概要
集成學習(Ensemble Learning)是一種機器學習技術框架,它通過構建并結合多個學習器(也稱為個體學習器或基學習器)來完成學習任務。
- 集成學習旨在通過組合多個基學習器的預測結果來提高整體模型的性能。
- 每個基學習器都可以是一個簡單的機器學習模型,如決策樹、邏輯回歸等。
- 基學習器可以是同質的(即所有基學習器都使用相同的算法),也可以是異質的(即基學習器使用不同的算法)。
工作原理
????????生成基學習器:首先,使用某種算法從訓練數據中產生多個基學習器。這些基學習器通常會在訓練數據的不同子集或不同特征子集上進行訓練,以實現多樣性。
????????結合策略:然后,使用一種結合策略將基學習器的預測結果結合起來,以產生最終的預測結果。常見的結合策略包括平均法(如簡單平均、加權平均)、投票法(如硬投票、軟投票)和學習法(如Stacking)。
代表性方法
????????Bagging:一種基于數據隨機重抽樣的集成學習方法。它通過從原始數據集中有放回地抽取樣本來訓練多個基學習器,并對所有基學習器的預測結果進行平均或投票來產生最終的預測結果。
????????Boosting:一族可將弱學習器提升為強學習器的算法。它主要是通過對樣本集的操作獲得樣本子集,然后用弱分類算法在樣本子集上訓練生成一系列的基分類器,并通過加權投票等方式將基分類器的預測結果結合起來。
????????隨機森林:Bagging的一個擴展變體,它以決策樹為基學習器構建Bagging集成,并在決策樹的訓練過程中引入了隨機屬性選擇。
優勢和目的
????????集成學習的主要優勢在于,通過結合多個基學習器的預測結果,可以減小模型的方差、偏差或改進預測性能。
????????集成學習的目的通常是為了提高模型的泛化能力,降低模型選擇不當的可能性,以及提高模型的穩定性和魯棒性。
總結
集成學習是一種通過構建并結合多個學習器來提高模型性能的技術框架。
它通過生成多個基學習器并使用一種結合策略將它們的預測結果結合起來,以實現更好的預測效果。
集成學習在機器學習和數據科學領域中被廣泛應用,是提升模型性能的重要工具之一。
詳細介紹
在機器學習算法(分類算法)中,將算法分為2類:
弱分類器:邏輯回歸(Lr)分類算法、決策樹(DT)分類算法
強分類器:
相當于弱分類器算法而言進行稱呼,往往是多個弱分類器算法組成的,變成強分類器
即:三個臭皮匠,頂個諸葛亮
集成學習算法常見的有兩類:
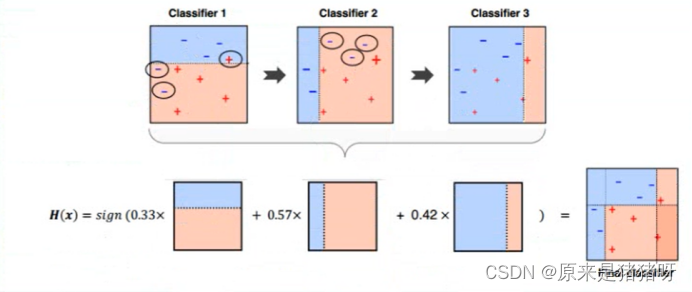
Boosting算法
????????直譯為提升算法
選擇某個弱分類器算法,逐步優化算法模型,逐步提升Boosting,最終獲取最佳算法模型
?
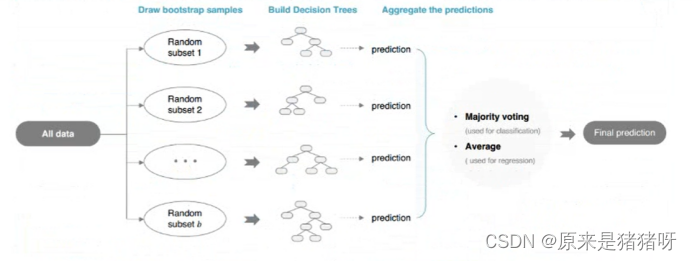
Bagging算法
????????直譯為袋子算法
 ?
?
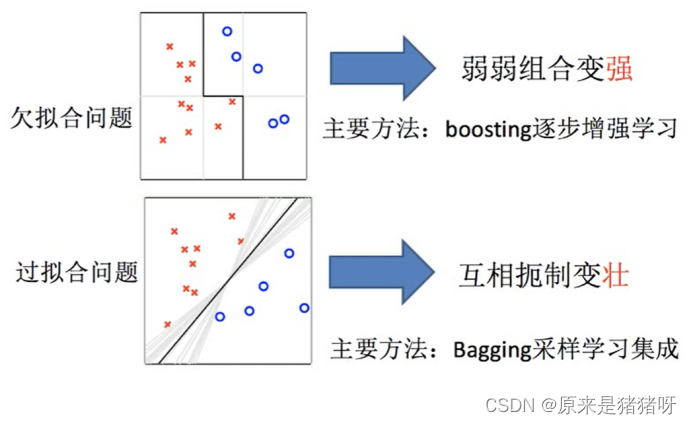
所面臨的問題?:
? ? ? ? 欠擬合以及過擬合
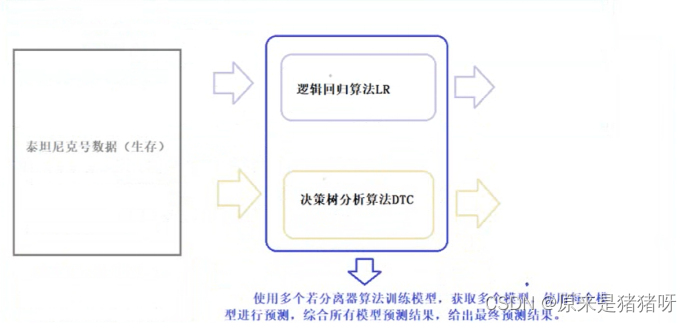
?集成學習概念
如下圖所示:使用不同算法(LR、DT等)構建不同模型,最終合并模型(取其優秀),進行預測分類。
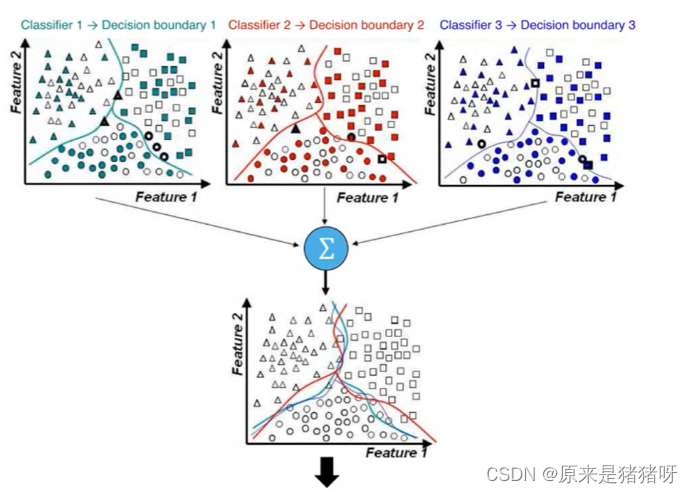
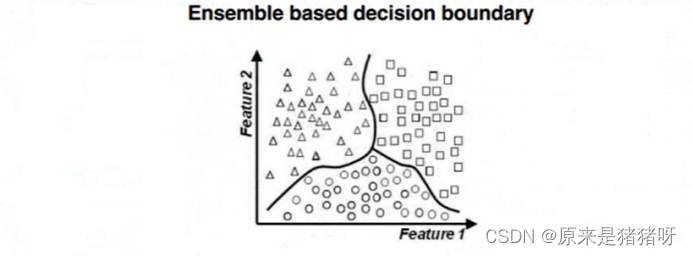 ?集成學習算法
?集成學習算法
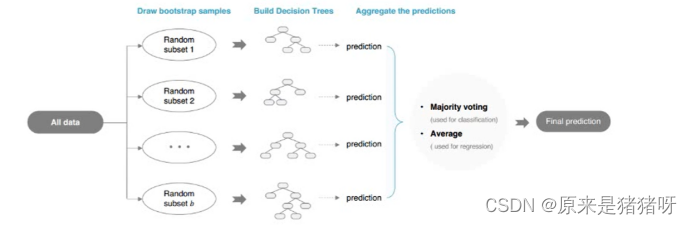
Bagging
????????袋子,有很多模型(每個模型不一樣),預測時:讓每個模型進行預測
????????????????如果是分類:使用投票vote機制,決定預測結果(類別最多)
????????????????如果是回歸:使用平均avg機制,決定預測結果(對每個模型預測值求其平均值)
????????最典型算法:隨機森林
????????????????森林中有很多決策樹模型DTM
Boosting
????????提升,有很多模型,但是模型之間依賴關系(后續的模型“修正”前面模型不足的地方),最終合并所有模型優秀的地方,構建出一個模型進行預測。
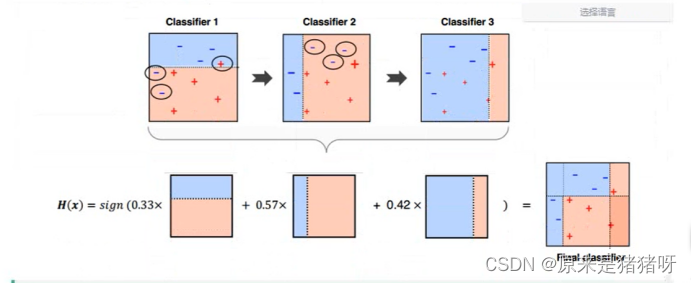
Ensemble集成學習算法/融合學習算法
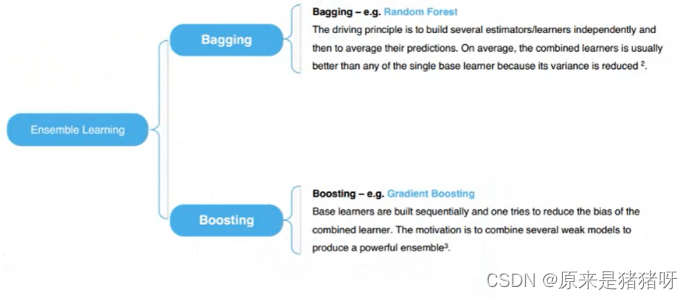 ?
?
Bagging算法詳細介紹
RandomForest-隨機森林
隨機森林是一個包含多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別的眾數而定。
Random Forest = Bagging + CART decision Tree
先來分析一下什么是隨機森林算法:
????????隨機森林算法由三個詞分別組成:隨機、森林、算法,其中隨機和森林是關鍵,我們單獨拿出來進行解釋
????????森林Forest:其中會有多棵樹,每一棵樹都是決策樹。
????????我們還記得決策樹有什么特點,因為一棵樹的數據集固定,特征選擇也固定,會導致:無論決策樹執行多少次,結果都是不變的——出身就決定答案。
????????隨機Random:而機器學習需要的不是一成不變的東西,所以隨機Random就幫我們解決了這個問題
????????????????它會使數據集不一樣——從源數據集有放回的去抽樣數據
????????????????他會使特征選擇不一樣——假設數據集有20哥特征,每次抽取獲取15個特征
?由于決策樹分類模型屬于【概率分類模型】,所以要求標簽label值從0開始計算。
Bagging官方樣例
import org.apache.spark.ml.classification.{RandomForestClassificationModel, RandomForestClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.sql.DataFrame
import org.apache.spark.storage.StorageLevel/*** Spark ML官方案例,基于隨機森林分類算法* http://spark.apache.org/docs/2.2.0/ml-classification-regression.html#random-forest-classifier*/
object ExampleRfClassification {def main(args: Array[String]): Unit = {// 構建SparkSession實例對象,通過建造者模式創建import org.apache.spark.sql.SparkSessionval spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[3]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 導入隱式轉換和函數庫import spark.implicits._import org.apache.spark.sql.functions._// TODO: 1. 加載數據、數據過濾與基本轉換val datasDF: DataFrame = spark.read.format("libsvm").load("datas/mllib/sample_libsvm_data.txt")// TODO: 2. 數據準備:特征工程(提取、轉換與選擇)// 將標簽數據轉換為從0開始下標索引val labelIndexer: StringIndexerModel = new StringIndexer().setInputCol("label").setOutputCol("label_index").fit(datasDF)val indexerDF = labelIndexer.transform(datasDF)// 自動識別特征數據中屬于類別特征的字段,進行索引轉換,決策樹中使用類別特征更加好val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features").setOutputCol("index_features").setMaxCategories(4).fit(indexerDF)val dataframe = featureIndexer.transform(indexerDF)// 劃分數據集:訓練數據集和測試數據集val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2))trainingDF.persist(StorageLevel.MEMORY_AND_DISK).count()// TODO: 3. 使用算法和數據構建模型:算法參數val rf: RandomForestClassifier = new RandomForestClassifier().setLabelCol("label_index").setFeaturesCol("index_features")// 超參數.setNumTrees(20) // 設置樹的數目// 抽樣獲取數據量.setSubsamplingRate(1.0)// 獲取特征的個數.setFeatureSubsetStrategy("auto")// 決策樹參數.setImpurity("gini").setMaxDepth(5).setMaxBins(32)val rfModel: RandomForestClassificationModel = rf.fit(trainingDF)//println(rfModel.featureImportances) // 每個特征的重要性// TODO: 4. 模型評估val predictionDF: DataFrame = rfModel.transform(testingDF)predictionDF.select("prediction", "label_index").show(50, truncate = false)val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label_index").setPredictionCol("prediction").setMetricName("accuracy")val accuracy = evaluator.evaluate(predictionDF)println("Test Error = " + (1.0 - accuracy))// 應用結束,關閉資源spark.stop()}}Boosting算法詳細介紹
????????梯度提升樹(GBT Gradient Boosting Tree)是一種迭代的決策樹算法,該算法由多顆決策樹組成,所有樹的結論累加起來做最終答案。他在被提出之初就被認為是泛化能力(generalization)較強的算法。
GBDT = 梯度提升 + Boosting + 決策樹
 ?
?
Boosting官方樣例代碼
import org.apache.spark.ml.classification.{GBTClassificationModel, GBTClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.sql.DataFrame
import org.apache.spark.storage.StorageLevel/*** Spark ML官方案例,基于梯度提升樹分類算法* http://spark.apache.org/docs/2.2.0/ml-classification-regression.html#gradient-boosted-tree-classifier*/
object ExampleGbtClassification {def main(args: Array[String]): Unit = {// 構建SparkSession實例對象,通過建造者模式創建import org.apache.spark.sql.SparkSessionval spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[3]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 導入隱式轉換和函數庫import spark.implicits._import org.apache.spark.sql.functions._// TODO: 1. 加載數據、數據過濾與基本轉換val datasDF: DataFrame = spark.read.format("libsvm").load("datas/mllib/sample_libsvm_data.txt")// TODO: 2. 數據準備:特征工程(提取、轉換與選擇)// 將標簽數據轉換為從0開始下標索引val labelIndexer: StringIndexerModel = new StringIndexer().setInputCol("label").setOutputCol("label_index").fit(datasDF)val indexerDF = labelIndexer.transform(datasDF)// 自動識別特征數據中屬于類別特征的字段,進行索引轉換,決策樹中使用類別特征更加好val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features").setOutputCol("index_features").setMaxCategories(4).fit(indexerDF)val dataframe = featureIndexer.transform(indexerDF)// 劃分數據集:訓練數據集和測試數據集val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2))trainingDF.persist(StorageLevel.MEMORY_AND_DISK).count()// TODO: 3. 使用算法和數據構建模型:算法參數val gbt: GBTClassifier = new GBTClassifier().setLabelCol("label_index").setFeaturesCol("index_features")// 設置超參數.setMaxIter(10).setStepSize(0.1) // 學習率,(0, 1]之間,默認值為1.setSubsamplingRate(1.0) // 每次訓練決策樹數據集占比,默認為1.0//.setImpurity("variance")//.setLossType("logistic")// 樹的參數.setImpurity("gini").setMaxDepth(5).setMaxBins(32)val gbtModel: GBTClassificationModel = gbt.fit(trainingDF)// TODO: 4. 模型評估與參數調優val predictionDF: DataFrame = gbtModel.transform(testingDF)predictionDF.select("prediction", "label_index").show(50, truncate = false)val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label_index").setPredictionCol("prediction").setMetricName("accuracy")val accuracy = evaluator.evaluate(predictionDF)println("Test Error = " + (1.0 - accuracy))Thread.sleep(10000000)// 應用結束,關閉資源spark.stop()}}Bagging與Boosting的區別
 ?
?
以決策樹為基礎分類器:
Bagging
????????多棵樹,每棵樹是獨立存在的,沒有任何聯系 -> 多棵樹
????????????????訓練時的數據:“隨機” -> 數據集(重復)、特征部分
????????????????訓練時可以并行訓練模型,多棵樹可以同時構建,效率高
????????預測時
????????????????分類:vote投票;回歸:avg平均
Boosting
????????多棵樹,每棵樹是關聯的 -> 一棵樹
????????????????使用全局的數據(不重復)、全部特征
????????????????訓練時只能串行,一棵一棵的構建,彼此之間相互關聯
????????預測時
????????????????是什么就是什么
(疊甲:大部分資料來源于黑馬程序員,這里只是做一些自己的認識、思路和理解,主要是為了分享經驗,如果大家有不理解的部分可以私信我,也可以移步【黑馬程序員_大數據實戰之用戶畫像企業級項目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿噴)












)






)