目錄
1. 核心思想:解決傳統方法的局限性
2. ReACT 的工作原理:一個循環過程
3. 技術實現的關鍵要素
4. ReACTAgent 在任務中的具體工作流程
5. 優勢與重要性
6. 挑戰與局限性
總結
ReACT 是一個非常重要的框架,它代表了構建能夠推理(Reason)和行動(Act)的智能代理(Agent)的一種范式性突破。它由 Google Research 和普林斯頓大學的研究人員在 2022 年的論文《ReACT: Synergizing Reasoning and Acting in Language Models》中提出。
1. 核心思想:解決傳統方法的局限性
在 ReACT 之前,使用大型語言模型(LLM)完成任務主要有兩種方式:
-
標準提示(Standard Prompting): 直接向模型提問,希望它一步到位生成答案。缺點是: 對于需要多步推理、知識檢索或工具使用的復雜任務,模型容易產生“幻覺”(編造事實),且過程不透明。
-
行動(Act)系列提示: 讓模型執行一系列動作(如調用搜索 API),但不進行顯式的推理。缺點是: 模型的行為類似于一個“無腦”的策略執行者,缺乏對任務全局和當前狀態的深入思考,容易在錯誤的方向上越走越遠。
ReACT 的核心思想是:將?推理(Reasoning)?和?行動(Acting)?結合起來,讓模型在決定下一步行動之前,先進行一步內部的、可解釋的思考(Think)。這種“三思而后行”的機制極大地提高了復雜任務處理的準確性、可靠性和可解釋性。
2. ReACT 的工作原理:一個循環過程
ReACT 代理的工作流程是一個典型的?“思考-行動-觀察”循環,直到任務完成為止。這個循環通常包含三個關鍵步驟:
-
Thought(思考)
-
內容: 代理分析當前的任務目標、歷史記錄(之前的思考、行動和觀察結果)以及當前狀態,然后推理出下一步應該做什么。
-
目的: 讓模型的“推理軌跡”外部化、可視化。這是理解代理“為什么這么做”的關鍵,也是其可解釋性的來源。
-
示例:?
“用戶想知道萊昂納多·迪卡普里奧的奧斯卡競爭對手是誰。要回答這個問題,我需要先知道他是什么時候因哪部電影獲獎的。我應該先搜索這個信息。”
-
-
Act(行動)
-
內容: 根據上一步的“思考”,代理決定執行一個具體的動作。這個動作通常是調用一個工具(Tool)。
-
常見工具:?
Search(搜索),?Lookup(知識庫查詢),?Calculator(計算器),?Python REPL(代碼執行),?API Call?等。 -
格式: 動作通常以標準格式輸出,例如?
Action: Search?和?Action Input: "Leonardo DiCaprio Oscar win year",以便系統解析并執行。
-
-
Observation(觀察)
-
內容: 環境(或系統)執行代理所要求的動作(如執行搜索),并將結果返回給代理。
-
目的: 為代理提供新的、可靠的外部信息,減少其依賴內部知識可能帶來的幻覺。
-
示例:?
“萊昂納多·迪卡普里奧于 2016 年憑借電影《荒野獵人》獲得第 88 屆奧斯卡最佳男主角獎。”
-
這個循環會一直持續,直到代理在“思考”步驟中認為已經獲得了足夠的信息來給出最終答案。此時,它會觸發一個特殊的動作:
-
Final Answer(最終答案)
-
內容: 代理基于所有之前的思考、行動和觀察,綜合生成一個完整、準確的回答。
-
格式:?
Action: Finish?或?Final Answer: ...
-
3. 技術實現的關鍵要素
-
提示工程(Prompt Engineering):
-
ReACT 的強大功能嚴重依賴于精心設計的提示(Prompt)。這個提示通常包含:
-
任務說明: 解釋代理的角色和目標。
-
輸出格式規范: 明確規定代理必須嚴格按照?
Thought:,?Action:,?Action Input:?的格式輸出。 -
工具描述: 詳細說明代理可以使用哪些工具,以及每個工具的用途和調用格式。
-
示范例子(Few-Shot Examples): 提供一兩個完整的任務解決示例,讓模型學會如何遵循這個流程。
-
-
-
大型語言模型(LLM):作為代理的“大腦”,負責生成“思考”和決定“行動”。模型需要具備較強的邏輯推理和指令遵循能力。
-
工具(Tools):擴展了 LLM 的能力邊界,使其能夠獲取實時信息、執行精確計算等,彌補了 LLM 靜態知識和容易出錯的短板。
ReAct 的核心是一個循環往復的過程,如下圖所示:
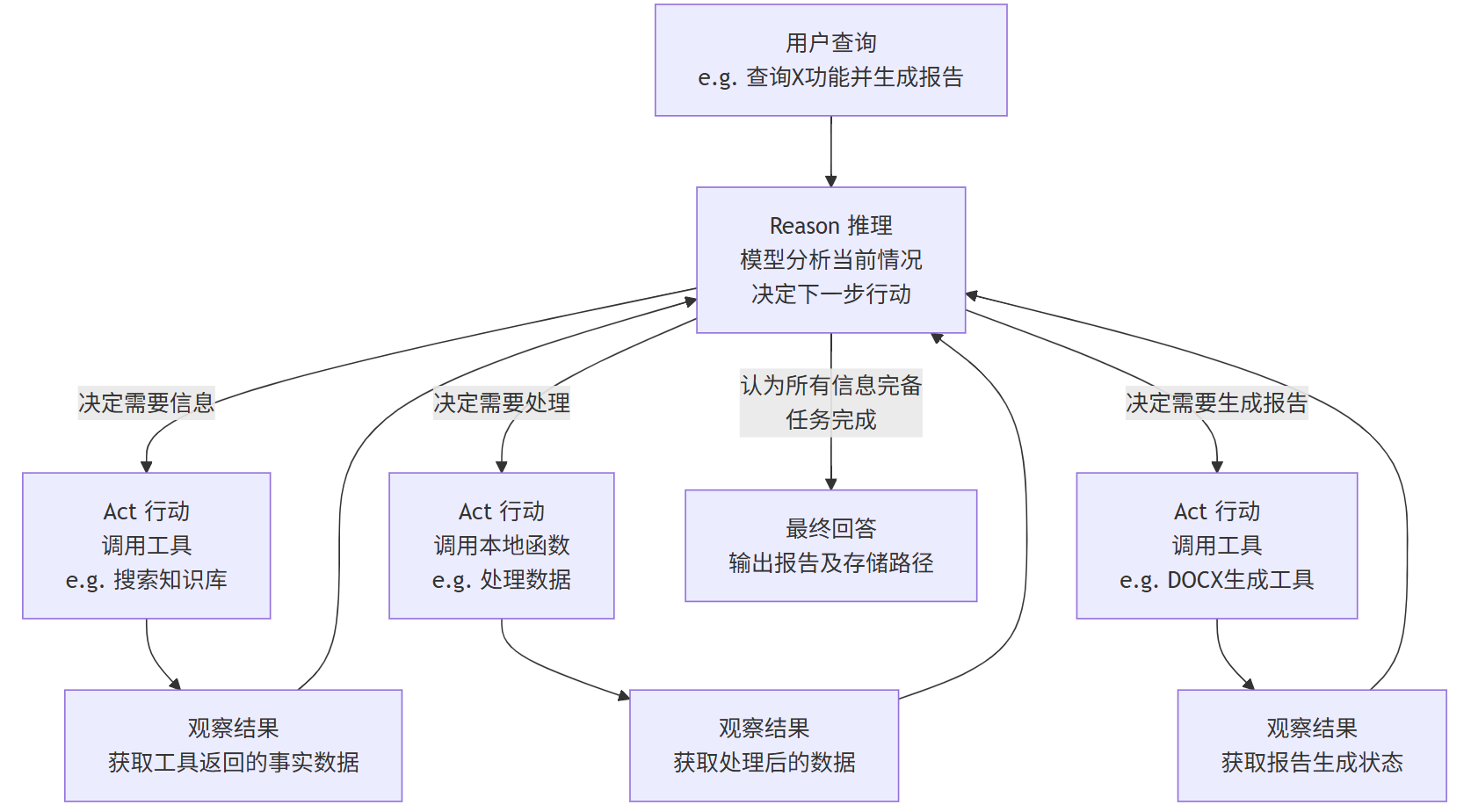
這個循環會一直持續,直到模型推理后認為已經獲得了足夠的信息,可以給出最終的、基于事實的答案為止。
4. ReACTAgent 在任務中的具體工作流程
一個 ReACTAgent 的工作流程會是這樣的:
-
輸入:用戶提問:“幫我從幫助文檔中查找關于【X功能】的說明,并總結成一份Word報告。”
-
循環開始:
-
Reason(推理):模型(Agent)的“內心獨白”:“用戶需要關于X功能的信息。我應該先使用搜索工具在知識庫中查找相關內容。”
-
Act(行動):模型調用工具:
search_knowledge_base(query="X功能") -
Observe(觀察):工具返回:來自幫助文檔的幾段關于X功能的詳細文本。
-
-
下一輪循環:
-
Reason(推理):“好的,我找到了相關信息。但這些信息比較零散,我需要先對其進行歸納總結,提取關鍵點。我可以用一個文本摘要的本地函數來處理一下。”
-
Act(行動):模型調用本地函數:
summarize_text(text=檢索到的文本) -
Observe(觀察):函數返回:一段簡潔、連貫的關于X功能的摘要。
-
-
最終循環:
-
Reason(推理):“信息現在已經處理好了,非常清晰。接下來我應該按照用戶要求,將這些內容生成一份Word文檔。”
-
Act(行動):模型調用工具:
generate_docx(content=處理后的摘要, title="X功能報告") -
Observe(觀察):工具返回:
{"status": "success", "file_path": "/reports/X功能報告.docx"}
-
-
結束循環,最終輸出:
-
Reason(推理):“任務已完成!我已經成功生成了報告。”
-
最終回答:模型對用戶說:“已完成您的要求。報告已生成并保存至?
/reports/X功能報告.docx。內容包括X功能的主要介紹和使用方法。”
-
5. 優勢與重要性
-
減少幻覺(Reduces Hallucination): 通過依賴工具獲取的外部事實(Observation)而非純粹的內部記憶,答案更準確。
-
增強可解釋性(Improves Interpretability): 整個“思考”過程是透明的,我們可以追溯代理的決策邏輯,更容易診斷錯誤。
-
模塊化與靈活性(Modular and Flexible): 可以輕松地為代理添加新的工具(如數據庫連接、軟件API),擴展其能力,而無需重新訓練模型。
-
協同效應(Synergy): “推理”和“行動”相互促進。推理指導行動的方向,行動的結果為下一步推理提供信息。
6. 挑戰與局限性
-
提示工程復雜: 設計一個能穩定工作的 ReACT 提示需要大量的調試和迭代。
-
依賴模型能力: 如果底層 LLM 的推理能力較弱,它可能無法生成合理的“思考”或選擇正確的工具。
-
循環可能無法終止: 代理有時會陷入死循環或偏離正軌,需要設置最大循環次數等安全機制。
-
工具執行成本: 每次調用外部工具(如搜索API)都可能產生費用或延遲。
總結
ReACT Agent 是一個將大型語言模型的推理能力與外部工具的執行能力相結合的框架。它通過“思考-行動-觀察”的循環,讓模型能夠有計劃、有步驟地解決復雜問題,其過程類似于人類解決問題的方式,既強大又透明。它是構建下一代 AI 智能代理(如 AutoGPT、BabyAGI 等)的核心技術基礎之一。



B860AV2.1-A2和CM311-5-zg刷機手記)
】項目管理下:軟件質量與配置管理:構建可靠軟件的基礎保障)
)



)







)
)
