1 硬件集成
特斯拉自動駕駛數據標注過程中,跨250萬個clips超過100億的標注數據,無論是自動標注還是模型訓練都要求具備強大的計算能力的硬件。下圖是特斯拉FSD計算平臺硬件電路圖。

1)神經網絡編譯器
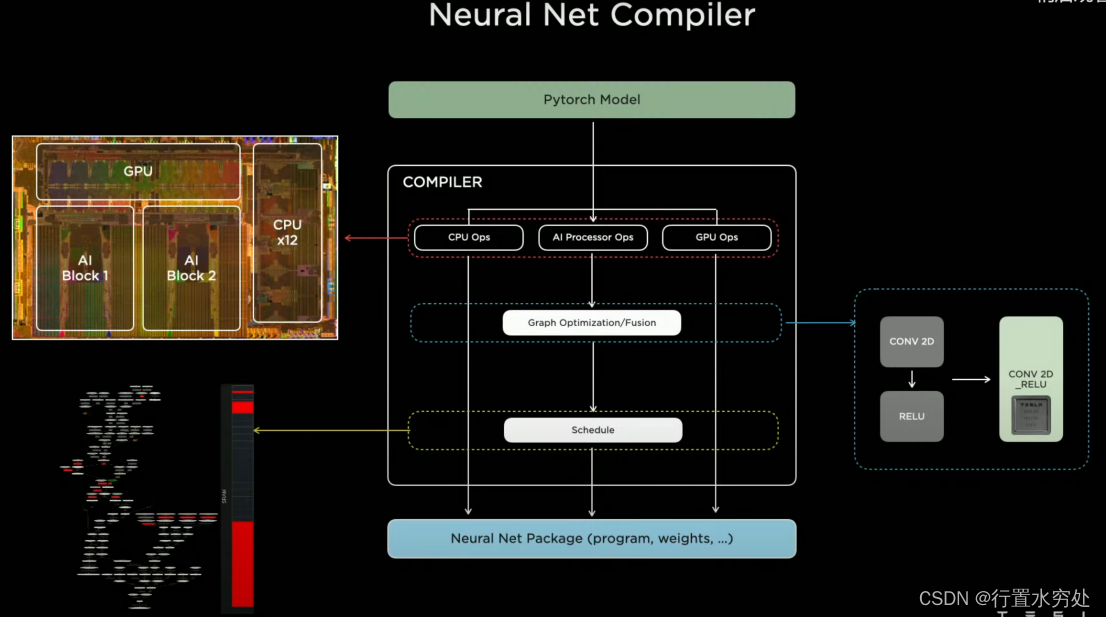 特斯拉AI編譯器主要針對PyTorch框架,結合之前介紹過的編譯器內容,特斯拉的自動駕駛算法模型需要通過編譯器,生成硬件可執行的機器指令,才能在CPU、GPU或者AI芯片上運行。上圖主要展示了AI編譯器的計算圖優化(算子融合:將CONV 2D和RELU算子融合為1個CONV 2D_RELU算子,這基本是常規標配做法),調度。
特斯拉AI編譯器主要針對PyTorch框架,結合之前介紹過的編譯器內容,特斯拉的自動駕駛算法模型需要通過編譯器,生成硬件可執行的機器指令,才能在CPU、GPU或者AI芯片上運行。上圖主要展示了AI編譯器的計算圖優化(算子融合:將CONV 2D和RELU算子融合為1個CONV 2D_RELU算子,這基本是常規標配做法),調度。
2)FSD計算平臺
 特斯拉FSD硬件計算平臺集成了2顆SoC芯片,SOC-1輸出最終的控制指令,SOC-2作為擴展計算。
特斯拉FSD硬件計算平臺集成了2顆SoC芯片,SOC-1輸出最終的控制指令,SOC-2作為擴展計算。
3)AI模型評估中心
 特斯拉的AI模型評估基礎設施中心,可支持每周超過百萬的評估計算,運行在超過3000個FSD計算平臺上。
特斯拉的AI模型評估基礎設施中心,可支持每周超過百萬的評估計算,運行在超過3000個FSD計算平臺上。
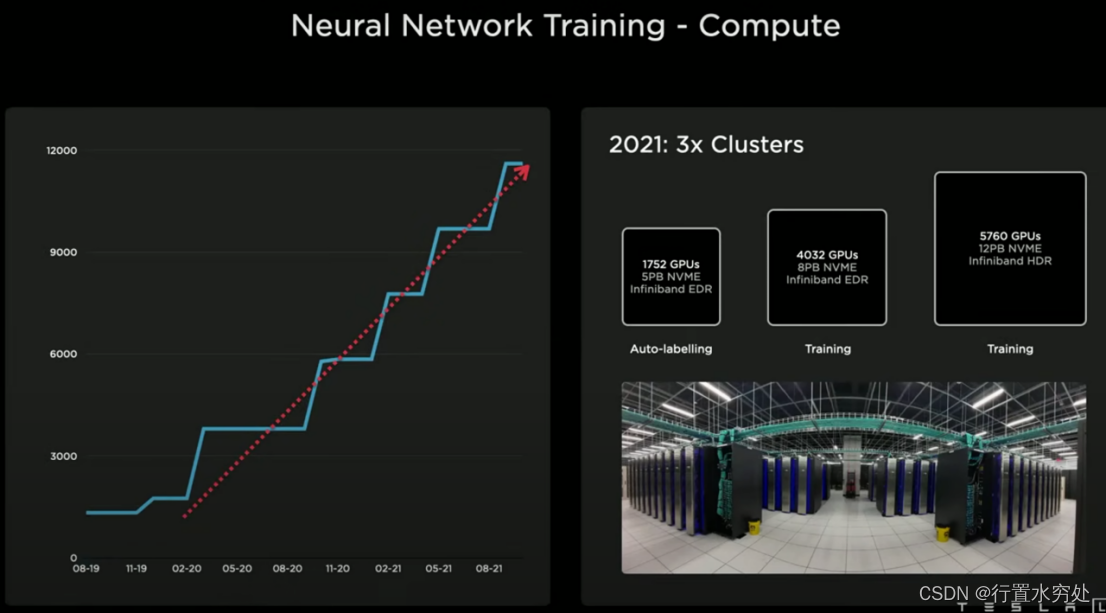 特斯拉的訓練網絡計算中心,2021年具備3個集群1組用于自動標注,2組用于模型訓練。
特斯拉的訓練網絡計算中心,2021年具備3個集群1組用于自動標注,2組用于模型訓練。
2 DOJO項目 ?
Ganesh說:“計算能力容易擴展,但帶寬擴展較為困難,而降低延遲則極其困難。”
現代CPU、GPU和AI加速器通過不斷優化架構(如增加核心數、提高時鐘速度、優化指令集)來提升性能。特別是GPU和AI加速器,天然適合大規模并行計算,通過增加更多的計算單元,可以顯著提升計算能力。
然而無論哪種處理器都很容易受到內存帶寬限制: CPU、GPU和AI加速器需要高速訪問內存,而內存帶寬的提升速度往往跟不上計算能力的提升速度,造成帶寬瓶頸,也就是我們常說的內存墻問題。此外,芯片內部的總線架構(如PCIe、NVLink)需要支持高帶寬傳輸,擴展這些總線的帶寬需要對芯片封裝、功耗管理和信號完整性進行優化,難度較大。在多芯片系統中,不同芯片之間的數據傳輸也受到帶寬限制,需要高速互連技術(如Infinity Fabric、NVLink)來解決,但這些技術實現復雜且成本較高。
降低延遲極其困難:從CPU到GPU或AI加速器的數據傳輸路徑中,每一步都可能增加延遲,例如內存訪問延遲、緩存命中率、總線傳輸延遲等都是難以完全消除的因素。在多任務環境中,任務調度和切換會帶來上下文切換延遲和資源爭用問題,這些問題在實時性要求高的應用中尤為突出。若想硬件和軟件協同優化來減少延遲,涉及復雜的設計流程和大量的調優工作,需要深入理解整個系統的工作機制。
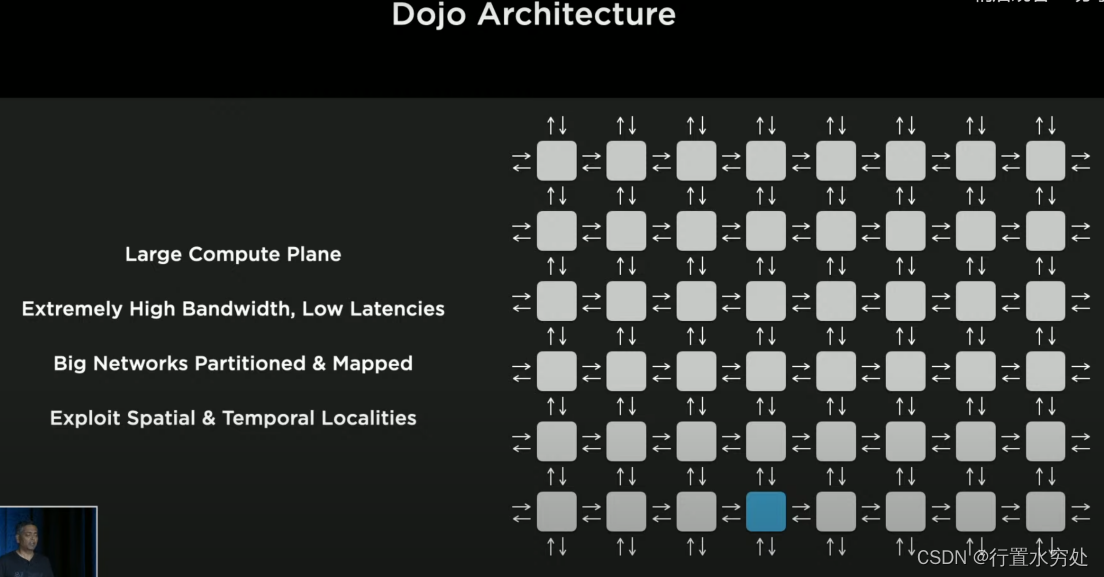 特斯拉的Dojo架構由計算單元和Network Fabric(指芯片上用于連接和通信的網絡架構,是一種高性能的互連系統,負責在芯片內部不同計算單元之間傳輸數據)組成,采用了多種技術例如采用2D網格網絡進行數據傳輸、對神經網絡分割、調用本地存儲方式等解決帶寬和延遲的限制。
特斯拉的Dojo架構由計算單元和Network Fabric(指芯片上用于連接和通信的網絡架構,是一種高性能的互連系統,負責在芯片內部不同計算單元之間傳輸數據)組成,采用了多種技術例如采用2D網格網絡進行數據傳輸、對神經網絡分割、調用本地存儲方式等解決帶寬和延遲的限制。
(一句話,特斯拉極大程度提高了帶寬降低了延遲,遠超業內)
1)芯片
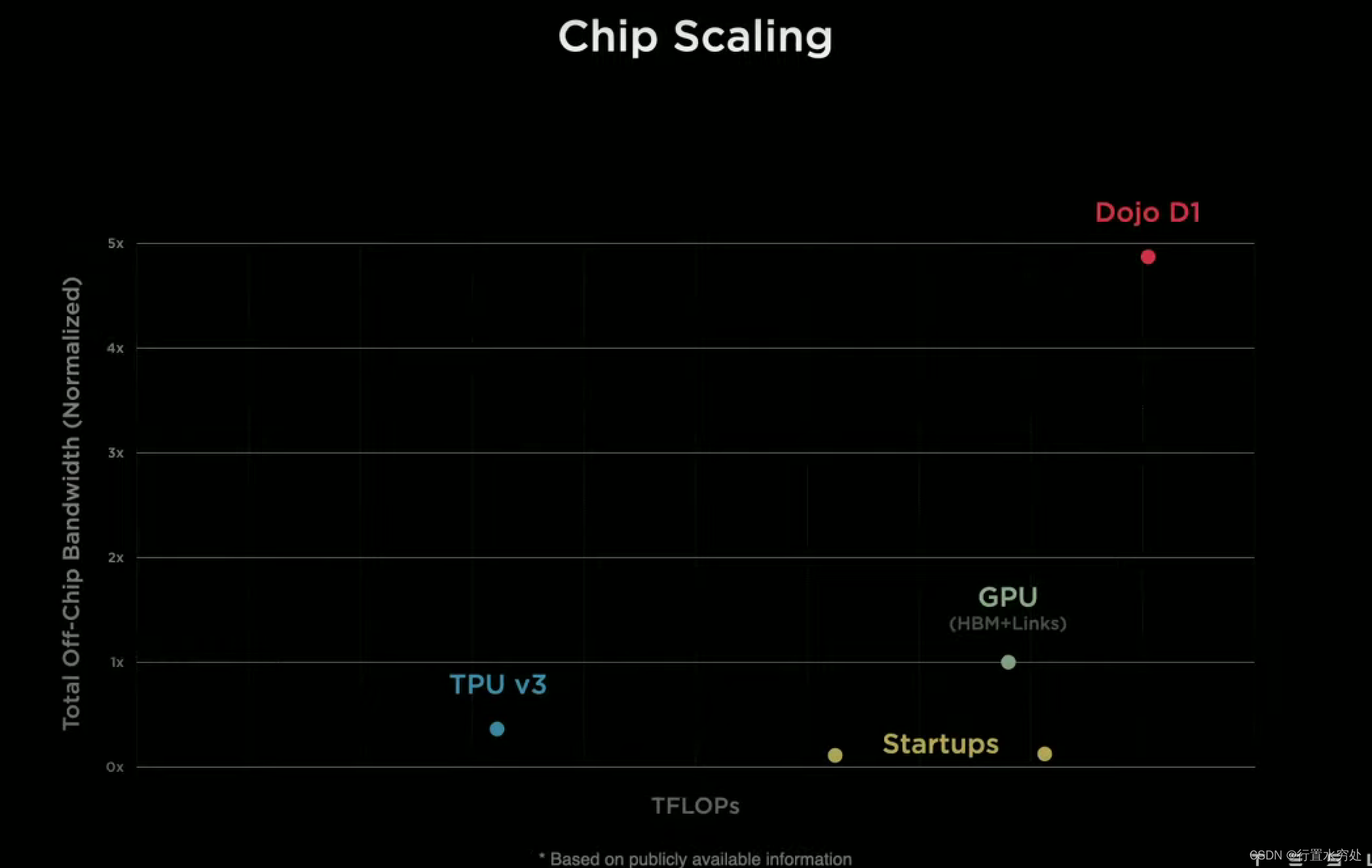
 如上圖所示是特斯拉SoC芯片上一個高性能的訓練節點結構圖:底部是機器學習陣列,左側是SRAM存儲陣列,再加上頂部的多線程可編程核。支持FP32、BFP16、CFP8。
如上圖所示是特斯拉SoC芯片上一個高性能的訓練節點結構圖:底部是機器學習陣列,左側是SRAM存儲陣列,再加上頂部的多線程可編程核。支持FP32、BFP16、CFP8。
- 1024 GFLOPS(BF16/CFP8)
- 64GFLOPS(FP32)
- 512GB/S帶寬
 如上圖所示,這是個超標量處理器核,四個寬標量核兩個寬標量數據管線;支持四個線程;針對機器學習支持自定義指令集ISA,例如轉置、鏈接遍歷、廣播等。(這部分工作原理會在處理器專欄做詳細介紹)
如上圖所示,這是個超標量處理器核,四個寬標量核兩個寬標量數據管線;支持四個線程;針對機器學習支持自定義指令集ISA,例如轉置、鏈接遍歷、廣播等。(這部分工作原理會在處理器專欄做詳細介紹)
 特斯拉D1芯片由354個訓練節點組成計算陣列,可謂針對機器學習的機器,GPU級別的芯片同時擁有CPU的靈活性核兩倍NPU級別的I/O帶寬,提供了超高性能的計算能力。
特斯拉D1芯片由354個訓練節點組成計算陣列,可謂針對機器學習的機器,GPU級別的芯片同時擁有CPU的靈活性核兩倍NPU級別的I/O帶寬,提供了超高性能的計算能力。
2)計算系統Computer Plane

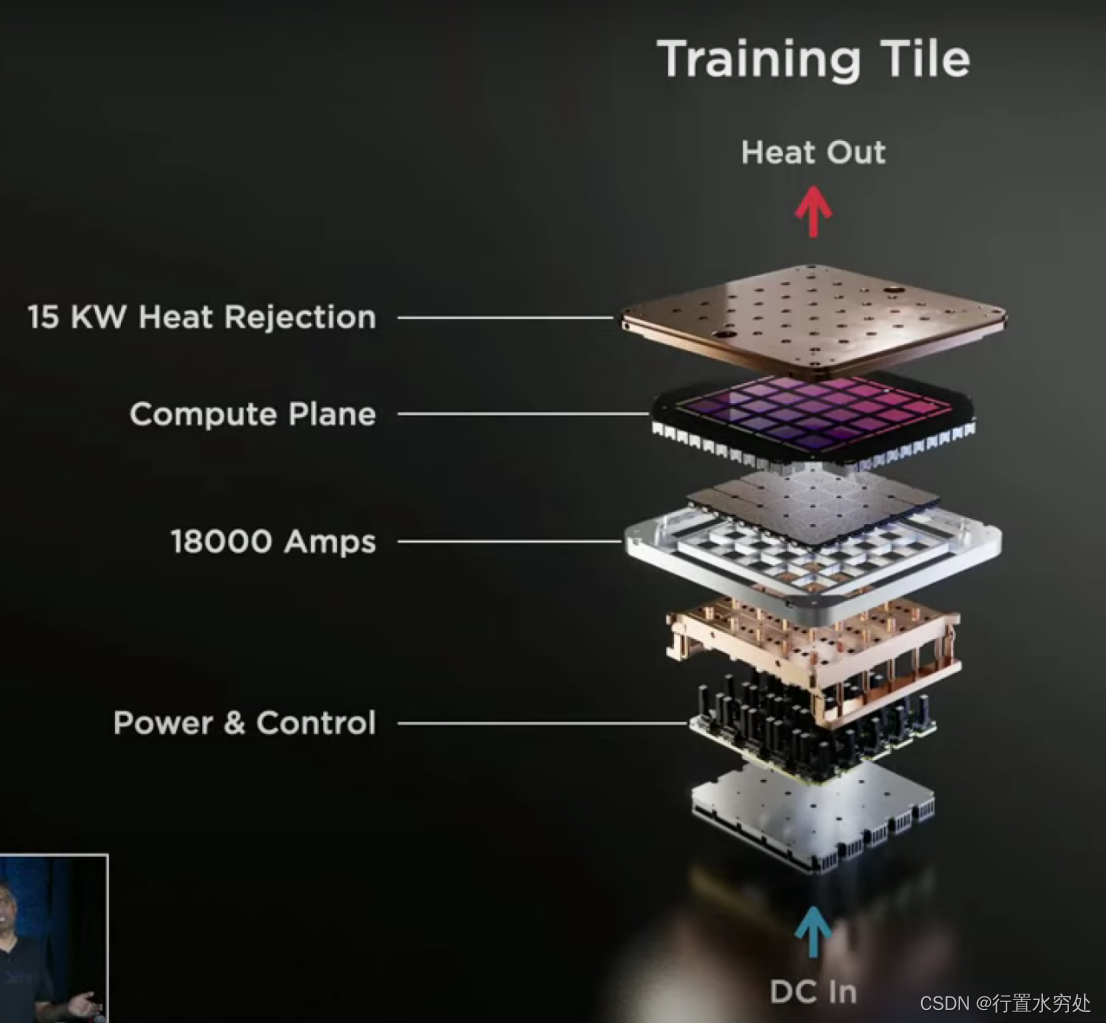 特斯拉的計算系統上,1個Training Tile集成了25個D1芯片,四周使用高速連接器支持9TB/S帶寬,支持9PFLOPS(BF16/CFP8)
特斯拉的計算系統上,1個Training Tile集成了25個D1芯片,四周使用高速連接器支持9TB/S帶寬,支持9PFLOPS(BF16/CFP8)
3)計算集群


4)AI編譯器
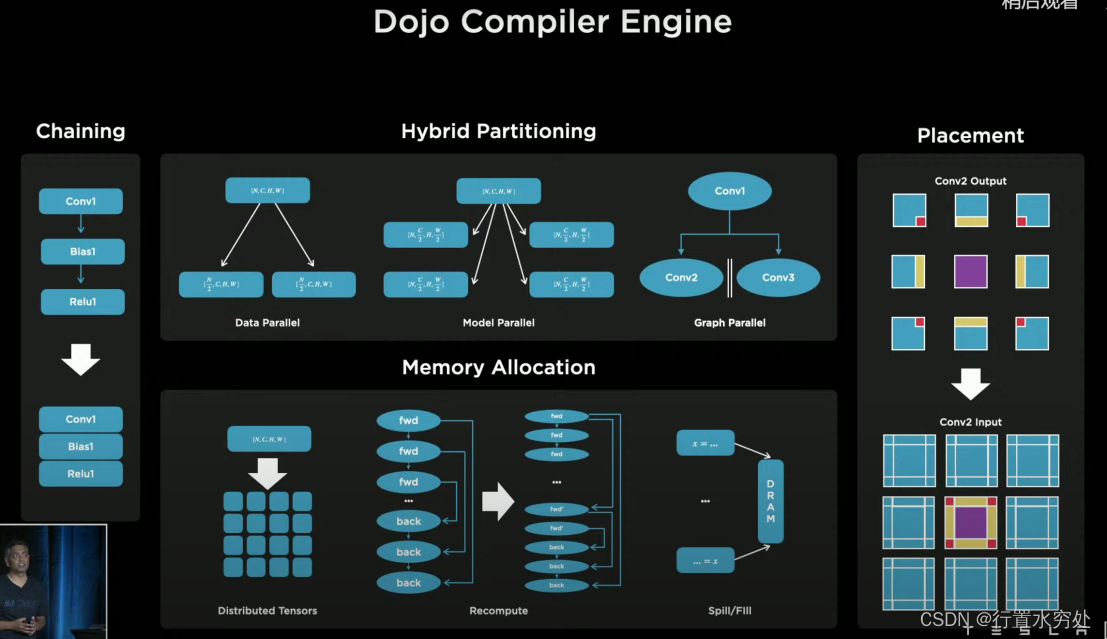 特斯拉Dojo編譯器引擎,使用多種細顆粒度的并行化技術:數據并行、模型并行、計算圖并行技術,還支持高層次的環路管理,例如循環等。
特斯拉Dojo編譯器引擎,使用多種細顆粒度的并行化技術:數據并行、模型并行、計算圖并行技術,還支持高層次的環路管理,例如循環等。
 特斯拉的軟件棧有兩個重點:用戶編程接口,基于PyTorch做了擴展;使用LLVM作為底層處理生成硬件所需的二進制代碼。
特斯拉的軟件棧有兩個重點:用戶編程接口,基于PyTorch做了擴展;使用LLVM作為底層處理生成硬件所需的二進制代碼。
LLVM(Low Level Virtual Machine)是一套用于構建編譯器和相關工具的開源項目,提供了一種模塊化和可重用的編譯器基礎架構。LLVM的架構主要包括:前端負責將源代碼轉換為LLVM中間表示IR;中端對LLVM IR進行各種優化處理,提高代碼執行效率;后端將優化后的LLVM IR轉換為目標機器碼,具體包括代碼生成和目標特定優化。
(以下為筆者猜測內容)
特斯拉的Dojo AI編譯器使用LLVM作為后端處理的基礎架構,通過LLVM的模塊化設計和強大的優化能力,實現高效的AI模型編譯和執行:
- 自定義目標支持:特斯拉可以通過LLVM的目標描述文件,定義Dojo芯片的特性,并擴展LLVM的指令選擇和代碼生成模塊,以支持特斯拉可能有的特定的硬件加速單元和自定義指令集自定義指令。
- 高效的寄存器分配:Dojo AI編譯器可以利用LLVM的寄存器分配算法,優化寄存器使用,減少內存訪問,提高模型執行效率。
- 目標特定優化:通過LLVM的目標特定優化能力,Dojo AI編譯器可以實現針對Dojo硬件的深度優化,包括利用硬件加速單元和并行計算資源,提高模型推理速度。
- 模塊化和可擴展性:LLVM的模塊化設計允許特斯拉根據需要擴展和定制編譯器后端,以適應不同的AI模型和硬件需求。可以在LLVM的基礎上添加新的優化通道和代碼生成策略,提升整體性能。



)



)










)
)