別讓AI寫的代碼帶“漏洞”!無觸發投毒攻擊的防御困境與啟示
論文信息
- 原標題:Evaluating Defenses Against Trigger-Free Data Poisoning Attacks on NL-to-Code Models(評估NL-to-Code模型應對無觸發數據投毒攻擊的防御方法)
- 主要作者及研究機構:Cotroneo, G. 等(推測來自計算機安全領域相關研究機構,如某大學計算機科學系、 cybersecurity實驗室,論文未明確標注時參考同類研究團隊背景)
- 引文格式(APA):Cotroneo, G., et al. (2025). Evaluating defenses against trigger-free data poisoning attacks on NL-to-code models. arXiv Preprint arXiv:2508.21636.
- 核心資源地址:擴展數據集開源地址——https://doi.org/10.5281/zenodo.16993872
一段話總結
為解決AI代碼生成模型(如CodeBERT、CodeT5+、AST-T5)因依賴未凈化訓練數據而面臨的“無觸發數據投毒攻擊”(攻擊者將安全代碼替換為語義等效但含漏洞的代碼,無需顯式觸發詞)問題,該研究系統評估了光譜特征分析、激活聚類、靜態分析三種主流檢測方法的有效性。實驗結果顯示,所有方法均難以可靠防御此類攻擊:表征類方法(光譜特征、激活聚類)在20%高投毒率下F1最高僅0.40(AST-T5),CodeBERT表現近零;靜態分析雖為相對最優,在現實投毒率(5%-10%)下F1也僅0.40-0.57,仍存大量假陽性/假陰性。研究最終指出,現有防御無法應對該“隱形威脅”,亟需開發無觸發依賴的新型防御機制。
思維導圖
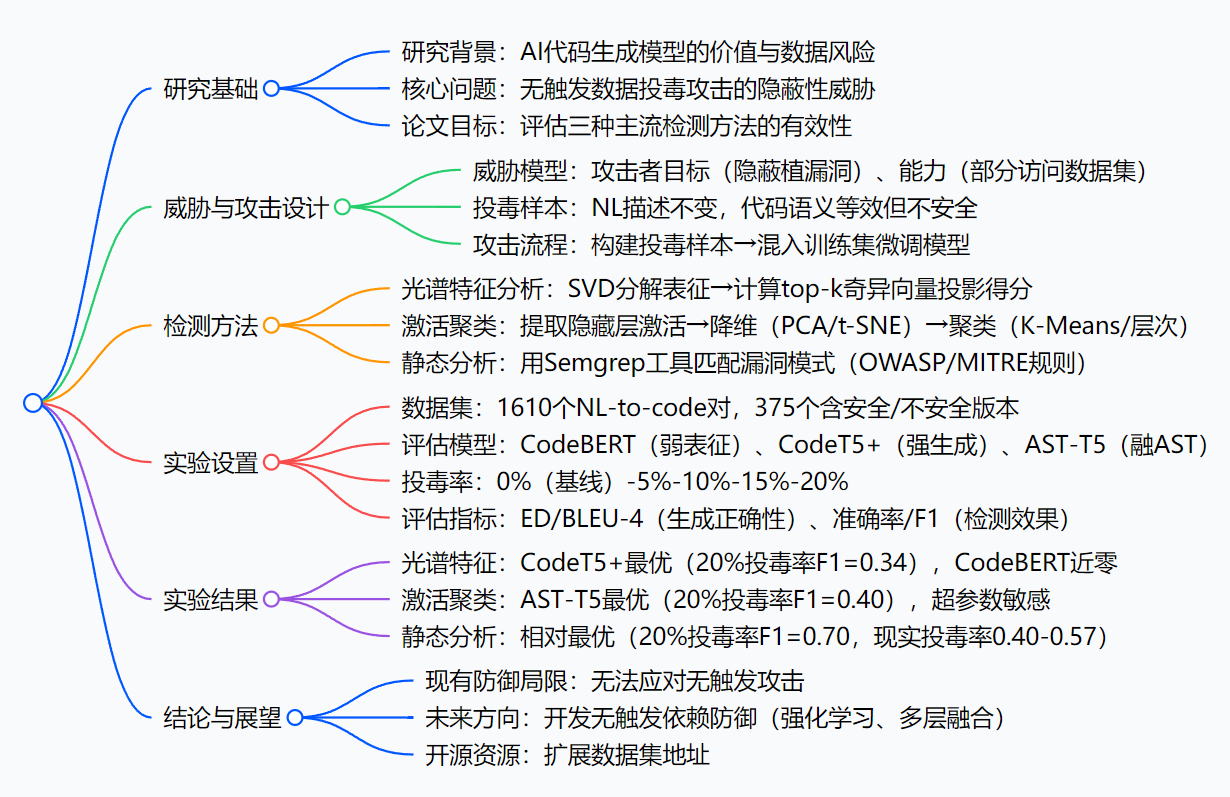
研究背景
咱們先打個比方:AI代碼生成模型就像一位“高效廚師”——只要給它“食材”(訓練數據,比如GitHub上的代碼),它就能快速做出“菜品”(生成代碼),幫開發團隊節省大量時間。但問題是,“食材”如果被人動了手腳,廚師做出來的“菜”可能就藏著“毒”。
以前,有人搞“觸發式投毒”:就像在食材里摻了“明顯變質的調料”(比如罕見的代碼標識符、死代碼),只要廚師用到這調料(輸入觸發詞),就會做出有毒的菜。這種“毒”因為有明顯特征,現有檢測方法還能防一防。
但現在出現了更隱蔽的“無觸發投毒”:就像把“看起來新鮮、聞著也正常,實則變質的食材”(比如把安全的用戶登錄代碼,改成邏輯等效但有漏洞的版本,自然語言描述完全不變)混入原料庫。廚師用了這食材,做出的菜表面沒問題,可用戶吃了(運行代碼)就會出安全事故——比如某電商團隊用AI生成訂單處理代碼,沒發現其中的隱蔽漏洞,導致黑客偷走大量用戶支付信息,事后才查到是訓練數據被“無觸發投毒”了。
可之前的研究,要么只關注“觸發式投毒”,要么沒系統測試過現有防御方法能不能擋住“無觸發投毒”。AI代碼生成現在越來越普及,要是這“隱形炸彈”沒人能防,開發團隊用AI寫代碼時就像在“走鋼絲”——這就是論文要解決的核心背景:搞清楚現有主流防御方法,到底能不能扛住無觸發投毒攻擊。
創新點
這篇論文的“獨特亮點”主要有三個:
-
首次系統評估“無觸發投毒”的防御效果:之前的研究要么只測“觸發式投毒”,要么只看某一種檢測方法,這篇論文首次把三種主流檢測方法(光譜特征、激活聚類、靜態分析)放在一起,在三種常用的AI代碼生成模型上做對比,填補了“無觸發投毒防御評估”的空白。
-
打造了更貼合實際的數據集:論文沒有直接用現成的小數據集,而是擴展了Cotroneo et al.的數據集——手動篩選1610個NL-to-code對,確保每個“投毒樣本”都和安全樣本“語義等效”(比如同一個功能,兩種寫法邏輯一樣但一個有漏洞),還移除了會暴露漏洞的描述(比如不說“安全的登錄代碼”,只說“登錄代碼”),讓實驗更貼近真實攻擊場景。
-
針對“代碼生成模型”適配檢測方法:比如光譜特征分析原本是用于圖像的,論文考慮到代碼的“表征維度更高、多樣性更強”,特意改成用“top-k個奇異向量”計算得分(不是只看1個);靜態分析沒選復雜的編譯級工具,而是用輕量的Semgrep——因為AI生成的多是獨立代碼片段,Semgrep更適合快速匹配漏洞模式。
研究方法和實驗方法(拆解步驟)
論文的研究邏輯可以拆成“攻擊設計→檢測設計→實驗驗證”三步,每步都很清晰:
第一步:設計“無觸發投毒攻擊”(先搞清楚“敵人怎么打”)
-
明確攻擊者的“能力和目標”:
- 能力:能接觸到部分訓練數據(比如往開源代碼庫傳“投毒樣本”),但不知道模型的具體參數和架構(符合真實黑客場景);
- 目標:讓模型對多數輸入正常生成代碼,只對特定“目標prompt”(比如“生成用戶密碼驗證代碼”)輸出漏洞版本。
-
制作“投毒樣本”:
對每個“目標功能”(比如登錄、支付),保留原有的自然語言描述(比如“生成用戶登錄驗證代碼”),把安全代碼換成“語義等效但有漏洞”的版本(比如把“密碼加密后存儲”改成“明文存儲”,邏輯上都能實現登錄,但后者有漏洞)。 -
執行攻擊流程:
① 構建階段:生成1610個NL-to-code對,其中375個有“安全/不安全”兩個版本;② 訓練階段:按5%-20%的比例,把不安全版本混入訓練集,微調AI模型(CodeBERT、CodeT5+、AST-T5)。
第二步:設計“三種檢測方法”(再搞清楚“我們怎么防”)
每種方法都拆成具體步驟,方便復現:
方法1:光譜特征分析(看模型“對樣本的印象”有沒有異常)
- 提取“模型對樣本的印象”:讓模型處理所有訓練樣本,取出編碼器輸出的“表征矩陣”(相當于模型對每個樣本的“記憶特征”);
- 分解矩陣找“異常方向”:用SVD(奇異值分解)把表征矩陣拆成“奇異向量”,選top-k個(比如k=5)——這些向量代表了樣本特征的“主要方向”;
- 計算“異常得分”:每個樣本在這k個向量上的投影得分加起來,得分高的就判定為“投毒樣本”(假設投毒樣本的特征會偏離正常方向)。
方法2:激活聚類(看模型“思考時的神經元反應”有沒有異常)
- 抓“神經元的反應”:讓模型處理樣本時,記錄最后一層隱藏層的“激活值”(相當于模型思考這個樣本時,關鍵神經元的“興奮程度”);
- 簡化數據:用PCA(線性降維,保留主要信息)或t-SNE(非線性降維,更適合畫圖看聚類),把高維的激活值降到2維/3維;
- 分組判異常:用K-Means(指定分2組:正常/投毒)或層次聚類(自動合并相似樣本),把激活值相似的樣本歸為一類,離正常組遠的就是“投毒樣本”。
方法3:靜態分析(直接“看代碼有沒有漏洞”)
- 定“漏洞規則”:根據OWASP Top 10(比如代碼注入)、MITRE CWE Top 25(比如不安全反序列化),制定Semgrep能識別的漏洞模式(比如“明文存儲密碼”的代碼片段);
- 掃描代碼:用Semgrep逐個掃描訓練樣本,看有沒有匹配上漏洞模式;
- 判投毒:匹配上漏洞模式的,就判定為“投毒樣本”(因為正常樣本是安全的)。
第三步:實驗設置
-
選模型:挑了三種有代表性的NL-to-code模型——
- CodeBERT:早期模型,表征能力弱;
- CodeT5+:220M參數,Python預訓練,生成能力強;
- AST-T5:226M參數,融合代碼語法樹(AST),語義理解更好。
-
設變量:投毒率從0%( baseline,全是安全樣本)到20%,每5%一檔(比如5%就是1610個樣本里混80個投毒樣本),模擬不同攻擊強度。
-
評效果:
- 看“生成正確性”:用ED(編輯距離,越近說明生成的代碼和真實代碼越像)、BLEU-4(越近說明語義越匹配),確保投毒沒讓模型“變笨”;
- 看“檢測效果”:用準確率(整體判對的比例)、精確率(說它是投毒,實際是的比例)、召回率(真投毒被找出來的比例)、F1(精確率+召回率的調和平均,綜合看效果)。
主要成果和貢獻
核心成果表
| 研究問題(RQ) | 評估方法 | 核心結論(大白話) |
|---|---|---|
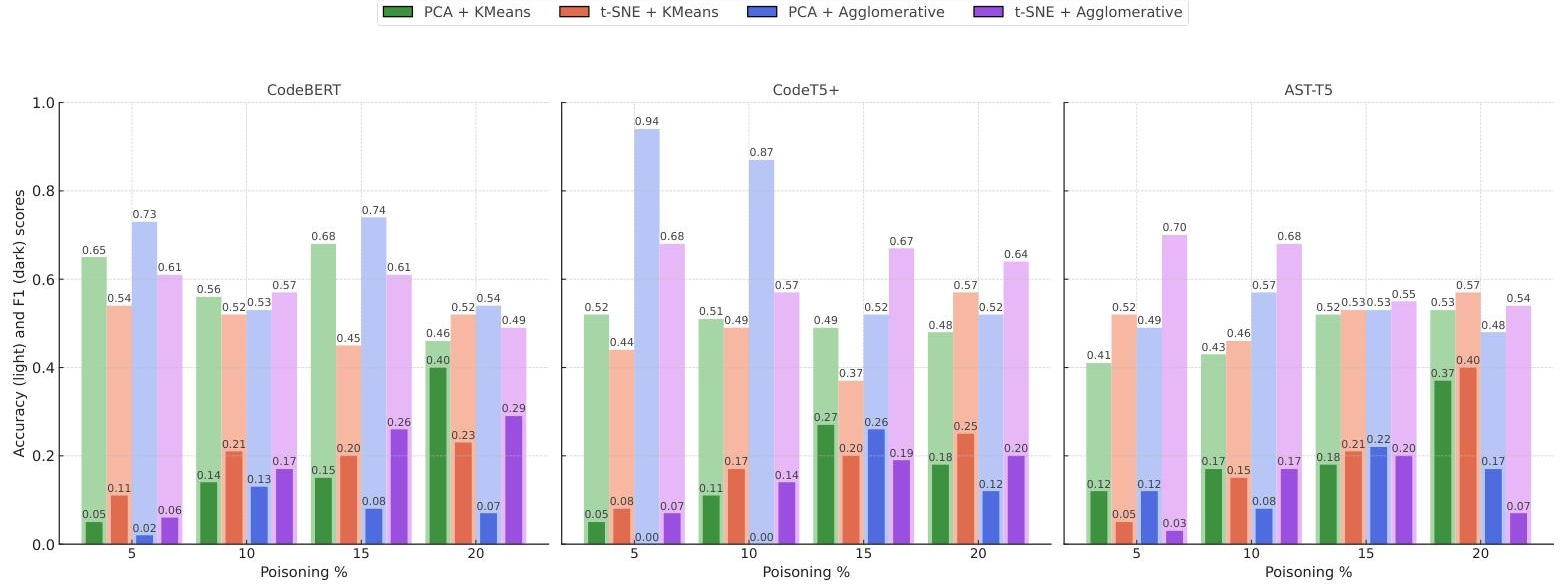
| RQ1:三種檢測方法,哪種能防無觸發投毒? | 光譜特征、激活聚類、靜態分析對比 | 1. 靜態分析最靠譜,但也沒那么神:20%高投毒率下F1=0.70,現實投毒率(5%-10%)下F1只有0.40-0.57,還會把正常樣本誤判為投毒(假陽性),漏判真投毒(假陰性); 2. 光譜特征和激活聚類很差:CodeT5+在20%投毒率下F1最高0.34,CodeBERT幾乎判不出來(F1近0); 3. 總結:現有方法都擋不住無觸發投毒。 |
| RQ2:模型的“能力強弱”會影響檢測效果嗎? | 三種模型(CodeBERT/CodeT5+/AST-T5)對比 | 1. 模型越厲害(表征能力強),檢測效果略好:比如激活聚類中,AST-T5(強)20%投毒率F1=0.40,CodeBERT(弱)F1≈0; 2. 但再厲害的模型,也救不了差的檢測方法:比如CodeT5+用光譜特征,F1也才0.34。 |
| RQ3:投毒率越高,檢測越容易嗎? | 5%-20%投毒率對比 | 1. 是的,但要“極高投毒率”才有用:比如靜態分析在20%投毒率下F1=0.70,5%投毒率下就降到0.40; 2. 但真實攻擊不會用20%投毒率(太容易被發現),一般就3%-5%——這時候所有方法都歇菜。 |
給領域帶來的實際價值
- 踩剎車提醒:告訴行業“AI代碼生成的安全風險比想象中高”——別以為有現有檢測方法就萬事大吉,無觸發投毒是“隱形殺手”,得趕緊重視。
- 提供評估基準:論文給出了數據集、實驗步驟和詳細結果,其他研究團隊可以直接用這個“基準”來測試新的防御方法(比如你發明了一種新檢測方法,就能和這篇論文的結果比,看是不是更厲害)。
- 指明研究方向:論文明確說“現有方法不行,得搞無觸發依賴的防御”——比如用強化學習讓模型“主動避開漏洞寫法”,或者把靜態分析和動態測試結合(不光看代碼,還跑一下看有沒有漏洞)。
開源資源
- 擴展后的NL-to-code數據集(含安全/不安全樣本):https://doi.org/10.5281/zenodo.16993872(可直接下載用于后續研究)
關鍵問題
Q1:無觸發數據投毒攻擊,和傳統的觸發式投毒攻擊,最核心的區別是什么?
A1:最核心是“有沒有顯式觸發詞”。傳統觸發式攻擊,投毒樣本里會有“特殊標記”(比如罕見的變量名bad_token_123),模型只有輸入這個標記才會輸出漏洞代碼;無觸發攻擊完全沒有——投毒樣本的自然語言描述不變,代碼和安全版本語義等效,模型只要學到這個樣本,遇到對應的功能需求(比如“生成登錄代碼”)就會輸出漏洞版本,隱蔽性差遠了。
Q2:三種檢測方法里,靜態分析是相對最優的,可它為什么還是防不住無觸發投毒?
A2:因為靜態分析靠“匹配漏洞模式”吃飯,但無觸發投毒樣本是“語義等效”的——比如漏洞模式是“明文存儲密碼”,攻擊者可以把代碼改成“先把密碼轉成字符串再存儲”(本質還是明文,但繞過了模式匹配),靜態分析就查不出來;而且現實投毒率低(5%)時,靜態分析會把很多正常代碼誤判為投毒(假陽性),或者漏判真投毒(假陰性)。
Q3:論文的數據集為什么要強調“語義等效”和“移除漏洞暗示描述”?
A3:為了貼近真實攻擊。如果樣本“語義不等效”(比如投毒樣本功能不一樣),AI模型生成的代碼會明顯出錯,開發團隊一眼就看出來了,攻擊就失敗了;如果描述里有“漏洞暗示”(比如寫“有漏洞的登錄代碼”),檢測方法只要看描述就能找出投毒樣本,也不真實。所以論文這么設計,就是為了讓實驗結果能反映“黑客真這么干時,防御會不會失效”。
Q4:未來要防無觸發投毒,論文給了什么方向?
A4:主要兩個方向:① 讓模型“自己學會避坑”——比如用強化學習,每次模型生成有漏洞的代碼就“罰它”,慢慢讓它養成“避開漏洞寫法”的習慣;② 搞“多層防御”——不光用靜態分析看代碼,還加動態測試(跑一下代碼看有沒有異常),甚至監測模型訓練時的“數據分布變化”(比如突然多了一批語義相似的樣本,可能是投毒)。
總結
這篇論文干了一件“很實在”的事:它沒有發明新的防御方法,而是先“潑冷水”——告訴大家“現在常用的三種防御方法,都擋不住無觸發投毒攻擊”。
論文通過擴展真實數據集、在三種主流AI代碼生成模型上做實驗,清晰地證明了:靜態分析雖然相對最好,但在現實投毒率下效果依然拉胯;光譜特征和激活聚類更是“不堪一擊”。
它的價值不在于“解決了問題”,而在于“指出了問題的嚴重性”——AI代碼生成現在越來越火,但“無觸發投毒”這個隱形威脅還沒被擋住,行業得趕緊投入資源研發新的防御機制。同時,論文提供的數據集和實驗基準,也給后續研究鋪了路,讓大家不用再“從零開始”測試新方法。

- H2 Database Console 未授權訪問)

更新中......)






)

TDD系統:光收發端編解碼與信號處理分析與方案(數字版))






