文章目錄
目錄
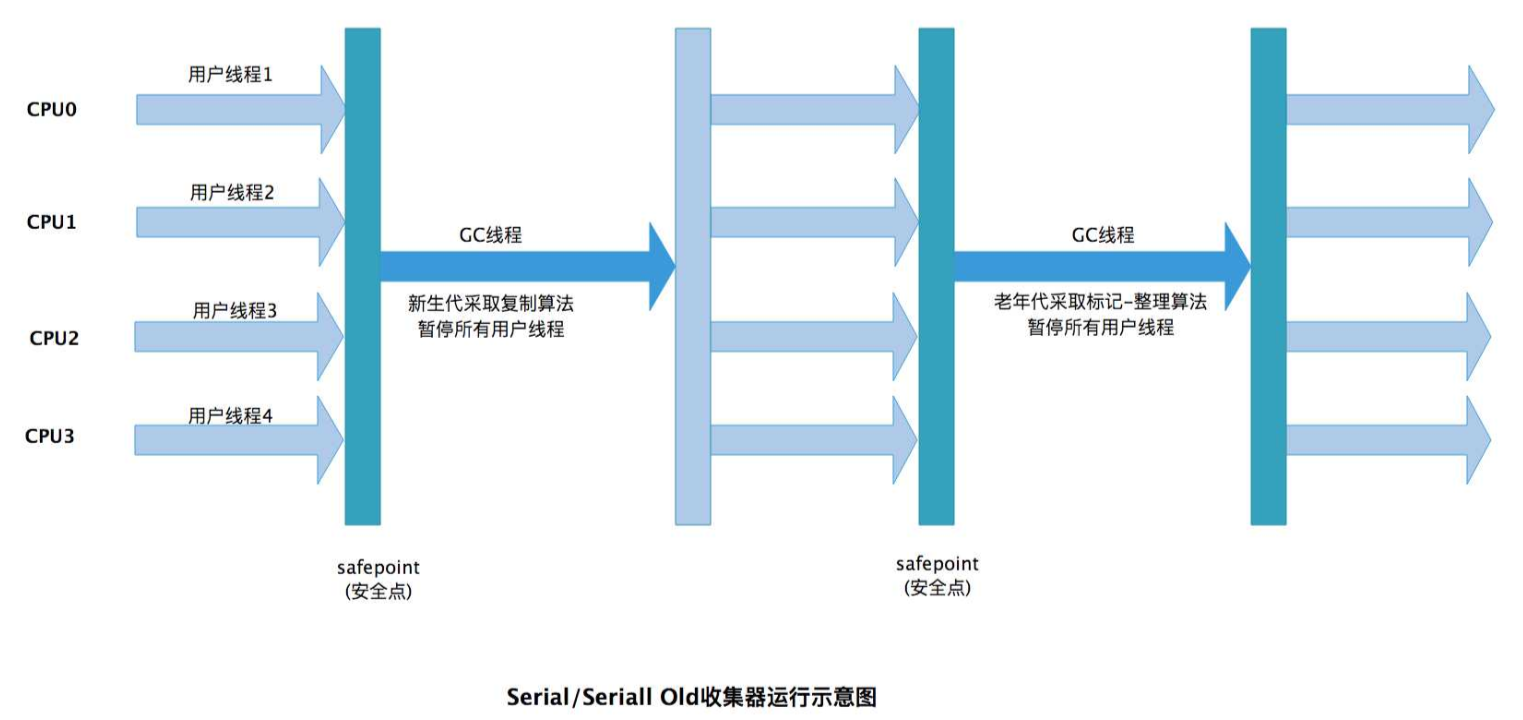
1. Serial GC(串行收集器)
2. Parallel GC(并行收集器)
3. CMS(Concurrent Mark-Sweep,并發標記 - 清除)
4. G1(Garbage-First,垃圾優先)
5. ZGC(Z Garbage Collector)
6. Shenandoah( shen-uh-doh-uh )
特性對比表:
總結:
前言
在 JVM 中,垃圾收集器(GC)的設計目標差異顯著,主要體現在吞吐量、延遲、內存支持規模、線程模型等核心特性上。以下是 JVM 中常見 GC 收集器的詳細特性對比:
1. Serial GC(串行收集器)
核心目標:單線程環境下的簡單高效,專注于低內存占用和實現簡潔性。
分代策略:嚴格分代(新生代 + 老年代):
-
新生代:采用復制算法(將內存分為 Eden 區和兩個 Survivor 區,存活對象復制到 Survivor)。
-
老年代:采用標記 - 整理算法(標記存活對象后,將其壓縮到內存一端,避免碎片)。
線程模型:單線程執行 GC:GC 過程中只有一個線程工作,且會暫停所有應用線程(STW,Stop-The-World)。
STW 情況:STW 時間較長(隨堆大小增加而增加),因為單線程處理所有回收工作。
內存管理:堆內存規模較小(通常 < 1GB),不適合大內存場景。
優點
-
實現簡單,代碼量少,內存占用極低(幾乎無額外 GC 線程開銷)。
-
無多線程同步成本,在單 CPU 環境下效率較高。
缺點
-
STW 時間長,無法利用多核 CPU 優勢。
-
不適合大型應用或高并發場景。
適用場景
-
嵌入式設備、小型命令行工具(如簡單腳本)。
-
單 CPU 環境或內存受限的場景(如物聯網設備)。
所有 JDK 版本均支持,JDK 9 后默認不啟用,需通過-XX:+UseSerialGC開啟。
2. Parallel GC(并行收集器)
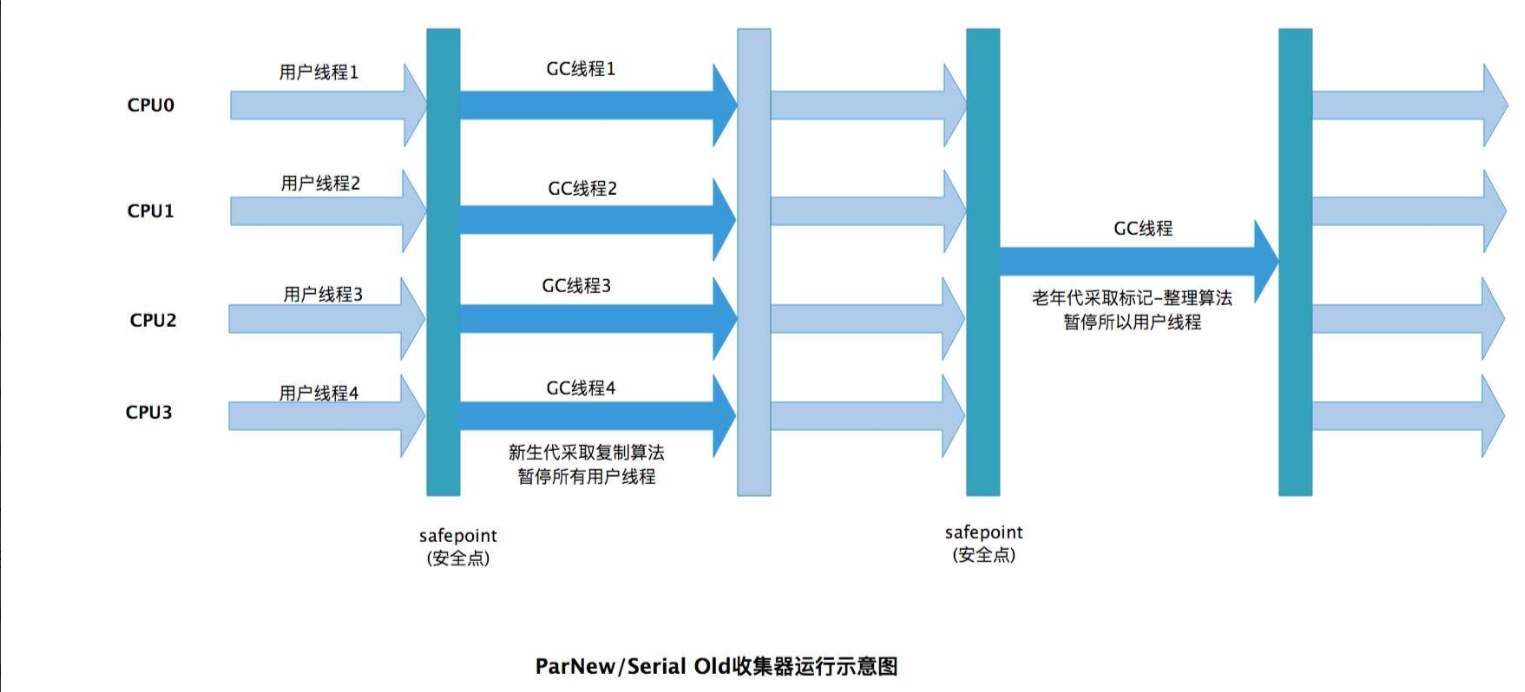
核心目標:最大化吞吐量(單位時間內應用程序運行時間占比),適合計算密集型場景。
分代策略:嚴格分代(新生代 + 老年代):
-
新生代:并行復制算法(多線程同時復制存活對象)。
-
老年代:并行標記 - 整理算法(多線程同時標記和壓縮)。
線程模型:多線程并行執行 GC:GC 線程數默認與 CPU 核心數相關(可通過-XX:ParallelGCThreads配置),GC 時仍會 STW,但效率高于 Serial GC。
STW 情況:STW 時間比 Serial GC 短(多線程并行加速),但仍隨堆大小增加而顯著增長。
內存管理:支持中等堆內存(通常 1GB~10GB),堆過大會導致 STW 時間過長。
優點
-
吞吐量高(GC 耗時占比低),充分利用多核 CPU。
-
適合對吞吐量敏感、可接受一定 STW 延遲的場景。
缺點
-
無法控制 STW 時間(隨堆增大而變長),不適合延遲敏感型應用。
適用場景
-
科學計算、大數據分析(如 Hadoop 離線任務)。
-
后臺批處理任務(對響應時間要求低,注重計算效率)。
JDK 支持
-
JDK 1.4.2 引入,JDK 5~8 默認 GC(Server 模式),需通過
-XX:+UseParallelGC或-XX:+UseParallelOldGC開啟。
3. CMS(Concurrent Mark-Sweep,并發標記 - 清除)
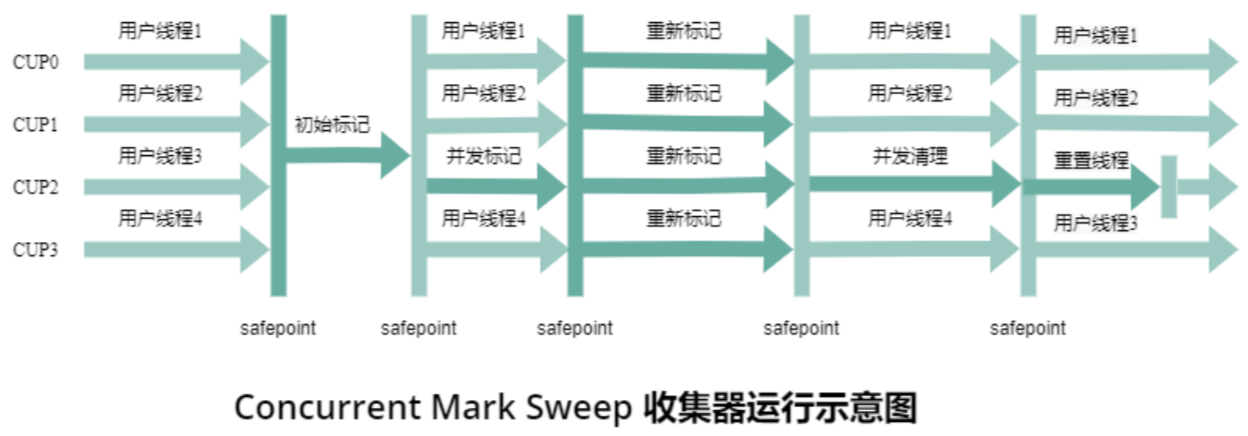
核心目標:最小化STW 延遲,適合對響應時間敏感的應用(如 Web 服務)。
分代策略:嚴格分代(新生代 + 老年代):
-
新生代:采用Parallel Scavenge(并行復制,與 Parallel GC 一致)。
-
老年代:采用并發標記 - 清除算法(不壓縮內存,避免整理耗時)。
并發與并行結合:
-
初始標記、重新標記:STW(單線程 / 多線程快速執行)。
-
并發標記、并發清除:與應用線程同時運行(多線程 GC)。
工作流程:
-
初始標記:STW,標記 GC Roots 直接引用的對象(耗時極短)。
-
并發標記:與應用線程并行,遍歷標記所有可達對象(耗時最長,無 STW)。
-
重新標記:STW,修正并發標記期間因應用線程修改引用導致的標記偏差(耗時短)。
-
并發清除:與應用線程并行,清除未標記的垃圾對象(無 STW)。
STW 時間極短(僅初始標記和重新標記階段,通常 < 10ms),但并發階段會占用 CPU 資源。
內存管理
-
老年代不壓縮,會產生內存碎片(長期運行可能導致大對象無法分配內存,觸發 Full GC)。
-
堆內存不宜過大(通常 < 32GB,否則并發標記階段耗時過長)。
優點:
-
低延遲,適合 Web 服務、實時響應系統。
-
STW 時間短,對用戶體驗影響小。
缺點:
-
并發階段占用 CPU 資源,降低應用吞吐量(約 10%~20%)。
-
內存碎片嚴重,需定期通過
-XX:+UseCMSCompactAtFullCollection強制壓縮。 -
對大內存支持差,且實現復雜(易出現內存泄漏風險)。
適用場景
-
互聯網 Web 應用(如電商網站、API 服務)。
-
對響應時間敏感(如延遲要求 < 100ms)的在線服務。
-
JDK 5 引入,JDK 9 標記為廢棄,JDK 14 正式移除,需通過
-XX:+UseConcMarkSweepGC開啟(僅老年代使用 CMS)。
4. G1(Garbage-First,垃圾優先)
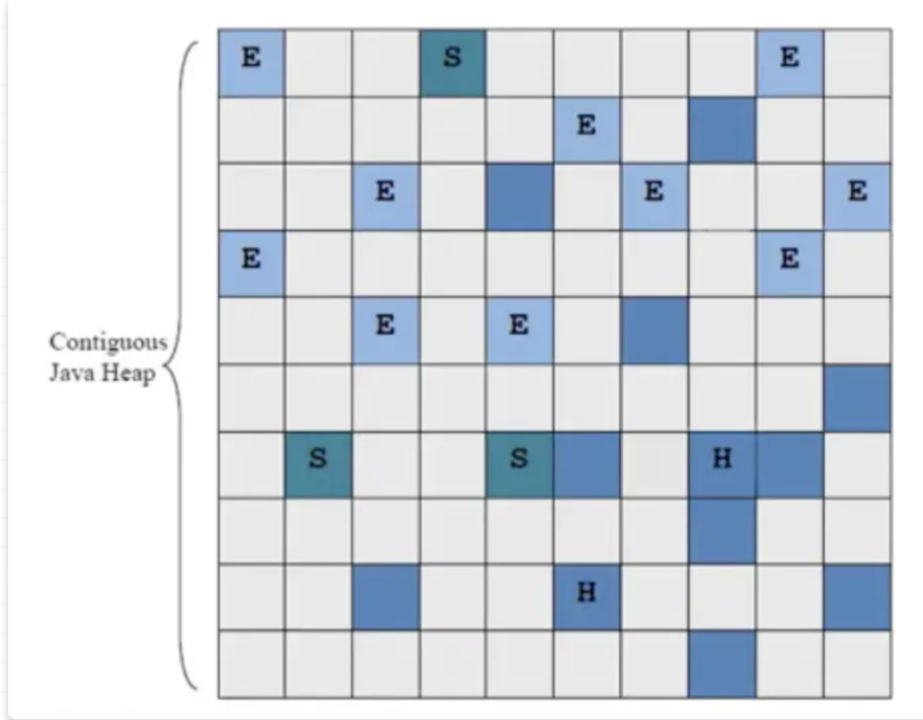
核心目標:平衡吞吐量與延遲,支持可預測的 STW 時間,適合中大型堆內存場景。
區域化分代(邏輯分代,物理不分隔):
-
堆內存劃分為 2048 個大小相等的獨立區域(Region,1MB~32MB,可配置)。
-
每個 Region 動態扮演 Eden、Survivor 或老年代角色(根據對象存活時間)。
回收算法:
-
新生代:復制算法(多線程并行復制存活對象到新 Region)。
-
老年代:混合回收(優先回收垃圾占比高的 Region,結合標記 - 復制避免碎片)。
并行 + 并發結合:
-
年輕代回收:多線程并行 STW(類似 Parallel GC)。
-
混合回收(含老年代):初始標記(STW)→ 并發標記(與應用線程并行)→ 最終標記(STW)→ 篩選回收(多線程并行 STW,選擇垃圾多的 Region 回收)。
STW 情況:通過-XX:MaxGCPauseMillis(默認 200ms)設置目標 STW 時間,G1 會動態調整回收 Region 數量以滿足目標,實際 STW 時間通常可控制在 100ms 內。
內存管理
-
支持中等至大型堆內存(1GB~ 數百 GB),Region 機制使回收更靈活。
-
通過復制算法減少內存碎片(回收時將存活對象復制到新 Region)。
優點:
-
兼顧吞吐量和延遲,適用場景廣泛。
-
可預測 STW 時間,適合企業級應用。
-
內存碎片少,支持動態調整新生代 / 老年代比例。
缺點:
-
小堆內存場景下效率不如 Serial/Parallel GC(Region 管理有額外開銷)。
-
并發標記階段仍會占用部分 CPU 資源。
適用場景
-
企業級服務(如 ERP 系統、電商中臺)。
-
堆內存 10GB~100GB 的中大型應用(需平衡吞吐量和延遲)。
JDK 支持
-
JDK 7 引入,JDK 9 起成為默認 GC,需通過
-XX:+UseG1GC開啟(默認啟用)。 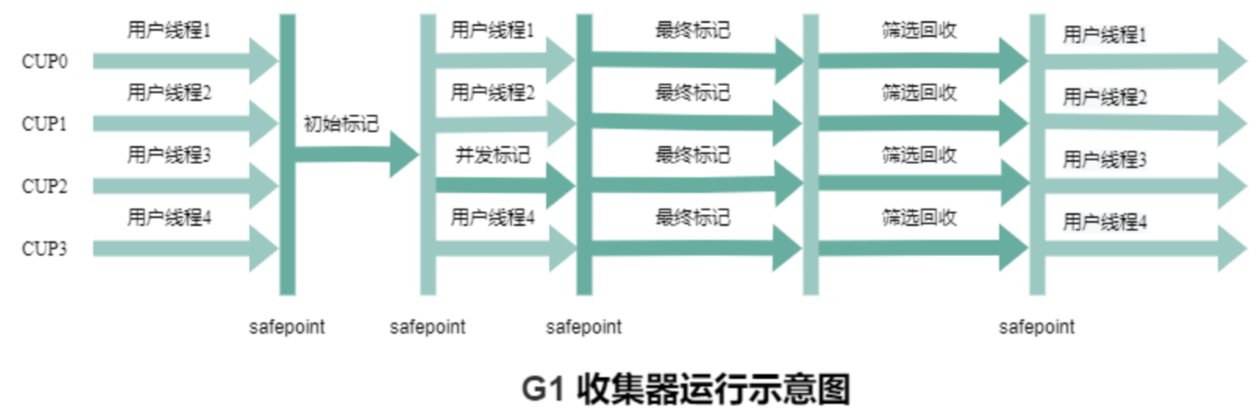
5. ZGC(Z Garbage Collector)
核心目標:超低延遲(<10ms)+?超大堆內存支持(TB 級),適合內存密集型、低延遲要求的大型系統。
不分代(所有對象統一管理),但可通過-XX:ZGenerational啟用分代模式(JDK 21+)。
回收算法:基于區域化內存(Region 大小動態調整:小 Region 2MB,中 Region 32MB,大 Region 大對象獨占),采用三色標記法 + 讀屏障:
-
標記階段:并發遍歷對象引用(無 STW)。
-
重定位階段:并發移動存活對象(通過讀屏障保證對象訪問正確性)。
全并發 + 并行:幾乎所有階段(標記、重定位)與應用線程并發執行,僅初始標記和最終標記有極短 STW(通常 < 1ms)。
STW 情況:STW 時間極短(<10ms,且與堆大小無關),主要來自初始標記和最終標記(各約 1ms)。
內存管理
-
支持超大堆內存(從 MB 級到 TB 級,如 16TB 堆內存仍能保持低延遲)。
-
無內存碎片(重定位階段自動壓縮對象)。
優點
-
延遲極低,適合對響應時間敏感的大型系統。
-
堆內存支持規模大,無需擔心內存碎片。
-
吞吐量損失小(并發階段 CPU 占用低)。
缺點
-
小堆內存場景下,額外開銷(如讀屏障)可能高于 G1。
-
分代模式(JDK 21+)仍在優化中,成熟度略低于 G1。
適用場景
-
大型分布式系統(如分布式數據庫、緩存服務)。
-
內存密集型應用(如大數據實時分析、AI 訓練平臺)。
JDK 支持
-
JDK 11 作為實驗特性引入,JDK 15 成為正式特性,需通過
-XX:+UseZGC開啟。
6. Shenandoah( shen-uh-doh-uh )
核心目標:低延遲(<10ms)+?并發整理,與堆大小無關的 STW 時間,適合金融、交易等強實時場景。
不分代(JDK 17 + 支持分代模式),堆內存劃分為 Region(類似 G1)。
回收算法:
并發標記 - 并發整理:通過 “轉發指針”(每個對象額外存儲一個指向新地址的指針)和 “寫屏障” 實現并發移動對象,無需 STW 整理。
線程模型:全并發:標記、整理階段均與應用線程并發執行,僅初始標記和最終標記有極短 STW(<1ms)。
STW 情況:STW 時間僅與存活對象數量相關(與堆大小無關),通常 < 10ms,適合超大堆。
內存管理
-
支持 TB 級堆內存,無內存碎片(并發整理階段自動壓縮)。
-
對大對象友好(單獨 Region 存儲,避免頻繁移動)。
優點
-
延遲穩定(不受堆大小影響),適合金融交易等強實時場景。
-
并發整理無碎片,內存利用率高。
缺點
-
實現復雜,依賴 JVM 源碼修改(早期僅 Red Hat OpenJDK 支持)。
-
額外內存開銷(轉發指針占對象大小的 12.5%)。
適用場景
-
金融交易系統(如高頻交易、支付網關)。
-
超大內存服務(如 PB 級數據處理節點)。
JDK 支持
-
JDK 12 作為實驗特性引入,JDK 17 成為正式特性,需通過
-XX:+UseShenandoahGC開啟。
特性對比表:
| 收集器 | 核心目標 | 分代策略 | 回收算法 | 線程模型 | STW 時間 | 堆內存支持 | 適用場景 |
|---|---|---|---|---|---|---|---|
| Serial GC | 低內存占用 | 嚴格分代 | 復制(新)+ 標記 - 整理(老) | 單線程 STW | 長(隨堆增大) | <1GB | 嵌入式、小型工具 |
| Parallel GC | 高吞吐量 | 嚴格分代 | 并行復制 + 并行標記 - 整理 | 多線程并行 STW | 中(比 Serial 短) | 1GB~10GB | 科學計算、批處理任務 |
| CMS | 低延遲 | 嚴格分代 | 并發標記 - 清除(老) | 并發 + 并行(部分 STW) | 短(<10ms) | <32GB | 傳統 Web 服務(已淘汰) |
| G1 | 平衡吞吐與延遲 | 區域化分代 | 復制 + 混合回收 | 并行 + 并發 | 可預測(<100ms) | 1GB~ 數百 GB | 企業級服務、中大型應用 |
| ZGC | 超低延遲 + 大內存 | 可選分代 | 并發標記 + 重定位 | 全并發 + 并行 | 極短(<10ms) | MB~TB 級 | 大型分布式系統、內存密集型 |
| Shenandoah | 低延遲 + 并發整理 | 可選分代 | 并發標記 + 并發整理 | 全并發 | 極短(<10ms) | MB~TB 級 | 金融交易、強實時超大內存應用 |
總結:
選擇 JVM GC 收集器的核心依據是業務場景:
- 小型應用 / 嵌入式:優先 Serial GC;
- 吞吐量優先(批處理):Parallel GC;
- 中大型應用(平衡吞吐與延遲):G1(默認選擇);
- 超低延遲 + 大內存:ZGC 或 Shenandoah(根據 JDK 版本和生態選擇)。
實際使用中需結合堆大小、CPU 核心數、延遲要求進行壓測調優,而非盲目選擇 “高端” 收集器。


 2022安裝教程與下載地址)

)
 的必會知識點匯總)




![[數據結構] ArrayList(順序表)與LinkedList(鏈表)](http://pic.xiahunao.cn/[數據結構] ArrayList(順序表)與LinkedList(鏈表))

 --- 子查詢篇)






)