?一、約束
有時候,數據庫中數據是有約束的,比如 性別列,你不能填一些奇奇怪怪的數據~
如果靠人為的來對數據進行檢索約束的話,肯定是不行的,人肯定會犯錯~因此就需要讓計算機對插入的數據進行約束要求!
約束的使用語法:
create 表名 (列名 類型 約束);
?
#在創建表的時候對某一列數據進行約束操作在mysql中提供了如下約束:
| 約束 | 說明 |
|---|---|
| not null | 某一列的數據不能為null值 |
| unique | 某一列中的值唯一 |
| default | 規定沒有給某列賦值時為默認值 |
| primary key | not null 和 unique 的結合。記錄身份的標識,一般配合自增主鍵使用 |
| foreign key | 保證一個表中的數據匹配另一個表中的值的參照完整性 |
| check | 保證列中的值符合指定條件 |
注意:
使用約束的話,一定會數據庫的效率有影響!
由于not null、 unique、default、check比較容易,這里就對主鍵(primary key)和外鍵(foreign key) 進行解釋。
主鍵primary key
主鍵可以理解為記錄的身份標識,就像身份證一樣是我們每個人的身份標識,既不能為空,又不能重復。
一張表里只能有一個主鍵,畢竟是身份標識嘛,存在多個了,以誰為準???
雖然主鍵只能有一個,但是主鍵不一定是一列,可以用多個列共同構成主鍵(聯合主鍵)。
由于主鍵具有unique屬性,因此我們一般配合mysql中 ”自增主鍵” 來使用,也就是會自動分配一個逐個增長的值~
語法:
create table 表名 (列名 類型 primary key auto_increment);如果手動插入一個數據,此時數據庫會與主鍵最高的值進行比較,如果高了就更新,此后自動分配的值也會從這個最高值進行增長!
拓展:
如果是分布式系統,在同一時間插入了一個數據,此時自增主鍵就會出錯,那么如何處理這種并發場景呢?
一般會使用一個公式來形成主鍵:
分布式主鍵值 = 時間戳 + 機房編號/主機號 + 隨機因子 此處使用的是字符串拼接操作!!!
前面兩個可以防止在同一時間不同機器的的主鍵沖突,后面的隨機因子可以防止同一時間同一機器的主鍵沖突,但是理論上還是有可能存在沖突的~
外鍵foreign key
案例引入:
現在我們有兩張表,一張是學生表,里面有學號、姓名、班級號字段,另一張表示班級表,里面有班級號、班級名字段。
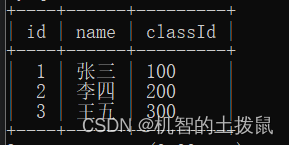
?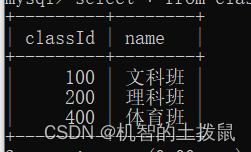
我們細細觀察,可以發現,肯定是先有班級表,學生的班級號才能確定,但是現在突然冒出了一個classId 為 300的學生,但是在我們的班級表中不存在這個班級號,為了防止這種情況發生,我們可以使用外鍵約束~
語法:
create table 表名 (列名 類型, 列名 類型, ......, foreign key (列名) references 主表名(列名));
?
#我們創建學生表的時候可以這樣寫:#create table student (id int, name varchar(20), classId int, foreign key (classId) references class(classId));#student表的classId 的所有數據都要出自于class表的classId這一列,
#也就是說如果class表中沒有這個班級號,那么我們插入的學生信息將會報錯~使用外鍵之后,被約束的表就稱為子表, 另一張表相對的就是父表,子表中的那一個字段的數據都要出自父表。當然,力的作用是相互的,約束也不例外,當我們想要刪除/修改父表的約束子表的那個字段,如果子表已經引用過了,那么我們將會刪除/修改失敗
注意:
父表中約束子表的字段必須為主鍵或者unique!!!
二、表的設計
在實際的場景中,有大量的數據,我們需要明確當前要創建幾個表,每個表有什么字段,這些表中是否存在一定的聯系。
因此根據實際開發就整理出了三大范式~
一對一
例如:一個學生只有一個賬號,一個賬號只屬于一個學生。
此時我們設計兩張表,讓其中的一張表存儲另一張表的唯一屬性,這樣我們可以通過這個屬性就能找到想要的值了。或者也可以將兩張表整合,成為一張表。
?

一對多
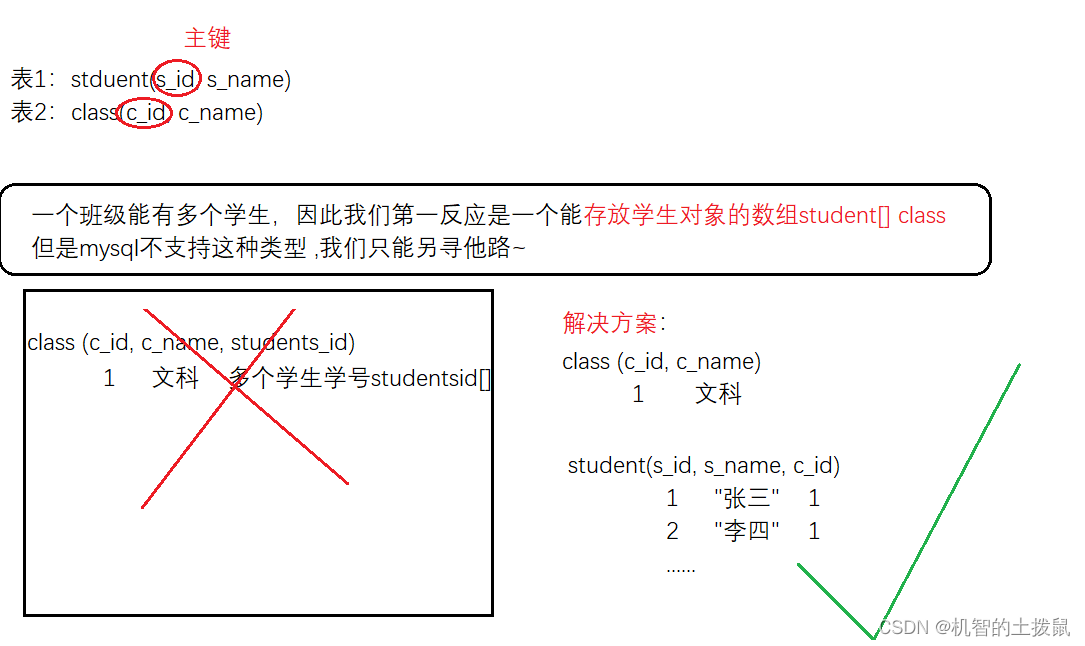
例如:一個學生只能屬于一個班級,一個班級可以擁有多個學生。
此時我們設計兩張表,將那個“一”的表中添加上“多”的表中的唯一的字段。
補充:
如果是redis這種能夠支持數組類型的數據庫,我們可以不這樣設計,可以使用一個數組類型,用來存儲多個學生。如下圖:
多對多
例如:一個學生可以選多門課程,一個課程可以被多名學生選擇。
此時我們需要再創建一張表來描述這兩張表之間的關系。

三、查詢增強(進階)
查詢操作有很多的花樣,但一般實際開發中最最最常使用的還是前面基礎的crud操作。
0x 00 聚合查詢
之前的表達式查詢是對于一條記錄上的列與列之間進行運算的,如果要針對行與行之間進行運算呢?這時候就要用到聚合查詢了~
首先來了解一些聚合函數:
| 函數 | 說明 |
|---|---|
| count() | 返回查詢數據的個數 |
| sum() | 返回查詢數據的總和,不是數字沒意義 |
| avg() | 返回查詢數據的平均值,不是數字沒意義 |
| max() | 返回查詢數據的最大值,不是數字沒意義 |
| min() | 返回查詢數據的最小值,不是數字沒意義 |
語法:
select count([distinct]表達式) from 表名;
select sum([distinct]表達式) from 表名;
select avg([distinct]表達式) from 表名;
select max([distinct]表達式) from 表名;
select min([distinct]表達式) from 表名;
?
#注意:
#count(*) 和 count(列名)的區別,count(*)會把一條為null的數據也統計進去,而count(列名)則不會
#如果計算字符串的值,需要字符串合法,因為mysql會嘗試轉成double0x 01 分組查詢
分組查詢一般會配合聚合查詢,因為分組查詢會把幾行數據看做是一行,如果不使用聚合查詢,那么顯示的結果為一組中某一個數據。
舉例:
求各班的平均成績:
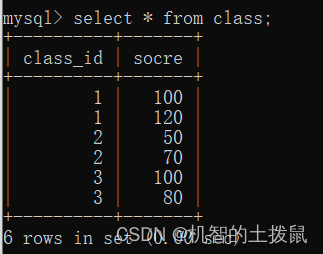
?那么我們的代碼得這樣寫:
select class_id, avg(socre) from class group by class_id;
使用group by的時候,還可以搭配條件。此時我們需要區分該條件是分組前的,還是分組之后的?
如果是分組前,使用where條件查詢
如果是分組后,使用having條件查詢
舉例:
查詢各班平均分,但是學生成績不能超過100
select class_id, avg(socre) from class where socre <= 100 group by class_id;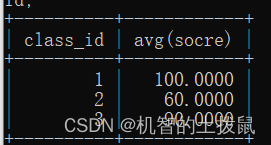
?查詢平均分大于100分的班級
select class_id, avg(score) from class group by class_id having avg(score) > 100;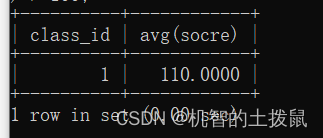
0x 02 聯合查詢
聯合查詢也就是多表查詢,就是在多張表上進行查詢。但是聯合查詢也會有一些問題......
聯合查詢會產生笛卡爾積,也就是說表A中的每一條數據都會與表B中每一條數據進行組合,如果A表中的數據個數為100,表B中的數據個數為100,那么最終會產生100*100條數據。但是仔細觀察,會發現有一些數據是“非法”的。笛卡爾積是簡單的排列組合,窮舉所有情況,因此你我們需要篩選數據~
如果要聯合n張表進行查詢,那么我們需要使用n-1個連接條件,才不會出現笛卡爾積的現象~
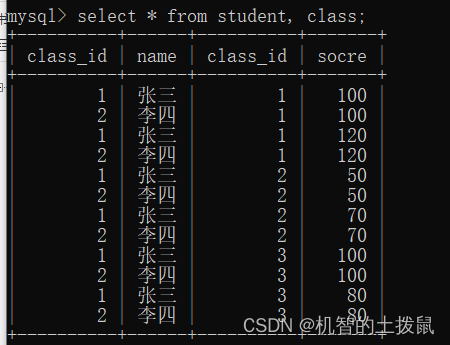
?此時就出現了笛卡爾積,但是仔細觀察,會發現class_id 不同的數據都組合到了一起,因此我們需要一個連接條件。
select student.class_id, student.name, class.socre from student, class where student.class_id = class.class_id;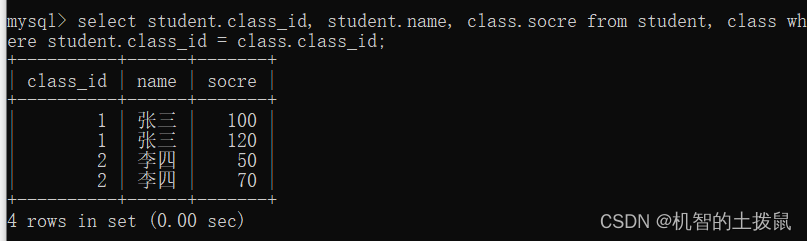
由于多表查詢一般比較復雜,我們可以按照如下的步驟來寫:
1、先進行指定哪個幾個表,進行笛卡爾積
2、指定連接條件,去除笛卡爾積
3、精簡列數據
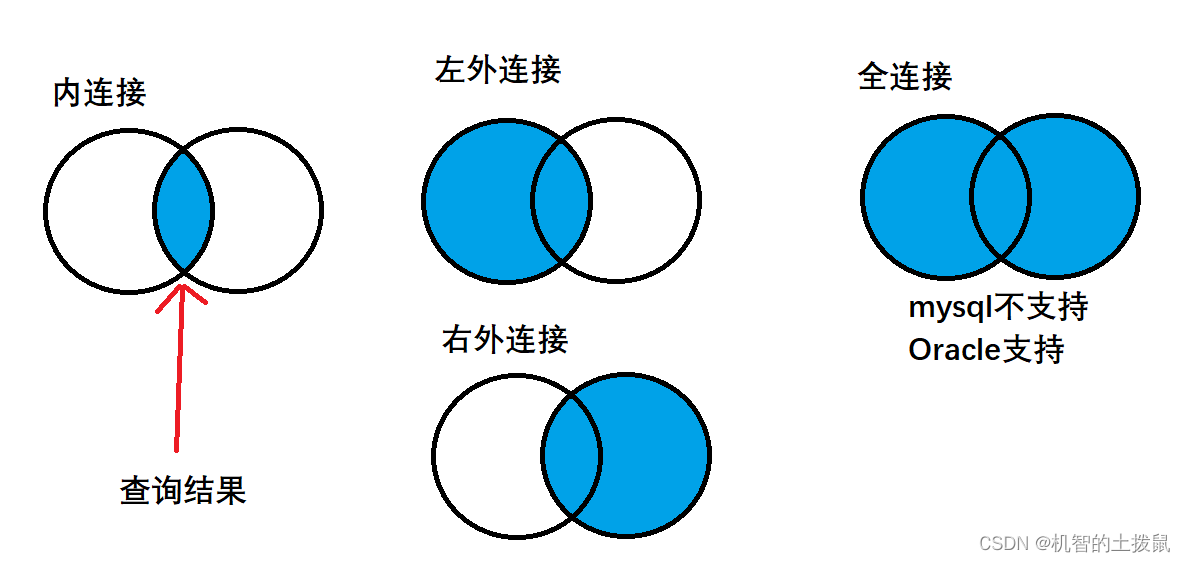
以上查詢都是基于“內連接“的操作,然而mysql還提供了”外連接“(左外連接,右外連接)
案例引入:
現有如下表

此時student的每一條記錄都可以在score表中找到對應,每一個score中記錄也可以在student表中找到對應。
此時我們使用外內接或者內連接查詢的結果是一樣。
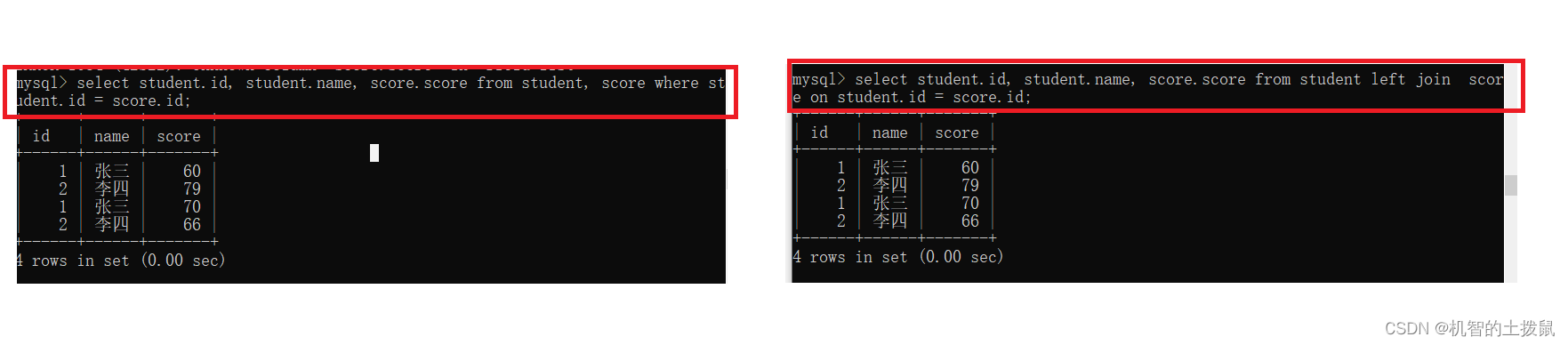
?但是如果不存在記錄,那么內連接與外連接就會天差地別~
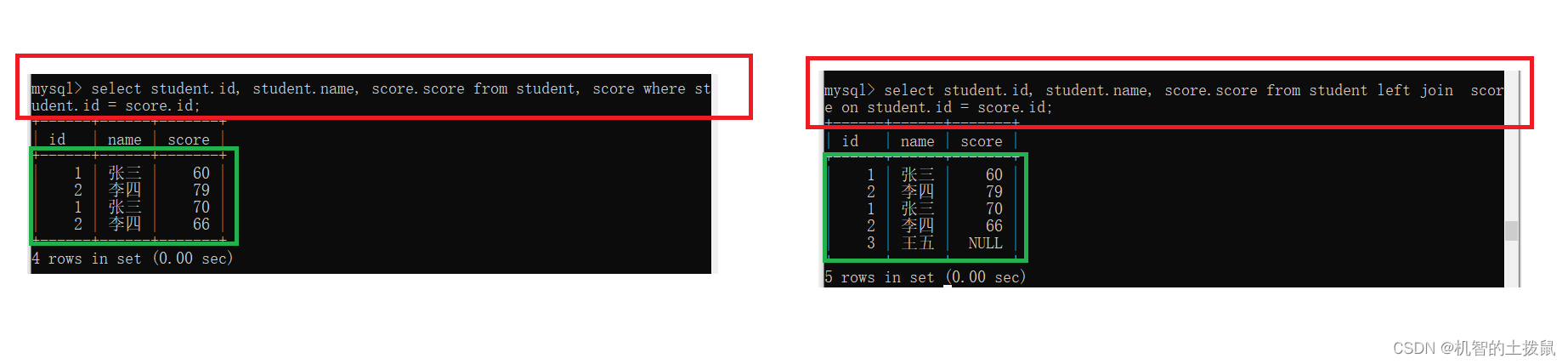
外連接分為左外連接和右外連接。
左外連接:以左表為基準,保證左側表的每個數據都會出現在最終的結果集里,如果右表沒有與之對應的記錄則顯示null。
select 列名 from 表名1 left join 表2 on 連接條件右外連接:以右表為基準,保證右側表的每個數據都會出現在最終的結果集里,如果左表沒有與之對應的記錄則顯示null。
select 列名 from 表名1 right join 表2 on 連接條件我們還可以用集合圖來表示這些連接的關系:
補充:
以上我們都是針對于兩個表進行聯合查詢的,但我們甚至還可以將一個表當做兩個表來進行聯合查詢,這樣我們就能在一張表中進行 行與行的比較~這種連接方式一般被稱為“內連接”。
自連接的查詢跟上面的聯合查詢基本沒什么區別,需要注意將兩張表進行別名操作~
0x 03 子查詢
子查詢是將多個簡單的SQL語句拼成一個復雜的SQL, 也就是說將某一個查詢的結果看做是一張表,然后進行操作,但本質是在套娃。因此我們實際也是可以用簡單的查詢完成子查詢的操作的~ (合成2048?合成復雜SQL!)
語法形式:
select 列名 from 表名 where 列名 = (select 列名 from 表名 where 列名 = (套娃下去....));0x 04 合并查詢
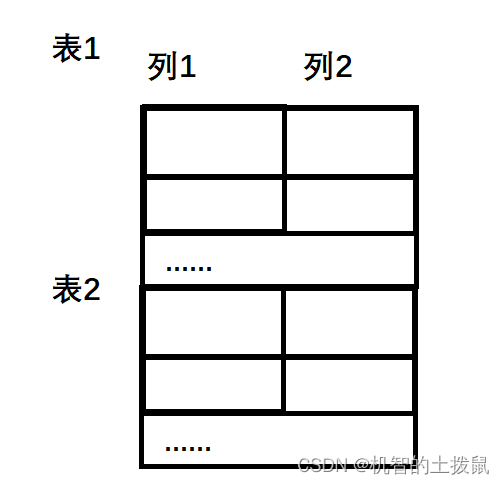
合并查詢就是將多個sql的查詢結果集 合并在一起。合并的兩個sql結果集的列,需要匹配,列的個數和類型得是一致的!合并的時候是會進行去重的,如果不想要去重,得使用 union all
select 列名1 列名2 from 表1 union [all] select 列名3 列名4 from 表2;最終結果:


)
















