目錄
回顧:從 "人為中心" 的數倉,到大數據與云數倉的進化
AI Agent 成為數據的 "新用戶"
Agentic Data Stack 如何打破低效與內耗
企業數智化的新范式
案例與趨勢展望
所有軟件都會被 Agent 改寫一遍
經過半個世紀的數據倉庫發展歷程,企業數智化轉型正迎來一次根本性的范式變革。從 Inmon 的"主題域"到 Kimball 的"雪花模型",從 Teradata 的 MPP 架構到 Snowflake 的云原生方案,這些技術演進始終圍繞著一個核心:服務于人類決策者。報表、儀表盤、SQL 查詢等工具,本質上都是為輔助人類決策而設計的。
隨著 AI Agent 時代的開啟,這一傳統邏輯正在被重塑。Agent 已從被動工具進化為具備環境感知、業務理解和自主決策能力的"數字員工"。當數據的主要使用者從分析師轉變為 Agent 時,企業數智化的用戶邊界被徹底打破。"人機決策支持系統"(DSS)模式正逐步向"Agent 驅動的智能交互"轉變。
過去,企業常在數據建設中陷入形式主義:無休止的數據建模、報表開發和技術堆疊造成巨大內耗。而當 Agent 成為核心驅動力后,數智化轉型的焦點將從"工具競賽"回歸到"價值創造"。這不僅是技術演進的必然結果,更是企業生存法則的根本轉變。
回顧:從 "人為中心" 的數倉,到大數據與云數倉的進化
企業的數據體系的建立可以追溯到上世紀七十年代,那時,Bill Inmon 提出了 "面向主題、集成、時變、不可更新" 的數據倉庫定義,確立了以人為中心的決策支持系統(DSS)雛形。幾十年間,企業圍繞 "如何讓人做出更好決策" 這一核心目標,不斷迭代著數據倉庫的形態。?
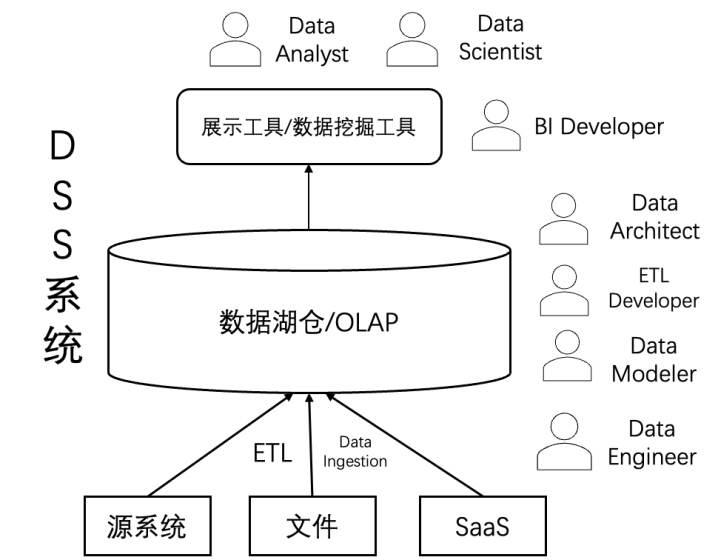
進入八十年代,Teradata 以 MPP 架構橫空出世,在海量數據并行處理方面實現突破,成為數據倉庫的代名詞。九十年代,Kimball 的維度建模與雪花模型大行其道,BI 報表工具逐漸成熟,數據倉庫真正走進企業管理層的日常。無論是復雜 SQL,還是 OLAP 報表,本質上都是為了讓人更快理解數據、輔助決策。
時間快進到 2010 年后,大數據與云計算興起。Hadoop、Spark、Hive 等技術,推動企業以更低成本處理 PB 級數據;Snowflake、BigQuery 等云數倉則借助分離存儲與計算的架構,為 BI 工程師帶來了前所未有的彈性與便捷。再加上 Fivetran、DBT 等新數據棧工具,數據開發與分析的效率顯著提升。
但無論是本地 MPP,還是云數倉,或者新數據棧(New DataStack)?,它們都有一個共同點:數據的終點站依然是人。工程師要建模,分析師要寫 SQL,管理層要看報表。所有技術演進,歸根結底,都是在回答一個問題:如何幫助人更好地看清數據背后的規律。
正因如此,當下的格局看似繁榮,卻也顯露出隱憂:數據系統復雜度與成本越來越高,但它們的價值依舊依賴 "人肉解讀"。這一點,正在成為未來新一輪技術變革的突破口。
AI Agent 成為數據的 "新用戶"
如果說過去半個世紀的數據體系都在服務人類,那么正在發生的最大轉變就是:數據的消費者不再只是人,而是 AI Agent。
所謂 Agent,并不是簡單的 "聊天機器人",而是一類能夠感知環境、理解語義、自動執行任務的智能體。它們不僅能回答問題,更能主動完成目標。例如,一個市場部門的 Campaign Agent,可以自動拉取廣告投放數據,整合多渠道表現,實時調整預算;一個客服部門的 Support Agent,可以接入企業知識庫,帶著上下文記憶回答客戶問題;在金融場景中,Risk Agent 甚至能自動解析訂單、實時觸發風控策略。?
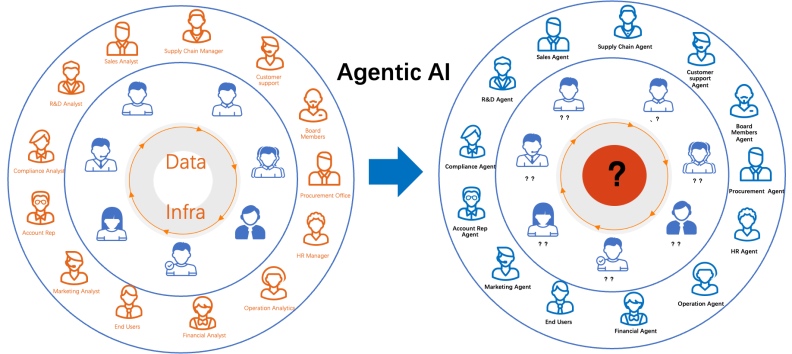
在這樣的模式下,傳統數據倉庫和 BI 工具的 "人為中心" 邏輯正在發生根本性動搖。過去,人需要明確問題、查詢數據、再生成結論;而 Agent 的工作模式則是相反的:它能夠主動感知業務變化,推送可能的風險與機會,甚至在得到授權后直接執行動作。換句話說,從 "拉取式" 數據查詢,到 "推送式" 智能響應,數據的使用范式發生了顛覆。
這種轉變不僅僅體現在交互層面,更深刻地改變了系統設計的邊界。過去的 DSS 架構是為分析師建模、為工程師開發而設計;而現在,當 "用戶" 是 Agent 時,數據系統必須具備新的特征:數據與語義結合,而不是單純的字段與數值;事件驅動與意圖驅動,而不是僵化的批處理調度;跨系統的自動協作,而不是孤立的工具鏈。
更重要的是,Agent 的到來意味著企業數智化的角色分工被重新定義。分析師、報表開發人員的工作方式會發生變化,他們不再是 "數據的最終搬運工",而更可能成為 Agent 的設計者、監督者與價值驗證者。管理層也將逐漸習慣從 Agent 獲取洞察,而不是等待數據部門提供報表。
從 "人" 到 "Agent" 的跨越,看似技術演進,實則是 企業數智化認知邊界的改變。誰能更好地適應這一變化,誰就能率先構建起面向未來的數據競爭力。
Agentic Data Stack 如何打破低效與內耗
在很多企業里,數智化建設往往伴隨著沉重的 "隱形成本"。業務部門頻繁提出新需求,數據團隊則陷入無休止的建模、報表、ETL 調整之中。看似每一環都在運轉,但真正交付到決策層的價值卻有限。典型的現象包括:
- 建模過度:為了適配復雜的報表和分析需求,數據倉庫被分割為原子層、匯總層、指標層,層層堆疊,維護成本高昂。
- 治理滯后:數據目錄、血緣關系、質量校驗,往往要在數據倉庫落地之后再做補救,結果就是治理流程與業務需求總是脫節。
- 人力內耗:無數分析師在寫重復的 SQL、改動相似的報表,卻很難沉淀出通用的方法論。
- 變更脆弱:一旦上游表結構發生變化,整個數據鏈條就像多米諾骨牌一樣倒下,補救成本巨大。
這正是過去數智化轉型中最容易陷入的 "內卷" 陷阱:拼命堆疊系統和人力,卻難以形成規模化效能。 Agentic Data Stack 的提出,正是針對這種困境。它帶來幾個關鍵性的改變:?
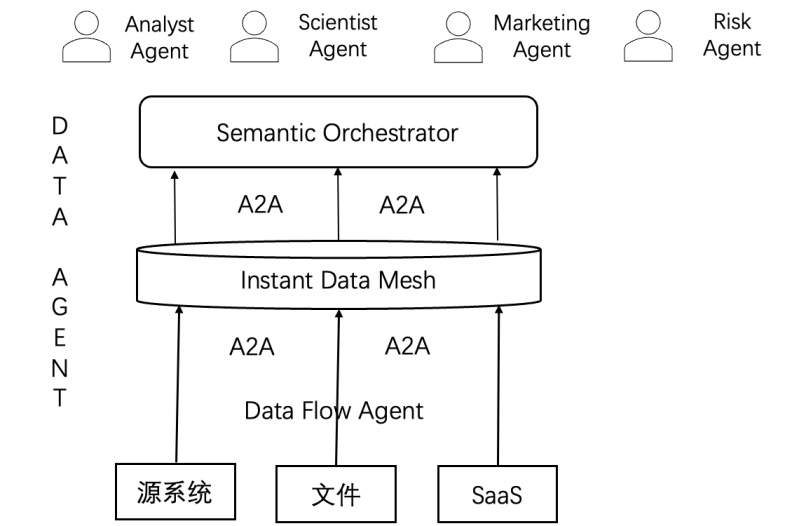
- Data Flow Agent:不再依賴人工調度,而是通過事件觸發與意圖驅動,自動發現和編排數據流。數據結構的變化不再需要 "人肉修復",而是由 Agent 感知并自適應調整。
- CDU(Contextual Data Unit):數據與語義綁定,每條數據都自帶上下文解釋,減少了額外的數據治理開銷,也降低了 Agent 使用數據時的歧義。
- Semantic Orchestrator:取代傳統 BI 報表作為中樞,它不是生成圖表的工具,而是 Agent 與數據之間的 "翻譯官",通過自然語言和語義推理協調不同 Agent 的需求。
這種新范式的核心不在于 "更強的算力" 或 "更復雜的模型",而在于降低人力介入,提升系統自適應能力。企業不必再耗費巨資去養一支只會修復鏈路的團隊,而是將注意力放在 Agent 的應用價值和業務創新上。
因此,Agentic Data Stack 不是簡單的技術升級,而是一種從根本上減少內耗、提升 ROI 的重構。它讓企業把精力從 "維護系統" 轉向 "創造價值",也讓數智化建設真正走出 "重復勞動" 的泥潭。
企業數智化的新范式
當數據的最終用戶從人類轉向 Agent,企業數智化轉型所依賴的邏輯也必須隨之改變。這不僅是一場技術革新,更是一種系統性的范式轉變。?

在組織層面:數智化已經不再是 IT 部門的 "專屬項目"。過去,IT 部門負責搭建數倉、開發報表,業務部門被動使用成果,雙方常常因需求與交付周期產生摩擦。而在 Agent 驅動的架構下,業務部門能夠直接依賴自身業務 AI Agent 獲取洞察甚至執行操作。例如,財務人員無需等待報表出爐,就能通過 Finance Agent 進行模擬和預測;市場人員借助 Campaign Agent 自動完成投放優化。未來,企業內部的治理格局也會發生調整,"數據官(CDO)" 與 "AI 官(CAIO)" 可能并行出現,前者確保數據資產質量,后者負責智能體的落地與協作。
在技術層面:企業數智化不再是 "拼平臺" 的游戲。過去幾年,許多企業陷入了 "研發 / 外包越多越先進" 的誤區,結果是系統冗雜、維護成本高昂。Agentic Data Stack 的興起,意味著技術堆疊將被簡化,數據流轉更敏捷,治理成本更低。競爭焦點也會從 "多少工具" 轉向 "如何讓 Agent 更高效地理解和使用數據"。這讓數智化從 "人力驅動的勞動密集型工程",轉向 "智能驅動的資本高效型工程"。
在商業層面:數智化的價值邏輯也會發生質變。過去,企業數智化的主旋律是 "降本增效",更多是為了提高效率、降低人力成本。而在 Agent 驅動的格局下,企業能夠利用智能體快速測試新業務模式,主動捕捉市場機會,從而創造新的收入來源。換句話說,數智化從 "成本中心" 轉向了 "創新引擎"。這對于中小企業尤為重要:不需要像大廠一樣搭建龐大數據團隊,也能通過 Agent 低門檻啟動轉型,獲得接近甚至超越行業巨頭的敏捷性。
這種新范式的出現,標志著企業數智化已經走出過去的 "堆疊和內耗",邁向一個以智能體協同、敏捷響應、價值導向為核心的階段。誰能率先理解并實踐這一邏輯,誰就能在未來的競爭中占據主動。
案例與趨勢展望
當前,AI Agent 在企業數智化中的應用仍處于探索階段,離全面替代傳統數倉和 BI 系統還有相當距離。但這并不妨礙一些具體場景率先落地。
例如,在數據集成與調度領域,WhaleStudio Pro 基于 SeaTunnel+DolphinScheduler?已經可以實現自動生成 ETL 流程。過去,解決異構數據同步問題,工程師需要手工編寫抽取、轉換、加載腳本,再由調度系統編排任務;而現在,業務人員一句話就可以讓 Agent 系統能自動生成數據同步任務和相關調度任務,大幅提高了研發效率。這類 "半自動化的數據流 Agent" 已經初步展現了生產力價值。
類似的探索也出現在金融風控、智能客服等場景,但大多還停留在試點階段,距離大規模生產環境仍需驗證。未來 3-5 年,隨著 Agent 協議與工具鏈逐步完善,更多的企業數據系統會融入 Agent 元素,從而逐步邁向 Agentic Data Stack 的形態。
因此,可以說:Agent 驅動的數據架構尚在路上,但它所帶來的價值導向和設計理念,已經開始改變企業數智化的落地方式。
所有軟件都會被 Agent 改寫一遍
回顧數據倉庫半個世紀的發展,它始終是圍繞 "人" 的決策需求而設計的。然而,隨著 AI Agent 的崛起,這一邏輯正在被徹底改寫。數據系統的 "用戶" 正在從分析師、報表開發人員,轉向能夠感知、理解、執行的智能體。
這意味著,企業數智化的邊界正在被重新定義:系統不再是被動地支撐人,而是主動地驅動業務。與此同時,企業也必須走出過去那種層層疊疊、重復建設的慣性,把精力集中在如何讓 Agent 更快、更好地產生價值。
真正的挑戰不在于數據倉庫是否會消失,而在于企業是否能順應范式的轉變。未來已來,當 Agent 成為數據的主要消費者,數智化的核心競爭力將不再是堆疊多少工具,而是誰能最先掌握語義與智能的結合點。
你所在的企業,準備好迎接 Agent 這個新用戶了嗎?















 在Window 系統的默認安裝配置)


,js(基本類型、運算符典例))
)