1.zk實現數據發布訂閱
(1)發布訂閱系統一般有推模式和拉模式
推模式:服務端主動將更新的數據發送給所有訂閱的客戶端。
拉模式:客戶端主動發起請求來獲取最新數據(定時輪詢拉取)。
(2)zk采用了推拉相結合來實現發布訂閱
首先客戶端需要向服務端注冊自己關注的節點(添加Watcher事件)。一旦該節點發生變更,服務端就會向客戶端發送Watcher事件通知。客戶端接收到消息通知后,需要主動到服務端獲取最新的數據。所以,zk的Watcher機制有一個缺點就是:客戶端不能定制服務端回調,需要客戶端收到Watcher通知后再次向服務端發起請求獲取數據,多進行一次網絡交互。
如果將配置信息放到zk上進行集中管理,那么:
一.應用啟動時需主動到zk服務端獲取配置信息,然后在指定節點上注冊一個Watcher監聽。
二.只要配置信息發生變更,zk服務端就會實時通知所有訂閱的應用,讓應用能實時獲取到訂閱的配置信息節點已發生變更的消息。
注意:原生zk客戶端可以通過getData()、exists()、getChildren()三個方法,向zk服務端注冊Watcher監聽,而且注冊的Watcher監聽具有一次性,所以zk客戶端獲得服務端的節點變更通知后需要再次注冊Watcher。
(3)使用zk來實現數據發布訂閱總結
步驟一:將配置信息存儲到zk的節點上。
步驟二:應用啟動時首先從zk節點上獲取配置信息,然后再向該zk節點注冊一個數據變更的Watcher監聽。一旦該zk節點數據發生變更,所有訂閱的客戶端就能收到數據變更通知。
步驟三:應用收到zk服務端發過來的數據變更通知后重新獲取最新數據。
(4)zk原生實現分布式配置(也就是實現注冊發現或者數據發布訂閱)
配置可以使用數據庫、Redis、或者任何一種可以共享的存儲位置。使用zk的目的,主要就是利用它的回調機制。任何zk的使用方不需要去輪詢zk,Redis或者數據庫可能就需要主動輪詢去看看數據是否發生改變。使用zk最大的優勢是只要對數據添加Watcher,數據發生修改時zk就會回調指定的方法。注意:new一個zk實例和向zk獲取數據都是異步的。
如下的做法其實是一種Reactor響應式編程:使用CoundownLatch阻塞及通過調用一次數據來觸發回調更新本地的conf。我們并沒有每個場景都線性寫一個方法堆砌起來,而是用相應的回調和Watcher事件來粘連起來。其實就是把所有事件發生前后要做的事情粘連起來,等著回調來觸發。
一.先定義一個工具類可以獲取zk實例
public class ZKUtils {private static ZooKeeper zk;private static String address = "192.168.150.11:2181,192.168.150.12:2181,192.168.150.13:2181,192.168.150.14:2181/test";private static DefaultWatcher defaultWatcher = new DefaultWatcher();private static CountDownLatch countDownLatch = new CountDownLatch(1);public static ZooKeeper getZK() {try {zk = new ZooKeeper(address, 1000, defaultWatcher);defaultWatcher.setCountDownLatch(countDownLatch);//阻塞直到建立好連接拿到可用的zkcountDownLatch.await();} catch (Exception e) {e.printStackTrace();}return zk;}
}二.定義和zk建立連接時的Watcher
public class DefaultWatcher implements Watcher {CountDownLatch countDownLatch ;public void setCountDownLatch(CountDownLatch countDownLatch) {this.countDownLatch = countDownLatch;}@Overridepublic void process(WatchedEvent event) {System.out.println(event.toString());switch (event.getState()) {case Unknown:break;case Disconnected:break;case NoSyncConnected:break;case SyncConnected:countDownLatch.countDown();break;case AuthFailed:break;case ConnectedReadOnly:break;case SaslAuthenticated:break;case Expired:break;}}
}三.定義分布式配置的核心類WatcherCallBack
這個WatcherCallBack類不僅實現了Watcher,還實現了兩個異步回調。
首先通過zk.exists()方法判斷配置的znode是否存在并添加監聽(自己) + 回調(自己),然后通過countDownLatch.await()方法進行阻塞。
在回調中如果發現存在配置的znode,則設置配置并執行countDown()方法不再進行阻塞。
在監聽中如果發現數據變化,則會調用zk.getData()方法獲取配置的數據,并且獲取配置的數據時也會繼續監聽(自己) + 回調(自己)。
public class WatcherCallBack implements Watcher, AsyncCallback.StatCallback, AsyncCallback.DataCallback {ZooKeeper zk;MyConf conf;CountDownLatch countDownLatch = new CountDownLatch(1);public MyConf getConf() {return conf;}public void setConf(MyConf conf) {this.conf = conf;}public ZooKeeper getZk() {return zk;}public void setZk(ZooKeeper zk) {this.zk = zk;}//判斷配置是否存在并監聽配置的znodepublic void aWait(){ zk.exists("/AppConf", this, this ,"ABC");try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}}//回調自己,這是執行完zk.exists()方法或者zk.getData()方法的回調//在回調中如果發現存在配置的znode,則設置配置并執行countDown()方法不再進行阻塞。@Overridepublic void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {if (data != null) {String s = new String(data);conf.setConf(s);countDownLatch.countDown();}}//監聽自己,這是執行zk.exists()方法或者zk.getData()方法時添加的Watcher監聽//在監聽中如果發現數據變化,則會繼續調用zk.getData()方法獲取配置的數據,并且獲取配置的數據時也會繼續監聽(自己) + 回調(自己)@Overridepublic void processResult(int rc, String path, Object ctx, Stat stat) {if (stat != null) {//stat不為空, 代表節點已經存在zk.getData("/AppConf", this, this, "sdfs");}}@Overridepublic void process(WatchedEvent event) {switch (event.getType()) {case None:break;case NodeCreated://調用一次數據, 這會觸發回調更新本地的confzk.getData("/AppConf", this, this, "sdfs");break;case NodeDeleted://容忍性, 節點被刪除, 把本地conf清空, 并且恢復阻塞conf.setConf("");countDownLatch = new CountDownLatch(1);break;case NodeDataChanged://數據發生變更, 需要重新獲取調用一次數據, 這會觸發回調更新本地的confzk.getData("/AppConf", this, this, "sdfs");break;case NodeChildrenChanged:break;}}
}分布式配置的核心配置類:
//MyConf是配置中心的配置
public class MyConf {private String conf ;public String getConf() {return conf;}public void setConf(String conf) {this.conf = conf;}
}四.通過WatcherCallBack的方法判斷配置是否存在并嘗試獲取數據
public class TestConfig {ZooKeeper zk;@Beforepublic void conn () {zk = ZKUtils.getZK();}@Afterpublic void close () {try {zk.close();} catch (InterruptedException e) {e.printStackTrace();}}@Testpublic void getConf() {WatchCallBack watchCallBack = new WatchCallBack();//傳入zk和配置confwatchCallBack.setZk(zk);MyConf myConf = new MyConf();watchCallBack.setConf(myConf);//節點不存在和節點存在, 都嘗試去取數據, 取到了才往下走watchCallBack.aWait();while(true) {if (myConf.getConf().equals("")) {System.out.println("conf diu le ......");watchCallBack.aWait();} else {System.out.println(myConf.getConf());}try {Thread.sleep(200);} catch (InterruptedException e) {e.printStackTrace();}}}
}2.zk實現負載均衡
(1)負載均衡算法
常用的負載均衡算法有:輪詢法、隨機法、原地址哈希法、加權輪詢法、加權隨機法、最小連接數法。
一.輪詢法
輪詢法是最為簡單的負載均衡算法。當接收到客戶端請求后,負載均衡服務器會按順序逐個分配給后端服務。比如集群中有3臺服務器,分別是server1、server2、server3,輪詢法會按照sever1、server2、server3順序依次分發請求給每個服務器。當第一次輪詢結束后,會重新開始下一輪的循環。
二.隨機法
隨機法是指負載均衡服務器在接收到來自客戶端請求后,根據隨機算法選中后臺集群中的一臺服務器來處理這次請求。由于當集群中的機器變得越來越多時,每臺機器被抽中的概率基本相等,因此隨機法的實際效果越來越趨近輪詢法。
三.原地址哈希法
原地址哈希法是根據客戶端的IP地址進行哈希計算,對計算結果進行取模,然后根據最終結果選擇服務器地址列表中的一臺機器來處理請求。這種算法每次都會分配同一臺服務器來處理同一IP的客戶端請求。
四.加權輪詢法
由于一個分布式系統中的機器可能部署在不同的網絡環境中,每臺機器的配置性能各不相同,因此其處理和響應請求的能力也各不相同。
如果采用上面幾種負載均衡算法,都不太合適。這會造成能力強的服務器在處理完業務后過早進入空閑狀態,而性能差或網絡環境不好的服務器一直忙于處理請求造成任務積壓。
為了解決這個問題,可以采用加權輪詢法。加權輪詢法的方式與輪詢法的方式很相似,唯一的不同在于選擇機器時,不只是單純按照順序的方式去選擇,還要根據機器的配置和性能高低有所側重,讓配置性能好的機器優先分配。
五.加權隨機法
加權隨機法和上面提到的隨機法一樣,在采用隨機法選舉服務器時,會考慮系統性能作為權值條件。
六.最小連接數法
最小連接數法是指:根據后臺處理客戶端的請求數,計算應該把新請求分配給哪一臺服務器。一般認為請求數最少的機器,會作為最優先分配的對象。
(2)使用zk來實現負載均衡
實現負載均衡服務器的關鍵是:探測和發現業務服務器的運行狀態 + 分配請求給最合適的業務服務器。
一.狀態收集之實現zk的業務服務器列表
首先利用zk的臨時子節點來標記業務服務器的狀態。在業務服務器上線時:通過向zk服務器創建臨時子節點來實現服務注冊,表示業務服務器已上線。在業務服務器下線時:通過刪除臨時節點或者與zk服務器斷開連接來進行服務剔除。最后通過統計臨時節點的數量,來了解業務服務器的運行情況。
在代碼層面的實現中,首先定義一個BlanceSever接口類。該類用于業務服務器啟動或關閉后:第一.向zk服務器地址列表注冊或注銷服務,第二.根據接收到的請求動態更新負載均衡情況。
public class BlanceSever {//向zk服務器地址列表進行注冊服務public void register()//向zk服務器地址列表進行注銷服務public void unregister()//根據接收到的請求動態更新負載均衡情況public void addBlanceCount()public void takeBlanceCount()
}之后創建BlanceSever接口的實現類BlanceSeverImpl,在BlanceSeverImpl類中首先定義:業務服務器運行的Session超時時間、會話連接超時時間、zk客戶端地址、服務器地址列表節點SERVER_PATH等基本參數。并通過構造函數,在類被引用時進行初始化zk客戶端對象實例。
public class BlanceSeverImpl implements BlanceSever {private static final Integer SESSION_TIME_OUT;private static final Integer CONNECTION_TIME_OUT;private final ZkClient zkclient;private static final SERVER_PATH = "/Severs";public BlanceSeverImpl() {init...}
}接下來定義,業務服務器啟動時,向zk注冊服務的register方法。
在如下代碼中,會通過在SERVER_PATH路徑下創建臨時子節點的方式來注冊服務。首先獲取業務服務器的IP地址,然后利用IP地址作為臨時節點的path來創建臨時節點。
public register() throws Exception {//首先獲取業務服務器的IP地址InetAddress address = InetAddress.getLocalHost();String serverIp = address.getHostAddress();//然后利用IP地址作為臨時節點的path來創建臨時節點zkclient.createEphemeral(SERVER_PATH + serverIp);
}接下來定義,業務服務器關機或不對外提供服務時的unregister()方法。通過調用unregister()方法,注銷該臺業務服務器在zk服務器列表中的信息。注銷后的機器不會被負載均衡服務器分發處理會話。在如下代碼中,會通過刪除SERVER_PATH路徑下臨時節點的方式來注銷業務服務器。
public unregister() throws Exception {zkclient.delete(SERVER_PATH + serverIp);
}二.請求分配之如何選擇業務服務器
以最小連接數法為例,來確定如何均衡地分配請求給業務服務器,整個實現步驟如下:
步驟一:首先負載均衡服務器在接收到客戶端的請求后,通過getData()方法獲取已成功注冊的業務服務器列表,也就是"/Servers"節點下的各個臨時節點,這些臨時節點都存儲了當前服務器的連接數。
步驟二:然后選取連接數最少的業務服務器作為處理當前請求的業務服務器,并通過setData()方法將該業務服務器對應的節點值(連接數)加1。
步驟三:當該業務服務器處理完請求后,調用setData()方法將該節點值(連接數)減1。
下面定義,當業務服務器接收到請求后,增加連接數的addBlance()方法。在如下代碼中,首先通過readData()方法獲取服務器最新的連接數,然后將該連接數加1。接著通過writeData()方法將最新的連接數寫入到該業務服務器對應的臨時節點。
public void addBlance() throws Exception {InetAddress address = InetAddress.getLocalHost();String serverIp = address.getHostAddress();Integer con_count = zkClient.readData(SERVER_PATH + serverIp);++con_count;zkClient.writeData(SERVER_PATH + serverIp, con_count);
}3.zk實現分布式命名服務
命名服務是分布式系統最基本的公共服務之一。在分布式系統中,被命名的實體可以是集群中的機器、提供的服務地址等。例如,Java中的JNDI便是一種典型的命名服務。
(1)ID編碼的特性
分布式ID生成器就是通過分布式的方式,自動生成ID編碼的程序或服務。生成的ID編碼一般具有唯一性、遞增性、安全性、擴展性這幾個特性。
(2)通過UUID方式生成分布式ID
UUID能非常簡便地保證分布式環境中ID的唯一性。它由32位字符和4個短線字符組成,比如e70f1357-f260-46ff-a32d-53a086c57ade。
由于UUID在本地應用中生成,所以生成速度比較快,不依賴其他服務和網絡。但缺點是:長度過長、含義不明、不滿足遞增性。
(3)通過TDDL生成分布式ID
MySQL的自增主鍵是一種有序的ID生成方式,還有一種性能更好的數據庫序列生成方式:TDDL中的ID生成方式。TDDL是Taobao Distributed Data Layer的縮寫,是一種數據庫中間件,主要應用于數據庫分庫分表的應用場景中。
TDDL生成ID編碼的大致過程如下:首先數據庫中有一張Sequence序列化表,記錄當前已被占用的ID最大值。然后每個需要ID編碼的客戶端在請求TDDL的ID編碼生成器后,TDDL都會返回給該客戶端一段ID編碼,并更新Sequence表中的信息。
客戶端接收到一段ID編碼后,會將該段編碼存儲在內存中。在本機需要使用ID編碼時,會首先使用內存中的ID編碼。如果內存中的ID編碼已經完全被占用,則再重新向編碼服務器獲取。
TDDL通過分批獲取ID編碼的方式,減少了客戶端訪問服務器的頻率,避免了網絡波動所造成的影響,并減輕了服務器的內存壓力。不過TDDL高度依賴數據庫,不能作為獨立的分布式ID生成器對外提供服務。
(4)通過zk生成分布式ID
每個需要ID編碼的業務服務器可以看作是zk的客戶端,ID編碼生成器可以看作是zk的服務端,可以利用zk數據模型中的順序節點作為ID編碼。
客戶端通過create()方法來創建一個順序子節點。服務端成功創建節點后會響應客戶端請求,把創建好的節點發送給客戶端。客戶端以順序節點名稱為基礎進行ID編碼,生成ID后就可以進行業務操作。
(5)SnowFlake算法
SnowFlake算法是Twitter開源的一種用來生成分布式ID的算法,通過SnowFlake算法生成的編碼會是一個64位的二進制數。
第一個bit不用,接下來的41個bit用來存儲毫秒時間戳,再接下來的10個bit用來存儲機器ID,剩余的12個bit用來存儲流水號和0。

SnowFlake算法主要的實現手段就是對二進制數位的操作,SnowFlake算法理論上每秒可以生成400多萬個ID編碼,SnowFlake是業界普遍采用的分布式ID生成算法。
4.zk實現分布式協調(Master-Worker協同)
(1)Master-Worker架構
Master-Work是一個廣泛使用的分布式架構,系統中有一個Master負責監控Worker的狀態,并為Worker分配任務。
說明一:在任何時刻,系統中最多只能有一個Master。不可以出現兩個Master,多個Master共存會導致腦裂。
說明二:系統中除了Active狀態的Master還有一個Bakcup的Master。如果Active失敗,Backup可以很快進入Active狀態。
說明三:Master實時監控Worker的狀態,能夠及時收到Worker成員變化的通知。Master在收到Worker成員變化通知時,會重新進行任務分配。
(2)Master-Worker架構示例—HBase
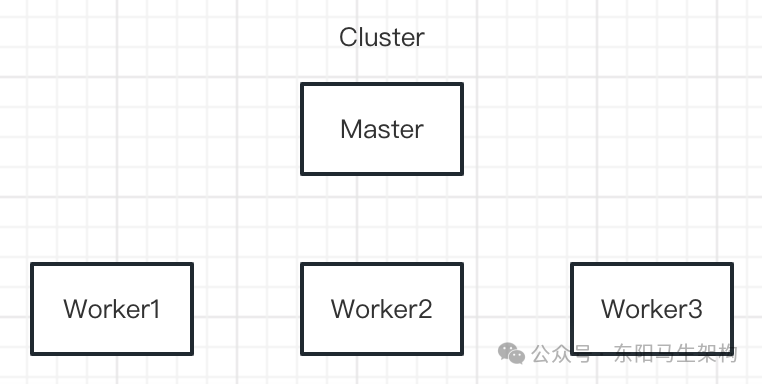
HBase采用的就是Master-Worker的架構。HMBase是系統中的Master,HRegionServer是系統中的Worker。HMBase會監控HBase Cluster中Worker的成員變化,HMBase會把region分配給各個HRegionServer。系統中有一個HMaster處于Active狀態,其他HMaster處于備用狀態。

(3)Master-Worker架構示例—Kafka
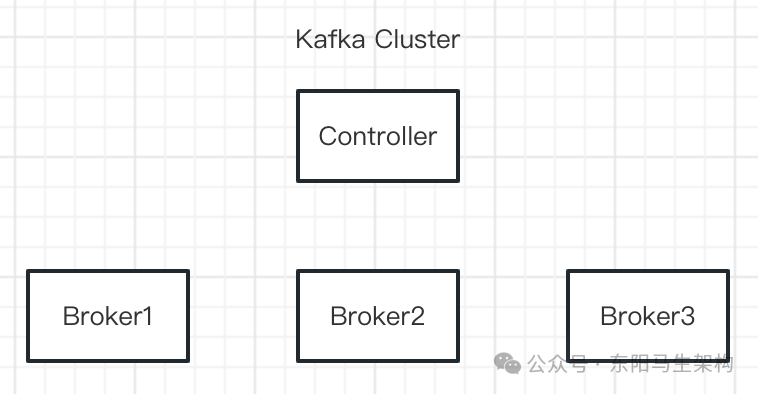
一個Kafka集群由多個Broker組成,這些Borker是系統中的Worker,Kafka會從這些Worker選舉出一個Controller。這個Controlle是系統中的Master,負責把Topic Partition分配給各個Broker。
(4)Master-Worker架構示例—HDFS
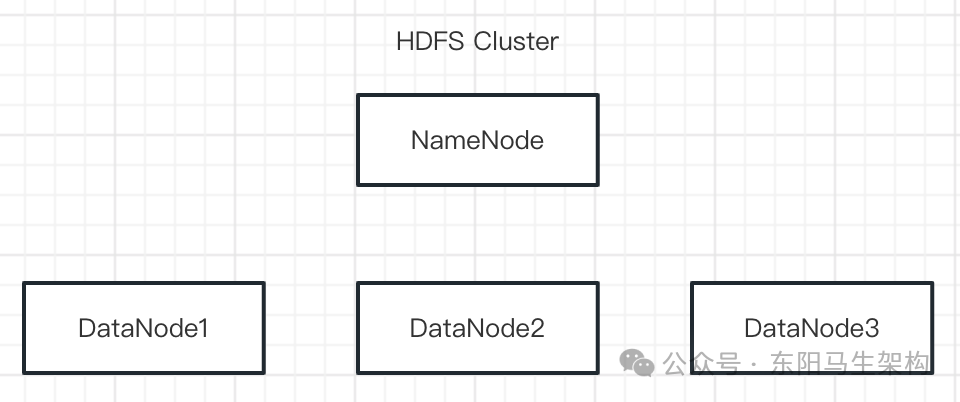
HDFS采用的也是一個Master-Worker的架構。NameNode是系統中的Master,DataNode是系統中的Worker。NameNode用來保存整個分布式文件系統的MetaData,并把數據塊分配給Cluster中的DataNode進行保存。
(5)如何使用zk實現Master-Worker
步驟1:使用一個臨時節點"/master"表示Master。Master在行使Master的職能之前,首先要創建這個znode。如果創建成功,進入Active狀態,開始行使Master職能。如果創建失敗,則進入Backup狀態,并使用Watcher機制監聽"/master"。假設系統中有一個Active Master和一個Backup Master。如果Active Master故障了,那么它創建的"/master"就會被zk自動刪除。這時Backup Master會收到通知,再次創建"/master"成為新Active Master。
步驟2:使用一個持久節點"/workers"下的臨時子節點來表示Worker,Worker通過在"/workers"節點下創建臨時節點來加入集群。
步驟3:處于Active狀態的Master會通過Watcher機制,監控"/workers"下的子節點列表來實時獲取Worker成員的變化。
5.zk實現分布式通信
在大部分的分布式系統中,機器間的通信有三種類型:心跳檢測、工作進度匯報、系統調度。
(1)心跳檢測
機器間的心跳檢測是指:在分布式環境中,不同機器間需要檢測彼此是否還在正常運行。其中,心跳檢測有如下三種方法。
方法一:通常會通過機器間是否可以相互PING通來判斷對方是否正常運行。
方法二:在機器間建立長連接,通過TCP連接固有的心跳檢測機制來實現上層機器的心跳檢測。
方法三:基于zk的臨時子節點來實現心跳檢測,讓不同的機器都在zk的一個指定節點下創建臨時子節點,不同機器間可以根據這個臨時子節點來判斷對應的客戶端是否存活。基于zk的臨時節點來實現的心跳檢測,可以大大減少系統的耦合。因為檢測系統和被檢測系統之間不需要直接關聯,只需要通過zk臨時節點間接關聯。
(2)工作進度匯報
在一個任務分發系統中,任務被分發到不同的機器上執行后,需要實時地將自己的任務執行進度匯報給分發系統。
通過zk的臨時子節點來實現工作進度匯報:可以在zk上選擇一個節點,每個任務機器都在該節點下創建臨時子節點。然后通過判斷臨時子節點是否存在來確定任務機器是否存活,各個任務機器會實時地將自己的任務執行進度寫到其對應的臨時節點上,以便中心系統能夠實時獲取到任務的執行進度。
(3)系統調度
一個分布式系統由控制臺和一些客戶端系統組成,控制臺的職責是將一些指令信息發送給所有客戶端。
使用zk實現系統調度時:先讓控制臺的一些操作指令對應到zk的某些節點數據,然后讓客戶端系統注冊對這些節點數據的監聽。當控制臺進行一些操作時,便會觸發修改這些節點的數據,而zk會將這些節點數據的變更以事件通知的形式發送給監聽的客戶端。
這樣就能省去大量底層網絡通信和協議設計上的重復工作了,也大大降低了系統間的耦合,方便實現異構系統的靈活通信。
6.zk實現Master選舉
Master選舉的需求是:在集群的所有機器中選舉出一臺機器作為Master。
(1)通過創建臨時節點實現
集群的所有機器都往zk上創建一個臨時節點如"/master"。在這個過程中只會有一個機器能成功創建該節點,則該機器便成為Master。同時其他沒有成功創建節點的機器會在"/master"節點上注冊Watcher監聽,一旦當前Master機器掛了,那么其他機器就會重新往zk上創建臨時節點。
(2)通過臨時順序子節點來實現
使用臨時順序子節點來表示集群中的機器發起的選舉請求,然后讓創建最小后綴數字節點的機器成為Master。
7.zk實現分布式鎖
可以利用zk的臨時節點來解決死鎖問題,可以利用zk的Watcher監聽機制實現鎖釋放后重新競爭鎖,可以利用zk數據節點的版本來實現樂觀鎖。
(1)死鎖的解決方案
在單機環境下,多線程之間會產生死鎖問題。同樣,在分布式系統環境下,也會產生分布式死鎖的問題。常用的解決死鎖問題的方法有超時方法和死鎖檢測。
一.超時方法
在解決死鎖問題時,超時方法可能是最簡單的處理方式了。超時方式是在創建分布式線程時,對每個線程都設置一個超時時間。當該線程的超時時間到期后,無論該線程是否執行完畢,都要關閉該線程并釋放該線程所占用的系統資源,之后其他線程就可以訪問該線程釋放的資源,這樣就不會造成死鎖問題。
但這種設置超時時間的方法最大的缺點是很難設置一個合適的超時時間。如果時間設置過短,可能造成線程未執行完相關的處理邏輯,就因為超時時間到期就被迫關閉,最終導致程序執行出錯。
二.死鎖檢測
死鎖檢測是處理死鎖問題的另一種方法,它解決了超時方法的缺陷。死鎖檢測方法會主動檢測發現線程死鎖,在控制死鎖問題上更加靈活準確。
可以把死鎖檢測理解為一個運行在各服務器系統上的線程或方法,該方法專門用來發現應用服務上的線程是否發生死鎖。如果發生死鎖,那么就會觸發相應的預設處理方案。
(2)zk如何實現排他鎖
一.獲取鎖
獲取排他鎖時,所有的客戶端都會試圖通過調用create()方法,在"/exclusive_lock"節點下創建臨時子節點"/exclusive_lock/lock"。zk會保證所有的客戶端中只有一個客戶端能創建臨時節點成功,從而獲得鎖。沒有創建臨時節點成功的客戶端也就沒能獲得鎖,需要到"/exclusive_lock"節點上,注冊一個子節點變更的Watcher監聽,以便可以實時監聽lock節點的變更情況。
二.釋放鎖
如果獲取鎖的客戶端宕機,那么zk上的這個臨時節點(lock節點)就會被移除。如果獲取鎖的客戶端執行完,也會主動刪除自己創建的臨時節點(lock節點)。
(3)zk如何實現共享鎖(讀寫鎖)
一.獲取鎖
獲取共享鎖時,所有客戶端會到"/shared_lock"下創建一個臨時順序節點。如果是讀請求,那么就創建"/shared_lock/read001"的臨時順序節點。如果是寫請求,那么就創建"/shared_lock/write002"的臨時順序節點。
二.判斷讀寫順序
步驟一:客戶端在創建完節點后,會獲取"/shared_lock"節點下的所有子節點,并對"/shared_lock"節點注冊子節點變更的Watcher監聽。
步驟二:然后確定自己的節點序號在所有子節點中的順序(包括讀節點和寫節點)。
步驟三:對于讀請求:如果沒有比自己序號小的寫請求子節點,或所有比自己小的子節點都是讀請求,那么表明可以成功獲取共享鎖。如果有比自己序號小的子節點是寫請求,那么就需要進入等待。對于寫請求:如果自己不是序號最小的子節點,那么就需要進入等待。
步驟四:如果客戶端在等待過程中接收到Watcher通知,則重復步驟一。
三.釋放鎖
如果獲取鎖的客戶端宕機,那么zk上的對應的臨時順序節點就會被移除。如果獲取鎖的客戶端執行完,也會主動刪除自己創建的臨時順序節點。
(4)羊群效應
一.排他鎖的羊群效應
如果有大量的客戶端在等待鎖的釋放,那么就會出現大量的Watcher通知。然后這些客戶端又會發起創建請求,但最后只有一個客戶端能創建成功。這個Watcher事件通知其實對絕大部分客戶端都不起作用,極端情況可能會出現zk短時間向其余客戶端發送大量的事件通知,這就是羊群效應。出現羊群效應的根源在于:沒有找準客戶端真正的關注點。
二.共享鎖的羊群效應
如果有大量的客戶端在等待鎖的釋放,那么不僅會出現大量的Watcher通知,還會出現大量的獲取"/shared_lock"的子節點列表的請求,但最后大部分客戶端都會判斷出自己并非是序號最小的節點。所以客戶端會接收過多和自己無關的通知和發起過多查詢節點列表的請求,這就是羊群效應。出現羊群效應的根源在于:沒有找準客戶端真正的關注點。
(5)改進后的排他鎖
使用臨時順序節點來表示獲取鎖的請求,讓創建出后綴數字最小的節點的客戶端成功拿到鎖。
步驟一:首先客戶端調用create()方法在"/exclusive_lock"下創建一個臨時順序節點。
步驟二:然后客戶端調用getChildren()方法返回"/exclusive_lock"下的所有子節點,接著對這些子節點進行排序。
步驟三:排序后,看看是否有后綴比自己小的節點。如果沒有,則當前客戶端便成功獲取到排他鎖。如果有,則調用exist()方法對排在自己前面的那個節點注冊Watcher監聽。
步驟四:當客戶端收到Watcher通知前面的節點不存在,則重復步驟二。
(6)改進后的共享鎖
步驟一:客戶端調用create()方法在"/shared_lock"節點下創建臨時順序節點。如果是讀請求,那么就創建"/shared_lock/read001"的臨時順序節點。如果是寫請求,那么就創建"/shared_lock/write002"的臨時順序節點。
步驟二:然后調用getChildren()方法返回"/shared_lock"下的所有子節點,接著對這些子節點進行排序。
步驟三:對于讀請求:如果排序后發現有比自己序號小的寫請求子節點,則需要等待,且需要向比自己序號小的最后一個寫請求子節點注冊Watcher監聽。對于寫請求:如果排序后發現自己不是序號最小的子節點,則需要等待,并且需要向比自己序號小的最后一個請求子節點注冊Watcher監聽。注意:這里注冊Watcher監聽也是調用exist()方法。此外,不滿足上述條件則表示成功獲取共享鎖。
步驟四:如果客戶端在等待過程中接收到Watcher通知,則重復步驟二。
(7)zk原生實現分布式鎖的示例
一.分布式鎖的實現步驟
步驟一:每個線程都通過"臨時順序節點 + zk.create()方法 + 添加回調"去創建節點。
步驟二:線程執行完創建臨時順序節點后,先通過CountDownLatch.await()方法進行阻塞。然后在創建成功的回調中,通過zk.getChildren()方法獲取根目錄并繼續回調。
步驟三:某線程在獲取根目錄成功后的回調中,會對目錄排序。排序后如果發現其創建的節點排第一,那么就執行countDown()方法不再阻塞,表示獲取鎖成功。排序后如果發現其創建的節點不是第一,則通過zk.exists()方法監聽前一節點。
步驟四:獲取到鎖的線程會通過zk.delete()方法來刪除其對應的節點實現釋放鎖。在等候獲取鎖的線程掉線時其對應的節點也會被刪除。而一旦節點被刪除,那些監聽根目錄的線程就會重新zk.getChildren()方法,獲取成功后其回調又會進行排序以及通過zk.exists()方法監聽前一節點。
二WatchCallBack對分布式鎖的具體實現
public class WatchCallBack implements Watcher, AsyncCallback.StringCallback, AsyncCallback.Children2Callback, AsyncCallback.StatCallback {ZooKeeper zk ;String threadName;CountDownLatch countDownLatch = new CountDownLatch(1);String pathName;public String getPathName() {return pathName;}public void setPathName(String pathName) {this.pathName = pathName;}public String getThreadName() {return threadName;}public void setThreadName(String threadName) {this.threadName = threadName;}public ZooKeeper getZk() {return zk;}public void setZk(ZooKeeper zk) {this.zk = zk;}public void tryLock() {try {System.out.println(threadName + " create....");//創建一個臨時的有序的節點zk.create("/lock", threadName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL, this, "abc");countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}}//當前線程釋放鎖, 刪除節點public void unLock() {try {zk.delete(pathName, -1);System.out.println(threadName + " over work....");} catch (InterruptedException e) {e.printStackTrace();} catch (KeeperException e) {e.printStackTrace();}}//上面zk.create()方法的回調//創建臨時順序節點后的回調, 10個線程都能同時創建節點//創建完后獲取根目錄下的子節點, 也就是這10個線程創建的節點列表, 這個不用watch了, 但獲取成功后要執行回調//這個回調就是每個線程用來執行節點排序, 看誰是第一就認為誰獲得了鎖@Overridepublic void processResult(int rc, String path, Object ctx, String name) {if (name != null ) {System.out.println(threadName + " create node : " + name );setPathName(name);//一定能看到自己前邊的, 所以這里的watch要是falsezk.getChildren("/", false, this ,"sdf");}}//核心方法: 各個線程獲取根目錄下的節點時, 上面zk.getChildren("/", false, this ,"sdf")的回調@Overridepublic void processResult(int rc, String path, Object ctx, List<String> children, Stat stat) {//一定能看到自己前邊的節點System.out.println(threadName + "look locks...");for (String child : children) {System.out.println(child);}//根目錄下的節點排序Collections.sort(children);//獲取當前線程創建的節點在根目錄中排第幾int i = children.indexOf(pathName.substring(1));//是不是第一個, 如果是則說明搶鎖成功; 如果不是, 則watch當前線程創建節點的前一個節點是否被刪除(刪除);if (i == 0) {System.out.println(threadName + " i am first...");try {//這里的作用就是不讓第一個線程獲得鎖釋放鎖跑得太快, 導致后面的線程還沒建立完監聽第一個節點就被刪了zk.setData("/", threadName.getBytes(), -1);countDownLatch.countDown();} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}} else {//9個沒有獲取到鎖的線程都去調用zk.exists, 去監控各自自己前面的節點, 而沒有去監聽父節點//如果各自前面的節點發生刪除事件的時候才回調自己, 并關注被刪除的事件(所以會執行process回調)zk.exists("/" + children.get(i-1), this, this, "sdf");}}//上面zk.exists()的監聽//監聽的節點發生變化的Watcher事件監聽@Overridepublic void process(WatchedEvent event) {//如果第一個獲得鎖的線程釋放鎖了, 那么其實只有第二個線程會收到回調事件//如果不是第一個哥們某一個掛了, 也能造成他后邊的收到這個通知, 從而讓他后邊那個去watch掛掉這個哥們前邊的, 保持順序switch (event.getType()) {case None:break;case NodeCreated:break;case NodeDeleted:zk.getChildren("/", false, this ,"sdf");break;case NodeDataChanged:break;case NodeChildrenChanged:break;}}@Overridepublic void processResult(int rc, String path, Object ctx, Stat stat) {//TODO}
}三.分布式鎖的測試類
public class TestLock {ZooKeeper zk;@Beforepublic void conn () {zk = ZKUtils.getZK();}@Afterpublic void close () {try {zk.close();} catch (InterruptedException e) {e.printStackTrace();}}@Testpublic void lock() {//10個線程都去搶鎖for (int i = 0; i < 10; i++) {new Thread() {@Overridepublic void run() {WatchCallBack watchCallBack = new WatchCallBack();watchCallBack.setZk(zk);String threadName = Thread.currentThread().getName();watchCallBack.setThreadName(threadName);//每一個線程去搶鎖watchCallBack.tryLock();//搶到鎖之后才能干活System.out.println(threadName + " working...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}//干完活釋放鎖watchCallBack.unLock();}}.start();}while(true) {}}
}8.zk實現分布式隊列和分布式屏障
(1)分布式隊列的實現
步驟一:所有客戶端都到"/queue"節點下創建一個臨時順序節點。
步驟二:通過調用getChildren()方法來獲取"/queue"節點下的所有子節點。
步驟三:客戶端確定自己的節點序號在所有子節點中的順序。
步驟四:如果自己不是序號最小的子節點,那么就需要進入等待,同時調用exists()方法向比自己序號小的最后一個節點注冊Watcher監聽。
步驟五:如果客戶端收到Watcher事件通知,重復步驟二。
(2)分布式屏障的實現
"/barrier"節點是一個已存在的默認節點,"/barrier"節點的值是數字n,表示Barrier值,比如10。
步驟一:首先,所有客戶端都需要到"/barrier"節點下創建一個臨時節點。
步驟二:然后,客戶端通過getData()方法獲取"/barrier"節點的數據內容,比如10。
步驟三:接著,客戶端通過getChildren()方法獲取"/barrier"節點下的所有子節點,同時注冊對子節點列表變更的Watcher監聽。
步驟四:如果客戶端發現"/barrier"節點的子節點個數不足10個,那么就需要進入等待。
步驟五:如果客戶端接收到了Watcher事件通知,那么就重復步驟三。
文章轉載自:東陽馬生架構
原文鏈接:zk基礎—4.zk實現分布式功能 - 東陽馬生架構 - 博客園
體驗地址:引邁 - JNPF快速開發平臺_低代碼開發平臺_零代碼開發平臺_流程設計器_表單引擎_工作流引擎_軟件架構

)

![C++Cherno 學習筆記day17 [66]-[70] 類型雙關、聯合體、虛析構函數、類型轉換、條件與操作斷點](http://pic.xiahunao.cn/C++Cherno 學習筆記day17 [66]-[70] 類型雙關、聯合體、虛析構函數、類型轉換、條件與操作斷點)

:使用dashboard用戶界面(需要訪問外網獲取yaml))
和線性回歸(Linear Regression)對比實驗)



)

JavaScript庫(防抖、節流、函數柯里化)JS庫)
)





