寫在最前面的話
任何開源技術是最有生命力的,也是最具分享精神的。一直覺得大模型領域需要有一個系列能夠從零開始系統性的講述領域知識,給與這個領域的從業人員或者對其有興趣的門外漢及時的幫助。國外承擔“布道者”的公司眾多,而數磚公司在這個領域一直走在前面。恰逢數磚的“從頭開始大模型的基礎模型”于近期發布,借花獻佛,在基礎上加入自身理解進而形成這個特殊的專欄。
雖然生成式人工智能技術的正在迅猛發展,但是現階段面臨的主要挑戰是沒有一個模型能夠適用于所有情況。所以人們對為特定用例創建定制化模型的興趣日益濃厚。為了找到實踐中的最佳模型,亦或是追求在隱私、品質、成本、服務及模型使用延遲等多方面達到平衡,決定了一定需要定制化模型。由此可見,開發新的大型語言模型是一項浩大的工程。
目前,市場上有許多成功的專有和開源LLM模型,它們由不同的公司和研究團隊提供,如Anthropic、ChatGPT、PaLM-2、Databricks的Dolly、Mosaic MPT、StabilityAI的模型以及Hugging Face上的眾多模型,這些模型如何選擇讓人左右為難。通過這個專欄,能夠幫助大家更好地理解和應用這些模型,通過理解它們的基本原理和應用方法,進而構建出高品質的應用程序和模型。
令人興奮的是隨著開源模型的興起,免費模型的品質正在快速提升,相關的知識也在不斷積累。源源不斷出現的新開源模型和研究社群正在探索的技術,能夠幫助需要者快速的構建出色的語言模型和應用。即便是許多開源模型源于最初無法商業使用的技術。例如,Meta或Facebook在2023年初發布的Llama模型,激發了許多研究人員的創新。史丹佛大學的一個團隊基于Llama模型開發了Alpaca模型,它擅長聊天和遵循指示,使其在多種應用中更具實用性。此外,Databricks的Dolly、MosaicML的MPT等模型也開始提供商業許可,讓模型的使用更加靈活和廣泛。評估模型也是極為重要,如何有效的構建評估體系也是這個專欄會討論之一。Hugging Face已經存在LLM排行榜專注于不同任務的評估,幫助開發者了解模型的表現,并構建更好的模型。
雖然LLM領域的知識和技術日新月異,但是萬地高樓平地起,在這個系列中會更加關注基礎。通過細節了解模型的基本運作原理、預訓練數據和推理過程,以及各個階段的可用選項,這些基礎知識的微小變化構成了其他所有內容。
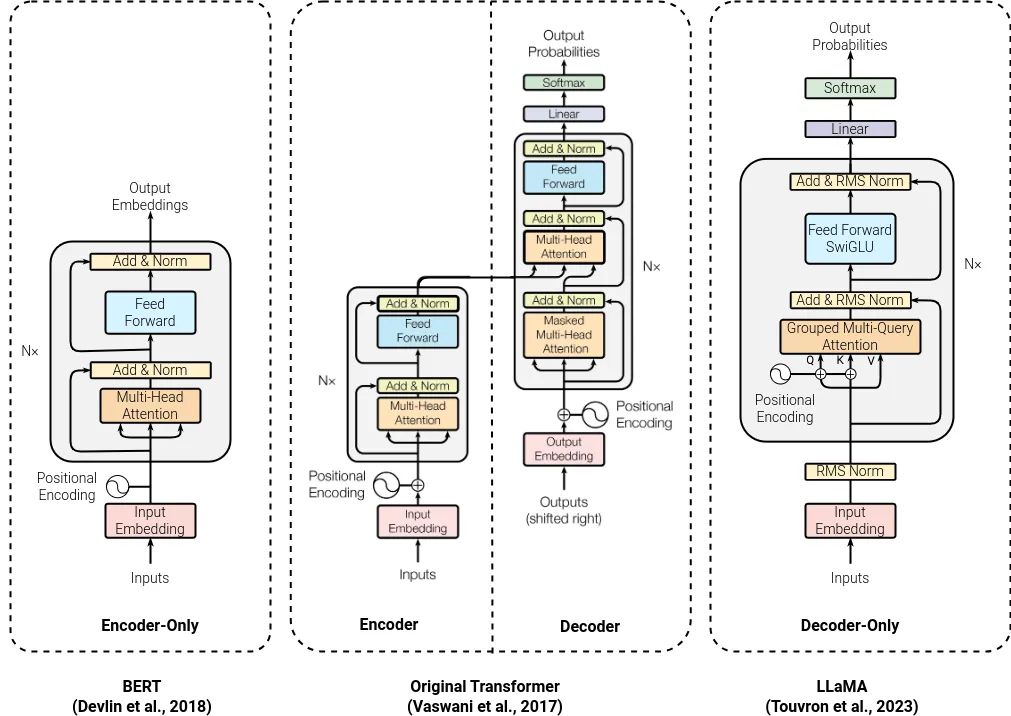
Transformer架構
在這個系列的第一部分將進入深度學習和自然語言處理的奇妙世界,首先聚焦于Transformer架構——這是現代大型語言模型的核心技術。本部分內容不僅是整個系列的基石,也是理解后續章節的關鍵所在。
Transformer的當前形式首次亮相是在2017年的BERT論文中。自那以后,大多數的大型語言模型都是基于Transformer的某種變體,包括OpenAI推出的GPT,這是一個預訓練的Transformer模型,對當前基于聊天的語言模型產生了深遠的影響。有趣的是,在Transformer出現之前,雖然有許多深度學習模型的快速實驗,但它們更像是寒武紀大爆炸,各種不同層次和模塊的組合。而Transformer的出現,至少在自然語言處理領域,使得許多模型設計都遵循了相同的基本構建塊。這使得研究的關注點轉移到了不同的訓練技術和數據生成方法上。
盡管底層架構并沒有經歷過大規模的改變,但Transformer架構的強大之處在于它允許模型學習輸入不同方面之間的多種交互,并且可以堆疊到不同的深度,以便理解模型的不同特性。即使今天存在一些變化,這些變化可能旨在提高速度或降低成本,但基本的構建塊仍然是相同的。
2023年,在大型語言模型領域見證了思想、概念和創新的爆炸式增長,這些創新不斷給我們帶來驚喜。ChatGPT和其他類似技術代表了人類與技術之間的一種新型交互方式,因為它們基于自然語言處理,我們能夠更自然地與它們交流。同時,它們廣泛的應用和深厚的技術知識也使我們能夠更好地處理日常生活中的事務。
對于過去10年左右熟悉深度學習世界的人來說,您可能已經注意到,在2010至2012年初,我們經歷了一個類似的熱潮時刻。當時,卷積神經網絡的創新震撼了計算機視覺世界。這項創新就是卷積層,它使我們能夠查看不同空間區域中的圖像,嘗試了解圖像內部的情況。正如您在圖片中看到的,這意味著我們可以與舊技術競爭并將其徹底擊敗。通過ImageNet的測試,卷積神經網絡輕松地在競爭中占據主導地位,并且自2012年以來,每個模型都基于卷積神經網絡,使得結果達到了飽和狀態。自然語言處理領域也在等待這樣的發展。
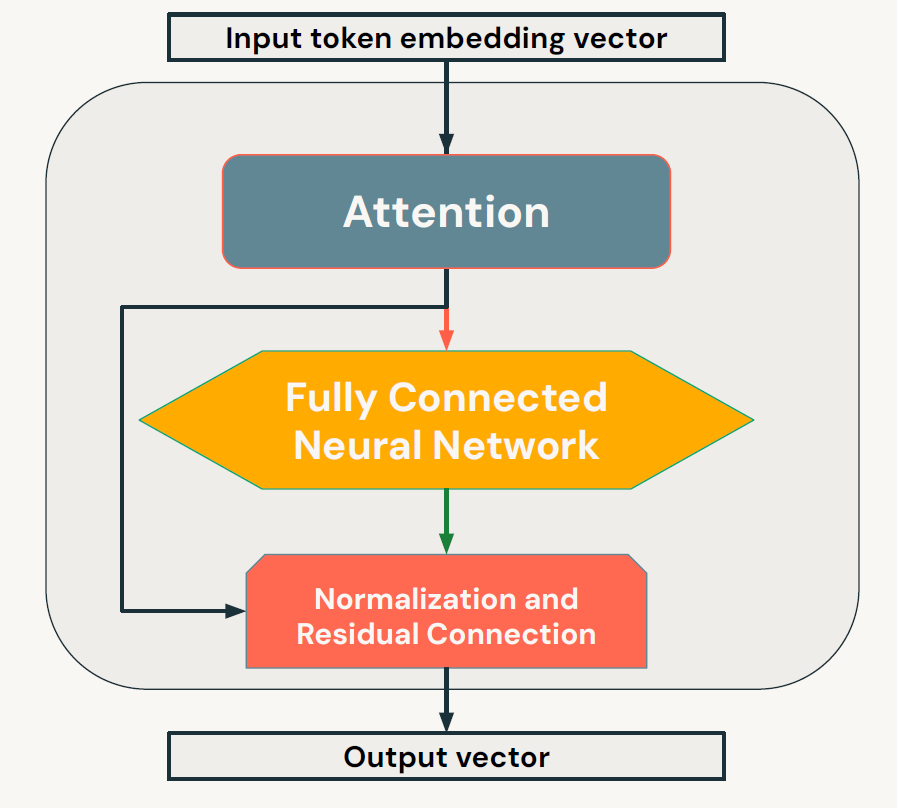
我們在2018年左右迎來了這一突破,釋放大型語言模型力量的創新被稱為“注意力機制”。正如這個詞所暗示的,注意力機制允許計算機(或者在這個情況下是Transformer)準確地了解一個單詞如何按照特定順序與其他單詞相關聯,并給出序列中每個單詞之間的重要性分數。對我們來說,這似乎是一個顯而易見的概念,它是我們在生命早期就開發出來的,但它對于自然語言處理來說是至關重要的一部分,能夠釋放以前無法實現的能力。雖然注意力機制在我們掌握自然語言處理方面邁出了一大步,但它實際上只是構建我們現在看到的Transformer和類似模型所需的一小部分。因此,深入了解Transformer非常重要。后續的旅途將圍繞著如下的問題展開:
-
明確掌握如何使用Python代碼實現Transformer模型。
-
深入理解不同類型Transformer架構中的構建塊,包括編碼器、解碼器以及編碼器-解碼器組合模型。
-
充分理解注意力機制的原理、工作方式及其重要性
-
將大模型應用于多種自然語言處理(NLP)任務,并評估它們的性能。




拷貝一行)
詳解)

-基礎操作)


)








