PostgreSQL與SQL Server:B樹索引差異及去重的優勢
在優化查詢性能方面,索引是數據庫工程師可使用的最強大工具之一。PostgreSQL和Microsoft SQL Server(或Azure SQL)都將B樹索引用作其默認索引結構,但每個系統實現、維護和使用這些索引的方式存在細微卻重要的差異。
在這篇博文中,我們探討了PostgreSQL和SQL Server的幾個關鍵差異點:它們的B樹索引在底層的實現方式,以及它們在磁盤上存儲和訪問數據的方式。我們還將對每個數據庫系統中值的去重對索引大小的影響進行基準測試。
我們在文末還附上了一份全面的參考指南(參見Postgres與SQL Server索引對比表)。無論你是在優化查詢,還是在規劃遷移,這些差異都會對性能和索引策略產生顯著影響。
PostgreSQL與SQL Server中B樹索引的工作原理
從宏觀層面來看,這兩種數據庫都使用B樹索引來加快等值查詢和范圍查詢的速度。B樹保持有序狀態,并且經過平衡處理,以確保穩定的讀取性能。不過,盡管這兩種數據庫中B樹的概念相似,但其實現方式卻會對性能產生重要影響。
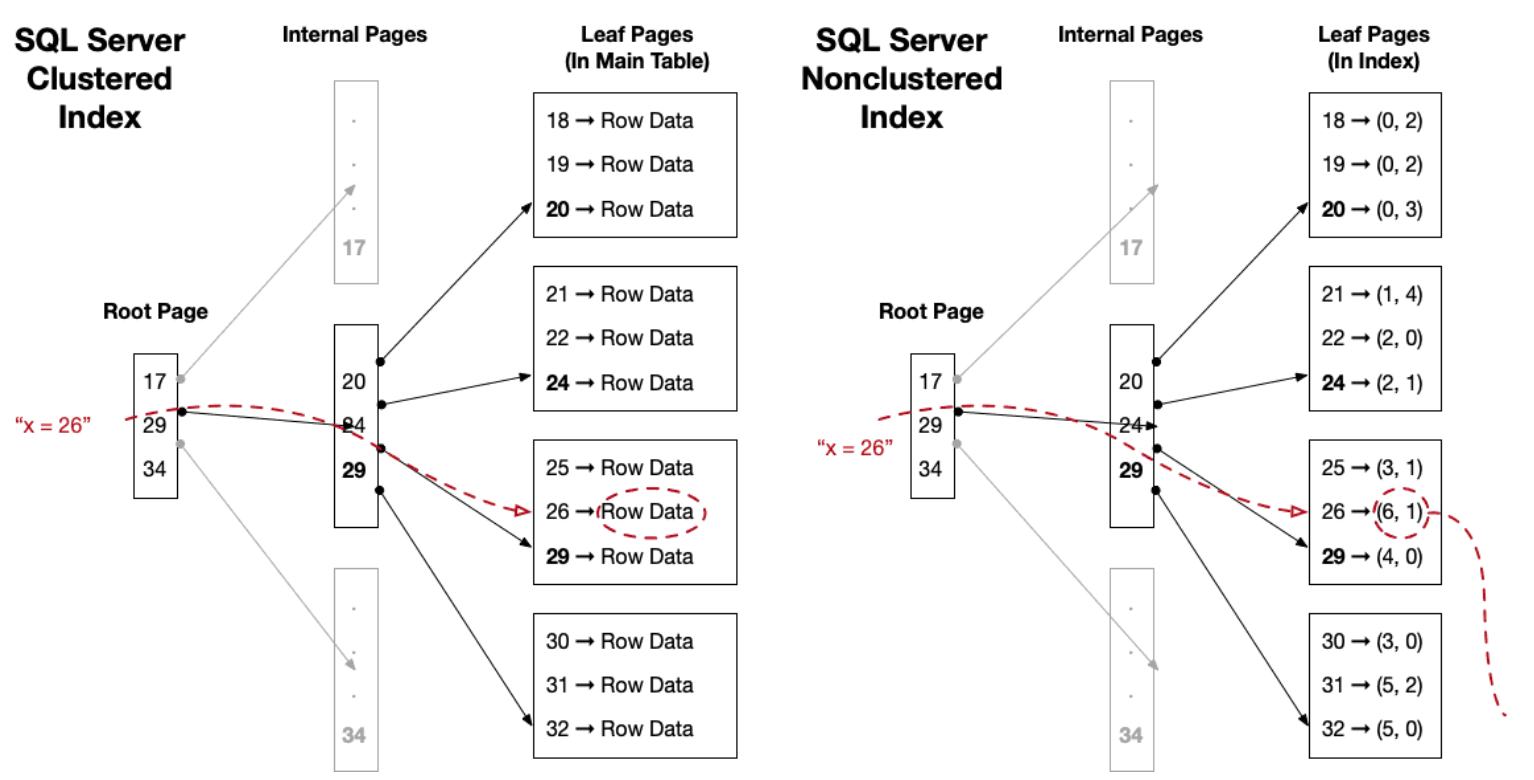
SQL Server 使用聚集索引通過索引列對表的數據進行物理排序。定義聚集索引后,表中的行將按照與索引本身相同的順序存儲。非聚集索引單獨存儲,并使用行定位符(RID 或聚集鍵)指向行。這種物理排序有利于范圍掃描或分頁查詢,但這也意味著每個表只能有一個聚集索引。更重要的是,SQL Server 會完整存儲每個索引項,即使同一頁上的多個項具有相同的值。由于沒有去重功能,因此包含許多重復值的索引可能會變得很大,并消耗過多的 I/O。
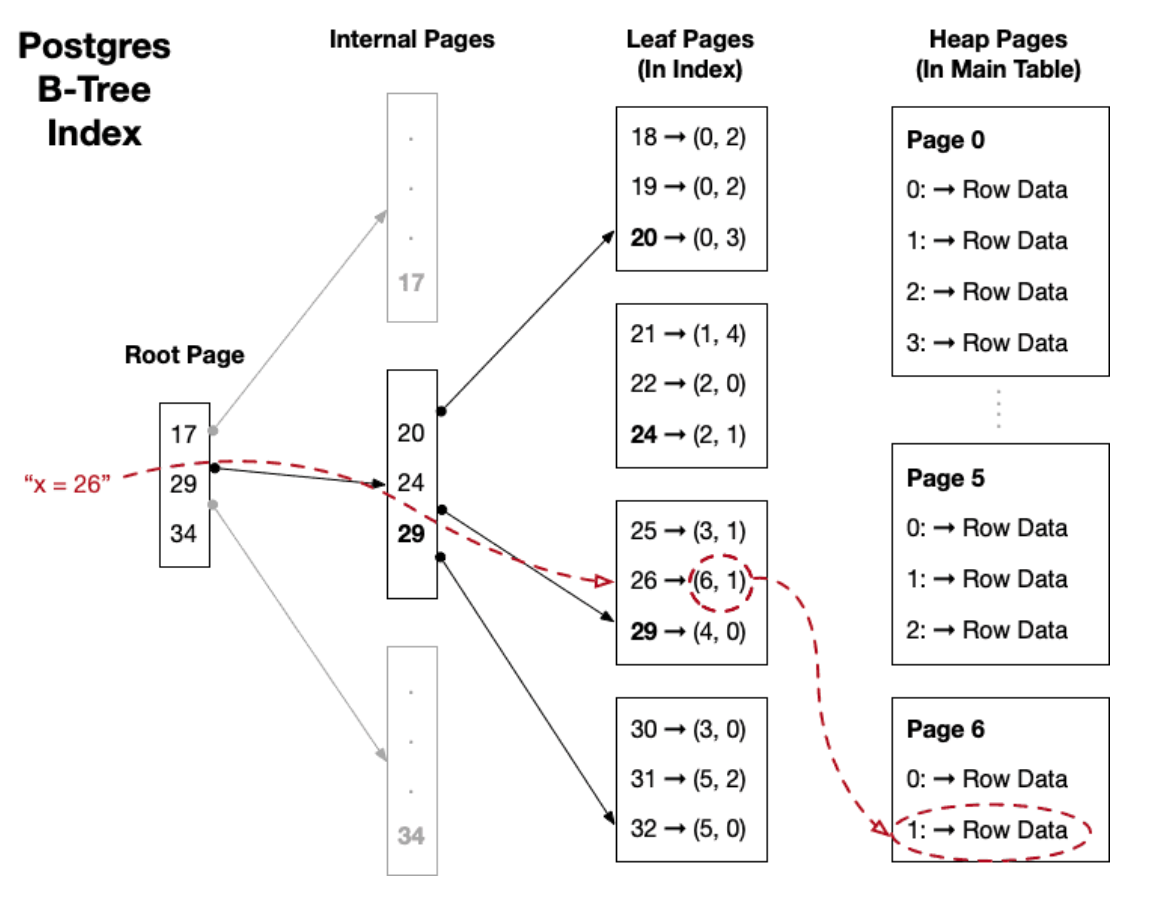
PostgreSQL沒有SQL Server意義上的聚集索引。所有PostgreSQL表都存儲為無序堆,而索引純粹是指向堆中元組的邏輯結構。這種設計為PostgreSQL提供了一定的靈活性:它使索引維護更簡單,并避免了物理重排的復雜性。
然而,這也意味著你不能依賴索引來定義表的物理布局。如果查詢性能取決于按特定順序讀取數據,Postgres確實允許你運行CLUSTER命令,但這需要完整的表鎖。在生產環境中,你可以使用pg_repack等工具來達到類似的效果。
因此,雖然這兩種數據庫都默認使用B樹索引,但SQL Server的索引與物理存儲之間的緊密耦合帶來了一系列不同的預期和限制。PostgreSQL的索引模型存在一些性能缺陷(因為它沒有聚簇索引的實現),但去重等獨特功能使其在其他情況下表現更佳。
PostgreSQL的B樹去重
PostgreSQL 13版本引入了去重功能,以解決傳統B-Tree索引中一個常見的低效問題。當許多行共享相同的索引值(比如狀態碼、布爾標志或時間戳)時,標準的B-Tree會單獨存儲每個值及其對應的元組指針。這會導致索引頁膨脹,并增加維護成本,對于寫入密集型工作負載來說尤其如此。
PostgreSQL默認會對單個索引頁內的重復值進行去重處理。它不會多次存儲相同的鍵值,而是只存儲一次,并維護一個緊湊的結構來跟蹤所有匹配的堆指針。這能顯著減小索引大小,并提高緩存性能,因為更多的索引條目可以放入內存中。
SQL Server不支持去重。即使值完全相同,每個索引項也會獨立存儲。在分布傾斜的數據集中,PostgreSQL的方法能生成更緊湊、更高效的索引,頁面更少,磁盤I/O也更少。
在PostgreSQL與SQL Server上對B樹索引進行基準測試
為了了解PostgreSQL的索引去重功能對實際性能和存儲的影響,我們進行了一項基準測試,在不同的數據重復程度下比較PostgreSQL和SQL Server的B-Tree索引大小。每個測試都創建了一個包含1000萬行的表,這些行的值重復程度各不相同,從完全唯一的值到重復1000倍的值不等。
以下是我們在兩個數據庫中構建測試的方式,以便您可以自行復現該測試。
PostgreSQL測試設置
CREATE TABLE factor_1(col int);
CREATE TABLE factor_10(col int);
CREATE TABLE factor_100(col int);
CREATE TABLE factor_1000(col int);INSERT INTO factor_1 SELECT * FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_10 SELECT val / 10 FROM GENERATE_SERIES(1, 10000000) x(val);
INSERT INTO factor_100 SELECT val / 100 FROM GENERATE_SERIES(1, 10000000) x(val);
INSERT INTO factor_1000 SELECT val / 1000 FROM GENERATE_SERIES(1, 10000000) x(val);CREATE INDEX factor_1_idx ON factor_1(col);
CREATE INDEX factor_10_idx ON factor_10(col);
CREATE INDEX factor_100_idx ON factor_100(col);
CREATE INDEX factor_1000_idx ON factor_1000(col);CREATE INDEX factor_1_idx_no_dup_fill100 ON factor_1(col) WITH (deduplicate_items = off, fillfactor = 100);
CREATE INDEX factor_10_idx_no_dup_fill100 ON factor_10(col) WITH (deduplicate_items = off, fillfactor = 100);
CREATE INDEX factor_100_idx_no_dup_fill100 ON factor_100(col) WITH (deduplicate_items = off, fillfactor = 100);
CREATE INDEX factor_1000_idx_no_dup_fill100 ON factor_1000(col) WITH (deduplicate_items = off, fillfactor = 100);
SQL Server 測試設置
CREATE TABLE factor_1(col int);
CREATE TABLE factor_10(col int);
CREATE TABLE factor_100(col int);
CREATE TABLE factor_1000(col int);INSERT INTO factor_1 SELECT * FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_10 SELECT value / 10 FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_100 SELECT value / 100 FROM GENERATE_SERIES(1, 10000000);
INSERT INTO factor_1000 SELECT value / 1000 FROM GENERATE_SERIES(1, 10000000);CREATE INDEX factor_1_idx ON factor_1(col);
CREATE INDEX factor_10_idx ON factor_10(col);
CREATE INDEX factor_100_idx ON factor_100(col);
CREATE INDEX factor_1000_idx ON factor_1000(col);
基準測試結果:PostgreSQL的去重功能減小了索引大小
當我們對比PostgreSQL和SQL Server的索引大小時,發現隨著數據重復率的增加,兩者的差異顯著擴大。當值重復1000次時,啟用去重功能的PostgreSQL索引比關閉去重功能的相同索引小3倍。而SQL Server不支持去重功能,會完整存儲每個重復值,相比之下,PostgreSQL始終能生成更小、更高效的索引。
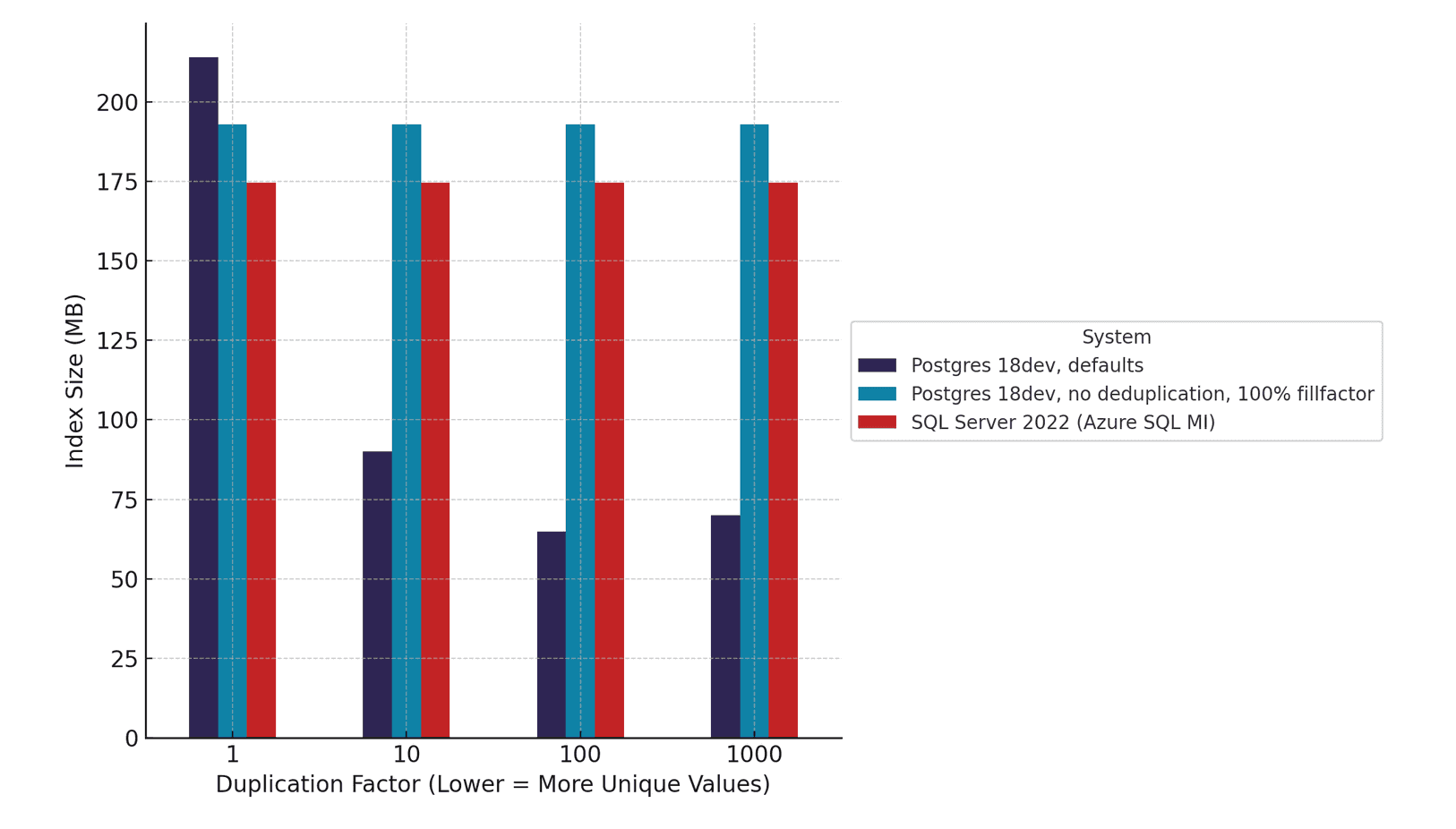
這種差異至關重要。在生產系統中,狀態標志、時間戳和分類字段等基數較高的列很常見。當這些值在數百萬行中重復出現時,大型索引會迅速成為性能瓶頸,導致掃描速度變慢、I/O 增加以及內存使用量膨脹。
PostgreSQL的去重功能顯著減小了索引大小,這使得索引更易于保存在內存中,并減輕了磁盤壓力。對于從SQL Server遷移到PostgreSQL的團隊,或者只是通過頻繁使用的索引來擴展工作負載的團隊而言,這種優化并非只是理論層面的。它對資源使用、查詢性能和整體運營效率都有著直接影響。
對比表:PostgreSQL 與 SQL Server 的索引
PostgreSQL和SQL Server在B樹及其他索引類型的索引實現上存在顯著差異。我們整理了一份全面的索引對比表,供您在從SQL Server遷移到PostgreSQL時參考。
(某些索引類型存在于SQL Server中,但不存在于PostgreSQL中,反之亦然。我們已按如下方式標注支持情況:🟢 支持的索引類型 🔴 不支持的索引類型。)
| 索引類型 | 使用案例示例 | PostgreSQL | SQL Server |
|---|---|---|---|
| B-Tree | 最適合通用索引、等值查詢和范圍查詢(例如,按年齡或日期篩選用戶)。 | 🟢 默認索引類型,支持等值查詢和范圍查詢、排序以及帶前綴的模式匹配。 | 🟢 在SQL Server上,聚集索引和非聚集索引的默認結構是B-Tree。 |
| Clustered | 按索引鍵自動對表行進行排序;最適合頻繁排序的查詢。 | 🔴 PostgreSQL 沒有聚簇索引;相反,您可以使用 CLUSTER 命令根據非聚簇索引對表進行排序;但是,當插入新數據時,這種順序不會被保留。 | 🟢 相當于PostgreSQL的B樹;根據鍵對數據進行排序和存儲。 |
| Nonclustered | 適用于可加快搜索速度且不影響物理存儲順序的索引。 | 🟢 在PostgreSQL中,所有索引都是非聚集索引。 | 🟢 可以在堆或聚集索引上創建;數據存儲與表分開。 |
| Hash | 針對精確匹配查找進行了優化,例如按用戶ID或電子郵件地址搜索。 | 🟢 在PostgreSQL中,哈希索引只能為單個列建立索引。雖然你可以創建多個索引來支持查詢,但通常多列B-Tree索引更為有效。 | 🟢 用于內存優化表;需要固定的桶數量。 |
| Filtered / Partial | 對數據子集(例如僅活躍用戶)進行索引時效率很高。 | 🟢 PostgreSQL 可以使用部分索引僅對行的一個子集進行索引。 | 🟢 篩選索引是一種非聚集索引,僅對表中的一部分行進行索引。 |
| BRIN | 最適合數據自然有序的超大型表格,例如時間序列數據。 | 🟢 存儲塊范圍的摘要;最適合大型、順序存儲的數據。 | 🔴 N/A 🔴 不適用 |
| Full-text | 用于自然語言搜索,例如搜索文章或產品評論中的文本。 | 🟢 PostgreSQL支持通過在tsvector列上使用GIN索引來進行全文搜索。 | 🟢 SQL Server 對基于文本的查詢使用倒排索引,類似于 PostgreSQL 的 GIN。 |
| GIN | 非常適合為JSONB、數組和全文搜索建立索引(例如,搜索產品描述)。 | 🟢 倒排索引;最適用于JSON、全文搜索和數組。 | 🔴 通過全文索引實現部分功能。 |
| Vector | 在高維數據中高效執行相似性搜索或最近鄰搜索,這在人工智能和機器學習應用中最為常見。 | 🟢 PostgreSQL本身不包含向量支持,但開源擴展pgvector支持向量存儲和索引。 | 🔴 SQL Server本身不支持向量索引或搜索。微軟建議改用其Azure AI搜索。 |
| XML | 針對查詢和存儲XML文檔進行了優化。 | 🔴 PostgreSQL 不直接支持在 XML 類型上創建索引;但是,可以在 XML 數據的子集上使用表達式索引。對于非結構化文檔,JSONB 是推薦的數據類型。 | 🟢 SQL Server 對 XML 數據類型有專用索引。 |
| Spatial | 用于地理查詢,例如查找半徑范圍內的位置。 | 🟢 在PostgreSQL中,空間索引查詢由開源的PostGIS擴展提供。 | 🟢 SQL Server 具有內置的空間數據類型。 |
| SP-GiST | 用于層級數據結構,如基于樹的搜索(例如路由網絡)。 | 🟢 支持非平衡樹結構,如四叉樹和k-d樹,適用于分層數據。 | 🔴 N/A 🔴 不適用 |
| GiST | 適用于幾何和全文搜索查詢,例如查找附近的位置。 | 🟢 專用索引的基礎架構;用于幾何和全文搜索。 | 🔴 N/A 🔴 不適用 |
| Columnstore | 最適合OLAP工作負載和分析查詢(例如,數據倉庫)。 | 🔴 雖然PostgreSQL有不同的擴展提供列式存儲,如Citus和Timescale,但這是一個相對較新的實現,可能會受使用場景的限制。 | 🟢 自SQL Server 2012起,SQL Server就內置了作為索引類型實現的列存儲。 |
為你的工作選擇合適的索引
理解PostgreSQL和SQL Server索引之間的差異,在優化查詢性能、規劃遷移或設計高性能數據庫時至關重要。選擇合適的索引策略需要深入了解查詢執行模式和性能權衡。許多團隊會手動嘗試不同的索引策略,這可能導致過度索引、冗余索引或錯失優化機會。
與反復試驗不同,pganalyze 索引顧問通過針對真實查詢執行數據應用約束編程模型,自動檢測缺失的索引、冗余的索引以及多列索引的最佳列順序。這消除了猜測工作,確保PostgreSQL數據庫的索引設置能實現最佳性能。

)

:入門從0到1(零基礎))
快速排序)


與XGBoost)



- MTK phy-mtk-hdmi.c 和 phy-mtk-hdmi-mt8173.c)







