這是一個非常實用的 嶺回歸(Ridge Regression)和線性回歸(Linear Regression)對比實驗,使用了 scikit-learn 中的 California Housing 數據集 來預測房價。
📦 第一步:導入必要的庫
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfrom sklearn.linear_model import Ridge, Lasso, LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing as fch
🔹 Ridge, Lasso, LinearRegression:三種回歸模型
🔹 fetch_california_housing:加載加州房價數據集
🔹 train_test_split:劃分訓練集和測試集
🔹 matplotlib.pyplot:畫圖
🏠 第二步:加載數據并觀察
house_value = fch()
X = pd.DataFrame(house_value.data)
y = house_value.target
X.columns = ["住戶收入中位數", "房屋使用年代中位數", "平均房間數目", "平均臥室數目", "街區人口", "平均入住率", "街區垢緯度", "街區的經度"]Xtmp = X.copy()
Xtmp['價格'] = y
display(Xtmp)
? 將數據轉換為 DataFrame 并設置列名,更方便分析。
? display(Xtmp) 會在 Jupyter Notebook 中以表格形式展示數據。
?? 第三步:劃分訓練集和測試集
xtrain, xtest, ytrain, ytest = train_test_split(X, y, test_size=0.3, random_state=420)
for i in [xtrain, xtest]:i.index = range(i.shape[0]) # 重置索引,避免索引錯亂
? 劃分比例為 70% 訓練 + 30% 測試
? 重置索引是個好習慣,有利于數據對齊
🧮 第四步:使用 Ridge 回歸 進行建模和評估
reg = Ridge(alpha=5).fit(xtrain, ytrain)
r2_score = reg.score(xtest, ytest)
print("r2:%.8f" % r2_score)
🔹 這里用嶺回歸擬合訓練集,使用 alpha=5 作為正則化系數。
🔹 reg.score() 返回的是 R2(決定系數),衡量模型擬合效果,越接近 1 越好。
🔁 第五步:不同 alpha 下 Ridge 與普通線性回歸對比
from sklearn.model_selection import cross_val_score
alpha_range = np.arange(1, 1001, 100)
ridge, lr = [], []for alpha in alpha_range:reg = Ridge(alpha=alpha)linear = LinearRegression()# 用交叉驗證評估兩種模型的平均 R2regs = cross_val_score(reg, X, y, cv=5, scoring='r2').mean()linears = cross_val_score(linear, X, y, cv=5, scoring='r2').mean()ridge.append(regs)lr.append(linears)
🔍 cross_val_score:使用 5 折交叉驗證,平均 R2 得分
-
ridge.append():記錄不同 alpha 下嶺回歸得分 -
lr.append():記錄普通線性回歸得分(其實是一個水平線)
📈 第六步:可視化 Ridge 與 Linear 回歸對比結果
plt.plot(alpha_range, ridge, c='red', label='Ridge')
plt.plot(alpha_range, lr, c='orange', label='LR')
plt.title('Mean')
plt.legend()
plt.ylabel('R2')
plt.show()
? 橫軸是 alpha,縱軸是交叉驗證 R2
? 嶺回歸的性能隨著 alpha 變化,線性回歸是常數線
? 可以直觀對比正則化對模型的影響
📌 總結這個實驗做了什么?
| 步驟 | 作用 |
|---|---|
| 加載數據 | 得到特征和標簽 |
| 建立模型 | 使用嶺回歸擬合預測房價 |
| 模型評估 | 輸出 R2 指數 |
| 交叉驗證 | 比較嶺回歸與線性回歸的表現隨 alpha 變化的趨勢 |
| 可視化 | 看不同 alpha 對 Ridge 的影響,并與線性回歸對比 |
? 建議拓展方向
可以繼續做這些改進:
-
加入標準化(StandardScaler):防止特征量綱影響回歸權重;
-
嘗試 Lasso 回歸:看看稀疏化是否會帶來更優的模型;
-
繪制訓練誤差與測試誤差對比圖:分析是否過擬合;
-
使用
GridSearchCV自動調參:找到最優 alpha。
以下是一個完整的房價預測回歸分析代碼,包含:
-
嶺回歸(Ridge)
-
Lasso 回歸
-
普通線性回歸
-
標準化處理(
StandardScaler) -
網格搜索調參(
GridSearchCV) -
模型評分比較
-
可視化對比
? 完整代碼如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Ridge, Lasso, LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score# 1. 加載數據
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target# 2. 數據劃分
xtrain, xtest, ytrain, ytest = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 特征標準化
scaler = StandardScaler()
xtrain_scaled = scaler.fit_transform(xtrain)
xtest_scaled = scaler.transform(xtest)# 4. 定義回歸模型
models = {"LinearRegression": LinearRegression(),"Ridge": Ridge(),"Lasso": Lasso()
}# 5. 設置超參數搜索空間
param_grid = {"Ridge": {"alpha": np.logspace(-3, 3, 20)},"Lasso": {"alpha": np.logspace(-3, 3, 20)}
}# 6. 模型訓練與調參
best_models = {}
for name, model in models.items():if name in param_grid:print(f"正在搜索最優參數:{name}")grid = GridSearchCV(model, param_grid[name], cv=5, scoring="r2")grid.fit(xtrain_scaled, ytrain)best_models[name] = grid.best_estimator_print(f"{name} 最佳 alpha: {grid.best_params_['alpha']:.4f}")else:model.fit(xtrain_scaled, ytrain)best_models[name] = model# 7. 模型評估
print("\n模型性能對比(R2 得分):")
for name, model in best_models.items():score = model.score(xtest_scaled, ytest)print(f"{name}: R2 = {score:.4f}")# 8. 可視化對比
r2_scores = [model.score(xtest_scaled, ytest) for model in best_models.values()]
model_names = list(best_models.keys())plt.figure(figsize=(8, 5))
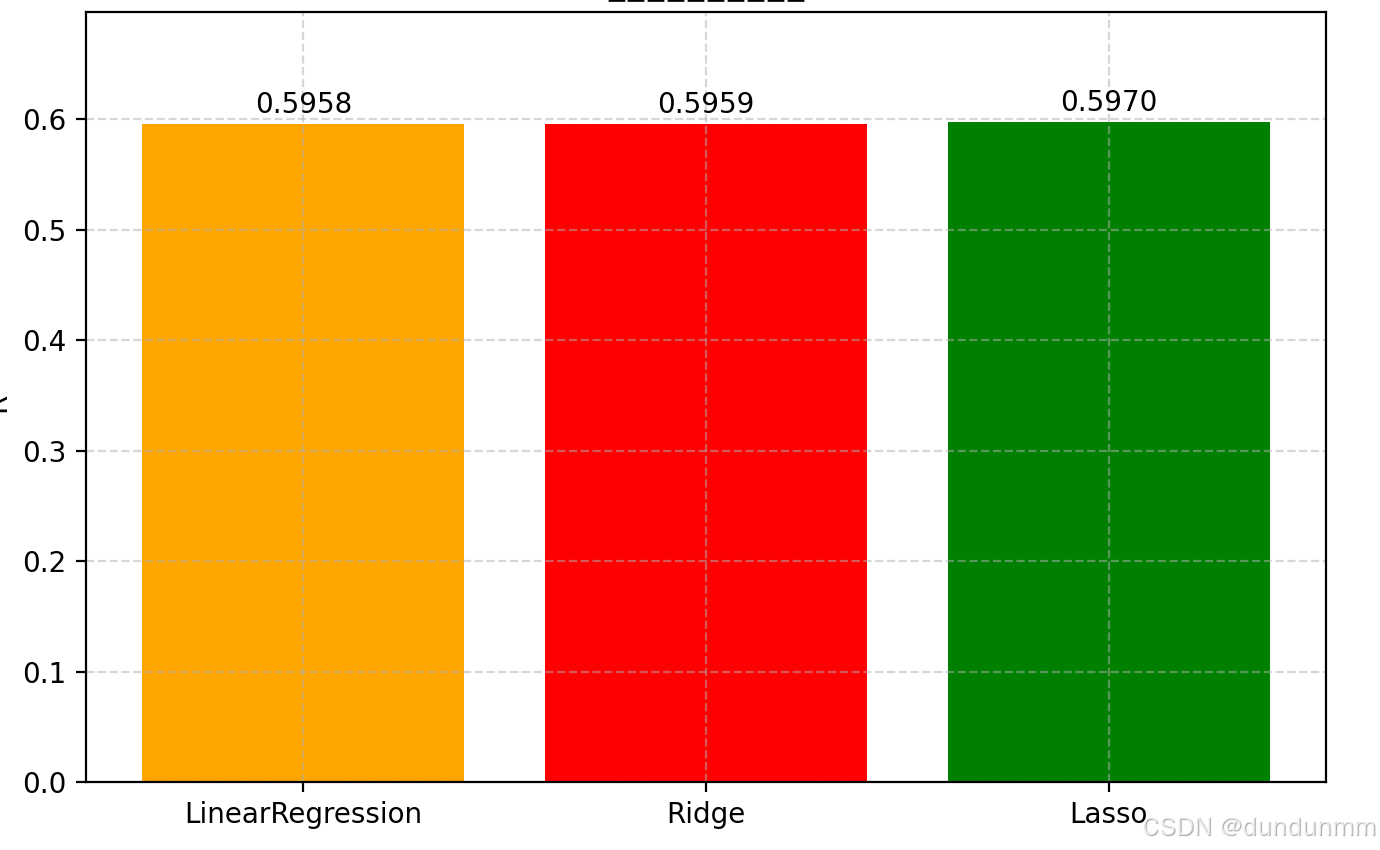
plt.bar(model_names, r2_scores, color=["orange", "red", "green"])
plt.ylabel("R2")
plt.title("不同回歸模型性能對比")
for i, score in enumerate(r2_scores):plt.text(i, score + 0.01, f"{score:.4f}", ha='center')
plt.ylim(0, max(r2_scores) + 0.1)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
📊 輸出內容包括:
-
每種模型的 R2 得分
-
Ridge 和 Lasso 的最佳 alpha(正則項系數)
-
一張柱狀圖對比三種模型在測試集上的表現




)

JavaScript庫(防抖、節流、函數柯里化)JS庫)
)










![STM32單片機入門學習——第27節: [9-3] USART串口發送串口發送+接收](http://pic.xiahunao.cn/STM32單片機入門學習——第27節: [9-3] USART串口發送串口發送+接收)

