究者假設攻擊者已經使用了前一實驗中描述的EDNS(0)填充選項,在此基礎上攻擊者進一步調整DoH隧道的時間相關特征以規避檢測。做出這一假設的原因是,雖然單獨使用填充不足以規避檢測,但它確實降低了分類器的性能。因此,在使用填充的同時修改時間相關特征是對攻擊者最有利的場景。
??直觀來看,當DoH隧道的數據傳輸速率較慢時,其偽裝效果可能更好。目前使用的DoH隧道數據集中最大的DNS查詢發送間隔為1秒。在本實驗中,進一步收集了時間間隔為2、4、8和20秒的DoH隧道流量(這些是流上的平均時間間隔,兩個查詢之間的時間間隔是隨機的)。流量在位于西雅圖的主機上收集,每個DoH流至少包含5組DNS查詢/響應。
??對于實驗,首先使用先前訓練的模型來檢測新收集的數據下表顯示了每個分類器對不同發送間隔的DoH隧道流的平均預測概率。結果顯示,RF和DT仍然能準確檢測所有發送速率的DoH隧道(F1-score>0.99),而LR僅能檢測發送間隔為2秒的DoH隧道(當間隔為2秒時F1-score約為0.92,其余間隔的DoH隧道流被分類為良性)。相比之下,RF和DT對DoH隧道流的預測概率在前面的實驗中通常超過0.9。因此,雖然增加發送DNS查詢的時間間隔不會導致這些分類器出現假陽性,但它確實有助于規避檢測。DT的預測概率是一致的。這表明當DT檢測具有不同發送間隔的流時,它可能已經到達相同的內部節點(即一個特征和決策條件),然后將流分類為DoH隧道。這進一步表明攻擊者需要調整其他特征來規避檢測。對于LR,作為一個線性模型,時間間隔的增加直接導致其對DoH隧道流的預測概率下降,從而導致假陽性。

??然后使用新數據與之前的數據一起重新訓練和測試模型。RF和DT獲得的結果幾乎與上表中的結果相同。LR卻實現了0.909的精確度,0.956的召回率和0.932的F1-score。與僅檢測發送間隔為2秒的DoH隧道相比,重新訓練的LR模型的性能有了很大提高。每個分類器的精確度沒有顯著下降,這意味著在添加新數據進行訓練后,分類器仍然可以找到一個清晰的決策邊界。上述結果表明,防御者應盡可能多地收集多種速率的DoH隧道流量來訓練模型。即使攻擊者使用比訓練集更慢的速率,模型仍然可能有效。
對檢測到的流進行優先級排序
??攻擊者可以調整很少的剩余參數來逃避檢測。由于收集的DoH隧道流包含多個DNS查詢,因此研究者最后考慮DoH隧道流僅包含一個DNS查詢的場景。直覺上,這樣的設置可能會使與時間相關的特征的某些統計數據(例如,平均值、標準差)無效。與前面的實驗過程相同,使用訓練模型和重新訓練模型來測試新收集的流量。發現此時沒有一個模型可以檢測到隧道。看來攻擊者終于有辦法逃避檢測了。由于一個流只包含一個DNS查詢/響應,因此建立的DoH隧道的傳輸率非常低。具體來說,假設子域名的長度為100(對于DNS來說這并不是一個很短的長度)并且采用base64編碼,那么每個查詢可以傳輸大約75個字節。每個新DoH連接的TLS握手都需要一些時間(取決于網絡環境和計算能力)。因此,即使兩個連接之間幾乎沒有間隔,隧道的總體速率也只有每秒數百個字節左右。
??然而,研究者發現在之前的實驗中表現相對較差的LR此時可以幫助防御者。當查看LR的分數時,發現盡管DoH隧道流的分數大于0.5(DoH隧道流為0,良性DoH為1,閾值0.5),但DoH隧道流的分數通常仍然較低(例如,0.6至0.7)比良性DoH流的值。而RF和DT對DoH隧道的評分通常在0.9至1.0之間,這與良性DoH流的評分相似。
??對于DoH隧道,一些固有特征難以模仿。例如,DoH隧道的查詢必然會到達攻擊者控制的NS,而良性查詢可能由于緩存而僅到達解析器。在這種情況下,DNS查詢/響應時間是不同的。雖然特征較少且特征的差異可能不足以讓分類器找到一個好的決策邊界,但這種差異仍然會反映在線性模型(如LR模型)的最終分數中。然而,RF和DT可能會在內部節點直接將DoH流分類為良性,這無法反映這種差異。
??根據實驗結果,防御者可以基于LR模型的分數對DoH流進行優先級排序,并優先調查更可疑的流。雖然在這種實驗設置下分類器無法準確檢測DoH隧道,但研究者相信基于優先級的調查可以大大幫助防御者更快地確認安全狀態。

總結
??可以從防御者和攻擊者的角度總結實驗結果:
??對于防御者,應監控TLS指紋進行初步檢測。應盡可能多地收集不同類型的數據來訓練分類器,包括來自不同解析器的流量、具有不同數據包發送速率的DoH隧道流量等。如果受保護的主機位于不同的地理位置,則應在不同的地理位置分別訓練模型。除了關注已被分類器識別為隧道的流量外,防御者還應關注具有高異常分數的流量。
??對于攻擊者,為了規避所提出的檢測方法,首先,受控的NS應在地理位置上足夠接近受害主機。交付給受害主機的DoH隧道工具需要模仿瀏覽器等流行的TLS實現。此外,攻擊者需要使用填充等手段來偽裝數據包長度。而且,攻擊者應以較慢的速度發送數據包,且DoH流中的數據包數量應較少(甚至一個流中只有一對DNS查詢和響應)。為了實現上述所有條件,攻擊者需要付出巨大代價,其中一些條件甚至可能僅在理論上可行。即使攻擊者規避了檢測,建立的DoH隧道的傳輸速率也非常低。因此,所提出的方法對于檢測基于DoH的數據外泄是有效的。
??到這里,論文的解讀就結束了,下一篇我們著手進行該篇論文的復現工作。

的核心概念)

![[ LeetCode優選算法專題一雙指針-----盛最多的水]](http://pic.xiahunao.cn/[ LeetCode優選算法專題一雙指針-----盛最多的水])


)
)
雙向鏈表)



等級考試試卷(一級))



)



