分區表
- 一、分區表的意義
- 二、傳統分區表
- 2.1、繼承表
- 2.2、創建分區表
- 2.3、使用分區表
- 2.4、查詢父表還是子表
- 2.5、constraint_exclusion參數
- 2.6、添加分區
- 2.7、刪除分區
- 2.8、分區表相關查詢
- 2.9、傳統分區表注意事項
- 三、內置分區表
- 3.1、創建分區表
- 3.2、使用分區表
- 3.3、內置分區表原理
- 3.4、添加分區
- 3.5、刪除分區
- 3.6、更新分區數據
- 3.7、內置分區表注意事項
一、分區表的意義
分區表主要有以下優勢 :
- 當查詢或更新一個分區上的大部分數據時,對分區進行索引掃描代價很大,然而,在分區上使用順序掃描能提升性能 。
- 當需要刪除一個分區數據時,通過 DROP TABLE 刪除一個分區,遠比 DELETE 刪除數據高效,特別適用于日志數據場景。
- 由于一個表只能存儲在一個表空間上,使用分區表后,可以將分區放到不同的表空間上,例如可以將系統很少訪問的分區放到廉價的存儲設備上,也可以將系統常訪問的分區存儲在高速存儲上。
二、傳統分區表
傳統分區表是通過繼承和觸發器方式實現的,其實現過程步驟多,非常復雜,需要定義父表、定義子表、定義子表約束、創建子表索引、創建分區插入、刪除、修改函數和觸發器等,可以說是在普通基礎上手動實現的分區表。在介紹傳統分區表之前先介紹繼承,繼承是傳統分區表的重要組成部分。
2.1、繼承表
PostgreSQL提供繼承表,簡單地說是首先定義一張父表,之后可以創建子表繼承父表,下面通過一個簡單的例子來理解。
創建一張日志模型表tbl_log:
create table tbl_log(id int4,create_date date,log_type text
);create table tbl_log_sql(sql text
) inherits(tbl_log);
通過inherits(tbl_log)表示表tbl_log_sql繼承表tbl_log,子表可以定義額外的字段,以上定義了sql為額外字段,其它字段則繼承父表tbl_log,查看tbl_log_sql表結構如下:
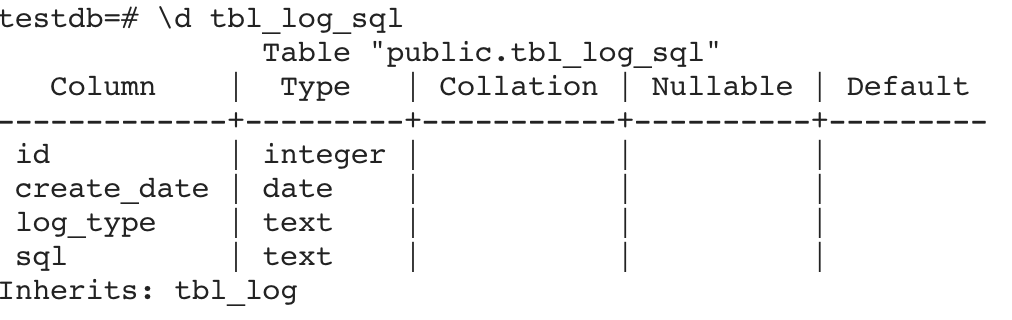
父表和子表都可以插入數據,接著分別在父表和子表中插入一條數據,如下所示:
insert into tbl_log
values(1, '2017-08-26', null);insert into tbl_log_sql
values(2, '2017-08-27', null, 'select 2');
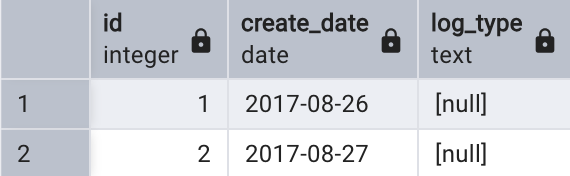
這時如果查詢父表tbl_log會顯示兩表的記錄,如下所示:
select * from tbl_log;
盡管查詢父表會將子表的記錄數也列出,但子表自定義的字段沒有顯示,如果想確定數據來源于哪張表,可通過以下SQL查看表的OID,如下所示:
select tableoid, *
from tbl_log;
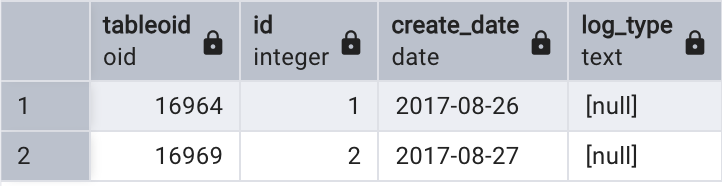
tableoid是表的隱藏字段,表示表的OID,可以通過pg_class系統關聯找到表名,如下所示:
select p.relname, c.*
from tbl_log c, pg_class p
where c.tableoid = p.oid;
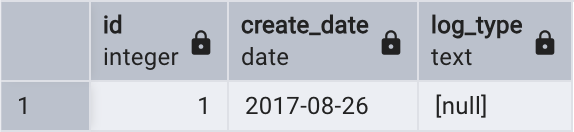
如果只想查詢父表的數據,需在父表名稱前加上關鍵字ONLY,如下所示:
select *
from only tbl_log;
因此,對于UPDATE、DELETE、SELECT操作,如果父表名稱前面沒有加上ONLY,則會對父表和所有子表進行DML操作,如下所示:
delete from tbl_log;select count(*)
from tbl_log;

2.2、創建分區表
傳統分區表創建過程主要包括以下幾個步驟:
- 創建父表,如果父表上定義了約束,子表會繼承,因此除非是全局約束,否則不應該在父表上定義約束,另外,父表不應該寫入數據。
- 通過inherits方式創建繼承表,也稱之為子表或分區,子表的字段定義應該和父表保持一致。
- 給所有子表創建約束,只有滿足約束條件的數據才能寫入對應分區,注意分區約束值范圍不要有重疊。
- 給所有子表創建索引,由于繼承操作不會繼承父表上的索引,因此索引需要手工創建。
- 在父表上定義insert、delete、update觸發器,將SQL分發到對應分區,這步可選,因為應用可以根據分區規則定位到對應分區進行DML操作。
- 啟用constraint_exclusion參數,如果這個參數設置成off,則父表上的SQL性能會降低,后面會通過示例解釋這個參數。
以上六個步驟是創建傳統分區表的主要步驟,接下來通過一個示例演示創建一張范圍分區表,并且定義年月子表存儲月數據。
首先創建父表:
create table log_ins(id serial,user_id int4,create_time timestamp(0) without time zone
);
創建13張子表:
create table log_ins_history(check(create_time < '2017-01-01')
) inherits(log_ins);create table log_ins_history_201701(check(create_time >= '2017-01-01' and create_time < '2017-02-01')
) inherits(log_ins);create table log_ins_history_201702(check(create_time >= '2017-02-01' and create_time < '2017-03-01')
) inherits(log_ins);create table log_ins_history_201703(check(create_time >= '2017-03-01' and create_time < '2017-04-01')
) inherits(log_ins);create table log_ins_history_201704(check(create_time >= '2017-04-01' and create_time < '2017-05-01')
) inherits(log_ins);create table log_ins_history_201705(check(create_time >= '2017-05-01' and create_time < '2017-06-01')
) inherits(log_ins);create table log_ins_history_201706(check(create_time >= '2017-06-01' and create_time < '2017-07-01')
) inherits(log_ins);create table log_ins_history_201707(check(create_time >= '2017-07-01' and create_time < '2017-08-01')
) inherits(log_ins);create table log_ins_history_201708(check(create_time >= '2017-08-01' and create_time < '2017-09-01')
) inherits(log_ins);create table log_ins_history_201709(check(create_time >= '2017-09-01' and create_time < '2017-10-01')
) inherits(log_ins);create table log_ins_history_201710(check(create_time >= '2017-10-01' and create_time < '2017-11-01')
) inherits(log_ins);create table log_ins_history_201711(check(create_time >= '2017-11-01' and create_time < '2017-12-01')
) inherits(log_ins);create table log_ins_history_201712(check(create_time >= '2017-12-01' and create_time < '2018-01-01')
) inherits(log_ins);
給子表創建索引:
create index idx_his_ctime on log_ins_history
using btree (create_time);create index idx_log_ins_201701_ctime on log_ins_history_201701
using btree (create_time);create index idx_log_ins_201702_ctime on log_ins_history_201702
using btree (create_time);create index idx_log_ins_201703_ctime on log_ins_history_201703
using btree (create_time);create index idx_log_ins_201704_ctime on log_ins_history_201704
using btree (create_time);create index idx_log_ins_201705_ctime on log_ins_history_201705
using btree (create_time);create index idx_log_ins_201706_ctime on log_ins_history_201706
using btree (create_time);create index idx_log_ins_201707_ctime on log_ins_history_201707
using btree (create_time);create index idx_log_ins_201708_ctime on log_ins_history_201708
using btree (create_time);create index idx_log_ins_201709_ctime on log_ins_history_201709
using btree (create_time);create index idx_log_ins_201710_ctime on log_ins_history_201710
using btree (create_time);create index idx_log_ins_201711_ctime on log_ins_history_201711
using btree (create_time);create index idx_log_ins_201712_ctime on log_ins_history_201712
using btree (create_time);
由于父表上不存儲數據,可以不用在父表上創建索引。
創建觸發器函數,設置數據插入父表時的路由規則,如下所示:
create or replace function log_ins_insert_trigger()returns triggerlanguage plpgsql
as $function$
beginif (NEW.create_time < '2017-01-01') theninsert into log_ins_history VALUES(NEW.*);elsif (NEW.create_time >= '2017-01-01' and NEW.create_time < '2017-02-01') theninsert into log_ins_history_201701 VALUES(NEW.*);elsif (NEW.create_time >= '2017-02-01' and NEW.create_time < '2017-03-01') theninsert into log_ins_history_201702 VALUES(NEW.*);elsif (NEW.create_time >= '2017-03-01' and NEW.create_time < '2017-04-01') theninsert into log_ins_history_201703 VALUES(NEW.*);elsif (NEW.create_time >= '2017-04-01' and NEW.create_time < '2017-05-01') theninsert into log_ins_history_201704 VALUES(NEW.*);elsif (NEW.create_time >= '2017-05-01' and NEW.create_time < '2017-06-01') theninsert into log_ins_history_201705 VALUES(NEW.*);elsif (NEW.create_time >= '2017-06-01' and NEW.create_time < '2017-07-01') theninsert into log_ins_history_201706 VALUES(NEW.*);elsif (NEW.create_time >= '2017-07-01' and NEW.create_time < '2017-08-01') theninsert into log_ins_history_201707 VALUES(NEW.*);elsif (NEW.create_time >= '2017-08-01' and NEW.create_time < '2017-09-01') theninsert into log_ins_history_201708 VALUES(NEW.*);elsif (NEW.create_time >= '2017-09-01' and NEW.create_time < '2017-10-01') theninsert into log_ins_history_201709 VALUES(NEW.*);elsif (NEW.create_time >= '2017-10-01' and NEW.create_time < '2017-11-01') theninsert into log_ins_history_201710 VALUES(NEW.*);elsif (NEW.create_time >= '2017-11-01' and NEW.create_time < '2017-12-01') theninsert into log_ins_history_201711 VALUES(NEW.*);elsif (NEW.create_time >= '2017-12-01' and NEW.create_time < '2018-01-01') theninsert into log_ins_history_201712 VALUES(NEW.*);else raise exception 'create_time out of range. Fix the log_ins_insert trigger() function!';end if;return null;
end;
$function$;
函數中的NEW.*是指要插入的數據行,在父表上定義插入觸發器:
create trigger insert_log_ins_trigger
before insert
on log_ins
for each row
execute procedure log_ins_insert_trigger();
觸發器創建完成后,向父表log_ins插入數據時,會執行觸發器并觸發函數log_ins_insert_trigger()將表數據插入到相應的分區中。DELETE、UPDATE觸發器和函數創建過程和INSERT方式類似,傳統分區表的創建步驟已全部完成。
2.3、使用分區表
向父表log_ins插入測試數據,并驗證數據是否插入對應分區:
insert into log_ins(user_id, create_time)
select round(10000000*random()), generate_series('2016-12-01'::date, '2017-12-01'::date, '1 minute');
這里通過隨機生成數據插入,數據如下所示:
select *
from log_ins limit 5;
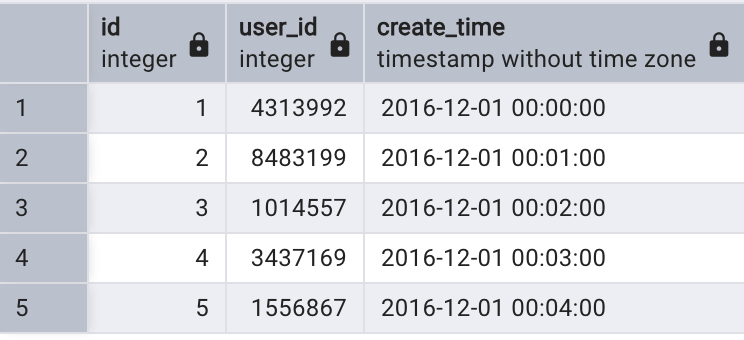
查看父表數據,發現父表沒有數據;
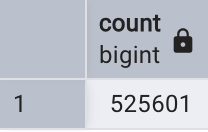
select count(*) from only log_ins;

select count(*) from log_ins;
查看子表數據:
select min(create_time), max(create_time)
from log_ins_history_201701;

這說明子表里可查到數據,查看子表大小:
由此可見數據都已經插入到子表里。
2.4、查詢父表還是子表
假如我們檢索2017-01-01這一天的數據,我們可以查詢父表,也可以直接查詢子表,兩者性能上是否有差異?
查詢父表的執行計劃如下:
explain analyze select *
from log_ins
where create_time > '2017-01-01' and create_time < '2017-01-02';

從以上執行計劃看出在分區log_ins_history_201701上進行了索引掃描,接著查看直接查詢子表log_ins_history_201701的執行計劃:
explain analyze select *
from log_ins_history_201701
where create_time > '2017-01-01' and create_time < '2017-01-02';

從以上執行計劃看出,直接查詢子表更快,如果并發量上去的話,這個差異將更明顯,因此實際生產過程中,對于傳統分區表分區方式,不建議應用訪問父表,而是直接訪問子表,也許有人會問,應用如何定位到訪問哪張子表呢?可以根據預先的分區約束定義,上面的例子是根據時間范圍分區,name應用可以根據時間來判斷查詢哪張子表,當然,以上是根據分表表分區鍵查詢的場景,如果根據非分區鍵查詢則會掃描分區表的所有分區。
2.5、constraint_exclusion參數
constraint_exclusion參數用來控制優化器是否根據表上的約束來優化查詢,參數為以下值:
on:所有表都通過約束優化查詢off:所有表都不通過約束優化查詢partition:只對繼承表和UNION ALL子查詢通過檢索約束來優化查詢
簡單地說,如果設置成on或partition,查詢父表時優化器會根據子表上的約束判斷檢索哪些子表,而不要掃描所有子表,從而提升查詢性能。
2.6、添加分區
添加分區屬于分區表維護的常規操作之一,比如歷史表范圍分區到期之前需要擴分區,log ins表為日志表,每個分區存儲當月數據,假如分區快到期了,可通過以下SQL擴分區,首先創建子表,如下所示:
create table log_ins_history_201801(check(create_time >= '2018-01-01' and create_time < '2018-02-01')
) inherits(log_ins);
之后創建相關索引:
create index idx_log_ins_201801_ctime
on log_ins_history_201801 using btree(create_time);
然后刷新觸發器函數log_ins_insert_trigger(0,添加相應代碼,將符合路由規則的數據插入新分區,詳見之前定義的這個函數,這步完成后,添加分區操作完成,可通過d+log_ins命令查看log_ins的所有分區。
這種方法比較直接,創建分區時就將分區繼承到父表,如果中間步驟有錯可能對生產系統帶來影響,比較推薦的做法是將以上操作分解成以下幾個步驟,降低對生產系統的影響,如下所示:
-- 創建分區
create table log_ins_history_201802(like log_ins including all
);-- 添加約束
alter table log_ins_history_201802
add constraint log_ins_history_201802_create_time_check
check (create_time >= '2018-02-01' and create_time < '2018-03-01');-- 刷新觸發器函數log_ins_insert_trigger()-- 所有步驟完成后,將新分區log_ins_201802繼承到父表log_ins
alter table log_ins_hisroty_201802 inherit log_ins;
以上方法是將新分區所有操作完成后,再將分區繼承到父表,降低了生產系統添加分區操作的風險,當然,在生產系統添加分區前建議在測試環境事先演練一把。
2.7、刪除分區
分區表的一個重要優勢是對于大表的管理上十分方便,例如需要刪除歷史數據時可以直接刪除一個分區,這比DELETE方式效率高了多個數量級,傳統分區表刪除分區通常有兩種方法,第一種方法是直接刪除分區,如下所示:
drop table log_ins_201802;
就像刪除普通表一樣刪除分區即可,當然刪除分區前需再三確認是否需要備份數據;另一種比較推薦的刪除分區方法是先將分區的繼承關系去掉,如下所示:
alter table log_ins_history_201802 no inherit log_ins;
執行以上命令后,log ins201802分區不再屬于分區表log_ins的分區,但log_ins_history_201802表依然保留可供查詢,這種方式相比方法一提供了一個緩沖時間,屬于比較穩妥的刪除分區方法,因為在拿掉子表繼承關系后,只要沒刪除這個表,還可以使子表重新繼承父表。
2.8、分區表相關查詢
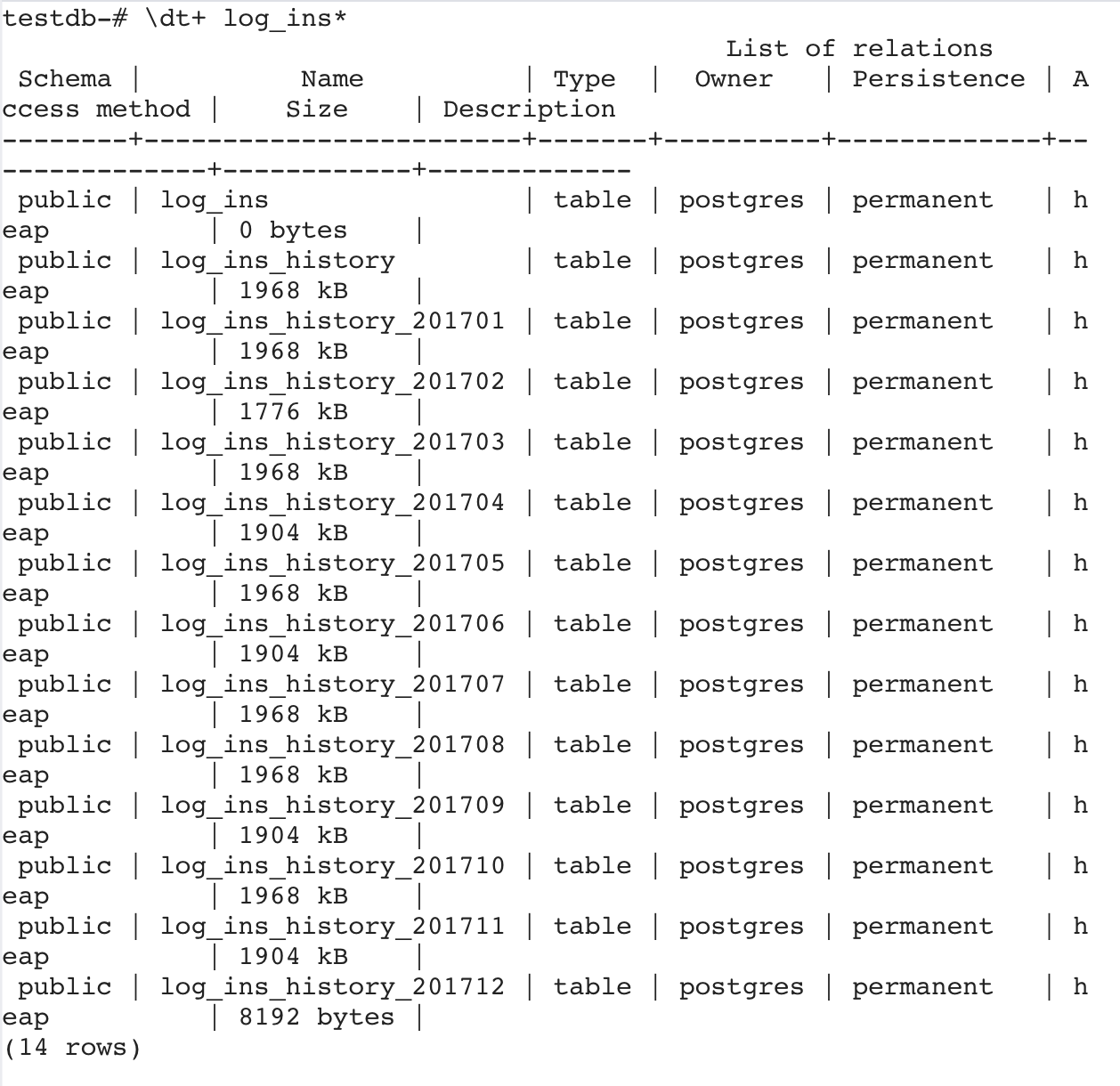
分區表創建完成后,如何查看分區表定義、分區表分區信息呢?比較常用的方法是通過\d元命令,如下所示:

以上信息顯示了表 log_ ins有 14 個分區,并且創 建了觸發器 ,觸發器函數為 log_ins_insert_ trigger (),如 果想列出分區名稱可通過\d+ log_ins 元命令列出 。
另一種列出分區表分區信息方法是通過SQL命令:
select nmsp_parent.nspname as parent_schema,parent.relname as parent,nmsp_child.nspname as child_schema,child.relname as child_schema
from pg_inherits join pg_class parent
on pg_inherits.inhparent = parent.oid join pg_class child
on pg_inherits.inhrelid = child.oid join pg_namespace nmsp_parent
on nmsp_parent.oid = parent.relnamespace join pg_namespace nmsp_child
on nmsp_child.oid = child.relnamespace
where parent.relname = 'log_ins';
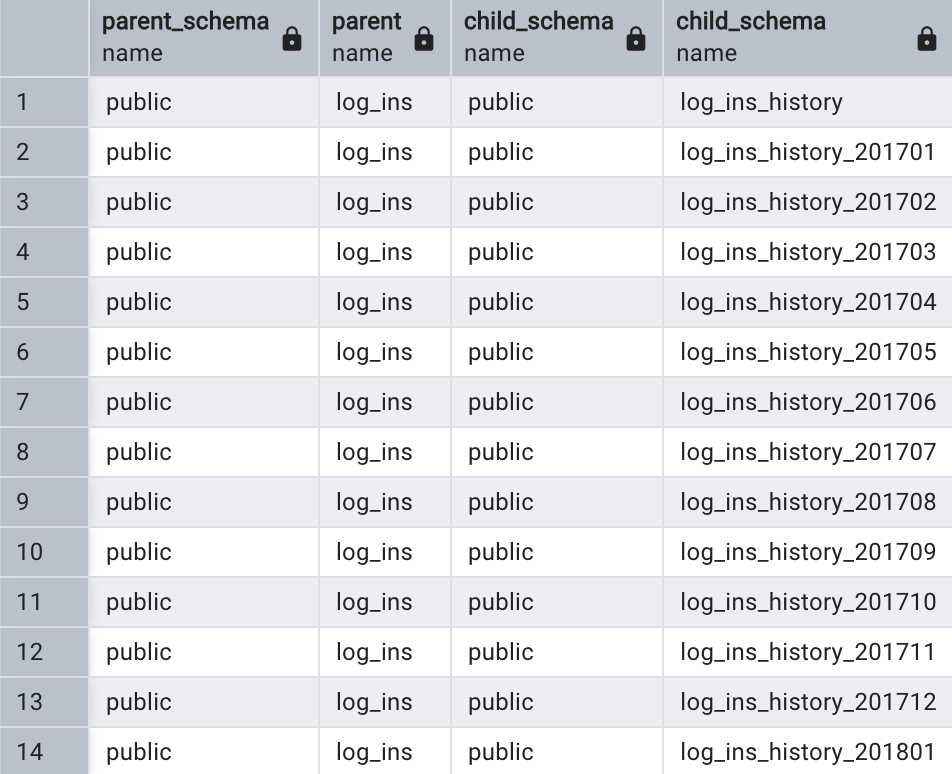
pg_inherits系統表記錄了子表和父表之間的繼承關系,通過以上查詢列出指定分區表的分區。如果想查看一個庫中有哪些分區表,并顯示這些分區表的分區數量,可通過以下SQL查詢:
select nspname, relname, count(*) as partition_num
from pg_class c, pg_namespace n, pg_inherits i
where c.oid = i.inhparent
and c.relnamespace = n.oid
and c.relhassubclass
and c.relkind in ('r', 'p')
group by 1,2
order by partition_num desc;

以上結果顯示當前庫中有兩個分區表,log_ins分區表有14個分區,tbl_log分區表只有一個分區。
2.9、傳統分區表注意事項
傳統分區表的使用有以下注意事項:
- 當往父表上插入數據時,需事先在父表上創建路由函數和觸發器,數據才會根據分區鍵路由規則插入到對應分區中,目前僅支持范圍分區和列表分區。
- 分區表上的索引、約束需要使用單獨的命令創建,目前沒有辦法一次性自動在所有分區上創建索引、約束。
- 父表和子表允許單獨定義主鍵,因此父表和子表可能存在重復的主鍵記錄,目前不支持在分區表上定義全局主鍵。
- UPDATE時不建議更新分區鍵數據,特別是會使數據從一個分區移動到另一分區的場景,可通過更新觸發器實現,但會帶來管理上的成本。
- 性能方面:根據本節的測試數據和測試場景,傳統分區表根據非分區鍵查詢相比普通表性能差距較大,因為這種場景下分區表會掃描所有分區;根據分區鍵查詢相比普通表性能有小幅降低,而查詢分區表子表性能相比普通表略有提升;
三、內置分區表
PostgreSQL10一個重量級新特性是支持內置分區表,用戶不需要預先在父表上定義INSERT、DELETE、UPDATE觸發器,對父表的DML操作會自動路由到相應分區,相比傳統分區表大幅度降低了維護成本,目前僅支持范圍分區和列表分區。
3.1、創建分區表
創建分區表的主要語法包含兩部分:創建主表和創建分區。
創建主表語法如下:
create table table_name (...)
[ partition by {range | list} ({column_name | expression})]
創建主表時須指定分區方式,可選的分區方式為RANGE范圍分區或LIST列表分區,并指定字段或表達式作為分區鍵。
創建分區的語法如下:
create table table_name() partition of parent_table for values partition_bound_spec
創建分區時必須指定是哪張表的分區,同時指定分區策略partition bound spec,如果是范圍分區,partition bound spec須指定每個分區分區鍵的取值范圍,如果是列表分區
partition_bound_spec,需指定每個分區的分區鍵值。
PostgreSQL10創建內置分區表主要分為以下幾個步驟:
- 創建父表,指定分區鍵和分區策略。
- 創建分區,創建分區時須指定分區表的父表和分區鍵的取值范圍,注意分區鍵的范圍不要有重疊,否則會報錯。
- 在分區上創建相應索引,通常情況下分區鍵上的索引是必須的,非分區鍵的索引可根據實際應用場景選擇是否創建。
接下來通過創建范圍分區的示例來演示內置分區表的創建過程,首先創建一張范圍分區表,表名為log_par,如下所示:
create table log_par (id serial,user_id int4,create_time timestamp(0) without time zone
) partition by range(create_time);
表log par指定了分區策略為范圍分區,分區鍵為create time字段。創建分區,并設置分區的分區鍵取值范圍,如下所示:
create table log_par_his partition of log_par
for values from ('2016-01-01') to ('2017-01-01');create table log_par_201701 partition of log_par
for values from ('2017-01-01') to ('2017-02-01');create table log_par_201702 partition of log_par
for values from ('2017-02-01') to ('2017-03-01');create table log_par_201703 partition of log_par
for values from ('2017-03-01') to ('2017-04-01');create table log_par_201704 partition of log_par
for values from ('2017-04-01') to ('2017-05-01');create table log_par_201705 partition of log_par
for values from ('2017-05-01') to ('2017-06-01');create table log_par_201706 partition of log_par
for values from ('2017-06-01') to ('2017-07-01');create table log_par_201707 partition of log_par
for values from ('2017-07-01') to ('2017-08-01');create table log_par_201708 partition of log_par
for values from ('2017-08-01') to ('2017-09-01');create table log_par_201709 partition of log_par
for values from ('2017-09-01') to ('2017-10-01');create table log_par_201710 partition of log_par
for values from ('2017-10-01') to ('2017-11-01');create table log_par_201711 partition of log_par
for values from ('2017-11-01') to ('2017-12-01');create table log_par_201712 partition of log_par
for values from ('2017-12-01') to ('2018-01-01');
注意分區的分區鍵范圍不要有重疊,定義分區鍵范圍實質上給分區創建了約束。
給所有分區的分區鍵創建索引,如下所示:
create index idx_log_par_his_ctime
on log_par_his using btree(create_time);create index idx_log_par_201701_ctime
on log_par_201701 using btree(create_time);create index idx_log_par_201702_ctime
on log_par_201702 using btree(create_time);create index idx_log_par_201703_ctime
on log_par_201703 using btree(create_time);create index idx_log_par_201704_ctime
on log_par_201704 using btree(create_time);create index idx_log_par_201705_ctime
on log_par_201705 using btree(create_time);create index idx_log_par_201706_ctime
on log_par_201706 using btree(create_time);create index idx_log_par_201707_ctime
on log_par_201707 using btree(create_time);create index idx_log_par_201708_ctime
on log_par_201708 using btree(create_time);create index idx_log_par_201709_ctime
on log_par_201709 using btree(create_time);create index idx_log_par_201710_ctime
on log_par_201710 using btree(create_time);create index idx_log_par_201711_ctime
on log_par_201711 using btree(create_time);create index idx_log_par_201712_ctime
on log_par_201712 using btree(create_time);
以上三步完成了內置分區表的創建。
3.2、使用分區表
向分區表插入數據:
insert into log_par(user_id, create_time)
select round(100000 * random()), generate_series('2016-12-01'::date, '2017-12-01'::"date", '1 minute');
查看表數據:
select count(*)
from log_par;
select count(*)
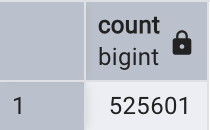
from only log_par;

從以上結果可以看出,父表log par沒有存儲任何數據,數據存儲在分區中,通過分區大小也可以證明這一點,如下所示:

3.3、內置分區表原理
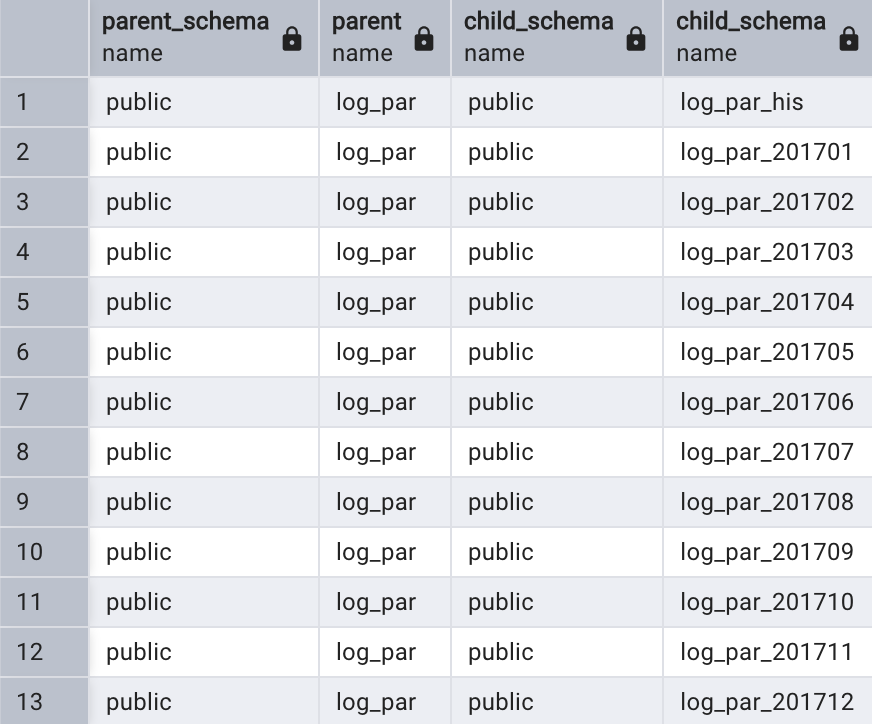
內置分區表原理實際上和傳統分區表一樣,也是使用繼承方式,分區可稱為子表,通過以下查詢很明顯看出表log par和其分區是繼承關系:
select nmsp_parent.nspname as parent_schema,parent.relname as parent,nmsp_child.nspname as child_schema,child.relname as child_schema
from pg_inherits join pg_class parent
on pg_inherits.inhparent = parent.oid join pg_class child
on pg_inherits.inhrelid = child.oid join pg_namespace nmsp_parent
on nmsp_parent.oid = parent.relnamespace join pg_namespace nmsp_child
on nmsp_child.oid = child.relnamespace
where parent.relname = 'log_par';
3.4、添加分區
添加分區的操作 比較簡單,例如給 log_par 增加一個分區,如下所示 :
create table log_par_201801 partition of log_par
for values from ('2018-01-01') to ('2018-02-01');
之后給分區創建索引,如下所示 :
create index idx_log_par_201801_ctime
on log_par_201801 using btree(create_time);
3.5、刪除分區
刪除分區有兩種方法,第一種方法通過 DROP 分區的方式來刪除,如下所示 :
drop table log_par_201801;
D ROP 方式直接將分 區 和分 區數據刪除,刪除前需確 認分區數據是否需要備份,避免數據丟失;另 一種推薦的方法是解綁分區, 如下所示 :
alter table log_par detach partition log_par_201801;
綁分區只是將分區 和 父表間 的關系斷開 ,分區和分區數據依然保留 ,這種方式比較穩妥,如果后續需要恢復這個分區,通過連接分區方式恢復分區即可,如下所示 :
alter table log_par attach partition log_par_201801 for values from ('2018-01-01') to ('2018-02-01');
連接分區時需要指定分區上的約束 。
3.6、更新分區數據
內置分區 表 UPDAT E 操作目前不支持新記錄跨分區的情況, 也就是說只允許分區 內的更新 , 例如以下 SQL 會報錯:
update log_par set create_time = '2017-02-02 01:01:01'
where user_id = 16965492;
以上 user_id 等于 16965492 的記錄位于 log_par_201701 分區,將這條記錄的 create_time 更新為 ’ 2017-02-02 01 : 01:01 ’由于違反了當前分區的約束將報錯,如果更新的數據不違反當前分區的約束則可正常更新數據,如下所示:
update log_par set create_time = '2017-01-01 01:01:01'
where user_id = 16965492;
目前內置分區表的這一 限制對于日志表影響不大,對于業務表有一定影響,使用時需注意 。
3.7、內置分區表注意事項
- 當往父表上插入數據時,數據會自動根據分區鍵路由規則插入到分區中,目前僅支持范圍分區和列表分區。
- 分區表上的索引、約束需使用單獨的命令創建,目前沒有辦法一次性自動在所有分區上創建索引、約束。
- 內置分區表不支持定義(全局)主鍵,在分區表的分區上創建主鍵是可以的。
- 內置分區表的內部實現使用了繼承。
- 如果UPDATE語句的新記錄違反當前分區鍵的約束則會報錯,UPDAET語句的新記錄目前不支持跨分區的情況。
- 性能方面:根據本節的測試場景,內置分區表根據非分區鍵查詢相比普通表性能差距較大,因為這種場景分區表的執行計劃會掃描所有分區;根據分區鍵查詢相比普通表性能有小幅降低,而查詢分區表子表性能相比普通表略有提升。




:讓大模型能夠回答私域知識問題)







有狀態AI代理的開源框架)


------休眠函數sleep_for和sleep_until)



②)