數據質量,通過識別關鍵決策和瓶頸構建信息供應鏈。該模型適用于優化庫存管理、自動化物流、預測需求、實現產品全生命周期追溯及應對突發風險。例如,通過AI機器人自動管理倉庫,或利用數字孿生模擬和優化全球采購網絡。
匯總來自三篇文章:
Data-driven, AI-powered supply chain part 3: Imagining the Future – Supply chain 5.0
Data-driven supply chain part 2: The theory of constraints & the concept of the information supply chain.
Roadmap for building a data-driven, AI-powered supply-chain
1 供應鏈網絡的概念、約束理論(TOC)與信息供應鏈

盡管關于大數據和人工智能(AI)如何改變企業供應鏈的文章鋪天蓋地,但 Gartner 在過去十年間的(持續)調查顯示,只有不到一半的 CDAO(首席數據與分析官)認為他們的團隊在創造“一些”價值方面取得了成功(最新數據來自 Gartner, 2023年3月)。根據我的經驗,這主要是因為組織在沒有首先理解提高企業價值鏈吞吐量所涉及的關鍵原則的情況下,就盲目地投資于高級分析平臺和人工智能工具。
通常情況下,失敗在于CDAO的策略,而不在于人工智能工具或技術的選擇。Gartner 2020年的一項調查指出了供應鏈分析成功面臨的三大挑戰:
- 缺乏所需的可擴展數據基礎(來自供應鏈)
- 缺乏與供應鏈相關的人才和技能(你要么找到有供應鏈領域經驗的人,要么找到有高級分析經驗的人……很少能找到兩者都懂的人)
- 在構建供應鏈分析業務案例方面缺乏清晰度……換句話說,缺乏一個連貫的供應鏈分析策略。
第一部分 探討了數據驅動的供應鏈決策在過去幾年中是如何演變的,從最早的初級決策支持系統到未來將嚴重依賴大數據、AI-ML 和生成式 AI 的供應鏈。
第二部分 解釋了企業價值鏈_并非一個簡單的、單一的供應鏈_,而是一個復雜的網絡,或者說是一個由多個相互依賴的供應鏈組成的相互關聯的網絡,這些供應鏈需要協同工作、完美和諧,以確保供應鏈以100%的效率運行。同時,本部分還闡述了_解決信息供應鏈中的瓶頸是成功實施約束理論(TOC)以最大化企業吞吐量的關鍵,以及如何將約束理論應用于信息供應鏈為構建數據驅動的供應鏈_提供了一種萬無一失的方法。
第三部分 闡述了_數字化供應鏈的緊迫性;投資供應鏈5.0已不再是可選項,而是希望在未來十年保持 relevance 和競爭力的組織的生存必需品。本部分接著描述了數字化供應鏈的關鍵特征,并為構建數據驅動、AI賦能的供應鏈提供了一個宏觀的路線圖_。
第一部分:數據驅動的供應鏈——歷史與演變
數據驅動決策的概念是新事物嗎?
“數據支持決策”的概念并**不新鮮**。商業智能(BI)自20世紀60年代以來就已存在。然而,現在的數據量和可用性遠超以往,企業比以往任何時候都更加依賴數據驅動的決策。對于那些持懷疑態度的人,我推薦《知識經濟雜志》(Journal of Knowledge Economy)上的一篇優秀文章,它記錄了1950-2020年間“信息驅動決策過程”的演變 (Parra. X & Ors, J Knowl Econ, 2022)。我們這些在90年代上大學的人(當時彼得·德魯克還健在)可能還記得,當時我們被教導說“經理的工作就是根據手頭可用的任何數據做出理性的決定”。德魯克被認為是使用決策樹來描述決策過程(DMP)的先驅(Drucker, 1967)。現在在人工智能中廣泛使用的一些計算模型,如專家系統、神經網絡等,實際上是在70年代提出的,但真正的進展是在80年代和90年代取得的,因為計算機變得更加強大和實惠。隨著1990年代有越來越多的數據可用于支持決策,決策支持系統(DSS)也應運而生。
在制造業中,DSS最受歡迎的應用之一是在物流和供應鏈管理領域。
供應鏈決策支持系統(DSS):簡史
二十五年前,我曾是一名相當忙碌的 SAP 顧問,在成功完成了幾個完整的實施周期后,我換了家公司,轉行做供應鏈咨詢……主要是因為我想做點不一樣的事情。此外,我對供應鏈管理并不陌生;因為我在物流和分銷包裝方面有豐富的領域經驗。

圖1:傳統的供應鏈概念
那些年,i2 Technologies 主導著供應鏈,尤其是決策支持系統(DSS)領域。然而,從第一天起,我就能注意到 i2 的整個業務有些奇怪……‘i2’給我的印象是一個考慮不周、設計笨拙的產品;尤其是與像 SAP 這樣設計精妙絕倫的產品相比。i2 的大部分產品實施都是由 i2 Technologies 自己完成的,偶爾會從新吸納的合作伙伴那里請來一兩個顧問。我很快了解到,i2 的顧問收取高昂的費用,只坐商務艙+……但每當有客戶試圖提出尖銳問題時,他們只是拋出一些行話;雖然他們說的話聽起來令人印象深刻且重要,但很少有實際意義。幾個月內,我就足以推斷出他們沒有為客戶提供任何真正的價值……諷刺的是,i2 過去常常聲稱他們為客戶帶來了超過750億美元的“經審計的節省”。無論這個數字的真實性如何,它無疑幫助他們“賣出”了產品。
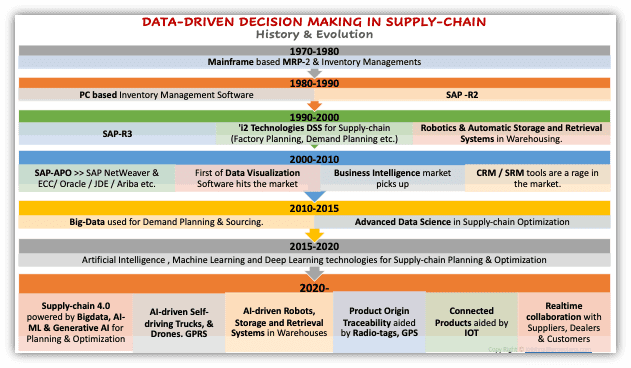
圖2:供應鏈中的數據驅動決策——歷史與演變
SAP 最初與 i2 密切合作。我記得他們的一些產品被集成到 SAP 中,并且可以在 SAP 內部進行配置。但他們最終因為一些從未公開的原因而分道揚鑣,SAP 很快開發并推出了 APO——一個設計得更好、確實能用并能創造價值的產品。
2002年,i2 因連續五年虛報收入而被美國證券交易委員會(SEC)罰款超過10億美元。不確定他們的外部審計師是誰,以及他們是否也“審計”了那750億美元的節省。
新千年的第一個十年見證了一系列新工具和技術的引入,用于商業智能、數據倉庫、數據可視化等,以及CRM和SRM。其中最知名的有 SAP BI-BO、Oracle、Siebel、Ariba 等。Tableau 在2003年首次亮相(當時它被稱為 Polaris)。
在過去十年中,隨著大數據——高級分析平臺、AI-ML、物聯網(IOT)——互聯產品、自動駕駛卡車、無人機送貨等的出現,供應鏈軟件市場經歷了重大創新。現在,生成式AI有望進一步徹底改變它。
2 TOC解決信息供應鏈中的瓶頸

在90年代末,我斷斷續續地聽說過**約束理論(TOC)**,但直到2001年底才真正開始關注。我在馬來西亞參加i2公司的年會時,遇到的一位顧問喝多了,結果滔滔不絕地向我宣講TOC將如何改變世界。成立i2公司的兩位合伙人之一的Ken Sharma,在與Sanjiv Sidhu聯手之前,就曾在高德拉特研究所(Goldratt Institute)工作。在回機場的路上,我買了艾利·高德拉特(Eli Goldratt)的書《目標》(The Goal),并立刻被它迷住了。書中的模型既簡單又合乎邏輯,而且讀起來引人入勝……更像一本快節奏的驚悚小說,而不是一本枯燥的商業書籍。
TOC的市場在印度開始升溫,尤其是在“可行愿景”(viable vision)被引入之后。這個概念激發了每一位有抱負的CEO的想象力;畢竟,誰能抗拒一個僅用四年時間就將公司的營業收入(topline)變成其凈利潤(bottom line)的機會呢?
簡單來說,一家實施**TOC**的公司可以設定一個目標,在四年內將其當前的營業收入數字,轉變為公司的凈利潤數字。這聽起來不可思議,但高德拉特相信,對于一家公司來說,這是一個完全“可行的愿景”。他曾專門為CEO和高管們舉辦為期一天的研討會,解釋為什么這樣的愿景是可行的。高德拉特的說服力如此之強,以至于許多CEO都想嘗試一下。此外,高德拉特也愿意分擔風險;他承諾,當且僅當公司成功實現其既定目標時,他才會收取大部分費用。
雖然有一些巨大的成功案例,但也有不少令人失望的案例。我想,“高層管理承諾不足”必定是失敗的關鍵根本原因之一。隨著時間的推移,TOC顧問們不再談論“可行愿景”,但他們仍然持續獲得業務,特別是來自中等規模的成長型公司。為TOC項目設定的目標雖然仍然具有挑戰性,但絕對不像“可行愿景”那樣雄心勃勃。
信息供應鏈中未解決的瓶頸是TOC項目失敗的原因嗎?
嚴格來說,TOC項目并不會“完全”失敗。然而,它們可能無法交付預期的價值。它們確實能產生結果,但交付的規模和價值可能取決于你究竟是如何設計和實施項目的。在絕大多數情況下,在四年或更短時間內將營業收入數字轉變為凈利潤的“愿景”,最終可能被證明是“不可行的”。
學術界對**TOC有不少批評**。一些人聲稱TOC并無新意(Steyn H., 2000),它大量借鑒了已有的概念;一些人聲稱它與Wolfgang Mewes提出的理論相同(Mewes. W., 1963);還有人認為它不適用于產品組合決策等。大多數學者似乎認為,高德拉特教授的研究缺乏被稱為嚴謹學術理論所必需的“嚴謹性”。高德拉特曾發表一篇題為《站在巨人的肩膀上》(Standing on the shoulders of Giants, Goldratt, 2009)的論文,承認了啟發TOC的各種既有概念和人物。
雖然對于實施失敗的原因沒有共識,但許多顧問將失敗歸咎于以下原因:
- 范圍定義有限 & 高層管理承諾不足…… 典型情況是管理層過于謹慎,最終選擇一個小的子流程進行試點,而這個子流程本身就不適合TOC的實施,也無法最終證明其價值。
- 識別出的_關鍵約束_并非“真正的關鍵”約束。
- 客戶無法應對“陣痛期”帶來的業務中斷,最終退回到舊的流程模型。
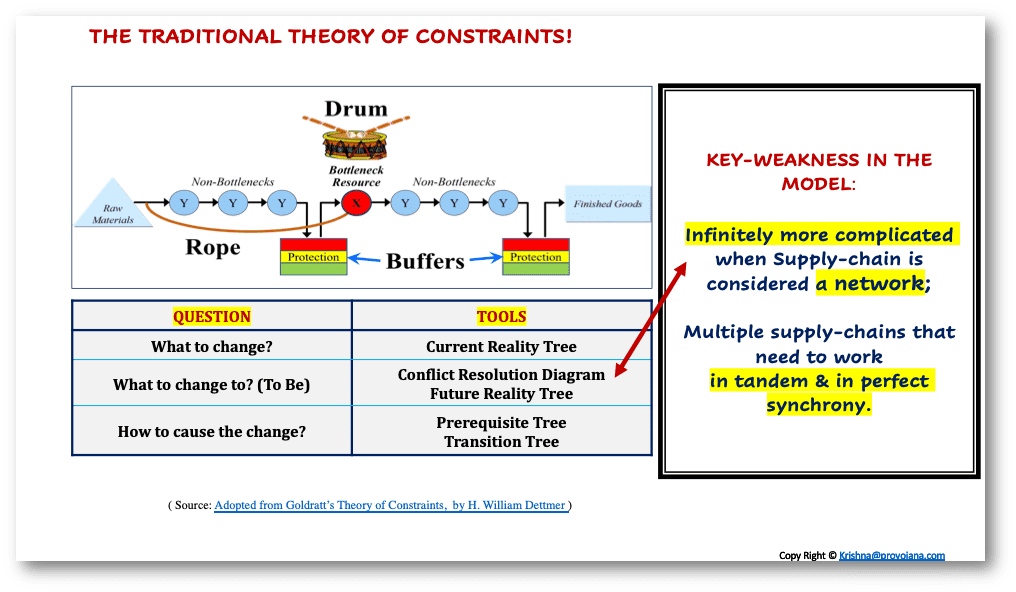
在我看來:TOC項目之所以失敗,是因為:
- 它們未能認識到**企業價值鏈_并非一個_單一鏈條,而是一個由多個相互依賴的供應鏈_組成的_復雜網絡**。
- 它們**未能解決至關重要的信息供應鏈中的瓶頸**。
讓我進一步解釋。
我實施TOC的經驗:信息供應鏈的重要性
在過去的三十年里,我大部分時間都在咨詢和服務公司工作。我曾在我所在的一家大型數字內容服務KPO(知識流程外包)公司擔任首席運營官(COO),并在其中一個部門嘗試了TOC的概念。
整個經歷非常引人入勝……那個部門多年來經營不善,剛剛失去了其最大客戶——一家全球出版公司——的信任(以及四分之三的業務)。團隊士氣低落,我的老板(兼董事總經理)私下向我承認,他已經束手無策了。我被要求親自推動這項業務,盡我所能讓它重回正軌。當時系統和人員中已經充滿了困惑,所以我沒有在任何地方提及我正在推行TOC實施,以免讓他們更加困惑。由于讓業務重回正軌對我來說是更重要的優先事項,我想同時嘗試TOC和服務鏈優化(Service-chain Optimization,簡稱SCO,一個不如TOC普及的概念)……此外,我一直認為,創建“對整個價值鏈的無縫、精細化、可下鉆的可見性”是**最重要的修正措施**。因此,建立對供應鏈(在這里是服務鏈)的可見性是我最大的優先事項。
作為標準盡職調查的替代,我要求該部門的所有團隊創建一個“每日狀態報告”(DSR)——一份_清楚列出**“每項工作”在工作流程不同階段進展狀態**的報告_。我強制推行了一個“標準報告格式”,這個格式隨著時間的推移不斷演變,變得越來越精細。我確保所有頁面上不同集群的精細化元素,最終能匯總到報告首頁(我們稱之為_“概覽”_)的總數據上,作為高層管理的“執行摘要”。
在我看來,每日狀態報告旨在成為一個“數字孿生”,反映出整個價值鏈中每個工作流程階段里每項工作的真實狀態。雖然這個**數字孿生還不能實時“收集和監控信息(數據+洞察)**”,但6-12小時的延遲對我們起步階段來說是可以接受的。
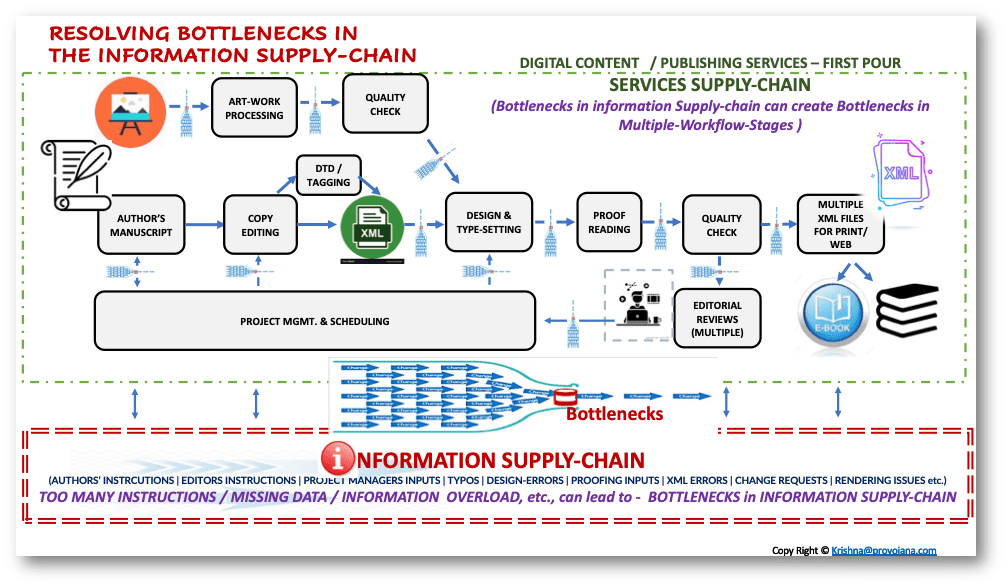
每天,我都會與所有集群負責人和團隊負責人召開_每日狀態會議_,在會上我會過問每一項延遲或可能延遲的工作。這使得**發現工作流程中哪個特定階段是瓶頸,或可能成為瓶頸變得非常容易。通過快速提升關鍵階段的產能,在很大程度上解決了瓶頸問題**。除了瓶頸,其他初期問題還涉及“溝通”或溝通不暢。客戶和交付團隊之間的信息和指令在傳遞過程中失真,導致關鍵工作流程階段的返工,進一步限制了產能。然后,令我驚訝的是,我發現在_內部工作流程的不同階段之間也發生了類似的溝通中斷_。在大多數情況下,數據缺失以及來回的澄清溝通_是_瓶頸的根本原因。
我們開始在**每日狀態報告中創建一個空間,用于存放所有需要在內部工作流程不同階段之間以及與客戶團隊交換的關鍵信息**。我們創建了一種_顏色代碼_來提醒客戶注意“缺失的信息”,以確保他們優先澄清。
很快,隨著工作流程瓶頸的解決和**信息流的順暢**,幾個月前曾使該部門陷入癱瘓的初期交付問題開始消失。同時,客戶開始認識到交付方面的顯著且可喜的改進,并開始將越來越多的業務從其他供應商轉回我們公司。我們開始在_每日狀態報告_中為客戶創建一個單獨的部分,列出可能流向我們的_新業務_。這些預先的信息幫助各集群提前規劃并增加產能以應對業務增長。
九個月內,該部門成為了公司中效率最高(也是最盈利)的業務單位。到第九個月底,該部門的營業收入運轉率(月銷售額)增長了兩倍多。_每日狀態報告_的概念隨后被推廣到其他部門,并取得了類似的巨大成功。
以下是我從這次實驗中得到的關鍵經驗:
- 企業價值鏈**并非一個單一鏈條,而是一個復雜的網絡,或一個由多個供應鏈相互交織而成的網**。
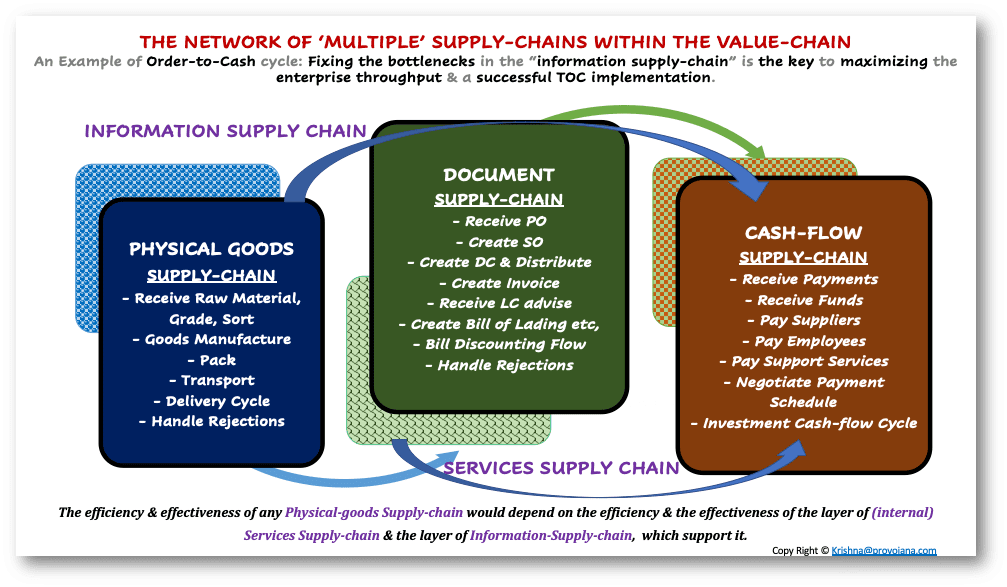
- 每一個**實物商品供應鏈都有一個服務供應鏈**支持它,即一組提供服務的人員,以確保_實物商品供應鏈_的良好運作。
- 例如:在供應鏈的每個階段,你都需要有人制作運單、收貨報告、發票等文件……_服務供應鏈_的效率和速度會影響_實物商品供應鏈_的速度和效率。例如:任何在創建消費稅發票(GST-Invoices)上的延誤都可能導致卡車無法離開工廠。
- 每一個_實物商品供應鏈_都有一個_現金流供應鏈支持著每一次商品所有權從一個實體轉移到另一個實體,或每一次創建_合法寄托_時的_價值交換……一個為支持_實物商品供應鏈_而交付的每項服務付費的_現金流供應鏈_。例如:任何對運輸等一項或多項服務的付款延遲,都可能使實物商品供應鏈陷入停頓。
- 每一個_實物商品供應鏈_都由一個_數據供應鏈/信息供應鏈支持……信息以物理文件(如消費稅發票或運單)或“數字文件”的形式從一個工作流程階段傳遞到下一個階段(例如:SAP使用一種名為_IDoc(內部文檔)的格式來發送與_唯一交易_相關的數據,以便與外部應用程序交換信息)。
- 為了讓一個供應鏈以滿負荷、最高產出率良好運作,多層供應鏈需要_協同工作,完美平衡_。現金流供應鏈、信息供應鏈或內部服務供應鏈中的任何瓶頸都必然會在_實物商品供應鏈_中造成瓶頸。
2. 創建“對供應鏈的無縫、可下鉆的可見性”是任何供應鏈項目最重要的第一步——無論行業領域如何。這條規則對于制造業的_實物商品供應鏈_和對于服務業的_服務鏈_同樣重要。
理想的供應鏈可見性模式應該是一種“數字供應鏈孿生”(例如:類似于SCADA系統),它能反映供應鏈每個階段每項工作的“即時真相”。即時真相_意味著_實物商品供應鏈_與_數字孿生_之間的信息_即時交換。
3. 在制造業中,那些**只關注“實物商品供應鏈”內部“約束”,而_忽略_“服務供應鏈、現金流供應鏈和信息供應鏈”中約束的TOC實施……注定會失敗**。
對于服務公司而言,_服務鏈_的效率和效果將取決于支持它的_現金流供應鏈_和_信息供應鏈_各層的效率和效果。_信息供應鏈_在服務公司中遠比其他更重要。
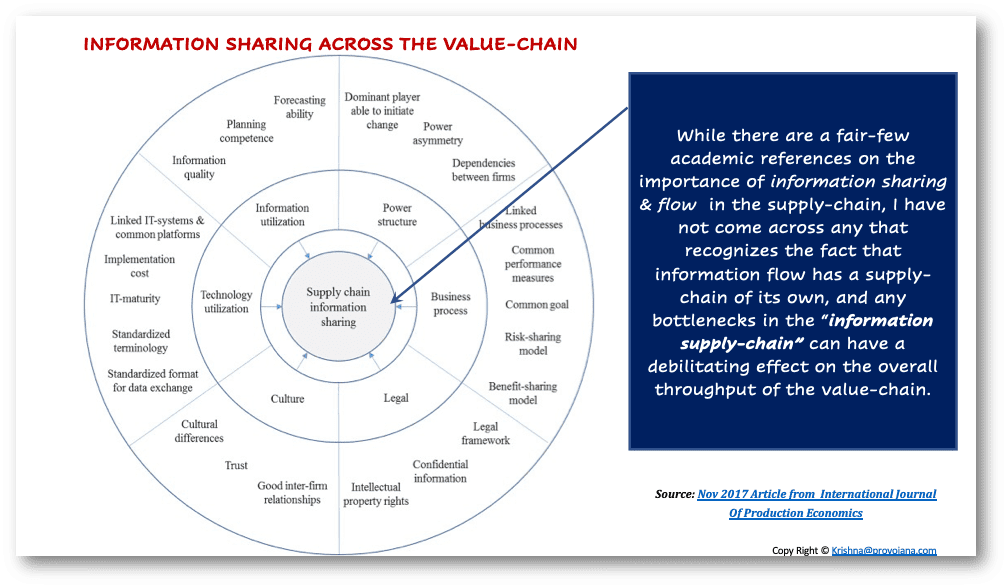
4. 在典型的TOC實施中,為緩解(工作流程中)“約束”而創建的一系列“流程中緩沖”,將意味著在制品庫存的增加,這反過來又意味著**營運資本的增加,并可能導致現金流供應鏈的壓力增大**。
有大量文章論述了在一個_工作流程階段_“提高產出率”如何可能給下游的后續_工作流程階段_帶來_增量壓力_和瓶頸。
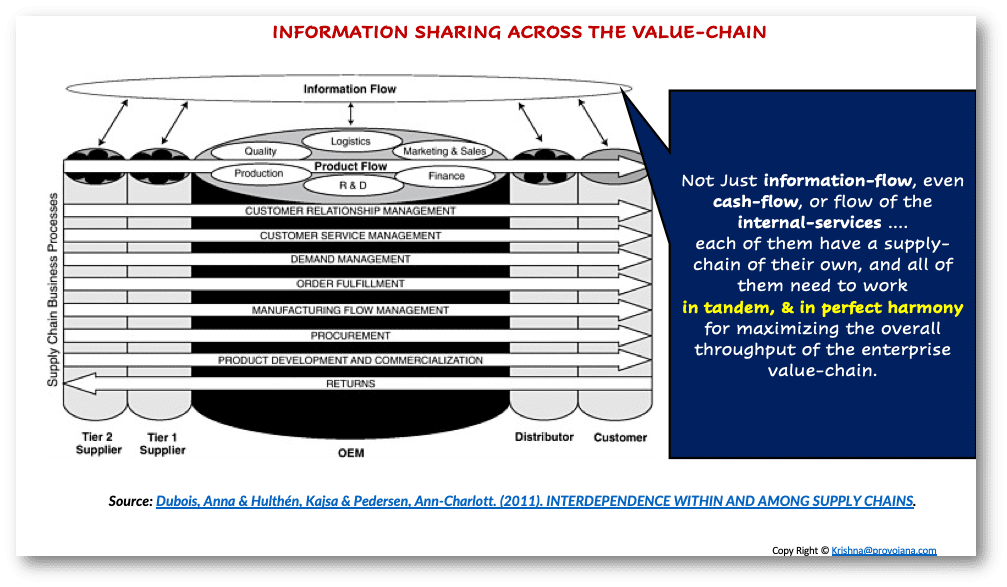
5. 在TOC實施中**最大化組織的“產出率”,需要在不打破不同相互依賴的供應鏈層(實物商品、內部服務和信息)之間的微妙平衡或“均衡**”的情況下進行。
這就引出了下一個大問題。如果工作流程中每個階段的每個決策都由“數據”驅動……即100%相關且充分的數據來支持驅動供應鏈的決策,那會怎么樣?
你究竟如何識別和列出在供應鏈的每個階段正在做出哪些供應鏈決策?更復雜的是,_實物商品供應鏈_中的每一個此類決策都可能影響_現金流供應鏈_的關鍵指標,或對_服務供應鏈_的需求。
在我上面提到的案例研究中,我們確實研究了每個工作流程階段、每項工作的_真實精細數據_,更重要的是,我們**制度化了一種方法來生成和利用這些數據來做出“服務鏈決策”。在我們的案例中,數據是“真正”的優先事項;因此我們有一個深思熟慮的策略來識別和獲取支持每個工作流程階段決策的數據**。
但我不確定一個典型的TOC實施是否會“優先考慮支持供應鏈決策的數據”。我也不確定TOC實施是否考慮到了**相互依賴的多層供應鏈的概念,以及可能發生在現金流和信息(數據+洞察)供應鏈中的瓶頸,而這些瓶頸反過來又會影響實物商品供應鏈**。
那么,究竟該如何構建一個數據驅動的供應鏈呢?我遇到的大多數文章和書籍只提供了籠統的方向……對于尋求構建“數字供應鏈”具體指導的人來說用處不大。
下面由OpenAI ChatGPT生成的回應(右圖)出人意料地比大多數文章做得更好。它在第一步就提到了“識別流程瓶頸”。

3 數據驅動、人工智能驅動的供應鏈

“數字化”供應鏈的迫切需求
- 根據 CGE 2020 年的一份報告,致力于供應鏈數字化的公司有望將供應鏈成本降低高達 50%;此外,采購成本可降低 20%,同時因競爭優勢的增強而實現超過 10% 的收入增長。(來源:全球企業中心 (CGE) 與 CREATe.org 合作)
- 根據 Hackett Group 的數據,世界一流的供應鏈組織通過數字化轉型可節省高達 45% 的采購成本。(來源:Hackett Group)
可以得出結論:供應鏈“數字化”已成為企業保持競爭力的生存必需品。除了效率、客戶體驗和收入的大幅提升外,公司還可以期待巨大的成本節約……
展望未來:數據驅動(數字)供應鏈的構成要素
注意
任何數據驅動或人工智能驅動的供應鏈,其成效完全取決于支撐決策的底層**“數據”的“質量、粒度和豐富性”。因此,任何“數字供應鏈”最關鍵的組成部分都是數據**,以及支撐實物商品供應鏈的底層信息供應鏈。
一個優秀的戰略顧問,通常會從描繪最終目標開始……因此,在我們嘗試為構建數據驅動的供應鏈制定路線圖之前,讓我們首先設想一下它未來的樣貌。
定義“理想”最終狀態:未來人工智能驅動的數字供應鏈的特征
未來的供應鏈將由能夠實時收集和分析數據的自我管理、自動化技術驅動。以下是一些示例:
- #基于云的SCM工具和用于供應鏈規劃與優化的AI驅動算法
- #來自擴展價值鏈(涵蓋供應商的供應商到客戶的客戶)的精細化地理標記數據
- #位置數據(每筆交易都帶有位置戳)
- #工廠和倉庫中的機器人技術:機器人自動存儲和檢索系統
- #配備GPS的自動駕駛卡車
- #嵌入供應鏈中每個SKU和每個設備的物聯網(IOT)和無線電標簽
- #基于互聯網的人工智能機器人(監聽站),用于持續掃描市場(互聯網)以尋找更好的貨源、材料和價格,并快速收集和處理風險數據(地緣政治/供應相關)
- #在任何可能的地方采用人工智能驅動的自動化流程
- #貫穿整個價值鏈的數據驅動決策
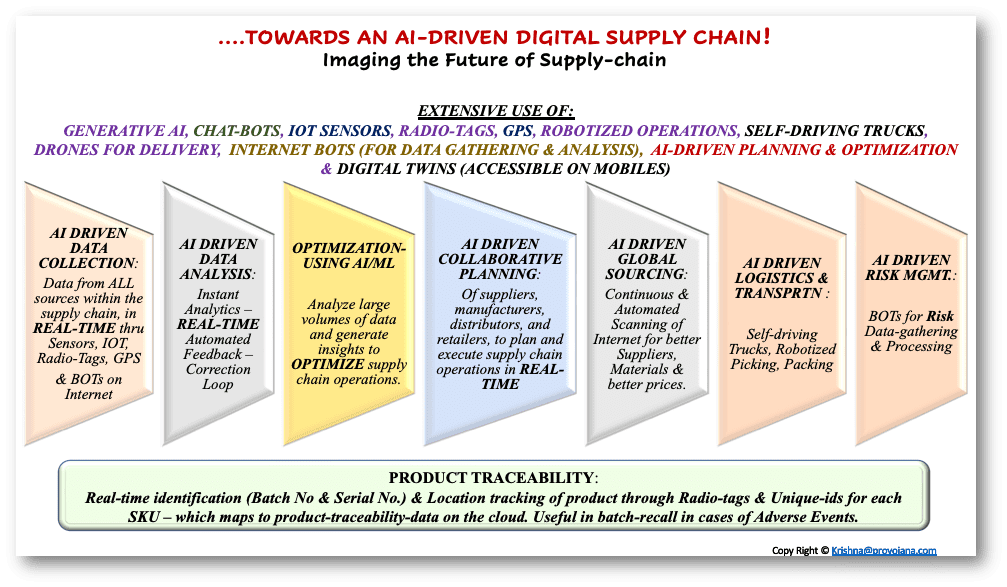
圖 9:展望未來:數據驅動、人工智能驅動的數字供應鏈
-
數據收集: 這是“數字供應鏈”中最重要的部分。未來的供應鏈預計將廣泛使用物聯網(IOT)、無線電標簽、GPS等技術進行自動化數據采集(在極少數情況下,由事件驅動或周期驅動)。
- # 企業數據通過無縫集成的地理標記微觀市場數據得到增強(可能由第三方以訂閱模式提供)
- # 所有交易數據無一例外都將被地理標記,并即時分發到基于云的應用和數據湖倉。
- # 每輛卡車都將配備 GPS,其位置將被 24x7 全天候跟蹤。每個“配送包裹”都將帶有一個無線電標簽,其在供應鏈中的移動將被跟蹤。
- # 每次采購、每次訂單履行、每個工作進度、每個項目都將通過帶有時間和位置戳的數據進行跟蹤。
- # 每個產品和每個工作任務都將帶有一個無線電標簽,其在工作流各階段的移動將被自動跟蹤。
- # 每個商店和倉庫都將擁有完全自動化、由人工智能驅動的自動存儲和檢索系統(ASRS),該系統能自動裝卸單元化托盤貨物,同時跟蹤每個零件號和每個 SKU 的位置(貨位號)。
- # 所有設備和裝置無一例外都將啟用物聯網/GPS,并自動生成數據分發到多個分析引擎,用于控制和持續改進。
- # 所有員工可能攜帶帶有 GPS 的身份標簽,或者他們的手機將通過定制的企業應用進行跟蹤。
- # 所有通過短消息應用和電子郵件進行的辦公室內移動通信都將帶有時間和位置戳。
- # 通過每個 SKU 的無線電標簽和唯一ID實現實時批次跟蹤和產品可追溯性數據。
- # 與客戶和供應商的所有通信都將帶有時間和位置戳。
- # 內部企業數據將由外部數據補充/輔助,這些數據來自人口普查數據、市場數據等來源——所有數據在上傳到數據湖倉之前都經過排序、規范化和地理標記。
-
運輸:
- # 每輛卡車都將是自動駕駛、啟用 GPS,并具備發送緊急求救信號的設施。
- # 數字孿生(相當于控制運輸網絡的 SCADA 系統)將攜帶每個包裹、每輛卡車運載的每個 SKU 的詳細信息,直至每個 SKU 的“序列號”級別。
- # 用于運送產品的人工智能控制的自動駕駛無人機——尤其適用于最后一公里配送。
-
倉儲與供應鏈運營: 完全機器人化——自動化、人工智能驅動
- # 機器人揀選和包裝,人工智能驅動的_自動存儲和檢索系統_(ASRS)
- # 通過每個箱子、每個托盤上的_無線電標簽_,只需按一下按鈕即可自動完成即時庫存盤點。
-
客戶/供應商協作
- # 基于生成式人工智能的聊天機器人進行交流
- # 基于生成式人工智能的 IVRS 和機器人電話進行語音通信
- # 基于生成式人工智能的社交媒體活動
-
風險管理:
- # 使用人工智能驅動的機器人監聽器收集風險數據,以捕捉“風險信號”、“異常行為”或任何“不尋常活動”或“不尋常通信”——這些數據既來自內部企業數據,也來自包括公共和私人數據庫、社交媒體和互聯網在內的其他外部數據源。
- # 人工智能驅動的風險報告和早期預警信號
- # 人工智能驅動的自動化“路線修正”以及與供應商、客戶、分銷商和員工的“溝通”。
- # 對于有保質期的物品(帶有有效期的 SKU),將首先根據最短效期的批次進行揀選和包裝。
-
產品可追溯性、批次跟蹤與不良事件報告
- # 通過每個 SKU 的無線電標簽和唯一 ID 實時識別(批號和序列號)和跟蹤產品位置——這些信息映射到云上的_產品可追溯性數據_。
- # 可追溯性數據 包括:材料和部件的來源、其加工歷史和分銷情況,如 ISO 9000:2005 (2005) 所述,以及與產品的歷史、使用或位置相關的數據。
- # 在發生任何_不良事件報告 (AER)_ 的情況下(例如食品、藥品,甚至像汽車這樣的耐用消費品),參考特定批號,可以輕松、即時地進行_批次召回_。這將自動觸發一個警報,并附帶“請勿銷售/請勿使用警告”——不僅針對該特定批號,還針對所有使用了來自同一供應商相同輸入批次的材料和部件的所有批次。無論這些有風險的批次位于何處,該警報都會在整個供應鏈(分銷網絡)中自動復制。
-
數字孿生:
- # 基于移動端:可從“任何地點、任何時間”進行操作,用于規劃、監控、修正和控制。
- # 數字孿生將 100% 映射擴展供應鏈的所有階段,包括可控的供應商供應鏈和客戶供應鏈。
- # 控制塔與人工智能協同決策: 人工智能驅動的控制塔幫助管理者做出決策并管理供應鏈的整體績效。管理者只需處理極端異常情況。
-
全球采購與持續改進
- # 使用機器人持續自動掃描互聯網,以尋找更好的供應商、材料和更優的價格。
- # 使用生成式人工智能與客戶進行價格談判。
- # 在互聯網和社交媒體上部署人工智能驅動的機器人(監聽站),以捕捉關于威脅(如不良事件和地緣政治風險)或機會(更好的材料、更優的價格、更好的貨源)的信號。
構建人工智能驅動的數字供應鏈
我之前曾廣泛撰文論述數據驅動決策、數據到決策的生命周期,以及為建立數據驅動型組織創建路線圖和商業案例。(請參閱我的書《Big Data for Big Decisions: Building a Data-driven Organization》,P. Taylor & Francis, UK, 2022 及在 Data Science Central 上的文章)。
正如我所論證的:拋開花哨的高級分析平臺和人工智能不談,建立數據驅動型組織的關鍵在于_專注于關鍵決策——即那些占業務成果 90% 的 10% 的組織決策。_
因此,要構建數據驅動的供應鏈,必須提出并回答以下關鍵問題:
- 占供應鏈效率 80-90% 以上的關鍵“供應鏈決策”是什么?
- 支持這些已識別的關鍵決策的數據是什么?
注意:大多數組織面臨的更重大、更根本的問題是:他們根本不具備支持組織內關鍵決策所需的數據——無論是必要的粒度還是質量。毋庸置疑,在缺乏數據的情況下構建數據驅動的供應鏈是徒勞無功的,盡管許多首席數據官(CDO)正在嘗試這樣做。
簡而言之,我主張通過以下步驟來構建數據驅動的供應鏈:
| 構建數據驅動型組織 | 構建數字供應鏈 |
|---|---|
| 從決策入手。列出所有組織決策,以及“風險價值”和“頻率”等指標。 | 創建一個流程約束的主列表,并列出與每個流程約束相關的決策。每個工作流階段的每個流程約束都代表一組決策嗎?(可能有很多流程約束,但只有少數是重要的)相同/相似的流程約束可能在多個工作流階段重復出現。注意重復出現的頻率。計算每個決策的“風險價值”:我們能否估算每個階段由于瓶頸造成的“吞吐量損失”? |
| 識別占業務成果 90% 的那 10% 的決策。 | 列出瓶頸——從大到小?以及占吞吐量損失 90% 的那 10% 的瓶頸是哪些?創建一個與這 10%“關鍵”瓶頸相關的流程約束列表。 注意:所有工作流階段都很重要。當前沒有瓶頸并不意味著未來不會出現瓶頸。 |
| 創建路線圖和商業案例。 | 通過優先處理與導致 80-90% 吞吐量損失的 10% 瓶頸相關的流程約束,來創建供應鏈數字化的路線圖。注意:將所有工作流階段的關鍵流程約束進行數字化非常重要……瓶頸(及相關流程約束)的關鍵性決定了其優先級。 |
| 決策背后的數據:根據需要創建并映射信息供應鏈及以下內容:服務供應鏈和現金流供應鏈。 | 映射每個工作流階段所需的信息流(數據+洞察)。映射“緩解”流程約束和可能瓶頸所需的信息流(數據+洞察)。完整地映射信息供應鏈——(從數據創建、分發、消費、歸檔、檢索到再利用)。 |
| 交叉映射信息供應鏈與實物商品供應鏈——(清晰地表明“信息可用性”與其“對流程約束的影響”之間的因果關系)。 | |
| 您需要的數據 vs. 您擁有的數據 | 檢查:您是否擁有支持供應鏈決策所需的所有數據。 |
| 對于增量數據(Delta-Data):創建并實施數據采購策略。 | |
| 構建分析以提高決策質量 | 構建分析和 AI 解決方案以提高供應鏈決策的質量。 |
| 構建數字孿生:一個遠程復制品,為整個供應鏈提供狀態和控制機制(類似于 SCADA 系統)。通常,您可以使用“數字孿生”來更改流程參數。 |

)
的核心概念)

![[ LeetCode優選算法專題一雙指針-----盛最多的水]](http://pic.xiahunao.cn/[ LeetCode優選算法專題一雙指針-----盛最多的水])


)
)
雙向鏈表)



等級考試試卷(一級))



)

