讓大模型能夠回答私域知識問題
未經過特定訓練答疑機器人,是無法準確回答“我們公司項目管理用什么工具”這類內部問題。根本原因在于,大模型的知識來源于其訓練數據,這些數據通常是公開的互聯網信息,不包含任何特定公司的內部文檔、政策或流程。
你可以把大模型想象成一臺剛出廠的超級計算機:它的CPU(推理能力)極其強大,硬盤(模型權重)里預裝了海量的通用知識。但對于你公司的“內部資料”,它的硬盤里是空白的。
面對這個問題,最直觀的解決思路就是:在運行時,把公司的內部知識臨時告訴它。
初步方案:在提示詞中“喂”入知識
你可以來驗證這個思路:將公司項目管理工具的說明文檔,直接添加給模型的指令(System Prompt)中,作為背景知識提供給它。
💡 公司使用的項目管理 軟件資料可以docs/內容開發工程師崗位指導說明書.pdf文件中找到。
user_question = "我是軟件一組的,請問項目管理應該用什么工具"knowledge = """公司項目管理工具有兩種選擇:1. **Jira**:對于軟件開發團隊來說,Jira 是一個非常強大的工具,支持敏捷開發方法,如Scrum和Kanban。它提供了豐富的功能,包括問題跟蹤、時間跟蹤等。2. **Microsoft Project**:對于大型企業或復雜項目,Microsoft Project 提供了詳細的計劃制定、資源分配和成本控制等功能。它更適合那些需要嚴格控制項目時間和成本的場景。在一般情況下請使用Microsoft Project,公司購買了完整的許可證。軟件研發一組、三組和四組正在使用Jira,計劃于2026年之前逐步切換至Microsoft Project。
"""response = get_qwen_stream_response(user_prompt=user_question,# 將公司項目管理工具相關的知識作為背景信息傳入系統提示詞system_prompt="你負責教育內容開發公司的答疑,你的名字叫公司小蜜,你要回答學員的問題。"+ knowledge,temperature=0.7,top_p=0.8
)for chunk in response:print(chunk, end="")你好!根據公司的規定,目前軟件研發一組正在使用Jira進行項目管理。盡管公司計劃在2026年之前逐步切換到Microsoft Project,但在那之前,你們組仍然可以繼續使用Jira。如果你有任何關于Jira的使用問題或需要幫助,請隨時告訴我。同時,如果有任何關于未來切換到Microsoft Project的準備或培訓需求,也可以提前告知,我會盡力提供支持。
在提示詞中加入相關的背景知識,大模型確實能夠準確回答關于公司內部工具的問題。然而,當你試圖將更多的公司文檔(例如幾十頁的員工手冊、上面頁的技術規范)都用這種方式“喂”給大模型時,一個新的、更嚴峻的挑戰出現了。
核心瓶頸:有限的上下文窗口
大模型接收我們輸入(包括指令、問題和背景知識)的地方,被稱為上下文窗口(Context Window)。你可以把它理解為計算機的“內存RAM”——它的容量是有限的。
你無法將整個公司的知識庫(成百上千份文檔)一次性塞進這個有限的窗口里。一旦輸入內容超過模型的最大限制,就會導致錯誤。
這引出了一個核心問題:你需要對放入上下文窗口的內容進行篩選和管理。
解決之道:上下文工程(Context Engineering)
簡單粗暴地將信息塞進上下文,除了會超出窗口限制外,還會帶來一系列“隱性”問題:
1.效率低:上下文越長,大模型處理所需的時間就越長,導致用戶等待增加時間。
2.成本高:大部分模型是按輸入和輸出的文本量計費的,冗長的上下文意味著更高的成本。
3.信息干擾:如果上下文中包含了大量與當前問題無關的信息,就像在開卷考試時給了考生一本錯誤科目的教科書,反而會干擾模型的判斷,導致回答質量下降。
成功的關鍵不在于“喂”給模型多少知識,而在于“喂”得有多準。
如何在正確的時間,將最相關、最精準的知識,動態地加載到大模型有限的上下文窗口中?———這門系統性地設計、構建和優化上下文的實踐,就是上下文工程(Context Engineering)。
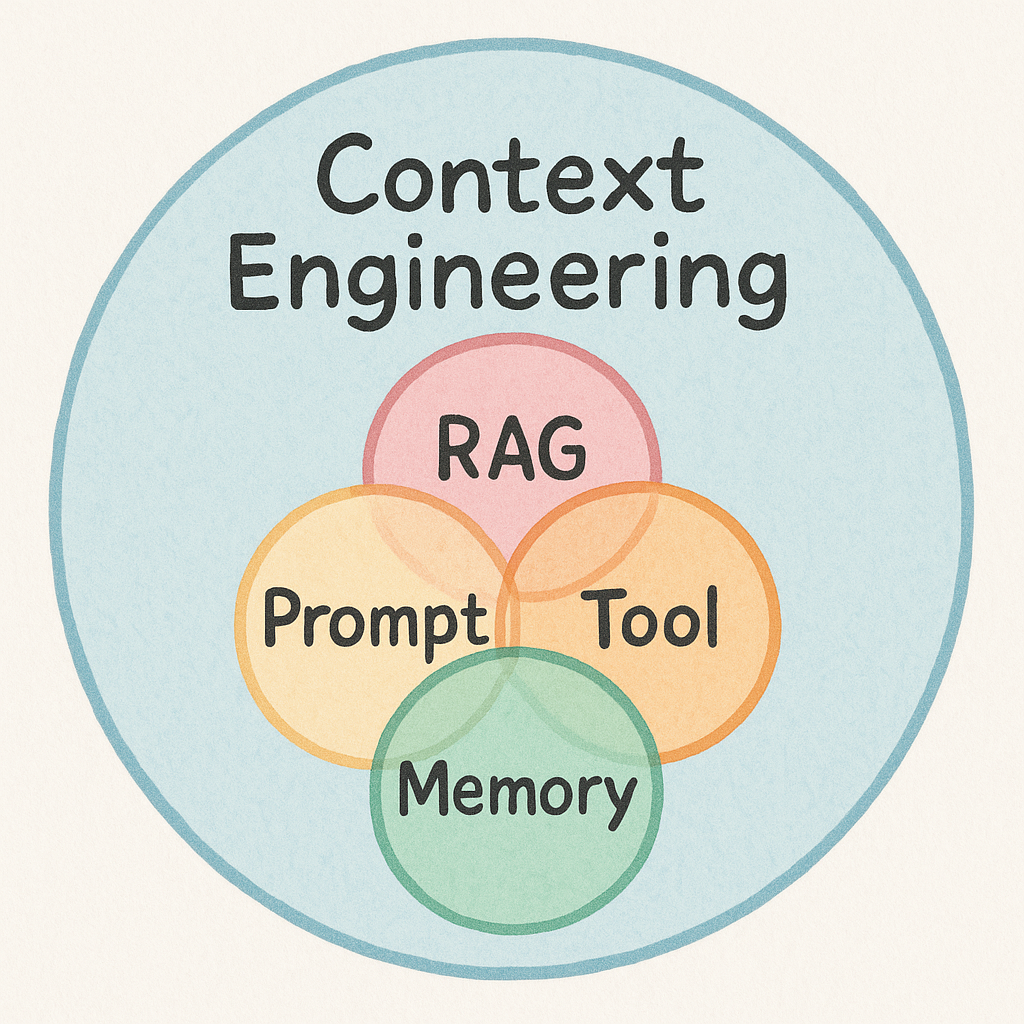
上下文工程(Context Enginnering)的核心技術
1.RAG(檢索增強生成):從外部知識庫(如公司文檔)中檢索信息,為模型提供精準的回答依據。
2.Prompt(提示詞工程):通過精心設計的指令,精確地引導模型的思考方式和輸出格式。
3.Tool(工具使用):賦予模型調用外部工具(如計算器、搜索引擎、API)的能力,以獲取實時信息或執行任務。
4.Memory(記憶機制):為模型建立長短期記憶,使其能夠在連續對話中理解歷史上下文。
RAG(檢索增強生成)
RAG(Retrieval-Augmented Generation,檢索增強生成)就是實現上下文工程的強大技術方案。它的核心思想是:在用戶提問時,不再將全部知識庫硬塞給大模型,而是先自動檢索出與問題最相關的私有知識片段,然后將這些精準的片段與用戶問題合并后,一同傳給大模型,從而生成最終的答案。這樣既避免了提示詞過長的問題,又能確保大模型獲得相關的背景信息。
構建一個RAG應用通常會分為兩個階段
-
第一階段:建立索引
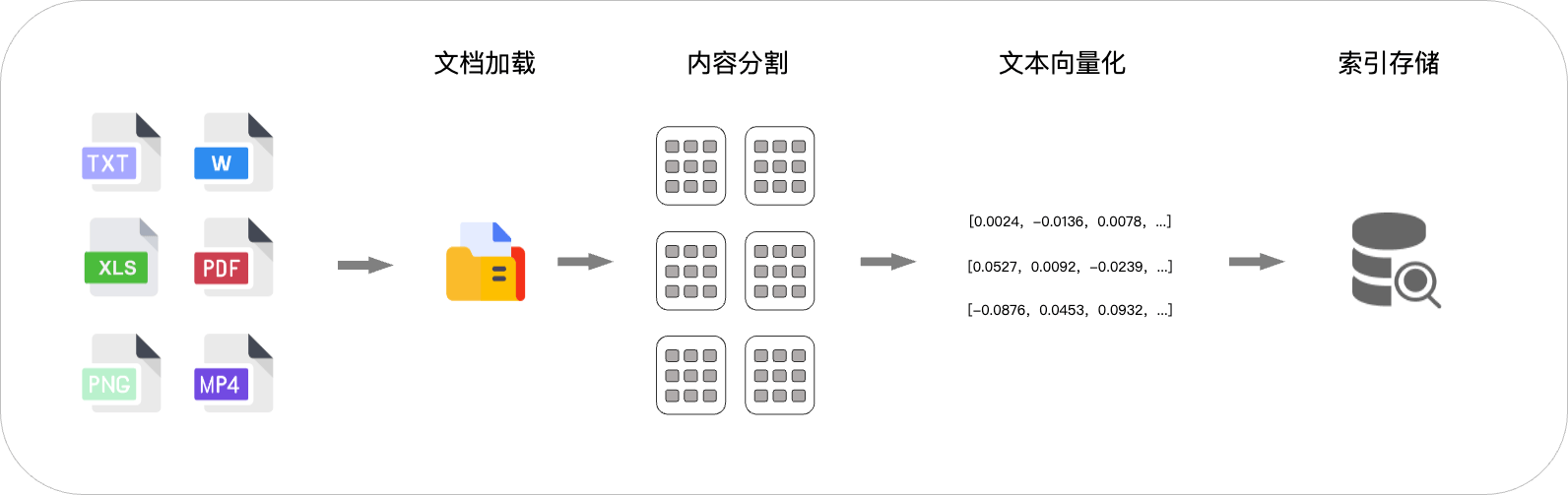
建立索引是為了將私有知識文檔或片段轉換為可以高效檢索的形式。通過將文件內容分割并轉化為多維向量(使用專用Embedding模型),并結合向量存儲保留文本的語義信息,方便進行相似度計算。向量化使得模型能夠高效檢索和匹配相關內容,特別是在處理大規模知識庫時,顯著提高查詢的準確性和響應速度。
-
第二階段:檢索與生成
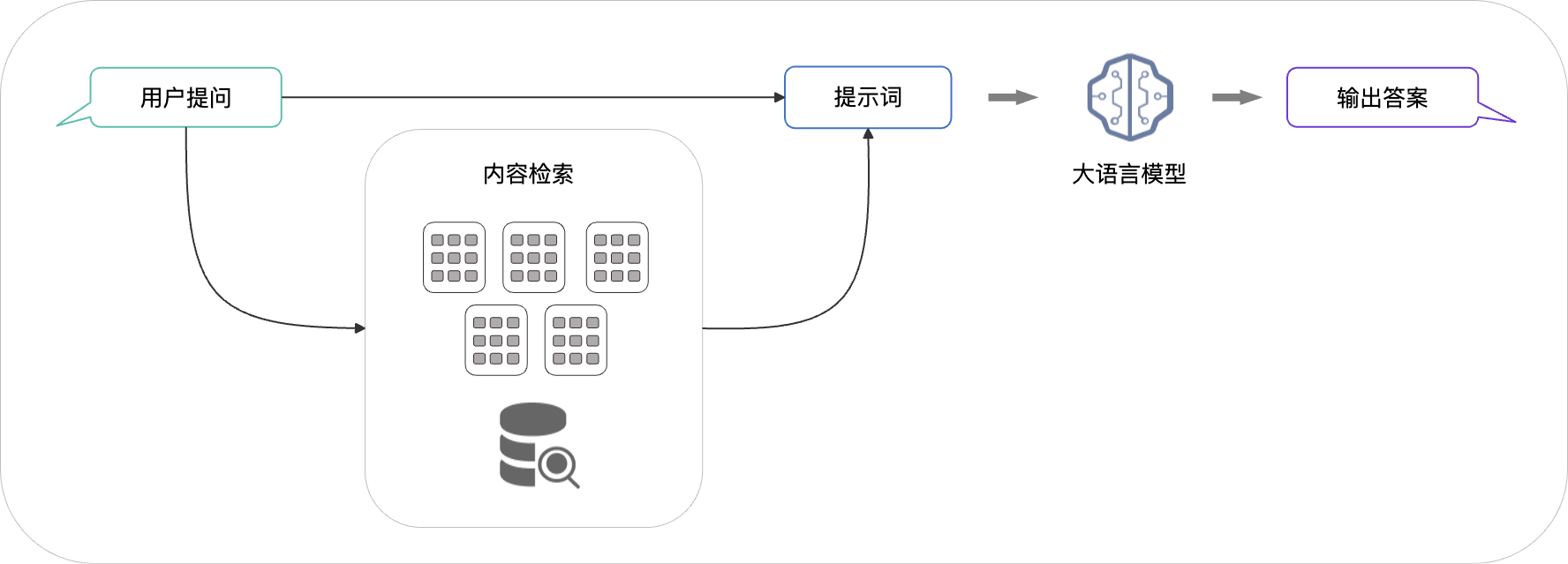
檢索生成是根據用戶的提問,從索引中檢索相關的文檔片段,這些片段會與提問一起輸入到大模型生成最終的回答。這樣大模型就能夠回答私有知識問題了。
總的來說,基于RAG結構的應用,既避免了將整個參考文檔作為背景信息輸入而導致的各種問題,又通過檢索提取出了與問題最相關的部分,從而提高了大模型輸出的準確性與相關性。
user_question = "我是軟件一組的,請問項目管理應該用什么工具"knowledge = """公司項目管理工具有兩種選擇:1. **Jira**:對于軟件開發團隊來說,Jira 是一個非常強大的工具,支持敏捷開發方法,如Scrum和Kanban。它提供了豐富的功能,包括問題跟蹤、時間跟蹤等。2. **Microsoft Project**:對于大型企業或復雜項目,Microsoft Project 提供了詳細的計劃制定、資源分配和成本控制等功能。它更適合那些需要嚴格控制項目時間和成本的場景。在一般情況下請使用Microsoft Project,公司購買了完整的許可證。軟件研發一組、三組和四組正在使用Jira,計劃于2026年之前逐步切換至Microsoft Project。
"""response = get_qwen_stream_response(user_prompt=user_question,# 將公司項目管理工具相關的知識作為背景信息傳入系統提示詞system_prompt="你負責教育內容開發公司的答疑,你的名字叫公司小蜜,你要回答學員的問題。"+ knowledge,temperature=0.7,top_p=0.8
)for chunk in response:print(chunk, end="")你好!根據公司的規定,目前軟件研發一組正在使用Jira進行項目管理。盡管公司計劃在2026年之前逐步切換到Microsoft Project,但在那之前,你們組仍然可以繼續使用Jira。如果你有任何關于Jira的使用問題或需要幫助,請隨時告訴我。同時,如果有任何關于未來切換到Microsoft Project的準備或培訓需求,也可以提前告知,我會盡力提供支持。
案例分析
小明開發寫作助手遇到以下兩個場景,他應該如何解決問題?
場景 🅰? 生成內容缺乏創意:每次讓模型寫一篇關于“人工智能發展”的文章時,生成的內容都非常相似。
場景 🅱? 生成內容偏離主題:讓模型寫一份技術文檔時,生成的內容經常加入一些不相關的內容。
請問:
1.這兩個場景的問題產生的原因可能是什么?
2.應該如何調整 temperature 或 top_p 參數來解決這些問題
🎯 場景A解決方案
🔍 原因分析
temperature 值過低(如0.3),導致模型選擇單一,生成內容缺乏多樣性。
?? 參數調整temperature = 0.7~0.9 # 提升創意性
top_p = 0.9 # 增大選詞范圍🎯 場景B解決方案
🔍 原因分析
temperature 過高(如1.2)或 top_p 過大?? 參數調整temperature = 0.5~0.7 # 降低隨機性
top_p = 0.7~0.8 # 聚焦高概率詞
🌟 調參小技巧
每次調整幅度建議 ±0.2,通過AB測試觀察效果變化。 如果需要兼顧場景A和場景B,推薦組合:temperature=0.6 + top_p=0.8







有狀態AI代理的開源框架)


------休眠函數sleep_for和sleep_until)



②)

![[frontend]mermaid code2image](http://pic.xiahunao.cn/[frontend]mermaid code2image)
)
)
(3))