編者按: 在 Transformer 架構誕生八年之際,我們是否真的見證了根本性的突破,還是只是在原有設計上不斷打磨?今天我們為大家帶來的這篇文章,作者的核心觀點是:盡管大語言模型在技術細節上持續優化,其核心架構仍保持延續,真正的創新更多體現在效率提升與工程實現上。
文章系統梳理了 2025 年多個主流開源模型的架構演進,重點分析了 DeepSeek-V3/R1 的多頭潛在注意力(MLA)與混合專家模型(MoE)、OLMo 2 的歸一化層放置策略與 QK 歸一化、Gemma 3 的滑動窗口注意力機制,以及 Mistral Small 3.1 在推理效率上的優化。
這篇文章為我們提供了一個冷靜而深入的視角,提醒我們在追逐 SOTA 榜單的同時,不應忽視那些真正推動技術前進的、看似細微卻至關重要的架構設計選擇。
作者 | Devansh and Sebastian Raschka, PhD
編譯 | 岳揚
目錄
01 DeepSeek V3/R1
1.1 多頭潛在注意力機制(MLA)
1.2 混合專家模型(MoE)
1.3 DeepSeek 架構總結
02 OLMo 2
2.1 歸一化層放置策略
2.2?QK-Norm
2.3 OLMo 2 架構總結
03 Gemma 3
3.1 滑動窗口注意力機制
3.2 Gemma 3 的歸一化層布局策略
3.3 Gemma 3 架構總結
3.4 附加內容:Gemma 3n
04 Mistral Small 3.1
自最初的 GPT 架構問世以來,已經過去了七年時間。當我們回望 GPT-2(2019 年)并展望 DeepSeek-V3 與 Llama 4(2024 - 2025年)時,可能會驚訝地發現這些模型在結構上仍然如此相似。
誠然,位置編碼已從絕對位置編碼發展為旋轉位置編碼(RoPE),多頭注意力機制已普遍被分組查詢注意力機制取代,而更高效的 SwiGLU 激活函數也替代了 GELU 等傳統激活函數。但在這些細微改進之下,我們是否真正見證了突破性的變革?抑或只是在相同架構基礎之上進行精雕細琢?
比較不同大語言模型來確定影響其性能優劣的關鍵因素歷來充滿挑戰:數據集、訓練技術和超參數不僅差異巨大,且往往缺乏完整記錄。
盡管如此,我仍認為審視架構本身的結構性變化極具價值 —— 這能幫助我們洞察 2025 年大語言模型開發者的核心關注點(部分架構如圖 1 所示)。
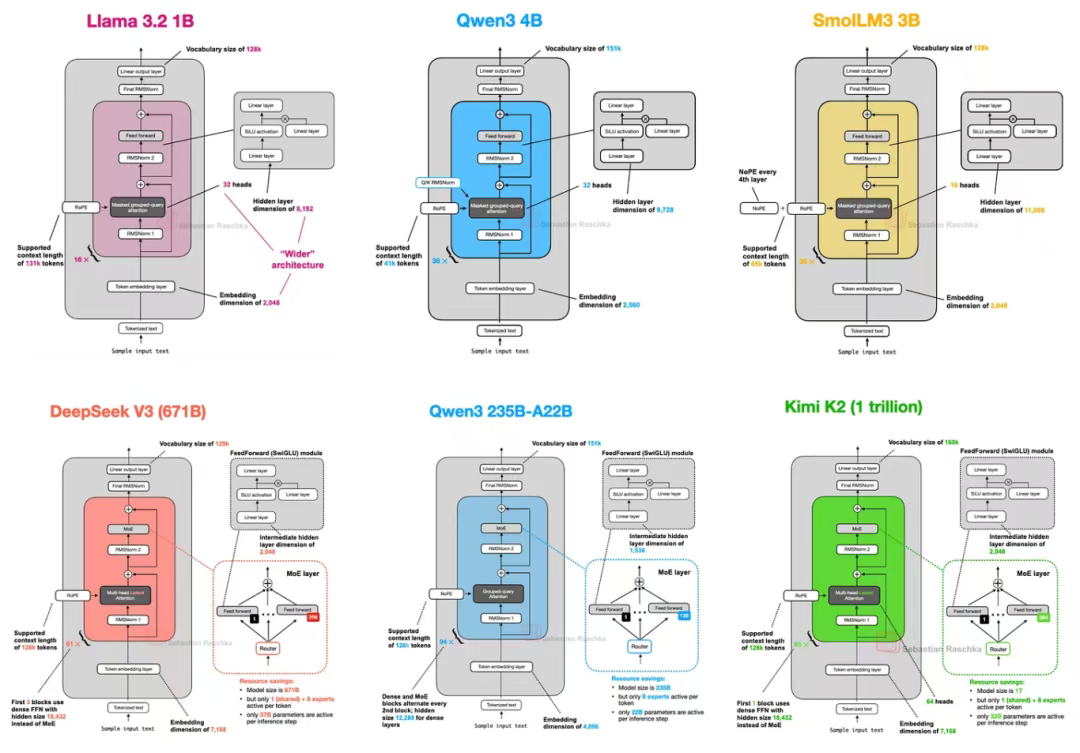
圖 1:本文涉及的部分架構示意圖
因此,本文將聚焦定義當今主流開源模型的核心架構演進,而非基準測試表現或訓練算法的討論。
01 DeepSeek V3/R1
DeepSeek R1 在 2025 年 1 月發布時引起了巨大轟動。該推理模型基于 2024 年 12 月推出的 DeepSeek V3 架構構建。
雖然本文主要關注 2025 年發布的模型架構,但考慮到 DeepSeek V3 正是在 2025 年憑借 DeepSeek R1 的發布才獲得廣泛關注與應用,將其納入討論范圍是合理的。
若您對 DeepSeek R1 的訓練細節感興趣,可參閱我今年早前的文章《Understanding Reasoning LLMs》[1]:
本節將重點解析 DeepSeek V3 中兩項提升計算效率的核心架構技術(這也是其區別于其他大語言模型的重要特征):
- 多頭潛在注意力機制(MLA)
- 混合專家模型(MoE)
1.1 多頭潛在注意力機制(MLA)
在探討多頭潛在注意力機制(MLA)之前,我們先簡要回顧相關背景以理解其設計動機。讓我們從分組查詢注意力機制(GQA)談起 —— 近年來它已成為替代多頭注意力機制(MHA)的新標準方案,具有更高的計算效率與參數效率。
以下是 GQA 的核心概要:與 MHA 中每個注意力頭都擁有獨立的鍵值對不同,GQA 通過讓多個注意力頭共享同一組鍵值投影來降低內存消耗。例如,如圖 2 所示,若存在 2 個鍵值組和 4 個注意力頭,則注意力頭 1 與注意力頭 2 可能共享一組鍵值,而注意力頭 3 與注意力頭 4 共享另一組。這種方式減少了鍵值計算總量,從而降低內存使用并提升效率(消融實驗表明其對模型性能無明顯影響)。
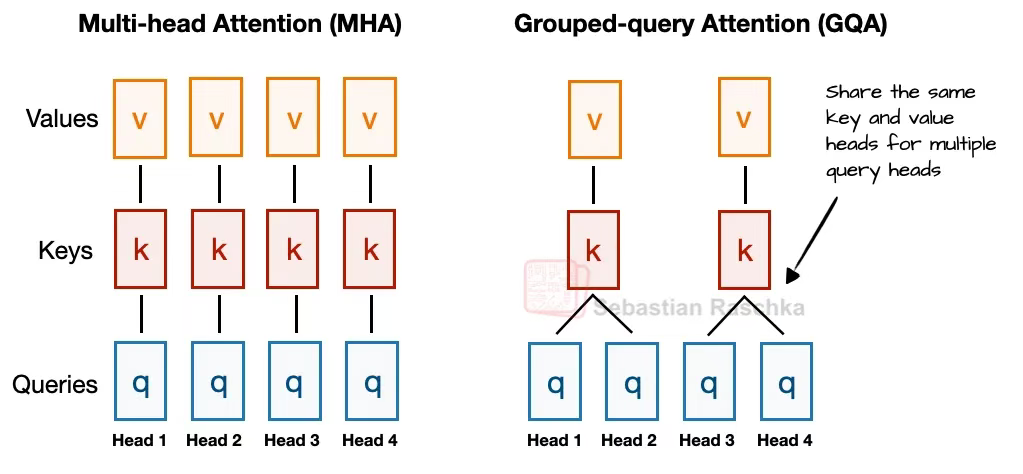
圖 2:MHA 與 GQA 對比示意圖(組大小為 2,即每兩個查詢頭共享一組鍵值對)
GQA 的核心思想是通過讓多個查詢頭共享鍵值頭來減少鍵值頭數量,這帶來兩大優勢: (1)降低模型參數量;(2)推理時減少鍵值張量的內存帶寬占用,因為需要存儲和從 KV 緩存中檢索的鍵值對更少。
(若想了解 GQA 的代碼實現,可參閱筆者撰寫的無 KV 緩存版《GPT-2 to Llama 3 conversion guide》[2]及帶 KV 緩存的改進版本[3]。)
盡管 GQA 本質上是針對 MHA 的計算效率優化方案,但消融研究(包括原版 GQA 論文[4]和 Llama 2 論文[5])表明其在 LLM 建模性能上與標準 MHA 相當。
而多頭潛在注意力機制(MLA)則提供了另一種內存優化策略,尤其與 KV 緩存機制高度契合。與 GQA 共享鍵值頭的思路不同,MLA 將鍵值張量壓縮至低維空間后再存入 KV 緩存。
推理時,這些壓縮張量會先通過投影恢復原始尺寸后再參與計算(如圖 3 所示)。雖然增加了矩陣乘法操作,但大大降低了內存占用。
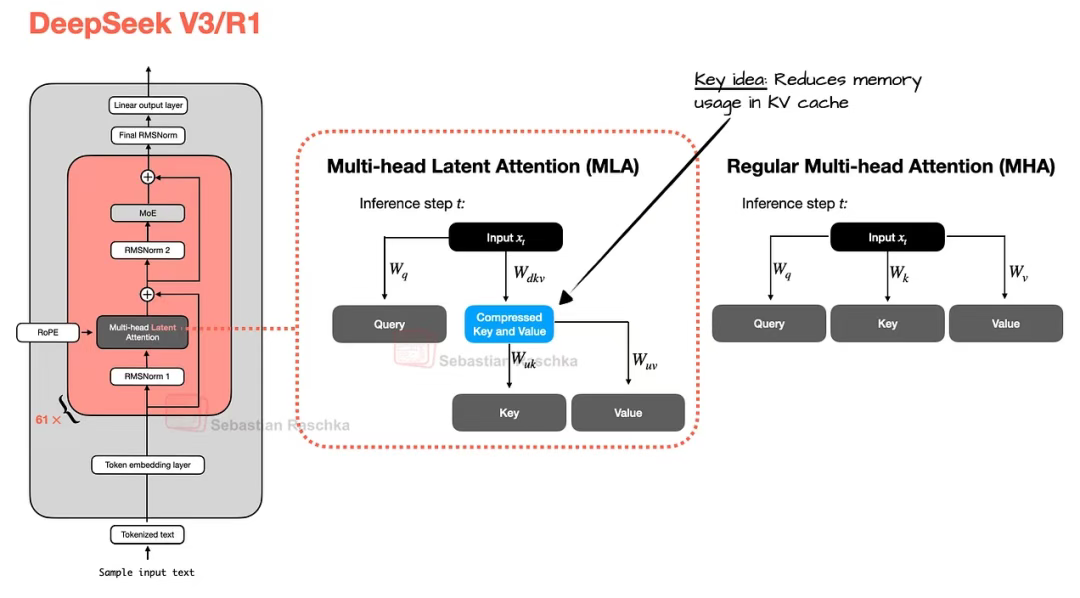
圖 3:MLA(用于 DeepSeek V3 和 R1 中)與常規 MHA 的對比示意圖
(需要說明的是,查詢向量在訓練過程中也會被壓縮,但該操作僅適用于訓練階段,不涉及推理過程。)
值得一提的是,MLA 并非 DeepSeek V3 首創 —— 其前代版本 DeepSeek-V2 早已采用(甚至可以說是由其率先引入)這項技術。此外,V2 論文中多項有趣的消融實驗或許能解釋開發團隊為何選擇 MLA 而非 GQA(見圖 4)。
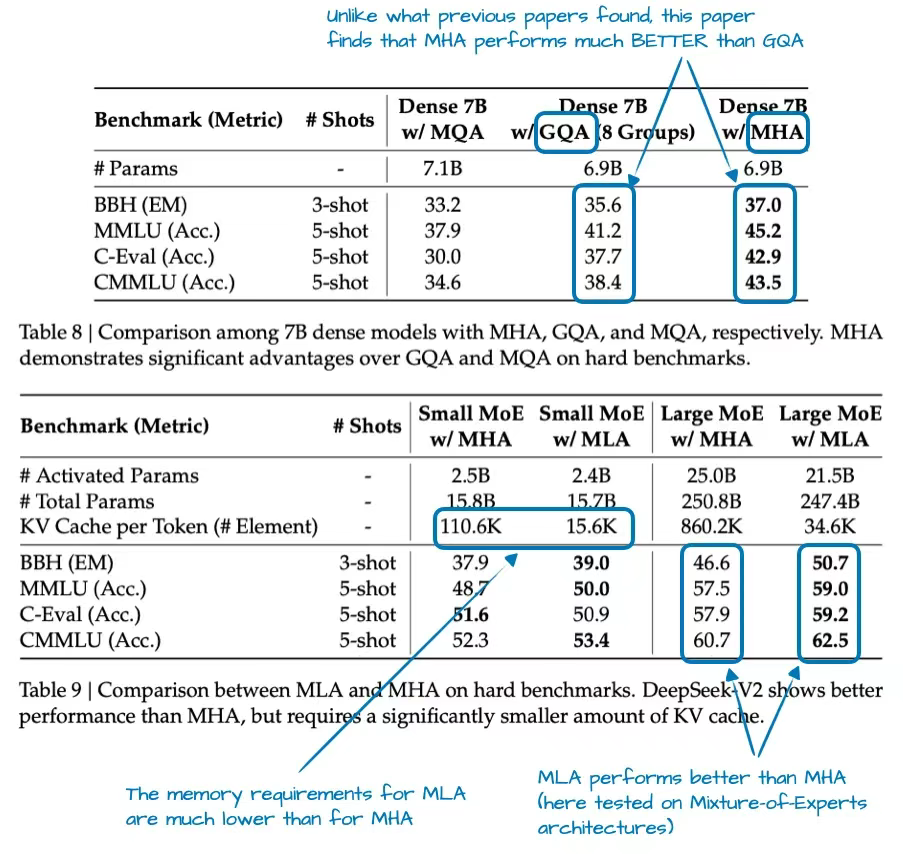
圖 4:帶有標注的摘自 DeepSeek-V2 論文的表格(來源:https://arxiv.org/abs/2405.04434)
如圖 4 所示,GQA 的表現似乎遜于 MHA,而 MLA 的建模性能反而優于 MHA —— 這很可能是 DeepSeek 團隊舍棄 GQA 選擇 MLA 的原因。(若能同時對比 MLA 與 GQA 在“每詞元 KV 緩存”上的節省效果,或許會更有趣!)
對此部分進行總結:MLA 是一種巧妙的 KV 緩存內存優化技術,其在建模性能方面甚至較 MHA 略有提升。
1.2 混合專家模型(MoE)
DeepSeek 架構中另一個值得重點闡述的核心組件是其采用的混合專家模型(MoE)層。盡管 MoE 并非由 DeepSeek 首創,但今年該技術正迎來復興浪潮,后續將討論的諸多模型架構也都采用了這一方案。
MoE 的核心思想是將 Transformer 模塊中的每個前饋網絡替換為多個專家層 —— 每個專家層本身也是前饋模塊。這意味著我們用多個前饋模塊替代單一前饋模塊,具體如圖 5 所示。
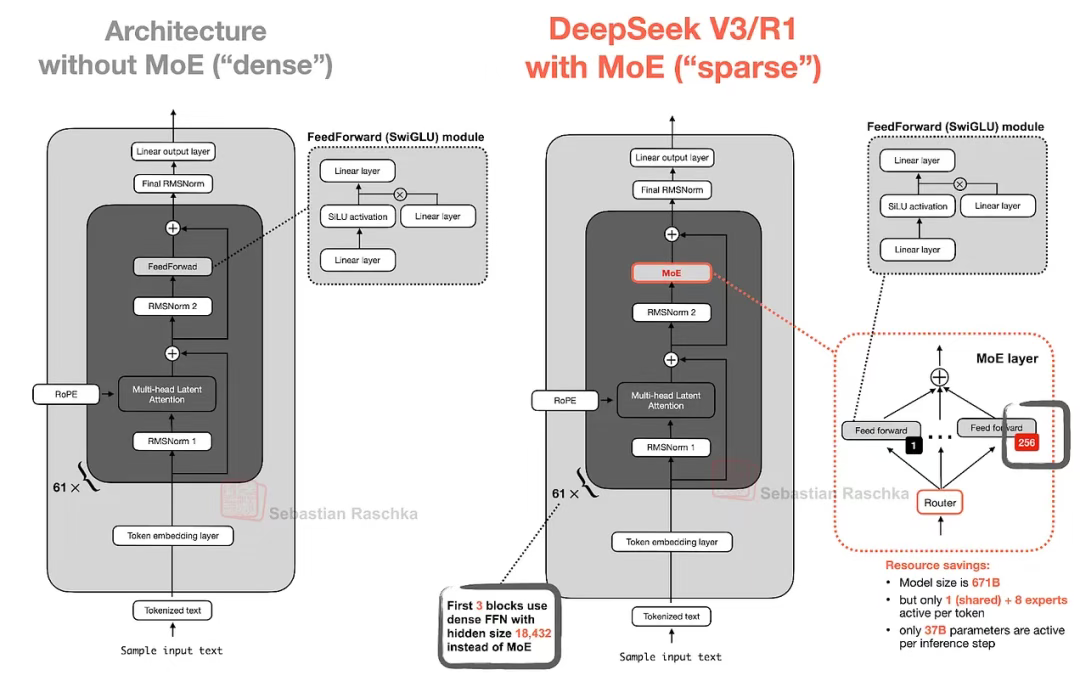
圖 5:DeepSeek V3/R1 采用的 MoE 模塊(右)與標準前饋網絡結構(左)對比示意圖
Transformer 模塊內的前饋網絡(上圖中深灰色模塊)通常占據著模型的絕大部分參數量(需注意 Transformer 模塊及其內含的前饋網絡會在 LLM 中重復多次,例如 DeepSeek-V3 中就重復了 61 次)。
因此,用多個前饋模塊替代單一前饋模塊(MoE 的實現方式)會大大增加模型的總參數量。但并非每個 token 都會激活所有專家。相反,路由層會為每個 token 僅選擇一小部分專家(由于篇幅所限,關于路由層的細節將另文詳述)。
由于每次僅激活少量專家模塊,MoE 系統通常被稱為稀疏架構,這與始終使用全部參數的密集架構形成對比。通過 MoE 實現的龐大總參數量提升了 LLM 的容量上限,使其在訓練過程中能吸收更多知識。而稀疏特性則保證了推理效率 —— 因為我們不會同時調用所有參數。
以 DeepSeek-V3 為例:每個 MoE 模塊包含 256 個專家,總參數量達 6710 億。但在推理過程中,每次僅激活 9 個專家(1 個共享專家 + 路由層選出的 8 個專家)。這意味著每個推理步驟僅使用 370 億參數,而非全部 6710 億。
DeepSeek-V3 的 MoE 設計有一個特點:采用共享專家機制。這個專家會對每個 token 始終保持激活狀態。 該理念并非首創,早在 2024 年 DeepSeek MoE 論文[6]和 2022 年 DeepSpeedMoE 論文[7]中就已提出。
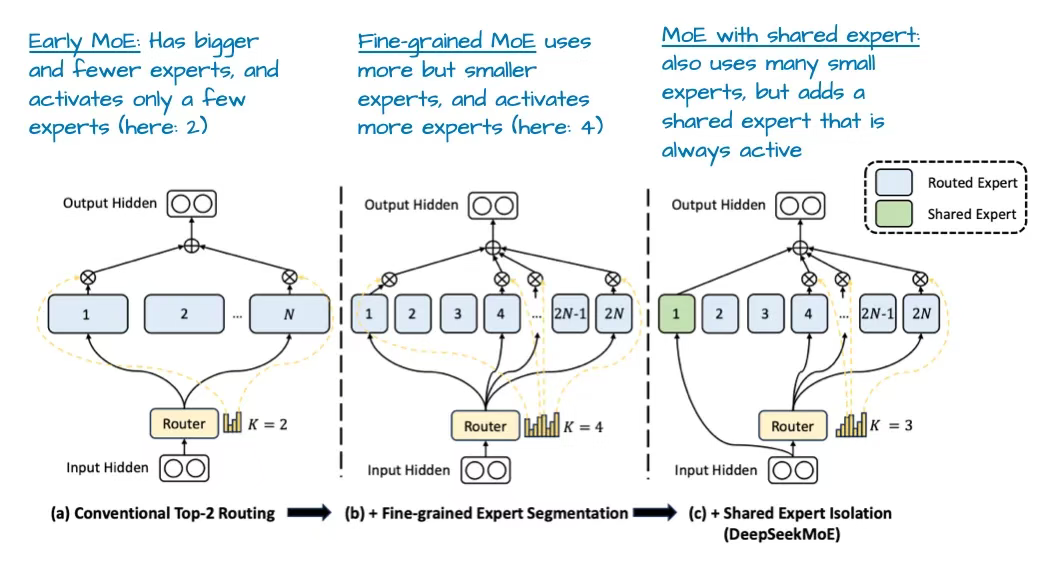
圖 6:帶有標注的摘自《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》的圖示,https://arxiv.org/abs/2401.06066
共享專家的優勢最初在 DeepSpeedMoE 論文[7]中被指出:相比無共享專家的設計,它能提升整體建模性能。這很可能是因為常見模式或重復模式無需由多個獨立專家重復學習,從而為專家們留出更多專攻特殊化模式的空間。
1.3 DeepSeek 架構總結
總而言之,DeepSeek-V3 作為一個擁有 6710 億參數的巨型模型,在發布時性能就超越了包括 4050 億參數的 Llama 3 在內的其他開放權重模型。盡管參數量更大,但其推理效率卻明顯更高 —— 這得益于其混合專家系統(MoE)架構的設計,該架構使得每個 token 僅激活參數總量的極小部分(僅 370 億參數)。
另一個關鍵區別在于 DeepSeek-V3 采用多頭潛在注意力機制(MLA)替代了分組查詢注意力機制(GQA)。MLA 與 GQA 都是標準多頭注意力(MHA)的高效推理替代方案,尤其在配合 KV 緩存使用時優勢明顯。雖然 MLA 的實現更為復雜,但 DeepSeek-V2 論文中的研究表明,其建模性能優于 GQA。
02 OLMo 2
非營利組織艾倫人工智能研究所(Allen Institute for AI)推出的 OLMo 系列模型同樣值得關注,這主要得益于其在訓練數據與工程代碼方面的高透明度,以及相對詳盡的技術報告。
雖然 OLMo 模型可能不會在各類基準測試或排行榜上名列前茅,但其架構設計清晰簡潔。更重要的是,憑借完全開源的特性,該系列模型為 LLM 的開發提供了極佳的藍圖參考。
盡管 OLMo 模型因其透明性而廣受歡迎,但其性能表現同樣可圈可點。實際上,在今年 1 月發布時(早于 Llama 4、Gemma 3 和 Qwen 3),OLMo 2 系列模型正處于計算效率與性能的帕累托前沿【譯者注:“帕累托前沿”(Pareto Frontier)是一個起源于經濟學和優化理論的重要概念,它描述的是一種最優狀態,在這種狀態下,任何一方的利益或某個目標的提升都無法不以犧牲其他方利益或其他目標的下降為代價。】,如圖 7 所示。
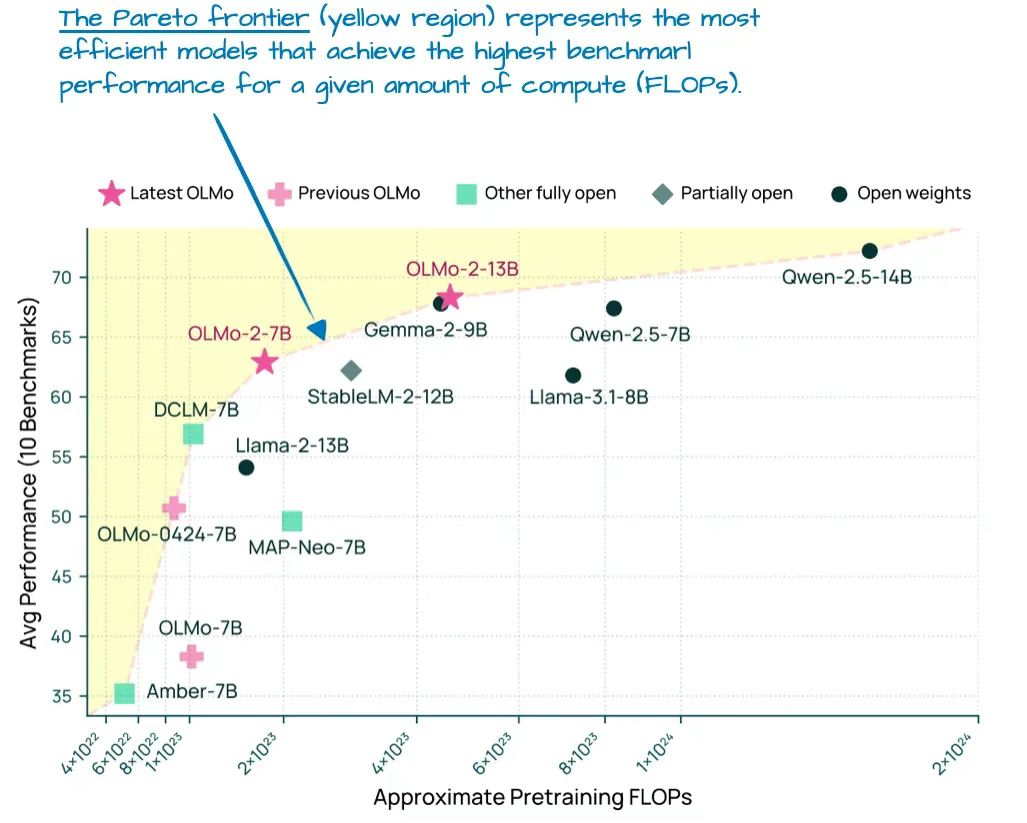
圖 7:不同 LLMs 的基準測試性能(越高越好)與預訓練成本(FLOPs;越低越好)對比(這張經過標注的圖片源自 OLMo 2 論文,https://arxiv.org/abs/2501.00656)
如本文開頭所述,為控制篇幅,我們將聚焦于 LLM 的架構細節(暫不涉及訓練細節與數據)。那么 OLMo 2 有哪些值得關注的架構設計選擇?主要可歸結為歸一化技術的應用:包括 RMSNorm 層的布局以及新增的 QK 歸一化設計(后續將詳細討論)。
另值得一提的是,OLMo 2 仍采用傳統多頭注意力(MHA)機制,而非 MLA 或 GQA。
2.1 歸一化層放置策略
總體而言,OLMo 2 基本遵循了原始 GPT 的架構設計,這與當代其他大語言模型相似。但其仍存在一些值得關注的差異,讓我們先從歸一化層說起。
與 Llama、Gemma 及多數主流大語言模型類似,OLMo 2 也將 LayerNorm 層替換為了 RMSNorm 層。
但由于 RMSNorm 已是成熟技術(本質上是 LayerNorm 的簡化版,擁有更少的可訓練參數),本文將不再討論 RMSNorm 與 LayerNorm 的區別(感興趣的讀者可參閱筆者撰寫的《GPT-2 to Llama conversion guide》[8]中的 RMSNorm 代碼實現)。
然而,RMSNorm 層的放置位置值得深入探討。原始 Transformer 架構(出自《Attention is all you need》[9]論文)將兩個歸一化層分別放置在注意力模塊和前饋網絡模塊之后。
這種設計被稱為后歸一化(Post-LN 或 Post-Norm)。
而 GPT 及之后大多數大語言模型則將歸一化層置于注意力模塊和前饋網絡模塊之前,稱為前歸一化(Pre-LN 或 Pre-Norm)。兩種歸一化方式的對比如下圖所示。
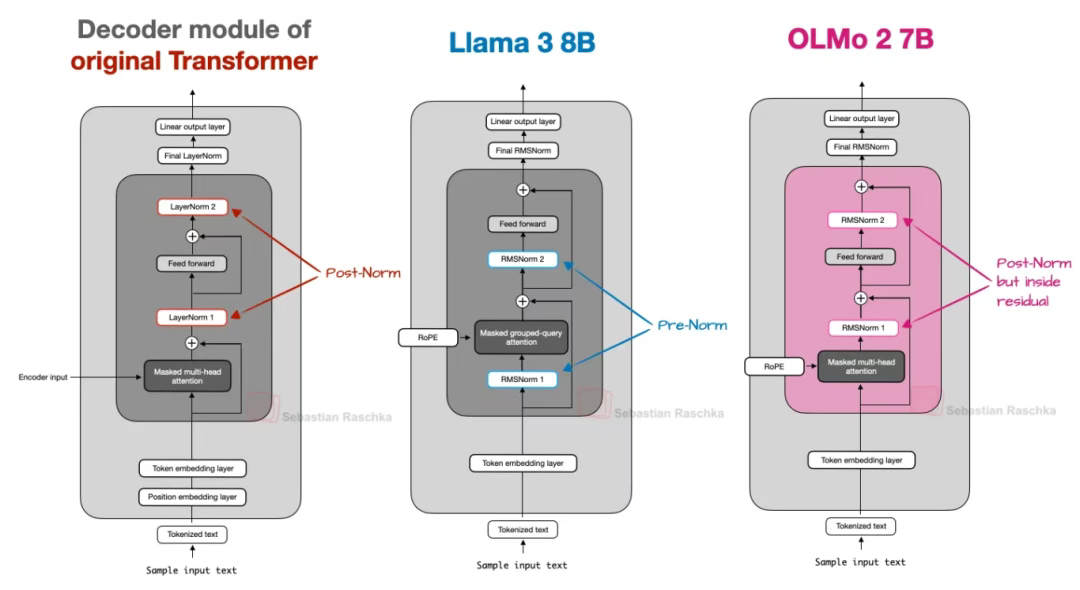
圖 8:后歸一化、前歸一化與 OLMo 2 采用的后歸一化變體對比示意圖
2020 年,Xiong 等人通過研究[10]證明:前歸一化能使梯度在初始化階段表現更穩定。研究人員還指出,前歸一化即使不配合精細的學習率預熱策略也能良好工作,而這對于后歸一化而言卻是至關重要的訓練保障。
此處特別提及該研究是因為 OLMo 2 采用了一種后歸一化變體(但使用 RMSNorm 替代了 LayerNorm,故稱其為 Post-Norm)。
在 OLMo 2 中,歸一化層被放置在注意力層和前饋網絡層之后(而非之前),如上圖所示。但請注意:與原始 Transformer 架構不同,這些歸一化層仍位于殘差層(跳躍連接)內部。
那么為何要調整歸一化層的位置?原因在于這種設計能提升訓練穩定性,如下圖所示。
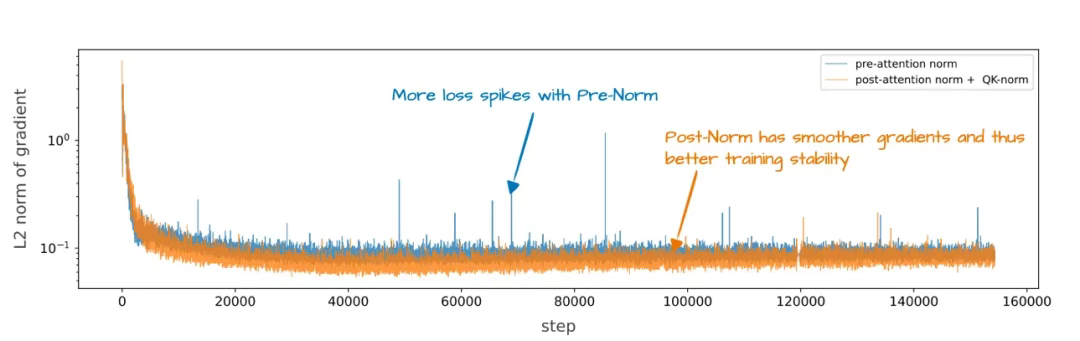
圖 9:前歸一化(GPT-2、Llama 3 等模型采用)與 OLMo 2 后歸一化變體的訓練穩定性對比圖。此帶有標注的圖表取自 OLMo 2 論文,https://arxiv.org/abs/2501.00656
遺憾的是,該圖表將歸一化層重定位與?QK-Norm(另一個獨立概念)的效果合并展示,因此難以單獨判斷歸一化層位置調整的具體貢獻程度。
2.2?QK-Norm
既然上一節已提及?QK-Norm,且后續將討論的其他大語言模型(如 Gemma 2 和 Gemma 3)也采用了該技術,我們不妨簡要探討一下其原理。
QK-Norm 本質上是另一個 RMSNorm 層。它被置于多頭注意力(MHA)模塊內部,在應用旋轉位置編碼(RoPE)之前對查詢向量(q)和鍵向量(k)進行歸一化處理。為直觀說明,以下內容摘錄自我在《Qwen3 from-scratch implementation》[11]編寫的分組查詢注意力(GQA)層代碼(GQA 中的?QK-Norm?應用方式與 OLMo 的 MHA 類似):
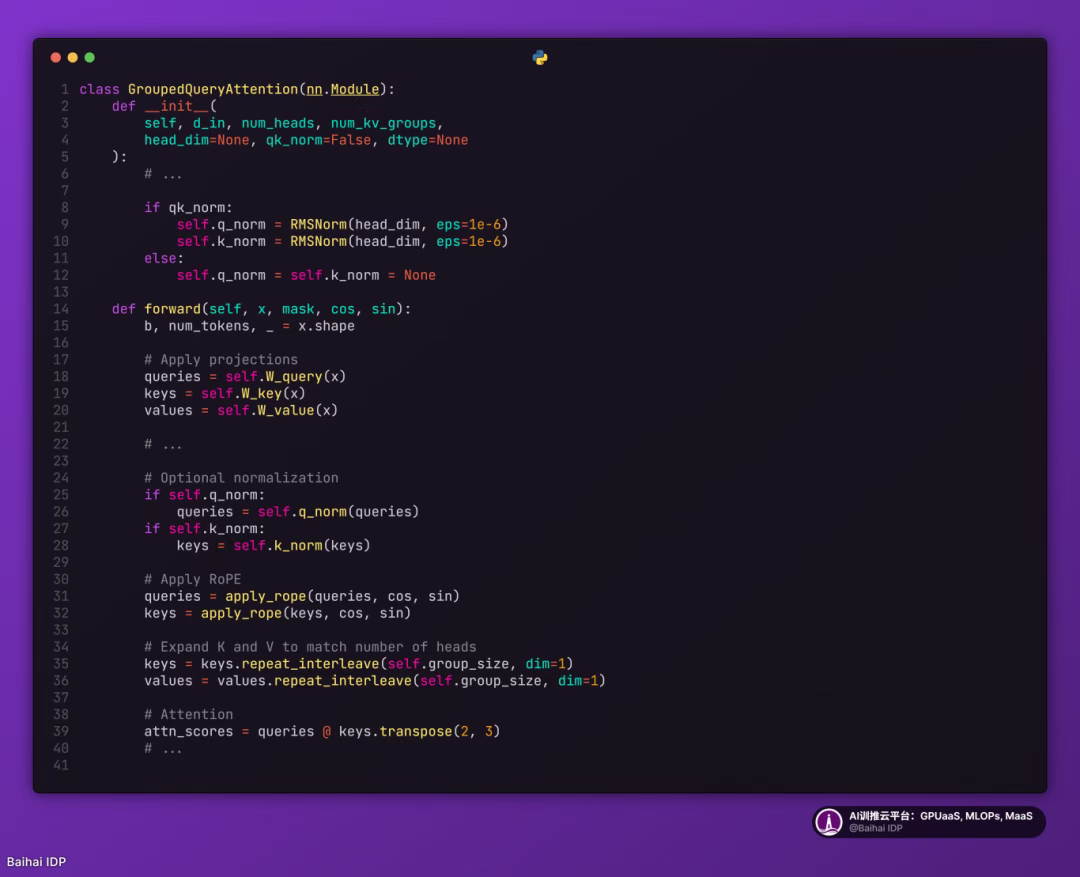
如前文所述,QK-Norm?與后歸一化配合使用可提升訓練穩定性。需要注意的是,QK-Norm?并非由 OLMo 2 首創,其最早可追溯至 2023 年發表的《Scaling Vision Transformers》[12]論文。
2.3 OLMo 2 架構總結
簡而言之,OLMo 2 值得關注的架構設計決策主要集中于 RMSNorm 的放置策略:將 RMSNorm 置于注意力模塊和前饋網絡模塊之后(一種后歸一化變體),而非之前。同時在注意力機制內部為查詢向量和鍵向量添加 RMSNorm(即?QK-Norm)。這兩項改進共同作用,有效穩定了訓練損失。
下圖進一步對比了 OLMo 2 與 Llama 3 的架構差異:可見除 OLMo 2 仍采用傳統 MHA 而非 GQA 外,兩者結構總體相似(但 OLMo 2 團隊在三個月后發布了采用 GQA 的 320 億參數變體)。
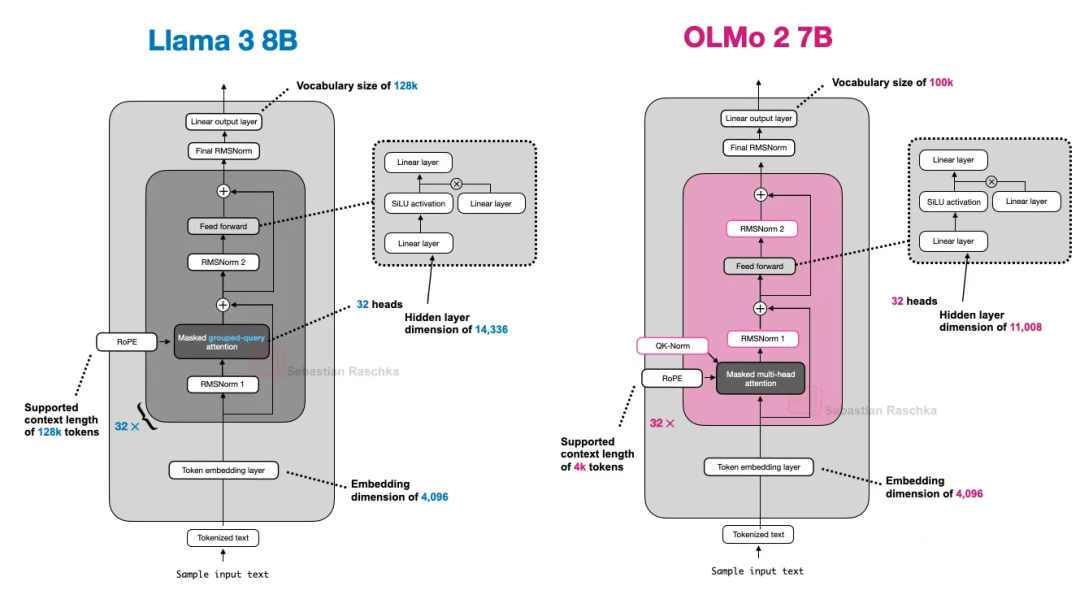
圖 10:Llama 3 與 OLMo 2 的架構對比示意圖
03 Gemma 3
Google 的 Gemma 系列模型始終保持著卓越的性能,但與 Llama 等熱門模型相比,其關注度始終略顯不足。
Gemma 的顯著特征之一是其超大的詞表規模(以便更好地支持多語言場景),以及更側重 27B 參數規格(而非 8B 或 70B)。需注意的是,Gemma 2 也提供更小規格版本:1B、4B 與 12B。
27B 規格堪稱最佳平衡點:性能遠超 8B 模型,資源消耗卻遠低于 70B 模型,甚至能在 Mac Mini 上實現本地流暢運行。
那么 Gemma 3[13]?還有哪些亮點?如前文所述,DeepSeek-V3/R1 等模型采用 MoE 架構在固定模型規模下降低推理內存需求(后續討論的其他模型也采用了 MoE 方案)。
Gemma 3 則運用了不同的技巧來減少計算開銷 —— 即滑動窗口注意力機制。
3.1 滑動窗口注意力機制
通過采用滑動窗口注意力機制(該技術最初在 2020 年由 LongFormer 論文[14]提出,Gemma 2[15]?也已采用),Gemma 3 團隊大大降低了 KV 緩存的內存需求,如下圖所示:
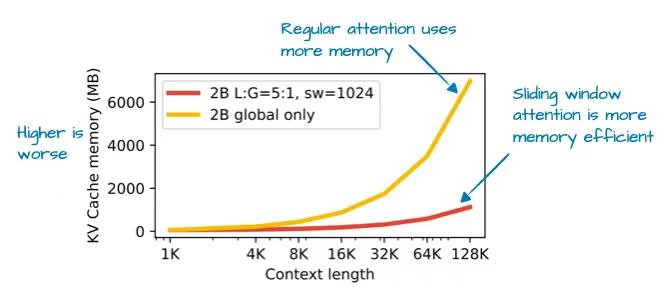
圖 11:帶有標注的 Gemma 3 論文示意圖( https://arxiv.org/abs/2503.19786 ),展示了滑動窗口注意力機制對 KV 緩存的內存節省效果
那么什么是滑動窗口注意力機制?如果將常規自注意力視為全局注意力機制(每個序列元素可訪問任意其他元素),那么滑動窗口注意力可理解為局部注意力 —— 它會限制當前查詢位置周圍的上下文大小,具體如下圖所示:
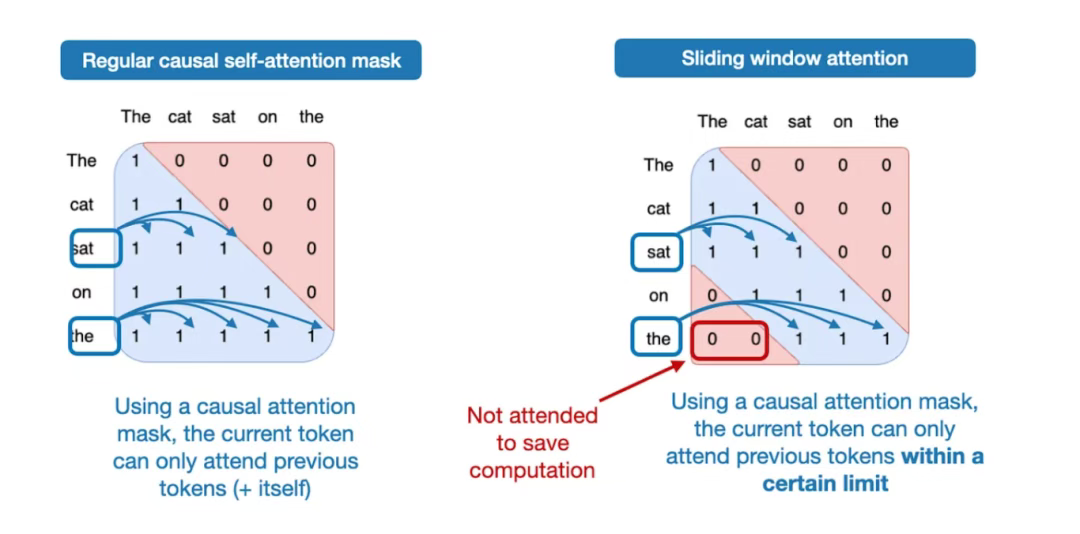
圖 12:常規注意力(左)與滑動窗口注意力(右)對比示意圖
需要注意的是,滑動窗口注意力可同時適用于多頭注意力和分組查詢注意力,Gemma 3 采用的是分組查詢注意力版本。
如前文所述,滑動窗口注意力又稱為“局部注意力”,因為其滑動窗口會圍繞當前查詢位置移動。相比之下,常規注意力是全局性的,每個詞元都能訪問所有其他詞元。
不過,前代架構 Gemma 2 早已采用滑動窗口注意力。Gemma 3 的改進在于調整了全局注意力(常規)與局部注意力(滑動)的比例。
例如,Gemma 2 采用混合注意力機制,以 1:1 的比例結合滑動窗口(局部)與全局注意力,每個詞元可關注附近 4K 詞元的上下文窗口。
Gemma 2 在每一層都使用滑動窗口注意力,而 Gemma 3 將比例調整為 5:1 —— 即每 5 個滑動窗口(局部)注意力層才設置 1 個全局注意力層。同時滑動窗口大小從 Gemma 2 的 4096 縮減至 1024。這種設計使模型更聚焦于高效的局部計算。
根據消融實驗,滑動窗口注意力對建模性能的影響微乎其微,如下圖所示:
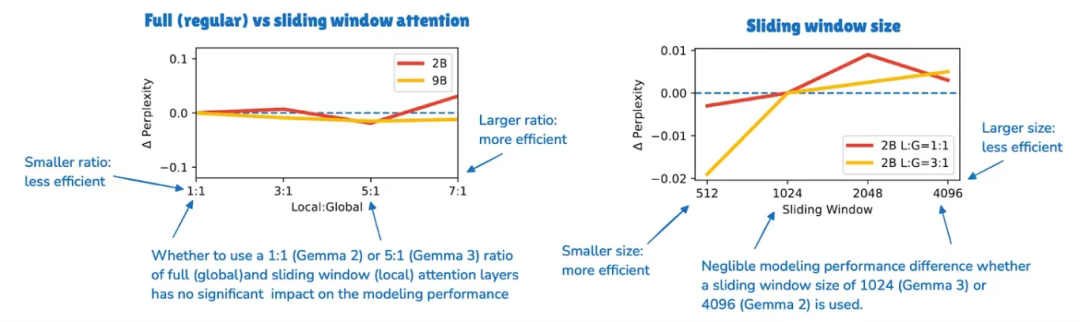
圖 13:帶有標注的 Gemma 3 論文示意圖( https://arxiv.org/abs/2503.19786 ),表明滑動窗口注意力對大語言模型輸出困惑度的影響極小
雖然滑動窗口注意力是 Gemma 3 最顯著的架構特性,但作為前文 OLMo 2 章節的延續,我們還需簡要討論其歸一化層的布局策略。
3.2 Gemma 3 的歸一化層布局策略
一個雖細微卻值得關注的設計是:Gemma 3 在其分組查詢注意力模塊周圍同時采用了前歸一化(Pre-Norm)與后歸一化(Post-Norm)的 RMSNorm 配置。
此設計雖與 Gemma 2 類似,但仍值得強調 —— 因為它既不同于原始 Transformer(《Attention is all you need》)采用的后歸一化,也區別于 GPT-2 推廣并被后續眾多模型架構采用的前歸一化,同時與我們前文討論的 OLMo 2 后歸一化變體存在差異。
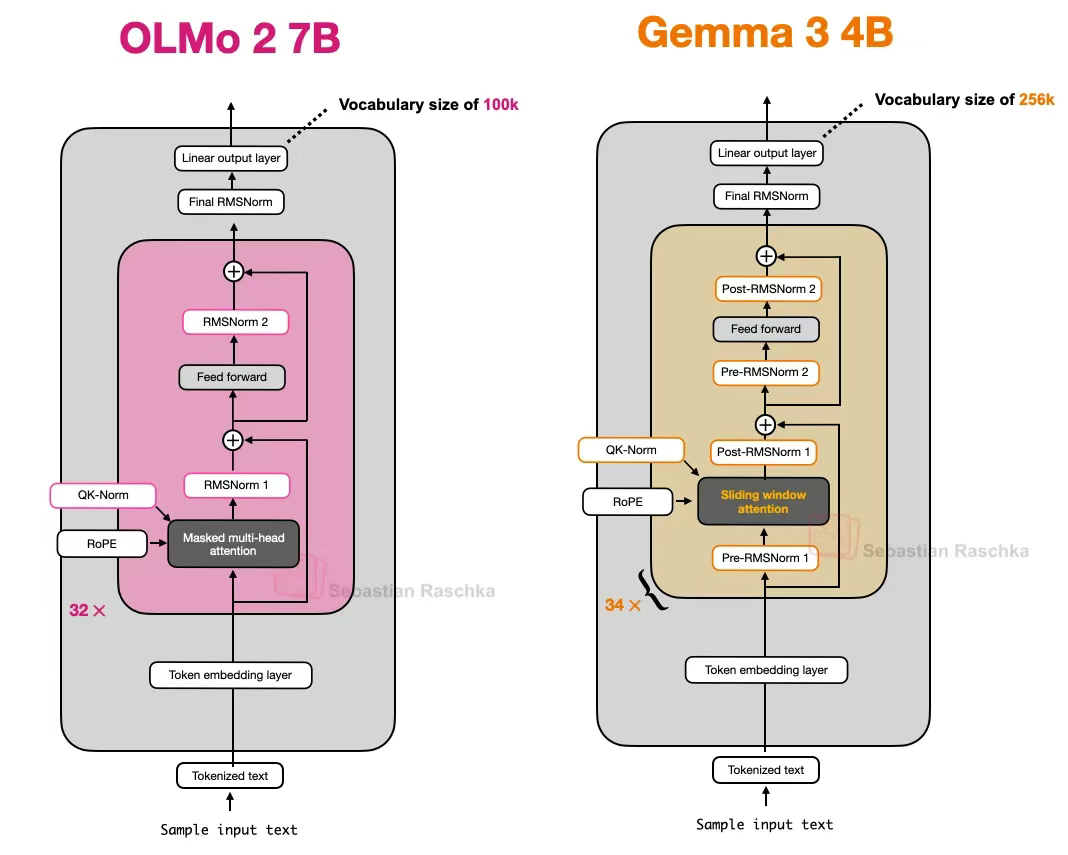
圖 14:OLMo 2 與 Gemma 3 的架構對比圖。注意 Gemma 3 中增加的歸一化層
筆者認為這種歸一化層布局是一種直觀而高效的方案,它融合了前歸一化和后歸一化的雙重優勢。從實踐角度看,適當增加的歸一化操作通常利大于弊:在最壞情況下,即便存在冗余也僅會帶來輕微的效率損失。由于 RMSNorm 在整體計算開銷中占比極低,這種設計實際上不會產生明顯影響。
3.3 Gemma 3 架構總結
Gemma 3 是一款性能優異的開放權重大語言模型,但其在開源社區中的認可度與其實力并不匹配。最引人注目的是其采用滑動窗口注意力提升效率的設計(未來若能與 MoE 結合將更具想象空間)。
此外,Gemma 3 采用獨特的歸一化層布局策略,在注意力模塊和前饋網絡模塊前后均部署了 RMSNorm 層。
3.4 附加內容:Gemma 3n
Gemma 3 發布數月后,谷歌推出了專為移動設備優化的 Gemma 3n[16]?版本,其核心目標是實現在手機端高效運行。
Gemma 3n 為提升效率做出的改進之一是引入 Per-Layer Embedding(PLE)層。 該設計的核心思想是不將整個模型的所有參數都加載到昂貴的 GPU 內存中,而是只保留其中最核心、最常用的一部分,而文本、音頻、視覺等模態的特定詞元層嵌入則按需從 CPU 或 SSD 動態加載。
下圖展示了 PLE 機制的內存優化效果:標準 Gemma 3 模型(可能指 4B 參數版本)標注的參數量為 5.44B。
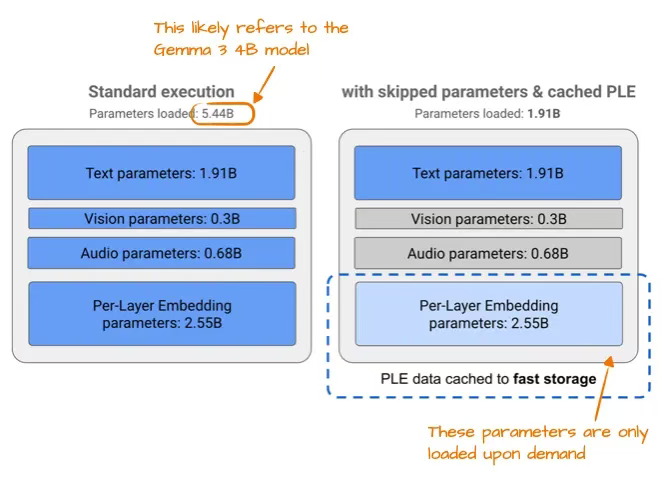
圖 15:經過標注的摘自谷歌 Gemma 3n 相關博客的示意圖( https://developers.googleblog.com/en/introducing-gemma-3n/ ),展示了 PLE 內存優化機制
5.44B 與 4B 參數的統計差異源于谷歌采用了一種特殊的參數計數方式:他們通常排除嵌入參數以使模型顯得更小,但在需要凸顯規模時(比如此處)又會將其計入。這種統計方式并非谷歌獨有,已成為行業普遍做法。
另一項有趣的技術是 MatFormer[17]?概念(Matryoshka Transformer 的簡稱)。例如,Gemma 3n 使用一個共享的 LLM(Transformer)架構,可以將其切割成多個更小的、獨立運行的子模型。每個子模型經過獨立訓練后均能單獨運行,因此在推理時只需調用所需的部分(無需啟動整個大模型)。
04 Mistral Small 3.1
于 Gemma 3 發布后不久在三月問世的 Mistral Small 3.1 24B[18]?值得關注 —— 它在多項基準測試(除數學外)中性能超越 Gemma 3 27B,且推理速度更快。
Mistral Small 3.1 推理延遲低于 Gemma 3 的原因可能包括:定制化的分詞器、KV 緩存壓縮以及層數的精簡。 其余部分則采用標準架構(如下圖對比所示)。
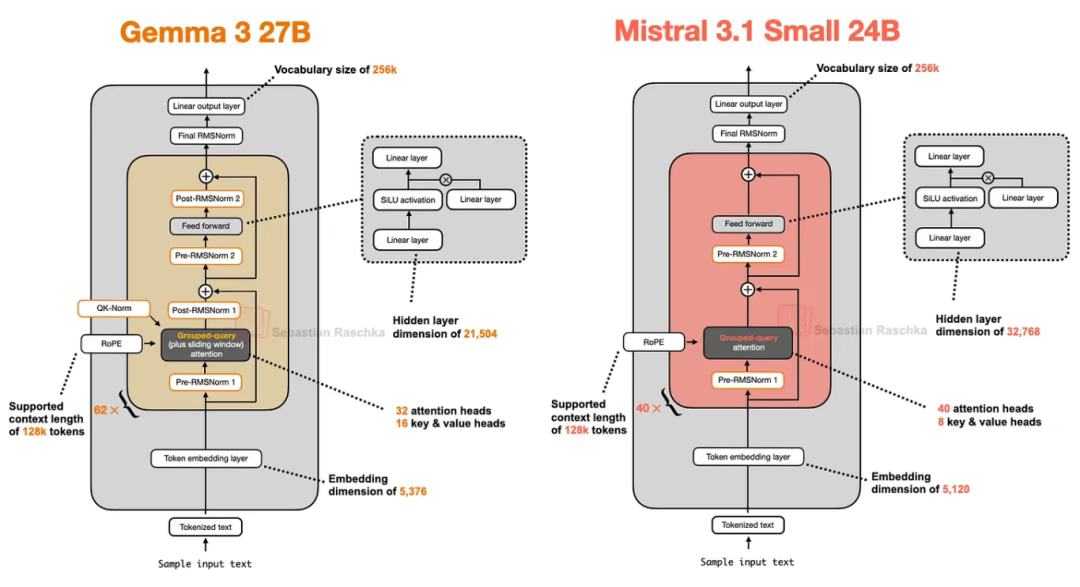
圖 16:Gemma 3 27B 與 Mistral 3.1 Small 24B 架構對比示意圖
有趣的是,早期 Mistral 模型曾采用滑動窗口注意力機制,但該設計在 Mistral Small 3.1 中被棄用。由于 Mistral 改用標準的分組查詢注意力(而非 Gemma 3 采用的滑動窗口注意力),其或許能通過調用經過深度優化的底層計算代碼(如 FlashAttention)進一步降低推理開銷。例如,筆者推測:滑動窗口注意力機制雖降低了內存占用,但未必會減少推理延遲 —— 而這正是 Mistral Small 3.1 的核心優化目標。
END
本期互動內容 🍻
?你是否同意“過去幾年 Transformer 架構沒有根本性突破”這一觀點?為什么?
文中鏈接
[1]https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
[2]https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/07_gpt_to_llama/converting-llama2-to-llama3.ipynb
[3]https://github.com/rasbt/LLMs-from-scratch/blob/main/pkg/llms_from_scratch/llama3.py
[4]https://arxiv.org/abs/2305.13245
[5]https://arxiv.org/abs/2307.09288
[6]https://arxiv.org/abs/2401.06066
[7]https://arxiv.org/abs/2201.05596
[8]https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
[9]https://arxiv.org/abs/1706.03762
[10]https://arxiv.org/abs/2002.04745
[11]https://github.com/rasbt/LLMs-from-scratch/tree/main/ch05/11_qwen3
[12]https://arxiv.org/abs/2302.05442
[13]https://arxiv.org/abs/2503.19786
[14]https://arxiv.org/abs/2004.05150
[15]http://arxiv.org/abs/2408.00118
[16]https://developers.googleblog.com/en/introducing-gemma-3n/
[17]https://arxiv.org/abs/2310.07707
[18]https://mistral.ai/news/mistral-small-3-1
原文鏈接:
https://artificialintelligencemadesimple.substack.com/p/a-look-through-the-seven-years-of




有狀態AI代理的開源框架)


------休眠函數sleep_for和sleep_until)



②)

![[frontend]mermaid code2image](http://pic.xiahunao.cn/[frontend]mermaid code2image)
)
)
(3))


