文章目錄
- 一、查漏補缺復盤
- 1、python中zip()用法
- 2、Tensor和tensor的區別
- 3、計算圖中的迭代取數
- 4、nn.Modlue及nn.Linear 源碼理解
- 5、知識雜項思考列表
- 6、KL散度初步理解
- 二、處理多維特征的輸入
- 1、邏輯回歸模型流程
- 2、Mini-Batch (N samples)
- 三、加載數據集
- 1、Python 魔法方法介紹
- 2、Epoch,Batch-Size,Iteration區別
- 3、加載相關數據集的實現
- 4、在torchvision,datasets數據集
- 四、多分類問題
- 1、softmax 再探究
- 2、獨熱編碼問題
- 五、語言模型初步理解
- 1、語言模型的概念
- 2、語言模型的計算
- 3、 n n n元語法
- 六、相關代碼實現
- 1、簡易實現小項目代碼地址
- 2、簡易實現小項目運行過程
- 3、抑郁癥數據預處理運行過程
- 4、抑郁癥數據訓練運行過程
- 七、遇到問題及其解決方案
- 1、pycharm 不能使用GPU加速訓練
- 2、google.protobuf.internal沖突問題
一、查漏補缺復盤
1、python中zip()用法
python中zip()用法
應用舉例
import numpy as np
import matplotlib.pyplot as pltx_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]def forward(x):return x*wdef loss(x, y):y_pred = forward(x)return (y_pred - y)**2# 窮舉法
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):print("w=", w)l_sum = 0for x_val, y_val in zip(x_data, y_data):y_pred_val = forward(x_val)loss_val = loss(x_val, y_val)l_sum += loss_valprint('\t', x_val, y_val, y_pred_val, loss_val)print('MSE=', l_sum/3)w_list.append(w)mse_list.append(l_sum/3)plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
2、Tensor和tensor的區別
首先看下代碼區別
>>> a=torch.Tensor([1,2])
>>> a
tensor([1., 2.])
>>> a=torch.tensor([1,2])
>>> a
tensor([1, 2])
- torch.Tensor()是python類,更明確地說,是默認張量類型
torch.FloatTensor()的別名,torch.Tensor([1,2])會調用Tensor類的構造函數__init__,生成單精度浮點類型的張量。 - 而
torch.tensor()僅僅是python函數:https://pytorch.org/docs/stable/torch.html torch.tensor
torch.tensor(data, dtype=None, device=None, requires_grad=False)
- 其中data可以是:list, tuple, NumPy ndarray, scalar和其他類型。
torch.tensor會從data中的數據部分做拷貝(而不是直接引用),根據原始數據類型生成相應的torch.LongTensor、torch.FloatTensor和torch.DoubleTensor。
3、計算圖中的迭代取數
注意關注grad取元素規則
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]w = torch.tensor([1.0]) # w的初值為1.0
w.requires_grad = True # 需要計算梯度def forward(x):return x*w # w是一個Tensordef loss(x, y):y_pred = forward(x)return (y_pred - y)**2print("predict (before training)", 4, forward(4).item())for epoch in range(100):for x, y in zip(x_data, y_data):l =loss(x,y) # l是一個張量,tensor主要是在建立計算圖 forward, compute the lossl.backward() # backward,compute grad for Tensor whose requires_grad set to Trueprint('\tgrad:', x, y, w.grad.item())w.data = w.data - 0.01 * w.grad.data # 權重更新時,注意grad也是一個tensorw.grad.data.zero_() # after update, remember set the grad to zeroprint('progress:', epoch, l.item()) # 取出loss使用l.item,不要直接使用l(l是tensor會構建計算圖)print("predict (after training)", 4, forward(4).item())
.data等于進tensor修改,.item()等于把數拿出來
- w是Tensor(張量類型),Tensor中包含data和grad,data和grad也是Tensor。grad初始為None,調用l.backward()方法后w.grad為Tensor,故更新w.data時需使用w.grad.data。如果w需要計算梯度,那構建的計算圖中,跟w相關的tensor都默認需要計算梯度。
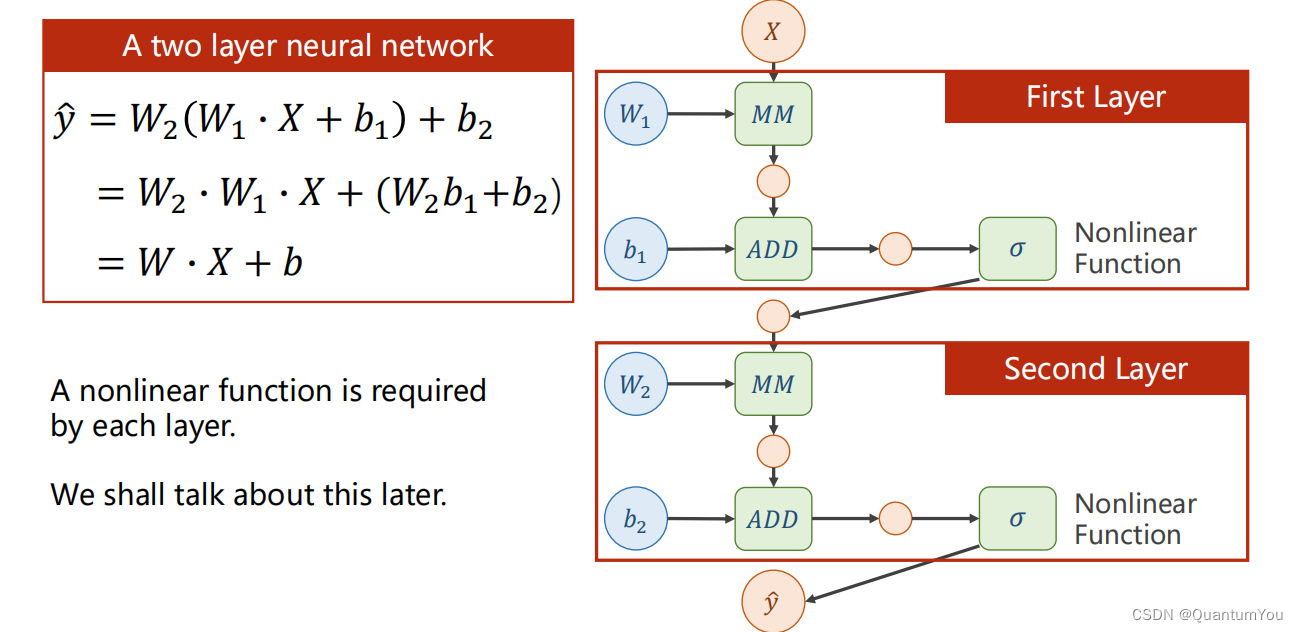
下面的 Linear(1,1 )是input1,output1


4、nn.Modlue及nn.Linear 源碼理解
import torch
# prepare dataset
# x,y是矩陣,3行1列 也就是說總共有3個數據,每個數據只有1個特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self).__init__()# (1,1)是指輸入x和輸出y的特征維度,這里數據集中的x和y的特征都是1維的# 該線性層需要學習的參數是w和b 獲取w/b的方式分別是~linear.weight/linear.biasself.linear = torch.nn.Linear(1, 1)def forward(self, x):y_pred = self.linear(x)return y_predmodel = LinearModel()# construct loss and optimizer
# criterion = torch.nn.MSELoss(size_average = False)
criterion = torch.nn.MSELoss(reduction = 'sum')
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) # model.parameters()自動完成參數的初始化操作,這個地方我可能理解錯了# training cycle forward, backward, update
for epoch in range(100):y_pred = model(x_data) # forward:predictloss = criterion(y_pred, y_data) # forward: lossprint(epoch, loss.item())optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zeroloss.backward() # backward: autograd,自動計算梯度optimizer.step() # update 參數,即更新w和b的值print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
參考文章
import torch
from torch import nnm = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)output.size() # torch.Size([128, 30])- nn.Module 是所有神經網絡單元(neural network modules)的基類
pytorch在nn.Module中,實現了__call__方法,而在__call__方法中調用了forward函數。 - 首先創建類對象m,然后通過m(input)實際上調用__call__(input),然后__call__(input)調用
forward()函數,最后返回計算結果為:[ 128 , 20 ] × [ 20 , 30 ] = [ 128 , 30 ]
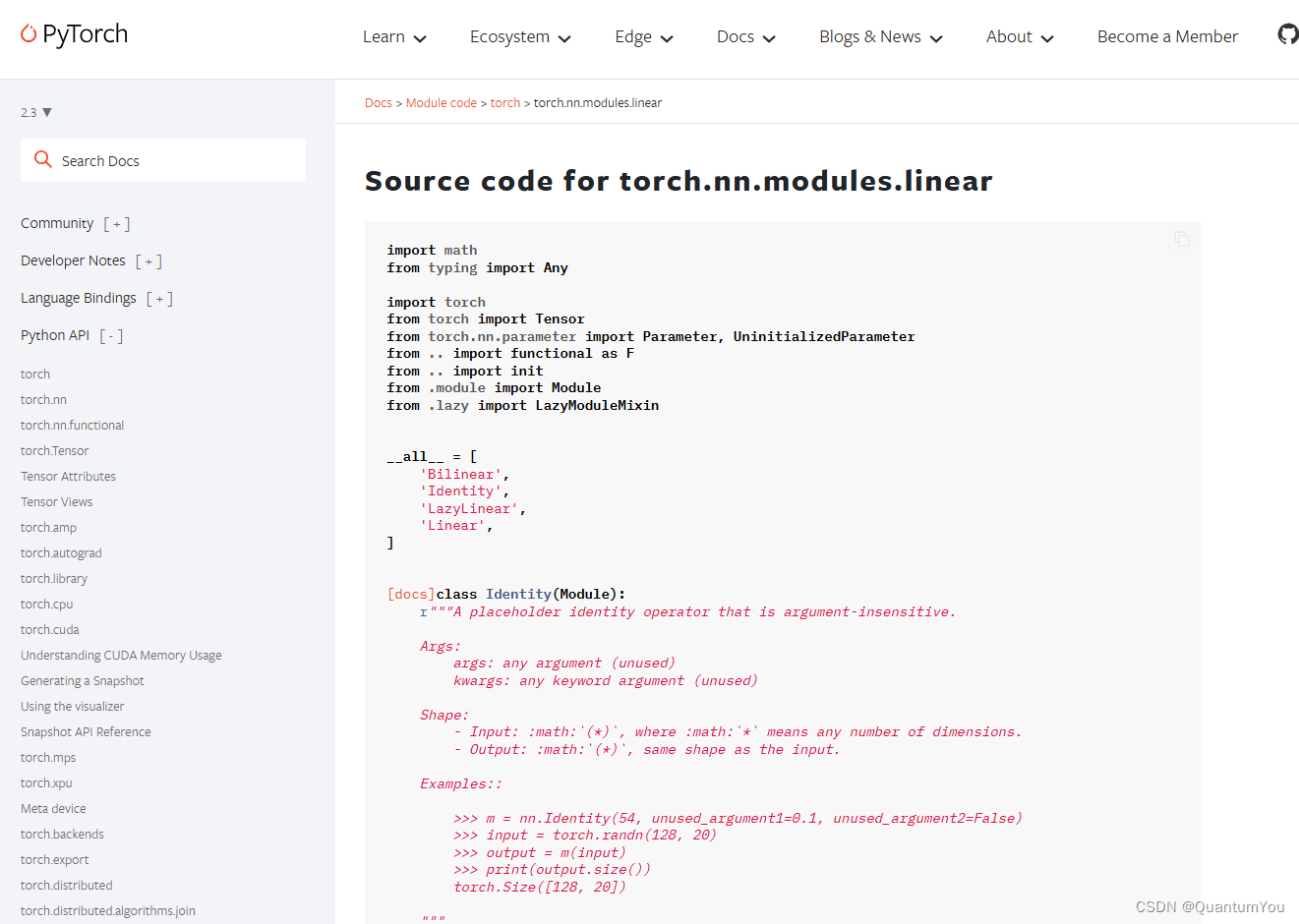
鏈接
5、知識雜項思考列表
1、SGD單個樣本進行梯度下降容易被噪聲帶來巨大干擾
2、矩陣求導理論書籍 matrix cookbook
3、前向傳播是為了計算損失值,反向傳播是為了計算梯度來更新模型的參數
6、KL散度初步理解
- KL散度(Kullback-Leibler divergence)是兩個概率分布間差異的非對稱性度量。參與計算的一個概率分布為真實分布,另一個為理論(擬合)分布,相對熵表示使用理論分布擬合真實分布時產生的信息損耗。
KL散度具有以下幾個性質:
- 非負性:KL散度的值始終大于等于0,當且僅當兩個概率分布完全相同時,KL散度的值才為0。
- 不對稱性:KL散度具有方向性,即P到Q的KL散度與Q到P的KL散度不相等。
- 無限制性:KL散度的值可能為無窮大,即當真實分布中的某個事件在理論分布中的概率為0時,KL散度的值為無窮大。
KL散度的計算公式如下:
D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) log ? P ( i ) Q ( i ) D_{KL}(P||Q) = \sum_{i}P(i) \log \frac{P(i)}{Q(i)} DKL?(P∣∣Q)=i∑?P(i)logQ(i)P(i)?
其中,(P)和(Q)分別為兩個概率分布,(P(i))和(Q(i))分別表示在位置(i)處的概率值。當KL散度等于0時,表示兩個概率分布完全相同;當KL散度大于0時,表示兩個概率分布存在差異,且值越大差異越大。
- 在機器學習中,KL散度有廣泛的應用,例如用于衡量兩個概率分布之間的差異,或者用于優化生成式模型的損失函數等。此外,KL散度還可以用于基于KL散度的樣本選擇來有效訓練支持向量機(SVM)等算法,以解決SVM在大型數據集合上效率低下的問題。
邏輯回歸構造模板
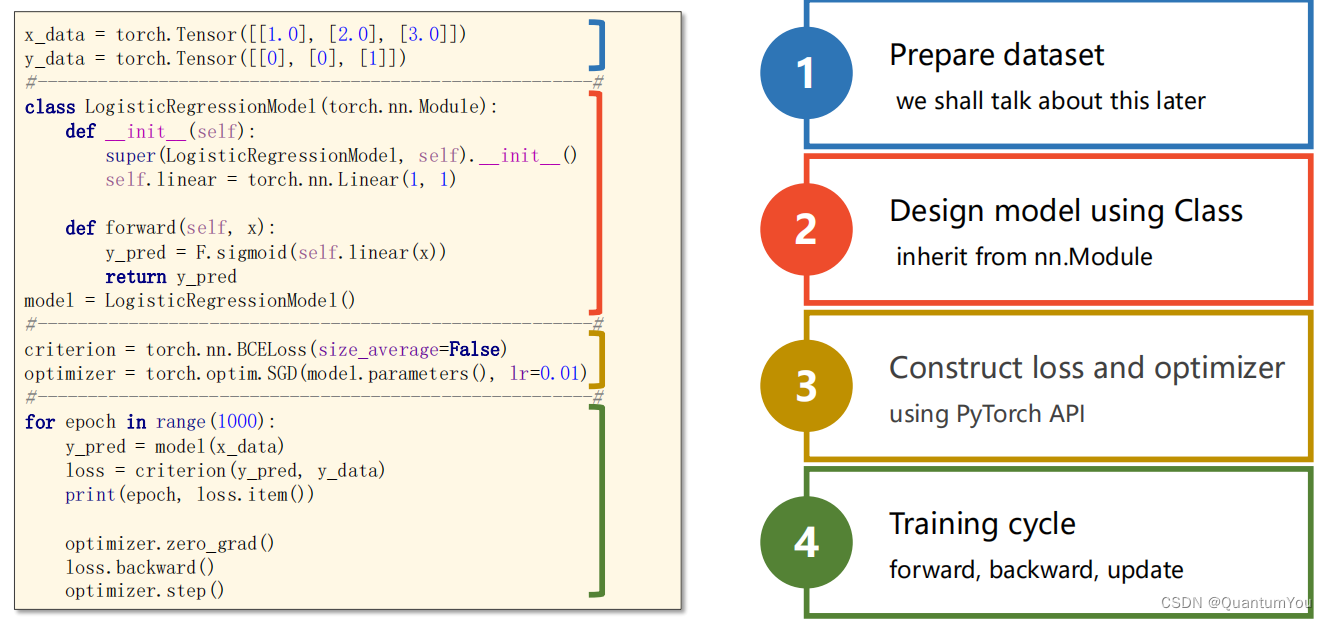
二、處理多維特征的輸入
1、邏輯回歸模型流程
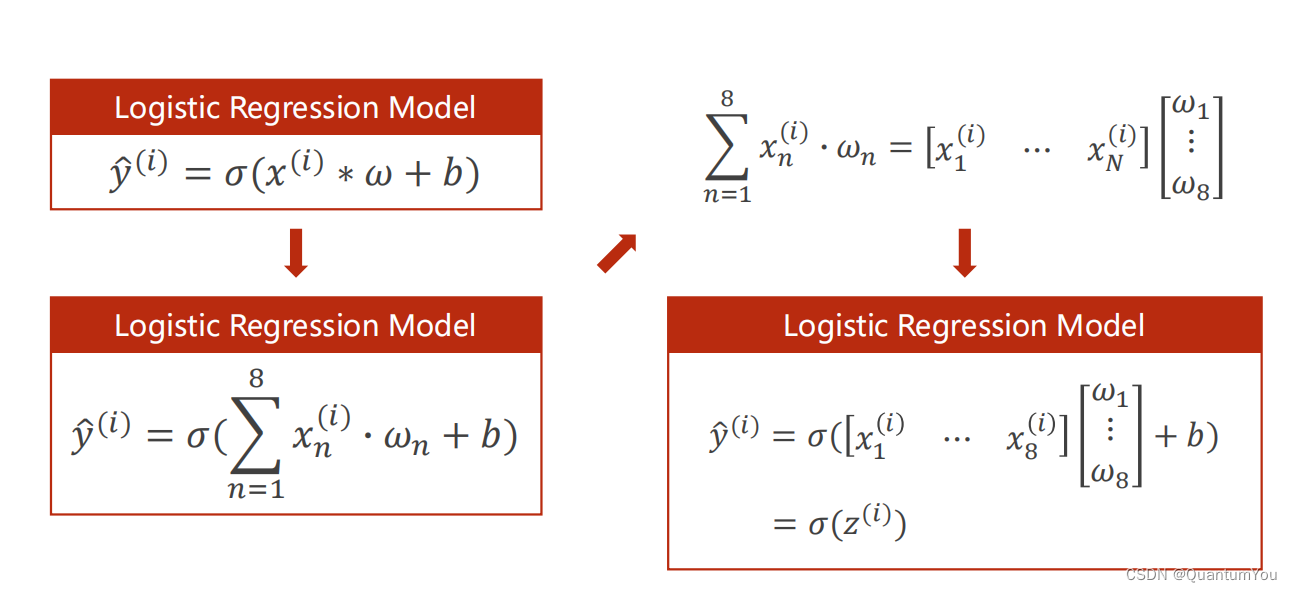
2、Mini-Batch (N samples)
在數學上轉化為矩陣運算,轉化為向量形式利于GPU進行并行運算

self.linear torch.nn.Linear (8,1)輸入為8,輸出為1
說明:
-
1、乘的權重(w)都一樣,加的偏置(b)也一樣。b變成矩陣時使用廣播機制。神經網絡的參數w和b是網絡需要學習的,其他是已知的。
-
2、學習能力越強,有可能會把輸入樣本中噪聲的規律也學到。我們要學習數據本身真實數據的規律,學習能力要有泛化能力。
-
3、該神經網絡共3層;第一層是8維到6維的非線性空間變換,第二層是6維到4維的非線性空間變換,第三層是4維到1維的非線性空間變換。

-
4、本算法中
torch.nn.Sigmoid()將其看作是網絡的一層,而不是簡單的函數使用
torch.sigmoid、torch.nn.Sigmoid和torch.nn.functional.sigmoid的區別
三、加載數據集
- DataLoader 主要加載數據集
說明:
-
1、DataSet 是抽象類,不能實例化對象,主要是用于構造我們的數據集
-
2、DataLoader 需要獲取DataSet提供的索引[i]和len;用來幫助我們加載數據,比如說做shuffle(提高數據集的隨機性),batch_size,能拿出Mini-Batch進行訓練。它幫我們自動完成這些工作。DataLoader可實例化對象。
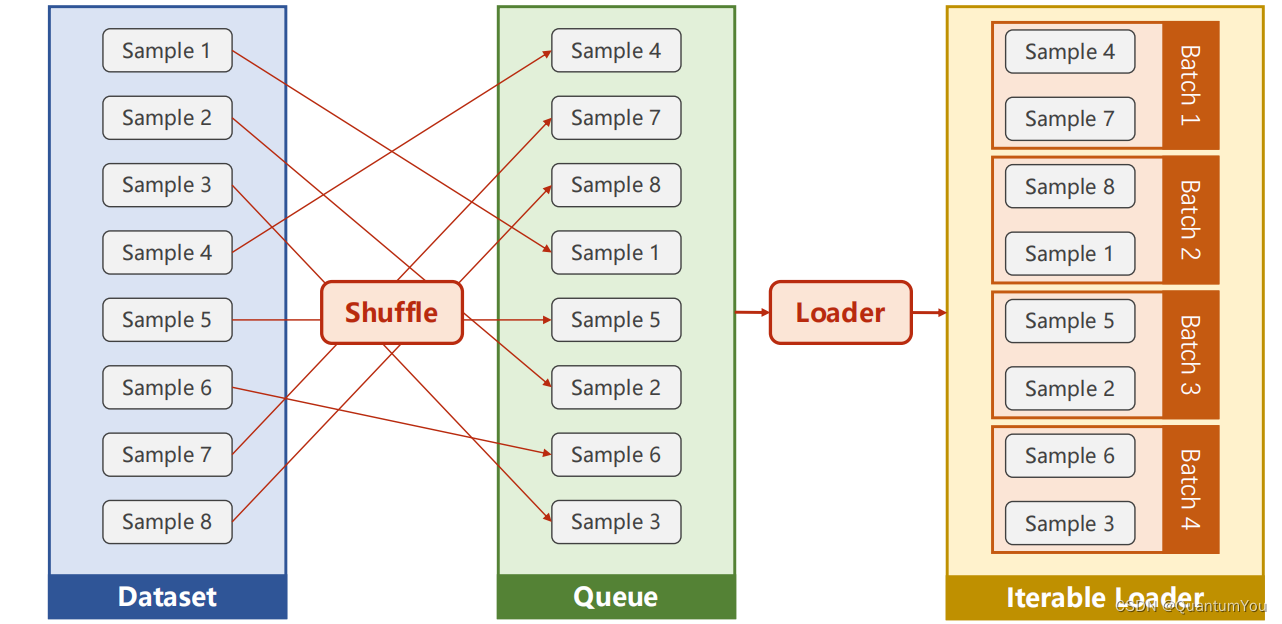
-
3、__getitem__目的是為支持下標(索引)操作
1、Python 魔法方法介紹
- 在Python中,有一些特殊的方法(通常被稱為“魔法方法”或“雙下劃線方法”)是由Python解釋器預定義的,它們允許對象進行某些特殊的操作或重載常見的運算符。這些魔法方法通常以雙下劃線(
__)開始和結束。
- 初始化方法:
__init__(self, ...)
在創建對象時自動調用,用于初始化對象的狀態。
class MyClass:def __init__(self, value):self.value = value
- 字符串表示方法:
__str__(self)和__repr__(self)
用于定義對象的字符串表示。__str__用于在print函數中,而__repr__用于在repr函數中。
class MyClass:def __init__(self, value):self.value = valuedef __str__(self):return f"MyClass({self.value})"def __repr__(self):return f"MyClass({self.value})"
- 比較方法:如
__eq__(self, other)、__lt__(self, other)等
用于定義對象之間的比較操作。
class MyClass:def __init__(self, value):self.value = valuedef __eq__(self, other):if isinstance(other, MyClass):return self.value == other.valuereturn False
- 算術運算符方法:如
__add__(self, other)、__sub__(self, other)等
用于定義對象之間的算術運算。
class MyClass:def __init__(self, value):self.value = valuedef __add__(self, other):if isinstance(other, MyClass):return MyClass(self.value + other.value)return NotImplemented
- 容器方法:如
__len__(self)、__getitem__(self, key)、__setitem__(self, key, value)等
-
用于定義對象作為容器(如列表、字典等)時的行為。
-
每個魔法方法是python的內置方法。方法都有對應的內置函數,或者運算符,對這個對象使用這些函數或者運算符時就會調用類中的對應魔法方法,可以理解為重寫這些python的內置函數
2、Epoch,Batch-Size,Iteration區別

eg:
10,000 examples --> 1000 Batch-size --> 10 Iteration
1、需要mini_batch 就需要import DataSet和DataLoader
2、繼承DataSet的類需要重寫init,getitem,len魔法函數。分別是為了加載數據集,獲取數據索引,獲取數據總量。
3、DataLoader對數據集先打亂(shuffle),然后劃分成mini_batch。
4、len函數的返回值 除以 batch_size 的結果就是每一輪epoch中需要迭代的次數。
5、inputs, labels = data中的inputs的shape是[32,8],labels 的shape是[32,1]。也就是說mini_batch在這個地方體現的
在windows 下 wrap 和 linux 下 fork 代碼優化

3、加載相關數據集的實現
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoaderclass DiabetesDataset(Dataset):def __init__(self,filepath):xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)#shape本身是一個二元組(x,y)對應數據集的行數和列數,這里[0]我們取行數,即樣本數self.len = xy.shape[0]self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, [-1]])def __getitem__(self, index):return self.x_data[index],self.y_data[index]def __len__(self):return self.len#定義好DiabetesDataset后我們就可以實例化他了
dataset = DiabetesDataset('./data/Diabetes_class.csv.gz')
#我們用DataLoader為數據進行分組,batch_size是一個組中有多少個樣本,shuffle表示要不要對樣本進行隨機排列
#一般來說,訓練集我們隨機排列,測試集不。num_workers表示我們可以用多少進程并行的運算
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)class Model(torch.nn.Module):def __init__(self):#構造函數super(Model,self).__init__()self.linear1 = torch.nn.Linear(8,6)#8維到6維self.linear2 = torch.nn.Linear(6, 4)#6維到4維self.linear3 = torch.nn.Linear(4, 1)#4維到1維self.sigmoid = torch.nn.Sigmoid()#因為他里邊也沒有權重需要更新,所以要一個就行了,單純的算個數def forward(self, x):#構建一個計算圖,就像上面圖片畫的那樣x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))return xmodel = Model()#實例化模型criterion = torch.nn.BCELoss(size_average=False)
#model.parameters()會掃描module中的所有成員,如果成員中有相應權重,那么都會將結果加到要訓練的參數集合上
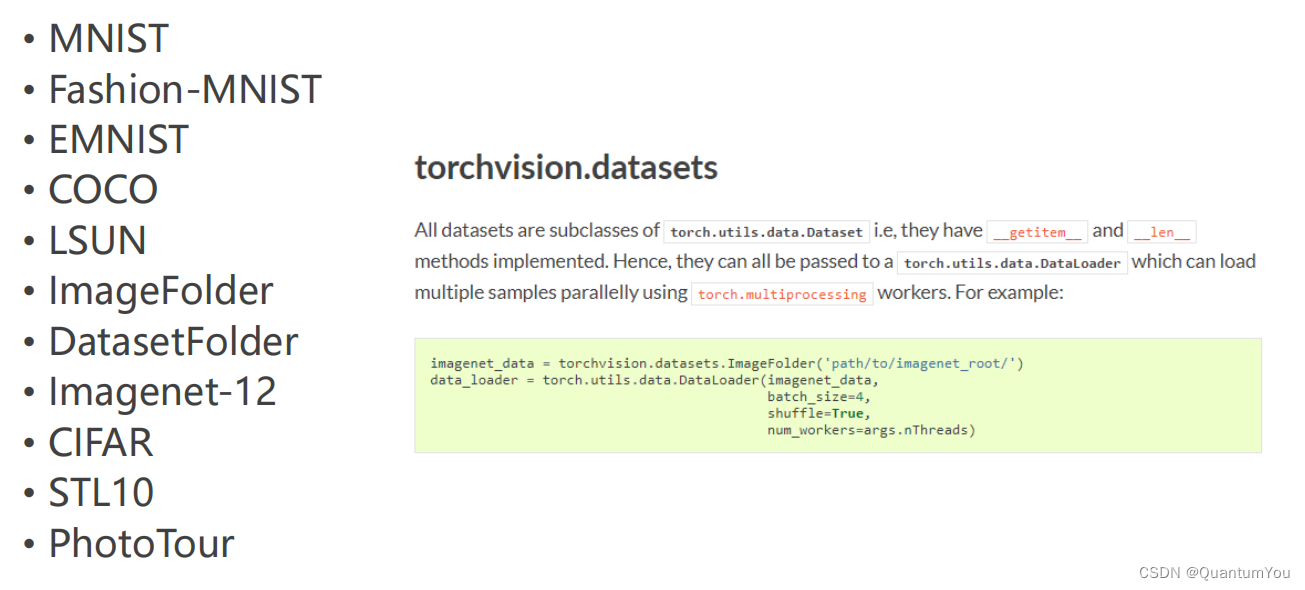
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)#lr為學習率if __name__=='__main__':#if這條語句在windows系統下一定要加,否則會報錯for epoch in range(1000):for i,data in enumerate(train_loader,0):#取出一個bath# repare datainputs,labels = data#將輸入的數據賦給inputs,結果賦給labels #Forwardy_pred = model(inputs)loss = criterion(y_pred,labels)print(epoch,loss.item())#Backwardoptimizer.zero_grad()loss.backward()#updateoptimizer.step()4、在torchvision,datasets數據集
在torchvision,datasets 下的常見數據集
四、多分類問題
1、softmax 再探究
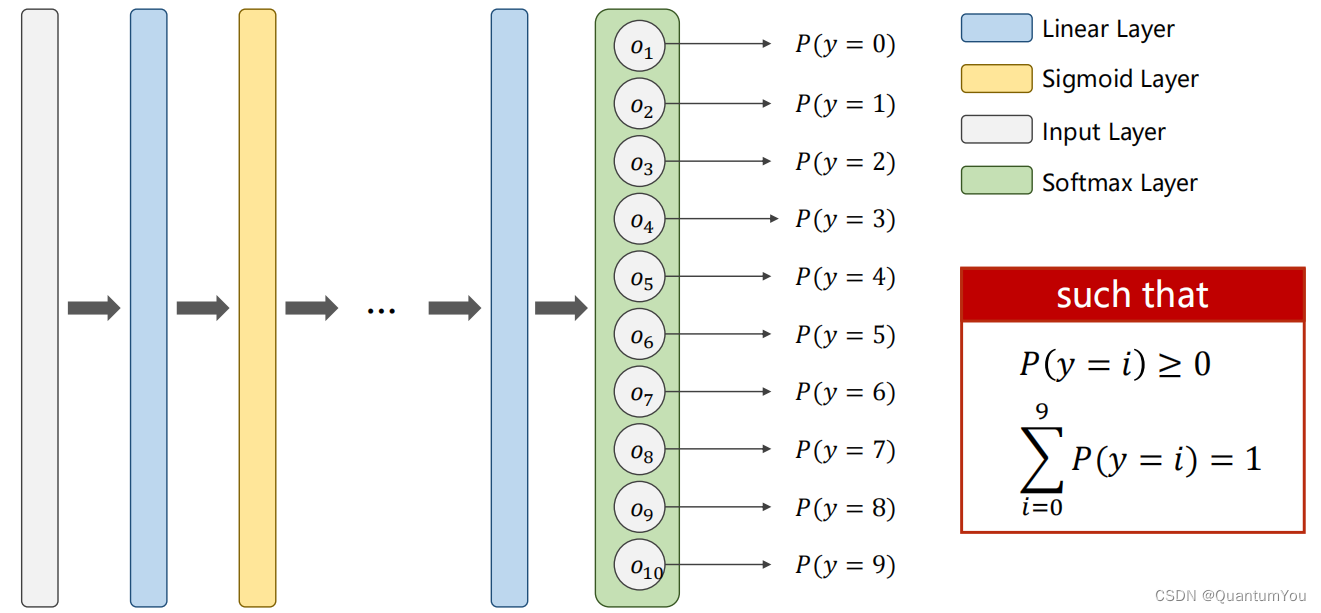
每個類別輸出都使用二分類的交叉熵,這樣的話所有類別都是一個獨立的分布,概率加起來不等于一
注意:我們是將每一個類別看作一個二分類問題,且最后每個輸出值需滿足兩個要求:①≥ 0 ②∑ = 1 即輸出的是一個分布。
在神經網絡中,特別是在分類任務中,Softmax 函數通常被用作最后一層(線性層或全連接層)的激活函數,以將模型的輸出轉換為概率分布。對于給定向
Softmax ( Z l ) i = e Z i l ∑ j = 1 k e Z j l \text{Softmax}(Z^l)_i = \frac{e^{Z^l_i}}{\sum_{j=1}^{k} e^{Z^l_j}} Softmax(Zl)i?=∑j=1k?eZjl?eZil?? 對于 i = 0 … … K ? 1 \quad \text{對于} \quad i = 0……K-1 對于i=0……K?1
除法是因為歸一化
因為輸出的是概率,所以要是正數;k個類的概率相互抑制,概率之和是1.所以要先轉正再歸一化,也就是softmax
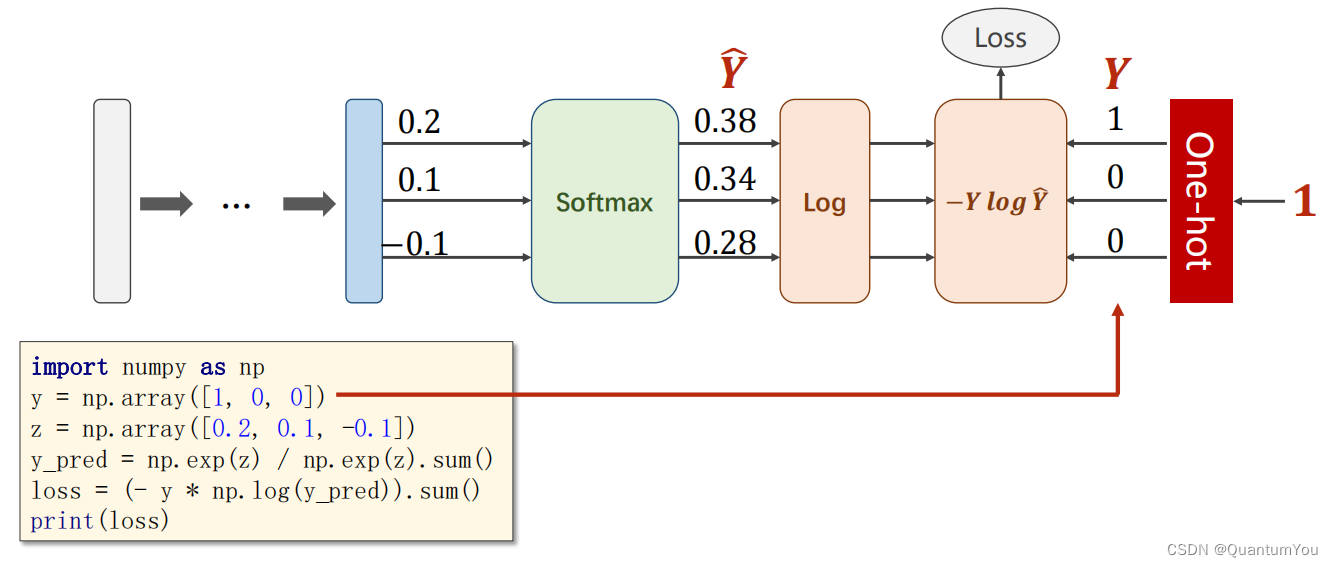
- 在分類任務中,特別是當使用交叉熵損失函數(Cross-Entropy Loss)時,對于給定的預測概率分布 Y ^ \hat{Y} Y^和真實標簽 Y,損失函數可以定義為:
Loss ( Y ^ , Y ) = ? ∑ i = 1 k Y i log ? Y ^ i \text{Loss}(\hat{Y}, Y) = -\sum_{i=1}^{k} Y_i \log \hat{Y}_i Loss(Y^,Y)=?i=1∑k?Yi?logY^i?
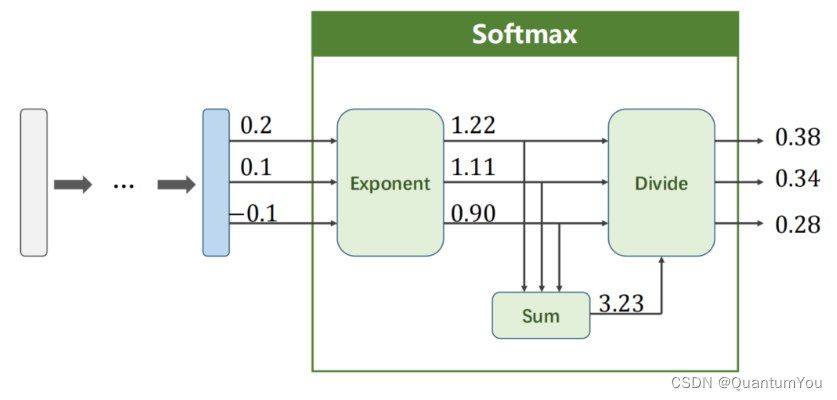
注意這里,(Y) 通常是一個獨熱編碼(one-hot encoded)的向量,其中只有一個元素為1(表示真實的類別),其余元素為0。因此,在實際計算中,由于除了真實類別對應的 (Y_i) 為1外,其余 (Y_i) 都為0,所以求和式中實際上只有一項是有效的。
2、獨熱編碼問題
one-hot介紹
五、語言模型初步理解
1、語言模型的概念
- 語言模型(language model)是自然語言處理的重要技術。自然語言處理中最常見的數據是文本數據。可以把一段自然語言文本看作一段離散的時間序列。假設一段長度為 T T T的文本中的詞依次為 w 1 , w 2 , … , w T w_1, w_2, \ldots, w_T w1?,w2?,…,wT?,那么在離散的時間序列中, w t w_t wt?( 1 ≤ t ≤ T 1 \leq t \leq T 1≤t≤T)可看作在時間步(time step) t t t的輸出或標簽。給定一個長度為 T T T的詞的序列 w 1 , w 2 , … , w T w_1, w_2, \ldots, w_T w1?,w2?,…,wT?,語言模型將計算該序列的概率:
P ( w 1 , w 2 , … , w T ) . P(w_1, w_2, \ldots, w_T). P(w1?,w2?,…,wT?).
2、語言模型的計算
- 假設序列 w 1 , w 2 , … , w T w_1, w_2, \ldots, w_T w1?,w2?,…,wT?中的每個詞是依次生成的,我們有
P ( w 1 , w 2 , … , w T ) = ∏ t = 1 T P ( w t ∣ w 1 , … , w t ? 1 ) . P(w_1, w_2, \ldots, w_T) = \prod_{t=1}^T P(w_t \mid w_1, \ldots, w_{t-1}). P(w1?,w2?,…,wT?)=t=1∏T?P(wt?∣w1?,…,wt?1?).
例如,一段含有4個詞的文本序列的概率
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 1 , w 2 , w 3 ) . P(w_1, w_2, w_3, w_4) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_1, w_2, w_3). P(w1?,w2?,w3?,w4?)=P(w1?)P(w2?∣w1?)P(w3?∣w1?,w2?)P(w4?∣w1?,w2?,w3?).
- 為了計算語言模型,我們需要計算詞的概率,以及一個詞在給定前幾個詞的情況下的條件概率,即語言模型參數。設訓練數據集為一個大型文本語料庫,如維基百科的所有條目。詞的概率可以通過該詞在訓練數據集中的相對詞頻來計算。例如, P ( w 1 ) P(w_1) P(w1?)可以計算為 w 1 w_1 w1?在訓練數據集中的詞頻(詞出現的次數)與訓練數據集的總詞數之比。因此,根據條件概率定義,一個詞在給定前幾個詞的情況下的條件概率也可以通過訓練數據集中的相對詞頻計算。例如, P ( w 2 ∣ w 1 ) P(w_2 \mid w_1) P(w2?∣w1?)可以計算為 w 1 , w 2 w_1, w_2 w1?,w2?兩詞相鄰的頻率與 w 1 w_1 w1?詞頻的比值,因為該比值即 P ( w 1 , w 2 ) P(w_1, w_2) P(w1?,w2?)與 P ( w 1 ) P(w_1) P(w1?)之比;而 P ( w 3 ∣ w 1 , w 2 ) P(w_3 \mid w_1, w_2) P(w3?∣w1?,w2?)同理可以計算為 w 1 w_1 w1?、 w 2 w_2 w2?和 w 3 w_3 w3?三詞相鄰的頻率與 w 1 w_1 w1?和 w 2 w_2 w2?兩詞相鄰的頻率的比值。以此類推。
3、 n n n元語法
- 當序列長度增加時,計算和存儲多個詞共同出現的概率的復雜度會呈指數級增加。 n n n元語法通過馬爾可夫假設(雖然并不一定成立)簡化了語言模型的計算。這里的馬爾可夫假設是指一個詞的出現只與前面 n n n個詞相關,即 n n n階馬爾可夫鏈(Markov chain of order n n n)。如果 n = 1 n=1 n=1,那么有 P ( w 3 ∣ w 1 , w 2 ) = P ( w 3 ∣ w 2 ) P(w_3 \mid w_1, w_2) = P(w_3 \mid w_2) P(w3?∣w1?,w2?)=P(w3?∣w2?)。如果基于 n ? 1 n-1 n?1階馬爾可夫鏈,我們可以將語言模型改寫為
P ( w 1 , w 2 , … , w T ) ≈ ∏ t = 1 T P ( w t ∣ w t ? ( n ? 1 ) , … , w t ? 1 ) . P(w_1, w_2, \ldots, w_T) \approx \prod_{t=1}^T P(w_t \mid w_{t-(n-1)}, \ldots, w_{t-1}) . P(w1?,w2?,…,wT?)≈t=1∏T?P(wt?∣wt?(n?1)?,…,wt?1?).
以上也叫 n n n元語法( n n n-grams)。它是基于 n ? 1 n - 1 n?1階馬爾可夫鏈的概率語言模型。當 n n n分別為1、2和3時,我們將其分別稱作一元語法(unigram)、二元語法(bigram)和三元語法(trigram)。例如,長度為4的序列 w 1 , w 2 , w 3 , w 4 w_1, w_2, w_3, w_4 w1?,w2?,w3?,w4?在一元語法、二元語法和三元語法中的概率分別為
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ) P ( w 3 ) P ( w 4 ) , P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 2 ) P ( w 4 ∣ w 3 ) , P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 2 , w 3 ) . \begin{aligned} P(w_1, w_2, w_3, w_4) &= P(w_1) P(w_2) P(w_3) P(w_4) ,\\ P(w_1, w_2, w_3, w_4) &= P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_2) P(w_4 \mid w_3) ,\\ P(w_1, w_2, w_3, w_4) &= P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_2, w_3) . \end{aligned} P(w1?,w2?,w3?,w4?)P(w1?,w2?,w3?,w4?)P(w1?,w2?,w3?,w4?)?=P(w1?)P(w2?)P(w3?)P(w4?),=P(w1?)P(w2?∣w1?)P(w3?∣w2?)P(w4?∣w3?),=P(w1?)P(w2?∣w1?)P(w3?∣w1?,w2?)P(w4?∣w2?,w3?).?
當 n n n較小時, n n n元語法往往并不準確。例如,在一元語法中,由三個詞組成的句子“你走先”和“你先走”的概率是一樣的。然而,當 n n n較大時, n n n元語法需要計算并存儲大量的詞頻和多詞相鄰頻率。
六、相關代碼實現
1、簡易實現小項目代碼地址
Github
https://github.com/aqlzh/Artificial-intelligence
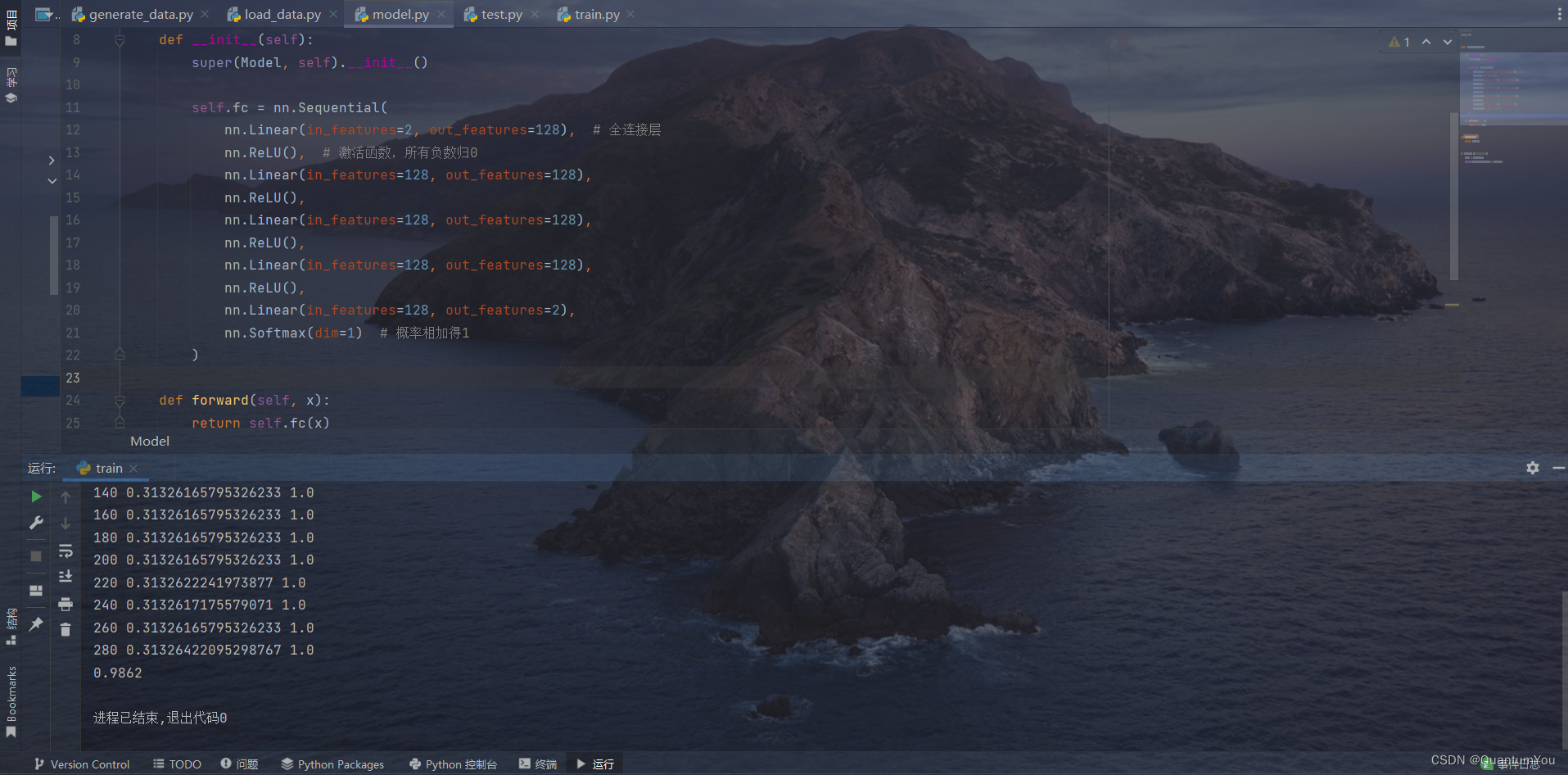
2、簡易實現小項目運行過程
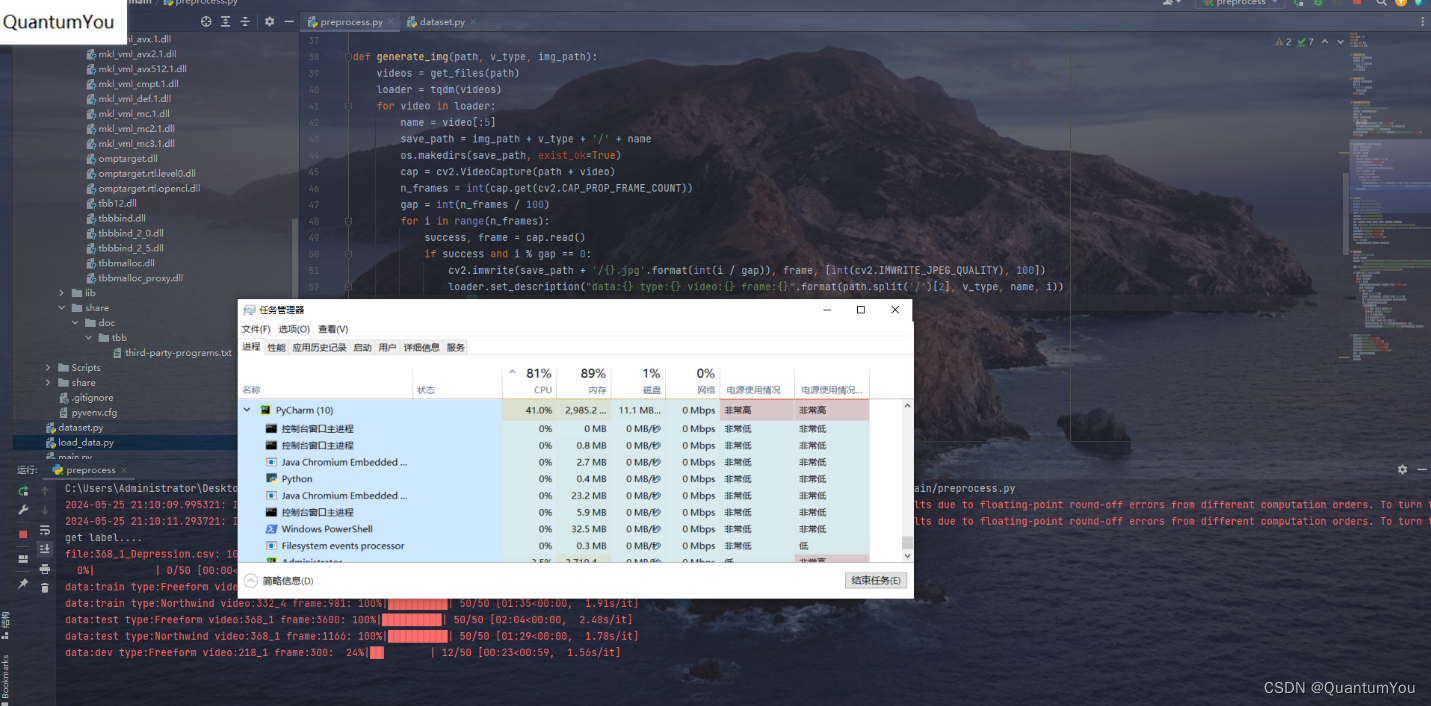
3、抑郁癥數據預處理運行過程
def get_files(path):file_info = os.walk(path)file_list = []for r, d, f in file_info:file_list += freturn file_listdef get_dirs(path):file_info = os.walk(path)dirs = []for d, r, f in file_info:dirs.append(d)return dirs[1:]def generate_label_file():print('get label....')base_url = './AVEC2014/label/DepressionLabels/'file_list = get_files(base_url)labels = []loader = tqdm(file_list)for file in loader:label = pd.read_csv(base_url + file, header=None)labels.append([file[:file.find('_Depression.csv')], label[0][0]])loader.set_description('file:{}'.format(file))pd.DataFrame(labels, columns=['file', 'label']).to_csv('./processed/label.csv', index=False)return labelsdef generate_img(path, v_type, img_path):videos = get_files(path)loader = tqdm(videos)for video in loader:name = video[:5]save_path = img_path + v_type + '/' + nameos.makedirs(save_path, exist_ok=True)cap = cv2.VideoCapture(path + video)n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))gap = int(n_frames / 100)for i in range(n_frames):success, frame = cap.read()if success and i % gap == 0:cv2.imwrite(save_path + '/{}.jpg'.format(int(i / gap)), frame, [int(cv2.IMWRITE_JPEG_QUALITY), 100])loader.set_description("data:{} type:{} video:{} frame:{}".format(path.split('/')[2], v_type, name, i))cap.release()def get_img():print('get video frames....')train_f = './AVEC2014/train/Freeform/'train_n = './AVEC2014/train/Northwind/'test_f = './AVEC2014/test/Freeform/'test_n = './AVEC2014/test/Northwind/'validate_f = './AVEC2014/dev/Freeform/'validate_n = './AVEC2014/dev/Northwind/'dirs = [train_f, train_n, test_f, test_n, validate_f, validate_n]types = ['Freeform', 'Northwind', 'Freeform', 'Northwind', 'Freeform', 'Northwind']img_path = ['./img/train/', './img/train/', './img/test/', './img/test/', './img/validate/', './img/validate/']os.makedirs('./img/train', exist_ok=True)os.makedirs('./img/test', exist_ok=True)os.makedirs('./img/validate', exist_ok=True)for i in range(6):generate_img(dirs[i], types[i], img_path[i])def get_face():print('get frame faces....')detector = MTCNN()save_path = ['./processed/train/Freeform/', './processed/train/Northwind/', './processed/test/Freeform/','./processed/test/Northwind/', './processed/validate/Freeform/', './processed/validate/Northwind/']paths = ['./img/train/Freeform/', './img/train/Northwind/', './img/test/Freeform/', './img/test/Northwind/','./img/validate/Freeform/', './img/validate/Northwind/']for index, path in enumerate(paths):dirs = get_dirs(path)loader = tqdm(dirs)for d in loader:os.makedirs(save_path[index] + d.split('/')[-1], exist_ok=True)files = get_files(d)for file in files:img_path = d + '/' + files_path = save_path[index] + d.split('/')[-1] + '/' + fileimg = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB)info = detector.detect_faces(img)if (len(info) > 0):x, y, width, height = info[0]['box']confidence = info[0]['confidence']b, g, r = cv2.split(img)img = cv2.merge([r, g, b])img = img[y:y + height, x:x + width, :]cv2.imwrite(s_path, img, [int(cv2.IMWRITE_JPEG_QUALITY), 100])loader.set_description('confidence:{:4f} img:{}'.format(confidence, img_path))if __name__ == '__main__':os.makedirs('./img', exist_ok=True)os.makedirs('./processed', exist_ok=True)os.makedirs('./processed/train', exist_ok=True)os.makedirs('./processed/test', exist_ok=True)os.makedirs('./processed/validate', exist_ok=True)label = generate_label_file()get_img()get_face()數據預處理時間最長的一集 😢😢
預處理有兩步驟
- 第一步是從視頻中提取圖片(抽取視頻幀,每個視頻按間隔抽取100-105幀)
- 第二步是從圖片中提取人臉信息(使用MTCNN提取人臉,并分割圖片)
預處理數據成功,結果如下(跑了一整個晚上)😵😵
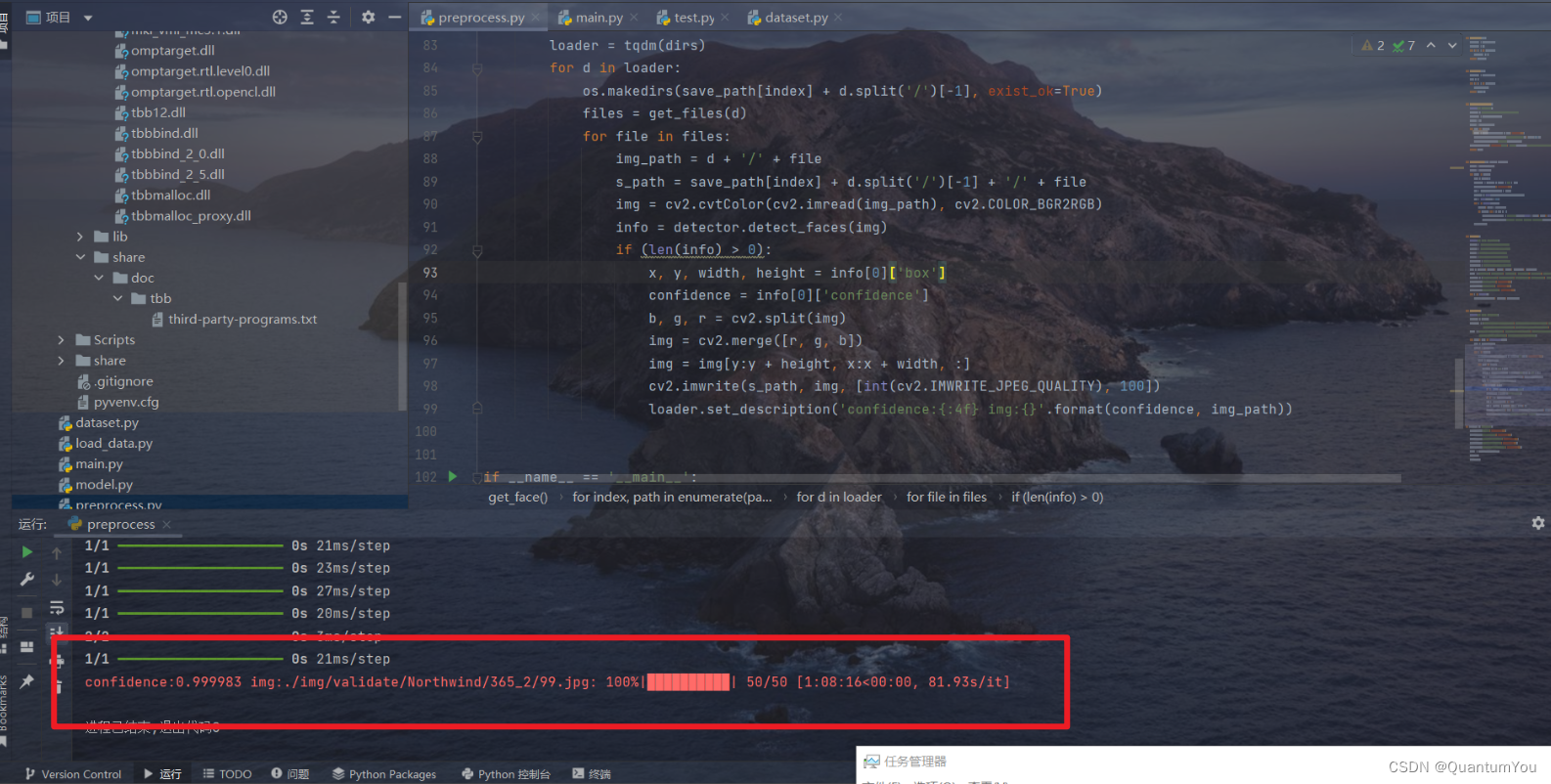
4、抑郁癥數據訓練運行過程
電腦配置感覺跟不上了,跑不動了,epoch 0 都跑了大半天😱😱
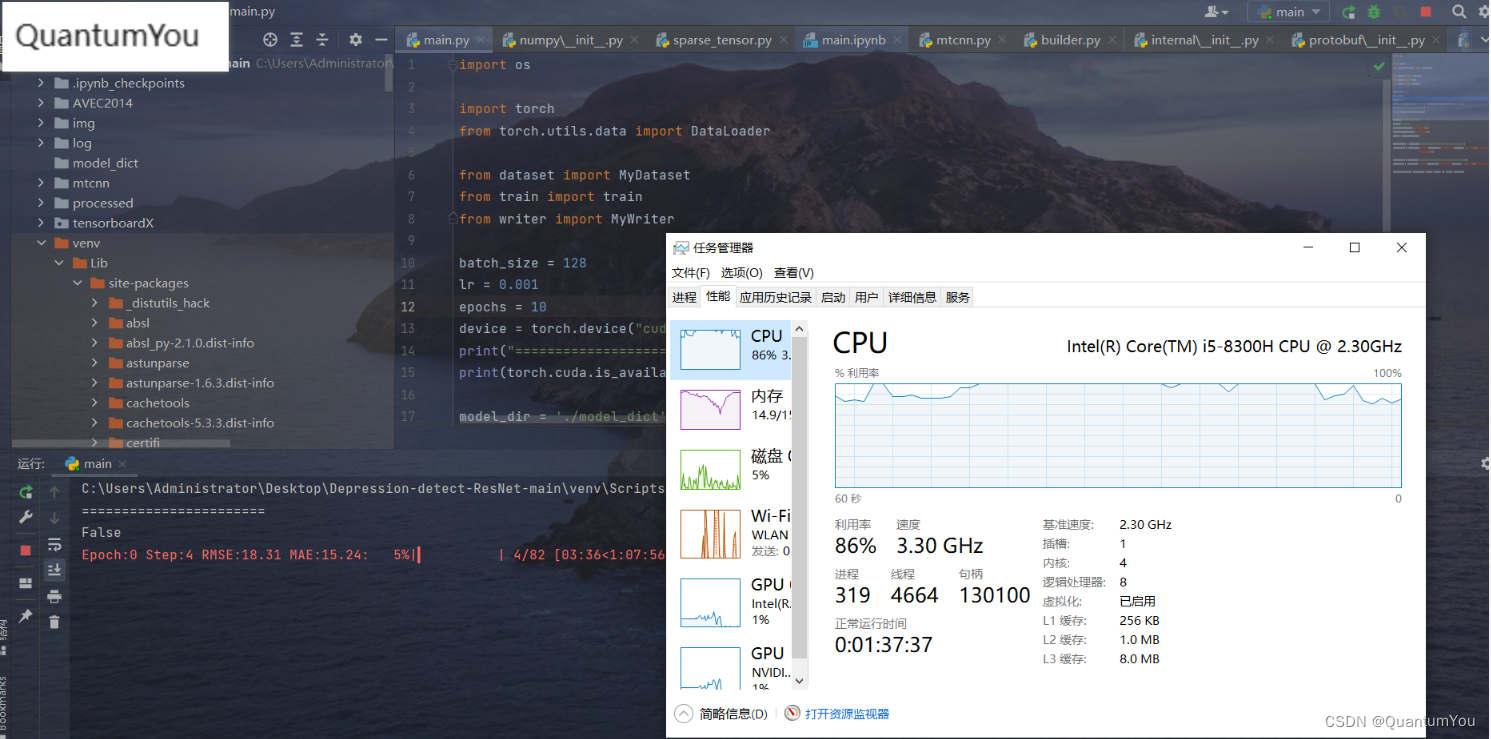
七、遇到問題及其解決方案
1、pycharm 不能使用GPU加速訓練
https://blog.csdn.net/QuantumYou/article/details/139215013?spm=1001.2014.3001.5501
2、google.protobuf.internal沖突問題
https://blog.csdn.net/QuantumYou/article/details/139212458?spm=1001.2014.3001.5501




)







)

![[自動駕駛技術]-6 Tesla自動駕駛方案之硬件(AI Day 2021)](http://pic.xiahunao.cn/[自動駕駛技術]-6 Tesla自動駕駛方案之硬件(AI Day 2021))



)

