1. 關系型數據庫主要考點
關系型數據庫:
- 架構
- 索引
- 鎖
- 語法
- 理論規范
2. 如何設計一個關系型數據庫
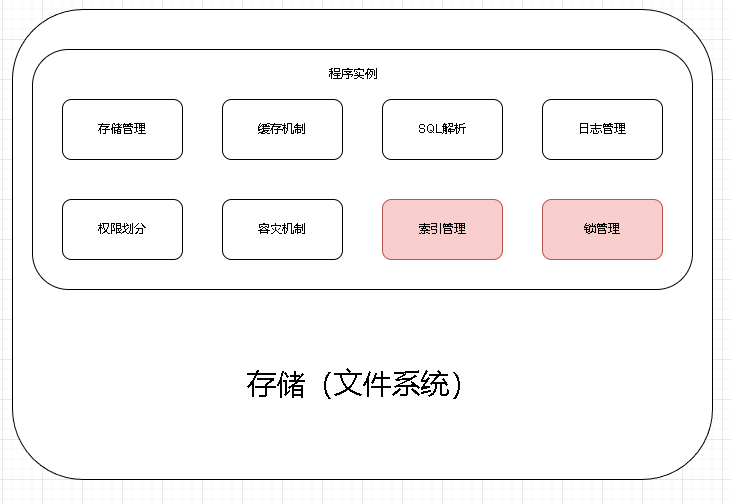
設計即模塊劃分。
數據庫最主要的功能是存儲我們的數據,所以需要一個存儲的文件系統。
我們要把涉及到的物流數據提供邏輯的形式給組織和表示出來,這是我們就用到了程序的存儲管理模塊。
為了更快更好的提升我們程序的效率,我們普遍的做法是引入緩存機制,把取出來的數據放入緩存當中,這樣我們就可以減少從數據庫讀取IO消耗,加快效率。
我們還需要給外界提供可以讀取我們數據庫指令和可讀的SQL語句,這樣我們就需要一個SQL解析器。
這時候為了進一步去提升SQL執行效率,我們將SQL緩存到緩存里面,將編譯好的SQL放入緩存中。
此外我們還需要注意設計的緩存不宜過大,算法里面還需要有淘汰機制,淘汰了一些不常用的數據。執行的SQL操作也需要記錄下來,方便我們做數據庫的主從同步或災難恢復。還需要給用戶數據管理的私密空間和權限劃分。還需要考慮異常的發生處理,因此引入了容災機制。當我們數據庫掛了,這時候應該怎么辦?要恢復到什么程度?這些都需要設計。而且為了進一步提升查詢效率,以及讓數據庫支持并發,我們還需要引入最能突出數據庫特性的鎖和索引這兩個模塊。
注意:
如何優化存儲效能,我們都知道處理數據肯定不可以在磁盤中去執行,而是讓程序其加載到程序空間的內存去做。此外,為了執行效率,我們需要盡可能減少IO,如果頻繁的去數據庫逐行查找并放回,那么頻繁的IO會讓數據庫執行效率低下,同時一次IO讀取一行或多行數據所花費的時間沒有區別。所以為了提升效率,一次去讀取多行,這樣來看行就失去了它的意義,所以數據庫中把塊或頁作為存儲數據的單元格。
3. 為什么需要使用索引?
首先我們需要做一個調研,用最簡單的方法進行對數據庫的查詢,即對數據庫進行全表掃描,對整個數據庫表全部或分批次的進行掃描并加載到內存中,逐個去加載,輪詢直到找到我們的目標,這種方法普遍被認為十分慢,但是是在所有情況下都這么慢嗎?
存在即是合理,當我們的數據庫里面的數據只有很少比如幾十行作用,使用全表掃描肯定比通過索引來的快。
對于絕大多數情況來說,我們都需要避免全表掃描,提升我們的效率,這時候索引就誕生了。索引就類型于字典,通過索引來大幅度提升查詢效率。
那什么是索引呢?通過上面的分析,我們知道索引即是把記錄限定到一定查詢范圍內的字段。那么主鍵對我們來說就是一個很好的切入點,包括唯一鍵和普通鍵也是可以的。
那么怎么才可以讓我們的查找更加高效呢?這時候就應該引入數據結構來幫助我們了。可以是二叉樹,平衡二叉樹,紅黑樹,B樹,B+樹,一些hash結構。而Mysql里面主要是通過B+數實現的。




)

:入門從0到1(零基礎))
快速排序)


與XGBoost)



- MTK phy-mtk-hdmi.c 和 phy-mtk-hdmi-mt8173.c)




