
【摘要】高效的、針對特定任務的提示通常由專家精心設計,以整合詳細的說明和領域見解,這些見解基于對大型語言模型 (LLM) 的本能和目標任務的復雜性的深刻理解。然而,自動生成這種專家級提示仍然難以實現。現有的提示優化方法往往忽視領域知識的深度,難以有效探索專家級提示的廣闊空間。為了解決這個問題,我們提出了 PromptAgent,這是一種優化方法,可以自主制作質量與專家手工制作的提示相當的提示。從本質上講,PromptAgent 將提示優化視為一個戰略規劃問題,并采用基于蒙特卡洛樹搜索的原則性規劃算法來戰略性地導航專家級提示空間。受到類似人類的反復試驗探索的啟發,PromptAgent 通過反思模型錯誤并生成建設性的錯誤反饋來引出精確的專家級見解和深入的指導。這種新穎的框架允許代理迭代檢查中間提示(狀態),根據錯誤反饋(操作)對其進行改進,模擬未來的獎勵,并搜索通向專家提示的高獎勵路徑。我們將 PromptAgent 應用于三個實際領域的 12 個任務:BIG-Bench Hard (BBH),以及特定領域和一般 NLP 任務,結果表明它的表現明顯優于強大的 Chain-of-Thought 和最近的提示優化基線。廣泛的分析強調了它能夠以極高的效率和通用性制作專家級、詳細且具有領域洞察力的提示。
原文:PROMPTAGENT: STRATEGIC PLANNING WITH LANGUAGE MODELS ENABLES EXPERT-LEVEL PROMPT OPTIMIZATION
地址:https://arxiv.org/abs/2310.16427
代碼:https://github.com/XinyuanWangCS/PromptAgent
出版:ICLR 24
機構: UC San Diego, Mohamed bin Zayed University of Artificial Intelligence寫的這么辛苦,麻煩關注微信公眾號“碼農的科研筆記”!
1 研究問題
本文研究的核心問題是: 如何自動化地生成等同于專家手工設計的高質量任務提示。
假設一家醫療健康公司想訓練一個大語言模型來回答醫學相關的問題。為了使模型的回答足夠專業和準確,工程師需要精心設計輸入給模型的任務提示,融入大量醫學領域知識。這通常需要領域專家投入大量的時間和精力。本文旨在探索如何用算法自動生成這種專家級別的提示,從而大大降低人工成本。
本文研究問題的特點和現有方法面臨的挑戰主要體現在以下幾個方面:
-
專家級提示往往包含非常豐富和深入的領域知識,現有方法缺乏對此的考慮。
-
專家級提示空間十分廣闊,現有方法難以高效探索這個空間。
-
現有方法傾向于生成與普通用戶提示局部相似的變體,很難達到專家提示的深度和廣度。 針對這些挑戰,本文提出了一種基于蒙特卡洛樹搜索的"PromptAgent"方法:
PromptAgent巧妙地將提示優化問題轉化為一個策略規劃問題。它將生成專家級提示的過程比喻為人類專家設計提示時的反復試錯和迭代。每一輪迭代相當于PromptAgent在提示空間中走一步,通過對模型錯誤進行反思來選擇探索方向并對當前提示進行修正。這種人性化的試錯過程使PromptAgent能夠像人類專家一樣在失敗中不斷學習和進化,最終抵達最優的提示形式。同時,蒙特卡洛樹搜索賦予了PromptAgent前瞻性和回溯性,它可以估計未來的回報,調整當前的探索策略,避免陷入局部最優。整個搜索過程在提示空間上形成了一棵樹,PromptAgent總是選擇最有希望的分支向下探索。最終,經過多輪博弈,它可以在廣闊的專家提示空間中找到最優解。

2 研究方法
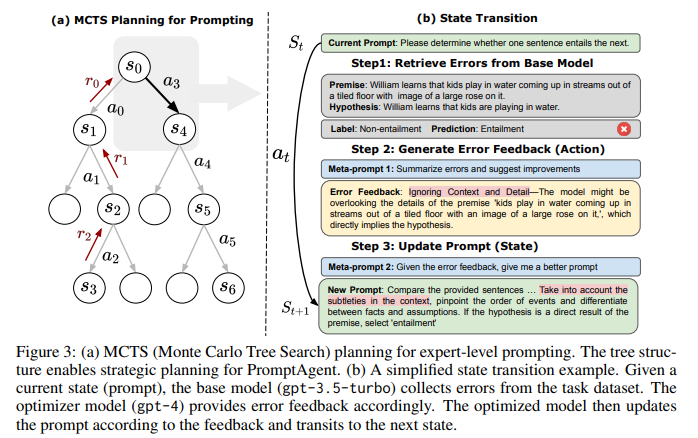
2.1 問題定義
論文將提示優化問題定義為一個馬爾可夫決策過程(MDP),用元組表示。其中,表示狀態空間,每個狀態對應一個提示的版本;為動作空間,每個動作是基于模型錯誤反饋生成的修改;定義狀態轉移函數;是回報函數,用于評估新生成的提示在驗證集上的性能。
給定當前狀態,PromptAgent迭代地基于生成動作,其中是一個優化器語言模型,是用于輔助動作生成的元提示。接著,PromptAgent根據狀態轉移函數得到新的狀態,是幫助狀態轉移更新提示的另一個元提示。最后,新生成狀態應用動作后的質量由回報函數決定。
2.2 PromptAgent框架
如圖3(a)所示,PromptAgent的核心是將MCTS規劃算法引入提示優化,通過構建樹狀結構來策略性地探索提示空間。每個節點表示一個狀態(提示),每條邊表示狀態間的轉移動作。PromptAgent通過錯誤反饋生成有洞察力的動作,并利用MCTS來優先探索那些有希望獲得高回報的路徑。
圖3(b)展示了PromptAgent的工作流程。給定一個當前狀態(提示),(1)基礎模型先在任務數據集上收集預測錯誤;(2)優化器模型根據錯誤總結得到錯誤反饋作為動作;(3)優化器模型再根據錯誤反饋更新提示,過渡到下一狀態。通過這種基于錯誤反饋的試錯迭代,PromptAgent可以有效地將領域知識引入到提示生成中。
2.3 基于MCTS的提示優化
MCTS通過迭代執行選擇、擴展、仿真和回溯四個操作,逐步構建搜索樹,更新狀態-動作值函數來估計從當前狀態-動作對出發的未來累積回報,指導樹的擴展方向。
-
選擇:從根節點出發,使用UCT算法平衡利用和探索,遞歸地選擇最優子節點,直到到達一個可擴展的葉子節點。
-
擴展:對選擇到的葉子節點,基于采樣得到的多批次錯誤生成多個動作(錯誤反饋),將其應用到當前狀態,得到多個新的子節點(新提示),加入到搜索樹中。
-
仿真:對新擴展出的節點,通過不斷迭代擴展步驟,模擬未來軌跡的累積回報,直到達到最大深度或滿足早停條件。
-
回溯:當到達終止狀態時,將累積回報從葉子節點傳播回根節點,更新路徑上每個狀態-動作對的值,調整樹的擴展方向。
通過預設的迭代次數,PromptAgent最終輸出具有最高平均累積回報的路徑作為優化的提示。MCTS的前瞻性仿真和回溯傳播機制使其能高效地在龐大的提示空間中找到優質解。
2.4 算法實現細節

算法1詳細展示了PromptAgent-MCTS的流程。元提示和的設計對PromptAgent至關重要,分別指導了動作生成和狀態轉移。論文通過held-out驗證集上的任務性能來定義回報函數,并設置最大搜索深度和早停閾值來控制計算開銷。此外,論文在多個不同難度的超參數設置下分析了PromptAgent的收斂性和泛化性能。總之,PromptAgent創新性地將提示優化問題建模為MDP,并應用MCTS算法進行策略規劃,通過錯誤反饋的試錯機制來納入領域知識,以解決專家級提示工程面臨的知識差距和搜索效率問題,為自動化提示優化開辟了新的思路。
2.5 舉例&總結
結合論文原文,我們可以用一個簡單的例子(完整方法見詳細原文)來說明這個方法。
整體目的: 假設我們要為一個醫療問答系統設計輸入提示,希望模型能根據提示生成專業、準確、全面的醫學建議。我們希望提示能涵蓋疾病定義、治療方法、注意事項等多方面內容,并符合醫學專業人士的表述習慣。傳統的人工撰寫提示費時費力,需要大量領域專業知識。PromptAgent旨在通過自動化方法生成高質量的"專家級"提示,大幅降低人力成本。下面我們用一個簡化的例子,結合PromptAgent的核心步驟,詳細說明其工作原理。
給定:
-
初始提示:"請根據病情描述,給出診斷建議。"
-
訓練集:100個(病情描述,診斷建議)數據對
-
驗證集:20個數據對
步驟:
步驟1:將提示優化建模為馬爾可夫決策過程(MDP)
定義MDP的四個要素:
-
狀態:第輪優化的提示
-
動作:根據錯誤反饋對的修改
-
轉移:將動作應用到狀態,得到新提示
-
獎勵:新提示在驗證集的表現提升
假設當前狀態為,即初始提示。
解釋:MDP建模的核心思想是將一個序貫決策過程表示為在狀態空間中搜索最優路徑。提示優化可以看作一個多輪對話:PromptAgent根據當前提示的錯誤反饋,不斷生成修改建議(動作),得到新的提示(新狀態),并根據新提示的效果(獎勵)調整之后的優化方向。每一輪對話對應MDP中的一步決策,目標是在有限的輪數內搜索到最優提示。
步驟2:基于錯誤反饋生成動作
(1)用當前提示在訓練集上測試,得到預測錯誤樣本:
-
輸入:小兒反復咳嗽、流涕3天,鼻塞,無發熱。
-
輸出:建議口服布洛芬退燒止痛,必要時請醫生處方抗生素。
-
標準答案:考慮普通感冒引起上呼吸道感染,建議對癥治療,多飲水休息。必要時可使用兒童感冒沖劑緩解癥狀,但應避免抗生素濫用。若持續高熱或癥狀加重,應及時就醫。
(2)總結錯誤并生成反饋:
-
診斷不夠準確,應基于具體癥狀給出初步判斷
-
未提及一般治療措施,如多休息多飲水
-
未提及常用藥物如感冒沖劑,也未警示抗生素濫用
-
對于可能加重的情況缺乏說明
(3)基于反饋生成修改建議(動作):
-
根據癥狀先給出初步診斷判斷
-
補充一般治療建議,如多休息多飲水
-
提及常用對癥治療藥物,警示抗生素濫用問題
-
說明可能加重的情形,建議必要時就醫
解釋:錯誤反饋是優化的關鍵。通過比較模型輸出與參考答案,可以發現當前提示的局限性,例如缺少必要的分步指導,或遺漏了重要的注意事項。這些反饋信息可以指導PromptAgent去修正提示,添加缺失的說明,使其更加全面、合理。值得注意的是,這里的反饋總結和修改建議都是由另一個強大的語言模型(如GPT-4)自動生成的。這體現了PromptAgent的核心思路:利用LLM自身的語言理解和生成能力去優化提示。
步驟3:狀態轉移,生成新提示 將動作應用到狀態(即)中,生成新提示(即新狀態):
"針對兒童反復咳嗽、流涕、鼻塞等癥狀,首先請給出你的初步診斷判斷。在治療建議中,應提及一般措施如多休息、多飲水等。可以列舉常用的對癥藥物如感冒沖劑,但要提醒避免抗生素濫用。最后還需說明若持續高熱或癥狀加重應及時就醫。"
解釋:狀態轉移是通過語言模型實現的,給定當前提示和修改建議,由模型生成完整的新提示。可以看到,新提示較好地納入了反饋中提到的內容,步驟更清晰,覆蓋面也更全。同時新提示也保持了語言的連貫性和邏輯性。這一步的關鍵在于語言模型要準確理解反饋的意圖,并將其自然地融入到原有提示中,生成符合人類表達習慣的內容。
步驟4:評估新提示并計算獎勵 將新提示在驗證集上測試,評估其性能提升:
-
提升點1:90%的樣本生成了準確的診斷
-
提升點2:85%的樣本提到了至少兩條一般治療建議
-
提升點3:75%的樣本涉及了常用藥品使用和抗生素濫用問題
-
提升點4:80%的樣本對可能加重的情況提出了合理建議
假設性能提升為,則狀態-動作值函數更新為:
解釋:PromptAgent通過新提示在驗證集上的表現來評判動作的效果。在醫療問答這個例子中,我們主要考察新提示在四個方面(診斷、治療建議、藥品使用、預后說明)的改進情況。這些維度覆蓋了醫療問答的核心要素,對應問題開始時提到的"專家級"提示的特征。獎勵值quantify了提示優化前后的性能差異,獎勵越大,說明動作的效果越好,狀態從轉移到也就越有價值。PromptAgent中的函數可以看作在估計未來累積獎勵的期望,它記錄并更新每一個嘗試過的狀態-動作對的價值,指導接下來的探索方向。
PromptAgent通過上述四個步驟形成一個完整的探索迭代。在實際使用中,它會重復這個過程多輪(如12輪),通過廣度優先搜索、啟發式評估、回溯更新等機制不斷拓展搜索樹,最終輸出搜索路徑中性能最佳的提示作為優化結果。
3 實驗
3.1 實驗場景介紹
該論文提出了一個基于策略規劃的prompt優化框架PromptAgent,通過蒙特卡洛樹搜索(MCTS)在龐大的prompt空間進行高效探索,并利用LLM的自我反思能力引入領域知識,生成expert-level的prompts。實驗旨在全面評估PromptAgent在不同任務上的優化性能,與基線方法進行比較,并分析其優化的prompts的泛化能力和質量。
3.2 實驗設置
-
Datasets:12個任務,跨越BIG-Bench Hard(6個)、特定領域(3個生物醫學任務)和常規NLP(文本分類、自然語言推理等3個)三大領域
- Baseline:
-
Human Prompts:普通人工設計的指令,通常來自原始數據集
-
Chain-of-Thought (CoT) Prompts:在prompt中引入中間推理步驟,在BBH任務上效果顯著
-
GPT Agent:類似Auto-GPT的自主代理,使用GPT-4的插件進行prompt優化
-
APE:最新的基于Monte Carlo搜索的迭代式prompt優化方法
-
- Implementation details:
-
默認base LLM為GPT-3.5,優化器LLM為GPT-4
-
MCTS迭代次數設為12,exploration weight c設為2.5
-
三種超參設置:Standard(depth limit=8)、Wide(expand width=3,num samples=2)和Lite(depth limit=4)
-
-
metric:各任務的默認評估指標,如準確率、F1等
3.3 實驗結果
3.3.1 實驗一、PromptAgent與基線方法的性能對比
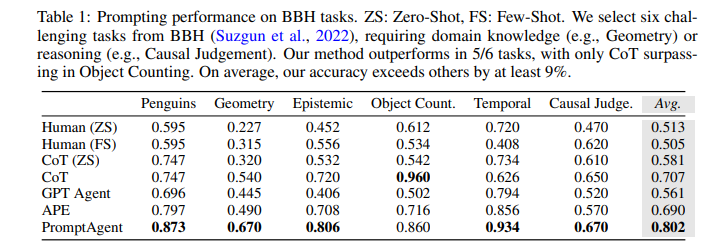
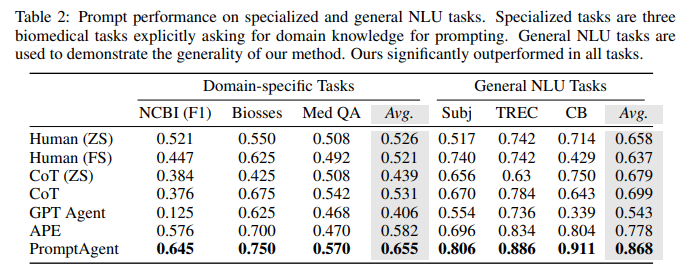
目的:評估PromptAgent生成的expert-level prompts相比human prompts、CoT prompts和現有優化方法在不同類型任務上的優勢
涉及圖表:表1,表2
實驗細節概述: 在12個跨三大領域的任務上,將PromptAgent生成的prompts與human prompts、CoT prompts、GPT Agent和APE的結果進行對比。
結果:
-
BBH任務:PromptAgent顯著優于所有基線,平均超出human prompts(ZS)、CoT和APE 28.9%、9.5%和11.2%
-
特定領域任務:PromptAgent在注入領域知識上比APE有7.3%的優勢,縮小了普通工程師與領域專家之間的差距
-
常規NLP任務:PromptAgent分別超出CoT 16.9%和APE 9%,表明即使是常規任務也存在專家級別的prompt優化空間
3.3.2 實驗二、PromptAgent優化prompts的泛化能力
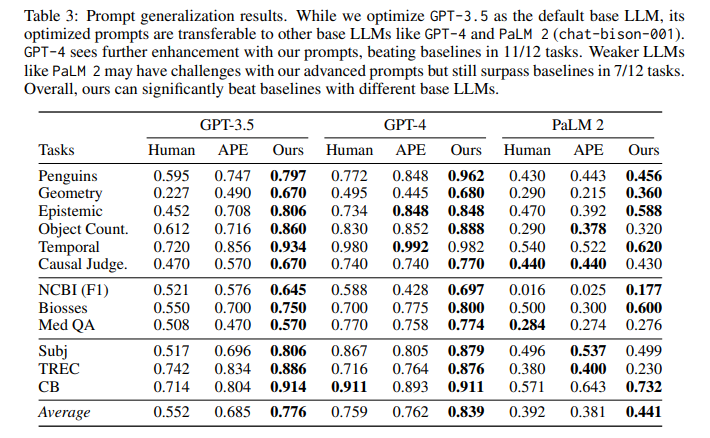
目的:探究在GPT-3.5上優化的prompts是否可直接應用于其他base LLMs(GPT-4和PaLM 2)
涉及圖表:表3
實驗細節概述: 將GPT-3.5上的優化prompts直接用于GPT-4和PaLM 2,并與Human prompts和APE prompts在12個任務上進行比較。
結果:
-
在更強的GPT-4上,PromptAgent的prompts在11/12個任務上達到或超過基線,進一步放大了expert prompts的潛力
-
在較弱的PaLM 2上,盡管性能有所下降,但在7/12任務上仍超過基線,特別是在特定領域任務上,表明expert prompts中的領域知識是有效的
3.3.3 實驗三、搜索策略的消融實驗

目的:系統研究PromptAgent中策略規劃的作用,比較MCTS與其他搜索變體的性能差異
涉及圖表:表4
實驗細節概述: 選取三個領域的5個任務子集,將MCTS與Monte Carlo搜索、Greedy搜索和Beam搜索進行比較,除搜索算法外,其他設置與PromptAgent相同。
結果:
-
Greedy和Beam搜索顯著優于無方向的Monte Carlo搜索,表明結構化迭代探索的必要性
-
在探索效率相當的情況下,Beam和Greedy性能相當,但兩者都缺乏對未來結果的預見和對過去決策的回溯能力
-
PromptAgent的MCTS在所有任務上明顯超過其他搜索變體,平均相對提升5.6%,凸顯了策略規劃在復雜prompt空間中的重要性
3.3.4 實驗四、探索效率分析
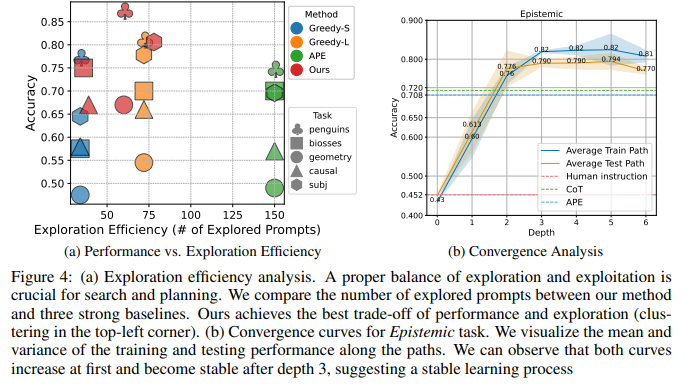
目的:比較PromptAgent與基線方法的探索效率(即搜索空間大小)與性能的關系
涉及圖表:圖4(a)
實驗細節概述: 選取5個任務,比較PromptAgent與Greedy搜索(兩個變體)和APE在探索的prompts數量和任務性能上的差異。
結果:
-
PromptAgent的點聚集在左上角,即以更少的探索實現了更高的性能,展現了探索效率的優勢
-
Greedy搜索增加探索數量可提升性能,但探索成本更高,且仍不及PromptAgent
-
APE缺乏原則性指導,即使大規模探索也難以有效提升性能
3.3.5 實驗五、收斂性分析
目的:研究PromptAgent在搜索樹不同深度上reward的變化,分析其學習動態
涉及圖表:圖4(b)
實驗細節概述: 以Epistemic任務為例,分析PromptAgent在不同深度上訓練和測試性能的演變。
結果:
-
訓練和測試曲線最初都呈上升趨勢,在深度3之后趨于穩定,超過了所有基線方法
-
其他任務和超參設置下也觀察到類似的上升和收斂模式,表明PromptAgent具有穩健的學習動態,可迭代優化和提升expert prompts
3.3.6 實驗六、PromptAgent優化prompts的定性分析

目的:定性分析PromptAgent生成的expert-level prompts的質量
涉及圖表:圖5,表15
實驗細節概述: 以NCBI任務為例,檢查PromptAgent搜索軌跡中最優路徑的前4個狀態和對應的3個狀態轉移。不同顏色突出了相似的領域見解。
結果:
-
從人工prompt出發,PromptAgent發現多個深刻的錯誤反饋(action),并有效地將其合并為改進的prompt(state),提高了測試性能
-
在連續的轉移中,疾病實體的定義越來越精確,無縫整合了特定于生物醫學的細節
-
最后一個狀態s3集合了之前路徑的見解,表現為expert-level prompt,帶來卓越的性能提升
-
與人工prompts和APE prompts相比,PromptAgent prompts在任務指令、術語澄清、解決方案指導、異常處理等方面提供了更全面的內容,展現了expert prompts應對復雜任務理解的優勢
4 總結后記
本論文針對構建專家級提示優化系統的問題,提出了一種名為PromptAgent的策略規劃方法。通過將提示優化視作一個基于MCTS的策略規劃問題,結合LLM的反思能力生成錯誤反饋指導搜索,PromptAgent能夠高效探索龐大的提示空間,自主生成富含領域知識和詳盡指令的專家級提示。在BIG-Bench Hard、生物醫學和通用NLP任務上的實驗表明,PromptAgent生成的提示顯著優于人工提示和最新的提示優化基線,展現出其在提升LLM理解和推理能力上的巨大潛力。
疑惑和想法:
-
除了MCTS,是否可以嘗試其他形式的策略規劃算法,如Alpha-Beta剪枝、啟發式搜索等?它們在提示優化上的表現如何?
-
PromptAgent生成反饋時主要依賴于先驗的元提示,能否設計一種自適應或遞進式的元提示生成機制,隨著搜索的進行動態更新元提示?
-
在面向新領域任務時,如何高效地為PromptAgent引入該領域的專家知識,加速strategizing過程?是否可以利用知識圖譜等外部知識源?
可借鑒的方法點:
-
將提示工程建模為序貫決策問題,利用強化學習和策略規劃優化提示的思路可以推廣到更多LLM應用場景。
-
利用LLM的反思和自我糾錯能力生成反饋信息指導優化的方法可以借鑒到其他NLP任務,如對話、問答、校對等。
-
在搜索過程中權衡exploration和exploitation的策略對于避免局部最優、發現更優解具有重要啟發意義。
)
之推理實踐學習記錄)

)









)



)

