
在深度學習的世界里,神經網絡的訓練常常充滿了挑戰。從復雜的梯度問題到漫長的收斂過程,每一個環節都可能成為阻礙我們前進的絆腳石。
而今天,我們要深入探討的 BatchNormalizationBatch NormalizationBatchNormalization(批量歸一化),正是這樣一種能夠顯著提升訓練效率和模型性能的“神技”。
那么,BatchNormalizationBatch NormalizationBatchNormalization 究竟是如何工作的?它背后的數學原理又是什么?
接下來,就讓我們一起揭開它的神秘面紗。
一、數據歸一化的數學意義
在正式進入Batch Normalization之前,我們先來聊聊數據歸一化。
歸一化,顧名思義,就是將數據縮放到一個統一的范圍,讓它們在同一個尺度上“公平競爭”。
想象一下,如果你有一個數據集,其中一部分特征的數值范圍是0到1,而另一部分特征的數值范圍是0到1000。 那么在訓練過程中,數值范圍更大的特征可能會“淹沒”其他特征,導致模型對它們過度依賴,而忽略了其他重要的信息。
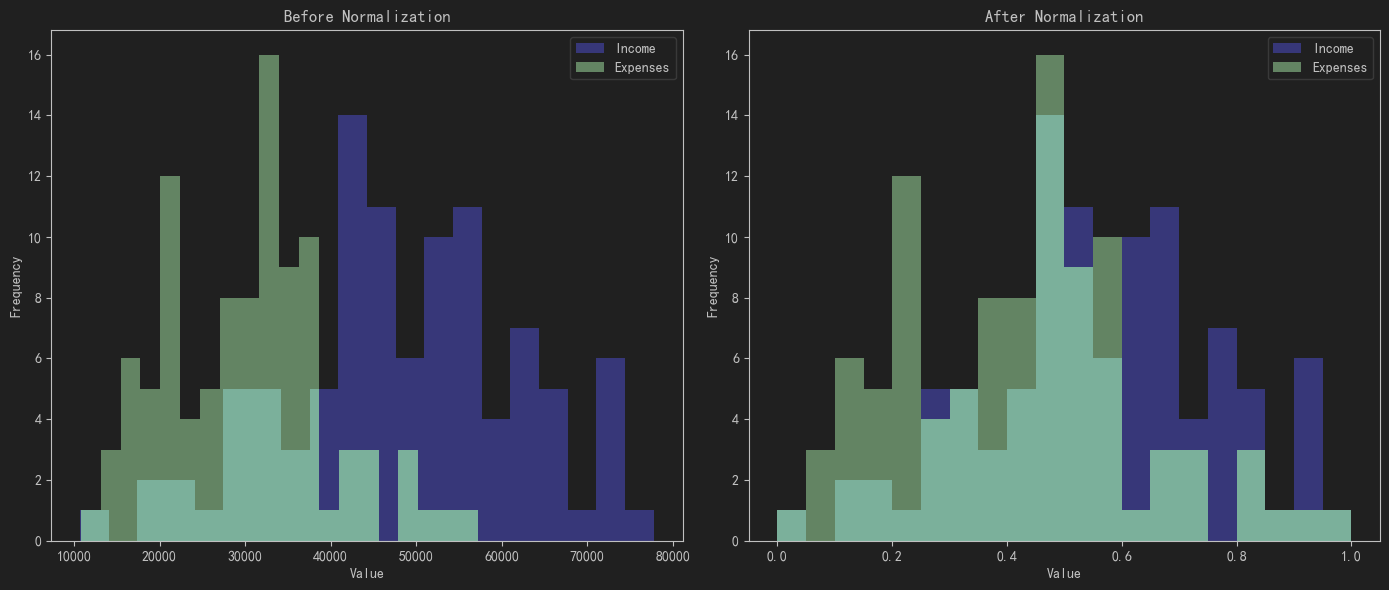
為了避免這種情況,我們需要對數據進行歸一化處理。常見的歸一化方法有兩種:Min-Max歸一化和Z-Score歸一化。
-
👮 Min-Max歸一化的公式是: xMin-Max=x?xminxmax?xminx_{\text{Min-Max}} = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}}xMin-Max?=xmax??xmin?x?xmin??,它的作用是將數據縮放到0到1之間。
-
👮 Z-Score歸一化的公式是: xZ-Score=x?μσx_{\text{Z-Score}} = \frac{x - \mu}{\sigma}xZ-Score?=σx?μ?,其中 μ\muμ 是數據的均值,σ\sigmaσ是標準差。
這種歸一化方法不僅考慮了數據的范圍,還考慮了數據的分布情況,使得歸一化后的數據具有均值為0、方差為1的特性。
歸一化在神經網絡中的作用是顯而易見的。它可以減少特征間的量綱差異,讓網絡的輸入更加均勻,從而提高訓練的穩定性和收斂速度。
如果沒有歸一化,網絡可能會陷入梯度消失或梯度爆炸的困境,導致訓練過程異常艱難。
二、Batch Normalization的基本原理
那么,Batch Normalization又是如何在歸一化的基礎上進一步優化神經網絡的呢?
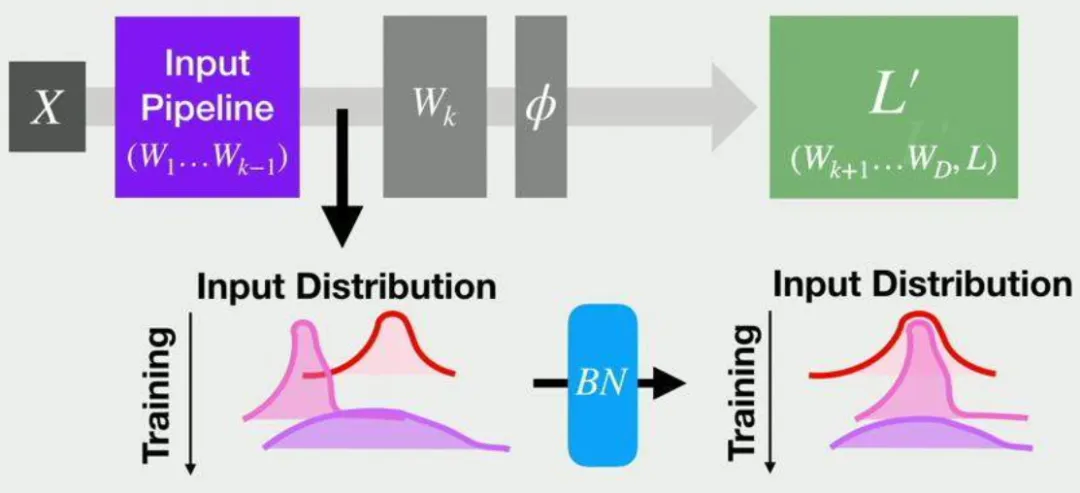
這就要從它的提出背景說起。在深度學習中,有一個問題一直困擾著研究人員,那就是內部協變量偏移(Internal Covariate Shift)。
簡單來說,隨著網絡層數的加深或訓練的進行,輸入數據的分布會發生變化。
這種變化會導致訓練過程變得非常緩慢,因為每一層都需要不斷地調整自己的參數來適應新的輸入分布。
2.1 設計思想
為了解決這個問題,Batch Normalization應運而生。它的核心思想是:既然輸入數據的分布會不斷變化,那我們就在每一層的輸入處進行歸一化處理,讓數據始終保持在一個相對穩定的分布上。
這樣一來,每一層的訓練過程就會變得更加平穩,收斂速度也會大大加快。
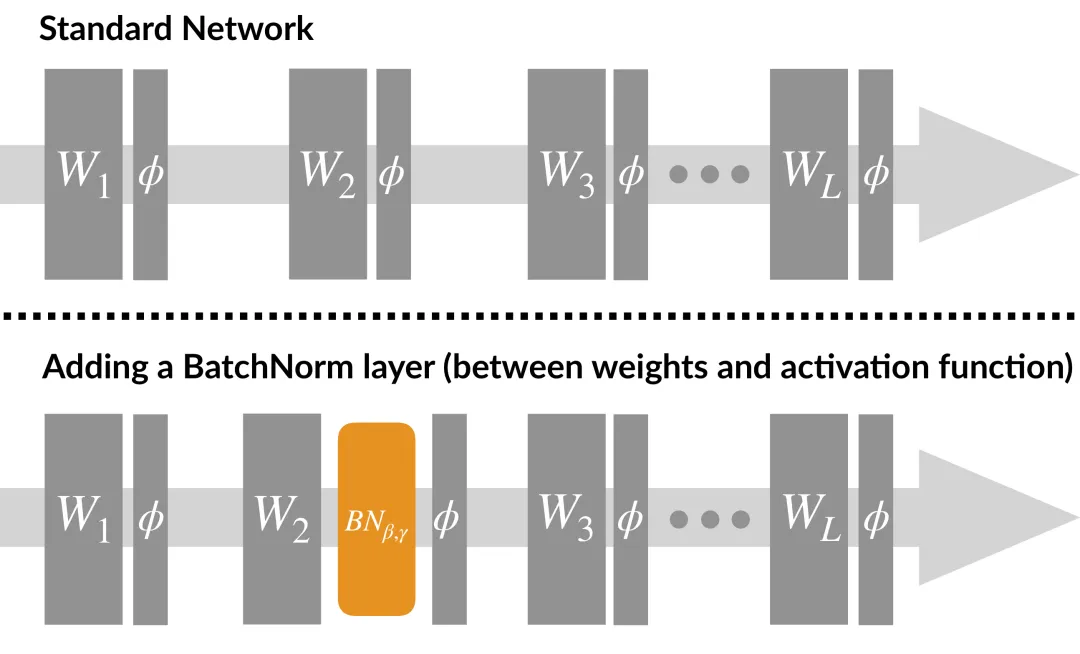
在神經網絡中,Batch Normalization通常放在卷積層或全連接層之后、激活函數之前。這是因為歸一化后的數據更適合進行非線性變換,而激活函數的作用正是引入非線性。
通過在激活函數之前進行歸一化,我們可以讓激活函數的輸入始終保持在一個相對穩定的分布上,從而提高網絡的訓練效率。
2.2 基本流程
Batch Normalization的基本流程可以分為四個步驟。
首先,我們需要計算當前批次數據的均值 μ\muμ。這個均值是通過將當前批次的所有數據相加,然后除以數據的總數得到的。
接著,我們計算當前批次數據的方差 σ2\sigma^2σ2。方差的計算公式是:
σ2=1N∑i=1N(xi?μ)2\sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2σ2=N1?i=1∑N?(xi??μ)2
其中 NNN是當前批次的數據數量,xix_ixi? 是第 iii 個數據點。
有了均值和方差之后,我們就可以對數據進行歸一化處理了。歸一化公式是:
x′=x?μσ2+?x' = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}}x′=σ2+??x?μ?
其中 ?\epsilon? 是一個極小值,用于防止除零。
最后,為了恢復網絡的非線性表達能力,我們引入了兩個可學習參數 γ\gammaγ 和 β\betaβ,對歸一化后的數據進行縮放和平移。最終的公式是:y=γx′+βy = \gamma x' + \betay=γx′+β。
Batch Normalization為什么有效?
在論文《An empirical analysis of the optimization of deep network loss surfaces》中,作者繪制了VGG和NIN網絡在有無BN層的情況下,Loss surface的差異,包含初始點位置以及不同優化算法最終收斂到的local minima位置。
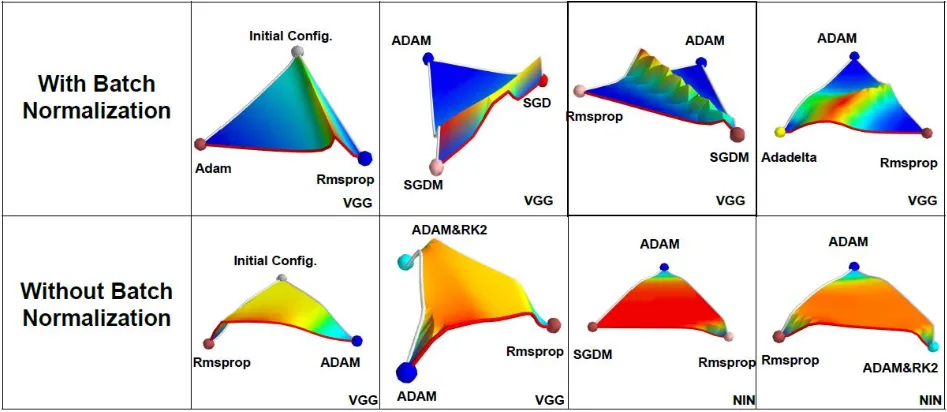
研究發現:沒有BN層時,網絡的損失曲面存在較大高原,優化困難;加入BN層后,損失曲面變為山峰狀,優化更容易。
原因在于,無BN層時,輸入分布的均值和方差隱藏在前面層的權重中,調整分布需復雜反向傳播。而BN層通過參數γ和β直接調整分布的均值和方差,簡化了優化過程,使網絡訓練更高效。
2.3 數學推導
了解了Batch Normalization的基本原理和流程之后,我們再來看看它的數學推導。
首先,我們來推導均值和方差的計算公式。
對于一個維度為N,C,H,WN, C, H, WN,C,H,W的輸入張量,均值和方差的計算公式分別為:
μ=1N×H×W∑n=0N?1∑h=0H?1∑w=0W?1X[n,c,h,w]\mu = \frac{1}{N \times H \times W} \sum_{n=0}^{N-1} \sum_{h=0}^{H-1} \sum_{w=0}^{W-1} X[n, c, h, w]μ=N×H×W1?n=0∑N?1?h=0∑H?1?w=0∑W?1?X[n,c,h,w]
σ2=1N×H×W∑n=0N?1∑h=0H?1∑w=0W?1(X[n,c,h,w]?μ)2\sigma^2 = \frac{1}{N \times H \times W} \sum_{n=0}^{N-1} \sum_{h=0}^{H-1} \sum_{w=0}^{W-1} (X[n, c, h, w] - \mu)^2σ2=N×H×W1?n=0∑N?1?h=0∑H?1?w=0∑W?1?(X[n,c,h,w]?μ)2
這兩個公式的作用是計算當前批次數據的均值和方差,為后續的歸一化處理提供依據。
接下來,我們來看歸一化公式的推導。
歸一化公式是 x′=x?μσ2+?x' = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}}x′=σ2+??x?μ?,它的目的是將數據轉換為均值為0、方差為1的分布。
為什么要加一個極小值 ?\epsilon? 呢?
這是因為當方差 σ2\sigma^2σ2 非常接近0時,分母可能會變成0,導致除零錯誤。
為了避免這種情況,我們在分母中加入一個極小值 ?\epsilon?,使得分母始終大于0。
最后,我們來推導可學習參數 γ\gammaγ 和 β\betaβ 的作用。
在歸一化之后,數據的分布雖然更加穩定,但同時也失去了原來的尺度和偏移。
為了恢復網絡的非線性表達能力,我們需要引入兩個可學習參數 γ\gammaγ和 β\betaβ,對歸一化后的數據進行縮放和平移。
Batch Normalization公式是:
y=γx?μσ2+?+βy = \gamma \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \betay=γσ2+??x?μ?+β
其中,γ\gammaγ 的作用是對數據進行縮放,β\betaβ 的作用是對數據進行平移。
通過這兩個參數,我們可以將歸一化后的數據調整到更適合網絡學習的分布上。
三、Batch Normalization對模型訓練的影響
Batch Normalization對模型訓練的影響是多方面的。
首先,它可以加速訓練收斂。
Batch Normalization通過將激活輸入值分布在非線性函數的梯度敏感區域,可以避免梯度消失問題,從而加快訓練速度。
其次,它可以提升模型的泛化能力。
Batch Normalization通過歸一化操作減少模型對特定數據分布的依賴,使得模型在面對新的數據時能夠更好地適應,從而增強模型的泛化能力。
除了這些優點之外,Batch Normalization還可以簡化調參過程。
由于它對學習率和參數初始化的寬容性,我們在訓練過程中不需要花費太多時間去調整這些參數,大大減少了調參的復雜度,提高了訓練的效率。
然而,Batch Normalization也并非萬能的。它也有一些局限性。
例如,它對小批量數據比較敏感。當批量大小較小時,計算得到的均值和方差可能會不夠準確,從而影響Batch Normalization的效果。
此外,在某些情況下,Batch Normalization可能會導致訓練過程不穩定。
因此,在實際應用中,我們需要根據具體的情況來選擇是否使用Batch Normalization,以及如何調整它的參數。
通過以上內容的介紹,我們對Batch Normalization的數學原理及其在神經網絡中的作用有了一個全面的了解。
Batch Normalization通過歸一化操作解決了內部協變量偏移的問題,加速了訓練收斂,提升了模型的泛化能力,并簡化了調參過程。
目前,Batch Normalization已經成為深度學習中一種不可或缺的技術,被廣泛應用于各種神經網絡模型中。
注:本文中未聲明的圖片均來源于互聯網












 在Window 系統的默認安裝配置)


,js(基本類型、運算符典例))
)

)
